MobileMoE: Scaling On-Device Mixture of Experts 精读¶
Meta AI · arXiv:2605.27358 · 2026-05-26(v1) 作者:Yanbei Chen, Hanxian Huang, Ernie Chang, Jacob Szwejbka, Digant Desai, Zechun Liu, Vikas Chandra, Raghuraman Krishnamoorthi
研究动机与背景¶
Mixture-of-Experts(MoE)已经成为千亿级语言模型的事实标准架构(DeepSeek-V3、Qwen3-MoE、Gemini、Grok 等),其核心优势是用稀疏激活把"总参数容量"与"单 token 推理算力"解耦——总参数随专家数量膨胀,但每个 token 只激活其中一小部分。然而在端侧(on-device)场景——手机、可穿戴、嵌入式 agent——主流小模型几乎全是稠密(dense)架构(MobileLLM、MobileLLM-Pro、Gemma、SmolLM2),sub-billion 激活参数规模下 MoE 几乎无人探索。本文要回答的核心问题是:在严格的移动端内存与算力约束下,MoE 架构应该如何设计与扩展,才能在 sub-billion 激活参数区间击败稠密模型?
作者把端侧 MoE 的价值拆成三层"效率":
- 参数效率(parameter efficiency):MoE 用众多专家网络扩展总容量,但每 token 只激活稀疏一小部分,以远低的推理算力匹配大得多的稠密模型;
- 运行时效率(runtime efficiency):稀疏激活降低推理 FLOPs,从而降低延迟、省电;
- 学习效率(learning efficiency):专家网络在不同领域(知识、代码、数学)上专业化,把多任务能力打包进一个统一模型。
一个关键的外部趋势是智能手机内存的快速增长(iPhone 13 的 4GB → iPhone 17 的 12GB;Galaxy S21 的 8GB → S25/S25 Ultra 的 12/16GB),这给"在手机上常驻一个高容量稀疏 LLM"提供了内存空间。
但现有的 scaling law 研究几乎全部面向服务器端:要么 scaling 到几十到几百 billion 参数用于云端部署(Chinchilla、joint-MoE scaling law),要么假设充裕的硬件资源使大模型 footprint 可行、推理可在多 GPU 上并行。端侧部署则必须同时考虑由激活参数决定的推理算力、以及由总参数决定的内存 footprint——这是服务器端 scaling law 不曾建模的联合约束。
本文贡献三点:
- MobileMoE-S/M/L:首个面向端侧部署的 sub-billion 激活 MoE 模型族,基于一条在联合内存 + 算力约束下推导的端侧 MoE 扩展律得到,识别出端侧 use case 的最优设计选择(适中稀疏度 + 细粒度专家 + 共享专家)。激活参数 0.3/0.5/0.9B,总参数 1.3/2.8/5.3B,INT4 权重 footprint <3GB。
- 四阶段训练配方(pre-training → mid-training → SFT → INT4 QAT),含 MoE 专用的稳定性与效率技术。仅用 ~6T 预训练 token(远少于稠密 baseline:Llama 3.2 1B 用 9T、SmolLM2 1.7B 用 11T)就达到 Pareto 领先精度,并以更少总参数超越 SOTA MoE OLMoE-1B-7B。
- 首个在商用智能手机(Samsung Galaxy S25、iPhone 16 Pro)上的高效端侧 MoE 推理:通过 ExecuTorch 上的自定义 fused MoE kernel + 系统化运行时 profiling。在同等 INT4 权重内存下,MobileMoE-S 相比稠密 baseline MobileLLM-Pro 实现 1.8–3.8× 更快 prefill、2.2–3.4× 更快 decode。
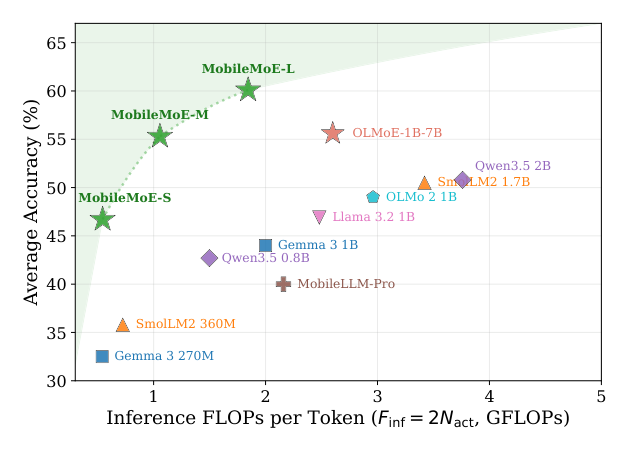
如 Figure 1 所示:较小的 MobileMoE-S/M 在同等内存下用 2–4× 更少的推理 FLOPs 匹配或超过稠密 baseline;MobileMoE-L 进一步把前沿推到 sub-billion 激活规模下的 SOTA 精度。相比 SOTA MoE OLMoE-1B-7B,MobileMoE-M 用 ~60% 更少的激活与总参数即匹配其精度,MobileMoE-L 则以 30% 更少激活参数、23% 更小总参数 footprint 取得显著更高精度。
核心方法(一):端侧 MoE 设计空间¶
MoE 预备与三个设计因子¶
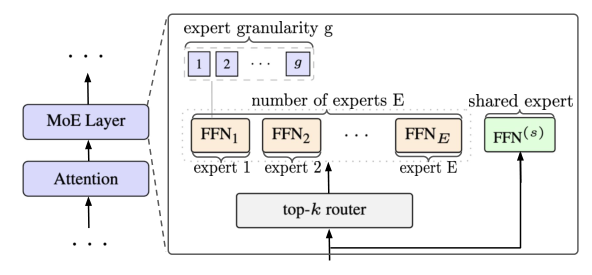
考虑一个 $n_l$ 层、维度 $d_{\text{model}}$ 的 decoder-only Transformer。每层包含分组查询注意力(GQA,$n_h$ query heads、$n_{\text{kv}}$ KV heads)+ 隐藏维度 $d_{\text{ff}}$ 的前馈网络(FFN)。MoE 把稠密 FFN 替换为 $E$ 个路由专家 FFN + 一个 top-$k$ 路由器,每 token 选取得分最高的 $k$ 个专家。现有 SOTA MoE 在架构选择上分歧很大:DeepSeek-V3 用 256 个细粒度专家 + top-8 + 共享专家;Qwen3-MoE 用 128 专家 + top-8、无共享专家;Mixtral 用 8 个粗粒度专家 + top-2。这些差异说明端侧规模下的关键设计选择缺乏共识。
本文系统研究三个设计因子(Figure 2 左):
- (i) 模型稀疏度 $(E, k)$:路由专家数 $E$ 与激活专家数 $k$ 共同决定激活参数与总参数之比;
- (ii) 专家粒度 $g$:每个路由专家被切分为 $g$ 个隐藏维度 $d_{\text{ff}}/g$ 的子专家,得到 $gE$ 个专家、每 token 激活 $gk$ 个;
- (iii) 共享专家 $s$:一个总是激活、绕过路由的"通才"专家。
MoE 层的输出形式化为:
$$\mathbf{y} = \sum_{i \in \text{Top-}gk} \text{router}_i(\mathbf{x}) \cdot \text{FFN}_i(\mathbf{x}) + \text{FFN}^{(s)}(\mathbf{x}) \tag{*}$$
三个尺度的基础骨架(base architecture)固定为:扩展比 $d_{\text{ff}}/d_{\text{model}}=4$、纵横比 $d_{\text{model}}/n_l \approx 40$(端侧偏好更深窄的架构,与 GPT-3 的纵横比 128 相反)、4 KV heads、SwiGLU。具体配置:
| 尺度 | $d_{\text{model}}$ | $d_{\text{ff}}$ | $n_h$ | $n_{\text{kv}}$ | $n_l$ | 搜索范围 $E$ | $g$ | Shared |
|---|---|---|---|---|---|---|---|---|
| Small (S) | 768 | 3072 | 12 | 4 | 20 | {1–32} | {1–16} | {✓,✗} |
| Medium (M) | 1024 | 4096 | 16 | 4 | 26 | {1–32} | {1–16} | {✓,✗} |
| Large (L) | 1280 | 5120 | 20 | 4 | 32 | {1–32} | {1–16} | {✓,✗} |
端侧 MoE 扩展律¶
本文提出一条广义的端侧 MoE 扩展律,同时把激活参数、数据、专家数、架构选择纳入一个 loss 预测公式:
$$\mathcal{L}(N_{\text{act}}, D, \hat{E}, x) = A_x \hat{E}^{\delta_x} N_{\text{act}}^{\alpha_x + \gamma_x \ln \hat{E}} + B_x \hat{E}^{\omega_x} D^{\beta_x + \zeta_x \ln \hat{E}} + c_x \tag{1}$$
其中 $\mathcal{L}$ 为模型 loss,$N_{\text{act}}$ 为激活参数,$D$ 为训练数据量,$\hat{E}$ 是专家数 $E$ 的一个单调变换($E$ 决定了总参数 $N_{\text{total}}$ 与稀疏度 $1 - N_{\text{act}}/N_{\text{total}}$),$x$ 指架构选择(粒度 $g$、共享专家 $s$,它们不必改变 $N_{\text{act}}$、$N_{\text{total}}$),$c_x$ 是不可约 loss。这一形式可退化为两个已知 scaling law 作为特例:
退化形式 I(架构 $x$ 固定)—— joint MoE scaling law:
$$\mathcal{L}_x(N_{\text{act}}, D, \hat{E}) = A\hat{E}^{\delta} N_{\text{act}}^{\alpha + \gamma \ln \hat{E}} + B\hat{E}^{\omega} D^{\beta + \zeta \ln \hat{E}} + c \tag{2}$$
它吸收 $x$ 为常数,用于寻找内存最优的专家数。其中 $\hat{E}$ 的单调变换定义为 $\frac{1}{\hat{E}} = \frac{1}{E - 1 + (\frac{1}{E_{\text{start}}} - \frac{1}{E_{\text{max}}})^{-1}} + \frac{1}{E_{\text{max}}}$。
退化形式 II(专家数 $\hat{E}$ 固定)—— Chinchilla scaling law:
$$\mathcal{L}_{\hat{E}}(N_{\text{act}}, D, x) = \tilde{A}_x N_{\text{act}}^{\tilde{\alpha}_x} + \tilde{B}_x D^{\tilde{\beta}_x} + c_x \tag{3}$$
它吸收 $\hat{E}$ 为常数($\tilde{A}_x = A_x \hat{E}^{\delta_x}$,$\tilde{\alpha}_x = \alpha_x + \gamma_x \ln \hat{E}$,$\tilde{B}_x = B_x \hat{E}^{\omega_x}$,$\tilde{\beta}_x = \beta_x + \zeta_x \ln \hat{E}$),等价于标准 scaling law,用于寻找算力最优的架构选择。
端侧优化目标与内存函数¶
端侧部署的架构优化要同时满足算力与内存约束,于是最小化式 (1) 受制于:
$$\arg\min_{N_{\text{act}}, D, \hat{E}, x} \mathcal{L}(N_{\text{act}}, D, \hat{E}, x) \tag{4}$$
$$\text{s.t.}\quad \text{算力: } F_{\text{train}} = 6 N_{\text{act}} D,\quad F_{\text{inf}} = 2 N_{\text{act}};\qquad \text{内存: } \mathcal{M}(N_{\text{total}}, T) \leq M$$
其中 $F_{\text{train}}$ 为训练算力预算,$F_{\text{inf}}$ 为每 token 推理算力(仅前向),$M$ 为设备 DRAM 预算(当前智能手机 app 使用大致上限 ~5GB)。内存函数同时计入总参数与 KV cache:
$$\mathcal{M}(N_{\text{total}}, T) = \underbrace{\frac{b_w}{8} N_{\text{total}}}_{\mathcal{M}_{\text{weight}}} + \underbrace{\frac{b_{\text{kv}}}{8} \cdot 2 T n_l n_{\text{kv}} d_h}_{\mathcal{M}_{\text{KV cache}}},\quad \mathcal{M}(N_{\text{total}}, T) \leq M \tag{5}$$
其中 $b_w$ 为权重比特精度(INT4 取 4),$b_{\text{kv}}$ 为 KV cache 比特精度(INT8 取 8),$T$ 为上下文长度,$d_h$ 为 head 维度。$\mathcal{M}$ 作为承载模型所需端侧内存的可处理 proxy(静态权重 + KV cache,不含可被运行时优化的瞬态激活 buffer)。
分而治之的架构搜索¶
三个设计轴在固定激活参数 $N_{\text{act}}$ 下结构上解耦:$E$ 单独改变 $N_{\text{total}}$(即内存),$g$ 改变专家网络但保留 $N_{\text{act}}/N_{\text{total}}$,$s$ 增加一条稠密通路(共享专家可定尺寸以同时保持 $N_{\text{act}}$、$N_{\text{total}}$)。因此作者分而治之,做三个受控消融,每次只孤立一个因子。所有消融在 8 nodes(64 张 NVIDIA H100 96GB)上、$N_{\text{act}} \in \{0.3, 0.5, 0.9\}$B、$D \in \{100, 150, ..., 500\}$B token 上跑,用 LBFGS 拟合扩展律系数。
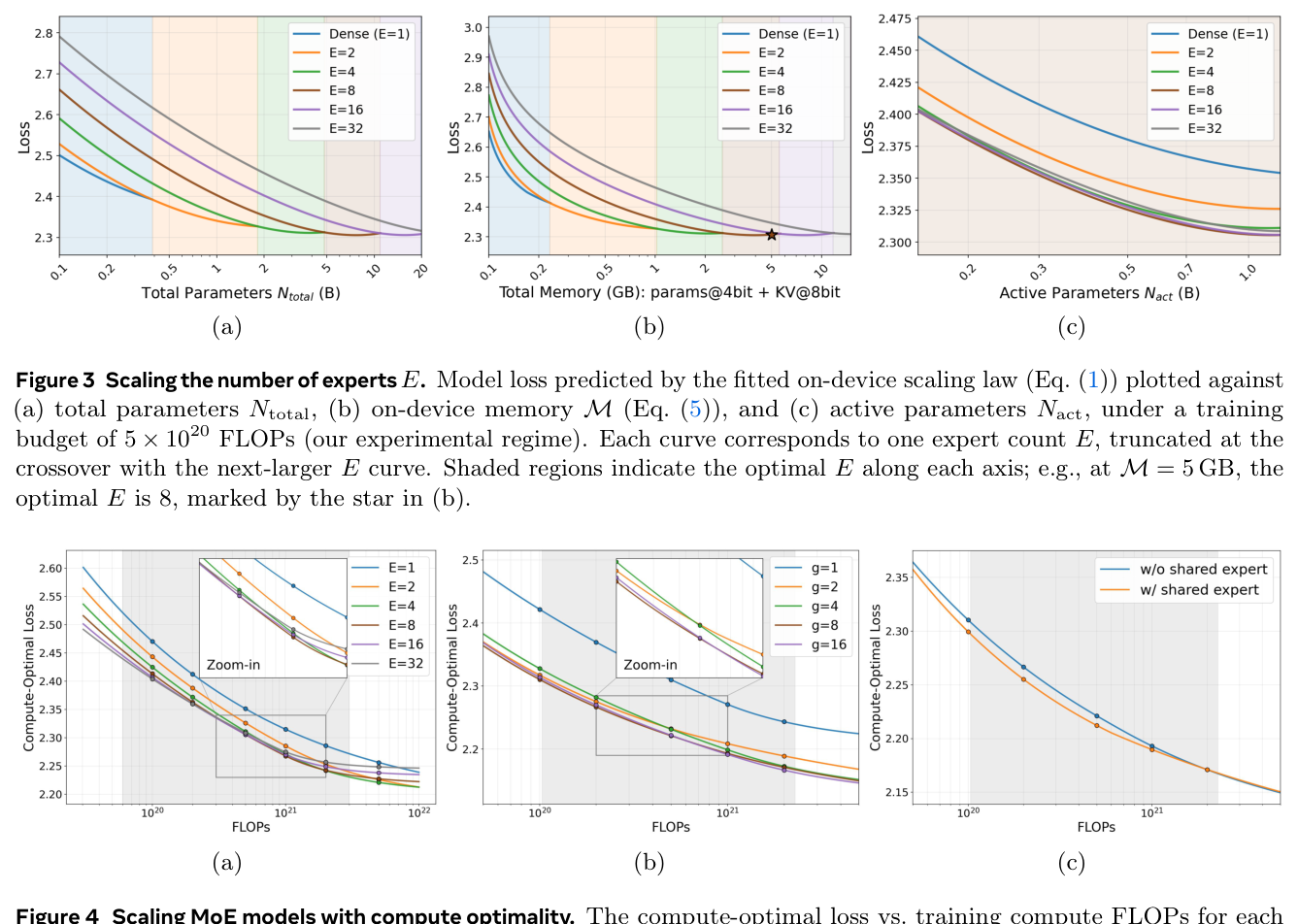
Finding 1(专家数 $E$):MoE 既能比稠密内存最优也能算力最优。在固定内存($M > 0.25$GB)下,MoE($E>1$)比稠密取得更低 loss(Figure 3(b));在固定算力(固定 $N_{\text{act}}$ 与 $F_{\text{train}}$)下,增加 $E$ 降低 loss 但 $E=8$ 之后收益递减(Figure 3(c)、4(a))。最优 $E$ 随内存增长,但适中稀疏度 $E \in \{4,8\}$ 是端侧实用甜点。→ 选 $\text{MoE}(E=8)$。

Finding 2(专家粒度 $g$):细粒度专家($g>1$)在固定算力下取得显著更低 loss(Figure 4(b)),因为 $g \cdot E$ 个细粒度专家 + top-$k \cdot g$ 路由让路由器能组合出更多样的专家组合、走更专业化的路由路径;但 $g=8$ 之后收益递减。→ 选 $\text{MoE}(E=8, g=8)$ = 64 个细粒度专家 + top-8 路由(此细粒度切分保持内存 footprint 不变)。
Finding 3(共享专家 $s$):加入共享专家后,端侧 MoE 在固定算力 FLOPs 下取得比无共享专家更低的 loss(Figure 4(c))。为公平消融,作者把 8 个激活路由专家中的 4 个替换为一个 $4\times$ 大小的共享专家,得到 60 个路由专家 + top-4 路由 + 1 个共享专家——既保持路由专家数可被专家并行度(EP=4)整除,又保持 $N_{\text{act}}$、$N_{\text{total}}$ 不变。共享专家(通才)补充路由专家(专才)。
最终 MobileMoE 架构:$\text{MoE}(E=8, g=8, s=\checkmark)$ —— 60 个细粒度路由专家 + top-4 路由 + 1 个共享专家。套用到三个基础架构得到 MobileMoE-S/M/L:激活参数 {0.3, 0.5, 0.9}B,总参数 {1.26, 2.82, 5.33}B,均在 3–5GB 端侧内存预算(INT4)内。
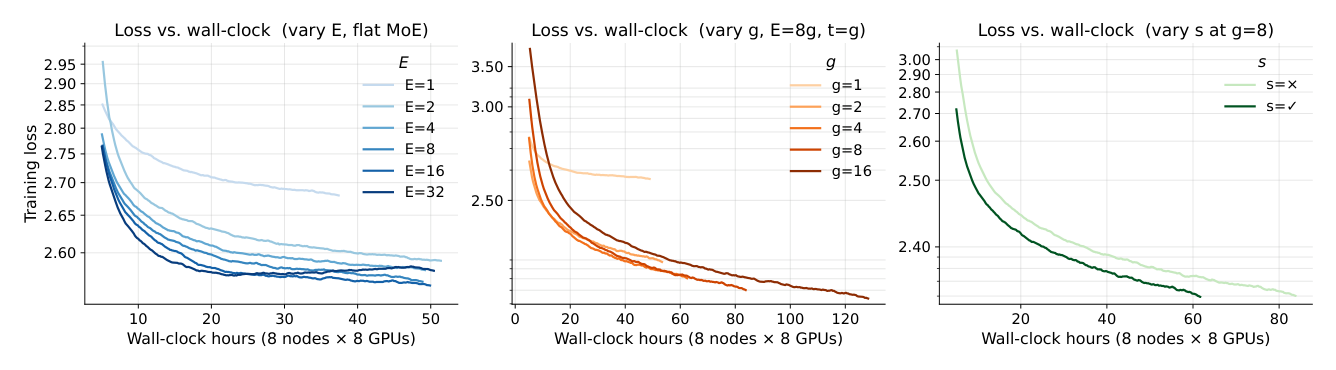
训练效率视角(Figure 5):稠密 baseline($E=1$)每步最快但收敛到更高 loss;$E \geq 2$ 的 MoE 共享大致相同的训练吞吐,但 $E=32$ 出现性能回退(总参数/内存更高);$E=8$ 是兼顾内存与训练效率的工作点。$g=16$ 比 $g=8$ 多 ~50% wall-clock 但 loss 几乎不降(<0.01),故 $g=8$ 是训练高效甜点。共享专家进一步以更高吞吐 + 更低最终 loss 改进训练。这从训练效率角度独立地佐证了 $\text{MoE}(E=8, g=8, s=\checkmark)$ 的选择。
核心方法(二):四阶段训练配方¶
Pre-training (2k 上下文) → Mid-training (8k) → Instruct SFT (8k) → QAT (INT4)
↓ ↓ ↓ ↓
(无产物) MobileMoE-Base MobileMoE-SFT MobileMoE-QAT
预训练(Pre-training)¶
三个尺度均在上下文 2048 下预训练,$\text{MoE}(E=8, g=8, s=\checkmark)$,RoPE $\theta=500{,}000$,Llama-3 分词器(128K 词表)。约 6T token 开源数据,web 重(>60%)以提供广泛语言覆盖,加上数学/代码/知识/科学的多样领域覆盖以鼓励专家专业化。尽管 6T 预算小于近期小模型(Llama 3.2 1B 9T、SmolLM2 11T),三个尺度的精度在 6T 训练中仍持续提升,且用远少的 FLOPs 匹配/超过稠密模型。
MoE 训练稳定性技术:
- 辅助-loss-free 负载均衡(bias 更新率 $\lambda_{lb}=10^{-3}$):根据 token 负载不均衡调整专家 bias,不反传额外 loss;
- router z-loss 正则($\lambda_z=10^{-4}$)稳定 router logits;
- sigmoid gating + per-token top-$k$ 归一化:每个专家独立打分而非 softmax 竞争,产生更平滑的路由分布;
- 所有 router 计算在 FP32 精度下进行(数值稳定)。
MoE 训练效率技术:
- 细粒度专家下每个专家 FFN 极小(MobileMoE-S 60 个 $768\times384$ FFN vs Mixtral 8x7B 的 8 个 $4096\times14336$,约 200× 更小),naïve 逐专家计算低效;用 grouped MLP(GMM kernel) 把所有专家批进单个 fused 分组矩阵乘,替换众多小型顺序 GEMM;
- drop-and-pad token dispatching(capacity factor 1.5)给每个专家分配固定大小 token buffer,确保 batched kernel 的统一 buffer 尺寸;
- 专家并行 EP=4,每张 GPU 持有 60/4=15 个路由专家以节省内存。
Mid-training¶
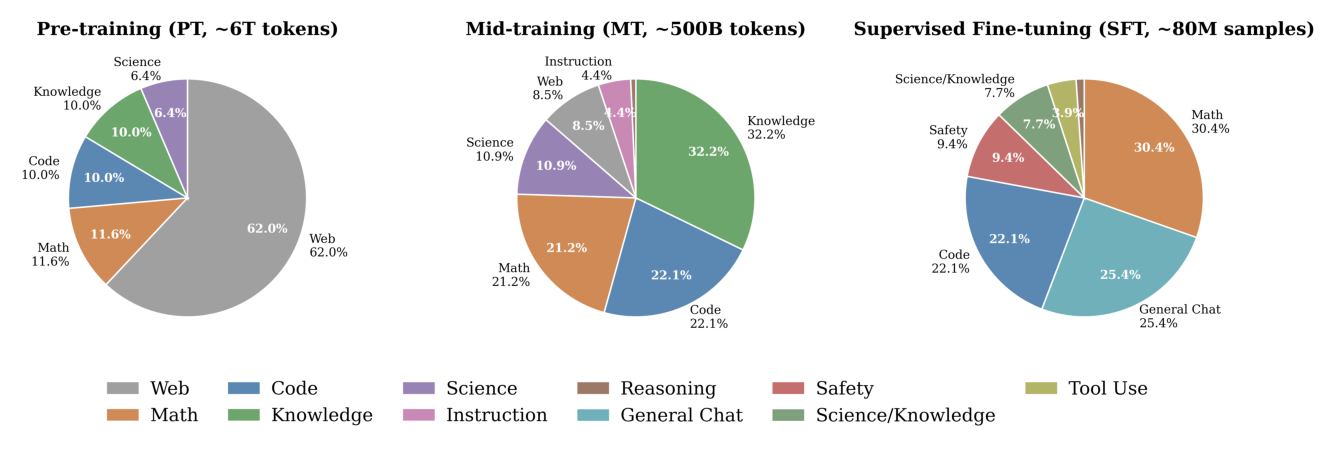
预训练后做 mid-training:把上下文从 2048 扩到 8192,同时把数据分布转向领域特定(数学、代码、知识、科学)。8K 上下文下,MobileMoE 紧凑的 KV cache 配置($n_{\text{kv}}=4$、$d_h=64$)使 KV cache 仍在端侧内存预算内。训练 ~500B token(~8% 预训练预算),线性 LR 退火,在精选数据上逐步收敛 → 产出 MobileMoE-Base。预训练 web 占比 62%→9%,知识 10%→32.2%,代码 10%→22.1%,数学 11.6%→21.2%。
监督微调(SFT)¶
在 ~80M 样本(数学、代码、指令跟随、科学,8K 上下文,序列打包)上微调 MobileMoE-Base。切换为 dropless token dispatching——drop-and-pad 会丢弃结构化指令-回复对中的 token、扭曲学习信号、降低 SFT 质量。→ 产出 MobileMoE-SFT。数据混合:数学 30.4%、通用对话 25.4%、代码 22.1%、安全 9.4%、科学/知识 7.7%(每个数据集按其规模 $w_i = \max(1, \lfloor n_i/N \times 100 \rfloor)$ 加权采样,保证小但重要的领域充分代表)。
量化感知训练(QAT)¶
为塞进端侧内存预算(≤3–5GB),对所有线性层应用 INT4 QAT,从 SFT checkpoint 初始化。router 保持 FP32 以保留路由稳定性(仅 ~0.5% 额外内存)。所有线性权重(attention、MoE FFN、embedding)做对称分组 INT4(组大小 32),激活动态量化为 INT8。权重量化为:
$$\bar{\mathbf{W}}_g = s_g \cdot \text{clamp}\left(\left\lfloor \frac{\mathbf{W}_g}{s_g} \right\rceil, q_{\min}, q_{\max}\right),\quad s_g = \frac{2 \max(|\mathbf{W}_g|)}{2^b - 1} \tag{6}$$
其中 $\mathbf{W}_g$ 是共享缩放因子 $s_g$ 的一组权重(组大小 $g=32$),$q_{\min}=-2^{b-1}$、$q_{\max}=2^{b-1}-1$、$b=4$。→ 产出 MobileMoE-QAT,权重 footprint $\mathcal{M}_{\text{weight}} = 0.68/1.48/2.75$GB(S/M/L),均在现代手机 DRAM 预算内。
训练超参(Table 1)¶
| 超参 | Pre-training | Mid-training | SFT | QAT |
|---|---|---|---|---|
| 上下文长度 | 2,048 | 8,192 | 8,192 | 8,192 |
| 总 token | ~6T | ~500B | ~126B | ~21B |
| 全局 batch size | 2,048 / 3,072† | 512 / 768† | 256 | 256 |
| 每步 token | 4.2M / 6.3M† | 4.2M / 6.3M† | 2.1M | 2.1M |
| 峰值 LR | 4×10⁻⁴ | 4×10⁻⁵ | 4×10⁻⁶ | 4×10⁻⁶ |
| LR schedule | Cosine | Linear | Cosine | Cosine |
| LR 最小比 | 0.1 | 0.1 | 0.0 | 0.0 |
| Warmup 步数 | 8,000 | 50 | 3,000 | 500 |
| Token dispatch | drop-and-pad | drop-and-pad | dropless | dropless |
| 硬件(H100 nodes) | 16–32 | 16–32 | 4–8 | 4–8 |
| Wall-clock | 3–4 周 | ~2 天 | ~2–3 天 | ~2–3 天 |
† 第一个值用于 MobileMoE-S 和 -M,第二个用于 MobileMoE-L。优化器 AdamW($\beta_1=0.9$、$\beta_2=0.95$、$\epsilon=10^{-15}$),权重衰减 0.1,梯度裁剪 1.0,BF16 模型权重 + FP32 router/优化器状态/梯度,序列打包。QAT 专属:权重 INT4(组大小 32)、激活 INT8、embedding INT4。峰值 LR 从 PT 到 SFT 降低 10×,QAT 继承 SFT 的 LR。
实验设置¶
14 个基础 benchmark(5 大核心能力):常识(HellaSwag、PIQA、SIQA、WinoGrande)、知识(MMLU、NaturalQuestions、TriviaQA)、科学(ARC-C、ARC-E、OpenBookQA)、阅读(BoolQ、DROP)、推理(BBH、GSM8K)。 8 个进阶 benchmark(小模型常崩的前沿能力):数学(MATH-500、GSM-Plus)、代码(HumanEval、MBPP)、指令跟随(IFEval、IFBench)、知识与推理(MMLU-Pro、GPQA)。
baseline:Gemma 3(270M、1B)、SmolLM2(360M、1.7B)、MobileLLM-Pro(1.1B)、Llama 3.2(1B)、OLMo 2(1B)、Qwen3.5(0.8B、2B)、以及 SOTA MoE OLMoE-1B-7B(1.3B 激活、6.9B 总)。所有 baseline 在相同设置下用贪心解码重新评测。评测用 lm-eval(vLLM 后端、bf16、贪心解码、instruct 非思考模式)。
主要实验结果¶
数据 scaling 结果¶
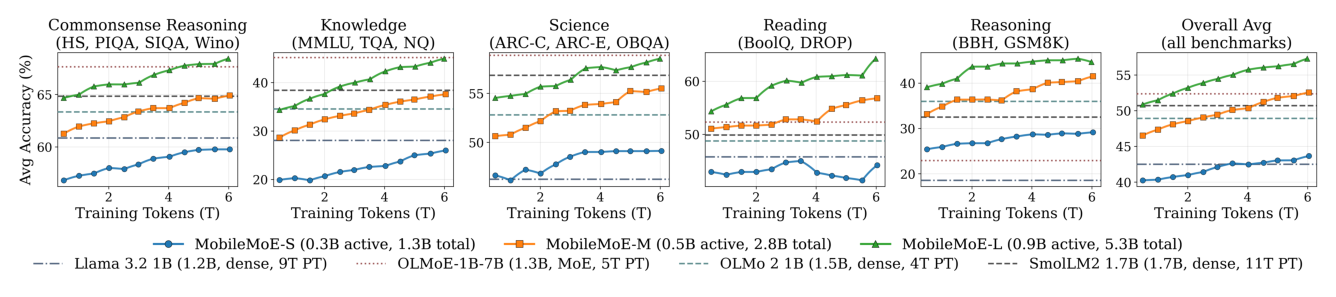
(1) MoE 受益于持续数据 scaling,尤其在知识上:三个尺度的总平均在 6T 内单调提升(S: 40→44,M: 46→53,L: 51→57),知识维度斜率最陡(L 在 MMLU+TQA+NQ 上 34→45),反映 MoE 更大总容量比相同激活参数的稠密模型能吸收更多知识。(2) MobileMoE-L 在 token 效率上同时超过稠密与 MoE baseline:~0.5T token 时即超过 Llama 3.2 1B(9T,蒸馏,Avg 42),~1T 时超过 SmolLM2-1.7B(11T,Avg 51),~2T 时超过 OLMoE-1B-7B(5T,MoE,Avg 52)。(3) 6T 时 MobileMoE-L(Avg 57,922M 激活)超过 OLMoE-1B-7B base(Avg 52,1.3B 激活),激活参数少 30%。
模型 scaling 结果(MobileMoE-Base,Table 2)¶
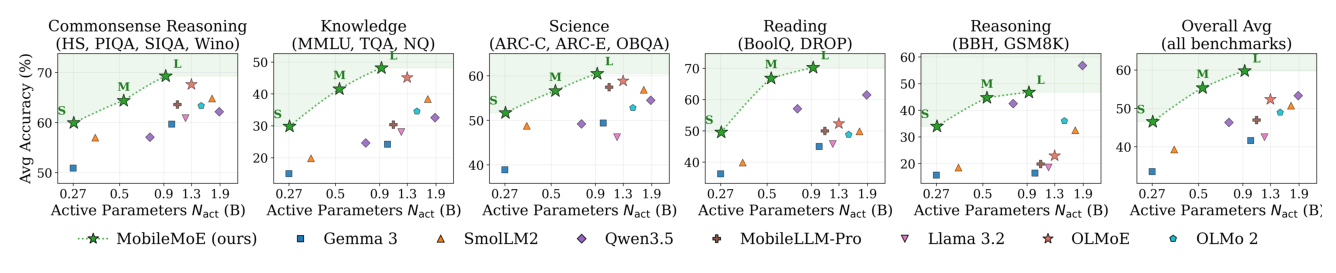
Table 2 基础 benchmark 对比($N_{\text{act}}/N_{\text{total}}$ = 激活/总参数;上标为 few-shot 数):
| Model | $N_{\text{act}}/N_{\text{total}}$ | HS | PIQA | SIQA | Wino | MMLU⁵ | NQ⁵ | TQA⁵ | ARC-C²⁵ | ARC-E | OBQA | BoolQ | DROP³ | BBH³ | GSM8K⁸ | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemma 3 270M | 270M | 41.4 | 68.3 | 40.2 | 53.7 | 26.7 | 4.1 | 14.3 | 29.4 | 56.8 | 30.4 | 58.3 | 14.2 | 29.5 | 1.8 | 33.5 |
| SmolLM2 360M | 362M | 56.5 | 71.7 | 40.7 | 59.0 | 25.2 | 7.4 | 26.8 | 40.5 | 68.1 | 37.6 | 61.3 | 17.9 | 31.7 | 5.3 | 39.3 |
| MobileMoE-S | 272M/1.3B | 58.9 | 75.4 | 46.8 | 58.6 | 43.7 | 12.6 | 33.2 | 46.5 | 73.9 | 34.6 | 60.2 | 39.0 | 31.8 | 36.2 | 46.5 |
| Qwen3.5 0.8B | 749M | 54.9 | 71.3 | 42.1 | 59.9 | 48.2 | 6.2 | 19.5 | 44.0 | 67.6 | 36.0 | 74.6 | 39.6 | 40.9 | 44.1 | 46.4 |
| MobileMoE-M | 528M/2.8B | 68.3 | 77.5 | 50.2 | 61.6 | 54.7 | 20.9 | 49.0 | 51.0 | 79.4 | 39.4 | 75.1 | 58.5 | 37.7 | 51.6 | 55.4 |
| Gemma 3 1B | 1.0B | 62.2 | 74.9 | 42.9 | 58.8 | 26.2 | 10.7 | 35.7 | 39.3 | 72.2 | 36.8 | 66.6 | 23.4 | 30.5 | 2.3 | 41.6 |
| MobileLLM-Pro | 1.1B | 66.2 | 76.6 | 48.4 | 63.2 | 32.3 | 15.6 | 43.2 | 52.5 | 76.6 | 43.2 | 77.5 | 22.5 | 33.0 | 6.6 | 47.0 |
| Llama 3.2 1B | 1.2B | 64.2 | 75.1 | 42.8 | 61.3 | 31.4 | 12.0 | 40.7 | 40.3 | 61.8 | 36.6 | 63.6 | 27.9 | 29.8 | 7.3 | 42.5 |
| OLMo 2 1B | 1.5B | 68.4 | 75.9 | 44.0 | 65.0 | 42.4 | 14.1 | 47.1 | 45.2 | 73.4 | 39.8 | 62.9 | 34.6 | 33.3 | 38.6 | 48.9 |
| SmolLM2 1.7B | 1.7B | 71.4 | 77.6 | 44.2 | 66.1 | 50.4 | 19.6 | 49.6 | 53.3 | 73.4 | 43.8 | 72.4 | 27.3 | 34.0 | 31.0 | 50.7 |
| Qwen3.5 2B | 1.9B | 65.9 | 74.7 | 43.5 | 64.6 | 54.1 | 10.9 | 32.6 | 54.3 | 71.4 | 37.8 | 69.4 | 53.6 | 48.2 | 65.3 | 53.3 |
| OLMoE-1B-7B | 1.3B/6.9B | 77.0 | 80.5 | 43.9 | 69.1 | 52.0 | 20.6 | 62.3 | 55.0 | 76.6 | 45.0 | 74.8 | 29.8 | 33.5 | 12.3 | 52.4 |
| MobileMoE-L | 922M/5.3B | 74.6 | 80.0 | 54.3 | 68.2 | 59.6 | 26.7 | 58.1 | 57.0 | 81.7 | 42.8 | 75.7 | 64.7 | 37.8 | 55.7 | 59.8 |
分析:(1) MobileMoE-Base 在 sub-billion 激活区间建立新 Pareto 前沿:MobileMoE-L(922M 激活,Avg 59.8)超过 OLMoE-1B-7B base(1.3B 激活,Avg 52.4)+7.4,激活参数少 30%、总参数少 23%(5.3B vs 6.9B);MobileMoE-L base 已超过 instruct 版 OLMoE-1B-7B(SFT Avg 55.6)+4.2。(2) MobileMoE-Base 用 2–4× 更少激活参数匹配更大稠密模型,增益集中在知识与阅读:MobileMoE-S(272M)逼近 Qwen3.5 0.8B(用 2.8× 更少激活),MobileMoE-M(528M)超过 Qwen3.5 2B +2.1(用 3.6× 更少激活)。增益最强在 MMLU/NQ/TQA(知识)和 BoolQ/DROP(阅读),印证 MoE 更大总容量最适合需要存储事实知识与理解的任务。例外是推理:Qwen3.5-2B 在更大规模(~2× MobileMoE-L 激活参数)下推理仍更强。
SFT 结果(Table 3、Table 4)¶
Table 3 instruct 基础 benchmark 对比(约定同 Table 2):
| Model | $N_{\text{act}}/N_{\text{total}}$ | HS | PIQA | SIQA | Wino | MMLU⁵ | NQ⁵ | TQA⁵ | ARC-C²⁵ | ARC-E | OBQA | BoolQ | DROP³ | BBH³ | GSM8K⁸ | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MobileMoE-S | 272M/1.3B | 56.5 | 74.9 | 42.2 | 58.4 | 42.6 | 10.8 | 30.2 | 43.1 | 73.4 | 32.4 | 72.3 | 32.3 | 32.2 | 52.2 | 46.7 |
| MobileMoE-M | 528M/2.8B | 66.6 | 77.6 | 49.0 | 63.0 | 53.9 | 17.5 | 46.6 | 52.5 | 79.9 | 38.2 | 76.7 | 46.6 | 39.0 | 67.5 | 55.3 |
| Qwen3.5 2B | 1.9B | 62.2 | 72.8 | 41.0 | 63.0 | 57.4 | 8.8 | 28.1 | 53.2 | 66.0 | 35.2 | 71.7 | 44.7 | 45.2 | 61.3 | 50.8 |
| OLMoE-1B-7B | 1.3B/6.9B | 78.8 | 79.7 | 50.8 | 68.7 | 52.7 | 17.2 | 54.1 | 57.6 | 75.9 | 46.8 | 81.1 | 29.3 | 37.1 | 49.1 | 55.6 |
| MobileMoE-L | 922M/5.3B | 73.0 | 78.9 | 53.4 | 66.1 | 60.1 | 22.4 | 54.9 | 57.9 | 81.9 | 43.2 | 81.1 | 50.1 | 40.1 | 77.6 | 60.1 |
(其余 baseline:Gemma 3 270M 32.5 / SmolLM2 360M 35.8 / Qwen3.5 0.8B 42.7 / Gemma 3 1B 44.0 / MobileLLM-Pro 40.0 / Llama 3.2 1B 46.9 / OLMo 2 1B 49.0 / SmolLM2 1.7B 50.5)。MobileMoE-S 超 Gemma 3 270M +14.2、SmolLM2 360M +10.9;MobileMoE-M 超 Qwen3.5 2B +4.5;MobileMoE-L 超 OLMoE-1B-7B +4.5(30% 更少激活、23% 更少总参数)。SFT 配方保留了 Base 的架构优势。
Table 4 instruct 进阶 benchmark 对比(Avg 为能力内均值,Overall 为跨能力均值,非思考模式):
| Model | $N_{\text{act}}/N_{\text{total}}$ | MATH500 | GSM+ | 数学Avg | HumanEval | MBPP | 代码Avg | IFEval | IFBench | IF Avg | MMLU-Pro | GPQA | K&R Avg | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MobileMoE-S | 272M/1.3B | 21.0 | 28.9 | 24.9 | 44.5 | 27.8 | 36.2 | 54.1 | 13.8 | 33.9 | 18.2 | 27.8 | 23.0 | 29.5 |
| MobileMoE-M | 528M/2.8B | 27.2 | 42.3 | 34.7 | 60.4 | 43.0 | 51.7 | 60.8 | 20.9 | 40.8 | 28.3 | 24.8 | 26.5 | 38.4 |
| Qwen3.5 2B | 1.9B | 31.0 | 42.4 | 36.7 | 50.0 | 41.2 | 45.6 | 73.3 | 30.3 | 51.8 | 38.8 | 34.3 | 36.6 | 42.7 |
| OLMoE-1B-7B | 1.3B/6.9B | 8.4 | 28.1 | 18.2 | 36.0 | 30.2 | 33.1 | 48.1 | 16.6 | 32.4 | 19.5 | 24.2 | 21.9 | 26.4 |
| MobileMoE-L | 922M/5.3B | 32.2 | 50.2 | 41.2 | 65.2 | 52.4 | 58.8 | 67.3 | 20.1 | 43.7 | 34.0 | 33.8 | 33.9 | 44.4 |
分析:(1) MobileMoE-SFT 在代码与数学上一致领先:代码上 S/M/L(36.2/51.7/58.8)大幅超过同规模 baseline(vs Qwen3.5 2B 45.6、OLMoE-1B-7B 33.1);数学上 MobileMoE-L(41.2)领先 Qwen3.5 2B(36.7)+4.5、OLMoE-1B-7B(18.2)+23.0。(2) 指令跟随与知识&推理上 MobileMoE-SFT 整体排第二,仅次于 Qwen3.5 2B——Qwen3.5 2B 的优势可能来自其更先进的后训练(蒸馏、思考能力),这激励未来配方加入蒸馏与思考训练。
训练阶段进展(Table 5、Figure 10)¶
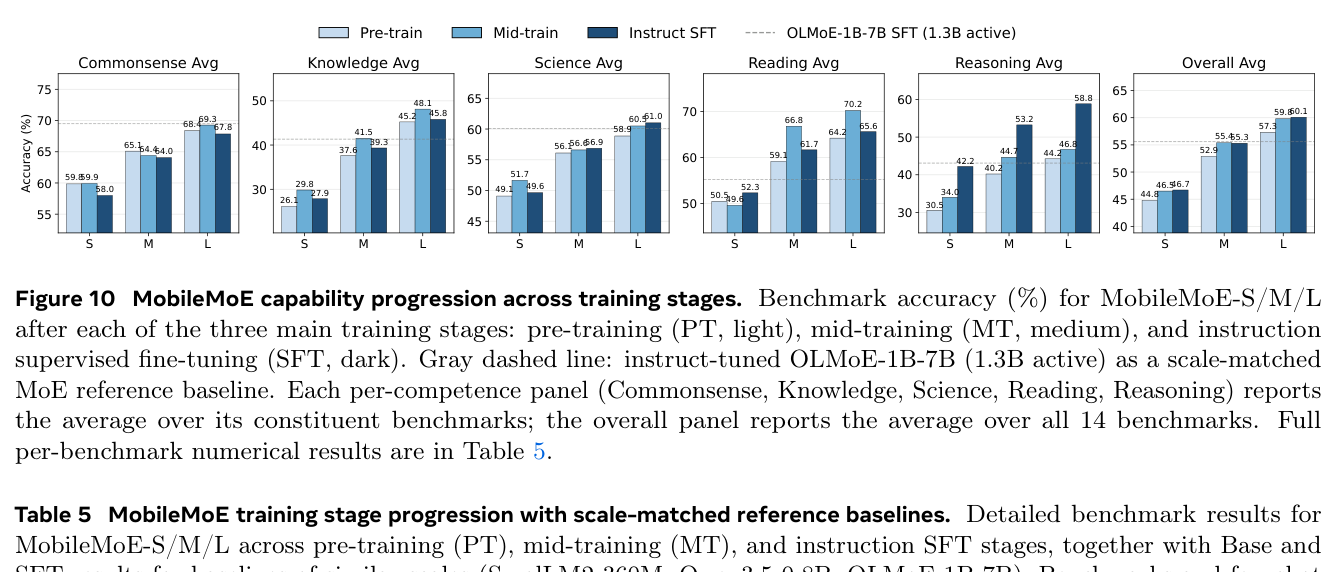
四点观察:(1) 预训练主导常识推理:HS/PIQA/SIQA/Wino 在 PT 末已饱和,MT/SFT 仅 ±2 点。(2) Mid-training 驱动最大的知识与阅读增益:MMLU(S 33.5→43.7、L 55.5→59.6)、DROP(M 47.2→58.5、L 54.2→64.7),印证 MT 是强化事实召回与长上下文理解的主要机制。(3) 指令 SFT 解锁推理:GSM8K 出现最戏剧性的 MT→SFT 跃升(L 55.7→77.6,+21.9),说明指令微调对多步 CoT 推理至关重要。(4) MobileMoE-L 对 OLMoE-1B-7B 的优势在 PT 建立、经 SFT 复利放大。
端侧部署¶
QAT 结果(Table 6)¶
Table 6 INT4 QAT 量化模型对比(Mem = INT4 模型权重内存 GB):
| Model | Mem | HS | PIQA | SIQA | Wino | MMLU⁵ | NQ⁵ | TQA⁵ | ARC-C²⁵ | ARC-E | OBQA | BoolQ | DROP³ | BBH³ | GSM8K⁸ | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MobileLLM-Pro | 0.55 | 64.7 | 75.6 | 47.4 | 62.8 | 30.4 | 13.9 | 39.9 | 51.6 | 75.2 | 42.8 | 76.8 | 20.5 | 31.4 | 4.1 | 45.5 |
| MobileMoE-S | 0.68 | 53.5 | 73.5 | 45.5 | 55.7 | 39.8 | 8.6 | 25.0 | 43.3 | 69.7 | 33.2 | 70.8 | 24.6 | 31.4 | 40.8 | 44.0 |
| MobileMoE-M | 1.48 | 63.7 | 76.7 | 49.0 | 61.2 | 52.4 | 5.0 | 42.1 | 51.2 | 79.1 | 36.6 | 75.8 | 43.2 | 36.2 | 62.6 | 52.5 |
| MobileMoE-L | 2.75 | 71.0 | 79.0 | 52.9 | 65.2 | 57.0 | 19.4 | 52.4 | 55.1 | 80.3 | 42.4 | 78.1 | 44.6 | 38.3 | 73.2 | 57.8 |
(1) QAT 以 4× 权重压缩保留几乎全部 BF16 精度:相比 BF16 SFT,总平均仅降 2–3 点(S 46.7→44.0、M 55.3→52.5、L 60.1→57.8),说明 MoE 路由与专家计算在 4-bit 下数值稳定。(2) 同等 INT4 权重内存下,MobileMoE-S(0.68GB,Avg 44.0)匹配 MobileLLM-Pro(0.55GB,Avg 45.5)总平均(差 1.5 点)但知识大幅更高(MMLU +9.4);MobileMoE-L(2.75GB,Avg 57.8)已超过 BF16 SFT 的 OLMoE-1B-7B(Avg 55.6,~13.8GB BF16),footprint 小 ~5×。
自定义 MoE kernel¶
现有移动 CPU 推理后端(XNNPACK)提供高度优化的 INT4 稠密 matmul kernel,但缺少 fused MoE 前馈算子。作者在 ExecuTorch 中实现自定义 MoE 算子,遵循两条原则:(1) 把稀疏专家分发转为稠密 grouped GEMM——先按分配的专家 ID 用计数排序重排 token,使分配给同一专家的 token 在内存中连续,让每个专家把其 token 切片作为单个 batched matmul(torchao 的 INT4 GEMM kernel)处理;(2) 把 MoE FFN 内每个子操作 fuse 进单个算子——top-$k$ 专家选择、token 分发、逐专家 gate/up 投影(每专家 fuse 成一个 GEMM)、SwiGLU 激活、down 投影、加权 scatter 反排列共享一次 op 调用,摊销 kernel 启动与激活量化开销。Attention 与 embedding 层继续用 XNNPACK INT4 稠密路径。
运行时延迟(Table 7、Table 8)¶
在 Samsung Galaxy S25(Snapdragon 8 Elite,4 CPU 线程)与 iPhone 16 Pro(Apple A18 Pro,2 CPU 线程)上,用 ExecuTorch CPU 后端 + XNNPACK、batch=1、INT4 对称权重(组 32)+ INT8 激活,用真实 prompt(代码/知识/数学)跨上下文长度做 profiling(短上下文生成 input∈{256,512,1024}、长上下文生成 input∈{2048,4096,8192},output=1024)。MoE 专家利用率是 input 相关的,故用真实 prompt 而非 dummy 重复 token。
Table 8 MoE 加速比(MobileMoE-S vs MobileLLM-Pro,跨设备/处理器):
| 设备/后端 | Prefill 加速 (512/1k/2k) | Decode 加速 (512/1k/2k) |
|---|---|---|
| Galaxy S25(Snapdragon CPU, XNNPACK) | 1.9× / 2.1× / 1.8× | 2.3× / 2.5× / 2.2× |
| iPhone 16 Pro(Apple CPU, XNNPACK) | 2.8× / 2.8× / 2.7× | 3.3× / 3.1× / 2.8× |
| iPhone 16 Pro(Apple GPU, MLX) | 3.6× / 3.8× / 3.7× | 2.5× / 2.6× / 2.5× |
(1) MobileMoE-S 在每个上下文长度、两台手机上都取得 Pareto 胜利:同等 INT4 权重(0.68 vs 0.55GB)下精度相近(Avg 44.0 vs 45.5),S25 上 1.8–2.2× 更快 prefill、2.2–2.6× 更快 decode;iPhone 上进一步到 2.7–3.1× prefill、2.8–3.4× decode。(2) MobileMoE-M/L 以可比或适度的运行时代价换取 +7.0/+12.3 的 Avg 提升。加速比跨硅(Qualcomm vs Apple)、跨处理器(CPU vs GPU)、跨后端(XNNPACK vs MLX)一致成立。
运行时内存(Table 9 Peak RSS)¶
Table 9 端侧峰值运行时内存(Samsung Galaxy S25,真实 prompt):
| Model | Mem | Avg | 256 | 512 | 1k | 2k | 4k | 8k |
|---|---|---|---|---|---|---|---|---|
| MobileLLM-Pro | 0.55 | 45.5 | 0.90 | 0.93 | 0.98 | 1.07 | 1.35 | 1.91 |
| MobileMoE-S | 0.68 | 44.0 | 0.93 | 0.97 | 1.02 | 1.10 | 1.23 | 1.49 |
| MobileMoE-M | 1.48 | 52.5 | 1.98 | 2.04 | 2.12 | 2.24 | 2.43 | 2.77 |
| MobileMoE-L | 2.75 | 57.8 | 3.66 | 3.75 | 3.87 | 4.06 | 4.27 | 4.71 |
(1) 真实 prompt 对有效 MoE 内存 profiling 不可或缺:真实 prompt 下 Peak RSS 升至 dummy 的 1.2–2.1×(MoE 的 input 相关路由会激活更多样专家、把更多专家权重载入 RAM),而稠密 MobileLLM-Pro 保持 ~1.0×。(2) MobileMoE-S 在短上下文匹配稠密 RAM,长上下文反而更省——8k 时 1.49 vs 1.91GB(低 22%),因更少 Transformer 层(更小 KV cache)、更窄 $d_{\text{model}}$、以及只把激活的专家 mmap 进 RAM。(3) MobileMoE-L 即便在 8k 上下文下 Peak RSS 仍 <5GB(4.71GB),全部变体都适合端侧部署。
为什么 MoE 在端侧更快:prefill 是算力受限——逐 token FFN matmul 随激活(非总)参数 scale,MoE 更小的 $N_{\text{active}}$ 缩小主导的 prefill 成本;decode 是内存带宽受限——每步从 RAM 读权重也随激活参数 scale,MoE 每 token 传输更少字节、提高吞吐。MoE 激活参数 <1/3 稠密(同等精度),自定义 MoE kernel 把这些理论 FLOPs/带宽节省转为实测加速。
专家利用率分析(Appendix D)¶
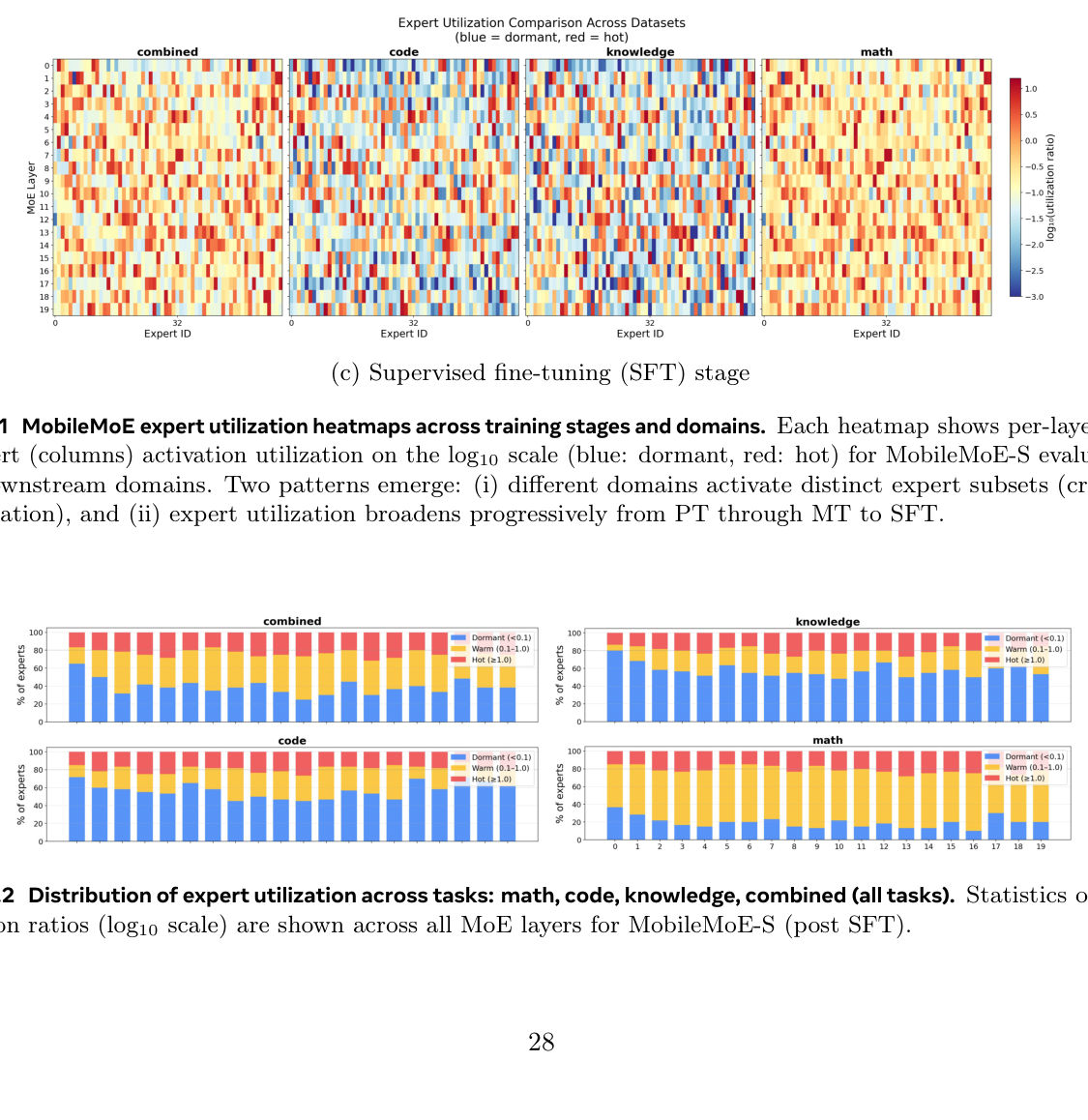
(1) 专家专业化随任务不同:不同领域(代码、数学、知识)激活不同的专家子集,说明 60 个细粒度专家在不同领域上专业化。(2) 专家利用率随训练拓宽:PT 时少数专家高利用,经 MT/SFT 逐步激活更多专家,下游训练拓宽专家利用同时保持跨任务专业化。(3) 任务相关的稀疏性:数学激活更广的专家集,代码/知识集中在更窄子集——这意味着并非每个专家权重都需在推理时载入,为通过选择性专家加载或任务条件剪枝节省端侧内存开辟了路径。
核心贡献总结¶
- 首条端侧 MoE 扩展律(式 1):把激活参数、数据、专家数、架构选择统一进一个 loss 预测式,并在联合内存(式 5)+ 算力约束(式 4)下求解最优架构;可退化为 joint-MoE law(式 2)与 Chinchilla law(式 3)。
- 分而治之的架构发现:三个解耦消融得到端侧甜点 $\text{MoE}(E=8, g=8, s=\checkmark)$——适中稀疏度 + 细粒度专家 + 共享专家,同时内存最优与算力最优。
- 完整四阶段配方 + MoE 专用稳定性(aux-loss-free 均衡、router z-loss、sigmoid gating、FP32 router)与效率技术(grouped MLP/GMM、drop-and-pad、EP=4),仅 6T token 即 Pareto 领先。
- 首个商用手机端侧 MoE 部署:ExecuTorch 自定义 fused MoE kernel(计数排序重排 + 单 op fuse),systematic 跨 CPU/GPU 运行时 profiling,实测 1.8–3.8× prefill、2.2–3.4× decode 加速。
与已归档相关工作的对比¶
[[2511.06719]] MobileLLM-Pro (Meta, 2025-11)¶
关系:显式引用,本文的主要稠密 baseline 与架构前身;原文已在 Table 6/7/8/9 充分对比量化精度/延迟/内存 · 已加载对方精读补充配方设计层面的对比
- 共同关注的问题:两者都是 Meta 出品、面向手机端常驻部署的 sub-billion 基座 LLM,都直面同一组结构性约束——在 ≤几 GB 的移动 DRAM 预算内、用 4-bit 量化压缩、跨多阶段训练把一个小模型打磨到"手机可用"。MobileMoE 直接把 MobileLLM-Pro 选作主 baseline,QAT 评测里甚至用 MobileLLM-Pro 公开的 INT4 checkpoint 作对照。
- 相近的技术骨架:都采用四阶段训练配方 + 4-bit QAT 收尾;都用 GQA(4 KV heads)压 KV cache、tied embedding、深窄架构(MobileMoE 纵横比 ≈40,MobileLLM-Pro 30 层 / 1280 hidden 同样偏深窄);都把 QAT 当作"最后 ~5% 算力的量化对齐"阶段以塞进端侧内存。
- 本文的差异与推进:MobileLLM-Pro 是稠密 1.084B,其四阶段是「语言习得(1.4T,2k)→ 隐式位置蒸馏扩窗到 128k(20B)→ 专家模型合并(60M)→ 4-bit QAT(80B)」,且全程以 Llama 4-Scout 为 teacher 做 logit 蒸馏、把重心放在长上下文(128k)与合并。MobileMoE 则是稀疏 MoE 族,四阶段是「PT(6T,2k)→ mid-training 扩窗到 8k(500B)→ SFT(126B)→ QAT(21B)」,不依赖蒸馏(全开源数据、无 teacher),把重心放在用扩展律推导 MoE 架构 + 专家专业化。两者代表端侧小模型的两条互补路线:MobileLLM-Pro 在稠密架构内靠蒸馏 + 合并 + 长窗榨取容量,MobileMoE 用稀疏激活把"总容量"与"推理算力"解耦。
- 可比的方法/实验差异:同等 INT4 权重内存下(0.68 vs 0.55GB),MobileMoE-S 总平均 44.0 vs MobileLLM-Pro 45.5(略低 1.5),但 MMLU 39.8 vs 30.4(知识 +9.4),且 8k 上下文 Peak RSS 1.49 vs 1.91GB(低 22%)、prefill/decode 在 S25 上快 1.8–2.2×/2.2–2.6×、iPhone 上快 2.7–3.1×/2.8–3.4×。BF16 SFT 阶段 MobileLLM-Pro 反而 Avg 40.0(Table 3)落后 MobileMoE-S 46.7——但需注意公开 MobileLLM-Pro 偏重长上下文,两者评测口径(few-shot、上下文)一致下的此对比仍说明 MoE 在知识/数学维度的容量优势。
讨论与局限性¶
核心贡献与可借鉴设计:本文最有价值的不是某个单点技巧,而是把"端侧约束"形式化进 scaling law 并据此做架构搜索这一方法论——先用一条同时含激活参数/数据/专家数/架构的扩展律 + 显式的内存函数(式 5)框定可行域,再分而治之地孤立每个设计轴做受控消融,最后落到一个内存最优 ∩ 算力最优 ∩ 训练高效的三重甜点。这种"约束建模 → 解耦消融 → 训练效率交叉验证"的范式,对任何资源受限下的架构选择(包括推荐系统里的端侧/边缘排序模型、稀疏专家排序架构)都有借鉴意义。其次,把稀疏 MoE 真正落到商用手机的工程闭环(自定义 fused MoE kernel + 真实-prompt 运行时 profiling + Peak RSS 上界)也很扎实——尤其"真实 prompt 才能暴露 MoE 的 input 相关内存峰值"这一观察,纠正了沿用稠密 LLM dummy-token profiling 的误区。
局限与争议:(1) 推理能力仍落后于更先进后训练的稠密模型:Qwen3.5-2B 在推理(BBH/GSM8K)与指令跟随上仍领先,作者归因于其蒸馏 + 思考训练的后训练配方——MobileMoE 当前配方未含蒸馏/思考,这是明显的能力天花板。(2) 真实 prompt 下 MoE Peak RSS 升到 dummy 的 1.2–2.1×:input 相关的专家激活意味着最坏情况内存难以静态预估,端侧内存规划要按真实负载留余量;MobileMoE-L 在 8k 下 4.71GB 已逼近 5GB 预算上限。(3) 专家利用率不均:Appendix D 显示任务相关的稀疏性(数学激活更广、代码/知识更窄),说明并非所有专家权重都需常驻——作者把"选择性专家加载/任务条件剪枝"列为 future work,意味着当前部署仍把全部专家权重载入。(4) 依赖自定义 kernel:主流移动后端(XNNPACK)缺原生 MoE 支持,加速依赖作者自实现的 ExecuTorch fused op,可移植性/可维护性是落地门槛。(5) 与既有 MoE scaling law(joint-MoE law [41]、Chinchilla)相比,式 (1) 的核心增量是把它们统一并嵌入端侧内存约束,方法本身在 scaling law 谱系上属于"约束特化"而非全新范式。
对推荐系统的迁移性:本文是纯端侧 LLM 工作,与推荐主线(生成式推荐、SID、CTR 排序)无直接重叠。但其中MoE 稀疏激活解耦容量与算力、细粒度 + 共享专家的设计甜点、约束下的 scaling law 架构搜索、以及专家专业化随训练拓宽等结论,对正把 MoE 引入工业排序(如 TokenMixer-Large TokenMixer-Large 的 Sparse-Pertoken MoE 把排序模型扩到 15B)的方向有方法论参考价值;其端侧量化 + 自定义 kernel 的部署闭环,也可类比端侧推荐 agent(如 RecGPT-Mobile RecGPT-Mobile)的工程路径。