Scaling Laws for Behavioral Foundation Models over User Event Sequences¶
单作者论文(Rickard Brüel Gabrielsson,Unbox AI),用约 600 次 iso-FLOP 训练($10^{15}$–$10^{19}$ FLOPs),系统地为"行为基础模型(Behavioral Foundation Model)"这一新兴范式——特征化事件嵌入器(event embedder)+ decoder-only Transformer(contextualizer)预测下一事件——标定 scaling law。它不提出新架构,而是回答一个工程问题:如果从业者已经在训练这套现已标准化的
event-embedder → transformer栈,下一次实验该按什么 scaling 法则配置?四条核心结论:(1) 计算最优时嵌入器只需约 2% 参数;(2) 行为模型在低算力下比文本 LM 更"数据偏多",但随算力上升向 Chinchilla 启发式靠拢;(3) 关键 batch size、冻结后最优负样本数、loss 与排序质量的一致性都随算力与所选评测指标漂移;(4) 评测指标本身是 scaling law 的一部分——换指标会改变计算最优配方。
研究动机与背景¶
Scaling law 把大语言模型(LLM)的研发从"一堆 ad hoc 的训练尝试"变成了一个定量的资源分配问题:给定 compute budget,应该训多大的模型、用多少 token、什么 batch size、什么优化器配方。这个问题如今正出现在文本之外的场景——工业系统越来越多地在人类行为序列上训练基础模型:推荐、购买、支付、金融事件、劳动力活动等(论文引用了 Visa TREASURE、TransactionGPT、Stripe PFM、Revolut PRAGMA、J.P. Morgan TradeFM、HSTU、Wukong、Netflix 基础模型等一长串工业系统)。这些模型已经大到"scaling-law 决策出错代价很高"的程度,但该领域几乎没有 Chinchilla 级别的定量指导。
行为基础模型与文本 LM 的本质差异(影响 scaling):文本 LM 中一个 token 通常是不透明的词表 id;而行为模型中一个事件是特征丰富的——一个商品或交易可以带文本、类别元数据、视觉特征、价格、时间戳、支付渠道等结构化字段,而且 catalogue(商品目录)会随时间变化。现代系统因此采用两段式架构:
- 事件嵌入器(event embedder):一个特征化模块,把每个多模态 item 映射成一个稠密向量;
- 上下文器(contextualizer):通常是 decoder-only Transformer,对一串事件嵌入建模并预测下一个事件。
这个架构带来了文本 LM 里不存在的 scaling 问题。嵌入器最好端到端地在序列目标上训练,但在百万级 item 目录上、每个候选 item 都重新过一遍嵌入器做 full softmax,serving 时代价高到不可行。现有做法是两阶段配方:先用 in-batch sampled softmax 把嵌入器和上下文器联合训练,然后冻结并缓存嵌入器,只继续训练上下文器、并用一个更大的采样负样本池。由此这套系统至少有四个耦合旋钮:
- 多少容量应该分给嵌入器(vs 上下文器);
- batch size 怎么选才数据高效;
- compute 怎么在模型规模 $N$ 和数据量 $D$ 之间切分;
- 嵌入器冻结后采样多少负样本 $K$。
论文在单一行为模型栈 + 单一真实交互语料上标定这四个旋钮,研究跨度约 600 次运行、$C \in [10^{15}, 10^{19}]$ FLOPs,全程共享同一套评测管线。目标不是提出新架构,而是回答更基础的问题:如果从业者已经在训练这套标准的 event-embedder → transformer 栈,下一次实验该用什么 scaling law 指导?
四条主要发现(Introduction 自述):
- 计算最优的事件嵌入器很小。 跨四个数量级的 compute,两项 iso-FLOP 拟合把最优嵌入器份额放在 $s^\star \approx 2\%$ 参数的窄带内。原因是两个不对称:嵌入器参数每个 item 被触碰更多次,且热门 item 在一次训练里被重复成百上千次而上下文窗口几乎不重复。
- 行为 scaling 初期数据偏多,但向 Chinchilla 启发式移动。 计算最优的 $D/N$ 比从 $10^{15}$ FLOPs 的约 340 降到 $10^{19}$ FLOPs 的约 36,逼近文本 LM 的经验值。拟合的模型规模指数为 $N^\star \propto C^{0.617 \pm 0.025}$(在 val_loss 下),各排序指标下指数相近。
- 评测指标是 scaling law 的一部分。 跨 budget 的指数在各指标间相对稳定,但可执行的配方不稳定:关键 batch size、冻结后最优负样本数、loss 与排序质量的一致性,都依赖 compute、评测 regime 和目标指标。特别是训练用的 sampled-softmax loss 并不总是 full-catalogue 排序质量的可靠代理。
- 负采样在大规模上从 compute 问题变成 memory 问题。 小 budget 下平滑拟合把有用负样本数放在十万量级且依赖指标;到 $C=10^{19}$,所有 headline 指标在我们训过的最大 $K$ 处仍在改善,约束变成了 candidate-axis 内存而非 FLOPs。
下表(Table 1)是论文的实验地图,全文按此表组织。
| Axis(轴) | 主问题 | 主扫描范围 | Headline 结果 |
|---|---|---|---|
| Architecture | 嵌入器应该多大? | $s = 0$–$50\%$ | $s^\star \approx 2\%$ |
| Batch size | 数据效率的拐点在哪? | $B = 64$–$2048$ | $B_{\mathrm{crit}}$ 依赖指标 |
| Model/data 分配 | compute 怎么切成 $(N,D)$? | $10^{15}$–$10^{19}$ FLOPs | $D/N$ 从 $344 \to 36$ |
| Negative sampling | 冻结后采样多少负样本? | $K = 0$–$2\mathrm{M}$ | 依赖指标;高 $C$ 时受内存约束 |
| Metric/eval regime | 各指标和候选池排序一致吗? | 跨指标 + 局部 vs 全局相关性 | regime 内高度相关;局部 loss ≠ 全局 loss |
核心方法 / 模型架构¶
模型¶
所有实验用同一套两段式 next-event 预测架构。特征化嵌入器消费每个目录 item 的原始字段,产出一个隐藏维 $h$ 的事件嵌入。上下文器是一个 decoder-only Transformer,消费一段 $L_{\mathrm{seq}} = 256$ 个事件嵌入的序列,用 sampled softmax 预测下一个事件。
参数计数 $N$ 不含词表参数,分解为嵌入器参数 $p_e$ 与上下文器参数 $p$;定义嵌入器份额
$$s = p_e / N \tag{1a}$$
两阶段训练¶
遵循已部署的配方,所有运行都用两阶段:
- Stage 1(嵌入器未冻结):嵌入器和上下文器在 next-event 目标上联合训练,用 in-batch sampled softmax——正样本是真实的下一个 item,负样本是同一个全局 batch 里其他位置的 target,所以候选池是 batch 里 $\le BL_{\mathrm{seq}}$ 个唯一 item。
- Stage 2(嵌入器冻结):训练好的嵌入器被冻结、事件嵌入被缓存,只有上下文器继续训练;此时每个位置对一个更大的、$K$ 个均匀采样的额外负样本池(叠加在 in-batch 候选之上)打分。
Stage 1 决定架构、batch size、$(N,D)$ 分配;Stage 2 在固定 Stage 1 骨干上单独研究负样本池大小 $K$。这个切分正是让百万级目录在 serving 时可行的关键,也定义了下面两个评测 regime。
数据¶
所有扫描在一个匿名的真实世界零售交互语料上训练,混合线下和线上消费者活动(商品搜索、浏览、点击、购买),组织成每个训练样本 $L_{\mathrm{seq}} = 256$ 个事件的序列。每个事件是多模态的:自由文本描述、类别字段(事件类型、商家、设备等)、数值字段(价格、时间戳等)、可选视觉特征。目录规模约 $10^8$ 个唯一动作,训练消耗约 $10^9$ 个事件 token。 Item 流行度强烈长尾:一小撮高频动作在单次训练里被观察成百上千次,而长尾大部分只被看 1–2 次。正是这个不对称驱动了嵌入器/上下文器的 compute 权衡。
训练配方¶
AdamW,weight decay 0.1,bf16 混合精度,全分片数据并行(FSDP)。架构、分配、采样实验用 cosine 学习率衰减 + 5–10% 线性 warm-up。batch-size 实验用常数学习率,使得"updates-to-target"衡量的是优化效率而非 schedule 形状。学习率按每个 cell 从训练 loss(不是 validation loss)选取。
计算核算(Compute accounting)¶
训练 compute 用标准化分桶报告,目标 $C \approx 6ND$(沿用 LM scaling-law 惯例),其中 $D = TBL_{\mathrm{seq}}$ 是 $T$ 步优化、全局 batch size $B$ 下消费的事件 token 数。实验生成器用更细的 Kaplan 式 per-step 公式:
$$F_{\mathrm{step}} = 6\,B\,L_{\mathrm{seq}}\,(t\,p_e + p + 3\,B\,L_{\mathrm{seq}}\,h) \tag{1}$$
其中 $t = 24$ 是嵌入器以事件计的上下文长度。隐藏维 $h$ 不是全局常数:它按架构 cell 设定,既决定事件嵌入维度、又决定 in-batch contrastive 打分的维度。在嵌入器份额扫描里,改变目标份额 $s = p_e/N$ 同时改变 $h$ 和嵌入器参数 $p_e$;上下文器参数 $p$ 由固定 $D/N$ 比下的目标总量 $N$ 推出。第三项 $3BL_{\mathrm{seq}}h$ 是 in-batch contrastive 打分项(候选嵌入在数据并行 rank 间 all-gather 后)。定义 $N_{\mathrm{eff}} \equiv p + t p_e$ 用于解释嵌入器/上下文器权衡。
评测¶
评测协议刻意把训练系统用的两个 regime 分开:
- 嵌入器冻结前(Stage 1,batch-local):checkpoint 对每个 validation batch 里的唯一 target item 打分,匹配训练用的 in-batch sampled softmax;
- 冻结后(Stage 2,full-catalogue / global):checkpoint 对完整缓存的已部署商品目录打分,匹配已部署的检索设置。为可重复评测,对约 13.6M item 的固定子集打分(仍比 batch-local 池大约 1500 倍)。
报告指标:cross-entropy、perplexity、recall@$k$、NDCG@10、MRR@10、coverage@$k$、predictive entropy。全文 "training loss" 指模型优化的 sampled-softmax 目标,"validation loss" 指对应评测 regime 下的留出 cross-entropy。
指标定义(附录 A,公式完整摘录)。 每个 query position $q$ 对候选集 $\mathcal{C}$ 打分,按点积分数 $z_{q,j} = \langle h_q, e_j\rangle$ 排序;$r_q$ 是真实下一个事件在 $\mathcal{C}$ 上的 1-索引排名($r_q=1$ 是 top hit):
$$\mathrm{recall}@K = \frac{1}{N}\sum_{q=1}^{N}\mathbb{1}[r_q \le K],\quad \mathrm{NDCG}@K = \frac{1}{N}\sum_{q=1}^{N}\frac{\mathbb{1}[r_q \le K]}{\log_2(r_q+1)},\quad \mathrm{MRR}@K = \frac{1}{N}\sum_{q=1}^{N}\frac{\mathbb{1}[r_q \le K]}{r_q} \tag{7}$$
$$\mathrm{CE} = \frac{1}{N}\sum_{q=1}^{N}\big(-\log p_q(\mathrm{target}_q)\big),\quad \mathrm{perplexity} = e^{\mathrm{CE}},\quad \mathrm{entropy} = \frac{1}{N}\sum_{q=1}^{N}\Big(-\sum_{j\in\mathcal{C}} p_{q,j}\log p_{q,j}\Big) \tag{9}$$
候选集 $\mathcal{C}$ 同时固定了排序池($r_q$)和 softmax 归一化项($p_q$),所以 loss / entropy / 排序分数只在同一个 stage 内可比——这正是 §7 为什么按 stage 报告 loss-排序相关性的原因。
关键技术细节与主要实验结果¶
1. 嵌入器份额扫描(§3.1):计算最优嵌入器约 2% 参数¶
问题:固定 compute 下,多少容量该给特征化嵌入器、多少给 Transformer 上下文器?设置:固定 $D/N \approx 15$(Chinchilla),在四个 compute budget 上扫嵌入器份额 $s \in [0, 50\%]$(6% 以下更密),每 cell 三个学习率,按训练 loss 选最佳 LR,不碰 validation set,再对每个 per-budget 的 share-loss 曲线拟合两项 iso-FLOP 形式:
$$\mathrm{sign}\cdot y(s) = \underbrace{a\,s^{\alpha}}_{\text{上下文器饥饿}} + \underbrace{b\,s^{-\beta}}_{\text{嵌入器饥饿}} + E \tag{2}$$
闭式最优 $s^\star = (b\beta/(a\alpha))^{1/(\alpha+\beta)}$,$\mathrm{sign}=+1$ 用于"越小越好"的指标。$\alpha$ 是上下文器饥饿指数(过度分配给嵌入器的惩罚),$\beta$ 是嵌入器饥饿指数($s\to 0$ 的惩罚)。
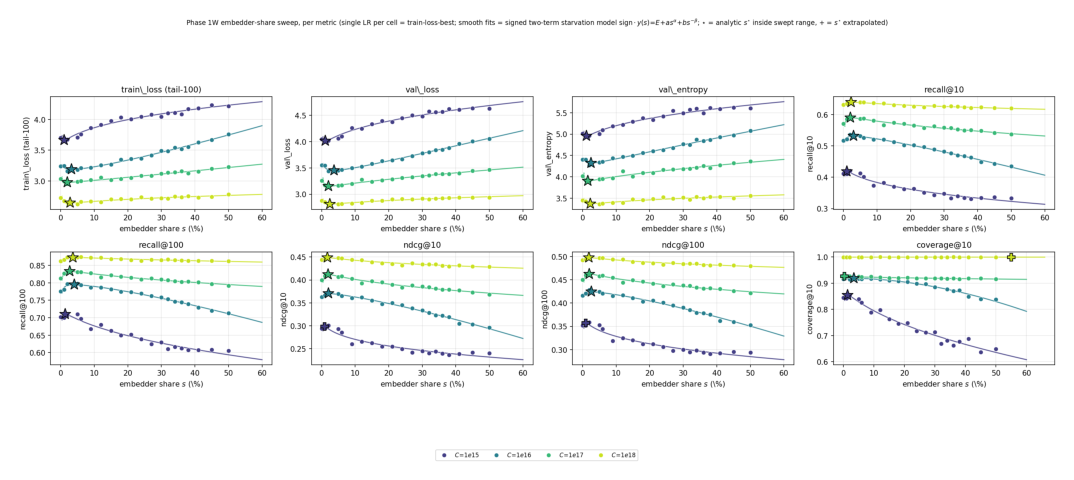
发现:share-loss 关系干净——loss 在小份额带 $s \in [2,6]\%$ 几乎平坦($\Delta \le 0.06$ nat);超过 6% 单调上升(从 6% 到 27% 在 $C=10^{15}$ 要付约 0.40 nat,$C=10^{18}$ 降到约 0.09 nat);低于 2% 时浅下降。两项拟合 $L(s) = E + a s^\alpha + b s^{-\beta}$ 把每个 budget 坍缩成单一闭式最优 $s^\star \in [1.1\%, 3.7\%]$:最优嵌入器份额在四个 budget 上恒为 $s^\star \approx 2$–$3\%$(val_loss 拟合 $s^\star \propto C^{+0.07}$,斜率与零无法区分)。换其他每个 headline 指标,$s^\star$ 都落在 $[1\%, 6\%]$ 带内,$1\sigma$ 内一致(recall@10/NDCG@10/NDCG@100 给 $s^\star \propto C^{+0.10}$;recall@100 漂移最大,$s^\star \in [1.4\%, 4.1\%]$、$s^\star \propto C^{+0.11}$——因为 100 长的推荐列表能容忍更多目录表征容量)。
下表(Table 2)给出各 budget、各指标的解析 $s^\star$ 与 val_loss 指数:
| Budget | $s^\star$(val_loss) | $s^\star$(recall@10) | $s^\star$(NDCG@10) | $s^\star$(coverage@10) | $\alpha$ | $\beta$ |
|---|---|---|---|---|---|---|
| $10^{15}$ | 1.1% | 1.1% | boundary | 1.3% | 0.40 | 1.03 |
| $10^{16}$ | 3.7% | 3.0% | 2.8% | 3.5% | 0.94 | 0.26 |
| $10^{17}$ | 2.0% | 2.1% | 1.9% | boundary | 0.75 | 1.65 |
| $10^{18}$ | 2.4% | 2.3% | 1.8% | boundary | 0.48 | 1.06 |
为什么嵌入器这么小(两个不对称,论文核心机制论证):
- (i) Compute 不对称:上下文器每个 $B\times L$ batch 只跑一次,而嵌入器内部的文本编码器对 $BL$ 段短序列每步都跑。每个嵌入器参数因此被触碰约 $t$ 倍于每个上下文器参数(正是 §2 的 $N_{\mathrm{eff}} = p + t p_e$ 修正)。
- (ii) 有效 epoch 不对称:在 sub-one-epoch 的训练 schedule 下,上下文器实际上从不两次看到同一个 $L$-事件窗口,而嵌入器把每个热门 item 看成百上千次。嵌入器因此在同样的全局正则化下,比上下文器暴露在多得多的记忆压力下,所以 $s^\star \approx 2\%$ 应被读作"当前(基本无正则)配方"的答案;加嵌入器特有正则可能把 $s^\star$ 上移(留作 future work)。
论文还把这个尺度与多模态基础模型对比:LLaVA / Flamingo / BLIP-2 的视觉编码器占总参数的几十个百分点;这些系统据作者所知没用同样的 encoder-share scaling-law 扫描标定过,检验多模态编码器是否服从类似的 share law 是自然的 future work。
深度作为次级旋钮(§3.2):宽度扫描固定深度变份额;深度扫描则在 iso-FLOP 深度和约束($L_{\mathrm{ctx}} + L_{\mathrm{text}}$ 固定)上交换文本编码器深度与上下文器深度。发现 per-budget 深度最优 cell 诱导出的嵌入器份额仍落在宽度扫描的 $s \approx 2\%$ 带内($C=10^{16}$ 给 $s^\star = 1.82\%$,$C=10^{17}$ 给 $s^\star = 1.80\%$)。结论:深度是二阶旋钮,一旦 $s \le 2\%$ 设好,任何配置都可接受;$s^\star \approx 2\%$ 保留为主架构推荐。
2. 跨指标的关键 batch size(§4)¶
问题:全局 batch 能涨多大才停止"买"到成比例的进步?设置:在 $B \in \{64,128,256,512,1024,2048\}$ 上训练,平方根 LR 缩放 + 常数 LR schedule,读出 $S_m(B)$(指标首次越过 per-metric iso-target $T_m$ 的最小更新数),拟合 Kaplan / McCandlish 关键 batch 模型:
$$S_m(B) = S_m^{\min}\left(1 + \frac{B_{\mathrm{crit}}^{(m)}}{B}\right) \tag{3}$$
下表(Table 3)给出 per-metric 的关键 batch size:
| Metric | $T_m$ | $S(64)$ | $S(512)$ | $S(2048)$ | $B_{\mathrm{crit}}$ | $R^2$ |
|---|---|---|---|---|---|---|
| val_loss | 3.86 | 7700 | 1450 | 1550 | 574 | 0.96 |
| recall@10 | 0.486 | 7350 | 1450 | 1250 | 544 | 0.99 |
| NDCG@10 | 0.314 | 6550 | 1500 | 1650 | 274 | 0.99 |
| MRR@10 | 0.257 | 5950 | 1850 | 1850 | 201 | 0.99 |
| val_entropy | 5.39 | 7650 | 350 | (单调,无平台) | —* | 0.92 |
发现:(i) loss 和 recall 共享拐点:val_loss 与 recall@10 的 $B_{\mathrm{crit}} \approx 570$ 几乎相同——cross-entropy 的 batch-size 拐点和主导检索指标的拐点重合。(ii) 位置加权排序指标更早饱和:NDCG@10 / MRR@10 在 $B_{\mathrm{crit}} \approx 200$–$275$ 就饱和。论文给出敏感度论证:下游指标 $M = f(L)$ 在工作带内有小 $|f'(L)|$ 时,更大 $B$ 的梯度噪声降低只换来成比例更小的 $M$ 进步,于是在更小 $B$ 就进入 Kaplan 曲率区。(iii) $B = 2048$ 刚好越过 val_loss 拐点,$S_m(2048) \ge S_m(1024)$,是测过的最大单节点 batch,推荐给吞吐受限的生产训练。
3. 模型/数据分配(§5):行为模型初期数据偏多,逐渐逼近 Chinchilla¶
问题:给定 compute,训更大的模型用更少 token,还是更小的模型用更多数据?设置:在主固定架构网格 $(h, L_{\mathrm{ctx}})$ 上训 45 个上下文器,全部用嵌入器份额 $s = 2\%$,全局 batch 按 budget 缩放,cosine LR 衰减。以 val_loss(batch-local 池)为主目标。
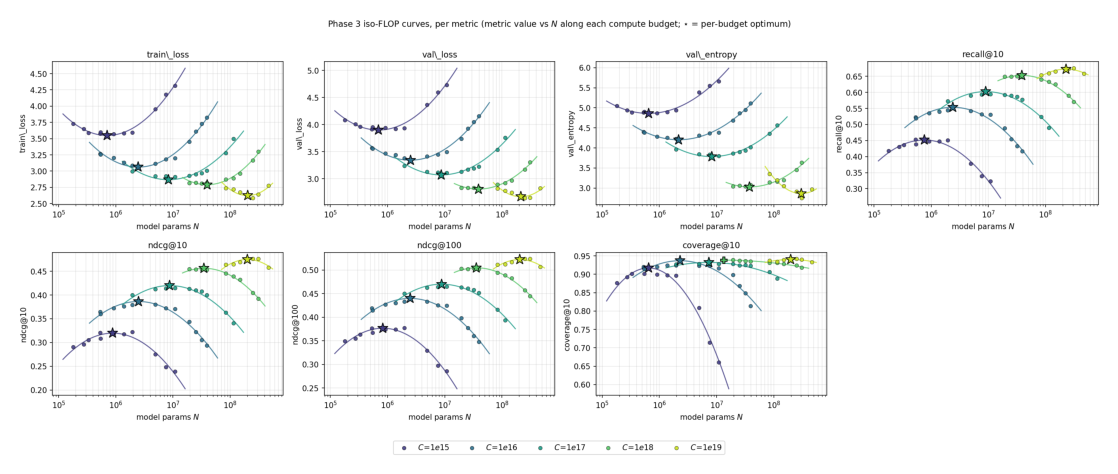
下表(Table 4)给出 val_loss 最优分配(grid winner 与 parabolic 拟合两套):
| Budget | $N^\star$(grid) | $D^\star$(grid) | val_loss | R@10 | NDCG@10 | $D/N$(grid) | $N^\star$(parab) | $D^\star$(parab) | $D/N$(parab) |
|---|---|---|---|---|---|---|---|---|---|
| $10^{15}$ | 532k | 84M | 3.914 | 0.453 | 0.302 | 157 | 695k | 240M | 345 |
| $10^{16}$ | 1.95M | 251M | 3.376 | 0.544 | 0.380 | 128 | 2.51M | 664M | 265 |
| $10^{17}$ | 10.9M | 537M | 3.108 | 0.594 | 0.414 | 49 | 8.67M | 1.92B | 222 |
| $10^{18}$ | 19.4M | 2.63B | 2.832 | 0.649 | 0.455 | 135 | 38.9M | 4.28B | 110 |
| $10^{19}$ | 251M | 3.65B | 2.641 | 0.673 | 0.476 | 15 | 216M | 7.73B | 36 |
Power-law 拟合(val 最优,抛物线,Hoffmann Approach 2):
$$N^\star(C) = 3.35\times 10^{-4}\,C^{0.617 \pm 0.025} \tag{4}$$ $$D^\star(C) = 4.97\times 10^{2}\,C^{0.383 \pm 0.025} \tag{5}$$
其中 $b + b' = 1$ 由 Approach 2 构造保证。分配适度偏参数($b_N > b_D$)。
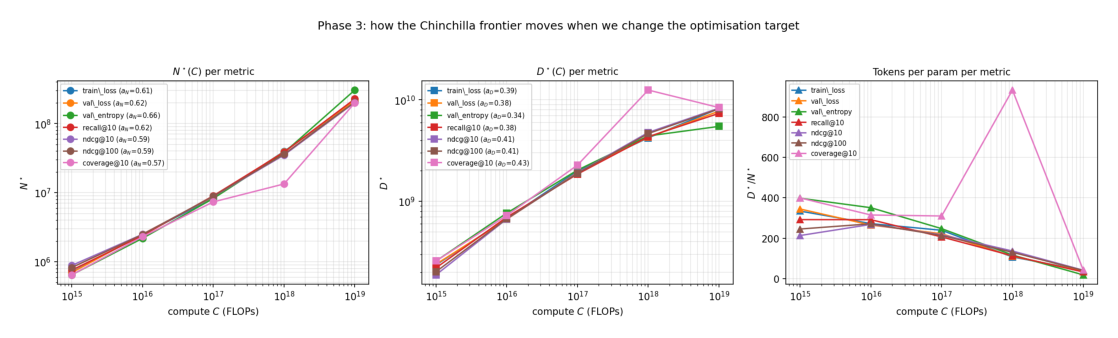
数据偏多但向 Chinchilla 收窄:val 最优点给出的 $D^\star/N^\star$ 随 $C$ 单调下降:$344 \to 265 \to 222 \to 110 \to 36$(对应 $C = 10^{15} \to 10^{19}$)。在较低四个 budget 上几乎比文本 LM 的 Chinchilla 启发式 $D/N \approx 20$ 高近一个数量级;$C = 10^{19}$ 把最优拉到 Chinchilla 的约 2 倍以内,并把轨迹外推向生产规模的文本 LM 启发式。
分配律对指标稳健(Table 5,Hoffmann 风格指数):对每个指标的抛物线最优重拟 $N^\star \propto C^{a_N}$,五个 headline 指标全落在窄带 $a_N \in [0.57, 0.66]$(val_loss $0.617\pm0.025$、recall@10 $0.616\pm0.029$、NDCG@10 $0.586\pm0.033$、coverage@10 $0.574\pm0.079$);val_loss-vs-NDCG@10 的指数差 $\Delta a_N \approx 0.03$ 在自身斜率不确定性内。所以 per-budget 的胜出 $(h,L)$ cell 在各指标间确实有分歧(即"该上线哪个 cell"会变),但 scaling law 本身是共享的——指数可跨指标转移,配方不行。
4. 负样本候选池缩放(§6):从 compute 问题变成 memory 问题¶
嵌入器冻结后,缓存目录让训练能用多得多的采样负样本。设置:在每个 budget 的 grid-winner $N^\star$ 上下文器上,扫 $K \in \{0,16k,32k,64k,131k,262k,524k,1M,2M\}$。所有 $K^\star$ 声明都来自 full-catalogue 评测(部署候选集),不是训练 sampled-softmax(其候选数 $V_{\mathrm{softmax}} = 16384 + K$ 随 $K$ 变)。把 iso-FLOP 曲线建模为两个相反项 + 不可约地板:
$$y(K) = \underbrace{a\,K^{\alpha}}_{\text{饥饿}} + \underbrace{b\,K^{-\beta}}_{\text{采样偏差}} + E \tag{6}$$
闭式最优 $K^\star = (b\beta/(a\alpha))^{1/(\alpha+\beta)}$。饥饿项是线性-in-$K$ 的 per-step 成本(在固定 $C$ 下缩短可用步数 $T$);采样偏差项是 sampled-softmax 配分函数估计的 $\propto 1/K$ 方差。
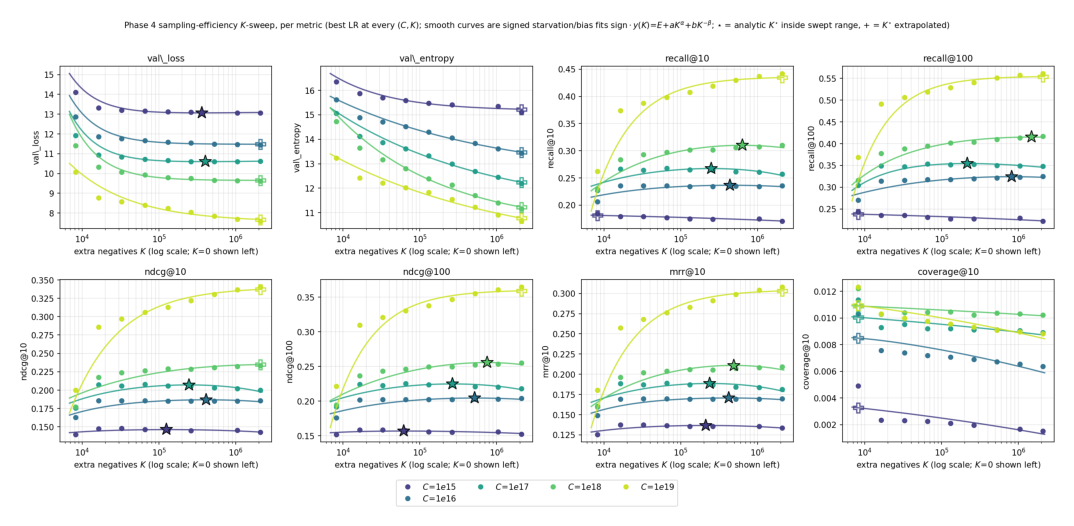
下表(Table 6)给出各 budget、各指标的解析 $K^\star$(括号内是离散网格 argmax):
| Budget | $K^\star$(val_loss) | $K^\star$(recall@10) | $K^\star$(NDCG@10) | $K^\star$(MRR@10) | $\beta$(val_loss) | $\beta$(recall@10) |
|---|---|---|---|---|---|---|
| $10^{15}$ | 360k (2M) | bound. (0) | 125k (33k) | 212k (33k) | 1.24 | 2.00† |
| $10^{16}$ | bound. (2M) | 437k (16k) | 412k (65k) | 420k (65k) | 1.19 | 0.39 |
| $10^{17}$ | 403k (1M) | 249k (65k) | 237k (65k) | 245k (65k) | 1.17 | 0.40 |
| $10^{18}$ | bound. (2M) | 632k (2M) | bound. (2M) | 489k (2M) | 1.17 | 0.41 |
| $10^{19}$ | bound. (2M) | bound. (2M) | bound. (2M) | bound. (2M) | 0.55 | 0.87 |
发现:(i) "正确" $K$ 依赖指标:离散网格上 full-catalogue val_loss 和 recall@10 会选很不同的点($C=10^{17}$ 时分别是 1M 和 65k 个负样本);从平滑拟合读则差距缩小到 400k vs 250k,但不消失——loss-like 指标总比排序指标偏好更多负样本(当两者都有内部最优时)。(ii) 可执行范围比原始网格更窄:跨内部拟合,排序指标最优落在 $K^\star \in [125k, 870k]$,跨 budget 斜率弱($K^\star \propto C^{0.08}$–$C^{0.15}$)。偏差指数 $\beta$ 也把 loss 和排序分开:val_loss 的 $\beta \approx 1.2$ vs 排序指标 $\beta \in [0.39, 0.56]$。(iii) 最大 budget 上 $K$ 不再受 compute 限制:$C=10^{19}$ 时每个指标在训过的最大 $K=2M$ 处仍在改善,解析最优落在 swept 范围外;瓶颈变成 candidate-axis 的 softmax-logit 内存占用(随 $K$ 线性增长),要继续往前推需要 candidate-axis checkpointing / candidate sharding / 采样或分层近似配分函数。简单配方:内存不绑时用十万量级的 $K$,$C \approx 10^{18}$ 时封顶约 $10^6$,$C \ge 10^{19}$ 当成内存工程问题而非纯算力分配问题。
5. 跨指标、跨 regime 评测(§7):评测指标是 scaling law 的一部分¶
这是论文的方法论核心。优化器看到的是 sampled-softmax loss,而部署系统服务的是 full-catalogue 排序指标。这两类量经常相关,但不总选同一个 batch size、架构 cell 或负采样配方。本节汇总 408 个 validation evaluation:
regime 内相关性很紧:在任一 stage 内,val_loss、val_ppl、val_entropy 和排序指标(recall@$k$、NDCG@$k$,$k \in \{1,5,10,20,50,100\}$)互相相关 $|\rho_S| \ge 0.94$。Coverage 是唯一明显解耦的指标。
为什么训练 loss 和排序会分歧(机制,公式)。每步模型对从采样分布 $q$ 抽的候选集 $\mathcal{B} \subset \mathcal{V}$ 打分,最小化 sampled cross-entropy:
$$\mathcal{L}(h, \mathcal{B}) = -\log\frac{\exp\langle h, e_\theta(y^+)\rangle}{\sum_{x\in\mathcal{B}}\exp\langle h, e_\theta(x)\rangle} \tag{8a}$$
由标准重要性加权论证,只有当每个候选 logit 被 $-\log q(x)$ 修正时这才是 full softmax 的无偏估计;没有修正时唯一最小化者满足 $f^\star_\theta(y\mid h) \propto p(y\mid h)/q(y)$。Stage 1 里每个候选本身是一个 target,$q \approx p$,loss 最小化者对目录是均匀的(绝对流行度从 in-batch 目标里不可辨识,只学到 within-batch 排序)。Stage 2 里 $K$ 个均匀额外负样本时,$q$ 随 $K\to\infty$ 趋于均匀,最小化者逼近真实条件分布。Eval 指标对完整目录打分、依赖边际 $f_\theta$,所以 $1/q$ 修正的缺失直接体现在 loss-to-NDCG 映射里,机制上产生 §7(c) 的符号翻转和 (d) 的跨 regime 不对称。
高相关不是全部:两个 $\rho_S = -0.99$ 的指标仍可能在"哪个 cell 在每个 budget 胜出"上分歧——排行榜挤在一起时尤其如此。四条轴上的具体分歧:
- (a) Per-metric 关键 batch(§4):位置加权排序(NDCG@10/MRR@10)$B_{\mathrm{crit}} \approx 200$–$275$ vs val_loss/recall@10 的约 570;同模型、同 iso-target 机制,四个不同拐点。
- (b) Per-metric Stage 2 $K^\star$(§6):iso 拟合的解析最优跨指标分歧,$C=10^{17}$ 时 $K^\star_{\mathrm{loss}} = 400k$ vs $K^\star_{\mathrm{recall@10}} = 250k$,四个内部 budget 上排序指标 $K^\star \in [125k, 870k]$。loss 在 $\log K$ 上的 landscape 在大 budget 浅,但每个 budget loss-vs-ranking 的排序是保持的:loss 偏好更多负样本。
- (c) Stage 2 loss-vs-ranking 排序相关随 compute 翻号:Stage 2 $K$-扫描里 val_loss(越小越好)和 recall@10(越大越好)的 Spearman 从 $C=10^{15}$ 的 $\rho_S = +0.93$(不对齐)到 $C=10^{18}$ 的 $\rho_S = -1.00$(完美对齐)。Stage 1 里 loss-vs-ranking 锁在 $\rho_S \approx -0.98$。符号翻转源于变化源不同:Stage 1 变架构(更大模型 → 更低 loss 且更高 recall),Stage 2 变 $K$。更多负样本锐化条件分布,但最终可能压平或恶化排序。$C=10^{18}$ 的对齐确认:一旦流行度偏差被移除($K$ 大到采样分布逼近均匀),两个 regime 在 $K$-cell 排序上一致。
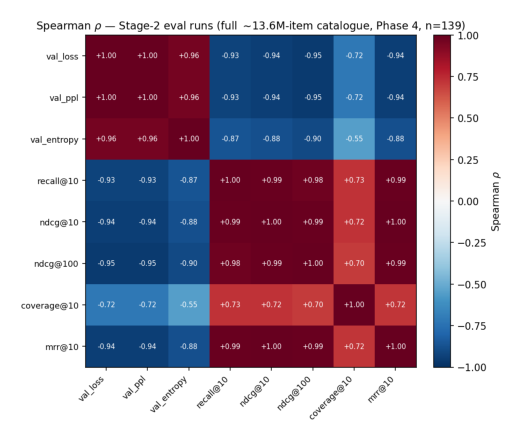
- (d) batch-local 和 full-catalogue 评测主要在 loss 上分歧:成对重评同一批 checkpoint 时,batch-local val_loss 是 full-catalogue val_loss 的差代理($\rho_S = -0.95$,$B=512$,$C=10^{19}$);但 batch-local 排序指标尤其 NDCG@10/MRR@10 仍与 full-catalogue 排序强相关($\rho_S = +0.90$ 和 $+0.95$)。所以 batch-local 排序指标是比较架构/分配 cell 的实用代理,但要注意接近平手 cell 间的边际排序差距跨 regime 不可靠。
(e) 排序对打分历史长度的稳定性依赖扫描:每个 checkpoint 在打分历史长度 $cl \in \{3,5,10,20,50,100\}$ 上记指标。架构/分配扫描下稳定(worst-case 配对 Spearman $\rho_{\min} \ge 0.93$,$C \le 10^{18}$);Stage 2 $K$ 扫描在小 budget 不稳($C \le 10^{17}$ 时 $\rho_{\min} \in [0.26, 0.73]$,意味着最佳 $K$ 可能取决于评测强调短/长历史 query),$C \ge 10^{18}$ 重新对齐($\rho_{\min} \ge 0.87$)。
实践教益:跨 budget 的 Hoffmann 指数在指标间一致到斜率不确定性内(scaling law 跨指标转移),但 per-budget 配方(该上哪个 $(h,L)$ cell 或哪个 $K$)会变,在负采样轴上影响最大。在拟合 scaling law 之前 选好部署目标指标,是这篇能带到其他行为基础模型的唯一实践建议。
消融与分析¶
最大更新参数化(MuP):一个负结果¶
论文把 MuP(Maximal Update Parametrization,Yang & Hu 2021)在四个模型规模(约 10M 到约 500M 总参数)上扫描,对比默认的 truncated-normal 风格初始化,LR 范围 $[10^{-5}, 5\times 10^{-2}]$。MuP 兑现了它核心的 LR-可转移承诺:MuP 最优 LR 跨宽度的跨度是 0.30 个数量级 vs 默认的 0.70,且每个 MuP 最优都是验证过的局部极小。但默认初始化在每个规模上 loss 都更低 0.68–0.92 nat(Table 14):
| Init | TINY | SMALL | MEDIUM | LARGE |
|---|---|---|---|---|
| Default | 4.626 | 4.210 | 3.594 | 2.904 |
| MuP | 5.547 | 5.103 | 4.516 | 3.584 |
| Default − MuP | −0.921 | −0.893 | −0.922 | −0.680 |
每个试过的 MuP 变体(含 per-layer MuP 和 FLOP-budget-matched 变体)都是同样的 pattern。论文因此保留默认初始化,付每阶段 LR 扫描的小代价。
训练 loss 是否能代理评测指标¶
附录 G 给出 train-surrogate 分配(Table 13,tail-100 训练 loss 最优):$D/N$ 给 $68 \to 128 \to 49 \to 56 \to 15$,train-surrogate $N^\star \propto C^{0.612\pm0.024}$,与 val-surrogate 的 $0.617$ 在 0.005 内。三项参数式拟合 $L_{\mathrm{train}}(N,D) = 2.570 + 2.46\times 10^3/N^{0.696} + 8.08\times 10^2/D^{0.384}$ 在 48 个合并训练点上 RMSE = 0.084 nat。
但 Stage 2 的便宜 in-batch 训练 loss 是对 $K$ 选择最坏的信号:因为优化的是 batch-local + extra-candidate cross-entropy 的平均,$K$ 增大时 extra-candidate 项(对越来越大的负样本池打分)主导梯度,优化器交易掉 in-batch loss,所以 in-batch loss 随 $K$ 上升,即便模型在 full-catalogue 任务上变好($C=10^{18}$/$10^{19}$ 时 in-batch loss 与每个部署指标几乎完美反相关,$\rho_S \approx +0.97$ 到 $+1.00$)。最小化 in-batch loss 的 $K$ 是 $K=0$,但每个 full-catalogue 指标一直改善到最大 $K=2.1M$。 便宜的训练时 loss 对选 $K$ 至少无信息、最坏有害。
与已归档相关工作的对比¶
Compute Optimal Tokenization Compute Optimal Tokenization(Meta FAIR,2026-05-02)¶
关系:独立并发(本文未引用该工作,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都识别出"Chinchilla scaling law 隐藏了一个被忽视的轴,把这个轴显式纳入会改变 compute-optimal 配方"。BLT 论文的隐藏轴是 tokenizer 压缩率 $T$(数据到底以 token 还是 byte 计),并把 Chinchilla 的"20 token/param"推广为更稳健的"约 60 byte/param";本文的隐藏轴是嵌入器/上下文器的参数切分 $s$ 和评测指标本身,并发现行为模型的 $D/N$ 从约 340 向 Chinchilla 收窄。
- 相近的技术骨架:两者方法流程图几乎抽象重合——在一个 (compute $C$ × 额外轴) 的笛卡尔网格上跑数百到上千次 iso-FLOP 训练(BLT:988+320 个模型;本文:约 600),对每个网格做 IsoFLOP 抛物线拟合找 per-budget 最优,再把最优点拟成 $C$ 的双幂律(BLT 的 $N^\star \cong N_0 C^{1-\alpha} T^{1-\beta}$ vs 本文的 $N^\star \propto C^{0.617}$),并定义一个"每参数应配多少数据"的比值(BLT 的 byte/param $\rho^\star$ vs 本文的 $D/N$)随 compute 的趋势。两者都遵循 Li et al. (2025) 风格的两阶段 fit(先估最优 $(B^\star/N^\star)$,再估最优 loss)。
- 本文的差异与推进:BLT 在文本 LM、单一 cross-entropy 目标上做;本文在行为序列、两阶段 frozen-embedder + sampled-softmax 设定上做,并多出一个 BLT 没有的核心洞见——训练目标(sampled loss)与部署目标(full-catalogue 排序)系统性地分歧,使"评测指标本身成为 scaling law 的一部分"。BLT 的额外轴(压缩率)在训练时可控且单一目标;本文的额外轴涉及两个评测 regime 的不可比性(§7),更复杂。
- 可比的方法/实验差异:BLT 发现最优压缩率随 budget 下降(更大预算用更细 tokenizer);本文发现最优嵌入器份额近常数($C^{+0.07}$)、$D/N$ 下降。两者都用"换一个指标/单位会改变配方"作为核心论点,但 BLT 的结论可跨语言验证,本文的结论可跨 7 个排序/loss 指标验证。
Prescriptive Scaling Laws for Data Constrained Training Prescriptive Scaling Laws for Data-Constrained Training(Cornell,2026-05-02)¶
关系:独立并发(本文未引用,框架相近)· 已加载对方精读
- 共同关注的问题:两篇都在"标准 Chinchilla 形式漏掉了一个机制,补上它会给出定性不同的 compute-optimal 建议"。Cornell 补的是多 epoch 重复训练下的过拟合回升(更大模型在重复数据上过拟合更快,loss 会回升,Chinchilla 完全错过);本文补的是采样目标与排序指标的不可比性以及嵌入器特有的有效-epoch 不对称(热门 item 被重复成百上千次)。两者都关心"数据被重复消费"导致的标准 scaling law 失效。
- 相近的技术骨架:都在 (N × D/repetition) 网格上训数百个模型(Cornell:300+,15M–1B 参数、最高 16 epoch;本文:约 600),都对 Chinchilla 三项式做加性修正并用拟合优度 / 信息准则在复杂度阶梯上选形式。
- 本文的差异与推进:Cornell 是纯文本 LM、把过拟合孤立成单系数 $P$ 用于跨配置对比(并解释强 weight decay 的作用);本文不显式建过拟合项,而是把"重复暴露"作为嵌入器小份额($s^\star \approx 2\%$)的机制解释,并指出加嵌入器特有正则可能上移 $s^\star$——这其实正是 Cornell 用 weight decay 削减过拟合惩罚 $P$ 的行为模型版对应。两篇的"正则/weight decay 调节数据受限场景"的洞见高度互补。
被剔除的近似候选(防止门槛放水):
- HSTU HSTU(Meta,2024-02):本文引用 [5] 作为"单轴 $N$ scaling 有利"的参考。剔除原因:HSTU 提出一个新架构并只在单轴上展示 favorable scaling,本文不提架构、联合扫四个轴;问题(序列推荐架构设计)与解法骨架不同构。作为 related-work / scaling-law 谱系处理,不作孪生。
- 2605.29232 On the Practice of Scaling Search CVR(Coupang,2026-05-28):也把缩放拆成 backbone/embedding/data 三维并发现收益近似可加。剔除原因:它是工业上线导向的经验调优(小数据架构搜索 + warmstart + GPU serving 优化 + 线上 A/B),问题根因是"严格延迟约束下可预测地把 CVR 模型做大",解法是工程范式而非 iso-FLOP scaling-law 拟合;问题层相关但解法骨架(无 power-law 拟合、无 compute-optimal 闭式)显著偏离。
- 2208.08489 Ardalani et al. "Understanding scaling laws for recommendation models":本文引用 [7],是奠基性前置工作(DLRM 风格 scaling),不在文档库内、且本文已在 related work 一笔带过;结构化对比由 DAG 兜底,不作孪生章节。
讨论与局限性¶
核心贡献:这是第一篇为"特征化事件嵌入器 → decoder-only Transformer"这套现已标准化的行为基础模型栈、在两阶段 frozen-embedder 配方下、联合标定四个部署相关轴(架构切分、batch size、$(N,D)$ 分配、负样本池)的 scaling-law 工作。三个最有价值的结论:(1) 计算最优嵌入器很小($s^\star \approx 2\%$),且这是结构性的(compute 与有效-epoch 双重不对称);(2) 行为模型在低算力强烈数据偏多($D/N \approx 340$)、随算力向文本 LM 的 Chinchilla 收窄(到 36);(3) 评测指标是 scaling law 的一部分——sampled-softmax loss 不是 full-catalogue 排序质量的可靠代理,关键 batch / 最优 $K$ / loss-排序一致性都随指标和算力漂移。论文把可执行建议蒸馏成一个决策顺序(Table 7):先选部署指标 → 设小嵌入器 → 按数据效率/吞吐权衡定 batch → 在 $N$/$D$ 间分配 → 在全目录排序指标下调冻结后负样本池。
值得借鉴的设计:把"评测 regime(batch-local vs full-catalogue)刻意分开"并系统量化两者的 loss/排序相关性,是任何用 sampled-softmax 训、用 full-catalogue 排序服务的推荐系统都应做的诊断;用两项"饥饿 + 偏差/饱和"闭式拟合(公式 2、6)把一条扫描曲线坍缩成单一解析最优,是干净的 scaling-law 工程范式。
局限性:
- Stage 1 评测是 batch-local:架构和分配扫描对 validation batch 里的唯一 target(约 5–10k item)打分而非全目录,跨 budget 的绝对 loss 不直接可比;论文用 Stage 2 $K$-扫描 cell 上的同 checkpoint 重评来论证 batch-local 排序能转移到部署指标(Figure 9),但全目录重评覆盖完整架构/分配网格仍是 open work。
- 架构覆盖有限:宽度扫描不在固定深度下变隐藏维;深度扫描不变文本编码器份额;完整 5D 网格(share × width × depth × embedder-depth × LR)是自然的下一步。$s^\star \approx 2\%$ 也是基本无正则配方的结论,加嵌入器正则可能上移。
- 上下文长度固定:所有扫描固定训练上下文器序列长度 $L_{\mathrm{seq}} = 256$;模型从头在更小/更大 $L_{\mathrm{seq}}$ 上训时 $N^\star/D^\star/s^\star/K^\star$ 如何漂移、in-batch contrastive 项 $3BL_{\mathrm{seq}}h$ 如何随 $L_{\mathrm{seq}}$ scale、attention 的 $L\cdot L_{\mathrm{seq}}^2$ 项变得不可忽略后 iso-FLOP 权衡是否仍被 Kaplan 公式捕捉——都是没扫的计划中的轴。
- Compute 范围:主 $(N,D)$ 分配 budget 跨 $C \in [10^{15}, 10^{19}]$ FLOPs,更大 budget 留作 open work。
- 可复现性 / 透明度:单作者、"Unbox AI",数据是匿名零售语料(约 $10^8$ item、约 $10^9$ token),没有线上 A/B、没有公开 benchmark 数据集、没有代码,所有结论建立在单一 stack + 单一语料上,外部可验证性受限。
工业落地价值:论文本身没有上线实验,但其产出(Table 7 的决策顺序、$s^\star \approx 2\%$、$D/N$ 随算力的轨迹、$B \approx 2048$ 的吞吐推荐、$K \in [2.5\times 10^5, 9\times 10^5]$ 的负样本带)对任何在训行为/交易/支付基础模型的团队都是直接可用的工程先验——尤其"先选部署指标再拟 scaling law"和"sampled loss 不能用来选 $K$"两条,能避免实打实的 compute 浪费。
方法论可扩展性评估¶
这篇恰恰是元层面研究"如何 scaling"的工作,本身不固化任何码本/离散空间。值得注意的是:它研究的两阶段 frozen-embedder 配方是一个显式解耦(冻结嵌入器、缓存、只训上下文器),按本项目 reading-criteria 的扩展性视角这通常是个隐患信号——但本文并非在推广这个解耦,而是在量化"在这个已部署的解耦配方下该怎么分配 compute"。论文自己也指出,加嵌入器特有正则、把上下文长度作为新轴、做完整全目录重评,都是把表征能力(嵌入器)与序列建模能力(上下文器)一起 scale 的自然延伸方向。因此扩展性瓶颈更多在它研究对象的两阶段配方上,而非这篇方法论本身。
精读评分 8/10:大规模(约 600 次运行)、跨四个数量级算力的严谨实证,核心洞见原创且工程上直接可用(嵌入器约 2% 参数、$D/N$ 向 Chinchilla 收窄、评测指标是 scaling law 的一部分、sampled loss 不能选 $K$)。扣分项:不提新架构、无线上 A/B、单一匿名语料 + 单作者无公开代码、Stage 1 评测受限于 batch-local,外部可复现性偏弱。综合落在"扎实的工作"上沿,与摘要分一致。