Denoising Implicit Feedback for Cold-start Recommendation¶
Kuaishou Technology 等 · arXiv 2606.19658 · 2026-06-17 · KDD '26
研究动机与背景¶
隐式反馈(implicit feedback,如观看、点击)因获取门槛低、数据量大,是工业推荐系统的主要训练燃料。但隐式反馈天然带噪:用户的点击/观看并不等于真实满意,存在 clickbait(标题党)导致的假正样本(false positive) 与 position bias / 浏览疲劳导致的假负样本(false negative)。已有去噪工作大多没有意识到——冷启动物品(cold-start item)比暖物品更容易产生噪声标签。
本文用快手平台的真实数据论证了这一点:
- 假正方向:得益于工业界日益成熟的多模态内容理解,作者发现处于 clickbait 评分前 10% 区间的冷启动视频数量,比处于后 10% 区间的高出 37.7%——即冷启动视频更容易因标题党被误点;
- 假负方向:分析 100 万用户会话发现,冷启动视频被放在曝光列表尾部三个位置的比例,比放在头部三个位置的比例高 28.3%——位置偏差使冷启动视频更容易被错过,产生假负样本。
冷启动问题本身已是工业推荐的核心障碍:快手等头部短视频平台每天上传数千万新视频,新视频因交互稀少、embedding 训练不充分,难以获得曝光机会,进而陷入「rich gets richer」的马太效应。而对冷启动物品而言,正反馈样本是优化其表征的关键信号——无论是假正还是假负样本,都会误导模型、浪费宝贵且有限的试错曝光机会,形成「不准确学习」的反馈闭环,加剧冷启动物品的错误表征,最终既损害用户体验,也打击内容生产者的积极性、可能扼杀一个本可爆款的物品。因此面向冷启动的隐式反馈去噪成为一项关键任务。
既有去噪方法可粗分两类,但都依赖启发式模式(heuristic patterns):
- 样本选择(sample selection):训练中挑选「干净」样本、丢弃噪声样本;
- 样本重加权(sample re-weighting):给被判定为噪声的交互赋予更低权重。
这些方法的成败高度依赖「干净 vs 噪声」的区分准确性,常用信号包括 loss 值偏高、预测分数、梯度 等(噪声样本往往 loss 更大)。问题在于:冷启动物品本身就天然表现为「更大的 loss、更小的预测分数、更高的梯度」——这些恰恰是上述去噪方法用来识别噪声的信号。于是这些方法在冷启动场景下根本无法区分「真噪声」与「仅仅因为冷启」,无法直接迁移到工业冷启动推荐。
为此本文提出模型无关(model-agnostic)的去噪方法 DIF(Denoising Implicit Feedback),围绕四个关键问题展开设计:
- (i) 如何为冷启动物品设计合理的伪标签策略? 核心观察是「用户对内容的偏好是稳定的」——因此一个用户是否对冷启动物品感兴趣,可以通过它内容相似的暖物品(warm item)来合理推断。暖物品的用户兴趣表征和协同表征都训练充分,能提供有意义的伪标签。作者还从理论上证明:即使内容相似性不完美,只要暖物品数量足够,伪标签仍能逼近真实标签。
- (ii) 如何在在线流式训练中为冷启动物品生成伪标签? 检索内容相似的暖物品及其协同表征,在工业系统中因缺乏全量候选集与实时更新而具挑战,作者给出了完整的工程落地方案。
- (iii) 如何进一步提升伪标签准确性? 不仅取 top-$k$ 暖物品生成多个伪标签做聚合,还按内容相似度显式建模每个伪标签的置信度。
- (iv) 如何基于最终伪标签修正噪声标签? 用相对熵 + 冷启动状态估计样本标签不确定性,在样本级别自适应地引导伪标签对噪声标签的修正强度。
DIF 已部署在十亿用户规模的短视频应用快手上,在冷启动场景下显著提升了多项商业指标,方法本身同时具备理论支撑 + 真实数据集大量实验验证。
核心方法 / 模型架构¶
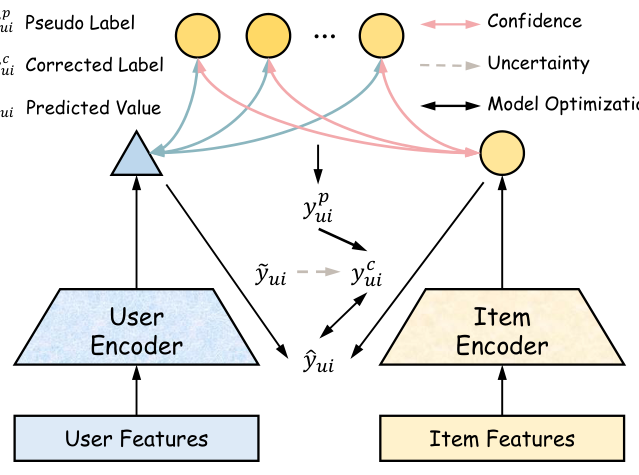
问题定义(Preliminary)¶
令 $u \in \mathcal{U}$、$i \in \mathcal{I}$ 分别表示用户与物品,$\tilde{\mathbf{Y}} \in \mathbb{R}^{|\mathcal{U}|\times|\mathcal{I}|}$ 是观测到的隐式反馈矩阵。$\tilde{y}_{ui}=1$ 表示用户与物品有交互,$\tilde{y}_{ui}=0$ 表示无交互。以往工作默认 $\tilde{y}_{ui}=1$ 就意味着用户对物品感兴趣,但隐式反馈可能因 clickbait、position bias 等因素产生噪声标签(假正 / 假负)。目标是从含噪的 $\tilde{\mathbf{Y}}$ 中学到无噪表征,尤其针对冷启动物品。 在快手的应用中,冷启动物品被定义为:发布不足 24 小时(含)且被观看少于 5 万次的短视频。
工业推荐通常采用多阶段级联架构(retrieval → pre-ranking → ranking)来权衡精度与效率。本文方法理论上对所有阶段都适用、是模型无关的;实践中作者将其部署在召回阶段的双塔(dual-tower)模型上。双塔结构是工业召回的主流:用户塔与物品塔分别把用户侧、物品侧特征映射为 embedding $\mathbf{e}_u$、$\mathbf{e}_i$,二者的相似度(内积)刻画用户 $u$ 对物品 $i$ 的相关性 $\hat{y}_{ui}$。预测时物品 embedding $\{\mathbf{e}_i\}$ 离线/近线预计算好,只需在线前向用户塔 + ANN 检索即可亚线性地召回最近物品。
整体概览(Overview)¶
如 Figure 1,DIF 集成在一个基础推荐模型之上。一般去噪方法基于模型对样本的预测做伪标签,但冷启动物品的预测本身不准;与之相反,一些暖物品的协同表征是训练充分的。DIF 的核心策略是:基于「内容相似暖物品的协同表征」+「用户兴趣表征」为冷启动物品生成伪标签。为此需要建立两套服务——检索冷启动物品内容相似暖物品的服务,以及实时获取暖物品协同表征的服务。其后:
- 检索 top-$k$ 内容相似暖物品,得到 $k$ 个伪标签;
- 按内容相似度建模伪标签置信度,加权聚合多个伪标签提升准确性;
- 通过相对熵 + 冷启动状态估计样本标签不确定性,在样本级自适应执行标签修正。
伪标签生成(Pseudo-labeling)¶
暖物品的用户兴趣与协同表征可视为训练充分。因此预测「用户 $u$ 与暖物品 $i$ 是否交互」可作为「用户是否会与内容相似的冷启动物品交互」的有价值参考。对一个样本 $(u, i, \tilde{y}_{ui})$,双塔模型通过 $\mathbf{e}_u$ 与 $\mathbf{e}_i$ 的内积预测交互概率。为保持伪标签与样本标签的同质性,伪标签也用内积生成。对内容相似于物品 $i$ 的 $k$ 个暖物品,得到 $k$ 个伪标签:
$$\left[y^p_{ui,1}, y^p_{ui,2}, \dots, y^p_{ui,k}\right] = \mathbf{e}_u \cdot \left[\mathbf{e}^1_i, \mathbf{e}^2_i, \dots, \mathbf{e}^k_i\right] \tag{1}$$
其中 $\cdot$ 表示内积,$\mathbf{e}^j_i$ 是第 $j$ 个内容相似暖物品的协同 embedding。
置信度建模(Confidence Modeling)¶
虽然后文理论证明 DIF 无需强相似性假设也能逼近真实标签,但不同相似度水平应当反映不同的指导强度。因此按冷启动物品与暖物品之间的内容相似度对每个伪标签建模置信度。设 $s^j_i$ 为物品 $i$ 与其第 $j$ 个暖物品的内容相似分,归一化置信度为:
$$c^j_i = \frac{\exp\!\left(s^j_i / \tau\right)}{\sum_{z=1}^{k} \exp\!\left(s^z_i / \tau\right)}, \quad j = 1, 2, \dots, k \tag{2}$$
再做加权求和得到更准确的聚合伪标签 $y^p_{ui}$:
$$y^p_{ui} = \sum_{j=1}^{k} c^j_i\, y^p_{ui,j} \tag{3}$$
其中 $\tau$ 为温度系数。作者指出:得益于成熟的多模态内容理解,线上观测到的相似分普遍在 0.9 以上,因此引入 $\tau$ 来放大不同暖物品之间的区分度(否则相似分过于接近、置信度趋于均匀)。
不确定性估计(Uncertainty Estimation)¶
为有效执行标签修正,DIF 从两个视角估计噪声样本标签 $\tilde{y}_{ui}$ 的不确定性,以在样本级自适应地引导伪标签 $y^p_{ui}$ 的作用强度。
视角一:相对熵 $r_{ui}$。 以预测值 $\hat{y}_{ui} = [\mathbf{e}_u]^\top \cdot \mathbf{e}_i$ 的(二元)熵作为不确定性的关键指标,相对熵越高、样本越可能被错标:
$$r_{ui} = -\hat{y}_{ui} \log \hat{y}_{ui} - (1 - \hat{y}_{ui}) \log(1 - \hat{y}_{ui}) \tag{4}$$
当预测越接近 0.5(模型越「拿不准」)时熵越大,提示标签与模型认知冲突、更可能是噪声。
视角二:冷启动状态 $\gamma_i$。 既然冷启动物品更易产生噪声,作者显式地把物品 $i$ 的冷启动状态作为第二个不确定性指标:
$$\gamma_i = e^{-\alpha g_i} \tag{5}$$
其中 $e$ 是自然常数,$g_i$ 是物品 $i$ 的交互计数,$\alpha$ 控制定义冷启动状态的阈值。交互越多 $\gamma_i$ 越趋近 0,交互越少 $\gamma_i$ 越趋近 1——这有效防止对暖物品训练产生任何不利影响(暖物品 $\gamma_i \approx 0$,几乎不被修正)。
把二者结合得到最终的不确定性估计 $t_{ui}$,并约束其小于 1:
$$t_{ui} = r_{ui}\, \gamma_i \tag{6}$$
即:只有「相对熵高(标签可疑)」且「冷启动状态强(物品新)」的样本,才被赋予高不确定性,从而被伪标签大幅修正。
模型优化(Model Optimization)¶
为缓解标签噪声影响,DIF 在样本级根据不确定性自适应修正样本标签。先把不确定性归一化到 $[0,1]$ 区间得到权重 $w$:
$$w = \frac{t_{ui}}{t_{ui} + 1} \tag{7}$$
再得到每个样本的修正软标签 $y^c_{ui}$(即用 $w$ 在伪标签 $y^p_{ui}$ 与原始噪声标签 $\tilde{y}_{ui}$ 之间做线性插值):
$$y^c_{ui} = w\, y^p_{ui} + (1 - w)\, \tilde{y}_{ui} \tag{8}$$
最后用常用的交叉熵损失训练:
$$\mathcal{L} = -\sum_{(u,i) \in \mathcal{D}_{train}} \left( y^c_{ui} \log \hat{y}_{ui} + (1 - y^c_{ui}) \log(1 - \hat{y}_{ui}) \right) \tag{9}$$
直觉上:不确定性 $t_{ui}$ 越大(标签越可疑、物品越冷),$w$ 越大、越信任伪标签;反之(暖物品或预测确定)$w \to 0$,几乎保留原标签,不破坏暖物品的训练。
工业落地实践¶
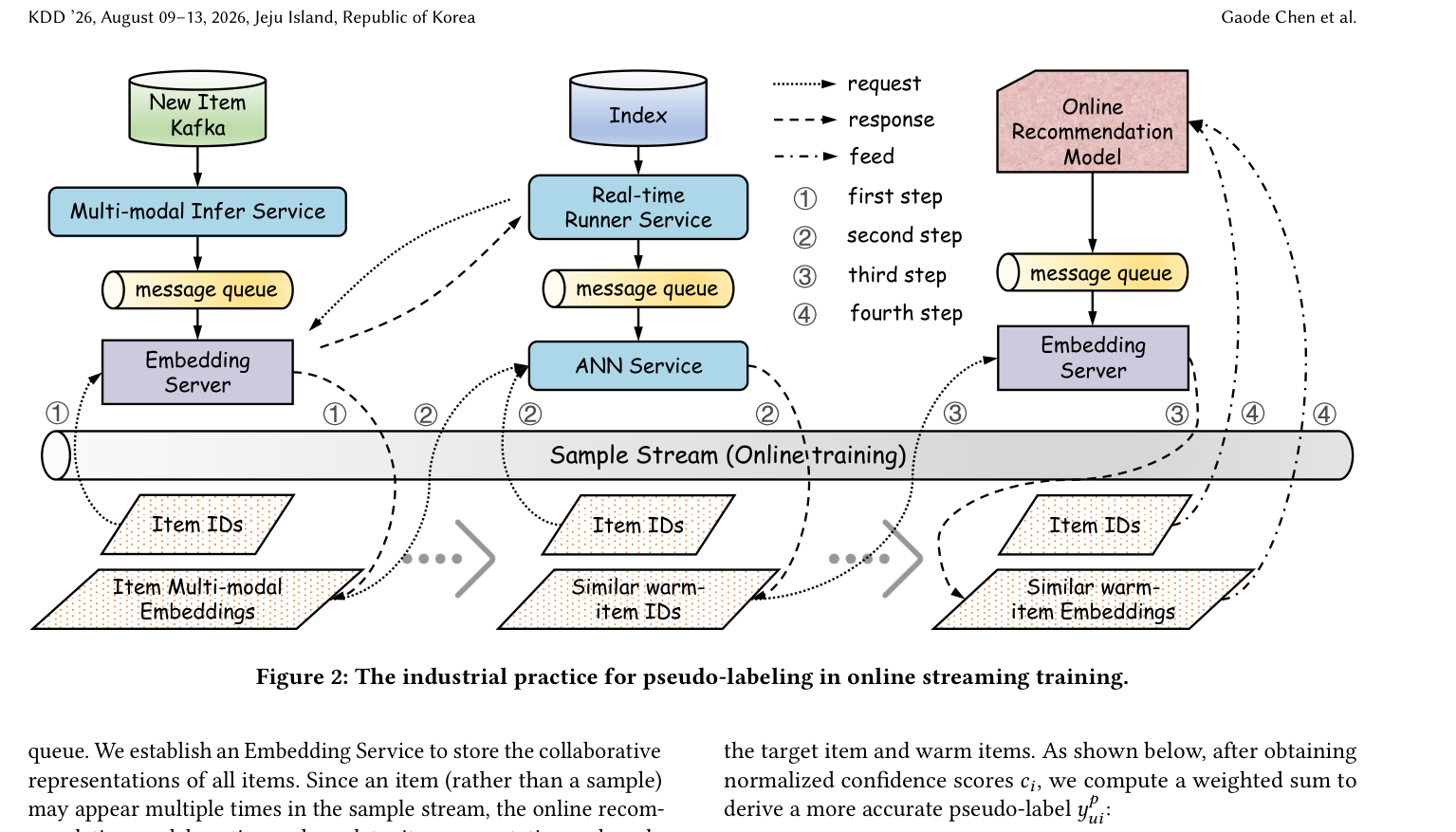
DIF 部署在快手的大规模分布式近线(near-line)学习系统上:每天数亿用户在快手观看与互动,产生数百亿条观看/交互日志。每条日志被实时收集、经 Kafka 流处理平台预处理、产出样本流。近线训练系统用最新的用户-视频交互增量更新模型参数。在线流式训练下要为冷启动物品生成伪标签,必须解决两个工程问题:(a) 如何检索内容相似的暖物品;(b) 如何获取这些暖物品的协同表征。 对应 Figure 2 的四步:
- Step ①(内容表征入库):每个新上传的短视频 $i$,经 Multi-modal Inference Service 得到多模态内容表征,送入消息队列;Embedding Service 实时读取并存储所有新物品的内容表征。需要时即可请求该服务查询物品 $i$ 的内容表征。
- Step ②(item-to-item ANN 检索):构建 item-to-item ANN 服务,左侧 item 为 query,右侧 item 为已构建的暖物品桶。Real-time Runner Service 持续从 Index 拉取合格暖物品(如观看数 > 5 万的视频)作为检索候选,并请求 Embedding Service 取其内容表征,送入消息队列以持续更新 ANN 候选。把物品 $i$ 及其内容表征喂给 ANN 服务,快速检索 top-$k$ 内容相似暖物品及相似分 $S_i = \{s^1_i, s^2_i, \dots, s^k_i\}$。
- Step ③(协同表征入库):在线推荐模型持续把用户、物品的协同表征送入消息队列,由 Embedding Service 存储全量物品协同表征(同一物品在样本流中可多次出现,故需持续更新)。把暖物品 ID 喂给该服务查询,得到 top-$k$ 暖物品的协同表征 $\mathbf{E}_i = [\mathbf{e}^1_i, \mathbf{e}^2_i, \dots, \mathbf{e}^k_i]$。
- Step ④(在线伪标签):在线推荐模型用上述协同表征执行伪标签生成与标签修正。
在流式训练中,DIF 通过不确定性估计最小化对暖物品训练的影响,同时聚焦于在早期阶段修正冷启动物品的噪声标签,从而释放其增长潜力。
理论分析¶
作者给出两条理论结论,分别回答「伪标签能否逼近真实标签」与「线性插值权重的最优形式」。
设 $\mathbf{e}_i \in \mathcal{E} \subseteq \mathbb{R}^d$ 为冷启动物品 $i$ 的归一化多模态 embedding,$N_k(i)$ 是按内容相似度检索到的 $k$ 个最近暖物品集合,$\eta^*_{ui} = \eta^*_u(\mathbf{e}_i)$ 为用户 $u$ 与物品 $i$ 的真实交互概率,$y^p_{ui}$ 为置信度加权后的伪标签。
假设:
- Assumption 2.1:观测冷启动标签 $\tilde{y}_{ui}$ 是真实交互概率 $\eta^*_{ui}$ 的有偏估计:$\tilde{y}_{ui} = \eta^*_{ui} + \epsilon_{ui}$,$\mathbb{E}[\epsilon_{ui}] = b_{ui}$(系统性偏差,来自 clickbait / position bias),$\mathrm{Var}[\epsilon_{ui}] = \sigma^2_{ui}$(相对较大)。
- Assumption 2.2:暖物品伪标签 $y^p_{ui,j}$ 是真实交互概率 $\eta^*_{uj}$ 的无偏估计:$y^p_{ui,j} = \eta^*_{uj} + \epsilon'_{ui,j}$,$\mathbb{E}[\epsilon'_{ui,j}] = 0$,$\mathrm{Var}[\epsilon'_{ui,j}] = \sigma'^2_u$(因暖物品表征训练充分,近似误差可忽略、方差小)。
- Assumption 2.3:内容表征空间 $\mathcal{E}$ 是 $\mathbb{R}^d$ 的紧子集,密度 $p(\mathbf{e})$ 远离零($p(\mathbf{e}) \ge p_{inf} > 0$)——保证任意物品的小邻域内存在有效的最近邻。
- Assumption 2.4:真实交互概率函数 $\eta^*_u(\mathbf{e})$ 在内容表征空间上 $\alpha$-Hölder 连续:$|\eta^*_u(\mathbf{e}_i) - \eta^*_u(\mathbf{e}_j)| \le L\|\mathbf{e}_i - \mathbf{e}_j\|^\alpha$——内容相近则真实偏好相近(这正是「用户内容偏好稳定」假设的数学化)。
Theorem 2.1(伪标签的逼近误差界):在 Assumptions 2.2/2.3/2.4 下,对任意冷启动物品 $i$、用户 $u$、$\delta \in (0,1)$:
$$\left|y^p_{ui} - \eta^*_{ui}\right| \le O\!\left( L \left( \frac{k}{N_{warm}} \right)^{\frac{\alpha}{d}} \right) + O\!\left( \frac{\sigma'_u}{\sqrt{k}} \right)$$
其中 $k$ 是内容相似邻居数,$N_{warm}$ 是暖物品总数,$d$ 是内容空间维度。证明把误差拆为两部分:第一项是近似误差(approximation error)——由 Hölder 连续性,最近邻到 query 的距离约 $O((k/N_{warm})^{1/d})$,代入得偏差上界;第二项是统计误差(statistical error)——对 $k$ 个无偏伪标签做加权平均,由 Hoeffding 不等式得方差约 $O(\sigma'_u/\sqrt{k})$。Remark 4 指出:当暖物品数 $N_{warm}$ 足够大、选取合适的 $k$ 时,$y^p_{ui}$ 与 $\eta^*_{ui}$ 之间的误差界会很小,从而证明了伪标签的「干净」程度——这就是即使内容相似不完美、伪标签仍可用的理论依据。
Theorem 2.2(最优插值权重):在 Assumptions 2.1/2.2 下,假设观测噪声 $\epsilon_{ui}$ 与伪标签噪声 $\epsilon'_{ui,j}$ 不相关,则存在最小化 MSE 风险 $R(y^c_{ui}) = \mathbb{E}[(y^c_{ui} - \eta^*_{ui})^2]$ 的最优权重 $w^* \in [0,1]$:
$$w^* = \frac{\lambda_{ui}}{\lambda_{ui} + 1}, \qquad \lambda_{ui} = \frac{R(\tilde{y}_{ui})}{R(y^p_{ui})}$$
其中 $\lambda_{ui}$ 是「原始标签噪声」对「伪标签噪声」的比值。证明(Eq. 15):把修正标签的 MSE 展开,因两类噪声不相关、交叉项消失,得
$$R(y^c_{ui}) = w^2 R(y^p_{ui}) + (1-w)^2 R(\tilde{y}_{ui})$$
对 $w$ 求导置零 $2wR(y^p_{ui}) - 2(1-w)R(\tilde{y}_{ui}) = 0$,解得 $w^* = \frac{R(\tilde{y}_{ui})}{R(\tilde{y}_{ui}) + R(y^p_{ui})} = \frac{\lambda_{ui}}{\lambda_{ui}+1}$。Remark 5 指出:该最优形式与 Eq. (7) 的加权方案 $w = t_{ui}/(t_{ui}+1)$ 数学同构——由于真实噪声水平 $R(\tilde{y}_{ui})$、$R(y^p_{ui})$ 未知,DIF 用不确定性 $t_{ui}$(由相对熵 $r_{ui}$ 与冷启动状态 $\gamma_i$ 构成)作为噪声比 $\lambda_{ui}$ 的有效估计器。这把工程上启发式的 Eq. (7) 与理论最优解严格对应起来。
实验设置¶
数据集¶
遵循文献做法,在三个真实多模态推荐数据集(Amazon-Sports、Amazon-Baby、Tiktok,均公开于 HKUDS/MMSSL 仓库)上做离线实验。统计如下:
| 数据集 | Amazon-Sports | Amazon-Baby | Tiktok |
|---|---|---|---|
| 模态 | V, T | V, T | V, A, T |
| Embed 维度 | V=4096, T=1024 | V=4096, T=1024 | V=128, A=128, T=768 |
| User | 35,598 | 19,445 | 9,319 |
| Item | 18,357 | 7,050 | 6,710 |
| Interactions | 256,308 | 139,110 | 59,541 |
| Sparsity | 99.961% | 99.899% | 99.904% |
(V=Visual 视觉,A=Acoustic 音频,T=Textual 文本。Amazon 的文本 embedding 由 Sentence-Bert 基于标题/描述/品牌/类目生成,视觉 embedding 由商品图生成;Tiktok 为短视频的视觉/音频/标题多模态特征,文本同样用 Sentence-Bert 编码。)
评估协议¶
每个数据集按 8:1:1 随机划分为训练/验证/测试集。采用 Precision@N、Recall@N、NDCG@N,默认 N=20,报告测试集所有用户的平均值。结果分 Cold(冷启动物品)/ Warm(暖物品)/ Overall(整体) 三档汇报。
Baseline 与骨干¶
与三类 SOTA 的模型无关去噪/冷启动方法对比:
- DECL:捕获噪声引起的不确定性、分离干净与噪声数据,用于「带噪对应」学习;
- RINCE:提出对噪声数据视图鲁棒的新对比学习目标;
- MWUF:用 meta-scaling 与 shifting 网络,在暖特征空间内为冷启动物品生成初始 embedding 表征。
骨干模型(base model)三种:NeuMF(GMF + MLP)、LightGCN(高阶邻居传播图卷积)、SimGCL(简化对比损失、优化均匀性的对比学习推荐)。「Normal」表示骨干本身不加任何去噪。
实现细节¶
embedding 维度 $d=64$(所有模型统一);Adam 优化器;batch size 1024;学习率 0.001;内容相似暖物品数 $k=5$;温度系数 $\tau=0.3$;Xavier 初始化;以各数据集交互计数的第 20 百分位区分暖/冷物品;$\alpha$、$\gamma$ 在不确定性估计中按数据集确定具体值。
主要实验结果¶
Table 2 给出 Cold / Warm / Overall 三档、三骨干、三数据集下的 Recall@20 与 NDCG@20。加粗为最优、下划线为次优。
冷启动物品(Cold):
| 骨干 | 方法 | Sports R@20 | Sports N@20 | Baby R@20 | Baby N@20 | Tiktok R@20 | Tiktok N@20 |
|---|---|---|---|---|---|---|---|
| NeuMF | Normal | 0.00244 | 0.00228 | 0.00142 | 0.00157 | 0.00104 | 0.00010 |
| NeuMF | RINCE | 0.00271 | 0.00222 | 0.00197 | 0.00172 | 0.00674 | 0.00298 |
| NeuMF | DECL | 0.00266 | 0.00191 | 0.00186 | 0.00149 | 0.00622 | 0.00234 |
| NeuMF | MWUF | 0.00302 | 0.00250 | 0.00166 | 0.00158 | 0.00052 | 0.00013 |
| NeuMF | DIF (Ours) | 0.00461 | 0.00259 | 0.00385 | 0.00188 | 0.00881 | 0.00227 |
| LightGCN | Normal | 0.00191 | 0.00192 | 0.00143 | 0.00122 | 0.00106 | 0.00026 |
| LightGCN | RINCE | 0.00266 | 0.00294 | 0.00258 | 0.00248 | 0.00415 | 0.00125 |
| LightGCN | DECL | 0.00277 | 0.00306 | 0.00179 | 0.00168 | 0.00231 | 0.00065 |
| LightGCN | MWUF | 0.00253 | 0.00222 | 0.00186 | 0.00161 | 0.00155 | 0.00050 |
| LightGCN | DIF (Ours) | 0.00325 | 0.00341 | 0.00303 | 0.00261 | 0.00518 | 0.00117 |
| SimGCL | Normal | 0.00218 | 0.00210 | 0.00180 | 0.00184 | 0.00155 | 0.00040 |
| SimGCL | RINCE | 0.00293 | 0.00312 | 0.00285 | 0.00289 | 0.00466 | 0.00101 |
| SimGCL | DECL | 0.00317 | 0.00361 | 0.00219 | 0.00184 | 0.00259 | 0.00072 |
| SimGCL | MWUF | 0.00319 | 0.00270 | 0.00236 | 0.00227 | 0.00207 | 0.00060 |
| SimGCL | DIF (Ours) | 0.00347 | 0.00379 | 0.00350 | 0.00356 | 0.00570 | 0.00154 |
暖物品(Warm):
| 骨干 | 方法 | Sports R@20 | Sports N@20 | Baby R@20 | Baby N@20 | Tiktok R@20 | Tiktok N@20 |
|---|---|---|---|---|---|---|---|
| NeuMF | Normal | 0.04535 | 0.02134 | 0.05534 | 0.02456 | 0.11095 | 0.04033 |
| NeuMF | RINCE | 0.06619 | 0.02755 | 0.05435 | 0.02220 | 0.09690 | 0.03936 |
| NeuMF | DECL | 0.06073 | 0.02595 | 0.05487 | 0.02236 | 0.08667 | 0.03324 |
| NeuMF | MWUF | 0.04594 | 0.02058 | 0.05768 | 0.02489 | 0.11119 | 0.04685 |
| NeuMF | DIF (Ours) | 0.06281 | 0.02848 | 0.05980 | 0.02832 | 0.11095 | 0.04440 |
| LightGCN | Normal | 0.06381 | 0.02769 | 0.05882 | 0.02438 | 0.09429 | 0.04429 |
| LightGCN | RINCE | 0.09695 | 0.04314 | 0.08852 | 0.03838 | 0.12119 | 0.05403 |
| LightGCN | DECL | 0.09937 | 0.04436 | 0.06250 | 0.02632 | 0.11500 | 0.04423 |
| LightGCN | MWUF | 0.06953 | 0.03029 | 0.06316 | 0.02696 | 0.11024 | 0.04769 |
| LightGCN | DIF (Ours) | 0.10862 | 0.04869 | 0.09494 | 0.04257 | 0.12667 | 0.05134 |
| SimGCL | Normal | 0.06550 | 0.02972 | 0.05934 | 0.02546 | 0.09571 | 0.04785 |
| SimGCL | RINCE | 0.09815 | 0.04444 | 0.09316 | 0.04132 | 0.12167 | 0.05183 |
| SimGCL | DECL | 0.10749 | 0.04943 | 0.06177 | 0.02609 | 0.09833 | 0.04669 |
| SimGCL | MWUF | 0.07235 | 0.03227 | 0.06189 | 0.02614 | 0.12524 | 0.05732 |
| SimGCL | DIF (Ours) | 0.11410 | 0.05312 | 0.10098 | 0.04427 | 0.12881 | 0.05758 |
整体(Overall):
| 骨干 | 方法 | Sports R@20 | Sports N@20 | Baby R@20 | Baby N@20 | Tiktok R@20 | Tiktok N@20 |
|---|---|---|---|---|---|---|---|
| NeuMF | Normal | 0.02932 | 0.01375 | 0.04261 | 0.01891 | 0.06949 | 0.02763 |
| NeuMF | RINCE | 0.04270 | 0.01776 | 0.04191 | 0.01710 | 0.06852 | 0.02791 |
| NeuMF | DECL | 0.03922 | 0.01674 | 0.04231 | 0.01723 | 0.06134 | 0.02351 |
| NeuMF | MWUF | 0.02987 | 0.01335 | 0.04442 | 0.01917 | 0.07635 | 0.03214 |
| NeuMF | DIF (Ours) | 0.04114 | 0.01829 | 0.04674 | 0.02182 | 0.07879 | 0.03113 |
| LightGCN | Normal | 0.04073 | 0.01768 | 0.04524 | 0.01875 | 0.06493 | 0.03043 |
| LightGCN | RINCE | 0.06189 | 0.02754 | 0.06809 | 0.02952 | 0.08434 | 0.03741 |
| LightGCN | DECL | 0.06344 | 0.02832 | 0.04807 | 0.02024 | 0.07912 | 0.03309 |
| LightGCN | MWUF | 0.04445 | 0.01935 | 0.04858 | 0.02073 | 0.07602 | 0.03283 |
| LightGCN | DIF (Ours) | 0.06934 | 0.03109 | 0.07303 | 0.03275 | 0.08842 | 0.03555 |
| SimGCL | Normal | 0.04207 | 0.01904 | 0.04564 | 0.01958 | 0.06607 | 0.03291 |
| SimGCL | RINCE | 0.06266 | 0.02837 | 0.07165 | 0.03178 | 0.08483 | 0.03583 |
| SimGCL | DECL | 0.06862 | 0.03156 | 0.04751 | 0.02007 | 0.06819 | 0.03208 |
| SimGCL | MWUF | 0.04641 | 0.02066 | 0.04760 | 0.02011 | 0.08646 | 0.03946 |
| SimGCL | DIF (Ours) | 0.07287 | 0.03392 | 0.07767 | 0.03405 | 0.09005 | 0.03993 |
结论分析(why,不仅是 what):
- 所有去噪方法都优于 Normal,尤其在冷启动物品上提升明显——印证了「为冷启动推荐去噪隐式反馈」的必要性。
- 不同骨干的去噪收益不同:在冷启动物品上,NeuMF 的去噪收益比图类方法(LightGCN/SimGCL)更显著。原因是图类方法严重依赖沿边传播的协同信号,在数据丰富场景更有效;而 DIF 是模型无关的,在各种骨干上都能取得冷启动物品的最佳结果,体现了其优越的可扩展性。
- DECL、RINCE 作为通用去噪方法迁移到推荐,能同时改善冷/暖物品,但增益不大;MWUF 在冷启动物品上表现尚可,但对暖物品与整体提升有限。相比之下,DIF 专注冷启动去噪,且不损害暖物品/整体性能,甚至有所提升。
- DIF 在 Tiktok 上没能取得冷启动物品的最佳 NDCG(RINCE 在多个骨干上 NDCG 更高)。作者归因于:Tiktok 数据规模小且更稀疏;且本文主要聚焦召回优化而非排序——这也是未来方向之一。
- DIF 对暖物品的增益归功于两点:(1) 基于内容的去噪策略对暖物品也起作用;(2) 不确定性估计让 DIF 精准利用伪标签、引导样本标签修正过程。
消融实验¶
在 Tiktok 与 Amazon-Sports 上、以 LightGCN 为骨干,逐项移除关键组件,汇报 Recall@20(Cold / Warm / Overall):
| 数据集 | 方法 | Cold | Warm | Overall |
|---|---|---|---|---|
| Tiktok | w/o CM | 0.00311 | 0.10857 | 0.07537 |
| Tiktok | w/o RE | 0.00152 | 0.12214 | 0.08385 |
| Tiktok | w/o CS | 0.00104 | 0.10619 | 0.07308 |
| Tiktok | DIF | 0.00518 | 0.12667 | 0.08842 |
| Sports | w/o CM | 0.00293 | 0.09804 | 0.06259 |
| Sports | w/o RE | 0.00278 | 0.09685 | 0.06182 |
| Sports | w/o CS | 0.00264 | 0.09318 | 0.05954 |
| Sports | DIF | 0.00325 | 0.10862 | 0.06934 |
(CM = Confidence Modeling 置信度建模;RE = Relative Entropy 相对熵;CS = Cold-start Status 冷启动状态。)
逐项分析:
- w/o CM(去掉置信度建模,改为平均池化聚合伪标签):对冷启动物品影响最小。说明当前多模态表征已足够可靠、检索到的暖物品相似度有良好保证,是否按相似度加权差别不大。
- w/o RE(不确定性估计去掉相对熵分量):显著影响冷启动物品,对暖物品影响有限。高相对熵指示标签更可能是噪声;而暖物品协同表征已训练充分、出现高相对熵的情形很少(故 w/o RE 时 Tiktok 暖物品 Recall 反而略高,但冷启动物品大幅下降)。
- w/o CS(去掉冷启动状态):对冷启动物品影响最大。归因于两点:(1) 没有考虑不同冷启动状态下标签噪声概率的差异;(2) 会对暖物品的表征学习产生潜在扰动,进而影响用户建模与冷启动物品的最终推荐——这解释了为何 w/o CS 连暖物品/整体也下降。
噪声鲁棒性¶
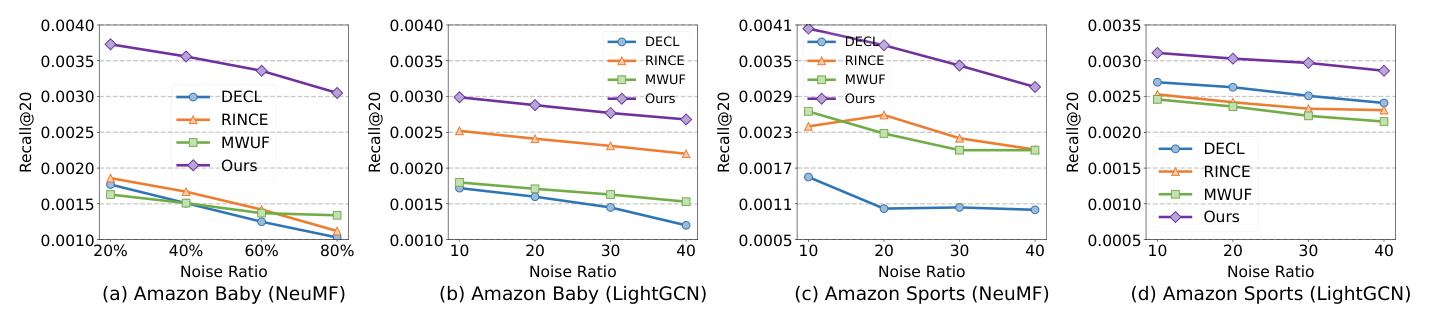
在 Amazon 数据集上、用 NeuMF 与 LightGCN 骨干做随机注入噪声的训练,噪声比例从 20% 到 80%,与三个最强的模型无关去噪基线(DECL、RINCE、MWUF)对比冷启动物品的 Recall@20(Tiktok 等其余设置结论一致,篇幅原因省略)。结果显示:
- 随着噪声比例上升,所有方法(含 DIF)性能整体下降——数据腐蚀加剧使冷启动物品表征学习与用户偏好建模都更困难;
- DIF 在所有噪声比例下都持续优于其他去噪方法——凸显其在冷启动场景的强噪声鲁棒性,这归功于其「通过内容相似暖物品生成伪标签」的策略。
在线 A/B 测试¶
在快手短视频流式场景做了严格的线上 A/B(2025-01-12 至 2025-01-16,每天数亿用户)。出于公司隐私,不能报告真实指标绝对值,仅报告由 DIF 带来的性能增益比。指标分「观看相关」与「行为相关」两类:
| 类别 | 指标 | 增益 | 指标 | 增益 |
|---|---|---|---|---|
| 观看相关 | Effective View | +2.327% | Watch Time | +2.921% |
| 观看相关 | Long View | +2.688% | Short View | -2.030% |
| 行为相关 | Like | +2.921% | Comment | +2.435% |
| 行为相关 | Follow | +2.790% | Share | +0.876% |
- Effective View 定义为观看时长超过阈值(如 5 秒);Long View 标准更严格;指标按视频时长分档。
- 在真实大流量场景中,1% 的增益比通常已代表推荐能力的大幅提升。DIF 让冷启动物品的「观看相关」与「行为相关」指标几乎全面正向显著提升(Short View 下降 2.030% 是良性信号——短停留减少意味着推荐更精准、减少了无效曝光),为冷启动推荐效率带来实质增强。
核心贡献总结¶
- 指出并实证了一个被忽视的事实:冷启动物品对噪声隐式反馈尤其脆弱(快手数据上 clickbait 假正 +37.7%、position bias 假负 +28.3%),从而凸显了「面向冷启动的去噪」的必要性,并指出既有启发式去噪(loss/score/gradient)在冷启动上失效。
- 提出理论扎实的模型无关方法 DIF:用多模态语义相似性,从内容相似的暖物品「借」训练充分的协同表征为冷启动物品生成伪标签,并给出完整工业部署方案。
- 在伪标签聚合中引入置信度建模,并在标签修正中用相对熵 + 冷启动状态显式度量样本级标签不确定性,自适应控制修正强度。
- 两条理论保证:Theorem 2.1 给出伪标签逼近真实标签的误差界(暖物品足够多时误差很小);Theorem 2.2 推导出最优插值权重 $w^* = \lambda_{ui}/(\lambda_{ui}+1)$ 并证明其与工程加权方案 Eq.(7) 数学同构。
- 三数据集 × 三骨干的充分离线实验 + 快手十亿级线上部署,在冷启动场景取得多项商业指标的显著提升。
与已归档相关工作的对比¶
Shallow-RHS Shallow-RHS: Bridging the Semantic-Collaborative Gap(Tubi × Kumo AI, 2026-06-04)¶
关系:独立并发(本文未引用 Shallow-RHS,两者发布仅相差约两周,殊途同归)· 已加载对方精读
- 共同关注的问题:两文都直面「冷启动物品没有/缺乏可用协同信号」这一 root cause,且都明确指出内容相似 ≠ 协同偏好——Shallow-RHS 称之为「语义-协同鸿沟(semantic-collaborative gap)」,DIF 则用「用户对内容偏好稳定」假设 + Assumption 2.4 的 Hölder 连续性把这条鸿沟量化为可被理论界控制的逼近误差。两者也都把方案落地到工业流式平台(Tubi vs 快手),并都依赖 ANN 检索内容相似的暖物品。
- 相近的技术骨架:核心机制高度同构——用内容相似的「暖代理邻居(warm surrogate neighbor)」把暖物品训练充分的协同信号迁移给零/少交互的冷启动物品。Shallow-RHS 的「浅 RHS 内容塔」被强制把内在特征映射进 CF 感知空间、训练完成后对暖/冷物品统一编码,本质与 DIF「用暖物品协同 embedding $\mathbf{e}^j_i$ 表征冷启动物品偏好」是同一思路的两种实现。
- 本文的差异与推进:作用空间不同。Shallow-RHS 在表征空间解题——把冷启动重构为「归纳式图补全 / 时序链接预测」,直接为冷启动物品生成一个 CF 感知 embedding(替换物品塔)。DIF 在标签空间解题——保持基础模型不动(真正模型无关、可插拔),用暖邻居生成伪标签去修正噪声交互标签。换言之,Shallow-RHS 修「物品长什么样」,DIF 修「训练信号对不对」。
- 可比的方法 / 实验差异:Shallow-RHS 是非对称双塔 + GNN 消息传递(左塔做邻域聚合、右塔刻意「浅」),重在「零边新内容也能被立即检索」的服务约束;DIF 是即插即用的损失层改造(Eq.7-9),额外引入「置信度建模 + 不确定性估计」做样本级自适应。Shallow-RHS 仅有线上指标(TVT、冷内容晋升),DIF 则有三公开数据集的离线 Cold/Warm/Overall 对比 + 理论误差界 + 快手 A/B,二者在「内容→协同迁移」这条路线上形成了表征侧与标签侧的互补证据。
AKT-Rec AKT-Rec: From Head to Tail(Alibaba/天猫 + 北大, 2026-05-22)¶
关系:独立并发(本文未引用 AKT-Rec,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两文都要把「头部/暖物品训练充分的信号」迁移给「尾部/冷物品」,且都显式担忧迁移会反向损害暖/头部物品——AKT-Rec 把这点上升为核心主张「知识应主要从头流向尾」,DIF 则用冷启动状态 $\gamma_i = e^{-\alpha g_i}$(交互越多越趋近 0)把暖物品几乎排除在标签修正之外,其消融 w/o CS 正好证明:不保护暖物品时,暖物品与整体性能都会下降。这种「助冷而不伤暖」的不对称保护是两文共享的关键 insight。
- 相近的技术骨架:都按「内容/语义相似」把物品聚类/检索,并以相似度为桥从暖/头部物品向冷/尾部物品转移协同知识。AKT-Rec 用高碰撞率 RQ-VAE 把相似物品聚到同一语义簇、用 cluster embedding 承载簇内共享语义;DIF 用 ANN 检索 top-$k$ 内容相似暖物品。两者都先用对比学习/共现把协同信号注入内容表征,再做转移。
- 本文的差异与推进:转移机制不同。AKT-Rec 在表征空间用「带停止梯度的非对称 InfoNCE」做头→尾对比对齐(拉近尾部 embedding 与同簇头部 embedding),解决的是长尾 CTR 排序中尾部表征欠拟合;DIF 在标签空间用伪标签+不确定性加权做样本级标签修正,解决的是冷启动召回中的噪声隐式反馈。AKT-Rec 的「不对称」靠 stop-gradient 实现单向保护,DIF 的「不对称」靠 $\gamma_i$ 门控实现。
- 可比的方法 / 实验差异:AKT-Rec 依赖大模型(GME-Qwen2-VL-7B 抽物品表示、Qwen3-30B 抽用户表示)+ RQ-VAE 离线生成语义 ID,是较重的两阶段流水线,验证为判别式 CTR(AUC/GAUC + 天猫 A/B +3.47% GMV);DIF 是轻量损失层改造、验证为召回式 Recall@20/NDCG@20(+ 快手 A/B)。两者共同表明「暖→冷 / 头→尾的内容桥接 + 保护暖物品」是一条被多家工业团队独立验证的有效路线,而 DIF 的标签修正视角是其中区别于「表征对齐 / 表征生成」主流的一条独立分支。
讨论与局限性¶
核心贡献与值得借鉴的设计:
- 问题视角的原创性:把「冷启动物品天生更易带噪、且既有启发式去噪信号(loss/score/gradient)恰与『冷』混淆」这一矛盾点明,是本文最有价值的洞察。
- 「内容相似暖物品 → 协同伪标签 → 标签修正」三段式干净、模型无关、可插拔,且工程落地路径(Figure 2 四步服务化)描述详尽,是工业可复现的范本。
- 理论与工程的咬合:Theorem 2.2 把启发式权重 Eq.(7) 与 MSE 最优权重严格对应,$t_{ui} = r_{ui}\gamma_i$ 作为噪声比 $\lambda_{ui}$ 的有效估计器,让「相对熵 + 冷启动状态」的设计不只是直觉。
局限与争议:
- 依赖多模态内容相似度的质量:整套方法的前提是「内容相似 → 偏好相似」(Assumption 2.4)。论文自称线上相似分普遍 > 0.9,但这本身依赖成熟的多模态理解服务;在内容理解较弱或品类语义稀薄的场景,伪标签质量与置信度建模都可能退化。w/o CM 消融显示置信度建模当前贡献很小,某种程度上也反映「相似度区分度被压缩在 0.9 以上的窄区间、$\tau$ 只能勉强拉开」。
- 聚焦召回、排序仍是短板:DIF 在 Tiktok 冷启动 NDCG 上不及 RINCE,作者承认主要做召回优化、排序留待未来;其在 ranking 阶段的有效性尚未充分验证(虽声称模型无关)。
- 工程复杂度:需要额外维护 Multi-modal Inference / Embedding / item-to-item ANN / Real-time Runner 等多套实时服务与消息队列,部署门槛与运维成本不低,小团队难以照搬。
- 冷启动定义与超参的平台特异性:「< 24h 且 < 5 万次观看」「第 20 百分位分冷暖」「$\alpha$、$\gamma$ 按数据集调」都带较强平台经验色彩,跨平台迁移时需重新校准。
- 理论假设的现实差距:Theorem 2.2 关键依赖「观测噪声与伪标签噪声不相关」,但 clickbait/position bias 与内容相似检索未必独立;Assumption 2.2 把暖物品伪标签视为无偏,对「也带一定噪声的暖物品」是理想化处理。