Fine-Tuned LLM as a Complementary Predictor Improving Ads System:把微调 LLM 当"广告主预测器"而非排序器接入工业广告系统¶
来自 Pinterest(美国)的工业实践论文(arXiv 2605.27856v1,2026-05-27)。核心主张极其克制:不让 LLM 去做端到端排序,而是把一个微调过的开源 LLM 当作"广告主预测器"(advertiser predictor)这一辅助/互补(complementary / ancillary)信号源——从用户画像与转化历史出发,预测该用户接下来最可能转化的一批广告主(advertiser),再把这些预测同时灌进①召回阶段(作为定向过滤构造一路互补候选生成器)与②排序阶段(作为下游转化模型的特征)。在 Pinterest 真实广告系统上线后,U.S. Shopping 切片的 Return on Ad Spend(RoAS)提升 4.94%(p=0.021),opt-in 切片提升 6.69%(p=0.029)。
研究动机与背景¶
为什么 LLM 难以直接搬进工业广告系统¶
工业级推荐系统普遍采用多阶段级联架构:前端召回(candidate generation)强调高召回率与效率(常用 dual-encoder / two-tower + ANN 近邻检索),把海量物品收敛成一份可管理的候选;后端排序(ranking)强调精度,部署 Wide&Deep、DCN、深度稀疏架构来捕捉高阶特征交叉与长尾效应。历史上工业推荐的提升主要来自协同过滤信号(在相似用户/物品间传播偏好)+ 越来越丰富的特征交叉 + 大规模表征学习。
把 LLM 直接移植进这套生产栈被证明非常困难,论文归纳出三重根本错配:
- 稀疏 ID 中心特征 vs token 语义空间:工业推荐重度依赖稀疏的 ID 类特征(用户 ID、物品/广告主 ID、campaign/creative ID),这些与 LLM 的 token 化语义表征天然不对齐;
- 深度特征交叉与校准目标难以映射进 LLM:现代排序栈显式建模深度特征交叉与复杂的校准目标,把这些归纳偏置塞进 LLM 并不平凡;
- 参数规模与解码成本压垮实时服务预算:LLM 的参数量与解码开销在推荐流量下会击穿严苛的尾延迟 SLO、内存占用与成本约束。
已有三条 LLM-in-RecSys 路线及其在广告上的空白¶
论文把目前 LLM 在工业推荐里"看得见的成功"归为三类:
- (a) 生成式检索(generative retrieval):用 LLM 直接产出下一个 item 或 semantic ID 做候选生成,常借助受限解码或学习码本;
- (b) 后段重排(late-stage reranking):用 LLM 当重排器,强大但昂贵;
- (c) 辅助信号增强(auxiliary signal enrichment):prompt 或微调 LLM 去推断 side information(物品类型、用户兴趣、hashtag 等),再作为特征喂回传统模型。
然而在广告推荐上能拿出可观规模化收益的工作仍然稀少——广告场景里 advertiser 实体、定向约束、转化历史扮演核心角色,又引入额外稀疏性,且与纯文本语义错配。
本文的互补范式¶
论文提出一条为广告量身定制的互补范式:把微调过的开源 LLM 不当排序器,而当一个广告专用的辅助预测器,基于用户画像与转化历史,预测该用户接下来最可能转化的广告主。方法围绕三步展开:
- 在用户画像与广告中心特征(过往转化、top 广告主/品牌/品类/URL、人口属性)之上做结构化编译与 prompt 模板;
- 微调 LLM 去从这份结构化上下文里预测 next-advertiser 候选 + 相关辅助标签(用户兴趣);
- 把这些预测同时注入早期召回(广告主定向的候选过滤)与后段转化模型(作为额外特征)。
论文的三点贡献: 1. 识别并解决 LLM 语义与广告 RecSys 之间的核心错配——把任务形式化为"广告主预测(advertiser-prediction)",在 advertiser names 与 advertiser IDs 之间引入一层转化层(conversion layer),以借力 LLM 的世界知识; 2. 给出一套可落地的配方(数据编译、prompt 设计、微调),产出在召回与排序两阶段都可用、且延迟/成本可接受的稳定信号; 3. 在大规模生产广告系统上端到端验证:紧凑的 LLM 衍生预测能补充而非模仿既有协同/特征工程信号,在全链路上解锁收益。
核心方法 / 模型架构¶
系统总览¶
整套系统把微调 LLM 当"互补广告主预测器"而非直接端到端广告排序器。给定一份结构化的用户画像 + 近期行为摘要,模型预测出一组高转化意图的广告主,外加一份简短的用户兴趣列表。LLM 的输出有两种消费方式:(1) 作为广告主定向候选生成的额外信号(召回);(2) 作为下游转化模型的特征化输入(排序)。
整个系统含四个阶段:用户筛选 → 特征编译 → 基于 prompt 的广告主预测 → 下游消费。用户筛选把每日推理限制在"额外 LLM 信号最有用"的高价值人群,以适配生产延迟与成本;特征编译把异构的站内/站外用户活动转成紧凑文本表征;LLM 经后训练从结构化上下文预测广告主;预测出的广告主作为召回过滤与排序特征使用。
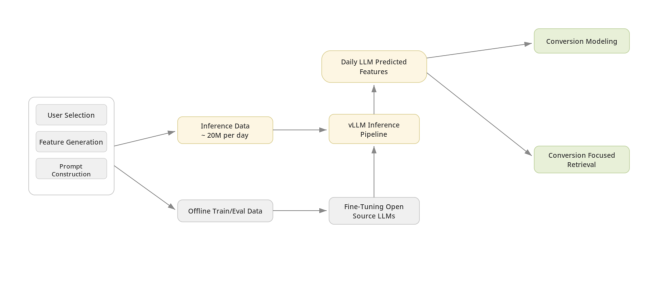
数据流水线¶
用户筛选(User Selection):每日推理需在用户覆盖度与推理成本/速度间权衡,主要瓶颈是大规模每日 LLM 推理。论文把服务人群限制在近 90 天内有活跃过往转化(含 on-Pinterest 与 off-Pinterest 转化信号)的美国活跃 Pinterest 用户,既聚焦有真实商业意图的用户,又在工程上可行。离线数据生成时,每条样本锚定在日期 $x$,只有在 $x+1$ 之后存在有效未来转化标签的用户才纳入;标签只取在 Pinterest 上活跃且有广告投放的广告主,且只用高优先级转化类型。
标签构造(Label Construction):核心预测目标是用户在预测窗口内首个转化的广告主。离线评估中,标签定义为窗口 $x+1$ 到 $x+7$ 内首个被转化的广告主。用"首次转化"而非多标签,是为了把训练对齐到 next-advertiser 预测任务——这恰好匹配"为召回与排序提供广告主先验"的预期用途。训练/评估按用户随机切分以防泄漏,当前切分比 0.9/0.1。
用户特征编译(User Feature Compilation):从画像特征 + 行为序列构造结构化用户表征。
- 用户画像:年龄、性别、user state;
- 行为序列(behavior summary):站内搜索;站外归因转化(offsite attributed conversions);站外匹配转化(offsite matched conversions);与转化相关的站外搜索;与转化相关的站外 URL;从归因转化/匹配转化/站内搜索/站外搜索导出的 top 品类/兴趣;来自 query 数据的站内品类;来自 URL 数据的站外品类;站外物品品牌;从 URL 抽取的站外品牌。
- 广告主池(Advertiser pools):prompt 构造用两个来源——① 用户有活跃过往转化的广告主;② 由每日 top-revenue 美国 shopping 广告主(OCPM 与 ROAS)构成的预设广告主池(preset advertiser pool)。
这份表征在 prompt 长度限制内尽量保留时效性与商业相关性。
Prompt 设计¶
所有阶段共享同一份结构化用户上下文,prompt 输入都包含:(1) 有过往转化的活跃广告主,(2) 用户画像字段,(3) 行为摘要(归因转化、匹配转化、站内搜索、站外搜索、站外 URL、top 品类、top 品牌)。三个阶段的差别只在预测目标、请求广告主数量、输出格式上,见 Table 1:
Table 1: 各阶段 prompt 设计概览
| 阶段 | 预测目标 | 广告主数量 | 输出格式 |
|---|---|---|---|
| SFT | 单个 next advertiser | 1 | 自由文本 |
| GRPO | 排序广告主 + 兴趣 | 20 + 5 | 结构化 XML |
| Inference | 排序广告主 + 兴趣 | 20 + 5 | 结构化 XML(同 GRPO) |
- SFT prompt:简化预测目标,只预测单个 next advertiser,训练标签即监督窗口内的单个 next advertiser。把模型聚焦到最精确的广告主预测子任务,同时保留结构化用户上下文。
- GRPO prompt:SFT 之后用 GRPO 进一步优化,要求生成排序的 20 个广告主 + 至多 5 个兴趣。监督仍来自单个 next advertiser,但更丰富的输出空间能提供更有信息量的奖励信号。选 20 而非 5 个广告主,是因为更长的排序列表能在每个 GRPO step 给出更大的奖励方差。
- Inference prompt:输入同后训练,输出格式与 GRPO 保持一致(返回恰好 20 个广告主 + 至多 5 个兴趣的 XML)。推理与 GRPO 对齐可减小 train-test mismatch,并让输出可直接被下游系统消费。
后训练(Post-Training)¶
研究了两种后训练策略:监督微调(SFT)与 GRPO 强化学习。
3.4.1 SFT:聚焦预测单个 next advertiser,训练标签即标签构造步骤里定义的单个 next advertiser,直接优化广告主预测任务最精确的版本。
3.4.2 GRPO 训练:GRPO 阶段训练 prompt 与推理对齐——模型预测 20 个广告主 + 5 个用户兴趣,但 ground-truth 监督仍来自单个 next advertiser。预测 20 个(而非 5 个)的动机是让每个 GRPO step 产生更高的奖励方差。
总奖励定义为:
$$R_{\text{total}} = R_{\text{match}} - P_{\text{adv\_len}} - P_{\text{interest\_len}} \tag{1}$$
其中 $R_{\text{match}}$ 奖励 ground-truth 广告主是否出现在预测列表中、以及出现的位置。若正确广告主排在位置 $i$,则
$$R_{\text{match}}(i) = R_{\text{base}}(i) + R_{\text{bonus}}(i) \tag{2}$$
其中
$$R_{\text{base}}(i) = 0.1 \times (20 - i) \tag{3}$$
$$R_{\text{bonus}}(i) = \begin{cases} 2.0, & \text{if } i \le 4, \\ 0, & \text{otherwise.} \end{cases} \tag{4}$$
长度惩罚同时用于广告主数量与兴趣数量:
$$P_{\text{len}}(n, n^*) = \begin{cases} 0, & \text{if } n = n^*, \\ \min(0.1 \times |n - n^*|,\ 1.0) + 1.0, & \text{otherwise.} \end{cases} \tag{5}$$
含义:$R_{\text{base}}$ 是一个随排名线性衰减的位置奖励(越靠前奖励越高);$R_{\text{bonus}}$ 给 top-4 命中额外重奖,强烈鼓励把正确广告主推到最前;$P_{\text{len}}$ 对"输出数量偏离目标值 $n^*$"施加阶跃式惩罚(只要不等于目标值就至少 +1.0 的惩罚底),强制严格的格式/数量服从。整套奖励同时鼓励正确的广告主排序与严格的格式遵守。
Semantic ID(SID)增强¶
在既有设计之上,论文通过对开源 LLM base model 做持续预训练(continued pre-training, CPT)、再接 SFT,引入 SID 知识。离线评估做 side-by-side 对照:text-only 模型只收到含文本特征的 prompt,SID-enabled 模型收到一份仅额外加入近期 SID 的、其余完全相同的 prompt,从而把性能差异完全归因到 SID 的有无。本研究使用 5 层、每层 20248 个码 的 SID,由多模态 PinCLIP embeddings 经 RQ-VAE 构造。
为缓解灌入 SID 时的灾难性遗忘,论文用多阶段后训练:
- Phase 1:先做 special SID token 与普通 text token 空间的初步对齐。CPT 数据来自 Pinterest 用户画像、Pin 元数据、用户互动序列以及 SID 信息(结合 Pin 标题、描述、taxonomy),量级数十亿条。此阶段只更新 SID token 的 embedding,冻结普通 text token embedding 与 transformer 参数;
- Phase 2:解冻整个模型,做全参数预训练把推荐知识灌进 LLM。混入大量通用域数据进一步缓解灾难性遗忘;
- Phase 3:在前两阶段得到"既有 SID 推荐知识、又有通用世界知识"的 LLM 后,做任务特定微调。对广告主预测任务,用与前文相同的后训练配方,prompt 现在在文本之外还包含 SID。也可微调模型去预测 next SID,从而既能当候选检索生成器、又能作为排序特征。
下游集成¶
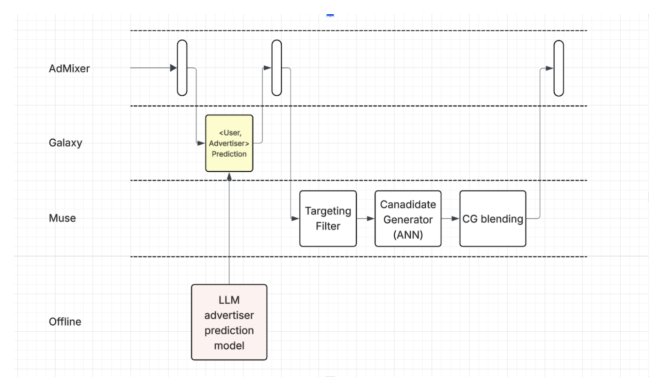
召回:LLM-based 候选生成器(CG)。论文开发了一个把 LLM 预测广告主纳入广告召回的新 CG:把预测出的广告主当作定向过滤器(targeting filter),在这些广告主下用一个面向用户互动优化的 two-tower 模型做检索。该 CG 被设计成一路互补的检索通道,而非替换主候选生成器,目标是从高转化意图的广告主带来额外流量,同时保住下游漏斗存活率与用户体验,对既有信号覆盖较弱的用户尤其有用。
排序:LLM 衍生特征。LLM 预测的广告主与用户兴趣被特征化,作为下游转化模型(包括 ctcvr、vtcvr)的输入。
服务与生产化¶
用分布式 vLLM + Ray 栈做大规模批推理(见 Figure 2),三点工程收益:重复 prompt 模板的 prefix caching;通过 paged attention 做高效 KV-cache 管理;通过 continuous batching 拉高 GPU 利用率。可靠性上,推理流程用带 checkpointing 的 virtual epochs,失败的 run 从最近未完成的 epoch 恢复而非重启;并做增量更新——只对有新观测活动的用户重新推理,大幅降低每日推理量。
实验设置¶
特征快照建在日期 $x$,特征时间范围在 prompt 长度约束与性能间权衡(如站内搜索 query 取近 3 个月、URL 取近 2 周)。在两个数据版本上评估:
- V0:实验数据集,用户具备足够长的序列特征;具体把 matched-conversion 与 attributed-conversion 序列长度过滤到 $\ge 10$;
- V1:与日期 $x$ 的线上服务流量对齐的数据集,标签是 $x+1$ 到 $x+7$ 的高优先级转化;更接近生产流量,但特征表达力更弱。
广告主预测用 recall 类指标;此外做特征消融,并研究 LLM 衍生广告主对下游转化模型的影响。比较 zero-shot prompting、SFT、GRPO 后训练三类,主要对比包括:(1) base 开源模型上的 zero-shot prompting,(2) 不同解码策略的 SFT,(3) 带/不带显式 reasoning prompting 的 GRPO。下游评估 LLM 预测广告主对 ctcvr、vtcvr 等转化模型以及广告召回阶段一个生产候选生成器的影响。
主要实验结果¶
广告主预测质量¶
Table 2(V0,更丰富的离线设定):所有后训练变体都优于 zero-shot。在这一富特征设定下,SFT + beam search 与 no-reasoning 变体整体最强;SFT + sampling 不如 beam search。说明即便 base 开源模型已具强世界知识,后训练仍带来实质提升。
Table 2: V0 上的离线广告主预测结果
| 方法 | Recall@1 | Recall@5 | Recall@20 |
|---|---|---|---|
| Zero-shot prompting | 0.346 | 0.567 | 0.655 |
| SFT + beam search | 0.480 | 0.720 | 0.780 |
| SFT + sampling | 0.443 | 0.664 | 0.707 |
| GRPO (reasoning) | 0.496 | 0.684 | 0.766 |
| Zero-shot w/o reasoning | 0.333 | 0.586 | 0.680 |
| GRPO w/o reasoning | 0.490 | 0.688 | 0.778 |
Table 3(V1,更贴近线上):呈现从 zero-shot → SFT → SFT+GRPO → SID-enabled 的一致递进,反映三条学习阶段效应:第一,在 20-广告主 prompt 上做 SFT 能提升性能,但在该格式上继续训练可能破坏格式服从;第二,在 1-广告主 prompt 上做 SFT 主要提升最精确的 recall 指标(Recall@1);第三,在 1-广告主 SFT 初始化之上做 GRPO,大幅提升大 K 的 recall(Recall@20),对最精确指标的增益较小。
Table 3: V1 上的离线广告主预测结果
| 方法 | Recall@1 | Recall@5 | Recall@20 |
|---|---|---|---|
| Zero-shot prompting | 0.117 | 0.301 | 0.422 |
| SFT (20-advertiser prompt) | 0.156 | 0.314 | 0.456 |
| SFT (1-advertiser prompt) | 0.214 | 0.413 | 0.501 |
| SFT (1-advertiser prompt) + GRPO | 0.223 | 0.461 | 0.683 |
| SID-enabled SFT (1-advertiser prompt) + GRPO | 0.248 | 0.515 | 0.755 |
论文同时指出显式 reasoning 对该任务普遍无用,用更简单的 SFT 式训练常能达到相近整体性能——这与任务结构一致:预测 next advertiser 更接近偏好/意图聚合,而非长链推理。
SID 增强效果(Table 3 末两行):SID 知识把 LLM 模型的候选 recall 在 Recall@1/5/20 上均提升超过 10%。说明 SID 提供了超出 prompt 中已有文本字段的互补信号——直觉上,SID 编码了多模态内容语义与共现结构(经 PinCLIP + board 级 curation),这些是单靠广告主名、query 文本、URL 字符串难以重建的。
特征消融¶
Table 4(zero-shot 4B 设定;负值表示相对 baseline 的性能下降):"有过往转化的活跃广告主"是迄今最重要的单一输入特征组(去掉后 Recall@5 暴跌 0.1000)。行为特征里,站外 URL 与站外搜索影响次之,说明广义的站外商业意图携带了有用的广告主级信号。匹配转化、站内搜索、top 品牌也有正贡献;用户画像特征边际贡献相对小;去掉 top 品类反而略升 Recall@5,提示该特征在当前 prompt 形式下偏噪声。序列顺序实验进一步表明:朴素地重排或删除行为序列不仅无益、还可能显著伤害性能,说明原本的recency-aware 编译对模型质量本就重要。
Table 4: zero-shot 4B 设定下的特征消融
| 消融操作 | Δ Recall@5 |
|---|---|
| 去掉 active advertisers with past conversions | -0.1000 |
| 去掉 offsite URLs | -0.0290 |
| 去掉 offsite searches | -0.0140 |
| 去掉 matched conversions | -0.0098 |
| 去掉 onsite searches | -0.0098 |
| 去掉 top brands | -0.0079 |
| 去掉 user profile | -0.0020 |
| 去掉 attributed conversions | +0.0000 |
| 去掉 top categories | +0.0039 |
| Reorder by performance descending | -0.0049 |
| Reorder + delete negative-performing sequence | -0.0170 |
| Delete negative-performing sequence | -0.0059 |
注:该消融跑在 "zero-shot 4B" 设定上,是全文唯一一处透露 base 模型规模约为 4B 参数级的开源 LLM(论文未公开具体模型名)。
下游模型影响¶
Table 5:加入 LLM 衍生广告主特征后,两个转化目标都改善,在 PR-AUC 上提升尤其明显(稀疏转化设定下 PR-AUC 更关键)。
Table 5: 加入 LLM 衍生广告主特征后转化建模的离线提升
| 模型 | Δ Loss | Δ AUC | Δ PR-AUC |
|---|---|---|---|
| ctcvr | -0.12% | +0.06% | +0.71% |
| vtcvr | -0.64% | +0.09% | +1.64% |
线上部署结果¶
召回实验设计:在 Home Feed、Related Pins、Search 三种 view 上为美国 opt-in 用户部署该 LLM-based 候选生成器。对 two-tower 召回模型测了三种训练目标:impressions 为正例、带时长权重的 clicks 为正例、conversions 为正例。结论是损失函数选择至关重要:训 impressions 提升存活率但伤害用户互动;直接训 conversions 因标签稀疏而不稳定;用带时长权重的 clicks 在漏斗存活与互动间取得最佳平衡。此外该 CG 的 L0 quota 必须谨慎调节——由于 CG 聚焦高转化意图广告主,其广告往往 CTR/CVR 评分偏高,quota 过大会在候选混合时形成主导,去重后反而损害广告主多样性。
线上指标(Table 6):在 U.S. Shopping Ads 内,新候选生成器把 RoAS 提升 4.94%(p=0.021),treatment(opt-in)切片提升 6.69%(p=0.029)。最强的增量来自 CG 带来了既有检索通道覆盖不足、但转化意图强的广告主流量。生产实践还表明:召回模型目标、CG quota、目标用户人群三者都对成败有实质影响。
Table 6: LLM-based 候选生成器在美国 Shopping 切片上的线上影响
| 指标 | 相对变化 |
|---|---|
| US Shopping Slice — Return on Ad Spend | +4.94% |
| Opt-in US Shopping Slice — Return on Ad Spend | +6.69% |
核心贡献总结¶
- 范式层面:首次系统化地把"微调开源 LLM"定位为广告系统里的互补广告主预测器而非排序器/生成式检索器,并在 advertiser names ↔ advertiser IDs 之间引入转化层这一关键设计,使 LLM 的世界知识可被广告栈消费。
- 配方层面:给出一条端到端可复制的工业配方——结构化特征编译 + 阶段化 prompt(SFT 单广告主 / GRPO 20+5 / 推理对齐)+ 带位置奖励与长度惩罚的 GRPO + 多阶段 SID CPT,产物在召回与排序两阶段都可用且延迟/成本可接受。
- 落地层面:真实 Pinterest 生产部署 + 带 p 值的线上 A/B(RoAS +4.94% / +6.69%),并用消融定位了"过往转化广告主 + 站外意图"是收益主力、简单画像贡献有限这一可操作结论。
与已归档相关工作的对比¶
LLM Retrieval for Stable and Predictable Ad Recommendations LLM Retrieval for Stable and Predictable Ad Recommendations (Meta, 2026-05-21)¶
关系:独立并发(本文未引用该 Meta 工作,两者相隔 6 天、殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都在解同一个 root cause——如何把一个微调过的 LLM 接入大规模工业广告系统的召回侧、作为一路"互补候选生成器"(而非取代或充当排序器),用 LLM 的语义/世界知识去触达传统 ID/协同信号漏掉的语义相关候选,并最终改善 final-stage recall 与线上顶线指标。两者都明确把 LLM 设计成既有级联栈之上的新增检索通道,不替换主栈。
- 相近的技术骨架:都是"先在广告数据上做召回特定微调,再把 LLM 产出的离散语义信号灌进 ANN/检索",最终在大规模广告系统线上 A/B 上拿到召回 + 顶线收益。
- 本文的差异与推进:信号的语义锚点不同。Pinterest 走用户侧——LLM 从用户画像/转化历史预测广告主实体(advertiser)这一广告原生粗粒度实体,既喂召回(定向过滤)又喂排序(ctcvr/vtcvr 特征);方法重心在后训练(SFT→GRPO 带定制奖励→SID CPT)。Meta 走物品侧——LLM 从广告创意抽取层级语义属性并构建 ad-to-ad 语义图,靠图遍历 + Jaccard 模糊集合匹配做 ad-to-ad 扩展;且额外提出一套"可预测性/稳定性"度量框架(A/A' StatSigDiff)作为核心新贡献。
- 可比的方法 / 实验差异:Pinterest 报告 U.S. Shopping RoAS +4.94%/+6.69%(带 p 值),并有 SFT/GRPO/SID 的离线 recall 阶梯(V0/V1);Meta 报告 final-stage recall +1.2%、topline +0.45%,外加 A/A' -8.62%、MAD +45% 的稳定性提升。两者把"LLM 当互补召回"这一思路分别推进到了用户→广告主意图预测与广告→广告语义图扩展两个互补方向,且都强调要把 LLM CG 当作独立通道、谨慎调节其与主栈的混合(本文是 L0 quota,Meta 是稳定性护栏)。详见 LLM Retrieval for Stable and Predictable Ad Recommendations。
讨论与局限性¶
核心贡献与可借鉴设计。这篇论文最值得借鉴的是它的克制:在 LLM-for-RecSys 已经卷向"端到端生成式排序/检索"的当下,它反其道把 LLM 放在一个低风险、可叠加、不上实时关键路径的位置——每日批量推理产出广告主先验,既喂召回又喂排序。这套定位让它绕开了 LLM 直接做实时排序的三大障碍(稀疏 ID 错配、深度交叉难映射、解码成本击穿 SLO),又能拿到真实线上收益。advertiser 这一粒度的选择是点睛之笔:它比"预测下一个 item/SID"粗、空间小得多,因此 recall 任务更稳、更适合 LLM 的偏好聚合能力(论文也实证了显式 reasoning 在此任务上无用);又比"预测品类/兴趣"具体、可直接转成定向过滤。GRPO 奖励里用"20 个广告主换更大奖励方差"、用 top-4 bonus 拉前排,也是值得参考的工程细节。
局限与争议:
- 非端到端、信号互补但解耦。LLM 与下游召回/排序模型无法联合优化,LLM 只产出离线先验再被消费;这是论文的设计初衷,但也意味着收益上限受制于"广告主先验"这一中间表征,且参数 scaling 时表征能力与下游建模能力难以同步增长。
- SID 增强仅离线验证。Table 3 里 SID-enabled 变体离线最强(recall 提升 >10%),但论文在结论中明确:多模态 SID 扩展尚未线上验证,被排除在本文主要实证主张之外——线上 RoAS 收益来自 text-based 的 LLM CG。
- 关键细节未公开:base 模型只透露约 4B 规模、未给名称;线上 topline/顶线指标的具体定义、preset advertiser pool 规模、每日 ~20M 推理的成本数字均未披露,复现性受限。
- 每日批量、非实时:依赖"只对有新活动用户增量推理"来控成本,对活动高频变化或强时效场景的适配性存疑。
工业落地价值:作为生产实践报告,它提供了完整的服务化方案(vLLM + Ray、prefix caching、paged attention、continuous batching、virtual epochs 容错、增量推理)与上线踩坑经验(召回 two-tower 损失函数选 duration-weighted clicks、L0 quota 过大伤多样性、目标人群选择),对任何想在广告/推荐栈里"低成本接入一路 LLM 互补信号"的团队都有直接参考价值。