Prescriptive Scaling Laws for Data Constrained Training¶
研究动机与背景¶
训练算力的增长速度已经远远超过高质量数据的供给速度。在 state-of-the-art pipeline 中,激进的质量过滤(FineWeb 系列、Penedo 等 2024)、对精选子集的 upsampling(Olmo et al., 2025)以及在数学/代码/小语种等垂直语料上的 mid-training(Allal et al., 2025;Olmo et al., 2025)已经成为常态——这反映了一个新的现实:瓶颈不再是 compute,而是 data。在数学、代码、低资源语言这类专门领域里,约束更加严苛——专域数据集往往比 compute budget 能消耗的量小一两个数量级(Lewkowycz et al., 2022)。
这把 Chinchilla(Hoffmann et al., 2022)所建立的"如何在无限数据假设下最优分配 compute"问题,扭转成了"如何从一个固定的数据池里榨取最大价值"——此时 compute 实质上不再是瓶颈。
最简单的应对就是 多 epoch 重复训练。但 Chinchilla scaling law 假设每个 token 都是 unique 的;既有的扩展(Muennighoff et al., 2023 的 effective-data 公式)虽然能描述"重复带来的递减回报",却无法表达 loss 因过拟合而 回升 的区间。在实际的多 epoch 训练里,更大的模型在同样的重复数据上过拟合得更快——这种 model size × repetition 的交互效应被既有 scaling law 完全错过。如果不把过拟合显式地建模进 scaling law,就无法准确刻画数据受限场景下的 LM 训练行为。
本文(Cornell 团队,Lovelace 等)针对这一空白:
- 在 15M–1B 参数、50M–6B unique tokens、最高 16 epochs 的网格上训练 300+ 模型;
- 提出一个简单的 加性过拟合惩罚项,以 1 / 2 / 4 自由参数的复杂度阶梯形成 Pareto 前沿;
- 证明该 law 能给出与既有方法 定性不同 的 compute-optimal 分配建议——超过某个阈值后,继续重复 弊大于利,compute 应当转去扩大 model;
- 把过拟合惩罚孤立成一个单一系数 $P$,使得训练配置之间可以直接量化对比;作为案例,证明 强 weight decay($\lambda=1.0$)能把 $P$ 削减约 70%,为 Kim et al. (2026) 关于"数据受限场景最优 weight decay 比标准做法大一个数量级"的经验发现给出了 scaling-law 层面的解释。
既有 scaling law 与其失效¶
Chinchilla 形式¶
Hoffmann et al. (2022) 把训练完一个 LM 后的最终 loss 写成三项之和:
$$L(N, D) = E + \frac{A}{N^\alpha} + \frac{B}{D^\beta} \tag{1}$$
其中 $N$ 是参数量,$D$ 是训练 token 数。三项含义清晰:
- $E$:自然语言固有不可预测性的下界("地板"),无论 compute 怎么增长都无法跌破;
- $A/N^\alpha$:"模型太小"代价——参数不够无法表达全部语言模式,随 $N$ 增大而衰减;
- $B/D^\beta$:"数据太少"代价——见过的数据不够,随 $D$ 增大而衰减;指数 $\beta$ 控制衰减速率。
Chinchilla 的实际推论:训练 FLOPs 大约 $C \approx 6ND$,所以给定 $C$ 就能解出最优 $(N, D)$ pair。但 Chinchilla 假设每个 token 见且仅见一次——这在数据稀缺场景里被频繁违反。
Muennighoff 的 effective-data 扩展¶
Muennighoff et al. (2023) 把 Chinchilla 中的 raw token 数 $D$ 替换为一个 effective 数据量 $\hat{D}$,思想是 "重复 token 的边际贡献按指数衰减"——第一次重复几乎和新数据一样有用,第二次差点意思,再后面几乎不增加任何信号。设 $U_D$ 为 unique token 数、$R_D$ 为 额外 epoch 数($R_D=0$ 表示只过一次),
$$\hat{D}(U_D, R_D) = U_D \cdot \left(1 + R_D^* \cdot \left(1 - e^{-R_D/R_D^*}\right)\right) \tag{2}$$
其中 $R_D^*$ 是控制衰减快慢的拟合常数。$R_D$ 很小时近似线性 $\hat{D} \approx U_D \cdot (1+R_D)$;$R_D$ 很大时饱和到 $U_D \cdot (1+R_D^*)$。代入 Chinchilla 即得:
$$L(N, U_D, R_D) = E + \frac{A}{N^\alpha} + \frac{B}{\hat{D}(U_D, R_D)^\beta} \tag{3}$$
但这个形式 完全把 repetition 看成 data-side 现象,没有 model-size 依赖。经验上更大的模型在重复数据上过拟合更快,所以 repetition cost 应该同时取决于 $N$ 和 $D$。Muennighoff 等再为参数加同样的饱和项:定义 over-parameterization 比率 $R_N = (N/U_N) - 1$($U_N \equiv \min\{N_{\rm opt}, N\}$),
$$\hat{N}(U_N, R_N) = U_N + U_N \cdot R_N^* \cdot \left(1 - e^{-R_N/R_N^*}\right) \tag{4}$$
把两个 effective 量都代回 Chinchilla:
$$L(U_N, R_N, U_D, R_D) = E + \frac{A}{\hat{N}(U_N, R_N)^\alpha} + \frac{B}{\hat{D}(U_D, R_D)^\beta} \tag{5}$$
这引入了 model size × repetition 的交互——over-parameterized 模型的 effective capacity $\hat{N}$ 会饱和,从而抬高 loss。但形式上仍然是 间接 的:把 over-parameterization 表达为"effective model size 的递减回报",而不是显式过拟合代价;并且没有理由说"参数过多"应当遵循和"数据重复"一样的指数饱和形式。
既有形式在哪里崩坏¶
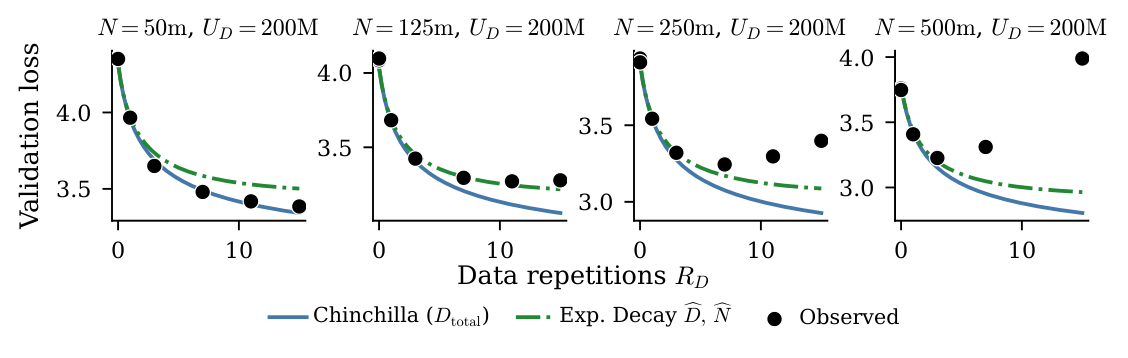
作者把上述两种形式拟合到他们的 $U_D = 200$M 数据上(Figure 1)。两种 baseline 在重复轮数较高时都 系统性低估 loss——它们能描述 loss 的下降和饱和,但描述不出"loss 在某点之后开始上升"的过拟合阶段。两个规律性现象浮出水面:
- 预测-观测差距 随 repetition count 增长而扩大,说明 effective-data 形式系统性地低估高 epoch 处 loss;
- 这个差距 随 model capacity 与 unique data 比值的增大而扩大,证实存在 effective-data 形式无法捕捉的 model size × repetition 交互。
加性过拟合惩罚¶
残差揭示超线性¶
作者用一个残差分析来寻找正确的函数形式。先把 Chinchilla 单 epoch 数据拟合出 $(E, A, B, \alpha, \beta)$;然后用 $D = U_D \cdot (1 + R_D)$(当作"全部 token 都新鲜")来预测多 epoch loss;观测 loss 减去这个预测得到 残差——这就是 repetition 引入的额外代价。
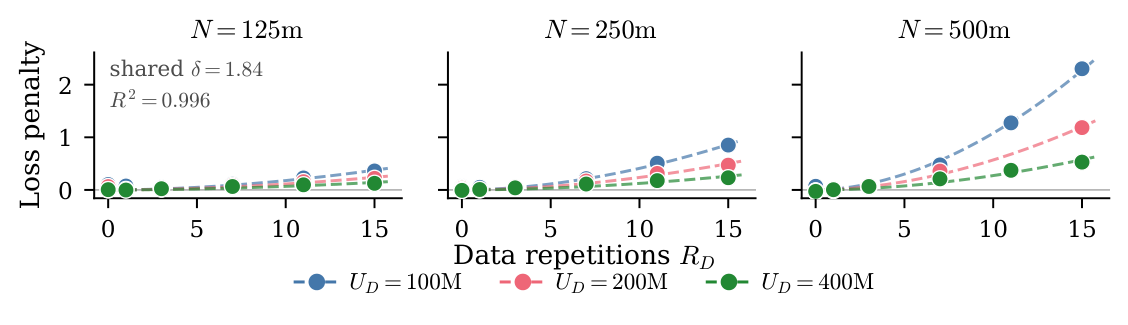
把残差作为 $R_D$ 的函数画出来(Figure 2,三种 model sizes × 三种 unique data budgets),共享指数 $\delta$ 的 power-law 拟合给出 $\delta = 1.84$,$R^2 = 0.996$。$\delta > 1$ 直接证明 repetition damage 是超线性的——每多一个 epoch 造成的损害比上一个 epoch 更大。每个 (model, budget) cell 的系数 $P_i$ 还呈现出明显规律:模型越大、unique data 越小,slope 越陡。
复杂度阶梯:1p / 2p / 4p¶
基于以上观察,作者构造一个加性 penalty 的复杂度阶梯,每一级在自由参数数与拟合质量之间形成 Pareto 前沿:
单参数(1p)形式——只用一个自由参数 $P$ 配合 $N/U_D$ 比值:
$$L(N, U_D, R_D) = E + \frac{A}{N^\alpha} + \frac{B}{(U_D \cdot (1 + R_D))^\beta} + P \cdot R_D \cdot \frac{N}{U_D} \tag{6}$$
注意第三项里 $D = U_D \cdot (1 + R_D)$,这是 naive 把所有重复 token 当 fresh 计入数据项。
两参数(2p)形式——给 capacity 比值加一个非线性指数 $\kappa$:
$$L(N, U_D, R_D) = E + \frac{A}{N^\alpha} + \frac{B}{(U_D \cdot (1 + R_D))^\beta} + P \cdot R_D \cdot \left(\frac{N}{U_D}\right)^\kappa \tag{7}$$
跨配置发现 $\kappa > 1$,说明过拟合惩罚 随 model capacity 与 unique data 比值超线性增长。
四参数(4p)形式——再为 $R_D$ 加上超线性指数 $\delta$、为数据预算解耦出指数 $\gamma$:
$$L(N, U_D, R_D) = E + \frac{A}{N^\alpha} + \frac{B}{(U_D \cdot (1 + R_D))^\beta} + P \cdot R_D^\delta \cdot \left(\frac{N}{U_D^\gamma}\right)^\kappa \tag{8}$$
关键观察:$R_D = 0$ 时(单 epoch),三种形式 精确地退化到 Chinchilla——penalty 项消失。与 effective-data 方法的关键概念差异是:重复 token 被赋予了双重角色——它们继续降低 data-sufficiency 项 $B/D^\beta$(不被浪费),同时在 penalty 项中累积过拟合代价。
实验设置¶
- 架构:Llama 2 解码器(MHA + RoPE + SwiGLU + RMSNorm),Flash Attention 2 +
torch.compile,词表 32k。 - 数据:FineWeb sample-10BT(Penedo et al., 2024),文档打包为 512 token 定长块,EOS 分隔。
- scaling 网格:9 个 model size(15M、25M、35M、50M、125M、250M、500M、750M、1B),8 个 unique data budget(50M、100M、200M、400M、800M、1.5B、3B、6B),repetition $R_D \in \{0, 1, 3, 7, 11, 15\}$。
- 两种 weight decay:标准 $\lambda = 0.1$ 与 strong $\lambda = 1.0$;其他超参(lr、warmup、batch size 等)跨条件保持一致以单独隔离正则化效应。
- 超参:AdamW,peak lr $2 \times 10^{-4}$(cosine 衰减到 10% peak,1% 步线性 warmup),$\beta_1, \beta_2 = (0.9, 0.95)$,gradient clipping 1.0,sequence length 512,batch size 128,bf16 mixed precision。
- 评测:CLM validation loss(6400 个 validation 文档,无 early stopping);下游用 OLMES(Gu et al., 2025),报告 19 个语言理解任务的平均 BPB。
模型配置见 Table 5(scaling 用 9 size)和 Table 6(held-out 验证用 4 个额外 size:280M、350M、390M、720M)。
scaling law 拟合质量¶
跨模型大小的预测吻合¶
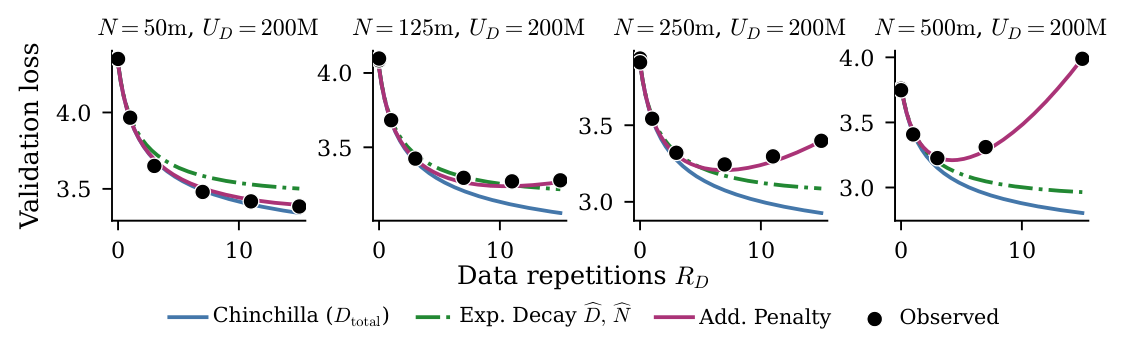
Figure 3 横向对比 Chinchilla(蓝实线)、Exp. Decay $\hat{D}, \hat{N}$(绿点划线)和本文 Add. Penalty(紫红实线)在 $U_D = 200$M、四个 model size 下的预测。Add. Penalty 同时捕捉到了"loss 先降后升"的过拟合行为——这是 baseline 们做不到的,尤其在 $N=500$M 时观测点出现明显回升,只有本文的 law 能跟上。
Huber loss 与 $R^2$¶
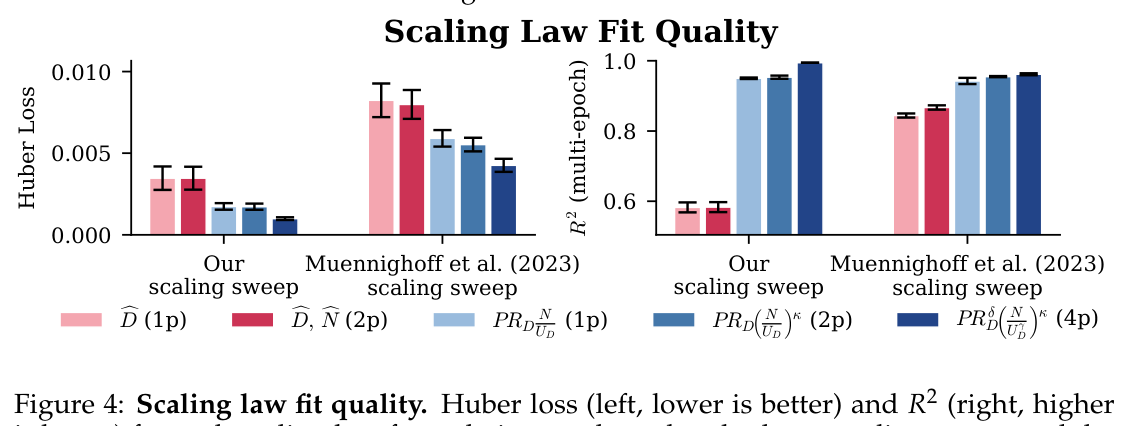
Figure 4 给出五种 form 在两个独立 scaling sweep(本文 FineWeb sweep + Muennighoff 公开 C4 sweep)上的 Huber loss 与 multi-epoch $R^2$。即便最简单的 1p 加性 penalty(Eq. 6)也已 实质性地优于 两种 baseline;4p 形式(Eq. 8)在本文数据上达到近完美拟合。改进同样泛化到 Muennighoff 数据——其 model size 范围和 repetition 范围都更广。
具体数值(Appendix D):
标准 weight decay 研究 ($\lambda=0.1$, n=157):
| Form | $R^2$ | $R^2_{\text{multi}}$ | Huber |
|---|---|---|---|
| Exp. Decay ($\hat{D}$) | 0.8866 | 0.5825 | 0.003469 |
| Eff. Param. ($\hat{D}, \hat{N}$) | 0.8868 | 0.5832 | 0.003468 |
| Add. Penalty (1p) | 0.9852 | 0.9503 | 0.001739 |
| Add. Penalty (2p) | 0.9860 | 0.9533 | 0.001722 |
| Add. Penalty (4p) | 0.9971 | 0.9945 | 0.000992 |
即使是 1p 加性 penalty,multi-epoch $R^2$ 也从 0.58 跃升到 0.95——结构性差距而非边际改进。
强 weight decay 研究 ($\lambda=1.0$, n=126):
| Form | $R^2$ | $R^2_{\text{multi}}$ | Huber |
|---|---|---|---|
| Exp. Decay ($\hat{D}$) | 0.9741 | 0.9476 | 0.001463 |
| Eff. Param. ($\hat{D}, \hat{N}$) | 0.9737 | 0.9466 | 0.001463 |
| Add. Penalty (1p) | 0.9921 | 0.9875 | 0.000925 |
| Add. Penalty (2p) | 0.9948 | 0.9936 | 0.000860 |
| Add. Penalty (4p) | 0.9958 | 0.9958 | 0.000759 |
值得注意:Exp. Decay 在 strong WD 下的 $R^2_{\text{multi}}$ 跳到 0.95,反映 repetition 在强正则下行为更"温和"——这给后续的 weight decay 研究埋下伏笔。
Muennighoff C4 数据外推(n=158, 至 64 epochs):
| Form | $R^2$ | $R^2_{\text{multi}}$ | $R^2_{\text{single}}$ | Huber |
|---|---|---|---|---|
| Exp. Decay ($\hat{D}$) | 0.8953 | 0.8442 | 0.9763 | 0.008239 |
| Eff. Param. ($\hat{D}, \hat{N}$) | 0.9119 | 0.8670 | 0.9832 | 0.007987 |
| Add. Penalty (1p) | 0.9557 | 0.9426 | 0.9763 | 0.005910 |
| Add. Penalty (2p) | 0.9633 | 0.9549 | 0.9763 | 0.005528 |
| Add. Penalty (4p) | 0.9675 | 0.9617 | 0.9763 | 0.004256 |
所有加性 penalty form 在单 epoch 上 $R^2_{\text{single}} = 0.9763$ 完全一致——这是因为 penalty 项在 $R_D = 0$ 处自动消失,construction 上保证了 Chinchilla 单 epoch 拟合不被破坏。$\hat{D}, \hat{N}$ 的 $R^2_{\text{single}} = 0.9832$ 略高,是因为 $\hat{N}$ 饱和会修改 over-parameterized 单 epoch 预测。多 epoch 行为上加性 penalty 全面胜出。
Compute-optimal 分配建议¶
与 Chinchilla / effective-data 的定性差异¶
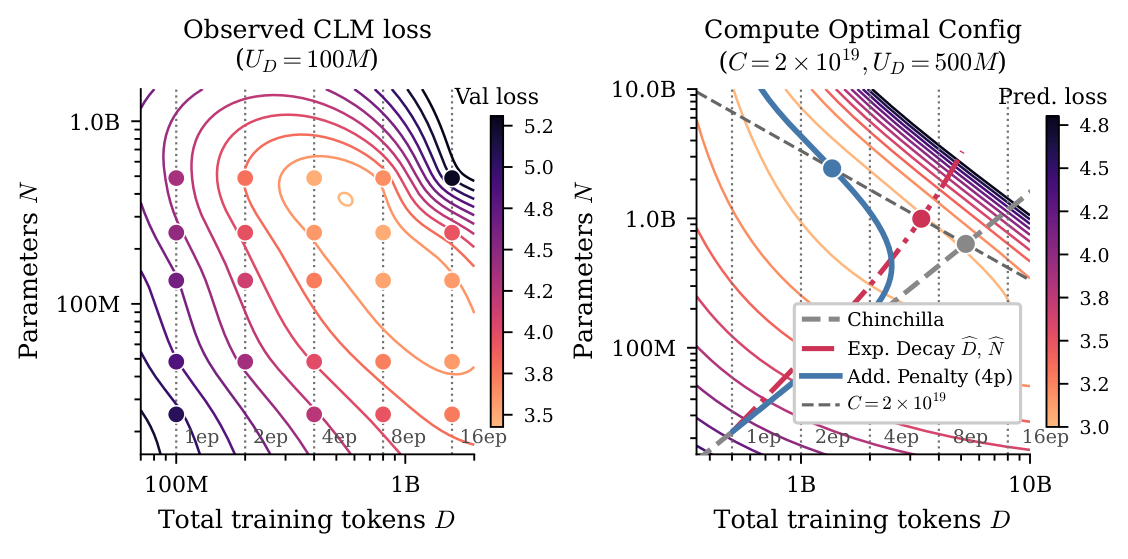
Figure 5 (Right) 在 $C = 2 \times 10^{19}$ FLOPs、$U_D = 500$M 下对比三种 law 给出的最优 $(N, D)$ 前沿。质的差异:
- Chinchilla(黑虚线)忽略过拟合,永远建议加 epoch——optimal $D$ 随 $C$ 线性增长($U_D$ 固定),即 epoch 越多越好;
- Muennighoff effective-data(橙线)描述 repetition 的递减回报,但 从不建议停止重复——最多趋于平台;
- 本文 4p law(蓝粗实线)预测一个 compute budget 阈值,超过后继续重复反而 counterproductive;前沿 回弯,建议在高 compute 区段 放大 model 而 减少 epoch。
这是一个明确可操作的工程指导:给定固定数据预算,存在一个 compute level,超过它后训练更大模型 + 更少 epoch 比训练较小模型 + 更多 epoch 更优。
表 1:prescriptive validation¶
作者用每个 law 推荐的最优配置实际训出来,看哪个配置在 perplexity 和下游 BPB 上最好(Table 1):
| $U_D$ | $C$ | Scaling law | Params | Epochs | Perplexity ↓ | OLMES BPB ↓ |
|---|---|---|---|---|---|---|
| 250M | $5 \times 10^{18}$ | Chinchilla | 280M | 12 | 25.31 | 1.52 |
| 250M | $5 \times 10^{18}$ | Eff. Param. | 500M | 7 | 23.91 | 1.50 |
| 250M | $5 \times 10^{18}$ | Ours | 700M | 5 | 22.90 | 1.45 |
| 500M | $1 \times 10^{19}$ | Chinchilla | 390M | 8 | 18.95 | 1.35 |
| 500M | $1 \times 10^{19}$ | Eff. Param. | 550M | 6 | 18.65 | 1.35 |
| 500M | $1 \times 10^{19}$ | Ours | 700M | 5 | 18.48 | 1.30 |
| 500M | $2 \times 10^{19}$ | Chinchilla | 670M | 10 | 18.90 | 1.37 |
| 500M | $2 \times 10^{19}$ | Eff. Param. | 950M | 7 | 19.34 | 1.40 |
| 500M | $2 \times 10^{19}$ | Ours | 2.2B | 3 | 17.73 | 1.34 |
Ours 一致地推荐更大的模型 + 更少 epoch,并且在所有设定下取得最好 perplexity 与 BPB。$C = 2 \times 10^{19}$ 行特别戏剧化:本文推荐的 2.2B × 3ep 配置 perplexity 17.73 vs. Chinchilla 推荐 670M × 10ep 的 18.90,差距相当显著。
表 17:下游每任务 BPB¶
Appendix E 给出 $U_D = 250$M, $C = 5 \times 10^{18}$ 三个推荐配置在 19 个 OLMES 任务上的 per-task BPB(节选):
| Task | Add. Penalty (700M) | Chinchilla (280M) | Eff. Param. (500M) |
|---|---|---|---|
| arc_easy | 1.3871 | 1.4751 | 1.4091 |
| hellaswag | 1.0503 | 1.0817 | 1.0591 |
| sciq | 1.4761 | 1.6006 | 1.5211 |
| sciriff_yesno | 0.6709 | 0.8108 | 1.0329 |
| lambada | 0.9948 | 1.0356 | 1.0209 |
| Average | 1.4469 | 1.5201 | 1.4979 |
本文配置在 19 个任务里赢下绝大多数(Average 1.4469 vs. baseline 1.49–1.52)。
与 Muennighoff 的"建议反向"如何调和(Appendix A)¶
Muennighoff et al. (2023) 当年得出的结论 看似与本文相反——他们建议 data-constrained compute 应该投向 更小的模型 * 更多 epoch。作者把分歧追溯到一个方法论选择:Muennighoff 使用的是 Hoffmann et al. (2022) 在 C4 上 scrape 的 isoFLOP 点拟合的 已发布 Chinchilla 参数,而不是用他们自己 scaling sweep 重新拟合 baseline。
Table 3 显示,已发布的 Chinchilla 参数在 Muennighoff 的 29 个 single-epoch run 上只解释 71.1% 的方差($R^2 = 0.711$);用 Muennighoff 自己的数据 重新拟合 Chinchilla baseline 后 $R^2 = 0.989$,Huber loss 下降 3 倍。也就是说 published Chinchilla baseline 本身在 Muennighoff 数据上是 misspecified。
Table 4 进一步显示:在 published base 之上加 $\hat{D}, \hat{N}$ 机制能把 $R^2$ 从 0.445 拉到 0.791($+0.346$,看上去机制贡献巨大);但在 refit base 上,同样机制只能把 $R^2$ 从 0.861 拉到 0.931($+0.070$)——绝大部分"机制贡献"其实是在补偿 baseline 本身的拟合误差。
机制层面也可解:在 published base 下拟合的 effective-parameter rate constant $R_N^* = 5.31$,意味着 $\hat{N}$ 很快饱和,把 optimal allocation 推向小模型;在 refit base 下 $R_N^* = 3294$,effectively 无穷大——optimizer 把 $\hat{N}$ 机制 关掉了,allocation 反向倒回大模型 + 少 epoch,与本文一致。
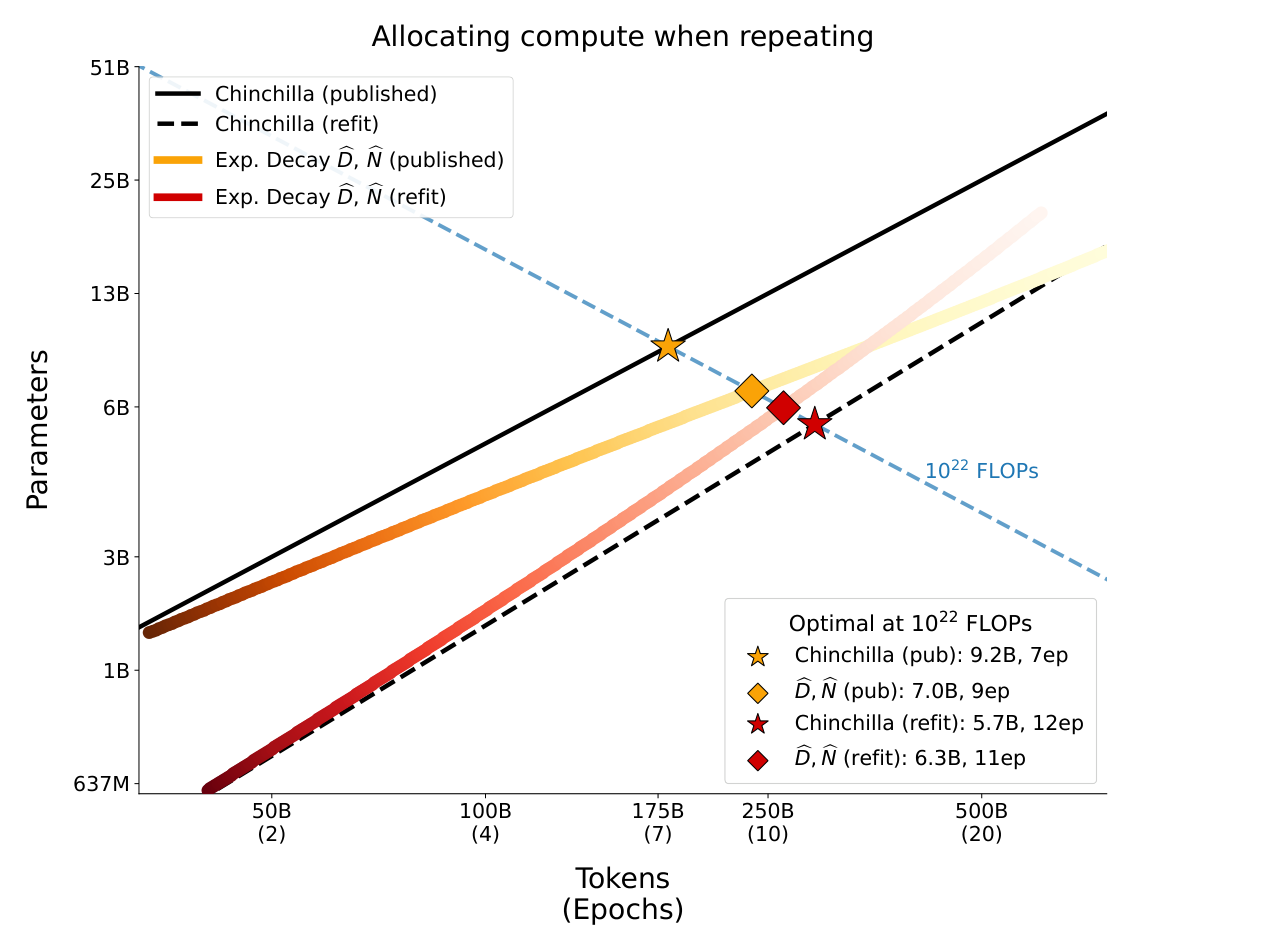
Figure 9 在 $U_D = 25$B、$10^{22}$ FLOPs 下直观展示这个反转:published $\hat{D}, \hat{N}$(黄)推荐 7B × 9ep(向小模型偏移);refit $\hat{D}, \hat{N}$(红)推荐 6.3B × 11ep——但 refit Chinchilla(黑虚线)已经推荐 5.7B × 12ep,refit $\hat{D}, \hat{N}$ 只比 Chinchilla 多了一点扩大模型的偏向。结论:表面分歧来自 baseline misspecification 被 $\hat{N}$ 机制吸收。当 baseline 修正后,分配建议与本文一致。
案例研究:weight decay 改善对重复的鲁棒性¶
系数 $P$ 是 配置鲁棒性 的直接刻画¶
由于 4p 加性 penalty 把过拟合代价孤立成单一系数 $P$(且单 epoch 行为完全由 Chinchilla 部分决定),$P$ 就成了"训练配置对 repetition 的脆弱程度"的直接量化指标。这把 跨配置 的对比从需要扫整个 (N, D, R_D) 网格简化成只比较 1 个数。
单 epoch 的代价¶
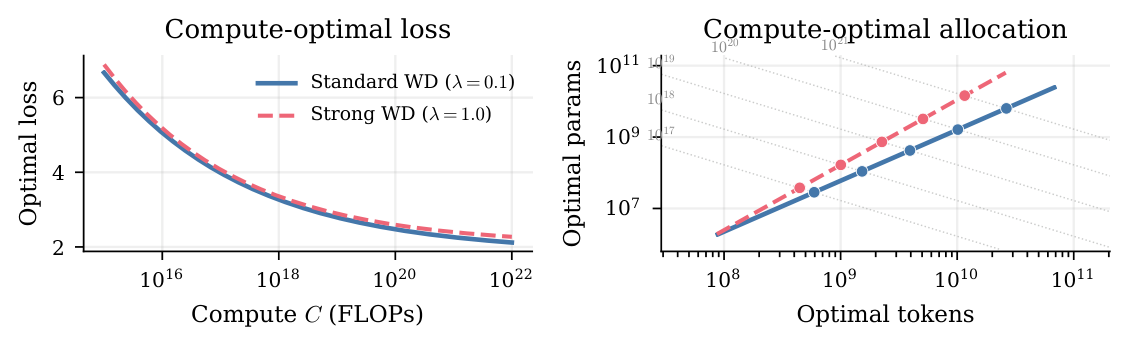
先把单 epoch 行为拟合出 $(E, A, B, \alpha, \beta)$(Table 12):strong WD 把 entropy floor $E$ 抬高了约 0.2 nats,同时把 $B$ 从 4964 提到 29370、$\beta$ 从 0.43 提到 0.53(更陡的数据 exponent,与 strong regularization 降低 effective model capacity 的解释一致)。结果是 strong WD 在 每个 compute budget 上 的 single-epoch compute-optimal loss 都比 standard 略高(Figure 6 Left);compute-optimal allocation 也偏向更大的模型 + 更少数据(Figure 6 Right)。这是 strong WD 的"单 epoch 税"。
多 epoch 的红利¶
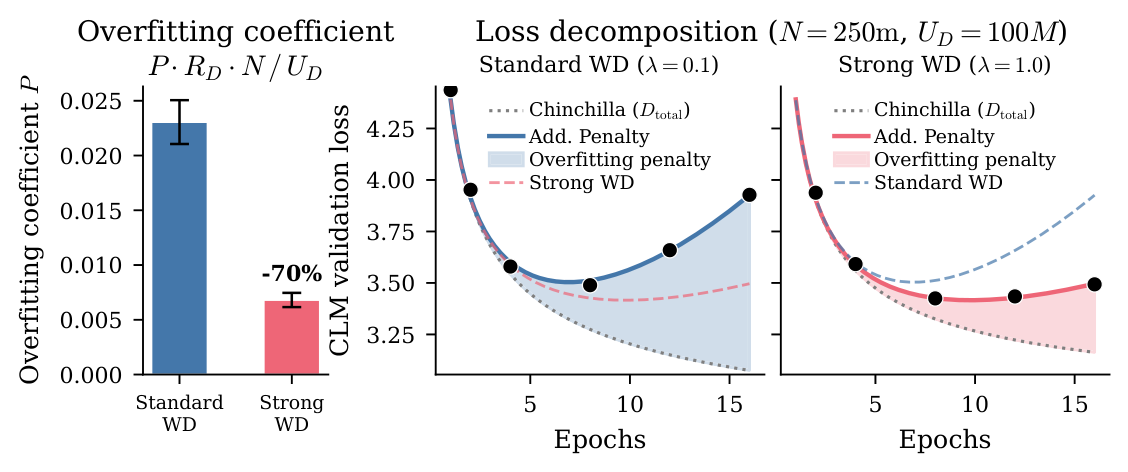
在 single-epoch 参数固定后,分别为两种 WD 拟合 penalty(Eq. 8)。Figure 7 (Left) 给出 1p form 下的 $P$:standard $P = 0.022 \pm 0.001$,strong $P = 0.0068 \pm 0.0007$,strong WD 把 $P$ 削减 ≈ 70%。Figure 7 (Center, Right) 把 $N=250$M, $U_D=100$M 的 loss 分解为"Chinchilla 部分 + overfitting penalty"——strong WD 下两条紫红实线和数据点几乎贴合到 16 epochs 都没明显回升,而 standard 在 ~7 epochs 后开始回升。
具体的 Phase 2 拟合参数(Table 14, 4p form, strong WD):
- $P = 0.00257$, $\delta = 1.563$, $\kappa = 1.391$, $\gamma = 1.024$
- 对照 standard WD 的 $\delta = 1.674$, $\gamma = 0.635$, $\kappa = 1.345$
- 关键观察 1:strong WD 的 $\gamma \approx 1.02$ vs. standard 的 0.64——data-budget exponent 本身被 regularization 调高,意味着大量数据预算的"稀释效应"在 strong WD 下更接近线性;
- 关键观察 2:Exp. Decay form 的 $R^* = 12.73$ (strong) vs. $7.76$ (standard)——effective-data 形式自己的拟合常数也证实 strong WD 下 repetition 大约 多 60% 可容忍。
Crossover:什么时候 strong WD 反超¶
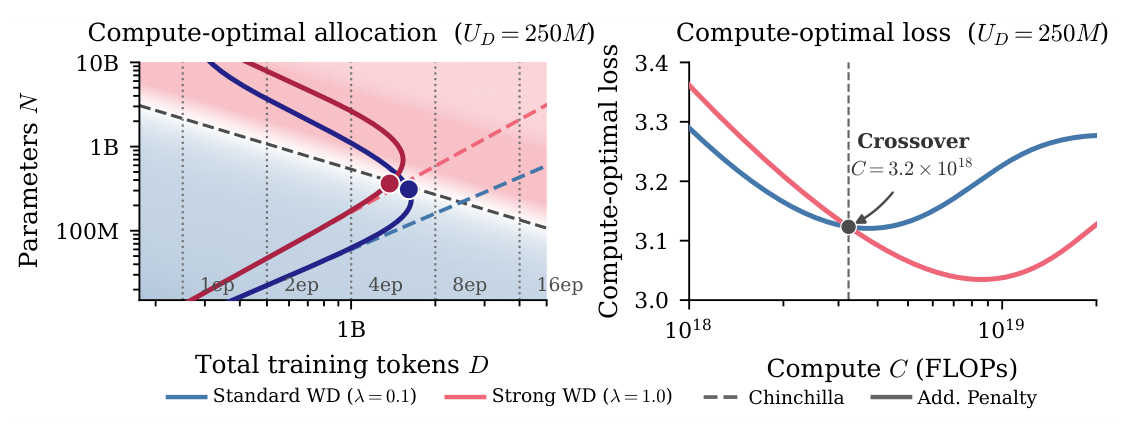
虽然 strong WD 有 single-epoch loss premium,但其 70% 更低的 overfitting cost 创造了一个 crossover 点(Figure 8):
- $U_D = 250$M 下,standard WD 在 modest compute 占优;
- $C \approx 3.2 \times 10^{18}$ FLOPs 处 strong WD 反超——本文 scaling law 预测 这个 crossover:strong WD 的 lower penalty 在足够多 compute 处补偿了它的 single-epoch tax。
Table 2 在 held-out 配置上验证这个 prescriptive 预测:
| $U_D$ | $C$ | WD | Params | Epochs | Perplexity ↓ | BPB ↓ |
|---|---|---|---|---|---|---|
| 250M ($C^\times \approx 3 \times 10^{18}$) | $3 \times 10^{18}$ | 0.1 | 350M | 6 | 23.38 | 1.46 |
| 250M | $3 \times 10^{18}$ | 1.0 | 350M | 6 | 22.93 | 1.47 |
| 250M | $5 \times 10^{18}$ | 0.1 | 700M | 5 | 22.91 | 1.47 |
| 250M | $5 \times 10^{18}$ | 1.0 | 550M | 6 | 21.66 | 1.41 |
| 250M | $1 \times 10^{19}$ | 0.1 | 3B | 2 | 23.13 | 1.52 |
| 250M | $1 \times 10^{19}$ | 1.0 | 1B | 6 | 20.34 | 1.36 |
| 500M ($C^\times \approx 1 \times 10^{19}$) | $1 \times 10^{19}$ | 0.1 | 700M | 5 | 18.52 | 1.36 |
| 500M | $1 \times 10^{19}$ | 1.0 | 830M | 4 | 18.75 | 1.32 |
| 500M | $3 \times 10^{19}$ | 0.1 | 5B | 2 | 18.16 | 1.35 |
| 500M | $3 \times 10^{19}$ | 1.0 | 2.5B | 4 | 16.65 | 1.30 |
模式很清晰:在 $C^\times$ 附近两种 WD 表现相当;超过 $C^\times$ 越远,strong WD 优势越大。$U_D = 500$M, $C = 3 \times 10^{19}$ 一行 strong WD 把 perplexity 从 18.16 降到 16.65(−1.5)。
与 Kim et al. (2026) 的呼应:他们经验地发现"数据受限场景下最优 weight decay 比标准做法大一个数量级"。本文给出的 $P$ 70% 削减 + 预测 crossover 给出了 scaling-law 层面的解释——这不是孤立的 hyperparameter trick,而是 strong WD 通过修改 (single-epoch base, repetition penalty) 二者的 trade-off 取得"不同 compute 区段的不同最优"。
实践含义¶
- 数据受限实践者有两个互补的工具:把 regularization 加强(降低 $P$ 70%),以及选择正确的 model size–epoch trade-off(compute-optimal 前沿);
- 不要不加思考地照搬 Chinchilla,因为它建议 epoch 越多越好;当 $C$ 超过某阈值,它的建议会显著差于本文;
- 把训练配置之间的对比简化为单数 $P$ 之比,可以替代昂贵的 per-config hyperparameter sweep。
局限与讨论¶
已知局限: 1. scaling sweep 只到 1B 参数 + 16 epochs,无法 证实 fitted exponents 在前沿规模(10B+ 参数、几十到上百 epoch)保持不变。 2. 当前 form 没有捕捉 double descent(Nakkiran et al., 2020)等现象——loss 在过拟合后是否还会再次下降,本文 law 不预言。 3. 只测了两个 weight decay 值($\lambda \in \{0.1, 1.0\}$),用独立 sweep 给出 prescriptive 结论;把正则化强度 直接进入 scaling law 是一个开放方向。 4. 实验都在 FineWeb 一个语料 + Llama 2 一种架构上做的;扩展到 Muennighoff 的 C4 数据验证了 generalization,但不同 tokenization、pre-processing 是否影响 fitted constants 仍未完全厘清(参考 Li et al., 2025 关于 scaling-law fitting 的稳定性问题)。
核心贡献评价:
- 形式简洁、可解释、向后兼容($R_D = 0$ 退化到 Chinchilla),1p form 已经能达到 multi-epoch $R^2 \approx 0.95$,是一个非常 frugal 的扩展;
- 真正的实践价值在于 prescriptive:给出明确的 "epoch 阈值" 和 "model–epoch trade-off 反弯点",从此 data-constrained 训练有了具体可操作的指导,而不是"epoch 越多越好"的模糊建议;
- 把过拟合表达为单一系数 $P$ 是漂亮的设计:它既是 scaling law 的拟合参数,也是 配置鲁棒性的度量,让正则化、optimizer 选择、batch size 等设定可以被定量比较。
值得借鉴的设计:
- "重复 token 的双重角色"——同时贡献于 data-sufficiency 项与 overfitting 项——是一种比 effective-data 替换更物理的建模视角;
- 1p / 2p / 4p Pareto 阶梯让读者看到"加多少自由参数能换多少拟合质量",这种 complexity ladder 在 scaling-law 类工作里值得推广;
- Appendix A 关于 Muennighoff baseline misspecification 的反思——scaling law 拟合常数不能跨数据集移植,这是 Li et al. (2025) 的发现在另一个具体场景下的再次确认;
- prescriptive 验证而非仅 descriptive 拟合:作者训出每个 law 推荐的 config 并对比,这是对 scaling-law 工作"被信赖"的高 bar 验证标准。
与已有工作的差异:
- Muennighoff et al. (2023):本文显式把 repetition 拆成"data 项 + overfitting 项",给出与 Muennighoff 相反 的 allocation 建议,并通过 reanalysis 解释分歧根源;
- Hoffmann et al. (2022) Chinchilla:本文是 Chinchilla 的 严格扩展——单 epoch 退化即得;
- Kim et al. (2026):本文给 Kim 的"data-constrained 下最优 WD 大一个数量级"经验发现提供了 scaling-law 形式化的解释。
工业落地价值:在 LLM pretraining 的实际操作里,本文最直接可用的两个建议: 1. 当 unique data 给定且 compute 充裕时,考虑放大模型 + 减少 epoch 而不是相反——按 Table 1 数据,$U_D = 500$M, $C = 2 \times 10^{19}$ 下作者推荐 2.2B × 3ep(perplexity 17.73)显著优于 Chinchilla 推荐的 670M × 10ep(18.90); 2. 当数据受限时,把 weight decay 调到 1.0 量级——会损失 single-epoch 上的少量 loss,但在 $C \gg C^\times$ 区段反超,且 70% 减少 overfitting 系数。