Efficient Listwise Reranking with Compressed Document Representations (RRK)¶
一、研究动机与背景¶
1.1 LLM 列表式重排器的效率瓶颈¶
现代信息检索(IR)通常分两阶段:第一阶段(first-stage)从大规模语料中召回候选段落(BM25、SPLADE、密集检索),第二阶段(reranker)对召回结果进行精细重排。LLM-based 列表式重排(listwise reranking)一次性接收 query 和数十个候选文档的完整文本,让模型在所有候选间显式做 cross-passage attention,效果显著优于传统 cross-encoder 与 pointwise reranker。然而该范式在工业场景下面临严重效率问题:
- 输入长度爆炸:把 50–100 个候选文档的全文拼接成 prompt,序列长度轻易突破 10k token,self-attention 的 $O(L^2)$ 复杂度让推理延迟急剧上升。
- 模型规模代价:listwise 重排器通常基于 7B/8B LLM;即便用 0.6B/4B 的小模型,sliding-window 的多次推理也叠加成显著延迟。
- 生成开销:原始 RankGPT 风格做法要 LLM 显式生成排序后的文档 ID 序列(n→4.5n token),后续工作(Gangi Reddy 2024, E2Rank 2026, jina-reranker-v3)通过 first-token logits 或 embedding 得分把生成开销压到 0,但输入侧的长度问题仍未解决。
1.2 软压缩方向的启发¶
近期 RAG 社区涌现一批 soft compression 方法,把文档压缩成少量 memory token 供 LLM 在长上下文 / RAG-QA 中复用:
- AutoCompressor(Chevalier et al. 2023):递归在 LM 训练目标上学到压缩 token;
- ICAE(Ge et al. 2023):In-Context AutoEncoder,固定解码器、用文档自编码任务预训练;
- xRAG(Cheng et al. 2024):直接把检索器 embedding 通过适配器投影到冻结 decoder 输入空间;
- PISCO(Louis et al. 2025):完全用知识蒸馏训练 compressor 与 decoder,重现 teacher 的输出,在 RAG-QA 上做到 16× 压缩、0–3% 精度损失;
- ArcEncoder(Pilchen et al. 2025):单 token 压缩文本用于 LLM 输入;
- PE-Rank(Liu et al. WWW 2025):把 first-stage Jina embedding 当作 passage 的压缩表示送入 reranker,但仍依赖 sequential decoding 输出排列;
- E2Rank(Liu et al. 2026):把第一阶段 retrieval embedding 与 listwise reranking 联合训练,复用 embedding 做最终打分。
1.3 RRK 的核心问题¶
PE-Rank、E2Rank 都用 IR 任务训出来的 retrieval embedding 作为 passage 压缩表示。论文的核心问题是:
Soft compression(即从 LLM 自身内部语义提炼的多 token 富表示)能否替代 IR-based embedding,作为更适合 listwise 重排的 passage 压缩表示?
贡献:提出 RRK(compressed version of ReRanker),首个把 PISCO-style soft compression 与 listwise reranking 结合的端到端框架。RRK 8B 参数模型在 BEIR 上比 0.6–4B 的小型 reranker 快 3×–18×,效果不降;在长文档(MS-MARCO Document, ~1k token)场景优势进一步放大到 10×–58×。这一发现支持"压缩表示的 质量 比 长度 更重要"的核心论点:LLM-derived 软压缩比 IR-derived embedding 保留更丰富的细粒度语义,因此即便用 8B 大模型 + 短输入也能跑赢 4B/0.6B + 长输入。
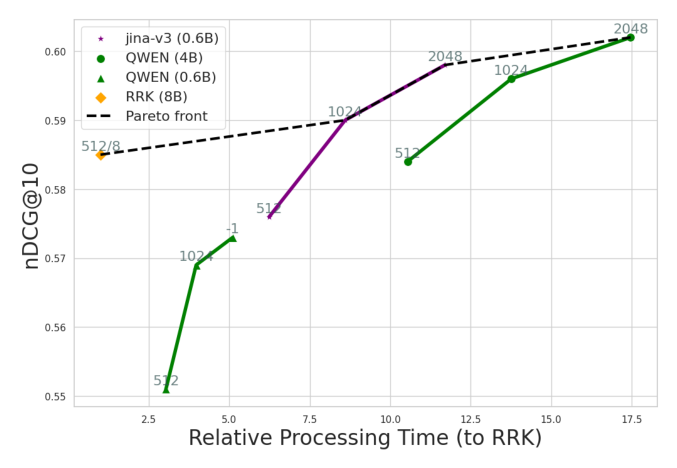
二、核心方法 / 模型架构¶
2.1 系统概览¶
RRK 由两个 LoRA-finetuned 组件组成:
- Compressor $f_{\theta_c}: d_i \to \mathbf{c}_i$:基于 PISCO 模型,把每个文档 $d_i$ 映射成 $l$ 个 memory token 的 embedding 序列 $\mathbf{c}_i = (c_i^1, \ldots, c_i^l)$。论文固定 $l = 8$。
- Decoder reranker $g_{\theta_r}(q, \mathbf{c}_1, \ldots, \mathbf{c}_k)$:接收 query 和 $k$ 个候选文档的压缩表示,输出每个候选的相关性分数 $s_i$。
形式化:给定文档集合 $\mathcal{D} = \{d_i\}_{i=1}^N$ 和 query $q$,第一阶段检索器返回 top-$k$ 子集 $D_k = \{d_1, \ldots, d_k\}$,重排器输出分数 $s_i = g_{\theta_r}(q, \mathbf{c}_i)$ 用于排序。
2.2 文档压缩(PISCO Compressor)¶
训练完成后,每个文档 $d_i$ 在离线(offline)阶段被一次性压缩并存盘——这是 RRK 工业部署友好的关键。对每个 $d_i$,附加 $l$ 个 memory token $(m_1, \ldots, m_l)$ 形成 $(d_i; m_1, \ldots, m_l)$ 输入压缩器,取这些 memory token 的最终隐藏态作为文档 embedding:
$$\mathbf{c}_i = (c_i^s)_{s=1\ldots l} \tag{1}$$
PISCO 训练时使用 $l = 8$、最大文档长度 128 token,对应 16× 压缩比。但论文实验证明 PISCO compressor 可自然外推到长文档(最长 2048 token,对应 256× 压缩比,见 §6.1),这是 RRK 在长文档场景效率优势进一步放大的根本原因。
对于 BEIR 平均文档长度(约 200 token)和 $l = 8$,单文档压缩到 8 token,attention 复杂度的二次项被显著降低。
2.3 列表式 LLM 重排器¶
RRK reranker 的输入借鉴 jina-reranker-v3 的设计:query 在序列首尾各出现一次("repeating the query at both the beginning and end may compensate for the lack of bidirectional attention and enhances the results")。对 query $q$ 和候选 $\{d_1, \ldots, d_k\}$,输入序列:
$$X = (q; \mathbf{c}_1; [\text{SEP}]; \mathbf{c}_2; [\text{SEP}]; \ldots; \mathbf{c}_k; [\text{SEP}]; q) \tag{2}$$
记 reranker hidden state 为 $H = \text{Decoder}_{\theta_r}(X)$。打分协议:
- Query 表示 $\mathbf{q}$:取最后一个 token 的 hidden state $\mathbf{q} = H_{|X|}$(global aggregation embedding);
- 文档表示 $\mathbf{h}_i$:取第 $i$ 个 SEP token位置的 hidden state(紧跟在 $\mathbf{c}_i$ 后);
- 相关性分数:
$$s_i = \cos(\mathbf{q}, \mathbf{h}_i) \tag{3}$$
生成 token 数 = 0,单次前向就能给所有候选打分。打分阶段读取压缩 embedding 的开销不超过总重排时间的 10%(论文实测)。
2.4 训练目标:RankNet Listwise Loss¶
RRK 用 RankNet pairwise ranking loss 训练。设 $\mathcal{P}$ 为 preference 对集合 $(d_i, d_j)$($d_i$ 比 $d_j$ 更相关),温度 $\tau = 1/8$:
$$\mathcal{L}(q, D_k) = \sum_{(i,j) \in \mathcal{P}} \log\left(1 + \exp\left(\frac{s_i - s_j}{\tau}\right)\right) \tag{4}$$
关键点:compressor 与 reranker 联合训练——通过 $s_i = g_{\theta_r}(q, f_{\theta_c}(d_i))$ 把排序梯度反向传到 compressor,使后者学会保留对排序有用的信息(而非通用 RAG-QA 信息)。训练完成后,文档可被 offline 压缩,inference 时 reranker 读 embedding 即可。
2.5 复杂度分析¶
记 $k$ 为候选数、$|q|$ 为 query token 数、$|d|$ 为平均文档 token 数。
- 标准 LLM listwise reranker(如 jina-v3):处理长度 $|q| + k|d|$ 的序列,注意力复杂度
$$O((|q| + k|d|)^2) \tag{5}$$
- RRK:处理长度 $2|q| + k(l + 1)$ 的序列(query 重复一次、$l$ 压缩 token + 1 个 SEP),复杂度
$$O((2|q| + k(l+1))^2) \tag{6}$$
由于 $l \ll |d|$(如 BEIR 中 $l = 8$ vs $|d| \approx 200$),attention 二次项显著缩小。这正是 RRK 速度优势的来源——文档越长,优势越大。
2.6 Pointwise 变体(RRK PW)¶
为消融对比,论文还训了一个 pointwise 版本:reranker 输入 $(q; \mathbf{c}_i)$ 并把最后一层最后 token 通过线性头映射到标量分数,用 MSE loss 拟合教师的分数:
$$\mathcal{L}_{\text{PW}} = \frac{1}{N}\sum_i (s_i^{\text{student}} - s_i^{\text{teacher}})^2$$
实验显示 RRK PW 比 RRK listwise 略弱,验证 listwise 训练对学好"跨文档对比"信号不可或缺。
三、关键技术细节¶
3.1 蒸馏教师选择¶
论文不依赖大规模人类标注,全用蒸馏训练。教师选择经过对比实验:
- 第一阶段检索器:SPLADE-V3(Lassance et al. 2024)——快、对域外鲁棒;
- Listwise 教师:jina-reranker-v3(Wang et al. 2025)——基于 Qwen3-0.6B 的 listwise reranker,在 BEIR 上效果与 Qwen3-4B reranker 相当(Zhang et al. 2025)。
教师在 top-50 上提供 ranking permutation,作为蒸馏信号。这一点与 SumRank 用 Qwen2.5-72B 做教师、ResRank 用 Qwen3-Max 重新标注 PE-Rank 数据集的做法殊途同归。
3.2 学生骨干:Qwen2.5-8B + LoRA¶
PISCO 模型基于 Qwen2.5-8B-Instruct(与 PISCO 原始论文一致),LoRA 微调 compressor 和 reranker。lora rank、alpha 等超参未在正文显式说明。
3.3 训练数据¶
两份数据集组合:
- MS MARCO passage(Bajaj et al. 2018):500k query,每条配 16 个文档(top-50 中随机抽),相关性由 SPLADE-v3 + jina-v3 教师生成;
- E2RANK 数据集(Campagnano et al. 2025):150k query,每条配 16 个文档,由 Qwen-32B 作为 zero-shot 教师生成相关性分数;该集源自 BGE-M3。
最终用 MS-MARCO + E2RANK 联合训练效果最好(avg nDCG@10 = 58.4)。
3.4 训练超参¶
- 2 epoch(再多无进一步提升);
- 1 张 A100;16 docs/query, batch size 2, gradient accumulation 16,等效 batch 32;
- 学习率 $1\times 10^{-4}$;
- Pointwise 版本:4 docs/query, batch size 8(同样 ~48h 训练);
- 推理 batch size 128(~90% A100 显存利用率,输入长度 512);
- 整体训练 ~48 小时。
3.5 三类基线¶
| 类别 | 模型 | 备注 |
|---|---|---|
| Public reranker | jina-v3 (0.6B), Qwen3-0.6B, Qwen3-4B | 用 7M/12M 大数据训练,规模和数据量均显著占优 |
| Fine-tuned 文本输入(无压缩) | ModernBERT-large, Qwen2.5-8B | 用同 RRK 数据训练,作为效果上界与文本输入对照 |
| RRK 系列 | RRK†(listwise), RRK PW(pointwise) | †标记 listwise reranker |
baseline 与 RRK 都用 SPLADE-V3 top-50 作为输入候选,确保公平对比。
四、实验设置¶
4.1 数据集与评估¶
- TREC DL 2019/2020(passage 任务);
- BEIR:12 个 OOD 数据集(排除 ArguAna,因其与多数 BEIR 任务在 counter-argument 检索目标上不同);
- MS-MARCO Document DL19/20:长文档场景(平均长度 ~1000 token);
- 主指标:nDCG@10 ×100;效率指标:latency ratio(相对 RRK 的 query-per-second 比值,RRK 始终最快)。
4.2 评估协议¶
- 候选数 $k = 50$(除特别声明);
- 输入长度配置 512 / 1024 / 2048(或 -1 表示 jina-v3 的全长无截断);
- 所有 latency 在单卡 A100、batch size 128 下测量;输入长 512 默认满 90% 显存利用率,更短输入用 batch 256。
五、主要实验结果¶
5.1 BEIR 综合表现(Table 1)¶
| Model | Len. | nDCG@10 | Latency Ratio | s/q ↓ |
|---|---|---|---|---|
| RRK Rerankers (Qwen2.5-8B) | ||||
| RRK † (listwise) | 512 | 58.4 | 1× | 0.06 |
| RRK PW (pointwise) | 512 | 57.5 | 3× | 0.21 |
| Public Rerankers | ||||
| jina-v3 † (Qwen3-0.6B) | 512 | 57.6 | 6× | 0.44 |
| jina-v3 † | 1024 | 59.0 | 8× | 0.53 |
| jina-v3 † | -1 | 59.8 | 11× | 0.72 |
| Qwen3-0.6B | 512 | 55.1 | 3× | 0.18 |
| Qwen3-0.6B | 1024 | 56.9 | 4× | 0.24 |
| Qwen3-0.6B | 2048 | 57.3 | 5× | 0.31 |
| Qwen3-4B | 512 | 58.4 | 10× | 0.64 |
| Qwen3-4B | 1024 | 59.6 | 14× | 0.84 |
| Qwen3-4B | 2048 | 60.2 | 17× | 1.0 |
| Fine-tuned without compression | ||||
| ModernBERT-Large | 512 | 57.2 | 2× | 0.13 |
| Qwen2.5-8B | 512 | 59.7 | 20× | 1.26 |
关键观察:
- 8B + 8 token 压缩跑赢 0.6B/4B + 全文输入:RRK 58.4 仅落后 Qwen3-4B@2048 的 60.2 1.8 个点,但快 17 倍;与 Qwen2.5-8B 文本版(59.7)相比,速度快 20 倍只损失 1.3 点。
- 超过同量级公开模型:RRK 58.4 > Qwen3-0.6B 任意输入长度,且 RRK 比 Qwen3-0.6B@2048 还快 5×。
- 比 ModernBERT-Large 快 2×、效果高 1.2 点:表明压缩-输入策略不仅适合大模型,对小型 reranker 也是替代方案。
5.2 BEIR 细粒度对比(Table 2)¶
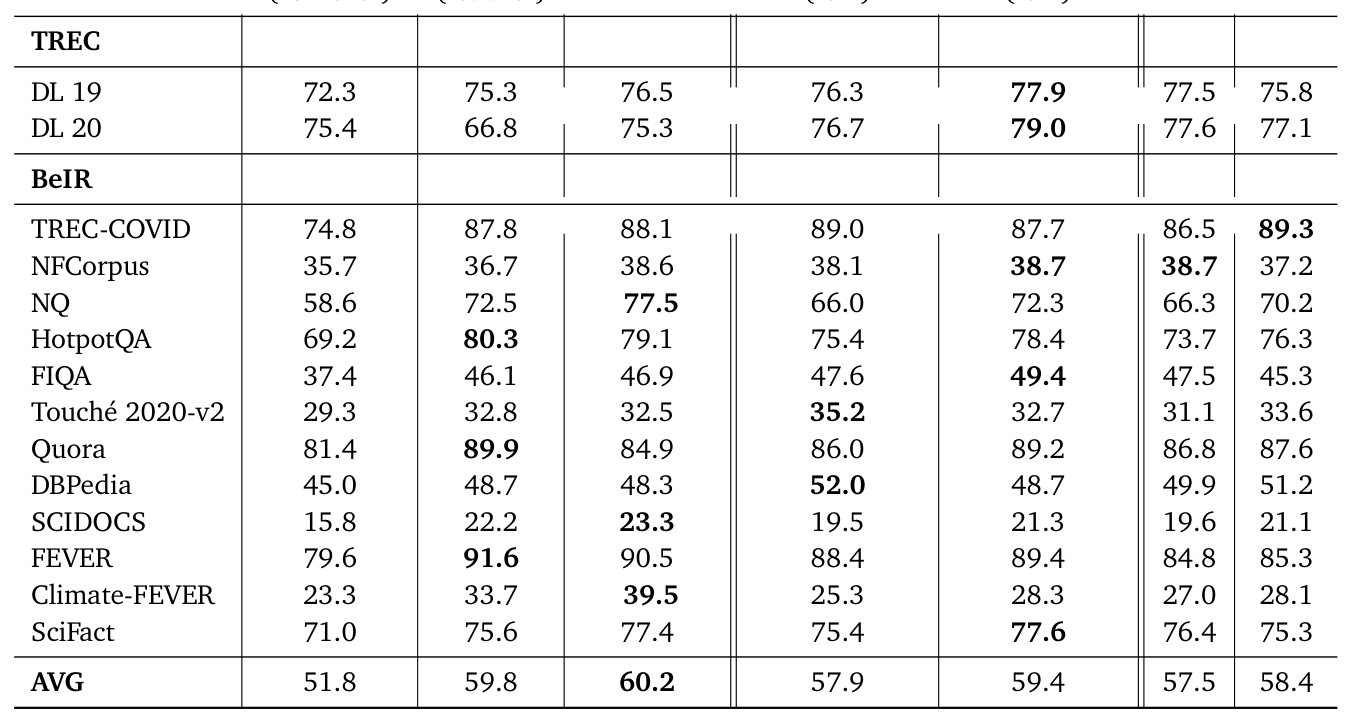
| SPLADE-V3 | Jina-v3 † | Qwen3 4B | ModernBERT (text) | Qwen-2.5 8B (text) | RRK | RRK † | |
|---|---|---|---|---|---|---|---|
| TREC DL 19 | 72.3 | 75.3 | 76.5 | 76.3 | 77.9 | 77.5 | 75.8 |
| TREC DL 20 | 75.4 | 66.8 | 75.3 | 76.7 | 79.0 | 77.6 | 77.1 |
| TREC-COVID | 74.8 | 87.8 | 88.1 | 89.0 | 87.7 | 86.5 | 89.3 |
| NFCorpus | 35.7 | 36.7 | 38.6 | 38.1 | 38.7 | 38.7 | 37.2 |
| NQ | 58.6 | 72.5 | 77.5 | 66.0 | 72.3 | 66.3 | 70.2 |
| HotpotQA | 69.2 | 80.3 | 79.1 | 75.4 | 78.4 | 73.7 | 76.3 |
| FIQA | 37.4 | 46.1 | 46.9 | 47.6 | 49.4 | 47.5 | 45.3 |
| Touché 2020-v2 | 29.3 | 32.8 | 32.5 | 35.2 | 32.7 | 31.1 | 33.6 |
| Quora | 81.4 | 89.9 | 84.9 | 86.0 | 89.2 | 86.8 | 87.6 |
| DBPedia | 45.0 | 48.7 | 48.3 | 52.0 | 48.7 | 49.9 | 51.2 |
| SCIDOCS | 15.8 | 22.2 | 23.3 | 19.5 | 21.3 | 19.6 | 21.1 |
| FEVER | 79.6 | 91.6 | 90.5 | 88.4 | 89.4 | 84.8 | 85.3 |
| Climate-FEVER | 23.3 | 33.7 | 39.5 | 25.3 | 28.3 | 27.0 | 28.1 |
| SciFact | 71.0 | 75.6 | 77.4 | 75.4 | 77.6 | 76.4 | 75.3 |
| AVG | 51.8 | 59.8 | 60.2 | 57.9 | 59.4 | 57.5 | 58.4 |
分析:RRK † 在 12 个 BeIR 子集中没有任何一项夺魁,但通过保持稳定中游表现拿下平均第二(仅次于 Qwen3-4B)。在 TREC-COVID 上 RRK † 89.3 居首,说明对长查询、短文档的 ad-hoc 任务有特殊优势。RRK 在 HotpotQA、FEVER 等多跳/事实核查类任务上显著落后 jina-v3 与 Qwen3-4B(差距 ~5 点),可能是因为压缩损失了支持多跳推理的细粒度证据。
5.3 长文档场景(Table 3)¶
| Doc Length | RRK-MS † | RRK † | jina-v3 † | Qwen3 4B | Qwen3 0.6B | MBerT |
|---|---|---|---|---|---|---|
| nDCG/Lat | nDCG/Lat | nDCG/Lat | nDCG/Lat | nDCG/Lat | nDCG/Lat | |
| MS MARCO Document DL19 | ||||||
| 512 | 68.5 / 1× | 70.6 / 1× | 62.6 / 11× | 60.3 / 4× | 60.3 / 4× | 69.7 / 6× |
| 1024 | 68.6 / 1× | 72.1 / 1× | 66.4 / 24× | 66.9 / 21× | 64.5 / 5× | 70.0 / 7× |
| 2048 | 68.6 / 1× | 72.0 / 1× | 68.3 / 58× | 70.0 / 37× | 65.5 / 10× | 69.7 / 8× |
| MS MARCO Document DL20 | ||||||
| 512 | 66.1 / 1× | 67.7 / 1× | 60.0 / 12× | 58.5 / 13× | 55.0 / 4× | 66.3 / 6× |
| 1024 | 66.5 / 1× | 67.0 / 1× | 62.6 / 24× | 62.8 / 20× | 59.4 / 6× | 66.4 / 7× |
| 2048 | 67.0 / 1× | 68.6 / 1× | 64.5 / 59× | 66.9 / 35× | 63.7 / 10× | 67.4 / 8× |
关键发现:
- 长文档场景效率优势放大:在 2048 token 时 RRK 比 jina-v3 快 58–59×,比 Qwen3-4B 快 35–37×,比 Qwen3-0.6B 快 10×。
- 长文档反而提效:从 512 到 2048,RRK 自身延迟几乎不变(压缩比 256×),nDCG 反而提升(DL19 70.6→72.0、DL20 67.7→68.6),说明 PISCO compressor 即便在 128-token 训练下也自然外推到 2K 输入。
- 公开模型在长文档下集体失速:jina-v3 从 512→2048 延迟翻 5×;Qwen3-4B 翻 9×;表明非压缩 listwise reranker 在长文档场景几乎不可部署。
- ModernBERT-Large 效果接近 RRK 但效率劣势:MBerT 67.4 vs RRK 68.6 (DL20@2048),但前者用的是真实文本输入(受其 8K context 限制)。
论文原文:"This confirms that listwise reranking, when used without compression, does not by itself provide sufficient efficiency benefits."(无压缩的 listwise 重排,单凭 listwise 训练本身不足以解决效率问题。)
5.4 训练数据消融(Table 4)¶
| Training set | Nb. queries | nDCG@10 |
|---|---|---|
| MS-MARCO | 0.50M | 57.7 |
| MS-MARCO | 0.15M | 57.1 |
| E2RANK | 0.15M | 55.6 |
| MS MARCO + E2RANK | 0.65M | 58.4 |
结论:
- 单独 MS MARCO 0.15M 子样本(57.1)强于 E2RANK 0.15M(55.6),尽管 E2RANK 用了更强的 Qwen3-32B 教师。论文推断这是因为 RRK 对域适配敏感(MS-MARCO 是 in-domain),而 E2RANK 教师分布漂移导致蒸馏效果下降;
- MS-MARCO + E2RANK 联合最优(58.4):listwise 训练能融合多个不同教师的排序信号,在多教师场景中比 pointwise 更鲁棒。这也是 RRK PW 在该联合数据上未观察到同等增益的原因。
5.5 PISCO Compressor 消融(Table 5)¶
| Compressor configuration | nDCG@10 |
|---|---|
| Frozen PISCO compressor | 55.5 |
| Compressor from scratch | 57.7 |
| Fine-tuned PISCO compressor | 58.4 |
关键洞察:原始冻结的 PISCO compressor(仅基于 RAG-QA 任务预训练)在 reranking 任务上效果有限(55.5);从头训练的 compressor(57.7)反而比冻结预训练好——这暗示 RAG-QA 与 ranking 是不同任务,前者要求保留答案级语义、后者要求保留可比较的排序证据。LoRA 微调 PISCO 预训练权重最优(58.4),印证"从 LM 内部抽取的 soft compression 比 IR-task embedding 更适合 listwise reranking"的核心论点。
5.6 与 PE-Rank、E2RANK 的横向对比(Table 6)¶
| Model | nDCG@10 | Lat. Ratio |
|---|---|---|
| RRK†-MS | 55.4 | 1.0 (0.06) |
| RRK† | 56.5 | 1.0 (0.06) |
| E2RANK† (MS) | ||
| 0.6B | 53.9 | 2.1× |
| 4B | 56.2 | 7.0× |
| 8B | 56.8 | 10.4× |
| E2RANK† (BGE) | ||
| 0.6B | 55.0 | 2.1× |
| 4B | 57.0 | 7.0× |
| 8B | 57.2 | 10.4× |
| PE-RANK† (7B, MS) | 51.3 | 7× |
评测协议:BM25 top-100 重排,BeIR 5 子集(TREC-COVID, SciFact, Web-Touché, NFCorpus, DBPedia)。
核心结论:
- RRK 同时碾压 PE-Rank 与 E2RANK:PE-Rank 51.3(7B)、E2RANK 8B 56.8/57.2,RRK 8B 56.5(与 E2RANK 8B 持平)但快 10×;
- PE-Rank 落后明显:用 IR-based first-stage embedding + AR decoding,效果与效率均不及 RRK;
- E2RANK 输入侧仍依赖 20 个文档全文("to compute query, the top 20 documents in text form are concatenated with the query"),输入长度受限,无法享受 RRK 的纯 8 token 文档输入优势;
- 论文总结:"Built on a richer compressed representation using 8 compression tokens, RRK consistently outperforms PE-Rank in both effectiveness and efficiency. It also surpasses E2RANK in speed while achieving comparable effectiveness on the shared datasets."
完整 5 子集对比见附录 Table 8(RRK MS+BGE 在 TREC-Covid 上达 87.6,超过所有基线)。
六、消融与讨论¶
6.1 长文档外推¶
PISCO compressor 在 128 token 上预训练,但论文实验证明它能自然外推到 2048 token。原因推测是 PISCO 的 self-attention 在更长序列上 memory token 仍能聚合全段语义;但 BEIR 多数文档较短(avg ~200 token),看不到这种增益,因此 RRK 在 BEIR 上从 512→1024 输入长度反而无显著提升。这是一个与文档长度强相关的优势:
"Interestingly, RRK, although trained to compress short documents (128 tokens in the PISCO setting), effectively handles long documents and responds favourably to increased document lengths within these collections, a phenomenon not observed with the BeIR collection."
6.2 Pointwise vs Listwise¶
RRK PW 在 Table 1 中比 RRK 落后 0.9 点(57.5 vs 58.4)但速度慢 3×。原因:
- pointwise 用 MSE 损失,分数分布漂移会因数据集差异(multi-teacher)放大;
- listwise 的 RankNet 损失只关心 相对 序,对教师分数尺度不敏感,能更好地融合多教师信号;
- listwise 的 cross-passage attention 在 reranker 内部产生 contextualized 表示,比 pointwise 的"独立打分"信息密度更高。
6.3 与三大公开 reranker 的差异化定位¶
公开 reranker 用 7M / 12M 大规模标注数据训练,RRK 仅用 0.65M 蒸馏数据:
"While public models perform the best when considering a long input length (2048), their latency compares badly to our RRK models using compressed document representation."
论文不试图在效果上击败 Qwen3-4B (60.2) ——这种规模的训练数据和 fine-tuning 工程是 NAVER LABS 的复现成本难以承受的。RRK 的核心价值是效率维度的 Pareto 前沿推进:在可接受的效果范围内提供 3×–18× 的速度增益。
七、核心贡献总结¶
- 首次把 PISCO-style soft compression 用于 listwise reranking:把 RAG-QA 中证明有效的多 token 软压缩方法迁移到 IR 重排,证明 LLM-derived 压缩比 IR-derived embedding 更适合排序任务。
- 8 token 富压缩 + cosine 打分的极简架构:8B 模型用 8 token/文档 跑赢 4B + 全文,效率/效果 Pareto 占优。
- 联合微调 compressor 与 reranker:通过排序损失反向传播让 compressor 学到"为排序服务"的语义,而非通用 RAG 摘要。
- 长文档场景的部署友好性:在 MS-MARCO Document(~1k token)上比公开 reranker 快 10×–58×,效果反而提升。
- 完整效率-效果对比:与 PE-Rank、E2RANK 在同一评测协议下的横向对比,揭示了 IR-based vs LLM-based 压缩的本质差异。
八、与已归档相关工作的对比¶
ResRank ResRank: Unifying Retrieval and Listwise Reranking via End-to-End Joint Training (Alibaba Qwen, 2026-04-24)¶
关系:独立并发(本文未引用 ResRank,二者发布间隔仅 5 天,殊途同归)· 已加载对方精读
- 共同关注的问题:LLM listwise reranker 同时受困于「输入侧候选拼接的二次注意力开销」与「输出侧自回归生成排列」两大瓶颈,工业部署延迟巨大。RRK 与 ResRank 用几乎相同的两条路径对症下药:(a) 把每个 passage 压缩成少量 token 注入 reranker;(b) 用 cosine similarity 替代 AR decoding 把生成开销降为 0。两篇论文都把 RankNet 系列损失作为核心训练目标。
- 相近的技术骨架:ResRank = 1 token/doc(Qwen3-Embedding-4B)+ 残差融合 + 端到端 joint InfoNCE+RankNet;RRK = 8 token/doc(PISCO)+ 直接拼接 + LoRA 联合训练 + RankNet。两者输入序列结构高度同构:(query;压缩 token;分隔符);打分协议同构:query 全局表示与文档表示做 cosine。
- 本文的差异与推进:
- 压缩源不同:ResRank 复用现成的 Qwen3-Embedding-4B 检索模型作为 encoder(IR 任务源压缩),RRK 复用为 RAG-QA 训练的 PISCO compressor(语言建模源压缩)。RRK 的 Table 5 实验间接支持"从 LM 内部学到的 soft compression 比 IR encoder 输出更适合排序"——这是两篇论文最深刻的分歧点。
- token 数选择不同:ResRank 取 1 token,靠残差结构补偿;RRK 取 8 token,靠丰富表示直接承担排序信号。两条路径都成立,是设计空间的不同点。
- 训练目标差异:ResRank 用 InfoNCE+RankNet 双目标保护 encoder 的独立检索能力;RRK 完全放弃保护 compressor 作为独立检索器的能力,仅用 RankNet。RRK 更纯粹的 reranker-only 定位,ResRank 更通用的两阶段端到端定位。
-
模型规模:RRK 用 Qwen2.5-8B,ResRank 用 Qwen3-4B(reranker)+ Qwen3-Embedding-4B(encoder)。
-
可比的方法 / 实验差异:ResRank 的 BEIR 8 子集平均 nDCG@10 = 0.5440(single-pass),RRK 在 BEIR 12 子集的 nDCG@10 = 58.4。两者评测覆盖范围与教师不同(ResRank 用 Qwen3-Max + PE-Rank/E2Rank 数据 232K+87K,RRK 用 jina-v3 + MS MARCO/E2Rank 0.65M),不能直接对比绝对数字,但都在 PE-Rank 与 E2RANK 这两个 baseline 上展现压制性优势。两篇论文共同构成 2026 年 4 月「LLM soft-compression listwise reranker」这一新范式的最初证据。
SumRank SumRank: Aligning Summarization Models for Long-Document Listwise Reranking (RUC, 2026-03-25)¶
关系:同根问题、不同压缩路径(textual summary vs. latent token)· 已加载对方精读
- 共同关注的问题:长文档(数千 token)下 listwise reranker 的有效性 + 效率双下降。两篇都聚焦"先压缩文档再 listwise 排序"的范式,且都把 MS-MARCO Document、TREC DL(passage 任务) 作为核心评测。两者都发现"无压缩的 LLM listwise reranker 在长文档场景几乎不可部署"。
- 相近的技术骨架:都把"从大模型蒸馏"作为核心训练范式,都用 listwise teacher 对 student(compressor 或 summarizer)端到端反向传递排序信号;都强调"压缩器不能独立于下游排序任务训练"。
- 本文的差异与推进:
- 压缩表示差异(核心分歧):SumRank 输出人类可读的文本摘要(约 100 token),让 frozen 的下游 listwise reranker(Qwen2.5-32B)继续在文本上做 sliding window 排序;RRK 输出8 个不可读的 latent token,由专门 fine-tuned 的 reranker 直接消费。SumRank 保留了文本通用性(可换任意下游 reranker),RRK 牺牲通用性换取更激进的压缩比(256× vs ~10×)和零生成开销。
- 训练范式:SumRank 三阶段(SFT + RL 数据构造 + GRPO)在 NDCG@10 奖励下对齐摘要器;RRK 一阶段联合 LoRA fine-tune compressor + reranker 用 RankNet 损失。SumRank 的 RL 流程成本远高于 RRK 的纯监督蒸馏,但 RRK 不需要 NDCG 直接奖励即能反向传递排序信号。
- 下游推理协议:SumRank 仍依赖 sliding window(w=20, sz=10)多次推理;RRK single-pass 把 50 个候选一次性吞下。RRK 的 single-pass 是其 3×–18× 速度增益的核心来源。
-
模型规模:SumRank 摘要器 3B/7B + 32B reranker(共两阶段大模型);RRK 8B compressor + 8B reranker(同骨干、同步训练)。
-
可比的方法 / 实验差异:两者都用 SPLADE / BM25 作为第一阶段,都报告 long-document 场景的延迟优势。SumRank 的延迟优势主要来自"摘要后下游 reranker 输入变短",RRK 的延迟优势来自"压缩 token 注入 + single-pass + cosine 打分"三重因素叠加。SumRank 更适合"无法 fine-tune 下游 reranker"的工业场景(如调用 GPT-4 reranker),RRK 更适合"自有 reranker 可控"的部署。两条路径互补,未来可融合(如 RRK 上层套用 SumRank 多教师 RL 训练范式)。
九、讨论与局限性¶
9.1 主要局限(论文 §Limitations)¶
- 依赖短 query:RRK 的速度优势建立在"query 远短于文档"的前提上。若 query 与文档同长(如 BRIGHT 数据集,query 长度堪比 BeIR 文档),输入序列中 query 主导部分使压缩收益消失,RRK 不再快。
- 缺乏轻量化 compressor:RRK 用 8B 作为 compressor,作者尝试过 1–4B 模型但未成功。若有能用的 1B 级 compressor,部署成本可大幅降低(同时减少索引存储维度)。
- 存储开销:每文档 $c \times h = 8 \times 3584 = 28,672$ float16 ≈ 57 KB。MS-MARCO 8.8M 文档需要 ~230 GB 索引;这与 ColBERT v1 早期版本的 286 GB 相当,但比 first-stage 检索的稠密 embedding(dense 0.5–4 KB/doc)大数十倍。论文承认这是亟待解决的问题,建议用 quantization 缓解。
9.2 值得借鉴的设计¶
- 8 token 是经验甜点:1 token 太少(信息瓶颈),更多 token 边际收益递减;这与 ICAE、PISCO 等先驱工作的发现一致。
- 训练时优于冻结:Table 5 显示从头训 compressor (57.7) 比冻结 PISCO (55.5) 强,进一步微调 PISCO (58.4) 最佳——这给"冻结 compressor + 训 reranker"的简化方案盖棺:行不通。
- RankNet 优于 MSE:在多教师蒸馏下 listwise + RankNet 比 pointwise + MSE 鲁棒得多。
- Query 头尾重复:借鉴 jina-reranker-v3 在 causal attention 下的 query 双端重复技巧,缓解 first-half query 没有 attention 到后续文档的问题。
9.3 与已有工作的差异¶
- vs PE-Rank / E2RANK:RRK 的本质创新是用LM-derived soft compression 替代 IR-derived embedding作为压缩源;同样多 token 数(8 vs PE-Rank 1)下也支持更细粒度排序信号。
- vs Compressed-prompt RAG(PISCO 等):RRK 把这些方法从 RAG-QA 任务迁移到 listwise reranking,在新任务上重训 compressor 后效果更佳。
- vs SumRank:见 §八。SumRank 走文本压缩路径,RRK 走 latent 压缩路径,二者互补。
- vs ResRank:见 §八。两者几乎同时发布、独立工作,构成同一新范式的双证据点。
9.4 对工业落地的启示¶
- 如果 reranker 可自训:RRK 范式(8 token + single-pass + cosine)是当前 latency / quality 折衷的最优解之一;
- 如果 reranker 不可改:SumRank 范式(输出可读 summary)更合适,但效率收益较小;
- 存储是隐性瓶颈:57 KB/doc 在 100M 级语料上意味着 5+ TB 索引,需 quantization 或更小 hidden dim 的 compressor 才能规模化;
- 教师选择决定上界:RRK 用 Qwen3-0.6B 教师(jina-v3)即达 58.4,工业上若用 GPT-4 类大教师重做蒸馏,仍有显著上行空间。