LLM Retrieval for Stable and Predictable Ad Recommendations:用 LLM 语义召回换取广告系统的"可预测性"¶
来自 Meta Platforms(Menlo Park & New York),发表于 SIGIR Workshop AgentSearch 2026。这是一篇偏"问题框架 + 系统设计"的工业短文(5 页),核心贡献有两条:(1) 提出一套量化广告推荐系统稳定性 / 可预测性(stability / predictability)的度量框架——尤以 A/A'(StatSigDiff) 指标为代表;(2) 提出一个由微调 LLM 驱动的语义召回框架——从广告创意中抽取层级语义属性,构建 ad-to-ad 语义图并图遍历扩展候选,在 Meta 大规模广告系统的线上 A/B 中同时改善了可预测性和传统性能指标。
研究动机与背景¶
从"预测准确率"到"可预测性"的范式转变¶
传统广告推荐系统几乎只围绕预测准确率做优化:用 Recall、NDCG、Normalized Entropy 等标准指标衡量点击 / 转化事件的预测质量。但随着生成式 AI 技术推动广告库存(inventory)和流动性(liquidity)的超高速增长,论文提出一个被工业界长期忽视的维度——预测的稳定性与可预测性(prediction stability and predictability)正变得愈发关键。
论文给"可预测系统"下的定义是:一个系统的输出,应当随输入 / 数据 / 参数的变化以一种鲁棒、可解释、因果的方式改变,并与广告主的预期相一致。 直觉上,稳定性 / 可预测性刻画的是系统对微小 / 噪声级输入扰动(广告、创意的轻微改动)的鲁棒程度。缺乏这种鲁棒性会直接引发广告主可感知的问题:
- 可重复性(repeatability):同一广告主对创意做了无关紧要的小改动,投放结果却天差地别;
- 冷启动(cold start):新创意因缺乏历史信号被系统埋没;
- 欠探索(under-exploration):系统过度依赖少数非语义信号,无法触达语义上等价的候选。
问题的 root cause:系统依赖非语义特征¶
论文把这一系列问题的根因归结到——系统在召回 / 排序时过度依赖原始 ad ID、稀疏特征等非语义信号。这些信号对创意的微小扰动极其敏感:换一个 ad ID、改一处创意文本,系统就可能给出截然不同的投放路径。
该问题在排序阶段已有人尝试解决——通过把特征从 raw ad ID 迁移到 semantic ID(论文引用 [2],RecSys'25 关于 semantic id 增强 embedding 表征稳定性的工作)。而本文聚焦于召回(retrieval / candidate generation)阶段,主张用 LLM 做语义感知的候选生成,从根上提升系统的语义感知能力,从而让"语义等价"的广告变体获得一致、可解释的投放结果。
为什么选 LLM:语义感知 + 层级结构¶
论文论证了在召回阶段引入 LLM(如 Llama)的三点理由:
- 丰富的上下文理解(Rich Contextual Understanding):LLM 能处理海量上下文,产出细腻的广告表征,提升候选选择的准确性;
- 语义感知(Semantic Awareness):LLM 利用广告的 title、description 等输入捕捉语义含义,把语义相近的广告在表征空间里聚到一起;
- 从 LLM 元数据导出层级 / 图结构(Hierarchy/Graph Structure):LLM 生成的元数据可用于构建"广告为节点、共享属性为边"的图,支撑高效的候选扩展与系统可预测性。
论文反复强调召回阶段需要的两个关键属性是 semantic-aware(语义感知) 与 hierarchical(层级化):语义感知保证抓住"用户真正在乎的高层概念"(在售的产品、被推广的 App);层级结构则便于做基于聚类的高效计算。LLM(尤其 Llama)恰好同时具备这两点。
度量定义:可预测性框架(本文核心新贡献)¶
论文建立了一套度量系统可预测性与性能提升的指标体系:
- Recall@k:衡量集合级相关性,检索评估的标准指标;
- Online top-line metric(线上顶线指标):在大规模工业广告系统里,衡量线上 A/B 中投放出去的广告价值(论文未披露具体定义,属内部顶线指标);
- Predictability(又称 A/A' difference):在输入发生微小改动时维持一致的投放表现。这里 A' 表示 A 的一个微扰版本(A 是广告或创意这类输入实体)。它确保广告表现不会随创意小更新而不可预测地剧烈波动,避免投放低效;
- Median Absolute Deviation(MAD,中位绝对偏差):量化上述 A/A' difference 在一段时间内的波动性。
A/A' 与 StatSigDiff 的构造(论文最值得借鉴之处)¶
由于"可预测性"是个相对新的概念,论文对其度量构造做了较详细的说明。其高层思想是:在不改变语义含义的前提下,衡量系统输出对输入扰动(A vs A')的差异。
为落地这一系统级 A/A' 差异,Meta 内部搭了一套框架:为每条原始广告(primary ad)发布一份影子副本(shadow ad)。所谓 A/A',shadow 就是 primary 的一份拷贝——拥有独立的 ad ID,并对某个关键特征做扰动以模拟一次微小改动。系统通过比较 primary 与 shadow 的归一化转化数来度量可预测性(即 A/A' 差异)。
对一对 (primary, shadow) 广告 $(ad_p, ad_s)$,记其转化数的相对差异为 $\Delta$。在"两条广告被等量投放"的零假设下,$\Delta$ 的方差可用高斯近似为 $2/(conv(ad_p)+conv(ad_s))$,其中 $conv(\cdot)$ 是该广告被优化的转化数。据此定义两者之间的 Stat-Sig Difference(统计显著差异):
$$ \mathrm{StatSigDiff}(ad_p, ad_s) = \max\left(0,\ \Delta - 1.65 \cdot \sqrt{\frac{2}{conv(ad_p) + conv(ad_s)}}\right). \tag{1} $$
其中 1.65 个标准差对应高斯分布零假设下的 90% 置信区间——即扣除掉在统计上不显著的部分,只保留"真实超出噪声"的差异。
系统级的 StatSigDiff 指标则是把所有 (primary, shadow) 对的 $\mathrm{StatSigDiff}(ad_p, ad_s)$ 按收入加权聚合,再用总收入归一化:
$$ \mathrm{StatSigDiff} = \frac{\displaystyle\sum_{i=1}^{N} \mathrm{StatSigDiff}(ad_p^i, ad_s^i)\cdot \sqrt{rev(ad_p^i)+rev(ad_s^i)}}{\displaystyle\sum_{i=1}^{N} \sqrt{rev(ad_p^i)+rev(ad_s^i)}}, \tag{2} $$
其中 $N$ 是生成的 (primary, shadow) 对的总数,$rev(\cdot)$ 是广告的总收入。用 $\sqrt{rev}$ 加权,既让高收入广告对的差异占更大权重,又避免被极少数巨头广告完全主导。
物理含义:低 StatSigDiff 反映强语义感知——系统对语义等价的微扰输出一致,说明它真的"理解"了广告的语义;高 StatSigDiff 则表明系统依赖非语义特征,一换 ID / 改创意就投放剧变。论文指出 StatSigDiff 由于固有随机性不可能为零,但它是模型开发中一道关键护栏指标(guardrail)。
MAD 的定义¶
可预测性的波动性用 MAD 衡量。先定义一对 (primary, shadow) 在某天的曝光相对差异:
$$ \text{rel. diff. of impression} := \frac{\sum_{(ad_p,ad_s)} \text{Impression}(ad_p)}{\sum_{(ad_p,ad_s)} \text{Impression}(ad_s)} - 100\%, $$
再取其在测试期内逐日序列对中位数 $m$ 的绝对偏差中位数:
$$ \mathrm{MAD} := \mathrm{median}\big(\,|\text{rel. diff. of impression}(day_i) - m|\,\big). $$
MAD 越小,说明系统在时间维度上越稳定。
核心方法 / 模型架构¶
高层设计¶
大多数大规模广告推荐系统采用级联多阶段(cascading multi-stage)范式:多路召回(multi-routed candidate generation) + 一个或多个重排(re-ranking)阶段。论文主张,提升系统可预测性(式 (2) 定义)的关键,是为用户和物品找到正确的语义表征;本文只聚焦召回阶段。召回器的首要目标是在 infra 容量允许的范围内,尽可能多地把潜在相关候选传给下游,以提升最终阶段召回率。
论文的高层设计三步走:
- 取一个预训练 LLM,在广告数据集上用召回特定任务做微调(本文称已有一个在广告互动数据上微调好的自研 LLM);
- 用该 LLM 推断广告的层级语义属性,以及一张基于属性相似度(如 Jaccard 相似度)的关系图;
- 应用图遍历算法从种子广告(seed ads)出发扩展,实现语义 ad-to-ad 相似度扩展并优化召回。
根本假设(fundamental hypothesis):微调后的 LLM 能更好地召回那些属于同一语义等价类(semantic equivalence class)、却会被传统方法漏掉的广告候选。
端到端系统设计:四大支柱¶
论文列出实现 LLM 召回的四个系统组件:
4.1 LLM 驱动的广告表征学习。 把广告创意和产品描述转换成高维语义向量。这一步用先进的 Instruct LLM,将世界知识编码成召回特定的离散 token,并据此构建语义图,从而支撑 ad-to-ad 扩展的候选召回。该法能捕捉细致的文本与品类细微差别,显著提升后续推荐质量。
4.2 可扩展的 LLM 处理基础设施。 大规模产出广告级表征需要一套鲁棒、可扩展的分布式处理框架,满足严苛的延迟与吞吐要求。如 Figure 1 所示,关键组件包括 LLM 广告元数据生成、Ad-to-Ad 相关性打分、跨高性能 GPU 的水平扩展,以支持高效批推理。
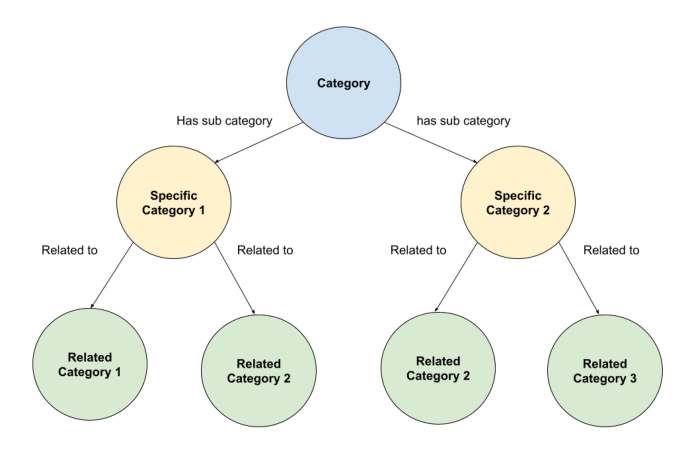
![Figure 1: LLM Ad to Ad Generator——输入种子广告 Ad_x,经"Ad Metadata from LLM"做候选召回(Category / Specific Category / Related Categories)得到候选集 {Ad_x1, Ad_x2, ...},再经 Relevance Scoring(Brand-Product / Temporal / Personalized 三类相关性)输出带相关性分数的相关广告列表 [(Ad_x5, S_x5), (Ad_x10, S_x10), ...]](figures/fig_02.png)
4.3 语义导航——图遍历算法。 语义导航基于一张由 LLM 抽取的品类与属性构成的图来扩展候选广告。通过遍历这张语义图,系统找到上下文相似广告的簇,实现动态、相关的推荐(见 Figure 2)。具体分两步:
- Step1 – Retrieval(召回):用 LLM 表征计算品类级相关性,为每个候选检索一批近似相关的候选;
- Step2 – Relevance Scoring(相关性打分):在 brand、product、上下文属性等更深维度上对 ad-to-ad 相似度打分。
两步都采用基于 Jaccard 相似度的模糊集合匹配(fuzzy set matching):先做短语级匹配,匹配不足时回退到 token 级匹配:
$$ S_R(Ad_1, Ad_2) = \begin{cases} S(P_{Ad_1}, P_{Ad_2}) & \text{if } S(P_{Ad_1}, P_{Ad_2}) \ge \theta \\ S(T_{Ad_1}, T_{Ad_2}) & \text{otherwise} \end{cases} $$
其中 $P_{Ad_1}, P_{Ad_2}$ 是短语集合,$T_{Ad_1}, T_{Ad_2}$ 是 token 集合,$\theta$ 是短语匹配的阈值。这种"短语优先、token 兜底"的设计,在保证精度的同时保留了召回的鲁棒性。
4.4 实时候选召回与服务。 实时召回 / 服务层提供高吞吐召回,并与下游排序模块兼容。论文自建的实时召回服务框架是候选生成的基础设施,通过优化 LLM 推理来最大化 GPU 主机利用率,确保低延迟服务与高效在线召回。
两阶段候选生成的形式化¶
借助上述四大支柱,LLM 候选生成主要发生在两个阶段(对应 Figure 1):
Stage 1:品类、属性与上下文标题生成。 把广告映射到带分数的品类集合:
$$ f_1(Ad) \longrightarrow S_{textAd}(C) \longrightarrow \{(c_1, s_1), (c_2, s_2), \cdots, (c_n, s_n)\}, \tag{3} $$
其中 $S_{Ad}(C)$ 是该广告的品类集合,$C$ 是品类,$s$ 是对应分数。
Stage 2:相似广告召回。 召回函数对两条广告在其共同品类上的分数做内积求和:
$$ S_R(Ad_1, Ad_2) = \sum (S_{Ad_1}(c) \times S_{Ad_2}(c)), \quad \text{for } c \in C_{Ad_1} \cap C_{Ad_2}. \tag{4} $$
即:两条广告共享的品类越多、且在这些品类上的 LLM 置信分越高,它们的 ad-to-ad 相似度就越大,越可能被互相召回为语义变体。
实验设置¶
Infra setup¶
- 模型:采用开源、纯文本的 Llama3-8B Instruct 模型,利用其 zero-shot 推理能力生成补充元数据(注:此处与 §3 "已有自研微调 LLM"的表述存在口径不一致,见局限性讨论);
- 数据:约数千万(tens of millions)条数据点,仅使用文本描述生成补充元数据;
- 评估形式:线上 A/B test。
- Test 臂:在广告召回阶段引入 LLM 召回器,其余投放链路保持不变;
- Baseline 臂:一个由 two-tower、embedding、graph-based 召回器组成的集成(ensemble),用以衡量 LLM 语义召回器带来的增量价值。
评估框架¶
评估看两类指标:(1) 标准广告性能指标——广告点击与转化;(2) A/A' 可预测性指标(式 (2)),并额外测量逐日的曝光相对差异的 MAD,量化 A/A' 在时间维度的波动。
主要实验结果¶
投放性能提升(Delivery Performance)¶
在标准广告性能指标上,实验显示对实验分段的线上顶线指标有统计显著的 +0.45% 提升;从召回角度看,treatment 让最终阶段召回率提升 1.2%,验证了语义候选生成在捕捉用户意图、投放高相关内容上的核心假设。
论文用 Table 1 展示了 LLM 召回器的质量感知排序行为(数值经脱敏处理,以 X / Y 占位表示比例,非绝对值):
| Top-K | Recall Alignment Ratio | Incremental Recall Potential |
|---|---|---|
| 5 | 0.51X | 1.00Y (baseline) |
| 10 | 0.44X | 1.15Y |
| 50 | 0.21X | 1.62Y |
| 100 | 0.13X | 1.77Y |
| 200 | 0.07X | 1.89Y |
表 1 解读:
- Recall Alignment Ratio(召回对齐比)从 Top-5 的 0.51X 单调下降到 Top-200 的 0.07X——在小 K 处的质量对齐浓度高出约 7 倍。论文解释:假设 1.0X = Top-K 候选的 100%,这一单调下降模式证明 LLM 有效地把与 baseline 顶部推荐对齐的高质量候选优先排在前面(即 LLM 召回的头部候选与现有系统的优质推荐高度重合,说明它没跑偏);
- Incremental Recall Potential(增量召回潜力)则相反,从 Top-5 的 1.00Y 增长到 Top-200 的 1.89Y(约 1.89 倍)。论文称即便在 Top-5,LLM 也能带来 0.49X(记作 Y)的增量召回潜力,到 Top-200 扩张到 1.89 倍——说明 LLM 在对齐既有优质候选之余,还有可观的能力去补充多样、互补的新推荐。
这两条曲线一升一降,共同刻画 LLM 召回器的理想行为:头部对齐(不破坏现有优质投放)、尾部扩展(带来增量多样候选)。
系统可预测性提升(A/A')¶
实验在线上 A/B 中展示了顶线 A/A' difference 相对降低 8.62%(test vs control,统计显著)。此外如 Figure 3 所示,test 相比 control 在逐日曝光差异的 MAD 上改善了 45%。这印证了本方法在降低方差、通过召回层实现更一致广告表现上的有效性。
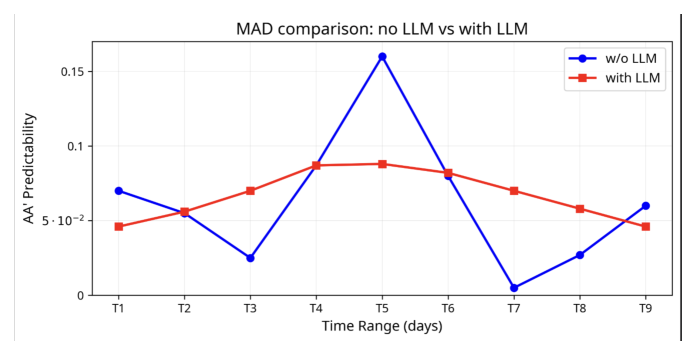
图 3 解读:不带 LLM 的对照组(蓝线)在测试期内可预测性曲线大起大落(T5 尖峰、T7 谷底),意味着同一对 A/A' 广告的投放在不同日子里极不稳定;带 LLM 的实验组(红线)则把曲线压平到一个窄区间内。可预测性的改善直接来自召回层语义感知的增强——语义等价的广告变体被一致地召回和投放,而非随非语义特征漂移。
核心贡献总结¶
- 提出广告系统"可预测性"度量框架:用 A/A' difference、StatSigDiff、MAD 等指标,首次较系统地把"系统对微扰输入的鲁棒性"量化为可优化、可监控的护栏指标(shadow ad 机制 + 收入加权的 StatSigDiff 是其最具借鉴价值的设计);
- 提出 LLM 语义召回框架:从广告创意抽取层级语义属性 → 构建 ad-to-ad 语义图 → 图遍历扩展候选,保证语义变体被一致召回;
- 大规模工业验证:在 Meta 广告系统线上 A/B 中,同时取得顶线 +0.45%、最终召回 +1.2%、A/A' difference −8.62%、MAD +45% 的改善;
- 可迁移的通用框架:虽在广告栈验证,但论文主张该框架可广泛迁移到任何面临类似 scaling 与可预测性挑战的大规模推荐 / 召回系统。
与已归档相关工作的对比¶
本文最值得对照的,是 2026 年第二季度多家工业团队"不约而同"地得出的同一条核心 insight:工业推荐系统对非语义 item-ID 特征的依赖,是冷启动 / 不稳定 / 不可预测的 root cause,而解法是用 (M)LLM 从物品内容派生出层级语义表征。本文未引用以下两篇,三者属独立并发、殊途同归。
FLUID FLUID:用多模态语义码彻底退役"短命 item ID"(TikTok, 2026-05-20)¶
关系:独立并发(本文未引用 FLUID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两文的问题框架几乎重合——ID-based 协同过滤依赖的 item ID 是脆弱的非语义信号:FLUID 指出直播间中位生命周期仅约 40 分钟,item ID embedding 在下播前都欠训练(40 分钟时范数仅 0.86,比稳态 1.2 低约 28%),"ID-dominance 从可容忍麻烦升级为根本瓶颈";本文则指出 raw ad ID / 稀疏特征对创意微扰极敏感,引发 repeatability / cold-start / under-exploration。两者都把矛头指向"非语义 ID 的脆弱性",都把冷启动与稳定性作为核心诉求。
- 相近的技术骨架:两文都主张用内容编码器(LLM)派生层级语义表征来取代 / 增强脆弱的 ID。FLUID 用跨域 SigLIP2+Qwen3 编码器产出 128 维 embedding,经 RQ-KMeans 离散成 4 级分层码 LUCID;本文用 LLM 从创意抽取 category→specific→related 的层级属性。两者都强调层级化(hierarchical)是关键属性。
- 本文的差异与推进:(1) 作用阶段不同——FLUID 作用于排序器(late-fusion 把 LUCID 作为 token 注入、退役候选侧 item ID),本文作用于召回 / 候选生成阶段;(2) 表征形态不同——FLUID 是离散量化码 + token 融合,本文是显式文本属性 + Jaccard 相似度图 + 图遍历;(3) 稳定性的度量——FLUID 用线上观看时长 / 冷启动房间曝光等业务指标侧证稳定性,本文则专门设计了 A/A'(StatSigDiff)护栏指标直接量化"对微扰的鲁棒性",这是本文相对 FLUID 在"可预测性"度量上的独特推进。
- 可比的方法 / 实验差异:FLUID 线上 +0.55% Quality Watch Duration、+2.05% Cold-Start Room Views,方法描述与消融远比本文充分(本文数值全脱敏、无消融);但本文的 shadow-ad / StatSigDiff 框架提供了 FLUID 缺失的"可预测性可量化"视角。两者结合可看作"内容语义表征"这一思路在召回与排序两端、图遍历与离散码两种形态上的并行探索。
IDProxy IDProxy:用 MLLM 代理 ID embedding 救冷启动(Xiaohongshu, 2026-03-02)¶
关系:独立并发(本文未引用 IDProxy,两者殊途同归)· 已加载对方精读
- 共同关注的问题:IDProxy 的 root cause 同样是 ID embedding 在冷启动 / 新物品上训练不充分 → CTR 预测差,小红书持续上传海量新内容使该问题尤为突出;与本文"非语义 ID 对微扰 / 新创意脆弱"高度同构。两文都服务工业广告 / 内容场景(IDProxy 在 Display Ads + Content Feed 上线)。
- 相近的技术骨架:两文都用 (M)LLM 作为内容编码器,产出可替代 / 增强脆弱 ID 的语义表征。IDProxy 用 InternVL 的中间层隐藏状态产出 proxy embedding,且采用层级表示分区(把 transformer 层 k-means 聚成浅 / 中 / 深三组)——与本文"层级语义属性"在"层级化"思想上呼应。
- 本文的差异与推进:(1) 目标取向不同——IDProxy 把内容表征对齐到既有 ID embedding 空间(对比学习把 proxy 拉向 ID embedding),哲学上是"让内容模仿 ID";本文则用语义属性图直接驱动召回,哲学上是"用语义取代 / 旁路 ID"。(2) 作用阶段不同——IDProxy 注入 CTR 排序器(把 proxy 作为 item 特征端到端训练),本文作用于召回。(3) 稳定性维度——IDProxy 主打冷启动 AUC 增益(离线 +0.14% ΔAUC),未显式度量"对微扰的可预测性";本文的 A/A' 框架是其没有的视角。
- 可比的方法 / 实验差异:IDProxy 有清晰的两阶段方法、对比学习损失、残差门控融合与系统消融(v1–v5),严谨度高于本文;本文胜在提出了可监控的可预测性护栏。三篇并置可见:"LLM 内容语义表征救 ID 脆弱性"是 2026 工业界的一条共识路线,分歧只在于切入的流水线阶段(召回 / 排序)、表征形态(属性图 / 离散码 / 代理 embedding)与稳定性的度量方式。
讨论与局限性¶
值得借鉴的设计:本文最大的亮点不在召回方法本身(LLM 抽属性 + 图遍历并不新颖),而在 A/A' 可预测性度量框架。"为每条 primary 广告发布一份扰动过关键特征的 shadow 副本,用收入加权的 StatSigDiff(扣除 90% 置信噪声后的转化差异)做系统级护栏"——这是一套可直接迁移到任意大规模推荐系统的、把"鲁棒性 / 可预测性"工程化为可监控指标的方法论,弥补了传统只盯准确率指标的盲区。
局限与争议:
- 方法描述高度抽象:四大支柱、两阶段流程多停留在框架图层面,缺乏关键工程细节(图如何增量构建与维护、遍历的复杂度与截断策略、属性抽取的 prompt / 任务设计等均未交代);
- 实验数据全脱敏、不可复现:Table 1 用 0.51X / 1.00Y 等占位符,无任何绝对数值;无公开学术 benchmark;baseline 仅一个未具名的集成召回器;无消融实验,无法判断是 LLM 语义、图遍历还是单纯多一路召回带来的增益;
- LLM 口径自相矛盾:§3 称"已有在广告互动数据上微调好的自研 LLM",§5.1 却称用"Llama3-8B Instruct 的 zero-shot 推理"——到底是微调还是 zero-shot,论文未澄清,这对"微调让 LLM 召回同语义等价类候选"这一核心假设的成立性是个隐患;
- 多阶段解耦的扩展性隐患:LLM 属性抽取 → 离线建图 → 在线遍历是显式解耦的流水线,图一旦构建即固化,无法与下游排序端到端联合优化;参数量 scaling 时,"如何表征广告"与"如何召回 / 建模"两条路径难以同步增长;
- 作为 SIGIR Workshop 短文,本文定位更接近"问题框架 + 工业实践分享",技术深度与实验严谨度都明显弱于同主题的 FLUID / IDProxy 等正会工作。
综合判断:核心贡献是"可预测性"这一被忽视维度的度量框架(A/A' / StatSigDiff / MAD)与 Meta 级线上验证,值得作为"如何工程化衡量推荐系统稳定性"的参考;但其召回方法本身偏薄、实验脱敏、口径不一,方法层面的可借鉴度有限。