Context Features Are Cheap: Rank-Aware Decomposition for Efficient Feature Interaction in Recommender Systems¶
Yevgeny Tkach(Taboola, Israel,单作者)· arXiv:2605.27450v1 · 2026-05-24
一句话总结¶
工业排序模型对同一请求里的 N 个候选共享同一套用户/上下文特征,标准实现却把"上下文-only 的计算"在每个候选上重复跑 N 次;本文指出上下文特征是 rank-2(跨候选共享)、目标特征是 rank-3(逐候选变化),任何线性/双线性算子在这种 rank 划分下都存在精确(identity-equivalent)的分块分解,可把上下文-only 计算从"每候选一次"降到"每请求一次"。把这一原理实例化到 FM 配对积、FC 投影层、DCNv2 cross 层、self-attention 上,并在 Taboola 生产 DLRM 排序器上不改任何模型结构、预测逐位相同地把单 pod 吞吐提升 87.5%(峰值 pod 数减少 47%)。进一步提出架构变体 rDCN,把"上下文不被目标污染"的 rank 纪律贯穿到全深度,在训练噪声内匹配 DCNv2 精度而省 67% 总 FLOPs。
1. 研究动机与背景¶
1.1 多目标打分的结构性浪费¶
工业推荐系统通常是两阶段"召回-排序"流水线:廉价的召回阶段把百万级物料缩到每请求 N 个候选;深度排序模型再把这 N 个候选针对同一组用户/上下文信号(用户画像、历史、会话状态、页面上下文)逐一打分。排序阶段面临一个根本张力:模型表达力要求引入越来越丰富的特征交互(配对积、cross 层、attention),而多目标打分的总成本随模型深度与每请求候选数 N 同时增长。对于服务数十亿日请求的生产系统,这个成本直接等价于基础设施占用。
现代排序架构——DLRM、DeepFM、DCNv2 及其变体——共享一个结构特性:它们把上下文 embedding 与目标 embedding 合并成一个统一特征向量,再喂给交互层和投影层。许多实现会在计算开始前就把上下文特征广播(broadcast / tile)到候选 batch 维度。于是只涉及上下文字段的下游操作——上下文-only 的配对积、线性投影、attention——被冗余地计算了 N 次。
对一个有 K 个上下文字段、M 个目标字段、为 N 个候选打分的模型,仅"上下文-上下文 FM 交互"一项每请求就浪费
$$(N-1)\cdot \binom{K}{2}\cdot D \ \text{FLOPs} \tag{0}$$
其中 D 是 embedding 维度。
1.2 已有工作只啃下了线性那一半¶
近期服务优化工作已经在全连接(FC)层里处理了这种冗余,节省随上下文字段数线性增长。但在 DLRM 这种主流工业范式里,与特征相关的计算大头落在交互层(interaction layer)——配对组合让节省随 $O(K^2)$ 二次增长。随着模型引入更丰富的上下文(更长用户历史、会话信号、更丰富的页面特征),K 不断增大,线性(MLP)节省与二次(interaction)节省之间的差距持续拉开。本文要啃的正是这块二次的硬骨头。
1.3 三条核心贡献¶
-
一条 rank-aware 分解原理:任何在 rank 划分输入上的线性或双线性操作都存在精确、无近似的分块分解。本文把这条原理系统地实例化到主流交互机制:FM 配对交互(用于 DLRM、DeepFM、NFM、PNN)、self-attention、DCNv2 cross 层、FC 投影层。
-
成本不对称(Cost Asymmetry):rank-aware 分解让上下文特征比目标特征便宜得多。这给出一个新的设计权衡——加上下文 vs 加目标特征的代价不再对称。闭式分析与消融印证:把 K 增大 3× 只让 RPS 降 39%,而把 M 增大 3× 让 RPS 降 64%。
-
架构设计原理:标准 rank-aware 分解只在第一层成立,因为在 cross 网络和 attention 中,后续每一层都会在输出里"混 rank"(context 与 target 混合)。这激励一种结构设计原理——用"全程都能 rank-aware 分解"的层来搭建推荐架构。本文提出 rDCN(rank-aware cross network),把这一限制提升到全深度,并草拟了对应的可分解 attention 层。
-
生产验证:在 Taboola 的 DLRM 排序器上不做任何架构改动地应用分解,单 pod 吞吐提升 87.5%(峰值 pod 数减少 47%),且预测逐位相同。
2. 背景与相关工作¶
2.1 推荐系统中的特征交互(按"是否可 rank 分解"梳理)¶
各类架构主要在"如何把特征组合进交互层"上不同:
- FM 系神经网络:DeepFM 在双线性配对交互旁并联一支 DNN;NFM 用 bi-interaction pooling 后接 MLP;PNN 用内/外积层喂 MLP;DLRM 是主流工业模板:FM 系配对交互后接顶层 MLP。
- Cross 网络:DCN / DCNv2 通过残差层算特征交叉,形式为 $x_{l+1} = x_0 \odot (W_l x_l + b_l) + x_l$。GDCN 加信息门控,DCNv3 用指数 cross 扩展。
- Attention 系:AutoInt 用多头 self-attention 作用于字段 embedding;InterHAt 加分层聚合;FiBiNET 结合 SENET 重加权与双线性交互;MaskNet 用 instance-guided mask。
以上架构都把上下文与目标特征合并,正是本文要消除的冗余来源。
2.2 让多目标打分更轻——三条已有路线¶
(a) 结构分离与蒸馏。 LightSUAN 显式指出 early-fusion 架构(DIN/ETA/TWIN 这类用户行为序列建模、或 shared-bottom)里多目标打分的代价:上下文-上下文计算被重复 N 次。它用蒸馏解决——重 teacher(SUAN)压成轻 student,牺牲容量换效率。Two-tower 走更极端的结构路线:用户塔与物品塔独立、打分退化成点积,对百万级召回足够高效但牺牲了联合 user–item 与深度 cross 交互,因此很少用于最终排序。本文的 rank-aware 分解与它们形成对照:数学上精确、完整保留表达力,但只适用于"上下文与目标在交互层仍分别可访问"的场合(early-fuse 架构是未来工作)。
(b) 基础设施层优化。 ROO(Meta, 2025)重构训练数据,让每行对应一个完整请求(一套用户特征 + N 个候选物品的数组),而非每行一个 (user, item) 对,从而去重用户特征与 embedding 查表,后期排序训练吞吐 +32%~100%。AIF 把"交互无关的路径"(user-only、item-only)异步执行,并用一个学习到的 bridge embedding 近似被跳过的 cross 交互(+5.80% RPM,延迟几乎不增)。两者都在系统层,与本文的代数层方法互补。
(c) 模型专用的交互层重写。 Low Rank FwFM 把 Rendle 的 FM 线性时间求值技巧推广到 field-weighted 变体:把 FwFM 交互矩阵分解为 $R = U^T \mathrm{diag}(e)U + \mathrm{diag}(d)$(对角 + 低秩),利用它把上下文侧的和每请求只算一次,在某生产广告系统报告平均 34% 推理延迟下降。该法数学优雅但仅限 FwFM、需要对 R 做近似、且无法推广到"FM 输出还要喂下游层"的 FM 系深度推荐。
(d) MaRI(Kuaishou, 2026)——与本文最接近。 MaRI 用图着色自动检测冗余的 FC/MatMul 计算。当 MatMul 的输入有 tiled 结构 $x = [x_u^{\text{tiled}}; x_i; x_c]$ 时,MaRI 分解权重矩阵以计算 $\mathrm{Tile}(x_u W_u) + x_i W_i + x_c W_c$,在 Kuaishou 报告 5.9% 硬件节省。但 MaRI 的范围限于 MatMul(data, weight) 节点:节省随上下文维度 $d_c$ 线性增长,且不覆盖配对 FM 交互(没有权重矩阵 → 图里没有节点可检测)、cross 网络层、attention。本文恰好补上这块二次节省。
本文与 MaRI 的关键差异:MaRI 是"在已有计算图上自动找冗余 matmul 节点",节省线性于 $d_c$;本文是"先验地用 rank 代数把配对/双线性交互拆开",节省二次于 K,并覆盖 FM/cross/attention 这些 MaRI 检测不到的算子。
3. Rank-Aware 分解(第一族贡献:精确、identity-equivalent)¶
本节给出系统性的、与原模型预测逐位相同的分块分解,利用多目标打分里上下文与目标特征之间的 rank 不对称。先陈述统一代数原理(§3.2),再依次实例化到 FM(§3.3)、FC(§3.4)、DCNv2 cross(§3.5)、attention(§3.6),最后用一张表总结适用性(§3.7)。
3.1 问题设定与记号¶
一个推荐请求包含:
- 上下文特征 $c = \{c_1, \dots, c_K\}$,embedding $e_{c_k} \in \mathbb{R}^D$,对所有候选相同。"上下文"指请求内对候选恒定的所有特征——用户特征(画像、历史)与会话/页面特征。(同一用户在一次请求里被多个不同曝光上下文打分的情形,可把每个曝光当作独立请求,或引入额外一个 rank 表示曝光维度;本文聚焦"每请求单上下文"。)
- 候选物品 $n = 1, \dots, N$,各有目标特征 $t^{(n)} = \{t_1^{(n)}, \dots, t_M^{(n)}\}$、embedding $e_{t_m}^{(n)} \in \mathbb{R}^D$。堆叠后写作 $T \in \mathbb{R}^{N \times M \times D}$(embedding 拉平后为 $\mathbb{R}^{N \times d_t}$,$d_t = M\cdot D$)。
- 模型须产出 N 个分数 $\hat{y}_1, \dots, \hat{y}_N$。
Tensor rank 约定(全文核心):
| 类型 | rank | shape | 是否随候选变化 |
|---|---|---|---|
| 上下文 embedding | rank 2 | $[B, D]$ | 否(跨候选共享) |
| 目标 embedding | rank 3 | $[B, N, D]$ | 是(逐候选) |
B 是请求 batch size(并行处理的请求数);下文取 B=1,所有 FLOP 计算都吸收 B。
3.2 统一原理¶
§3.3–3.6 的所有分解都是同一条代数原理的实例:任何在输入上线性或双线性的操作,当输入按 $x = [x_c; x_t]$ 划分时,都存在一个分块分解。
线性情形。 对 $f(x) = Wx$,把权重按输入块划分 $W = [W_c \mid W_t]$:
$$Wx = W_c x_c + W_t x_t \tag{1}$$
$W_c x_c$ 这一项在 $x_c$ 为 rank 2(跨候选共享)时只算一次。这覆盖 FC 层、DCNv2 的 $W_l x_l$、线性门控。
双线性情形。 对 $f(x, y) = x^T W y$,$x = [x_c; x_t]$、$y = [y_c; y_t]$:
$$x^T W y = x_c^T W_{cc} y_c + x_c^T W_{ct} y_t + x_t^T W_{tc} y_c + x_t^T W_{tt} y_t \tag{2}$$
$x_c^T W_{cc} y_c$ 这一项只算一次。这覆盖 FM 交互、FwFM、双线性(FiBiNET)、外积(xDeepFM 的 CIN)、attention 分数。
标准做法 vs 本文做法。 标准做法在任何交互计算前就把上下文 embedding 广播(tile)到 rank 3,得到统一的 $[N, (K+M)\cdot D]$ 特征张量——之后所有计算都是 $O(N)$,无论特征类型。本文做法:推迟广播。在 rank 2 上算上下文-only 操作,在 rank 3 上算目标-only 与 cross 操作,只在"混合"时才把结果广播。
该原理在哪里会失效(两种"混 rank"情形):
- 混合操作:当一个操作把 rank-2 上下文与 rank-3 目标混进单一输出时,输出维度被"rank 混合",下游任何消费它的算子看到的是一个不再纯粹的 rank-3"上下文"。这正是 FC 与 DCNv2 cross 层在第 0 层之后失效的根源(§3.5)。
- 目标 attention:DIN、TWIN、ETA 这类——用户表示按设计依赖目标,因此根本不存在上下文-only 的路径。
3.3 FM 交互分解¶
FM 计算所有 K+M 个特征 embedding 的配对内积。沿用现代工业表述:每个 $e_i \in \mathbb{R}^D$ 是字段级 embedding(查激活值得到;多值字段对激活 embedding 池化)。这包含了经典表述 $\sum_{i<j}\langle v_i, v_j\rangle x_i x_j$——字段 embedding $e_i = x_i v_i$ 吸收了稀疏特征值与 one-hot。DLRM 风格里把 FM 输出当作配对点积向量(而非经典的标量和),供下游 FC 层消费:
$$\mathrm{FM}(e) = \big[\langle e_i, e_j\rangle\big]_{1 \le i < j \le K+M} \in \mathbb{R}^{\binom{K+M}{2}} \tag{3}$$
Rank-aware 分解。 把配对按 tensor rank 分成两组:
$$\mathrm{FM}(e) = \big[\ \underbrace{\mathrm{FM}_{\mathrm{ctx}}(c)}_{\text{rank 2, 只算一次}}\ ;\ \underbrace{\mathrm{FM}_{\mathrm{tgt}}(c, T)}_{\text{rank 3, 逐候选}}\ \big] \tag{4}$$
其中(在配对维度上拼接):
$$\mathrm{FM}_{\mathrm{ctx}}(c) = \big[\langle e_{c_i}, e_{c_j}\rangle\big]_{1\le i<j\le K} \in \mathbb{R}^{\binom{K}{2}} \tag{5}$$
$$\mathrm{FM}_{\mathrm{tgt}}(c, T^{(n)}) = \big[\langle e_{t_i}^{(n)}, e_{t_k}^{(n)}\rangle\big]_{i<k}\ \big\|\ \big[\langle e_{c_i}, e_{t_j}^{(n)}\rangle\big]_{i,j} \tag{6}$$
- $\mathrm{FM}_{\mathrm{ctx}}$ 只依赖上下文 embedding——每请求算一次,对每个候选都相同。
- $\mathrm{FM}_{\mathrm{tgt}}$ 捕获任何至少涉及一个目标字段的交互:既包含目标-目标对,也包含上下文-目标对。把这两类合在一起,是因为它们共享同一 rank(3)、同一逐候选成本结构,并且能用单个非对称 matmul 同时算完。这种"以目标为锚(target-anchored)"的分组,是后面 rDCN(§4.2)和 rank-aware attention(§4.3)会反复出现的模式。
表 1:Rank-aware FM 分解
| 组件 | 配对数 | Rank | 每请求执行 |
|---|---|---|---|
| $\mathrm{FM}_{\mathrm{ctx}}$ | $K(K-1)/2$ | 2 | 一次 |
| $\mathrm{FM}_{\mathrm{tgt}}$ | $KM + M(M-1)/2$ | 3 | N 次 |
实现。 两个构件实现该分解:
- $\mathrm{FM}_{\mathrm{ctx}}$:$K\times K$ 上下文内积矩阵的上三角;所有操作数 rank 2,结果是大小 $\binom{K}{2}$ 的 rank-2 张量,每请求算一次。
- $\mathrm{FM}_{\mathrm{tgt}}$:单个非对称 matmul——每个目标字段 embedding 与堆叠块 $[c; T^{(n)}]$ 相乘,同时覆盖上下文-目标与目标-目标对。上下文 embedding 只在该算子内部才广播到 rank 3。
FLOP 节省。 标准实现在 rank 3 上算全部 $\binom{K+M}{2}$ 个交互,每请求 $N\cdot\binom{K+M}{2}\cdot D$ FLOPs。本文分解成本为 $\binom{K}{2}\cdot D + N\cdot(KM + \binom{M}{2})\cdot D$。绝对节省:
$$\Delta_{\mathrm{FM}} = (N-1)\cdot\binom{K}{2}\cdot D \tag{7}$$
是 K 的二次函数。占总 FM FLOPs 的节省比例:
$$\frac{\Delta_{\mathrm{FM}}}{\mathrm{FLOPs}^{\mathrm{std}}_{\mathrm{FM}}} = \frac{(N-1)\cdot K(K-1)}{N\cdot(K+M)(K+M-1)} \tag{8}$$
M 越小,节省比例越大。
FM 变体的适用性。 上述分解对标准 FM 公式书写,但原样适用于任何交互层算配对 embedding 积的架构,含 DLRM、DeepFM、NFM、PNN。对 field-aware 变体 FFM(字段专属 embedding),同样的两路分解成立——只需在内积两侧各自代入字段专属 embedding。
3.4 FC 层分解¶
推荐模型通常在交互层后堆叠若干 FC 层。第一个 FC 层的输入是 rank-2 上下文部分 $x_c$($\mathrm{FM}_{\mathrm{ctx}}$ 输出)与 rank-3 目标部分 $x_t$($\mathrm{FM}_{\mathrm{tgt}}$ 输出)的拼接。Rank-aware FC 就是线性情形(Eq.1)的直接应用:
$$h = \sigma\big([x_c; x_t]W + b\big) \tag{9}$$ $$= \sigma\big(x_c W_c + x_t W_t + b\big) \tag{10}$$
其中 $x_c$ rank-2、$x_t$ rank-3、$W = [W_c; W_t]$ 沿输入维度划分(与 Eq.1 同一 $W_c, W_t$ 划分)。
RankSplitDense。 在 rank 2 上算一次 $x_c W_c$,广播到 rank 3,在非线性前加到逐候选的 $x_t W_t$。节省:
$$\Delta_{\mathrm{FC}} = (N-1)\cdot |x_c|\cdot U \tag{11}$$
U 是该 FC 层单元数,$|x_c|$ 是 rank-2 上下文输入的大小。
为何只有第一层 FC。 经过 $\sigma(x_c W_c + x_t W_t + b)$ 后,上下文与目标信号在每个神经元上被非线性激活混合。之后所有层都作用在形状 $[N, U]$、完全依赖目标的张量上,不再有 rank 分离的计算可做。
与 FM 节省的二次复合。 当 FC 位于 rank-aware FM 下游时,上下文-only FM 输出 $x_c = \mathrm{FM}_{\mathrm{ctx}}(c)$ 大小是 $\binom{K}{2}$(Eq.5)——本身就二次于上下文字段数。代入 Eq.11:
$$\Delta_{\mathrm{FC}} = (N-1)\cdot\binom{K}{2}\cdot U \tag{12}$$
也二次于 K。于是 DLRM 风格模型在前向的两个阶段都享受二次-于-K 的节省:一次在配对交互层(算 $\binom{K}{2}$ 个上下文-上下文对处),再一次在第一个 FC 层(投影这些对处)。这种复合正是该优化对"交互重"模型如此有冲击力的原因,而在纯 MLP 架构里不存在——后者上下文输入只线性于 K。
3.5 DCNv2 Cross 层分解¶
DCNv2 cross 层形式:
$$x_{l+1} = x_0 \odot (W_l x_l + b_l) + x_l \tag{13}$$
matmul $W_l x_l$ 恰是 §3.2 的分块线性情形(Eq.1),输入划分 $x_l = [x_l^c; x_l^t]$,权重分四块:
$$W_l x_l = \begin{bmatrix} W_{cc} & W_{ct} \\ W_{tc} & W_{tt} \end{bmatrix}\begin{bmatrix} x_l^c \\ x_l^t \end{bmatrix} = \begin{bmatrix} W_{cc}x_l^c + W_{ct}x_l^t \\ W_{tc}x_l^c + W_{tt}x_l^t \end{bmatrix} \tag{14}$$
在 $l=0$ 层($x_0 = [x_0^c; x_0^t]$),$W_{cc}x_0^c$ 与 $W_{tc}x_0^c$ 只依赖上下文,每请求算一次。第一个 cross 层的节省比例:
$$\frac{d_c^2}{(d_c + d_t)^2} \tag{15}$$
为何深度是问题(rank 在第 0 层后被"重新纠缠")。 节省只在第 0 层成立。阻断者就是 §3.2 的第二种失效:任何输入同时含 rank-2 上下文与 rank-3 目标的线性操作,会产出"上下文维度依赖目标特征"的输出行。具体地,$W_l x_l$ 的上下文输出行是 $W_{cc}x_l^c + W_{ct}x_l^t$。一旦第 0 层吐出这个 rank-混合输出,之后每层的 $x_l^c$ 都依赖目标,不再是可预算的 rank-2。Hadamard 积 $x_0 \odot(\cdot)$ 只是顺带:它保留但不创造 rank-3 性;把 $\odot$ 换成求和或任何逐元素算子也救不回 rank 分离,因为 rank 混合已经发生在 $W_l x_l$ 内部。第 0 层之后,实际节省衰减到零。 §4.2 的 rDCN 专门修这个问题。
与 DCNv2 低秩参数化兼容。 原版 DCNv2 也用低秩 $W_l = U_l V_l^T$($U_l, V_l \in \mathbb{R}^{D\times r}$)减参。它与 rank-aware 分块分解可组合:把行划分为 $U_l = [U_c; U_l]$、$V_l = [V_c; V_l]$,诱导出分块因子化 $W_{cc} = U_c V_c^T$,不增参数;每请求一次的上下文 matmul $W_{cc}x_0^c = U_c(V_c^T x_0^c)$ 仍是 rank 2。
3.6 Attention 层分解¶
Attention 层(AutoInt、InterHAt)对字段 embedding 做 self-attention:
$$\mathrm{Attn}(Q,K,V) = \mathrm{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right)V \tag{16}$$
$Q = W_Q E$、$K = W_K E$、$V = W_V E$,E 是堆叠的字段 embedding 矩阵。
Q/K/V 投影直接分解。 每个投影是对"上下文+目标拼接 embedding"的 MatMul,是 Eq.1 的实例:
$$W_Q E = W_Q[E_c; E_t] = W_{Q,c}E_c + W_{Q,t}E_t \tag{17}$$
上下文侧投影 $W_{Q,c}E_c$、$W_{K,c}E_c$、$W_{V,c}E_c$ 每请求算一次;目标侧逐候选。
Attention 矩阵的分块结构。 字段按上下文(C)/目标(T)划分,全 attention 矩阵按双线性情形(Eq.2)分解:
$$A = \mathrm{softmax}\!\left(\begin{bmatrix} Q_cK_c^T & Q_cK_t^T \\ Q_tK_c^T & Q_tK_t^T \end{bmatrix}\right) \tag{18}$$
$Q_cK_c^T$ 块(上下文 query 关注上下文 key)是 rank 2,算一次;其余块 rank 3。
Softmax 注意点。 softmax 归一化在每行分母里混合了上下文与目标贡献。但未归一化的上下文-上下文积可预算,行 softmax 可用 FlashAttention 式的分块 log-sum-exp 组装——把预算的上下文部分和与逐候选目标贡献结合,每个 query 位置只多 O(1) 工作。Attention 节省随"只涉及上下文字段的操作占比"增长,分数计算约 $K^2/(K+M)^2$,二次于 K;同样因末端混 rank,只适用于第一层。
3.7 跨架构适用性¶
表 2:rank-aware 分解对各架构家族交互层的适用性(FC 栈在所有情形都可分解,故省略)
| 架构 | 交互层可分解程度 |
|---|---|
| DLRM / DeepFM | FM pairs:完全 |
| FM / FFM / NFM / PNN | FM/bilinear:完全 |
| FinalMLP | Two-stream:完全 |
| DCNv2 / GDCN | Cross:仅第一层 |
| AutoInt / InterHAt | Attention:部分 |
| FiBiNET | Bilinear:部分 |
| MaskNet | Gated:部分 |
| xDeepFM | Outer products:部分 |
| DHEN | 逐子模块 |
DLRM 这类(主流工业范式)完全适用;cross 网络部分(仅第 0 层,见 §4.2 rDCN);attention 部分(softmax 注意点)。
4. Rank-Aware 架构设计(第二族贡献:放弃严格等价,换全深度节省)¶
§3 的分解优化既有架构而不改预测,但节省有上界:cross 网络与 attention 每层都在输出里混 rank,所以分解只在第一层成立。§4 引入一类互补的架构变体——通过对层的形式施加约束、接受"不再 identity-equivalent",换取沿深度复合的节省。离线评估显示这些变体精度在训练噪声内(§5.1)。
4.1 非对称加载原理(Asymmetric Loading Principle)¶
混 rank 有特定来源:在 DCNv2 里,off-diagonal 的 $W_{ct}$ 块把 rank-3 目标输入加载进层状态的"上下文维度那一半";在 self-attention 里,上下文字段输出去关注目标字段的 key/value,产出依赖每个候选的上下文输出。
由此提出非对称加载原理:架构应当只把"上下文×目标"交互加载到目标流(rank 3)上,而上下文流只通过"上下文×上下文"动态演化——这样 rank 分离就能贯穿全深度传播。这条方向性约束是否限制表达力是个经验问题(需要对两种架构都做超参调优才能公平比较)。本文为 cross 网络(§4.2)与 attention(§4.3)各实例化一次。该原理与 §3.4 的 FC 分解可组合:任何 rank-aware 交互栈最终都收敛到"rank-2 上下文表示 + rank-3 目标表示",正好喂给 rank-分解的 FC 层。
4.2 Rank-Aware DCN:rDCN¶
对 DCNv2 cross 网络实例化非对称加载——结构性地删掉 $W_{ct}$ 块(§3.5 的混 rank 元凶),维护两个分别定型的状态:rank-2 上下文流 $c_l$ 与 rank-3 目标流 $T_l$,各由自己的 DCNv2 式层并行更新:
$$T_{l+1} = T_0 \odot \big(\underbrace{W_l^{ct}c_l}_{\text{rank 2, 算一次}} \oplus \underbrace{W_l^{t}T_l + b_l^{t}}_{\text{rank 3}}\big) + T_l \tag{19}$$
$$c_{l+1} = c_0 \odot (W_l^{c}c_l + b_l^{c}) + c_l \tag{20}$$
其中 $W_l^c \in \mathbb{R}^{D_c\times D_c}$、$W_l^{ct} \in \mathbb{R}^{D_t\times D_c}$、$W_l^t \in \mathbb{R}^{D_t\times D_t}$,$\oplus$ 表示沿 N 轴广播加。等价地,对每个候选 j:$T_{l+1}^{(j)} = T_0^{(j)} \odot (W_l^{ct}c_l + W_l^t T_l^{(j)} + b_l^t) + T_l^{(j)}$。
图 1(论文中以等价分块矩阵形式 $[W_l^t \mid W_l^{ct}][T_l; c_l]$ 可视化目标流;$c_l$ 这片拼接输入同时也是上下文流 cross 层的输入)展示了一层 rDCN 的双流结构:
图 1(论文原图,矢量图未提取为位图,此处文字描述):一层 rDCN 分上下两条流。 - 上行:目标流(rank-3,逐候选)。$T_{l+1} = T_0 \odot (\text{Feat. Crossing} \times [T_l; c_l] + \text{bias}) + T_l$,特征交叉块用 $[W_l^t \mid W_l^{ct}]$ 同时吃自己的目标状态 $T_l$ 和共享的上下文状态 $c_l$。 - 下行:上下文流(rank-2,每请求一次)。$c_{l+1} = c_0 \odot (W_l^c c_l + b_l^c) + c_l$,是只作用在 $c_l$ 上的标准 DCNv2 stack。 - 关键:$c_l$ 张量被两条流共享——它驱动自己的上下文 cross,也被目标流通过 $W_l^{ct}c_l$ 读入;但没有任何权重矩阵从目标输入产出上下文维度输出,所以两条流在每一层分别严格保持 rank-2 / rank-3。
可用如下 Mermaid 概括双流的数据流(论文图 1 的语义骨架):
flowchart LR
subgraph 上下文流["上下文流 c (rank-2, 每请求一次)"]
c0["c_l"] -->|"W_l^c · c_l"| cx["⊙ c_0 + c_l"] --> c1["c_{l+1}"]
end
subgraph 目标流["目标流 T (rank-3, 逐候选 N)"]
T0["T_l"] -->|"W_l^t · T_l"| Tmix["⊕ 广播加"]
c0 -->|"W_l^ct · c_l (rank-2, 算一次, 广播)"| Tmix
Tmix -->|"⊙ T_0 + T_l"| T1["T_{l+1}"]
end
- 上下文流(Eq.20) 就是只作用在 $c_l$ 上的标准 rank-2 DCNv2 stack,沿深度通过高阶 ctx×ctx 交叉演化上下文表示。
- 目标流(Eq.19) 是非对称加载:通过 rank-2 cross matmul $W_l^{ct}c_l$(每请求算一次、沿 N 广播)读入已演化的上下文 $c_l$,与逐候选状态 $W_l^t T_l$ 结合,再与 $T_0$ 做 Hadamard。没有权重矩阵从目标输入产出上下文维度输出,于是两条流在每层分别保持 rank-2 与 rank-3。
- 上下文流是"load-bearing"(承重)的:经验上删掉上下文流会造成非平凡的精度退化(表 3 最后一行 DCN,记作 rDCN**),尽管它带来的 FLOP 节省微乎其微——这证明它捕获的高阶 ctx×ctx 动态确实重要。
每层参数。 rDCN 只读上下文 $c_l$,无需 target-to-context 耦合。基线 DCNv2 每层 $(D_c+D_t)^2$ 个权重参数;rDCN 三个矩阵合计 $D_c^2 + D_cD_t + D_t^2$,每层省 $D_cD_t$。
每层 FLOPs。 上下文流贡献 $\Theta(D_c^2)$(独立于 N)。目标流贡献每请求一次的 cross matmul $\Theta(D_tD_c)$ 加上逐候选目标 matmul $\Theta(ND_t^2)$。基线 DCNv2 每层 $\Theta(ND^2) = \Theta(N(D_c^2 + 2D_cD_t + D_t^2))$($D = D_c+D_t$)。rDCN 坍缩为 $\Theta(D_c^2) + \Theta(N(D_tD_c + D_t^2))$:上下文驱动的 matmul 被整个移出 N-循环,剩余逐候选工作只线性于上下文维度 $D_c$,而基线是二次。
4.3 Rank-Aware Attention(草拟)¶
同样的双流设计搬到 attention:维护 rank-2 上下文流 $c_l$ 与 rank-3 目标流 $T_l$,各由自己的 attention 子层更新。
- 上下文流:标准 rank-2 self-attention,Q/K/V 全来自 $c_l$;每层 $\Theta(D_c^2)$,独立于 N。
- 目标锚定流(target-anchored):query 只从目标侧取,$Q = T_l W_Q$(rank 3)。Key/Value 按来源拆分:$K^c = c_l W_K^c$、$V^c = c_l W_V^c$ 在 rank 2(每请求算一次),$K^t = T_l W_K^t$、$V^t = T_l W_V^t$ 在 rank 3。目标 query 关注拼接 $[K^c; K^t]$,输出 $[V^c; V^t]$ 的加权和。因上下文 key/value 在 rank 2 产出,其投影成本摊到全部 N 个候选。
生产实现与经验评估留作未来工作。
5. 实验¶
评估分三段:(1) 在两个架构家族(DCN 系、DLRM 系)上对比 rank-aware 各组件贡献(FLOPs + 离线指标,§5.1);(2) 在生产硬件上扫特征数刻画单 pod 吞吐(§5.2);(3) Taboola 平台生产部署结果(§5.3)。
5.1 组件贡献对比¶
表 3:跨架构家族的组件贡献。 ΔFLOPs 是相对各家族 vanilla 基线的百分比变化;LogLoss 为绝对值,括号内为相对 vanilla 的百分比变化。变体名列出应用了 rank-aware 优化的组件("+FC"表示在交互层变体之上再叠 rank-aware FC);rDCN** 表示删掉并行上下文流的 rDCN。
DCN 系($K=26, M=16, d_c=514, d_t=577, L=4$):
| 变体 | Int. ΔFLOPs | FC ΔFLOPs | Total ΔFLOPs | LogLoss (Δ%) |
|---|---|---|---|---|
| DCNv2 + FC | −18% | −36% | −20% | 0.3876 (+0.02%) |
| rDCN + FC | −72% | −36% | −67% | 0.3877 (+0.05%) |
| rDCN** + FC | −72% | −36% | −67% | 0.3886 (+0.27%) |
DLRM 系($K=27, M=4, d_c=3456, d_t=512$):
| 变体 | Int. ΔFLOPs | FC ΔFLOPs | Total ΔFLOPs | LogLoss (Δ%) |
|---|---|---|---|---|
| FM | −87% | 0% | −17% | 0.3875 (+0.03%) |
| FM + FC | −87% | −69% | −73% | 0.3875 (+0.01%) |
结论分析:
- identity-equivalent 分解逐位复现 vanilla:每个家族内,精确 rank-aware 分解把预测重现到噪声水平(±0.0001 logloss),与"数学精确重写"的预期一致。这验证了 §3 的分解确实无近似。
- rDCN 用一点点精度换巨大的 compute/参数下降:架构变体 rDCN+FC 放弃严格等价,在 ±0.0002 logloss 内匹配 DCNv2,却省 67% 总 FLOPs、且没有 $W_{ct}$ 块。
- 并行上下文流是承重的:删掉它(rDCN**,DCN 最后一行)几乎不带来额外 FLOP 节省,却让 logloss 退化约 0.001——比表里其它"噪声内"差异大一个数量级,证明并行流捕获的 c×c 交互确实 load-bearing。
- 为何生产选 DLRM 而非 rDCN:DLRM 系目前在生产;rDCN 已离线验证但未上线。虽然 rDCN 在 DCN 家族内大幅减 compute(表 3),但 DLRM 系 FM+FC 变体在更低总 compute 下就达到同等离线精度。rDCN 的 $\Theta(D_tD_c)$ 每层成本意味着在 DCN 家族内扩张上下文(当前 $d_c=514$ vs DLRM 的 3456)会比 DCNv2 便宜得多——这个方向留作未来工作。
5.2 吞吐刻画¶
在合成 DLRM 系模型(FM 交互层 + FC 层)上经验验证理论,每次只变一个特征数参数。每个配置建两遍——vanilla 与 rank-aware 分解——在同一硬件上服务:16-vCPU pod,16 GiB RAM,Intel Xeon Silver 4510(Sapphire Rapids, 2.4–4.1 GHz, AMX/AVX-512 VNNI),跑 TensorFlow Serving 2.x + oneDNN。客户端在闭环里维持 64 个并发在途请求(一个响应返回就立刻派发新请求),记录稳态 RPS。报告归一化 RPS:每个测量值 / 最小模型 vanilla 基线(K=4, M=4)的 RPS = 1.00。
实验 A:变上下文特征 K(M=4 固定)。
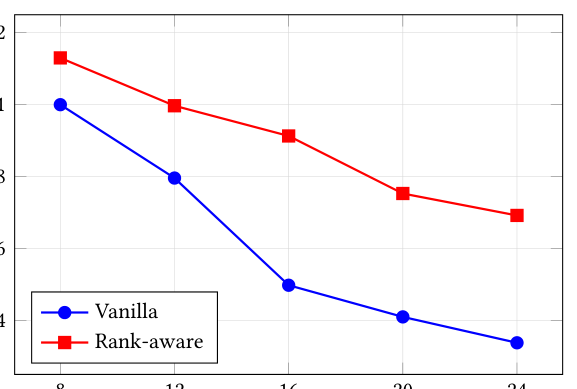
Vanilla 陡降(1.00 → 0.34),rank-aware 平缓得多(1.13 → 0.69)。rank-aware 优势从 K=8 的 +13% 拉宽到 K=24 的 +105%。这直接印证 §3.3/3.4 的二次-于-K 节省:上下文越多,被摊掉的冗余越大。
实验 B:变目标特征 M(K=8 固定)。
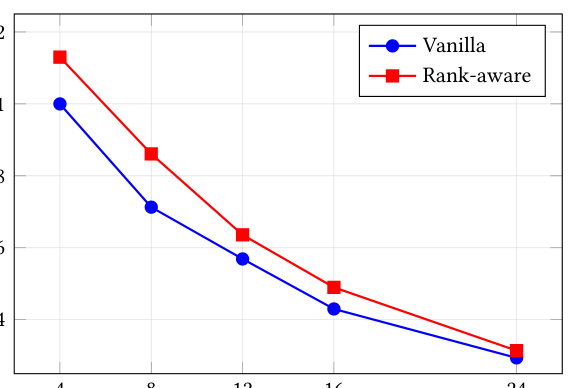
两线近乎同步下降(vanilla 1.00 → 0.29;rank-aware 1.13 → 0.31);rank-aware 优势停在 +7~+21% 的窄带。随 M 增大,目标侧计算主导,上下文-only 的 rank-aware 节省占总工作的比例缩小。这正是"成本不对称"的经验体现:加上下文几乎免费(K↑ 优势变大),加目标才真贵(M↑ 优势被淹没)。
5.3 生产验证¶
把 DLRM 系 FM+FC rank-aware 变体(§5.1)上线到 Taboola 推荐平台,与 vanilla 基线对比。
表 4:DLRM 系排序器生产部署结果。 所有值为相对 vanilla 基线的百分比变化。单 pod RPS 在固定延迟 SLA 下的峰值流量测得;p50、p99 为平均延迟。
| 变体 | RPS/pod | p50 | p99 |
|---|---|---|---|
| FM rank-aware | +25% | −17% | −26% |
| FM + FC rank-aware | +87.5% | −30% | −33% |
结论分析:
- 生产排序模型跑在 CPU 基础设施上,自动扩缩的 Kubernetes pod 维持固定延迟 SLA,因此单 pod 吞吐(RPS/pod)直接度量服务效率。
- 仅 FM 优化就把单 pod 吞吐提升 25%;叠加 FC 优化复合到 +87.5%(等价于峰值 pod 数减少 47%)。FC 优化并非对 FM 优化的边际微调——它捕获了剩余冗余里有意义的一份额,与 §3.4 一致:两个阶段都贡献二次-于-K 的节省,沿前向复合。
- wall-clock 延迟:两个百分位都随 rank-aware 优化单调下降;p99 降得比 p50 多(−33% vs −30%),与"上下文-上下文冗余在 vanilla 实现里不成比例地影响尾延迟"一致。
核心贡献总结¶
- 一条统一代数原理 + 全覆盖实例化:任何 rank-划分输入上的线性/双线性算子都可精确分块分解,把上下文-only 计算从"每候选一次"降到"每请求一次"。实例化到 FM 配对积、FC、DCNv2 cross、self-attention,给出每处的 FLOP 节省闭式。
- 揭示成本不对称:节省二次于 K(上下文字段数)、对 M(目标字段数)不敏感——这一不对称在纯 MLP 架构里不存在(FC 节省只线性于 K)。它把"加上下文 vs 加目标"变成一个新的、不对称的设计权衡。
- identity-equivalent 的工程价值:不改模型结构、预测逐位相同,生产 DLRM 排序器单 pod 吞吐 +87.5%、p50 −30%、p99 −33%。这是"零模型风险"的纯工程收益。
- rDCN:把 rank 纪律推到全深度:识别"混 rank"的元凶是 DCNv2 的 off-diagonal $W_{ct}$ 块,结构性删除之、改双流并行,在训练噪声内匹配 DCNv2 而省 67% 总 FLOPs;并草拟了对应的 rank-aware attention。
与已归档相关工作的对比¶
OneTrans OneTrans:统一因果 Transformer 骨干 + Cross-Request KV Caching(ByteDance, 2025-10-30)¶
关系:独立并发 / 殊途同归(本文未引用 OneTrans,两者从完全不同的工具箱抵达同一服务优化)· 已加载对方精读
- 共同关注的问题(同一 root cause):两篇都精确指向多目标打分里的同一结构性浪费——一次请求里的 N 个候选共享同一套用户/上下文(OneTrans 的 S-tokens / 本文的 context 特征),但标准实现把上下文-only 的计算逐候选重复了 N 次。OneTrans §2.5.1 原话:"同一请求的多个候选物品共享相同的 S-tokens(用户行为历史),仅 NS-tokens 因候选物品不同而变化……KV 缓存将 S 侧计算分摊到所有候选物品上,时间复杂度从 $O(C)$ 降至 $O(1)$"——这与本文 Eq.4 把 FM 拆成"$\mathrm{FM}_{\mathrm{ctx}}$ 每请求一次 + $\mathrm{FM}_{\mathrm{tgt}}$ 逐候选"是同一诊断。
- 相近的技术骨架(抽象可重合):两者的方法流程图在正确抽象层上重合——"识别出'用户/上下文不变'的子计算 → 每请求只算一次 → 跨 N 个候选复用/广播 → 只在与候选混合时才进入 N-循环"。OneTrans 把它做成两阶段推理(Stage I:S 侧每请求一次,缓存 KV;Stage II:NS 侧逐候选,与缓存 KV 做 cross-attention);本文把它做成 rank-2/rank-3 的分块代数(context 块算一次、target 块逐候选、broadcast-add 混合)。OneTrans 的"S 侧 / NS 侧"恰好对应本文的"rank-2 context / rank-3 target",cross-attention 对应本文的"非对称 matmul 混合"。
- 本文的差异与推进:(1) 精确 vs 架构内建——本文是 identity-equivalent 的纯代数重写,不改模型结构、预测逐位相同、零训练,可直接套到既有 FM/DCN/attention 上;OneTrans 的摊销是内建在一个全新的统一 Transformer 骨干 + KV 缓存机制里,需要替换整个排序架构并重训。(2) 一般性——本文把"rank 不对称"抽象成一条覆盖 FM/cross/attention/FC 的通用原理,并给出每处节省的闭式(二次于 K);OneTrans 的 KV 缓存是其 Transformer 架构的一个具体工程优化,绑定在 attention 上。(3) 节省的代数刻画——本文显式证明节省二次于上下文字段数 K 且对目标数 M 不敏感(成本不对称),OneTrans 只给出 $O(C)\to O(1)$ 的复杂度陈述,未刻画与上下文规模的标度关系。
- 可比的方法 / 实验差异:OneTrans 在 GPU、生成式 Transformer 骨干、+5.68% GMV/u 在线,KV 缓存让推理延迟/内存各降约 30%/53%(其表 4);本文在 CPU、判别式 DLRM/DCN、不改预测地 +87.5% 单 pod 吞吐(其表 4)。两者还有一个互补的"额外维度":OneTrans 的 KV 缓存因用户行为序列是追加式的,还能跨请求复用($O(L)\to O(\Delta L)$);本文的分解是请求内的精确摊销,跨请求复用不在其范围。一句话:OneTrans 把摊销焊进架构、顺带拿到跨请求复用;本文把摊销证成代数恒等式、换来零模型风险与可移植性。详细精读见 OneTrans。
讨论与局限性¶
核心可借鉴的设计。
- "rank 即 batch 维度"的视角极简而锋利:把"跨候选共享 = rank-2、逐候选 = rank-3"形式化后,"哪些计算能摊销"变成纯粹的 rank 簿记问题,无需逐算子手工分析。这套语言可以直接迁移到任何多目标打分系统。
- 成本不对称是真正的"设计杠杆":它把"加特征"从一个对称决策变成不对称的——上下文特征近乎免费(实验 A:K↑3× 仅 −39% RPS),目标特征才贵(实验 B:M↑3× −64% RPS)。这给特征工程一个反直觉但可操作的指引:优先把信息塞进上下文侧。
- identity-equivalent 是部署友好性的极致:predictions 逐位相同意味着零 A/B 风险、零重训、可灰度,这是工业界最稀缺的"白拿"。
局限与争议。 1. 单作者、单平台、缺公开 benchmark:所有离线/在线数字都来自 Taboola 生产数据与合成模型,没有任何公开学术数据集(Amazon、MovieLens 等)或可复现的 benchmark 表,外部无法独立验证 87.5% 这个数字的可迁移性。 2. rDCN 仅离线:第二族贡献(rDCN、rank-aware attention)只有离线 logloss,且 rank-aware attention 仅是"草拟"(Eq.17-18 + §4.3 文字),无实现无实验。作者自己也承认生产选了 DLRM+FM 而非 rDCN,因为 DLRM 系在更低 compute 下已达同等精度——rDCN 的实际卖点(在 DCN 家族内廉价扩张上下文)尚未被任何实验支撑。 3. 适用边界明确但收窄:分解只在"上下文与目标在交互层仍分别可访问"时成立。对 early-fuse / target-attention 架构(DIN、ETA、TWIN——恰恰是当前长序列建模主流)根本不存在上下文-only 路径,本文方法失效。作者把这列为未来工作(可借 TransAct 式 target-token injection 处理,但那本身就破坏 rank 纪律)。 4. 与既有工作的边界:相对 MaRI(自动图着色找冗余 matmul,线性于 $d_c$)、Low Rank FwFM(仅 FwFM、需近似)、ROO/AIF(系统层、训练侧或近似),本文的差异化是"先验代数 + 二次节省 + 覆盖配对/cross/attention + 精确"。但 §2 对这些工作的对比多停留在定性叙述,缺与 MaRI/AIF 在同一系统上的并排实验。
与已有工作的差异(一句话定位)。 本文是把"用户/上下文计算在 N 个候选间共享"这个工业界人尽皆知的直觉,第一次系统地证成一条覆盖 FM/cross/attention 的、二次节省的、identity-equivalent 的代数原理——既不像 OneTrans 那样要换架构,也不像 MaRI 那样停在线性、只看 matmul 节点。它的价值不在某个新模型,而在于给"上下文特征是廉价的"这句口号配上了精确的代数与生产级的吞吐证据。