Recommendation as Generation:把"检索固定库存"升级为"按需生成个性化视频"¶
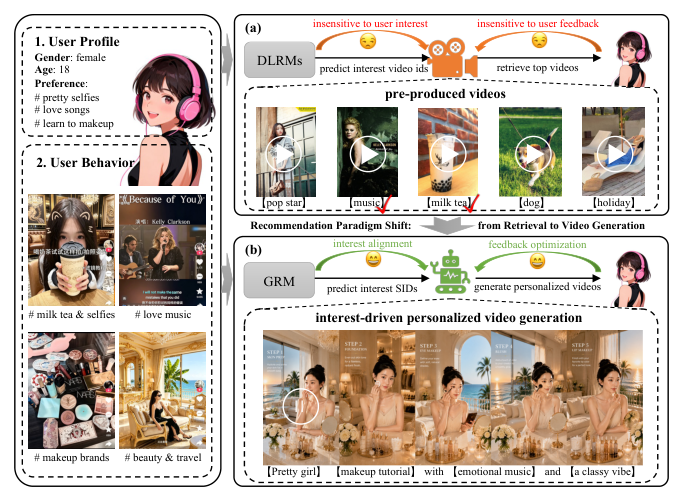
RaG(Recommendation-as-Generation)来自 Kuaishou Technology(快手,部分作者为北航实习生),部署在超过 4 亿日活(400M DAU)的快手广告系统上。它提出一个新范式:推荐系统不再从一个固定的、可枚举的内容库里检索/排序已有视频,而是直接为用户从其被推断的兴趣中生成一条全新的个性化视频。统一的接口是 Disentangled Semantic IDs(D-SIDs,解耦语义 ID)——既作为生成式推荐模型(GRM)的预测目标,又作为视频生成的条件。线上广告 A/B 相比强生产 GRM 基线提升广告收入 +1.870%(相比 DLRM 基线 +5.462%)。
研究动机与背景¶
传统推荐被"固定内容库"锁死¶
过去十年的工业短视频推荐遵循 content-first(内容先行) 范式:视频先离线生产好,推荐模型(DLRM)再从一个固定池里检索并排序。深度学习推荐模型(DLRMs)提升了匹配精度,生成式推荐模型(GRMs)进一步把这个范式扩展为在语义 ID(SID)上做大规模自回归生成——但无论 DLRM 还是 GRM,输出永远只能是这个固定池里已经存在的视频。
论文用一句话点出 root cause:即使用户兴趣落在池子之外,推荐系统也只能返回池内"次优"的近似匹配。在现代短视频平台上用户兴趣更动态、更长尾、更多样,这个"固定池限制"使得基于检索的系统在本质上无法忠实地刻画细粒度用户兴趣。
与此同时,AIGC(AI-generated content)的突破让视频生成模型已能产出影院级、高保真、可语义控制的内容。于是论文提出核心问题:
推荐系统能否超越"检索已有内容",直接从被推断的用户兴趣生成个性化视频?
两大挑战¶
回答这个问题要解决推荐与生成之间两个深层割裂:
挑战一:如何把推荐与生成统一进一个框架。 推荐模型在异构离散数据(用户画像、物品特征、行为序列)上训练,目标是预测兴趣;视频生成模型在多模态连续信号(文本、图像、音频、运动)上训练,目标是生成连贯高保真视频。两者在数据表示和学习目标上根本不同,导致推荐与生成长期被当作两个独立任务分别发展。这种割裂还阻断了用户反馈回流到生成过程,限制了产出内容的多样性与兴趣对齐度。
挑战二:如何在工业规模上生成高质量且兴趣对齐的视频。 SOTA 视频生成模型虽然画质强,但难以部署到大规模推荐:它们依赖人工 prompt、多阶段精修、专业工具后处理,产出一条令用户满意的视频就有很高的延迟与算力成本;再乘上"为数亿用户、跨长尾兴趣个性化"的放大因子,直接把这类模型搬进生产是不可行的。
RaG 的核心主张与三条贡献¶
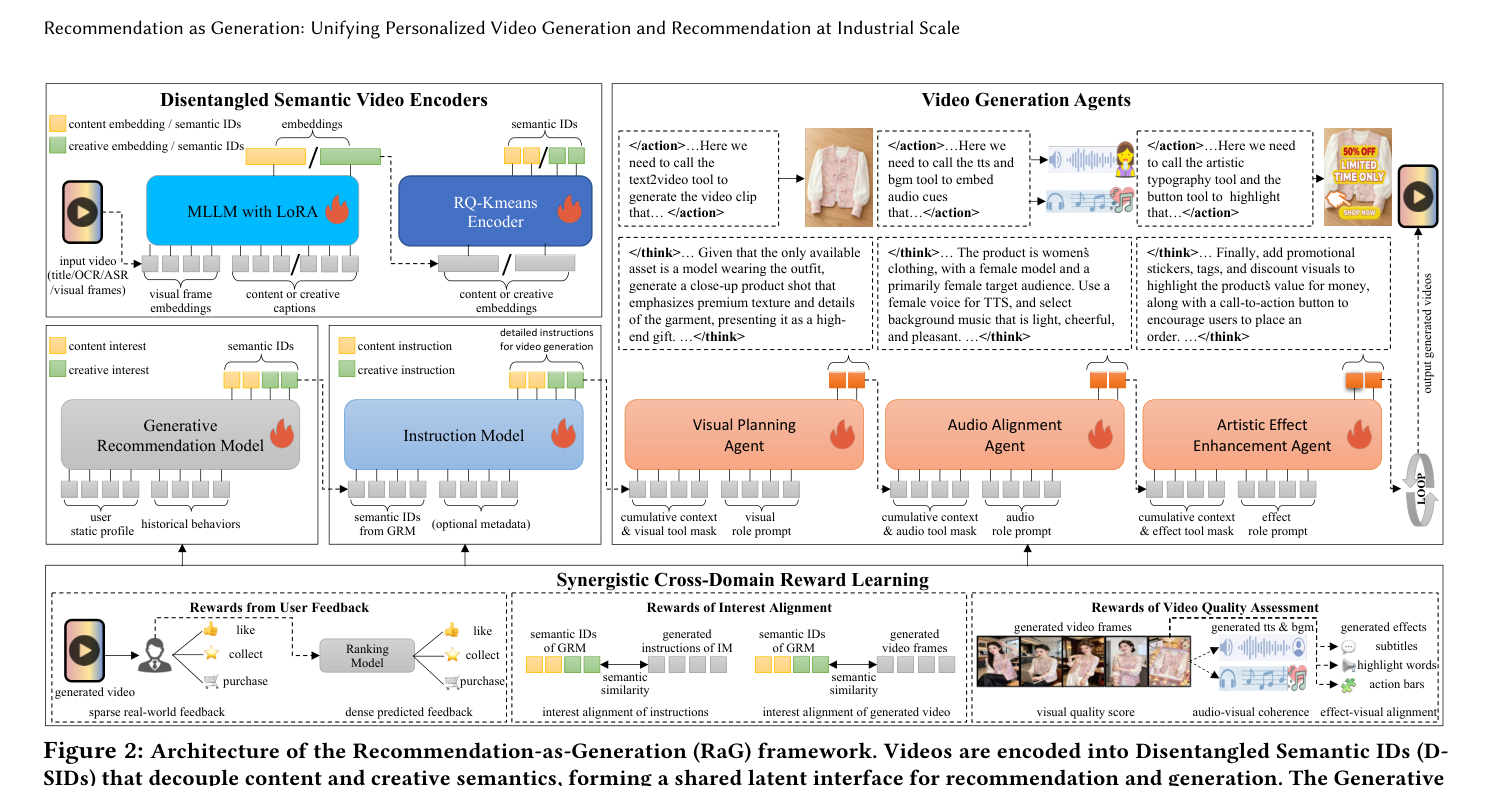
针对上述挑战,论文提出 Recommendation-as-Generation(RaG),在一个闭环框架里统一推荐与个性化视频生成。一个核心 idea 是用 Disentangled Semantic IDs(D-SIDs) 作为推荐与生成之间的统一隐式接口:一个多模态大模型把每条视频编码成两组因子化嵌入——一组表示 content(内容:实体、主题),一组表示 creative(创意:风格、节奏、氛围),再分别量化为离散的 content SIDs 与 creative SIDs,共同构成视频的 D-SIDs。在推荐侧,GRM 自回归预测用户兴趣对应的 D-SIDs;在生成侧,预测出的 D-SIDs 被解码成新生成的个性化视频,把细粒度兴趣建模与可控视频生成连接起来。
为在规模上实现可控生成,RaG 设计了 Video Generation Agents(VGAs,视频生成智能体):相比单体、高成本、重 prompt 工程的扩散/生成流水线,VGAs 采用分层规划与精修框架。论文还引入 Synergistic Cross-Domain Reward Learning(SCRL,协同跨域奖励学习) 来闭合优化回路,联合强化兴趣对齐、用户反馈与视频质量。
三条贡献:
- 提出 RaG 新范式:把推荐从"在固定池里检索视频"转向"从被推断兴趣直接生成个性化视频"。D-SIDs 作为推荐与生成的统一隐式接口;SCRL 通过强制兴趣对齐、用户反馈、视频质量来闭合回路。
- 工业级 VGAs:带分层规划、协同多智能体执行、迭代式精修,实现可扩展、高质量的个性化视频生产。
- 大规模线下实验 + 线上 A/B(生产广告平台):验证大规模个性化视频生成对推荐的实质增益。
论文强调,据其所知这是首个真正统一推荐与个性化视频生成的生产级系统。
核心方法 / 模型架构¶
总览¶
RaG 由四个模块串成一条闭环流水线(见 Figure 2):
- Disentangled Semantic Video Encoders(§2.2):把视频编码成解耦的 content / creative 嵌入并量化为 D-SIDs,形成共享离散隐空间;
- Generative Recommendation Model(GRM,§2.1 / Appendix C):从用户上下文自回归预测兴趣 D-SIDs;
- Instruction Model(IM,§2.3):把预测出的 D-SIDs 翻译成 shot-level(镜头级)结构化生产指令;
- Video Generation Agents(VGAs,§2.4):三个角色专精的智能体执行指令、分层生成最终视频;
整条流水线在 Synergistic Cross-Domain Reward Learning(SCRL,§2.5) 下联合优化。
2.1 范式转变:把推荐重述为生成¶
给定视频 $v$,解耦语义视频编码器 $\mathcal{E}$ 产出一串 token:
$$\text{D-SIDs} = \mathcal{E}(v) = (s^1_{\text{content}}, \ldots, s^L_{\text{content}};\ s^1_{\text{creative}}, \ldots, s^L_{\text{creative}}) \tag{1}$$
即联合表示视频的内容结构与创意结构。在此语义空间上,推荐被重述为生成式兴趣建模:给定用户画像与交互历史,GRM 自回归预测代表用户未来兴趣的 D-SID 序列:
$$p(\text{D-SIDs} \mid \mathbf{c}_{\text{user}}) = \prod_{t=1}^{2L} p(s_t \mid s_{<t}, \mathbf{c}_{\text{user}}) \tag{2}$$
其中 $\mathbf{c}_{\text{user}}$ 是用户上下文。与以往把预测 SID 当作检索 key 的工作不同,RaG 把 D-SIDs 当作可以直接解码成新内容的"生成式兴趣表征",超越固定池。整条流水线是:
$$\text{D-SIDs} = \mathcal{E}(v) \rightarrow p(\text{D-SIDs} \mid \mathbf{c}_{\text{user}}) \rightarrow \hat{v} = \mathcal{G}(\text{D-SIDs}) \tag{3}$$
用户兴趣在隐语义空间中被建模,并被解码成个性化视频。由于直接优化生成器 $\mathcal{G}$ 同时兼顾生成质量与兴趣对齐很难,论文把生成过程分解为一个分层框架:先用 Instruction Model 把 D-SIDs 翻译成自然语言指令(可解释、结构化的引导),再用 VGAs 生成视频。
2.2 解耦语义视频编码器¶
2.2.1 多模态表征学习¶
编码器基于 Qwen2.5-VL-7B-Instruct,构建一个 instruction-guided 的解耦表征框架,把同一条视频的内容语义与创意属性分开。多模态输入处理上直接复用 Qwen2.5-VL 原生视觉编码器与文本 tokenizer。视觉表征:$H = \mathcal{F}(v),\ H \in \mathbb{R}^{N \times d}$,$H$ 是捕捉时空语义的视觉 token 序列。
为得到解耦信号,论文用自研稠密字幕模型 CapModel 生成因子专属的文本描述:
$$D_m = \text{CapModel}(v, \text{PROMPT}_m), \quad m \in \{\text{content}, \text{creative}\} \tag{4}$$
其中 $D_{\text{content}}$ 描述语义内容(实体、主题),$D_{\text{creative}}$ 刻画创意属性(风格、节奏、氛围)。指令经文本 tokenizer 编码为 $Q_m = \mathcal{T}(D_m),\ Q_m \in \mathbb{R}^{L_m \times d}$。把视觉与文本联合送入 Qwen2.5-VL-7B,取最后一层最后一个 token 的隐状态作为池化的多模态表征:
$$\mathbf{z}_m = \text{Normalize}(\text{VLM}(H, Q_m)), \quad \mathbf{z}_m \in \mathbb{R}^d,\ \|\mathbf{z}_m\|_2 = 1 \tag{5}$$
得到 L2 归一化的 $\mathbf{z}_{\text{content}}$ 与 $\mathbf{z}_{\text{creative}}$。
为鼓励表征一致性,每个模块用对比损失:
$$\mathcal{L}_m = -\log \frac{\exp(\text{sim}(\mathbf{z}^i_m, \mathbf{z}'^i_m)/\tau)}{\sum_k \exp(\text{sim}(\mathbf{z}^i_m, \mathbf{z}^k_m)/\tau)} \tag{6}$$
$\mathbf{z}'^i_m$ 是 batch 内 $\mathbf{z}^i_m$ 的正样本对,$k$ 遍历所有候选(含正样本)。为减少两路因子之间的串扰(cross-factor leakage),加一个正交约束:
$$\mathcal{L}_{\text{orth}} = \|\mathbf{z}_{\text{content}}^\top \mathbf{z}_{\text{creative}}\|_2^2 \tag{7}$$
最终目标:
$$\mathcal{L} = \mathcal{L}_{\text{content}} + \gamma_1 \mathcal{L}_{\text{creative}} + \gamma_2 \mathcal{L}_{\text{orth}} \tag{8}$$
这套设计同时实现了细粒度用户兴趣建模与可控视频生成——把"是什么内容"和"什么风格"显式拆开,使得后续既能精确对齐用户内容兴趣,又能可控地生成创意风格。
2.2.2 离散 tokenization¶
为在隐空间内做生成式推荐,把解耦的多模态表征离散化为语义 ID。每个表征 $\mathbf{z}_m$ 独立地用 Residual Quantization(RQ)-based K-means 量化,得到一个量化嵌入 $\mathbf{e}_m$,它把 $\mathbf{z}_m$ 近似成 $L$ 个分层码本向量之和:
$$\mathbf{e}_m = \sum_{l=1}^{L} \mathbf{e}^l_m(s^l_m) \approx \mathbf{z}_m, \quad \mathbf{e}_m \in \mathbb{R}^d \tag{9}$$
$s^l_m$ 是模态 $m$ 在第 $l$ 层的离散码索引,$\mathbf{e}^l_m(\cdot)$ 是对应的码本查表。每个模态维护一套独立码本,每层 8192 个 entry。最终 D-SIDs 由两模态的码序列拼接而成:$\text{D-SIDs} = [s^{1:L}_{\text{content}};\ s^{1:L}_{\text{creative}}]$。
关键工程取舍:论文(Table 2)选择 RQ-KMeans 而非 RQ-VAE,因为在工业流式重训练节奏下 RQ-VAE 容易码本坍塌,而 K-means 拟合后给出稳定划分(这一点与 FLUID FLUID 殊途同归,见后文对比)。
2.2.3 三阶段训练¶
D-SID 编码器采用三阶段训练: 1. 阶段一:冻结骨干 LLM,只优化投影 $\phi(\cdot)$,把 D-SIDs 的嵌入对齐到语言空间; 2. 阶段二:投影与 LLM 参数联合微调,提升语义保真与可控指令生成; 3. 阶段三:用强化学习 + 奖励优化进一步增强(详见 §2.5)。
2.3 Instruction Model(指令模型)¶
IM 把 D-SIDs 翻译成 shot-level 视频生产指令,显式指定场景构图、镜头运动、时间节奏、电影风格,作为离散用户兴趣与可控视频生成之间的语义桥。
2.3.1 监督构造¶
由于没有现成的"镜头级指令"数据集,论文从强多模态教师蒸馏监督:对每条视频 $v$,先抽取其 D-SIDs,再用精心设计的指令模板提示 Gemini2.5 Pro 产出目标镜头级脚本:
$$D_{\text{inst}} = \text{Gemini}(v, \text{PROMPT}_{\text{inst}}) = (y_1, y_2, \ldots, y_{L_{\text{inst}}}) \tag{10}$$
$D_{\text{inst}}$ 是长度 $L_{\text{inst}}$ 的 token 序列,作为 ground-truth 监督。为适配广告场景(生成视频须促销特定产品),论文额外引入可选元数据因子 $D_{\text{meta}}$(如产品信息、营销主题)作为辅助条件;当不可用时(如纯有机视频)$D_{\text{meta}}$ 被简单 mask,使指令生成只条件于 D-SIDs。
2.3.2 模型与优化目标¶
IM 用 Qwen3-8B 实例化,消费两条异构 token 序列——主 D-SIDs 与辅助 $D_{\text{meta}}$(不可用时 mask)——映射到 LLM 输入嵌入空间后拼接。对 D-SIDs,用逆向 RQ-Kmeans 从离散码重建连续嵌入 $\mathbf{e}_{\text{D-SIDs}} = [\mathbf{e}_{\text{content}};\mathbf{e}_{\text{creative}}] \in \mathbb{R}^{2 \times d}$,经可学习投影 $\phi(\cdot)$ 映成 $\mathbf{h}_{\text{D-SIDs}} = \phi(\mathbf{e}_{\text{D-SIDs}}) \in \mathbb{R}^{2 \times d'}$;元数据由 LLM 原生 tokenizer 编码为 $Q_{\text{meta}} = \mathcal{T}(D_{\text{meta}})$。模型自回归预测指令序列:
$$\hat{D}_{\text{inst}} = \text{LLM}(\mathbf{h}_{\text{D-SIDs}}, Q_{\text{meta}}) \tag{11}$$
用标准 next-token 预测损失对齐 Gemini 蒸馏出的监督:
$$\mathcal{L}_{\text{NTP}} = -\sum_{t=1}^{L_{\text{inst}}} \log P(y_t \mid y_{<t}, \mathbf{h}_{\text{D-SIDs}}, Q_{\text{meta}}) \tag{12}$$
使 $\hat{D}_{\text{inst}}$ 逐 token 逼近 $D_{\text{inst}}$。
2.3.3 三阶段训练¶
IM 同样三阶段:阶段一冻结骨干、只训投影 $\phi(\cdot)$ 把 D-SIDs 嵌入对齐到语言空间;阶段二投影与 LLM 联合微调;阶段三用 §2.5 的 RL 奖励优化进一步增强。
2.4 Video Generation Agents(VGAs,视频生成智能体)¶
工业级个性化视频生成无法用单体生成器搞定:一次性产出视觉、音频、特效常导致语义不一致和可控性差。而且视频生产有层级依赖:视觉规划决定叙事流,音频与特效要条件于视觉状态。论文因此把视频生成建模为一个有序多智能体决策过程,在一个不断演化的生成状态上展开。
智能体形式化(Agentic Formulation)。 在每个 step $t$,激活的子智能体观察状态 $\mathcal{S}_t$,按策略 $\pi_\theta$ 选动作 $a_t$,再经确定性算子 $\mathcal{P}$ 转移到下一状态:
$$a_t \sim \pi_\theta(a_t \mid \mathcal{S}_t), \qquad \mathcal{S}_{t+1} = \mathcal{P}(\mathcal{S}_t, a_t) \tag{13}$$
状态被序列化为一个有序前缀 + 阶段相关 token:
$$\mathcal{S}_t = [\ \underbrace{\hat{D}_{\text{inst}};\ D_{\text{tool}}}_{\text{shared prefix}};\ \underbrace{O_{<t};\ \text{PROMPT}_{\text{role}}}_{\text{stage-dependent}}\ ] \tag{14}$$
其中 $\hat{D}_{\text{inst}}$ 是 IM 产出的指令序列;$D_{\text{tool}}$ 是所有可用工具的描述(含自研预训练的 text-to-video / image-to-video 模型,以及外部音频合成、特效 API);$O_{<t}$ 是此前各子智能体角色 prompt 与产出的运行拼接;$\text{PROMPT}_{\text{role}}$ 是激活当前子智能体的短角色 prompt。动作 $a_t$ 对应一个模态专属调用(视觉 / 音频 / 特效生成)。
VGAs 由三个角色专精子智能体组成,各按自己的策略行动:
$$\pi_\theta(a_t \mid \mathcal{S}_t) = \{\pi_{\text{visual}}, \pi_{\text{audio}}, \pi_{\text{effect}}\}(a_t \mid \mathcal{S}_t) \tag{15}$$
- Visual Planning Agent(VPA,视觉规划):$\text{PROMPT}_{\text{role}} = \text{PROMPT}_{\text{visual}}$,$O_{<t}$ 为空(或携带上一轮反射内容)。VPA 充当全局控制器,产出 clip 级故事板:场景分段、布局配置、时间边界 $\mathcal{I}_{\text{visual}} = \pi_{\text{visual}}(\mathcal{S}_t)$。
- Audio Alignment Agent(AAA,音频对齐):$\text{PROMPT}_{\text{role}} = \text{PROMPT}_{\text{audio}}$,$O_{<t}$ 扩展进 $(\text{PROMPT}_{\text{visual}}, \mathcal{I}_{\text{visual}})$。AAA 生成与场景过渡时序对齐的音频(语音 + 音乐)$\mathcal{I}_{\text{audio}} = \pi_{\text{audio}}(\mathcal{S}_t)$。
- Artistic Effect Enhancement Agent(AEEA,艺术特效增强):$\text{PROMPT}_{\text{role}} = \text{PROMPT}_{\text{effect}}$,$O_{<t}$ 进一步扩展进 $(\text{PROMPT}_{\text{audio}}, \mathcal{I}_{\text{audio}})$。AEEA 做后期精修:加字幕、视觉特效、转场、行动号召(call-to-action)元素如 action bar。$\mathcal{I}_{\text{effect}} = \pi_{\text{effect}}(\mathcal{S}_t)$。
分层生成与有界反射(Hierarchical Generation with Bounded Reflection)。 三路意图输出经统一生成算子合成最终视频:
$$\mathcal{V} = \mathcal{G}(\mathcal{I}_{\text{visual}}, \mathcal{I}_{\text{audio}}, \mathcal{I}_{\text{effect}}) \tag{16}$$
为提升跨模态一致性,VGAs 在一个有界反射循环里运转,遵循标准 Observe→Think→Act 周期,上限 2 次迭代,在产出质量与生成效率间平衡。
共享骨干与 KV-Cache 复用。 三个子智能体并非三个独立模型,而是共享一个 Qwen2.5-32B 骨干、全参数共享;差异仅来自状态 $\mathcal{S}_t$ 中 $\text{PROMPT}_{\text{role}}$ 激活的目标子智能体,attention mask 对 $D_{\text{tool}}$ 把它限制在可访问的工具子集,$O_{<t}$ 提供累积的上游上下文。这种序列化设计直接支持 KV-cache 复用:子智能体被顺序调用、$O_{<t}$ 只增不改,先前生成的 token 留在 KV cache 中,后续子智能体只需编码自己的 $\text{PROMPT}_{\text{role}}$,大幅降低每请求推理延迟。结合 SID-indexed cache(摊销生成成本),VGAs 可在工业规模上为数亿用户可靠服务。
2.5 Synergistic Cross-Domain Reward Learning(SCRL)¶
2.5.1 跨域奖励形式化¶
SCRL 构建一个三目标协同奖励:video quality(视频质量)、interest alignment(兴趣对齐)、user feedback(用户反馈)。除非另有说明,所有奖励模型共享同一 Transformer 架构、在任务专属数据上训练。
1. 视频质量奖励 $R_{\text{quality}} = R_{\text{visual}} + R_{\text{audio}} + R_{\text{effect}}$:
- $R_{\text{visual}}$:视觉质量(美学吸引力 + 时空一致性,确保连贯运动与稳定渲染);
- $R_{\text{audio}}$:音视频对齐(含 TTS 语音同步与背景音乐 BGM 一致性);
- $R_{\text{effect}}$:特效质量与对齐(字幕、高亮、action bar 等交互元素)。
2. 兴趣对齐奖励 $R_{\text{align}} = R_{\text{instr-align}} + R_{\text{rep-align}}$:
- $R_{\text{instr-align}}$:强制 GRM 生成的 D-SIDs 与生成指令之间的语义一致性;
- $R_{\text{rep-align}}$:度量 GRM 生成的 D-SIDs 与生成视频之间的语义相似度。
3. 用户反馈奖励 $R_{\text{feedback}} = R_{\text{real}} + R_{\text{pred}}$:
- $R_{\text{real}}$:来自真实反馈的稀疏但高保真交互信号(点击、点赞、购买等);
- $R_{\text{pred}}$:排序模型估计的稠密参与度信号,捕捉超出显式交互的偏好强度。 论文指出真实交互稀疏且延迟,单靠它不足以稳定高效地优化策略,故用排序模型的稠密估计去增广稀疏信号。
2.5.2 用 GDPO 做约束策略优化¶
为联合优化这些异构、跨域奖励,SCRL 把奖励学习形式化为一个约束策略优化问题,用 GDPO([[2601.05242]] 谱系)求解,应对两个实际难题:(i) 异构奖励间的尺度失配与优化不稳定;(ii) 在不牺牲主导目标的前提下静态平衡竞争目标之难。
问题设定。 给定输入 $x$,策略 $\pi_\theta$ 采样候选集 $\mathcal{Y} = \{y_1, \ldots, y_K\} \sim \pi_\theta(\cdot \mid x)$,每个候选 $y_i$ 被一组异构奖励函数评估:用户反馈 $R_{\text{feedback}}(y_i)$、兴趣对齐 $R_{\text{align}}(y_i)$、视频质量 $R_{\text{quality}}(y_i)$。
约束奖励形式化。 把用户反馈指定为主目标,把兴趣对齐与视频质量当作不等式约束(目标阈值 $\tau_{\text{align}}$、$\tau_{\text{quality}}$)。每个候选的复合奖励:
$$R(y_i) = R_{\text{feedback}}(y_i) - \sum_{c \in \{a, q\}} \lambda_c(t)\,\text{ReLU}(\tau_c - R_c(y_i)) \tag{17}$$
其中 $\lambda_a(t), \lambda_q(t) \ge 0$ 是时变拉格朗日乘子,用 PID 控制规则按约束违反量更新,避免朴素 primal-dual 更新的振荡与超调。每个阈值相对 SFT baseline 在留出验证集上的分布校准:$\tau_c = \mu_c^{\text{base}} + k_c \sigma_c^{\text{base}}$,严格因子 $k_c$ 编码该模块在 RaG 中的角色——VGAs 取最严格的 $k_c = 1.1$(对 $\tau_a, \tau_q$,因为它直接决定最终视频质量);IM 取较可比的 $k_a = 0.8$(指令级对齐);GRM 取宽松的 $k_a = 0.3$,且对后两个模块省略视频质量约束。
Group-decoupled 归一化与优势。 在式(17)约束奖励基础上,GDPO 进一步消除残余尺度失配:聚合前对每个奖励通道做 per-reward 标准化,并在采样候选集 $\mathcal{Y}$ 上计算组相对优势:
$$A_i = \frac{R(y_i) - \mu(\mathcal{Y})}{\sigma(\mathcal{Y}) + \epsilon} \tag{18}$$
$\mu(\mathcal{Y}), \sigma(\mathcal{Y})$ 是奖励在组上的均值与标准差。这种解耦归一化稳定了不同量纲奖励的联合优化。
优化目标。 策略以相对冻结 SFT 参考 $\pi_{\text{ref}}$ 的组相对优势为锚更新:
$$\mathcal{L}_{\text{GDPO}} = -\mathbb{E}_{(x, y_i)}\left[A_i \log \frac{\pi_\theta(y_i \mid x)}{\pi_{\text{ref}}(y_i \mid x)}\right] \tag{19}$$
(为简洁省略了重要性采样比裁剪与对 $\pi_{\text{ref}}$ 的 KL 正则,实现中均保留,遵循标准 GDPO。)总体上,SCRL 把推荐与视频生成统一进单一闭环优化,使用户兴趣、内容质量、真实反馈协同演化。
3. 部署(Deployment)¶
RaG 部署在快手大规模广告系统,服务超 4 亿用户(Figure 3)。系统在严格延迟约束下统一了实时大规模用户兴趣建模与大规模个性化视频生成。由于视频生成比兴趣推断慢若干数量级(Appendix A / Table 5),论文设计了一个解耦部署架构,在保持端到端个性化质量的同时弥合效率鸿沟。系统含三个解耦模块:
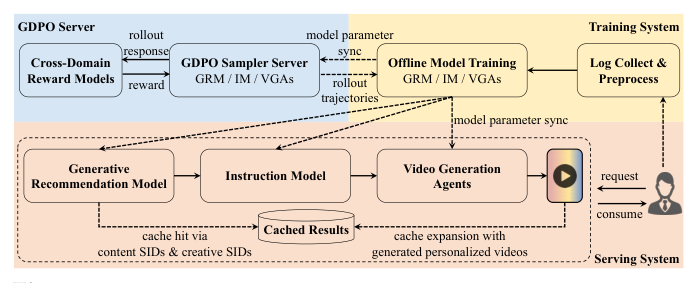
- 实时兴趣建模(Real-Time Interest Modeling):GRM 在流式用户交互日志(曝光、点击、观看时长、转化)上持续训练以适应非平稳行为,流式监督更新 + 周期性 GDPO 优化。在线低延迟自回归生成结构化 SIDs,作为下游内容生成的语义目标。
- 近线视频生成(Nearline Video Generation):IM 与 VGAs 在高质量视频整理出的大规模 agentic 监督数据上训练,经 SFT + 约束 GDPO 联合优化生成质量与兴趣对齐;两者周期性全 batch 更新以适应演化的用户兴趣与新视频模式。服务时,条件于 GRM 生成的 SIDs,IM 与 VGAs 在近线流水线生成个性化视频;VGAs 用 KV-cache 复用,产出持续累积进一个不断增长的个性化视频空间,把视频生成与实时服务解耦。
- 延迟感知服务(Latency-Aware Serving):按"请求的内容级 SIDs 是否被 cache 覆盖"组织分层服务策略:
- Case 1:content-SIDs 命中。 若匹配的 cache 条目也覆盖 creative-level SIDs,直接返回之前生成的视频(几乎零延迟);否则返回一条 content 一致的 cached 视频,同时异步调度缺失的 creative 变体(高频 creative 在生成队列里优先)。
- Case 2:content-SIDs 未命中。 返回与最近邻 SIDs 关联的视频供即时消费,把未覆盖的 SIDs 入队优先生成。
4. 实验¶
4.1 线上 A/B 测试¶
在快手真实广告平台做大规模线上 A/B,聚焦两点:(1) 解耦语义 ID(D-SIDs)对生成式推荐的有效性;(2) D-SID 驱动的个性化视频生成带来的额外增益。
Table 1:线上 A/B 结果(相对生产基线的相对提升,Rev = 广告收入)
| Method | Rev(%↑) vs DLRM 基线 | Rev(%↑) vs GRM 基线 |
|---|---|---|
| Production Baseline | ||
| DLRM baseline | – | – |
| GRM baseline | +3.526% | – |
| Enhanced GRM | ||
| GRM + Disentangled-SIDs (D-SIDs) | +4.460% | +0.902% |
| Full System (RaG) | ||
| RaG (GRM + D-SIDs + IM + VGAs + SCRL) | +5.462% | +1.870% |
结论分析: 把生产 DLRM 流水线换成 GRM 已带来一致的广告收入增益;在 GRM 之上引入 D-SIDs 把提升从 +3.526% 抬到 +4.460%,印证"解耦 content 与 creative 语义产生更结构化的隐空间、缓解自回归生成时的干扰"。但这两个变体仍属检索范式——从固定池里选候选。最后完整 RaG(GRM + D-SIDs + IM + VGAs + SCRL)拿到 +5.462%(相比强 GRM 基线 +1.870%),这部分额外增益直接来自 D-SID 驱动的个性化视频生成——证明从"检索式"到"生成式"的范式跃迁:用户兴趣主动驱动个性化内容生产,而不仅仅匹配现有候选。
4.2 离线消融研究¶
消融 RaG 的关键组件——D-SIDs、IM、VGAs、SCRL 优化——评估各自对语义表征质量、指令生成能力、奖励驱动视频生成的贡献。
4.2.1 解耦 SID 的质量¶
D-SIDs 含两个核心组件:多模态表征学习 + 语义量化。
Table 2:解耦 SID 的质量(语义检索质量 R@K + 离散化质量;Cpr = 压缩率↓,Col = 碰撞率↓)
| Method | R@1↑ | R@5↑ | R@10↑ | Cpr↓ / Col↓ |
|---|---|---|---|---|
| VLM2Vec-V2 | 0.485 | 0.690 | 0.756 | – |
| QARM | 0.541 | 0.812 | 0.893 | 1.14 / 18.24% |
| Qwen2.5-VL-7B | 0.769 | 0.948 | 0.977 | – |
| Ours (D-SIDs) | 0.896 | 0.985 | 0.994 | 1.02 / 2.62% |
| Impr. | +16.5% | +3.9% | +1.7% | -10.5% / -15.6pp |
结论分析(多模态表征学习): 在产品级检索设置下,本方法在 R@1/5/10 上一致超越所有 baseline(0.896/0.985/0.994),其中 R@1 相比最强 baseline(Qwen2.5-VL-7B)+16.5%,说明同等检索条件下语义判别力更强。
结论分析(语义量化): D-SIDs 用 RQ-KMeans 对 content / creative 嵌入分别残差量化;为公平对比,D-SIDs 与 QARM 都用同样的 4 层码本、每层 8192 码。本方法离散化质量更优——压缩失真降到 1.02、碰撞率降到 2.62%。相比 QARM(1.14 / 18.24%),相当于压缩误差 -10.5%、碰撞率 -15.6pp,即更紧凑、更抗碰撞的语义空间。
4.2.2 指令模型配置¶
以生成指令与 ground-truth 摘要的余弦相似度(用 Qwen3-Embedding-8B 度量)衡量 IM 解码保真度。增大训练数据与模型容量都带来一致提升:从 0.7760(8B 模型,100K 样本)→ 0.8096(8B,1M 样本)→ 进一步 0.8212(32B,1M)。综合性能与算力效率,论文取 8B 模型 + 1M 样本作默认配置,在显著更低部署成本下达到有竞争力的解码保真度。
4.2.3 视频生成的性能分析¶
从两个角度评估 VGAs:(i) 与传统生产流水线的系统级对比;(ii) 不同奖励组件对优化的贡献。评估三方面:生成质量(automated + 人类偏好)、兴趣对齐分。
系统级对比。 对比对象是一个传统 workflow baseline——手工搭的固定顺序流水线(指令生成、粗剪视觉合成、精剪 TTS 合成与后期),其刚性执行无法适配多样的用户特定生成需求,正是 VGAs agentic 设计要解决的。
Table 3:VGAs vs workflow baseline 的视频评估(Automated Score 报均值 / 中位数)
| Metric | Workflow Baseline | VGAs | Impr. |
|---|---|---|---|
| Automated Score ↑ | 62.4 / 62.0 | 71.3 / 76.0 | +14.3% / +22.6% |
| Automated Win Rate ↑ | 28.7% | 70.1% | +41.4pp |
| User Study Win Rate ↑ | 34.4% | 52.9% | +18.5pp |
结论分析: VGAs 在所有指标上一致领先。增益来自两点能力——reasoning(分层结构化端到端框架支持连贯跨模态规划)与 reflection(迭代式自我纠正与重规划提升产出质量,上限 2 次迭代以把延迟控制在与 workflow baseline 可比)。
奖励贡献分析(Table 4)。 由于用户反馈始终是主目标且永远保留,这里聚焦两个约束侧奖励:视频质量与兴趣对齐。每个视频质量子奖励在自己的测试集上评估,Base 表示不带任何奖励优化训练的策略。
Table 4:奖励消融(对应评估指标)
| 视频质量奖励组合 | Automated Win Rate(Base → Ours) |
|---|---|
| $R_{\text{visual}}$ | 29.3% → 50.7% (+21.4pp) |
| $R_{\text{audio}}$ | 24.0% → 48.0% (+24.0pp) |
| $R_{\text{effect}}$ | 22.7% → 41.3% (+18.6pp) |
| $R_{\text{visual}} + R_{\text{audio}} + R_{\text{effect}}$ | 37.3% → 56.0% (+18.7pp) |
| + 兴趣对齐奖励 | Interest Alignment Score(Base → Ours) |
|---|---|
| $R_{\text{align}}$ | 0.707 → 0.828 (+17.1%) |
结论分析: 每个视频质量子奖励(视觉保真、音频对齐、特效增强)独立都能提升 Automated Win Rate;三者联合优化给出最强结果,印证平衡三种感知维度的必要性。在此之上再加兴趣对齐奖励,把 Interest Alignment Score 从 0.707 抬到 0.828,说明生成内容与用户兴趣的一致性显著增强。总体上,质量奖励与对齐奖励互补——前者保感知保真,后者强语义相关;在主用户反馈目标锚定下联合优化,产出更鲁棒、更对齐用户的生成策略。
4.2.4 个性化视频生成的定性分析¶
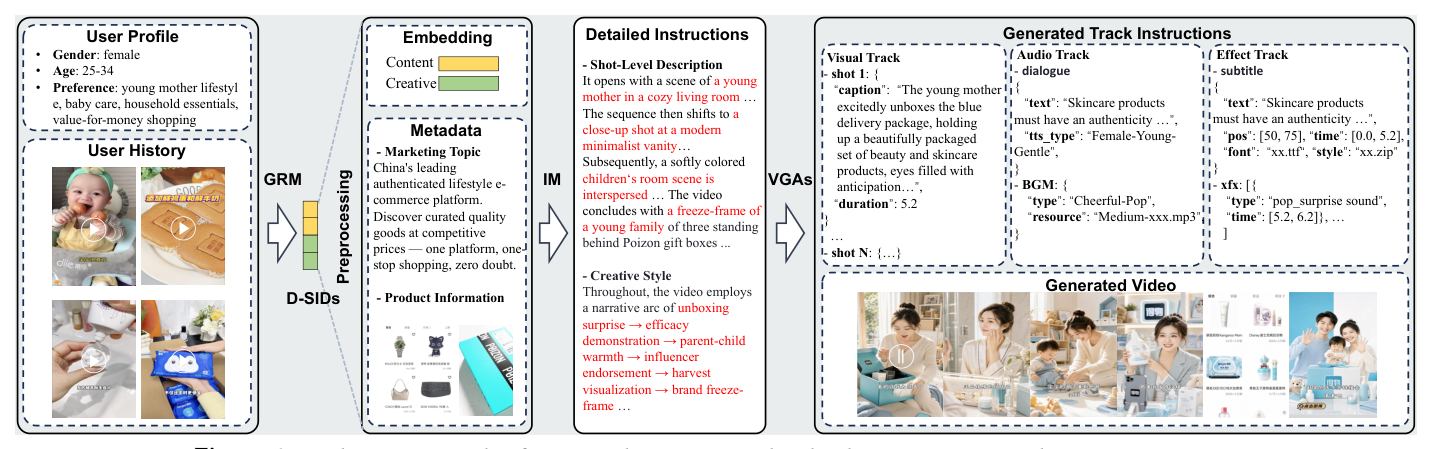
Figure 4 展示了端到端流水线:用户兴趣被直接转译为视频生成——User Profile/History → GRM 推断 D-SIDs → IM(条件于 D-SIDs + Metadata)产出 Shot-Level Description 与 Creative Style → VGAs 产出 Visual/Audio/Effect 三轨指令 → 生成最终视频。
4.3 推理效率(Appendix A)¶
Table 5:RaG 各模块推理效率
| Component | D-SIDs | GRM | IM | VGAs |
|---|---|---|---|---|
| 部署 | Nearline | Online | Nearline | Nearline |
| Latency | ~4s | ~100ms | ~2.5s | ~180s |
GRM 在线实时(~100ms)做兴趣推断,而 D-SIDs(~4s)、IM(~2.5s)、VGAs(~180s)因算力与生成延迟更高而走近线流水线。VGAs 的 ~180s 是主导延迟瓶颈——这正是论文采用"实时兴趣 + 近线生成 + 延迟感知缓存"解耦架构的根本原因,也是结论中点名的未来攻坚方向。
评估协议补充(Appendix B)¶
- Interest Alignment Score:评估生成视频是否忠实遵循源自兴趣 SID 的指令。用 三判官集成(GPT-5.1、Gemini-2.5 Pro、Claude-4.5 Sonnet),在 1000 条多类目视频实例的同一协议(Box B.1)上各自打分,沿 5 维(语义一致、属性准确、主题对齐、完整性、叙事连贯)给 [0,1] 连续分,取三判官 per-instance 均值。
- Automated Quality Evaluation:同样三判官集成,沿 4 维评(指令吸引力/钩子/节奏/CTA、BGM 兼容与节拍同步、SFX 与贴纸/字幕设计、指令-视觉对齐),产出归一化 Automated Score ∈ [0,1] 与 Good-Same-Bad(GSB)下的 Automated Win Rate。
- Human Preference Assessment:20 名来自算法/产品/广告主多背景的标注员,各做 50 对 pairwise(共 1000 对),盲、随机序、每对至少 3 人独立评、取多数票为 User Study Win Rate。
核心贡献总结¶
- 范式层面的转变:首次把推荐从"检索固定池"重述为"从兴趣生成新内容",并在 4 亿用户广告系统上落地——这是论文最重的 insight,打破了"推荐只能服务已存在内容"的固定池天花板。
- D-SIDs 作为统一接口:用 MLLM(Qwen2.5-VL)把视频解耦成 content / creative 两路因子化嵌入,正交约束去串扰,RQ-KMeans 量化(8192×4),既当 GRM 的预测目标、又当视频生成的条件;离散化质量(压缩 1.02、碰撞 2.62%)显著优于 QARM。
- 工业级 VGAs:把视频生成建模为共享 Qwen2.5-32B 骨干的有序多智能体决策(VPA/AAA/AEEA),分层规划 + 有界反射(≤2 次),KV-cache 复用 + SID-indexed cache 把成本摊销到可服务规模。
- SCRL / GDPO:把异构跨域奖励(质量 / 对齐 / 反馈)写成"反馈为主目标、质量与对齐为约束"的约束策略优化,PID 控制拉格朗日乘子、group-decoupled 归一化,使三类信号协同演化。
- 解耦部署架构:实时 GRM(~100ms)+ 近线生成(VGAs ~180s)+ 延迟感知缓存(content/creative SID 命中分级),在严格延迟下统一兴趣建模与个性化生成。
与已归档相关工作的对比¶
FLUID FLUID: From Ephemeral IDs to Multimodal Semantic Codes(TikTok / ByteDance, 2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者在"表征接口"上殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直指同一 root cause——推荐器被一个固定、可枚举的 item-ID 集合锁死。FLUID 的切入点是直播间中位生命周期仅 ~40 分钟、item ID 长期欠训练(范数在 40min 仅 0.86、比稳态 1.2 低 ~28%),ID-centric 排序器无法泛化;RaG 的切入点是固定内容池让推荐永远只能返回池内次优匹配。表述不同(FLUID 叫 "ephemeral ID"、RaG 叫 "fixed pool"),但都是"逃离封闭 item 词表"。
- 相近的技术骨架:两者的表征接口配方高度同构——(1) 用跨域多模态大模型编码器把内容编码成连续嵌入(FLUID:SigLIP2 ViT + Qwen3-Embedding;RaG:Qwen2.5-VL-7B),(2) 用 RQ-KMeans 离散成分层语义码(FLUID:LUCID,4 层×64;RaG:D-SIDs,4 层×8192),(3) 都显式拆成两个互补的语义因子(FLUID:slice 瞬态 vs room 持久;RaG:content vs creative)。最惊人的趋同细节是:两篇都明确选择 RQ-KMeans 而非 RQ-VAE,且理由完全一致——RQ-VAE 在工业流式重训练节奏下会码本坍塌,K-means 拟合后给出稳定划分。
- 本文的差异与推进:这是两者真正分叉、也是 RaG 把对比价值拉满的地方。FLUID 拿到分层语义码后,用途仍停在"用语义码替换 item ID、喂进排序器做更好的检索/排序"(后融合 + 分阶段 warmup 退役 item ID),输出依然是池内已有直播间;而 RaG 把同样的分层语义码当作"可解码的生成式兴趣表征",GRM 预测的 D-SIDs 不是检索 key 而是 IM + VGAs 的生成条件,解码出一条全新的视频。换句话说:FLUID 用多模态码逃离 item ID 的记忆陷阱,RaG 用多模态码逃离内容池本身——RaG 在 FLUID 共享的"编码器→RQ-KMeans→分层码"前半段之上,接了一段 FLUID 没有的"解码生成"后半段。
- 可比的方法 / 实验差异:FLUID 是 ByteDance/TikTok 直播排序、十亿用户、增益指标是 Quality Watch Duration(+0.55%)/Cold-Start Room Views(+2.05%);RaG 是 Kuaishou 广告、4 亿用户、增益指标是广告收入(+1.87% vs GRM 基线)。FLUID 的离散化关心的是 prefix-n-gram embedding 解决"残差量化深层级跨子树共享语义"的问题,RaG 的离散化关心的是 content/creative 正交解耦 + 压缩率/碰撞率(1.02/2.62% vs QARM 1.14/18.24%)。两者一个把码用于判别式排序、一个用于生成式内容生产,恰好构成"同一表征接口、两种下游用途"的互补样本。
讨论与局限性¶
核心价值与可借鉴设计。 RaG 最有价值的是范式级的重新框定:当 AIGC 已能产出可控高保真视频,"推荐 = 从固定池检索"这个延续十年的前提第一次被认真挑战。D-SIDs 作为"推荐与生成的统一离散接口"是一个干净且可复用的抽象——把"是什么内容"与"什么风格"正交拆开,让兴趣建模与可控生成各取所需。工程侧也有可借鉴点:共享骨干 + KV-cache 复用把多智能体生成压成单模型推理;SID-indexed cache + 延迟感知分级服务把 180s 的生成延迟摊销到可上线;约束策略优化(反馈为主、质量/对齐为约束、PID 拉格朗日)是处理"多个异构奖励、且不能牺牲主目标"的实用模板。
局限与争议。
- 实验严谨度受限于内部评测:全文没有公开学术 benchmark;线上只报相对收益(+1.87% 等),离线质量大量依赖 LLM-judge 自动分(GPT-5.1/Gemini/Claude 三判官)与内部检索集,生成视频质量难以被外部完全复核;"GRM 基线 / DLRM 基线"均未具名(且参考文献编号存在前后不一致,Table 1 的 "[27]" 在文末解析到视频生成模型 Wan 而非 GRM,疑为预印本引文错位)。
- 多阶段解耦的可扩展性隐患:整条流水线是 4 个独立模型串联(Qwen2.5-VL 编码器 → GRM → Qwen3-8B IM → Qwen2.5-32B VGAs),码本一旦固化(8192×4)即约束下游可表达的语义空间,且压缩器与下游生成器无法端到端联合优化。参数量 scaling 时,"如何表征视频"与"如何生成"两条路径难以同步增长——这正是精读评分标准点名的"先离线压缩再下游建模"类瓶颈。
- 延迟与实时性:VGAs ~180s 是主导瓶颈,系统目前只能近线生成、靠缓存兜实时消费,真正"on-the-fly 个性化生成"仍是未来工作(论文结论亦坦承)。这也意味着首次出现的兴趣若缓存未命中,只能先返回最近邻 SID 的近似视频。
- 商业与内容风险未展开:广告场景下生成视频须促销特定产品(靠可选 $D_{\text{meta}}$ 注入),但生成内容的真实性、合规性、品牌安全、以及"AI 生成广告"对用户信任的影响,论文未做讨论。
工业落地价值。 即便有上述保留,RaG 是首个把推荐与个性化视频生成真正合一的生产级系统,在 4 亿用户广告场景拿到 +1.87% 广告收入(相比已经很强的 GRM 基线),收益的额外部分明确归因于"生成"而非"更好的检索",这使它不只是一个 demo,而是一个经过线上验证、闭环可优化的新推荐范式起点。