Beyond Positive Signals: Unlocking Implicit Negative Behaviors for Enhanced Sequential User Modeling¶
Zexuan Cheng, Yue Liu, Jun Zhang, Jie Jiang —— Tencent Inc., Beijing, China arXiv:2606.15252(2026-06-13)
研究动机与背景¶
用户行为序列建模(user behavior sequence modeling)已经是现代 CTR 预估的核心组件。过去几年,社区把大量精力投入在「如何编码序列」(how to encode)这件事上:从 DIN 的 target-aware attention、DIEN 的兴趣演化网络,到把序列建模与特征交叉统一进单一骨干的 OneTrans / HyFormer / MixFormer 等架构,路线层出不穷。但本文指出,一个同样根本、却被严重忽视的问题是:行为序列里到底应该装什么(what should constitute the behavior sequence)。
当前主流做法默认一个隐含假设——行为序列只由正向交互构成(点击、购买、完播)。而数量上远更丰富的隐式负向行为(implicit negative behaviors:划走 / skip、低参与、快速滑过、低完播)却几乎没有被利用。本文的核心论点是:这个「只看正信号」的设计选择,虽然历史上可以理解,却留下了巨大的未释放价值。
作者用三个收敛的因素解释「为什么负向上下文长期被忽视」:
- 偏好中心视角(preference-centric view):正向行为被视作用户兴趣的清晰指示,负向行为则被认为语义模糊、建模回报低;
- 正序列扩展的边际收益递减(diminishing returns):把正向历史拉长(更长的序列、更好的注意力、更高效的检索)带来的清晰可量化收益,吸走了社区的全部注意力,把负向行为留在了未开发区;
- 同序列内的语义冲突(semantic conflict):正负 token 占据同一个 embedding 空间却携带相反语义,先前试图利用负反馈的工作因此普遍诉诸双流结构或独立编码器,把负样本从主序列建模管线里隔离出去。
为什么现在重提这件事? 动机既实用又有原则性。实用层面:随着序列建模能力被不断增强,扩展正向序列的收益正逼近天花板——正向历史本质上受限于用户真实的参与率(在广告这类场景里正交互极其稀疏),而隐式负向历史则长得多(KuaiRec 上正样本率仅 7.4%,KuaiRand 37.9%,TAAC 6.3%)。原则层面:只由偏好构建的用户表征是不完整的——它捕捉了用户喜欢什么,却没捕捉用户拒绝什么,限制了模型区分「表面相似但实际收到完全不同用户响应」的物品的能力。
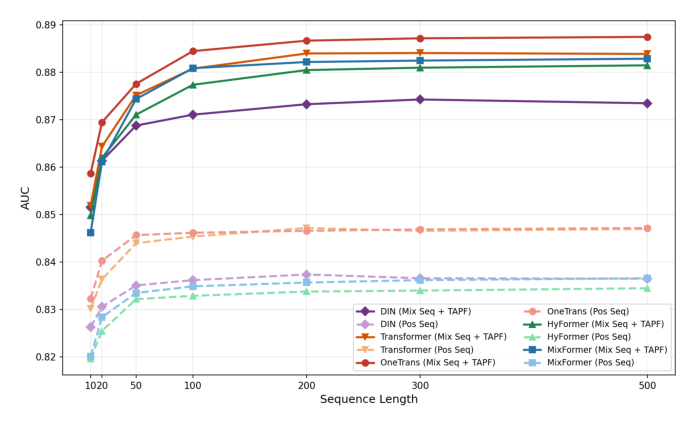
这个汇合点引出了一个自然的问题:隐式负向行为能否为 CTR 预估提供有效信息? 本文给出肯定回答。如下图所示,在固定长度预算内把隐式负向行为交错进行为序列,在 KuaiRec 上让混合极性序列相对纯正向序列取得 4.2%~5.5% 的相对 AUC 提升,且随序列长度预算增大,差距进一步拉开。
本文做出三点贡献:
- 数据层贡献(核心):证明「混合极性序列」(mixed-polarity sequence,把正负 token 按时序交错进同一固定长度预算)在传统两阶段架构(DIN、Transformer)和统一骨干架构(OneTrans、HyFormer、MixFormer)上都一致优于纯正向序列,且几乎不增加计算开销。作者反复强调这首先是一个数据层贡献:在相同算力预算下,仅仅把一部分正向 token 替换成时序上较新的负向 token,就能拿到观测到的绝大部分增益。
- TAPF 机制:识别出正负 token 共享 embedding 空间导致的「语义不可区分性」问题,提出 Target-Aware Polarity Fusion(TAPF),一个轻量的、以目标物品为条件的门控机制,对负向证据做极性感知的语义校准。
- 机制分析:包含注意力极性 gap、用户活跃度分层、冷启动评估、负向行为标签消融等系统性分析,解释「为什么 + 何时」负向上下文最有效。
相关工作定位¶
传统两阶段范式把特征交叉模块与序列建模模块解耦:特征交叉一路从 LR / FM / Wide&Deep 到 DeepFM、DCN/DCN-V2,再到把特征交互当作 token-mixing 的 Hiformer、Wukong、RankMixer、TokenMixer-Large、UniMixer;序列建模一路从 DIN(target-aware attention pooling)、DIEN(兴趣演化)到 BST/SASRec/BERT4Rec 的自注意力,再到为超长序列服务的 MIMN(外部记忆)、SIM、ETA、TWIN、LONGER。这些方法共享一个结构性局限:特征交互与序列建模模块解耦,跨模态信息流受限。
统一架构(unified architectures)则把行为 token 与特征 token 一起喂进共享注意力,在编码阶段就做跨模态交互而非后融合:OneTrans 用因果掩码在一个 Transformer block 里处理候选特征与历史行为 token;HyFormer 用 Global Tokens + Query Decoding / Query Boosting 消除独立压缩阶段;MixFormer 交替 sequence-level 与 feature-level mixing;MTGR 在生成式框架内保留交叉特征并做 user-level 序列压缩。但这些 SOTA 架构与传统模型共享同一特征——它们的行为序列仍然只含正向交互,隐式负向行为里的潜在信号基本未被开发。
负向行为建模已有的工作大多处理显式负反馈(用户主动 dislike、踩)或仅把负样本用作训练期的监督信号:协同过滤里的 BPR、hard negative mining 构造 pairwise ranking 目标但不把负样本编码进用户表征;CL4Rec 构造合成负向视图做自监督预训练;DFN 用专门的反馈交互模块建模显式踩;XDM 在召回阶段用 set-level 对比信号利用未点击;FeedRec 用反馈类型专属交互模块编码异质反馈并引入解耦 loss。这些方法主要依赖显式负信号或领域专属反馈分类法。而本文把隐式负向行为当作一等序列 token,与正向 token 在同一条时序注意力里参与计算,再用极性感知机制做语义校准——这是关键区别。
核心方法¶
总体框架¶
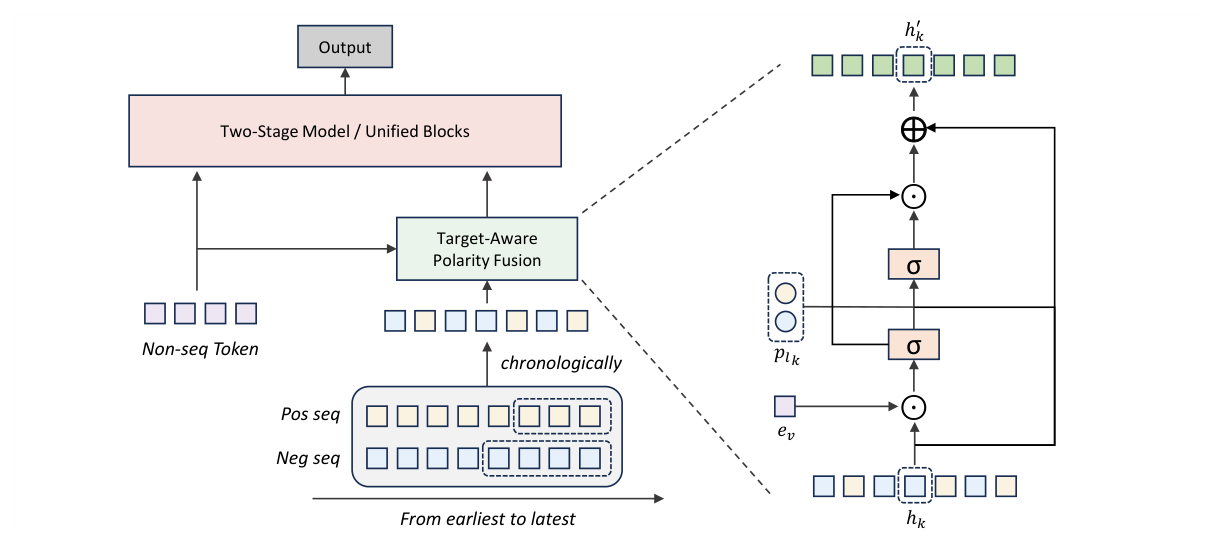
给定用户的正向与负向行为历史,框架分三步:(1) 按时间戳把两者交错成一条混合极性序列;(2) 用极性感知语义校准(§极性感知校准)编码;(3) 通过 TAPF 做目标条件聚合。最终的用户表征与非序列特征拼接,可喂给任意下游 CTR 架构(两阶段或统一 block)。
问题形式化¶
标准 CTR 设定:用户集 $\mathcal{U}$、物品集 $\mathcal{I}$。每个用户 $u$ 关联上下文特征 $\mathbf{x}_u$(人口统计、设备类型等)和一条有序交互历史。本文按行为极性把历史拆成两部分:
- 正向历史 $\mathcal{H}_u^+ = \{(i_1^+, t_1^+), \ldots, (i_{N^+}^+, t_{N^+}^+)\}$:用户正向参与(点击、购买、高完播)的物品,按时间戳排序;
- 隐式负向历史 $\mathcal{H}_u^- = \{(i_1^-, t_1^-), \ldots, (i_{N^-}^-, t_{N^-}^-)\}$:曝光给用户但遭遇 disengagement(划走、低完播、快速滑过)的物品。
给定候选物品 $v \in \mathcal{I}$ 及其特征 $\mathbf{x}_v$,已有序列 CTR 模型只从 $\mathcal{H}_u^+$ 构造行为序列。本文框架从 $\mathcal{H}_u^+$ 和 $\mathcal{H}_u^-$ 两者抽取,构造混合极性序列 $\mathcal{S}_u$,CTR 预估变为:
$$\hat{y} = f(\mathcal{S}_u, \mathbf{x}_u, \mathbf{x}_v) = P(y = 1 \mid \mathcal{S}_u, \mathbf{x}_u, \mathbf{x}_v) \tag{1}$$
其中 $\mathcal{S}_u$ 同时编码正负两种行为信号。
时序交错的混合极性序列构造¶
给定固定序列长度预算 $L$ 和正样本比例超参 $r \in [0, 1]$,构造过程为:
- 从 $\mathcal{H}_u^+$ 取最近 $\lfloor rL \rfloor$ 个交互,从 $\mathcal{H}_u^-$ 取最近 $\lfloor (1-r)L \rfloor$ 个交互;
- 按时间戳合并成单条时序有序序列 $\mathcal{S}_u = \{(i_k, t_k, p_k)\}_{k=1}^{L}$,其中 $p_k \in \{+1, -1\}$ 表示每个 token 的极性。
两个关键设计:时序排序保留了用户行为的自然时间上下文(例如「划走某物品后紧接着点击了一个相关物品」这种序列模式);总长度 $L$ 不变——负向 token 是替换掉一部分正向 token,而非追加在后面,因此序列编码器的推理成本完全不变。后者是本文反复强调的「免费午餐」性质:在相同算力预算下换数据成分,不加任何在线推理代价。
极性感知语义校准:从 PBE 到 TAPF¶
混合极性序列构造完成后,立刻出现一个根本的语义挑战:正负 token 共享同一个物品 embedding 空间,编码器在没有显式极性信息时无法区分它们。本文从一个 naive baseline 渐进到最终方案。
Naive 方案:极性 Bias Embedding(PBE)¶
最直接的做法是给每个 token 加一个可学习的极性类型 embedding,类比语言模型里的 segment embedding。第 $k$ 个 token 的初始表征:
$$\mathbf{h}_k^{(0)} = \mathbf{e}_{i_k} + \mathbf{b}_{p_k} + \mathbf{pos}_k \tag{2}$$
其中 $\mathbf{e}_{i_k} \in \mathbb{R}^d$ 是物品 embedding,$\mathbf{b}_{p_k} \in \mathbb{R}^d$ 是可学习的极性 embedding(零初始化以保证稳定优化),$\mathbf{pos}_k$ 是位置编码。这给编码器提供了一个区分正负 token 的显式信号。
PBE 的局限¶
PBE 解决了基本的类型消歧,但它对所有负向 token 施加一个统一的、与物品无关的偏移:无论用户具体划走了哪个物品、那个物品与当前候选语义上有多相关,每个负向交互都收到完全相同的 $\mathbf{b}_{-1}$。这种刚性使模型无法区分「信息量高的负信号」(例如划走了一个与候选同品类的物品)与「信息量低的负信号」(划走了一个完全不相关的物品)。负向行为的语义角色本质上是相对于目标物品的,静态 bias 捕捉不到这种相对性。
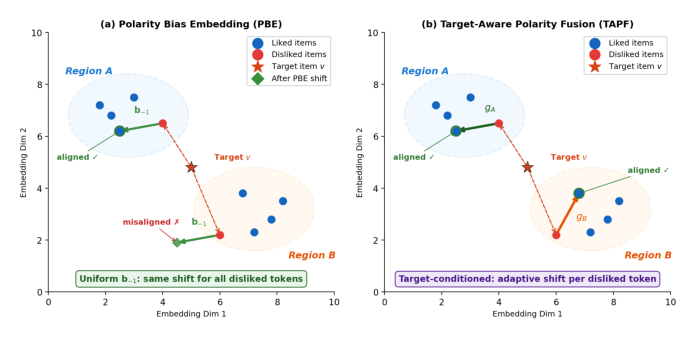
本文方案:Target-Aware Polarity Fusion(TAPF)¶
为解决 PBE 的语义不可区分性,TAPF 引入目标条件化、逐位置的门控交互实现极性感知校准,分三步:
Step 1:目标感知交互(Target-Aware Interaction)。 对每个序列 token $\mathbf{h}_k$,计算它与目标物品 embedding $\mathbf{e}_v$ 的逐元素交互,再过一个非线性层得到交互特征:
$$\mathbf{e}_k = \mathrm{ReLU}(\mathbf{W}_{\mathrm{int}}(\mathbf{h}_k \odot \mathbf{e}_v)) \tag{3}$$
其中 $\mathbf{W}_{\mathrm{int}} \in \mathbb{R}^{d \times d}$ 是可学习投影,$\odot$ 是逐元素乘。这一步捕捉每个历史行为与当前候选之间的相关性。
Step 2:内容自适应门控(Content-Adaptive Gating)。 从原始 token、交互特征、极性 embedding 的拼接计算门控向量:
$$\mathbf{g}_k = \sigma(\mathbf{W}_g [\mathbf{h}_k \,\|\, \mathbf{e}_k \,\|\, \mathbf{b}_{p_k}]) \in (0, 1)^d \tag{4}$$
其中 $\mathbf{b}_{p_k} \in \mathbb{R}^{d_p}$ 是由极性 $p_k \in \{+1, -1\}$ 索引的可学习极性 embedding,$\mathbf{W}_g \in \mathbb{R}^{d \times (2d + d_p)}$。门控作用在全维度 $d$ 上,实现逐维度的细粒度控制。
Step 3:带符号残差融合(Signed Residual Fusion)。 用极性符号 $p_k$ 直接构造带符号残差,得到校准后的表征:
$$\mathbf{h}_k' = \mathbf{h}_k + p_k \cdot (2\mathbf{g}_k - 1) \odot \mathbf{e}_k \tag{5}$$
其中 $(2\mathbf{g}_k - 1) \in (-1, +1)^d$ 充当一个可学习的缩放因子,与极性符号 $p_k$ 结合后,使模型自适应地把正向 token 推向目标、把负向 token 推离目标,且幅度和方向逐维度独立控制。直观上:门控决定「这一维度上要不要校准、校准多强」,极性符号决定「往目标方向推还是反方向推」。
计算成本。 TAPF 只含线性投影和逐元素运算,引入线性计算复杂度,相对于骨干编码器的开销可忽略不计。这与「数据层贡献、不加在线推理代价」的整体立意一致。
实验设置¶
实验围绕四个研究问题(RQ)展开:RQ1 跨架构通用性、RQ2 序列长度 scaling、RQ3 正负组成比例、RQ4 机制理解。
数据集¶
| 统计量 | KuaiRec | KuaiRand | TAAC-2025 |
|---|---|---|---|
| #Users | 7,176 | 1,000 | 9.4M |
| #Items | 10,728 | 4.37M | 2.3M |
| #Interactions | 12.5M | 5.1M | 174M |
| 正样本率 Pos. Rate | 7.4% | 37.9% | 6.3% |
| 最大正向序列长 Max Pos. Len | 2,244 | 20,487 | 57 |
| 最大完整序列长 Max Full Len | 16,015 | 127,647 | 99 |
- KuaiRec:快手稠密观测短视频数据集,正标签定义为 watch ratio ≥ 2.0;
- KuaiRand:随机曝光推荐日志,无偏标签;其随机曝光协议带来更 noisy 的正样本,作为鲁棒性压力测试;
- TAAC-2025:腾讯广告的工业级 CTR 数据集,含 click/conversion 标签。
KuaiRec / TAAC 按用户划分,KuaiRand 按时间划分。注意三者的正样本率都很低(6.3%~37.9%),而最大完整序列长远超最大正向序列长——这正是「负向历史比正向历史丰富得多」的直接证据。
Baseline 架构¶
评估五个模型,横跨两个范式:
- 传统两阶段:DIN、Transformer(标准 Transformer 序列编码器);
- 统一骨干:OneTrans、HyFormer、MixFormer。
每个架构都测三种序列设置:Pos Seq(纯正向,$r=1.0$)、Mix Seq + PB(混合极性 + 极性 bias embedding,$r=0.5$)、Mix Seq + TAPF(混合极性 + TAPF,$r=0.5$)。
实现细节¶
所有模型 embedding 维度 $d=64$,batch size 2048,Adam(lr $10^{-3}$;KuaiRand 用 $5 \times 10^{-4}$),训练 1 个 epoch。序列长度 KuaiRec/KuaiRand 取 $L=100$,TAAC 取 $L=50$。主实验正样本比例 $r=0.5$(完整比例 sweep 见 RQ3)。主指标为 AUC,5 个随机种子平均,标准差以下标形式给出。
主要实验结果(RQ1:跨架构通用性)¶
Table 2 是主结果。对每个架构,报告纯正向 baseline 以及 PB / TAPF 两种混合极性变体。
Table 2:主实验结果(5 seed 均值,下标为标准差)。Δ:相对 Pos Seq 的绝对 AUC 提升;Imp.:相对提升 %。
| 类型 | 模型 | Sequence | KuaiRec AUC (Δ / Imp.) | KuaiRand AUC (Δ / Imp.) | TAAC-2025 AUC (Δ / Imp.) |
|---|---|---|---|---|---|
| 两阶段 | DIN | Pos Seq | 0.8362 (— / —) | 0.6094 (— / —) | 0.7437 (— / —) |
| Pos Seq + TAPF | 0.8387 (+0.0025 / 0.3%) | 0.6098 (+0.0004 / 0.1%) | 0.7432 (−0.0005 / −0.1%) | ||
| Mix Seq + PB | 0.8650 (+0.0288 / 3.4%) | 0.6624 (+0.0530 / 8.7%) | 0.7557 (+0.0120 / 1.6%) | ||
| Mix Seq + TAPF | 0.8711 (+0.0349 / 4.2%) | 0.6655 (+0.0561 / 9.2%) | 0.7607 (+0.0170 / 2.3%) | ||
| 两阶段 | Transformer | Pos Seq | 0.8454 (— / —) | 0.6113 (— / —) | 0.7390 (— / —) |
| Pos Seq + TAPF | 0.8488 (+0.0034 / 0.4%) | 0.6126 (+0.0013 / 0.2%) | 0.7422 (+0.0032 / 0.4%) | ||
| Mix Seq + PB | 0.8719 (+0.0265 / 3.1%) | 0.6654 (+0.0541 / 8.8%) | 0.7514 (+0.0124 / 1.7%) | ||
| Mix Seq + TAPF | 0.8808 (+0.0354 / 4.2%) | 0.6698 (+0.0585 / 9.6%) | 0.7570 (+0.0180 / 2.4%) | ||
| 统一 block | OneTrans | Pos Seq | 0.8462 (— / —) | 0.6209 (— / —) | 0.7349 (— / —) |
| Pos Seq + TAPF | 0.8497 (+0.0035 / 0.4%) | 0.6228 (+0.0019 / 0.3%) | 0.7358 (+0.0009 / 0.1%) | ||
| Mix Seq + PB | 0.8777 (+0.0315 / 3.7%) | 0.6602 (+0.0393 / 6.3%) | 0.7428 (+0.0079 / 1.1%) | ||
| Mix Seq + TAPF | 0.8845 (+0.0383 / 4.5%) | 0.6623 (+0.0414 / 6.7%) | 0.7488 (+0.0139 / 1.9%) | ||
| 统一 block | HyFormer | Pos Seq | 0.8329 (— / —) | 0.6201 (— / —) | 0.7397 (— / —) |
| Pos Seq + TAPF | 0.8384 (+0.0055 / 0.7%) | 0.6208 (+0.0007 / 0.1%) | 0.7413 (+0.0016 / 0.2%) | ||
| Mix Seq + PB | 0.8745 (+0.0416 / 5.0%) | 0.6720 (+0.0519 / 8.4%) | 0.7532 (+0.0135 / 1.8%) | ||
| Mix Seq + TAPF | 0.8774 (+0.0445 / 5.3%) | 0.6762 (+0.0561 / 9.0%) | 0.7573 (+0.0176 / 2.4%) | ||
| 统一 block | MixFormer | Pos Seq | 0.8349 (— / —) | 0.6162 (— / —) | 0.7364 (— / —) |
| Pos Seq + TAPF | 0.8377 (+0.0028 / 0.3%) | 0.6197 (+0.0035 / 0.6%) | 0.7401 (+0.0037 / 0.5%) | ||
| Mix Seq + PB | 0.8724 (+0.0375 / 4.5%) | 0.6609 (+0.0447 / 7.3%) | 0.7514 (+0.0150 / 2.0%) | ||
| Mix Seq + TAPF | 0.8809 (+0.0460 / 5.5%) | 0.6667 (+0.0505 / 8.2%) | 0.7545 (+0.0181 / 2.5%) |
观察 1:跨范式的普遍提升。 混合极性序列在两阶段(DIN、Transformer)和统一 block(OneTrans、HyFormer、MixFormer)两类范式上都取得一致提升,相对提升从 +1.9% 到 +9.6%,在全部 15 个模型-数据集组合上无一例外。这强烈说明:负向行为上下文的价值很大程度上独立于具体架构设计,是一个所有模型都能利用的数据层贡献。值得注意的是 KuaiRand 上提升幅度最大(6.7%~9.6%)——这与它正样本率较高(37.9%)但同时正样本 noisy 的特性相符,负向信号在这里提供了更强的判别性补充。
观察 2:TAPF 一致优于 PB。 在所有模型上,Mix Seq + TAPF 都比更简单的 Mix Seq + PB 取得额外增益。KuaiRec 上 MixFormer 0.8809 vs 0.8724(+0.0085)、HyFormer 0.8774 vs 0.8745(+0.0029)、DIN 0.8711 vs 0.8650(+0.0061)。TAPF 的目标条件门控提供了比 PB 的统一 bias 更细粒度的极性区分。
但作者诚实地补充了一个关键观察:即便在纯正向序列上(Pos Seq + TAPF),TAPF 也能在 15 个组合里的 14 个取得相对 vanilla Pos Seq 的一致提升(KuaiRec 上 +0.3%~+0.7%),说明目标条件门控机制本身就有效。然而这些增益远小于引入负向行为(Mix Seq)带来的增益——这恰恰反证了:主要的提升来源是混合极性的数据范式本身,而非 TAPF 这个机制。这是本文最重要的自我定位。
TAPF 组件消融¶
为理解 TAPF 各组件的贡献,在 KuaiRec(OneTrans,3 seed)上做组件消融:
Table 3:TAPF 组件消融(KuaiRec,OneTrans,3 seed)。Δ:相对 Full TAPF 的 AUC 变化。
| 配置 | AUC | Δ | Δ% |
|---|---|---|---|
| Full TAPF | 0.8845 | — | — |
| − 极性 embedding | 0.8842 | −0.0003 | −0.03% |
| − 内容自适应门控 | 0.8838 | −0.0007 | −0.08% |
| − 极性符号($m=2$) | 0.8833 | −0.0012 | −0.14% |
| − 残差连接 | 0.8816 | −0.0029 | −0.33% |
| − 目标交互(target interaction) | 0.8807 | −0.0038 | −0.43% |
| − 目标交互 & 门控 | 0.8760 | −0.0085 | −0.96% |
| PB only(无 TAPF) | 0.8777 | −0.0068 | −0.77% |
消融揭示:目标感知交互是最关键的组件(移除时 −0.0038),其次是残差连接(−0.0029)。同时移除目标交互和门控后,TAPF 退化到 PB only 的水平(0.8760 vs PB 0.8777,相当)。这证实 TAPF 的有效性主要来自计算目标相关的交互特征,而非门控或极性编码本身——也就是说 Eq.(3) 的目标条件特征变换是本质机制,Eq.(4)(5) 的门控和极性符号是锦上添花的细粒度调节。
序列长度 Scaling(RQ2)¶
生产系统关心的核心问题是:更长的序列是否值得它的算力成本?本文在 KuaiRec 上用全部五个架构、序列长度 $L \in \{10, 20, 50, 100, 200, 300, 500\}$ 考察混合极性序列相对纯正向序列的 scaling 行为。
Table 4:KuaiRec 序列长度 scaling。$\Delta_{10\to100}$:$L=10$ 到 $L=100$ 的 AUC 增益;$\Delta_{10\to500}$:到 $L=500$ 的增益;Ratio:Mix Seq + TAPF 相对 Pos Seq 的斜率改善倍数。
| 类型 | 模型 | Setting | L=10 | L=50 | L=100 | L=500 | $\Delta_{10\to500}$ | Ratio |
|---|---|---|---|---|---|---|---|---|
| 两阶段 | DIN | Pos Seq | 0.8263 | 0.8351 | 0.8362 | 0.8365 | +0.0102 | — |
| Mix + TAPF | 0.8516 | 0.8688 | 0.8711 | 0.8735 | +0.0219 | 2.15× | ||
| 两阶段 | Transformer | Pos Seq | 0.8302 | 0.8440 | 0.8454 | 0.8470 | +0.0168 | — |
| Mix + TAPF | 0.8519 | 0.8752 | 0.8808 | 0.8839 | +0.0320 | 1.90× | ||
| 统一 | OneTrans | Pos Seq | 0.8323 | 0.8457 | 0.8462 | 0.8472 | +0.0149 | — |
| Mix + TAPF | 0.8587 | 0.8776 | 0.8845 | 0.8875 | +0.0288 | 1.93× | ||
| 统一 | HyFormer | Pos Seq | 0.8196 | 0.8322 | 0.8329 | 0.8345 | +0.0149 | — |
| Mix + TAPF | 0.8498 | 0.8711 | 0.8774 | 0.8815 | +0.0317 | 2.13× | ||
| 统一 | MixFormer | Pos Seq | 0.8201 | 0.8335 | 0.8349 | 0.8366 | +0.0165 | — |
| Mix + TAPF | 0.8462 | 0.8744 | 0.8809 | 0.8829 | +0.0367 | 2.22× |
观察 1:混合序列取得约 2× 更陡的 scaling 斜率。 五个架构上,$L=10 \to L=500$ 的斜率约为纯正向序列的两倍,倍数从 1.90×(Transformer)到 2.22×(MixFormer)。这一优势对两阶段和统一 block 同等成立,说明改善的 scaling 主要是数据成分的属性而非某种特定架构机制。
观察 2:纯正向序列因固有长度约束过早饱和。 纯正向曲线在 $L \approx 50\sim100$ 后明显走平。例如 OneTrans(Pos Seq)从 $L=100$ 到 $L=500$ 只涨 +0.0010(0.8462→0.8472)。关键原因是:用户的正向历史本质上受其真实参与率上界约束;一旦序列长度超过可用正交互数,继续拉长只能 padding,带来递减信息。相比之下混合序列从大得多的池子(正+负历史合并)抽取,既有更丰富的信息量、又有更大的持续 scaling 空间——OneTrans(Mix Seq)在同一区间涨 +0.0030(0.8845→0.8875),保持有意义的提升。
观察 3:是「信号质量」而非「数据充足度」驱动提升。 一个潜在混淆是:纯正向序列可能因数据不足(短历史用户被 padding)而吃亏,混合序列只是用负样本填满了空槽。为隔离信号质量与数据充足度,作者在 KuaiRec 的满序列子集(正向历史 ≥ 100,占测试样本 28.6%)上重测——此时 Pos Seq 和 Mix Seq 都被完全填满、无 padding。
Table 5:KuaiRec 满序列子集 scaling(正向历史 ≥ 100,两种设置均无 padding)。
| 模型 | Setting | L=10 | L=50 | L=100 | $\Delta_{10\to100}$ | Ratio |
|---|---|---|---|---|---|---|
| DIN | Pos Seq | 0.7833 | 0.7925 | 0.7938 | +0.0105 | — |
| Mix + TAPF | 0.8194 | 0.8374 | 0.8405 | +0.0211 | 2.01× | |
| Transformer | Pos Seq | 0.7830 | 0.7956 | 0.7969 | +0.0139 | — |
| Mix + TAPF | 0.8243 | 0.8422 | 0.8498 | +0.0255 | 1.83× | |
| OneTrans | Pos Seq | 0.7878 | 0.7994 | 0.8019 | +0.0141 | — |
| Mix + TAPF | 0.8268 | 0.8455 | 0.8525 | +0.0257 | 1.82× | |
| HyFormer | Pos Seq | 0.7867 | 0.7964 | 0.7981 | +0.0114 | — |
| Mix + TAPF | 0.8232 | 0.8400 | 0.8464 | +0.0232 | 2.04× | |
| MixFormer | Pos Seq | 0.7796 | 0.7913 | 0.7945 | +0.0149 | — |
| Mix + TAPF | 0.8185 | 0.8408 | 0.8498 | +0.0313 | 2.10× |
在这个无 padding 子集上,Mix Seq + TAPF 相对 Pos Seq 的 scaling 倍数仍维持 1.82~2.10×,仅略低于全测试集的 1.90~2.22×。这证实混合极性序列的优势主要由负向行为信息的更高信号质量驱动,而非仅仅填满了原本空着的序列槽位。
正负组成比例(RQ3)¶
系统地扫描正样本比例 $r \in \{0.0, 0.1, \ldots, 1.0\}$,控制固定长度预算里分给正向 token 的比例。
![Figure 4: 三个数据集上 AUC 随正样本比例 r 的变化。所有曲线都呈倒 U 形,最优 r* ∈ [0.2, 0.7],且有一段宽阔的性能平台期。](figures/fig_07.png)
倒 U 形 + 宽平台。 每一个模型-数据集组合都产生一条从 $r=0.0$ 上升、在中段到达平台、再向 $r=1.0$ 下降的曲线。这种形状在三个差异巨大的数据集、架构迥异的模型上的一致性,说明混合极性建模捕捉的是用户行为的一般特征,而非某个数据分布的 artifact。绝大多数最优比例落在 $r^* \in [0.2, 0.7]$,且在这个区间内性能极其稳定(KuaiRec 上 OneTrans 在 $r \in [0.2, 0.7]$ 的 AUC 变化小于 0.005)。这个鲁棒性有很强的实践意义:默认 $r=0.5$ 就能在所有测试场景里拿到绝大部分提升,无需昂贵的超参搜索。两个端点($r=0$ 纯负、$r=1$ 纯正)都次优,说明正负信号是互补的。
机制理解(RQ4):混合极性序列为什么有效?¶
作者用六个互补分析逐一回答「负向行为如何、为何改善预测」。
4.1 注意力如何变化?¶
观察到 DIN 在 KuaiRec 上 $r \approx 0.5$ 处有一个尖锐的 AUC 跳变(对应 Figure 4a),这把注意力引向该转折点的内部机制。定义注意力极性 gap为:正样本与负样本两类测试样本分配给正向 token 的注意力之差,$\text{gap} = \mathbb{E}[a^+ \mid y=1] - \mathbb{E}[a^+ \mid y=0]$。
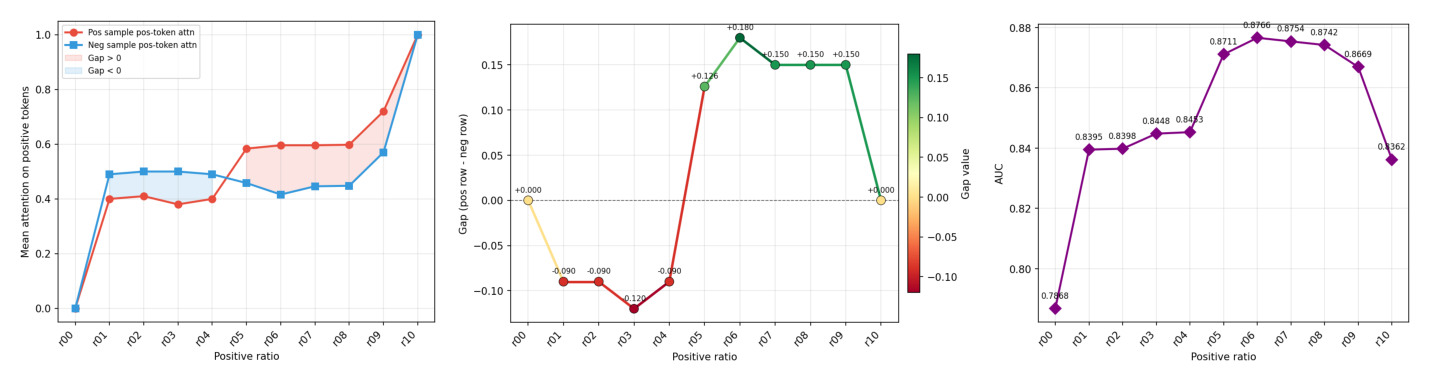
Table 6:$r=0.5$ 时的注意力极性 gap。
| 数据集 (模型) | Pos→PosToken | Neg→PosToken | Gap |
|---|---|---|---|
| KuaiRec (OneTrans) | 0.659 | 0.611 | +0.048 |
| KuaiRec (DIN) | 0.584 | 0.458 | +0.125 |
| TAAC (OneTrans) | 0.236 | 0.109 | +0.128 |
Table 6 和 Figure 5 揭示:模型自发学到了极性判别性注意力——正样本测试样本给正向历史 token 分配更多注意力,负样本测试样本则把注意力转向负向 token。非零 gap(无论正负)表明模型对正负测试样本表现出差异化的注意力分配,反映其区分能力。更关键的是,gap 在 $r \approx 0.5$ 处经历一个从负到正的尖锐相变(Figure 5b),恰好与 AUC 跳变的位置重合(Figure 5c)。这一强相关说明:AUC 提升与模型差异化地注意「极性相关 token」的能力紧密关联。
4.2 是否所有用户都同等受益?¶
按正向序列长度对用户分层:
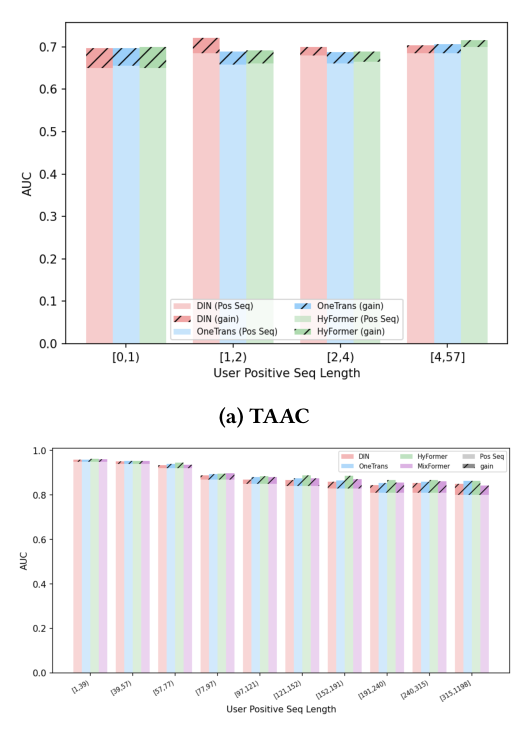
- TAAC(Figure 6a):拥有 0-1 个正向行为的用户增益 +0.041~+0.050,而拥有 4-57 个正向行为的用户仅 +0.013~+0.021。对数据稀疏用户,负向 token 提供了奠基性信息:模型从「什么都不知道」转变为「知道用户不喜欢什么」,在原本几乎空白的表征里提供了强信号。
- KuaiRec(Figure 6b):与 TAAC 相反。KuaiRec 用户正向历史很长(最大 2,244),远超长度预算 $L=100$,意味着大多数用户的正向行为本就远超预算。这里模式反转了:高活跃用户(315-1200 个正向行为)增益 +0.042~+0.063,低活跃用户(1-39 个)仅 +0.004~+0.012。对数据丰富的用户,在相同预算内用近期负向行为替换过时的正向行为能得到更好的表征——因为近期的 dispreference 信号比陈旧的正向交互携带更多价值。
结论:负向行为扮演双重角色——对数据稀疏用户是奠基性的(从无到有),对正向序列被截断的数据丰富用户是互补性的(用近期负反馈替换过时正反馈)。
4.3 冷启动物品是否受益?¶
评估训练集零曝光(cold-start)物品。KuaiRec 30.1% 冷物品,TAAC 25.2% 冷物品。
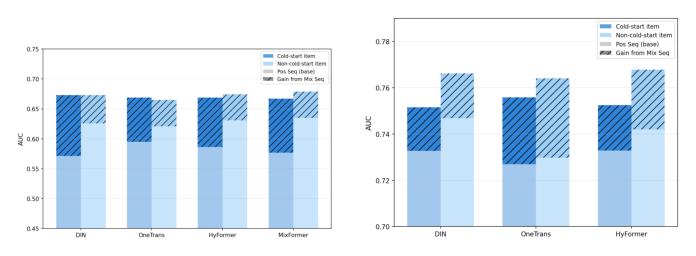
- KuaiRand:冷启动物品从混合序列获得 +0.074~+0.102 AUC,而非冷物品仅 +0.043~+0.047(1.5~2× 更大)。当目标物品 embedding 未训练时,模型无法依赖物品级表征;用户序列里的负向 token 提供了间接的排除信号(indirect exclusion signals),无需物品专属 embedding 就能约束预测。
- TAAC:冷物品与非冷物品增益相当,说明冷启动优势在 embedding 空间足够表达力时更显著。
4.4 「负向」标签本身重要吗?¶
设计三个隔离不同因素的消融条件(对应原文 Figure 8:真实负样本按近期性选取,一致优于随机替代方案):
- (a) 提升是否需要真实的负向行为? 把负向 token 替换成随机全集物品(globally sampled,与用户无关)。KuaiRec(仅 10K 物品)上随机全集略优于 Pos Seq,说明物品空间小时多样性带来边际收益;但在 KuaiRand(4.37M 物品)和 TAAC(2.3M 物品)上,随机全集低于 Pos Seq——从大词表里随机采样引入的主要是无关噪声。真实工业系统运行在百万级物品空间,因此任意物品注入的多样性不太可能是提升来源;增益来自真实负向行为携带的 genuine dispreference 语义。
- (b) 近期性重要吗? 把近期负样本替换成随机历史负样本(忽略近期性)。近期性在所有数据集上一致胜出,说明近期负向行为携带更强的相关性信号——最近被划走的物品更可能与用户当前兴趣语义相关。
- (c) 准确的极性标签重要吗? 用正确物品但随机分配极性标签构造混合序列。这产生了所有数据集上最严重的退化,甚至显著低于纯正向 baseline。说明准确极性标签起决定性作用:随机极性会主动腐蚀用户表征,导致比「干脆忽略负样本」还差的结果。
小结:准确、真实的负向行为是性能提升的关键驱动;近期性贡献了有意义的一部分。
4.5 TAPF 在机制上改变了什么?¶
用 §4.1 的注意力分析方法,测量分配给正向 vs 负向 token 的注意力比例。
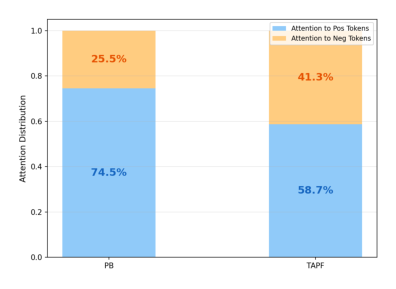
在 KuaiRec(OneTrans)上,PBE 把 74.5% 注意力分给正向 token、仅 25.5% 给负向 token——严重低估了负向行为。TAPF 把这个比例再平衡到 58.7%:41.3%(Figure 9),负向 token 利用率提升 62%。结合 TAPF 带来的 +0.0068 AUC 提升(0.8777→0.8845),说明 TAPF 的目标条件门控更充分地利用了负向行为携带的信息,相比 PBE 的统一 bias 实现了更有效的极性感知校准。
4.6 为什么用混合序列,而非分离的双流?¶
一个自然的替代是用独立编码器分别处理正负历史、在预测阶段融合输出。在 KuaiRec(OneTrans,5 seed)上对比两种替代方案:
Table 7:序列构造方式消融(KuaiRec,OneTrans,5 seed)。两种替代方案都不如时序交错的混合序列。
| 配置 | AUC | Δ vs Mixed |
|---|---|---|
| Mixed Seq(时序交错) | 0.8802 | — |
| Polarity-Grouped Concat(按极性分组拼接) | 0.8586 | −0.0216 |
| Dual-Stream Encoder(双流编码器) | 0.8537 | −0.0265 |
- Mixed > Dual-Stream(−0.0265):双流的劣势说明编码阶段的跨极性交互是有价值的——在同一注意力里联合 attend 正负行为,能捕捉「喜欢与不喜欢之间的相互作用」,这是双流架构无法捕捉的。
- Mixed > Polarity-Grouped Concat(−0.0216):把所有正向 token 放前、所有负向 token 放后(单编码器但按极性分组)也退化,说明时序交错携带一种独特的 alternation 信号——「划走后点击」或「点击后划走」这种序列模式编码了行为上下文,一旦按极性分组就丢失了。
这一组消融是本文方法论选择的关键支撑:既不要分离编码(要跨极性交互),也不要按极性分组(要保留时序 alternation),时序交错的单序列是最优解。
核心贡献总结¶
- 「行为序列里装什么」是一个被低估的设计维度。 在「如何编码序列」被卷到极致、正向序列扩展边际收益递减的当下,本文把研究重心拉回到数据成分本身——简单地把一部分正向 token 替换成时序近期的负向 token,就能在五种架构、三个数据集上一致取得 +1.9%~+9.6% 的相对 AUC 提升,且零额外在线推理成本(长度预算不变)。
- 混合极性是数据层贡献,TAPF 是机制层补充。 作者用 Pos Seq + TAPF 的小增益(+0.3%~0.7%)vs Mix Seq 的大增益清晰地区分了两者——绝大部分提升来自数据范式,TAPF 只是解决正负 token 共享 embedding 的「语义不可区分性」的轻量校准器,其核心是目标感知交互(Eq.3)。
- 系统性的机制分析。 注意力极性 gap 的相变与 AUC 跳变重合、负向行为对稀疏用户「奠基」/对丰富用户「互补」的双重角色、冷启动物品 1.5-2× 增益、三种负样本标签消融证明「真实 + 近期 + 准确极性」三者缺一不可、时序交错优于双流/分组——这套分析把「负向行为为何有效」讲得相当透彻。
讨论与局限性¶
值得借鉴的设计。 本文最大的价值是一个简洁、可迁移、近乎免费的 insight:在固定算力预算下,把行为序列的一部分让给隐式负向行为。这与任意 CTR 骨干正交,工业系统几乎可以零成本试验(只需改数据构造 pipeline + 加一个轻量 TAPF 模块)。倒 U 形 + 宽平台($r^* \in [0.2, 0.7]$,默认 0.5 即可)进一步降低了落地门槛。对正样本极稀疏的广告场景(TAAC 正样本率 6.3%),「负向历史远长于正向历史」这一结构性事实使该方法尤其有吸引力。
与已归档相关工作的差异(一个值得注意的对照)。 本文的核心机制是「时序交错」正负 token,并在 §4.6 用消融证明交错优于双流/分组。这与档案库中 LinkedIn 的 AttnMVP(AttnMVP)形成了一个有意思的对立:AttnMVP 在生成式推荐设定下论证交错(item token 与 action token 的交错)有害——带来语义异质性、因果稀释、注意力噪声、序列长度翻倍——主张取消交错、用双流 + item-条件 action pooling。两篇论文都在讨论「如何在序列里安排非纯正向信号」,却给出了相反的架构结论。但它们并非问题+解法双同构的孪生工作:(1) AttnMVP 的「交错」指的是 item↔action 两类异质 token的交错,本文的「交错」指的是同一物品空间内正↔负极性的交错;(2) AttnMVP 是生成式自回归预测、本文是判别式 CTR;(3) AttnMVP 的 root cause 是 item-action 因果绑定的表示,本文的 root cause 是「该不该把负向行为放进序列」。两者的「交错」是同名异义。因此本文未将其列为正式的孪生对比,但读任一篇时知道另一篇的存在很有价值——尤其本文 §4.6 在判别式设定下提供了「交错 > 双流」的直接经验证据,恰好与 AttnMVP 在生成式设定下的「双流 > 交错」结论互为镜像。
存在的局限。
- 缺乏线上 A/B 实验。 尽管用了腾讯 TAAC-2025 工业级数据集、方法本身轻量可部署,全部结论仍是离线的。混合极性序列在真实生产环境的线上收益、对长期用户体验的影响(例如过度强调 dispreference 是否会过度收窄推荐)都未验证。对一篇主打工业落地价值的论文,这是最明显的短板。
- TAPF 机制本身增量有限。 作者自己的消融(Pos Seq + TAPF 仅 +0.3~0.7%、组件消融显示退化到 PB only 时仍接近)说明 TAPF 是个温和的校准器;真正的「重活」是数据范式。这在科学上是诚实的,但也意味着方法贡献的新颖性集中在 insight 而非机制。
- 隐式负向标签的定义依赖场景。 「划走 / 低完播」作为负向信号在短视频里清晰,但在不同业务(电商、搜索)里「隐式负向」的界定、噪声水平、与上下文因素(注意力分散、误触)的混淆程度差异很大;§4.4(c) 已表明错误极性标签会让效果比纯正向还差,因此该方法对负向标签质量高度敏感,跨场景迁移时需要谨慎的标签工程。
- TAAC 上的增益偏小。 工业广告数据集上 TAPF 的相对提升仅 1.9~2.5%,明显低于 KuaiRec/KuaiRand,且 TAAC 序列较短($L=50$,max full len 99)——在序列预算本就紧张、正负历史都不长的工业广告场景,方法的天花板可能受限。
总体而言,这是一篇实验异常翔实、insight 简洁可迁移、方法 model-agnostic 的扎实工作。它把「行为序列该装什么」这个被忽视的维度重新摆上台面,并用近乎穷尽的离线分析支撑了「隐式负向行为是被低估的现成信号」这一论点。若能补上线上 A/B 与跨场景的负向标签工程,落地说服力会更强。