Compute Optimal Tokenization¶
研究动机与背景¶
Kaplan et al. (2020) 与 Hoffmann et al. (2022, "Chinchilla") 已经把 LM 训练的 compute-optimal 设计写成两条铁律:
- 给定 compute budget $C$,最优 model size $N^\star$ 和最优数据量 $D^\star$ 都是 $C$ 的幂律函数;
- Chinchilla 的"经验法则":每个参数大约配 20 个 token(即 $D/N \approx 20$)。
但这两条法则被一个被忽视的变量遮蔽:数据量到底用什么单位计量?Chinchilla 说"20 token / 参数"——这个 20 是相对 BPE tokenizer 测出来的,不同的 tokenizer 把同一段文本切成不同数量的 token。从信息论角度看,"信息量"的真正物理单位是 byte,而 token 只是 tokenizer 引入的人造单位。如果换一个压缩率不同的 tokenizer,"20 token / 参数"是会平移到"X byte / 参数",还是会维持"20 token / 参数"?这两种假设给出完全不同的工程指导。
Meta FAIR 的这篇工作把 tokenizer 的核心属性——压缩率 $T$(每个 token 平均代表的字节数)——显式纳入 scaling law。已有 BPE 的压缩率约为 $T \approx 4.57$;character-level tokenizer 的 $T \approx 1$;近期的 SuperBPE 把多个英文单词合并为一个 token,达到 $T \approx 6.16$。但 BPE 是一个"自由参数固定"的离散算法,无法平滑扫描压缩率;本文借助 Byte Latent Transformer (BLT, Pagnoni et al. 2025) 这个最近提出的潜在分块架构——它通过一个 entropy-based segmenter 把字节流切成 latent tokens,并允许通过 entropy 阈值精确地控制平均压缩率。
作者在 BLT 上构建一个 5×10^18 至 2×10^21 FLOPs 跨度的实验网格(总计训练 988 个 latent tokenized 模型 + 320 个 subword tokenized 模型,参数从 50M 到 7B),系统回答四个研究问题:
- R1:压缩率如何影响 compute-optimal 的 N/D 比例?应该用 token 还是 byte 作度量单位?
- R2:是否存在最优压缩率?它如何随 compute 变化?
- R3:上述结论对 latent 与 subword tokenizer 是否一致?
- R4:最优压缩率是否取决于语言?
四条核心发现(Findings)将逐一对应回答这四个问题,整体结论是把 Chinchilla 的"20 token / param"推广为更稳健的"~60 byte / param",并揭示最优压缩率随训练 budget 缓慢下降——也就是说,更大的训练预算反而应当用 更细粒度 的 tokenizer。
实验方法¶
模型架构¶
所有模型都遵循 Llama 3 架构家族(Vaswani et al. 2017 的 Transformer)。两条架构线:
Latent Tokenized Models (BLT):分层架构,三个模块: 1. Encoder:把 byte-level 输入聚合成 latent tokens; 2. Global Module(latent module):在 latent token 上跑大 Transformer——这是论文里"主体参数"的归属; 3. Decoder:把 latent 表征映射回 byte-level 做 next-byte 预测。
BLT 通过 entropy spike 切割:训练一个独立的小 byte-level LM,当下一个 byte 的预测熵超过阈值就切一个新 latent token;调整阈值即可精确扫描 $T \in \{1, 2, 4, 6, 8, 12\}$。
作者对原始 BLT 做了两点改动:
- 省略 hash n-gram embedding——n-gram 的跨度可能比 latent token 还宽,会干扰目标压缩率;
- 修改 local module 的 scaling recipe——优先扩 width 而非 depth:local module 的 layer 数取 global layer 的 1/4(向上取整),head 数取 global head 的 1/4 + 8;hidden dim 是 head 数的 64 倍;feed-forward 用 4× upscaling。这套 recipe 让 local module 的 compute 开销与 isotropic 模型的 embedding 层相当。
Subword Tokenized Models(isotropic baseline):标准 Llama 3 架构,所有模块在同样粒度的 token 上工作。压缩率由 tokenizer 决定,不能直接控制:
- Character-level:$T \approx 1.01$,$V = 148{,}000$;
- BPE (Llama 3):$T \approx 4.57$,$V = 126{,}000$;
- BPE 词表 mask 75%(但仍保留 $V = 126{,}000$ 用于 FLOP 计算):$T \approx 4.16$;
- BPE 词表 mask 90%:$T \approx 3.71$;
- SuperBPE (Liu et al. 2025):$T \approx 6.16$,$V = 200{,}000$。
为低压缩对应"character"基线(不是 byte),是为了让词表大小与 isotropic 家族其它配置同量级。
训练与评估¶
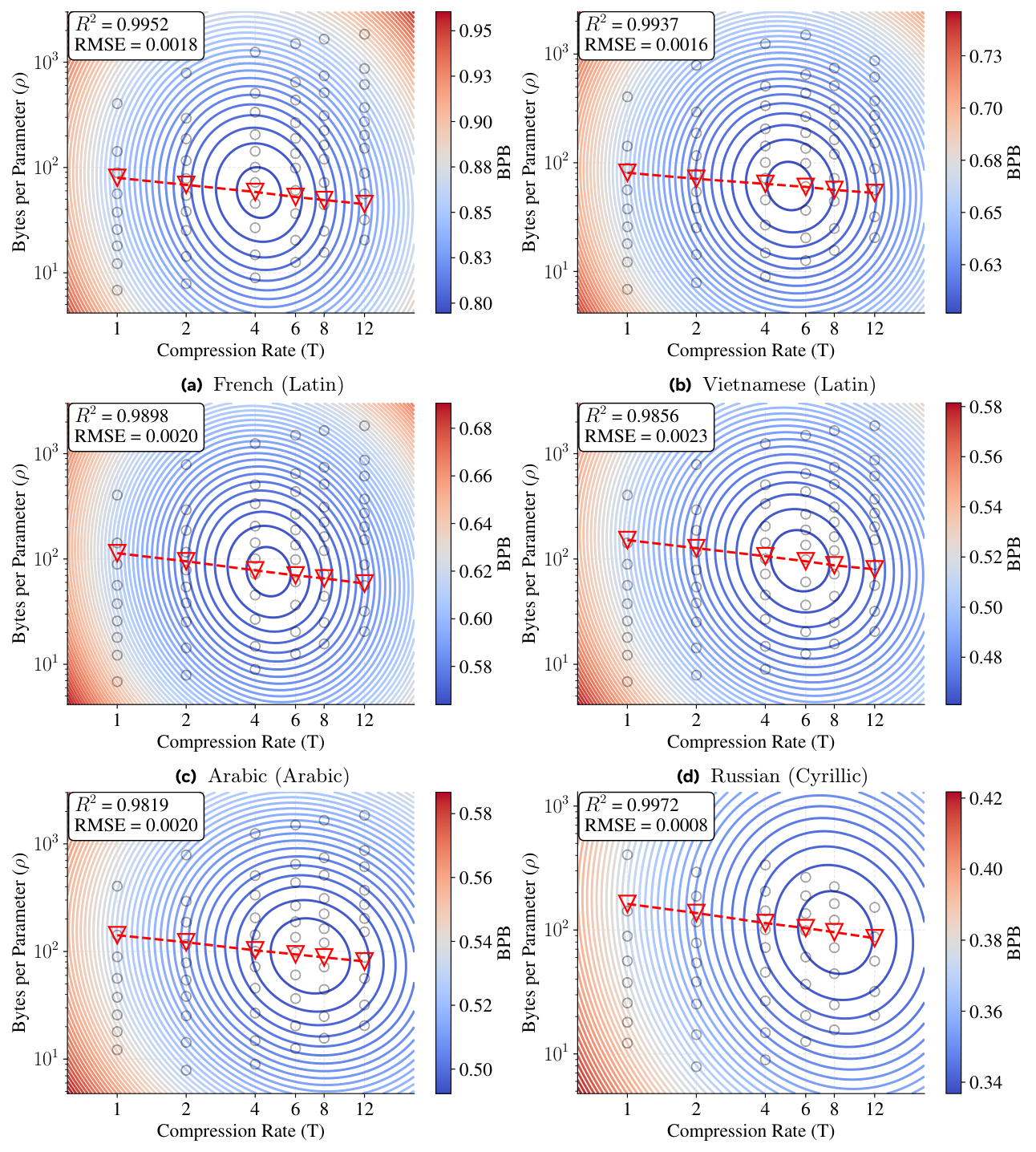
训练 budget $C \in [5\times 10^{18},\, 2\times 10^{21}]$ FLOPs,精确计算训练 FLOPs(不用 $6ND$ 近似)。988 个 BLT + 320 个 subword 模型;数据量 4B–1.1T bytes。每个 budget 在 (compression $T$, parameters $N$) 笛卡尔积上扫一组配置(Figure 2 展示 $C = 10^{20}$ 的扫格):
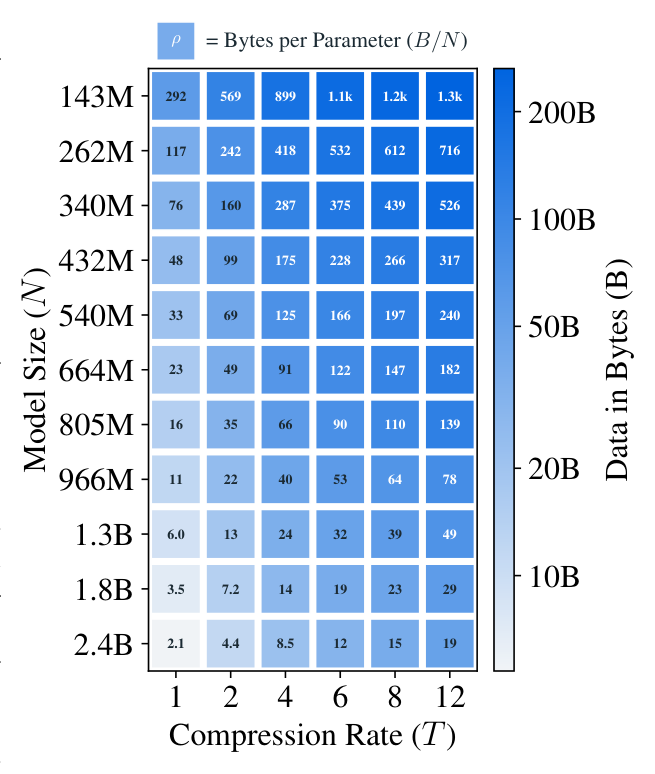
固定 batch size = 2M bytes,learning rate $4 \times 10^{-4}$,AdamW + warmup-stable-decay schedule。训练默认在 DCLM 数据集(Li et al. 2024,纯英文经过过滤),评估在 C4 验证集 上。
评估指标:跨 tokenizer 公平比较的关键是放弃"token 损失"——用 bits-per-byte (BPB):把 cross-entropy loss 除以总 byte 数。每个评估样本固定 8192 byte(即 $T = 4$ 时是 2048 token,$T = 8$ 时是 1024 token)。
Power Law 拟合¶
Scaling law 拟合分两阶段,遵循 Li et al. (2025) 的 "two-stage fit" 经验:先估 optimal $(B^\star, N^\star)$,再估 optimal loss $L^\star$。核心拟合工具是 IsoFLOP 抛物线 / 抛物面——对每个 $(C, T)$ 网格,把 $\log(B)$ vs $L$ 做二次多项式拟合,最低点就是 $B^\star$;二维 IsoFLOP 把 $(C, T)$ 联合做曲面拟合。BFGS 优化,多 random seed 初始化,95% 置信区间用 Hessian 数值近似。
Scaling Law I:Optimal Data 与 Parameters¶
Law I 的形式¶
针对每个 $(C, T)$ 网格用 IsoFLOP 拟出 $B^\star(C, T)$,假设它是 $C$ 与 $T$ 的双幂律:
$$B^\star(C, T) \cong B_0 \cdot C^\alpha \cdot T^\beta \tag{1}$$
三个待拟合参数:$B_0$(基础常数),$\alpha$(compute scaling 指数),$\beta$(compression scaling 指数)。
为了让 fit 跨 tokenizer 一致,作者只把 latent module 的参数 $N$ 算进 fit(不包括 BLT 的 encoder/decoder,也不包括 subword 模型的 embedding)。在固定 scaling recipe 下,latent module 参数与总参数严格成比例。Latent module 的 compute 可近似为:
$$C \approx 6 \cdot N \cdot \frac{B}{T} \tag{2}$$
其中 $B/T$ 就是常规 scaling 文献中以 token 计的数据量 $D$。把 (1) 代入 (2) 解出 $N^\star$:
$$N^\star(C, T) \cong \frac{1}{6 B_0} \cdot C^{1-\alpha} \cdot T^{1-\beta} = N_0 \cdot C^{1-\alpha} \cdot T^{1-\beta} \tag{3}$$
进一步定义 byte-per-parameter 比 $\rho^\star \equiv B^\star / N^\star$:
$$\rho^\star(C, T) \cong \frac{B_0}{N_0} \cdot C^{2\alpha - 1} \cdot T^{2\beta - 1} \tag{4}$$
公式 (4) 把所有 hypothesis 都参数化进 $\alpha, \beta$ 的取值,给出几个 先验意义:
- $\alpha \approx 0.5$ → $\rho^\star$ 随 $C$ 不变(数据与参数 1:1 比例缩放,即 Hoffmann 等的 Chinchilla 等价物);
- $\beta \approx 0.5$ → $\rho^\star$ 随 $T$ 不变(更高压缩省下来的 compute 应该平均分配给数据和参数);
- $\beta \approx 1$ → 可以丢掉 compression 维度,直接用 $D = B/T$(token 量)做 scaling,这就是传统 scaling law 的隐含假设。
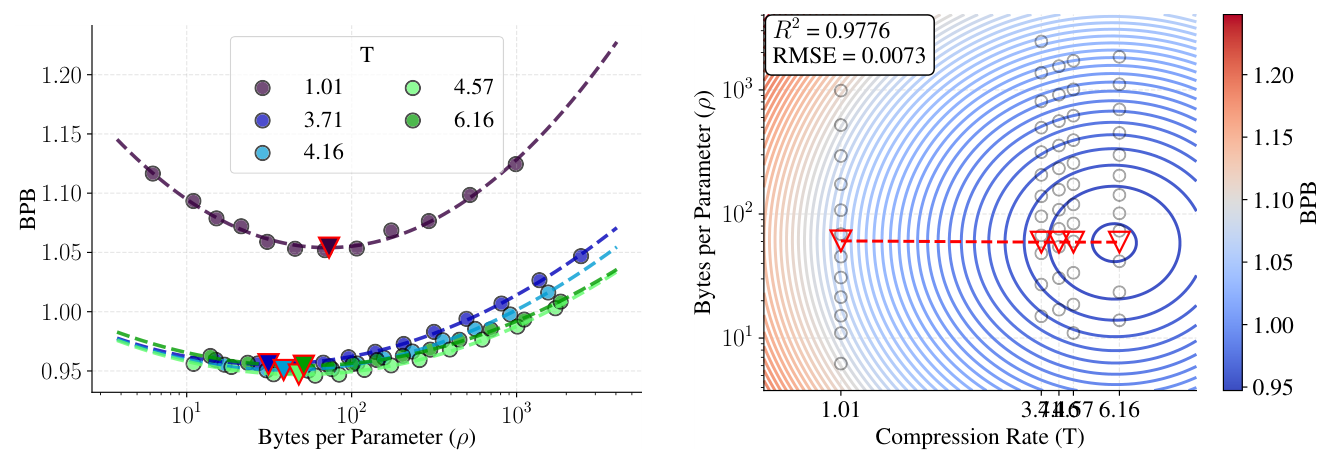
Law I 拟合结果¶
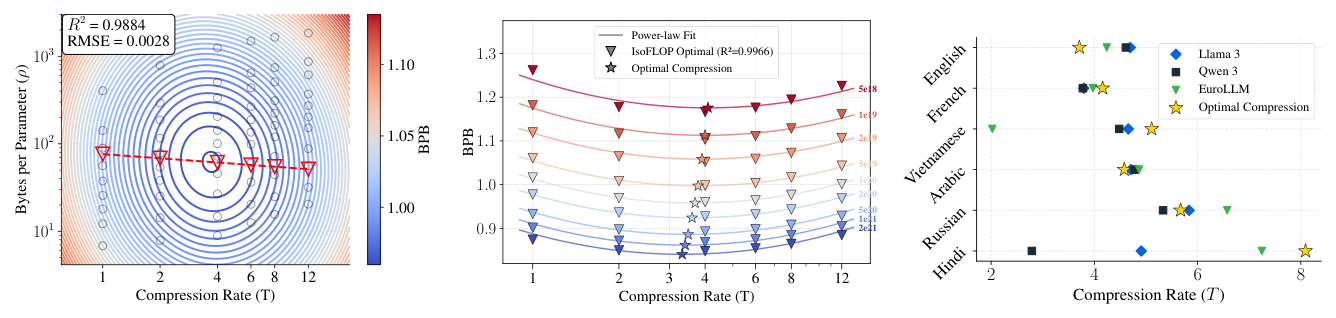
在 $C = 10^{20}$ 的 IsoFLOP 切片上(Figure 3),二维抛物线(每个 $T$ 一条曲线)和三维抛物面拟合都得到极小,最优 byte/parameter 比 $\rho^\star \approx 60$ 跨所有压缩率几乎不变:
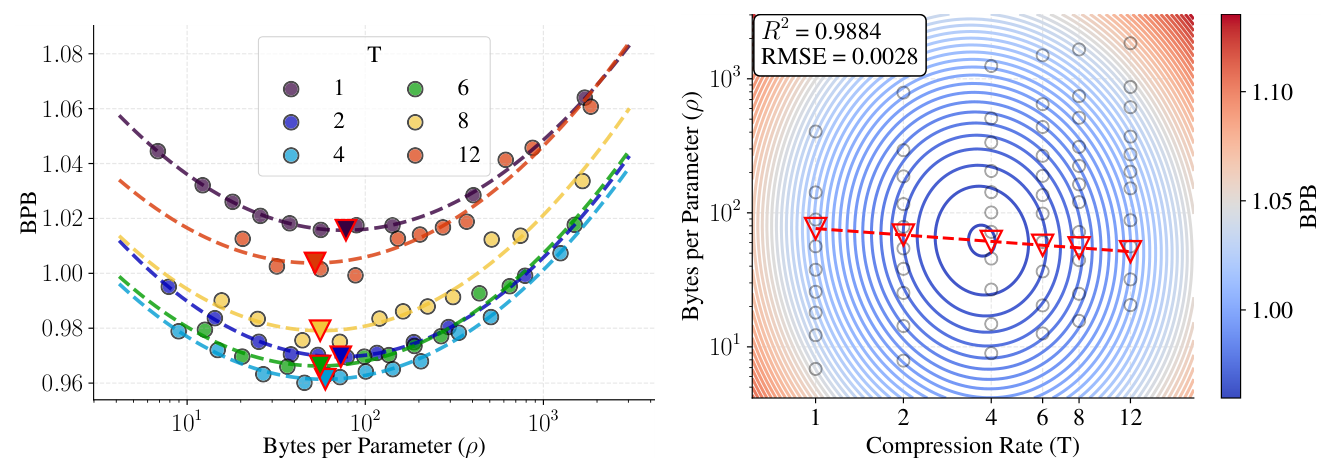
把 $B^\star, N^\star$ 跨所有 $(C, T)$ 画成 log-log 散点(Figure 4)后,能看到 (1)/(3) 形式确实贴合:
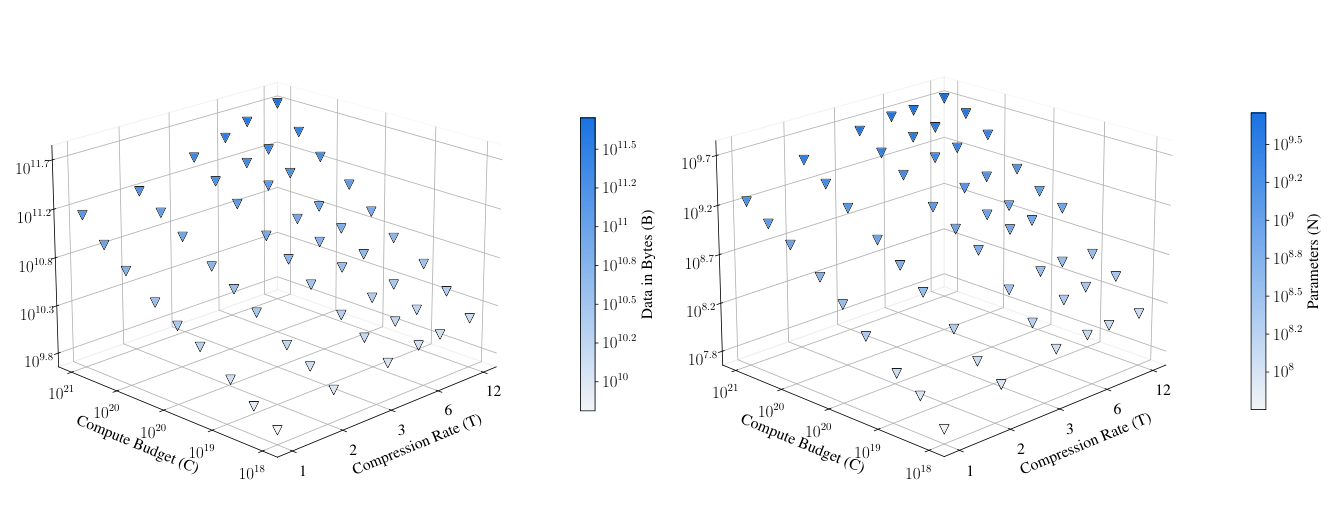
最终拟合参数:$B_0 = 17.5$,$N_0 = 9.5 \times 10^{-3}$,$\alpha = 0.465$,$\beta = 0.471$。关键观察:$\alpha, \beta$ 都非常接近 0.5,意味着 byte-per-parameter 比 $\rho^\star$ 在所有 $C$ 与 $T$ 下近似恒定(这就是 Finding 1)。
Finding 1:optimal byte-per-parameter 比 $\rho^\star$ 跨 compute budget 与 compression rate 都近似恒定。把 scaling recipe 推广到不同 tokenizer 时,应当匹配 byte/parameter 比,而不是 token/parameter 比。
实际数值:$\rho^\star \approx 60$ bytes / parameter(英文 DCLM 数据上)。读者可对比一下:在 BPE($T \approx 4.57$)下这等价于约 $60 / 4.57 \approx 13$ tokens/parameter——略低于 Chinchilla 的 20,但同 order。Chinchilla 的 20 实质是"BPE 的副产品"。
Scaling Law II:Optimal Loss Dynamics¶
Law II 的形式¶
定义 $L^\star(C, T) \equiv L(B^\star(C, T), N^\star(C, T))$ 为给定 $(C, T)$ 下最优配置取得的 loss。作者假设:
$$L^\star(C, T) \cong L_0 \cdot C^\gamma + f(C, T) \tag{6}$$
主项 $L_0 \cdot C^\gamma$($\gamma < 0$)是 compute-only 的下降;剩余 $f(C, T)$ 包含 irreducible loss 与 compression-specific 残差。$f$ 不预设解析形式,先从经验拟合起。
Law II 拟合结果¶
把 latent BLT 的 $L^\star$ 画成 $C, T$ 的曲面(Figure 5):
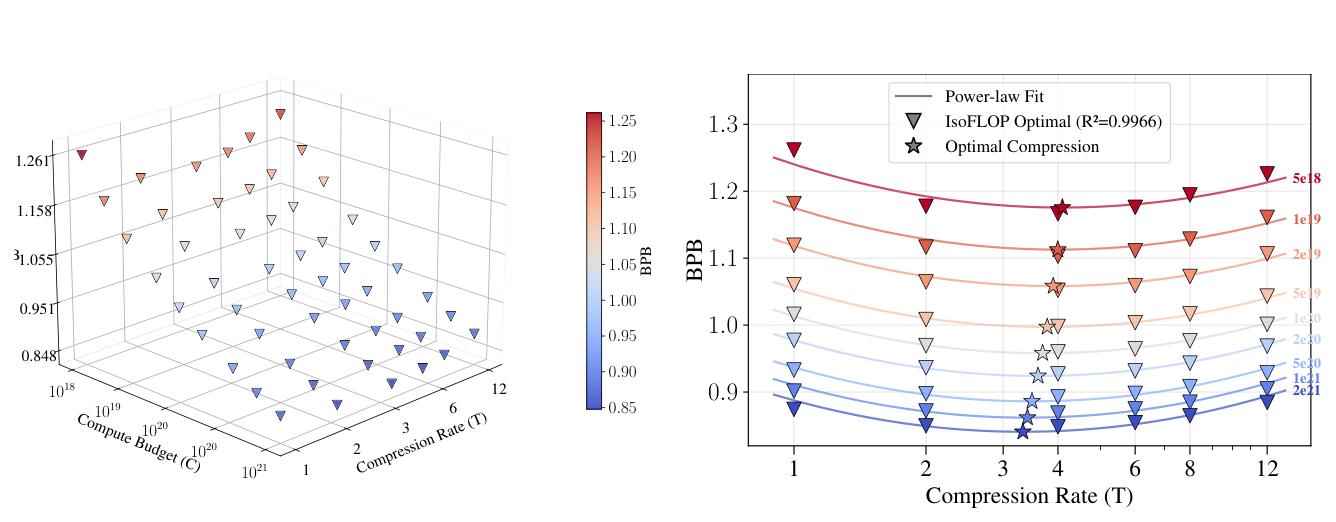
画法 1:先固定 $C$ 看 $T$ → 得到一族 U 形曲线,最低点在 $T \approx 4$。$L^\star$ 是 $T$ 的非单调凸函数——压缩率太低或太高都不好。同时随 $C$ 增大,整条曲线下移,最低点往左滑(最优压缩率随 budget 下降)。
附录 B.3 比较了三种 $f$ 形式(mean residual、constant $T^\star$、compute-dependent $T^\star$),后者用 log-quadratic 形式取得 $R^2 = 0.997$、外推 RMSE = 0.0086(最优):
$$f(C, T) = F \cdot \log^2\!\left(\frac{C^\delta T}{T_0}\right) + E \tag{7}$$
可以看出最优压缩率 $T^\star = T_0 / C^\delta$ 随 $C$ 缓慢下降。Latent 拟合参数:$L_0 = 3342$,$\gamma = -0.206$,$F = 0.032$,$\delta = 0.035$,$T_0 = 18.2$,$E = 0.70$。
实际数值:$T^\star = 3.69$ for $C = 10^{20}$,$T^\star = 3.33$ for $C = 2 \times 10^{21}$——20 倍 compute 让最优压缩率下降约 10%。
| Parameter | Latent | Subword | 95% CI (Subword) |
|---|---|---|---|
| $\alpha$ | 0.465 | 0.501 | [0.471, 0.532] |
| $\beta$ | 0.471 | 0.446 | [0.387, 0.506] |
| $B_0$ | 17.5 | 2.8 | [0.7, 11.0] |
| $N_0$ | 0.0095 | 0.059 | [0.015, 0.229] |
| $\gamma$ | -0.206 | -0.181 | [-0.226, -0.1352] |
| $L_0$ | 3342 | 1087 | [171, 6896] |
Table 1:latent 与 subword tokenized 家族的拟合参数对比。
Finding 2:每个训练 budget 都有一个最优压缩率 $T^\star$;偏离它(无论更高还是更低)都增加 loss。$T^\star$ 随训练 budget 单调下降(更大的训练预算应该用更细粒度的 tokenizer)。
附录 B.4 给出 loss 对 $T$ 的 边际敏感度(Figure 16):偏离最优时,subword 模型最多可恶化 0.2 BPB,latent 模型最多 0.1 BPB——subword 对压缩率的选择比 latent 敏感得多,因为 subword 没法"用完整 byte stream"补偿粒度损失。
Optimal Tokenization at Inference¶
Section 3.5 把视角切到推理阶段。在 $C = 2 \times 10^{21}$ FLOPs 下,作者训练了不同 model size × 不同压缩率的 BLT 模型,用 FLOPs/byte 衡量推理代价:
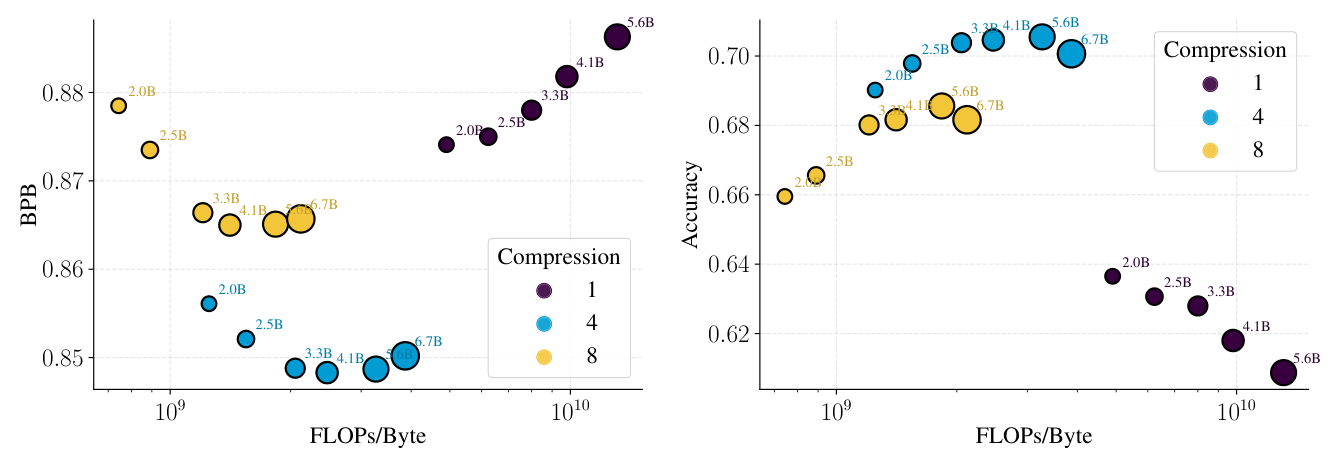
两条规律: 1. 同 model size 下,更高压缩率降低单 byte 推理 cost(每 byte 走的 token 少); 2. 在等推理-cost 切片上看,压缩率接近最优 $T^\star$ 的模型 endtask 表现更好——例如 $T = 4$ 的 3.3B 模型在 $2.1 \times 10^9$ FLOPs/byte 时 HellaSwag 达 74.1%,而 $T = 8$ 的 6.7B 模型同 cost 只到 68.2%。
这给出一个重要的 deployment 直觉:当 inference 成本是关键约束时,应当选择压缩率高于训练-时-最优的 tokenizer 对应的 (smaller, higher-compression) 模型——这是 LM 设计中"为推理 over-train 较小模型"做法在 tokenizer 维度上的对应物。
Compute Optimal Subword Tokenization¶
Section 4 把分析迁移到 isotropic subword 模型(Llama 3 风格),用三种 tokenizer × 两种 vocab masking 扫压缩率:character ($T = 1.01$)、BPE 90% mask ($T = 3.71$)、BPE 75% mask ($T = 4.16$)、原始 BPE ($T = 4.57$)、SuperBPE ($T = 6.16$)。
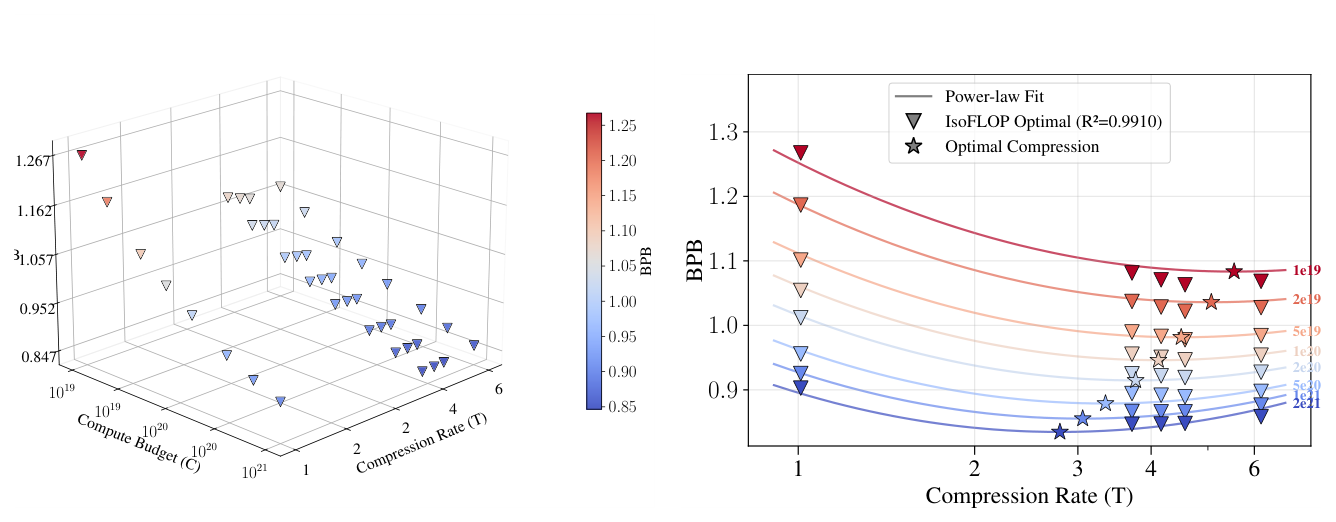
Subword 的拟合给出 $\alpha = 0.501$、$\beta = 0.446$,与 latent 的 $\alpha = 0.465$、$\beta = 0.471$ 在 95% CI 内重合。Scaling Law I 在 latent 与 subword 上几乎一致。Loss dynamics 也类似——存在最优压缩率,且随 budget 下降。
| Compute (FLOPs) | Character | BPE V.mask=90% | BPE V.mask=75% | BPE Original | SuperBPE |
|---|---|---|---|---|---|
| $1 \times 10^{19}$ | 1.2678 | 1.0819 | 1.0709 | 1.0635 | 1.0682 |
| $2 \times 10^{19}$ | 1.1812 | 1.0381 | 1.0281 | 1.0214 | 1.0273 |
| $5 \times 10^{19}$ | 1.0989 | 0.9887 | 0.9819 | 0.9769 | 0.9840 |
| $1 \times 10^{20}$ | 1.0519 | 0.9554 | 0.9502 | 0.9461 | 0.9532 |
| $2 \times 10^{20}$ | 1.0126 | 0.9254 | 0.9220 | 0.9186 | 0.9272 |
| $5 \times 10^{20}$ | 0.9556 | 0.8942 | 0.8916 | 0.8891 | 0.8976 |
| $1 \times 10^{21}$ | 0.9253 | 0.8665 | 0.8658 | 0.8659 | 0.8763 |
| $2 \times 10^{21}$ | 0.9027 | 0.8466 | 0.8469 | 0.8479 | 0.8582 |
Table 2:固定 compute budget 下 subword 模型的最低 BPB。每个 budget 用粗体标的最佳 tokenizer 在 compute 较小时是 Original BPE ($T = 4.57$),但 budget 增大后 逐步切换到 BPE V.mask=75% ($T = 4.16$) 与 V.mask=90% ($T = 3.71$)——也就是更细粒度的 tokenizer。这与 latent 实验的结论吻合。
一个反直觉发现:把 BPE 词表 mask 90%(同一个 tokenizer,但 90% 词条无法被组合),其 FLOP 还按 $V = 126{,}000$ 算,性能依然好过 original BPE。作者推测这给出一个 "BPE-dropout 类似机制" 的暗示,即较低压缩允许模型在推理时对每个样本投入更多 compute,可能被 future work 利用。
Finding 3:在 latent (BLT) 上观察到的 scaling 规律对 subword 家族 (BPE / SuperBPE) 同样成立。
Compute Optimal Tokenization Beyond English¶
Section 5 把实验推广到 6 种语言。每种语言独立训练一组 BLT 模型于 FineWeb-2 单语数据集:French (Latin)、Vietnamese (Latin)、Russian (Cyrillic)、Arabic (Arabic)、Hindi (Devanagari)。此外,作者用 "在每对 UTF-8 byte 间插一个 dummy byte" 的方式人工构造一个 English ×2(信息密度减半)作 sanity check。
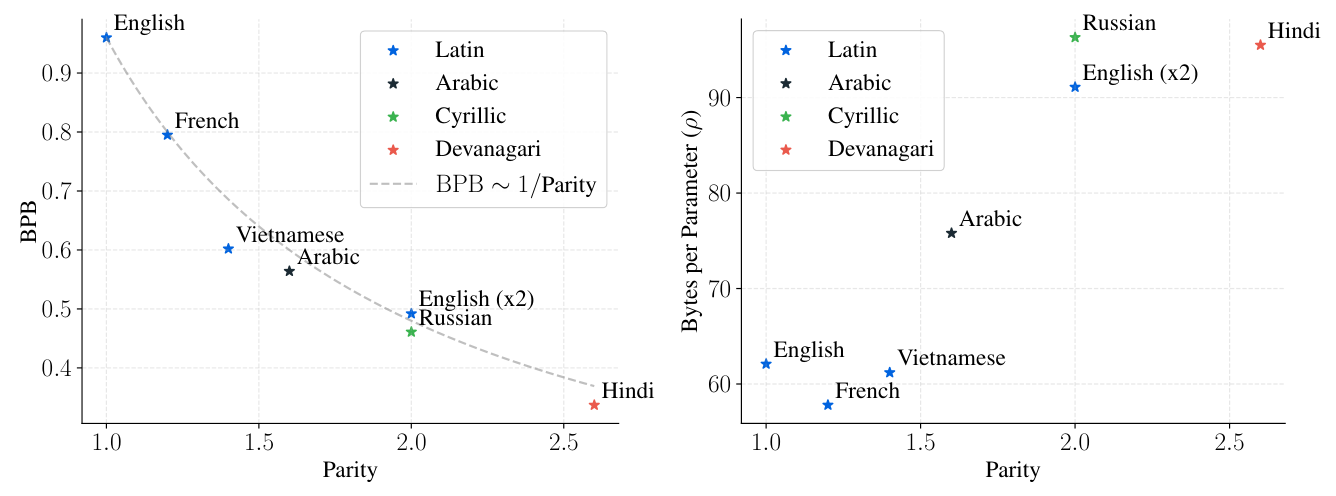
跨语言度量:作者用 parity 量化"语言信息密度"——FLORES-200 平行句子在 该语言 与 英文 中的 byte 长度比。Hindi 的 parity = 2.6 表示同一句话用 Hindi 的 UTF-8 字节是英文的 2.6 倍。
| Language | Parity | $\rho^\star_l$ | $T^\star_l$ | BPB |
|---|---|---|---|---|
| English | 1.0 | 62.1 | 3.71 | 0.960 |
| French | 1.2 | 57.8 | 4.16 | 0.795 |
| Vietnamese | 1.4 | 61.2 | 5.11 | 0.602 |
| Arabic | 1.6 | 75.8 | 4.58 | 0.564 |
| Russian | 2.0 | 96.3 | 5.67 | 0.461 |
| English (×2) | 2.0 | 91.1 | 6.97 | 0.492 |
| Hindi | 2.6 | 95.5 | 8.09 | 0.337 |
Table 3:单语模型在 $C = 10^{20}$ 下的 compute-optimal byte/parameter 比与压缩率。
观察:
- BPB 与 parity 反比——信息密度低(高 parity)的语言 byte-level loss 更低,因为每个 byte 携带的信息少;
- $T^\star_l$ 与 parity 几乎成 1:1 正比关系(Figure 14)——更稀疏编码的语言需要更高压缩率;
- $\rho^\star_l$ 也随 parity 升高(Russian 96.3 vs English 62.1)——粗粒度编码语言更受益于扩数据而非扩参数;
- 流行的多语 BPE tokenizer(Llama 3、Qwen 3、EuroLLM)实测压缩率与 $T^\star_l$ 偏离很大——对 high-resource 语言(英语、阿拉伯语)过度压缩,对 low-resource 语言(越南语、Hindi)压缩不足(Figure 15)。
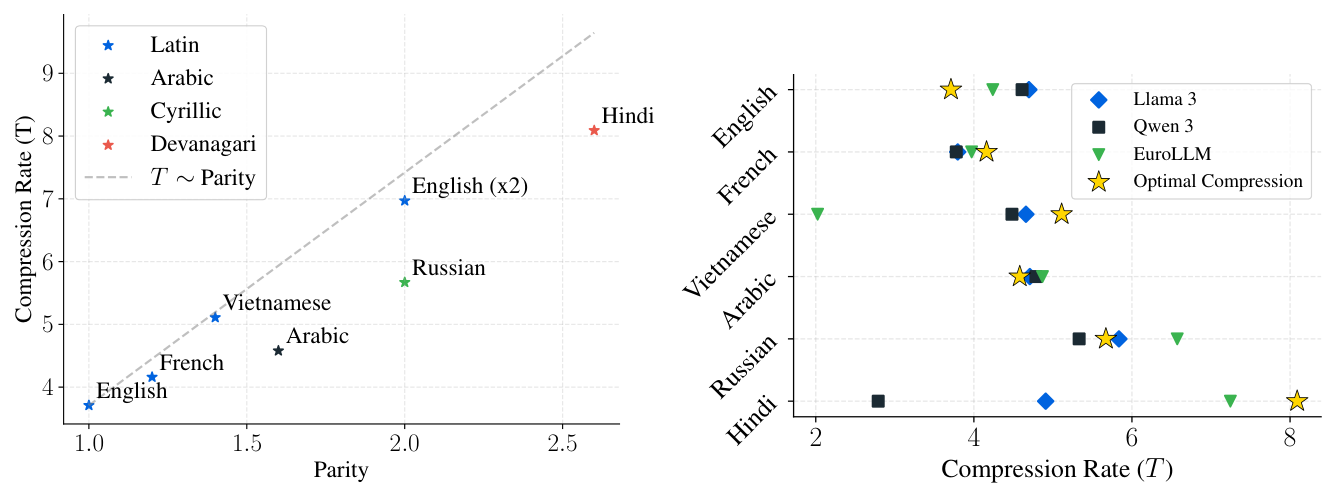
Finding 4:optimal byte/parameter 比 $\rho^\star$ 与最优压缩率 $T^\star$ 都因语言而异,且都与该语言的 parity 正相关(即与该语言 byte 的平均信息密度负相关)。
附录 D 还做了 联合多语训练:6 种语言按 parity 加权混合,所有语言共训一个 BLT。多语联合训练下 $\rho^\star$ 收敛到所有语言的 中位数 附近(约 70),最优压缩率仍随 parity 变化但整体下移。这给 latent tokenizer "为每种语言定制压缩率" 提供了更强的论据——subword tokenizer 因为词表/算法绑定无法做到。
影响与讨论¶
对 LLM 设计的指导¶
- 替换 Chinchilla 法则:跨 tokenizer 设计 LLM 时,把 "20 token / param" 替换为 "≈60 byte / param"(英文);其他语言按 parity 调整。这条法则对从 byte-level 到 superword-level 的全谱 tokenizer 都成立。
- 训练-时-最优压缩率不是一个常数——较小的训练 budget 偏好高压缩,较大的训练 budget 偏好低压缩。原因:低压缩允许模型在每个样本上花更多 compute 处理。
- 推理-时-最优压缩率高于训练-时-最优——为了节省推理 cost,可以选 (smaller, higher-compression) 模型。这与 LM 社区"为推理 over-train"的工程惯例方向一致。
- 多语 tokenizer 应针对 low-resource 语言增加压缩率——已有 Llama 3 / Qwen 3 / EuroLLM 都对低资源语言压缩不足,而 latent tokenizer (BLT) 的"按语言调压缩"能力是理论与工程上对 subword 多语 tokenizer 的明显改进。
局限性¶
- 超参未单独 tune:lr、batch size 等跨 budget 固定,可能造成系统偏差;
- 未覆盖所有 tokenizer 算法:未实验 Unigram、其他 latent 切割策略(hash n-gram、token boundary predictor);这些差异预计影响有限;
- 数据域限于 plain text:未覆盖 code、math、speech;
- 架构限于 dense Transformer:MoE 架构下 compression 与 sparsity 的交互未知。
未来工作¶
- 把 compression 维度推广到其他模态(vision、speech、code),各模态都有自己的 "tokenization"(VQ-VAE、ViT patch 等);
- 把 compression 引入 MoE scaling law(与 Ludziejewski et al. 2024 的 MoE 扩参规律结合);
- 探索 BPE-dropout 等"压缩 + 正则化"的混合方法。
与已归档相关工作的对比¶
Prescriptive Scaling Laws for Data Constrained Training Prescriptive Scaling Laws for Data Constrained Training (Cornell, 2026-05-02)¶
关系:独立并发(同一天 arXiv 投稿,本文未引用对方)· 已加载对方精读
-
共同关注的问题:Chinchilla 形式 $L = E + A/N^\alpha + B/D^\beta$ 遗漏了一个关键变量,导致它在某个真实场景下给出错误的 compute-optimal 建议。本文揭示的"漏维"是 tokenization 压缩率 $T$;Cornell 揭示的"漏维"是 unique data 上限 $U_D$ 与重复轮数 $R_D$(即多 epoch 过拟合)。两条工作都在论证:Chinchilla 的"数据 + 参数双幂律"形式不充分,应当扩展。
-
相近的技术骨架:
- 都用 IsoFLOP 网格 + 多种子 BFGS 拟合 + 95% CI Hessian 的标准 scaling law fitting recipe;
- 都做"先拟合 baseline scaling,再分析残差,再加修正项"的两阶段策略——本文的 $f(C,T)$ 残差以 log-quadratic 形式拟合(公式 7);Cornell 的 overfitting penalty 残差以 power-law 形式拟合(其 1p/2p/4p 阶梯);
-
都对原始 Chinchilla 的"约 20 token/param"建议进行 修正方向相反但精神一致 的覆盖:本文把它推广为"60 byte/param 跨 tokenizer 不变"(横向扩展);Cornell 给出"超过某 compute 阈值后应当扩 model 而非重复数据"(垂直深化)。
-
本文的差异与推进:
- 正交的修正维度:本文加 $T$ 维(tokenizer 粒度),Cornell 加 $R_D$ 维(数据重复轮数);两条 law 在概念上完全 orthogonal,可以叠加使用——一个未来方向是建立"在 tokenizer 压缩 × 多 epoch"双约束下的统一 scaling law;
- 样本量:本文 ~1300 个模型(latent + subword),Cornell ~300 个模型;
- 跨语言:本文做了 6 语言扫描,Cornell 仅英文;
-
深度的不同:Cornell 把 overfitting cost 单独凝聚到一个系数 $P$,使得不同正则化设置(如 $\lambda = 1.0$ vs $\lambda = 0.1$)能直接量化对比;本文把 $T^\star$ 表达为 $T_0 / C^\delta$ 形式,但没有把它绑到具体可调的训练超参(如 entropy 阈值的硬度)。
-
可比的方法 / 实验差异:
- 数据:本文用 DCLM(plain English),Cornell 用 FineWeb(plain English),两者 corpus 接近;
- 架构:本文用 BLT(latent)+ Llama 3 isotropic(subword),Cornell 用 Llama 2 dense;
- Compute scope:本文 $5 \times 10^{18}$–$2 \times 10^{21}$ FLOPs(参数 50M–7B),Cornell 跨 15M–1B 参数 + 50M–6B unique tokens;
- Loss form:本文模型 BPB(per-byte),Cornell 模型 cross-entropy per-token——这本身体现了两条工作的关注点差异。
读者价值:两篇都在 Chinchilla 之上加新维度,对设计 LLM 训练 recipe 都是必读组合。如果你只关心 plain English、单 epoch 训练,本文的 60 byte/param 法则与 $T^\star \approx T_0/C^\delta$ 修正完全够用;如果你要训练数据稀缺的专域(code、math、低资源语言)或必须重复数据,那么 Cornell 的 $P \cdot R_D^\delta \cdot (N/U_D)^\kappa$ penalty 是必要补丁。