OneReason Technical Report 精读¶
快手 OneRec 团队的推理基础模型。核心命题:生成式推荐里"想一想再回答"的 thinking 模式长期打不过直接预测的 non-thinking 模式;OneReason 把根因归到感知(perception)与认知(cognition)两条腿都没站稳,并通过「四粒度感知预训练 + 三层认知 CoT 的 SFT + 专精后统一(specialize-then-unify)的 RL」第一次让 thinking 模式在真实工业 benchmark 上稳定超越 non-thinking 模式。已在快手本地生活广告线上部署,ROI > 5,开源 OneReason-8B / OneReason-0.8B。
1. 研究动机与背景¶
1.1 两条来自 LLM 的属性¶
Transformer LLM 展现出两条值得迁移到工业推荐系统的属性:
- Scaling 属性(预训练):模型规模、数据、算力扩大时收敛 loss 呈可外推的衰减趋势(Kaplan 2020;Hoffmann 2022),多个 benchmark 同步提升。OneRec V1/V2 系列已在快手工业推荐场景验证了 scaling 属性,带来显著业务收益。
- Reasoning 属性(后训练):SFT + RL 让模型学会 CoT,形成 "think-before-answer" 范式(OpenAI o1、DeepSeek-R1),显著增强复杂问题求解能力。
1.2 一个反常现象:thinking 打不过 non-thinking¶
OneRec 模型只在纯 itemic 序列数据上训练,学到的是扁平的转移模式,没有任何底层逻辑链,无法自己解锁推理能力。本团队近期的 OneRec-Think(Liu 2025)和 OpenOneRec(Zhou 2026)引入了 interleaved itemic-text 推荐数据 + 通用域推理数据,成功把 "think-before-answer" 范式泛化到推荐任务上——但都观察到一个反常现象:
thinking 模式在推荐 benchmark 上并未显著优于 non-thinking 模式。
1.3 从 MLLM 文献找根因:感知 + 认知¶
作者转向多模态大模型(MLLM)文献,那里观察到惊人相似的 "reasoning-mode brittleness":
- Sun 2026b(Reading, Not Thinking):文本与视觉模态对齐不足时,模型倾向于机械地"读"表层视觉文字,而非真正推理底层视觉语义——说明深度跨模态对齐是真推理的前提。
- Zhou 2025a:系统综述了 MLLM 的 perception-to-cognition 路径,结论是没有稳固的感知对齐,高级交互推理无法涌现。
- Jiang 2025b(Corvid):即使模态已对齐,若 CoT trace 本身不是逻辑连贯、coarse-to-fine 的结构,推理鲁棒性仍然脆弱(幻觉、over-thinking)。
由此提炼出解锁真推理的两根支柱:
- 感知中的模态对齐(perception):把 itemic token grounding 到底层语言语义,使其成为可指代、可组合的语义单元,而非不透明的 ID;
- 认知中的 CoT 质量(cognition):在对齐之上提供连贯的 coarse-to-fine 推理轨迹,实现忠实的 think-before-answer。
1.4 推荐推理的特殊性:abductive 而非 deductive¶
第 2 节"推理设计哲学"指出推荐推理与经典 LLM 推理本质不同:经典推理(数学/代码/符号逻辑)有唯一正确答案、是演绎(deductive)的;而推荐同时存在多个合理候选,用户意图永不可直接观测,只能从长 itemic 序列中反绎(abductive)推断。因此推荐 CoT 应当:选取相关行为作为假设的兴趣点 → 压缩成可解释的偏好 → 建模兴趣点之间的时间转移 → 最后把推断出的偏好状态关联到推荐 item。
作者据此把推荐推理拆成两维四能力(也就是 OneReason-Bench 的诊断轴):
- R0 Perception(感知):把 itemic token grounding 到语义内容,是一切的基础;
- R1 Derivation(派生):从单 item 语义推理出 item-to-item 关系;
- R2 Evolution(演化):把同一兴趣下的 item 当作时间过程来推理;
- R3 Recommendation(推荐):综合 R0-R2 在所有业务域上产生高质量决策。
1.5 三大贡献¶
- 预训练:构造复杂多样的 coarse-to-fine 对齐语料,强化 itemic token 感知能力(四粒度语料,共 578B token 对齐 itemic-token 与 text-token 语义空间);
- SFT:设计标准化的三层认知 CoT 结构,保证 CoT 质量;
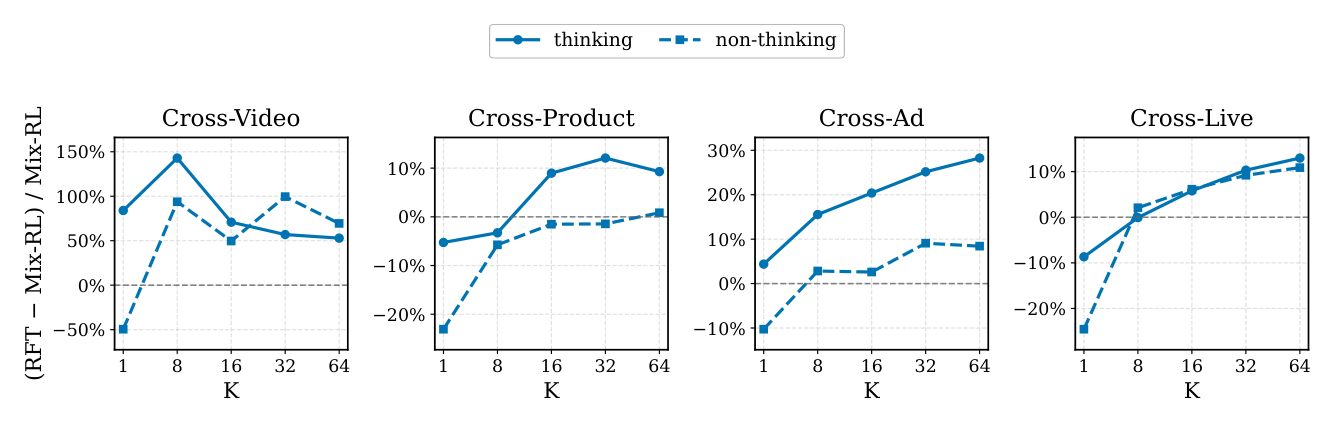
- RL:发现 thinking 在单域 RL 下能稳超 non-thinking、但混合多域 RL 下又掉回去,于是提出 specialize-then-unify 策略——先域内 RL 充分解锁 thinking,再用 RFT 或 MOPD 做跨域平衡与统一。
最终 OneReason 成为(据作者称)第一个让 thinking 模式在多个真实业务推荐 benchmark 上稳定超越 non-thinking 模式的工作;并额外发现:在相同 token 预算下,用推荐 CoT 监督替换纯 unCoT 数据,能在若干域提升 non-thinking 推理——即 CoT 监督的部分收益可迁移到直接解码。
2. OneReason-Bench:面向推理的推荐评测基准¶
把 benchmark 放在模型描述之前是有意为之:四粒度预训练、compression-then-reasoning 的 SFT、specialize-then-unify 的 RL,每一步都对应 OneReason-Bench 在 R0-R3 上暴露的具体 gap。它扩展自 OpenOneRec 的 RecIF-Bench,把评测推向多层推理。
统一任务形式化:所有任务都写成序列生成 $Y = \mathcal{F}(X)$,其中 $X$ 由任务指令 $I$ 和上下文 $C$(itemic 模式、用户画像、交互历史)组成,目标 $Y$ 可以是 itemic 模式、答案选项、自然语言回复或结构化演化链,使 R0-R3 共享同一套生成式评测协议。
Table 1 | OneReason-Bench 四层任务分类
| 层 | 任务 | 输入 $X$ | 目标 $Y$ | 指标 |
|---|---|---|---|---|
| R0 感知 | Item Understanding | item $i$ | item 描述 | LLM-as-a-Judge |
| Itemic Pattern Grounding | item 描述 | item $i$ | Pass@K, Recall@K | |
| Item QA | item $i$ + 选项 $O^a$ | 正确选项 $o^a$ | Accuracy | |
| R1 派生 | Item2Item | 源 item $i$ + 候选 $O^{item}$ | 正确选项 $o^{item}$ | Accuracy |
| R2 演化 | Evolution Action Selection | 历史 $\mathcal{H}$ + 主题 $t$ | 相关行为 $\mathcal{A}$ | F1 |
| Evolution Topic Gen | 历史 $\mathcal{H}$ + 主题 $t$ | 演化链 $\mathcal{E}_t$ | Action–Logic Score | |
| Evolution Direct Gen | 历史 $\mathcal{H}$ | 演化链集合 $\{\mathcal{E}\}$ | Multi-Chain Action–Logic Score | |
| R3 推荐 | Single-Domain Rec(视频/商品/广告/直播) | 画像 $\mathcal{P}$ + 域内历史 $\mathcal{H}^d$ | 下一组 item $\{i\}$ | Pass@K, Recall@K |
| Cross-Domain Rec | 画像 $\mathcal{P}$ + 多域历史 $\mathcal{H}$ | 下一组 item $\{i\}$ | Pass@K, Recall@K |

评测协议:Item Understanding 复用 OpenOneRec 的 LLM-as-a-Judge(double-weighted F1);单答选择题(Item QA、Item2Item)用 Accuracy;多答选择(Evolution Action Selection)用 F1;演化生成用 Action–Logic Score(动作对齐 + 逻辑对齐,详见附录 B.4.2,公式见 §8);推荐与 grounding 用 Pass@K / Recall@K(生成的 itemic 模式先解码成 item ID 再在 item 粒度上计算)。此外保留 MMLU-Pro 等通用智能 sanity check,确保推荐特化不牺牲通用推理。
附录 B.3 的 Table 23 进一步表明:OneReason-Bench 是唯一同时覆盖「多域知识 / 指令遵循 / 推理中心 / 序列推荐 / 跨域推荐」五项能力的 benchmark(经典 Rec benchmark 如 Yelp/MovieLens/Amazon/KuaiSAR 只覆盖 SeqRec;RecIF-Bench 缺"推理中心"维度)。
3. 整体流水线总览¶
下面按预训练 → SFT → RL → CoT 诊断 → 实验 → 部署的顺序展开。
4. 预训练流水线(Section 4)¶
4.1 Itemic Tokenizer¶
为得到紧凑且语义 grounded 的 item 嵌入,联合训练一个多模态 encoder 和一个 decoder LLM 做 item-understanding:encoder 集成 Vision Transformer(ViT)+ 从 Qwen3-VL 初始化的 LLM + 一个音频 encoder,把封面图、视频帧、文本描述、音频蒸馏成一个紧凑稠密嵌入;嵌入作为 soft prefix 喂给独立 decoder LLM,后接 item 文本描述做端到端优化。
随后用 RQ-KMeans 量化:三层 codebook、每层 8192 codes。每个 item 表示为「一个 domain-aware begin token + 三个 sub-token」,例如:
$$\texttt{<|domain\_begin|><a\_5028><b\_6733><c\_2559>}$$
其中 domain ∈ {video, prod, ad, living}(四个推荐场景)或 sid(通用域多模态数据)。与 OpenOneRec 不同,OneReason 丢弃了尾部 end token,从而减少 itemic 模式消耗的上下文长度,给推理 trace 留出更多容量——这是其 thinking 范式的工程前提。
4.2 预训练数据:四粒度推荐语料¶
先前工作(OneRec-Think、OpenOneRec)按任务类型(item captioning / 行为序列 / persona-text interleaving)组织数据并混合训练,留下三个结构性 gap:① item/user 语义表达同质、语言多样性不足;② 数据停在任务层,未显式建模 itemic token 内部的细粒度语义层级或 item 间关系逻辑;③ 用户建模依赖"完整画像→完整行为序列"的窄条件范式。OneReason 据此把语料重构成四个递进粒度,从微观 token 语义到宏观用户行为:

- Token 粒度:在最细粒度对齐。除了沿用单 token 语义预测,新增两个组件:
- Compositional Prefix Semantic Prediction:预测前缀 sub-token 对
<a_xxxx><b_xxxx>的组合语义(用 LLM 汇总共享该前缀的 item 的共同语义),显式教模型 sub-token 语义如何在中间粒度合并、交互;并构造反向的 Prefix Itemic Token Grounding(给语义描述检索正确前缀对)。 -
Part-to-Whole Semantic Prediction:两步语义预测——先逐个 sub-token 预测细粒度语义解释,再综合成完整 item caption,强制 parts→whole 的结构化多步语义预测。
-
Item 粒度:把 itemic 模式与文本模态对齐,相比 OpenOneRec 的 Itemic Dense Caption 有两点推进:
- Capacity-Aware Caption Coarse-Graining:三个 sub-token 只能承载粗语义,强行对齐过细 caption 会逼模型幻觉;因此先粗化 caption(去掉 OCR/ASR/型号等 code 无法恢复的噪声;把精确价格/年龄映射成价格带/语义标签;保留品类、品牌、IP、卖点、受众、材质等高区分骨架),且对 video/product/live/ad 分别设计粗化规则。
-
Multi-Perspective Item QA:从受众偏好、核心卖点、视觉风格、负反馈理由等多角度提问,把对齐从单一描述映射升级成多维语义审讯。
-
Relational 粒度:用自然语言显式解释 item 间协同连接。每条样本形如:
$$\text{Itemic\_Pattern}_0 \rightarrow \text{Textual\_Explanation}_0 \rightarrow \text{Itemic\_Pattern}_1 \rightarrow \cdots \rightarrow \text{Itemic\_Pattern}_n \tag{1}$$
涵盖直接 item-to-item 关联($n=1$,用内部 search-after-play 表:用户看完视频后搜索并正向交互某商品)和多 item 兴趣流($n>1$)。为扩大模态覆盖额外引入 TagNext CF Relations 和滑窗共现对;为提升 inter-item 非平凡性,构建跨用户全局 item 图、随机采样 item 链再抽 sub-chain(相邻节点语义过相似则丢弃);为提升解释质量,用 LLM 结合中间节点 caption 生成转移解释。
- User 粒度:把对齐扩展到完整序列演化。先用开源 LLM 把噪声大、模板化的原始用户画像 recaption 成流畅叙事,再设计两种格式:① Domain-Grouped Behavior Sequences(按域分组,用多轮 QA 动态展开,常用一个域的历史条件预测另一个域的行为,让文本充当主动控制信号);② Chronologically Interleaved Behavior Sequence(严格按时间戳重排,概率性地把部分 itemic 模式替换成其 caption,形成 NL 与离散 itemic 模式深度融合的混合时间线)。
通用域语料:保留大比例通用文本(数学、代码、科学、医学、指令遵循)+ 多模态(image-text 对、图文交错文档、image-editing 三元组、text-to-image),只保留粗粒度视觉语义样本,充当正则器防止过拟合规则合成的推荐语料、并把开放世界视觉概念锚定进 itemic 空间。数据组成策略:从指令微调过的 Qwen3 backbone 继续预训练,把噪声大的模板化业务数据路由进 loss-masked context,把 loss-bearing target 留给高质量文本;有效训练目标约呈 1:1 的 QA 风格 vs free-form 比例。
4.3 推荐语料消融(Section 4.3)¶
在 0.8B 模型、固定 30B token 预算下做消融,五个配置逐步叠加(token/relational 是新增能力,item/user 是替换升级),隔离每个粒度的边际贡献:
- Exp1(baseline)= 标准 OpenOneRec 数据集
- Exp2 = Exp1 + Token
- Exp3 = Exp2 + Item(替换 baseline caption)
- Exp4 = Exp3 + Relational
- Exp5 = Exp4 + User(替换 baseline user 数据)
Table 2 | 四粒度消融(Itemic Pattern Grounding 与 Cross-Domain Rec 用 pass@64,其余用 macro-F1,%)
| 任务 | Exp1 | Exp2 | Exp3 | Exp4 | Exp5 | |
|---|---|---|---|---|---|---|
| R0 Pattern Grounding | ad | 0.48 | 0.80 | 2.40 | 0.48 | 1.92 |
| live | 0.40 | 1.01 | 1.21 | 1.21 | 1.21 | |
| prod | 2.42 | 5.81 | 5.33 | 2.91 | 5.33 | |
| video | 0.35 | 0.35 | 0.87 | 1.05 | 1.05 | |
| R0 Item Understanding | ad | 16.37 | 37.86 | 31.65 | 29.69 | 32.56 |
| live | 35.16 | 46.16 | 37.39 | 37.39 | 35.52 | |
| prod | 20.58 | 28.62 | 29.51 | 29.78 | 28.75 | |
| video | 22.56 | 36.76 | 30.77 | 30.77 | 31.63 | |
| R1 Item2Item QA | 0.00 | 20.57 | 20.73 | 25.65 | 29.72 | |
| R2 Evolution Direct Gen | mixed | 0.13 | 0.00 | 0.32 | 0.18 | 0.37 |
| R3 Cross-Domain Rec | ad | 9.06 | 8.75 | 9.54 | 8.58 | 10.84 |
| live | 2.29 | 2.32 | 3.49 | 3.25 | 8.56 | |
| product | 1.15 | 0.94 | 1.29 | 1.54 | 1.65 | |
| video | 0.65 | 0.74 | 0.72 | 0.73 | 0.66 |
三条 key insight:① token & relational 粒度是增量(augmentation,引入 baseline 没有的新能力,如 Item2Item QA 从 0% → 20.57%);item & user 粒度是替换升级(refine existing)。② 训练中存在能力 trade-off(加 relational 提升 R1 但暂时降 R0 retrieval,后续阶段会恢复)。③ User 粒度是终极整合器:把所有先验知识 contextualize 进时间行为,把 Cross-Live 从 3.25%→8.56%、Cross-Ad 从 8.58%→10.84% 推到峰值。
Table 3 给了一个 video 域 Item Understanding 案例:baseline(Exp1)退化成重复无内容的幻觉、编造剧名;加 token 数据(Exp2)保持类型忠实;但加 item 数据(Exp3)反而编造出具体的错误剧名(把都市言情误判成医疗剧)——说明业务 caption 残留噪声会带来新幻觉,这正是 Capacity-Aware Coarse-Graining 要解决的。
4.4 三阶段训练 recipe(Table 4)¶
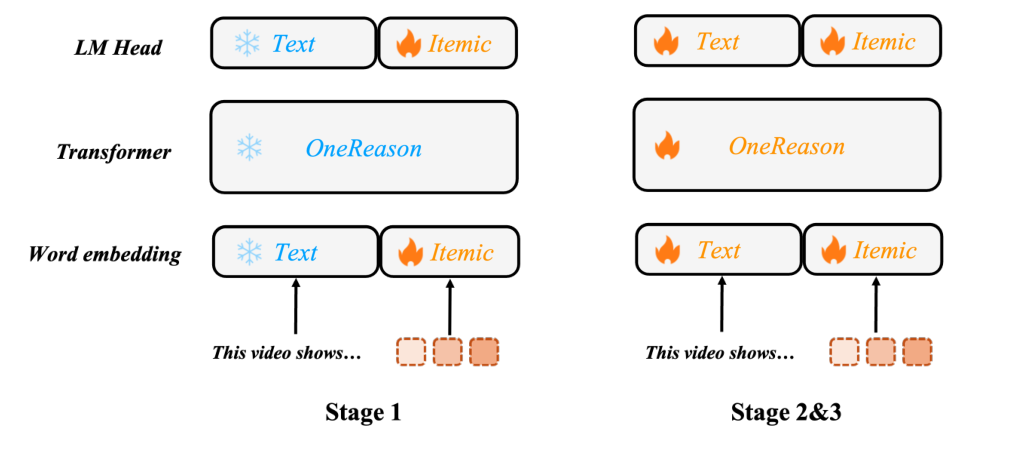
Table 4 | 训练阶段总结
| 配置 | Stage 1 | Stage 2 | Stage 3 |
|---|---|---|---|
| 可训练参数 | 扩展词表 + LM head | All | All |
| 学习率 | $2\times10^{-4}\to1\times10^{-5}$ | $1\times10^{-4}\to1\times10^{-5}$ | $1\times10^{-5}\to1\times10^{-6}$ |
| Token 预算 | 110B | 449B | 19B |
所有阶段用 sample packing 打包成 48K token 序列。Stage 1/2 限制单样本 ≤4K token 保吞吐,只训练新引入的 itemic embedding + LM head(其余冻结),让新嵌入"安顿"进语义空间而不扰动预训练权重;Stage 2 解冻全部参数吸收四粒度推荐知识;Stage 3 把单样本上限提到 32K token,在完整用户长历史上训练长程依赖。三阶段合计 578B token(对应结论中"用 578B token 对齐 itemic-token 与 text-token 语义空间")。
5. SFT 流水线(Section 5)¶
预训练给了感知基础(itemic token ↔ NL,吸收协同信号);SFT 在此之上培养推荐认知——在指令格式下操作 grounded itemic token 的能力。SFT 围绕同样的 R0-R3 层级,但有两条互补训练轴:
- 压缩轴(compression axis):教模型把长噪声历史压缩成 typed persona state + 紧凑兴趣演化 motif,使后续推理在 evidence-backed 假设上比较而非在原始行为日志上;
- 推理轴(reasoning axis):教动态操作——R1 派生一跳 item-item bridge、R2 跟踪时间兴趣演化、R3 做转移判断。
5.1 R0 Perception(~941K 样本)¶
把预训练建立的层级 itemic token 空间转成显式 SFT 监督。两个互补任务族:① itemic token ↔ NL 双向映射(在 instruction-style grounding 下);② 平台内容 QA(属性识别、受众理解、负反馈分析、开放语义理解)。caption 数据覆盖 video/product/live/ad 四域,QA 数据覆盖 video/product 两域。caption 含 thinking 与 non-thinking 两个变体:thinking 变体先解释每个 itemic token 如何贡献到最终 item 含义再产出 caption(教 coarse-to-fine grounding,供 R1/R2/R3 复用语义底座);unCoT 变体监督直接 itemic-token→caption 生成。共约 941K(682K caption + 259K QA)。
5.2 R1 Derivation(~400K 样本)¶
针对跨 item 关系派生:从理解单 item 升级到解释"为什么一个 item 自然引出另一个"——最小有用的 source-to-follow-up bridge。给一个源 item,模型要生成并论证一个合理的 follow-up itemic 答案,identify need / clue / scenario / constraint / refinement。源-目标对经教师 LLM 标注 explicitly related / explicitly unrelated / uncertain,只保留关系能被可见 item 证据(metadata、dense caption)直接支撑的对,移除依赖"受众重叠/流行度/平台共现"等弱假设的对。对高置信对,教师 LLM 进一步抽取紧凑 bridge 变量(source-side need、bridge type、abstract bridge、continuation direction、reason seed、confidence),把关系解释与目标 item 表面内容分离——防 target leakage(目标只用于一致性检查,解释必须从源侧证据写)。从 358K TagNext CF 对 + 388K after-play-search 对 refine 出约 400K。
5.3 R2 Evolution(~130K 样本)¶
针对用户兴趣演化建模:从静态偏好理解升级到时间结构化的行为解读——哪些行为是触发器、哪些后续行为修正/纠正了早期、多个事件如何累积成可解释轨迹。从全域用户时间线构造,用强 LLM 识别表示兴趣 meaningful shift/refinement/closure 的关键演化节点,转成带显式时间结构的 evolution chain;再经独立的 LLM-as-a-Judge 质量评估(11 项检查:order sensitivity、cognitive increment、trigger-source evidence、strong causal-style exclusivity、evidence closure、no-mind-reading 等)过滤伪逻辑链、随机消费链、同品类漂移、弱 grounded 转移。构造三个任务族(Evolution Action Selection / Topic Generation / Direct Generation),部分含 CoT rationale、部分保 direct-answer 保格式鲁棒。约 130K。
5.4 R3 Recommendation:推荐 CoT 的核心¶
R3 是 SFT 的组合层——R0-R2 各自训练专门能力,R3 在最终 next-interaction 预测中把它们组合起来。核心设计原则:把推荐 CoT 当作 two-axis compression plus transition judgement:
- 第一轴 persona-type compression:汇总稳定偏好先验、人口/生命阶段线索、时间节律、内容偏好、价格敏感度、交互深度、可能的共享设备模糊性;
- 第二轴 interest-evolution-type compression:识别近期轨迹 motif(触发搜索、需求扩展、参数收窄、场景延续、饱和替换、跨域回声、从浏览到购买的闭合)。
这些压缩状态降低长历史噪声,提供后续推理可操作的 typed 变量。概念层面写作三阶段协议——Persona Abstraction → Interest Expansion → Transition Inference:
$$\mathcal{C}_u = \text{Abstract}(\mathcal{P}_u, \mathcal{H}_u), \qquad \mathcal{Z}_u = \text{Expand}(\mathcal{C}_u, \mathcal{H}_u), \tag{2}$$
$$z_u^\star = \text{Infer}_{\text{trans}}(\mathcal{Z}_u \mid \mathcal{C}_u, \mathcal{H}_u, d) = \arg\max_{z\in\mathcal{Z}_u} s(z \mid \mathcal{C}_u, \mathcal{H}_u, d), \tag{3}$$
其中 $\mathcal{C}_u$ 是压缩用户状态,$\mathcal{Z}_u$ 是扩展候选兴趣假设集,$d$ 是目标域,$s(\cdot)$ 综合 evidence strength / recency / temporal continuity / persona compatibility / target-domain compatibility 打分。最终 CoT 把 text 与 itemic-token 引用交错写成,目标 itemic token 只在推理 trace 之后才发射(不进入推理 span,防泄漏)。
- Persona Abstraction:把稀疏噪声行为压缩成紧凑可解释的 soft typed 先验(如中年家庭主妇、直播购物达人、共享设备用户),缩小候选兴趣方向,但最终推断仍须 grounding 在观测行为上。
- Interest Expansion:从兴趣演化 motif 出发,把最 informative 的行为信号打开成一小组 evidence-grounded 假设。四条启发式保持"broad but evidence-grounded":behavior motivation(解释 informative 行为尤其搜索意图)、temporal sensitivity(尊重事件顺序)、transition coverage(保留 plausible before-after 方向)、noise attenuation(下权常规补货/随机消费/重复曝光/一次性动作)。要求推理 trace 达到"证据支持的最细可靠粒度"(具体某款手游而非泛泛"游戏")。

- Transition Inference:把扩展假设与完整上下文比较,commit 到最可能的后续交互方向,复用 R1 的 local bridge 和 R2 的时间演化判断。五条约束保证 decision-oriented & leakage-safe:evidence priority、transition bridge(合法 bridge 含 feedback / bottleneck / cognitive refinement / scenario continuation / parameter narrowing / need completion,单纯主题相似不够)、granularity calibration、conflict resolution、leakage control。
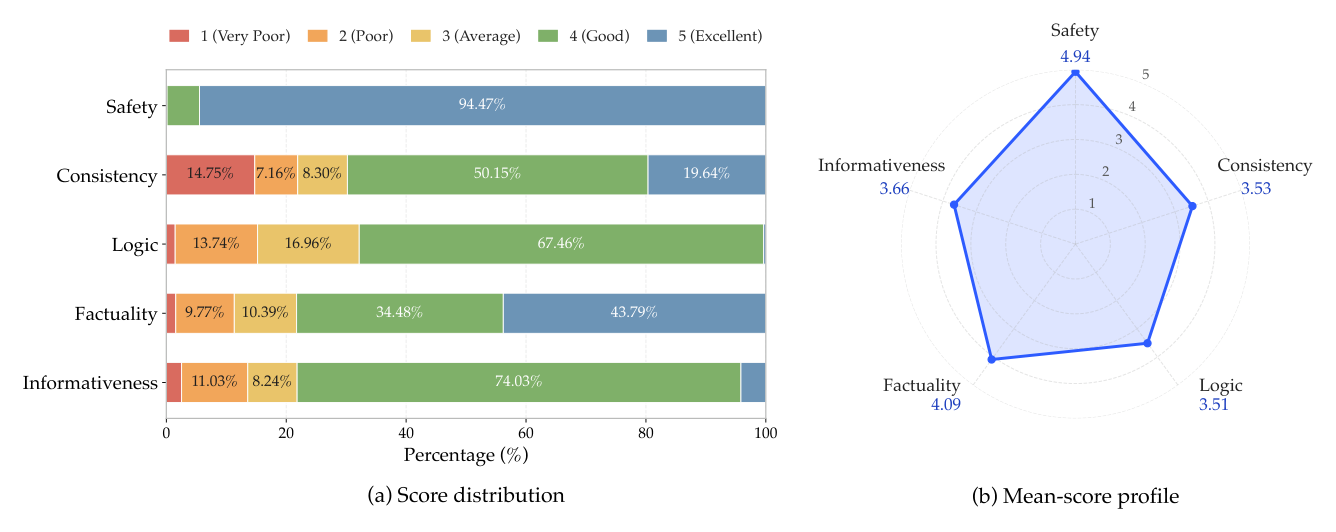
5.4.2 推理 trace 质量评估(五维)¶
沿五个互补维度评估推荐推理 trace 质量:
- Safety:CoT 是否直接暴露目标内容(item id、itemic token、标题等可唯一识别目标的实体);
- Consistency:trace 结论/偏好方向/行为解释是否与意图目标一致;
- Logic:是否展现可迁移/可泛化推理,而非表层拼接、强行关联、单实例记忆;
- Factuality:是否准确反映观测历史(无编造行为、错误归因、夸大趋势、时间混淆);
- Informativeness:是否提供有用且具体的推荐指引(兴趣方向、场景、功能、风格、属性、排除项)而不泄漏目标。
5.5 Itemic Instruction Data(~103K)¶
提升 itemic token 显式出现在输入时的指令遵循鲁棒性(预训练模型常忽略用户指令、自行解释 token 或把输入误判成兴趣分析问题)。围绕 itemic-token-grounded task execution 构造 6 个任务组:Conversion & Editing、Retrieval & Selection、Matching & Classification、Comparison & Aggregation、Generation & Verification、Instruction Control(即使 itemic token 作为干扰上下文也要遵循用户指令)。把 itemic token 当作 grounding signal 而非解释目标。约 103K。
5.6 General-Domain Data(~1.5M)¶
为防过特化,纳入 StepFun 公开的 Step-3.5-Flash-SFT,只保留标准三角色对话、去掉 tool-use trace、去掉格式损坏样本,约 1.5M 高质量 SFT 样本,作为推荐认知周围的 stabilizer。
SFT 整体规模约 3951.7K(Figure 2 圆环图),其中通用域数据约占 38%、R0/R3 各约 22-24%、R1/R2/itemic-instruction 占其余。
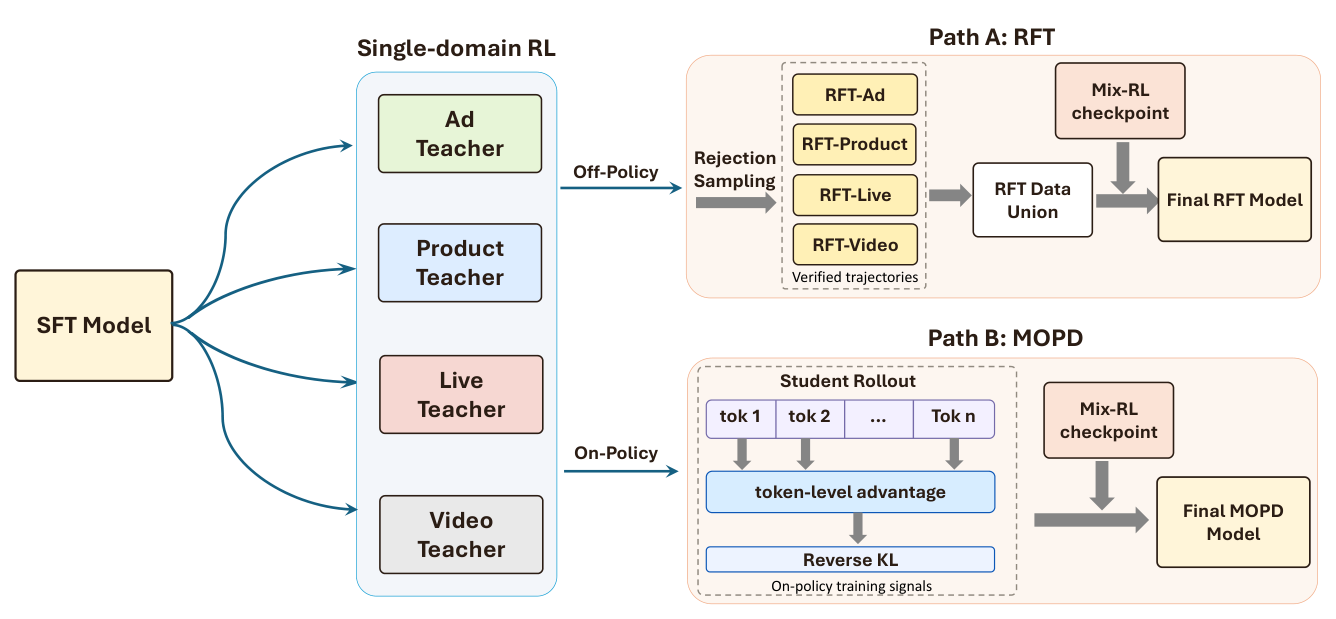
6. RL 流水线(Section 6):specialize-then-unify¶
SFT 让模型模仿教师推理轨迹,性能上界仍受教师限制。直接在混合多域数据上 RL 会因不同域的用户意图、item 语义、reward landscape 差异引发跨域干扰。OneReason 采用 specialize-then-unify:
6.1 推荐导向的 GRPO(域内专精)¶
先用 GRPO 在每个域单独优化。对用户 $u$ 与上下文 $q$,采样一组推荐 rollout,每条含一个推理 trace + 生成的 itemic token:
$$\mathcal{G}_u = \{(\text{CoT}_{u,i}, \mathbf{c}_{u,i})\}_{i=1}^{G} \tag{4}$$
每条 rollout 由 outcome reward $R_{u,i}$ 评价(生成的 itemic token 是否命中目标),GRPO 在组内归一化得相对 advantage:
$$\hat{A}_{u,i} = \frac{R_{u,i} - \text{mean}(\{R_{u,k}\}_{k=1}^G)}{\text{std}(\{R_{u,k}\}_{k=1}^G) + \delta} \tag{5}$$
Rollout 设计(两阶段 rollout):推荐命中率天然极低、候选空间巨大,每次推荐前还要先生成推理 trace,reward 覆盖代价高。为此设计两阶段 rollout(Figure 11):对每个用户先采 $N$ 条推理 trace $\{\text{CoT}_{u,i}\}_{i=1}^N$,再以每条 trace 为条件并行生成 $K$ 条 itemic token 序列:
$$\mathbf{c}_{u,i,j} = [\langle\texttt{|domain\_begin|}\rangle, c^{(1)}_{u,i,j}, c^{(2)}_{u,i,j}, c^{(3)}_{u,i,j}] \tag{6}$$
这样只生成 $N$ 条推理 trace 就得到 $N\times K$ 条有效推荐 rollout,reward 覆盖大幅提升而额外开销很小。
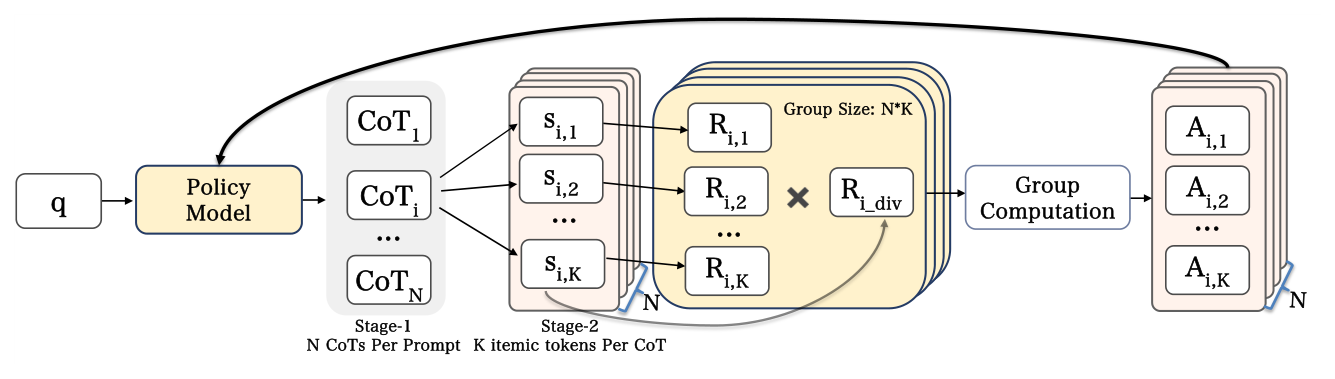
Reward 设计:推荐是 set-wise 优化,理想推理 trace 应覆盖多样相关 item,故 reward 同时考虑 item 准确度与多样性:
$$R_{u,i,j} = R_{\text{rule}}(\mathbf{c}_{u,i,j}) \cdot R_{\text{div}}(\text{CoT}_{u,i}) \tag{7}$$
$$R_{\text{rule}}(\mathbf{c}_{u,i,j}) = \mathbb{I}[\mathbf{c}_{u,i,j} \in C_u^{+}] \tag{8}$$
多样性 reward 鼓励同一推理 trace 派生的 $K$ 条 itemic 序列覆盖更广品类——聚焦第一位 sub-token(粗粒度品类),令 $m_i^{(1)}$ 为 $\{c^{(1)}_{u,i,j}\}_{j=1}^K$ 中不同第一位值的个数:
$$R_{\text{div}}(\text{CoT}_{u,i}) = \frac{\max(0, m_i^{(1)} - 1)}{K - 1} \tag{9}$$
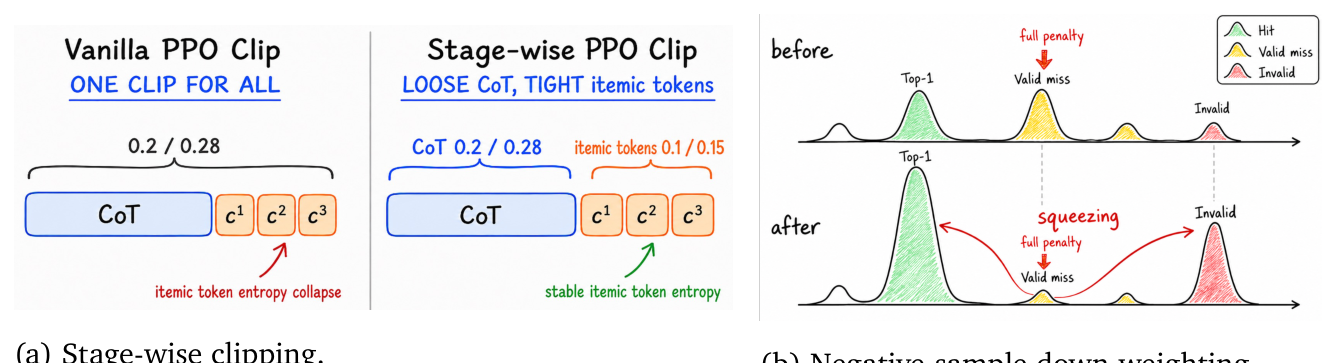
Optimization(两个稳定器):token $o_t$ 的重要性比:
$$r_t(\theta) = \frac{\pi_\theta(o_t \mid o_{<t})}{\pi_{\text{old}}(o_t \mid o_{<t})} \tag{10}$$
推理 token 长、主要支持探索;itemic token 短、直接决定 reward。用同一 clip range 会让 itemic token 分布变化过猛、entropy collapse。故 stage-wise clipping——推理 token 用更松的 clip、itemic token 用更紧的 clip:
$$\boldsymbol{\epsilon}_{\text{CoT}} = (\epsilon^-_{\text{CoT}}, \epsilon^+_{\text{CoT}}), \qquad \boldsymbol{\epsilon}_{\text{item}} = (\epsilon^-_{\text{item}}, \epsilon^+_{\text{item}}) \tag{11}$$
$$\bar{r}_t(\theta) = \text{clip}\big(r_t(\theta), 1-\epsilon^-(t), 1+\epsilon^+(t)\big), \quad \boldsymbol{\epsilon}(t) = \begin{cases}\boldsymbol{\epsilon}_{\text{CoT}}, & o_t \in \text{CoT}\\ \boldsymbol{\epsilon}_{\text{item}}, & o_t \in \mathbf{c}\end{cases} \tag{12}$$
其中 $\epsilon_{\text{CoT}}$ 比 $\epsilon_{\text{item}}$ 更松(论文用 0.2/0.28 vs 0.1/0.15)。又因命中稀疏、多数 rollout 拿 0 reward 和负 advantage,会主导梯度推向过保守更新;故 negative-sample down-weighting——按命中状态给整条 response-level actor loss 加标量权重:
$$w_{u,i,j} = \begin{cases}1.0, & \text{if } R_{\text{rule}}(\mathbf{c}_{u,i,j}) = 1\\ \beta, & \text{otherwise}\end{cases} \quad (\beta < 1) \tag{13}$$
advantage 估计不变,保留成功 rollout 的完整梯度、下权 non-hit。
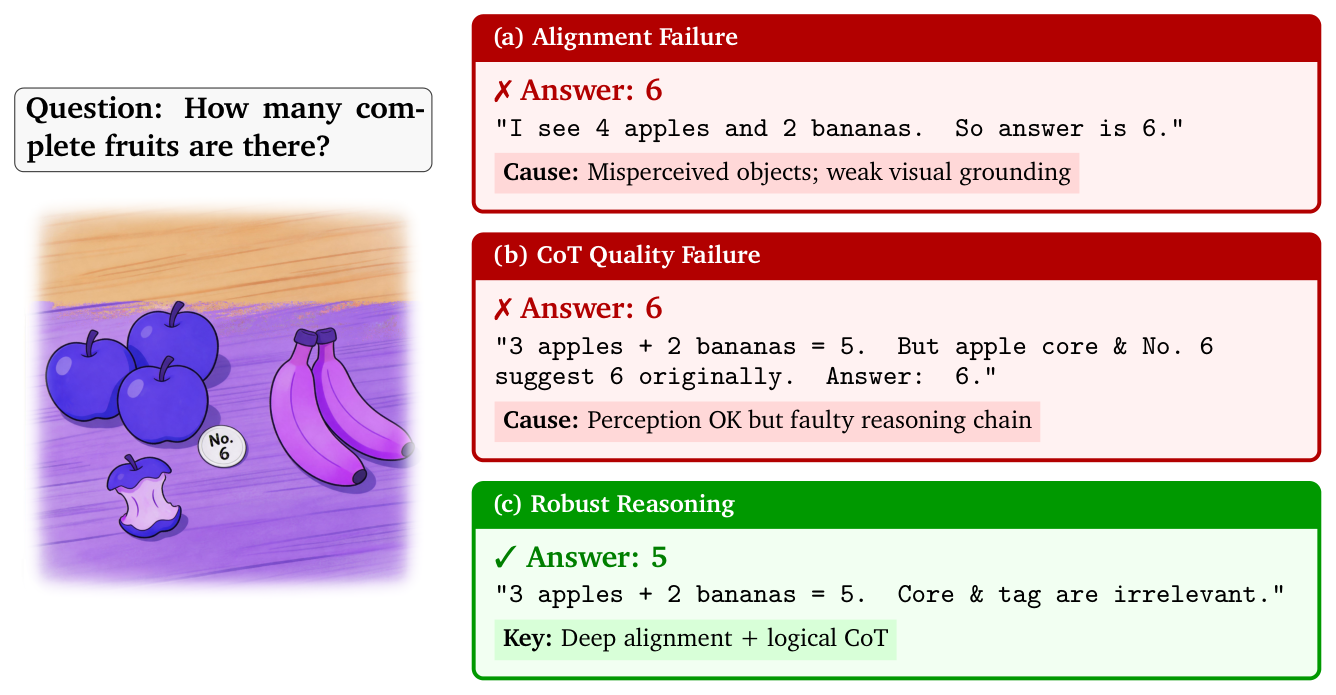
四个 RL 消融(Cross-Live,think/nonthink 双模式):两阶段 rollout(Figure 13)同时降单步训练时间且提升性能,think 模式增益更明显;多样性 reward(Figure 14)在更大 K 上增益更大;stage-wise clipping(Figure 15)一致提升、尤其 Recall@8/@32;negative-sample down-weighting(Figure 16)显著降低训练崩塌风险(去掉后 Validity@32 一度从 ~0.8 跌到 ~0.5)。
6.2 Rejection Sampling Fine-tuning(RFT,off-policy 统一)¶
GRPO 锐化输出分布、使模型集中在少数高置信 item,与"推荐应覆盖多样兴趣"目标不完全对齐。RFT 作为补充:每个域专精 GRPO 模型作教师生成推理增强轨迹,保留预测命中 $C_u^+$ 且推理一致的轨迹,跨四域合并得拒绝采样数据集:
$$\mathcal{D}_{\text{RFT}} = \{(x_u, \text{CoT}_u, \mathbf{c}_u)\} \tag{14}$$
先用 GRPO 在覆盖 R2+R3 全域的混合数据上训练到收敛得 Mix-RL checkpoint,以此初始化,再在 $\mathcal{D}_{\text{RFT}}$ 上用标准 NTP 训练:
$$\mathcal{L}_{\text{RFT}} = -\mathbb{E}_{(x_u,\text{CoT}_u,\mathbf{c}_u)\sim\mathcal{D}_{\text{RFT}}} \sum_{t=1}^{|y_u|} \log \pi_\theta(y_{u,t} \mid x_u, y_{u,<t}), \quad y_u = [\text{CoT}_u; \mathbf{c}_u] \tag{15}$$
6.3 Multi-Teacher On-Policy Distillation(MOPD,on-policy 统一)¶
把四个域专家在 on-policy 下蒸馏进统一学生。采用 Monte Carlo RL 形式(Li 2026),log-prob 比只在学生自采 token 上评估,教师只需提供单点 log-prob、无需全词表分布。设 $\mu_\theta$ 为学生部署在推理引擎的 behavior policy、$\pi_\theta$ 为训练引擎中被优化的 policy;对 prompt $x$ 采完整 rollout $y=(\text{CoT};\mathbf{c})\sim\mu_\theta$,按域路由到对应教师 $\pi_{\text{domain}_i}$,在每个 timestep 用 reverse-KL 定义 token 级蒸馏 advantage:
$$\hat{A}_{\text{MOPD},t} = \text{sg}\big[\log\pi_{\text{domain}_i}(y_t\mid x, y_{<t}) - \log\pi_\theta(y_t\mid x, y_{<t})\big] \tag{16}$$
为校正 off-policy 偏差引入截断重要性权重:
$$w_t(\theta) = \begin{cases}\text{sg}\Big[\frac{\pi_\theta(y_t\mid x,y_{<t})}{\mu_\theta(y_t\mid x,y_{<t})}\Big], & \epsilon_{\text{low}} \le \frac{\pi_\theta(y_t\mid x,y_{<t})}{\mu_\theta(y_t\mid x,y_{<t})} \le \epsilon_{\text{high}}\\ 0, & \text{otherwise}\end{cases} \tag{17}$$
$$\mathcal{L}_{\text{MOPD}}(\theta) = -\mathbb{E}_{x\sim\mathcal{D}, y\sim\mu_\theta(\cdot\mid x)}\Big[\frac{1}{|y|}\sum_{t=1}^{|y|} w_t(\theta)\,\hat{A}_{\text{MOPD},t}\,\log\pi_\theta(y_t\mid x,y_{<t})\Big] \tag{18}$$
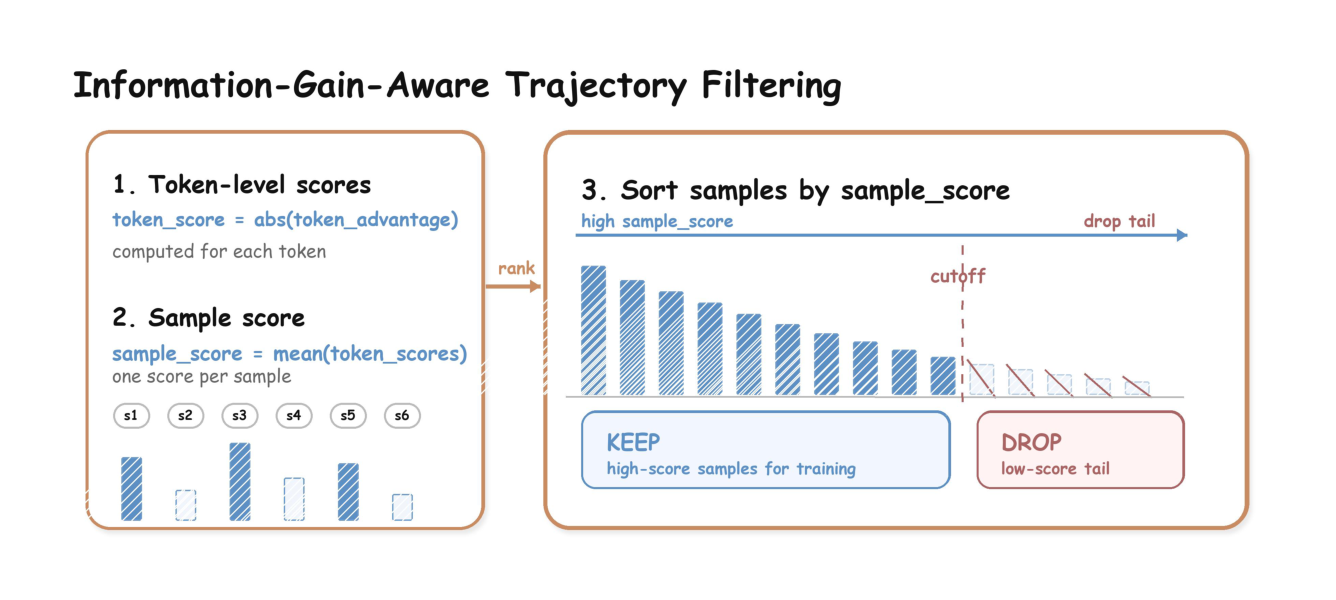
Information-Gain-Aware Trajectory Filtering:生成式推荐命中率极低,on-policy 训练里学生很快在通用热门 head item 上与教师对齐($|\hat{A}_{\text{MOPD},t}|\approx 0$),稀有但关键的长尾 insight($|\hat{A}|$ 大)被冗余梯度淹没——gradient-dilution。用 token 级 advantage gap 作 label-free 信息增益指标,对每条轨迹 $y_j$ 算 token 平均绝对 gap 作 informativeness 分:
$$s(y_j) = \frac{1}{T_j}\sum_{t=1}^{T_j} |\hat{A}_{\text{MOPD},j,t}| \tag{19}$$
给定 batch $\mathcal{B}$ 和目标信息增益比 $\rho$(如 0.8),按 $s$ 降序排,取覆盖 $\rho$ 的最短前缀长度:
$$M = \min\Big\{m : \frac{\sum_{j=1}^m s(y_{(j)})}{\sum_{j=1}^{|\mathcal{B}|} s(y_{(j)})} \ge \rho\Big\} \tag{20}$$
只在 active subset $\mathcal{S}=\{y_{(1)},\dots,y_{(M)}\}$ 上算 MOPD loss,把预算集中到最具挑战、最 informative 的样本。
MOPD 严格正向(Figure 19a),K 越大相对增益越大;但 K>16 后学生与教师仍有 gap(reverse-KL mode-seeking 的理论极限)。IG 过滤带来一致增益(Figure 20)、PG loss 更平滑(Figure 21)。Figure 22 显示无论 SFT / SFT→RFT / SFT→Mix-RL 起点,学生都能受益但被教师上界限制(弱学生能追平教师、难以显著超越)。
6.4 RFT vs MOPD 对比(Table 9)¶
Table 9 | 不同优化策略性能对比(部分,Recall,%;thinking / non-thinking)
| 域 | 指标 | 模式 | SFT | Mix-RL | Single-RL | RFT | MOPD |
|---|---|---|---|---|---|---|---|
| Cross-Live | Recall@8 | think | 5.63 | 8.29 | 8.39 | 8.70 | 8.82 |
| nonthink | 5.76 | 7.39 | 7.80 | 7.82 | 8.58 | ||
| Recall@32 | think | 11.17 | 13.03 | 14.69 | 14.63 | 14.82 | |
| nonthink | 11.74 | 12.86 | 14.42 | 14.25 | 14.71 | ||
| Cross-Ad | Recall@32 | think | 2.78 | 4.83 | 6.20 | 6.14 | 5.94 |
| Cross-Product | Recall@64 | think | 1.65 | 3.79 | 3.87 | 4.19 | 4.11 |
| Cross-Video | Recall@64 | think | 0.06 | 0.14 | 0.15 | 0.24 | 0.18 |
关键结论:① 所有 post-SFT 策略都显著超 SFT baseline——自探索能超越监督模仿。② 直接混域 RL(Mix-RL)一般弱于域内 Single-RL(异构域有冲突信号),佐证 specialize-then-unify。③ RFT 一致保证 thinking > non-thinking(拒绝采样只蒸馏 CoT 与正确推荐逻辑对齐的"golden"路径,稳住推理增益);MOPD 的 think/nonthink 高度同步(on-policy 蒸馏在共享参数空间整体校准 prompt-to-item 语义嵌入,大幅增强 non-thinking"直觉",但成功 CoT 极稀疏、缺严格 off-policy 过滤会吸入噪声/无根 CoT,使 thinking 难以完全甩开被极大增强的 non-thinking)。④ MOPD 在 Product/Live 表现最佳(甚至超 Live 教师),RFT 在 Video/Ad 大 K 上更稳。
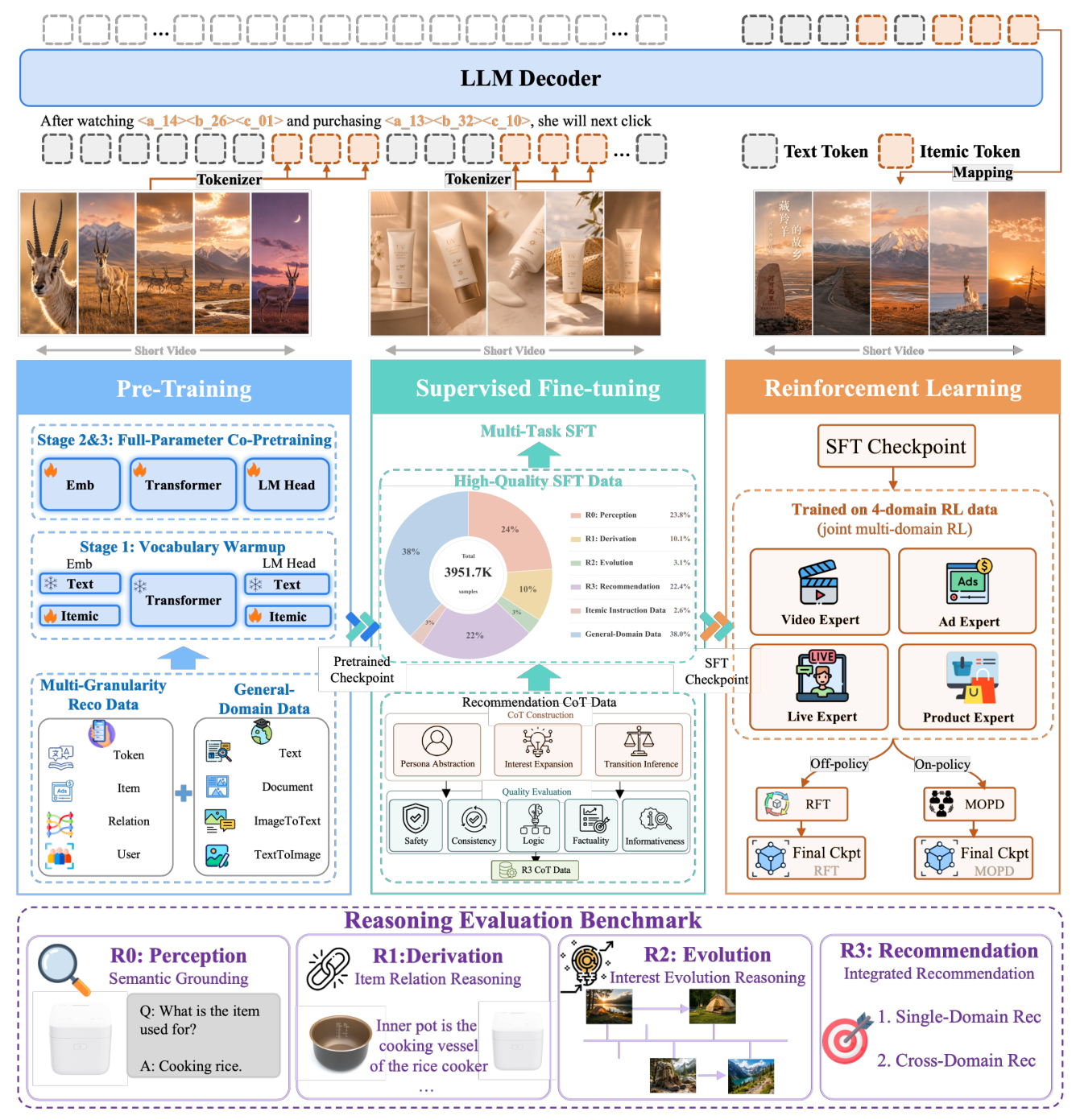
7. CoT 分析指标(Section 7):四维诊断框架¶
除目标准确度外,推荐推理 trace 的实用性取决于 CoT 是否真正贡献到最终 itemic 预测、忠于观测历史、尊重 itemic token 空间结构约束、遵循连贯意图演化轨迹。受 Zhang 2026b(Why Thinking Hurts,诊断 OpenOneRec 的 non-thinking>thinking gap、归因于 textual inertia)启发,设计 2×2 诊断框架:Symbolic vs Probabilistic(检查种类)× Local vs Global(参照范围),四格各守一种失败模式(Table 10)。
Criterion 1:CoT Likelihood Gain
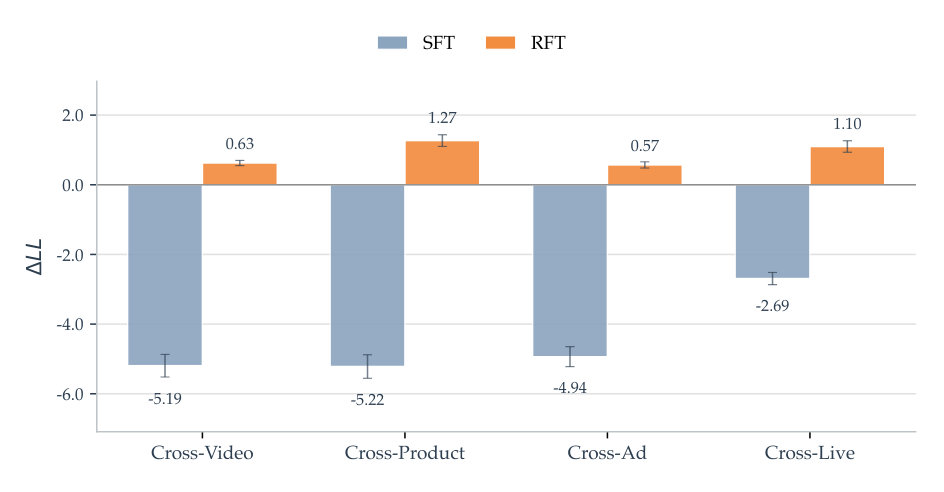
$$\Delta\text{LL} = \log p(y_{\text{GT}}\mid \mathbf{x}, c) - \log p(y_{\text{GT}}\mid \mathbf{x}) \tag{21}$$
正值表示 CoT 提高了正确目标的似然。SFT 在所有域 $\Delta\text{LL}$ 持续为负(CoT 反而分散注意力),RFT 在四域均为正(Figure 23)。
Criterion 2:沿 CoT 的似然递进。用 DeepSeek 把 CoT 切成语义连贯段 $c = \{c_1, c_2, \dots, c_T\}$ (式 22),对每个前缀算条件似然 $\ell_t = \log p(y_{\text{GT}}\mid\mathbf{x}, c_1, \dots, c_t)$ (式 23)。逐段加入 CoT 前缀一致提升目标似然(Figure 24),说明 CoT 提供增量预测证据而非事后解释;RFT 比 SFT 更早饱和(揭示 CoT 压缩/early-stopping 空间)。
Criterion 3:Item Legality
$$\gamma_{\text{legal}} = \frac{|\mathcal{S}(c)\cap\mathcal{V}_{\text{item}}|}{|\mathcal{S}(c)|} \tag{24}$$
CoT 中引用的 itemic 模式是否都对应合法 item。SFT/RFT 四域均饱和到 1.00。
Criterion 4:History Item Reference Validity(条件于 legality)
$$\gamma_{\text{hist}\mid\text{legal}} = \frac{|(\mathcal{S}(c)\cap\mathcal{V}_{\text{item}})\cap\mathcal{S}(\mathbf{x}_{\text{hist}})|}{|\mathcal{S}(c)\cap\mathcal{V}_{\text{item}}|} \tag{25}$$
合法 item 是否都真实出现在用户历史中(低值=prompt-violating 幻觉)。
Table 11 | CoT itemic 引用的 $\gamma_{\text{legal}}$ 与 $\gamma_{\text{hist|legal}}$(%)
| 指标 | 方法 | Video | Ad | Live | Product |
|---|---|---|---|---|---|
| $\gamma_{\text{legal}}$↑ | SFT | 100.00 | 100.00 | 100.00 | 100.00 |
| RFT | 100.00 | 100.00 | 100.00 | 100.00 | |
| $\gamma_{\text{hist|legal}}$↑ | SFT | 97.50 | 94.93 | 100.00 | 97.92 |
| RFT | 100.00 | 99.20 | 98.82 | 83.33 |
RFT 在 Video/Ad 收紧 history grounding(+2.50/+4.27pt),但 Live/Product 反而下降(−1.18/−14.59pt)——与 Table 9 中 RFT 在 Live/Product 相对 Mix-RL 增益较小一致。
定性案例(Table 12/13):一个 18-23 岁战术射击直播观众,ground-truth 是《三角洲行动》(仅 1 次 in-feed 广告点击曝光,需 cross-IP 泛化)。SFT trace 停在表层 IP(《和平精英》→更多《和平精英》),落到错误 IP 家族(对应负 $\Delta$LL);RFT trace 把候选提升到 catalogue-grounded 量化先验(【游戏】占 69.57%)和潜在品类轴("战术射击"),经 R1 派生的兴趣演化桥接到《三角洲行动》——这种品类级泛化正是 2×2 诊断框架要检测、也是 RFT 系统性交付的。
8. 实验(Section 8)¶
8.1 性能对比(Table 14)¶
baseline 按 item 表示分三类:ID-Based(SASRec、HSTU);Text-Based(Qwen3-8B/32B/235B-A22B、Deepseek-V3.2、Claude-Opus-4.6、Gemini-3-Preview、GPT-4o-mini、GPT-5.4,零样本+thinking,caption 经 Qwen3-Embedding-8B 编码后 ANN 检索);Itemic Token-Based(TIGER、LC-Rec 三变体、OneReason SFT/RFT)。
Table 14 | 跨域推荐 baseline 对比(%;Pass@64 / Recall@64)
| 类别 | 模型 | CV Pass | CV Rec | CP Pass | CP Rec | CA Pass | CA Rec | CL Pass | CL Rec |
|---|---|---|---|---|---|---|---|---|---|
| ID | SASRec | 0.03 | 0.01 | 0.31 | 0.25 | 1.04 | 0.37 | 1.76 | 0.40 |
| ID | HSTU | 0.10 | 0.01 | 0.32 | 0.24 | 2.79 | 0.78 | 2.32 | 2.14 |
| Text | GPT-5.4 | 0.24 | 0.02 | 1.43 | 1.15 | 1.64 | 0.43 | 7.20 | 6.38 |
| Text | Qwen3-235B-A22B | 0.24 | 0.02 | 0.64 | 0.49 | 0.77 | 0.19 | 5.10 | 4.66 |
| Itemic | TIGER | 0.88 | 0.07 | 0.21 | 0.17 | 7.65 | 2.39 | 2.32 | 1.78 |
| Itemic | LC-Rec-PT-SFT-8B | 1.49 | 0.13 | 3.95 | 3.00 | 15.85 | 6.55 | 19.32 | 16.70 |
| Itemic | OneReason SFT (nonthink) | 1.33 | 0.11 | 3.94 | 2.96 | 15.73 | 6.49 | 18.05 | 15.52 |
| Itemic | OneReason SFT (think) | 0.71 | 0.06 | 2.18 | 1.65 | 9.16 | 3.41 | 16.43 | 14.32 |
| Itemic | OneReason RFT (nonthink) | 2.08 | 0.19 | 5.20 | 3.96 | 17.56 | 7.28 | 21.01 | 18.17 |
| Itemic | OneReason RFT (think) | 2.41 | 0.24 | 5.47 | 4.19 | 17.78 | 7.50 | 21.10 | 18.35 |
(CV=Cross-Video, CP=Cross-Product, CA=Cross-Ad, CL=Cross-Live;Video Recall@64 整体偏低因 target 集最大 avg. 13.92 items。)
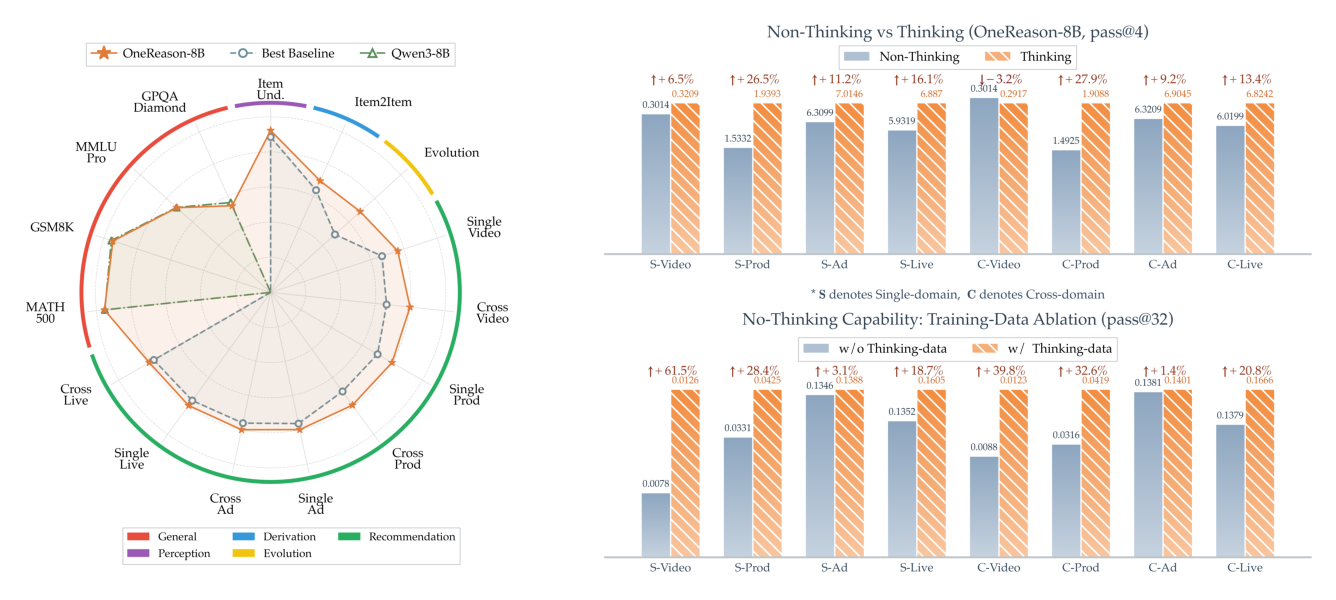
关键观察:① 冷启动敏感:ID-based 在跨域评测下挣扎(33.69% 目标 item ID 训练时未见),而只有 11.55% 目标 itemic 模式未见——itemic 表示支撑 content-based 泛化。② Text-based LLM 推荐能力与通用智能/规模不可靠相关(缺协同信号 + ANN caption 检索引入误差)。③ OneReason 预训练是强语义底座:LC-Rec-PT-SFT-8B(从 OneReason 预训练 checkpoint 初始化)显著超 LC-Rec-SFT-Only 各变体。④ 注意:SFT 阶段 thinking < non-thinking(印证反常现象),但 RFT 后 thinking 全面反超 non-thinking——这是 OneReason 的核心结果。
8.2 非推荐能力 & 通用智能(Table 15/16)¶
Table 15(R0-R2):RFT thinking 在 R0 上略逊 non-thinking(perception-task overthinking),但 R1/R2 平均更优——RL 在强化推荐同时增强高级推理。OneReason 用紧凑 itemic token 即可在 R2 部分子任务上超过若干更大的 text LLM(如 R2 Direct Gen RFT 20.31 vs GPT-5.4 17.61)。
Table 16 | 通用 benchmark(%)
| 模型 | MMLU-Pro | GPQA-Diamond | MATH-500 | GSM8K |
|---|---|---|---|---|
| Qwen3-8B (think) | 72.35 | 56.06 | 95.20 | 95.68 |
| LC-Rec-PT-SFT-8B | 39.72 | 35.86 | 81.00 | 51.55 |
| OneReason SFT (think) | 71.01 | 51.52 | 95.60 | 95.00 |
| OneReason RFT (think) | 72.08 | 54.04 | 95.40 | 94.69 |
OneReason thinking 模式基本保住 Qwen3-8B backbone 的通用能力(推荐特化未灾难性退化),而 LC-Rec 各变体在通用 benchmark 上大幅退化。
8.3 thinking 监督对 non-thinking 的迁移增益(Section 8.2)¶
token-aligned 实验(相同 0.25B token 预算):100K unCoT vs 40K CoT + 50K unCoT。
Table 17 | token-aligned non-thinking 推荐性能(%)
| 指标 | 设置 | CV | CP | CA | CL |
|---|---|---|---|---|---|
| Pass@64 | 100K unCoT | 1.64 | 4.38 | 16.08 | 18.12 |
| CoT+unCoT | 1.95 | 4.86 | 15.84 | 20.32 | |
| Recall@64 | 100K unCoT | 0.18 | 3.33 | 6.72 | 15.59 |
| CoT+unCoT | 0.21 | 3.67 | 6.68 | 17.69 |
相同预算下,用 CoT 数据替换部分 unCoT 提升 Video/Product/Live 的 non-thinking 性能(Cross-Ad 是例外,更偏 unCoT-heavy)。再做 mixture sweep,设 unCoT 比例 $\alpha = N_{\text{unCoT}}/(N_{\text{CoT}}+N_{\text{unCoT}})$ (式 26),相对 100% unCoT 的 Pass@32 增益 $G_d(\alpha)$ (式 27)。Figure 25 显示各域有不同最优 CoT 比例(Video 55%、Product 95%、Ad 25%、Live 55%)。作者给出概念分解(式 28:$G_d(\alpha) = B_d + A_d^{\text{uncot}}(\alpha) + I_d^{\text{cot}}(1-\alpha) - C_d^{\text{trace}}(1-\alpha) - C_d^{\text{format}}(\alpha, 1-\alpha)$)与最优点条件 $\partial G_d/\partial\alpha|_{\hat\alpha_d^\star}\approx 0$ (式 29),强调 CoT 监督有用但 domain-dependent、并非越多越好——CoT 监督的部分收益(压缩 + 推理信号)可在行为层面迁移到直接解码,但 causal separation 待后续 ablation。
9. 工业部署(Section 9)¶
OneReason 已部署在快手 App 快速增长的本地生活广告场景(不在训练数据内),在严格延迟、强 baseline、item 可投放约束下稳定上线,带来快手本地生活广告"最显著业务增益之一"。
9.1 "Fast-Slow Thinking" 在线架构¶
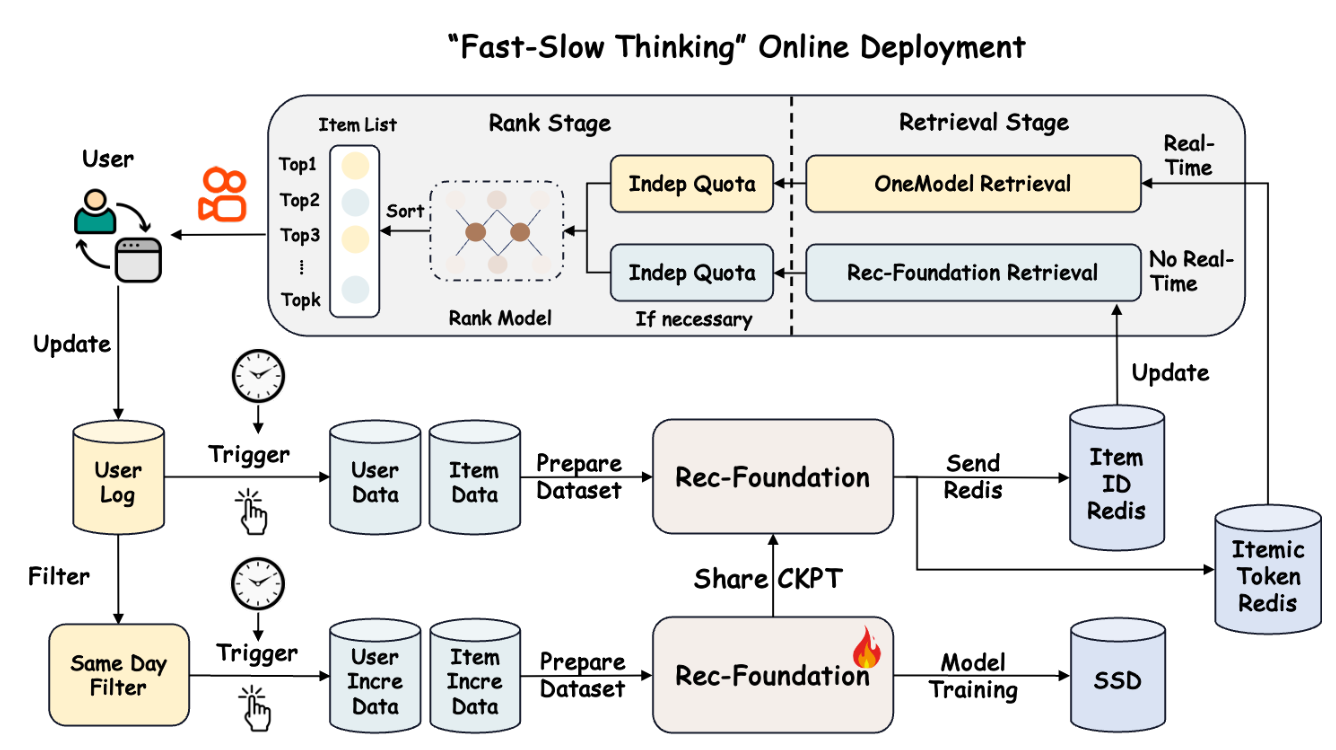
LLM 规模 + 推理系统限制使 OneReason 难以直接实时部署,故提出 Fast(在线)+ Slow(nearline)协作:① Pipeline Design:解耦的 nearline 检索流水线不参与早期竞争,集成进下游排序模型联合打分,OneReason 不可用时回退 OneRec 保稳定。② Dataset Trigger:周期性(日/时)聚合用户行为/画像/item 内容,触发数据 fetch/clean/feature 形成端到端 data flywheel。③ Offline Inference:加载最新 OneReason checkpoint 离线预测用户最可能 next itemic token,解码成 item ID。④ Online Serving:item ID 写入 Redis 形成候选池,nearline OneReason 结果 + 实时 OneRec 结果联合喂排序模型统一融合。
在线增量训练:Pre-Training Incremental(固定时间窗对新 item 持续预训练 + 采样通用域防遗忘)+ SFT Incremental(用当天用户交互做日增量训练,建模短期兴趣动态)。
两种应用范式:① Slow Pipeline: OneReason(直接用 OneReason 检索);② Fast Pipeline: OneReason for OneRec(用 OneReason 输出增强 OneRec,引入 Thinking Token 把 OneReason 知识蒸馏进在线 OneRec)。
9.2 在线 A/B(Table 18)¶
10 天、5% 流量 A/B:
Table 18 | 在线性能对比
| 模型 | Impressions | Revenue |
|---|---|---|
| OneReason | +0.940% | +4.528% |
| OneReason for OneRec | +6.831% | +4.636% |
| Combined | +10.332% | +8.234% |
直接用 OneReason(Slow)主要提升 Revenue(语义匹配改善流量质量);增强 OneRec(Fast)主要扩大系统规模/检索覆盖;两者结合最佳,对应快手平台年化数亿元人民币商业收入,ROI > 5。
9.3 附录部署分析(A.3/A.4)¶
- Table 19(流量效率):Combined 在 Conv. +12.643% / Click +1.709% / CVR +1.865% / CTR +0.519%,检索份额 27.2%。
- Table 20(用户分层):低活跃用户 Revenue +13.323%(远超活跃用户 +2.419%)——推理能力对稀疏交互用户价值最大(reasoning-based 兴趣补全)。
- ROI(A.4.4):系统约 600 旗舰 GPU/天服务 4 亿用户,估计 ROI > 5。
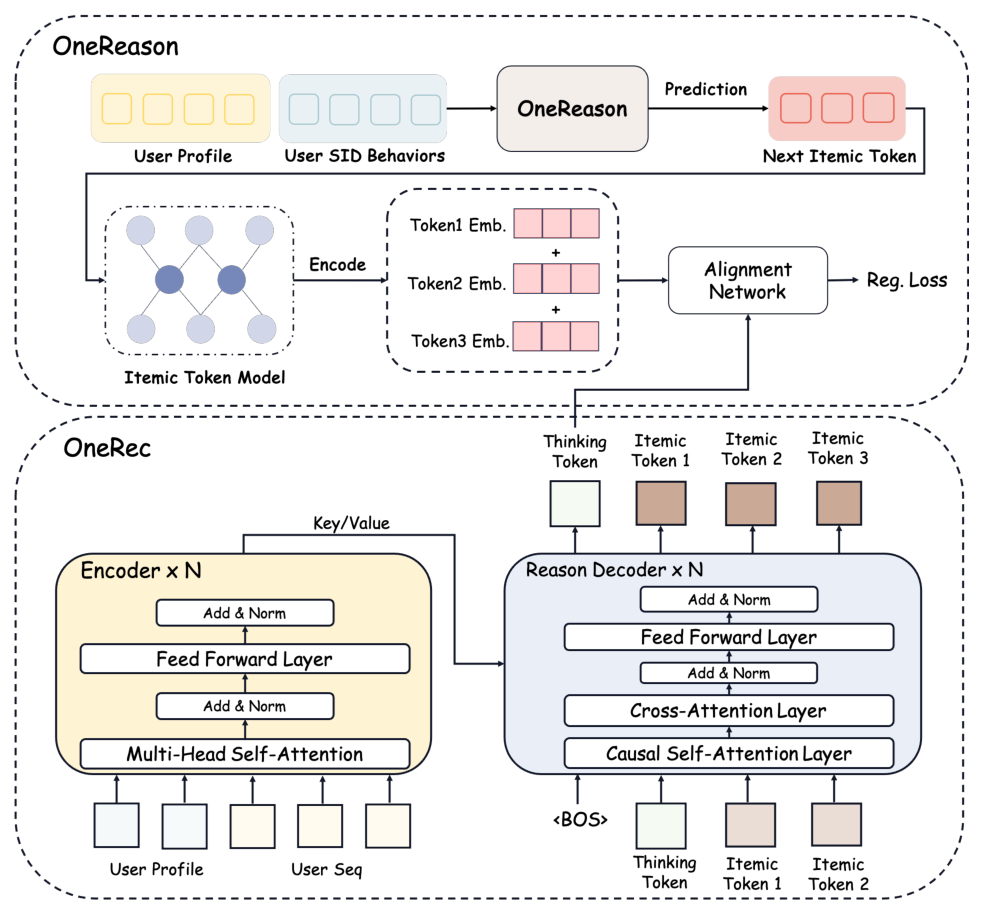
10. 核心贡献总结¶
- 诊断 + 处方:把生成式推荐"thinking 打不过 non-thinking"的反常现象归因到感知(模态对齐)+ 认知(CoT 质量)两根支柱,并逐根加固;
- 四粒度感知预训练:Token / Item / Relational / User 四个递进粒度(含 compositional prefix、part-to-whole、capacity-aware coarse-graining、relational chain、时间交错替换等新组件),578B token 对齐 itemic-text 语义空间;
- 三层认知 CoT:Persona Abstraction → Interest Expansion → Transition Inference 的标准化 coarse-to-fine 结构 + 五维质量评估,把推荐推理形式化为 two-axis compression + transition judgement;
- specialize-then-unify RL:域内推荐导向 GRPO(两阶段 rollout、diversity reward、stage-wise clipping、negative-sample down-weighting)→ RFT(off-policy 拒绝采样,保 thinking>non-thinking)或 MOPD(on-policy 多教师蒸馏 + 信息增益过滤,同步增强 think/nonthink);
- OneReason-Bench + 四维 CoT 诊断框架(ΔLL / 似然递进 / item legality / history validity),把训练每一步都对齐到可测的诊断轴;
- 首次让 thinking 模式在多个真实业务 benchmark 稳超 non-thinking,并发现 CoT 监督可迁移提升 non-thinking;
- 真实工业落地:快手本地生活广告 Fast-Slow Thinking 架构上线,年化数亿元、ROI>5、低活跃用户 +13.3% Revenue;开源 OneReason-8B / 0.8B。
11. 与已归档相关工作的对比¶
OneRec-Think OneRec-Think: In-Text Reasoning for Generative Recommendation(Kuaishou, 2025-10-13)¶
关系:显式引用 + 直接前代(同团队 OneRec 家族)· 原文在 intro/related work 叙述为预备工作但未在 Table 14 展开对比 · 已加载对方精读
- 共同关注的问题:两者都要把显式、可读的 think-before-answer 推理引入生成式推荐,弥合离散 itemic item 与连续推理空间的语义鸿沟。OneRec-Think 正是 OneReason intro 里那个"成功泛化 think-before-answer 但 thinking 不显著优于 non-thinking"的预备研究——OneReason 的全部动机就是回答 OneRec-Think 留下的反常现象。
- 相近的技术骨架:都走"itemic 对齐预训练 → 推理激活 SFT → RL"三段式。OneRec-Think 的四任务 Itemic Alignment(Interleaved User Persona Grounding / Sequential Preference / Itemic Dense Captioning / General LM)对应 OneReason 的四粒度预训练;OneRec-Think 的 "Reasoning Activation"(用 top-k 剪枝上下文 bootstrapping 推理)对应 OneReason 压缩轴的 Persona Abstraction(都在"去长历史噪声")。
- 本文的差异与推进:① 从"任务级对齐"升级到"粒度级对齐":OneRec-Think 的 dense caption 是单层 itemic↔caption 映射,OneReason 显式建模 sub-token 组合语义(compositional prefix / part-to-whole)和 inter-item 关系链,并对 caption 做 capacity-aware 粗化以防幻觉。② 从"剪枝 bootstrapping"升级到"结构化三层认知 CoT + 五维质量评估":OneRec-Think 靠相似度 top-k 剪枝生成推理,OneReason 用 Persona Abstraction→Interest Expansion→Transition Inference 的标准 coarse-to-fine 结构并显式质量打分。③ 从"单一 RL"升级到 specialize-then-unify:OneReason 发现混域 RL 有干扰,先域内专精再 RFT/MOPD 统一——这是让 thinking 真正反超 non-thinking 的关键,而 OneRec-Think 未解决此反超。④ 规模:OneRec-Think 工业 warmup 6B token + LoRA,OneReason 全参 578B token 预训练。
- 可比的方法/实验差异:OneRec-Think 上线 +0.159% APP Stay Time(推荐主场景);OneReason 落在本地生活广告,Combined +8.234% Revenue / ROI>5。两者 itemic token 都丢/留 end token 策略不同(OneReason 丢尾 token 省上下文)。详细精读见 OneRec-Think。
TwiSTAR TwiSTAR: Think Fast, Think Slow, Then Act(Tsinghua SIGS, 2026-05-12)¶
关系:独立并发(OneReason 未引用 TwiSTAR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都直击同一个反常观察——慢思考 / CoT 推理并不能均匀地帮助生成式推荐,在简单/高频样本上强行推理甚至掉点。TwiSTAR §6.4 实证"当 fast 模型已能处理大量 easy 样本时,强行用 slow 推理反而让 slow 模型表现下降";OneReason intro 的"thinking mode does not show significant advantages"是同一现象的不同侧面。两者都在 SID/itemic-token 自回归生成式推荐范式内。
- 相近的技术骨架:都把"协同/I2I 隐式信号显式语言化"作为推理增强数据来源(TwiSTAR 的 I2I co-occurrence commonsense injection ↔ OneReason 的 Relational 粒度 Textual_Explanation 链 + R1 derivation bridge),都用"SFT 模仿 + RL"两阶段培养推理。
- 本文的差异与推进:最根本的分歧在"是否让模型学会何时思考"。TwiSTAR 接受"thinking 不总是有用",把推荐重构成 agentic 系统,用 learned planner 在 fast retriever / rank / slow think-and-rec 之间自适应路由——目标是"该快则快、该慢则慢"。OneReason 则改造训练让 thinking 永远赢:不在样本级 gate 推理,而是通过 perception+cognition+specialize-then-unify 让 thinking 模式稳定超越 non-thinking,成本问题完全交给部署侧 Fast-Slow 架构(nearline 慢 OneReason + 在线快 OneRec)而非 per-sample routing。可以说 TwiSTAR 在"推理调度"维度优化,OneReason 在"推理质量"维度优化。
- 可比的方法/实验差异:TwiSTAR 公开 Amazon(Beauty/Toys/Sports),并显式在 12 个 metric-dataset 格子上击败 OneRec-Think(OneReason 的前代),把两条线放进同一对话;OneReason 工业 Kuaishou 四域 + OneReason-Bench,已部署 400M 用户。详细精读见 TwiSTAR。
SAPO SAPO: Step-Aligned Policy Optimization(University of Virginia, 2026-05-17)¶
关系:独立并发(OneReason 未引用 SAPO,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都诊断出outcome-reward GRPO 在"推理 token + SID/itemic token"混合 rollout 上的信用分配错配。SAPO 命名为 action-granularity mismatch:rollout 级标量 advantage 广播到推理 token 和全部 K 个 SID token,无法定位是哪个 SID 位置出错、还把无关推理 token 与正确 SID token 一并奖惩。OneReason 独立地指出"推理 token 长、主要支持探索;itemic token 短、直接决定 reward;用同一 clip range 会让 itemic token entropy collapse"——同一个"推理 token 与 itemic/SID token 必须差异化对待"的洞察。
- 相近的技术骨架:都在 verifiable exact-match 反馈下做 RL、都不引入 learned reward model,都把"推理段 vs SID/itemic 段"作为需要分别处理的两类 token。
- 本文的差异与推进:处方落点不同。SAPO 把"一个 thinking block + 配对的一个 SID token"设为 RL 的 action unit,导出 per-step verifiable match reward + per-step group-relative advantage + step-normalized token 聚合——治的是信用分配的粒度(让 near-miss 的前两位对了的信息不被抹掉)。OneReason 保留 rollout 级 GRPO,但用 stage-wise clipping(推理 token 松 clip / itemic token 紧 clip,式 11-12)+ negative-sample down-weighting(式 13)+ diversity reward(式 9)+ 两阶段 rollout(式 6)——治的是信任域粒度 + reward 稀疏。两者殊途同归:SAPO 修信用分配,OneReason 修信任域与稀疏命中,都瞄准 GRPO 里推理/SID token 的非对称性。
- 可比的方法/实验差异:SAPO 公开三个 Amazon 类目、聚焦 RL 单阶段、无工业部署;OneReason 把 RL 嵌入 specialize-then-unify 全栈并工业上线。SAPO 的 per-step reward 能精确定位 SID 位置错误,OneReason 的 diversity reward 作用在第一位(粗品类)、stage-wise clip 稳住 itemic token entropy。详细精读见 SAPO。
12. 讨论与局限性¶
值得借鉴的设计:① "thinking 打不过 non-thinking"是生成式推荐推理化的真问题,OneReason 把它拆成 perception/cognition 两根支柱并逐根处方,方法论清晰且可复用;② 四粒度预训练里的 capacity-aware caption coarse-graining("三个 sub-token 承载不了的细节会逼模型幻觉")是非常实在的工程洞察;③ specialize-then-unify(域内专精→RFT/MOPD 统一)为"多域 RL 干扰"提供了通用解;④ 四维 CoT 诊断框架(ΔLL / 似然递进 / legality / history validity)把"CoT 是否真有用"变成可测量,是难得的 reasoning 可解释性工具;⑤ Fast-Slow Thinking 部署架构(nearline 慢 + 在线快 + 回退)是把重模型落地实时系统的可复用范式。
局限/争议:① 机制未厘清:作者诚实承认"CoT 监督提升 non-thinking"只是行为层证据,没区分收益来自压缩、推理还是二者交互(causal separation 待 ablation)。② MOPD 受教师上界限制:弱学生能追平教师、难显著超越;reverse-KL mode-seeking 在 K>16 留下与教师的 gap。③ RFT 在 Live/Product 收紧 history grounding 失败($\gamma_{\text{hist|legal}}$ 反降,Product −14.59pt),符号诊断与下游指标在这两域对齐较弱,作者把它留作 future work。④ 成本高:~600 旗舰 GPU/天、无法真正实时(靠 nearline 妥协),未来要靠 0.8B 级小模型 + 推理基础设施压成本。⑤ 离散码本固化:RQ-KMeans 三层 8192 码本一旦训练即固定,理论上限制下游表征空间——这是 LLM-backbone 之外唯一明显的 scalability 隐患(参数 scaling 时表征能力受码本约束),但对本工作的整体质量影响有限。
与已有工作的差异:相比 OneRec-Think/OpenOneRec(同团队前代,发现 thinking 不占优但未解决),OneReason 第一次系统性让 thinking 反超;相比 TwiSTAR(自适应何时思考)走"提质量"而非"调调度"路线;相比 SAPO(修 GRPO 信用分配)从信任域/稀疏命中角度治同一 GRPO 病灶;相比纯 LLM-as-enhancer(ReaRec/OnePiece/OneSearch-V2/REG4Rec)追求的是端到端可直接产出推荐决策的工业 GFM。