Adaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation 精读¶
JD.com / 早稻田大学 / 电子科技大学,RecSys '25。作者 Kewei Xu, Junbo Qi, Yanyan Zou(项目负责人), Pengfei Zhang, Xingzhi Yao, Shengjie Li。
1 研究动机与背景¶
生成式推荐(Generative Recommendation, GR)正在把传统「召回—排序」级联范式改写成 LLM 风格的自回归解码:给定用户历史 $\mathbf{x}=(x_1,\dots,x_T)$ 作为 prompt,模型直接逐 token 生成下一个物品的 Semantic ID(SID)。SID 是从学习到的码本 $\mathcal{S}$($|\mathcal{S}|\ll|\mathcal{V}|$)里抽出的 $L$ 码序列 $\mathrm{sid}(v)=(s_1,\dots,s_L)$,语义相近的物品共享前缀 token,于是「召回」被内化进 Transformer 的参数记忆,天然覆盖长尾与语义相关物品。
SFT 阶段用 next-token likelihood 模仿行为日志,本质上只是「复刻历史」,并不直接优化用户满意度。一个自然的想法是用 RL 来弥合这道精度鸿沟:把一个多目标排序模型(production ranker)当作 reward model(RM),用它对 GR 策略 rollout 出的候选打分,再用 GRPO 微调策略。GRPO 不需要 value network,用 group 内相对优势更新,已成为该方向的标准载体。
但作者指出 RL 在 GR 上的有效性被一个常被忽视的前提卡住:RL 的成功严格取决于 RM 在它所评估样本上的可信度(trustworthiness)。而工业 ranker 是在曝光偏置(exposure-biased) 的日志上训练的——用户只与「被展示过」的物品交互,绝大多数 user–item 对从未被观测(稀疏 + 偏置)。在这种日志上训出来的 RM 继承了它的盲区:它对高频曝光物品的打分可能很准,但对长尾、新上架、或落在它有效训练分布之外的物品却不可靠。已有的 GR-RL 工作(Rank-GRPO、MiniRec 等)都只在改进「怎么用这个 RM 信号」(reward masking、ranking-importance 加权),却没人审视 GR 策略与 RM 之间因架构/目标/特征体系完全不同而产生的「能力错配(capability conflict)」,仍然把 reward 信号均匀地施加到所有训练样本上。
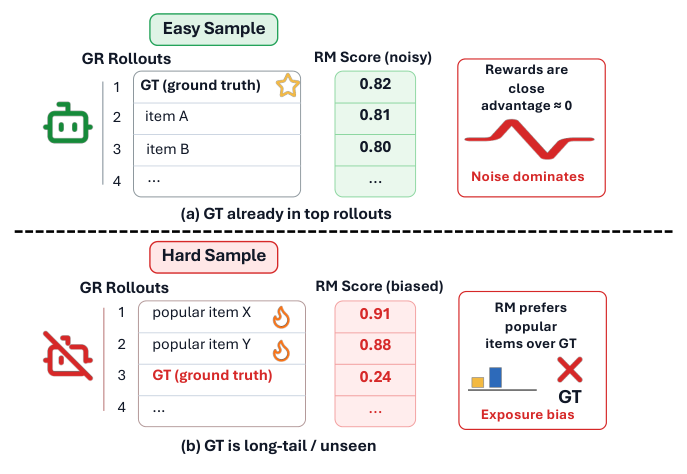
两种相互对立的失败模式(Figure 1):
- 简单样本(easy):策略本就把 ground-truth 排在自己 rollout 的前列,RM 给这一组的打分聚得很紧、围绕 group 均值,GRPO 的相对优势 $A_k$ 坍缩到接近 0,残余的 RM 噪声主导了梯度,驱动那种典型的 over-optimization(reward-hacking)。
- 困难样本(hard):当 ground-truth 落在 RM 局部 miscalibrate 的区域(长尾物品在日志里 underrepresented),RM 会把流行的干扰项打到 ground-truth 之上,由此产生的 policy-gradient 更新把模型推离正确答案。
作者用一组分层分析(见 §4)把这幅图量化精确:在全部样本上聚合时,RM 对 ground-truth 排名的影响接近于零($K=50$)甚至为负($K=128$);但这个「近零」是一个被构成性效应掩盖(masked)的均值——当策略对该样本不确定(uncertain)且 RM 能有效判别(discriminate)ground-truth 时,RM 的逐样本影响会变得相当可观。RM 不是全局无用,而是有条件地有价值(conditionally valuable),并且这两个条件都能在 GRPO rollout 时从 rollout 统计量里算出来。
这组观察催生了 AdaGRPO:把 reward 引导的优化从「均匀压力」重构为「选择性准入(selective admission)」。监督 NLL 作为锚定每个样本的稳定项始终保留,而 GRPO 项被一个逐样本二值 clip 门控——门控由两个 rollout 诊断决定:policy-side difficulty(策略侧困难度) 与 reward discriminability(奖励侧可判别性)。任一诊断不通过的样本退化为纯监督更新。从概念上,AdaGRPO 把 PPO 的 clip 原则从 ratio 域抬到了 sample 域:它定义的 trust region 不约束「每个 token 能更新多远」,而约束「哪些样本被允许贡献 policy-gradient 信号」。
核心结论(也是 abstract 的点睛句):RL 用于生成式推荐的中心挑战不是设计更强的奖励,而是辨别奖励信号何时可被信任("not in designing stronger rewards, but in discerning when the reward signal can be trusted")。
2 相关工作¶
生成式检索 for 推荐:把推荐重构为对 item identifier 的自回归解码(P5、TIGER、GenRec 等),绕开召回—排序级联。SFT-based 对齐(TALLRec)与 retrieval-augmented 变体已建立强 baseline;本文针对的是其后的 RL 微调阶段。
LLM 的 RL 对齐:RLHF 及其衍生(PPO、DPO、GRPO)构成标准工具箱,DeepSeek-R1 证明纯 RL 能解锁超出 SFT 的能力。PPO 是最接近的机制先例——它对每步更新做 importance-sampling ratio 的 clip(一个 per-token 的 trust region);AdaGRPO 把 clip 搬到 sample 域,门控某个样本的 policy gradient 是否参与。推荐侧的 Rank-GRPO 引入 reward masking 与 ranking-importance 权重,MiniRec 用 RL-specific filtering 改进采样效率——这些都在精炼「怎么用 RM」,本文问的是「何时该信 RM」。
难度感知训练(Difficulty-aware training):Ji et al. 指出只有中等难度样本才产生干净的 policy gradient(推理任务);Pikus et al. 量化了在困难样本上多至 47% 的额外 GRPO 收益。GRPO-LEAD、DiPO、DART-Math 等用 advantage 重加权与难度感知拒绝调优来操作化它。但把「难度」迁移到推荐有两个非平凡障碍:(i) 难度是 ill-posed 的——用户兴趣隐式且语境相关,难度必须从「策略对带噪行为日志的不确定性」推断,而非来自确定性 verifier;(ii) 推荐的 RM 在被 upweight 的样本上也未必可信(production ranker 有实时性、目录每日更新、日志选择偏置等域内偏差),简单地 upweight 困难样本是不安全的。AdaGRPO 通过把难度条件与一个局部 RM-可判别性检查相合取(conjoin) 来解决这一点。
3 预备知识¶
3.1 生成式推荐即自回归解码¶
设物品目录为 $\mathcal{V}$,用户历史 $\mathbf{x}=(x_1,\dots,x_T)\in\mathcal{V}^T$ 作为 prompt,任务是预测下一个物品 $y^*\in\mathcal{V}$。每个物品 $v$ 被赋予一个 $L$ 码 SID $\mathrm{sid}(v)=(s_1,\dots,s_L)$,码本 $\mathcal{S}$ 构造成「语义相近物品共享前缀 token」。参数为 $\theta$ 的 LLM 定义策略:
$$\pi_\theta(y\mid\mathbf{x})=\prod_{t=1}^{L}\pi_\theta(s_t\mid\mathbf{x},s_{<t}) \tag{1}$$
推理时用 beam search 生成候选,只保留映射到合法物品的序列。论文用 rollout 指一条采样序列、group 指一个 prompt 的 $K$ 条 rollout。
3.2 监督微调(SFT)¶
给定历史—目标对 $\mathcal{D}=\{(\mathbf{x}^{(i)},y^{*(i)})\}_{i=1}^{N}$,NLL 目标为:
$$L_{\mathrm{NLL}}(\theta)=-\mathbb{E}_{(\mathbf{x},y^*)\sim\mathcal{D}}\Big[\sum_{t=1}^{L}\log\pi_\theta(s_t^*\mid\mathbf{x},s_{<t}^*)\Big] \tag{2}$$
NLL 稳定、锚定在被观测行为上、不需要 RM,提供 RL 微调所基于的 base policy。
3.3 Group Relative Policy Optimization(GRPO)¶
GRPO 用 group-level 奖励统计取代 PPO 的 value network。对每个 prompt $\mathbf{x}$,从 $\pi_{\theta_{\mathrm{old}}}$ 采样 $K$ 条 rollout $\{y_1,\dots,y_K\}$,逐条打分 $r_k=\mathrm{RM}(y_k,\mathbf{x})$。group-relative advantage:
$$A_k=\frac{r_k-\bar r}{\sigma_r+\epsilon} \tag{3}$$
其中 $\bar r,\sigma_r$ 是组均值与标准差。以 importance ratio $w_k(\theta)=\pi_\theta(y_k\mid\mathbf{x})/\pi_{\theta_{\mathrm{old}}}(y_k\mid\mathbf{x})$,GRPO 优化 clip 后的代理目标:
$$L_{\mathrm{GRPO}}(\theta)=-\mathbb{E}_{\mathbf{x},\{y_k\}\sim\pi_{\theta_{\mathrm{old}}}}\Big[\frac{1}{K}\sum_{k=1}^{K}\min\big(w_kA_k,\ \mathrm{clip}(w_k,1-\epsilon,1+\epsilon)A_k\big)\Big] \tag{4}$$
这个 token-level ratio clip 正是 AdaGRPO 在 §5 抬到 sample-level 的机制。
4 RM 有条件地有用:困难 + 高判别样本¶
在提出方法前,作者先做一个纯实证测试:RM 是否提供有用的训练信号?答案是「有条件的」——这一发现直接决定 AdaGRPO 该 clip 什么。
4.1 协议¶
对 held-out 集的每个 prompt $\mathbf{x}$,用 beam width $K$ 跑 beam search 得候选集 $\mathcal{R}=\{y_1,\dots,y_K\}$。分别按两种方式排序:(1) 按 beam 的 top-down log-prob 降序(LLM order),(2) 按 reward 分数降序(RM order),记录 ground-truth 在两种排序里的位置 $\mathrm{idx}_{\mathrm{LLM}}$ 与 $\mathrm{idx}_{\mathrm{RM}}$。定义 RM 的影响(influence):
$$\Delta=\mathrm{idx}_{\mathrm{LLM}}-\mathrm{idx}_{\mathrm{RM}}$$
$\Delta>0$ 表示 RM 把 ground-truth 往前推(有帮助),$\Delta<0$ 表示推远(有害)。注意:本分析用 beam search 以保证可复现,而 GRPO 训练用 sampling,二者有分布差异,所以下面的分层规律是「指示性」而非「对训练时条件的直接测量」,但它们恰恰动机化(motivate) 了 clip 的设计(clip 本身在 §6 端到端验证)。
4.2 全样本上 RM 的聚合影响接近零¶
Table 1:全样本下 ground-truth 平均位置(LLM vs RM 排序)。 $\Delta>0$ 表示 RM 有帮助。
| Beam width $K$ | Avg $\mathrm{idx}_{\mathrm{LLM}}$ | Avg $\mathrm{idx}_{\mathrm{RM}}$ | $\Delta$ |
|---|---|---|---|
| 50 | 15.79 | 15.31 | +0.48 |
| 128 | 35.57 | 35.86 | −0.28 |
分析:聚合影响在 $K=50$ 时近零、在 $K=128$ 时转负。这种退化与曝光偏置一致——更大的 beam width 会surface 出更多 RM 从未被校准过的 out-of-distribution 候选。一个固定的 NLL–GRPO 混合(uniformly 信任 RM)继承的正是这个近零的净信号——所以「均匀施加」从一开始就注定低效。
4.3 RM 只在困难样本上提供强引导¶
把样本按 LLM difficulty 切分:若 ground-truth 落在 LLM 排序的 top-$\lfloor\tau K\rfloor$ 之外则记为 HARD,否则 EASY(与后面 clip 条件 $f_1$ 同一划分)。
Table 2:仅 HARD 样本上的 ground-truth 平均位置。
| $K$ | Avg $\mathrm{idx}_{\mathrm{LLM}}$ | Avg $\mathrm{idx}_{\mathrm{RM}}$ | $\Delta$ | Coverage |
|---|---|---|---|---|
| 50 | 30.07 | 18.66 | +11.41 | 42.2% |
| 128 | 77.09 | 46.33 | +30.77 | 33.9% |
分析:在 HARD 分区上 RM 把 ground-truth 位置改善了 11.4($K=50$)与 30.8($K=128$),而且收益随候选集增大而增大——与聚合趋势完全相反。在 EASY 分区上影响近零甚至为负,正是它把聚合均值拉了下来。RM 是有条件有价值的,而那个条件(策略自身的不确定性)在训练时是可观测的。
4.4 RM 可判别性进一步翻倍逐样本影响(代价是覆盖率)¶
难度是必要但不充分条件。HARD 样本里仍有一些是「RM 不可靠」的——ground-truth 落在 RM 训练分布之外。于是加第二个条件(对应 clip 的 $f_2$):只保留 RM 把 ground-truth 排进 top-$\lfloor\tau K\rfloor$ 且每个 in-batch 负例都掉到 bottom-$\lfloor\rho K\rfloor$ 的 HARD 样本——此时 RM 对「相关 vs 无关」有清晰分离。
Table 3:同时施加两个条件后的影响。
| $K$ | $\Delta$ | Coverage |
|---|---|---|
| 50 | +23.24 | 11.6% |
| 128 | +59.93 | 13.4% |
分析:可判别性条件把逐样本影响大约再翻一倍($K=50$:60 名 → 23 名;$K=128$:约翻倍),但覆盖率掉到只剩 12–13%。clip 解决的正是这个 precision–coverage 权衡:把 RL 更新花在高影响的少数样本上,其余退回监督。
5 方法:AdaGRPO¶
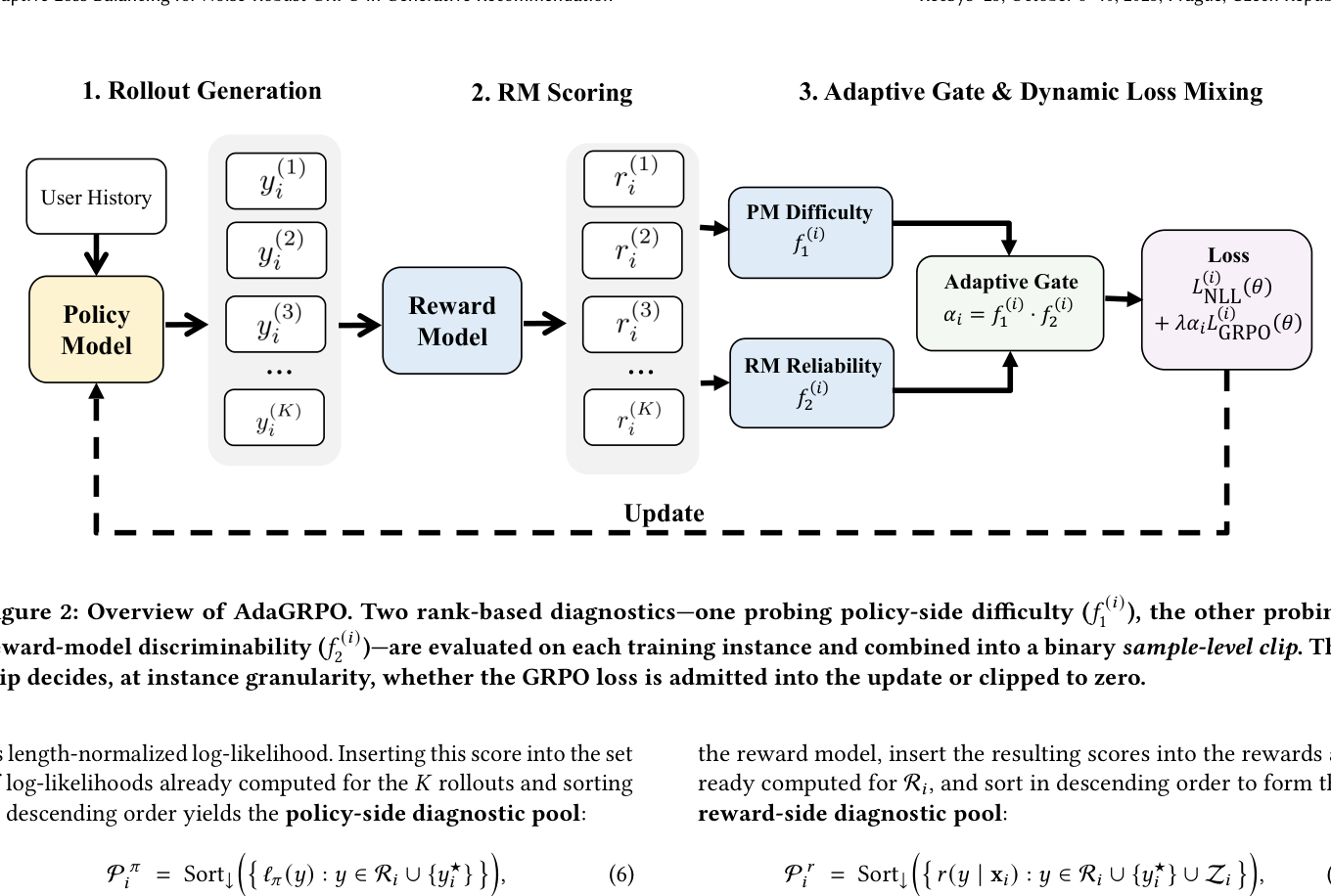
AdaGRPO 瞄准「RM 只在一个真子集上提供有信息梯度」的机制。它保留监督 NLL 作为静止锚(stationary anchor),而对每个实例的 GRPO 项做一个 sample-level clip:要么原样通过、要么 clip 到零,clip 决策由该实例自己 rollout group 上的诊断驱动。逐实例目标:
$$L_i(\theta)=L_{\mathrm{NLL}}^{(i)}(\theta)+\lambda\,\alpha_i\,L_{\mathrm{GRPO}}^{(i)}(\theta),\qquad \alpha_i\in\{0,1\} \tag{5}$$
其中 $\lambda>0$ 是全局缩放系数,$\alpha_i$ 是实例 $i$ 的 clip 系数,由 rollout group 上两个 rank-based 诊断决定。$\alpha_i$ 是 detached 的(无梯度流经它的计算),所以 clip 只是重塑优化 landscape,不引入有偏的代理梯度。$\alpha_i=0$ 时 clip 掉 GRPO 项、留下纯监督更新;$\alpha_i=1$ 时在实例 $i$ 上施加完整 GRPO 修正。
为何推荐里的难度估计是非平凡的。推荐场景的「样本难度」与推理任务里的对应物根本不同:(1) 推理里有 policy-independent 的「难」概念、有 pass-rate 这种干净的二值操作代理;推荐里没有——难度与当前参数化、时变目录、用户特异历史纠缠;(2) 推荐的 reward 是稠密连续的(production ranker 给每条 rollout 打连续分),pass-rate 式代理失效。这逼出门控 sample-level clip 的三条 desiderata:(i) 可从 rollout 统计量计算,不依赖额外模型/启发式;(ii) 独立于稀疏的 correctness 信号;(iii) 即便所有 rollout 都拿到非平凡 reward 也有意义。下面的 rank-based 诊断同时满足三条,且复用 GRPO 已经物化的同一个 rollout group——对 clip 不增加任何采样开销。
Rank-threshold 超参数。两个诊断都把 rollout group 大小 $K$ 转成两个标量秩阈值:prominence fraction $\tau\in(0,1)$ 与 suppression fraction $\rho\in(0,1)$,$\tau<\rho$。阈值 $\lfloor\tau K\rfloor$ 标出排序诊断池的 top-$\tau$ 部分,$\lfloor\rho K\rfloor$ 标出它互补的尾部。默认 $\tau=1/3$(top-tertile)、$\rho=0.9$(bottom-decile),全程沿用,并经实验验证跨任务稳健。把阈值表达成 $K$ 的分数使 clip 对 rollout 数 scale-free。
5.1 Policy-side 诊断:difficulty $f_1$¶
对每个 prompt $\mathbf{x}_i$,从 reference policy $\pi_{\theta_{\mathrm{old}}}$ 抽 $K$ 条 rollout $\mathcal{R}_i=\{y_i^{(1)},\dots,y_i^{(K)}\}$。设 $y_i^\star$ 为监督集里的 ground-truth target。在 $\pi_{\theta_{\mathrm{old}}}$ 下用 teacher forcing 算 $y_i^\star$ 的长度归一化 log-likelihood,插进 $K$ 条 rollout 已算好的 log-likelihood 集合并降序排,得 policy-side 诊断池:
$$\mathcal{P}_i^{\pi}=\mathrm{Sort}_{\downarrow}\big(\{\,\ell_\pi(y):y\in\mathcal{R}_i\cup\{y_i^\star\}\,\}\big) \tag{6}$$
其中 $\ell_\pi(y)$ 是 $\pi_{\theta_{\mathrm{old}}}$ 下的长度归一化 log-prob。设 $\mathrm{rk}_\pi(y_i^\star)$ 为 $y_i^\star$ 在 $\mathcal{P}_i^\pi$ 里的 1-indexed 排名,difficulty 诊断:
$$f_1^{(i)}=\mathbb{1}\big[\mathrm{rk}_\pi(y_i^\star)>\lfloor\tau K\rfloor\big] \tag{7}$$
当 ground-truth 落在策略自身排序的 top-$\tau$ 之外时它点火(=1),表明策略尚未把高 likelihood 赋给正确目标——此时单靠监督梯度的纠正信号有限,GRPO 项值得保留。反之 ground-truth 已在 top-$\tau$ 内时,实例已被 $L_{\mathrm{NLL}}$ 很好服务,GRPO 项冗余,应被 clip。
5.2 Reward-side 诊断:reliability $f_2$¶
仅靠难度不足以准入 GRPO:一个困难实例可能恰恰是 RM 缺乏判别保真度的那种,此时 policy-gradient 信号是主动误导的、必须 clip。于是加第二个诊断,探测 RM 能否把 ground-truth 与语境无关的干扰项分开。
对实例 $i$,构造负例集 $\mathcal{Z}_i=\{z_i^{(1)},\dots,z_i^{(M)}\}$:从同一 mini-batch 的其它实例均匀采 $M$ 条 rollout(实验中 $M=5$)。这些是 contrastive probe:对 $\mathbf{x}_i$ 而言语境无关、但语法合理的模型生成。用 RM 给 $y_i^\star$ 和 $\mathcal{Z}_i$ 每个元素打分(注意 $r(\cdot\mid\mathbf{x}_i)$ 都条件在 $\mathbf{x}_i$ 上),插进 $\mathcal{R}_i$ 已算好的 reward 集合降序排,得 reward-side 诊断池:
$$\mathcal{P}_i^{r}=\mathrm{Sort}_{\downarrow}\big(\{\,r(y\mid\mathbf{x}_i):y\in\mathcal{R}_i\cup\{y_i^\star\}\cup\mathcal{Z}_i\,\}\big) \tag{8}$$
reliability 诊断 $f_2$ 是两个秩约束的合取——ground-truth prominence 与 distractor suppression:
$$f_2^{(i)}=\mathbb{1}\big[\mathrm{rk}_r(y_i^\star)\le\lfloor\tau K\rfloor\big]\cdot\mathbb{1}\big[\min_{m\in[M]}\mathrm{rk}_r(z_i^{(m)})>\lfloor\rho K\rfloor\big] \tag{9}$$
第一个因子(ground-truth prominence)要求 RM 把 ground-truth 排进 reward 排序的 top-$\tau$;第二个因子(distractor suppression)要求每个干扰项都掉进 bottom-$(1-\rho)$ 部分。两者合起来认证「干净的 rank separation」——把语境相关与无关项分开。任一子条件被破坏,RM 在该实例上就被判为局部 miscalibrate,$f_2^{(i)}=0$,无论它的难度如何都 clip。
5.3 sample-level clip 与 sample-domain trust region¶
clip 系数是两个诊断的合取:
$$\alpha_i=f_1^{(i)}\cdot f_2^{(i)} \tag{10}$$
GRPO loss 当且仅当两个诊断同时为 1 才存活:实例对当前策略同时是困难的、且被一个局部可靠的 RM 信号支撑。其余实例 clip 到零、只贡献监督更新。两个诊断刻出一张互补的失败分类法——一边是「冗余监督」($f_1=0$),一边是「不可靠奖励」($f_2=0$),都被 clip 掉,只准入两关都过的实例。
sample-domain trust region。这条规则把 PPO 的 clip 原则从 ratio 域推广到 sample 域:PPO clip importance-sampling ratio 来 bound 每步更新幅度;AdaGRPO clip 整个 per-sample loss 来排除 policy-gradient 信号冗余或不可靠的实例。两者都定义一个 certified-safe trust region,但 AdaGRPO 的 trust region 定义在哪些样本可以说话,而非 每个样本能走多远。
设计性质:
- 超参精简(hyperparameter-lean):唯一自由量是 rank-threshold 分数 $\tau,\rho$,都相对 $K$ 定义、跨任务经验稳定;
- 构造即可解释(interpretable by construction):每个 clip 决策是二值的、无歧义地归入 GRPO-active 集或其补集,两个诊断直接暴露某实例为何被 clip(诊断即解释);
- 无全局 RM 质量假设:clip 只在两个诊断局部认证 RM 可信处准入 GRPO loss,是一条保守、实例级的准入规则。
6 实验¶
6.1 实验设置¶
- 数据:大规模电商平台的专有交互日志,训练集约 175K 条 user–item 交互序列(取一周窗口),评估在随后两周的 held-out 测试集。训练规模刻意小于 同平台 SFT 用的语料(后者在 $10^8$ 量级)。两个原因:(i) 电商流量强非平稳,预实验里把训练窗口扩到数月会因 user intent / 目录构成的 concept drift 反而损伤 held-out HR;(ii) 标准 GRPO recipe 在更大 RL 训练集下触发 reward hacking(HR@10 骤降、RM artefact 被利用),稳健修法仍在开发——故限定到一个保守工作点,让所有 baseline 与 AdaGRPO 在同一基础上公平对比(更长训练 horizon 列为开放问题,见 §7 局限)。
- Base model:decoder-only LLM,在 user–item 序列上做 SFT;物品表示为从层次化商品分类导出的 SID。除非另说,每个 rollout group $K=50$,reward-side 诊断用 $M=5$ 条 in-batch 负例。
- Reward model:用一个 production encoder–decoder Transformer ranker 的 CTR head,它在 logged click/purchase 信号上经多任务 + MoE 训练,输出层 AUC ≈ 0.76——一个有信息但不完美的 reward 信号。
- Baselines:四个训练变体。Base = SFT-only;GRPO = 标准 policy-gradient(用 RM 分数);GRPO+NLL = 用一个在验证集调好的常数混合系数 $\lambda$ 的混合目标;AdaGRPO = 本文 clip 目标,分两档——w. $f_1$(仅 difficulty 条件)与 w. $f_1$&$f_2$(difficulty + discriminability 双条件)。
- 指标:offline 报 HR@$k$、ClkRwd@$k$、OrdRwd@$k$($k\in\{1,10,50\}$)。HR 衡量与 held-out next-item target 的一致性;ClkRwd / OrdRwd 衡量 RM 在 click / order 目标下的偏好。online 报 effective IPV、UCTR、dwell time,以及被曝光/被点击的三级品类数(多样性诊断)。Hallucination = 生成不映射到合法物品的 SID 的比例。
6.2 Offline 结果¶
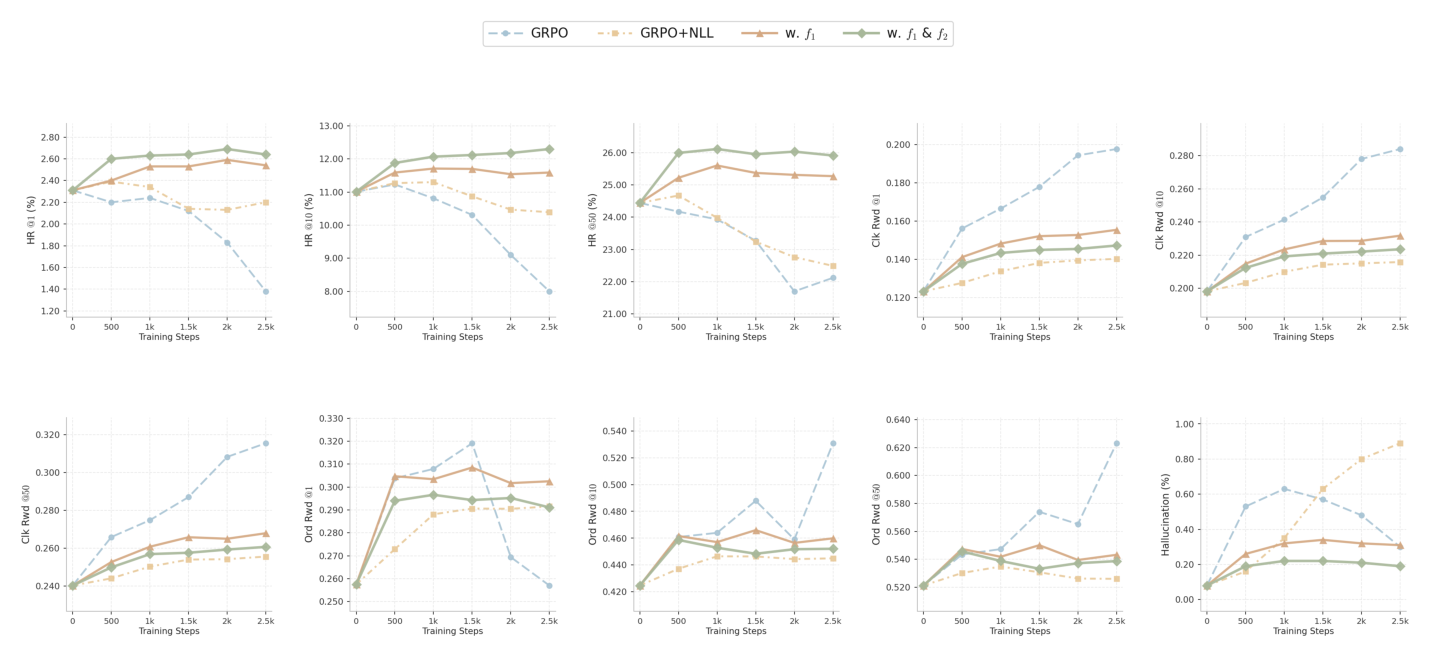
Table 4:最终 checkpoint 的 offline 表现(应读作「稳定性对比」而非「最佳 checkpoint 选择」——Figure 3 才是最佳中间 checkpoint)。
| Method | HR@1 | HR@10 | HR@50 | ClkRwd@1 | ClkRwd@10 | ClkRwd@50 | OrdRwd@1 | OrdRwd@10 | OrdRwd@50 | Halluc.%↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| Base | 2.31 | 11.01 | 24.44 | 0.1232 | 0.1981 | 0.2403 | 0.2575 | 0.4247 | 0.5212 | 0.08 |
| GRPO | 2.20 | 10.39 | 22.49 | 0.1402 | 0.2158 | 0.2556 | 0.2915 | 0.4450 | 0.5260 | 0.89 |
| GRPO+NLL | 2.30 | 11.06 | 24.14 | 0.1629 | 0.2391 | 0.2747 | 0.2976 | 0.4479 | 0.5280 | 0.59 |
| AdaGRPO w. $f_1$ | 2.40 | 11.48 | 25.12 | 0.1521 | 0.2345 | 0.2710 | 0.2958 | 0.4589 | 0.5451 | 0.31 |
| AdaGRPO w. $f_1$&$f_2$ | 2.46 | 11.63 | 25.43 | 0.1508 | 0.2331 | 0.2698 | 0.2950 | 0.4617 | 0.5487 | 0.27 |
三条关键观察:
- 纯 reward GRPO 抬高 RM 分数但后期坍缩:GRPO 稳步抬高 ClkRwd / OrdRwd,但策略最终在 over-optimization 下坍缩——最终 HR@10、HR@50 从 Base 的 11.01% / 24.44% 退到 10.39% / 22.49%,同时 hallucination 从 0.08% 暴涨到 0.89%。这说明「只优化 RM」会主动破坏策略对 held-out target 检索的结构性知识。
- 固定混合目标更稳但仍不足:GRPO+NLL 相对纯 GRPO 减缓了检索指标下滑,大致维持住 Base(最终 HR@10 11.06%),但 hallucination 仍向上漂移、训练末达 0.59%。这印证了 clip 的中心前提——单个全局混合系数无法刻画样本级的 RM 可靠度差异,于是它不可避免地在 RM 无信息的实例上把噪声泄进梯度。值得注意:GRPO+NLL 在 ClkRwd 上达到峰值(相对 $f_1$&$f_2$ 变体),与 clip 的设计意图一致——clip 在不可靠 reward 区域withhold RL 更新以保长期生成质量,代价是绝对 ClkRwd 上一个温和、可接受的下降。
- AdaGRPO 保稳并改善 HR–reward–hallucination 三方权衡:与 baseline 不同,AdaGRPO 在不坍缩的前提下安全抬升性能。沿训练轨迹,AdaGRPO(w. $f_1$&$f_2$)在中间步达到最佳 checkpoint HR@10 12.18%(vs Base 11.01%)且 hallucination ≤0.22%(Figure 3);在最终 checkpoint 它仍是 final 模型里检索最好的(HR@10 11.63%、HR@50 25.43%)且 hallucination 控在 0.27%。对比两行 AdaGRPO:加上 discriminability 条件 $f_2$ 把 hallucination 从 0.31% 进一步降到 0.27% 并改善 HR,印证了 reward-discriminability 诊断的价值。
6.3 难度分层分析¶
把测试集按「ground-truth 在 base 模型 rollout 下的排名」分成五个等质量 bin(0–20% 最易,80–100% 最难),报最终 checkpoint 的 per-bin HR@10。
Table 5:难度分层 HR@10(%)。 $\Delta$ = AdaGRPO − GRPO+NLL(按论文表中所印数值转录)。
| Difficulty bin | GRPO+NLL | AdaGRPO | $\Delta$ |
|---|---|---|---|
| 0–20%(最易) | 24.31 | 24.16 | −0.015 |
| 20–40% | 12.83 | 12.90 | +0.007 |
| 40–60% | 8.47 | 8.64 | +0.017 |
| 60–80% | 5.21 | 5.38 | +0.017 |
| 80–100%(最难) | 2.48 | 2.49 | +0.001 |
分析:收益最大处在中等难度区(40–80%),相对 GRPO+NLL 最高 +0.017;最易 bin 上略负(−0.015),最难 bin 上近零(+0.001)。这与 clip 的预期行为一致——它在「策略不确定且 reward 可靠」处准入 RL 更新、在「策略已自信」处 clip、在「rollout 集离 RM 可靠区太远」处也 clip。作者强调这应读作诊断性证据而非对因果机制的完整验证。
6.4 在线 A/B 实验¶
Table 6:在线 A/B(每个数字是相对其同期 production 对照的 lift)。 GRPO+NLL 跑 01/03–15/03,AdaGRPO 跑 24/03–31/03;两个实验对照不同,列间不可直接横比,仅为紧凑并列。上标 $*$ 表示 $p_{\mathrm{value}}<0.05$。
| Metric | GRPO+NLL | AdaGRPO |
|---|---|---|
| Eff. IPV | +0.09% | +0.43%$^*$ |
| Strict IPV | +0.14% | +0.35%$^*$ |
| UCTR | −0.09% | +0.27%$^*$ |
| Dwell time | +0.01% | +0.23%$^*$ |
| Exposed cats. | +0.14%$^*$ | +0.25%$^*$ |
| Clicked cats. | +0.16%$^*$ | +0.28%$^*$ |
分析:GRPO+NLL 在用户参与度指标上只有小而统计不显著的变化(尽管 offline reward 指标改善),说明更高的 RM 分数本身不一定转化为可度量的用户参与收益。AdaGRPO 在 effective IPV、UCTR、dwell time 上取得统计显著的正向提升,并增加了被曝光/被点击的三级品类数——说明 clip 没有把策略坍缩到一小撮 reward-favored 品类上。online 与 offline 结论一致:把 GRPO 更新 clip 到局部可靠的实例,提升了 reward-model 训练的有用性。但因两实验在不同时间窗、对不同同期对照运行,证据应视为「各方法相对自身对照的 production 支持」,而非 GRPO+NLL 与 AdaGRPO 之间的确定性 head-to-head 因果对比。
7 核心贡献总结¶
- 诊断性发现:通过分层分析(§4)揭示,把 production ranker 当 RM 时,其对 ground-truth 排名的聚合影响接近零甚至为负,但这是一个被构成性效应掩盖的均值——RM 的价值是有条件的,仅在「策略不确定 + RM 可判别」的样本上显著,且这两个条件在 GRPO rollout 时可计算。
- 方法贡献 AdaGRPO:把 reward 引导从「均匀压力」重构为「选择性准入」。以 NLL 为静止锚,对 GRPO 项施加一个 detached 的二值 sample-level clip,由两个 rank-based 诊断(policy-side difficulty $f_1$ + reward-side reliability $f_2$)的合取门控。把 PPO 的 clip 从 ratio 域抬到 sample 域,超参精简(仅 $\tau,\rho$)、构造即可解释、不对 RM 质量作全局假设。
- 实证验证:大规模电商数据上,offline 把 HR@10 从 11.01% 提到最佳 12.18%、hallucination 压到 ≤0.22%,并保持 final-checkpoint 最强;online A/B 取得 effective IPV +0.43% 等统计显著的参与度提升。
- 观念贡献:RL 用于生成式推荐的中心挑战不是设计更强的奖励,而是辨别奖励何时可信。
8 与已归档相关工作的对比¶
GenRec GenRec: A Preference-Oriented Generative Framework (JD.com, 2026-04-16)¶
关系:显式引用([26]),同一团队的直接前作,但本文未做方法级表格对比 · 已加载对方精读
- 同源关系:GenRec 与本文是 JD.com 同一团队工作(Yanyan Zou、Kewei Xu、Junbo Qi、Shengjie Li 同时署名两篇),GenRec 是本文的直接前作/底座。
- 共同关注的问题:GR 的 SFT 只在「模仿行为日志」,缺乏对用户满意度的直接优化;naive 用 RL(GRPO)对齐会 reward hacking——策略生成 RM 打分高但无关/非法的 SID 组合。两篇 root cause 一致。
- 相近的技术骨架:GenRec 的 GRPO-SR 把 GRPO 与一项 NLL 正则(Supervised Regularization) 用常数权重 $\alpha$ 组合(其目标 $\mathcal{L}_{\text{GRPO-SR}}=\text{GRPO} - \alpha\cdot\text{NLL}_{\mathcal{D}^+}$),并对 reward 加 gate($\mathcal{G}_i=\mathbb{1}(s_i>\tau)$,分数过阈才有效,否则抹零)防 hack。这正是本文 Table 4 里
GRPO+NLLbaseline 的化身——一个全局固定混合系数的 NLL–GRPO 目标。 - 本文的差异与推进:本文的核心论点恰恰是「单个全局混合/gate 系数无法刻画样本级的 RM 可靠度差异」(§6.2 第 2 条),于是把 GenRec 的「固定全局混合 + 标量 reward gate」升级为 per-sample 二值 clip,由 policy-difficulty $f_1$ × reward-reliability $f_2$ 两个 rank-based 诊断决定每个实例是否准入 GRPO 项。GenRec 的 gate 作用在「单条 rollout 的 reward 是否够高」(reward 域的硬阈),AdaGRPO 的 clip 作用在「整个实例是否值得且可信地用 RL」(sample 域的 rank 诊断)。可以说本文是把 GenRec 经验式的「NLL anchor + reward gate」做了机制化、诊断化的细化。
- 可比的实验差异:GenRec 在 JD 首页 feed 5.6 亿序列上做 PW-NTP SFT + GRPO-SR,月级 A/B 取得 click +9.5% / transaction +8.7%;本文刻意把 RL 训练集缩到 175K(避免 concept drift 与 reward hacking),聚焦 RL 目标本身的稳健性,A/B 报 effective IPV +0.43% 等更细粒度参与度指标。两篇在「训练规模哲学」上互补——一个做全量上线框架、一个做 RL 目标的受控研究。
ReCast ReCast: Recasting Learning Signals for RL in Generative Recommendation (Huawei, 2026-04-24)¶
关系:独立并发(本文未引用 ReCast,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直击「GRPO 的 group-relative 信号在生成式推荐里并非自动可用的学习单元」这一同构 root cause。ReCast 观测到 sparse-hit 下约 85% 的 group 是 all-zero、96% 响应零奖励——组内无正负边界、advantage 全为 0;本文 Figure 1(a) 描述的「简单样本 advantage 坍缩到 0、RM 噪声主导」是同一退化现象的另一侧切面。两篇都认定:问题不在「奖励怎么算」,而在「这个 group 能否构成可靠的 policy-improvement 信号」。
- 相近的技术骨架:两篇都保留外层 RL 框架不动(rollout 采样 + KL/clip 三件套),只在 within-group / per-instance 层面做干预,且都用层次化 SID 的秩结构来构造诊断信号(ReCast 的结构核 $\phi$ 用三元组前缀匹配;本文的 $f_1/f_2$ 用 rank-threshold $\tau,\rho$)。
- 本文的差异与推进——殊途同归的对立解法:面对同一个「退化 group」,ReCast 选择 repair-and-keep:all-zero 时注入 ground-truth anchor 替换掉最不 informative 的负例,把组拽回「至少一对正负」的最小可学态,再做「最强正例 + 最难 near-miss」的边界对比更新——目标是让梯度继续流动。AdaGRPO 选择 gate-and-drop:当实例「太易」(策略已自信、advantage 近零)或「RM 局部不可信」时,直接 clip 掉 GRPO 项、退回纯 NLL 监督——目标是让不可靠的梯度不要流动。一个救活信号、一个掐断信号,构成一组漂亮的对照。
- 可比的方法差异:ReCast 的触发条件是「reward 稀疏/全零」(二值 hit reward 场景),不显式处理 RM 的可信度/校准问题;AdaGRPO 的 $f_2$ 专门探测 RM 是否把 ground-truth 与干扰项分开(dense continuous reward + exposure-biased RM 场景)。换言之 ReCast 解决「信号太稀疏不可学」,AdaGRPO 解决「信号有但可能误导」。两者若结合(先 repair 救活 all-zero 组,再用 reliability 诊断 gate 掉 RM 不可信的组)可能是有意思的后续方向。
9 讨论与局限性¶
clip 不是 naive filtering。它只作用在 GRPO 项上,NLL 项对所有实例始终活跃——即便被 clip 的样本仍通过监督维持模型的推荐行为。clip 作用在秩分位($\lfloor\tau K\rfloor,\lfloor\rho K\rfloor$)而非绝对分数幅度,决策取决于实例在诊断池里的相对位置,是一条保守的实例级准入规则,而非「RM 正确」的证明。$f_1,f_2$ 是 policy uncertainty 与 RM discriminability 的可计算代理,存活的 clip 只表示该实例「适合一次 GRPO 更新」,并不表示 RM 被完美校准或因果对齐。该原则适用于「有监督 target、reward 信号有噪、rollout 诊断能检出局部有信息引导」的场景;缺乏 ranked 候选集、可识别 ground-truth、或有意义 in-batch 负例的领域则需要替代诊断。
局限:(1) 引入了超参 $\tau,\rho,\lambda,M$,需基于验证集调;(2) $f_2$ 对 batch composition 敏感(in-batch 负例来自同一 mini-batch);(3) 依赖 ground-truth target($f_1/f_2$ 都要 $y^\star$);(4) online 评估只在单一 production 设置、且两个实验对不同同期对照——需要跨用户分群、物品流行度、目录新鲜度的更多 A/B 才能确立更广的稳健性结论;(5) 更长训练 horizon 下 GRPO reward hacking 的稳健修法仍是开放问题(本文刻意用小 RL 训练集回避了 concept drift)。
值得借鉴的设计:把「trust region」从 ratio 域(PPO/GRPO 的 per-token clip)抬到 sample 域(per-instance 准入),是一个简洁且可解释的范式;用 rollout group 已有的统计量「免费」算诊断、不加采样开销;用「policy 不确定性 × RM 可判别性」的合取来定义「何时该信奖励」,对任何「RM 来自有偏 production 信号」的 RLHF/RL-rec 场景都有迁移价值。