Beyond Static Best-of-N: Bayesian List-wise Alignment for LLM-based Recommendation¶
研究动机与背景¶
把大语言模型(LLM)接入推荐系统形成的 LLM4Rec 范式,是把推荐改写为「以用户历史为 prompt、用 LLM 自回归生成下一个 item 标题(或 SID)序列」的条件序列生成任务。BIGRec、TallRec、LLaRA 等代表性工作把这条 pipeline 走通后,下一个核心问题就变成:如何让 LLM 的训练目标对齐到真正决定推荐质量的非可微 list-wise 指标(NDCG、Recall@K、Fairness、Diversity)上?
主流后训练方案——SFT 直接最大似然 ground-truth、DPO 在 token / pair 层做偏好——目标都是 token-level 或 pair-level 局部信号,而 NDCG / 公平性 / 多样性等指标定义在整列推荐 list 之上,是离散、非可微、捕捉 item-item 全局交互的 holistic reward。这就在「训练目标」与「推理时被评估的指标」之间留下一道天然的 misalignment 缝隙。
绕过非可微性的两条路:
- 推理时 Best-of-N(BoN)搜索([31, 36, 37]):每个 prompt 采 N 条候选 list,按 list-wise reward 选最优。BoN 在 LLM 对齐文献里早被证明是非常强的基线。但代价是推理延迟随 N 线性放大——图 1(a)、1(b) 显示 NDCG@5 与 N 同步上升时 Time Cost 也同步线性上涨,对实时推荐服务(user-facing latency 约束)不可接受;
- BoN Alignment(BoN 蒸馏)([2, 29]):把 BoN 的搜索能力蒸馏进模型权重,使单次前向就能采到「BoN 等价」的高质量回复。Bond [29]、Bonbon [16] 等用 variational 视角把 BoN 的诱导分布 $\pi_\text{BoN}$ 直接当作目标,让 policy 通过 KL 最小化 / quantile-based reward 来逼近。
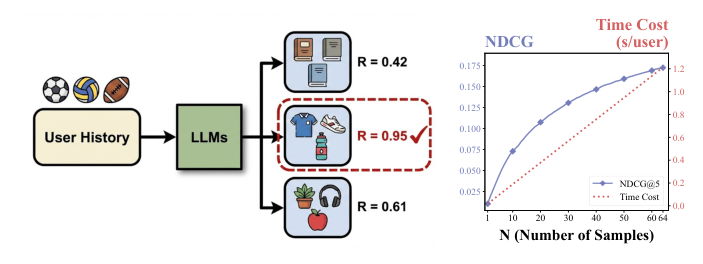
但作者把 BoN Alignment 应用到 list-wise 推荐场景后,识别出两个根植于 static reference 的结构性瓶颈:
- Indiscriminate Supervision:BoN 目标分布是参考分布的一次重加权,CDF 用一组固定的 reference 样本 $\mathcal{D}_\text{ref}$ 经验估计。一旦 policy 学到了 reward 高于 $\mathcal{D}_\text{ref}$ 经验最大值 $R_\text{max}$ 的候选,估计的 CDF 就饱和到 1,所有「超过参考上限」的候选被赋同样的 target probability。优化目标就无法在 superior candidates 之间分辨好坏,丢掉关键的 ranking guidance;
- Gradient Decay:随着 policy 朝高奖励区域漂移,rollouts 的 reward 越来越落在 reference CDF 的稀薄右尾,$F_\text{ref}(R(y)) \to 1$ 使 quantile reward $(N-1)\log F_\text{ref}(R(y))$ 趋于零,有效监督信号迅速衰减,训练在到达全局最优前就提前停滞。
形式上,对静态 reference 的 quantile 估计:
$$\pi_\text{BoN}(y) = \sum_{k=1}^{N}\binom{N}{k}(F_\text{ref}(R(y)))^{N-k}\pi_\text{ref}(y)^{k}, \tag{5}$$
直接优化 reverse-KL 太昂贵,故采用其 variational 下界:
$$\mathcal{J}_\text{BoN}(\theta) = \mathbb{E}_{y\sim\pi_\theta}\left[(N-1)\log F_\text{ref}(R(y)) - \log\frac{\pi_\theta(y)}{\pi_\text{ref}(y)}\right]. \tag{6}$$
把上式写成「对 KL 做最小化」的形式可得:
$$\mathcal{J}(\theta) \simeq \mathbb{E}_{y\sim\pi_\theta}\left[\underbrace{(N-1)\log F_\text{ref}(R(y))}_{\text{Quantile Reward}} - \underbrace{\log\frac{\pi_\theta(y)}{\pi_\text{ref}(y)}}_{\text{KL Regularization}}\right]. \tag{7}$$
这里 quantile reward 正是问题源头:估计依赖 $\mathcal{D}_\text{ref}$ 的固定支撑,一旦 policy 越过它就无法继续提供有意义的梯度。
为系统化地解决这两个静态参考瓶颈,作者提出 BLADE(Bayesian List-wise Alignment via Dynamic Estimation)——把对齐从「锚到一个固定参考」转向「追逐一个自演化目标」。BLADE 用一个贝叶斯框架把 historical prior(static reference)和 dynamic evidence(policy 当前 rollouts)做闭式融合,构造一个self-evolving target distribution,让 supervision 在整个训练轨迹里始终与 model 当前能力匹配。同时通过「shared sampling」把 Bayesian estimation 与 GRPO advantage 计算共用同一组 rollouts,使总体计算开销与 static BoN alignment 完全相同。
主要贡献:
- 系统性地剖析了 BoN 策略在 LLM4Rec 的两个核心瓶颈(Indiscriminate Supervision、Gradient Decay),并把它们追溯到「static reference distribution」这一统一根因;
- 提出 BLADE:用 Bayesian dynamic estimation 在线融合 static prior 与 dynamic evidence,构造 self-evolving target,配合 GRPO 实现 critic-free、零额外采样成本的优化;
- 在 3 个数据集(Amazon CDs and Vinyl、Steam、Goodreads)上证明 BLADE 一致优于 SOTA baseline,同时框架可推广到 fairness(MGU)、diversity(ILD)等复杂 list-wise 目标。
核心方法¶
任务形式化¶
记用户集 $\mathcal{U}$、item 集 $\mathcal{I}$。对每个 $u \in \mathcal{U}$,根据交互历史构造文本 prompt $x$,policy $\pi_\theta$ 自回归生成 token 序列 $y = (y_1, \dots, y_T)$,其概率分解为:
$$\pi_\theta(y \mid x) = \prod_{t=1}^{T}\pi_\theta(y_t \mid x, y_{<t}). \tag{1}$$
response $y$ embedding 着一个 size-$K$ 的 ordered 推荐 list;优化目标是非可微 list-wise reward $R(y; u)$(如 NDCG、Diversity 等)。
GRPO 作为 critic-free RL backbone¶
PPO 类方法依赖 critic 估算期望回报,引入 value approximation error 与 doubled memory。Group Relative Policy Optimization(GRPO)[30] 给同一 prompt $x$ 一次性采样 $G$ 条独立 candidate list $\{y_1, \dots, y_G\}$,用组内统计构造 advantage:
$$A_i = \frac{R(y_i) - \mu_G}{\sigma_G}, \tag{2}$$
其中 $\mu_G, \sigma_G$ 是组内 reward 的均值与标准差。最终目标带 token-level clipped 重要性比:
$$\mathcal{J}(\theta) = \mathbb{E}_{\pi_{\theta_\text{old}}}\Big[\frac{1}{G}\sum_{i=1}^G\frac{1}{T_i}\sum_{t=1}^{T_i}\big(\min(\rho_{i,t}A_i, \text{clip}(\rho_{i,t}, 1-\epsilon, 1+\epsilon)A_i) - \beta\mathbb{D}_\text{KL}(\pi_\theta(\cdot \mid h_{<t}) \| \pi_\text{ref}(\cdot \mid h_{<t}))\big)\Big], \tag{3}$$
其中 $\rho_{i,t} = \pi_\theta(y_{i,t} \mid x, y_{i,<t}) / \pi_{\theta_\text{old}}(y_{i,t} \mid x, y_{i,<t})$ 是 token-level importance ratio。GRPO 天生 critic-free、内存友好,并且能直接吃任意 list-wise reward $R(y)$,是把非可微 list-wise 指标接入 LLM 训练的理想 backbone。
Static BoN Alignment 的两个失败模式¶
把 BoN 视角嫁接到 GRPO 的 reward 信号上:BoN 选样的概率分布 $\pi_\text{BoN}$(公式 5)的 reverse-KL 下界推得 quantile reward $(N-1)\log F_\text{ref}(R(y))$ 加 KL 正则(公式 6, 7),是当下 LLM4Rec BoN alignment 的标准实现。当 $F_\text{ref}$ 用 $\mathcal{D}_\text{ref}$ 静态估计时,作者形式化地证明两点缺陷:
1. Indiscriminate Supervision。设 $R_\text{max} = \max_{y' \in \mathcal{D}_\text{ref}} R(y')$。一旦 $R(y) > R_\text{max}$,$\hat{F}_\text{ref}(R(y)) = 1$。考虑两个超越参考上限的候选 $y_1, y_2$ 满足 $R(y_1) > R(y_2) > R_\text{max}$,他们仍被赋同分:
$$(\hat{F}_\text{ref}(R(y_1)))^{N-1} = (\hat{F}_\text{ref}(R(y_2)))^{N-1} = 1. \tag{8}$$
监督在 high-utility region 完全 indiscriminate,policy 无法继续向 globally optimal solution 收敛。
2. Gradient Decay。Quantile reward 项的策略梯度(在 trick 化简下)满足:
$$\nabla_\theta \mathcal{J}_\text{qt}(\theta) = \mathbb{E}_{y\sim\pi_\theta}[\nabla_\theta \log\pi_\theta(y) \cdot (N-1)\log F_\text{ref}(R(y))]. \tag{9}$$
随训练进行,$\pi_\theta$ 的 mass 不断向 high-reward region 偏移,越来越多 rollouts 落在 reference 的稀疏右尾,$F_\text{ref}(R(y)) \to 1$,从而:
$$\lim_{F_\text{ref}\to 1}\log F_\text{ref}(R(y)) = 0. \tag{10}$$
有效 supervision 信号迅速归零,训练在到达全局最优前提前停滞——这是「static reference 不再能反映 policy 当前能力」的典型副作用。
总览:从静态参考到自演化目标¶
BLADE 的破局点是把 target 的构造过程改成一个动态贝叶斯估计。每个训练 step 接收 evolving policy 实时 rollouts,把它们当作 "dynamic evidence",与 static prior 闭式融合得到 posterior target distribution,自适应跟随 model 当前 capability 而 scale。这同时解决两个症结:
- 通过把 dynamic 真实 rollouts 引入估计,恢复 high-reward 区的 ranking discrimination(破 Indiscriminate Supervision);
- 通过 recalibrate probability scale,避免梯度因 quantile 饱和而消失(破 Gradient Decay)。
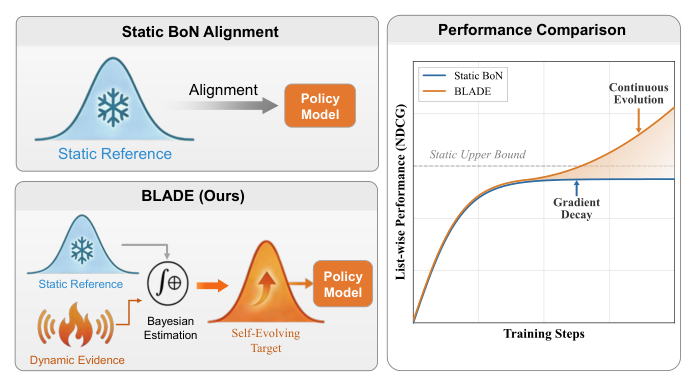
图 2 左对比:static BoN alignment 把 policy 锚到 frozen reference 上,因 signal saturation 在某个时刻停滞;BLADE 把 prior 与 dynamic evidence 实时融合得到 self-evolving target,使训练 trajectory 越过 static upper bound 持续演化。图 2 右用「Latewise Performance vs Training Steps」给出 schematic:static BoN 在某个 plateau 之后停滞,BLADE 持续上行。
Bayesian Dynamic Estimation¶
把 self-evolving target 的核心建模成「robust 估计 reward CDF $F(r) = P(R(y) < r)$」的 real-time Bayesian inference:
Probabilistic Formulation。对每个 reward 阈值 $r$,把对应 quantile $\theta_r = F(r)$ 视为随机变量。由于 $\theta_r \in [0, 1]$,自然选 threshold-specific Beta 分布:
$$\theta_r \sim \text{Beta}(\alpha^r, \beta^r). \tag{11}$$
Beta family 的优势:(a) 支撑集天然匹配 CDF 值域;(b) Beta 与 Binomial likelihood 共轭,posterior 闭式可解,更新极轻。
Bayesian Update Mechanism。Estimator 由两部分构成:
- 静态先验 来自 reference 统计 $\mathcal{D}_\text{ref}$($M$ 个样本),记 $N_\text{ref}^{<r}$ 为参考集中 reward $< r$ 的样本数;
- 动态证据 来自当前 batch $\mathcal{D}_\text{batch}$($G$ 个 rollout),记 $N_\text{batch}^{<r}$ 为 batch 中 reward $< r$ 的样本数。
先验 hyperparameters 从 reference 统计初始化:$\alpha_0^r = N_\text{ref}^{<r}$、$\beta_0^r = M - N_\text{ref}^{<r}$。
为避免 batch evidence 因小样本噪声主导更新,引入 power-scaled likelihood with dynamic coefficient $\tau \geq 0$:
$$P(\theta_r \mid \mathcal{D}_\text{batch}) \propto P(\theta_r) \cdot [P(\mathcal{D}_\text{batch} \mid \theta_r)]^\tau. \tag{12}$$
代入 Beta + Binomial 闭合形式:
$$P(\theta_r \mid \mathcal{D}_\text{batch}) \propto \theta_r^{\alpha_0^r - 1}(1 - \theta_r)^{\beta_0^r - 1} \left[\theta_r^{N_\text{batch}^{<r}}(1 - \theta_r)^{G - N_\text{batch}^{<r}}\right]^\tau$$ $$= \theta_r^{\alpha_0^r + \tau N_\text{batch}^{<r} - 1}(1 - \theta_r)^{\beta_0^r + \tau(G - N_\text{batch}^{<r}) - 1}. \tag{12}$$
立刻识别出仍是 Beta,参数更新:
$$\alpha_\text{new}^r = \alpha_0^r + \tau \cdot N_\text{batch}^{<r}, \quad \beta_\text{new}^r = \beta_0^r + \tau \cdot (G - N_\text{batch}^{<r}). \tag{13}$$
$\tau$ 的物理意义:
- $\tau = 0$:纯 prior 模式,等价于 static estimator(退化回 static BoN alignment);
- $\tau = 1$:标准 Beta-Binomial 共轭更新,batch 与 prior 等量贡献;
- $0 < \tau < 1$:保守模式,把 batch evidence 的有效样本数 tempered 缩小,缓解 small-batch 估计方差。
Posterior 点估计:取 posterior 期望即得 BLADE Dynamic Estimator:
$$\hat{F}_\text{BLADE}(r) = \mathbb{E}[\theta_r \mid \mathcal{D}_\text{batch}] = \frac{\alpha_\text{new}^r}{\alpha_\text{new}^r + \beta_\text{new}^r} = \frac{N_\text{ref}^{<r} + \tau \cdot N_\text{batch}^{<r}}{M + \tau \cdot G}. \tag{14}$$
公式 14 是整篇论文的核心 closed-form:分子里 $N_\text{ref}^{<r}$ 是 static prior、$N_\text{batch}^{<r}$ 是 dynamic evidence、$\tau$ 控制两者权重;分母 $M + \tau G$ 是 effective sample size。整个估计器只需对 reference 做一次预统计,每 step 在 batch 上做一次 binary count 即可更新,几乎零额外计算代价。
通过 Shared Sampling 实现的高效优化¶
BLADE 把得到的 dynamic estimator 直接代入 GRPO 的 reward 项,用 proxy reward 替代 quantile reward:
$$r_i = (N - 1)\log \hat{F}_\text{BLADE}(R(y_i)). \tag{15}$$
进一步代入 GRPO 的 advantage 计算,更新都由 self-evolving target 驱动。
Shared Sampling 机制:BLADE 注意到一个关键 synergy——Bayesian 估计需要一组 rollouts 来计算 $N_\text{batch}^{<r}$,GRPO 的 group-relative advantage 也需要同一组 rollouts 来算 $\mu_G, \sigma_G$。BLADE 把这两件事合二为一:同一批 $\mathcal{D}_\text{batch}$ 同时充当 dynamic evidence 与 advantage baseline,先用它更新 posterior,再立刻用 posterior 计算 policy gradient。这样 BLADE 与 static BoN alignment 完全相同的 sampling 预算就达成 dynamic target 的全部收益(Table 1 中 BLADE 与 BoN Alignment 的 inference cost 都是 1×)。
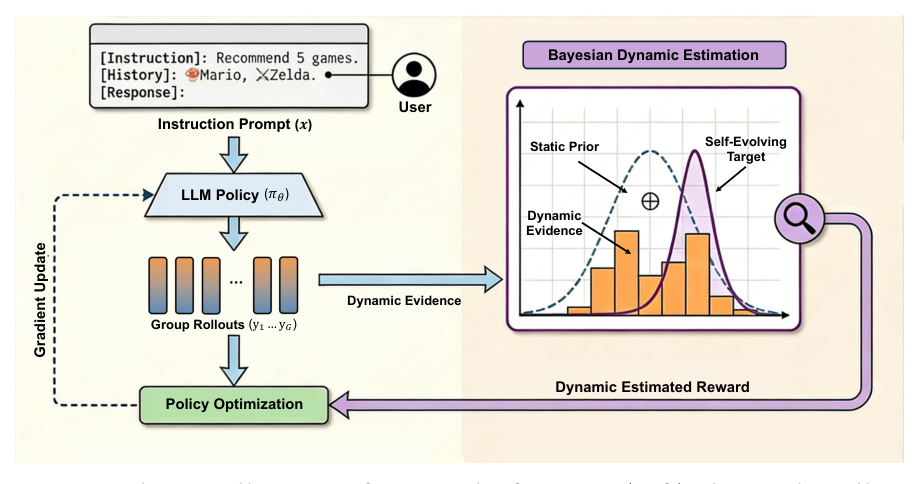
Algorithm 1(BLADE Training)伪码:
Require: π_θ, D_ref, τ, N
1: 预计算 static 统计 {N_ref^{<r}}
2: for batch X ⊂ D do
3: 生成 candidates {y_i}_{i=1}^G ~ π_θ(· | X)
4: for each candidate y_i do
5: # 1. Dynamic Evidence
6: N_batch^{<R(y_i)} ← Σ_{j=1}^G I(R(y_j) < R(y_i))
7: # 2. Estimate Target (Bayesian Fusion)
8: F_hat_i ← (N_ref^{<R(y_i)} + τ N_batch^{<R(y_i)}) / (|D_ref| + τ G)
9: # 3. Proxy Reward
10: r_i ← (N - 1) log F_hat_i
11: end for
12: # 4. Update:GRPO 优化 step
13: end for
最关键的几点:
- 整个估计与更新都在同一组 rollouts 上完成,zero-overhead 相对 static BoN;
- $\hat{F}_\text{BLADE}$ 处处依赖当前 batch 的真实分布,不会因为 policy 漂移而饱和;
- 当 prior 占主导($\tau$ 小或 $G$ 小)时退化为静态估计,保证 stability;当 batch 信号充足时迅速吸收新信号,保证 adaptivity。
Table 1:理论框架的紧凑对照¶
| Method | NDCG@5 | Time (s) | Inference Cost |
|---|---|---|---|
| Base | 0.0283 | 44.56 | 1× |
| BoN ($N = 2$) | 0.0380 | 89.12 | 2× |
| BoN ($N = 4$) | 0.0470 | 178.24 | 4× |
| BoN Alignment | 0.0333 | 44.56 | 1× |
| BLADE | 0.0410 | 44.56 | 1× |
- 推理时 BoN($N=2/4$)证明 list-wise alignment 上限确实存在,但延迟代价不可接受;
- BoN Alignment 把延迟拉回 1× 但 NDCG 只有 0.0333,明显落后于 inference-time BoN——印证 static reference 的 supervision 上限;
- BLADE 在 1× 延迟下达到 0.0410,接近 BoN $N=4$ 的 0.0470 上限,且无需额外推理预算。
实验设置¶
数据集与评估协议¶
三个公开数据集(统计见 Table 2):
| Dataset | # Users | # Items | # Interactions |
|---|---|---|---|
| Steam | 3,050 | 1,473 | 23,217 |
| Goodreads | 5,762 | 3,261 | 101,292 |
| Amazon CDs | 21,347 | 13,078 | 185,855 |
预处理:交互少于 10 的用户被过滤;Steam 与 Goodreads 取 top 15% 最热门 item 以保证 dense interactions。滑动窗口 list-wise sequence:用户历史前 10 个 item 当 context、后 10 个 item 当 target list。
为平衡 alignment 阶段计算成本,alignment 数据子集为 4,096 训练 + 512 验证;所有评估都在完整测试集上——保证 unbiased。
Baselines¶
8 类全方位对照:
- BIGRec [3]:标准 SFT 基线;
- S-DPO [10]:DPO 变体,softmax loss over 多负样本;
- ReRe [34]:constrained beam search RL,加 auxiliary ranking reward;
- SPRec [13]:self-play 把模型生成视作负样本,做 self-debiasing;
- Beam Search [33]:纯 point-wise decoding,按 sequence prob 选 top-K;
- D³ [4]:缓解 amplification bias 与 homogeneity 的 decoding 校准;
- List DPO [27]:标准 RLHF 协议下用 list pair 做 DPO;
- BoN Alignment [2]:本文方法的 static counterpart——核心对照。
S-DPO / List-DPO 在 alignment 阶段前都做了 warm-up SFT;DPO 类 KL $\beta = 0.1$,S-DPO 用 3 个负样本;评估全部 greedy decoding,Beam Search / D³ 用其原始协议。
指标¶
- Recall@k、NDCG@k($k \in \{3, 5\}$):标准准确率;
- Mean Group Unfairness(MGU)[19]:衡量生成 list 与用户 history 在 genre 分布上的差异,
$$\text{MGU} = \frac{1}{|C|}\sum_{c \in C}|P(c \mid L) - P(c \mid H)|, \tag{16}$$
数值越小越公平;
- Intra-List Diversity(ILD)[45]:基于 genre Jaccard 距离,
$$\text{ILD} = \frac{1}{N(N-1)}\sum_{i \neq j}\left(1 - \frac{|g_i \cap g_j|}{|g_i \cup g_j|}\right), \tag{17}$$
值越大越多样。
实现细节¶
- Backbone:Llama-3.2-1B-Instruct [16];
- 硬件:4× NVIDIA A100;
- SFT 阶段:full dataset,3 epochs,lr $1\times 10^{-4}$;
- BLADE 阶段:3 epochs,AdamW,lr $5\times 10^{-6}$,linear decay;group size $G = 16$;reference set $M = 128$;dynamic coefficient $\tau \in \{0.1, 0.3, 0.5, 1.0\}$;rollout temperature 0.8,repetition penalty 1.05。
主要实验结果(RQ1)¶

| Method | Amazon CDs | Steam | Goodreads | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@3 | N@3 | R@5 | N@5 | R@3 | N@3 | R@5 | N@5 | R@3 | N@3 | R@5 | N@5 | |
| BIGRec | 0.0079 | 0.0331 | 0.0103 | 0.0283 | 0.0101 | 0.0375 | 0.0158 | 0.0357 | 0.0166 | 0.0602 | 0.0195 | 0.0545 |
| S-DPO | 0.0099 | 0.0391 | 0.0120 | 0.0319 | 0.0093 | 0.0329 | 0.0147 | 0.0317 | 0.0175 | 0.0642 | 0.0195 | 0.0605 |
| ReRe | 0.0110 | 0.0410 | 0.0135 | 0.0345 | 0.0106 | 0.0382 | 0.0157 | 0.0358 | 0.0176 | 0.0644 | 0.0202 | 0.0584 |
| SPRec | 0.0104 | 0.0409 | 0.0125 | 0.0336 | 0.0109 | 0.0397 | 0.0168 | 0.0374 | 0.0175 | 0.0639 | 0.0195 | 0.0606 |
| Beam Search | 0.0069 | 0.0251 | 0.0095 | 0.0190 | 0.0070 | 0.0253 | 0.0073 | 0.0187 | 0.0013 | 0.0039 | 0.0013 | 0.0028 |
| D³ | 0.0094 | 0.0345 | 0.0119 | 0.0284 | 0.0069 | 0.0232 | 0.0107 | 0.0221 | 0.0118 | 0.0409 | 0.0163 | 0.0358 |
| List DPO | 0.0095 | 0.0380 | 0.0121 | 0.0308 | 0.0096 | 0.0336 | 0.0151 | 0.0325 | 0.0177 | 0.0649 | 0.0196 | 0.0612 |
| BoN Alignment | 0.0098 | 0.0401 | 0.0120 | 0.0333 | 0.0114 | 0.0416 | 0.0168 | 0.0384 | 0.0179 | 0.0653 | 0.0212 | 0.0588 |
| BLADE-R | 0.0130 | 0.0451 | 0.0156 | 0.0379 | 0.0116 | 0.0419 | 0.0171 | 0.0395 | 0.0184 | 0.0672 | 0.0219 | 0.0606 |
| BLADE-N | 0.0119 | 0.0474 | 0.0144 | 0.0410 | 0.0111 | 0.0407 | 0.0155 | 0.0393 | 0.0183 | 0.0686 | 0.0206 | 0.0618 |
BLADE-R 与 BLADE-N 分别用 Recall 与 NDCG 作 reward signal。三处关键 takeaway:
1. 突破 static BoN 上限。Amazon CDs 上 BLADE-N 把 BoN Alignment 的 NDCG@5 从 0.0333 拉到 0.0410(+23.1%),NDCG@3 从 0.0401 拉到 0.0474(+18.2%)。这证实 dynamic target 真实地越过了 static reference 设下的性能 plateau。
2. 优于标准 LLM-based alignment。S-DPO、BIGRec 等 token-level / pair-level 局部目标方法能比 base SFT 提升,但都被 BLADE 拉开明显距离——直接优化 list-level utility 经过 Bayesian framework 更有效。
3. Inference-time decoding 不足以替代权重对齐。Beam Search、D³ 等不更新参数的 decoding 策略表现明显劣于 alignment 类方法;其根因在于「独立采样多个 item 容易陷入 high-prob narrow distribution、产生 semantic repetition」,D³ 用启发式约束抑制重复但无法捕捉 inter-item compatibility 所需的 holistic coherence。BLADE 把这种复杂 inter-item 依赖直接内化到 model parameters,自然产出 diverse-coherent 推荐。
4. 优化目标可控性。BLADE-R 与 BLADE-N 在 Recall vs NDCG 上呈现明确 trade-off:BLADE-R 在 Recall metrics 上更强(如 Amazon CDs R@3 0.0130 > BLADE-N 0.0119),BLADE-N 在 NDCG metrics 上更强(如 Amazon CDs N@5 0.0410 > BLADE-R 0.0379)。这说明 BLADE 框架可以通过选择不同 reward signal 显式 steer policy 到下游 reward landscape,而非仅在某个固定目标上压参数。
Bayesian Dynamic Estimation 机制分析(RQ2)¶
4.3.1 Dynamic Coefficient $\tau$ 的影响¶
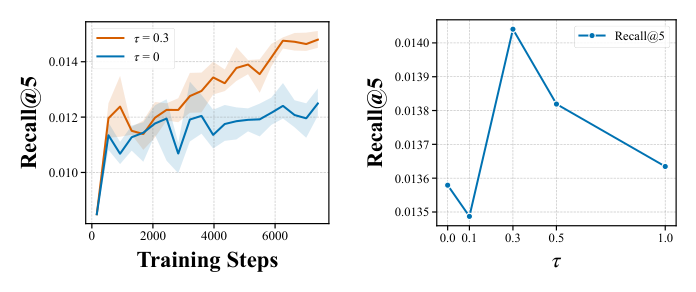
抗 Gradient Decay。图 4(a) 给出 Recall@5 在训练 step 上的曲线:$\tau = 0$(static baseline)训练初期与 $\tau = 0.3$ 几乎重合,但很快 plateau;$\tau = 0.3$ 持续上行,差距随 step 拉大——直接验证「static reference 在 high-reward 区供不出梯度」的诊断,dynamic update 维持了整个 trajectory 的 informative supervision。
先验与 evidence 的平衡。图 4(b) 展示 $\tau \in \{0, 0.1, 0.3, 0.5, 1.0\}$ 的 test Recall@5:$\tau$ 从 0 升到 0.3 性能上升,再升到 1.0 性能开始下降。
- $\tau$ 太小:dynamic evidence 几乎不更新,model 被 anchored 到 suboptimal static prior,restricted exploration;
- $\tau$ 太大:batch 噪声主导,small batch 估计方差爆炸;
- $\tau \approx 0.3$ 是 stability vs adaptivity 的 sweet spot。
4.3.2 Robustness:随 G 的 scaling 与先验稳定作用¶
随 G 的 scaling:图 5 显示 G 从 2 增到 16 时 NDCG@5 与 Recall@5 都单调上升——更大 search space 提供 better dynamic statistics,BLADE 能直接把这种额外计算预算转化为 alignment gain。
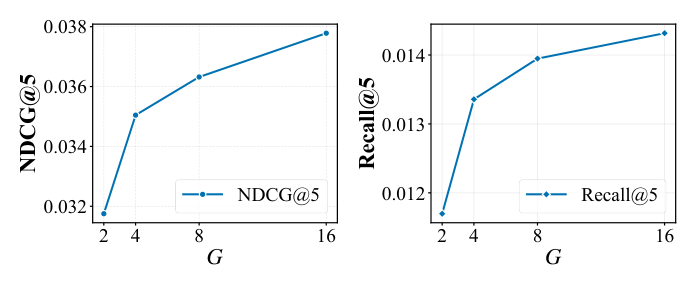
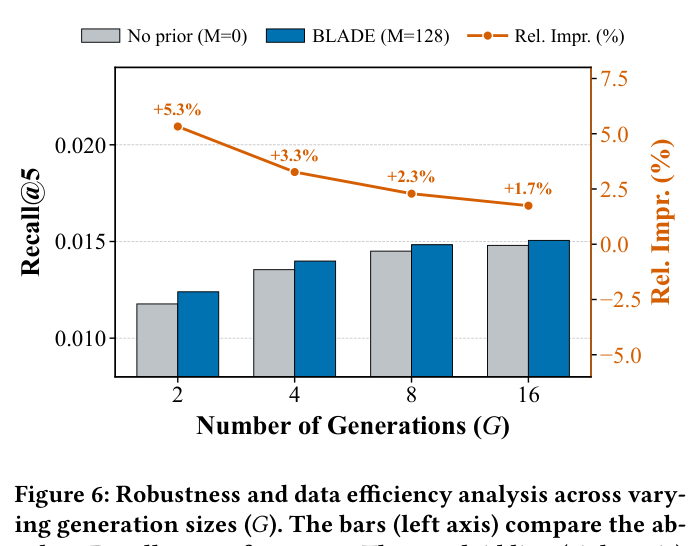
先验的稳定作用:图 6 把 BLADE($M = 128$ 静态先验)与「无先验」($M = 0$,纯靠 batch 估计 CDF)对比:
- $G = 2$ 时 BLADE 比 No-Prior 提升 +5.3%;
- $G = 4$ 时 +3.3%;
- $G = 8$ 时 +2.3%;
- $G = 16$ 时 +1.7%。
差距随 $G$ 减小——当 batch 自身样本充足、CDF 估计趋稳时 prior 的 stabilizer 作用自然减弱;反之 G 越小 prior 越关键。这印证 BLADE 在 resource-constrained 场景特别 robust——只用极小 sampling cost 也能拿到 substantial gain。
推广到多种 list-wise 目标(RQ3)¶
Composite Reward Formulation¶
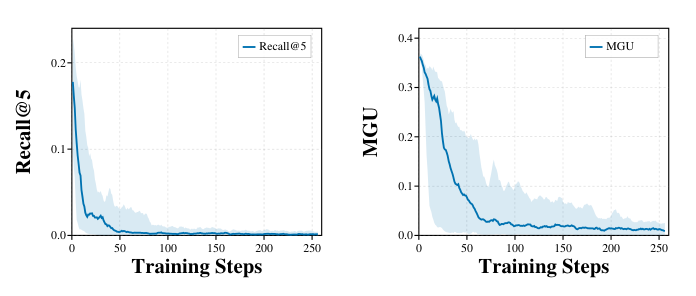
直接优化纯 fairness 或 diversity 这种 auxiliary list-wise 目标,会让 model 快速漂离 relevance manifold。图 7 给出极端案例:单独优化 MGU 的训练曲线下,MGU 确实下降,但 Recall@5 在 50 step 内几乎归零——model 学会了「输出 genre 分布与历史一致但与具体相关性无关」的 cheap solution。
为此 BLADE 用 NDCG 作为 relevance grounding,与 auxiliary 目标做 composite reward:
$$R_\text{fair}(y) = R_\text{NDCG}(y) - \lambda \cdot \text{MGU}(y), \tag{18}$$ $$R_\text{div}(y) = R_\text{NDCG}(y) + \lambda \cdot \text{ILD}(y), \tag{19}$$
$\lambda$ 控制 fairness / diversity 与 utility 的相对权重。
Fairness 优化(MGU)¶
图 8(a) 给出 NDCG@5 vs MGU 散点:
- Pareto Dominance:SFT 基线在 low-accuracy + high-unfairness 角落;BLADE 在所有 $\lambda \in \{0, 0.1, 0.5, 1.0, 2.0\}$ 下都 strictly Pareto-dominate baseline——既更准也更公平,不只是 trade-off;
- 非单调灵敏度:$\lambda \approx 0.5$ 是 fairness sweet spot,再大反而 fairness 收益递减但 NDCG 下降——这种「sweet spot」是 composite reward 设计的常见 pattern。
Diversity 优化(ILD)¶
图 8(b) 给出 NDCG@5 vs ILD 散点:
- 显著 diversity 提升:SFT 与 unconstrained BLADE($\lambda = 0$)都 low-diversity(倾向于推荐 popular item);引入哪怕 $\lambda = 0.1$ 都能 trigger ILD 的快速 adaptation——证明 BLADE 对静态方法忽视的稀疏 high-diversity signal 高度敏感;
- High-Utility Diversity:peak diversity 点($\lambda = 0.5$)下 NDCG 仍显著高于 SFT baseline——多样性 gain 不是 random exploration 来的,而是真的检索到「relevant + diverse」的优质 item。
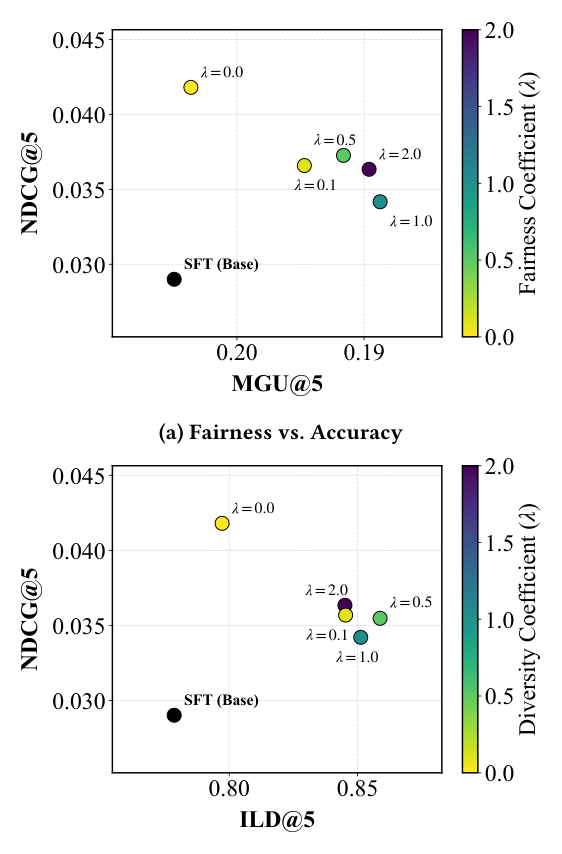
这两组结果进一步坐实 BLADE 是metric-agnostic 框架:把 reward 函数换掉就可以把 alignment 推到任意 holistic list-wise 目标方向,且都能保持高 utility。
与已归档相关工作的对比¶
ReCast ReCast: Recasting Learning Signals for Reinforcement Learning in Generative Recommendation (Huawei, 2026-04-24)¶
关系:独立并发(本文未引用 ReCast,两者发表时间相隔约 12 天)· 已加载对方精读
- 共同关注的问题:BLADE 与 ReCast 都把 LLM4Rec 后训练阶段 GRPO 的 supervision signal 在生成式推荐设定下退化视为关键瓶颈。两者都不是攻击 reward 设计本身,而是攻击「supervision 信号是否还能驱动有意义梯度」。
- 相近的技术骨架:两者都不动 GRPO 的 outer 目标(KL-regularized clipped 策略梯度),只重构 within-group 的 advantage / reward 来源——属于「在 GRPO 的 reward / advantage 接口上做 lightweight drop-in」这一类设计。
- 本文的差异与推进:BLADE 与 ReCast 在 supervision 失效的方向上是镜像对称的:
- BLADE 关注 high-reward 区:当 policy 学到比 static reference 更优的候选,CDF 在右尾饱和($F_\text{ref}\to 1$),quantile reward 与梯度同时塌缩;
- ReCast 关注 low-reward 区:sparse-hit 推荐里大部分 group 是 all-zero(85% in OpenOneRec),group-relative advantage 全部归 0,整组 sample 没有正负边界。
对应解法也镜像:BLADE 用 Bayesian fusion 把 dynamic batch CDF 注入 reference,把右尾里的「都很好」的候选重新展开成有梯度的 ranking;ReCast 用 anchor injection + boundary contrast 把全零组拉回「至少一对正负」的可学状态。两者合起来描绘了 GRPO-LLM4Rec 训练里 supervision 退化的两个并行端点。
- 可比的方法 / 实验差异:BLADE 报 NDCG@5 0.0410(Amazon CDs,Llama-3.2-1B),且做 fairness / diversity composite reward 推广;ReCast 报 Pass@1 +9.1%-36.6%(5 任务,Qwen3-1.7B/8B/14B),强调 search-update decoupling 的 scaling 优势。两者方法在 within-group signal 这一层互不冲突,理论上可以叠加:先 ReCast 修复全零 group,再 BLADE 在修复后的 group 上做 dynamic CDF 估计。
TAWin TAWin: Objective Shaping with Hard Negatives — Windowed Partial AUC Optimization (USTC + Meta AI + RIT, 2026-04-24)¶
关系:独立并发(本文未引用 TAWin,两者同源 USTC 但课题独立)· 已加载对方精读
- 共同关注的问题:TAWin 与 BLADE 都正面攻击 LLM4Rec 后训练中 GRPO 隐式优化目标与 list-wise 评测指标(Recall@K / NDCG)的 misalignment——前者把这个 misalignment 形式化为 「GRPO + binary reward $\equiv$ AUC max;与 Top-K 弱相关」;后者把它形式化为「BoN alignment 的 quantile reward 估计在 high-reward 区 saturates,无法持续刻画 NDCG/Recall」。
- 相近的技术骨架:两者都在 GRPO 框架内做 information-shaping(不是换 RL 算法、不是换 backbone),且都给出严格的理论推导(TAWin: Lemma 3.1-3.5, Theorem 3.4 推 WPAUC 紧界;BLADE: Eq. 5-14 推 Bayesian closed-form)。
- 本文的差异与推进:作用层不同:
- TAWin 改 negative sampling:通过把 constrained random sampling 换成 constrained beam search 再 windowed reweight,把 GRPO 的隐式 objective 从 AUC 推到 OPAUC 再推到 WPAUC,以更紧地对齐 Recall@K;
- BLADE 改 reward 信号:通过 Bayesian dynamic CDF 把 quantile reward 的尺度随 policy 演化重新校准,让 supervision 在 high-reward 区不饱和。
TAWin 解决的是「优化哪个 list-wise 指标」(objective alignment),BLADE 解决的是「优化信号在训练中是否还有效」(signal dynamics)。两者完全正交:TAWin 的 windowed reweighting 给的是 negatives 的采样分布,BLADE 给的是 reward 函数的 calibration——理论上一个完整 LLM4Rec RL stack 可以同时受益。
- 可比的方法 / 实验差异:BLADE 在 Amazon CDs / Steam / Goodreads 上 Recall@5 0.0156 / 0.0171 / 0.0219;TAWin 在 Toys / Industrial / Office 上 Recall@3 提升 +5-10% relative;两者均使用 Llama / Qwen 系列 small backbone。BLADE 还做了 fairness、diversity 的 generalization,TAWin 把焦点放在 Recall@K 的紧 bound 与 hard-negative 解构上。
讨论与局限性¶
核心贡献回顾¶
BLADE 把 LLM4Rec 后训练里两个分散的瓶颈——Indiscriminate Supervision 与 Gradient Decay——统一到「static reference distribution」这一根因下,并给出一个 closed-form 的 Bayesian dynamic estimator(公式 14)作为统一解。整个 framework 的优雅之处在于:
- 概率上的自然性:把 quantile $\theta_r = F(r)$ 当 random variable,Beta 先验 + Binomial likelihood 共轭,更新闭式可解;
- 工程上的轻量:与 static BoN alignment 共享 sampling 预算,zero-overhead;
- 对接 GRPO 的最小改动:proxy reward 替换原 quantile reward,KL / advantage / clip 全保留——是个真正的 drop-in。
值得借鉴的设计¶
- 「dynamic evidence 与 advantage baseline 共用一组 rollouts」的 shared sampling pattern:在所有需要做 group-relative RL 又同时需要 distribution statistics 的场景都可以借用——比如把它推到 OneRec 系或 AgenticRec 系都成立;
- Power-scaled likelihood 的 $\tau$ 调谐:用一个标量同时控制 prior 与 evidence 的有效样本数,避免 small batch 噪声破坏估计——这种 tempered Bayesian update 在大模型 RL 里值得作为通用 technique;
- Composite reward + grounding signal 的工程惯例:fairness / diversity 类目标必须挂着 NDCG 这类 relevance grounding,否则 model 学到 cheap solution。这是 RLHF/RLAIF 里 reward hacking 的经典预防 pattern。
局限性与未尽事项¶
- 仅学术数据集验证:Amazon CDs/Steam/Goodreads 都是中小规模公开 benchmark,无线上 A/B、无工业 latency profiling。Llama-3.2-1B-Instruct 也是 small backbone,未验证在 7B+ 与 industrial-scale catalog 下方法是否依然 robust;
- Beta 假设的表达力:Beta-Binomial conjugate 形式优雅,但对 reward 分布做了「单一 quantile 用 Beta 描述」的假设。对于多模态 reward(如 reward 在两个 cluster 各自集中)可能 underfit,更复杂的 Dirichlet / mixture-of-Beta 是潜在 follow-up;
- Reference set 静态 vs 多次 refresh:先验 $\mathcal{D}_\text{ref}$ 仅在训练开始时 pre-compute 一次,全程不更新。当 policy 已经远离初始 SFT 分布时,prior 本身可能会变得不合时宜——是否 periodic refresh prior 或者用一阶 EMA 来 track,是个开放问题;
- 与 list-wise objective 的耦合方式:BLADE 用 reward 的 quantile 充当对齐目标,但这其实只刻画了「policy 排在 reference 之上的概率」。对 NDCG 的位置敏感性、ILD 的 pairwise 距离结构等,BLADE 仍把它们简化为单维 scalar;可否把 quantile estimate 升级为 per-position quantile(多 threshold 联合)以更细粒度地保留 list 内部结构,是值得探索的方向;
- 与并发工作的关系尚未交叉验证:与 ReCast(low-reward signal repair)、TAWin(windowed negative sampling)的 stack 实证收益未做 ablation,这些都是发表时间相近、机制互补的方向。