LLM-Based User Personas:把"自然语言用户兴趣画像"做进十亿级视频推荐的实时服务链路¶
来自 Google / Google DeepMind(Haoting Wang、Haokai Lu、Minmin Chen、Ed Chi、Lichan Hong 等)。一句话:在一个服务十亿级用户的商业视频推荐平台上,用 LLM 实时生成自然语言的用户兴趣画像(persona)——既有总结现有兴趣的 Summarized Interests(开发/exploitation),又有借 LLM 世界知识外推新主题的 Exploration Interests(探索/exploration),二者在单次推理调用里一起产出;再用知识蒸馏(Gemini 1.5 Pro 教师 → Gemini Nano/Flash 学生)+ 异步离线生成 + 量化的服务架构,把"在线 LLM 推理"这件昂贵的事压进工业延迟/成本预算。线上 A/B(30+ 天)拿到观看时长 +0.04%、活跃用户 +0.03%(均 $p<0.05$),且增益主要来自轻度用户(casual users);用户调研中 >80% 认为画像"非常贴切",57% 在与知识图谱实体基线的对比中明确偏好 LLM 画像。
⚠️ 注:这是一篇工业系统/落地导向的论文,正文几乎不含数学公式,核心价值在于(a)"自然语言画像 + 探索"的产品定位,(b)蒸馏 + 异步服务的成本工程,以及(c)离线/调研/线上三层实验证据。本文忠实重现其全部关键实验数值与表格。
研究动机与背景¶
LLM 进入推荐:三条已有路径,以及它们共同回避的东西¶
近年 LLM 进入推荐系统主要走了三条路:
- 内容理解:用 LLM 从标题、描述等文本元数据里抽取更丰富的 item embedding(refs [12,14]);
- 视觉理解:用缩略图、采样帧等视觉信息增强 item 表征(ref [22]);
- 结构化输出:让 LLM 直接产出 结构化 ID(content id / cluster id,refs [15,22,24]),喂给传统的基于 ID 的检索/排序链路。
论文一针见血地指出:这些方法普遍绕开了"自然语言生成",转而用结构化 ID 来和现有的 ID-based 推荐基础设施无缝对接。这个权衡牺牲了文本描述里那种丰富、细腻的语义,也放弃了面向用户、可读的兴趣摘要(human-readable interest summaries)这类用户侧特征。此外,由于巨大的算力成本和严苛的延迟约束,这些应用几乎只能在离线或近离线容量下运行,无法响应用户的即时意图、无法捕捉快速演化的兴趣。
现有 LLM 用户理解工作的三大硬伤¶
论文把已有 LLM 用户理解工作(PALR [28]、TALLRec [1]、RLP [7] 等)的局限归纳为三点:
- (1) 同步设计在十亿级规模下成本/延迟不可行:这些工作多为同步(synchronous)设计,代价与延迟都无法部署到十亿用户规模,因此只在学术 benchmark 上评测——而学术数据缺乏工业生产环境的规模、复杂度与噪声特征。
- (2) 微调 LLM 去做传统推荐任务,反而强化反馈回路偏差:这些工作通常把 LLM 微调去做 item ranking、二分类预测等传统推荐任务,结果无意中强化了现有系统反馈回路(feedback loop)的偏见。
- (3) 绕开显式自然语言画像,牺牲可解释性与 serendipity:一些工作直接绕过显式的自然语言用户画像生成,从而放弃了语义画像本可提供的可解释性与意外惊喜(serendipity)。
论文特别点名近期工业工作 Fabbri et al. [6]:它确实用了自然语言用户画像,但(a)严格限于离线评测、仅涉及 47 个用户;(b)在其框架里 LLM 画像仅作为对现有兴趣的被动验证器(passive verifier),而非生成源。本文的根本推进在于:把 LLM 画像直接嵌入实时服务链路,作为主动驱动用户探索的实时检索源。
论文还把自己与其它"规模化推理"工业框架(refs [16,22,24,25])做了两维对比:
- 用户表征维度:受限于离线查找表(lookup table)的组合复杂度,像 [16,22,25] 这类方法只能用用户最后 2 个观看视频的 cluster 标签,抓不住长期兴趣;本文直接处理长上下文观看历史,能对长期 + 快速演化的兴趣同时推理。
- 画像质量维度:已有工作把 LLM 限制在一个小而固定的预定义 cluster 词表里输出,且严格离线批处理;本文让 LLM 作为真正开放式的搜索代理,生成自由形式的自然语言兴趣 + 显式推理轨迹(reasoning traces),从而捕捉细腻语义并直接提供用户侧可解释特征。
两大核心贡献¶
- 高质量自然语言画像生成(High-Quality Natural Language Persona Generation):提出一种把噪声交互数据合成为简洁、细腻的文本兴趣摘要的方法;关键是它超越了单纯的兴趣总结——借助 LLM 的世界知识与推理能力外推出新颖主题做兴趣探索(exploration),直接缓解反馈回路。为让这个"总结 + 探索"双目标可规模化,采用知识蒸馏把大教师模型的复杂推理能力迁移到高效的小学生模型。
- 成本高效的在线推理架构(Cost-Efficient Online Inference Architecture):设计并实现一套能在十亿用户规模下、严苛延迟/资源预算内做在线 LLM 推理的基础设施;核心是一条异步生成流水线(asynchronous generation pipeline),把"推理"与"在线服务"解耦,辅以模型量化和鲁棒安全机制。
通过大规模 A/B 验证,论文报告了观看者价值(viewer value)统计显著的提升,并通过用户调研确认了对 LLM 生成兴趣画像的高满意度。
3. 预备知识(Preliminaries)¶
3.1 分层规划范式(Hierarchical Planning Paradigm)¶
本文建立在一个混合分层规划范式(refs [22,23,25])之上:用 LLM 推理出用户的兴趣画像(自然语言),把"自然语言兴趣"转化为 item 推荐。推荐过程被解耦成:
- 高层语言策略(high-level language policy):LLM 生成一段对用户"下一个兴趣"的语言描述;
- 低层 item 策略(low-level item policy):经典推荐模型把这些兴趣接地(ground)到 item 空间。
把文本兴趣映射回 item 空间已有几种做法:
- 用基于 transformer 的序列模型(ref [21])配合受限最近邻搜索(restricted nearest neighbor search)(ref [8]);
- Covington et al. [4] 在 item embedding 与 user embedding 的点积空间里做最近邻检索。
本文在这套架构上引入一个语义约束:把最近邻检索限制在与 LLM 生成的文本兴趣语义相关的 item 子集上,从而把生成空间收束到用户的文本兴趣之内。另一类做法是双编码器深度网络(refs [2,10,13,29]),把用户搜索查询与历史交互编码成稠密向量。本文最终采用transformer 序列模型 + 受限最近邻搜索,以充分复用生产环境里已经高度优化的序列模型。
3.2 用户历史聚类(User History Clustering)¶
为给 LLM 提供一个语义可读的用户表征,论文比较了两种聚类用户历史的方式:
- 基于 embedding 的聚类(Embedding-based Clusters):用一种分层视频聚类算法(ref [17])对音频/视觉 embedding 聚类。该算法可扩展、在线、基于密度,处理新视频的连续流,产出两级层级(底层细粒度 cluster + 随时间合并邻近细 cluster 得到的宏 cluster),并产出稳定的 cluster 标识。问题:其组织原则是感知相似性(perceptual similarity)——把"看起来/听起来像"的视频归在一起,而非共享某个抽象概念,因此缺乏语义意义,不适合生成细腻、人类可读的兴趣画像。
- 基于语义的聚类(Semantic-based Clusters):采用 Infinite Concept Personalized Clustering 算法(ref [3]),按语义概念把历史视频分组。每个视频用 salient terms(显著词)表示——一组 unigram/bigram,每个带一个 $[0,1]$ 的 salience score(显著度),描述该词与视频的相关程度。算法按时间顺序遍历用户历史:对每个新 item,计算其 salient terms 与各已有 cluster 质心的余弦相似度,据相似度阈值新建 cluster 或更新最近 cluster;最后剪除视频数过少的 cluster。
论文在离线评测里发现:语义聚类产出的兴趣画像质量更高(见 Figure 3(a)),因此训练数据收集阶段采用语义聚类来组织用户历史。
4. 方法(Method)¶
方法部分解决两个核心挑战:(1) 生成高质量的用户兴趣画像;(2) 构建能在十亿用户规模下、逐用户做 LLM 推理的成本高效系统。
4.1 用户兴趣画像生成(User Interest Personas Generation)¶
在单次推理调用里完成一个复杂的双功能任务,生成一份兼顾开发与探索的整体画像:
- Summarized Interests(总结兴趣,开发):分析用户交互历史,合成简洁、人类可读的文本标签,刻画其已有偏好;
- Exploration Interests(探索兴趣):借助 LLM 的世界知识与推理,为每个总结兴趣生成新颖但语义相关的主题,facilitating 探索。
4.1.1 用户表征(User Representation)¶
要让 LLM 同时做"总结 + 探索",必须把用户交互历史表示成LLM 语义可达的格式。传统推荐里用户被表示成一串 item ID,再映射到稠密 embedding,但这些数值 ID 对 LLM 不透明——缺乏自然语言推理所需的语义上下文。因此必须从 ID-based 转向 text-based 用户表征。论文研究了"哪种文本表征最适合总结任务",得到三条洞察:
- Insight 1:视频元数据(Video Metadata)——用观看视频的文本元数据构造画像,发现视频标题(title)显著优于视频描述(description)和 salient terms。归因:标题信噪比更高,是对内容简洁的语义表征;而描述常含大量推广文案、版权署名(如背景音乐 credits)等与视频实际主题无关的噪声;salient terms 又过于宽泛,缺乏精准画像所需的具体细节。
- Insight 2:结构化输入(Structured Input)——输入的结构对 LLM 输出的粒度有深刻影响。把用户观看历史简单地按时间顺序排成序列喂给模型,往往产出过宽、抽象的兴趣摘要;先把观看历史按语义连贯性分组成 cluster 再构造提示词,显著提升了 LLM 总结兴趣的语义丰富度与具体度。
- Insight 3:模型规模(Model Size)——更大的模型在总结任务上一致更好,但到某个规模出现性能平台期。如 Figure 3(c),Gemini Pro 和 Gemini Ultra 都显著优于 Gemini Flash,但从 Pro 到 Ultra 提升趋于饱和——说明生成用户兴趣画像所需的推理能力存在一个饱和点。
Insight 3 直接催生了知识蒸馏的决策:借大模型的能力,同时满足工业系统的成本/延迟约束。
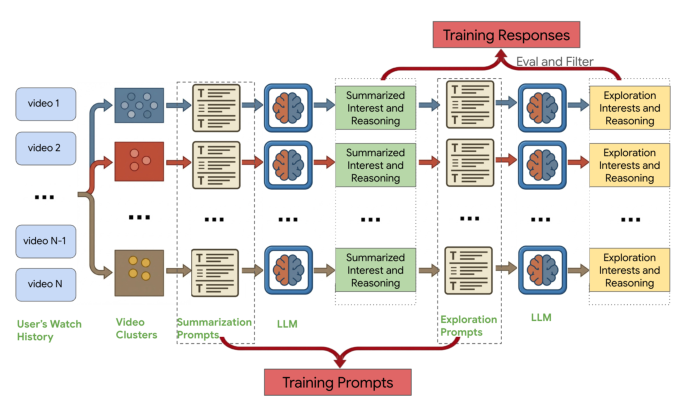
4.1.2 蒸馏(Distillation)¶
在线服务环境延迟/资源约束严苛,论文设计了一条统一 LLM 提示词,在单次推理调用里同时完成兴趣总结与探索。但这个双目标任务的复杂度需要一个有充分推理能力的模型——如 §5.1、§5.2 所示,现成的小模型无法有效胜任这种同时任务。
为此采用知识蒸馏,把大模型的能力迁移到小而高效的架构,达到服务成本与生成质量之间的最优权衡。教师选用 Gemini 1.5 Pro [20](部署时的 SOTA),生成训练数据。
数据收集(Data Collection) 五步:
- 用户采样(User Sampling):随机采样数万名合格用户及其观看历史序列;资格限制为同意数据用于训练、且拥有足够的近期高满意度观看历史的用户;进一步移除不安全/敏感视频。
- 输入结构化(Input Structuring):把用户近期观看历史按 salient term 相似度聚成语义 cluster(消融见 §4.1 / Figure 3(a),clustered 格式优于原始序列);剔除视频数过少的 cluster。
- 多步推理工作流(Multi-step Reasoning Workflow):为得到高质量 ground-truth 标签,把用于在线服务的统一提示词(Prompt B.1)拆解成多步推理过程(见 Figure 1);用多次 LLM 调用 + Chain-of-Thought 提示 [26],分别生成并精炼"总结兴趣"与"探索主题"及其推理。
- 教师响应质量控制(Quality Control):对教师响应做严格质检,只保留兴趣数量与格式都符合提示词要求的响应。
- 数据集划分(Dataset Splitting):从上一步合格响应里随机取 80% 训练 / 20% 评测。
这份高质量数据集成为蒸馏学生模型的基础。
4.2 成本高效的在线服务架构(Cost-Efficient Online Serving Architecture)¶
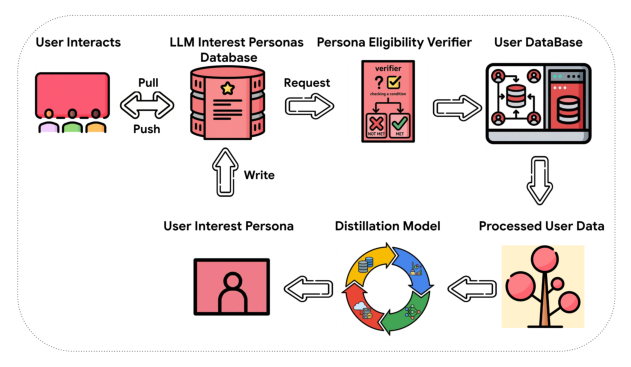
异步 LLM 推理(Asynchronous LLM Inference)——如 Figure 2,流程从用户访问网站开始:系统先在画像数据库中查是否已有最新画像;若有且未过期,立即取用于下游;若缺失或陈旧,触发一个异步后台任务去重新生成。关键在于:当前请求不等待这次生成——后台任务独立地拉取用户历史、查询 LLM、更新数据库,确保下次访问时拿到新鲜画像。这套架构把生成频率与流量解耦,引入极小的用户侧延迟并优化推理成本。异步推理本质上是一种权衡:可能漏掉瞬时、突发的兴趣;系统因此设计成高度可配置——更新频率与"用户观看历史的近期窗口"都可调,以缓解陈旧更新。最后,为进一步节省 LLM 服务成本,应用了量化(quantization)。
输入数据预处理(Preprocess Input Data):用户只有在拥有足够观看事件时才有资格生成 LLM 画像;用长观看历史序列以同时捕捉长期与近期兴趣;移除用户明确举报为负反馈的 item 以保证兴趣标签质量;把过滤后的近期观看聚成少量 cluster,每个 cluster 采样少量标题代表该 cluster,组装进提示词。
安全(Safety):对 LLM 输出施加一个安全分类器,检测并过滤潜在不安全/敏感的兴趣文本;一旦新响应被标记,系统自动回退到该用户此前已生成的、安全且合格的画像。
兴趣到 item 检索(Interests to Item Retrieval):为增强个性化,复用领域专用的检索模型。两种检索选项:
- 传统双塔模型(Conventional Two-Tower)(ref [13]):user 塔编码 LLM 生成的画像,item 塔编码候选视频,按 embedding 余弦相似度最大化来检索;
- 序列 transformer 模型(ref [21])+ 受限最近邻搜索(ref [8]):在 user embedding 与"与 LLM 生成画像语义相关"的视频之间检索。
这两个选项都能与现有推荐链路无缝衔接,也让论文能去探索"总结兴趣 vs 探索兴趣"在检索行为上的差异。
5. 实验与结果¶
5.1 离线研究:用户表征(Offline Study: User Representation)¶
为找出生成高质量兴趣摘要的最佳输入格式,论文做了一组离线实验,把 LLM 生成的摘要对照一个 ground-truth 数据集打分。Ground truth:数百名独立用户 + 他们点击过的一组文本主题(topic);这些点击是用户兴趣的高置信度信号(点击某主题直接把用户引向该主题相关视频页)。考察两个维度:
- 视频表征(Video Representation):title / description / salient terms;
- 输入结构(Input Structure):按时间顺序(Prompt A.1)vs 按语义/音视频相似度分组成 cluster(Prompt A.2)。
用 BLEURT [18] 分数衡量 LLM 总结兴趣与 ground-truth 点击文本的接近度。
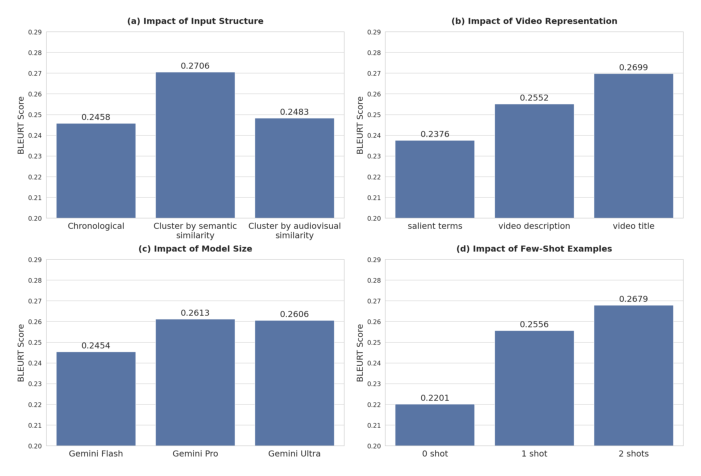
四组消融的 BLEURT 数值如下:
| 消融维度 | 配置 | BLEURT |
|---|---|---|
| (a) 输入结构 | Chronological(时间序列) | 0.2458 |
| Cluster by semantic similarity(语义聚类) | 0.2706 | |
| Cluster by audiovisual similarity(音视频聚类) | 0.2483 | |
| (b) 视频表征 | salient terms | 0.2376 |
| video description | 0.2552 | |
| video title | 0.2699 | |
| (c) 模型规模 | Gemini Flash | 0.2454 |
| Gemini Pro | 0.2613 | |
| Gemini Ultra | 0.2606 | |
| (d) Few-shot 样例数 | 0-shot | 0.2201 |
| 1-shot | 0.2556 | |
| 2-shot | 0.2679 |
结论分析:clustered(语义聚类)+ title(标题)+ few-shot(2-shot)的组合产出最高质量的兴趣画像。具体地:(a) 语义聚类 0.2706 显著高于时间序列 0.2458 与音视频聚类 0.2483,印证 Insight 2(结构化输入提升粒度)与 §3.2(语义聚类优于感知聚类);(b) 标题 0.2699 > 描述 0.2552 > salient terms 0.2376,印证 Insight 1(标题信噪比最高);(c) Pro/Ultra 显著超 Flash 但 Pro→Ultra 饱和,印证 Insight 3 并支撑蒸馏决策;(d) few-shot 从 0→1→2 单调提升(0.2201→0.2556→0.2679),说明示范样例对结构化输出帮助显著。因此后续所有实验都采用 clustered、基于 title 的用户表征作为 LLM 标准输入。
Table 1(定性对比)用一个真实例子展示了输入结构对输出粒度的影响:
| 输入结构 | LLM 输出(总结兴趣) |
|---|---|
| Sequential(Prompt A.1) | bengali tv shows(孟加拉语电视节目,宽泛) |
| Clustered(Prompt A.2) | bengali tv series "mon ditey chai";bengali tv series "icche putul" & "kar kache koi moner kotha";bengali tv series "bojhena se bojhena"(精确到具体剧名) |
结论:序列输入只给出"孟加拉语电视节目"这种泛化标签,而聚类输入能精确到具体剧集名称——这就是 Insight 2 所说的"输入结构对输出粒度的深刻影响"。
5.2 离线评测:蒸馏性能(Distillation Performance)¶
为在性能与服务成本间取最优平衡,论文蒸馏出两个学生模型变体——Gemini Flash 与 Gemini Nano——用 §4.1.2 的数据训练,并基于评测集做 epoch 选择。三个指标:
- Instruction Following Rate(IFR,指令遵循率):衡量工业场景下模型的可靠性——一个响应只有在同时完成总结与探索任务、严格遵循格式、生成提示要求的精确兴趣数量时,才算"指令合规"。高 IFR 对下游解析成功与 TPU 资源利用至关重要。
- BLEURT Score:评估总结任务(开发)质量——把教师模型的总结兴趣作为参考,对照学生模型预测,衡量学生对教师摘要语义细腻度的保真程度。
- Creativity Score(创造力分):评估探索任务——用一个逐对(side-by-side)LLM 自动评审,比较学生与教师产出的 {总结兴趣, 探索兴趣} 对,判定谁的输出更新颖、更有创造力。
Table 2(学生模型跨训练 epoch 的性能演化):
| Epoch | IFR(%) Nano | IFR(%) Flash | BLEURT Nano | BLEURT Flash | Creativity Nano | Creativity Flash |
|---|---|---|---|---|---|---|
| 0.00 | 0.07 | 1.82 | N/A | 0.286 | N/A | -0.588 |
| 4.37 | - | 99.54 | - | 0.334 | - | 0.008 |
| 10.92 | 98.97 | 99.75 | 0.321 | 0.338 | -0.012 | 0.016 |
| 26.20 | 99.08 | 99.68 | 0.328 | 0.345 | -0.018 | 0.023 |
注:
-表示该 checkpoint 未评测;BLEURT/Creativity 仅在通过 IFR 的样本上计算;N/A表示因 IFR 接近 0、有效样本不足以可靠计算。
结论分析:
- 格式快速收敛(Rapid Convergence of Formatting):IFR 很早就饱和,说明模型迅速学会了结构性要求。epoch 0 时所有学生模型 IFR 都极低(Nano 0.07%、Flash 1.82%)——这直接证明:若要用小模型服务线上流量,蒸馏是必要的(未蒸馏的小模型几乎无法遵循这个复杂的双任务格式)。
- 总结持续改善(Continuous Improvement in Summarization):BLEURT 全程稳步上升;两个学生在 epoch 26.20 都达到各自最高 BLEURT。值得注意的是,更小的 Gemini Nano 在 26.20 拿到 0.328,已可比拟更大变体(Flash)的初始水平,佐证了延长训练的价值。
- 创造力的权衡(Creativity Trade-Offs):创造力趋势随模型规模而异。Gemini Flash 达到最佳平衡,新颖度分数全程持续改善(-0.588→0.008→0.016→0.023);而更小的 Gemini Nano 始终挣扎(创造力为负且不升反降:-0.012→-0.018),说明它可能缺乏足够的参数容量来有效生成新颖的探索兴趣。
5.3 用户调研:对 LLM 生成兴趣的满意度¶
为理解 LLM 总结兴趣的质量,论文在调研前一周内活跃的数千名美国用户中做了调研。对每位参与者:把其近期观看历史聚成语义 cluster,提示 LLM 为每个 cluster 生成一个兴趣;随机选一个 cluster,展示其中 3 个代表性视频。先问用户是否记得看过这些视频(若答"是"),再展示生成的兴趣标签,请其按 5 点 Likert 量表("Not at all" 到 "Extremely")回答两题:
- Accuracy(准确性):"[兴趣标签] 对这些视频主题的概括有多贴切?"
- Preference(偏好):"你有多想看更多关于 [兴趣标签] 的视频?"
结果:超过 80% 的受访者认为 LLM 生成的标签对其观看历史"Very Closely"或"Extremely Closely"贴切;此外 71% 的用户表达了对"看更多该主题视频"的强烈兴趣——验证了这些画像对个性化推荐的价值。
为严格对照现有抽取式方法,论文做了第二个对比调研:让用户在 LLM 生成画像 与一个来自知识图谱实体的主题基线 [5] 之间比较。结果:57% 的用户严格偏好 LLM 画像,另有 20% 认为二者等价——清晰显示对生成式方法的偏好。
最后分析了用户不满意的主要原因(未来工作方向):漏掉用户的某些主要兴趣、基于零星活动推断兴趣、提到过时兴趣、生成重复的兴趣标签。论文指出,持续精炼画像、解决这些具体局限,是重要的未来方向。
5.4 线上实验(Live Experiment)¶
5.4.1 实验设置¶
在一个服务十亿级用户的商业视频推荐平台上做线上实验:等量、不重叠的用户流量分到 control 与 experiment 两臂,运行 30+ 天。
- Control(对照臂):现有生产推荐链路,无 LLM 画像;
- Experiment(实验臂):用视频标题作元数据,按 §3.2 的基于 embedding 的聚类把用户历史分组,送进学生 LLM(统一提示 Prompt B.1)。最终选用 Gemini Nano(epoch 26.20)——尽管 Table 2 中 Flash 创造力更高,但 Nano 的总结质量已可比拟,为满足在线服务的严苛延迟/成本约束,优先选 Nano。
每次请求:随机各采样 1 个总结兴趣 + 1 个探索兴趣,用这些文本兴趣经受限最近邻搜索 [8] 引导序列 transformer 模型,把高层兴趣画像映射到具体 item 候选,再交给下游排序,以自然方式呈现给用户。刻意用随机采样而非确定性的打分排序——以强制一个均匀的探索策略,让用户体验到多样的会话内发现(intra-session discovery),而非反复看到最高分兴趣;这一策略还有效抵消了生产系统严重的近期偏差(recency bias),回溯性地重新浮现休眠的长期兴趣,带来更整体的探索。
5.4.2 结果与分析¶
观看者价值提升(Increase in Viewer Value)——把 LLM 画像集成进现有链路后,相对一个高度优化的生产基线:
- 观看时长(User Watch Time):统计显著($p<0.05$)+0.04%;
- 活跃用户数(#Active Users):统计显著($p<0.05$)+0.03%。
相对百分比看似很小,但在该平台规模下,转化为观看者参与度的巨大绝对增量。这确认了自然语言画像通过引入细腻语义理解与世界知识,为推荐系统带来了独特价值。
轻度用户 vs 核心用户(Cohort 分析):把用户群按活跃度分为 casual users(轻度,平台使用较少) 与 core users(核心,高度活跃)。发现满意观看时长的提升主要来自轻度用户。两点归因:(1) 相比传统用户建模 [30],LLM 画像更擅长从稀疏数据推断用户偏好;(2) 轻度用户的兴趣通常更集中,因此从其画像采样到的兴趣更可能实现对其主要偏好的全面覆盖,带来更相关、更满意的推荐。
兴趣探索(Interest Exploration):实验观察到用户探索新主题方面的显著上升——参与主题数(number of engaged topics)+0.04%($p<0.05$),拥有多个持久参与主题的用户数 +0.03%($p<0.05$)。这些指标证明了一个正向行为转变:LLM 画像成功把偶然的发现转化为持久的长期兴趣。论文进一步把这一影响在两类兴趣间分解:
- 曝光差距(Exposure Gap):由探索兴趣检索到的 item,比由总结兴趣检索到的 item 少获得 40.91% 的曝光(impressions)——暗示下游排序模型不擅长浮现新颖内容;
- 推荐效率(Recommendation Efficiency):然而在被呈现的条件下,探索兴趣检索的 item 被观看的概率比总结兴趣的高 13.6%。
这个差异确认:新颖性增益主要由探索兴趣画像驱动——它们成功发掘出了传统推荐系统会错过的高契合度主题。
长期影响(Long-Term Impact):LLM 画像的影响超越了初次点击。观察到那些观看了来自这些画像的推荐视频的用户,表现出更长的后续观看者价值(prolonged viewer value),在随后访问中带来更多观看。这表明语言兴趣具有持久的正向影响,带来更深、更持续的平台互动。
附录中的关键提示词(Prompts)¶
论文附录给出了三套关键提示词,直接揭示了方法的实现:
- Prompt A.1(序列式 2-shot 总结):"I'm a brilliant video topic summarization expert that speaks all languages. Given a set of videos a person watched, I can describe the interests of that person and explain why respectively. I can also wrap interests of that person using ." 用户活动以时间顺序的扁平序列**表示。
- Prompt A.2(聚类式 2-shot 总结):同样的角色设定,但用户活动先分组成 cluster(
[Group 0]、[Group 1]…),LLM 对每个 group 描述兴趣并解释原因([Group 0]: **<Summarized Interests 0>**: <Reasoning 0>)。这就是 Table 1 里产出精确剧名的那个提示。 - Prompt B.1(总结 + 探索统一提示,在线服务用):角色设定后给出两个任务——Task 1:对每个 group 描述兴趣并解释(用
**包裹);Task 2:对 Task 1 里的每个总结兴趣,想出 3 个既相关又新颖、提供新视角的创造性探索兴趣(用&&包裹)。这正是 §4.1 双功能任务"在单次推理调用里同时做总结 + 探索"的落地形态,也是蒸馏学生模型要学会的目标。
核心贡献总结¶
- 产品定位创新——把"自然语言画像 + 探索"做进实时链路:不同于把 LLM 用作离线 item 编码器或结构化 ID 生成器,本文让 LLM 产出自由形式的自然语言用户画像,且在"总结现有兴趣"之外显式产出"探索兴趣",作为主动驱动用户探索的实时检索源——直接缓解推荐反馈回路、提供可解释的用户侧特征。
- 成本工程——蒸馏 + 异步 + 量化让十亿级在线 LLM 推理可行:用 Gemini 1.5 Pro 教师蒸馏出 Gemini Nano/Flash 学生(多步 CoT 生成高质量训练数据 + 严格质控);异步生成流水线把推理与请求解耦(查库命中即返、缺失则后台再生),配合量化与安全回退。
- 三层实验证据:离线(BLEURT 消融确立 clustered+title+few-shot 最优、模型规模饱和催生蒸馏)、用户调研(>80% 贴切、57% 偏好 LLM 画像 vs 知识图谱基线)、线上 A/B(观看时长 +0.04%、活跃用户 +0.03%,均 $p<0.05$,增益主要来自轻度用户;探索兴趣在被曝光时观看概率 +13.6%)。
与已归档相关工作的对比¶
AIR AIR: Atomic Intent Reasoning(香港理工大学 + 快手,2026-06-09)¶
关系:独立并发(本文未引用 AIR,两者殊途同归;AIR 2026-06-09,本文 2026-06-10)· 已加载对方精读
- 共同关注的问题:两篇都直击同一个 root cause——在工业级(十亿/4 亿月活)推荐场景里,在线 LLM 推理在毫秒级延迟约束下成本高得不可接受;而周期性的离线用户画像更新又跟不上快速演化的用户兴趣。AIR 把这一点明确列为"两道工业落地硬坎"之一,本文则在动机里反复强调"已有 LLM 用户理解工作同步设计、成本/延迟不可行,只能离线/近离线运行,无法捕捉即时意图"。问题陈述实质同构。
- 相近的技术骨架:两篇都走"把 LLM 语义推理从在线请求路径上挪走"这条主路线——离线/异步地让 LLM 产出可复用的语义产物,落进一个数据库/知识库;在线只做轻量检索把语义产物映射回 item。两者的方法流程图能抽象重合:
LLM 离线产语义 → 存库 → 在线检索映射回 item。 - 本文的差异与推进:(a) LLM 是否完全离线——AIR 在线完全不调用 LLM(纯离线产"原子行为-意图对" + 在线意图树检索 + MHA 融合),本文则保留 LLM 但走异步生成(请求不等待、后台再生 + 命中即返),并辅以蒸馏 + 量化把 LLM 本身压小;(b) 语义产物形态——AIR 产出的是结构化的层级意图路径/意图树(作为下游排序的特征),本文产出的是自由形式的自然语言画像(可读、可直接作用户侧特征),并显式区分总结/探索两类;(c) 是否强调探索——本文把 Exploration Interests(借世界知识外推新主题) 作为一等公民,用随机采样抵消近期偏差、回捞休眠兴趣;AIR 聚焦"目标 item 条件下的精准意图检索",不强调探索/serendipity。
- 可比的方法/实验差异:AIR 报告约 400× 在线吞吐增益与快手电商 +3.446% GMV(纯离线、目标感知、电商转化场景);本文报告观看时长 +0.04% / 活跃用户 +0.03%($p<0.05$,十亿级视频内容消费场景,增益集中在轻度用户)。两者的指标量级差异很大程度源于场景不同(电商 GMV 转化 vs 内容观看时长)与"产物粒度"不同(目标 item 条件意图 vs 通用兴趣画像 + 探索)。可以认为它们是同一根因下、为不同业务目标做的两种"LLM 离线化"工程实现,互为很好的对照。
讨论与局限性¶
值得借鉴的设计:
- 异步服务范式:把"画像生成"与"在线请求"彻底解耦(查库命中即返、缺失/陈旧才后台再生),是把任何重量级 LLM 推理塞进低延迟链路的通用工程模板,且更新频率与近期窗口都可配置以调节"新鲜度 vs 成本"。
- 蒸馏目标的设计:用多步 CoT(把单次服务提示拆成多步)+ 严格质控来制造高质量训练数据,再蒸进单次调用的小模型——这是"复杂双任务(总结+探索)如何蒸馏"的可复用配方。Table 2 的 IFR/BLEURT/Creativity 三指标也给出了一个评估"小模型是否学到了复杂格式 + 语义保真 + 新颖性"的实用框架。
- 自然语言画像作为可解释特征:相比 cluster ID/embedding,自由文本画像天然可读、可直接作用户侧展示,且能借 LLM 世界知识做受控探索。
局限与争议:
- 下游排序对新颖内容不友好:探索兴趣检索到的 item 曝光少 40.91%——说明即便上游画像挖出了好的新主题,下游排序仍是探索的瓶颈;论文自身也把"开发能持续浮现新颖内容的机制"列为未来工作。
- 画像质量的具体失败模式:调研暴露了漏掉主要兴趣、从零星活动过度推断、提到过时兴趣、重复标签等问题——这些都是自然语言画像在生产中的真实痛点。
- 异步的固有取舍:可能漏掉瞬时/突发兴趣;依赖"近期窗口 + 更新频率"配置来缓解,但本质上无法做到真正的请求级实时。
- 线上绝对增益偏小:+0.04% / +0.03% 在统计上显著,但相对幅度很小,价值主要靠平台规模放大;且增益集中在轻度用户,对核心用户的边际贡献有限。
- 指标与场景的耦合:本文在生产实验臂实际只用了视频标题这一种元数据(离线实验里 title 最优),多模态/跨域画像被列为未来工作。
工业落地价值:整套系统已部署在十亿级用户的商业视频推荐平台,经 30+ 天大规模 A/B 验证观看者价值提升,并通过数千人用户调研确认了对生成式画像的高满意度——证明了 LLM 不只是"离线数据处理器",而能作为驱动可量化观看者价值的实时推理引擎集成进工业推荐系统。未来工作包括:把画像扩展到多模态与跨域数据、收集用户反馈做 human-in-the-loop 画像精炼、开发语义画像更具交互性的用例。