ToolRec: Calibrated Preference Alignment for Query Recommendation in On-Device Assistants 精读¶
OPPO AI Center / 华中科技大学,作者 Zihan Luo, Lingkui Chen, Ruike Zhang, Hong Huang(通讯), Boyang Zhang, Ziniu Chen, Lizhong Wang。arXiv 2606.08466v1(2026-06-07),投稿 ACM 会议。第一作者于 OPPO AI Center 实习期间完成。
1 研究动机与背景¶
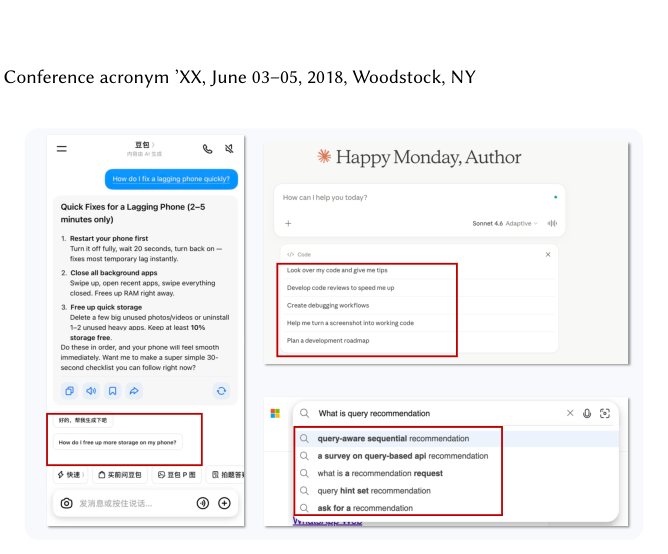
Query Recommendation(查询推荐) 是搜索引擎与智能助手中的关键能力:在用户当前输入旁主动推荐相关或改进后的候选查询(如图 1 中"query-words-sequential recommendation""ask for a recommendation"等浮层建议),既能降低交互门槛,也能引导用户发现更有价值的内容、提升交互量。
近年来,借助 LLM 的零样本泛化与世界知识,生成式查询推荐取得突破:例如 Min et al. 用 DPO(Direct Preference Optimization) 把 LLM 的生成对齐到人类点击行为,鼓励模型输出高质量、多样化的查询建议;也有工作用高斯分布刻画用户偏好的不确定性,并通过 GRPO(Group Relative Policy Optimization) 做偏好对齐。
但作者指出:这些方法虽然在标准聊天机器人场景表现出色,却无法精确捕捉端侧智能助手(如 OPPO 小布 Xiaobu)场景下的用户内在偏好。该场景存在两个尚未被探索、且制约实际部署的挑战:
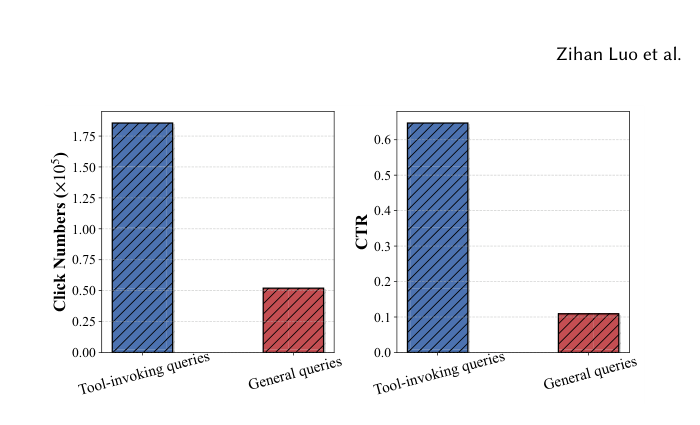
挑战一:如何捕捉端侧助手中的"工具调用意图"(tool-invocation intent)? 与传统聊天机器人不同,端侧助手用户的主导行为是借助助手快速触发设备上的系统级功能。例如用户问"为什么我手机这么卡?",他们通常更想要"清理设备缓存"这类能立即带来系统级效用的可执行动作,而非被动的排障说明。作者基于线上数据将推荐查询划分为 tool-invoking queries(工具调用类) 与 general queries(普通类)——划分依据是该推荐查询是否会触发一个系统级工具。如图 2 所示,过去六个月的统计显示:工具调用类查询的点击率(CTR)与点击量都显著高于普通查询。因此,提供高质量的工具相关查询推荐,对优化用户体验、维持参与度至关重要。
挑战二:如何校准隐式偏好信号的"可变可信度"(varying reliability)? 现有对齐方法普遍把点击当作金标准(golden label),忽略了点击信号在不同场景下的可信度差异。作者从两个视角剖析其噪声与偏置:
- 用户侧:用户活跃度差异巨大。对一个极不活跃或挑剔的用户,其"非点击"行为很大程度上不是因为生成的查询质量差,而是源于其本身就弱的交互意愿。盲目地把这类低质量偏好信号对齐进去,反而可能损害模型性能。
- 系统侧:标准对齐无法区分工具调用类与普通类查询。既然端侧场景用户真正的偏好是快速触发系统级效用,那么把工具调用类与普通类的点击同等对待,就无法把模型导向用户的"执行导向(execution-oriented)"需求。
为此,作者提出 ToolRec——一个为端侧查询推荐量身定制的校准式偏好对齐框架。其要点:(1) 构建 SysToolkit(708 个系统工具的仓库)+ 上下文感知工具检索,把查询推荐锚定到可执行动作;(2) 提出双层偏好校准机制,从用户侧(按活跃度过滤噪声)与系统侧(上调成功触发工具的高频查询权重)精炼原始点击数据;(3) 用校准后的样本权重,通过样本级加权 KTO(Kahneman-Tversky Optimization) 对齐模型。在 OPPO 小布(>1.5 亿 MAU)上的大规模在线 A/B 显示,ToolRec 在 CTR 与总点击量上显著超越强 baseline,同时保持高查询相关性。
核心贡献:
- 强调端侧助手中"工具调用意图"的重要性,构建 SysToolkit——一个涵盖 708 个系统级工具的综合仓库,为 LLM 查询推荐赋能。
- 提出 ToolRec,引入用户侧 + 系统侧双层偏好校准机制,显著降低偏好数据噪声,把模型有效对齐到真实执行导向需求。
- 在 OPPO 小布(>1.5 亿 MAU)上做了大规模在线 A/B,证明 ToolRec 在 CTR 与总点击量上优于已有对齐 baseline,同时保持高相关性。
2 相关工作¶
LLMs for Recommendation:早期工作用 LLM 做用户/物品特征增强(如 LLMRec 增强 side information、FLIP 在特征级对齐多模态做 CTR 预测)。由于 LLM 训练任务与推荐任务存在固有 gap,直接套用效果欠佳,于是出现用点击/点赞等行为信号对齐 LLM 的工作:早期用 SFT(监督微调) 把推荐表述为指令跟随的 next-item 预测,更近的工作用 DPO / GRPO 等优化算法做端到端对齐。但这些方法都倾向把点击当成金标准,忽视不同用户点击信号置信度的差异——这正是 ToolRec 要解决的。
Query Recommendation:旨在基于用户当前输入、行为信号或上下文,主动建议相关/改进查询。早期形式是 Query Auto-Completion(QAC),从历史日志中按前缀匹配检索候选,其局限是无法为日志中未出现过的前缀生成建议。随后 Seq2Seq 模型让系统能为未见前缀生成补全并提升个性化。最近基于 LLM 的查询推荐(含 RL4Sugg、GaRM、GQS 等)展现出强泛化与零样本能力。ToolRec 区别于上述工作之处:聚焦端侧智能助手场景,并进一步为模型赋予工具调用能力,以支持更丰富、更可执行的交互。
3 预备知识¶
3.1 问题形式化¶
给定用户输入查询 $q_u$、智能助手对应响应 $\mathcal{A}$、历史对话上下文 $C$、可用工具集 $\mathcal{T}$,LLM 推荐模型 $\mathcal{M}_\theta$ 在单次前向中生成一组 $K$ 个候选查询 $Q_r$:
$$\mathcal{M}_\theta(q_u, \mathcal{A}, C, \mathcal{T}) \to Q_r \tag{1}$$
其中 $Q_r=\{q_r^1, q_r^2, \dots, q_r^K\}$,$K$ 是由推理延迟上限预先设定的超参。生成的候选 $Q_r$ 会经下游 rerank 与召回模块进一步处理(不在本文范围),最终一组 $N$ 个候选 $Q_r'$ 暴露给用户($N$ 预先设定)。
实践中用点击定义正负样本:$y(q_r)\in\{0,1\}$ 表示查询 $q_r$ 的点击指示。候选集 $Q_r$ 被记为正样本 $Q_r^+$ 当且仅当 $\exists q_r\in Q_r$ 使 $y(q_r)=1$;反之若 $\forall q_r\in Q_r, y(q_r)=0$ 则为负样本 $Q_r^-$。目标是把 $\mathcal{M}_\theta$ 对齐到真实用户偏好,从而提升推荐查询的质量。
3.2 Kahneman-Tversky Optimization(KTO)¶
KTO 区别于 PPO/DPO 之处在于:它无需成对偏好数据即可工作。给定参考策略 $\pi_{ref}$ 与 prompt-response 对数据集 $D=\{(x,y)\}$,KTO 目标为:
$$\mathcal{L}_{KTO}(\pi_\theta, \pi_{ref}) = \mathbb{E}_{x,y\sim D}\big[w\,(1 - v(x,y;\beta))\big] \tag{2}$$
其中 $v$ 是基于前景理论(prospect theory)的人类价值函数:
$$v(x,y;\beta) = \begin{cases} \sigma\big(r(x,y) - z_{ref}\big) & \text{if } y\sim y^+ \\ \sigma\big(z_{ref} - r(x,y)\big) & \text{if } y\sim y^- \end{cases} \tag{3}$$
$\sigma$ 是激活函数,隐式奖励 $r(x,y)=\beta\log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)}$ 度量相对参考模型的缩放偏离,$\beta$ 是 KL 惩罚系数。参考点 $z_{ref}$ 定义为数据集上期望 KL 散度,充当动态 baseline:
$$z_{ref} = \mathbb{E}_{x'\sim D}\big[\beta\,\mathrm{KL}\big(\pi_\theta(y'|x') \,\|\, \pi_{ref}(y'|x')\big)\big] \tag{4}$$
权重 $w$ 在 Eq.(2) 中对"理想/非理想结局"施加非对称惩罚($\lambda_D$ 与 $\lambda_U$),建模前景理论的损失厌恶:
$$w = \begin{cases} \lambda_D & \text{if } y\sim y^+ \\ \lambda_U & \text{if } y\sim y^- \end{cases} \tag{5}$$
在查询推荐语境下,$x$ 表示用户的综合交互上下文(当前输入 $q_u$、对话历史 $C$、助手响应 $\mathcal{A}$);$y^+$、$y^-$ 分别表示被点击/未被点击的推荐查询 $Q_r^+$、$Q_r^-$。ToolRec 的关键改造,就是把 Eq.(5) 里那个固定的常数权重 $w$,替换为逐样本计算的校准权重——这是全文方法的落点。
4 方法:ToolRec¶
4.1 整体框架¶
ToolRec 建立一个从线上部署到模型优化的闭环系统(图 3):
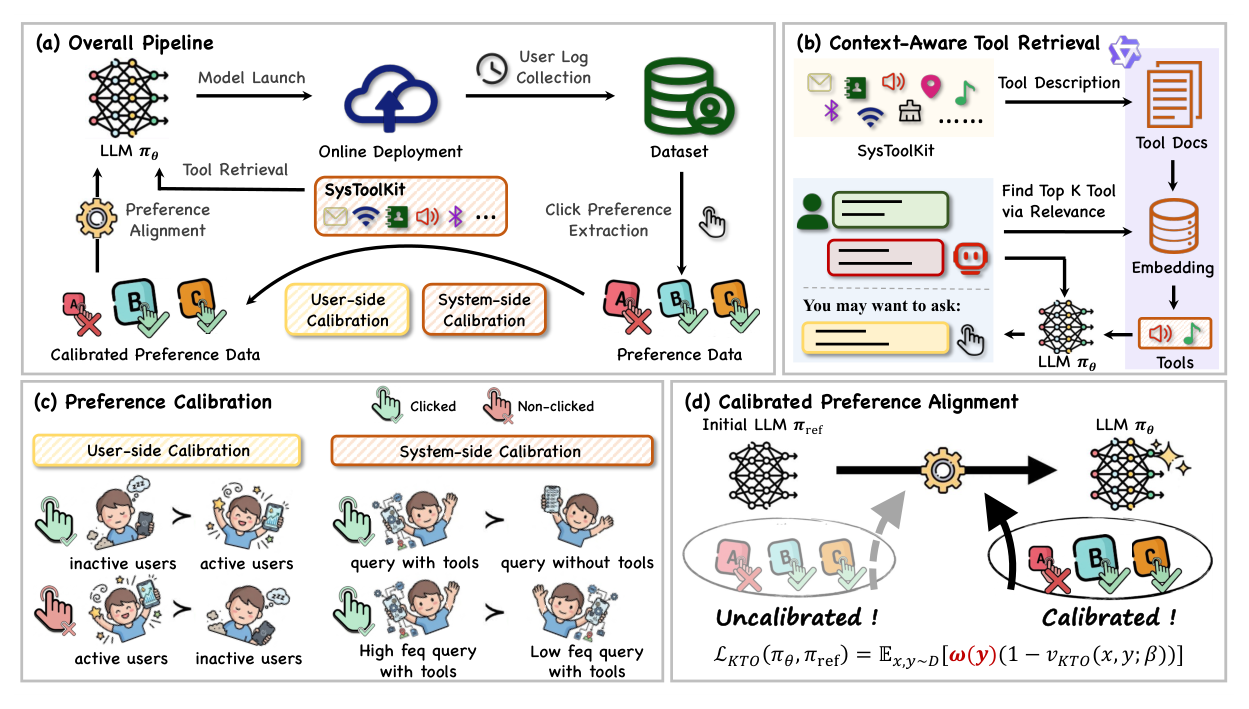
流程为:(a) 模型上线 → 采集用户日志 → 抽取原始点击偏好数据;(b) 线上服务时,上下文感知工具检索模块主动从 SysToolkit 拉取相关工具作为上下文;(c) 对原始点击偏好数据施加用户侧 + 系统侧双层校准;(d) 校准后的偏好数据驱动最终的加权 KTO 对齐,优化 LLM 后再次上线。
4.2 SysToolkit:系统级工具仓库¶
与传统搜索/聊天场景不同,端侧助手的核心用户需求是快速调用相关系统功能。为此作者构建 SysToolkit,从两方面设计:
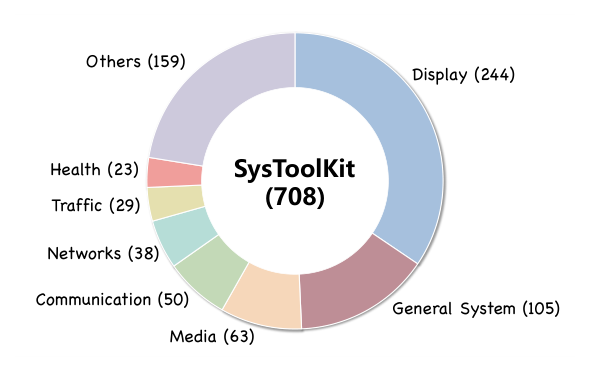
工具准备(Tool Preparation):如图 4,SysToolkit 含 708 个工具,全面覆盖端侧日常使用模式的多个功能域——Display(显示,244 个)、General System(通用系统,105 个)、Media(媒体,63 个)、Communication(通信,50 个)、Networks(网络,38 个)、Traffic(交通,29 个)、Health(健康,23 个)、Others(其他,159 个)。这些类别涵盖从"播放音乐"等日常任务到"清理空间"等设备维护动作,为后续工具调用类查询推荐打下坚实基础。
工具检索(Tool Retrieval):由于 SysToolkit 规模大,把全部工具塞进 LLM prompt 不现实。作者设计上下文感知工具检索机制(图 3b):先用 Qwen-3-embedding 模型 把每个工具的文本描述编码进向量库;推理时把用户对话历史同样编码,再用 Qwen-3-reranker 过滤、抽取 top-$N$ 个最相关工具作为上下文。好处有二:(1) 通过减少喂给 LLM 的工具数,缓解上下文窗口负担;(2) 由于只提供相关工具,生成的工具相关查询天然与用户对话历史保持高相关。
4.3 双层偏好校准(Dual-level Preference Calibration)¶
模型部署后采集线上日志、从点击行为导出初始偏好数据。原始点击数据噪声大,作者从用户侧与系统侧两方面精炼。
用户侧校准(User-side Calibration):标准 KTO(Eq.2)对所有样本赋予均匀权重,忽略了不同活跃度用户的行为偏差。直觉:高活跃用户的"非点击"(负样本)是更强的"无关"信号;而普遍不活跃/挑剔用户的"罕见点击"(正样本)可能强烈暗示了异常的相关性与精确意图。为此基于用户点击率 $uctr$ 设计动态权重 $w_u$,提升模型对"高活跃用户负反馈"与"不活跃用户正反馈"的敏感度:
$$w_u = \begin{cases} 1 - \alpha\cdot\tanh\!\Big(\dfrac{uctr - \mu}{s}\Big) & \text{if } Q_r \sim Q_r^+ \\[2mm] 1 + \alpha\cdot\tanh\!\Big(\dfrac{uctr - \mu}{s}\Big) & \text{if } Q_r \sim Q_r^- \end{cases} \tag{6}$$
其中 $\alpha$ 定义权重界,$s$ 是所有用户 $uctr$ 的标准差。鉴于真实世界 $uctr$ 的长尾分布,$\mu$ 经验设为 0.07($uctr$ 分布的上四分位数)。设计含义:对活跃用户($uctr>\mu$),$\tanh$ 为正,于是放大其负样本权重、同时打折其正样本;反之对不活跃用户($uctr<\mu$),自然地上调其罕见正样本(点击)的权重。
系统侧校准(System-side Calibration):为把"执行导向"需求置于"闲聊"之上,引入系统级校准——它不平等对待所有查询,而是显式把 ToolRec 导向能成功触发 SysToolkit 内工具的可执行查询 $Q_r^t$,并对关联到高频工具的查询赋予更高权重。对推荐查询 $Q_r$,系统侧权重 $w_s$ 为:
$$w_s = \begin{cases} (1+\gamma)\,p^{k} & \text{if } Q_r \sim Q_r^+ \ \&\ Q_r \sim Q_r^t \\ 0 & \text{if } Q_r \sim Q_r^- \ \&\ Q_r \sim Q_r^t \\ 1 & \text{else} \end{cases} \tag{7}$$
其中 $\gamma$ 控制最大权重界,$p\in[0,1]$ 是被调用工具的归一化频率分位数,超参 $k$ 调节权重对点击频率的敏感度(基于线上交互日志统计分析,经验设为 3)。关键设计:Eq.(7) 第二条显式把"未点击的工具调用类查询"权重置 0——这相当于在训练时屏蔽这些负样本,确保模型不会因"工具推荐不完美"而受罚,从而防止模型转向"偏好安全、通用响应"的保守策略、维持其工具调用的主动性。
4.4 校准式偏好对齐(Calibrated Preference Alignment)¶
线上真实部署中,为同一输入同时标注 chosen 与 rejected 响应(成对偏好)极不现实,因此对齐阶段依赖 KTO(天然支持非成对反馈)。把 §4.3 的双层校准权重融进 KTO,得到样本级加权 KTO 目标:
$$\mathcal{L} = \mathbb{E}_{x,y\sim D}\big[w(Q_r)\,(1 - v(x,y;\beta))\big] \tag{8}$$
最终样本权重 $w(Q_r)$ 的聚合策略为:
$$w(Q_r) = \begin{cases} \max(w_u, w_s) & \text{if } Q_r \sim Q_r^+ \\ \min(w_u, w_s) & \text{if } Q_r \sim Q_r^- \end{cases} \tag{9}$$
这一聚合策略意在平衡优化的激进程度:
- 对正样本 $Q_r^+$,取 $\max$ 充当激进的奖励机制——只要"高用户置信度"或"高系统效用"二者之一成立,该查询就被强烈鼓励;
- 对负样本 $Q_r^-$,取 $\min$ 充当保守的惩罚——除非用户信号与系统效用都自信地指向负偏好,否则不会过度惩罚非点击。
5 实验¶
5.1 实验设置¶
数据集:在 OPPO 小布(>1.5 亿 MAU)上做大规模在线 A/B。主市场流量平均分给 control 与 treatment 组以保公平。正式实验前两组先监测 12 小时以上,验证用户请求分布一致、无初始偏差。
评估指标:三个主指标——总点击量(total clicks)、CTR、相关性(relevance)。相关性度量"给定样本内被判定为与用户上下文相关的推荐查询比例";由于日活交互量巨大、全量算相关性算力不可行,作者每个模型从线上日志随机抽 1,000 个推荐实例,用 Doubao-Seed-1.8 评估上下文相关性。
可复现性:8× NVIDIA A100 GPU + 200GB RAM;基座 Qwen-3-14B,用 LoRA(rank=8,作用于网络全部层) 做参数高效微调;训练 batch size 32;AdamW 优化器,学习率 $5\times10^{-6}$,cosine LR scheduler,warmup ratio 0.1;KTO 的 $\beta=0.01$;控制校准权重的超参 $\alpha=0.25$、$\gamma=1.25$。
5.2 主要在线结果¶
对比 SFT 与 KTO 等已建立的对齐算法。注意:因线上数据特性,无法为同一输入获取成对正负样本,故 DPO、SimPO 被排除。在线 A/B 于 2026 年 4 月 21–27 日进行,每模型分到 5% 流量。
Table 1:不同策略对比(在线 A/B,各 5% 主市场流量)。
| Strategies | Click Number | CTR | Relevance |
|---|---|---|---|
| Base | 1,063,499 | 0.3095 | 0.9710 |
| SFT | 1,069,529 | 0.3098 | 0.9590 |
| Vanilla KTO | 1,100,807 | 0.3167 | 0.9560 |
| ToolRec | 1,113,871 | 0.3198 | 0.9570 |
| Improve. | +4.74% | +3.32% | −1.44% |
分析:
- 尽管 SFT 与 KTO 都比 Base 有持续增益,ToolRec 在所有对齐方法中点击量与 CTR 提升最大——相对 Base 分别 +4.74%、+3.32%。即便只部署在 5% 流量,这一相对提升也意味着数万次额外用户点击的绝对增量。
- 相比 Base,所有对齐方法的相关性都有下降。作者认为:对齐前 Base 模型严格贴合历史上下文;而对齐后的模型被优化为生成"符合用户偏好"而非"严格追求上下文相关"的查询。
- 但 ToolRec 并未显著牺牲相关性——其相关性 0.9570 与 SFT/KTO 相当,作者归因于上下文感知工具检索机制(保证生成查询仍严格锚定当前对话)。
5.3 离线对比¶
为在线上指标之外进一步验证,作者随机抽 2,000 条真实对话历史作为 ToolRec 与 baseline 的输入上下文,采用 LLM-as-a-judge(Doubao-Seed-1.8)做严格 pairwise 评估:对每个上下文,judge 基于"工具调用的有用性 + 推荐查询的多样性"判定 ToolRec 相对各 baseline 为 Win/Tie/Loss。
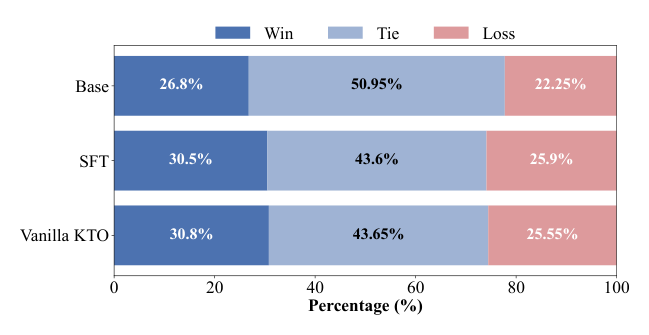
分析:ToolRec 对全部三个 baseline 都 Win 率高于 Loss 率。值得注意的是 Tie 比例很高(43.6%–50.95%)——作者归因于端侧交互的固有特性:很多用户请求是直接且确定性的(如"打开 Wi-Fi""设个闹钟"),最优工具查询相对固定;而所有模型共享同一基座(Qwen-3-14B),对这些常规任务都能生成完全正确的查询,留给改进的空间很小。
5.4 消融实验¶
设计四个变体评估各组件贡献:(1) vanilla KTO(无校准);(2) 仅用户侧校准;(3) 仅系统侧静态权重(校准权重与工具频率无关);(4) 用户侧 + 系统侧静态校准组合。在线 A/B 于 2026 年 4 月 28 日–5 月 4 日,每模型 2% 流量。
Table 2:消融实验(各 2% 主市场流量)。 $w_u$=用户侧权重,static $w_s$=静态系统侧权重,dynamic $w_s$=动态(频率敏感)系统侧权重。
| ID | $w_u$ | static $w_s$ | dynamic $w_s$ | Click Number | CTR |
|---|---|---|---|---|---|
| 1 | ✗ | ✗ | ✗ | 423,561 | 0.3051 |
| 2 | ✓ | ✗ | ✗ | 434,084 | 0.3090 |
| 3 | ✗ | ✓ | ✗ | 429,931 | 0.3080 |
| 4 | ✓ | ✓ | ✗ | 446,527 | 0.3162 |
| ToolRec | ✓ | ✗ | ✓ | 458,334 | 0.3226 |
分析: 1. 变体 2、3 对比变体 1:单独施加用户侧或系统侧静态校准,CTR 与总点击均明显提升——证明两类校准各自的有效性。 2. 变体 4 对比变体 2、3:用户侧与系统侧校准不冲突、高度互补,联合使用比单用任一更好。 3. 完整 ToolRec 对比变体 4:把系统侧从静态升级为基于工具频率的动态校准,带来又一次显著性能跃升——按工具频率加权能促使模型优先生成"与高频用户交互相关"的工具查询。
5.5 超参分析¶
研究两个关键权重超参 $\alpha$、$\gamma$。受限于并发在线实验槽位,超参 A/B 跨两个时段(4 月 4–6 日与 4 月 11–13 日)各分 2% 流量;为缓解两时段间 CTR 的时序波动,报告各超参配置相对 vanilla KTO baseline 的相对 CTR 提升。
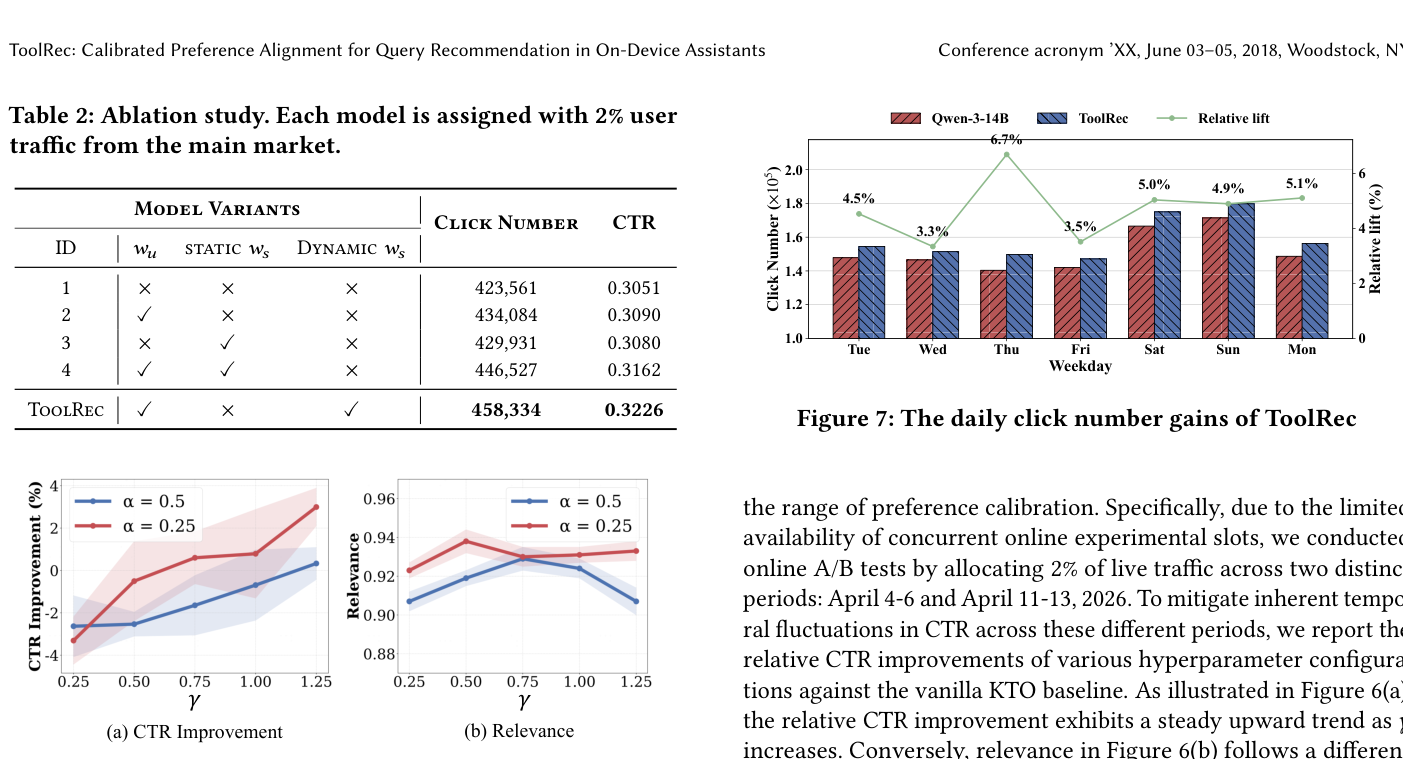
分析:(a) 相对 CTR 提升随 $\gamma$ 增大稳步上升;(b) 相关性则呈不同轨迹——先升后平台甚至下降,因为过度强调生成工具相关查询会损害上下文连贯/相关性。综合二者,$[\alpha=0.25,\ \gamma=1.25]$ 取得最佳平衡,给出极具竞争力的性能。
5.6 细粒度性能评估¶
逐日性能(Day-wise):图 7 展示 4 月 21–27 日一周内 ToolRec 相对 Base 的逐日点击量与相对提升(5% 流量)。周末交互量明显高于工作日(用户闲暇时间更多、设备使用更频繁)。尽管日流量波动,ToolRec 始终稳定超越 Base,相对点击量提升稳定在 3.3%–6.7%——证明方法对时序波动稳健。
分层用户分析(Stratified User Analysis):按历史 CTR 把用户分为高活跃(high-ctr)与低活跃(low-ctr)两组,评估 ToolRec 跨活跃度的有效性。
Table 3:高 CTR / 低 CTR 用户组的性能(各 5% 流量)。
| Models | Click(High-ctr) | Click(Low-ctr) | CTR(High-ctr) | CTR(Low-ctr) |
|---|---|---|---|---|
| Base | 467,449 | 27,372 | 0.8330 | 0.0939 |
| SFT | 470,639 | 27,568 | 0.8320 | 0.0938 |
| Vanilla KTO | 493,373 | 26,584 | 0.8417 | 0.0904 |
| ToolRec | 509,043 | 27,519 | 0.8358 | 0.0945 |
分析:ToolRec 在两组中都竞争力很强——点击量与 CTR 均稳居前二。尤其在低活跃用户组拿到最高 CTR(0.0945),且总点击仅微弱低于 SFT。作者归因于用户侧偏好校准:通过按个体点击倾向动态调权,有效缓解了行为噪声、产出更高质量的偏好数据。(注:Vanilla KTO 虽在高活跃组 CTR 最高 0.8417,但其低活跃组 CTR 0.0904 反而低于 Base,说明无校准的 KTO 会被低活跃用户的噪声反噬。)
查询类型分布分析(Query Type Distribution):ToolRec 的根本目标是激励生成可执行的工具调用类查询。统计 4 月 21–22 日各模型相对 Base 在"工具调用类查询占比"上的相对变化(5% 流量)。
Table 4:工具调用类查询占比的相对提升(各 5% 流量)。
| Strategies | Relative Improvement |
|---|---|
| Base | — |
| SFT | −0.19% |
| Vanilla KTO | +0.45% |
| ToolRec | +1.44% |
分析:ToolRec 取得最大相对提升 +1.44%,显式验证了系统侧偏好校准的有效性。考虑到小布日交互量巨大,1.44% 的占比提升仍很可观——即便在 5% 流量限制下,也意味着约 20,000 次用户请求被导向了工具调用类查询。
5.7 案例研究¶
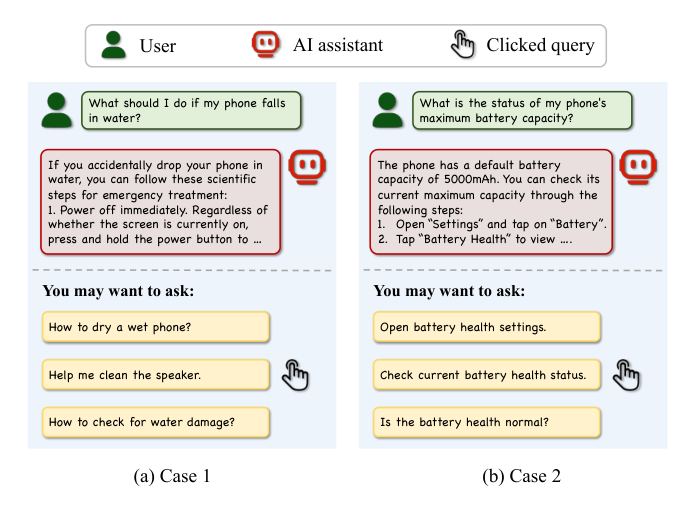
- Case 1:用户似乎在求助"手机进水后该怎么办"。除标准文本排障说明外,ToolRec 主动推荐了一组后续查询,其中含工具调用类查询 "Help me clean the speaker."(帮我清理扬声器)。在这种时间敏感语境下,直接触发设备内置的排水工具远比泛泛的信息性建议更实用、更紧迫——用户对该推荐的点击也佐证了这一点。
- Case 2:用户询问设备最大电池容量(通常暗示对电池退化/快速耗电的担忧)。在给出导航步骤的文本指南后,ToolRec 立即surface 出工具调用类查询如 "Open battery health settings" 与 "Check current battery health status"。用户对后者的点击进一步确认:相比手动导航,用户高度偏好一键可执行动作。
这些案例表明 ToolRec 有效弥合了对话理解与系统级执行之间的鸿沟:通过把对话上下文精确锚定到设备能力空间,模型能持续提供贴合真实用户意图的可执行推荐。
6 核心贡献总结¶
ToolRec 的价值在于把"端侧助手查询推荐"这一具体业务痛点拆成两个被前人忽视的子问题并给出工程化解法: 1. 工具调用意图的显式建模:构建 708 工具的 SysToolkit + 上下文感知检索(Qwen3-embedding/reranker),把查询推荐从"生成文本"升级为"锚定可执行动作",既保相关性又把推荐导向高价值的工具触发。 2. 点击信号可信度的双层校准:用户侧按 $uctr$ 用 $\tanh$ 动态调权(放大活跃用户负反馈、上调不活跃用户罕见正反馈),系统侧用 $(1+\gamma)p^k$ 上调高频工具的正样本、置 0 屏蔽工具负样本;二者经 $\max/\min$ 聚合融入样本级加权 KTO,把"均匀信任点击"改造为"按置信度区分对待"。 3. 全部用真实大规模在线 A/B(OPPO 小布 >1.5 亿 MAU)验证,CTR +3.32%、点击 +4.74%、工具查询占比 +1.44%,相关性几乎无损。
与已归档相关工作的对比¶
AdaGRPO AdaGRPO: Adaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation(JD.com,2026-06-07)¶
关系:独立并发(本文未引用 AdaGRPO,两者殊途同归 · 同一投稿日 2026-06-07)· 已加载对方精读
- 共同关注的问题:两篇论文指向同一个 root cause——在用生成式/LLM 推荐做偏好/RL 对齐时,驱动对齐的监督信号并非均匀可信,把所有样本同等对待是次优的。ToolRec 关注的是隐式点击信号的可信度异质性(随用户活跃度、随查询类型变化);AdaGRPO 关注的是奖励模型(production ranker as RM)的可信度异质性(曝光偏置使 RM 只在困难且可判别的样本子集上提供有信息梯度)。两者都明确反对"uniform treatment / 均匀施加"的对齐范式。
- 相近的技术骨架:两者都把"逐样本可信度诊断 → 折进对齐目标的样本级权重"作为方法主轴。ToolRec 计算连续权重 $w(Q_r)$(用户侧 $\tanh$ + 系统侧 $(1+\gamma)p^k$,经 $\max/\min$ 聚合)注入加权 KTO(Eq.8-9);AdaGRPO 计算二值门控 $\alpha_i\in\{0,1\}$(difficulty $f_1$ ∧ RM-discriminability $f_2$)门控 GRPO 项、不通过则退回纯 NLL 监督。把两者方法流程图叠在一起,骨架高度重合:都是"per-sample reliability gate/weight on the alignment loss"。
- 本文的差异与推进:(1) 载体不同——ToolRec 用 KTO(非成对、无需 RM),因为线上无法为同一输入获取成对偏好;AdaGRPO 用 GRPO(需要一个 RM 打分 rollout)。(2) 可信度信号的来源不同——ToolRec 的权重来自离线的用户画像统计($uctr$)与工具频率,是数据侧校准;AdaGRPO 的门控来自在线 rollout 时的统计量(策略对该样本是否困难、RM 是否能判别),是rollout 时校准。(3) 形态不同——ToolRec 是连续软加权(且对正负样本用 $\max/\min$ 非对称聚合);AdaGRPO 是二值硬门控(把 PPO 的 clip 从 token-ratio 域抬到 sample 域)。
- 可比的方法/实验差异:ToolRec 面向端侧助手的查询推荐(生成自然语言查询、对齐点击),实验是 OPPO 小布的工业在线 A/B(CTR/点击/相关性);AdaGRPO 面向SID 自回归生成式推荐(生成 Semantic ID、对齐 production ranker),实验是公开 Amazon 数据集 + JD 在线 A/B(HR@10、effective IPV)。两者一个在"人类点击=金标准"上做置信度校准,一个在"RM=金标准"上做置信度校准,正好覆盖了生成式推荐对齐里"两类监督信号都不可全信"的互补侧面,是一组很好的"同一思想、不同信号源"的独立并发对照。
讨论与局限性¶
值得借鉴的设计:
- 把"信号可信度"显式建模进对齐目标,而非把点击当金标准——这是与 AdaGRPO 共享的、可能成为生成式推荐对齐新范式的核心思想。ToolRec 的 $\tanh$ 用户侧调权 + 工具频率系统侧调权都很轻量,几乎零额外训练成本,工业落地友好。
- 用 KTO 而非 DPO/PPO 规避"线上无法构造成对偏好"的现实约束,是端侧/工业场景的务实选择。
- 负样本屏蔽(Eq.7 第二条置 0) 防止模型对"不完美工具推荐"过度自我惩罚、转向保守通用响应——这是一个很具洞察力的小设计。
- 上下文感知工具检索把 708 工具压缩成 top-N 上下文,兼顾上下文窗口与相关性。
局限与争议:
- 所有增益来自单一平台(OPPO 小布)的在线 A/B,缺乏公开数据集复现,外部可验证性弱;超参($\mu=0.07$、$k=3$、$\alpha=0.25$、$\gamma=1.25$)都"经验设定/基于本平台日志统计",迁移到其他助手是否成立未知。
- 相关性相对 Base 下降(−1.44%):虽然作者argue 其与 SFT/KTO 相当,但对齐确实以牺牲一定上下文相关性为代价换 CTR,长期是否影响用户信任未评估。
- 离线评估 Tie 高达 43.6%–51%,说明在大量确定性请求上各模型差异很小,ToolRec 的增量主要来自少数"有改进空间"的复杂请求;其 +1.44% 工具查询占比、+3.32% CTR 虽在亿级体量下绝对值可观,但相对幅度并不大。
- SysToolkit 的 708 工具如何构建/维护(覆盖度、随系统更新的同步)以及工具检索的召回质量,论文着墨较少,而这直接决定工具调用类查询的天花板。
- 论文的引用编号存在一些前后不一致(如正文 "Min et al. [14]" 与参考文献 [14] 作者不符),属草稿瑕疵,不影响方法本身。
工业落地价值:ToolRec 已在 OPPO 小布(>1.5 亿 MAU)线上部署验证,5% 流量即带来数万次额外点击、约 2 万次请求转向工具调用类查询。对"LLM 助手 + 系统工具调用"这一正在兴起的端侧形态,本文提供了一套可直接复用的偏好对齐配方:工具仓库 + 上下文检索 + 双层点击校准 + 加权 KTO。