DeRes:为可扩展 CTR 预测解耦残差稳定性与自适应性¶
研究动机与背景¶
CTR(点击率)预测处于搜索、信息流、电商排序的核心,微小的精度提升即可转化为可观的收入。近年来推荐排序模型从浅层特征交互(FM、DeepFM、DCN-v2)演进到深层 Transformer 架构(OneTrans、TokenMixer-Large、UniMixer),它们同时建模用户行为序列与特征交互,并通过加深 backbone 来 scaling。然而本文指出:当这些模型加深时,一个不显眼的组件成为瓶颈——残差连接(residual connection)。
标准残差 $\mathbf{x}_l = \mathbf{x}_{l-1} + f_l(\mathbf{x}_{l-1})$ 自 2015 年以来是默认的层间机制,它能保持梯度畅通,但在 CTR Transformer 里带来三个副作用:
- Pre-Norm 信号稀释(Pre-Norm signal dilution):在 Pre-Norm 下,层输出被加到已归一化的残差流上,早期层的特征被逐层"冲淡"。在 CTR 场景里,这些被冲淡的层往往恰好编码了用户最早的点击信号。
- 无法遗忘(No way to forget):恒等跳连以权重 1.0 保留一切。当用户兴趣发生漂移(interest drift)时,陈旧信号一直留在残差流里干扰预测,模型无法选择性地遗忘它们。
- 单层视野(Single-layer view):每一层只能看到直接前驱 $\mathbf{x}_{l-1}$,因此任何"跨越非相邻层"的模式都不可见。
语言模型领域已经有若干工作重新审视层间连接:DenseFormer 用静态深度加权平均(48 层匹配 72 层 Transformer);Attention Residuals(AttnRes)用 Softmax 跨层注意力替换固定权重,在 Kimi-48B 上以 <5% 开销获得约 25% 的等效 token 节省;Hyper-Connections(HC)/ Sinkhorn 投影的 mHC 把残差流本身扩展;MUDDFormer 为 Q/K/V/R 各拆一条动态连接。但这些方法全部针对语言模型,没有一个在 CTR 数据上验证过,更关键的是——没有一个把"动态跨层注意力"与"显式恒等保护路径"结合起来。
作者强调 CTR Transformer 并不是浅层语言模型,它有三点本质差异:(1) 深度通常只有 4–12 层(LLM 是 32–128 层);(2) 输入是类别/数值/序列混合的异构特征,而非同质 token 流;(3) 一次预测必须并行编码多个兴趣。Zhang et al.(FAT,本文 ref [36])通过 Rademacher 复杂度证明,CTR Transformer 的 scaling 杠杆是特征域数量 $F$(即有效交互阶数 $K$),而非序列长度 $n$。Wukong(ref [38])则用一个双路径设计(高阶探索的 FMB + 低阶复用的 LCB)在 146B 样本上跨两个数量级保持 scaling,而单路径 baseline 会饱和。
本文正是建立在双路径网络(Dual Path Networks, DPN)——它在 HORNN(高阶循环网络)框架下把 ResNet 的一阶复用与 DenseNet 的高阶探索结合——之上,提出 DeRes,一个面向 CTR Transformer 的双路径层间连接器。
核心方法:DeRes 架构¶
DeRes 的核心设计哲学是一句话:残差稳定性与跨层自适应性不应共用同一个算子(residual stability and cross-layer adaptivity should not share one operator)。纯残差稳定但静态;DenseFormer/AttnRes 自适应但丢掉了恒等保护;可学习残差矩阵增加了混合能力,却会随深度累积谱衰减(spectral attenuation)。DeRes 把这两个角色拆成并行的两条路径,再用门控融合。
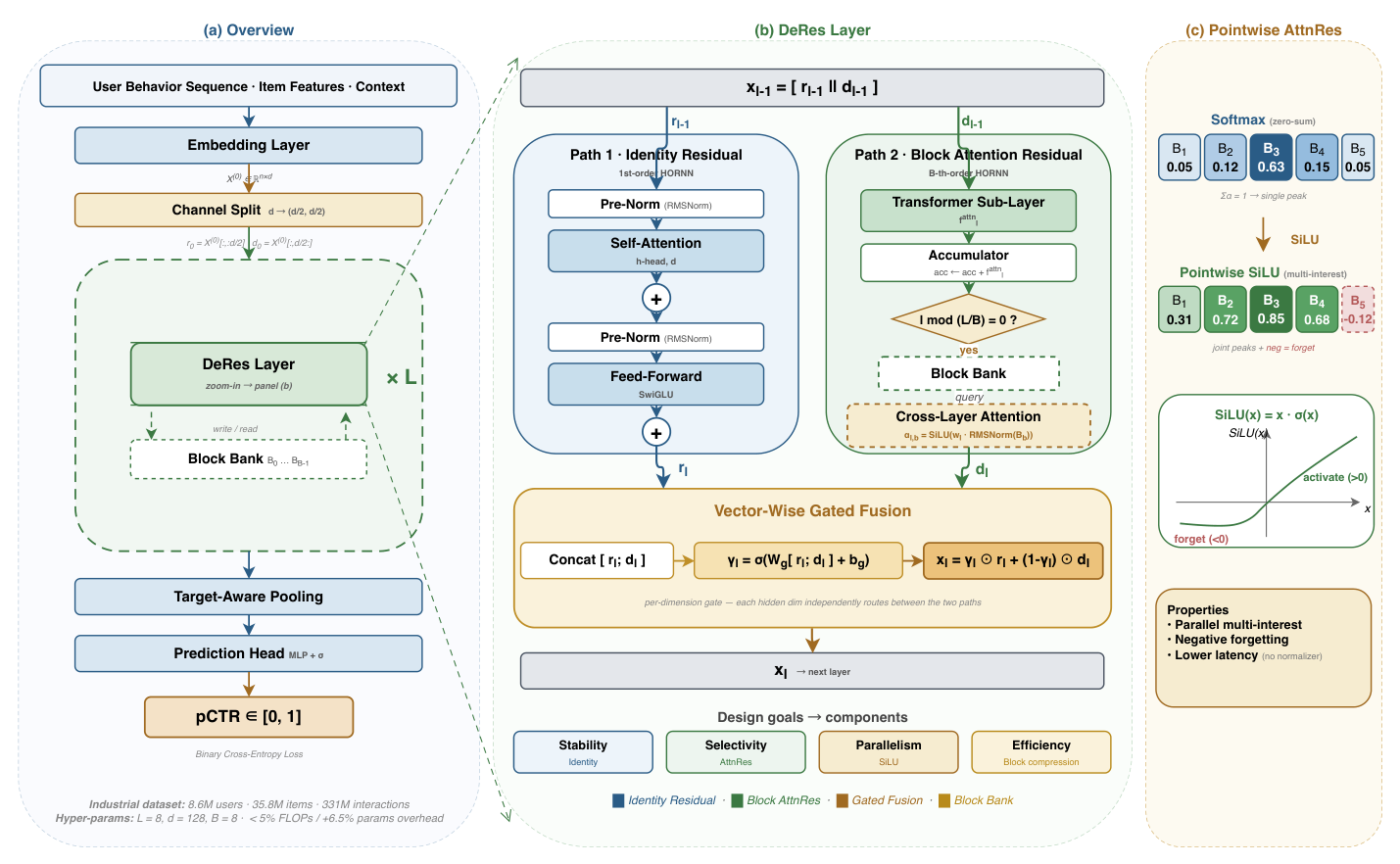
预备:CTR Transformer 与标准残差的局限¶
给定用户特征集合与行为序列,输入被嵌入为 $\mathbf{X}^{(0)} \in \mathbb{R}^{n \times d}$($n$ 为序列长度,$d$ 为隐藏维度)。$L$ 层 Transformer,每层含多头自注意力(MHA)+ 前馈(FFN),采用 Pre-Norm 与 LayerNorm:
$$\mathbf{Y}^{(l)} = \mathbf{X}^{(l-1)} + \text{MHA}(\text{LN}(\mathbf{X}^{(l-1)})), \quad \mathbf{X}^{(l)} = \mathbf{Y}^{(l)} + \text{FFN}(\text{LN}(\mathbf{Y}^{(l)})) \tag{1}$$
最终预测 $\hat{y} = \sigma(\mathbf{w}^\top \mathbf{x}^{(L)}_{\text{target}})$。恒等跳连给了直接的梯度路径,但限制了信息流:第 $l$ 层只能访问直接前驱,早期信号被逐步稀释,且信息一旦进入残差流就无法被选择性遗忘。
四个设计目标¶
作者把"一个 CTR 友好的层间连接器应满足"拆成四个标准,恰好映射到四个组件:
| 设计目标 | 含义 | 对应组件 |
|---|---|---|
| Stability(稳定性) | 保持梯度干净。恒等跳连是最可靠的方式 | Identity 路径 |
| Selectivity(选择性) | 判断哪些早期表示对当前预测重要,区分长期兴趣与过时兴趣 | AttnRes 路径 |
| Parallelism(并行性) | 用户同时持有多个兴趣,强迫跨层权重求和为 1 会压制次要兴趣 | Pointwise 激活(SiLU) |
| Efficiency(效率) | 必须装进排序阶段预算,把早期层压成 block 再注意 | block 压缩 |
Path 1:恒等残差路径(一阶特征复用)¶
第一条路径保持标准残差连接,使用固定的恒等权重:
$$\mathbf{r}_l = \mathbf{r}_{l-1} + f^{\text{res}}_l(\mathbf{r}_{l-1}) \tag{2}$$
其中 $f^{\text{res}}_l$ 是 Transformer 子层(MHA + FFN)。在 HORNN 视角下这是一个一阶循环,复用直接前驱的特征。作者坚持用固定恒等矩阵而非可学习残差矩阵,理由有二:(1) 理论上(见 Proposition 2)最小奇异值小于 1 的可学习残差矩阵会随深度累积指数衰减;(2) 实践上 Qwen3 的实验报告 $\mathbf{H}^{\text{res}} = \mathbf{I}$ 最终胜过可学习替代。
Path 2:块注意力残差路径(跨层探索)¶
第二条路径动态地对所有先前层的输出做注意力,为效率把它们分成 $B$ 个 block。把 $L$ 层划分为 $B$ 个 block,第 $b$ 个 block 的输出是该 block 内各层输出之和:
$$\mathbf{B}_b = \sum_{l \in \text{Block}_b} g_l(\mathbf{d}_l) \tag{3}$$
其中 $g_l$ 是 AttnRes 路径的 Transformer 子层。设 $b(l)$ 为第 $l$ 层之前(或恰在该层)写入的最近 block 索引。第 $l$ 层对 block $b$ 的跨层注意力权重(对每个 block 摘要施加 RMSNorm)为:
$$\alpha_{l,b} = \frac{\exp(\mathbf{w}_l \cdot \text{RMSNorm}(\mathbf{B}_b))}{\sum_{b'=0}^{b(l)} \exp(\mathbf{w}_l \cdot \text{RMSNorm}(\mathbf{B}_{b'}))} \tag{4}$$
其中 $\mathbf{w}_l \in \mathbb{R}^{d/2}$ 是第 $l$ 层的静态可训练 query 向量(匹配 $d/2$ 维的每路通道切分)。AttnRes 路径输出:
$$\mathbf{d}_l = \sum_{b=0}^{b(l)} \alpha_{l,b} \cdot \mathbf{B}_b \tag{5}$$
在 HORNN 视角下这是一个高阶循环:后面的层可以直接从任意早期阶段的压缩摘要读取,而不只是从直接前驱。
门控融合(Gated Fusion)¶
两条路径的输出经一个向量级 sigmoid 门融合:
$$\boldsymbol{\gamma}_l = \sigma(\mathbf{W}_g [\mathbf{r}_l ; \mathbf{d}_l] + \mathbf{b}_g) \tag{6}$$
$$\mathbf{x}_l = \boldsymbol{\gamma}_l \odot \mathbf{r}_l + (1 - \boldsymbol{\gamma}_l) \odot \mathbf{d}_l \tag{7}$$
其中 $\mathbf{W}_g \in \mathbb{R}^{(d/2) \times d}$,$\mathbf{b}_g \in \mathbb{R}^{d/2}$,$\sigma$ 是 sigmoid,$\odot$ 是逐元素乘。$\mathbf{r}_l, \mathbf{d}_l \in \mathbb{R}^{d/2}$(每路一个通道,最后拼接投影回 $\mathbb{R}^d$),门 $\boldsymbol{\gamma}_l \in \mathbb{R}^{d/2}$ 在相同的每路分辨率上作用。向量级门让每个隐藏维度独立选择信息来源——某些维度偏好稳定复用,另一些受益于跨层探索。
关键技术细节:Pointwise AttnRes for CTR¶
这是本文除双路径之外最具 CTR 针对性的设计。标准 AttnRes(式 4)用 Softmax,会在层之间制造零和竞争:增大一层的注意力权重必然减小其它层。在语言模型里这是合理的——主任务是从单一上下文预测下一个 token,竞争性选择是对的归纳偏置。但 CTR 不同:一个用户通常同时携带多个兴趣(比如电子产品与运动),模型必须并行编码它们。HSTU(ref [37])已经证明在推荐 Transformer 的注意力块内部移除 Softmax 有帮助;同样的直觉促使作者在层之间也移除 Softmax。
于是提出 Pointwise AttnRes,用 SiLU(Sigmoid Linear Unit)激活替换 Softmax:
$$\alpha_{l,b} = \text{SiLU}(\mathbf{w}_l \cdot \text{RMSNorm}(\mathbf{B}_b)) \tag{8}$$
其中 $\text{SiLU}(x) = x \cdot \sigma(x)$。SiLU 带来三个优势:
- 并行多兴趣编码:多个 block 可以同时取得大的正权重,不再互相挤压;
- 软遗忘机制:$\text{SiLU}(x<0)$ 的负分支让模型为不相关的层赋予负权重,相当于主动抑制陈旧信号;
- 更低延迟:没有 Softmax 分母,省去归一化计算。
作者用 Figure 1(c) 对比了两者:Softmax 归一化下增大一层权重必减小其它(单峰),而 Pointwise 允许独立加权——一个既关注电子产品又关注运动的用户可以同时强激活编码这两类兴趣的层而互不抑制。
理论分析:三个命题¶
DeRes 给出三个命题,分别覆盖表示能力、梯度稳定性、scaling 下界。
HORNN 框架(ref [27]):标准残差对应一阶循环
$$\mathbf{h}_l = \mathbf{h}_{l-1} + f_l(\mathbf{h}_{l-1}) \tag{9}$$
稠密连接对应 $L$ 阶循环
$$\mathbf{h}_l = \sum_{k=0}^{l-1} \omega_{l,k} g_{l,k}(\mathbf{h}_k) \tag{10}$$
后者可直接访问所有早期状态,代价是 $O(L^2)$ 内存。DPN(ref [5])证明结合两种阶数能得到严格大于任一单独阶数的函数容量——DeRes 把这一点形式化。
Proposition 1(表示能力):设 $\mathcal{F}^L_{\text{res}}, \mathcal{F}^L_{\text{attn}}, \mathcal{F}^L_{\text{dual}}$ 分别为相同每层 $f_l$、相同参数预算下,残差-only、AttnRes-only、DeRes 网络可实现的 $L$ 层函数族。则
$$\mathcal{F}^L_{\text{res}} \cup \mathcal{F}^L_{\text{attn}} \subsetneq \mathcal{F}^L_{\text{dual}}$$
证明思路:令门 $\boldsymbol{\gamma}_l = \mathbf{1}$ 恢复残差-only,$\boldsymbol{\gamma}_l = \mathbf{0}$ 恢复 AttnRes-only,故并集 $\subseteq$。要证严格包含,构造一个用非退化门 $\boldsymbol{\gamma}_l \in (0,1)^d$ 混合两路输出的 $h^*$,它无法被任一单路模型实现:(i) 残差-only 的输出落在 $\{\mathbf{x}_0, f_1(\cdot), \ldots, f_L(\cdot)\}$ 的仿射张成内且只有 depth-$l$ 访问;(ii) AttnRes-only 的输出是 block 输出的凸组合、无恒等保护。向量级门同时打破两个限制。
Proposition 2(恒等残差稳定性):设 $\mathbf{H}^{\text{res}}_l \in \mathbb{R}^{d \times d}$ 为第 $l$ 层可学习残差转移,$\|\mathbf{H}^{\text{res}}_l\| \le \kappa$ 且最小奇异值 $\sigma_{\min}(\mathbf{H}^{\text{res}}_l) \le \rho < 1$。定义累积残差映射 $\mathbf{P}_L = \prod_{l=1}^L \mathbf{H}^{\text{res}}_l$ 作用于浅层信号 $\mathbf{s}_0$,则
$$\|\mathbf{P}_L \mathbf{s}_0\|_2 \le \rho^L \|\mathbf{s}_0\|_2$$
即信号至少随深度指数衰减。相反,用恒等映射替换 $\mathbf{H}^{\text{res}}_l$ 得 $\mathbf{P}_L = \mathbf{I}$,$\|\mathbf{P}_L \mathbf{v}\|_2 = \|\mathbf{s}_0\|_2$ 对所有 $L$ 成立。证明由奇异值的次可乘性:$\sigma_{\min}(\mathbf{P}_L) \le \prod \sigma_{\min}(\mathbf{H}^{\text{res}}_l) \le \rho^L$。
数值实例化:对流形约束的 mHC(ref [34]),在 Qwen3-1.7B/8B 上经验观察到双随机矩阵 $\rho \approx 0.49$。把每个 MHA 与 FFN 子层视为独立转移($L=8$ 层共 16 次应用),Proposition 2 给出最坏界 $\sigma_{\min}(\mathbf{P}_{16}) \le 0.49^{16} \approx 1.1 \times 10^{-5}$——即对齐最坏方向的向量在抵达预测头前被衰减近五个数量级。恒等残差从构造上避免这种崩塌,这正是 DeRes Path 1 固定 $\mathbf{H}^{\text{res}}_l = \mathbf{I}$ 而非学习它的原因。
梯度流:结合 Proposition 2 与链式法则,损失 $\mathcal{L}$ 对浅层输入 $\mathbf{x}_0$ 的梯度包含来自恒等残差路径的贡献:
$$\frac{\partial \mathcal{L}}{\partial \mathbf{x}_0} = \frac{\partial \mathcal{L}}{\partial \mathbf{x}_L} \cdot \prod_{l=1}^L \left(\mathbf{I} + \frac{\partial f_l}{\partial \mathbf{x}_{l-1}}\right) + (\text{AttnRes-path terms}) \tag{11}$$
恒等路径的乘积在每一层都含无阻碍的恒等项 $\mathbf{I}$;AttnRes 路径贡献形如 $\sum_b \alpha_{l,b}(\partial g_{l,b}/\partial \mathbf{x}_b)$ 的附加项,依赖学到的注意力权重。双路径因此提供两条互补的梯度通道:Path 1 的保证恒等路由 + Path 2 的内容自适应路由。
Proposition 3($\gamma$ 的 scaling-law 下界):在 FAT 泛化界(ref [36])下,设 $K_{\text{res}}, K_{\text{dual}}$ 为残差-only 与 DeRes 网络的有效跨层交互阶数。若 $K_{\text{dual}} \ge K_{\text{res}} + 1$,则拟合的 scaling-law 指数($\text{AUC}(C) = \alpha - \beta C^{-\gamma}$)满足 $\gamma_{\text{dual}} > \gamma_{\text{res}}$。思路:更高的交互阶 $K$ 扩大可实现假设类,而 Rademacher 复杂度界只按 $\sqrt{F^K \log d / N}$(而非 $F^K$)增长,因此每单位算力 $C$ 买到更大的 AUC 增益、更陡的幂律指数。标准残差只支持 $K_{\text{res}}=1$(直接前驱),而 DeRes 的 AttnRes 路径能在近常数代价下对所有 $B$ 个 block 摘要做注意力,对任意 $B \ge 2$ 满足 $K_{\text{dual}} \ge K_{\text{res}}+1$。这定性地解释了实测的 $\gamma_{\text{DeRes}}=0.118 > \gamma_{\text{OneTrans}}=0.071$(1.66× scaling-效率差距)。
作者还把 DeRes 类比 Wukong:恒等路径的角色对应 Wukong 的线性压缩块(LCB,低阶域交互),AttnRes 路径对应 Wukong 的因子分解机块(FMB,高阶探索)。
复杂度与算法¶
DeRes 相对标准 Transformer 的每层开销是 $O(Bd + d^2)$:$O(Bd)$ 为跨层 block 点积,$O(d^2)$ 为门投影 $\mathbf{W}_g$(具体 $d^2/2$ FLOPs,$B \ll d$ 时为 $O(d^2)$,$d=128$)。相对主导的 Transformer 代价 $O(n^2 d)$,这增加 <5% FLOPs 和 6.5% 参数。两路用独立的半维参数(每路 $d/2$),使总参数量与 baseline 相当。
Algorithm 1 给出每序列前向(代价 $O(L(n^2 d + Bd + d^2))$),关键步骤:
输入:嵌入 X^(0) ∈ R^{n×d};层数 L;block 数 B
1: r_0 ← X^(0)[:, :d/2] # 残差路径初始化
2: d_0 ← X^(0)[:, d/2:] # AttnRes 路径初始化
3: BlockBuf ← [d_0]; acc ← 0 # block 缓冲 + 块内累加器
5: for l = 1 to L:
7: r_l ← r_{l-1} + TransformerLayer^res_l(r_{l-1}) # Path 1
9: acc ← acc + TransformerLayer^attn_l(d_{l-1}) # Path 2
10: if l mod (L/B) == 0: BlockBuf.append(acc); acc ← 0 # 写块并重置
14: K ← [RMSNorm(B_b)]_b
15: α_{l,b} ← SiLU(w_l · K_b) # Eq.8,逐块
16: d_l ← Σ_b α_{l,b} · BlockBuf[b]
18: γ_l ← σ(W_g[r_l; d_l] + b_g) # Eq.6
19: x_l ← γ_l ⊙ r_l + (1-γ_l) ⊙ d_l # Eq.7
21: return X^(L) = [x_L]
为什么 CTR 比 LLM 受益更多¶
作者专门讨论了 AttnRes 本为 LLM 而生,但 CTR 的四个特性放大了它的收益:(i) 浅层深度——工业 CTR 跑 4–12 层 vs LLM 的 32–128 层,每层承担更大比例的预测,改进层间流的收益按比例更大;(ii) 异构特征——ID、属性、上下文、行为序列天然处在不同深度,双路径把浅层信号留在恒等路径(呼应 Wukong),AttnRes 按需取回合适深度;(iii) 并行多兴趣——跨层 Softmax(零和)是错误归纳偏置,HSTU 已对块内注意力证明这点;(iv) 兴趣漂移——无权残差无法下调陈旧信号,AttnRes 可以,且 Figure 3 显示训练后的 SiLU 权重确实用负分支抑制了无关早期层。
实验设置¶
数据集:一个专有工业数据集 + 两个公开 CTR benchmark。
- Industrial:来自大规模社交媒体平台的序列推荐,860 万用户、3580 万 item、3.311 亿用户-item 交互,平均行为序列长度 38.5。每个 item 用预计算的 128 维 embedding 表示(融合文本、图像、行为信号),序列截断至最近 1000 个动作,按时间切分。规模与结构对标 OneTrans / TokenMixer-Large / UniMixer。
- Criteo:4580 万广告曝光,13 个数值 + 26 个类别特征(6 天训练、第 7 天测试,遵循 DCN-v2)。
- Avazu:4040 万移动点击记录,22 个类别字段(80/20 时序切分,遵循 AutoInt)。
预处理:Criteo 缺失值用字段均值填充、数值离散为 10 个等频桶并对计数特征做 log 变换;Avazu 高基数类别哈希到至多 10 万唯一值;全部按时序切分。
Baseline(12 个,四类):
- 特征交互:DeepFM、DCN-v2、AutoInt、FiBiNET
- 序列:DIN、SASRec
- 层间连接(原为 LLM,本文为 CTR 重新实现):DenseFormer、mHC、AttnRes
- 工业 Transformer CTR:OneTrans、TokenMixer-Large、UniMixer
为公平对比,所有 Transformer 方法共享 8 层 backbone($d=128$,4 头),每个 baseline 只改层间机制。
实现细节:DeRes 用 $L=8$ 层,$d=128$(每路 64),4 头,$B=8$ block。Adam(lr $=10^{-3}$,$\beta_1=0.9$,$\beta_2=0.999$),5% 步数线性 warm-up 后 cosine 衰减,50 epoch,batch 4096,dropout 0.1,二元交叉熵,梯度裁剪范数 1.0,验证 AUC 早停(patience 3),三个随机种子平均。$d=128, L=8$ 遵循 BARS-CTR 协议。硬件:PyTorch 2.1 + BF16 混精,单节点 8× A100-80GB + AMD EPYC 7742,每个 Industrial epoch 156 秒。
指标:AUC、LogLoss。工业 CTR 中 0.1% AUC 提升通常具统计意义,~0.2% RelaImpr 阈值对应可上线收益。Industrial 额外报告用户加权 GAUC 与 RelaImpr,$\text{RelaImpr}(M, M_0) = \frac{\text{AUC}(M)-0.5}{\text{AUC}(M_0)-0.5} - 1$,统计显著性用配对 bootstrap($10^4$ 重采样)。
主要实验结果¶
总体性能(Table 2)¶
DeRes 有两个变体:DeRes-S(Softmax 注意力,式 4)与 DeRes-P(Pointwise SiLU,式 8)。
| 方法 | Ind. AUC↑ | Ind. GAUC↑ | Ind. LogLoss↓ | Criteo AUC↑ | Criteo LogLoss↓ | Avazu AUC↑ | Avazu LogLoss↓ |
|---|---|---|---|---|---|---|---|
| DeepFM | 0.7891 | 0.7718 | 0.4452 | 0.8076 | 0.4434 | 0.7984 | 0.3743 |
| DCN-v2 | 0.7943 | 0.7774 | 0.4404 | 0.8129 | 0.4384 | 0.8004 | 0.3729 |
| AutoInt | 0.7912 | 0.7741 | 0.4429 | 0.8104 | 0.4407 | 0.7991 | 0.3737 |
| FiBiNET | 0.7926 | 0.7757 | 0.4416 | 0.8121 | 0.4391 | 0.8013 | 0.3722 |
| DIN | 0.7988 | 0.7825 | 0.4358 | 0.8071 | 0.4437 | 0.7986 | 0.3742 |
| SASRec | 0.8004 | 0.7846 | 0.4341 | 0.8086 | 0.4424 | 0.7993 | 0.3736 |
| DenseFormer† | 0.8003 | 0.7843 | 0.4345 | 0.8108 | 0.4402 | 0.8001 | 0.3732 |
| mHC† | 0.8011 | 0.7852 | 0.4336 | 0.8118 | 0.4393 | 0.7997 | 0.3738 |
| AttnRes† | 0.8029 | 0.7873 | 0.4317 | 0.8101 | 0.4411 | 0.8014 | 0.3721 |
| OneTrans† | 0.8019 | 0.7861 | 0.4327 | 0.8124 | 0.4387 | 0.8011 | 0.3724 |
| TokenMixer-L† | 0.8038 | 0.7884 | 0.4308 | 0.8138 | 0.4374 | 0.8016 | 0.3720 |
| UniMixer† | 0.8032 | 0.7878 | 0.4313 | 0.8133 | 0.4378 | 0.8022 | 0.3715 |
| DeRes-S† (ours) | 0.8056 | 0.7912 | 0.4290 | 0.8137 | 0.4376 | 0.8024 | 0.3713 |
| DeRes-P† (ours) | 0.8064 | 0.7926 | 0.4280 | 0.8146 | 0.4366 | 0.8030 | 0.3707 |
| 较最佳 baseline | +0.32% | +0.53% | −0.65% | +0.10% | −0.18% | +0.10% | −0.21% |
| 较 OneTrans RelaImpr | +1.49% | +2.27% | — | +0.70% | — | +0.63% | — |
(DeRes-P 三种子标准差:Ind. ±0.0005/±0.0006/±0.0007,Criteo ±0.0006/±0.0005,Avazu ±0.0008/±0.0007;标 † 者为以层间连接为主要贡献的方法。)
三点观察: 1. Industrial 上 DeRes-P 较最强 baseline(TokenMixer-L 0.8038/0.7884)取得 +0.32% AUC、+0.53% GAUC。这是行为序列最长、多模态 embedding 最丰富的数据集,跨层召回的信号最多。GAUC 增益超过 AUC 增益,说明收益来自逐用户个性化而非全局校准;GAUC-based RelaImpr 对 OneTrans 达 +2.27%,远超 ~0.2% 工业阈值(配对 bootstrap,$p<0.01$)。 2. Criteo 上仅领先 TokenMixer-L +0.10%,因为 DCN-v2 的显式交叉与 FiBiNET 的双线性交互在纯表格场景里已捕获大部分信号。 3. Avazu 上最强 baseline 是 UniMixer(0.8022),DeRes-P 领先 +0.10%;仅 22 个字段时所有 12 个方法落在 0.6% 带内。
消融实验(Table 3)¶
(a) 路径贡献(Industrial):
| 变体 | Path 1 | Path 2 | AUC↑ | LogLoss↓ |
|---|---|---|---|---|
| Residual Only(≡ OneTrans) | Identity | — | 0.8019 | 0.4327 |
| Learnable Res(≡ mHC 式) | Doubly stoch. | — | 0.8011 | 0.4336 |
| AttnRes Only(Softmax) | — | Softmax | 0.8029 | 0.4317 |
| AttnRes Only(SiLU) | — | SiLU | 0.8041 | 0.4304 |
| DeRes w/ Add Fusion | Identity | SiLU | 0.8052 | 0.4293 |
| DeRes w/ Learnable Res | Doubly stoch. | SiLU | 0.8044 | 0.4301 |
| DeRes-P(full) | Identity | SiLU | 0.8064 | 0.4280 |
结论:(1) 把恒等换成双随机可学习矩阵使残差-only 退化 0.08%(0.8019→0.8011),印证 Proposition 2 的谱衰减;(2) 单路 AttnRes 里 Softmax→SiLU 提升 +0.12%,支持多兴趣假设;(3) 双路一致优于任一单路,印证 Proposition 1;在双路设置里把恒等换成可学习残差反而损失 0.20%,说明保护必须在算子层面强制;(4) 门控融合(0.8064)优于加法融合(0.8052),SiLU 优于 Softmax(+0.08%)与 ReLU(+0.16%,其零点硬截断丢掉了 SiLU 负分支的软抑制);独立半维路径以 45% 的参数开销保留 92% 的独立全维性能。
(b) 设计选择:
| 维度 | 设置 | AUC | +FLOPs |
|---|---|---|---|
| 注意力激活 | Softmax | 0.8056 | +4.4% |
| Sigmoid | 0.8059 | +4.2% | |
| ReLU | 0.8048 | +4.0% | |
| SiLU | 0.8064 | +4.4% | |
| 参数 | Shared, $d$ | 0.8043 | +2.1% |
| Indep., $d/2$ | 0.8064 | +4.4% | |
| Indep., $d$ | 0.8068 | +9.7% |
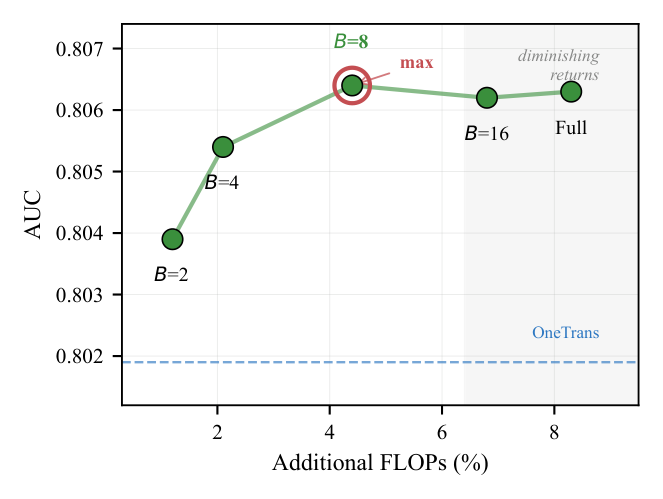
Block 粒度(Figure 2)在 $B=8$ 取峰值,$B=16$ 与 $B=L$ 在种子噪声内。
模态消融(Table 4):每个 item 携带预融合的 128 维 embedding(文本/图像/行为),重训练 DeRes-P 与 OneTrans 并屏蔽某模态。
| 使用的模态 | OneTrans | DeRes-P | Δ (pp) |
|---|---|---|---|
| 文本+图像+行为 | 0.8019 | 0.8064 | +0.45 |
| 文本+图像(无行为) | 0.7894 | 0.7942 | +0.48 |
| 文本+行为(无图像) | 0.7972 | 0.8003 | +0.31 |
| 图像+行为(无文本) | 0.7948 | 0.7984 | +0.36 |
| 仅行为 | 0.7841 | 0.7867 | +0.26 |
| 仅文本 | 0.7738 | 0.7755 | +0.17 |
| 仅图像 | 0.7706 | 0.7731 | +0.25 |
DeRes-P 的优势在文本+图像(无行为)最大(+0.48),紧随完整三模态(+0.45),输入退化到单模态时收窄。移除行为对 OneTrans 的伤害大于 DeRes-P(−1.56% vs −1.51%),暗示恒等路径已吸收大部分行为信号,留给 AttnRes 路径从异构内容特征里补偿。仅文本最弱(Δ=+0.17),仅图像(Δ=+0.25)恢复更多,因为视觉 embedding 保留了利于块级注意力的结构线索。
效率分析(Table 5)¶
DeRes-P 以 +6.5% 参数、+4.4% FLOPs 取得最佳 AUC,训练/推理代价与其它层间方法持平(149–158 s/epoch、3.3–3.5 ms/推理)。
| 方法 | 参数 (M) | FLOPs (G) | 训练 (s/ep) | 推理 (ms) | AUC |
|---|---|---|---|---|---|
| OneTrans | 12.4 | 1.82 | 142 | 3.1 | 0.8019 |
| DenseFormer | 12.9 | 1.91 | 158 | 3.4 | 0.8003 |
| mHC | 12.7 | 1.86 | 149 | 3.3 | 0.8011 |
| AttnRes | 13.0 | 1.85 | 153 | 3.4 | 0.8029 |
| TokenMixer-L | 13.1 | 1.88 | 151 | 3.4 | 0.8038 |
| UniMixer | 12.8 | 1.89 | 155 | 3.5 | 0.8032 |
| DeRes-P | 13.2 | 1.90 | 156 | 3.4 | 0.8064 |
DeRes-P 每 epoch 仅比 OneTrans 慢 9.9%(156 vs 142 s),略快于 DenseFormer。
消融与分析¶
注意力权重分布与可解释性(Figure 3)¶
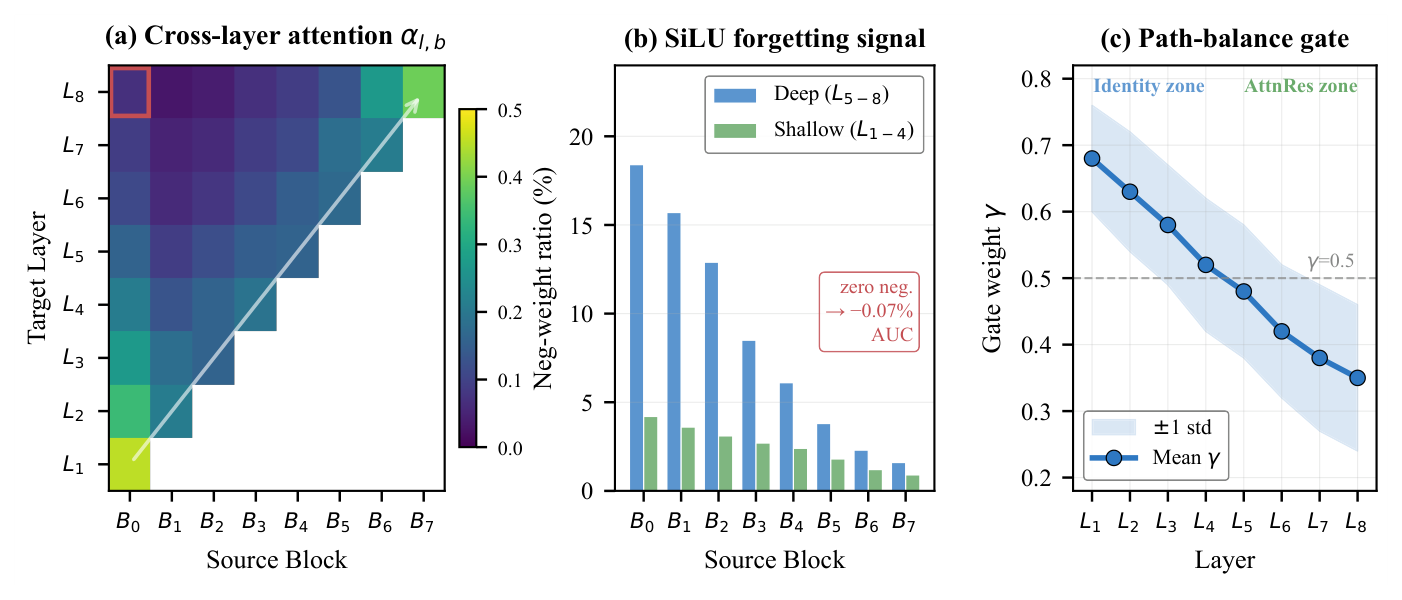
Figure 3 揭示三个模式:(i) 主对角线——每层聚焦近邻 block;(ii) 深层对 $\mathbf{B}_0$ 的持续注意力(红框)——深层回取 embedding 级信号;(iii) 无关 block 近零权重。图还分解了 SiLU 特有的遗忘行为:负权项集中在深层对早期 block($\mathbf{B}_0$ 处 18%),起抑制作用;在受控消融里把它们置零损失 −0.07% AUC,说明抑制是功能性的。Figure 3(c) 显示学到的门 $\gamma$ 从 0.68(L1)单调降到 0.35(L8)——浅层走恒等路径、深层转向 AttnRes,且 ±std 带(0.08–0.12)表明不同隐藏维度专门化方向不同,这正是向量级门优于标量门的原因。
增益集中在哪里¶
横跨四个正交切片(序列长度、模型深度、用户活跃度、item 流行度),DeRes-P 对 OneTrans 的优势随切片难度单调增长,反映一个共同机制:单个直接前驱残差无法独自携带足够信息。
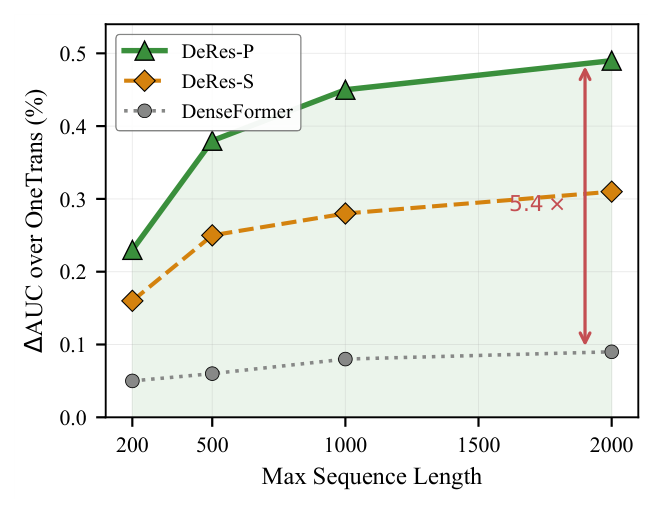
(i) 序列长度(Figure 4):上限 200→2000,增益 +0.23%→+0.49%,8→16 段最陡;DeRes-S 并行扩大(+0.07%→+0.18%),DenseFormer 因静态深度权重而持平。 (ii) 模型深度:$L \in \{4,8,12,16\}$ 时增益单调上升(+0.27/+0.45/+0.51/+0.54%),而 OneTrans 饱和(L=8→16 仅 +0.09%);FLOPs 开销因每层 AttnRes 代价 $O(Bd)$ 恒定而略降(+4.8%→+4.0%)。 (iii) 用户活跃度(Table 6a):短历史用户 +0.14% → 长历史 +0.51%,GAUC 增益系统性大于 AUC——个性化的标志。 (iv) item 流行度(Table 6b):从头部 +0.26% 升到尾部 +0.74%;mHC 在尾部反而劣于 OneTrans(−0.25%),正是谱衰减最伤的区间;AttnRes-only 仅微超 OneTrans(+0.20%)却远逊 DeRes——恒等保护把跨层召回转化为尾部友好信号。
| Table 6(a) 用户活跃度 | 占比 | OneTrans AUC | DeRes AUC | OneTrans GAUC | DeRes GAUC | ΔAUC | ΔGAUC |
|---|---|---|---|---|---|---|---|
| 短 (<200) | 31.4% | 0.7984 | 0.7998 | 0.7818 | 0.7833 | +0.14 | +0.15 |
| 中 (200–800) | 46.7% | 0.8024 | 0.8064 | 0.7910 | 0.7956 | +0.40 | +0.46 |
| 长 (>800) | 21.9% | 0.8057 | 0.8108 | 0.8001 | 0.8053 | +0.51 | +0.52 |
| Table 6(b) item 流行度 | OneTrans | mHC | AttnRes | TokenM-L | DeRes-P | Δ(pp) |
|---|---|---|---|---|---|---|
| Head | 0.8128 | 0.8123 | 0.8133 | 0.8146 | 0.8154 | +0.26 |
| Torso | 0.8017 | 0.8009 | 0.8021 | 0.8038 | 0.8062 | +0.45 |
| Tail | 0.7798 | 0.7773 | 0.7818 | 0.7822 | 0.7872 | +0.74 |
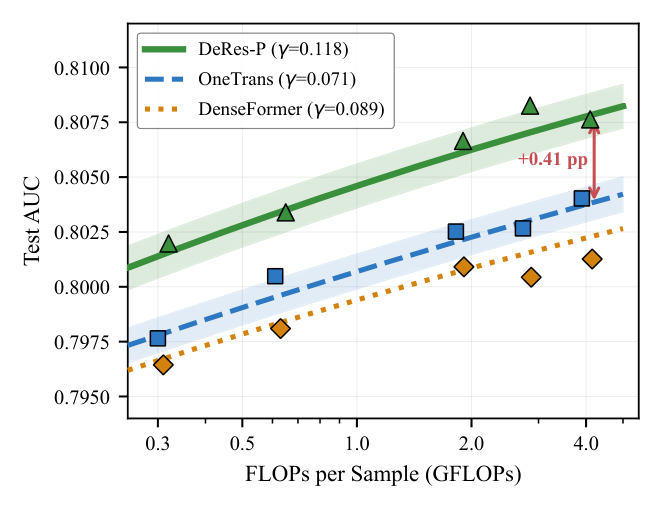
Scaling Law 分析(Figure 5)¶
遵循 Wukong 与 FAT,拟合幂律 $\text{AUC}(C) = \alpha - \beta \cdot C^{-\gamma}$(式 12)。在五个复杂度档($L \in \{2,4,8,12,16\}$,$d \in \{64,128\}$,FLOPs 0.3G–4.2G)训练 OneTrans、DenseFormer、DeRes-P。
$$\text{AUC}(C) = \alpha - \beta \cdot C^{-\gamma} \tag{12}$$
拟合 $(\alpha, \beta, \gamma)$:OneTrans (0.8333, 0.0326, 0.071),DenseFormer (0.8238, 0.0244, 0.089),DeRes-P (0.8256, 0.0210, 0.118)。DeRes 每单位算力买到 1.66× 于 OneTrans 的 AUC,AUC 差距随算力增大(2G FLOPs 时 +0.4 pp,更大规模继续扩大)。操作意义:DeRes 用 8 层达到 OneTrans-16L 的 AUC,等质量下约 2× 算力节省。训练动态上 DeRes-P 比 OneTrans 早约 15% 达到 99% 峰值 AUC(epoch 28 vs 33),并在高 +0.45 pp 处稳定(0.8064 vs 0.8019)。这与 HORNN 视角及 FAT 的 Rademacher 分析一致:标准残差只支持一阶特征传播,DeRes 的 AttnRes 路径抬高有效交互阶 $K$,使每加一层都既细化又重组早期信号。
核心贡献总结¶
- 首次把 Attention Residuals 引入 CTR Transformer,并证明其增益与语言模型相当——考虑到 CTR 的浅深度与异构输入,相对增益更大。
- DeRes:一个 DPN 式双路径层间连接器,把恒等残差与块级注意力残差配对,植根于 HORNN 视角,由 Proposition 1(表示能力)、Proposition 2(梯度稳定)、Proposition 3(scaling 下界)三命题支撑。
- Pointwise AttnRes(SiLU):CTR 专用的、替换跨层 Softmax 的方案,支持非竞争式并行多兴趣编码与负权软遗忘。
- 充分的实证:12 个 baseline × 3 个数据集,加上路径/激活/参数消融、模态消融、scaling-law 拟合(γ=0.118 vs 0.071,1.66× 差距)、四个正交切片分析,全程 <5% 额外 FLOPs。
与已归档相关工作的对比¶
TokenMixer-Large TokenMixer-Large(ByteDance AML,2026-02-06)¶
关系:显式引用,DeRes 把它当作 baseline(Industrial 上的最强 baseline),但原文仅作为表格里的性能数据点,未在层间机制层面展开对比(Table 1 的层间连接 taxonomy 也未收录它)· 已加载对方精读
- 共同关注的问题:两篇都把标准残差/层间连接判定为 ranking Transformer 深度 scaling 的瓶颈。TokenMixer-Large 明确列出"次优残差设计"(RankMixer 的 add&norm 直接相加 mixing 前后 token 导致语义错位)与"深层模型梯度更新不足";DeRes 列出 Pre-Norm 稀释、无法遗忘、单层视野。两者的 root cause 同构:朴素残差在加深时退化,限制深度 scaling。
- 相近的技术骨架:两者都额外引入跨层/层间残差通路来补偿标准残差。TokenMixer-Large 一方面用对称的 "Mixing-Reverting" 两层结构保证跨层维度一致、建立从输入到深层的连续信号通路,另一方面每隔 2–3 层加一次 inter-residual connections 缓解深层梯度衰减;DeRes 则在每层并行一条对所有历史 block 摘要做注意力的 Block AttnRes 路径。骨架都属"标准残差之外再开跨层通道以支撑深度"。
- 本文的差异与推进:(1) 静态 vs 动态拓扑——TokenMixer-Large 的 inter-residual 是固定/周期性、主要服务于梯度;DeRes 的跨层连接是内容自适应注意力($\alpha_{l,b}=\text{SiLU}(\mathbf{w}_l\cdot\text{RMSNorm}(\mathbf{B}_b))$),服务于多兴趣召回。(2) DeRes 显式保留恒等保护路径 + 逐维向量门,并用 Proposition 2 论证可学习残差矩阵的谱崩塌(恰是 TokenMixer-Large 用 Pre-Norm + ReZero 式小初始化在缓解的问题,但 DeRes 选择从构造上用恒等回避)。(3) DeRes 的 SiLU 支持负权遗忘,TokenMixer-Large 无对应机制。
- 可比的方法/实验差异:在 DeRes 的 Industrial 受控协议下 TokenMixer-L 是最强 baseline(AUC 0.8038 / GAUC 0.7884),DeRes-P 0.8064 / 0.7926(+0.32% / +0.53%)。但规模差三个量级:TokenMixer-Large 原文把模型推到 15B 参数 + Sparse-Pertoken MoE + 在线收益,DeRes 是 8 层 $d=128$(13.2M 参数)的 BARS-CTR 机制对照实验,并非生产规模复刻——两者一个回答"如何把 ranking 模型推到百亿参数",一个回答"在固定预算下层间连接本身能榨出多少"。
讨论与局限性¶
核心贡献与值得借鉴的设计:DeRes 最漂亮的地方是把"稳定性"和"自适应性"这两个常被同一个残差算子勉强兼顾的诉求显式解耦成两条路径,再用逐维门让每个隐藏维度自己选。配套的三个命题不是装饰:Proposition 2 的 $0.49^{16}\approx10^{-5}$ 谱崩塌数值给了"为何坚持固定恒等而非可学习残差"一个干净的理由,并被消融(双路里换可学习残差反降 0.20%)和尾部分析(mHC 在尾部劣于 OneTrans)双重印证。Pointwise SiLU 把"跨层 Softmax 是错误归纳偏置"这一来自 HSTU 的洞见从块内推广到层间,并用 Figure 3 的负权热图证明负分支真的在做遗忘——这是把"多兴趣"从口号落到机制的少见案例。scaling-law 的 γ=0.118 vs 0.071、8 层 DeRes ≈ 16 层 OneTrans 是很有说服力的卖点。
部署价值:作者把 DeRes 定位为"残差连接的 drop-in 替换",不改特征、候选生成、loss、serving 接口。+0.32% AUC / +0.53% GAUC 落在工业系统报告为可上线的区间(OneTrans +0.748% DAU、TokenMixer-Large +2.0% ads-success 作为参照),GAUC-based RelaImpr +2.27% 超过 ~0.2% 工业阈值。
局限与争议:
- (L1) 无线上 A/B:所有 Industrial 结果都是离线,作者引用别家的线上收益作为"可上线性"旁证,但 DeRes 自身没有线上数据——这是本文最大的留白。
- (L2) Block 粒度无闭式解:最优 $B$ 依赖 $L$ 与序列长度,靠经验扫($B=8$)。
- (L3) 单任务:只研究 pointwise CTR,多任务排序(ESMM、MMOE)需进一步的任务特定路由研究。
- (L4) 仅 Pre-Norm:未验证 Post-Norm 迁移性。
- (L5) SiLU 最优性无证明:SiLU 受 HSTU 与消融支持,但缺"它是 pointwise 激活中唯一最优"的闭式证明。
- 机构未披露:论文首页未列作者所属机构,"major social-media platform" 未具名,规模/对标对象(OneTrans、TokenMixer-Large、UniMixer)暗示是国内头部短视频/社交平台,但无法确证。
与已有工作的差异:相比 OneTrans(标准残差、统一 seq+feature 参数化、靠 KV cache 上线)DeRes 正交——它不碰统一化,只重做层间连接,并把 OneTrans 当作"Residual Only"消融基线;相比 TokenMixer-Large/UniMixer(都在 token-mixing 模块层面 scaling)DeRes 把杠杆放在残差拓扑而非 mixing 算子;相比纯 LLM 的 AttnRes/DenseFormer/mHC,DeRes 是第一个在 CTR 上验证、且唯一同时具备"动态跨层注意力 + 恒等保护"的设计。