1. 研究动机与背景¶
1.1 多模态推荐与 Semantic ID 的兴起¶
现代推荐系统越来越多地处理"具有丰富内容信号(文本、图像、视频)"的物品。传统稀疏 ID 表示虽然紧凑,但每个物品被当作孤立符号,无法在相关物品之间共享语义信号;这一缺陷在短视频等"物品被持续创作、消费、替换"的动态场景中尤为致命:稀疏 ID embedding 极易随时间漂移,对长尾和新增物品几乎无法学到稳定表示。
直接使用多模态连续表示虽然语义更丰富,但它们不能充当"稳定的物品标识符",也未在下游推荐监督下被显式优化为可索引的离散接口。Semantic ID(SID) 在此背景下兴起:通过 RQ-VAE 等量化方法将多模态特征压缩为很短的离散 token 序列,既保持语义信息又获得稀疏 ID 的紧凑、可学习与可检索特性,成为现代生成式与判别式推荐管线的统一离散接口。
1.2 SID 学习中的核心难题:碰撞(Collision)¶
把多模态特征投影到离散 SID 空间时,不同物品可能被分配到完全相同或高度混淆的离散码,这种现象称为 collision(碰撞)。collision 在推荐场景中尤其严重:
- SID 既是被压缩的表示,又是下游模型用来"区分物品"的离散接口;
- 当语义或行为不匹配的物品共享相似 SID 时,下游模型被迫用同一离散监督同时表示多个不同物品,导致优化信号互相冲突,最终损害推荐质量。
1.3 现有方法的两个局限¶
已有工作基本沿两条路线缓解 collision:
- 改进量化质量(GRVQ、Rotation Trick、Improved VQGAN、SimRQ、RQ-KMeans 等):通过更好的码本利用率或更稳的训练间接降低碰撞;
- 显式 collision-aware 目标(QuaSID 等):观察到一对物品 SID 重叠后,对其施加排斥惩罚以分离离散表示。
但对"已被观察到的重叠"本身的处理几乎完全是静态的,存在两类弱点:
- 空间静态:一旦判定为碰撞,所有重叠对几乎以同一规则被排斥,未区分"语义不兼容→应被分离"与"语义高度一致→可允许共享"的差别;
- 时间静态:碰撞惩罚强度从训练开始到结束保持恒定,未考虑离散结构在不同训练阶段需求不同(前期需要稳定结构、后期需要对齐推荐目标)。
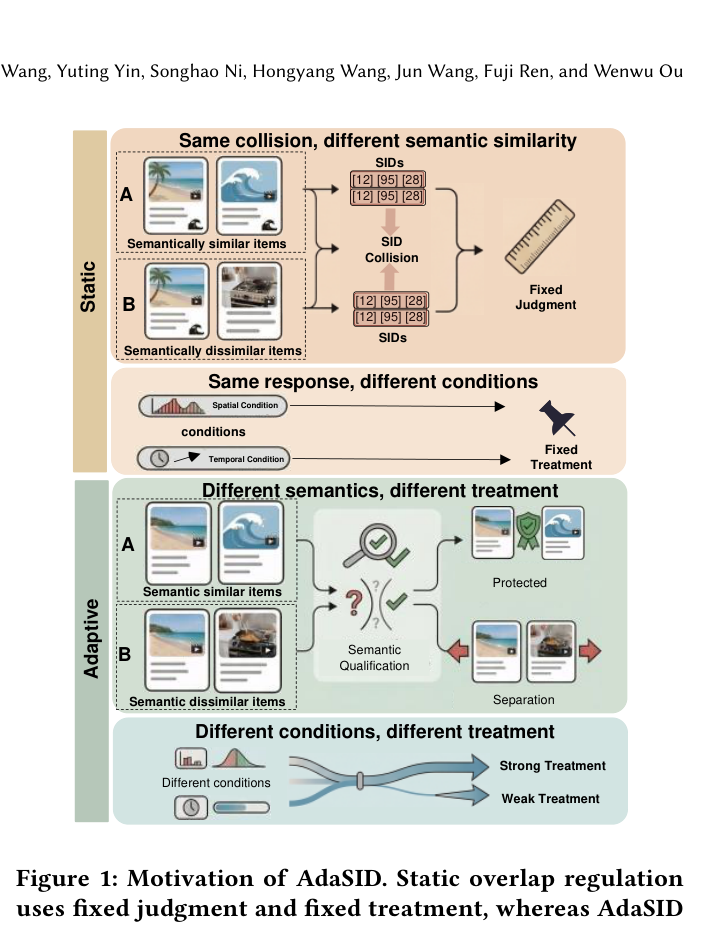
如图 1 所示,静态方法用"固定判决 + 固定治疗"来处理重叠:对所有"看似相同"的碰撞施加相同惩罚;而 AdaSID 引入"自适应语义资格判别 + 自适应压力分配"——首先判断观察到的重叠是否仍应受到排斥,再根据剩余重叠的局部碰撞负载和训练阶段动态调节排斥强度。
1.4 本文贡献¶
作者提出 AdaSID:一种面向推荐的自适应 SID 学习框架。核心思路是把 collision regulation 重新表述为两阶段自适应过程:
- Stage 1(语义自适应重叠松弛 SeAR):基于编码器侧多模态语义一致性,对每一个观察到的 overlap 决定它是否仍应被排斥,还是作为"语义可允许的共享"被保留;
- Stage 2(自适应压力分配):对剩余的、需要被排斥的 overlaps 进行空间和时间双重调节
- 空间维度(Load-Adaptive Strengthening LAS):根据当前 mini-batch 中"同一离散 overlap pattern"的局部负载强化排斥;
- 时间维度(Progress-Adaptive Rebalancing PAR):根据训练进度,动态调整 collision 正则与协作对齐损失的相对权重。
主要贡献:
- 首次系统性地把 SID overlap 从"固定治疗"转变为"两阶段自适应过程",在语义资格、空间负载、时间进度三个维度均加入自适应;
- 在 Amazon Toys/Beauty 两个公开 benchmark 上 Recall/NDCG 平均提升约 4.5%(最强 baseline 之上),同时改善码本利用率和 SID 空间多样性;
- 在快手电商进行 4 天在线 A/B 测试与 4 天离线排序评估,GMV +0.98%、Orders +0.91%、GPM +1.16%,AUC 在 CTCVR、Scenario-A CVR、Cold-start CVR 三项上均有正向 pp 提升。
2. 相关工作¶
2.1 多模态物品表示¶
利用 text/image/video 等异构信号丰富物品语义已成为推荐主流方向。代表性技术包括跨模态融合、对比对齐、预训练编码器、模态感知交互建模等。这些方法主要把物品建模为连续向量;而 SID 学习面向"如何把这些表示压缩为短的离散 token 序列",便于跨阶段共用、生成式建模和高效检索。
2.2 SID 学习¶
代表性 SID 构造路线包括:
- 乘积量化(RQ-VAE 系列);
- 残差量化 + 层级/树状 tokenization;
- 加入协作信号 / 多模态对齐(DAS、LC-Rec 等);
- 端到端下游监督。
但绝大多数工作把 overlap 当作"次要现象"——观察到后用固定规则一次性处理,缺乏对"哪些 overlap 应被惩罚、应惩罚多强、应何时惩罚"的自适应建模。AdaSID 正是把这部分静态处理替换为自适应规则。
3. 符号与问题定义¶
3.1 符号¶
- 训练对 $\mathcal{D} = \{(x_i^{\text{tr}}, x_i^{\text{ta}})\}_{i=1}^N$:来自 Swing 等协作信号构造的 trigger–target 物品对;
- 多模态特征 $x$:由预训练多模态模型从 text/image/video 提取;
- 共享编码器 $f_\theta(\cdot)$:将 $x$ 映射为连续向量 $z \in \mathbb{R}^d$;
- $L$ 层 RVQ 与码本 $\{C^{(l)}\}_{l=1}^L$,$C^{(l)} = \{c_1^{(l)}, \ldots, c_K^{(l)}\}$,$c_k^{(l)} \in \mathbb{R}^d$;
- SID $s_i = [s_i^{(1)}, \ldots, s_i^{(L)}]$:每层挑选最近码字得到的索引序列;
- 解码器 $h_\phi(\cdot)$:从量化 embedding 重建原始多模态特征。
RVQ 流程对每层 $l$ 选择最近码字 $s_i^{(l)} \in \{1, \ldots, K\}$、得到该层量化向量 $q_i^{(l)} = c_{s_i^{(l)}}^{(l)}$、并把残差更新为 $r_i^{(l)} = r_i^{(l-1)} - q_i^{(l)}$,初始 $r_i^{(0)} = z_i$。最终量化向量 $\hat{z}_i = \sum_{l=1}^L q_i^{(l)}$。
物品 $i$ 与 $j$ 在离散 SID 空间的重叠深度定义为:
$$ o_{ij} = \sum_{l=1}^{L} \mathbb{I}\left[ s_i^{(l)} = s_j^{(l)} \right] \tag{1} $$
$o_{ij} \in \{0, 1, \ldots, L\}$,越大表示两物品在离散空间越靠近。$\text{sim}_{ij}$ 表示编码器侧连续表示的余弦相似度,$\tau \in [0, 1]$ 表示归一化训练进度。
3.2 问题定义¶
给定协作对集合 $\mathcal{D}$,目标是学习一个 SID 映射 $x \mapsto s$,要求所学 SID 同时满足:
- 语义保留:在离散化下保留有用的多模态语义信息;
- 协作对齐:与协作关系结构良好对齐,便于下游推荐;
- 自适应 collision 处理:对离散重叠不再"统一治疗",而是基于"语义同构 / 局部负载 / 训练阶段"自适应调节。
4. 方法¶
4.1 总体框架¶
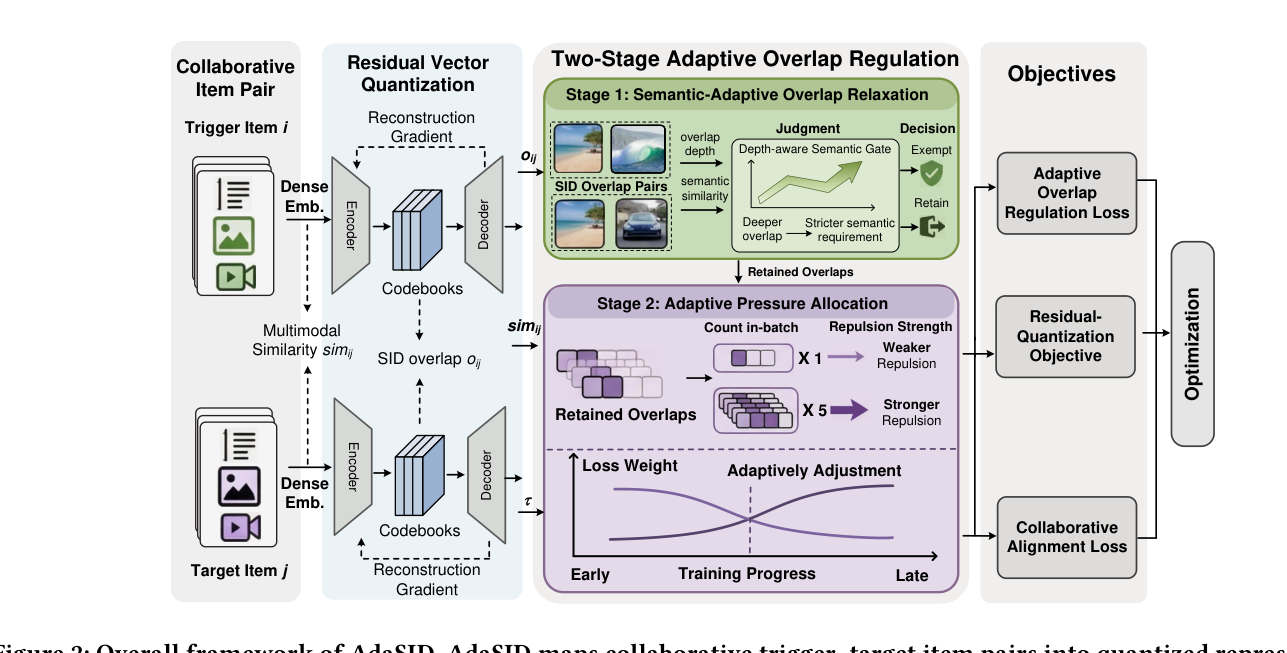
如图 2 所示,AdaSID 由三个模块串联:
- 共享多模态编码器 + 残差向量量化:把 trigger 和 target 都映射为连续向量并量化为 SID;
- Two-Stage Adaptive Overlap Regulation:Stage 1 SeAR 决定每个 overlap 是否要继续排斥,Stage 2 在保留 overlaps 上做空间与时间维度的自适应压力分配;
- 三个目标项:Adaptive Overlap Regulation Loss、Residual-Quantization Objective、Collaborative Alignment Loss。
设 $Q(\cdot)$ 为 RVQ 过程。前向传播写为:
$$ z_i^{\text{tr}} = f_\theta(x_i^{\text{tr}}), \quad (\hat{z}_i^{\text{tr}}, s_i^{\text{tr}}) = Q(z_i^{\text{tr}}), \quad \hat{x}_i^{\text{tr}} = h_\phi(\hat{z}_i^{\text{tr}}) \tag{2} $$
$$ z_i^{\text{ta}} = f_\theta(x_i^{\text{ta}}), \quad (\hat{z}_i^{\text{ta}}, s_i^{\text{ta}}) = Q(z_i^{\text{ta}}), \quad \hat{x}_i^{\text{ta}} = h_\phi(\hat{z}_i^{\text{ta}}) \tag{3} $$
其中最近邻码字查找不可微,作者采用 STE(Straight-Through Estimator) 把梯度直接从量化 embedding 传回编码器输出。
4.1.1 候选重叠对集合¶
给定 mini-batch,先收集所有 SID 重叠候选对:
$$ \mathcal{P} = \{ (i, j) \mid i < j, \, o_{ij} > 0 \} \tag{4} $$
对每个候选对 $(i, j) \in \mathcal{P}$,定义连续余弦距离与基础 collision 惩罚:
$$ d_{ij}^c = 1 - \frac{z_i^\top z_j}{\|z_i\|_2 \, \|z_j\|_2} \tag{5} $$
$$ \ell_{ij}^{\text{col}} = \max\left(0, \, m_{ij} - d_{ij}^c\right) \tag{6} $$
其中 $m_{ij}$ 为 margin(可由 overlap 类型或严重程度决定)。这是 AdaSID 的"通用 collision 排斥项",后续会被两阶段机制自适应缩放。
4.2 Stage 1:语义自适应重叠松弛(Semantic-Adaptive Overlap Relaxation, SeAR)¶
第一阶段的核心问题是:已经观察到的离散重叠 $(i, j)$,到底是有害的语义混淆,还是语义可允许的共享?
直觉很简单:
- 如果两个物品在多模态空间里语义本就高度一致,那么它们在离散空间共享 SID 不算"错误",应保留这种共享,不施加排斥;
- 如果两个物品语义差异显著但 SID 却高度重叠,则是真正的有害碰撞,应受到排斥。
4.2.1 编码器侧语义相似度¶
对候选对 $(i, j) \in \mathcal{P}$,计算编码器侧表示的余弦相似度:
$$ \text{sim}_{ij} = \frac{z_i^\top z_j}{\|z_i\|_2 \, \|z_j\|_2} \tag{7} $$
4.2.2 深度感知阈值向量¶
不同重叠深度承受的"语义资格门槛"不应相同:浅 overlap 表示两物品仅在底层量化层共享,下游容易区分;而深 overlap 意味着两物品几乎完全共享离散接口,下游模型几乎无法分辨它们,因此深 overlap 必须有更强的语义证据才能被免除排斥。
作者引入深度感知阈值向量:
$$ \boldsymbol{\eta} = [\eta_1, \eta_2, \ldots, \eta_L], \quad \eta_1 \le \eta_2 \le \cdots \le \eta_L \tag{8} $$
其中 $\eta_{o_{ij}}$ 是与重叠深度 $o_{ij}$ 关联的语义阈值;越深的重叠对应越严格(越大)的阈值。
4.2.3 松弛门控¶
定义 SeAR 的松弛门控:
$$ g_{ij} = \mathbb{I}\left[ \text{sim}_{ij} \ge \eta_{o_{ij}} \right] \tag{9} $$
$g_{ij} = 1$ 表示该 overlap 被免除排斥(语义资格通过),$g_{ij} = 0$ 表示该 overlap 继续接受排斥处理。这种"梯度阈值"避免了一刀切的松弛规则:浅 overlap 用相对宽松的语义证据即可获得豁免,而深 overlap 必须达到很高的连续语义一致性才能被认为"无害"。
4.3 Stage 2:自适应压力分配¶
经过 Stage 1 决定"哪些 overlap 仍需被排斥"之后,AdaSID 不会对它们一视同仁地施加压力,而是分别在空间维度(哪里压、压多重)和时间维度(何时压、压多长)做自适应。
4.3.1 负载自适应碰撞强化(Load-Adaptive Strengthening, LAS)¶
LAS 关注的是离散 SID 空间中"哪些区域被过度拥挤"。仅靠 overlap 深度 $o_{ij}$ 无法刻画"同一种 overlap 模式在 mini-batch 中被多频繁地复用"——而这恰恰是离散区域过载的关键信号。
定义对 $(i, j)$ 的层级 overlap 签名:
$$ \kappa_{ij} = \left[ \mathbb{I}\left[s_i^{(1)} = s_j^{(1)}\right], \, \mathbb{I}\left[s_i^{(2)} = s_j^{(2)}\right], \ldots, \mathbb{I}\left[s_i^{(L)} = s_j^{(L)}\right] \right] \tag{10} $$
mini-batch 内"同样 overlap 签名"的对数定义为局部碰撞负载:
$$ c_{ij} = \sum_{(u, v) \in \mathcal{P}} \mathbb{I}\left[ \kappa_{uv} = \kappa_{ij} \right] \tag{11} $$
$c_{ij}$ 越大,说明"同样的 overlap 模式"在当前 mini-batch 中被反复出现,对应离散邻域被过载使用,需更强的分离压力。
LAS 用一个有界单调缩放函数把 $c_{ij}$ 映射为强化系数:
$$ a_{ij} = g(c_{ij}; \, f_{\min}, f_{\max}, d_{\max}, \alpha) \tag{12} $$
其中 $f_{\max}$ 控制最大强化倍数(实验中 $f_{\max} \in \{2.0, 3.0\}$),$d_{\max}$ 控制饱和前的有效负载范围,$\alpha$ 控制增长锐度。这一设计保持了强化系数的有界性,又能给"高度拥挤的离散邻域"分配显著更大的惩罚权重。
直觉总结:overlap 深度告诉"两物品离得多近",但 LAS 系数告诉"该种邻近模式被多少对物品同时复用"。两者结合后,AdaSID 才能有的放矢地把更强的分离压力放在过载邻域。
4.3.2 进度自适应目标重平衡(Progress-Adaptive Rebalancing, PAR)¶
PAR 关注的是何时该重视 collision 正则、何时该重视协作对齐。作者的关键观察是:
- 训练早期:编码器和码本仍在共同形成"可用的离散结构",此时若不强化 collision 正则,离散空间会迅速塌陷;
- 训练后期:离散结构基本稳定,应让"协作对齐"在优化中扮演更大角色,使 SID 与下游推荐目标对齐,而非继续加压排斥。
归一化训练进度:
$$ \tau = \text{clip}\left( \frac{t - T_{\text{start}}}{T_{\text{end}} - T_{\text{start}}}, \, 0, \, 1 \right) \tag{13} $$
进度自适应的两个权重:
$$ \lambda_{\text{col}}(\tau) = 1 - (1 - \lambda_{\text{col}}^{\min}) \tau, \quad \lambda_{\text{cf}}(\tau) = \lambda_{\text{cf}}^{\max} \cdot \tau \tag{14} $$
即:collision 正则权重线性衰减到 $\lambda_{\text{col}}^{\min}$(实验中 $\in \{0.05, 0.02\}$),而协作对齐权重从 0 线性增长到 $\lambda_{\text{cf}}^{\max}$(实验中 $\in \{0.25, 0.35\}$)。这保证了"先稳定离散结构、再加强下游对齐"的渐进调度。
4.4 总体目标¶
把 SeAR 与 LAS 组合到 collision 项中:
$$ \mathcal{L}_{\text{col}}^{\text{ada}} = \sum_{(i, j) \in \mathcal{P}} a_{ij} \, (1 - g_{ij}) \, \ell_{ij}^{\text{col}} \tag{15} $$
其中 $(1 - g_{ij})$ 屏蔽了 SeAR 豁免的对,$a_{ij}$ 按局部负载自适应放大剩余对的压力。
最终训练目标:
$$ \mathcal{L} = \mathcal{L}_{\text{rec}} + \mathcal{L}_{\text{rq}} + \lambda_{\text{col}}(\tau) \, \mathcal{L}_{\text{col}}^{\text{ada}} + \lambda_{\text{cf}}(\tau) \, \mathcal{L}_{\text{cf}} \tag{16} $$
其中:
- $\mathcal{L}_{\text{rec}}$:解码器重建损失($\hat{x}_i$ 与原 $x_i$ 之间);
- $\mathcal{L}_{\text{rq}}$:标准残差量化的 commitment + codebook loss;
- $\mathcal{L}_{\text{cf}}$:协作对齐损失,论文中实例化为基于量化 embedding 的 InfoNCE 风格对比损失(trigger–target 对作为正样本);
- $\lambda_{\text{col}}(\tau)$ 与 $\lambda_{\text{cf}}(\tau)$ 由 PAR 控制随训练进度调整。
4.5 训练与推理流程¶
每个 mini-batch 内的训练步骤(伪代码描述):
- 多模态特征前向:编码器 $\to$ 残差量化 $\to$ 解码器;
- 收集所有 overlap pair 集合 $\mathcal{P}$,按 $(\text{对}, \text{深度}, \text{签名})$ 组织;
- Stage 1:用 sim$_{ij}$ 与 depth-aware 阈值 $\eta_{o_{ij}}$ 计算 $g_{ij}$;
- Stage 2-LAS:从 mini-batch overlap 签名分布估计 $c_{ij}$,得到 $a_{ij}$;
- Stage 2-PAR:按当前步 $t$ 计算 $\tau$,得到 $\lambda_{\text{col}}(\tau)$、$\lambda_{\text{cf}}(\tau)$;
- 拼装总损失(公式 16),STE 反传。
推理阶段:仅保留学习好的编码器和残差量化器,按标准 SID pipeline 生成离散索引序列;所有自适应模块只在训练时生效,因此线上不引入额外复杂度。
5. 实验¶
5.1 实验设置¶
5.1.1 离线数据集¶
公开 benchmark:Amazon 2018 review datasets 中的 Beauty 与 Toys & Games(缩写 Toys)。沿用前人工作的标准 5-core 过滤,丢弃交互少于 5 次的用户和物品,按 leave-one-out 切分为训练 / 验证 / 测试。物品文本字段拼接 Title, Brand, Categories, Price,用 Sentence-T5-XXL 提取语义 embedding。
| Dataset | #Users | #Items | #Interactions | Density |
|---|---|---|---|---|
| Amazon-Toys | 19,412 | 11,924 | 905,253 | 0.3911% |
| Amazon-Beauty | 22,363 | 12,101 | 1,048,296 | 0.3874% |
5.1.2 评估指标¶
- 推荐性能:Recall@K 和 NDCG@K,$K \in \{3, 5\}$;所有方法共用 TIGER 下游骨干,差异完全来自 SID 质量;
- 码本侧统计(用于刻画 SID 空间):
- SID Entropy:完整 SID 序列分布的熵(多样性);
- Average Perplexity:跨码本层的平均困惑度(整体码本利用率);
- Minimum Perplexity:最弱被利用层的困惑度(最弱层的利用程度,更严格的"层级欠利用"指标);
- Mean Top-1 Load Ratio:每层"最高频码字"承载的样本比例的均值,越小说明主导码字越分散。
工业验证:在线检索 A/B 报告 GMV / Orders / GPM 业务指标的相对增益(pp 百分比变化),离线排序报告 AUC 增益(pp 百分点)。
5.1.3 Baselines¶
所有方法在同一个 TIGER 下游、同样的 768 维输入特征、同样的下游配置下做公平比较,差异仅在于"如何学 SID"。三类 baseline:
- 标准量化 SID:vanilla RQ-VAE;
- 改进的量化 / 利用率方法:GRVQ(分组残差)、RQ-OPQ(联合优化乘积量化)、Rotation Trick(用旋转替代 STE)、Improved VQGAN(低维 + L2)、SimRQ(冻结码本 + 线性投影)、RQ-KMeans(两阶段聚类);
- collision-aware 方法:QuaSID(Hamming 引导的资格判别 + margin 排斥)。
5.1.4 实现细节¶
- SID 长度 $L = 3$,每层码本大小 $K = 256$(与 baseline 完全一致);
- 输入特征 768 维,码字 embedding 32 维;
- 下游 TIGER 配置统一;
- 关键超参:
- $f_{\max} \in \{2.0, 3.0\}$;
- 两组 depth-aware 语义阈值向量候选:$\{0.18, 0.24, 0.30\}$ 和 $\{0.14, 0.19, 0.24\}$;
- 自适应 rebalancing 起 / 止步:$(10000, 200000)$ 或 $(3000, 90000)$;
- $\lambda_{\text{col}}^{\min} \in \{0.05, 0.02\}$;
- $\lambda_{\text{cf}}^{\max} \in \{0.25, 0.35\}$。
5.2 主实验:离线推荐性能(Table 2)¶
| Tokenizer | Toys R@3 | Toys NDCG@3 | Toys R@5 | Toys NDCG@5 | Beauty R@3 | Beauty NDCG@3 | Beauty R@5 | Beauty NDCG@5 |
|---|---|---|---|---|---|---|---|---|
| RQ-OPQ | 0.0176 | 0.0152 | 0.0215 | 0.0178 | 0.0181 | 0.0152 | 0.0225 | 0.0170 |
| RQ-VAE | 0.0164 | 0.0142 | 0.0197 | 0.0161 | 0.0161 | 0.0131 | 0.0206 | 0.0149 |
| Improved VQGAN | 0.0191 | 0.0164 | 0.0224 | 0.0177 | 0.0178 | 0.0146 | 0.0231 | 0.0167 |
| GRVQ | 0.0170 | 0.0147 | 0.0192 | 0.0166 | 0.0189 | 0.0151 | 0.0246 | 0.0179 |
| Rotation Trick | 0.0182 | 0.0157 | 0.0221 | 0.0183 | 0.0193 | 0.0155 | 0.0245 | 0.0180 |
| SimRQ | 0.0191 | 0.0160 | 0.0216 | 0.0175 | 0.0182 | 0.0147 | 0.0236 | 0.0169 |
| RQ-KMeans | 0.0193 | 0.0160 | 0.0271 | 0.0187 | 0.0199 | 0.0151 | 0.0271 | 0.0184 |
| QuaSID | 0.0195 | 0.0157 | 0.0273 | 0.0191 | 0.0201 | 0.0155 | 0.0268 | 0.0186 |
| AdaSID | 0.0214 | 0.0175 | 0.0281 | 0.0202 | 0.0205 | 0.0164 | 0.0275 | 0.0190 |
(粗体=最佳,下划线=次佳;表格据论文 Table 2 重现。)
主要观察:
- AdaSID 在所有 8 项指标上同时取得最佳,相对最强 baseline 平均提升约 4.5%(Toys 6.2%、Beauty 2.9%);
- 在 Toys 上,AdaSID 把 Recall@3 从 0.0195 提到 0.0214(+9.6%)、NDCG@3 从 0.0164 提到 0.0175(+6.6%);NDCG@5 从 0.0191 提到 0.0202(+5.8%);
- 与最强 collision-aware baseline QuaSID 相比,AdaSID 在两个数据集的全部四个指标上都赢,平均相对增益 Toys 约 7.4%、Beauty 约 3.1%——说明把 collision 处理从"静态资格判别"升级为"两阶段自适应"是有效的;
- AdaSID 的优势不集中在某一指标或某一 cutoff,而是在 Recall/NDCG@3/5 与两个数据集上一致出现,说明改进来自 SID 空间的整体质量提升,而非单点过拟合。
5.3 码本质量分析(Figure 3)¶
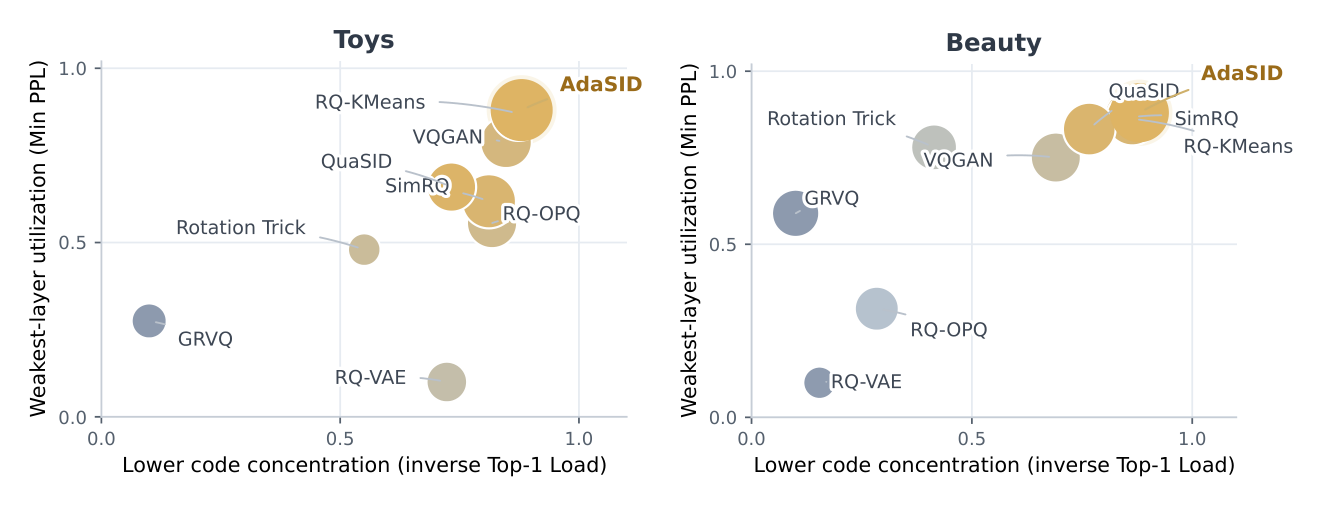
图 3 把每个 tokenizer 投影到二维平面:x 轴是 inverse normalized Top-1 Load(向右 = 主导码字越分散,码本利用越均匀),y 轴是归一化 Minimum Perplexity(向上 = 最弱层利用率越高),点的大小编码 Mean Perplexity,颜色编码 SID Entropy。
结论:
- Toys:AdaSID 接近右上前沿,且点最大、最深,意味着同时具备"高均匀性 + 高最弱层利用 + 高整体多样性",没有牺牲任何单一维度;
- Beauty:AdaSID 也位于前沿区,与 SimRQ、RQ-KMeans 同处可比位置,但综合指标(点大小+颜色)明显更优;
- 关键解读:AdaSID 的下游推荐增益不是来自"用单一码本统计指标过拟合",而是来自"整体 SID 空间向更平衡区域迁移",这与 Table 2 的多指标一致提升相互印证。
5.4 工业验证(Table 3)¶
在快手电商场景,作者从 image / text / keyframes / audio transcripts 等异构信号经多模态基础模型抽取 768 维特征,然后训练 AdaSID。在线侧用短视频检索模型做 4 天 A/B(覆盖数千万用户),离线侧用排序模型做 4 天评估。
| Panel A: Online Retrieval A/B | Gain |
|---|---|
| GMV | +0.98% |
| Orders | +0.91% |
| GPM | +1.16% |
| Panel B: Offline Ranking | AUC Gain |
|---|---|
| Overall CTCVR | +0.05 pp |
| Scenario-A CVR | +0.05 pp |
| Cold-start CVR | +0.08 pp |
业务解读:
- 在线 A/B 在 GMV、Orders、GPM 三项业务核心指标上同时达到统计显著正向——尤其 GPM +1.16% 直接表明"更好的 SID 提升了千次曝光的变现效率",这是 SID 学习真正影响推荐生态的核心信号;
- 离线排序的三项 AUC 增益方向一致,且冷启动 CVR 增益最大(+0.08 pp)——这与"更好的离散接口能让冷启动物品复用语义信号"的直觉吻合,是 SID 优于稀疏 ID 的典型证据;
- 在线增益与离线 AUC 改善方向一致,强化了"AdaSID 的提升不是 benchmark 噪声而是真实业务价值"的结论。
5.5 消融研究(Table 4)¶
| Dataset | Variant | R@3 | NDCG@3 | R@5 | NDCG@5 |
|---|---|---|---|---|---|
| Toys | AdaSID | 0.0214 | 0.0175 | 0.0281 | 0.0202 |
| Toys | w/o SeAR | 0.0192 | 0.0153 | 0.0246 | 0.0175 |
| Toys | w/o PAR | 0.0204 | 0.0169 | 0.0252 | 0.0189 |
| Toys | w/o LAS | 0.0205 | 0.0161 | 0.0271 | 0.0188 |
| Beauty | AdaSID | 0.0205 | 0.0164 | 0.0275 | 0.0190 |
| Beauty | w/o SeAR | 0.0184 | 0.0149 | 0.0263 | 0.0181 |
| Beauty | w/o PAR | 0.0182 | 0.0147 | 0.0236 | 0.0169 |
| Beauty | w/o LAS | 0.0201 | 0.0161 | 0.0269 | 0.0188 |
逐组件分析:
- w/o SeAR(移除语义自适应松弛):在 Toys 上 4 项指标全部跌到消融变体里最低;在 Beauty 上也持续跌。结论:SeAR 是 AdaSID 在 Toys 上最关键的组件——一旦失去"用语义证据豁免良性 overlap",统一压制反而损害了下游推荐质量;
- w/o PAR(移除进度自适应重平衡):在 Beauty 上四项指标跌到消融最差。结论:PAR 在 Beauty 上最关键——优化 emphasis 是否随训练进度演化对该数据集尤为敏感,可能与 Beauty 的协作信号结构需要更晚才"主导"训练有关;
- w/o LAS(移除负载自适应强化):在两个数据集上的退化都比较温和,但仍在 6/8 指标上落后于完整 AdaSID。结论:LAS 是稳定的"refinement"贡献者——它不主导整体增益,但在多指标多数据集上稳定地提供边际改进。
整体来看,三个自适应机制是协同的:仅靠均匀 collision 抑制(移除 SeAR)不足、仅靠空间负载(移除 PAR)也不足、缺了 LAS 又会损失局部精度调节,AdaSID 的增益来自"两阶段三维度"的协调。
5.6 超参数敏感性(Figure 4)¶
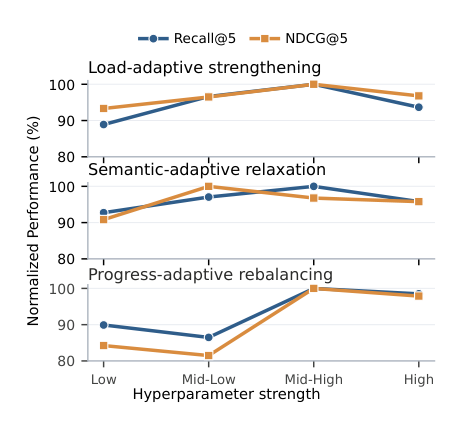
图 4 在 Beauty 上分别扫描三个自适应组件的"强度(Low → High)",看 Recall@5 / NDCG@5 的归一化变化。三条曲线显示:
- 三条曲线都不是单调上升:最佳性能出现在"中-中高"区段,说明有效的 SID 学习需要 calibrated 自适应控制——过弱不够、过强反而损害 SID 结构;
- PAR 最敏感:曲线落差最大,说明"训练进度上的优化重心切换"是 AdaSID 在 Beauty 上的关键机制;
- LAS 与 SeAR 较平缓:在更宽的强度区间都保持竞争力,便于在新场景上调参。
5.7 核心贡献总结¶
- 核心设计:把 SID overlap 处理从"固定治疗"重塑为两阶段自适应过程——SeAR 决定"该不该排斥",LAS+PAR 决定"在哪里排斥多强、何时排斥多重";
- 可观测改进:
- 公开 benchmark:8/8 指标最优,均提升 ~4.5%;
- 码本质量:在 SID 熵、平均/最弱层 perplexity、Top-1 Load 比上同时改善;
-
工业 A/B:GMV/Orders/GPM 三项业务指标同时正向,离线 AUC 三项一致正向;
-
训练 / 推理代价:所有自适应模块只在训练时生效,推理时不引入额外开销——这是工业部署友好的关键属性。
6. 与已归档相关工作的对比¶
QuaSID QuaSID: Qualification-Aware Semantic ID Learning(UESTC + Kuaishou,2026-02-28)¶
关系:显式引用并作为最强 baseline,原文仅在主表给出指标对比、未在方法层展开机制差异 · 已加载对方精读
- 共同关注的问题:两者都来自同一 UESTC + Kuaishou 联合团队,都聚焦"SID 学习中的 collision 处理"这一核心瓶颈,都注意到"已观察到的 overlap 不应被一视同仁"。两者都使用完全相同的 backbone(TIGER)、完全相同的 RVQ 设置($L=3, K=256$)、完全相同的 Amazon Toys/Beauty benchmark、完全相同的 Sentence-T5-XXL 输入特征,几乎可以视为同一研究路线的"前作 + 升级版"。
- 相近的技术骨架:都构造 trigger–target 对、都用编码器 + RVQ + 解码器 + 对比对齐 + collision 排斥的多目标训练。collision 项都采用基于编码器侧余弦距离的 margin-based hinge:$\ell^{\text{col}} = \max(0, m - d^c)$。
- 本文的差异与推进:
- 资格判别从 Hamming 距离换成连续语义相似度 + 深度感知阈值:QuaSID 用 Hamming 距离把碰撞分成 Full collision($H = 0$)和 Partial collision($0 < H \le R$),并对两类施加固定且不同的 margin($m_{\text{full}}, m_{\text{partial}}$);这本质仍是离散侧的静态分级。AdaSID 改为用编码器侧 $\text{sim}_{ij}$ 做语义资格判别,并用深度感知阈值向量 $\boldsymbol{\eta}$ 做"越深越严"的梯度门控,把"全部排斥 / 全部豁免"扩展为逐对、连续证据驱动的自适应豁免;
- 新增空间维度(LAS):QuaSID 不区分"同一种 overlap 模式被多频繁复用",AdaSID 通过 mini-batch 内 overlap 签名 $\kappa_{ij}$ 估计局部碰撞负载,对过载邻域分配更大权重;
- 新增时间维度(PAR):QuaSID 的 collision 与对比损失权重在训练全程基本固定;AdaSID 引入 $\tau$ 驱动的渐进调度,让 collision 正则在早期主导、协作对齐在后期主导;
-
AdaSID 在与 QuaSID 完全可比的设置下,在 Toys 上四项指标平均相对提升约 7.4%、Beauty 约 3.1%(见 Table 2)。这是"同设定、同背骨"的直接超越,可以认为 AdaSID 是 QuaSID 在"自适应化"方向上的实质性推进。
-
可比的方法 / 实验差异:QuaSID 将 HaMR 当作即插即用辅助目标在多种 baseline 上验证通用性;AdaSID 的当前论文未做"即插即用扩展"实验,但其 Stage 1/2 模块从结构上看同样可作为辅助目标移植到其他 SID 方法之上,是后续值得跟进的方向。
小结:AdaSID 与 QuaSID 是"同源升级"关系——QuaSID 解决了"判断哪些 overlap 是有害"的资格问题,AdaSID 把这个问题升级为"判断 + 强化 + 调度"的三维自适应,并在同设置下取得显著提升。
7. 讨论与局限性¶
7.1 论文的核心价值¶
- 概念贡献:把"SID collision 处理"从静态规则进化为"两阶段三维度自适应"——不仅看重叠是否存在、还要看语义同构 / 局部负载 / 训练进度三种自适应信号;
- 工程价值:所有自适应模块只在训练时生效,对推理 zero-cost;可以无侵入地嵌入 TIGER 类 RVQ 训练管线;
- 业务价值:在快手电商真实部署给出 GMV / Orders / GPM 同时正向的实测收益,且冷启动 CVR 的相对增益最大,与多模态 SID 的"语义复用提升新物品表示稳定性"的直觉强一致;
- 方法论启示:把"已观察到的现象"(overlap)当作"待自适应解释的事件"而不是"立刻惩罚的目标",这一视角对其他离散表示学习(如 codebook collapse、token 重复)也具借鉴价值。
7.2 局限与争议¶
- 超参数较多:深度感知阈值 $\boldsymbol{\eta}$、$f_{\max}$、$d_{\max}$、$\alpha$、$\lambda_{\text{col}}^{\min}$、$\lambda_{\text{cf}}^{\max}$、$T_{\text{start}}$、$T_{\text{end}}$ 等需要成对调优,论文虽给出参考区间但仍可能在新场景上需大量验证;
- PAR 调度形式较固定:当前用线性 schedule,是否需要更通用的 schedule(如 cosine、basis 函数)以及如何根据训练动态自适应 $T_{\text{start}}/T_{\text{end}}$ 仍是开放问题;
- LAS 估计来自 mini-batch 局部统计:在 batch 较小或 mini-batch 内 overlap 分布与全局分布偏差较大时,$c_{ij}$ 可能噪声较大;论文未讨论 batch 规模对 LAS 稳定性的敏感度;
- 与 QuaSID 的"即插即用"对照缺失:QuaSID 提供了"作为辅助目标插入多种 baseline"的扩展实验,AdaSID 当前论文没做类似扩展验证;
- 联合 user–item SID 建模未触及:论文方法仅作用于 item-side SID,未探索把同样的自适应思路引入 user 表示或更长 SID 配置(更大 $L$、更大 $K$)下的效果,这是作者在结论中提到的未来方向。
7.3 工业落地价值¶
AdaSID 的部署形态非常友好:
- 输入特征侧只需"多模态基础模型 + Sentence-T5-XXL 之类的语义抽取",与现有内容侧管线一致;
- 训练侧把 trigger–target 协作对当成 SID 学习的监督信号,能直接复用快手电商常见的 Swing 等协作推荐基础设施;
- 推理侧仅暴露"item → SID"映射,可作为下游召回(生成式 / 双塔)和排序的轻量语义信号,不改变下游服务架构;
- 对短视频和电商类"新增物品高频、长尾占比高"的场景特别友好——SID 的稳定性 + 自适应 collision 处理理论上能显著缩短新物品的"冷启动 ramp-up 时间",这一点也由 Cold-start CVR +0.08 pp 的离线结果间接验证。
整体而言,AdaSID 是"在已有 SID 学习管线上做精细化自适应"的一篇典型工业落地论文,方法思路清晰、改动局部、收益可验证,是值得在自有推荐系统中试点的方向。