InfoLaw: Information Scaling Laws for Large Language Models with Quality-Weighted Mixture Data and Repetition¶
研究动机与背景¶
LLM 预训练已经进入两个互相纠缠的现实:
- 高质量数据稀缺——在 state-of-the-art pipeline 中,激进的质量过滤(FineWeb, Penedo 2024;DCLM, Li 2025)已经把 Common Crawl 这样的"原始海量"语料压成有限的高质量子集,且这一比例还在被各种 mid-training/specialty corpus 抢占(Villalobos 2024 估计高质量人类文本将在 2026-2030 年区间被耗尽);
- 过训练(over-training)已成常态——为了部署侧的推理成本(Sardana 2024、Gadre 2024),实际训练 token 数已经远超 Chinchilla 最优点 $(D \approx 20 N)$,工业模型动辄 $D/N$ 在 100–500(如 Llama 3 的 15T tokens / 8B–70B 参数)。
把这两条放一起看,数据稀缺会被"过训练"放大:训练 token 不够时,被迫对高质量数据多次重复(high-quality upsampling),重复带来的边际增益却随 $D/N$ 增大而急剧衰减,并最终走向饱和甚至下降(Muennighoff 2023, Hernandez 2022)。
但既有 scaling law 对此力不从心:
- Chinchilla(Hoffmann 2022)假设每个 token 唯一,给不出"重复 epoch 数"和"质量分布"如何影响 loss;
- Muennighoff 的 effective-data 形式虽然能描述 repetition 的递减回报,但 (a) 不显式包含数据质量分布,(b) 不能预测在不同 mixture recipe 间的相对差异(你必须为每个 recipe 重新跑 grid search 拟合);
- 工业实践中常见的"对高质量子集 upsampling"无法事先评估增益,只能靠昂贵的网格搜索(Liu 2024 Regmix 用代理小模型,Kang 2025 Autoscale 用扰动法,Ye 2025 用 mixing-law 回归),这些方法都假设"recipe 之间 loss 差异是 model-scale-invariant",但 Liu 2024 自己指出该假设并不成立。
InfoLaw 的核心命题是:把训练过程重新刻画为一个信息累积过程——loss 是模型从语料中实际"提取"到的总信息量的幂律函数;这个"信息量"由两个组件决定:
- 质量密度函数 $f_d$:每个 quality bucket 的"信息密度"是其 quality 等级的递减函数;
- 指数衰减因子 $1 - e^{-\lambda(N) R_d / \log(K)}$:捕捉同一 token 重复学习的边际衰减,并显式让衰减速率随模型容量 $N$ 与训练 budget $K$ 变化。
最终把上述结构折叠到一个统一的 information–loss 幂律曲线上: $$L = \alpha \cdot \mathrm{info}^{-\beta}$$ 拟合参数仅来自 252M–1.2B 模型 + 3 种 LayerMix recipe(HQ/MQ/LQ)共 27 次训练,外推到 7B 和 425B token 的运行:mean abs error 0.15%,max 0.96%。在 25× 过训练度下也保持。InfoLaw 由此变成一个先验可计算的 data-recipe 选择器——给定 $(N, K, S)$ 直接预测最优 mixture 权重 $w^\star$,不需要再做 grid search。
作者:Fengze Liu, Weidong Zhou, Binbin Liu, Ping Guo, Zijun Wang 等(ByteDance;UC Santa Cruz)。Preprint, May 5, 2026 (arXiv 2605.02364)。
1. 问题刻画与传统 scaling law 的失效¶
1.1 LayerMix 采样函数¶
为了系统地扫描 quality × repetition 两个维度,作者构造了一个名为 LayerMix 的采样函数 $H(w, K, S, B)$:
- 源语料:3.7T tokens 的 Common Crawl 英文部分(覆盖 CC-MAIN-2013-20 至 2024-18 共 96 个 snapshot),全局 fuzzy dedup(Bi et al. 2024 流程);
- 质量打分:对每条文档用两个 quality classifier(Penedo 2024 FineWebEdu + Li 2025 DCLM)打分并取归一化平均;按百分位划分为 6 个 quality bucket:0–5%、5–20%、20–40%、40–60%、60–80%、80–100%(注意"低 d 表示更高质量",与日常直觉相反);
- 源分布:$B = [0.05, 0.15, 0.20, 0.20, 0.20, 0.20]$,反映 quality classifier 的天然分布;
- 目标 mixture:$w = [w_0, \dots, w_5]$,$\sum w_d = 1$,强制 $w_d \ge w_{d+1}$(高质量桶占比不低于低质量桶);
- 预设 mixture:HQ / MHQ / MQ / MLQ / LQ 五档(Table 1),其中均设 $w_5 = 0$(最低质量桶完全丢弃):
| Name | $w_0$ | $w_1$ | $w_2$ | $w_3$ | $w_4$ | $w_5$ |
|---|---|---|---|---|---|---|
| HQ (High Quality) | 0.80 | 0.10 | 0.03 | 0.03 | 0.02 | 0.0 |
| MHQ | 0.66 | 0.22 | 0.05 | 0.03 | 0.02 | 0.0 |
| MQ | 0.48 | 0.23 | 0.13 | 0.07 | 0.07 | 0.0 |
| MLQ | 0.38 | 0.21 | 0.20 | 0.11 | 0.08 | 0.0 |
| LQ | 0.24 | 0.20 | 0.19 | 0.18 | 0.17 | 0.0 |
| Optimal Recipe (2.5B, m=3.6) | 0.50 | 0.49 | 0.01 | 0.0 | 0.0 | 0.0 |
最后一行是 InfoLaw 优化求出的 2.5B 模型在 $m=3.6$ 过训练下的最优 recipe——明显比预设的 HQ 更激进地集中在前两档,几乎不用 $d \ge 2$ 的桶。
采样过程(Algorithm 1):对每个桶 $d$,源端有 $S_d = B_d S$ 个 token,目标端需 $K_d = w_d K$ 个 token;采样比 $\text{Ratio}_d = K_d / S_d$;先按 $\lfloor \text{Ratio}_d \rfloor$ 整数倍确定性复制每条文档,再按余数 $\text{Ratio}_d - \lfloor \text{Ratio}_d \rfloor$ 概率性补足。这给出实际 unique token 数 $M_d = \min(K_d, S_d)$ 与平均重复次数 $R_d = K_d / M_d$,当 $K_d \le S_d$ 时 $R_d = 1$(不重复),否则 $R_d > 1$。
关键工程细节:先把源语料按目标 scale 下采样使 unique token 数稳定,再做单 epoch 打包训练(避免 epoch-level 隐式重复)。除非另注,设 $K = S$(极限"刚好用完源语料",使 $w$ 与 $R_d$ 直接挂钩)。
1.2 传统 scaling law 失效¶
作者按 Gadre 2024 的"compute-optimal + overtraining factor $m$"约定,定义:
$$K_m = \sqrt{m} \cdot K_{\rm opt}, \quad N_m = \frac{1}{\sqrt{m}} \cdot N_{\rm opt}, \quad C_m = K_m \cdot N_m, \quad m=3.6$$
这把训练曲线压到一条等过训练度的轨迹上。然后在 252M–1.2B 模型上扫 LayerMix 的 HQ 和 MLQ 两种 recipe,画 $L$–$C_m$(Figure 1):
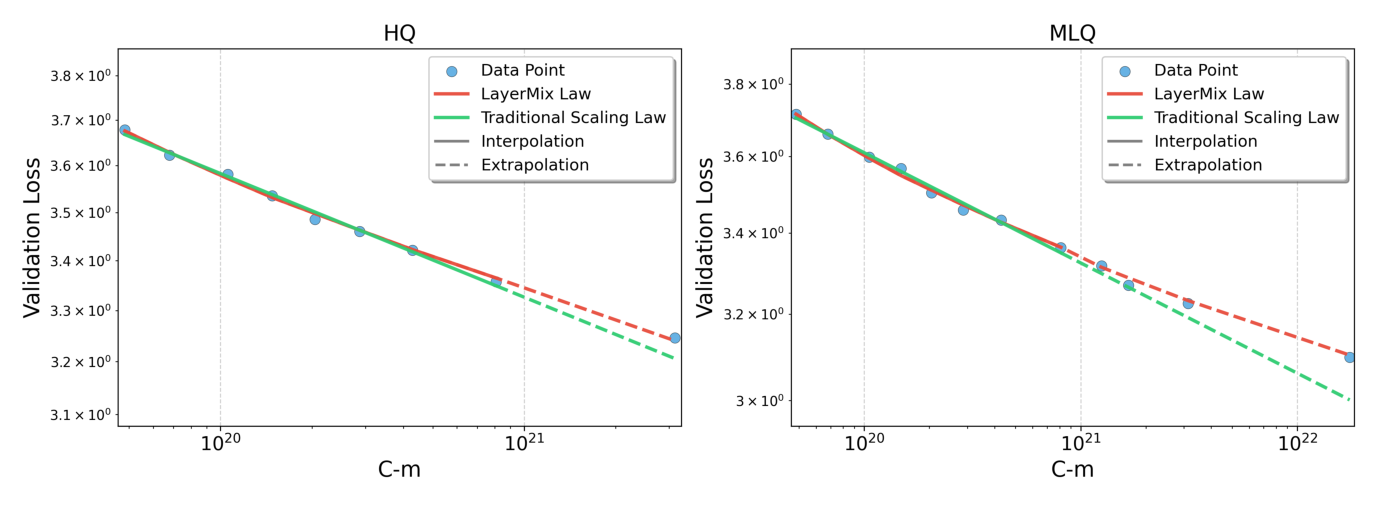
观察:
- 传统幂律 $L = E + A \cdot C^{-\alpha}$ 用 252M–1.2B 拟合后外推到大模型时系统性地低估 loss(绿色虚线偏低于实测点);这一 bias 在两种 recipe 上同时出现,说明问题不是"recipe 选错了"而是"compute 单变量根本不足以刻画 quality-mixed + repeated 数据下的 scaling 行为";
- 同样的 compute $C_m$ 下,HQ 与 MLQ 的 loss 差异显著,说明 mixture 的影响没有被吸收到 traditional law 的拟合常数里。
这一节的结论:需要一个明确包含质量分布与重复度的修正型 scaling law。
2. Information Scaling Laws:核心方法¶
2.1 Information measurement¶
作者把训练视为模型从数据中累积信息的过程。直觉锚点:在 850M 参数的两次对比中,HQ recipe 把 top-5% 的 quality bucket 重复约 $16\times$;MQ 重复约 $10\times$。两次实验初期 loss 接近,但重复次数更高的 HQ 在后期改进更慢、最终 loss 更差——直接观察到了"重复带来的边际衰减"。
基于此,对单文档的"第 $t$ 次重复学习"建模为指数衰减:
$$I_{i,\text{part}}(t, \lambda(N)) = I_i \cdot \lambda(N) \cdot e^{-\lambda(N) \cdot t} \tag{1}$$
其中 $I_i$ 是文档 $i$ 的总信息量,$\lambda(N) > 0$ 是与模型非嵌入 FLOPs/token $N$ 相关的衰减率。积分得到学习 $T$ 次后获得的总信息:
$$I_{i,\text{total}}(T, \lambda(N)) = \int_0^T I_{i,\text{part}}(t, \lambda(N))\,dt = I_i \cdot \left(1 - e^{-\lambda(N) \cdot T}\right) \tag{2}$$
公式 (2) 的含义十分清晰:每多一次重复都按指数饱和,最终趋向 $I_i$(即文档全信息)。
但 (2) 还差一步:不同 $K$(总训练 token 数)下,empirically 边际衰减不仅与重复次数 $T$ 有关,还与总训练预算有关——所以引入 $\log(K)$ 作为归一化项:
$$I_{i,\text{part}}(t, \lambda(N), K) = I_i \cdot \lambda(N) \cdot e^{-\lambda(N) \cdot t / \log(K)} \tag{3}$$
$$I_{i,\text{total}}(t, \lambda(N), K) = I_i \cdot \log(K) \cdot \left(1 - e^{-\lambda(N) \cdot T / \log(K)}\right) \tag{4}$$
为什么要 $\log(K)$ 归一化? Appendix B 比较了三种归一化(常数、power-law、logarithmic),结论是只有 log 形式能让所有 $(w, K, S)$ 配置坍缩到一条统一曲线(见 Section 2.3):
- 常数归一化:在大 budget 下系统性高估 information,导致过乐观的 loss 预测;
- power-law $K^a$ 归一化:完全无法形成 power-law 的 info–loss 关系,data points 散乱;
- log 归一化:唯一能把 information 与 loss 拟合成一条幂律的形式,且外推误差在 252M–7B 范围内最小。
把所有 quality bucket 累加,得到全语料的总信息量:
$$\mathrm{info}(w, K, S, f, \lambda(N)) = \sum_d I_d \cdot \log(K) \cdot \left(1 - e^{-\lambda(N) R_d / \log(K)}\right) = \sum_d f_d M_d \log(K) \cdot \left(1 - e^{-\lambda(N) R_d / \log(K)}\right) \tag{5}$$
其中:
- $d \in \{0, \dots, 5\}$ 是 quality bucket 索引;
- $I_d = f_d M_d \log(K)$ 是第 $d$ 桶的"原料信息量",$f_d$ 是质量密度函数(待拟合的标量序列),$M_d$ 是该桶 unique token 数;
- $R_d = w_d K / M_d$ 是该桶的平均重复次数;
- 第二项 $1 - e^{-\lambda(N) R_d / \log(K)}$ 表征模型在该重复次数下的"信息提取效率"。
公式 (5) 可拆为两部分:
- 数据原料项 $I_d = f_d M_d \log(K)$:完全由数据 + budget 决定,不依赖训练;
- 模型学习项 $1 - e^{-\lambda(N) R_d / \log(K)}$:单调递增于 $R_d$(学多次能提取更多)但有上界,递增速率由模型容量 $\lambda(N)$ 控制。
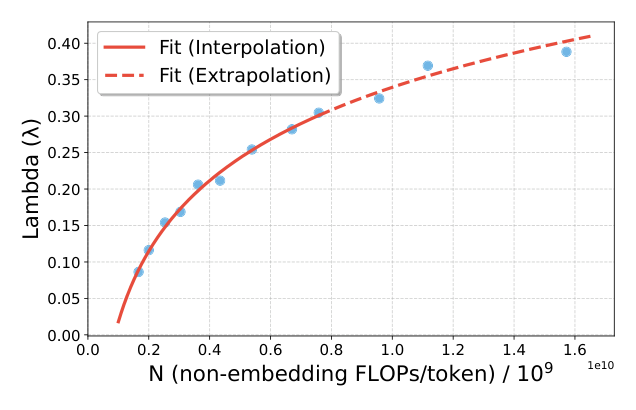
2.2 Information–Loss power law¶
代入 Figure 1 的同一组实验,把横轴从"compute $C_m$"换成"information",所有不同 recipe 的 data points 现在坍缩到一条单一的幂律曲线上:
$$L = \alpha \cdot \mathrm{info}^{-\beta} \tag{6}$$
实验拟合得 $\alpha = 3.7373$, $\beta = 0.0441$。在 log–log 图上是一条斜率 $-\beta$ 的直线(截距 $\log \alpha$)。
这就是 InfoLaw 的核心断言:一旦把 compute 换成"信息",loss 跨 mixture × scale × repetition 的关系是单一幂律。
2.3 拟合 $f_d$ 与 $\lambda(N)$(Section 5.2)¶
参数空间是 $(\theta, \{\lambda_N\}_N)$,其中:
质量密度 $f_d$ 用单参数指数族保证单调递减:
$$f_d(\theta) = e^{-\theta \cdot d}, \quad \theta > 0 \tag{8}$$
随 bucket 编号增大(质量下降),$f_d$ 指数衰减;这与"高质量数据的 marginal information 更高"直觉一致。
衰减率 $\lambda(N)$ 用对数函数(Appendix G 中比较了 exp/power 等替代形式):
$$\lambda(N)(a, b) = a \cdot \ln(N) + b \tag{9}$$
优化目标:选 $(f, \lambda)$ 使 Spearman 相关 $\rho_s\bigl(L_N, \mathrm{info}(w, K_N, S_N, f, \lambda(N))\bigr)$ 在所有训练运行 $(N, w)$ 上最小。Spearman 而非 Pearson 是为了消除"info 与 L 之间可能的 scale shift"。
具体流程: 1. 在参数空间随机采样 100,000 组 $(\theta, \{\lambda_N\})$; 2. 选 Spearman 最小化的 $\theta^\star$ 和 per-N $\lambda_N^\star$(拟合得 $\theta^\star = 0.922$); 3. 用现有 $\lambda_N^\star$ 拟合 $\lambda(N) = a \ln(N) + b$,得 $a^\star = 0.140$, $b^\star = 0.018$; 4. 验证:在固定 $\theta^\star$ 下、用更大 $N$ 计算的 $\lambda_N^\star$ 是否落在 (9) 的预测线上——结果强吻合(Figure 2b 的红实线是 in-domain,红虚线是 extrapolation,散点是观测); 5. 完成后,对任意 $(w, K, S, N)$ 都能直接计算 $\mathrm{info}$ 并预测 $L = \alpha \cdot \mathrm{info}^{-\beta}$。
Appendix G 显示对数形式比指数形式 $\lambda(x; a, b, c) = a(1 - e^{-bx + c})$ 与幂律形式 $\lambda(x; a, b) = a \cdot x^b$ 都拟合更好(Figure 7),因此被选为最终参数化。
3. 实验验证¶
3.1 训练设置¶
- 架构:Transformer(Vaswani et al. 2017)+ SwiGLU(Shazeer 2020)+ RoPE(Su et al. 2024);250k tokenizer;
- 模型规格 (Appendix D Table 3):14 个 size 从 252M 到 7.7B,覆盖 hidden dim 1024–4096、layer 数 20–32、head 数 16–40;
- 训练:max sequence length 2048,cosine decay LR schedule,初始 $\mathrm{lr} = \mathrm{round}(0.3118 \cdot C^{-0.1250}, 8)$,warmup 0.5%,AdamW $\beta_1=0.9, \beta_2=0.95$, weight decay 0.1;
- 过训练度:$m = 3.6$ 为主,所有 9 个拟合模型(252M–1.2B)按此训练 27 次(3 recipe × 9 size);
- 评测:5 个下游任务的 average perplexity——HellaSwag (Zellers 2019)、ARC-E/ARC-C (Clark 2018)、MMLU (Hendrycks 2021)、TriviaQA (Joshi 2017);按 Schaeffer 2023 的方法把 accuracy 转成 loss-like 的连续指标。
3.2 三大验证¶
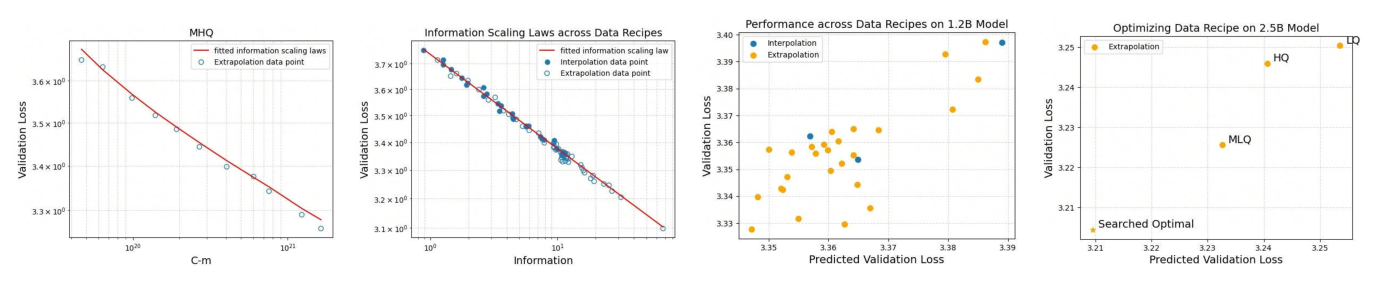
Verification (a–e):每个 mixture 独立拟合 $L = \alpha \cdot \mathrm{info}^{-\beta}$ 都对,证明信息 scaling 在每种 quality 分布下都成立。
Unification (f):所有 mixture 的点(LQ/MQ/MHQ/MLQ/HQ × 252M–1.2B 共数十次实验)放到同一坐标系下完全坍缩到一条幂律曲线——这是 InfoLaw 的关键断言:信息量是预测 loss 的"通用坐标轴"。
Application (g, h):
- (g) 用 252M–1.2B 拟合参数预测 1.2B 上 25 个随机采样 LayerMix 配置的 validation loss:interpolation 预测与实测的 Pearson 相关 0.76;extrapolation 部分(unseen mixture)也对齐良好;
- (h) 用 InfoLaw 在 100k random LayerMix 候选中选最优 recipe,部署到 2.5B 模型上训练;得到的 "Searched Optimal" 取得最低 validation loss,明显优于 HQ/MQ/LQ 的固定 baseline——证明 InfoLaw 不仅能预测,还能指导设计。
3.3 三轴外推(Section 6)¶
轴 1:未见 LayerMix 权重——在 1.2B 上随机 25 个 unseen $w$,预测点几乎完美贴在拟合曲线上(Figure 3)。
轴 2:更大模型——用 252M–1.2B + (MQ, LQ) 训练数据拟合,外推到 1.5B / 2.5B 上 (HQ, MQ, LQ),包括 2.5B + HQ 这种 mixture × scale 双外推条件,所有点都落在曲线上(Figure 3a-e 中空心点是 extrapolation)。
轴 3:组合外推(mixture × scale)——MHQ + MLQ × 1.5B–7B 共 25 组随机配置 + 7B 大模型,全部 overlay 到曲线(Figure 3f):
- mean abs error 0.15%,max abs error 0.96%——这是论文最强的外推证据。
轴 4:更高过训练度——主实验 $m = 3.6$;额外用 1.2B 模型在 640B tokens($m' = 25$,~$7\times$ 主实验)上跑实验。把 $C_m$ 替换为 $C_{m'}$ 后,新数据点继续落在原 $C_m$ 拟合的曲线上(Figure 4):
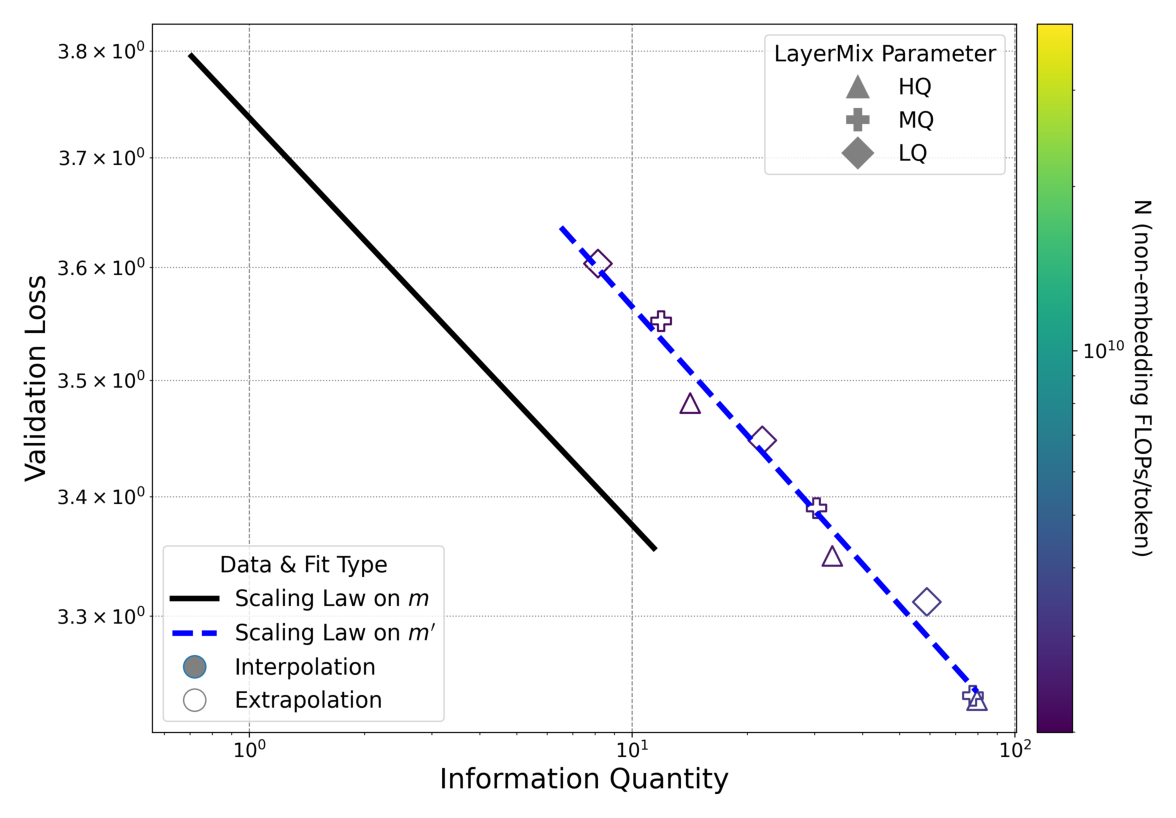
关键观察:$L$–$C$ 视图下,$m$ 和 $m'$ 给出两条近似平行的曲线(截距不同、斜率相同);切换到 $L$–info 视图下,两条线坍缩到同一条——再次印证 information 是"正确的横坐标"。
3.4 InfoLaw 优化的最优 recipe(Section 6, Table 2)¶
利用预测能力,作者扫了 100k 个 LayerMix 配置,选预测 loss 最低的作为最优。Table 2 给出 1.2B / 1.8B / 7B 模型在 200B–1000B 训练 token、500B 源 token 下的最优 recipe(节选):
| Model | Train | $w_0$ | $w_1$ | $w_2$ | $w_3$ | $w_4$ | $w_5$ |
|---|---|---|---|---|---|---|---|
| 7B | 300B | 0.548 | 0.444 | 0.004 | 0.003 | 0.002 | 0.000 |
| 7B | 500B | 0.496 | 0.492 | 0.007 | 0.003 | 0.002 | 0.000 |
| 7B | 800B | 0.439 | 0.430 | 0.130 | 0.001 | 0.000 | 0.000 |
| 7B | 1000B | 0.395 | 0.387 | 0.214 | 0.003 | 0.001 | 0.000 |
| 1.8B | 300B | 0.619 | 0.376 | 0.004 | 0.001 | 0.000 | 0.000 |
| 1.2B | 300B | 0.758 | 0.229 | 0.012 | 0.001 | 0.000 | 0.000 |
两个清晰趋势: 1. 固定 train token 时,更大模型的最优 recipe 倾向于 更分散——大模型从多样性中获益,相应地降低 $w_0$、提高 $w_1$ 甚至 $w_2$; 2. 固定模型时,train token 越多,越应该转向多样性——300B 时 $w_0 \approx 0.55$+,1000B 时降到 $0.4$ 左右;多余 budget 应当用来"看更多类型"而不是"重复看高质量桶"。
InfoLaw 的工程口诀:小模型/小 budget → 偏 quality;大模型/大 budget → 偏 diversity。这与"小模型先跑出 baseline,大模型转去 mid-training/multi-domain"的经验法则一致。
3.5 Loss 与下游表现的关系¶

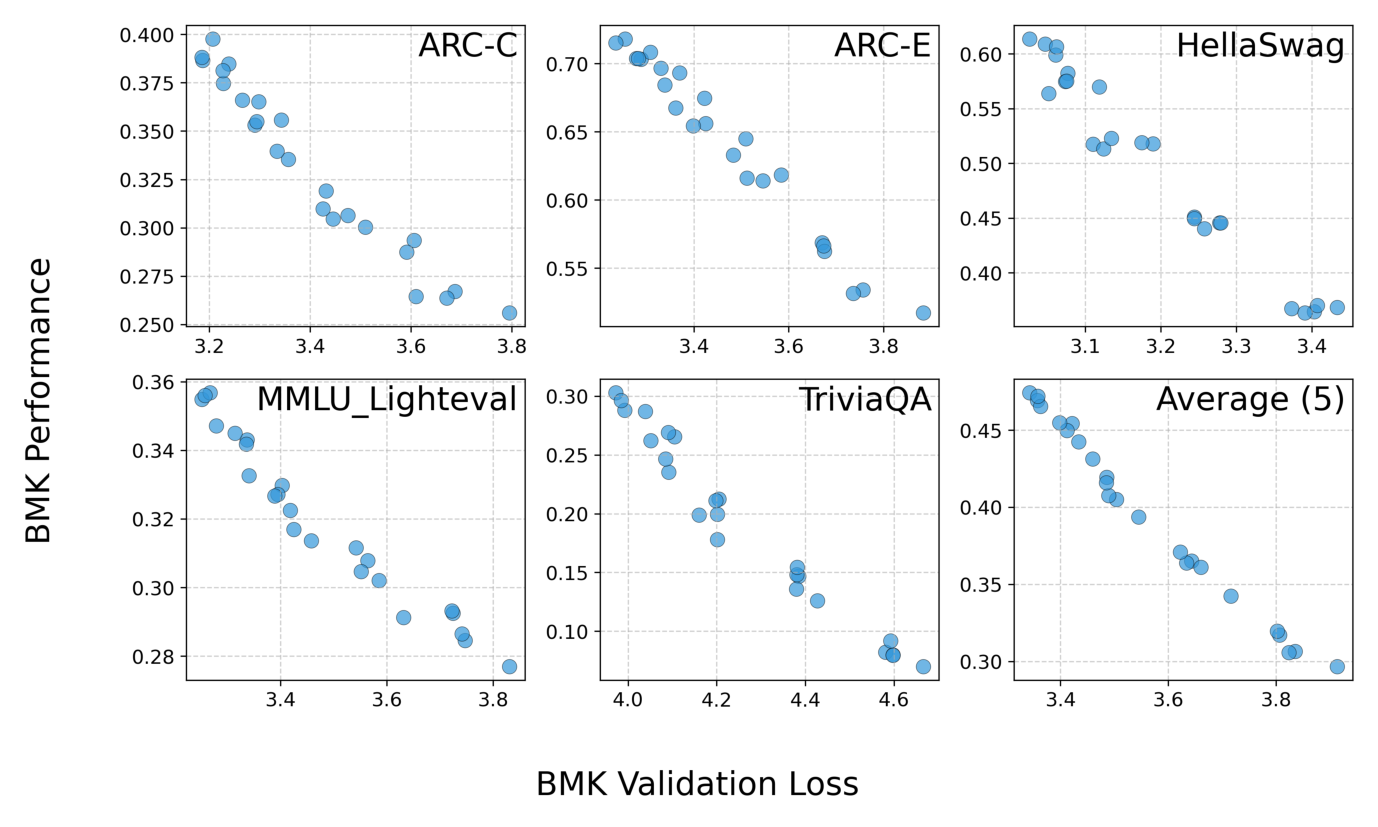
Spearman 相关系数(Table 4):
| Benchmark | Spearman $r_s$ | $p$-value |
|---|---|---|
| ARC-C | -0.979 | $1.02 \times 10^{-16}$ |
| ARC-E | -0.982 | $2.72 \times 10^{-17}$ |
| HellaSwag | -0.942 | $6.13 \times 10^{-12}$ |
| MMLU-LightEval | -0.989 | $1.26 \times 10^{-19}$ |
| TriviaQA | -0.970 | $4.53 \times 10^{-15}$ |
| Average (5) | -0.996 | $3.54 \times 10^{-24}$ |
下游任务表现与 validation loss 高度负相关($|r_s| > 0.94$,平均 $-0.996$),说明 InfoLaw 优化 validation loss 等价于优化下游表现。
3.6 RefinedWeb 跨 corpus 验证(Appendix K)¶
为了验证 InfoLaw 不依赖特定语料,作者在 RefinedWeb(Penedo 2023)上重复整套实验:
- 三个 model size(302M、566M、1.2B),HQ 与 LQ 用于拟合,MLQ holdout 做外推;
- 拟合得 $\theta^\star = 0.93$(vs CC 上的 0.92,仅差 1%),说明 quality density function 几乎不依赖语料;
- MLQ 外推:mean abs % error 0.24%,max 0.36%——再次验证 InfoLaw 是数据通用的。
4. 与已归档相关工作的对比¶
Prescriptive Scaling Laws for Data Constrained Training Prescriptive Scaling Laws for Data Constrained Training (Cornell, 2026-05-02)¶
关系:独立并发(本文未引用 Lovelace 等 2605.01640,两者发布相隔 2 天且 InfoLaw 参考文献中无 Cornell 工作)· 已加载对方精读
- 共同关注的问题:传统 Chinchilla scaling law 在数据受限 + 多 epoch 重复场景下系统性失效;既有的 Muennighoff effective-data 形式只能描述递减回报,不能刻画"过训练 + 重复"区间的额外代价;都需要一个显式包含重复机制的 scaling law。
- 相近的技术骨架:(1) 两者都是在 Chinchilla 基础上追加一个 model-size × repetition 交互项;(2) 都用大 grid(InfoLaw 252M–1.2B × 3 mixture × 9 size = 27 runs,Cornell 15M–1B × 8 budget × 6 epoch = 300+ runs)拟合参数;(3) 都做了 weight decay / 强正则的扩展验证;(4) 都给出"小模型/小 budget 偏 quality / less repetition、大模型/大 budget 偏 diversity / more fresh data"的 prescriptive 推论。
- 本文的差异与推进:
- 抽象层级不同:Cornell 把 repetition 处理为"对 Chinchilla loss 的加性过拟合惩罚 $P \cdot R_D^\delta \cdot (N/U_D)^\kappa$"——仍然在"compute–loss"坐标系内,penalty 项让 loss 可以回升(捕捉 over-training 后的 loss 上升);InfoLaw 抛弃 compute 坐标,引入"information"作为新坐标,通过 $\log(K)$ 归一化让所有 $(w, K, S)$ 坍缩到单调递减的幂律曲线——loss 不会回升而是单调饱和。两种路线对应不同假设:Cornell 显式建模 catastrophic over-training;InfoLaw 假设其训练范围内只看到 monotonic saturating regime(因此其 grid 没覆盖 Cornell 那种 16 epoch + 50M tokens 的极端 over-fit 区)。
- 质量维度的引入是 InfoLaw 的独有贡献:Cornell 的整个分析中没有 quality bucket / mixture weight 这一维——它把数据按 unique-token 数 $U_D$ 当一个均质池子处理;InfoLaw 显式拟合 quality density $f_d = e^{-\theta d}$,使 mixture weight $w$ 进入 loss 公式,从而把"质量分布对 loss 的影响"也纳入 scaling law。这是两者的最大不同——Cornell 的 law 不能被直接用来选 recipe,InfoLaw 可以。
- 应用层面:Cornell 的核心结论是"超过某个阈值后继续重复弊大于利,compute 应转向扩 model",并验证强 weight decay 能把 penalty $P$ 削减 70%——是个正则化 + epoch 上限的 prescriptive 法则;InfoLaw 的核心结论是"给定 $(N, K, S)$ 直接搜出最优 mixture $w^\star$",并通过 Table 2 给出 model × budget 网格上的最优配方表——是个recipe selector。
-
外推规模不同:Cornell 训练范围 15M–1B,外推验证用 280M–720M held-out;InfoLaw 训练 252M–1.2B,外推到 7B 和 425B token,error 0.15%/0.96%——InfoLaw 的外推幅度远超 Cornell。
-
可比的方法 / 实验差异:两者都做了 weight decay 灵敏性研究——Cornell 报告 $\lambda=1.0$ 把 over-fit penalty $P$ 削减 70%、$R^2_{\text{multi}}$ 从 0.58→0.99;InfoLaw 的 weight decay 固定为 0.1,没有报告 weight decay 对 $\lambda(N)$ 的影响——这是 InfoLaw 可以补的实验。两者都隐含承认"$\log(K)$ / weight decay 作用的物理机制"是未来工作。
价值:两者互相不可替代——Cornell 解决"什么时候停止重复"的问题,InfoLaw 解决"在重复约束下用什么混合配方"的问题;并联使用能形成完整的数据受限场景训练决策框架。从工业落地视角看,建议先用 Cornell 公式确定 epoch 上限,再用 InfoLaw 在该 budget 下搜最优 mixture。
Compute Optimal Tokenization Compute Optimal Tokenization (FAIR at Meta, 2026-05-02)¶
关系:弱关联(同样是数据受限/Chinchilla 推广路线,但研究维度正交:tokenizer 压缩率 vs. mixture 与 repetition)· 未加载对方精读
简要:FAIR 的 BLT 工作把 Chinchilla "20 token/param" 推广到"~60 byte/param",发现最优压缩率随 compute 缓慢下降——研究的是数据计量单位的 scaling 影响;InfoLaw 研究的是数据组成与重复的 scaling 影响。两者完全互补:BLT 的 byte-level 度量可以与 InfoLaw 的 information 度量结合,未来可能形成"byte × mixture × repetition"的三维 scaling law,但当前两篇工作没有交集。详细精读见 Compute Optimal Tokenization。
5. 讨论与局限性¶
5.1 核心贡献¶
- 概念创新:把 LM 训练重新刻画为"信息累积"过程,引入 information 作为坐标,使 quality-mixed + repeated data 下不同 recipe 的 loss 坍缩到一条幂律——这是 坐标变换 而非追加 correction term,比 Cornell 的加性 penalty 在哲学上更激进;
- 质量密度函数 $f_d = e^{-\theta d}$:用单参数模型显式刻画 quality bucket 的边际信息密度,使 LayerMix mixture 选择问题可微;
- $\log(K)$ 归一化:经过 Appendix B 的对照实验论证,logarithmic 是唯一能让 information 与 loss 坍缩到幂律的归一化形式——这是个经验上的强约束,作者承认其物理机制尚未被完全解释;
- 外推稳健性:从 252M–1.2B 拟合,外推到 7B + 25× over-training,mean error 0.15%、max 0.96%;跨语料(Common Crawl → RefinedWeb)泛化时 $\theta^\star$ 仅差 1%;
- prescriptive 工具:100k LayerMix 配置预测 + 选最优,2.5B 实验上比固定 baseline 取得最低 loss——把 InfoLaw 从"事后解释"升级为"事前选择";
- 下游对齐:5 个 benchmark 上 Spearman $r_s = -0.996$,证明 InfoLaw 优化 validation loss 等价于优化下游表现。
5.2 工业落地价值¶
ByteDance 这种规模的预训练运行(动辄数千卡 × 月级训练时间),一次 grid search(25–100 个 recipe × 1B 模型)就要消耗数百万美元。InfoLaw 把这一搜索从"训练 grid 后选最优"压缩成"算 100k 个解析公式",直接节省至少一个数量级的预训练 budget。Table 2 中 1.2B / 1.8B / 7B 的最优 recipe 表可以直接拷贝到生产,对中小厂尤其友好。
5.3 局限性(论文 Section L 与作者承认的盲区)¶
- 质量分桶是固定经验启发式:6 个 bucket 的边界(0–5%/5–20%/...)没做 ablation,可能不是最优;不同语料、不同任务可能需要不同的 bucket 划分;
- $\theta$ 的语料适配性:CC vs. RefinedWeb 的 $\theta^\star$ 仅差 0.92 vs 0.93——但这两者都从 Common Crawl 派生;对非 web 语料(如 code、math、专业书籍)是否还成立,未验证;
- 过训练度 $m$ 的物理机制未解释:作者观察到 $m$ 在 $L$–$C$ 视图中只平移截距不改变斜率,但为什么会这样在文中没有理论解释;
- 不能预测 loss 上升区:InfoLaw 假设 information–loss 是单调幂律,但 Cornell 已经证明在极端 over-fit($D/N$ 极小 + 16 epoch)下 loss 会回升——InfoLaw 在该区域会过拟合曲线、低估真实 loss;
- 缺 weight decay 维度:Cornell 显示 weight decay 对 over-fit penalty 影响巨大;InfoLaw 固定 weight decay 不变,未检验其稳定性;
- quality classifier 的可移植性:FineWebEdu + DCLM 都是 web text 领域的 classifier,对其他领域的"质量"定义(如 code 的可执行性、math 的推理深度)可能不可直接套用。
5.4 未来工作的方向¶
- 把 weight decay $\lambda$、batch size、learning rate schedule 也纳入 InfoLaw 的 information measure,看坍缩是否仍然成立;
- 与 Cornell 的加性 penalty 做形式上的统一——是否存在一个更通用的 form 同时覆盖 saturating regime 和 over-fitting regime?
- 跨模态(vision、audio)、跨语言(low-resource)下是否还能找到类似的"信息坐标";
- 工程层面:把 $f_d, \lambda(N)$ 做成 ByteDance 内部预训练 pipeline 的一个 module,每次发新数据时自动重新拟合并 update Table 2。
一句话评价:InfoLaw 是 2026 年 5 月初这一波"数据受限 scaling law"浪潮中的代表作之一(与 Cornell 的 Prescriptive Scaling Laws 几乎同期发表)。它的最大贡献不是某个数值结果,而是坐标变换的洞察——把训练 compute 替换为信息量后,跨 mixture × scale × repetition 的 loss 行为坍缩到一条统一幂律。这种"坐标重新发现"对工程落地意义重大,代价是必须信任作者拟合的 $\theta^\star, \lambda(N)$ 在自己的数据上仍然适用。