UniVA: Unified Value Alignment for Generative Recommendation in Industrial Advertising¶
研究动机与背景¶
生成式推荐(Generative Recommendation, GR)将推荐重新表述为基于离散 Semantic ID(SID)的 next-token 生成问题,借助 LLM 的建模能力将长链路、多模块的传统推荐系统压缩为端到端的统一架构,已经在搜索、电商和内容推荐等多个工业领域取得显著进展。然而,把 GR 直接平移到广告推荐并非平凡——广告系统是一个固有的多目标优化问题:除了优化用户兴趣外,必须同时考虑广告主侧的出价(bid)、ROI、eCPM 等商业信号,否则会损害平台收入或加剧投放质量恶化。
作者将这一问题归纳为"价值不一致"(Value Inconsistency),并指出现有 GR 流水线在以下三个层面均不足以贯通商业价值:
- Value-insensitive SID tokenization(SID 生成阶段缺乏价值感知):现有 RQ-based 分词器主要保留多模态语义相似性,但忽略广告内在的商业异质性。语义相似的两条广告可能对应截然不同的变现潜力,却被映射到相邻 SID 路径,token 空间本身就缺少商业可分性,使得后续语义连贯但商业偏离。
- Semantic-dominated SID decoding(SID 解码阶段商业信号断裂):商业目标通常只在训练目标级注入,自回归解码本身仍由 likelihood 主导。一旦商业前景较好的 SID 前缀在早期 beam 步被语义分数剪掉,后续目标无法挽回,商业可期的轨迹被过早剪枝。
- Value-unaware online serving(线上服务阶段价值外置):即使训练时已经引入价值感知,线上 beam 扩张仍依赖语义相似度和启发式过滤;在 full SID space 上 expand 还会浪费大量算力到违反库存/定向的非法候选上,传统补丁是再加一个外置的 value ranking 模块,引入额外延迟和系统复杂度。
作者的核心洞察是:商业价值不应该是生成之后才补丁式注入的辅助信号,而应该被贯穿地嵌入 SID 构造、自回归解码和在线服务三个环节。基于此提出 UniVA (Unified Value Alignment),覆盖:
- Commercial SID 分词器:在 SID 构造时显式注入价值相关属性(OG/ROI/Industry/Bid),得到 value-discriminative 的 token 表示;
- Generation-as-Ranking SID Decoder:在 SID 解码器内部引入 dual-head(generation head + value head),由监督学习和 eCPM-aware 强化学习联合训练,使生成与排序在同一次 decoding 中完成;
- Value-Guided Personalized Beam Search:将 generation-as-ranking 的融合 logits 直接复用为线上 value 评分,并配合个性化 trie tree 把 beam 扩张限制在请求合法的 SID 路径内。
实验在腾讯微信视频号(WeChat Channels)广告平台上进行:UniVA 在 offline Hit Rate@100 上比 baseline 提升 37.04%,在 online A/B 上获得 1.50% GMV 与 1.42% GMV(normal) 提升。
核心方法/模型架构¶
UniVA 整体框架如 Figure 1 所示,分为三个核心组件:a) Commercial Semantic ID、b) Generation as Ranking SID Decoder、c) eCPM-aware Reinforcement Learning,并配合 d) Value-Guided Personalized Beam Search 完成线上服务。
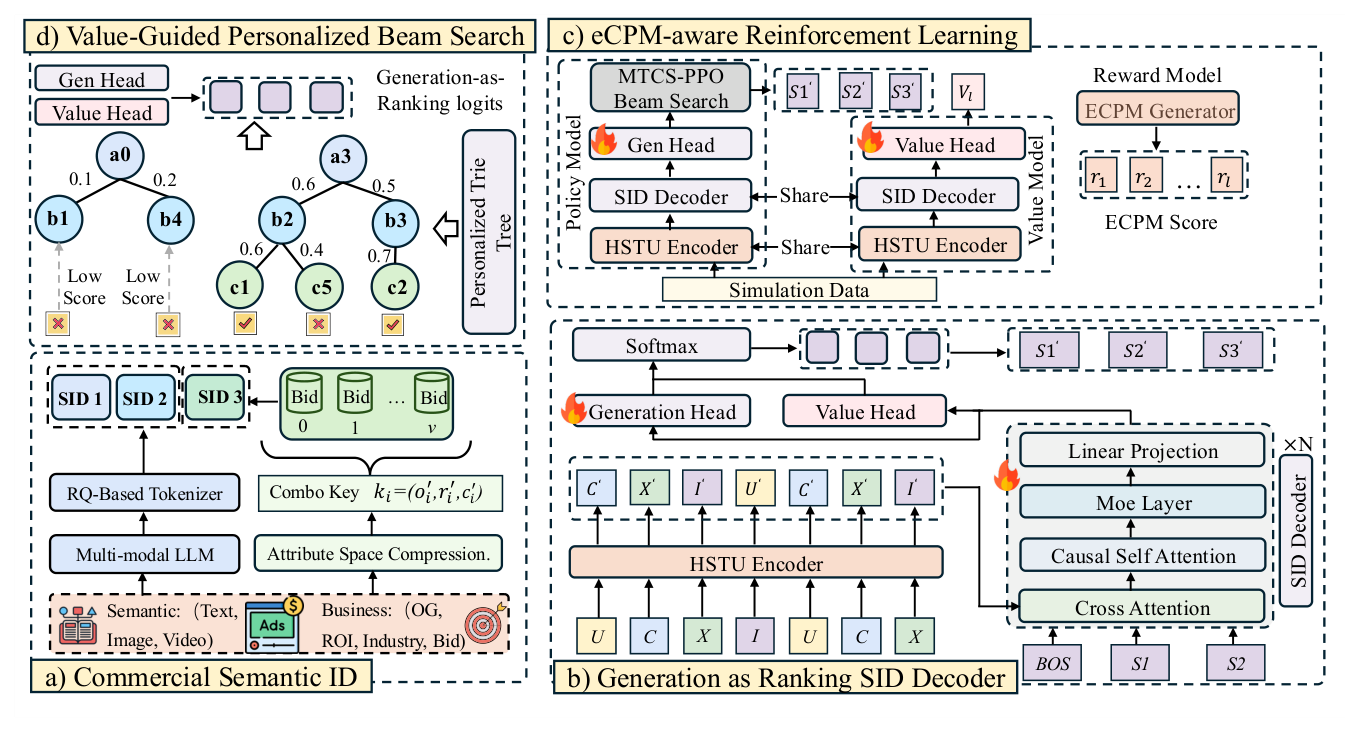
Preliminaries¶
Semantic ID:GR 把推荐建模为序列生成问题。给定用户 $u$、上下文 $c$ 和历史 item 序列 $\mathbf{i}_{1:T} = (i_1, i_2, \ldots, i_T)$,模型直接预测下一目标 item,而不是在候选集上排序。每个 item 通过映射 $s_i = \Phi(i) = \{s_i^1, s_i^2, \ldots, s_i^L\}$ 编码为长度 $L$ 的离散 SID 序列;推荐通过自回归生成 SID 完成。常见实现是 RQ:将 item embedding 残差量化为多级 codebook 索引:
$$s_i^{l+1} = \arg\min_k \|\mathbf{r}_i^l - \mathbf{c}_k^l\|_2^2, \quad \mathbf{r}_i^{l+1} = \mathbf{r}_i^l - \mathbf{c}_{s_i^l}^l \tag{1a}$$
Advertisement Attributes:每条广告 item $i$ 关联两类异构特征——
- 语义属性 $x_i^s = (x_i^\text{text}, x_i^\text{img}, x_i^\text{video})$;
- 商业属性 $x_i^c = (x_i^O, x_i^r, x_i^\text{ind}, x_i^b)$,分别对应优化目标(O)、ROI 目标(r)、行业(ind)和出价(b)。
UniVA 聚焦这四个商业属性,因为它们与计费和商业价值最紧密。
Objective:UniVA 的目标是在历史交互序列 $\mathbf{x}_{1:T}$ 之上自回归地生成下一条广告的 SID:
$$p_\theta(s_{T+1} \mid \mathbf{x}_{1:T}, u, c) = \prod_{l=1}^L p_\theta\bigl(s_{T+1}^l \mid s_{T+1}^{<l}, \mathbf{x}_{1:T}, u, c\bigr) \tag{2a}$$
模型需要同时优化"用户相关性"和"商业价值"。
3.1 Commercial SID Tokenization¶
UniVA 采用语义+商业混合 SID 结构:上层 codebook 仍由 RQ-Kmeans+ 提供的语义分词器 $\Phi_\text{sem}$ 生成,保留语义局部性;最后一层切换为商业感知 token $\Phi_\text{com}$,即
$$(s_i^1, \ldots, s_i^{L-1}) = \Phi_\text{sem}(x_i^s), \qquad s_i^L = \Phi_\text{com}(x_i^c) \tag{1}$$
这样 SID 路径的前 $L-1$ 层维持粗到细的语义层级,最后一层显式承担商业可分性。$\Phi_\text{com}$ 的构造分两步:属性空间压缩与价值感知离散化。
属性空间压缩(Attribute Space Compression)¶
原始商业属性空间过于稀疏——优化目标和行业都呈长尾分布,直接 Cartesian 乘积会导致词表爆炸和细粒度统计不稳定。UniVA 先对每个商业属性独立压缩:
$$x_i^{O'} = \phi_O(x_i^O), \quad x_i^{r'} = \phi_R(x_i^r), \quad x_i^{\text{ind}'} = \phi_I(x_i^\text{ind}) \tag{2}$$
具体策略:
- 优化目标 (O):保留覆盖 99% 数据的 value,剩余按 bid 分布相似度聚类,最终得到 25 个类别;
- ROI:保留覆盖 99% 数据的 value,长尾合并为单一 fallback 类,得到 8 类;
- 行业 (Industry):保留覆盖 75% 数据的 top-9 一级行业,长尾合并为 1 个 fallback 类,得到 10 类。
价值感知离散化(Value-Aware Discretization)¶
属性压缩后,UniVA 为每条广告构造一个组合键:
$$k_i = (x_i^{O'}, x_i^{r'}, x_i^{\text{ind}'}) \in \mathcal{K} \subseteq \mathcal{O} \times \mathcal{R} \times \mathcal{I} \tag{3}$$
每个 $k_i$ 代表了一个"局部商业上下文"——共享相似业务条件的广告集合。对每个 $k$,对应的样本集合为:
$$\mathcal{B}_k = \{x_i^b \mid k_i = k\} \tag{4}$$
使用 classify-then-bin 策略:广告先按 $k$ 聚类,再在每个 cluster 内按出价做等频 bin 化。bin 数量 $n_k$ 受样本量约束,且被限定在 $[n_\text{min}, n_\text{max}]$ 内。在词表预算 $\sum_{k \in \mathcal{K}} n_k \leq V$ 下,按下式选择 $\{n_k\}$ 以最大化加权熵:
$$H_k = -\sum_{j=1}^{n_k} p_j^{(k)} \log p_j^{(k)}, \qquad H = \sum_{k \in \mathcal{K}} w_k H_k \tag{5}$$
其中 $p_j^{(k)}$ 是 key $k$ 下第 $j$ 个 bin 的样本占比,$w_k$ 是 key $k$ 的样本权重。Weighted entropy 鼓励所有 bin 上样本分布平衡,从而获得更稳定的 bid 离散化:稠密商业上下文得到更细的 bid 分辨率,稀疏上下文则保持紧凑、鲁棒。
固定 binning 方案后,UniVA 给每个 (key, bin) 对分配一个全局商业 SID,最后一层 token 定义为:
$$s_i^L = \Phi_\text{com}(x_i^c) = \psi(k_i, x_i^b) \tag{6}$$
$\psi(\cdot)$ 把压缩后的 key 与 bid 值映射到对应的 global bin ID。未见过的 key 在推理期 fallback 到全局 bid 离散化。最终:共享同一 SID 全路径的广告,在内容上和商业上都更一致——既保持语义组织,又获得更强的价值聚合。
3.2 Generation-as-Ranking SID Decoder¶
Commercial SID 解决了 token 空间的可分性,但 SID 解码本身仍由 likelihood 主导。UniVA 借鉴 GPR 的统一输入 schema 与 HSTU encoder 骨干,在 decoder 顶部引入 Generation-as-Ranking 设计。输入序列包括四类 token:User Token (U)、Organic Token (O)、Environment Token (E)、Item Token (I),分别编码用户偏好、用户有机内容行为、请求上下文与历史广告交互。Encoder 输出 user-conditioned hidden state:
$$h = \text{Enc}(U, O, E, I) \tag{7a}$$
Context-Conditioned SID Decoding¶
给定 $h$,decoder 自回归生成目标 SID。在解码 step $t$,当前 SID hidden state 先做 cross-attention(注入 user context)再做 causal self-attention:
$$\bar{z}^{(t)} = \text{CrossAttn}(Q = z^{(t)}, K = h, V = h), \quad \hat{z}^{(t)} = \text{SelfAttn}(\bar{z}^{(t)}) \tag{7}$$
cross-attention 注入请求上下文,self-attention 整合 SID 前缀依赖,使每个 next-token 决策同时基于 user intent 与 SID-prefix 一致性。这里 SID hidden state 作为 query,encoder 输出作为 K/V。
Scalable SID Decoder:MoE × MoR¶
为进一步增强 decoder 容量,UniVA 同时融合 Sparse MoE 和 MoR (Mixture-of-Recursions),分别提供宽度上的条件特化和深度上的递归扩展。
MoE 部分:使用 $N$ 个 routed experts,每 token 激活 top-$K$ 个:
$$g(\hat{z}^{(t)}) = \text{Softmax}(W_r \hat{z}^{(t)}), \tag{8}$$
$$z^{(t+1)} = E_0(\hat{z}^{(t)}) + \sum_{m \in \text{TopK}(g(\hat{z}^{(t)}), K)} g_m(\hat{z}^{(t)}) E_m(\hat{z}^{(t)}) \tag{9}$$
其中 $W_r$ 是 routing 矩阵,$E_0$ 是始终激活的共享 expert(捕捉公共变换),$\{E_m\}$ 是上下文特化的 routed experts。为避免 router collapse(少数 expert 被反复选中),UniVA 引入动态负载均衡:维护历史 expert load 统计,超载 expert 在 top-$K$ 选择前 receive 较低 routing bias,欠载 expert 获得正向 bias。
MoR 部分:采用 Mixture-of-Recursions 在深度上递归共享一个中间 block:
$$h^{(0)} = \ell_\text{in}(x), \quad h^{(r)} = \ell_\text{mid}(h^{(r-1)}), \quad y = \ell_\text{out}(h^{(R)}) \tag{10}$$
通过反复施加同一中间变换,MoR 在不显著增加参数的情况下增加了有效深度,提供了"宽度特化 + 深度迭代精化"的统一 SID decoder backbone。
Dual-Head Generation-as-Ranking¶
在共享 decoder trunk 之上,UniVA 引入两个输出头:generation head $f_\text{gen}$ 与 value head $f_\text{value}$。在 SID level $l$ 处:
$$o_\text{gen}^{(l)} = f_\text{gen}(z^{(l)}), \quad o_\text{value}^{(l)} = f_\text{value}(z^{(l)}) \tag{11}$$
随后做 fused next-token 分布:
$$\tilde{\pi}_\theta(\cdot \mid s_{<l}, h) = \text{Softmax}\bigl(\text{Fuse}(o_\text{gen}^{(l)}, o_\text{value}^{(l)})\bigr) \tag{12}$$
实现中 $\text{Fuse}(\cdot, \cdot)$ 取逐元素求和。这个 dual-head 设计的关键意义是:generation head 仍然保留序列生成的能力,value head 则在每个 next-token 决策上注入 token 级商业偏好;两个 head 在同一次 decoding 内同时作用,从而在 SID 自回归过程中真正完成 generation-as-ranking,而不是先生成后再单独排序,从而避免了引入额外的 post-generation ranking stage。
SID Decoder 学习目标(监督学习阶段)¶
UniVA 先用 SL 建立稳定的 SID 生成行为:
$$\mathcal{L}_\text{SL} = -\sum_{(u, c, \mathbf{x}_{1:T}, s_{T+1}) \in \mathcal{D}_\text{SL}} \sum_{l=1}^L \log p_\theta\bigl(s_{T+1}^l \mid s_{T+1}^{<l}, h\bigr) \tag{13}$$
注意此阶段共享的 decoder trunk 与 generation head 都被 SL 优化,但 SL 本身不能直接给 token 选择提供 value 监督——这是后续 RL 的位置。
3.3 eCPM-aware Reinforcement Learning¶
仅靠 SL 无法直接优化商业回报。UniVA 引入 eCPM-aware RL 阶段:把 SL 训练好的 generation head 直接当作 RL policy head,把 value head 作为 critic 来估计商业价值。Reward 由一个线上 eCPM 生成器产生,decoder 通过迭代 SL-RL 共训练,在同一模型中学习稳定的 SID 生成与商业价值对齐。
Simulation-Based Value Optimization¶
直接对每条采样 SID path 调用真实的生产 ranking 服务来取奖励代价过高。UniVA 沿用 GPR 的 simulation-based post-training 范式,从最近的生产快照构造高保真离线模拟器——重现候选 inventory、特征 pipeline、业务约束和下游 ranking stack——为 RL 训练提供可扩展的 reward 评估能力,且无需占用 serving 资源。
RL 训练数据通过对录制的线上请求进行 simulation sampling 获得,因此 sampling 策略直接决定 policy learning 上限。UniVA 把原本的固定 5% 采样改为自适应采样到全流量,依据是历史学习难度与预测熵,并进一步用从用户最新状态推断的 simulated future requests 增广 replay。
Trajectory Collection(Beam Search + MCTS-PPO)¶
RL 阶段中,encoder 先产生 context state $h$,policy head 定义 token 生成 policy $\tilde{\pi}_\theta(\cdot \mid s_{<l}, h)$。Trajectory 由两条来源构成:
$$\mathcal{Y}(h) = \mathcal{Y}_\text{beam}(\tilde{\pi}_\theta(\cdot \mid h)) \cup \mathcal{Y}_\text{mcts-ppo}\bigl(\tilde{\pi}_\theta(\cdot \mid h), V_\theta(\cdot \mid h)\bigr) = \{y^{(1)}, \ldots, y^{(K)}\} \tag{14}$$
其中 $y^{(k)} = (a_1^{(k)}, \ldots, a_L^{(k)})$ 是一条完整 SID path,$V_\theta$ 是 value head 给出的中间 prefix 的价值估计。Beam search 提供 high-probability rollouts;MCTS-PPO 进一步以 value head 作为节点评估器在 SID 前缀上做结构化探索,发现高价值但 likelihood 偏低的有前途路径。在节点 $n$ 处,MCTS-PPO 按下式选择 action:
$$a^* = \arg\max_{a \in \mathcal{A}(n)} \left( \tilde{Q}(n, a) + c \sqrt{\frac{\log N(n)}{1 + N(n, a)}} \right) \tag{15}$$
其中 $\tilde{Q}$、$N(n)$、$N(n, a)$ 分别是运行平均 action value、节点访问数和边访问数。线上服务则只用 beam search 以保证效率——这一点很关键:MCTS 只在训练阶段提供探索能力,线上 inference 不会承担 MCTS 开销。
每条采样 path resolve 为具体广告并由复用的生产 pCTR/pCVR 模型产生 eCPM reward:
$$R_\text{eCPM}^{(k)} = g_\text{eCPM}(h, y^{(k)}) \tag{16}$$
UniVA 进一步在每个请求内做 batch-level normalization 来减少跨流量上下文的尺度差异:
$$\hat{R}^{(k)} = \frac{R_\text{eCPM}^{(k)} - \mu_R(h)}{\sigma_R(h) + \epsilon_r} \tag{17}$$
这样 policy update 取决于同一请求内候选间的相对 value 差异而非绝对值,与广告排序"在请求内做 list-wise 选择"的实际目标更一致。
Advantage Estimation 与 Loss¶
对采样 SID path $y = (a_1, \ldots, a_L)$,UniVA 用 PPO-style GAE 取得 token 级 advantage $A_l$。设 $a_l$ 是 level $l$ 的所选 token,则
$$v_l = o_\text{value}^{(l)}[a_l], \quad \hat{G}_l = A_l + v_l \tag{18}$$
$A_l$ 是相对当前 value baseline 的 advantage,$\hat{G}_l$ 即对应 return target,让 value head 学习预测当前 decoding policy 下 token 级未来 value。
设 $\tilde{\pi}_\text{ref}$ 是与 current model 同架构、参数周期性同步的 lagged reference policy。PPO ratio 与 clipped objective:
$$\rho_l = \frac{\tilde{\pi}_\theta(a_l \mid s_{<l})}{\tilde{\pi}_\text{ref}(a_l \mid s_{<l})}, \quad \mathcal{L}_\text{PPO} = -\mathbb{E}\left[\min\bigl(\rho_l A_l, \text{clip}(\rho_l, 1-\epsilon, 1+\epsilon)A_l\bigr)\right] \tag{19}$$
value head 用 MSE loss:
$$\mathcal{L}_\text{value} = \mathbb{E}\left[(v_l - \hat{G}_l)^2\right] \tag{20}$$
总 RL loss:
$$\mathcal{L}_\text{RL} = \mathcal{L}_\text{PPO} + \lambda_v \mathcal{L}_\text{value} \tag{21}$$
$\lambda_v$ 平衡 policy 更新与 value 回归。该目标使 SID decoding 同时偏向 high-eCPM 路径并学到 token 级价值估计。
3.4 Joint Optimization¶
SL 建立稳定的 SID 生成、RL 注入下游商业价值监督。UniVA 把两个阶段以协同迭代训练统一在同一个 decoder 中:
$$\mathcal{L}_\text{train} = \mathbb{I}_\text{SL} \mathcal{L}_\text{SL} + \mathbb{I}_\text{RL} \mathcal{L}_\text{RL} \tag{22}$$
$\mathbb{I}_\text{SL}$、$\mathbb{I}_\text{RL}$ 指示当前 batch 是 SL 还是 RL:SL batch 更新共享 decoder + generation head 走 $\mathcal{L}_\text{SL}$,RL batch 走 $\mathcal{L}_\text{RL}$ 同时更新融合 policy 与 value head。通过交替 SL/RL batches,UniVA 在同一 decoder 内渐进对齐 SID 生成与价值估计,使 decoding 过程趋向 commercially valuable paths——构成一个 training-time generation-as-ranking 与 serving-time 的闭环。
3.5 Value-Guided Personalized Beam Search¶
UniVA 把 value-guided 思想贯彻到线上服务,让 commercial value 直接参与 beam expansion:
Personalized Trie¶
首先在候选 inventory 上建一个全局 valid-path trie tree。对每个进入请求,将定向、库存、创意规则应用到全局 trie,得到个性化子树:
$$\mathcal{T}_u = \Gamma(u)(\mathcal{T}) \tag{23}$$
给定 SID prefix $s_{<l}$,它在 personalized trie 下的合法 next-token 集为:
$$\mathcal{V}(s_{<l}; \mathcal{T}_u) = \{s_l \in \mathcal{S}_l \mid s_{\leq l} = (s_{<l}, s_l) \in \mathcal{P}(\mathcal{T}_u)\} \tag{24}$$
其中 $\mathcal{S}_l$ 是 SID 第 $l$ 层 vocabulary,$\mathcal{P}(\mathcal{T}_u)$ 是 personalized trie 下的合法前缀集。条件在 user state 下,UniVA 仅在 $\mathcal{V}(s_{<l}; \mathcal{T}_u)$ 上做 beam search,substantially 减少非法路径扩张,把 decoding 预算集中在请求合法的候选上。
Value Guidance via Fused Logits¶
在受限搜索空间内,UniVA 把价值信号注入 SID 选择:dual-head decoder 给 candidate token 同时产生 generation 与 value 分数,二者直接 fused 用作 beam-expansion 信号。SID prefix 的累积 beam score 为:
$$\text{Score}(s_{\leq l}) = \sum_{t=1}^l \text{Fuse}\bigl(o_\text{gen}^{(t)}, o_\text{value}^{(t)}\bigr)[s_t], \quad \text{s.t. } s_{\leq l} \in \mathcal{P}(\mathcal{T}_u) \tag{25}$$
这样 commercial value 在线上 decoding 全程参与 token-level 竞争,而不是依赖 likelihood 过滤后的二段排序。结果:beam search 保留的 SID prefix 是 user relevance 与 monetization value 联合首选的,commercial-promising trajectory 在 early decoding 步被剪掉的风险显著降低。Personalized trie 与 value-guided beam scoring 形成互补:前者保证 request-validity 并压缩搜索空间,后者支撑轻量级 value-aware 在线 serving 而不引入额外的 value-ranking 模块。线上服务因此保持 single-pass generation-as-ranking 流程,并完全对齐端到端价值目标。
实验¶
实验设置¶
Datasets and Baselines:沿用 GPR,从一个大规模腾讯广告语料构造离线数据集——该语料混合广告与有机媒体(短视频、社交 feed、新闻),训练样本包含 session 级行为与 item 级多模态特征(含 textual metadata、视频帧采样的视觉信号),涵盖现实 mixed-context 评估。预处理上去重、再均衡 category、按 80%/20% 切分训练/测试。Baseline 系统级是 GPR(带 SID Decoder),decoder 级再加入 vanilla decoder-only Transformer 作为额外 baseline,并把 Commercial SID 与不同 SID-decoder 设计逐项叠加做消融。
Implementation Details:
- SID 结构:3 级,codebook size = 2048
- SID decoder:4 层、embedding 维度 256
- Commercial SID:自适应 bid-binning 超参 $n_\text{max} = 25$、$n_\text{min} = 3$,最终 binning 方案在词表预算 2048 下按 grid search 最大化 weighted entropy
- Sparse MoE:64 routed experts,每 token 激活 top-16;hidden dim 128
- 优化器:Adam,学习率 0.001,batch size 16
- 输入序列长度:2048
Evaluation Metrics:
- Offline:HR@K(next interacted item retrieval hit rate)。
- 在 GMV-weighted next-conversion set 上额外报告两个 value-oriented metric:
$$\text{ValueHR@K} = \frac{\sum_{t=1}^T \text{gmv}_{i_t} \cdot \mathbb{I}(i_t \in R_t^K)}{\sum_{t=1}^T \text{gmv}_{i_t}} \tag{value-hr}$$
$$\text{wNDCG@K} = \frac{\sum_{t=1}^T w_t \cdot \text{NDCG}_t @K}{\sum_{t=1}^T w_t}, \quad w_t = \log_{10}(1 + \text{gmv}_{i_t}) \tag{wndcg}$$
其中 $T$ 是 evaluation request 数,$i_t$ 是 ground-truth 转化 item,$\text{gmv}_{i_t}$ 是其 GMV,$R_t^K$ 是模型 top-K 候选集合。ValueHR@K 衡量"top-K 召回覆盖了多少转化金额";wNDCG@K 强调"高价值请求是否被排在前面"。
- 线上:GMV 与 GMV(normal)——前者直接反映商业回报,后者排除 ROI 类广告。
4.2 Overall Performance¶
Table 1 报告 SID-level 消融,逐项叠加 Commercial SID、深 decoder(layer2→layer4)、MoR、Sparse MoE,最终得到 UniVA Full。
Table 1: Offline next interacted item prediction performance (HR@100, ΔHR@100 vs. GPR+SID Decoder, Parameters/FLOPs 仅含 SID decoder)
| Model | Parameters | FLOPs | ΔHR@100 |
|---|---|---|---|
| Base | |||
| GPR + SID Decoder | 3M | 4.1G | +0.0% |
| SID Design | |||
| + Commercial SID | 3M | 4.1G | +5.78% |
| + (layer2→layer4) | 7M | 7.1G | +6.10% |
| + MoR | 5M | 7.1G | +13.56% |
| + Sparse MoE | 60M | 8.5G | +18.40% |
| UniVA (Full) | 80M | 23.2G | +37.04% |
分析:
- Commercial SID 单独贡献 +5.78%——在不增 decoder 参数和算力的情况下提升下一 item 召回。说明 Commercial SID 引入的 value-structured bias 让同 SID 路径的 item 在商业上更内聚,给模型带来更清晰的学习信号。
- decoder scaling:从 layer2 到 layer4 的纯加深只带 +6.10%,加 MoR 后冲到 +13.56%(递归复用提升 effective depth),加 Sparse MoE 后到 +18.40%(条件特化容量)。两条 scaling 路径互补:MoR 走深、MoE 走宽。
- UniVA Full:在 SID design + decoder scaling 之上叠加 eCPM-aware RL 与 joint optimization 后达 +37.04%,远超单纯参数扩展能给的上限。结论是:Commercial SID + 解码器规模化 + value-aware RL + 联合优化是相互独立、可叠加的改进维度。
4.3 Value Alignment Performance¶
为验证 UniVA 是否真的捕获到商业价值,作者在 GMV-weighted next-conversion set 上做 value-oriented 消融。Figure 2 横轴为 K(top-K cutoff),纵轴为 ValueHR 与 wNDCG。
四种 SID 配置对比:32048 SID、38192 SID、22048 SID + CSID、28192 SID + CSID。
- 2*2048 SID + CSID 在大多数 cutoff 上最优:在 K=10/32/50 都拿到最高的 ValueHR 与 wNDCG。在 K=100 时 ValueHR@100 = 0.0677、wNDCG@100 = 0.0554,明显优于两个 3-level 纯语义 SID 设置。
- 纯语义 SID 仅在最严格的小 K 处(如 wNDCG@1、wNDCG@10)保留些许优势,对应"pure semantic similarity 在最高严格匹配的小集合内有用"。
- 3-level vs. 2-level + CSID:增加 codebook size 反而不一定更好。8192 codebook 上 28192 SID + CSID 也只在某些 cutoff 上接近 22048 + CSID,说明中等大小 codebook 与 Commercial SID 配合更稳定——过大词表会 disperse 数据并削弱稳定的商业聚类。
- 整体结论:UniVA 不仅提升了 prediction accuracy,更显著强化了 value capture。
4.4 More Insights¶
Commercial SID Quality Analysis¶
Figure 3 比较引入 Commercial SID 前后在 path-level 上的 bid 离散性统计。横轴为 cutoff 统计量(Mean、P75、P99),纵轴为 log-scale 的 bid std / bid range。
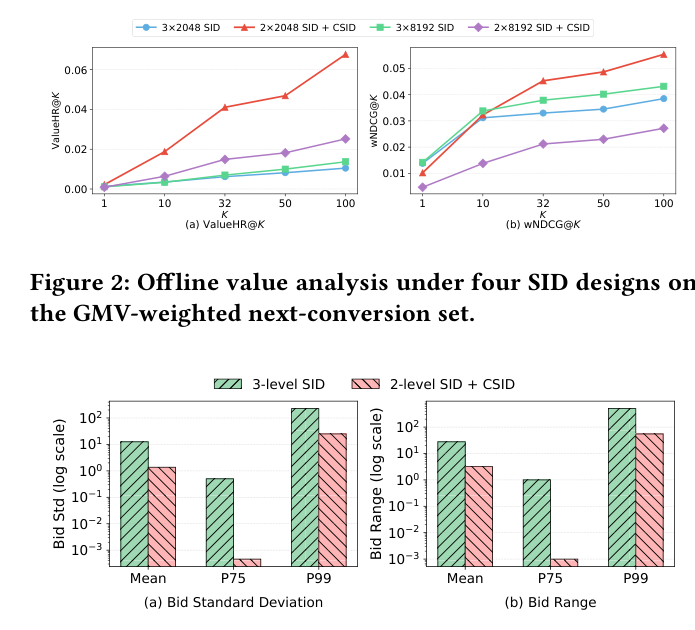
相对 3-level SID,2-level + CSID 在 Mean、P75、P99 三个统计量上 bid std 与 bid range 都降低约一个数量级。在 log scale 下,中段与尾部下降尤其明显——意味着同一 SID full path 内的 ad 在商业价值上变得更一致,而不再混合宽差距 bid 的广告。直接结论:Commercial SID 给 value-aware decoding 提供了更干净的结构基础,并降低了高方差的不稳定路径。
Commercial SID Strategy Analysis¶
Figure 4 在两个维度上对比 9 种 Commercial SID 构造组合:横轴 In-bin 策略(Equal-width / Equal-frequency / Clustering),纵轴 Overall 策略(Direct Binning / Classify-then-Bin / Cluster-then-Bin)。每格写出 weighted entropy $H$ 与 vocabulary size $V$,颜色表示 $H$。
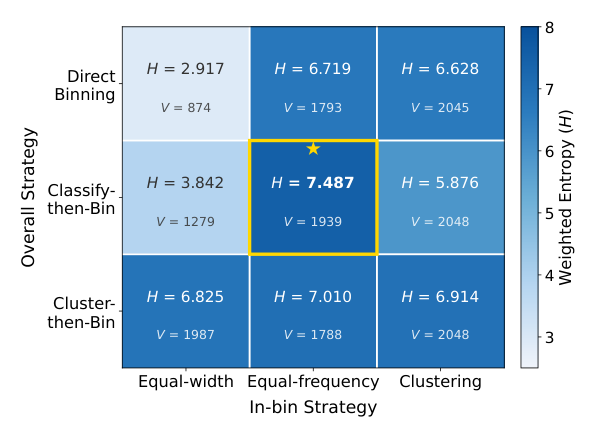
- Classify-then-Bin + Equal-frequency 取得最高 weighted entropy $H = 7.487$、$V = 1939$(接近预算 2048),是最平衡的策略组合。
- Direct Binning 忽略结构化商业属性,把异构广告混合后再做 bid 离散化,结果分区粗、不平衡。
- Cluster-then-Bin 改善了 bid 分布分组,但 cluster 不稳定,常以词表效率换取有限的 entropy 收益。
- In-bin 策略:Equal-width 对长尾出价分布敏感;Clustering 倾向消耗更多词表但 H 收益不一致。
整体结论:Classify-then-Bin + Equal-frequency 是 Commercial SID 构造的最佳折中。
Codebook Size Analysis¶
Table 2:HR@K comparison under different SID codebook sizes(值为百分点 %)
| SID Configuration | HR@1 | HR@10 | HR@32 | HR@50 | HR@100 |
|---|---|---|---|---|---|
| 3*2048 SID | 0.09 | 0.72 | 1.60 | 2.15 | 3.23 |
| 3*8192 SID | 0.10 | 0.83 | 2.06 | 2.77 | 4.03 |
| 2*2048 SID + CSID | 0.14 | 1.02 | 2.17 | 2.84 | 4.20 |
| 2*8192 SID + CSID | 0.09 | 0.92 | 1.98 | 2.63 | 3.84 |
分析:
- 22048 SID + CSID 在所有 cutoff 上一致最优,相比 32048 SID 在 HR@1/HR@10/HR@32/HR@100 上分别提升 55.56%/41.67%/32.09%/30.03%。
- 但 28192 SID + CSID 在所有 cutoff 上反而比 38192 SID 略差。原因是 Commercial SID 词表固定 2048,与 2048 semantic codebook 自然对齐;换成 8192 semantic codebook 后引入了词表 mismatch,反而削弱了细化语义切分的收益。
- 结论:Commercial SID 与中等规模 semantic codebook 配合最稳——明确价值建模补充语义结构,但不需要过度的语义碎片化。
4.5 Online A/B Test¶
Personalized Beam Search¶
在固定 beam width = 300 的条件下:
- Personalized trie-based beam search 产出 300 条 valid SID path;
- 未加 trie 的 beam search 仅产出 48 条——只有 16% 是 trie-合法的有效路径。
意味着 trie 在 expansion 之前就过滤了非法分支,beam capacity 集中到 feasible path 上而不是浪费在违反 inventory/targeting 的候选上。UniVA 因此节省了线上搜索资源,同时在相同 decoding budget 下产出更多 valid 广告创意。
Online GMV Results¶
Table 3:Online A/B test on Tencent WeChat Channels advertising traffic, March 7-11, 2026, 5% traffic(相对生产 baseline 的相对 lift)
| Online Version | GMV Lift | GMV(normal) Lift |
|---|---|---|
| v1 w/o Generation-as-Ranking | +1.03% | +1.17% |
| v2 with Generation-as-Ranking | +1.50% | +1.42% |
分析:
- v1(仅 Commercial SID + value-enhanced decoder,但不加 generation-as-ranking 的线上版本)已经获得 +1.03% GMV、+1.17% GMV(normal)。这验证了即使在 Generation-as-Ranking 之前,value-aware SID 构造与 value-enhanced decoder 在生产中已带来显著正向收益。
- v2 进一步引入 generation-as-ranking,GMV / GMV(normal) lift 上升到 +1.50% / +1.42%。说明 candidate generation 与 value guidance 在同一次 decoding 中统一后,SID decoder 真正在线上 search 中"使用价值信号",把 joint optimization 转化为可观察的真实 monetization 改进。
与已归档相关工作的对比¶
OneRanker OneRanker: Unified Generation and Ranking with One Model in Industrial Advertising Recommendation (Tencent WeChat Ads, 2026-03-03)¶
关系:独立并发(UniVA 与 OneRanker 同源 Tencent WeChat 广告系统但互不引用,各自给出截然不同的"统一生成+排序"路径)· 已加载对方精读
- 共同关注的问题:两者都瞄准微信视频号广告中的生成式广告推荐 + 兴趣/价值统一优化问题,都强调商业价值不能仅作为 post-generation 的下游辅助信号;都明确指出"生成器先做、排序器再做"的二段式范式存在 representation/optimization fragmentation。
- 相近的技术骨架:两者都把 GR backbone(HSTU-style decoder + GPR token schema)作为统一架构的起点,都在 decoder 内部把 value/ranking 信号"内化",避免线上额外加一段 ranking module;都用 list-wise 价值信号来训练,并都做了线上 A/B 验证。
- 本文(UniVA)的差异与推进:UniVA 把"价值统一"贯彻到了 token 空间本身——通过 Commercial SID(classify-then-bin + weighted entropy)让最后一层 SID 直接编码商业属性 + bid bin;同时通过 dual-head(generation head + value head)在每个 token-level 决策上融合价值,并且用 eCPM-aware PPO + MCTS-PPO 做 RL 后训练,再以 personalized trie + fused logits 把同一信号搬到线上 beam search。它的"统一"是 token-level 的,且关键改造在 SID 构造与 RL 阶段。
- OneRanker 的差异:OneRanker 把"统一"放在架构级三阶段(Generation → Multi-Task/Target-Aware → Unified Ranking),通过 task tokens(含独立的 value-aware task token)+ fake item tokens 做 target-aware 的多任务解耦;价值信号通过 BPR loss 与 KL 形式的 Distributional Consistency Loss 注入,而不是 RL/dual-head logits。Decoder 端不改 SID tokenizer,主要靠 R-Decoder + Cross-Attention prioritization。
- 可比的方法 / 实验差异:UniVA 强调 Commercial SID 单独 +5.78% HR@100、Full UniVA +37.04% HR@100、Online GMV +1.50%;OneRanker 不在同一表里直接对比,但报告其 Wechat Channels 部署 lift。两者各自承担互补假设:UniVA 倾向"在 SID 与 RL 上重做一遍",OneRanker 倾向"在 decoder 之上加一个统一 ranking 阶段",对未来工作可以作为同问题域的 architecturally orthogonal 候选。
GR4AD GR4AD: Generative Recommendation for Large-Scale Advertising (Kuaishou, 2026-02-26)¶
关系:显式引用但原文未展开对比(UniVA 把 GR4AD 与 LLaTTE/EGA-v2 一起作为"existing approaches still optimize commercial objectives in a fragmented manner"的代表,未在 ablation 中直接比对)· 已加载对方精读
- 共同关注的问题:完全同构——把 GR 范式落到工业广告系统时,需要协同重设 tokenization、训练、和服务三层,使商业价值(eCPM/GMV)成为一等公民;两者都坚信单纯靠在 loss 上加权或 post-rank 做不到 production-grade value alignment。
- 相近的技术骨架:两者都引入 value-aware 的 SID 分词器(UniVA 的 Commercial SID vs. GR4AD 的 UA-SID);都把训练分成 SL + value-aware RL(UniVA 的 SL+PPO/MCTS-PPO vs. GR4AD 的 VSL+RSPO);都引入 batch/request 级 normalization;都做 value-aware 的服务侧裁剪(UniVA 的 personalized trie + value-guided beam vs. GR4AD 的 Dynamic Beam Serving)。
- 本文(UniVA)的差异与推进:UniVA 的 value 信号在 SID 最后一层显式离散化 bid + 商业属性的组合(classify-then-bin + weighted entropy 选 bin),并通过 dual-head fused logits 在 decoding 内部参与 token 选择;RL 用 MCTS-PPO 做高价值低概率路径的探索。这两点是 GR4AD 没有的关键设计。
- GR4AD 的差异:GR4AD 的 UA-SID 在最后一层用 hash-based 数值映射处理非语义业务信号(vs. UniVA 的 attribute compression + classify-then-bin 真正离散化 bid);其 VSL 把 eCPM 离散化为序列尾的额外 token 而不是融入解码器输出 head;其 RL(RSPO)走 list-wise NDCG 上界 + reliability-gated reference policy,而 UniVA 走 single-request normalized PPO + MCTS。两者在工程取舍上互补:GR4AD 强调 inference 加速(LazyAR / DBS),UniVA 强调线上 trie + dual-head 的 single-pass generation-as-ranking。
- 数据点对比:UniVA 在 Tencent WeChat Channels 报告 +1.50% GMV / 5% traffic A/B;GR4AD 在 Kuaishou 报告 +4.2% ad revenue(量级不同、业务定义不同,不能直接比对)。两者协同验证了"value-aware GR 是 industrial advertising 的可落地方向"。
GEM-Rec GEM-Rec: One Model, Two Markets — Bid-Aware Generative Recommendation (Google Research, 2026-03-23)¶
关系:独立并发(UniVA 未引用 GEM-Rec,两者都把"价值/出价"引入 SID-based GR,但落点不同)· 已加载对方精读
- 共同关注的问题:均认为现有 SID-based GR 完全忽略商业价值/出价,需要让 decoder 直接处理经济信号而不是依赖外部 merge/blend 模块。
- 相近的技术骨架:两者都在 SID 解码阶段直接接入价值信号;都明确 single-pass decoding 内同时完成 candidate generation 与 value 评估。
- 本文(UniVA)的差异与推进:UniVA 面向的是纯广告场景下的 value alignment,价值信号通过 Commercial SID 的最后一层 token 与 dual-head value 在每个 token 级竞争中注入;并通过 eCPM-aware RL 学习端到端 generation-as-ranking policy。
- GEM-Rec 的差异:GEM-Rec 解决的是有机内容 + 赞助广告混合序列问题,引入
<ORG>/<AD>flag token 来显式分槽位,并用 inference-time logit modulation(slot-level + item-level)把实时出价注入 beam search,定价采用 first-price 拍卖;它的 value 信号主要通过 logit 加性 modulation 进入解码,没有 RL 后训练,也没有改 tokenizer。 - 核心差异:UniVA 是训练时 + 解码时双重价值对齐(重做 SID + 加 value head + RL);GEM-Rec 是仅解码时通过 logit 调制注入 bid,并把 organic vs. ad 的混合预算建模为分层采样问题。两者代表了"重 training-side 改造 (UniVA) vs. 轻 decoder-side 调制 (GEM-Rec)"两条对偶设计哲学,可在不同体量与业务约束下互相借鉴。
核心贡献总结¶
- 形式化 value inconsistency 问题:作者首次系统地将广告 GR 中的"价值不一致"分解为 tokenization、autoregressive decoding、online serving 三层断裂,并以此为问题域设计统一解。
- Commercial SID tokenizer:通过 attribute compression + classify-then-bin + weighted entropy 离散化 bid,让 SID 路径的最后一层从纯语义切到显式商业可分,为后续 value-aware decoding 提供了 token 级基础。
- Generation-as-Ranking SID Decoder:dual-head(gen + value)+ fused logits + MoE × MoR scalable backbone,使 generation 与 ranking 在同一次 SID 自回归内同时发生,避免传统 generate-then-rank 的额外 stage 与表示断裂。
- eCPM-aware RL (PPO + MCTS-PPO):以 simulation-based reward 与 batch-level normalized advantage 在 SID 自回归 policy 上做 RL,结合 MCTS 进行结构化 prefix 探索,发现高价值低概率路径。
- Value-Guided Personalized Beam Search:以 personalized trie 把 beam expansion 限制到 request-valid 路径,再以 dual-head fused logits 直接复用为线上 value 评分,不引入额外 ranking 模块。
- 生产验证:在 Tencent WeChat Channels 广告平台的离线 / 线上实验中,offline HR@100 +37.04%,online GMV +1.50%、GMV(normal) +1.42%,证明 value-aware GR 在量级最大的工业广告场景下可落地、可观测、可演进。
讨论与局限性¶
值得借鉴的设计:
- Token-level value injection(Commercial SID)相比仅在 loss / post-rank 加权更"原生"——它从结构上避免"语义路径上的高价值候选被早剪",对所有价值导向的 GR 都是值得复用的设计。
- Dual-head fused logits 用作线上 value 信号:把 RL 训练时学到的 value head 直接挪到线上 beam scoring,避免线上加额外 ranking 模型,是一个 cost-effective 的工程妙招。
- Personalized trie + valid-path constraint:把 inventory/targeting 规则作为生成时的 hard constraint 而不是事后过滤,让 beam capacity 集中在合法分支,是工业 GR 落地的一个重要 enabler。
- MCTS-PPO 仅用于训练阶段:保留高价值低概率路径的探索能力,又不付线上 MCTS 开销,对其它 industrial GR RL 后训练有借鉴意义。
局限与争议:
- Commercial SID 假设 bid 信号可观测且足够稳定——对于 ROI 类广告或冷启广告,bid 不存在或漂移大,需要 fallback 到全局 bid 离散化,这部分 inference 期 fallback 的覆盖与稳定性论文未充分量化。
- A/B lift 的可解释性:只有两个版本(v1 / v2),缺少把 RL、joint optimization、value-guided beam search 各自单独的线上 lift 拆开的细分实验,无法定位每个组件在生产中的贡献占比。
- simulation-based reward 与真实线上 reward 的 gap:UniVA 强调把 RL 的 reward 由真实 ranking 服务换成 simulator 来节省成本,但 simulator 与生产 ranker 的差距如何随时间漂移、是否需要 periodic recalibration 论文未说明。
- 可迁移性:所有实验都基于 WeChat Channels 单平台,token-level value 离散化中"O/r/ind"等属性的取值与 99% 覆盖切分都依赖该平台的具体分布,迁移到其它广告平台需重新做 attribute coverage 调参。
- 对长尾广告主公平性:value-guided beam 会偏向 high-eCPM 路径,长尾广告主的曝光是否被进一步压制?论文没有专门的 fairness / diversity 评估。
与已有工作的差异:相对 GPR、HSTU 等 semantics-centric GR backbone,UniVA 在 SID + decoder + RL + serving 四个层次上同时把"商业价值"作为一等信号嵌入;相对 GR4AD(Kuaishou)等同期工业广告 GR 工作,UniVA 在 SID 上选择"显式离散化 bid + classify-then-bin"路线,在 decoder 上选择"dual-head fused logits"路线,在 RL 上选择"PPO + MCTS-PPO"路线,与 GR4AD 的 LazyAR + VSL + RSPO 形成同问题域下的并行解法;相对 OneRanker,UniVA 更强调 token-level 价值嵌入而非架构级三阶段重构,是一种"轻架构改造、重 token+RL 改造"的对偶选择。
工业落地价值:UniVA 的几乎每一个设计——Commercial SID、dual-head、personalized trie、MCTS-PPO 仅训练用——都明确以 production-grade serving 为约束。其在 WeChat Channels 上的 5% 流量 A/B 已经验证 GMV +1.50%,对一个亿级 DAU 的广告系统而言意味着可观的实际收入提升。