FlowTime:用「流式个性化先验」实现连续生成式观看时长预测¶
Hongxu Ma、Han Zhou、Chenghou Jin、Jie Zhang、Xiaoyu Yang、Chunjie Chen、Jihong Guan、Shuigeng Zhou(Fudan University / Kuaishou Technology / Shanghai University of Finance and Economics / Tongji University),KDD '26,arXiv 2606.01352,2026-05-31。第一作者为快手实习期间工作,通讯作者周水庚。开源库 TimeRec:https://github.com/snailma0229/TimeRec.git
研究动机与背景¶
观看时长为何是核心指标¶
短视频平台(快手、抖音、TikTok 等)已成为全球信息消费的主入口,推荐系统的优化目标正从点击率(CTR)这类即时信号,转向以 观看时长(Watch Time) 为代表的「参与度 / 沉浸度」指标。观看时长被视为用户满意度与内容沉浸的关键代理变量,准确的 观看时长预测(Watch Time Prediction, WTP) 直接关系到流量分配、用户留存与营收增长。
然而,现有 WTP 方法分属三种范式,每一种都被自身的范式假设所束缚:
- 直接回归(Direct Regression):用 MSE 把 WTP 当作逐点回归任务,隐含「条件分布是单峰高斯」的假设。当真实分布是多峰时,MSE 最优解会坍缩到一个落在低密度区的「均值」(mean-collapse)。即便引入因果去偏(causal debiasing),这一结构缺陷依旧存在。
- 序回归(Ordinal Regression):把连续时间离散成若干有序区间做分类(如 CREAD、SWaT)。代价是 量化粒度固定带来的量化误差,以及「各区间决策条件独立」这一错误假设。
- 离散生成式回归(Discrete Generative Regression):以 GR 为代表,借鉴语言建模,把连续时间量化成离散 token,用自回归(AR)方式逐步生成。问题在于 启发式的词表设计 与 自回归迭代带来的高推理延迟。
共性缺陷:交互模式作为结构混淆因子¶
除各自的范式缺陷外,三者还共享一个被普遍忽视的根本缺陷:无法刻画观看时长分布内在的多峰性(multimodality)与异质性(heterogeneity)。
论文从因果视角重新审视 WTP:观看时长 $W$ 并非只由用户兴趣 $I$ 单向决定,而是受 用户–物品交互模式(User-Item Interaction Patterns, $P$) 调制——这些模式扮演了 结构混淆因子(structural confounder) 的角色。传统视角(Fig 1(a))只画出 $U,V \to I \to W$ 的链路;本文(Fig 1(b))把交互模式 $P$ 作为红色混淆边引入,指出「相同的兴趣会在不同的交互模式下映射成完全不同的观看时长分布拓扑」。
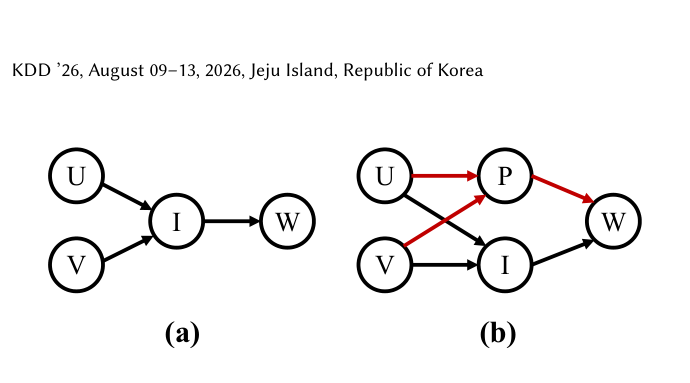
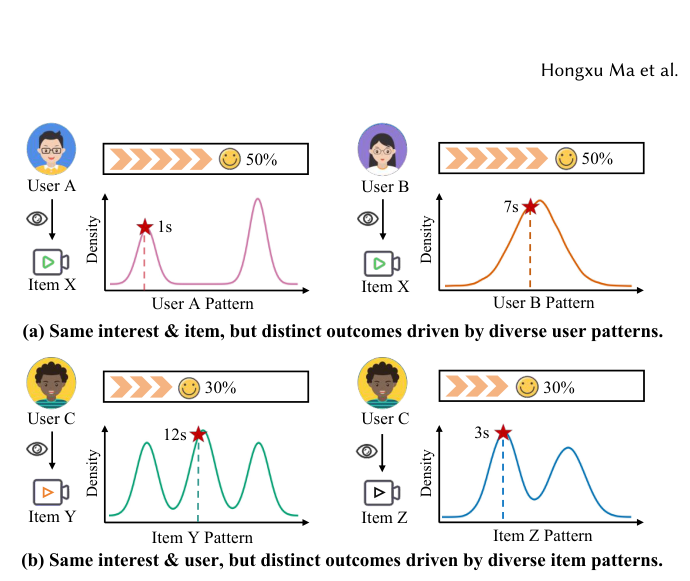
Fig 2 用具体例子说明这一点:在 相同兴趣、相同物品 的前提下,一个「激进型」用户 A 会呈现 双峰分布(要么立刻划走 1s、要么完整看完),而一个「耐心型」用户 B 呈现 单峰悬停分布(约 7s);同样,固定用户而改变物品(Item Y vs Item Z)也会把分布从三峰拉成另一种三峰拓扑。这意味着:相同兴趣会被不同的 user/item 交互模式映射成截然不同的分布形状,传统方法对此视而不见,从而限制了预测保真度。
核心贡献总结¶
- 提出新范式:把 WTP 形式化为 连续生成式回归(Continuous Generative Regression),作者称其为继直接回归、序回归、离散生成式回归之后的「第四种范式」,可直接拟合复杂、多峰的连续观看时长分布。
- 理论刻画前三种范式的内在缺陷:用四个命题分别量化了直接回归的均值坍缩、序回归的依赖误差、离散 AR 的误差上界,并从因果视角论证交互模式作为结构混淆因子的地位。
- 提出 FlowTime 框架:以 一步式(One-step)变分自编码器(VAE) 为骨架,绕开扩散类模型的迭代去噪延迟;再引入 Flow-based Personalized Prior,用条件 Normalizing Flows(NF)把标准高斯先验 warp 成由历史交互模式驱动的、个性化的复杂多峰流形,在不牺牲推理效率的前提下实现模式感知建模。
- 开源 TimeRec 基准库:作者构建了该领域首个开源 WTP 库 TimeRec,统一了数据集、特征工程、复现的 SOTA 基线与评测协议,并提出新的个性化保真度指标 PDF(Personalized Distributional Fidelity)。
- 充分的离线 + 线上验证:在 KuaiRec、KuaiRand 两个公开数据集与一个工业数据集上全面领先,并在快手(>4 亿 DAU 平台)做了线上 A/B,视频播放时长 +1.044%。
现有建模范式的理论剖析(Section 3)¶
论文先用理论工具系统性地拆解前三种范式的缺陷,作为 FlowTime 的立论基础。
3.1 传统回归的均值坍缩¶
逐点回归的 MSE 目标为:
$$\min_{f}\; \mathbb{E}_{x,y}\big[\,\|y - f(x)\|^2\,\big] \tag{1}$$
其最优解由一阶最优性条件给出条件期望:
$$f^*(x) = \mathbb{E}_{p_{\text{data}}}[y \mid x] \tag{2}$$
虽然在期望意义下最优,但当条件分布多峰时,这个「均值」会落在两个峰之间的 低密度区,即均值坍缩。
命题 1(均值坍缩效应):设 $\Delta = \min_{i\neq j}|\mu_i - \mu_j|$ 为任意两个模式之间的最小间隔。若 $\Delta/\sigma \to \infty$(即各峰充分分离),则回归解在真实条件分布下的似然消失: $$\lim_{\Delta/\sigma \to \infty} P_{\text{data}}\big(f^*(x)\mid x\big) = 0 \tag{3}$$
物理含义:峰越分离,逐点回归给出的预测越是一个「真实数据中几乎不会出现」的值。附录 A.2 在高斯混合(GMM)设定下给出了严格证明。
3.2 序回归的依赖误差¶
序回归方法(CREAD、SWaT 等)用阈值 $c_1 < \cdots < c_M$ 把连续观看时长 $y$ 编码成长度为 $M$ 的二元向量 $\mathbf{B}=(\mathbf{B}^1,\dots,\mathbf{B}^M)$,其中 $\mathbf{B}^m = \mathbb{1}(y > c_m)$,再用离散化近似条件期望:
$$\mathbb{E}[y \mid x] \approx \sum_{m=1}^{M} P(y > c_m)\,(c_m - c_{m-1}) \tag{4}$$
这一重构把连续回归降级为多个二分类问题,但引入了「区间决策条件独立」的结构性偏差。朴素模型假设:
$$P_{\text{naive}}(\mathbf{B}\mid x) = \prod_{m=1}^{M} P(\mathbf{B}^m \mid x) \tag{5}$$
命题 2(离散化建模的依赖误差):忽略区间间依赖造成的建模误差可由 KL 散度精确刻画: $$D_{\mathrm{KL}}(P_{\text{data}} \,\|\, P_{\text{naive}}) = \sum_{m=1}^{M} \mathbb{E}_{\mathbf{B}_i^{<m}}\big[D_{\mathrm{KL}}^{(m)}\big] \tag{6}$$
其中 $D_{\mathrm{KL}}^{(m)}$ 是第 $m$ 个区间决策在「给定历史决策」与「忽略依赖的边际」之间的 KL 散度。附录 A.1 进一步把这一误差展开成各区间「条件互信息」的累加:若区间间完全独立则误差为零,依赖越强误差越大。
3.3 离散生成式建模的误差上界¶
自回归(AR)模型(GR)把连续目标 $y$ 表示成值 token 序列 $\mathbf{s}=(s^1,\dots,s^T)$,按 $P(\mathbf{s}\mid x)=\prod_{t=1}^{T} P(s^t \mid x, s^{<t})$ 分解;用数值解码映射 $\phi(\cdot)$ 把 token 映回数值,目标与预测分别为 $y=\sum_t \phi(s^t)$、$\hat{y}=\sum_t \phi(\hat{s}^t)$,逐步回归误差 $\Delta_t \triangleq \phi(\hat{s}^t) - \phi(s^t)$。
命题 3(Token 化自回归回归的误差分解):设 $\phi(s^t),\phi(\hat{s}^t)\in[w_{\min},w_{\max}]$,且逐步偏置满足 $|\mathbb{E}[\Delta_t]|\le B$,则 AR 预测的期望平方误差上界为: $$\mathbb{E}\big[(\hat{y}-y)^2\big] \le T^2 B^2 + T^2 \frac{(w_{\max}-w_{\min})^2}{4} \tag{7}$$
由于偏置 $B$、序列长度 $T$、数值范围 $w_{\max}-w_{\min}$ 都由所选词表决定,启发式离散化在精度上存在一个由词表决定的内在上界:更细的词表会缩小每步误差但拉长序列 $T$,更粗的词表反之,二者构成一个绕不开的权衡(附录 A.4 给出偏差–方差完整推导)。
核心方法:FlowTime¶
4.1 问题形式化¶
给定数据集 $\mathcal{D}=\{(\mathbf{u}_i, \mathbf{v}_i, y_i)\}_{i=1}^N$,其中 $\mathbf{u}_i,\mathbf{v}_i\in\mathbb{R}^d$ 分别是用户、视频特征向量,$y_i\in\mathbb{R}^+$ 是观测观看时长。每个用户和物品还各有历史观看时长序列 $\mathcal{H}_u^i=\{h_1^u,\dots,h_{L_u}^u\}$、$\mathcal{H}_v^i=\{h_1^v,\dots,h_{L_v}^v\}$。传统 WTP 学一个确定性映射 $f:\mathbf{x}\to\mathbb{R}^+$($\mathbf{x}=(\mathbf{u},\mathbf{v})$),最小化 $\hat{y}$ 与 $y$ 的差距。
FlowTime 把 WTP 重构为连续生成式建模问题:把 $y$ 视为连续随机变量,目标是学习条件密度 $p_{\text{data}}(y\mid x)$,通过最大化观测的边际似然实现:
$$p_\theta(y\mid x) = \int_{\mathcal{Z}} p_\theta(y\mid z, x)\, p_\psi(z\mid x)\, dz \tag{8}$$
其中 $z\in\mathbb{R}^d$ 是潜变量,$\theta$ 参数化条件似然(解码器),$\psi$ 参数化潜空间上的条件先验。这一形式天然允许对真实分布中的多峰性与异质性建模。
4.2 整体架构¶
如 Fig 3 所示,FlowTime 以 VAE 为骨架做高效的一步式连续生成式回归,包含一个 概率编码器 和一个 生成式解码器。关键创新是把标准 VAE 的静态高斯先验替换为 Flow-based Personalized Prior(图中右上「Prior Latent Space」一路,由 Gaussian 经 Flow1…FlowK 逐步 warp 成多峰流形)。
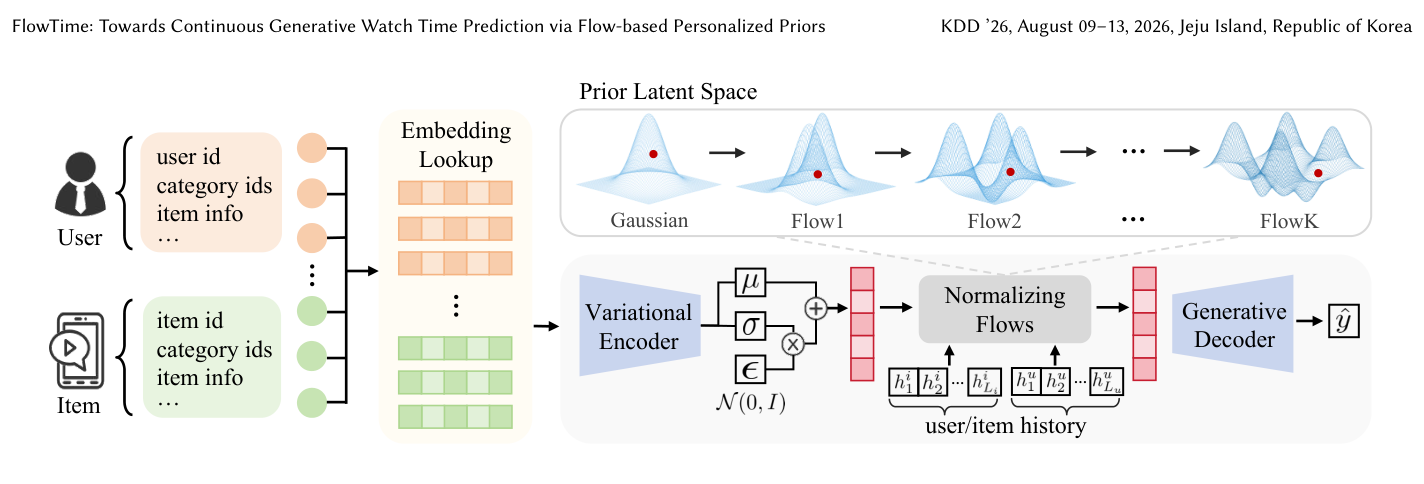
4.2.1 概率编码器:用条件高斯近似真实后验:
$$q_\phi(z\mid y_i, \mathbf{x}_i) = \mathcal{N}\big(z;\, \mu_\phi(y_i,\mathbf{x}_i),\, \sigma_\phi^2(y_i,\mathbf{x}_i)\,\mathbf{I}\big) \tag{9}$$
其中 $\mu_\phi(\cdot)$、$\sigma_\phi(\cdot)$ 是预测潜变量均值与对角协方差的 MLP。为让随机采样可反传,使用重参数化技巧:
$$z = \mu_\phi(y_i,\mathbf{x}_i) + \sigma_\phi(y_i,\mathbf{x}_i)\odot\epsilon, \quad \epsilon\sim\mathcal{N}(0,\mathbf{I}) \tag{10}$$
4.2.2 生成式解码器:解码器作为生成网络,从采样潜变量 $z$ 与静态特征 $\mathbf{x}_i$ 重构观看时长,似然建模为:
$$p_\theta(y_i\mid z,\mathbf{x}_i) = \mathcal{N}\big(y_i;\, \mu_\theta(z,\mathbf{x}_i),\, \sigma_\theta^2(z,\mathbf{x}_i)\big) \tag{11}$$
训练时 $z\sim q_\phi(z\mid y_i,\mathbf{x}_i)$;推理时 $y_i$ 不可见,改从条件先验 $z\sim p_\psi(z\mid\mathbf{x}_i)$ 采样,并直接取均值 $\hat{y}_i = \mu_\theta(z,\mathbf{x}_i)$ 做高效的确定性预测。
4.2.3 优化目标:最大化对数似然的 ELBO:
$$\mathcal{L}_{\text{VAE}} = \mathbb{E}_{q_\phi(z\mid y_i,\mathbf{x}_i)}\big[\log p_\theta(y_i\mid z,\mathbf{x}_i)\big] - \mathrm{KL}\big(q_\phi(z\mid y_i,\mathbf{x}_i)\,\|\,p_\psi(z\mid\mathbf{x}_i)\big) \tag{12}$$
第一项是高斯似然下的 MSE 重构损失,第二项把后验向先验 $p_\psi(z\mid\mathbf{x}_i)$ 正则。标准 VAE 把先验取为各向同性高斯 $\mathcal{N}(0,\mathbf{I})$,是单峰、全局共享、用户无关的,这种静态先验从根本上无法刻画分布异质性,常导致过度平滑或后验坍缩(posterior collapse)。这正是 FlowTime 要替换的对象。
4.3 Flow-based Personalized Prior¶
为突破各向同性高斯先验的表达力瓶颈,本模块用 NF 构造一个 以历史交互模式为条件 的复杂多峰先验 $p(z\mid\mathbf{x}_i)$。
4.3.1 模式编码(Pattern Encoding):先把用户/物品的历史观看时长分布压缩成 分位数统计(quantile statistics):从 $\mathcal{H}_u^i$、$\mathcal{H}_v^i$ 各抽取 $L$ 个分位点 $\mathbf{q}^u=\{q_1^u,\dots,q_L^u\}$、$\mathbf{q}^v=\{q_1^v,\dots,q_L^v\}$。分位序列是对长期观看模式紧凑而稳健的概括。再用 Transformer 把分位序列编码成稠密上下文嵌入(分位经投影并加位置编码以保留序结构):
$$\mathbf{E}^u = \text{Transformer}\big(\text{Proj}(\mathbf{q}^u) + \mathbf{P}\big),\quad \mathbf{E}^v = \text{Transformer}\big(\text{Proj}(\mathbf{q}^v) + \mathbf{P}\big) \tag{13}$$
其中 $\mathbf{P}$ 是位置嵌入;自注意力聚合分布模式后做均值池化 $\mathbf{h}^u=\text{MeanPool}(\mathbf{E}^u)$、$\mathbf{h}^v=\text{MeanPool}(\mathbf{E}^v)$。最终上下文条件由二者拼接得到:
$$\mathbf{h}_{\text{prior}} = [\mathbf{h}^u \,\|\, \mathbf{h}^v] \in \mathbb{R}^{2d} \tag{14}$$
4.3.2 用条件 NF 做流形 warping:以 $\mathbf{h}_{\text{prior}}$ 为条件,把简单基分布 $z^0$(由 $z$ 推断而来)经过 $K$ 个可逆映射 $f_k$ 逐步变换:
$$z^k = f_k(z^{k-1};\, \mathbf{h}_{\text{prior}}),\quad k=1,\dots,K \tag{15}$$
每个 $f_k:\mathbb{R}^d\mapsto\mathbb{R}^d$ 是以 $\mathbf{h}_{\text{prior}}$ 为条件的双射。本文实例化为 条件 Planar Flow,提供高效的非线性扩张/收缩密度机制:
$$z^k = z^{k-1} + \mathbf{u}_k(\mathbf{h}_{\text{prior}})\cdot \tanh\!\big(\mathbf{w}_k(\mathbf{h}_{\text{prior}})^\top z^{k-1} + b_k(\mathbf{h}_{\text{prior}})\big) \tag{16}$$
其中 $\mathbf{u}_k,\mathbf{w}_k,b_k$ 都由 $\mathbf{h}_{\text{prior}}$ 经 MLP 动态生成(这正是「个性化」的来源——流的参数随用户/物品历史而变)。按变量替换定理,变换后潜变量在个性化先验下的对数密度为:
$$\log p_\psi(z^K\mid \mathbf{c}) = \log p_0(z^0) - \sum_{k=1}^{K} \log\left|\det\frac{\partial f_k(z^{k-1};\mathbf{h}_{\text{prior}})}{\partial z^{k-1}}\right| \tag{17}$$
这样就把各向同性高斯 $z^0$ 自适应地 warp 成用户 pattern-specific 的复杂流形。解码器据此给出预测:
$$\hat{y} = \mu_\theta(z^K, \mathbf{x}) \tag{18}$$
从而实现「分布感知的连续回归」。
4.4 联合优化目标¶
为同时提升预测精度与分布保真度,本文设计多目标损失。
精度锚定(Accuracy Anchoring):在观测空间用 Huber 损失作为精度锚,兼顾点估计与对异常值的鲁棒:
$$\mathcal{L}_{\text{base}} = \mathcal{L}_{\text{Huber}}(y, \hat{y}) = \mathcal{L}_{\text{Huber}}\big(y,\, \mu_\theta(z^K,\mathbf{x})\big) \tag{19}$$
潜空间正则(Latent Space Regularization):把近似后验向标准高斯对齐,保证潜表示的连续性与可辨识性:
$$\mathcal{L}_{\text{latent}} = \mathrm{KL}\big(q_\phi(z^0\mid y,\mathbf{c})\,\|\,\mathcal{N}(0,\mathbf{I})\big) \tag{20}$$
分布对齐(Distribution Alignment):用基于 Wasserstein 距离的损失,把生成的观看时长分布与历史交互模式对齐。具体地,从 NF 先验采样潜向量 $z_l^K$ 生成样本 $\hat{y}^{(l)}=\mu_\theta(z_l^K,\mathbf{x})$,再把其序统计量与用户/物品分位 $\mathbf{q}^u,\mathbf{q}^v$ 对齐:
$$\mathcal{L}_{\text{W-Dist}} = \frac{1}{L}\sum_{l=1}^{L}\Big(\lambda\big|\hat{y}^{(l)} - q_l^u\big| + (1-\lambda)\big|\hat{y}^{(l)} - q_l^v\big|\Big) \tag{21}$$
其中 $\lambda$ 平衡用户级与物品级的分布对齐强度。总训练目标:
$$\mathcal{L} = \lambda_1\,\mathcal{L}_{\text{base}} + \lambda_2\,\mathcal{L}_{\text{latent}} + \mathcal{L}_{\text{W-Dist}} \tag{22}$$
4.5 用生成式建模捕捉多峰性(理论保证)¶
论文进一步从理论上论证:为什么生成式 + NF 的设计能避免均值坍缩。设优化后解码器均值 $\mu_\theta(z)$ 与真实条件分布 $p_{\text{data}}(y\mid x)$ 的一组主导条件模式 $\{\alpha_k\}_{k=1}^K$ 对齐,定义模式 $k$ 对应的潜区域:
$$\mathcal{Z}_k \triangleq \big\{\,z:\, \|\mu_\theta(z) - \alpha_k\| \le \varepsilon\,\big\} \tag{23}$$
命题 4(潜空间划分):设 $\mu_\theta(\cdot)$ 是 $L$-Lipschitz,$\Delta \triangleq \min_{i\neq j}\|\alpha_i - \alpha_j\|$ 为不同条件模式间最小间隔。若 $\Delta > 2\varepsilon$,则各潜区域 $\{\mathcal{Z}_k\}$ 两两不交,且 $$\|z_i - z_j\| \ge \frac{\Delta - 2\varepsilon}{L},\quad \forall z_i\in\mathcal{Z}_i,\, z_j\in\mathcal{Z}_j,\, i\neq j;\qquad z\in\mathcal{Z}_k \Rightarrow \|\mu_\theta(z)-\alpha_k\|\le\varepsilon \tag{24}$$
即 每个潜区域被解码到一个独立的高密度条件模式,从而避免坍缩到低密度的平均值。附录 A.3 进一步在 NF 采样下给出概率版本(命题 5–8):NF 作为「几何感知的采样机制」,在不参与训练/正则的情况下,以至少 $1-\delta$ 的概率把生成引向解码器已捕捉的高密度输出模式,保证「一致且非平均化」的生成。
实验设置¶
TimeRec 库与数据集¶
为应对 WTP 领域评测不一致的问题,作者构建了首个开源统一基准库 TimeRec,集成多数据集、严格特征工程与复现的 SOTA 方法。评测用两个公开数据集 + 一个工业数据集(Table 1):
| 数据集 | #Users | #Items | #Impressions | 特点 |
|---|---|---|---|---|
| KuaiRand-Pure | 27,285 | 7,583 | 1,186,059 | 无偏(随机曝光) |
| KuaiRec | 7,176 | 10,728 | 12,530,806 | 高密度(全曝光) |
| Indust | — | — | 多十亿曝光/天 | >4 亿 DAU 工业平台,极端稀疏 + 长尾 |
- KuaiRand-Pure:来自快手随机分发策略,无系统选择偏差,适合验证「无偏」下的精度;
- KuaiRec:全曝光高密度,富交互便于评测细粒度模式与长期习惯;
- Indust:大规模工业数据,反映真实部署的稀疏与长尾挑战。
特征工程:Indust 用严格的「时间切分」(连续 5 天训练、次日测试);KuaiRand/KuaiRec 按原工作的标准时序切分。用户特征用 user_id + onehot_feat0-17;物品特征含 item_id、duration 及 feat0-4(KuaiRec)/feat0-3(KuaiRand)。
基线与评测指标¶
基线 按三种范式组织:
- 直接回归:VR、D2Q、D2Co、CWM、EGMN、DIFL;
- 序回归:TPM、CREAD、PTPM、SWaT;
- 离散生成式回归:GR。
评测指标(两个标准指标 + 一个新指标):
- MAE(Mean Average Error):$\frac{1}{N}\sum_i|\hat{y}_i - y_i|$,逐点回归精度,越低越好。
- XAUC:在所有有效偏序对 $\mathcal{P}=\{(i,j)\mid y_i > y_j\}$ 上预测排序正确的比例,$\frac{1}{|\mathcal{P}|}\sum_{(i,j)\in\mathcal{P}}\mathbb{1}(\hat{y}_i > \hat{y}_j)$,衡量排序能力,越高越好。
- PDF(Personalized Distributional Fidelity,本文新提):用真值分布 $P_u$ 与预测分布 $Q_u$ 的直方图分桶后求平均 Jensen–Shannon 散度,评估「个性化分布捕捉」能力:
$$\text{PDF-U} = \mathbb{E}_u\!\left[\tfrac{1}{2}\mathrm{KL}(P_u\,\|\,M_u) + \tfrac{1}{2}\mathrm{KL}(Q_u\,\|\,M_u)\right],\quad M_u = \tfrac{1}{2}(P_u + Q_u) \tag{25}$$
分别报告用户级(PDF-U)与物品级(PDF-I),越低越好。
实现细节:所有模型训练 20 epoch,Adam($\beta_1=0.9,\beta_2=0.999$),batch size 1024,学习率 $5\times10^{-4}$。基线均采用其原论文最优超参;并严格对齐各模型参数量,确保增益来自方法本身而非模型容量。
主要实验结果¶
RQ1:离线性能对比¶
Table 2 给出三数据集上的主结果(粗体=最优,下划线=次优;每个实验重复 5 次取均值)。FlowTime 在 所有指标上均建立新 SOTA。
| 范式 | 方法 | KuaiRec MAE↓ | XAUC↑ | PDF-U↓ | PDF-I↓ | KuaiRand MAE↓ | XAUC↑ | PDF-U↓ | PDF-I↓ | Indust MAE↓ | XAUC↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 直接 | VR | 3.3973 | 0.5822 | 0.3073 | 0.1232 | 22.1504 | 0.6429 | 0.7386 | 0.7363 | 21.3199 | 0.6041 |
| 直接 | D2Q | 3.2696 | 0.6043 | 0.3210 | 0.1798 | 19.4258 | 0.6715 | 0.6697 | 0.5665 | 19.6098 | 0.6156 |
| 直接 | D2Co | 3.2633 | 0.5895 | 0.3055 | 0.1346 | 20.7854 | 0.6547 | 0.7435 | 0.6333 | 20.3233 | 0.6053 |
| 直接 | CWM | 3.3532 | 0.5899 | 0.3010 | 0.1521 | 19.6351 | 0.6668 | 0.6289 | 0.5908 | 19.9865 | 0.6085 |
| 直接 | EGMN | 3.1803 | 0.6125 | 0.2646 | 0.0874 | 19.3246 | 0.6682 | 0.6503 | 0.5414 | 18.2354 | 0.6155 |
| 直接 | DIFL | 3.2420 | 0.6055 | 0.3103 | 0.1544 | 19.3181 | 0.6708 | 0.6529 | 0.5374 | 17.5606 | 0.6188 |
| 序 | TPM | 3.4584 | 0.5819 | 0.2844 | 0.1238 | 22.5950 | 0.6303 | 0.7567 | 0.7770 | 19.2344 | 0.6055 |
| 序 | CREAD | 3.2290 | 0.6123 | 0.2741 | 0.1053 | 19.8087 | 0.6678 | 0.7028 | 0.6479 | 17.9823 | 0.6134 |
| 序 | PTPM | 3.2865 | 0.6033 | 0.2787 | 0.1169 | 20.6584 | 0.6679 | 0.7345 | 0.6993 | 18.4263 | 0.6111 |
| 序 | SWaT | 3.3496 | 0.5888 | 0.3308 | 0.1168 | 22.3353 | 0.6515 | 0.7456 | 0.7303 | 20.4522 | 0.6098 |
| 生成 | GR | 3.1985 | 0.6124 | 0.2644 | 0.0833 | 19.2742 | 0.6682 | 0.6664 | 0.6570 | 17.2503 | 0.6201 |
| 生成 | FlowTime | 3.1588 | 0.6174 | 0.2634 | 0.0823 | 19.1045 | 0.6751 | 0.5974 | 0.4861 | 16.9553 | 0.6243 |
结论分析: 1. vs 直接回归:在 KuaiRec 上 MAE 较次优降低约 0.676%(3.1803→3.1588)、XAUC 提升约 0.8%,验证了 FlowTime 有效缓解了 MSE 的均值坍缩。 2. vs 序/离散生成:靠避免量化误差取得优势,KuaiRand MAE 降约 0.704、Indust 同步提升(MAE、XAUC +1.777%)。 3. 个性化分布保真度最突出:相比基于混合密度的 EGMN,在 KuaiRec 上把 PDF-U、PDF-I 分别降低 0.454%、5.835%——这直接证明 flow-based 架构在刻画复杂交互模式分布上的表达力优势。注意在 KuaiRand 上 FlowTime 的 PDF-U(0.5974)、PDF-I(0.4861)相对次优(CWM 0.6289 / EGMN 0.5414)的领先幅度尤为明显。
在线 A/B 测试¶
在快手「热门视频推荐」场景(>4 亿 DAU 平台,10% 流量、连续 6 天)上线,所有核心指标显著为正(Table 3):
| 指标 | 提升 | P 值 | 95% 置信区间 |
|---|---|---|---|
| APP Usage Time | +1.027% | 0.003 | [0.82%, 1.23%] |
| Video Play Time | +1.044% | 0.001 | [0.91%, 1.18%] |
| Long-view Rate | +0.892% | 0.002 | [0.65%, 1.13%] |
| Share Rate | +1.236% | 0.005 | [0.95%, 1.52%] |
可见 FlowTime 不仅提升消费时长(Video Play Time +1.044%、APP Usage Time +1.027%),还显著拉动互动(Share Rate +1.236%),具备实际商业价值。
RQ2:效率–性能权衡¶
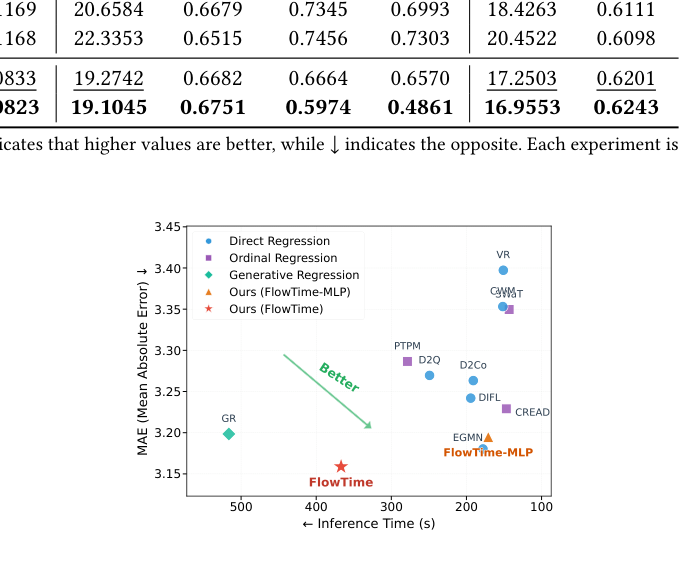
Fig 4 把推理速度与预测精度放在同一坐标(右下角=低误差 + 快推理为佳)。FlowTime 取得最优平衡:相比直接回归仅略慢,但精度显著更高;其 FlowTime-MLP 变体(把分位编码的 Transformer 换成 MLP)进一步加速、缩小速度差距。最关键的是,相比生成式基线 GR,FlowTime 在 提升精度的同时把推理延迟降低近 30%,实现「精度 + 效率」的双重超越——这正源于一步式连续生成架构相对自回归迭代机制的优势。
消融与分析¶
RQ3:核心组件消融¶
Table 4 沿三个维度做消融(KuaiRec):
| 变体 | MAE↓ | XAUC↑ | PDF-U↓ | PDF-I↓ |
|---|---|---|---|---|
| (a) FlowTime(完整) | 3.159 | 0.617 | 0.249 | 0.078 |
| 生成式架构 | ||||
| (b) w/ DDPM | 3.163 | 0.613 | 0.251 | 0.081 |
| (c) w/ Flow Matching | 3.161 | 0.614 | 0.250 | 0.080 |
| 分布建模 | ||||
| (d) w/o Normalizing Flows | 3.245 | 0.607 | 0.304 | 0.113 |
| 历史建模 | ||||
| (e) w/o User History | 3.281 | 0.599 | 0.303 | 0.081 |
| (f) w/o Item History | 3.235 | 0.605 | 0.253 | 0.111 |
| (g) w/o Both & NF | 3.318 | 0.593 | 0.308 | 0.127 |
| (h) Rep. Trans. w/ MLP | 3.195 | 0.611 | 0.251 | 0.081 |
逐项分析:
- 生成式架构(b、c vs a):把一步式 VAE 换成迭代式的 DDPM 或 Flow Matching,二者虽都超过 SOTA,但都不如一步式的 FlowTime。说明在高稀疏场景下,一步式方法提供了更鲁棒的归纳偏置,规避了迭代去噪的误差累积,同时保持低延迟。
- NF 的必要性(d vs a):把 flow-based 先验退回标准高斯 VAE,MAE 退化 2.72%、XAUC 退化 1.62%。这一显著下降验证了「静态先验无法刻画多峰性」,NF 在建模复杂偏好分布上不可或缺。
- 历史建模(e、f、g、h):同时去掉用户与物品历史(g)表现最差,证实历史交互模式对个性化的关键作用;用户历史比物品历史更重要(e 比 f 退化更大),说明用户习惯是观看时长的主导驱动;把分位编码的 Transformer 换成 MLP(h)使 XAUC 退化约 1%,凸显注意力机制对捕捉全局行为模式的必要性。
RQ4:个性化模式分析¶
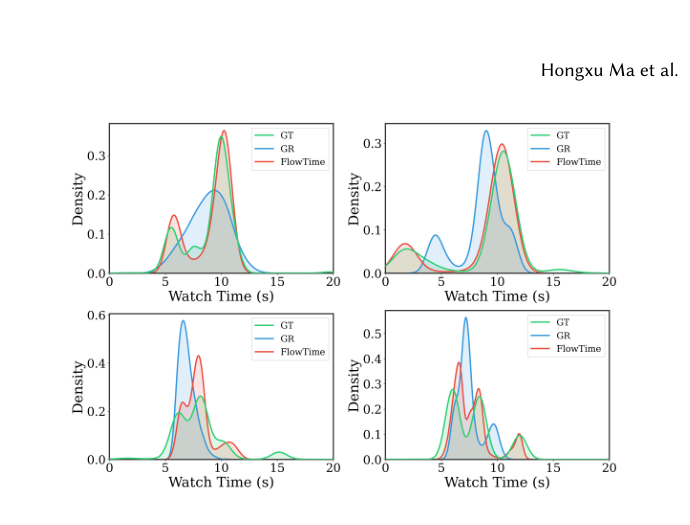
Fig 5 可视化代表性 user–item 对的预测观看时长分布。相比 GR,FlowTime 展现出更优的 分布保真度,能准确重构包括双峰、三峰在内的多样真值(GT)分布形状——这印证了通过 NF 建模潜流形确实捕捉到了个性化的 user-item 交互模式。
RQ5:超参数影响¶
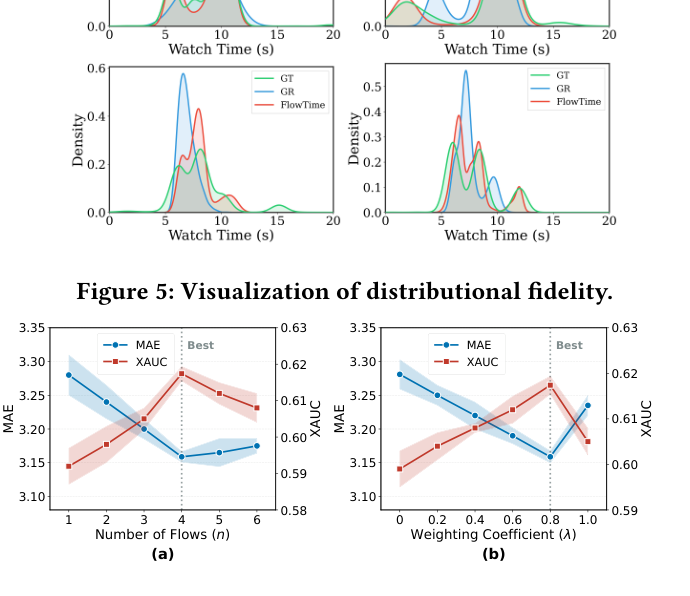
Fig 6 在 KuaiRec 上考察两个关键超参:
- 流步数 $K$(图 a):性能随 $K$ 增加而提升,在 $K=4$ 达峰 后略有下降。说明足够的流深度对建模复杂流形拓扑是必要的,但过多步数会带来过拟合或优化困难。
- 用户–物品权重 $\lambda$(图 b):性能随 $\lambda$ 增大而稳步提升、在 $\lambda=0.8$ 达峰 后下降。这佐证了「用户特定模式是观看时长的主要决定因素」,但 $\lambda$ 超过拐点后性能下降也说明 物品特定模式同样不可或缺,二者需平衡。
与已归档相关工作的对比¶
PEARL PEARL:对比学习无偏分位数估计(TikTok / ByteDance,2026-05-20)¶
关系:独立并发(本文未引用 PEARL,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直击「工业观看时长的逐用户分布异质性」这一 root cause,且都用 用户自身的历史观看时长分布 作为个性化锚点。FlowTime 把它表述为「交互模式作为结构混淆因子导致分布多峰/异质,逐点回归均值坍缩」;PEARL 把它表述为「行为强度失衡——同样 30s 对高活/低活用户意味完全不同的分位,绝对量级跨用户不可比」。本质都是:观看时长的绝对值不可直接拟合,必须以用户历史分布为参照做个性化校准。两者还都是工业落地(快手 vs TikTok)、同为 2026-05 的并发工作。
- 相近的技术骨架:两者方法流程图都可抽象为「编码用户历史观看时长分布 → 以该分布为参照产出分布感知的预测」。FlowTime 用历史 分位数 $\mathbf{q}^u,\mathbf{q}^v$ 作为 NF 先验的条件,并用 $\mathcal{L}_{\text{W-Dist}}$ 把生成样本的序统计量对齐到这些分位;PEARL 用 user-keyed reservoir 里的 历史样本 作对比参照,把「当前样本 > 随机历史样本」的二元指示在期望意义下逼近 CDF/分位。两者都把「用户经验观看时长分布」内化进训练目标。
- 本文的差异与推进:FlowTime 是 生成式路线——显式学条件密度 $p_\theta(y\mid x)$,用 VAE+条件 NF 把高斯 warp 成多峰流形,输出的是 观看时长数值 $\hat{y}$,并能可视化重构多峰分布(Fig 5);PEARL 是 判别式路线——不建密度,而是把回归 目标 改写成 0–1 的逐用户分位(CDF rank),用对比学习隐式估计,输出的是 分位/排序分数。一句话:同样「用历史分布去个性化」,FlowTime 选择「生成式建模整条密度」,PEARL 选择「把目标换成无偏分位再对比估计」。
- 可比的方法 / 实验差异:FlowTime 主打 MAE/XAUC/PDF(强调分布保真度 PDF 这一新指标),并对比三大范式 12 个基线;PEARL 主打 XAUC/UAUC(强调对低活用户的排序改善)+ 理论上的无偏性证明(Theorem 1–3)。FlowTime 线上 Video Play Time +1.044%、Share Rate +1.236%;PEARL 线上观看时长 +2.10%。二者面向的场景也不同(短视频 vs 直播),但都验证了「以用户历史分布为锚的个性化 WTP」在工业体量上的有效性。
被剔除的近似候选(防门槛放水): - DADF DADF(快手,2026-05-18):问题高度相邻——同样明确指出观看时长标签「长尾 + 多峰」、同为快手短视频 WTP。但 解法骨架不同构:DADF 是在 冻结的首阶段预测器 之上做事后乘性残差校正(group-specific Box-Cox + duration 分组专家),属「去偏/校准包装器」,并不建模多峰密度;FlowTime 则是从头替换预测器、用生成式密度建模。属「问题相似但解法差异大」,剔除。 - 2604.05365 LGCD(安徽大学):用了条件扩散生成,但问题是「跨域冷启动的偏好生成」,与 WTP 无关——解法相近(生成式)而问题不同构,剔除。 - 2605.24986 HeteGenCTR(阿里):离散扩散做 CTR 预训练,虽是生成式建模但目标是 CTR(判别式分值)且非观看时长——问题不同构,剔除。 - 补注:FlowTime 在 Table 2 中最相关的密度建模基线是 EGMN(指数–高斯混合网络,混合密度做多峰 WTP),但 EGMN 未归档于本库,作为基线由 benchmark / DAG 兜底,不在本节展开。
讨论与局限性¶
核心贡献与可借鉴之处:
- 范式层面的重构:把 WTP 从「点回归 / 离散分类 / 离散 token 生成」上升为「连续生成式回归」,并用四个命题把前三种范式的缺陷量化清楚,立论扎实。这种「先证伪旧范式、再立新范式」的写法值得借鉴。
- 一步式 VAE + 条件 NF 的工程取舍很聪明:既要生成式建模的多峰表达力,又要工业级低延迟,于是用一步式 VAE 绕开扩散的迭代去噪,再用条件 Planar Flow 单独补回多峰先验的表达力——把「表达力」与「延迟」解耦到两个模块。消融(b/c/d)清楚地支撑了这一取舍。
- 以历史分位数作为个性化条件 + Wasserstein 对齐:用分位统计而非原始序列作 NF 条件,紧凑且稳健;并用 $\mathcal{L}_{\text{W-Dist}}$ 把生成分布的序统计量直接锚到历史分位,是一个干净的「分布对齐」设计。
- 开源 TimeRec + 新指标 PDF:统一了 WTP 评测,PDF(基于 JSD 的个性化分布保真度)补上了「只看 MAE/XAUC 看不到分布形状」的盲区,对社区有基础设施价值。
局限与可商榷之处:
- 离线增益偏小:在 KuaiRec/KuaiRand 上 MAE、XAUC 的提升多在亚 1% 量级(如 KuaiRec MAE 3.1803→3.1588),最亮眼的提升集中在 PDF 这一本文自提的新指标上;「twofold improvement / 双重超越」等表述略偏乐观。真正的说服力更多来自线上 A/B 与 PDF。
- 方法新颖度集中在「迁移组合」:NF、VAE、Planar Flow、Wasserstein 对齐都是成熟工具,创新点在于把它们组合到 WTP 这一具体问题上并配以理论分析;条件 Planar Flow 的表达力相对 RealNVP/IAF 等更现代的流偏弱,论文也未深入讨论流类型的选择。
- 理论命题偏「印证性」:命题 1–4 多是对「多峰下点估计会坍缩 / 离散化有依赖误差」这类直觉的形式化印证,结论方向符合预期,对方法设计的指导性强于其本身的理论深度。
- 问题面较窄:WTP 是推荐排序中的一个子问题;分位数条件依赖用户/物品有足够历史,论文未充分讨论 冷启动(历史稀疏)下 Flow-based Personalized Prior 的退化行为。
工业落地价值:作为快手实习产出并在 >4 亿 DAU 平台的热门视频推荐场景上线,FlowTime 在 10% 流量、6 天的 A/B 中取得 Video Play Time +1.044%、APP Usage Time +1.027%、Share Rate +1.236% 的显著正收益,且推理延迟较生成式基线 GR 降低近 30%,FlowTime-MLP 变体进一步压缩延迟,具备真实可部署性。