Taiji:面向工业级 LLM-Enhanced 推荐的 Pareto 最优策略优化与 Semantics-IDs 权衡¶
作者:Yuecheng Li、Zeyu Song、Jing Yao、Chi Lu、Peng Jiang(Kuaishou Technology)、Kun Gai(Unaffiliated) 所属:快手科技(Kuaishou Technology),北京 ArXiv:2606.03866 · 2026-06-02 · Under Review 部署:快手广告平台,自 2026 年 5 月起全量上线,稳定服务 4 亿日活用户(DAU)
1. 研究动机与背景¶
把大语言模型(LLM)引入推荐系统、用 LLM 的能力来 scale 推荐,已是工业界的明显趋势。论文把 LLM for Recommendation(LLM4Rec)梳理为三条并行的技术路径:
- Generative Recommendation(生成式推荐):LLM 直接充当推荐器,自回归地生成 item。
- Ranking Model Scaling(排序模型扩展):把 LLM 式的架构/规模引入排序模型。
- LLM-as-Enhancer(LLM 作为增强器):用(冻结或微调后的)LLM 生成用户画像 / item 内容的语义表征,去增强下游推荐骨干模型的输入特征。
其中 LLM-as-Enhancer 在工业界被采纳得最广,原因有二:① 它在架构上与在线服务模型解耦(LLM 不直接参与在线打分,离线/近线产出特征即可),② 成本相对可控。本文正是沿这条路线。
LLM-as-Enhancer 内部又可细分为三种递进的方法论:
- Direct Inference(直接推理):如 KAR、HiT-LBM,用 prompting 或 tree-search 从 LLM 抽取用户偏好与 item 事实知识,转成与任意推荐模型兼容的增强向量。
- Domain Fine-tuning(领域微调):如 R⁴ec、TrackRec,用监督微调(SFT)+ 迭代式 refinement 来生成可靠的、推荐专用的思维链(Recommendation-specific Chain-of-Thought, RecCoT)数据,缓解 LLM 的幻觉。
- Reinforcement Alignment(强化对齐):如 DEEPER、RecLM、Rec-R1、LangPTune、RecGPT-v2,用 PPO / DPO / GRPO 等 RL 算法,直接用推荐指标(NDCG、Recall)或用户反馈(CTR、留存)作为奖励来优化 LLM 的生成策略。这条路能直接对齐真实推荐目标,从而缓解 SFT 固有的 exposure bias,让模型输出更贴合业务目标。
但现有 post-training 范式仍有两个关键瓶颈,恰好对应 SFT 阶段与 RL 阶段:
-
SFT 阶段——CoT 质量无法度量:以往工作过度依赖强力 teacher LLM 的 CoT 生成能力,或依赖启发式的 refinement 经验,并且只用最终答案是否正确来评判 CoT 质量。但推荐本质上是开放式生成任务(open-ended),不像数学/代码有唯一可验证的答案,因此「缺乏合理且系统的指标来准确度量推荐专用 CoT 的质量」。
-
RL 阶段——异构奖励的动态平衡被忽视:当前方法虽然同时用了 LLM 语义奖励与推荐反馈奖励,却没有考虑这两类异构信息之间的动态平衡。对 LLM-as-Enhancer 而言,「有效对齐并平衡 LLM 的世界知识语义 与 推荐系统的在线用户偏好」是核心问题;现有方法只关注「对齐」,缺乏深入的权衡(trade-off)机制。
为同时解决这两个挑战,作者提出 Taiji(取名「太极/阴阳」,象征 LLM 与推荐系统之间的动态统一与相互增强),一个工业级的 LLM-as-Enhancer 框架,包含四个关键模块:Data Construction(数据构建)、Reasoning Activation(推理激活)、LLM-Recommendation Collaboration(LLM-推荐协同)、Online Ranking(在线排序)。核心组件包括:
- Reverse-Engineered User Preference Reasoning(RUPR,逆向工程的用户偏好推理):用真实的 user–item 协同关系(即 ground-truth 下一个购买 item)作为 prompt 条件,从先进的 QwQ-32B teacher 蒸馏出高质量推理 CoT。
- Open-Ended Rejection Sampling Fine-Tuning(ORFT,开放式拒绝采样微调):用 困惑度(Perplexity, PPL) 过滤掉低质量 CoT 样本,然后在 DeepSeek-R1-7B 上做 SFT。
- Pareto Optimality Policy Optimization(POPO,Pareto 最优策略优化):在跨域空间里自适应地动态调整奖励权重,全面探索 LLM 语义奖励与推荐协同奖励之间的 Pareto 前沿。
- 最后,把 RL 对齐后的 LLM 输出编码为量化稀疏特征 + 检索到的跨用户序列,注入在线广告排序模型。
本文主要贡献:
- 提出 Taiji,一个工业级 LLM-Enhanced 推荐框架,针对常规 LLM-as-Enhancer 流水线 post-training 阶段的两个核心限制。
- SFT 阶段:整合 RUPR 与 ORFT,渐进式地提升推荐专用 CoT 的质量。
- RL 阶段:提出 POPO,动态自适应地调整 LLM 语义奖励与推荐偏好奖励的权重,带有理论保证的 Pareto 最优权衡。
- 大量离线实验 + 消融验证各模块有效性;在线 A/B 显示 Taiji 带来 +2.83% 的整体 ADVV(Advertiser Value,广告主价值) 与 +3.30% 的整体 Revenue(平台营收) 提升。
- 自 2026 年 5 月起全量部署,稳定支撑 4 亿日活。
2. Taiji 整体框架¶
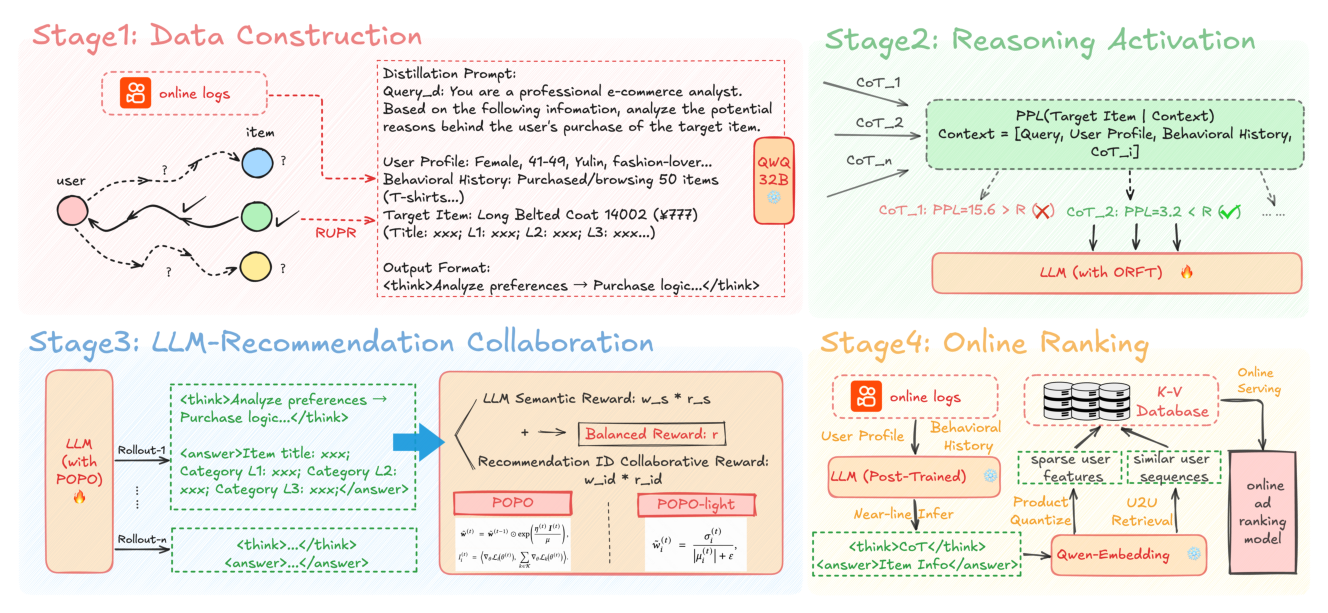
整个流水线如 Figure 1 所示,串成「离线数据构建 → SFT 激活推理 → RL 跨域对齐 → 在线特征增强」四级:
- Stage 1 Data Construction:从快手短视频平台的真实在线日志采样用户数据,转成 LLM 友好的自然语言;用 RUPR 构造蒸馏 prompt,让 QwQ-32B 在 ground-truth 答案条件下做逆向偏好推理,得到初始 CoT。
- Stage 2 Reasoning Activation:用 PPL 做开放式拒绝采样过滤 CoT,再对 DeepSeek-R1-7B 做 SFT(ORFT),激活其推理能力。
- Stage 3 LLM-Recommendation Collaboration:以 SFT 模型为起点,用 GRPO + POPO 做 RL,动态平衡 LLM 语义奖励 $r_s$ 与推荐 ID 协同奖励 $r_{id}$。
- Stage 4 Online Ranking:把后训练 LLM 部署做近线推理,将其推理输出量化成稀疏特征、并检索跨用户序列,拼接进在线广告排序模型。
3. 核心方法¶
3.1 Data Construction:逆向工程的用户偏好推理(RUPR)¶
3.1.1 数据采集¶
从快手真实在线日志采集大规模用户画像与行为序列,并转成自然语言文本,分两个关键组成:
- 多模态多维用户画像(Multimodal and Multidimensional User Profile):整合多张数据表,抽取综合用户特征,包括:
- 基础人口属性:性别、年龄、城市层级、婚姻状况、教育程度;
- 设备与生活方式属性:手机型号、居住地消费水平;
- 短视频平台上的多模态交互偏好:活跃 app、搜索 query、视频互动(收藏/点赞/评论)、直播互动、历史电商/广告行为。
-
这些细粒度特征被序列化为结构化的自然语言描述,给 LLM 提供丰富的个性化上下文。
-
细粒度历史行为序列(Fine-Grained Historical Behavioral Sequence):采集用户近期广告交互日志(item 浏览与购买)。为保证时效,保留最近 50 条交互,按时间倒序排列。每条交互抽取详细 item 元信息(标题、多级类目、价格),模板化成文本序列,形如
Item title: ...; Category L1: ...; Category L2: ...; Category L3: ...,使 LLM 能精准捕捉用户演变中的兴趣与购买逻辑。
通过上述采集与文本序列化,把传统的表格式推荐特征转换为语义丰富的 prompt,为后续 CoT 生成、模型微调、RL 对齐打基础。
3.1.2 CoT 生成¶
对 LLM-based 推荐这类开放式生成任务(不像数学推理/代码生成有可验证答案),从 teacher LLM 蒸馏 CoT 时,很难精确验证生成的推理轨迹与最终答案的准确性。
为此 Taiji 用 RUPR 生成初步、相对准确的 CoT,同时保证答案的 ground-truth 有效性——做法是:构造蒸馏 prompt(Figure 1 Stage 1),用 QwQ-32B,以用户的 ground-truth 下一个购买 item 作为条件来做偏好推理。这就是「逆向工程」的含义:把真实答案塞进 prompt,让 teacher 去「反推」为什么用户会购买它,从而产出与真实行为一致的、可解释的偏好推理链。
3.2 Reasoning Activation:开放式拒绝采样微调(ORFT)¶
本阶段用开放式拒绝采样进一步过滤高质量 CoT,再做 SFT 把推理能力激活进小模型。
3.2.1 CoT 精炼(CoT Refinement)¶
为提升推荐导向 CoT 的质量,Taiji 用用户 ground-truth 下一个购买 item $y$(包在 <answer>...</answer> 中)的困惑度(PPL) 作为 CoT(包在 <think>...</think> 中)质量的代理指标:
$$ \mathrm{PPL} = \exp\!\left(-\frac{1}{T}\,\log\_likelihood\right),\qquad \log\_likelihood = \sum_{t=1}^{T} \log P\!\left(y_t \mid context,\, y_1, \ldots, y_{t-1}\right) \tag{1} $$
其中 $context = [\,query,\ user\ profile,\ behavioral\ history,\ CoT\,]$,$y = [y_1, y_2, \ldots, y_T]$ 是 ground-truth 答案序列,$T$ 是 token 数。
物理含义:PPL 越低,说明在「问题 + 画像 + 历史 + 这条 CoT」的条件下,模型给 ground-truth item 分配的概率越高 → 这条 CoT 的推理轨迹越可靠。因此 PPL 直接把「无法验证的 CoT 好坏」转化成「该 CoT 是否能让真实答案变得更可预测」这一可量化信号,这是 Taiji 解决「开放式推荐 CoT 质量不可度量」瓶颈的关键。
具体做法:用 QwQ-32B 对每个用户专属蒸馏 prompt 生成 $k=3$ 条候选 CoT,保留满足 $\mathrm{PPL} < R$ 的作为训练数据(每个 prompt 因此保留 0–3 条)。阈值 $R$ 是预设的 PPL 截断,经验上取 PPL 分布的中位数(50 分位)。
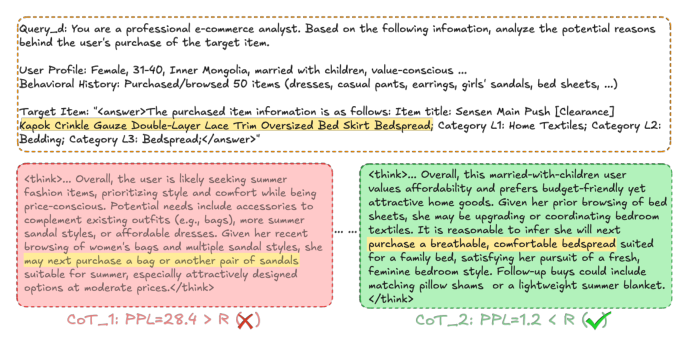
如 Figure 2 所示,当 PPL 过高时,CoT 与答案之间会出现逻辑不一致,这类训练样本极可能损害 LLM 的推理性能,因此被拒绝。
3.2.2 LLM 微调(LLM Fine-Tuning)¶
用精炼后的 CoT 数据对 DeepSeek-R1-7B 做 SFT,激活其推理能力。SFT 样本结构如下(Figure 3):

训练损失是标准的 next-token 预测目标,覆盖整条推理链 + 最终答案:
$$ \mathcal{L}_{\mathrm{ORFT}} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{l_i}\log P\!\left(t_j \mid q_i,\, t_{<j}\right) \tag{2} $$
其中 $q_i$ 是输入 query(含用户画像与行为历史),$t_j$ 是完整输出序列(同时包含 <think> CoT 段与 <answer> 段)的第 $j$ 个 token,$l_i$ 是输出总 token 数,$N$ 是 batch size。
3.3 LLM-Recommendation Collaboration:Pareto 最优策略优化(POPO)¶
SFT 后 LLM 的推理能力被激活,但跨多样化 user–item 交互模式的泛化能力仍有限,因此本节用一个 GRPO 式的 RL 过程进一步增强泛化。
核心问题:以往工作用固定权重组合 LLM 语义奖励与推荐侧偏好奖励,难以在两个目标间取得动态均衡——
- 从「有效性」看:静态权重难以刻画复杂的、非凸的 Pareto 前沿;
- 从「优化效率」看:不同奖励信号之间学习难度的差异,常导致次优的收敛率。
为此提出 POPO:在 GRPO 过程中动态调权,在 LLM 语义理解与推荐导向协同信号之间,达成 Pareto 最优权衡。
3.3.1 LLM 语义奖励(LLM Semantic Reward)¶
在文本语义空间评估 LLM 推理输出与 ground-truth 目标 item 的语义对齐度。用 Qwen3-Embedding-0.6B 把 LLM 预测的答案(从 <answer>...</answer> 抽取)和 ground-truth item 描述各自编码成语义嵌入,奖励取两者余弦相似度:
$$ r_s = \mathrm{CosineSim}\!\left(\mathbf{e}_{pred},\, \mathbf{e}_{gt}\right),\qquad \mathrm{CosineSim}(\mathbf{e}_{pred}, \mathbf{e}_{gt}) = \frac{\mathbf{e}_{pred}\cdot\mathbf{e}_{gt}}{\lVert\mathbf{e}_{pred}\rVert\,\lVert\mathbf{e}_{gt}\rVert} \tag{3} $$
其中 $\mathbf{e}_{pred} = \text{Qwen3-Emb}(\text{Answer}_{\mathrm{LLM}})$,$\mathbf{e}_{gt} = \text{Qwen3-Emb}(\text{Item}_{gt})$。该奖励捕捉 LLM 推理输出与真实购买之间的语义一致性,提供一个语言锚定(language-grounded)的监督信号,补充传统推荐指标。
3.3.2 推荐 ID 协同奖励(Recommendation ID Collaborative Reward)¶
在数值连续空间捕捉协同过滤信号。推荐 ID 协同奖励 $r_{id}$ 来自部署在广告系统里的在线排序模型——该排序模型综合用户特征、item 特征、交叉特征与历史交互标签,给出 user–item 交互的概率预测。为把 LLM 推理输出对齐到真实用户偏好,采用 点击转化率 CTCVR(click-through and conversion rate) 作为 ID 协同奖励:
$$ r_{id} = \mathrm{CTCVR}(u, i) = P\!\left(\text{click} \wedge \text{conversion} \mid u, i\right) \tag{4} $$
其中 $u$、$i$ 分别是用户与预测 item。对原始 CTCVR 做 min-max 归一化 以平衡跨奖励的优化。CTCVR 反映点击与转化两个事件的联合概率,是衡量用户购买意图的综合指标。
「Semantics-IDs trade-off」的本质:$r_s$ 来自 LLM 的语义世界(文本嵌入余弦),$r_{id}$ 来自推荐系统的 ID/协同世界(排序模型 CTCVR)。两者是异构、跨域的信号,标题里的「Semantics-IDs Trade-off」即指在这两个世界之间做最优权衡。
3.3.3 POPO:动态权重更新¶
记奖励来源集合 $\mathcal{K} = \{s,\ id\}$,$\mathcal{L}_k(\theta)$ 是由奖励 $r_k$ 诱导的 GRPO 目标,$w_k^{(t)}(\theta)$ 是第 $t$ 次 RL 迭代时它的权重。POPO 的更新规则为:
$$ \mathbf{w}^{(t)} = \frac{\tilde{\mathbf{w}}^{(t)}}{\sum_{k\in\mathcal{K}} \tilde{w}_k^{(t)}},\qquad \tilde{\mathbf{w}}^{(t)} = \tilde{\mathbf{w}}^{(t-1)} \odot \exp\!\left(\frac{\eta^{(t)}\,\mathbf{I}^{(t)}}{\mu}\right) \tag{5} $$
其中 $\eta^{(t)}$ 是学习率,$\mu>0$ 是正则因子,$\odot$ 是 Hadamard 积。梯度对齐指标(gradient alignment indicator) $\mathbf{I}^{(t)}$ 定义为:
$$ I_i^{(t)} = \left\langle \nabla_\theta \mathcal{L}_i\!\left(\theta^{(t)}\right),\ \sum_{k\in\mathcal{K}} \nabla_\theta \mathcal{L}_k\!\left(\theta^{(t)}\right) \right\rangle \tag{6} $$
直觉:$I_i^{(t)}$ 度量第 $i$ 个奖励的梯度与「所有奖励聚合梯度方向」的对齐程度。
- 当某个奖励目标梯度幅度大、且方向与其它目标良好对齐时,说明它能带来对所有奖励都有利的协同进展 → 分配更高权重;
- 反之,若它的梯度与其它目标冲突,权重被自动压制,防止它把策略拖离 Pareto 前沿。
Pareto 最优性保证:上述更新可被严格解释为如下双层优化(bi-level optimization)问题的一阶解:
$$ \mathbf{w}^* \in \arg\min_{\mathbf{w}\in\Delta^{|\mathcal{K}|}} \sum_{i\in\mathcal{K}} \mathcal{L}_i\!\left(\theta^*(\mathbf{w})\right),\quad \text{s.t.}\ \ \theta^*(\mathbf{w}) \in \arg\min_\theta \sum_i w_i\,\mathcal{L}_i(\theta) \tag{7} $$
其中 $\Delta^{|\mathcal{K}|} = \{\mathbf{w}\in\mathbb{R}_{\geq 0}^{|\mathcal{K}|} \mid \sum_k w_k = 1\}$ 是概率单纯形。下层问题退化为「在策略参数 $\theta$ 上做标准的加权 GRPO 更新」,上层问题则在最佳响应策略 $\theta^*(\mathbf{w})$ 之上进一步精炼奖励权重 $\mathbf{w}$。上面的指数梯度(exponentiated-gradient)更新可证明是这个双层问题的镜像下降(mirror-descent)近似,且其任一稳定点 $(\mathbf{w}^*, \theta^*(\mathbf{w}^*))$ 都满足 Pareto 最优条件:不存在策略 $\theta'$ 使得对所有 $k\in\mathcal{K}$ 都有 $\mathcal{L}_k(\theta')\leq\mathcal{L}_k(\theta^*)$ 且至少有一个严格不等。
POPO-light(轻量近似版):在工业级 RL 部署里,每步都显式计算跨域梯度内积 $I_i^{(t)}$(式 6)会带来不可忽视的时间与显存开销。为更好平衡效果与效率,POPO-light 用纯 rollout 级别的奖励统计量来近似每个奖励的「优化潜力」:
$$ \mathbf{w}^{(t)} = \frac{\tilde{\mathbf{w}}^{(t)}}{\sum_{k\in\mathcal{K}} \tilde{w}_k^{(t)}},\qquad \tilde{w}_i^{(t)} = \frac{\sigma_i^{(t)}}{\bigl|\mu_i^{(t)}\bigr| + \varepsilon} \tag{8} $$
其中 $\mu_i^{(t)}$、$\sigma_i^{(t)}$ 分别是第 $t$ 步奖励 $r_i$ 的组内(within-group)均值与标准差,$\varepsilon$ 是数值稳定常数。这个式子正是每个奖励的变异系数(coefficient of variation):
- 若某奖励相对其量级仍有较大组内方差 → 当前策略在该方向上仍高度可区分 → 应给更大权重;
- 一旦某奖励饱和(方差消失),其权重被自动衰减。
由于 POPO-light 只依赖前向的奖励标量、不需要额外的反向梯度内积计算,可零额外开销地直接插入 GRPO 训练循环,特别适合 web-scale 工业部署。
训练目标:在动态调权后的奖励下,用 GRPO 优化策略:
$$ \mathcal{L}_{\mathrm{POPO}}(\theta) = \mathbb{E}_{q\sim P(Q),\,\{o_i\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O\mid q)} \left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \Bigl\{\min\!\left[\rho_{i,t}(\theta)\hat{A}_{i,t},\ \mathrm{clip}\!\left(\rho_{i,t}(\theta),\,1-\varepsilon,\,1+\varepsilon\right)\hat{A}_{i,t}\right] - \beta\,\mathbb{D}_{\mathrm{KL}}\!\left[\pi_\theta\,\|\,\pi_{ref}\right]\Bigr\}\right] \tag{9} $$
其中重要性比 $\rho_{i,t}(\theta) = \dfrac{\pi_\theta(o_{i,t}\mid q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}\mid q, o_{i,<t})}$,组归一化优势 $\hat{A}_{i,t} = \dfrac{\tilde{r}_i - \mathrm{mean}(\{\tilde{r}_1,\ldots,\tilde{r}_G\})}{\mathrm{std}(\{\tilde{r}_1,\ldots,\tilde{r}_G\})}$。$G$ 是组大小(对每个 query 从 $\pi_{\theta_{old}}$ rollout 的候选响应数),$\varepsilon$、$\beta$ 分别是裁剪比与 KL 正则系数。每条 rollout 的标量奖励由两路异构奖励的 POPO 加权组合给出:
$$ \tilde{r}_i = w_s^{(t)}\,r_s(o_i) + w_{id}^{(t)}\,r_{id}(o_i) \tag{10} $$
其中 $w_s^{(t)}$、$w_{id}^{(t)}$ 是第 $t$ 次迭代由式 (5)/(8) 给出的自适应权重,参考策略 $\pi_{ref}$ 是 §3.2 SFT 初始化的模型。
3.4 Online Ranking:用户内特征量化 + 跨用户序列增强¶
RL 对齐后,把微调后的 LLM 部署做近线推理,去增强在线广告排序系统。Stage 4 通过两个互补机制,把 LLM 推理与传统推荐模型连起来:
-
用户内特征量化(Intra-User Feature Quantization):对每个到来的用户请求,从在线日志取用户画像与行为历史,喂给后训练 LLM,生成
<think>CoT</think>; <answer>Item Info</answer>格式的推理输出。为把文本推理转成排序模型可用的数值特征,用 Qwen-Embedding-0.6B 把CoT & Item Info编码成 dense 嵌入,再用乘积量化(Product Quantization, PQ) 产出稀疏 ID 向量,捕捉 LLM 对用户偏好的个性化理解。 -
跨用户序列检索(Cross-User Sequence Retrieval):为利用跨用户的协同信号,在嵌入空间做相似度检索——对目标用户 $u$,基于 LLM 生成嵌入的余弦相似度,检索 top-1 最相似用户;把该相似用户的最近 100 条行为序列聚合后作为额外特征喂给排序模型,使模型能捕捉跨用户的交互模式,与用户内推理互补。
-
与排序模型的整合:量化稀疏特征 + 检索到的跨用户序列,与传统特征拼接,一起喂进在线广告排序模型。这种混合特征表征让排序模型同时受益于 LLM 的深层语义理解与来自用户交互的协同过滤信号,从而提升线上排序表现。
4. 实验设置¶
4.1 数据集¶
- 从生产系统采样 111 万(1.11M)条用户记录,每条含用户画像 + 过去一个月的行为序列。划分如下:
- 100 万条用于 SFT(Stage 2):用 QwQ-32B teacher 对每个用户生成 $k=3$ 条候选 CoT。PPL 截断阈值 $R = 4.6$,由 2.3K 验证子集上算出的 PPL 中位数决定。
- 10 万条用于 RL(Stage 3):随机抽取。
-
剩余 1 万条作为测试集。
-
ground-truth 标签主要为 item 标题 + 三级类目信息。
4.2 评估指标¶
- 离线:准确率(ACC)、top-50 与 top-100 命中率(Hit-Rate@50 / Hit-Rate@100)、点击转化率(CTCVR)。
-
进一步分为两个维度:Semantic Hit-Rate(反映 LLM 在文本空间对用户偏好的推理质量:多级类目 ACC + item 标题 Hit-Rate@{50,100})与 Preference Hit-Rate(用离线模拟的 CTCVR,反映与在线用户行为信号的对齐程度)。
-
在线:A/B 测试,以 ADVV(Advertiser Value,广告主价值) 与 Revenue(平台营收) 作为关键业务指标,评估对广告主 ROI 与平台变现的影响。
4.3 实现细节¶
- 基座模型:DeepSeek-R1-7B(即 DeepSeek-R1-Distill-Qwen-7B)。
- 训练资源:3 节点 × 8 张 A800 GPU。
- SFT 阶段:全参数微调 1 epoch,学习率 $1\times10^{-7}$,单卡 batch size 32。
- RL 阶段:1 epoch,学习率 $2\times10^{-5}$,单卡 batch size 16,rollout 组大小 $G=4$,最大 prompt 长度 13,000 tokens,最大生成长度 2,048 tokens,奖励权重初始化为 $w_s = 0.5$、$w_{id} = 0.5$。
5. 主要实验结果(离线)¶
Taiji 与两个强基线对比:DeepSeek-R1-7B(未微调的基座)与 QwQ-32B(用于 CoT 蒸馏的 teacher)。在 1 万条 held-out 测试集上评估。
Table 1:测试集上的离线性能对比(粗体=最佳,下划线=次佳;百分比为相对 DeepSeek-R1-7B 基座的相对提升)
| 维度 | Metric | DeepSeek-R1-7B | QwQ-32B | Taiji (ORFT) | Taiji (ORFT+POPO-light) | Taiji (ORFT+POPO) |
|---|---|---|---|---|---|---|
| Semantic Hit-Rate | Category_L1_ACC | 0.1560 | 0.1974 | 0.2012 | 0.2347 (↑50.45%) | 0.2433 (↑55.96%) |
| Category_L2_ACC | 0.0608 | 0.0767 | 0.0690 | 0.0877 (↑44.24%) | 0.0888 (↑46.05%) | |
| Category_L3_ACC | 0.0251 | 0.0039 | 0.0245 | 0.0307 (↑22.31%) | 0.0347 (↑38.25%) | |
| Title_Hit-Rate@50 | 0.0496 | 0.0563 | 0.0449 | 0.0558 (↑12.50%) | 0.0567 (↑14.31%) | |
| Title_Hit-Rate@100 | 0.0646 | 0.0733 | 0.0606 | 0.0762 (↑17.96%) | 0.0720 (↑11.46%) | |
| Preference Hit-Rate | CTCVR | 0.003417 | 0.003675 | 0.003723 | 0.003802 (↑11.27%) | 0.003816 (↑11.68%) |
关键结论:
-
ORFT 有效激活了推理能力:Taiji (ORFT) 相对 DeepSeek-R1-7B,在类目级语义理解(Category_L1 +28.97%、Category_L2 +13.49%)与用户偏好对齐(CTCVR +8.96%)上显著提升,验证了逆向工程蒸馏的有效性。但在 title 级 hit-rate 上有性能折损(0.0449 < 0.0496),原因是 SFT 泛化能力有限——ORFT 只学到了训练样本里粗粒度的 item 匹配模式。另外 QwQ-32B 异常低的 Category_L3 ACC(0.0039)反映出它在缺乏领域微调时倾向于过于宽泛的预测。这些局限正说明了后续 RL 优化(带词法精度)的必要性。
-
POPO 同时超过 32B teacher 与 SFT-only 变体:给 ORFT 装上 POPO 后,几乎所有指标大幅提升——相对 QwQ-32B:Category_L1 +23.25%、CTCVR +3.84%;相对 DeepSeek-R1-7B:Title_Hit-Rate@50 +14.31%、CTCVR +11.68%。这证明动态平衡语义奖励与 ID 协同奖励,能在一个小得多的 7B 模型上对齐细粒度推荐偏好信号。
-
POPO 与 POPO-light 互补:完整 POPO 在 6 个指标中的 5 个取得最佳;轻量版 POPO-light 尽管只用 rollout 级奖励统计、开销可忽略,却在多数指标上取得次佳,甚至在 Title_Hit-Rate@100 上反超 POPO(0.0762 vs 0.0720)。GPU 预算紧张时 POPO-light 是很有吸引力的部署选择,训练成本不是瓶颈时则首选 POPO。
6. 消融与分析¶
6.1 RUPR 的作用(Table 3)¶
Table 3:RUPR 模块消融(w/o RUPR 直接用 QwQ-32B 从画像与行为生成的 CoT 与 item 预测;w/ RUPR 用在线日志的 ground-truth 标签引导推理;百分比为相对提升)
| 类型 | Metric | w/o RUPR | w/ RUPR | Improv. |
|---|---|---|---|---|
| Format Accuracy | Think_Tag_Presence_Rate | 0.9613 | 0.9947 | +3.47% |
| Think_Non_Empty_Rate | 0.9613 | 0.9921 | +3.20% | |
| Answer_Non_Empty_Rate | 0.9607 | 0.9892 | +2.97% | |
| Semantics Hit-Rate | Category_L1_ACC | 0.1679 | 0.2012 | +19.83% |
| Category_L2_ACC | 0.0535 | 0.0690 | +28.97% | |
| Category_L3_ACC | 0.0185 | 0.0245 | +32.43% | |
| Title_Hit-Rate@50 | 0.0405 | 0.0449 | +10.86% | |
| Title_Hit-Rate@100 | 0.0545 | 0.0606 | +11.19% |
分析:两点发现——① SFT 后的格式准确率本就很高(~99%),为后续 RL 训练打下稳定基础;② RUPR 显著提升语义命中率,尤其在细粒度指标上(Category_L3 +32.43%)。这说明「用 ground-truth 答案逆向引导 teacher 推理」相比「让 teacher 直接盲生成」,能产出语义上对齐真实购买的、更细粒度的 CoT,从而提供坚实的语义保证。
6.2 POPO 算法的作用(Table 4)¶
Table 4:POPO 算法消融(GRPO 用固定奖励权重 $w_s = w_{id} = 0.5$;POPO 动态调权实现 Pareto 最优;百分比为相对 GRPO 提升)
| Metric | ORFT+GRPO | ORFT+POPO-light | ORFT+POPO |
|---|---|---|---|
| Category_L1_ACC | 0.2180 | 0.2347 (↑7.66%) | 0.2433 (↑11.61%) |
| Category_L2_ACC | 0.0806 | 0.0877 (↑8.81%) | 0.0888 (↑10.17%) |
| Category_L3_ACC | 0.0269 | 0.0307 (↑14.13%) | 0.0347 (↑29.00%) |
| Title_Hit-Rate@50 | 0.0512 | 0.0558 (↑8.98%) | 0.0567 (↑10.74%) |
| Title_Hit-Rate@100 | 0.0698 | 0.0762 (↑9.17%) | 0.0720 (↑3.15%) |
| CTCVR | 0.003788 | 0.003802 (↑0.37%) | 0.003816 (↑0.74%) |
分析:与固定权重的 GRPO($w_s = w_{id} = 0.5$)相比,POPO 同时提升了 Semantic Hit-Rate 与 Preference Hit-Rate,而不是「牺牲一个目标换另一个」。这正验证了 POPO 的核心设计目标——把策略推向 Pareto 前沿,而非在两个目标间做零和交换。其中 Category_L3 这种细粒度指标提升最大(+29.00%),说明动态调权对「难、稀疏」的目标尤其有效(与 POPO-light 变异系数视角一致:难区分的奖励方向应获更大权重)。
7. 在线 A/B 实验(Table 2)¶
在快手广告推荐平台做大规模 A/B:给 baseline 与 Taiji 各分配 10% 流量,跑 一周。
Table 2:广告业务在线 A/B 结果(long-tail 设置聚焦交互历史稀疏的用户)
| Method | Setting | Intra-User Features ADVV | Intra-User Features Revenue | Cross-User Sequences ADVV | Cross-User Sequences Revenue | Overall ADVV | Overall Revenue |
|---|---|---|---|---|---|---|---|
| Taiji | all | +1.06% | +1.35% | +1.77% | +1.95% | +2.83% | +3.30% |
| Taiji | long-tail | +2.78% | +4.12% | +2.48% | +1.20% | +5.26% | +5.32% |
分析:Taiji 在 ADVV 与 Revenue 上都有显著提升;长尾用户(交互历史稀疏)收益更明显(ADVV +5.26%、Revenue +5.32%)。两个机制(用户内特征量化、跨用户序列)各自都有正向贡献,叠加得到整体增益。这说明 Taiji 的「推理增强推荐」有效弥合了用户意图与 item 属性之间的语义鸿沟,对行为数据有限的用户尤其有帮助——这正是 LLM 世界知识在协同信号稀疏处补位的价值体现。
8. 核心贡献总结¶
- 针对 SFT「CoT 质量不可度量」:提出 RUPR(用 ground-truth 答案逆向引导 teacher 推理,保证答案有效性)+ ORFT(用 PPL 把「CoT 好坏」量化成「让真实答案更可预测的程度」做拒绝采样),渐进式提升推荐专用 CoT 质量。
- 针对 RL「异构奖励不能动态平衡」:提出 POPO,用梯度对齐指标(或 POPO-light 的变异系数)在 GRPO 内动态调整 LLM 语义奖励与推荐 ID 协同奖励的权重,带镜像下降 / 双层优化的 Pareto 最优理论保证;并给出零额外开销的工业可部署变体 POPO-light。
- 完整的在线落地路径:把后训练 LLM 的推理输出量化为稀疏特征、并检索跨用户序列,注入在线广告排序模型,已在快手广告平台全量部署、服务 4 亿日活,A/B +2.83% ADVV / +3.30% Revenue。
9. 与已归档相关工作的对比¶
RPORec RPORec: Reinforced Preference Optimization for Reasoning-Augmented Recommendations(City University of Hong Kong × Kuaishou,2026-05-21)¶
关系:独立并发 / 同组兄弟工作(Taiji 未引用 RPORec;两文共享多位快手作者 Zeyu Song、Chi Lu、Peng Jiang、Kun Gai,是同一团队几乎同期的两条解法)· 已加载对方精读
-
共同关注的问题:两文指向同一 root cause——如何用 LLM 的显式 CoT 推理来做推荐,同时既不让推荐专用梯度扭曲 LLM 的推理能力,又不掉进「文本→item」的语义鸿沟。两者都不让 LLM 直接做在线打分,而是把 LLM 与真正的推荐/排序模块用一个接口解耦,再用 RL(GRPO)把 LLM 的推理对齐到推荐目标。两者都做了大规模工业广告 A/B(RPORec 40M 用户 Revenue +1.348%;Taiji 400M DAU Revenue +3.30%)。
-
相近的技术骨架:都是「显式
<think>/<answer>CoT 输出 + GRPO + 多路奖励」的范式;都用一个冻结/外部的推荐侧模块产出推荐导向的密集奖励(RPORec:冻结 Rechead 算 NDCG@k;Taiji:在线排序模型算 CTCVR),并配一个语义/推理质量奖励(RPORec:CoT 压缩相似度 + 熵奖励;Taiji:Qwen3-Embedding 余弦语义奖励)。两者都强调「用 CoT 但不被 CoT 噪声拖累」。 -
本文(Taiji)的差异与推进:① 奖励组合方式是最核心的差异——RPORec 把 6 路奖励用固定权重 $\alpha_0\ldots\alpha_5$ 线性相加(其 Eq. 11),正是 Taiji 在 related work 中批评的「static, hand-crafted weights」;Taiji 的 POPO 用梯度对齐 / 变异系数动态调权,并给出 Pareto 最优的理论保证。② 接口形式不同:RPORec 用「文本→Rechead 检索头」做端到端推荐,本质仍是一个推荐器;Taiji 是更彻底的 LLM-as-Enhancer——把推理输出量化成稀疏特征 + 跨用户序列检索喂给既有在线排序模型,与在线服务完全解耦。③ 数据侧:Taiji 额外强调 RUPR + PPL 拒绝采样的数据构建闭环,RPORec 则更聚焦 RL 阶段的奖励设计与两阶段迭代训练。
-
可比的方法 / 实验差异:RPORec 在三个 Amazon 公开数据集上与 SASRec/TIGER/R²ec/ReRe/LatentR³ 等推荐基线横向对比,工业侧只给 Revenue 单点;Taiji 几乎没有公开数据集与推荐基线对比,离线只与自己的 backbone(DeepSeek-R1-7B)和 teacher(QwQ-32B)比,但工业 A/B 给了 ADVV/Revenue + 长尾细分。两者结合看:RPORec 证明了「解耦接口 + 推荐侧密集奖励」路线在学术 benchmark 上的有效性,Taiji 则进一步给出「异构奖励该如何动态权衡」的答案与工业规模验证。详细精读见 RPORec。
注:被剔除的近似候选(仅一句理由)——ReRec(2604.07851):同为 reasoning+GRPO 做推荐,但面向复杂自然语言 query 的对话式推荐助手,创新点在 dual-graph 奖励塑形 / 推理感知优势估计 / 课程调度,问题场景与解法骨架都不同构;BLADE(2605.04559):同为 LLM4Rec 多目标 RL 对齐,但机制是 Bayesian 自演化分位数奖励校准(BoN/GRPO),与 Taiji 的「两路异构奖励 Pareto 调权」骨架不同;UniVA(2605.05803):同为工业广告 RL 对齐且有 relevance-vs-value 张力,但它是生成式推荐器(LLM 即排序器,eCPM-aware PPO + value-guided beam search),范式与解法均不同构。
10. 讨论与局限性¶
值得借鉴的设计:
- 「用 PPL 把不可验证的 CoT 质量变成可量化信号」 是个干净利落的 insight:推荐没有唯一可验证答案,但「这条 CoT 是否让 ground-truth 更可预测」是完全可算的代理,且阈值取分布中位数、可拒绝采样,工程上极易落地。
- POPO 把「多奖励权衡」从超参调参问题升级为有理论保证的动态优化问题。其两个视角——梯度内积(精确版)与变异系数(轻量版)——都很直观;POPO-light 零额外开销、纯前向标量即可,是工业 RL 里很实用的折中。
- 彻底的 enhancer 解耦 + 长尾增益:把 LLM 推理量化成特征、并叠加跨用户检索,让 LLM 的世界知识在协同信号稀疏的长尾用户处补位,A/B 长尾收益(+5.26% ADVV)显著高于大盘,符合直觉也有说服力。
局限与争议:
- 离线实验的基线偏弱:离线只对比了自家 backbone(DeepSeek-R1-7B)与 teacher(QwQ-32B),没有任何公开学术数据集、也没有与同类 LLM-Enhancer / RL-for-Rec 方法(RecLM、Rec-R1、RPORec 等)的横向对比。因此「POPO 相对其它动态/静态调权方法到底强多少」缺乏直接证据,可比性与可复现性受限。
- 理论保证的实践落差:POPO 的 Pareto 最优性建立在双层优化 + 镜像下降近似之上,但论文未给出收敛性的经验验证(如权重 $w_s/w_{id}$ 随训练的轨迹、是否真的逼近 Pareto 前沿),理论与实证之间留有空白。
- 多阶段、非端到端:整条链路是「LLM 后训练 → 量化稀疏特征 / 跨用户检索 → 喂给独立的在线排序模型」,LLM 与排序模型并非端到端联合优化;量化(PQ)与检索是固化的中间环节,长期看其表征上限与「参数 scaling 时同步扩充表征与序列建模能力」的能力存疑(典型的 enhancer 路线权衡)。
- 奖励仅两路:$\mathcal{K}=\{s, id\}$ 只有语义与 CTCVR 两个奖励;POPO 框架本身可扩展到更多目标(多样性、时长、留存等),但论文未在更多奖励、或在线 RL 场景下验证其可扩展性。
- 写作细节:related work 中把引用编号 [3] 同时对应到 DEEPER 与 OneRec,存在引用对应上的瑕疵(不影响主体方法)。
工业落地价值:作为 LLM-as-Enhancer 路线的工业代表作,Taiji 给出了一条「数据构建 → PPL 拒绝采样 SFT → Pareto 动态调权 RL → 量化特征 + 跨用户检索上线」的完整、可复制的工程闭环,并以 4 亿日活的规模、+2.83% ADVV / +3.30% Revenue 的 A/B 结果证明了其商业价值,对短视频/电商广告推荐的 LLM 增强有直接参考意义。