PEARL:面向工业级直播推荐的对比学习无偏分位数估计¶
Blake Gella, Wei Wu, Yuhao Yin, Zexi Huang, Zikai Wang, Emily Liu, Junlin Zhang, Wentao Guo, Qinglei Wang(TikTok / ByteDance,San Jose & Singapore),arXiv 2605.21752,2026-05-20。
研究动机与背景¶
行为强度失衡(Behavioral Intensity Imbalance)¶
现代推荐系统大量依赖用户的隐式交互信号(点击、观看时长、互动等)来优化用户参与度。然而这些信号在不同用户之间并不可比:不同用户的参与强度(engagement intensity)天然存在巨大差异。论文把由此产生的系统性失真命名为行为强度失衡(behavioral intensity imbalance)——一种源于异质参与模式的结构性偏差。
最直观的例子(论文反复使用的比喻):一段 30 秒的观看时长,对一个每天刷直播的高活跃用户而言可能只代表中等兴趣(约 50 分位),而对一个低活跃用户而言却可能意味着极高的兴趣(约 99 分位)。如果模型直接拟合 watch-time 的绝对量级,那么:
- 观测到的反馈信号不再忠实反映用户的真实偏好;
- 模型会不成比例地放大高活跃用户的信号、淹没低活跃用户的信号,因为高活跃用户的样本量级大、梯度强,主导了共享 backbone 的优化方向;
- 最终在大规模平台上同时损害推荐质量和鲁棒性。
这一问题在直播(livestream)推荐场景里尤为尖锐:直播是连续型、时长可变的内容,watch-time 既是核心反馈又是核心业务目标;同时直播用户的活跃分层极端(从"过去一个月从未看过直播"的 non-live 用户,到"每天消费直播内容"的 high-active 用户都在同一个排序模型里)。
相关工作脉络¶
论文在 Related Work 中梳理了三条线:
- 用户行为建模(User Action Modeling):从早期协同过滤、矩阵分解,到 DNN/序列建模、Transformer,再到表征学习——这条线提升的是"如何刻画用户与物品交互",但默认观测信号本身是可信的,没有处理信号的跨用户不可比性。
- 建模偏差的刻画(Capturing Modeling Biases):位置偏差(position bias)、选择偏差、流行度偏差等。已有方法多用反事实 / IPS / 倾向得分纠偏,关注的是物品侧或曝光侧偏差,而非"用户参与强度"这一用户侧的分布性偏差。
- 直播推荐中的去偏(Debiasing in Livestream Recommendation):直播的连续可变时长使 watch-time 偏差问题被放大。本文承接的最直接前作是 Relative Advantage Debiasing (RAD)(2025,short-video watch-time prediction,论文 [10]),并把它作为主要对比基线之一;PEARL 自述为"building upon relative advantage debiasing",即在相对优势去偏的思路上更进一步。
PEARL 的核心主张:不要建模绝对参与量级,而要建模相对偏好信号——具体而言,把每个用户自身历史分布上的分位数(percentile / CDF rank)作为去偏后的、跨用户可比的偏好目标。
问题形式化与核心挑战¶
形式化定义¶
给定用户 $u$ 与物品 $i$ 的一次交互,输入特征向量记为 $x = [x_u, x_i, x_c] \in \mathcal{X}$,其中 $x_u, x_i, x_c$ 分别表示用户画像、物品元数据、上下文信号。目标是学习一个参数为 $\theta$ 的预测映射 $f: \mathcal{X} \to [0,1]$,使得预测分数 $\hat{p}$ 逼近用户特定的真分位数:
$$p = F_a(y) = P(Y_a \le y) \tag{1}$$
其中 $Y_a$ 是表示用户 $a$ 参与量级的随机变量,$F_a$ 是该用户历史 watch-time 的累积分布函数(CDF)。模型预测:
$$f(x; \theta) = \hat{p} \approx F_a(y) \tag{2}$$
优化目标是在特征-量级联合分布上最小化期望风险:
$$\theta^* = \arg\min_{\theta} \; \mathbb{E}_{(x,y)\sim \mathcal{D}} \big[\ell\big(f(x;\theta), F_a(y)\big)\big] \tag{3}$$
其中 $\ell(\cdot)$ 是 ranking-compatible 的损失。通过拟合分位数 $F_a(y)$ 而非原始量级 $y$,模型把异质的行为信号变换到一个标准化、无偏的偏好空间。
两大核心挑战¶
直接套用上述定义在工业系统里不可行,论文指出两个根本困难:
- 分布追踪的系统性开销(Systematic Overhead of Distribution Tracking):精确获取 $F_a(y)$ 需要为亿级用户维护精确的历史分布(存储成本),并在推理时执行实时排序操作来定位分位(计算延迟)——在毫秒级延迟约束下完全不可行。
- 直接分位数回归的内在困难(Intrinsic Challenges in Direct Percentile Regression):即便真分位数可得,直接用标准回归目标(MSE、Weighted Cross-Entropy)去拟合有界且非线性的 $p \in [0,1]$ 也很困难——这类损失在分位边界处行为不稳定,高分位区间的小误差会带来显著的 ranking 失真。
PEARL 的方案就是用对比学习绕开这两个困难:既不显式维护分布、也不直接回归分位,而是用真实的对比样本去隐式逼近分位关系。
核心方法:PEARL 框架¶
PEARL 的整体架构由两个核心组件构成(见 Figure 1):(1) 一个 user-keyed reservoir pool(用户键控蓄水池,$N=50$),动态维护每个用户的无偏历史分布;(2) 一个 multi-sample comparator(多样本对比器),把模型预测与历史样本交叉比对,计算多样本对比损失 $\mathcal{L}_{\text{MBCE}}$,全程无需显式追踪分布。
![Figure 1: PEARL 整体架构——Percentile Estimation and Regression via Contrastive Learning。输入特征经深度网络同时输出 watch-time 回归头与 percentile [0,1] 头;右侧 user-keyed reservoir pool 以概率 P=min(1, N/Mu) 更新,contrastive comparator 把预测与历史样本对比。](figures/fig_01.png)
下面按照"单样本 → 多样本 → 价值加权 → 自举 → 协同训练"的递进展开。
3.1 单样本对比学习(Single-Sample Contrastive Learning)¶
核心洞见:把连续的分位数回归问题,转化为一个二元对比问题,只需从用户历史里抽一个随机样本作为参照点。
对比标签构造:设当前训练样本(用户 $u$)的参与量级为 $y$(如 watch-time)。从该用户历史分布 $f_a(\cdot)$ 中抽一个历史参照值 $Y'$,定义二元指示函数作为对比目标:
$$\mathbb{1}(y > Y') = \begin{cases} 1, & \text{if } y > Y' \\ 0, & \text{otherwise} \end{cases} \tag{4}$$
Theorem 1(分位数的无偏估计):设 $Y'$ 是服从密度 $f_a(\cdot)$ 的随机变量,对固定量级 $y$,二元指示的期望恰好是 CDF(即真分位数):
$$\mathbb{E}_{Y'\sim f_a}\big[\mathbb{1}(y > Y')\big] = \int_0^y f_a(t)\,dt = \mathrm{CDF}_a(y) \tag{5}$$
证明:由指示变量的基本性质,期望等于事件 $\{Y' < y\}$ 的概率。由于 $y$ 是当前样本的固定实现、$Y'$ 是从用户历史分布抽样的随机变量:
$$\mathbb{E}_{Y'}\big[\mathbb{1}(y > Y')\big] = 1\cdot P(Y' < y) + 0\cdot P(Y' \ge y) = P(Y' < y) \tag{6}$$
再由连续随机变量 CDF 的定义:
$$P(Y' < y) = \int_0^y f_a(t)\,dt = \mathrm{CDF}_a(y) \tag{7}$$
这证明了对比信号的期望是真分位数的无偏估计——关键在于:模型从未见过 $F_a$,只需对"当前样本是否大于一个随机历史样本"做二分类,期望意义下就拟合了分位数。
单样本 BCE 损失:在预测分位 $\hat{p} = f(x;\theta)$ 与对比指示之间取 Binary Cross-Entropy:
$$\mathcal{L} = -\Big[\mathbb{1}(y > Y')\log(\hat{p}) + \big(1 - \mathbb{1}(y > Y')\big)\log(1 - \hat{p})\Big] \tag{8}$$
由于对比标签的期望即真分位(Theorem 1),最小化该目标可使 $\hat{p}$ 收敛到无偏分位数 $F_a(y)$。
局限:单样本虽理论无偏,但单一随机参照点引入了很大的训练方差,导致梯度噪声大、训练不稳定——这引出多样本策略。
3.2 多样本对比学习(Multi-Sample Contrastive Learning)¶
Theorem 2(方差的定量分析):单对指示 $B = \mathbb{1}(y > Y')$ 是成功概率 $p = \mathrm{CDF}_a(y)$ 的 Bernoulli 变量,方差 $\mathrm{Var}(B) = p(1-p)$。为压制噪声,抽 $N$ 个独立历史参照 $\{Y'_1,\dots,Y'_N\}$ 构造多样本估计 $\bar{B} = \frac{1}{N}\sum_{j=1}^N \mathbb{1}(y > Y'_j)$。由 i.i.d. 性质,平均估计的方差为:
$$\mathrm{Var}(\bar{B}) = \frac{\mathrm{Var}(B)}{N} = \frac{p(1-p)}{N} \tag{9}$$
生产系统取 $N=50$,即获得 50 倍的方差缩减,提供更平滑的梯度面,使模型能从噪声流式数据中学到细粒度排序信号。
多样本 BCE 损失(MBCE):把损失定义为对整个对比池的期望:
$$\mathcal{L} = \frac{1}{N}\sum_{j=1}^{N}\Big[-B_j\log(\hat{p}) + (1 - B_j)\log(1 - \hat{p})\Big],\quad B_j = \mathbb{1}(y > Y'_j) \tag{10}$$
由 BCE 关于标签的线性性,这等价于一个使用软标签 $\bar{p} = \frac{1}{N}\sum_{j=1}^N B_j$ 的单个 BCE:
$$\mathcal{L} = -\bar{p}\log(\hat{p}) + (1 - \bar{p})\log(1 - \hat{p}) \tag{11}$$
由一阶最优性条件 $\partial \mathcal{L}/\partial \hat{p} = 0$,全局最优仍为 $\hat{p}^* = \bar{p}$,即当前对比池的经验分位数。因此 MBCE 在稳定训练的同时收敛到目标分位水平。
3.3 价值加权对比学习(Value-Weighted Contrastive Learning)¶
纯分位数只刻画"序",丢失了量级本身的"价值贡献"。为捕捉累积价值贡献,论文给每个历史参照 $Y'_j$ 的量级作为权重,定义价值加权 BCE(VWBCE):
$$\mathcal{L}_{vw} = \frac{1}{\sum_{j=1}^{N} Y'_j}\sum_{j=1}^{N} Y'_j \cdot\Big[-\mathbb{1}(y > Y'_j)\log(\hat{p}) - \big(1 - \mathbb{1}(y > Y'_j)\big)\log(1 - \hat{p})\Big] \tag{12}$$
同样由线性性等价于使用价值加权软标签 $\bar{p}_{vw}$ 的单个 BCE:
$$\mathcal{L}_{vw} = -\bar{p}_{vw}\log(\hat{p}) - (1 - \bar{p}_{vw})\log(1 - \hat{p}) \tag{13}$$
其中价值加权经验标签定义为 $\bar{p}_{vw} = \dfrac{\sum_{j=1}^{N} Y'_j\,\mathbb{1}(y > Y'_j)}{\sum_{j=1}^{N} Y'_j}$。这使最优 $\hat{p}^*$ 不再是简单的计数分位,而是"量级小于 $y$ 的交互所贡献的总价值占比"。
Theorem 3(全局最优为部分期望比):VWBCE 的唯一最优预测超越标准 CDF,对应部分期望比(Partial Expectation Ratio):
$$\hat{p}^* = \frac{\int_0^y t\, f_a(t)\,dt}{\int_0^\infty t\, f_a(t)\,dt} \tag{14}$$
证明(概要):最小化期望损失 $\mathbb{E}[\mathcal{L}_{vw}]$,对 $\hat{p}$ 的一阶最优条件给出部分期望与全局期望之比——即量级不超过 $y$ 的所有样本所贡献的总量级占比。由此模型把序(ordinal ranking)与绝对量级贡献统一进单一目标,提供了一个兼顾参与度与价值的统一度量。
3.4 自举对比学习(Bootstrapped Contrastive Learning)¶
前述范式假设目标分布相对连续。但工业系统中许多关键信号——打赏(gifting)、分享、负反馈——是高度稀疏且离散的(常为 0/1)。此时分位数估计面临两个根本困难:
- 排序分辨率坍塌(Loss of Ranking Resolution):对二值信号,指示函数 $\mathbb{1}(y > Y')$ 退化为阶跃——负交互 ($y=0$) 永远映射到 0 分位,正交互 ($y=1$) 永远 100 分位。这种"全有或全无"的监督无法区分相同二值标签下用户偏好的细粒度差异。
- 经验分布退化(Empirical Distribution Degeneracy):标签稀疏导致 $N=50$ 的历史队列对稀有事件常常全是负样本(如 50 个 0),对比目标恒为 0,梯度消失或不稳,模型学不到有意义的排序边界。
解法——基于预测的自举:不对比原始二值标签,而是引入一个连续先验预测来重定义分位。设 $\hat{Y}'$ 是预测当前样本期望量级 $\hat{y}$ 的先验回归模型。把 $\hat{y}$ 与历史样本的先验预测 $\hat{Y}'_j$ 对比,并复用 §3.2 的多样本方差缩减:
$$\bar{p}_{boot} = \frac{1}{N}\sum_{j=1}^{N}\mathbb{1}(\hat{y} > \hat{Y}'_j) \tag{15}$$
其中 $\hat{Y}'_j$ 是队列中历史样本的连续预测值。通过在预测空间(而非原始标签空间)里算分位,把离散的二值比较变成连续可微的概率密度。即便真标签相同(如多个零奖励样本),其先验预测 $\hat{y}$ 仍能反映潜在兴趣的细粒度差异。$\bar{p}_{boot}$ 在 MBCE 损失(式 11)中替换 $\bar{p}$,专用于离散目标。
3.5 分位数协同训练(Percentile Co-Training)¶
PEARL 通过相对排序有效缓解用户侧偏差,但很多工业排序系统仍不可或缺地需要预测绝对量级——因为业务逻辑里预测值直接对应经济效用或收入。
为什么绝对量级重要:典型例子是基于 eCPM 的广告定价系统,排序分 = 预测交互率 × 绝对出价量级;scale-agnostic 模型能判断哪个广告更可能被点,但给不出竞价结算所需的标定美元价值。类似地,直播打赏 / 电商里,一笔 $100 交易本质上比 $1 交易更有价值,即便在各自用户历史里相对排名相同。因此维持绝对尺度标定对价值驱动任务是必需的。
协同训练的联合优化:把 PEARL 作为去偏排序正则项,与既有回归目标联合:
$$\mathcal{L}_{total} = \mathcal{L}_{orig}(\hat{y}, y) + \lambda \cdot \mathcal{L}_{PEARL}(\hat{p}, \bar{p}, \mathcal{P}_u) \tag{16}$$
其中:
- $\mathcal{L}_{orig}(\hat{y})$ 保证模型在绝对尺度上的标定,最小化预测量级 $\hat{y} = f_{orig}(x;\theta)$ 与真值 $y$ 的误差;
- $\mathcal{L}_{PEARL}(\hat{p}, \bar{p}, \mathcal{P}_u)$ 作为排序正则,基于当前标签 $y$ 与用户历史对比池 $\mathcal{P}_u = \{Y'_j\}_{j=1}^N$ 优化预测分位 $\hat{p} = f_{pct}(x;\theta)$。
推理时主要服务预测的绝对量级 $\hat{y}$,但模型已从双头训练中获得了去偏表征。协同收益:
- 用户级序一致性(User-level Ordinal Consistency):强制共享 backbone 在每个用户自身分布内捕捉相对偏好,防止被高活跃用户的梯度主导,显著提升 intra-user 排序稳定性;
- 尺度标定(Scale Calibration):回归目标把输出锚定在物理量纲,保证最终分数是收入估计与竞价结算所需的标定量级。
工业落地:十亿级系统实现(§3.7)¶
在十亿用户、毫秒级延迟约束下部署 PEARL,论文聚焦两个工程挑战:高效状态管理 + 自适应梯度门控。
In-graph Reservoir Sampling(计算图内蓄水池采样)¶
为与 i.i.d. 采样假设(Theorem 1)保持数学一致、同时适配用户兴趣漂移,PEARL 把对比池 $\mathcal{P}_u$ 用蓄水池采样(Reservoir Sampling)实现在计算图内。Parameter Server (PS) 为每个用户存两份图内状态:(1) 大小 $N=50$ 的对比池 $\mathcal{P}_u$,存用户历史参与的真实量级;(2) 计数器 $M_u$,记录该用户已处理的流式交互总数。
当前交互(量级 $y$)到达时,状态更新:
$$M_u \leftarrow M_u + 1 \tag{17}$$
- 若 $M_u \le N$:直接把 $y$ 顺序追加进 $\mathcal{P}_u$;
- 若 $M_u > N$:以门控概率 $P = N / M_u$ 接受 $y$;若接受则随机覆盖池内一个槽位,否则丢弃。
这一经典图内流式执行保证任意时刻 $\mathcal{P}_u$ 都维持用户整个历史分布的均匀随机样本,且检索延迟近零、内存占用极小。
Gradient Gating(梯度门控,训练稳定性)¶
经验分位 $\hat{p}$ 的统计可靠性对蓄水池内的样本密度敏感。为抑制稀疏历史状态带来的高方差更新,论文设触发阈值 $\tau = 10$:仅当某样本的对比池已积累足够统计支持(即 $M_u \ge \tau$)时,它才贡献排序头的梯度更新;不满足阈值的样本完全跳过排序头优化。该选择性更新机制防止欠采样用户的噪声经验信号污染共享 backbone,保证十亿级流式环境下的稳定收敛。
实验设置¶
数据集与指标¶
工业流式数据集,取自论文所属工业推荐系统的排序阶段。统计如下:
| 数据集 | #Instances | #Features | #Targets |
|---|---|---|---|
| Industry | 168B | 4552 | 98 |
评估指标:
- UAUC(User-Averaged AUC):对每个用户分别算 AUC 再跨用户平均。与全局 AUC 不同,UAUC 考虑了用户行为强度,给出用户公平的个性化排序质量度量——这正是 PEARL 去偏目标对齐的指标。
- RegAUC / CRegAUC(Five-Group Averaged Regression AUC):用于回归目标,使回归任务与排序任务可比。沿用 [17] 的定义,Regression AUC 为:在均匀采样的物品对中,预测 watch-time 值能保持真值序关系的比例。
基线与训练设置¶
基线(均基于现代排序架构 [19] 作共享 backbone,各任务用独立 MLP tower 适配不同目标):
- Original:直接拟合原始目标的部署模型;
- CQE(Conditional Quantile Estimation)[20]:条件分位数估计;
- RAD(Relative Advantage Debiasing)[10]:相对优势去偏(本文最直接的前作思路)。
训练超参:优化器 RMSProp V2,学习率 0.0015,动量 0.999999,初始化因子 1.0。所有结果都以相对值报告,因生产环境敏感不便给绝对值。
主要实验结果¶
离线结果:watch-time 目标(Table 2)¶
| Method | UAUC |
|---|---|
| Original | 0.641 |
| CQE | 0.615 |
| RAD | 0.625 |
| PEARL (ours) | 0.648 |
分析:PEARL 取得最高 UAUC 0.648,优于原始部署模型(0.641)。值得注意的是,两个去偏基线 CQE (0.615) 与 RAD (0.625) 反而低于 Original——论文解释:CQE/RAD 这类去偏在"高活跃用户"上有效,却以牺牲低活跃用户为代价,或引入了与原始目标不一致的偏移;而 PEARL 在去偏的同时不损失全局排序质量。这说明朴素去偏可能"按下葫芦浮起瓢",PEARL 的无偏分位 + 协同训练设计才真正实现净增益。
多目标离线结果(Table 3)¶
PEARL 在多个目标(二分类与回归)上的 UAUC 改进;协同训练变体报告的是"带协同训练后原始目标"的表现:
| Target | PEARL 变体 | Baseline UAUC | PEARL UAUC |
|---|---|---|---|
| Interaction | Multi-sample Percentile (§3.3) | 0.606 | 0.648 (+6.93%) |
| Session Watch Time | Value-Weighted Percentile (§3.4) | 0.641 | 0.648 (+0.468%) |
| Consumption | Value-Weighted Percentile (§3.4) | 0.583 | 0.589 (+0.977%) |
| Report | Prediction-Based Bootstrapping (§3.5) | 0.743 | 0.780 (+4.96%) |
| Long-term Watch Time | Percentile Co-Training (§3.6) | 0.689 | 0.800 (+16.1%) |
分析:(1) 稀疏离散目标收益最大——Interaction (+6.93%) 与 Report (+4.96%) 验证了自举对比(§3.4)对稀疏信号的价值;(2) Long-term Watch Time 在协同训练下 +16.1% 是最大涨幅,说明把去偏分位作为正则项对长期目标的排序质量提升尤其显著;(3) Session Watch Time / Consumption 改进较小(< 1%),论文归因:Consumption 标签虽全局稀疏,但其正样本集中在特定用户子群内、在该群内形成高密度分布,个性化去偏的边际收益较低。每个目标都用了最匹配其分布特性的 PEARL 变体,体现了框架的灵活性。
去偏效果的核心证据:分用户活跃度的 UAUC(Figure 2)¶
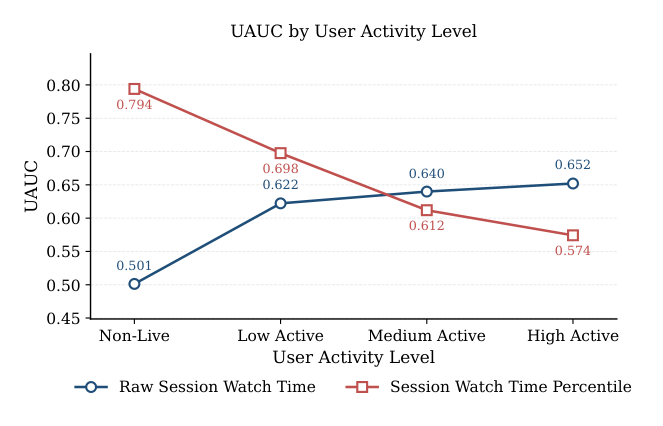
这张图最直观地揭示了 PEARL 的去偏机制。横轴为用户活跃度(Non-Live → Low Active → Medium Active → High Active),纵轴 UAUC:
| 用户群组 | Raw Watch Time(蓝) | PEARL Percentile(红) |
|---|---|---|
| Non-Live | 0.501 | 0.794 |
| Low Active | 0.622 | 0.698 |
| Medium Active | 0.640 | 0.612 |
| High Active | 0.652 | 0.574 |
分析:原始模型在非活跃用户上几乎等于随机(0.501)、在高活跃用户上表现最好(0.652)——这正是"行为强度失衡"的实证:模型被高活跃用户主导,对低活跃用户几乎无个性化能力。PEARL 把这条曲线完全翻转:非活跃用户 UAUC 飙到 0.794,低活跃 0.698,而高活跃用户略降到 0.574。两条曲线在 medium-active 附近交叉。
这说明 PEARL 本质上是在把模型质量从"被过度服务的高活跃用户"重新分配给"被忽视的低活跃用户"。由于平台上低活跃 / 非活跃用户占多数,整体净 UAUC 仍为正增益(Table 2 的 0.641→0.648)。这是一个关于"公平性 vs 整体指标"的漂亮 trade-off:牺牲头部用户的少量排序精度,换取长尾用户的大幅提升和更健康的生态。
在线 A/B 实验(Table 4)¶
多组 week-long 在线 A/B,把生产目标预测替换为 PEARL 去偏版本,部署到多个直播推荐场景:
| Target | Watch Session | Watch Duration | Consumption Amount | Interaction Rate | Report Rate |
|---|---|---|---|---|---|
| Session Watch Time | +0.608% | +0.665% | — | — | — |
| Long-term Watch Time | +1.165% | +1.222% | — | — | — |
| Consumption | +0.098% | +0.232% | +0.796% | — | — |
| Interaction | — | — | — | +1.494% | — |
| Report | — | — | — | — | −6.911% |
分析:
- 摘要里汇总的 +2.10% Watch Duration 实为三个部署在 Watch Duration 上增益之和(0.665 + 1.222 + 0.232 ≈ 2.119%);+0.80% Consumption Amount 对应 +0.796%;+1.49% Interaction Rate 对应 +1.494%。
- Report Rate −6.911% 看似负数,实则是重大改善——举报率下降意味着用户负反馈减少,摘要把它表述为 "+6.91% Report Rate" 的正向改进。Report 目标用的是自举对比(§3.4),印证了 PEARL 对稀疏负反馈信号去偏的实战价值。
- Long-term Watch Time 增益(+1.165%/+1.222%)显著高于 Session Watch Time(+0.608%/+0.665%),与离线 Table 3 中 Long-term +16.1% 的趋势一致:去偏对长期目标的杠杆最大。
核心贡献总结¶
- 问题命名与刻画:把推荐中跨用户的参与强度差异系统化为 "behavioral intensity imbalance",并用 Figure 2 实证原始模型在非活跃用户上近乎随机。
- 无偏分位估计的对比学习框架:Theorem 1 证明"是否大于一个随机历史样本"的二元指示,其期望恰为真分位数 CDF——从而无需显式维护用户分布、无需直接回归分位、无需辅助分布模型或分阶段管线,单一 BCE 即可隐式逼近无偏分位。
- 系统化的方法族:单样本 → 多样本方差缩减(Theorem 2,$N=50$ 降方差 50×)→ 价值加权(Theorem 3,最优解为部分期望比,统一序与量级)→ 自举(解稀疏离散目标)→ 协同训练(保绝对尺度标定)。
- 十亿级工程实现:图内蓄水池采样($N=50$,近零延迟均匀历史采样)+ 梯度门控($\tau=10$,防欠采样用户噪声污染 backbone)。
- 真实业务收益:十亿用户直播平台多场景在线 A/B,+2.10% Watch Duration、+0.80% Consumption Amount、+1.49% Interaction Rate、举报率改善 6.91%。
与已归档相关工作的对比¶
DADF DADF: A Distribution-Aware Debiasing Framework for Watch-Time Regression(Kuaishou,2026-05-18)¶
关系:独立并发(PEARL 发表于 2026-05-20,仅晚 2 天,未引用 DADF,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直击工业短视频 / 直播推荐中 watch-time 作为训练目标本身不可比、被系统性分布偏差污染这一 root cause——观测/预测的 watch-time 在某个分组维度上系统性失真,而全局聚合统计会掩盖局部的逐组偏差。DADF 把这种"宏观看似标定良好、局部却系统性高估短观看/低估长观看"的现象命名为 pseudo-balance(伪标定);PEARL 把"高活跃用户主导、低活跃用户被淹没"命名为 behavioral intensity imbalance。两者都在论证:直接拟合 watch-time 绝对量级会学到偏的信号。
- 相近的技术骨架:两者抽象流程图高度重合——沿某个分组变量把 watch-time 目标变换到一个组内归一化 / 分位化的空间,以消除系统性分布偏移。DADF 按 video duration 分 $K$ 组、用 group-specific Box–Cox 把长尾乘性校正因子压成近对称分布;PEARL 按用户分组(每用户 CDF)、用对比指示把 watch-time 映成 [0,1] 分位。二者都依赖"组内分布"这一概念,且都用类 CDF / 分位的变换抹平组间差异。
- 本文(PEARL)的差异与推进:(1) 分组轴不同——DADF 沿物品侧 video duration(治的是经典 duration bias:长视频天然观看更久),PEARL 沿用户侧活跃度 / 用户身份(治的是 behavioral intensity bias:高活跃用户量级整体偏大)。这是两种不同的偏差源。(2) 机制不同——DADF 是冻结首阶段预测器之上的事后(post-hoc)乘性残差校正(参数化 Box–Cox + 硬专家路由),PEARL 是端到端地用非参数对比分位估计直接替换 / 正则化目标(无任何分布模型)。(3) 服务对象——DADF 仍输出校正后的 watch-time 量级 $\hat{y}=\hat{y}_0\cdot\hat{b}$;PEARL 可服务分位(排序)或经协同训练服务标定后的量级。(4) 理论锚点不同——DADF 证"比值因子继承长尾⇒需 Box–Cox",PEARL 证"对比指示期望=CDF⇒无偏分位"。
- 可比的方法 / 实验差异:两篇都是 2026-05 的工业落地(Kuaishou vs ByteDance/TikTok),都报告在线时长类指标正收益(DADF +0.347% time-spent-per-device;PEARL +2.10% Watch Duration)。最大互补点:DADF 是"低成本、不动首阶段模型"的插件式残差修正,适合不能替换线上预测器的场景;PEARL 需要把对比分位作为目标 / 正则嵌入训练并维护图内蓄水池,改造更深但去偏更彻底(Figure 2 显示对长尾用户的提升极大)。若把 DADF 的"duration 分组 + Box–Cox"与 PEARL 的"用户分组 + 对比分位"并置,几乎可以拼出一张完整的"watch-time 分布去偏"设计空间图:分组轴(物品 duration / 用户活跃)× 机制(参数化事后校正 / 非参数端到端对比)。
讨论与局限性¶
值得借鉴的设计:
- 用"是否大于随机历史样本"的对比指示无偏逼近分位(Theorem 1)是非常优雅的工程化技巧——把"需要全局分布信息"的分位估计,降维成"只需一次/几次本地随机抽样"的二分类,彻底绕开了存储与排序延迟。这一思想可迁移到任何需要"个性化相对化目标"的场景。
- 蓄水池采样放进计算图内,用 PS 维护 $(\mathcal{P}_u, M_u)$ 两个状态,是把流式无偏采样与训练管线无缝融合的实用范式。
- 方法族按目标分布特性分工(连续→多样本/价值加权;离散稀疏→自举;需绝对值→协同训练),而非一招打天下,体现了对工业多目标系统的成熟理解。
局限与可商榷处:
- 评估透明度有限:仅一个内部工业数据集、所有数值都是相对值、无公开 benchmark、无方差/置信区间、无显著性检验,外部可复现性弱。
- 消融不够细:论文没有系统的消融把"多样本 vs 单样本""价值加权 vs 计数分位""梯度门控 $\tau$""池大小 $N$"逐项拆开做敏感性分析;$N=50$、$\tau=10$、$\lambda$ 的选择仅给结论未给扫描曲线。
- 头部用户的退化是真实代价:Figure 2 显示高活跃用户 UAUC 从 0.652 降到 0.574,是不小的下降。论文用"长尾用户占多数所以整体为正"来辩护,但对以高活跃用户为主要变现来源的业务,这一 trade-off 需要谨慎评估;协同训练(保留绝对量级头)部分缓解了这一点。
- 价值加权与协同训练的耦合:VWBCE 的"部分期望比"目标(Theorem 3)与协同训练的绝对量级头之间是否存在目标冲突 / 梯度打架,论文未深入讨论。
- 冷启动用户:梯度门控 $\tau=10$ 意味着交互数 < 10 的新用户完全不进排序头优化,这部分用户如何兜底(是否回退到原始目标)论文未明确。
工业落地价值:PEARL 是一套已在十亿级直播平台多场景验证的去偏方案,核心卖点是"无需替换分布模型、无需分阶段管线、单 BCE 隐式无偏分位",工程改造集中在图内蓄水池与目标层,对已有排序架构侵入相对可控;其对长尾用户体验与负反馈(举报率)的改善,对平台长期生态健康有明确意义。