From Head to Tail: Asymmetric Knowledge Transfer in Long-tail Recommendation with Generative Semantic IDs¶
阿里巴巴(天猫)+ 北京大学,arXiv:2605.23310(2026-05-22)。提出 AKT-Rec(Asymmetric Knowledge Transfer Recommendation),用 LLM/MLLM 生成的语义 ID 把"头部 → 尾部"的知识做非对称迁移,在天猫主站离线 +0.35% AUC / +1.53% GAUC、线上 A/B +2.76% CTR / +3.47% GMV。
研究动机与背景¶
电商平台的候选物品池和用户群规模持续膨胀,随之而来的是日益严重的长尾(long-tail)数据失衡:少数热门(head)物品占据绝大多数曝光,少数高活跃用户贡献了大部分被观测到的兴趣信号。这种重尾分布严重损害推荐系统在海量尾部物品上的表现——很难为它们学到可靠表示,也很难刻画尾部用户的多样偏好。
长尾推荐被研究了十余年,但已有方法仍有明显局限:
- 图结构方法(GCN 系):用 user-item 交互图 + 手工设计的建图规则,通过图卷积把信息传播到尾部节点。但它们受限于真实场景中尾部物品固有的数据稀疏,且人工建边常引入冗余/噪声边。
- 样本增广方法:生成合成的伪交互来缩小头尾分布差距。但合成样本不可避免地扭曲底层真实分布,质量难以控制,常导致次优性能。
- LLM 内容特征方法:用 LLM 抽取丰富的内容特征来替代或增广协同信号、辅助长尾建模。但实践中这些内容特征在仍由协同信号主导的模型里未被充分利用,收益有限。
本文识别出一个被现有工作普遍忽略的关键不对称性(asymmetry):以往的长尾方法大多孤立地"修补尾部 ID",却忽视了这种修补对头部物品可能产生的负面影响。头部物品本可以用充足的交互数据被精确建模,这份丰富的数据本应被用来支撑相似尾部 ID 的表示学习——但简单粗暴的知识共享会让尾部 ID 的噪声信号反向污染头部 ID 的表示学习。
因此本文的核心主张是:知识应当主要从头部流向尾部,而非反向。AKT-Rec 基于 LLM 生成的语义 ID 构建长尾推荐框架,融合多模态 + 协同特征,并实现这种头→尾的非对称知识迁移——既让尾部受益于头部的高质量语义簇知识,又保证头部物品的表示不被尾部噪声损害。
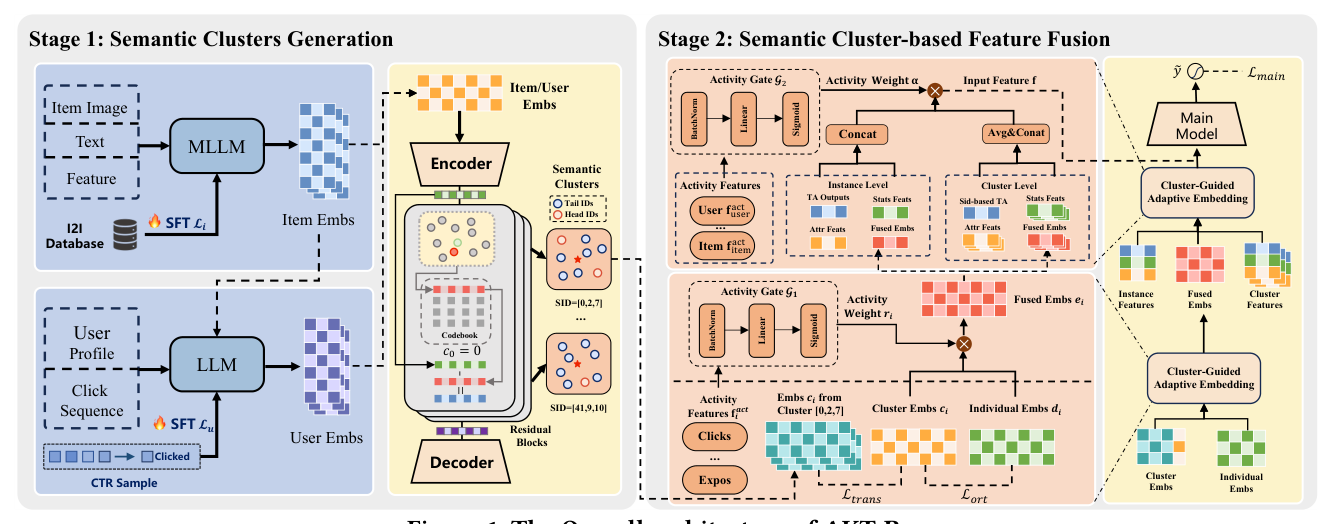
整体流水线分两个阶段(见 Figure 1):
- Stage 1(语义簇生成):用多模态大模型(MLLM)基于 item-to-item 共现关系抽取物品和用户表示,再用 Residual-Quantized VAE(RQ-VAE)对物品和用户分别量化,得到语义 ID。量化被刻意配置成高碰撞率(high collision)——让每个语义 ID 被多个相似物品/用户共享,从而天然形成"语义簇"。
- Stage 2(基于语义簇的特征融合):每个物品由两个 embedding 表示——编码簇内共享语义的 cluster embedding 和编码 ID 个性化信息的 individual embedding。引入活跃度感知的非对称 InfoNCE 目标做头→尾知识迁移,并用一个损失函数解耦两个 embedding、降低冗余。最后用特征聚合模块 + 融合网络把簇级特征与传统 item/user 特征整合。
核心贡献¶
- 提出 AKT-Rec——一个面向长尾推荐的、基于 LLM 的新框架。它利用语义簇把知识从头部 ID 迁移到尾部 ID,同时确保头部物品的表示学习不被尾部物品负面影响,从而缓解推荐系统的长尾问题。
- 提出一种自适应的、活跃度感知的 embedding 机制:为每个 ID 同时分配一个 cluster 表示和一个 individual 表示,并动态调整两者之间的平衡。
- 设计了一个语义簇感知的序列聚合模块,实现高效且精确的信息聚合。
- 在大规模工业数据集上做了充分实验,AKT-Rec 在生产环境的线上 A/B 测试中取得显著提升。
问题形式化¶
把长尾推荐建模为在含长尾分布的 user-item 交互数据上做 CTR(Click-Through Rate)预测,数据同时含长尾用户与长尾物品。设 $\mathcal{U}$ 为用户集合、$\mathcal{I}$ 为物品集合。对任意用户 $u \in \mathcal{U}$、物品 $i \in \mathcal{I}$,定义交互标签:
$$ y_{u,i} = \begin{cases} 1, & \text{若用户 } u \text{ 点击物品 } i \\ 0, & \text{否则} \end{cases} \tag{1} $$
假设用户活跃度与物品热度都服从长尾分布。用户 $u$ 与物品 $i$ 的交互频次定义为:
$$ f(u) = \sum_{i \in \mathcal{I}} y_{u,i}, \qquad f(i) = \sum_{u \in \mathcal{U}} y_{u,i} \tag{2} $$
$f(u)$ 与 $f(i)$ 均呈重尾分布。目标:利用头部用户/物品丰富的交互历史,提升长尾用户/物品的 CTR 预测精度,同时保持头部用户/物品的预测精度(这正是"非对称"的体现——不以牺牲头部为代价)。
核心方法 / 模型架构¶
AKT-Rec 在 embedding 与 feature 两个层面都做了解耦(decoupled)设计,以在不同粒度上保留信息,并促进头→尾的非对称知识迁移。
Stage 1:语义簇生成(Semantic Clusters Generation)¶
1) 表示抽取(Representation Extraction)¶
采用两阶段抽取范式:先生成物品 embedding,再结合用户的历史行为与属性导出用户 embedding。
物品表示:用预训练 MLLM(论文用 GME-Qwen2-VL-7B)抽取物品表示。Prompt 包含物品图像、文本描述,以及统计特征(如 N 天点击率 CTR、转化率 CVR、加购率),这些统计特征被量化为离散等级以便模型理解。为注入协同信号,识别频繁共现的物品对 $\langle i_1, i_2 \rangle$,用对比学习(InfoNCE)对齐其表示:
$$ \mathcal{L}_i = -\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp(\mathbf{z}_i \cdot \mathbf{z}_i^{+}/\tau)}{\exp(\mathbf{z}_i \cdot \mathbf{z}_i^{+}/\tau) + \sum_{j=1}^{K}\exp(\mathbf{z}_i \cdot \mathbf{z}_j^{-}/\tau)} \tag{3} $$
其中 $N$ 为 batch size,$K$ 为负样本数,$\mathbf{z}_i$ 是第 $i$ 个样本的 embedding,$\mathbf{z}_i^{+}$ 为对应正样本 embedding,$\mathbf{z}_j^{-}$ 为负样本 embedding,$\tau$ 为温度超参。这一步把 item-to-item 共现关系(协同信号)注入到 MLLM 抽取的多模态内容表示里——这是"内容 + 协同"对齐的关键。
用户表示:用另一个 LLM 从用户的交互历史与画像生成用户语义表示,遵循文献 [7] 的监督式范式。Prompt 包含用户属性与按时间排序的交互序列(如 30 天内的点击),并带类别和统计数据。模型生成一个 interest token 来刻画用户的未来偏好,并预测对应的物品类别。论文用 Qwen3-30B-A3B 在"用户画像 + 历史点击序列 + 来自传统 CTR 任务样本的 ground-truth 物品"上做监督微调,目标 $\mathcal{L}_u$ 为:
$$ \mathcal{L}_u = -\,\mathrm{sim}(\hat{\mathbf{e}}_t, \mathbf{e}_t) - \big[y_c \log(\hat{y}_c) + (1-y_c)\log(1-\hat{y}_c)\big] \tag{4} $$
其中 $\hat{\mathbf{e}}_t$ 是 interest token 的隐向量(作为用户语义表示),$\hat{y}_c$ 是预测类别,$\mathbf{e}_t$ 与 $y_c$ 分别是被点击物品的语义表示及其类别,$\mathrm{sim}(\cdot)$ 为余弦相似度。第一项让用户表示对齐被点击物品的语义,第二项是类别预测的交叉熵。
2) 簇生成(Cluster Generation)¶
用 RQ-VAE 把语义表示量化为离散标识符,形成"粗到细"的层级结构。给定编码器 $E$、解码器 $D$、初始残差 $r_0 = x$(输入表示),$N$ 层 codebook 每层大小为 $M$、含向量 $\{e_l\}_{l=1}^{M}$。标识符迭代生成:
$$ id_k = \arg\min_{l}\, \lVert r_{k-1} - e_l \rVert^2, \qquad r_k = r_{k-1} - e_{id_k}, \qquad 1 \le k \le N \tag{5} $$
对任意表示,$N$ 层 RQ-VAE 通过最近邻搜索生成序列 $(id_1, id_2, \ldots, id_N)$,构成最终的层级语义 ID。关键设计:刻意校准层数与 codebook 大小,使单个语义 ID 能代表多个相似物品(高碰撞率),从而促成语义簇的形成。这与一般 SID 工作"避免碰撞"的取向相反——AKT-Rec 把碰撞当作形成簇的特性而非缺陷。(实现中:物品/用户语义 ID 用 RQ-VAE,三个 codebook,大小 128/256。)
Stage 2:基于语义簇的特征融合¶
1) Cluster-Guided Adaptive Embedding(CGAE,簇引导的自适应嵌入)¶
把每个 ID 的表示分解为两个分量:cluster embedding $\mathbf{c}_i \in \mathbb{R}^m$(簇内共享语义)和 individual embedding $\mathbf{d}_i \in \mathbb{R}^m$(ID 个性化信息)。对同一语义簇内的 ID,用对比学习对齐其 cluster embedding。
为控制头→尾的知识迁移方向,使用非对称 InfoNCE 目标:
$$ \mathcal{L}_{\text{trans}} = \lambda_1\, \mathcal{L}_{\text{info}}\big(\mathbf{c}_i^{\text{head}},\, sg(\mathbf{c}_i^{\text{tail}})\big) + \lambda_2\, \mathcal{L}_{\text{info}}\big(\mathbf{c}_i^{\text{tail}},\, sg(\mathbf{c}_i^{\text{head}})\big) \tag{6} $$
其中 $\mathcal{L}_{\text{info}}(x, y)$ 是以 $y$ 为正样本的 InfoNCE 损失,$\mathbf{c}_i^{\text{head}}$、$\mathbf{c}_i^{\text{tail}}$ 分别是头部/尾部 ID 的 cluster embedding,$sg(\cdot)$ 是 stop-gradient(停止梯度)。非对称性的实现机制:通过 stop-gradient 切断反向更新方向,再令 $\lambda_1 < \lambda_2$,确保知识主要从头部流向尾部——即尾部 cluster embedding 被拉向(已停梯度的)头部,而头部只被很弱地($\lambda_1$ 小)拉向尾部,从而避免尾部噪声污染头部。这正是论文标题"From Head to Tail"的算法落点。
为避免 $\mathbf{c}_i$ 与 $\mathbf{d}_i$ 之间信息冗余(会导致优化坍缩 optimization collapse),引入软正交正则(soft orthogonality regularizer)鼓励两者编码互补信息:
$$ \mathcal{L}_{\text{ortho}} = \left(\frac{\mathbf{c}_i^{\top}\mathbf{d}_i}{\lVert\mathbf{c}_i\rVert_2 \cdot \lVert\mathbf{d}_i\rVert_2}\right)^2 \tag{7} $$
即两个 embedding 余弦相似度的平方——越接近正交,正则越小。
用户/物品的最终表示是两个 embedding 基于活跃度特征的自适应融合:
$$ r_i = \mathcal{G}_1(\mathbf{f}_i^{\text{act}}), \qquad \mathbf{e}_i = r_i \cdot \mathbf{c}_i + (1 - r_i)\cdot \mathbf{d}_i \tag{8} $$
其中 $\mathbf{f}_i^{\text{act}}$ 是该 ID 的活跃度特征,$\mathcal{G}_1$ 是前馈网络,$\mathbf{e}_i$ 为融合后的 embedding。设计动机:活跃度高的头部 ID 有充足数据训练自身的 individual embedding,门控 $r_i$ 会偏向 $\mathbf{d}_i$;活跃度低的尾部 ID individual embedding 训练不足,门控偏向共享的 cluster embedding $\mathbf{c}_i$——让尾部自动多吃簇知识、头部自动多用个性化信息,这是"自适应/活跃度感知"的核心。
2) Hierarchical Feature Aggregation(HFA,层级特征聚合)¶
为利用语义簇的层级结构,构造两个并行视图:instance level(实例级)与 cluster level(簇级)。
实例级聚焦单次交互中具体用户/物品的细粒度上下文。特征包含 individual embedding $\mathbf{e}_i$、$\mathbf{u}_i$,以及属性、统计特征(均表示为 embedding)。用户/物品特征向量:
$$ \mathbf{H}_u = [\mathbf{u}_{\text{attr}};\, \mathbf{u}_{\text{stats}};\, \mathbf{u}_i], \qquad \mathbf{H}_i = [\mathbf{i}_{\text{attr}};\, \mathbf{i}_{\text{stats}};\, \mathbf{e}_i] \tag{9} $$
用户交互历史 $\mathbf{s}_u = [\mathbf{h}_0, \mathbf{h}_1, \cdots, \mathbf{h}_L]$ 与候选物品 $i$ 通过 target-aware attention(目标感知注意力) [24] 编码:
$$ \mathbf{S}_{u,i} = \sum_{j=1}^{L}\alpha_{ij}\mathbf{h}_j, \qquad \alpha_{ij} = \frac{\exp(\mathbf{e}_i \mathbf{h}_j^{\top})}{\sum_{k=1}^{L}\exp(\mathbf{e}_i \mathbf{h}_k^{\top})} \tag{10} $$
这些分量拼接成实例级表示 $\mathbf{H}_{\text{inst}}$,以最大粒度保证预测精度。
簇级捕捉用户簇 $G(u)$ 与物品簇 $G(i)$ 的代表性上下文。簇级特征通过对簇内实例特征求平均得到:
$$ \mathbf{H}_{G(u)} = \frac{\sum_{u' \in G(u)}(\mathbf{H}_{u'})}{\lVert G(u)\rVert}, \qquad \mathbf{H}_{G(i)} = \frac{\sum_{i' \in G(i)}(\mathbf{H}_{i'})}{\lVert G(i)\rVert} \tag{11} $$
工程难点与解法:聚合一个簇内所有用户的行为会得到过长的序列,超出在线服务的延迟约束。遵循文献 [13],采用基于顶层语义 ID 的 target retrieval 策略,只取与候选物品最相关的行为;再对这条簇级序列施加 target attention 生成 $\mathbf{S}_{G(u),i}$,拼接为簇级表示 $\mathbf{H}_{\text{clust}}$。
3) Adaptive Feature Fusion(自适应特征融合)¶
不用简单拼接,而是用一个基于联合 user-item 活跃度的门控网络,自适应平衡两个层级视图的贡献。给定用户活跃度特征 $\mathbf{f}_{\text{user}}^{\text{act}}$、物品活跃度特征 $\mathbf{f}_{\text{item}}^{\text{act}}$、交叉特征 $\mathbf{f}_{\text{cross}}^{\text{act}}$,融合权重:
$$ \alpha = \mathcal{G}_2\big([\mathbf{f}_{\text{user}}^{\text{act}};\, \mathbf{f}_{\text{item}}^{\text{act}};\, \mathbf{f}_{\text{cross}}^{\text{act}}]\big) \tag{12} $$
其中 $\mathcal{G}_2$ 为前馈网络。最终特征输入 $\mathbf{f} = \alpha \cdot \mathbf{H}_{\text{clust}} + (1-\alpha)\cdot \mathbf{H}_{\text{inst}}$,喂入排序网络 $\mathcal{F}$(MLP 或多门混合专家 MMoE [12])预测点击偏好:
$$ \hat{y} = \mathcal{F}(\mathbf{f}), \qquad \mathcal{L}_{\text{main}} = -\big[y\log(\hat{y}) + (1-y)\log(1-\hat{y})\big] \tag{13} $$
其中 $y$ 为点击标签。两层门控的呼应:CGAE 的门控 $r_i$(式 8)在 embedding 级决定 cluster vs individual 的比例,HFA 的门控 $\alpha$(式 12)在 feature 级决定 cluster-level vs instance-level 视图的比例——两者都由活跃度驱动,共同实现"头部多用个体信息、尾部多用簇知识"的自适应倾斜。
训练目标¶
CTR 模型通过最小化总损失训练:
$$ \mathcal{L}_{\text{ctr}} = \mathcal{L}_{\text{main}} + \mathcal{L}_{\text{trans}} + \lambda\,\mathcal{L}_{\text{ortho}} \tag{14} $$
其中 $\lambda$ 是控制正交正则强度的超参。即"主 CTR 损失 + 非对称迁移损失 + 正交解耦正则"三项联合优化。
实验设置¶
数据集与指标¶
- 数据集:天猫(Tmall)移动端工业数据集,2025 年 6 月–8 月共两个月的点击日志,3600 万用户、约 3 亿物品。最后 5 天作为测试集,其余作训练集。
- 长尾定义:
- 长尾用户 = 训练集中交互少于 5 次的用户,占 85.58% 的用户;
- 长尾物品 = 训练集中曝光少于 10 次的物品,占 95.8% 的物品;
-
长尾样本 = 用户或目标物品任一为长尾 ID 的样本,占 22.4% 的样本。
-
离线指标:AUC、GAUC(Group AUC,按用户分组的 AUC)。
- 在线指标:Clicks、CTR、CTCVR(Click-Through Conversion Rate)、GMV(成交额)。
实现细节¶
- 从天猫平台的共现信号构建共现数据库,从训练集计算 MLLM prompt 用的物品特征。
- 多模态内容编码:GME-Qwen2-VL-7B [22]。
- 用户语义表示:在监督下微调 Qwen3-30B-A3B [17]。
- 用户/物品语义 ID:RQ-VAE,三个 codebook,大小 128/256。
Baseline¶
- 多模态冷启动方法:SaviorRec [21]、SimTier;
- 非多模态方法:POSO [3]、TailNet [16];
- 以及线上 base 模型。
主要实验结果¶
总体性能(Table 1)¶
| Model | Total AUC | Total GAUC | Head AUC | Head GAUC | Tail AUC | Tail GAUC |
|---|---|---|---|---|---|---|
| Online base | 0.7510 | 0.6385 | 0.7528 | 0.6477 | 0.7485 | 0.6137 |
| SaviorRec | 0.7521 | 0.6455 | 0.7534 | 0.6516 | 0.7507 | 0.6347 |
| TailNet | 0.7491 | 0.6370 | 0.7509 | 0.6453 | 0.7479 | 0.6448 |
| POSO | 0.7518 | 0.6412 | 0.7520 | 0.6472 | 0.7497 | 0.6321 |
| SimTier | 0.7515 | 0.6398 | 0.7529 | 0.6481 | 0.7496 | 0.6279 |
| AKT-Rec | 0.7536 | 0.6483 | 0.7543 | 0.6528 | 0.7522 | 0.6397 |
结论分析:AKT-Rec 在所有活跃度层级上的 AUC 与 GAUC 基本都领先。与线上 base 相比,长尾样本上的提升最显著——AUC +0.346%、GAUC +1.53%;头部样本上仍保持优势(Head AUC/GAUC 均最高),说明该方法在不牺牲头部精度的前提下改进了长尾建模,这正是"非对称"设计的目标验证。
⚠️ 一个值得注意的细节:在 Tail GAUC 这一列,TailNet 取得 0.6448,高于 AKT-Rec 的 0.6397。也就是说论文"在所有活跃度层级上一致领先"的表述在 Tail GAUC 上并不严格成立——专门为尾部设计的 TailNet 在这个指标上更强。AKT-Rec 的优势更多体现在 Tail AUC(0.7522 vs TailNet 0.7479)和 Total/Head 全维度的均衡领先。
消融研究(Table 2)¶
下表数值为相对完整 AKT-Rec 的相对变化(%),负值表示去掉该组件后性能下降:
| 移除的组件 | Full AUC | Full GAUC | Head AUC | Head GAUC | Tail AUC | Tail GAUC |
|---|---|---|---|---|---|---|
| w/o individual emb.(去个体嵌入) | -0.46% | -0.92% | -0.67% | -0.93% | -0.42% | -0.44% |
| w/o cluster emb.(去簇嵌入) | -0.19% | -0.82% | -0.03% | -0.17% | -0.44% | -1.20% |
| w/o CGAE gate(去 CGAE 门控) | -0.13% | -0.50% | -0.26% | -0.22% | -0.07% | -0.12% |
| w/o instance-level feature(去实例级特征) | -1.14% | -1.55% | -1.38% | -1.81% | -0.83% | -1.21% |
| w/o cluster-level feature(去簇级特征) | -0.17% | -0.34% | -0.12% | -0.21% | -0.26% | -0.63% |
| w/o HFA gate(去 HFA 门控) | -0.13% | -0.30% | -0.31% | -0.55% | -0.11% | -0.23% |
逐项分析:
- 去 individual embedding(仅用共享的 cluster embedding 表示):整体 AUC -0.46%、GAUC -0.92%,确认 individual 分量的必要性——纯靠簇共享会丢失 ID 个性化信息。
- 去 cluster embedding:整体下降明显,且尾部退化更大(Tail GAUC -1.20% vs Head GAUC 仅 -0.17%),印证"尾部 ID 不成比例地受益于簇级知识"这一核心假设。
- 去 CGAE 门控(用简单平均替代活跃度门控 $r_i$):AUC -0.13%、GAUC -0.5%,说明自适应门控有价值。
- 去 instance-level 特征:下降最剧烈(AUC -1.14%、GAUC -1.55%),尤其在头部样本(Head AUC -1.38%、Head GAUC -1.81%),确认个体行为序列对头部精度至关重要。
- 去 cluster-level 特征:整体 AUC -0.17%、GAUC -0.34%,尾部敏感度更高(Tail GAUC -0.63%),与簇知识利好尾部一致。
- 去 HFA 门控(用固定平均 $\alpha = 0.5$):性能退化,证明自适应融合权重对跨头尾最大化信息效用是关键。
整体规律:instance-level 特征 / individual embedding 主要服务头部精度,cluster-level 特征 / cluster embedding 主要服务尾部提升,两套门控负责在两者间自适应倾斜——消融结果清晰地把"头尾分工"映射到了具体组件上。
在线 A/B 测试(Table 3)¶
在天猫平台做了两周线上 A/B,实验组与对照组各分配 10% 流量:
| Online Metrics | Clicks | CTR | CTCVR | GMV |
|---|---|---|---|---|
| Gain(%) | +2.73% | +2.76% | +1.7% | +3.47% |
结论:CTR +2.76%、CTCVR +1.7%、GMV +3.47%。线上提升量级远大于离线 AUC 的相对提升(这是工业推荐常见现象——离线 AUC 千分位的提升常对应线上百分位的业务收益),验证了 AKT-Rec 在真实生产环境中处理长尾分布挑战的有效性与商业价值。
核心贡献总结¶
- 首次显式刻画长尾知识迁移的"非对称性":指出"孤立修补尾部"会让尾部噪声污染头部,主张知识应主要由头流向尾——并用 stop-gradient + $\lambda_1 < \lambda_2$ 的非对称 InfoNCE 把这一原则算法化。
- 用高碰撞 RQ-VAE 把语义 ID 当作"簇"而非"唯一标识":刻意校准 codebook 让相似实体共享同一 SID,天然形成语义簇,为头尾知识共享提供载体——这与主流 SID 工作"避碰撞"取向相反。
- 双层活跃度门控(CGAE + HFA):embedding 级 + feature 级两层门控都由活跃度驱动,自动让头部多用个体信息、尾部多吃簇知识,实现自适应平衡。
- 工业级验证:3 亿物品 / 3600 万用户的天猫数据,线上 A/B GMV +3.47%。
与已归档相关工作的对比¶
Ghost Ghost: 诊断并治理生成式推荐的流行度偏差(HK PolyU, 2026-05-16)¶
关系:独立并发(本文未引用 Ghost,两者殊途同归地处理"头→尾不对称")· 已加载对方精读
- 共同关注的问题:两篇都直击"head 主导、tail 被边缘化"的长尾/流行度偏差根因,且都明确把它刻画为一个头尾不对称(asymmetric)问题——头部数据充足、尾部信号稀缺,需要让头部的知识/结构反哺尾部,而非让尾部噪声反向干扰头部。两者都把语义 ID(SID / RQ-VAE 量化)作为承载头尾知识关系的基础设施。
- 相近的技术骨架:双方都提出"头部提供结构、尾部继承"+ 非对称损失这一组合。Ghost 的 Skeleton-Founded Tokenization (SKT) 让 tail item 强制继承最近 head item 的 SID 前缀骨架,再生成尾部专属后缀;其 Asymmetric Unlikelihood Optimization (AUO) 用非对称的 unlikelihood 惩罚救援尾部 token 梯度。AKT-Rec 的 CGAE 让尾部 cluster embedding 通过非对称 InfoNCE(式 6,stop-gradient + $\lambda_1<\lambda_2$)向头部对齐。两者"非对称"的拼写不同,意图同构。
- 本文的差异与推进:① 范式不同——Ghost 是生成式检索(SID 自回归 next-token 生成),AKT-Rec 是判别式 CTR 排序(SID 仅作簇级辅助特征融入 ranker);② "非对称"的实现位面不同——Ghost 在 tokenization(SKT 折叠 branching point)+ 解码损失(AUO)层面治理,AKT-Rec 在 embedding 对比损失(停梯度方向 + 非对称权重)层面治理;③ 理论 vs 工程——Ghost 给出 4 个引理证明 gradient starvation 与 bias amplification 的根因,偏理论诊断;AKT-Rec 偏工业落地,给出 3 亿物品规模的线上 A/B。
- 可比的方法/实验差异:Ghost 在 3 个 Amazon 公开数据集上报告 Tail HR/NDCG 平均 +63.91%/+70.66%(学术 setting);AKT-Rec 在天猫工业数据上 Tail AUC +0.346%、线上 GMV +3.47%(工业 setting)。两者不可直接比数,但共同印证"非对称头→尾迁移"在长尾问题上的有效性。
IDProxy IDProxy: MLLM 生成代理 ID 嵌入做冷启动(小红书, 2026-03-02)¶
关系:独立并发(本文未引用 IDProxy,两者在"MLLM 内容 → 融入 CTR 排序"这一路径上高度同构)· 已加载对方精读
- 共同关注的问题:两篇都解决"工业 CTR 排序模型里,新/尾部物品的 ID embedding 训练不充分"的问题,且都批判主流多模态对齐方法(含 SimTier)"未充分利用现有排序模型结构、内容特征被协同信号淹没、收益有限"——这一动机陈述几乎逐句对应(AKT-Rec 在 Intro、IDProxy 在 §1 都点名了这一痛点)。两者都属于"判别式 CTR 排序 + 多模态内容增强",而非生成式检索。
- 相近的技术骨架:都走 MLLM 抽取内容表示 → 对齐/投影到协同/ID 空间 → 用门控融合 → 注入现有 CTR ranker 这条主线。IDProxy 用对比学习把 MLLM 内容嵌入对齐到 ID embedding 空间(proxy alignment),用残差门控平衡粗/细粒度表示;AKT-Rec 用 InfoNCE 把共现协同信号注入 MLLM 物品表示(式 3),用活跃度门控平衡 cluster/individual 嵌入。两者都强调"让多模态特征继承 ID-based 排序模型的结构先验"(IDProxy 的 structure reuse vs AKT-Rec 把 individual embedding 留在 instance-level 主路)。
- 本文的差异与推进:① 是否量化成簇——IDProxy 直接产出连续的 proxy embedding,不做 RQ-VAE 离散化/语义簇;AKT-Rec 刻意用高碰撞 RQ-VAE 形成语义簇,并在簇内做头→尾非对称迁移——这是 AKT-Rec 独有、IDProxy 完全没有的机制。② 对齐方向——IDProxy 是"内容 → ID 空间"的单向对齐;AKT-Rec 额外引入"头部 → 尾部"的非对称对齐。③ 用户侧建模——AKT-Rec 还对用户做 LLM 语义表示 + 用户语义簇(interest token),IDProxy 聚焦物品侧冷启动。
- 可比的方法/实验差异:IDProxy 离线 ΔAUC +0.14%、新物品在线 ΔAUC +0.23%~0.32%、广告场景 CTR +0.23%;AKT-Rec 长尾 AUC +0.346%、线上 CTR +2.76%、GMV +3.47%。两者都用"对全量/头部无损、对尾部/新物品增益更大"的分层评估范式,结论一致。
讨论与局限性¶
核心贡献与可借鉴的设计:
- "非对称"是这篇论文最有价值的 insight。多数长尾工作默认"共享知识总是好的",本文指出共享是有方向的——尾部噪声会污染头部,因此用 stop-gradient + 非对称权重把梯度流"单向阀"化。这个 stop-gradient 技巧极轻量却切中要害,可直接迁移到任何"强弱样本知识共享"的场景(不限推荐)。
- 把"SID 碰撞"从缺陷变特性。主流 SID/RQ-VAE 工作(如 QuaSID QuaSID、VarLenRec VarLenRec)都在想方设法降低碰撞;AKT-Rec 反其道,刻意校准 codebook 提高碰撞率来形成语义簇。这是一个值得记住的"视角反转"——同一机制在不同任务目标下可以是 bug 也可以是 feature。
- 双层活跃度门控把"头尾分工"做成了端到端可学习的连续调节,比硬切分 head/tail 子网络(如 TailNet)更优雅,且消融证明两层门控都有效。
局限与争议:
- 离线提升幅度偏小、且并非全维度领先。Total AUC 仅 +0.346%,且在 Tail GAUC 上被 TailNet 反超(0.6397 vs 0.6448)——论文"一致领先"的表述并不严格成立。线上 A/B 的大幅提升(GMV +3.47%)与离线小幅提升之间的落差虽属工业常态,但缺乏对"为何线上收益放大如此之多"的机制解释。
- 作为 5 页短文,系统细节严重压缩。许多关键超参缺失:非对称权重 $\lambda_1/\lambda_2$ 的具体取值、正交正则 $\lambda$、RQ-VAE 训练细节、interest token 的接入方式、簇级 target retrieval 的 top-k 设置等都未给出,复现难度大。$f(i)$ 在式 (2) 原文写作 $i = \sum_u y_{u,i}$(疑为笔误)。
- 两个大模型(GME-Qwen2-VL-7B + Qwen3-30B-A3B)的离线成本与更新频率未讨论。3 亿物品规模下,语义 ID 的生成/刷新、新物品的实时编码延迟、codebook 漂移等工程问题均未触及。
- 缺乏与同期强 baseline 的对比。对比对象 TailNet/POSO 偏早期,未与同属"多模态 + 语义 ID + 工业 CTR"路线的并发工作(如本归档发现的 IDProxy)正面比较。
工业落地价值:方法已在天猫主站上线,线上 A/B GMV +3.47%、CTR +2.76%、CTCVR +1.7%,对一个 3 亿物品量级的成熟电商系统而言是可观的业务收益。"非对称头→尾迁移 + 高碰撞语义簇 + 活跃度门控"这套组合拳,为工业界处理长尾推荐提供了一条"既保头部、又托尾部"的可落地范式。