On the Practice of Scaling Search Conversion Rate Prediction(Coupang,2026-05-28)¶
Coupang 电商搜索团队的一篇经验研究(empirical study)论文。它不提出全新架构,而是回答一个非常工程化的问题:在严格的在线延迟/成本约束下,如何可预测、高效地把一个工业搜索转化率(CVR)预测模型「做大」? 论文把模型缩放拆成 backbone(骨干计算量)、embedding(参数量)、data(训练数据量)三个维度,逐一系统实测出各自的缩放规律,发现三个维度的收益largely 独立且可加,由此推导出一套"先在小数据上搜架构、再迁移到全量数据"的高效研发范式;再配合 warmstart 重训、解耦 CPU-GPU 图执行与动态批处理,最终在真实线上 A/B 中以 8× 推理算力、2.5× 训练数据换来 +2.6% 搜索转化率且延迟近乎不变。
研究动机与背景¶
转化率(Conversion Rate, CVR)预测是搜索与推荐系统的核心,尤其在电商场景。深度学习已经在模型质量上带来显著收益,但其真正潜力在于可缩放性(scalability)——用更复杂的架构、更大的数据获得更强的泛化。然而把"缩放红利"真正落到搜索域远比想象困难,原因在于多项研究都观察到:沿缩放轴的边际收益往往迅速衰减。论文把这个困难拆成几条结构性 root cause:
- CVR 模型架构高度异构(heterogeneous):模型输入混杂数值、类别、文本、序列等多种特征,缩放效应会在不同组件(不同 scaling factor、不同 embedding)之间错配(misaligned)。同时这类 embedding-centric 架构的大部分参数集中在巨大的 embedding 表里,用于表示高基数类别特征。
- 记忆与泛化的平衡难:输入混合了用户画像、查询上下文、物品属性等连续与离散特征,CVR 模型很难在 memorization 与 generalization 之间取得平衡;特征的异构性与规模也使大规模训练数据的预处理与生成变复杂。
- 在线 serving 的硬约束:在线 CVR 系统同时受延迟与资源双重约束,排斥过慢或过大的架构。
一个有前景的方向是把工程化特征替换为原始用户行为序列(如 HSTU、Wukong、BERT4Rec 路线),但直接建模全部用户的原始行为历史计算代价极高;而且搜索域与非搜索推荐不同——搜索包含大量时点(point-in-time)特征与特定查询意图,这些信号不一定能泛化为其他 session 的序列输入(例如某个物品当前的价格/可得性,对历史查询完全无关)。此外,无论搜索还是推荐,许多 SOTA 架构的骨干并不天然对齐语言模型那种已被验证可预测缩放的结构。
因此本文目标是:通过系统化实验,找到一种可泛化、稳健的搜索 CVR 缩放机制。具体而言,把模型拆成 backbone / embedding / data 三个主缩放维度,逐维度深入分析其缩放性质与有效缩放配方;并证明推理优化可以解锁缩放后模型的低成本/低延迟服务;最后用大规模线上 A/B 验证真实收益。论文的主要贡献:
- 系统刻画每个缩放因子在 SOTA 搜索 CVR 模型中的缩放性质与实际影响,为工业从业者提供"优先探索哪个方向"的可泛化指引;
- 基于 data 维度观察到的缩放性质,提出加速模型选型的实用策略:先在小数据上做架构搜索与超参优化,再把选中的配置迁移到全量数据做最终训练与部署;
- 提出精简的 warmstart 训练技术,显著降低常规模型迭代的训练时间;
- 提出一套优化 GPU 服务效率的实用框架,支撑大容量 CVR 模型的线上部署;
- 大规模线上 A/B 验证分析与缩放机制的有效性——其中包含 +2.6% 搜索转化率提升。
隐私声明:框架设计不包含任何客户 PII,使用的模型特征与训练数据均无法识别具体个人。
CVR 预测预备知识与模型框架¶
论文先把"现代 CVR 预测"的范式说清楚。考虑 purchase(购买) 作为目标转化行为:给定用户 $u$ 提交的查询 $q$ 与一组曝光候选物品 $D = \{d_i\}$,CVR 预测任务的目标是为每个候选 $d_i$ 产出排序分 $f(u, q, d_i)$,建模用户 $u$ 会购买 $d$ 的概率 $\mathbb{P}(\text{Purchase} \mid u, q, d_i)$。
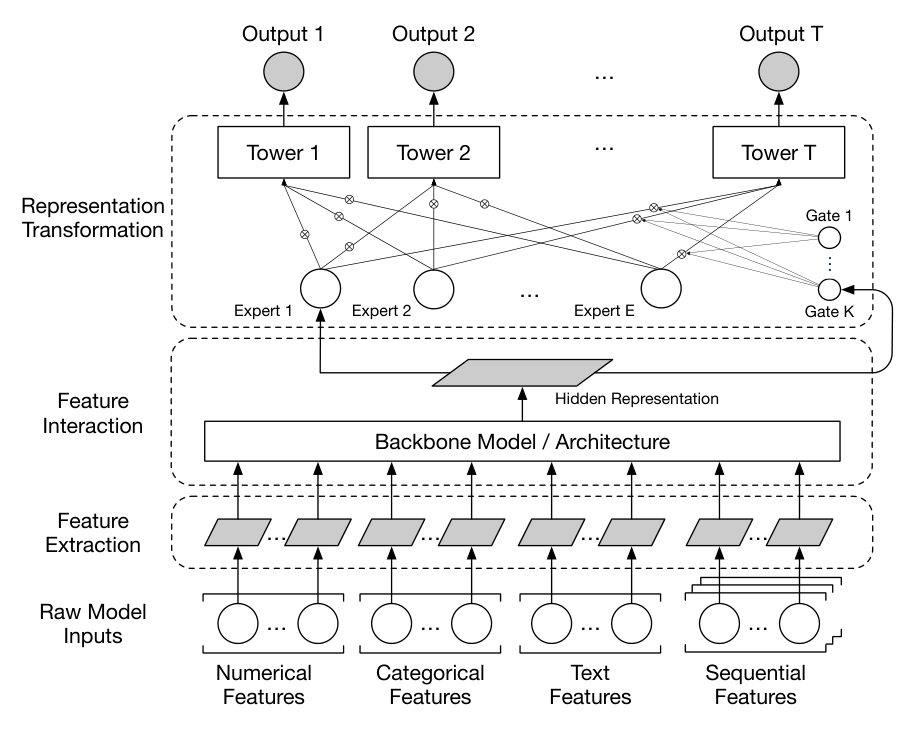
如 Figure 1,现代 CVR 模型可一般化为三个组件:
1) 特征抽取(Feature Extraction):原始输入无法被 ML 模型直接消费(非标准化),需转成稠密向量。论文把输入分为四类,并给出常规抽取方法:
- 数值特征(numerical):做 normal standardization + $\log 1p$ 变换,得到两个归一化特征;
- 类别特征(categorical):embedding 层把离散类别映射为连续 embedding 向量;
- 文本特征(text):先 tokenize 成 character n-grams,再映射为 n-gram embedding,最后 average pooling 得到文本 embedding;
- 序列特征(sequential):是用户历史行为在物品上的时间序列,用序列建模编码为稠密的客户 embedding 做个性化(不含任何 PII)。
本文重点缩放对搜索 CVR 关键的多种 embedding 特征,如 query embedding 与 item embeddings。
2) 特征交互(Feature Interaction):捕捉稠密向量间隐含语义的核心模块,是现代 CVR 模型的基石。具体由一个骨干模型或骨干集成(ensemble of backbones)——如 Deep & Cross Networks(DCN/DCNv2)、Transformer——把这些 embedding 映射为丰富的高阶 hidden representation。本文主要探索缩放的就是这个特征交互组件。
3) 表征变换(Representation Transformation):CVR 通常是多任务模型,把 CVR 与相关任务(如 CTR)联合学习。需要把特征交互的共享输出变换为每个任务的定制表征以捕捉任务特异信息。本文采用 Multi-gate Mixture-of-Experts(MMoE) 做表征变换(该组件本身不在本文研究范围,留作 future work)。
学习目标与优化¶
训练标签收集:为收集高质量标签,使用带归因窗口(attribution window)的客户行为——从搜索结果的物品曝光开始计时。这个延迟对正确归因非即时转化至关重要(例如用户当天加购、隔天才完成购买,归因机制要把这笔延迟购买正确链接回原始搜索曝光)。
多任务学习:目标转化行为(purchase)相对总曝光极度稀疏,为丰富学习信号、平滑学习过程,常借助点击、加购等其它互斥行为做多任务学习。对每个学习任务 $t$,用 Softmax 交叉熵损失(learning-to-rank):
$$\mathcal{L}_t = -\sum_i y_{i,t} \log \frac{\exp(s_{i,t})}{\sum_j \exp(s_{j,t})} \tag{1}$$
其中 $y_{i,t}$ 表示物品 $d_i$ 是否产生任务 $t$ 的目标行为;$s_{i,t}$ 是任务 $t$ 上物品 $d_i$ 的预测 logit。总目标是所有任务损失之和。优化用 Adam,第一个 epoch 的一部分做学习率 warm-up,之后用 cosine decay 直到训练结束。
高效模型缩放:三个维度的定义与方法¶
论文假设:用更多计算、更多参数、更多数据可以换来可观的质量增益。但缩放通常带来更高成本与硬件需求,如何可预测且高效地缩放才是难点。本文探索三条缩放策略:
- Backbone Scaling:提升特征交互骨干的计算强度,通常因每样本 FLOPs 增加而降低训练吞吐;
- Embedding Scaling:扩展 embedding 表的维度或数量来增加参数量,计算上往往高效,但显著增大显存占用、可能触发显存瓶颈;
- Data Scaling:在更大语料上训练(延长数据时间窗或提高采样率),导致更长训练周期,在严格训练预算下可能不可行。
1. Backbone Scaling¶
骨干模型的能力很大程度由其架构与配置决定。论文探索两个方向:(1) 对单个骨干沿不同 scaling factor 缩放;(2) 通过集成异构骨干来缩放特征交互的计算架构。考察的骨干包括 DCNv2、MaskNet、Transformer、RankMixer。
The Deep and Cross Family(DCNv2 与 MaskNet):这一族结合标准全连接 DNN(FC-DNN)与基于 Hadamard 乘积的交叉特征交互层。两者交叉逻辑不同——DCNv2 的交叉层为:
$$\mathbf{x}_{l+1} = \mathbf{x}_0 \odot (\mathbf{U}_l \mathbf{V}_l \mathbf{x}_l) + \mathbf{x}_l \tag{2}$$
MaskNet 则用:
$$\mathbf{x}_{l+1} = \mathbf{U}_l(\text{ReLU}(\mathbf{V}_l \mathbf{x}_0)) \odot \mathbf{x}_l \tag{3}$$
(为清晰省略 bias 项。)为无约束地增强交叉层表达力,论文提出对输入 $\mathbf{x}_0$ 做一层 relu 投影来缩放——这解决了 DCNv2 中交叉 rank 受输入向量长度限制的瓶颈。在 FC-DNN 连接上,MaskNet 把 DNN 紧接在 cross 网络输出之后;它使用 $n$ 个 MaskNet block $M_i(\mathbf{x}, \mathbf{x}_0)$,输出可并行拼接:
$$\text{Concat}\big(M_0(\mathbf{x}_0,\mathbf{x}_0),\, M_1(\mathbf{x}_0,\mathbf{x}_0),\, \cdots,\, M_n(\mathbf{x}_0,\mathbf{x}_0)\big) \tag{4}$$
或顺序堆叠:
$$M_n\big(\ldots\big(M_2(M_1(\mathbf{x}_0,\mathbf{x}_0),\mathbf{x}_0)\big),\ldots,\mathbf{x}_0\big) \tag{5}$$
随后 hidden representation 被直接投影到输出 logit。这种架构灵活性沿袭 DCNv2,FC-DNN 既可堆叠在 cross 输出之后,也可通过拼接并行融合。由此该族识别出 4 个关键 scaling factor:
- Cross Width:投影后的 cross-input 维度;
- Deep Width:FC-DNN 的隐层维度;
- Parallel Mask Blocks:MaskNet 并行 block 数;
- Sequential Mask Blocks:MaskNet 顺序堆叠 block 数。
The Sequence Model Family(Transformer 与 RankMixer):现代 CVR 越来越多利用序列 embedding 来释放 Transformer/RankMixer 的能力。Transformer 通过 self-attention 擅长捕捉高阶上下文交互;RankMixer 用高效的 multi-head token mixing 替代二次复杂度的注意力以增强可缩放性。为整合非序列信号(如 3 个月聚合转化率),论文采用既有做法——把特征拼接并均匀切分为一串"global tokens",并在切分前对原始特征做非线性投影增强表达力(呼应 Cross-Net 思路)。该族识别出 5 个关键 scaling factor:
- $d_{\text{model}}$:输入 embedding 大小;
- Sequence Length:序列"global tokens"的数量;
- $\text{ffn}_{\text{dim}}$:FFN 层维度;
- 模型层数;
- attention head 数。
Backbone Model Ensemble(骨干集成):用 deep hierarchical ensemble network(DHEN) 把多个骨干集成进一个 CVR 模型,研究不同集成方式下收益如何叠加。
2. Embedding Scaling¶
现代 CVR 依赖 embedding 处理高基数的物品 ID 与文本 token;这些可训练 embedding 表占据相当一部分模型参数。论文探索两个 embedding 缩放因子:(1) embedding 维度大小;(2) 词表大小(vocabulary size)。更宽的维度提升连续表征的丰富度;更大的词表让模型能区分更广范围的特征。为管理 n-gram 这类海量基数特征,使用 hashing trick——通过调整 hashing modulus divisor 精确控制词表大小。
3. Data Scaling¶
从历史互动行为学习是 CVR 建模的标准做法。从学习信号角度,靠提高采样率或延长时间窗来缩放训练数据,可提升模型质量与泛化(更大数据更全面覆盖客户行为,尤其对 torso/tail 查询这类天然稀疏的部分;更长训练窗能捕捉多样时间模式与演化的用户兴趣)。
但在生产中,特征集是动态演化的:新的数据分区往往有更好的特征覆盖。理想情况下应在整个训练回溯期生成所有特征,但这通常不可行。因此论文用一种技巧:对缺失特征用一个唯一的 'unseen' 占位符填充(populate with unseen placeholder),并评估"大规模 backfill 的高昂代价是否换来相称的性能收益"。鉴于数据缩放并非"免费午餐",论文优先做有针对性的特征探索——只 backfill 一个小范围的高影响信号子集。
实验设置¶
数据集:用 70 天的匿名购买数据做模型训练(数据缩放研究中会使用或多或少的天数)。每个训练样本是一个至少含一次购买的搜索结果列表,把购买 engagement 作为 learning-to-rank softmax 损失的正标签。
骨干与特征:骨干为 DCNv2、MaskNet、Transformer、RankMixer。特征涵盖 query-item engagement 特征、query engagement 特征、item engagement 特征、query-item understanding 特征、客户历史 engagement 序列;模型还使用原始 query、item title、document ID 特征,其 embedding 在训练中联合学习。
评估指标:计算所有搜索在未来 7 天对客户购买的 mean average precision(mAP)——论文发现该指标与线上客户 engagement 高度相关。形式上:
$$\text{mAP} = \frac{1}{Q}\sum_{q=1}^{Q} \text{AP}_q,\qquad \text{AP}_q = \frac{\sum_{i=1}^{n}\big(\text{precision@}k \times \text{item purchased@}k\big)}{\text{Number of purchased items for query } q} \tag{6}$$
由于大多数查询只产生一次购买,该指标的取值非常接近 Mean Reciprocal Rank(MRR)。实验报告的是模型改动带来的相对离线 mAP 差异(% of mAP)。
主要实验结果¶
4.1 Backbone Scaling 结果¶
论文沿每个 scaling factor 全面缩放四个骨干,核心结果汇总在 Table 1(粗体为各骨干默认值;默认 MaskNet 不含 sequential block)。表中给出每个因子取 V1→V4 四档时的 ΔmAP(相对默认)、Δ训练吞吐(ΔTraining Throughput)、推理 FLOPs(×10⁷)。
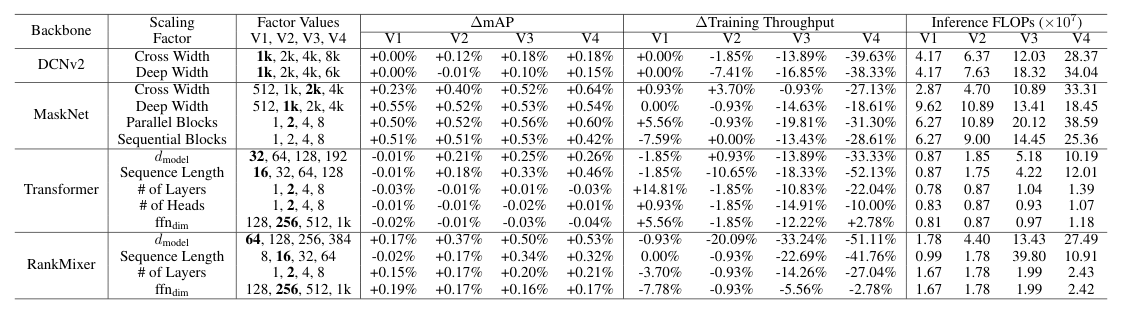
ΔmAP(相对各骨干默认配置)
| Backbone | Scaling Factor | Factor Values (V1,V2,V3,V4) | V1 | V2 | V3 | V4 |
|---|---|---|---|---|---|---|
| DCNv2 | Cross Width | 1k, 2k, 4k, 8k | +0.00% | +0.12% | +0.18% | +0.18% |
| DCNv2 | Deep Width | 1k, 2k, 4k, 6k | +0.00% | -0.01% | +0.10% | +0.15% |
| MaskNet | Cross Width | 512, 1k, 2k, 4k | +0.23% | +0.40% | +0.52% | +0.64% |
| MaskNet | Deep Width | 512, 1k, 2k, 4k | +0.55% | +0.52% | +0.53% | +0.54% |
| MaskNet | Parallel Blocks | 1, 2, 4, 8 | +0.50% | +0.52% | +0.56% | +0.60% |
| MaskNet | Sequential Blocks | 1, 2, 4, 8 | +0.51% | +0.51% | +0.53% | +0.42% |
| Transformer | $d_{\text{model}}$ | 32, 64, 128, 192 | -0.01% | +0.21% | +0.25% | +0.26% |
| Transformer | Sequence Length | 16, 32, 64, 128 | -0.01% | +0.18% | +0.33% | +0.46% |
| Transformer | # of Layers | 1, 2, 4, 8 | -0.03% | -0.01% | +0.01% | -0.03% |
| Transformer | # of Heads | 1, 2, 4, 8 | -0.01% | -0.01% | -0.02% | +0.01% |
| Transformer | $\text{ffn}_{\text{dim}}$ | 128, 256, 512, 1k | -0.02% | -0.01% | -0.03% | -0.04% |
| RankMixer | $d_{\text{model}}$ | 64, 128, 256, 384 | +0.17% | +0.37% | +0.50% | +0.53% |
| RankMixer | Sequence Length | 8, 16, 32, 64 | -0.02% | +0.17% | +0.34% | +0.32% |
| RankMixer | # of Layers | 1, 2, 4, 8 | +0.15% | +0.17% | +0.20% | +0.21% |
| RankMixer | $\text{ffn}_{\text{dim}}$ | 128, 256, 512, 1k | +0.19% | +0.17% | +0.16% | +0.17% |
推理 FLOPs(×10⁷,对应 V1→V4)
| Backbone | Scaling Factor | V1 | V2 | V3 | V4 |
|---|---|---|---|---|---|
| DCNv2 | Cross Width | 4.17 | 6.37 | 12.03 | 28.37 |
| DCNv2 | Deep Width | 4.17 | 7.63 | 18.32 | 34.04 |
| MaskNet | Cross Width | 2.87 | 4.70 | 10.89 | 33.31 |
| MaskNet | Deep Width | 9.62 | 10.89 | 13.41 | 18.45 |
| MaskNet | Parallel Blocks | 6.27 | 10.89 | 20.12 | 38.59 |
| MaskNet | Sequential Blocks | 6.27 | 9.00 | 14.45 | 25.36 |
| Transformer | $d_{\text{model}}$ | 0.87 | 1.85 | 5.18 | 10.19 |
| Transformer | Sequence Length | 0.87 | 1.75 | 4.22 | 12.01 |
| RankMixer | $d_{\text{model}}$ | 1.78 | 4.40 | 13.43 | 27.49 |
| RankMixer | Sequence Length | 0.99 | 1.78 | 39.80 | 10.91 |
(训练吞吐方面,缩放普遍降低吞吐:例如 MaskNet V4 变体在 $2.5\times10^8$ FLOPs 时吞吐下降约 29%,而序列模型在仅一半算力下吞吐已相近或更低——说明 MaskNet 在 per-FLOP 效率上显著更高。RankMixer Sequence Length 行 V3 的 39.80 为原文印刷数值,明显偏离单调趋势,疑似原文笔误,此处忠实转录。)
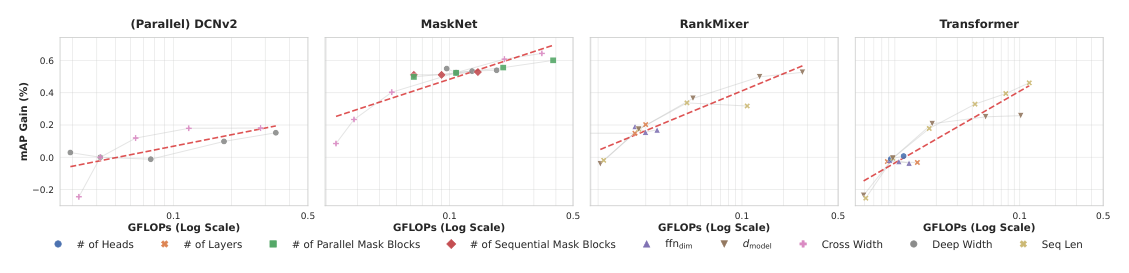
模型骨干层面的结论(Figure 2):
- 在相近 FLOPs 预算(约 $10^8$ FLOPs)下,序列模型(Transformer/RankMixer)优于 DCNv2,与先前发现一致(Transformer 一般优于 DLRM 族)。但精调后的 MaskNet 反超序列模型——作者推测 MaskNet 通过其 cross-scaling 机制更有效地捕捉特征交互,因而胜过带 attention 与 rank-mixing 的序列模型。
- 硬件效率:Table 1 显示 MaskNet V4 变体在 $2.5\times10^8$ FLOPs 时吞吐降 29%,但序列模型在一半算力下吞吐已相近或更低,MaskNet per-FLOP 效率明显更优。
- 显存(memory)是更关键的区分点:尽管 FLOPs 相当,序列模型显存开销不成比例地大,导致无法缩放超过 baseline 因子值的 6×(见 Table 1)。主因是要存储每个时间步的 hidden state 与注意力矩阵以做反传,比 deep-and-cross 同行更早触发 OOM;越深的序列模型显存瓶颈越突出。
- 选对 scaling factor 同样关键:对 deep-and-cross 族,cross-width 缩放比 deep-width 更有效;对 Transformer,缩放 sequence length 是最有效的因子。作者假设这是因为搜索/推荐任务本质上重视显式高阶特征交叉,扩展 MaskNet 的 cross 层与 Transformer 的序列容量能促成更充分的特征交叉。
为佐证这一点,论文做了置换特征重要性分析(permutation feature importance)——打乱单个特征/特征对后测 mAP 波动。结果(Table 2):一阶特征重要性在各模型间一致;但涉及客户 embedding 的二阶交互方差显著。更高 mAP 的模型,其二阶特征重要性分布与 MaskNet 高度吻合。
| Model Type | Feature Category Importance: Engagement | Item/Query Understanding |
|---|---|---|
| MaskNet | 47.90% | 52.10% |
| RankMixer | 46.14% | 53.86% |
| Transformer | 44.03% | 55.97% |
| DCNv2 | 42.36% | 57.64% |
Table 2 结论:顶配变体的 mAP 排名(MaskNet > RankMixer > Transformer > DCNv2)恰好与"二阶特征重要性分布越接近 MaskNet"的顺序一致——这暗示准确学习特征交叉的能力是优越预测性能的首要驱动。
Scaling Properties:与 LLM 中观察到的缩放律及既往研究一致,论文在各骨干和大多数 scaling factor 上观察到 log-linear(对数线性)改进;但不同轴的缩放效率不同,"选对该缩放哪个因子"与"选对初始骨干"同等重要。
4.2 Embedding Scaling 结果¶
对 item embedding,论文同时探索增大 embedding 维度 与 词表大小(靠增大 hash modulo 来扩词表,因系统用 item ID hashing)。结果见 Table 3(MaskNet,基线为 1× 词表 + 16 维 embedding):
| Vocab Size | Emb Dim 16 | 32 | 64 | 128 |
|---|---|---|---|---|
| 1x | +0.00% | +0.05% | +0.10% | +0.12% |
| 10x | +0.02% | +0.09% | +0.13% | +0.16% |
Table 3 结论:缩放 embedding 维度比扩词表更有效——把 embedding 维度翻倍带来的增益超过把词表扩 10×。作者推测这是因为用户互动高度集中在少量"top items"上,扩词表对长尾收益有限。两个维度的增益largely 可加(additive),说明它们捕捉互补信息。
对 query 与 product title 这类文本 embedding,论文聚焦缩放 token embedding 的维度大小:query embedding 翻倍只带来 0.03% mAP,之后即饱和;product title embedding 缩放完全无增益。作者假设:文本 embedding 缩放不像 item ID 这类类别特征那样奏效——单个 text token 需要在不同文本间共享且通用,相比语义非常具体的类别特征,每个 text token 更"泛",所以当 key 在于不同 text token 的混合时,缩放 token embedding 维度的收益有限。
4.3 Data Scaling 结果¶
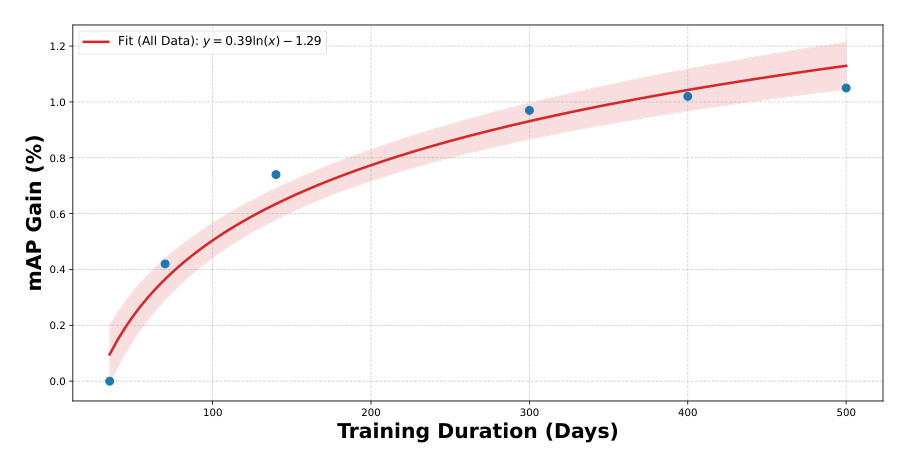
Figure 3 显示 mAP 增益随训练数据量呈可预测的 log-linear 缩放律,拟合为 $y = 0.39\ln(x) - 1.29$。由于训练成本与时间随数据量线性增长,而曲线趋平带来的收益递减,使得单纯靠数据量缩放在生产中极不划算。论文用后文的 warmstart 策略缓解该训练效率瓶颈。
更长训练窗除收益递减外,还带来一个特征 gap:历史日志通常缺少新开发的信号。为评估特征可得性,论文对比"全特征集"与"个性化 embedding 仅限最近 300 天"的配置(个性化 embedding 仅以历史 item engagement 作为输入序列,不含任何 PII):
| Training Days | Full Coverage | Recent 300 days only |
|---|---|---|
| 300 | 1.00% | 0.97% |
| 400 | 1.02% | 1.02% |
| 500 | 1.05% | 1.03% |
Table 4 结论:这个 coverage gap 并未实质性损害性能。这个关键观察支撑了一种更有针对性的特征探索策略——对新特征可以只优先用高信号、近期数据,而无需昂贵的历史 backfill 或仿真。
4.4 缩放的复合效应(Compound Effect)¶
论文检验"组合不同骨干、数据、算力、embedding"时收益能否叠加——若能独立叠加,就允许分别优化每一个,大幅加速整体研发。
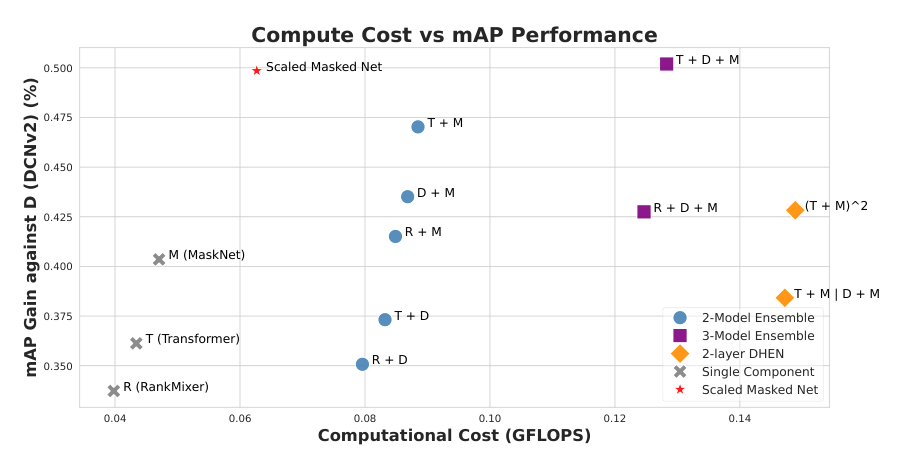
Backbone Ensemble(DHEN):如 Figure 4,单层模型集成在 mAP 上一致地优于单组件,但在评估 mAP-算力权衡时,最终被论文优化后的单骨干架构反超。DHEN 的稳定 mAP 增益使其成为立即拿到生产收益的可靠选择,但缩放单个骨干才是迈向长期 Pareto-最优的更可持续路径。
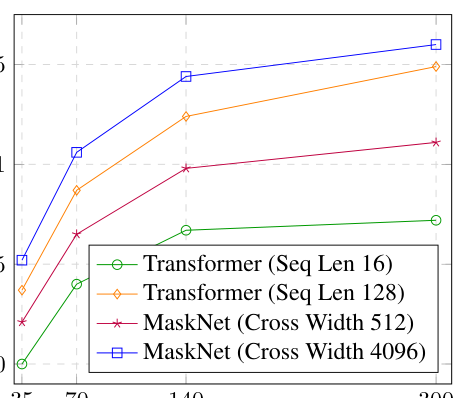
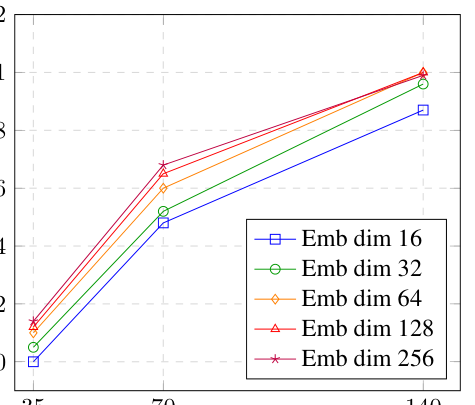
Backbone/Embedding + Data Scaling:Figure 5 显示在不同数据量、不同骨干、不同 item embedding 维度下,相对性能排序在不同数据规模间保持一致。这意味着架构精修可以在小数据上验证、并泛化到全量训练——这正是论文"先在小数据搜架构、再迁移全量"研发范式的实验依据。
All Scaling Combined:Table 5 汇总相对基线的 mAP 增益。同时缩放训练时长、骨干、embedding 共得 +0.74% 提升,证明三者效应互补且 largely 可加:
| Scaling Dimension | mAP Gains (%) |
|---|---|
| Data | +0.47% |
| Backbone | +0.10% |
| Embedding | +0.13% |
| Combined | +0.74% |
Combined (+0.74%) 与三项之和 (+0.70%) 接近,验证了可加性——这正是支撑"分维度独立优化再合并"研发策略的核心结论。
训练与服务优化¶
优化策略针对两大约束:服务延迟与训练迭代速度。论文给出 warmstart、解耦 CPU-GPU 执行、动态批处理三招,并通过连续特征剪枝与把特征预处理移出模型执行进一步降本。
Streamlined Warmstart(加速训练迭代)¶
快速的线上 A/B 需要频繁的离线模型迭代,训练效率因此关键。论文实现了一种 warmstart 策略:先用大数据(如一年数据 + 8× 骨干)训练一个高容量 base 模型,再在最近 140 天上 fine-tune 整个架构。
warmstart 的核心难点:特征变更常改变输入维度,使旧 checkpoint 不兼容。论文的设计是把输入状态投影到一个固定维度的 hidden layer(即前述 cross/sequence 族里对 $\mathbf{x}_0$ 的一层投影),从而可以从既有模型起步而无需关心内部参数兼容性或人工协调。当特征增删时,只重新初始化那一层初始投影,同时 warm-start 所有后续参数。这种"统一更新哲学"(一次性 warm 并更新所有可用层)使 fine-tune 过程和从头训练一样无缝,且评估显示对 mAP 影响可忽略——即 fine-tune 模型质量匹配从头训练。为防累积漂移并保持可复现,论文会周期性或在重大改进上线后重训 base 模型。
Inference Performance Optimization(服务优化)¶
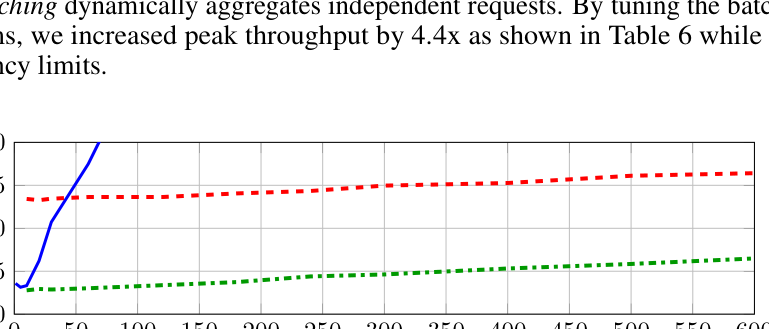
- Hybrid CPU-GPU Execution(解耦图执行):初始 profiling 发现 GPU 通信成为瓶颈,反而使纯 CPU 推理更快。通过拆分计算图——把预处理钉在 CPU、骨干放到 GPU——把 P99 延迟从 82ms 降到 32ms(2.6×)(Figure 6)。
- Dynamic Batching(双层批处理):为最大化 GPU 利用率,采用双层 batching:Client-Side Batching 在上游把候选物品分组,使 GPU 处理 20× 更大的 batch 而延迟开销极小;Server-Side Batching 对高并发流量动态聚合独立请求。把 batch timeout 调到最优的 10ms,在维持可接受延迟下把峰值吞吐提升 4.4×(Table 6)。
| Batch timeout | Peak QPS at 50ms | (×) | Peak QPS at 75ms | (×) |
|---|---|---|---|---|
| 0ms (无动态批处理) | 4.2k | — | 4.6k | — |
| 5ms | 14.0k | 3.33x | 17.1k | 3.72x |
| 10ms | 13.6k | 3.24x | 20.1k | 4.37x |
| 15ms | 13.8k | 3.29x | 19.9k | 4.33x |
| 20ms | 7.0k | 1.67x | 14.0k | 3.04x |
| 25ms | 6.1k | 1.45x | 11.7k | 2.54x |
| 30ms | 5.6k | 1.33x | 9.7k | 2.11x |
Table 6 结论:QPS 以"千物品/秒"计。timeout 太短(5ms)在 50ms 约束下吞吐最高(14.0k);但在 75ms 约束下 10ms timeout 达到峰值 20.1k(4.37×)。timeout 过长(≥20ms)反而因排队拖累吞吐——存在一个甜点。
4.6 在线 A/B 测试¶
系统化缩放在所有关键指标上带来累计增益。论文采用分阶段上线(phased launch)策略:把模型复杂度缩放到 8× FLOPs,同时配合专门的推理优化以保持延迟中性。
| Experiment | Δ Offline mAP | Δ Online Search CVR | Inference FLOPs |
|---|---|---|---|
| Embedding + Backbone Scaling | 1.5% | 1.9% | 8x |
| Data Scaling | 0.6% | 0.7% | 1x |
| Overall Impact | +2.1% | +2.6% | 8x |
Table 7 结论:组合缩放共得 +2.1% 离线 mAP 与 +2.6% 线上搜索转化率。值得注意的是,冷启动(cold-start)方式重训会带来 +264% 训练时间开销,而 warmstart 策略把它压到仅 +36%,从而解锁更高的迭代频率与模型更新速度。
核心贡献总结¶
- 把缩放拆成 backbone / embedding / data 三个维度并系统实测,发现三者收益largely 独立且可加——这是全文最有工程价值的结论,它把"缩放搜索 CVR"从一团混沌变成可分而治之的工程问题。
- "小数据搜架构、全量数据训最终模型"的研发范式:相对性能排序在不同数据规模间保持一致,于是架构搜索与超参优化可在便宜的小数据上做,再迁移到全量。
- Streamlined warmstart:通过固定维度投影层解耦输入变更与内部参数,使 fine-tune 质量匹配从头训练,却把重训开销从 +264% 降到 +36%。
- 服务侧工程配方:解耦 CPU-GPU 图执行(P99 82→32ms)+ 双层动态批处理(峰值吞吐 4.37×),让 8× 算力的大模型仍能低延迟上线。
- 真实线上验证:+2.6% 搜索转化率,延迟近乎不变。
与已归档相关工作的对比¶
HHSFT UniScale / HHSFT(Taobao & Tmall, Alibaba, 2026-03-25)¶
关系:独立并发(本文未引用 UniScale,两者同攻"工业搜索排序的模型缩放"且殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都正面攻击"纯参数/模型缩放在工业搜索排序中收益迅速递减"这一 root cause。UniScale 把它归因为"固定数据量下高表达力模型潜力受限"+"异构数据分布导致退化";本文则归因为"CVR 架构异构使缩放效应在组件/因子间错配 + 收益沿轴衰减"。问题陈述实质同构:都认为模型不能单独做大,必须和数据一起缩放。
- 相近的技术骨架:两者都把缩放显式分解为数据维度 + 架构/模型维度并分别处理,且都在工业搜索排序、用线上 GMV/CVR 验证。
- 本文的差异与推进:这是最有意思的对比——二者在"独立 vs 协同"上给出相反的微观结论。UniScale 的核心假设是数据缩放与架构缩放必须协同演进(synergistic co-design),因此专门设计了 ES3 全空间采样 + HHSFT 异构层次 Transformer + ESUIF 跨域兴趣融合等全新机制来联合缩放;而本文的核心发现恰恰是 backbone/embedding/data 三维largely 独立且可加,因此主张分维度独立优化再合并,并刻意只在既有骨干(DCNv2/MaskNet/Transformer/RankMixer)上做经验缩放。
- 可比的方法/实验差异:UniScale 的"数据缩放"是精巧的样本扩展系统(请求 2×、样本 5×、正样本 4×,含跨域 searchification);本文的"数据缩放"是朴素的时间窗/采样率扩展(70 天为基,最高 500 天),并发现简单扩量极不划算(log-linear 收益递减)。UniScale 几乎不谈 serving 优化,而本文用整整一节讲 warmstart + 解耦 CPU-GPU + 动态批处理。可以认为:UniScale 把工程力气投在"如何把更多更好的数据喂进一个新架构",本文把工程力气投在"如何廉价地缩放既有架构并把它低延迟服务出去"。
Towards Generalizable and Efficient Large-Scale Generative Recommenders Netflix:Generalizable & Efficient Large-Scale Generative Recommenders(Netflix Research, 2026-05-22)¶
关系:独立并发(与本文几乎同时,互不引用;同把"规模能涨"翻译成"生产能用")· 已加载对方精读
- 共同关注的问题:两篇都拒绝"把模型做大就够了"的天真叙事,转而问规模红利能否真正传导到生产。Netflix 的核心论断是 scaling is useful but uneven——不同下游任务有不同缩放轨迹与天花板;本文则强调缩放收益沿轴衰减、且必须在 serving 延迟/成本约束下兑现。两者都把 scaling-law 分析从"一张诊断图"变成"一个研发投资决策工具"。
- 相近的技术骨架:(a) 都用缩放律预判收益/剩余空间,据此决定下一步投资方向;(b) 都重视廉价高频重训(Netflix:采样 softmax + d→d/8 投影解码头;本文:warmstart,重训开销 +264%→+36%);(c) 都把服务约束写进建模/工程(Netflix:MTP 对齐缓存服务的过期标签;本文:解耦 CPU-GPU + 动态批处理)。
- 本文的差异与推进:最值得对照的是缩放律的函数形式之争。Netflix 明确反对 HSTU 式 log-linear $P=a\log N+b$(无法表达有界天花板),改用带饱和上限的 offset power law $P(N)=P_0-(N/N_0)^{-a}$,并用 $P_0$ 度量任务剩余空间;而本文在 backbone/embedding/data 各轴上报告 log-linear 拟合(数据缩放 $y=0.39\ln x-1.29$),并用"收益递减 + 成本线性"来论证单纯扩量不划算。两者其实在描述同一现象(缩放饱和),但 Netflix 把饱和显式参数化为可比的天花板,本文则停留在"曲线趋平、ROI 走低"的工程判断。
- 可比的方法/实验差异:Netflix 是生成式推荐(单骨干 2M→1B、支撑召回/排序/冷启动多任务),评估用 MRR + offset 幂律;本文是搜索 CVR 排序(多骨干 + MMoE 多任务),评估用 mAP(≈MRR)。两者的"独立性"主张维度不同:Netflix 强调缩放在不同下游任务间不均匀,本文强调缩放在不同因子(backbone/embedding/data)间独立可加——一个切任务、一个切因子,互为补充。
讨论与局限性¶
核心贡献与可借鉴之处:本文最大的价值不在任何单点技术,而在于把"工业搜索 CVR 缩放"做成了一份可操作的经验手册。三条最值得借鉴的设计:(1) 缩放维度的独立可加性——一旦验证(Table 5:Combined +0.74% ≈ 三项之和),就能把昂贵的"联合搜索"降维成"分头优化再相加",研发效率成倍提升;(2) 小数据搜架构、全量训部署——相对排序跨数据规模稳定(Figure 5),让架构选型几乎免费;(3) warmstart 的固定维度投影层——用一个工程小技巧把"特征变更导致 checkpoint 不兼容"这个老大难拆掉,重训成本从 +264% 砍到 +36%。服务侧的解耦图执行 + 动态批处理也是可直接复用的落地经验。
局限与争议:
- 不是新架构,是经验研究:论文自己定位为 empirical study,缩放的都是既有骨干;MMoE 表征变换组件被明确排除在研究之外(留作 future work)。这也是它在本库被打 7 分进精读、而非更高分的原因。
- "独立可加"可能是数据/场景特定的:本文在 Coupang 单一电商搜索数据上得出三维独立可加,而 UniScale 在 Taobao 得出"数据与架构必须协同"——两者结论相反,说明独立性本身可能依赖数据分布、特征体系与骨干族,并非普适规律。论文也坦承 "mileage may vary"。
- 缩放律形式偏弱:相比 Netflix 的 offset 幂律,本文的 log-linear 拟合无法显式表达天花板,只能靠"曲线趋平"做定性判断,对"还该不该继续投容量"的量化决策支撑较弱。
- 个别数据存疑:Table 1 中 RankMixer Sequence Length 的 V3 推理 FLOPs(39.80)明显破坏单调性,疑为印刷笔误。
工业落地价值:论文给出了完整的部署细节与业务收益——8× 推理 FLOPs、2.5× 训练数据、延迟近乎不变,换来线上搜索转化率 +2.6%(离线 mAP +2.1%),并通过分阶段上线 + warmstart 控制了训练与服务成本。对任何想把"缩放律"从论文搬进高流量在线 CVR 系统的团队,这是一份信息密度很高的工程参考。