DeGRe: Dense-supervised Generative Reranking for Recommendation¶
- 作者:Chaotian Song*(浙江大学软件学院,实习于淘宝闪购)、Jingyao Zhang、Chenghao Chen、Zisen Sang、Dehai Zhao、Guodong Cao、Boxi Wu†(通讯作者)、Deng Cai、Jia Jia
- 机构:浙江大学(软件学院 / CAD&CG 国家重点实验室)、Rajax Network Technology(淘宝闪购 / 饿了么,阿里巴巴)
- 会议:KDD '26
- Arxiv:2605.25749(2026-05-25)
- 部署:淘宝闪购(Taobao Flash Shopping)首页推荐,线上 A/B 已部署,GMV +3.75%
研究动机与背景¶
在工业级多阶段推荐系统(召回 recall → 排序 ranking → 重排 reranking)里,重排位于流水线末端,它不再像 ranking 那样对每个 item 独立做 point-wise 打分,而是要建模 item 之间的上下文关联(intra-list contextual dependency),输出一个整体效用(overall utility)最大的有序列表。重排的核心难点是:在一个指数级巨大的排列空间中寻找最优序列。论文设定下从 12 个候选中选 6 个并定序,排列空间约 $P(12,6) \approx 6.6 \times 10^5$,工业真实场景更大,无法穷举。
早期的单阶段贪心策略(如对候选重新编码再 rescore)受限于"先评估再重排(evaluation-before-reranking)"的范式,容易收敛到次优解。随后被广泛采用的是生成器-评估器(generator-evaluator)两阶段范式:生成器产出多个候选列表,评估器对每个列表打分并选出最优。但这一范式存在 目标不一致(goal inconsistency) 的关键问题——评估器的目标是拟合 list 级别的效用,生成器的目标是把候选变换成最优序列,两者目标分离、结构解耦,既妨碍端到端优化,又因为线上要同时部署生成器和评估器而显著增加系统复杂度与推理延迟。
为此,近期研究转向更高效的端到端生成式重排框架,例如 GReF(用 Ordered Multi-Token Prediction,OMTP,统一生成与评估)、NLGR 和 GoalRank(用 reward 信号指导生成器训练)。但论文指出,这些方法仍面临两个深层缺陷:
-
启发式标签偏差(Heuristic Label Bias):现有方法(如 GReF)基于简单启发式规则构造训练目标,例如"把点击过的 item 提到列表顶部"。这种做法忽略了列表上下文中的因果依赖,隐式假设"点击 item 无论放在什么位置都比未点击 item 价值更高"。结果模型只是去拟合一个有偏的数据分布,而非学习真正的全局最优排序,限制了模型在未曝光空间(unexposed space) 挖掘高价值序列的能力。
-
信用分配问题(Credit Assignment Problem):reward 模型通常依赖 list 级别的事后稀疏奖励(如整体 CTR 或 GMV)。这种粗粒度的标量信号很难归因到序列生成过程中的每一个局部决策。缺乏细粒度的 step-wise 指导,生成器无法分辨每一步动作的具体贡献,导致优化方向模糊,最终限制了性能上限。
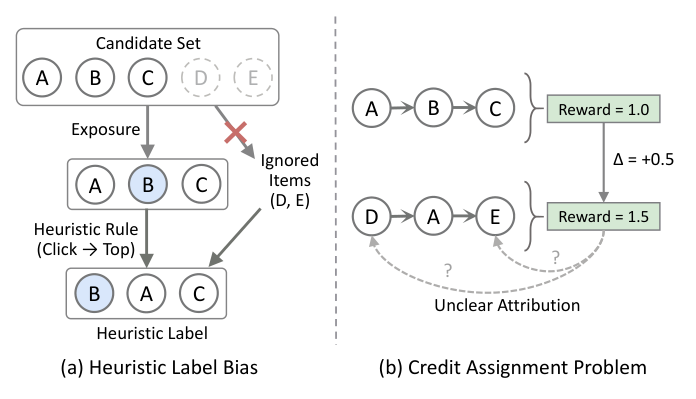
针对这两个问题,论文提出 DeGRe(Dense-supervised Generative Reranking)。其核心策略是 离线-在线解耦(offline-online decoupling):把计算密集的排列空间探索卸载到离线阶段,从而同时实现低在线延迟和高质量生成。具体而言:
- 离线阶段:引入一个基于累积回归(cumulative regression) 的 Lookahead Evaluator(前瞻评估器,DeGRe-E),它能估计在某个子序列后追加每个候选 item 的期望累积价值,并用 beam search 探索未曝光空间、挖掘高价值的前瞻序列(lookahead sequence)。
- 训练阶段:把评估器的 step-wise 价值估计转化为稠密监督信号(dense supervision),通过混合蒸馏(hybrid distillation)灌入一个轻量的 Online Generator(在线生成器,DeGRe-G)。
- 在线阶段:生成器只需一次高效的 贪心解码(greedy decoding) 即可逼近全局最优——评估器无需上线部署。
主要贡献:
- 提出 DeGRe 框架及离线-在线解耦策略,让丰富的离线算力主动挖掘未曝光空间中的高价值序列,从根本上缓解启发式标签带来的偏差;
- 提出基于 Lookahead Evaluator 的稠密监督机制,不同于依赖稀疏事后奖励的方法,它提供 step-wise 价值估计作为稠密指导,缓解信用分配问题;
- 在公开数据集和工业数据集上验证 DeGRe 超越现有 SOTA,同时保持高效推理;线上 A/B 实现 GMV +3.75%,已部署于淘宝闪购。
相关工作¶
重排(Reranking)方法分两类。第一类是单阶段方法:DLCM(用 GRU)、PRM(用 Transformer)编码初始列表的上下文信息,输出修正后的分值再做贪心排序;但它们受"先评估再重排"限制,常导致次优。第二类是两阶段方法:采用生成器-评估器框架,生成器产出多个候选序列,评估器基于估计的 list 价值挑选最优。它通常优于单阶段,但有两大问题:生成器与评估器分离导致目标不一致;以及需要采样并重打分大量候选序列,带来高计算复杂度,难以满足实时工业系统。为克服这些限制,近期转向高效端到端生成式重排:GReF 用 OMTP 统一生成与评估;NLGR 和 GoalRank 借助 reward 信号。但它们仍面临前述两大问题(GReF/NLGR 拟合有偏分布;NLGR/GoalRank 依赖稀疏事后反馈、缺乏细粒度指导)。
列表价值估计(List Value Estimation):从早期 point-wise 到 list-wise 模型,对上下文依赖的建模日益精细。NLGR、GoalRank 把这类模型当作 reward 函数。但 list-wise 评估器只能对完整列表打分,难以直接指导自回归生成中的 step-wise 决策。而累积回归通过建模离散指标的累积分布,天然适合估计子序列的渐进价值——DeGRe 据此构建 Lookahead Evaluator,为生成器提供每一步的细粒度价值信号。
问题定义¶
重排位于 ranking 之后。对每个用户请求 $u \in \mathcal{U}$,系统提供包含 $N$ 个 item 的候选集 $\mathcal{V}_u = \{v_1, \dots, v_N\}$ 及用户上下文特征 $\mathcal{X}_u$。重排的核心任务是从 $\mathcal{V}_u$ 中选出 $L$ 个 item($L < N$)并确定其展示顺序,生成最终推荐列表 $l = [v_{i_1}, \dots, v_{i_L}]$,各 item 互不重复。所有长度为 $L$ 的排列空间记为 $\Pi(\mathcal{V}_u)$,目标是找到使整体效用 $V(l|\mathcal{X}_u)$(如总点击数)最大的最优列表 $l^*$:
$$l^* = \arg\max_{l \in \Pi(\mathcal{V}_u)} V(l|\mathcal{X}_u) \tag{1}$$
生成式重排把任务建模为顺序决策过程。基于概率链式法则,生成列表 $l$ 的概率被分解为每一步条件概率之积:
$$P_\theta(l|\mathcal{V}_u, \mathcal{X}_u) = \prod_{t=1}^{L} P_\theta(v_{i_t} \mid l_{<t}, \mathcal{V}_u \setminus l_{<t}, \mathcal{X}_u) \tag{2}$$
其中 $l_{<t} = [v_{i_1}, \dots, v_{i_{t-1}}]$ 表示第 $t$ 步之前已生成的子序列。
累积回归(Cumulative Regression):为给生成过程提供稠密的中间反馈,需要估计任意长度子序列的实际累积价值。与传统直接回归标量值不同,累积回归建模离散价值的分布:给定子序列 $l_{1:t}$,预测当前累积价值 $V$(如目前已获得的总点击数)达到或超过阈值 $k$ 的条件概率:
$$P(V \geq k \mid l_{1:t}) = \sigma(f_k(l_{1:t})), \quad \forall k \in \{1, \dots, t\} \tag{3}$$
其中 $f_k \in \mathbb{R}$ 是阈值 $k$ 对应的 logit 输出。在时刻 $t$,模型输出一个维度为 $t$ 的向量,第 $k$ 个元素表示"当前价值至少为 $k$"的置信度。这一设计本质上把回归任务分解为一组有序的二元分类问题。子序列的期望累积价值可直接由这些概率求和得到:
$$\mathbb{E}[V \mid l_{1:t}] = \sum_{k=1}^{t} P(V \geq k \mid l_{1:t}) \tag{4}$$
核心方法 / 模型架构¶
DeGRe 采用离线-在线解耦设计,包含两个核心组件——Lookahead Evaluator(DeGRe-E) 与 Online Generator(DeGRe-G)——它们协作贯穿三个阶段:离线阶段评估器挖掘高质量前瞻序列以构造稠密监督信号;训练阶段生成器通过混合蒸馏内化前瞻规划能力;在线阶段生成器一次贪心解码逼近全局最优。
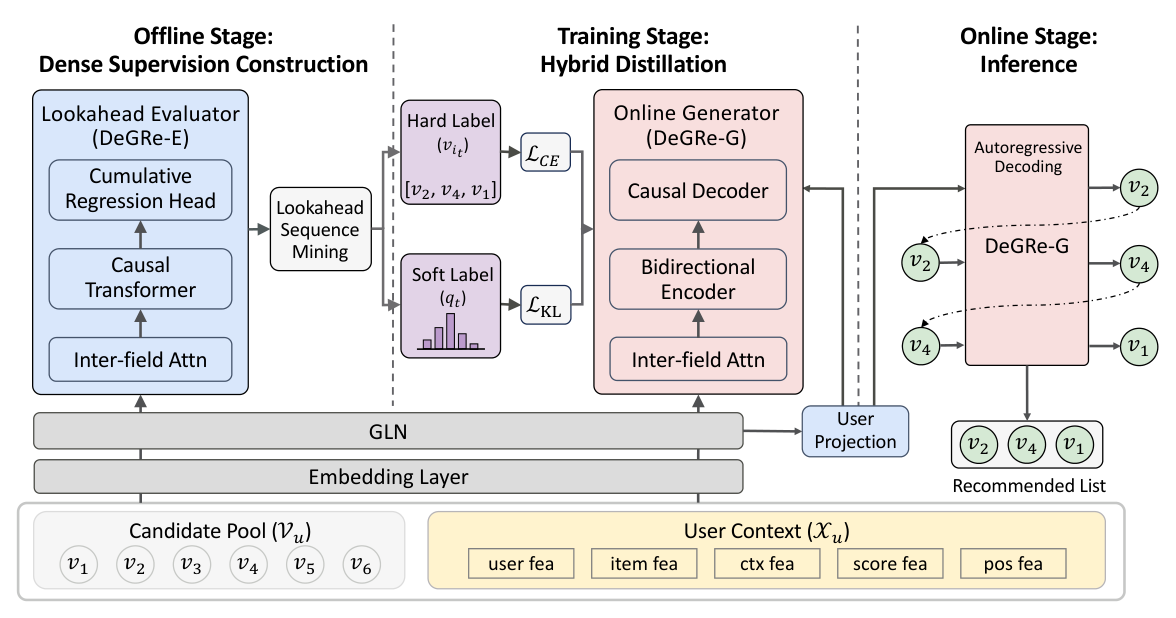
Lookahead Evaluator(前瞻评估器)¶
DeGRe-E 是一个基于 Causal Transformer 的累积回归模型 $E_\phi$,用于估计任意子序列 $l_{1:t}$ 的累积价值分布。
因果序列编码器(Causal Sequence Encoder):输入由 $N_f$ 个特征域(feature field)经 embedding 层映射构成,包括用户 embedding $\mathbf{e}_{user}$、item embedding $\mathbf{e}_{item}$、上下文 embedding $\mathbf{e}_{ctx}$、ranking 分数 embedding $\mathbf{e}_{score}$。静态特征(用户、上下文)沿序列维度复制以对齐 item 序列,所有特征堆叠成输入张量 $\mathbf{E} \in \mathbb{R}^{L \times N_f \times d}$($d$ 为 embedding 维度)。鉴于不同异构域(用户侧 vs item 侧)的分布差异,将 $\mathbf{E}$ 划分为若干异构特征组,并应用 Group Layer Normalization(GLN) 对每组独立归一化;随后引入跨域注意力(inter-domain attention) 生成增强表征 $\tilde{\mathbf{E}}$。最后把原始与增强表征 flatten,与位置编码 $\mathbf{P} \in \mathbb{R}^{L \times d_{pos}}$ 拼接,经线性层投影得到 Transformer 输入矩阵 $\mathbf{X} \in \mathbb{R}^{L \times d_{model}}$:
$$\mathbf{X} = \text{Linear}(\text{Flatten}(\mathbf{E}) \, \| \, \text{Flatten}(\tilde{\mathbf{E}}) \, \| \, \mathbf{P}) \tag{5}$$
其中 $\|$ 表示拼接。$\mathbf{X}$ 送入 $N_E$ 层 Causal Transformer 编码器,捕获序列内上下文依赖,输出隐状态序列 $\mathbf{H} \in \mathbb{R}^{L \times d_{model}}$:
$$\mathbf{H} = [\mathbf{h}_1, \mathbf{h}_2, \dots, \mathbf{h}_L] = \text{TransformerEnc}(\mathbf{X}) \tag{6}$$
累积回归头(Cumulative Regression Head):用累积回归建模离散指标(点击数)的分布。把 $\mathbf{H}$ 经 MLP 投影得到价值分布矩阵 $\mathbf{O} \in \mathbb{R}^{L \times L}$,再用 sigmoid 计算累积价值 $V$ 达到阈值 $k$($1 \leq k \leq t$)的概率:
$$P(V \geq k \mid l_{1:t}) = \sigma(O_{t,k}) \tag{7}$$
其中 $O_{t,k}$ 是"累积价值达到阈值 $k$"的未归一化 logit。
训练目标:采用有序二元交叉熵(ordered BCE)损失。对训练序列 $l$ 及其每一步的真实累积价值 $y_t$,构造稠密标签矩阵 $\mathbf{Y} \in \{0,1\}^{L \times L}$,其中 $y_{t,k} = \mathbb{I}(y_t \geq k)$。损失函数为:
$$\mathcal{L}_{Eval} = -\sum_{(l,y) \in \mathcal{D}} \frac{1}{L} \sum_{t=1}^{L} \sum_{k=1}^{t} \mathcal{L}_{BCE}(y_{t,k}, \sigma(O_{t,k})) \tag{8}$$
内层求和上限 $k \leq t$ 反映了"累积价值不可能超过当前步数"的内在约束,通过下三角 mask 实现。最终基于预测分布计算期望累积价值 $\hat{V}(l_{1:t}) = \sum_{k=1}^{t} P(V \geq k \mid l_{1:t})$,用于指导生成器训练。
稠密监督构造(Dense Supervision Construction)¶
为克服启发式标签在探索未曝光空间上的局限,DeGRe 在离线阶段用训练好的评估器 $E_\phi$ 构造稠密监督数据集。
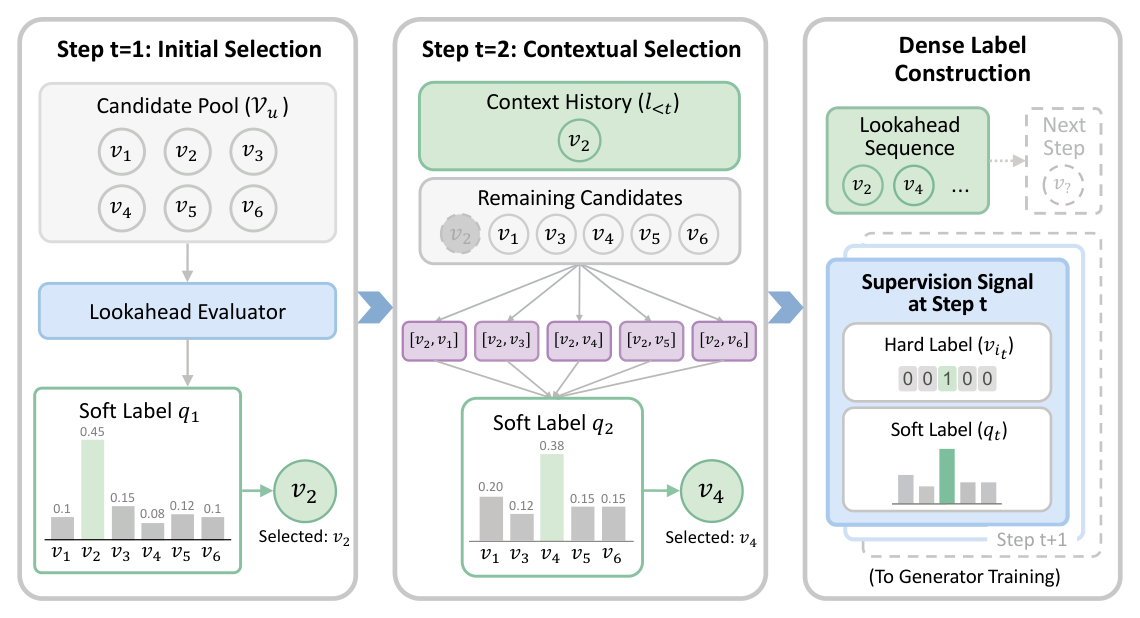
前瞻序列挖掘(Lookahead Sequence Mining):用 Lookahead Evaluator 引导一个 beam size 为 $B$ 的 beam search 主动挖掘未曝光空间中的高价值序列。如 Figure 3 所示,在每个搜索步 $t$,对当前维护的每条子序列,遍历所有剩余候选 item $\mathcal{V}_u \setminus l_{<t}$ 进行扩展,并依据评估器的价值估计 $\hat{V}([l_{<t}; v])$ 选出累积价值最高的 Top-$B$ 条路径。如此迭代直到序列长度达到 $L$,得到的前瞻序列集合 $\mathcal{T}_{syn} = \{l^{(b)}\}_{b=1}^{B}$ 即评估器视角下的潜在最优解集。
稠密标签构造(Dense Label Construction):为把评估器的规划能力蒸馏进生成器,在每个时刻 $t$ 构造结合确定性 + 概率性信息的混合监督信号。对 $\mathcal{T}_{syn}$ 中任意前瞻序列 $l = [v_{i_1}, \dots, v_{i_t}]$,把第 $t$ 步选中的 item $v_{i_t}$ 定义为硬标签(hard label),作为生成器要拟合的目标决策。同时,为吸收次优备选项的细粒度排序信息,用评估器对剩余候选的价值估计构造软标签(soft label) 分布 $q_t$:
$$q_t(v_i) = \frac{\exp(\hat{V}([l_{<t}; v_i]))}{\sum_{v_j \in \mathcal{V}_u \setminus l_{<t}} \exp(\hat{V}([l_{<t}; v_j]))} \tag{9}$$
该分布作为局部正则项(local regularizer),让生成器感知候选空间内非目标 item 的相对优劣。
序列加权(Sequence Weighting):虽然 $\mathcal{T}_{syn}$ 内都是潜在最优解,但序列之间仍有价值差异。为按前瞻价值重塑监督强度,引入序列加权:对任意 $l \in \mathcal{T}_{syn}$,归一化权重为
$$w_l = \frac{\exp(\hat{V}(l)/\tau_w)}{\sum_{l' \in \mathcal{T}_{syn}} \exp(\hat{V}(l')/\tau_w)} \tag{10}$$
优化时把 $w_l$ 乘以 $B$ 以消除 beam size 对损失幅度的影响;温度系数 $\tau_w$ 控制分布的尖锐程度,确保梯度更新主要由高置信度序列驱动。
离线挖掘的可扩展性:为应对更大候选集,可在每一步做 Top-$K$ 预截断来约束搜索空间。此外,由于每步评估的 $O(N \times B)$ 条扩展序列彼此严格独立,可合并到单个 GPU batch 并行打分,使计算开销可通过调节 beam size $B$ 灵活控制。
Efficient Online Generator(高效在线生成器)¶
DeGRe-G 采用轻量的 Encoder-Decoder 架构,以满足工业系统高吞吐、低延迟的严格约束。
双向候选编码器(Bidirectional Candidate Encoder):编码阶段生成器对候选集 $\mathcal{V}_u$ 有全局可见性。为最大化评估器→生成器的知识迁移效率,生成器采用与 Lookahead Evaluator 相同的底层特征处理架构(含 GLN 与跨域注意力)。在对齐特征基础上,用 $N_G$ 层双向 Transformer 并行编码候选集,得到上下文感知的候选表征矩阵 $\mathbf{M} \in \mathbb{R}^{N \times d_{model}}$,从而显式捕获候选 item 间的竞争与互补关系。
用户引导的因果解码器(User-Guided Causal Decoder):现有自回归模型通常以静态 <BOS> token 起始,导致第一个 item 决策缺乏个性化。DeGRe 把用户表征 $\mathbf{e}_{user}$ 经线性投影得到解码器的初始输入 embedding:
$$\mathbf{e}_{start} = \mathbf{W}_p \mathbf{e}_{user} + \mathbf{b}_p \tag{11}$$
随后把 $\mathbf{e}_{start}$ 与目标序列沿时间维拼接,再沿特征维拼接位置编码并经线性层融合。解码器主体用 $N_G$ 层 Causal Transformer 建模顺序依赖,每步输出捕获序列信息的隐状态 $\mathbf{h}_t^{dec}$。
候选受限解码(Candidate-Constrained Decoding):不同于在固定词表上生成的通用语言模型,DeGRe 借鉴 指针网络(pointer network) 思想,把输出空间严格约束在动态变化的候选集 $\mathcal{V}_u$ 内。模型以当前解码隐状态 $\mathbf{h}_t^{dec}$ 为 query,与整个候选表征矩阵 $\mathbf{M}$(作为 key)做点积,得到归一化选择概率:
$$P_\theta(v_i \mid l_{<t}) = \frac{\exp(\mathbf{h}_t^{dec} \mathbf{m}_i^\top)}{\sum_{v_j \in \mathcal{V}_u \setminus l_{<t}} \exp(\mathbf{h}_t^{dec} \mathbf{m}_j^\top)} \tag{12}$$
其中 $\mathbf{m}_i \in \mathbb{R}^{d_{model}}$ 是候选 item $v_i$ 在编码器输出矩阵 $\mathbf{M}$ 中的行向量。该机制确保生成 item 严格落在候选集 $\mathcal{V}_u$ 内且不重复。
训练目标与推理¶
混合蒸馏目标(Hybrid Distillation Objective):生成器通过混合蒸馏损失拟合离线构造的 $\mathcal{T}_{syn}$,总损失为:
$$\mathcal{L}_{Gen} = \sum_{l \in \mathcal{T}_{syn}} w_l \cdot \sum_{t=1}^{L} \Big[ \underbrace{\mathcal{L}_{CE}(v_{i_t}, P_{\theta,t})}_{\text{Lookahead Imitation}} + \alpha \underbrace{\mathcal{L}_{KL}(q_t \| P_{\theta,t})}_{\text{Value Alignment}} \Big] \tag{13}$$
其中 $P_{\theta,t}$ 是生成器第 $t$ 步的选择概率分布,每条序列的损失贡献由其重要性权重 $w_l$ 加权。$\mathcal{L}_{CE}$ 用硬标签 $v_{i_t}$ 监督生成器拟合评估器的目标决策,实现对前瞻序列的确定性模仿;$\mathcal{L}_{KL}$ 用软标签 $q_t$ 引导生成器对齐候选空间上的完整价值分布,保留细粒度排序信息。
高效推理(Efficient Inference):DeGRe 的核心优势在推理效率。线上服务时,计算昂贵的 Lookahead Evaluator $E_\phi$ 无需部署;生成器 $G_\theta$ 只需执行一次贪心解码就能产出推荐列表。由于生成序列长度 $L$ 通常很短($L < 10$),避免了传统两阶段范式中评估器引入的额外开销,满足工业实时系统的低延迟需求。
实验设置¶
数据集(Table 1):
| 数据集 | # Users | # Items | # Records |
|---|---|---|---|
| ML-1M | 6,040 | 3,706 | 1,000,209 |
| Taobao Ad | 1,141,729 | 99,815 | 26,557,961 |
| Taobao Flash Shopping | 3,511,657 | 1,753,654 | 167,911,273 |
- ML-1M:MovieLens 100 万版本,约 6,000 用户、3,700 部电影、100 万评分。评分 $\geq 5$ 视为正样本(隐式反馈)。
- Taobao Ad:淘宝展示广告系统的公开数据集(含 user ID、时间戳、机型、item 属性)。通过切分交互成列表并混入负样本来构造重排候选集。
- Taobao Flash Shopping(淘宝闪购):工业级数据集,服务超 1 亿日活。每个样本对应一次用户请求,含 12 个候选 item、6 个曝光 item,带点击与转化标签,并包含 user/item/context 特征及 ranking 阶段的打分信息。
Baselines:分两组对比。
- 生成器 baseline:NAR4Rec(非自回归生成 + 对比解码)、GReF(统一生成式重排,融合 Rerank-DPO 与 OMTP)、NLGR-G(NLGR 的生成器组件,用 neighbor list 作反事实信号、采样式非自回归)、GoalRank(基于 Group-Relative Optimization、用 reward 模型构造最优序列)。
- 评估器 baseline:DeepFM(point-wise,FM + DNN)、PIER(上下文感知,全向注意力 + list item 依赖)、NLGR-E(NLGR 的评估器组件,D-Attention 解耦特征上下文估计 list 价值)。
指标:
- 生成器指标:基于 Monte Carlo 采样的 HR@K%(Hit Rate @ Top-K%),衡量生成列表 $l_{gen}$ 在随机对比集 $\mathcal{S}_u$($|\mathcal{S}_u| = 10{,}000$)中能否排进前 $K\%$:
$$\text{HR@}K\% = \frac{1}{|\mathcal{D}|} \sum_{u \in \mathcal{D}} \mathbb{I}\left( \frac{\text{Rank}(l_{gen}, \mathcal{S}_u)}{|\mathcal{S}_u|} < \frac{K}{100} \right) \tag{14}$$
报告 $K \in \{1, 3, 10\}$。
- 评估器指标:R-AUC(Regression AUC),把二分类 AUC 推广到连续值域,衡量预测相对序与真实序一致的概率:
$$\text{R-AUC} = \frac{\sum_{i,j:\, y_i > y_j} \mathbb{I}(\hat{y}_i > \hat{y}_j)}{\sum_{i,j} \mathbb{I}(y_i > y_j)} \tag{15}$$
外加 PCOC(预测均值与真实均值之比,衡量校准,越接近 1 越好)与 RMSE(绝对预测误差)。
- 线上指标:CTR、ORDER、GMV。
实现细节:PyTorch + NVIDIA A100(80GB);评估器 $N_E = 6$ 层、生成器 $N_G = 4$ 层,embedding 维度 16;Adam,学习率 $5 \times 10^{-4}$,batch size 1,024;软标签蒸馏权重 $\alpha = 0.01$;重排设定为 12 选 6,全排列空间约 $P(12,6) \approx 6.6 \times 10^5$;采用 leave-one-out 切分(最后一个 session 作测试集)严格遵循时间因果;所有实验重复 5 次取均值。
主要实验结果¶
生成器性能(Table 2)¶
所有方法均由一个独立的外部评估器在统一配置下评测,确保公平。
| Model | ML-1M HR@1% | HR@3% | HR@10% | Taobao Ad HR@1% | HR@3% | HR@10% | Flash Shopping HR@1% | HR@3% | HR@10% |
|---|---|---|---|---|---|---|---|---|---|
| NAR4Rec | 0.1866 | 0.2863 | 0.4271 | 0.0966 | 0.1810 | 0.3378 | 0.1342 | 0.2234 | 0.4150 |
| GReF | 0.1926 | 0.2916 | 0.4368 | 0.1013 | 0.1932 | 0.3647 | 0.1618 | 0.2554 | 0.4564 |
| NLGR-G | 0.1656 | 0.3067 | 0.5224 | 0.0916 | 0.1955 | 0.4028 | 0.1225 | 0.2386 | 0.4645 |
| GoalRank | 0.5920 | 0.7871 | 0.9386 | 0.4211 | 0.6400 | 0.8501 | 0.3553 | 0.5669 | 0.8164 |
| DeGRe-G (B=1) | 0.7486 | 0.9204 | 0.9874 | 0.5222 | 0.7650 | 0.9458 | 0.6947 | 0.8554 | 0.9639 |
| DeGRe-G (B=8) | 0.8910 | 0.9669 | 0.9934 | 0.7106 | 0.8881 | 0.9833 | 0.8872 | 0.9670 | 0.9962 |
分析:(1) 基于 reward 的 GoalRank 全面优于 NAR4Rec——后者仅靠 MLE 拟合曝光数据,印证了在未曝光空间探索的价值。(2) DeGRe 超越所有 baseline:即便在最弱监督设定($B=1$)下,DeGRe 也已超过最强 baseline GoalRank;当离线探索增强($B=8$)时,DeGRe 在 ML-1M / Taobao Ad / Flash Shopping 上 HR@1% 分别达 89.10% / 71.06% / 88.72%,相对 SOTA 的绝对提升达 29.90% / 28.95% / 53.19%。这一跨数据集的稳定表现验证了 DeGRe 的鲁棒性与在非电商域的泛化能力。
评估器性能(Table 3,Taobao Flash Shopping)¶
| Metric | Point-wise DeepFM | List-wise PIER | List-wise NLGR-E | Cumulative DeGRe-E |
|---|---|---|---|---|
| R-AUC ↑ | 0.6979 | 0.7041 | 0.7036 | 0.7090 |
| PCOC → 1 | 1.0392 | 0.9132 | 0.8828 | 0.9932 |
| RMSE ↓ | 0.4985 | 0.4966 | 0.4973 | 0.4946 |
分析:list-wise 模型(PIER)在 R-AUC 上显著优于 point-wise 的 DeepFM,说明捕获上下文依赖的重要性。DeGRe-E 在所有指标上领先,PCOC 达 0.9932(最接近 1,校准最好)——验证了累积回归机制在拟合离散分布与校准预测上的有效性。
消融实验(Table 4,Taobao Flash Shopping,$B=2$)¶
四个消融变体:w/o Soft Label(去掉软标签蒸馏损失)、w/o Seq Weighting(去掉序列加权,所有序列等权)、w/o Hard Label(去掉硬标签损失,不再强制生成器复现评估器的最优序列)、Exposure Only(完全去掉前瞻规划模块,直接用历史曝光数据训练生成器,作为下界)。
| Variant | HR@1% | HR@10% |
|---|---|---|
| DeGRe (B=2) | 0.7910 | 0.9852 |
| w/o Soft Label | 0.7896 | 0.9856 |
| w/o Seq Weighting | 0.7856 | 0.9846 |
| w/o Hard Label | 0.2107 | 0.5631 |
| Exposure Only | 0.1577 | 0.4353 |
分析:(1) 去掉硬标签导致 HR@1% 暴跌至 0.2107(仅略好于 Exposure Only),说明 beam search 挖掘出的高质量前瞻序列是 DeGRe 性能的基石——硬标签提供的确定性模仿目标不可或缺。(2) 去掉序列加权使 HR 下降约 0.54%,说明价值感知加权帮助模型聚焦高置信度、高质量序列。(3) 去掉软标签使 HR 下降约 0.14%,说明软标签提供的分布信息帮助模型更好地逼近最优解。
超参数分析(Figure 4)¶
论文分析三个关键超参:beam size $B$、软标签权重 $\alpha$、序列加权温度 $\tau_w$。(1) 随 $B$ 增大,生成器性能显著提升但边际递减——印证更宽的离线搜索空间能挖掘出更高质量的前瞻序列。(2) 性能随 $\alpha$ 先升后降,在 $\alpha = 0.01$ 时达峰;软标签作为有效的辅助正则项引入细粒度排序信息,但 $\alpha$ 过大会导致分布过度平滑,干扰主任务。(3) 性能随 $\tau_w$ 呈倒 U 形——适中温度在"区分高价值序列"与"保持训练稳定"之间取得平衡。
线上 A/B 实验(Table 5,Taobao Flash Shopping)¶
在淘宝闪购首页推荐场景做 8 天、2% 流量的线上实验。引入工业经典单阶段重排模型 PRM 作为额外 baseline(base 策略为多目标融合的 point-wise 模型)。
| Model | CTR | ORDER | GMV | Cost (ms) |
|---|---|---|---|---|
| Base | 0.00% | 0.00% | 0.00% | - |
| PRM | +0.73% | +1.14% | +0.76% | +6.2 |
| DeGRe | +2.85% | +2.14% | +3.75% | +14.8 |
分析:相对 base,DeGRe 实现 CTR +2.85%、ORDER +2.14%、GMV +3.75%,说明通过生成式重排优化整体 list 效用能切实转化为交易增长。相对 PRM,DeGRe 在 ORDER 和 GMV 上进一步提升约 1.0% 与 2.99%,凸显生成式范式相对单阶段策略在优化全局 list 效用上的优势。得益于离线-在线解耦,评估器无需上线、自回归生成开销可控,平均推理延迟仅增加 14.8 ms,满足大规模实时系统的低延迟要求。
鲁棒性分析(Figure 5)¶
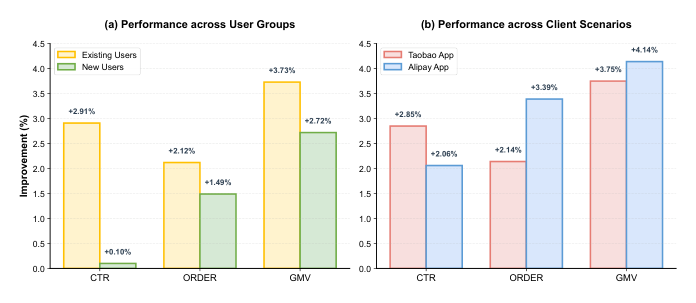
DeGRe 在不同用户组与客户端场景下均稳健:对历史行为丰富的老用户 GMV +3.73%,对行为稀疏的新用户 GMV 仍 +2.72%,说明它能很好泛化到不同历史行为密度的用户群。跨客户端方面,在流量分布差异很大的支付宝端 GMV +4.14%、订单量 +3.39%,展现了强跨场景泛化能力。
核心贡献总结¶
- 离线-在线解耦把昂贵的排列空间探索完全卸载到离线,线上只跑一次贪心解码、评估器不上线,从架构上同时解决"高质量生成"与"低延迟"的矛盾;
- 基于累积回归的 Lookahead Evaluator 提供 step-wise 的稠密价值估计,直接缓解了 list 级稀疏奖励难以归因的信用分配问题;
- beam search 前瞻序列挖掘 + 混合蒸馏(硬标签确定性模仿 + 软标签价值对齐 + 序列加权) 让生成器内化前瞻规划能力,绕开启发式标签偏差,主动逼近未曝光空间中的全局最优;
- 公开 + 工业数据集全面领先,线上 GMV +3.75% 且仅 +14.8ms,已部署淘宝闪购。
与已归档相关工作的对比¶
NSGR NSGR: Next-Scale Generative Reranking (Meituan, 2026-04-07)¶
关系:独立并发(本文未引用 NSGR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都直击生成式重排里 生成器-评估器目标不一致(goal inconsistency) 这一结构性 root cause,并都认识到在历史曝光数据上训练的评估器对未曝光排列的价值估计有偏、不能直接当 reward 硬灌生成器。两篇都是本地生活外卖/即时零售赛道的工业级重排工作(DeGRe 用淘宝闪购/饿了么,NSGR 用美团外卖),都共用 Taobao Ad 公开数据集,都报告 HR@1%/HR@10% 生成器指标,线上收益也惊人地接近(NSGR CTR +2.89%/GMV +3.15%;DeGRe CTR +2.85%/GMV +3.75%)。
- 相近的技术骨架:两者都坚持"生成器 + 评估器"双组件,但都拒绝把评估器的 list 级标量奖励当唯一信号,而是让评估器在比 list 级更细的粒度上给生成器提供监督——DeGRe 给的是 step-wise 的累积价值(每一步的稠密标签),NSGR 给的是 multi-scale 的列表效用($\log_2 m$ 个尺度上的相对奖励)。两者也都让生成器与评估器共享底层特征/表征结构以提升知识迁移效率(DeGRe 复用 GLN + 跨域注意力,NSGR 复用 multi-scale self-attention 的 $e^{(k)}$)。
- 本文(DeGRe)的差异与推进:DeGRe 走的是蒸馏 + 离线-在线解耦路线——离线用 beam search 主动挖掘高价值前瞻序列作为正例模仿目标(硬标签),再把评估器的整套价值分布蒸馏(CE + KL)进一个轻量生成器,线上评估器不部署、只跑一次自回归贪心解码。NSGR 走的是相对奖励对比学习路线——保留评估器在线参与的逻辑较弱(其评估器也是离线训练后冻结),核心是用 neighbor swap 构造 better/worse 邻居做多尺度对比损失(MSNL),生成机制是 $\log_2 m$ 步的树形粗到细二分。
- 可比的方法 / 实验差异:(1) 生成机制:DeGRe 是逐位置自回归(指针网络候选受限解码,$L$ 步),NSGR 是树形并行二分($\log_2 m$ 步,长列表下延迟更优)。(2) 如何对抗启发式标签偏差:DeGRe 靠"主动挖掘 + 模仿评估器认定的最优序列"(仍以评估器价值为绝对目标,受评估器 bias 上界约束),NSGR 靠"相对邻居奖励"(只比较 better/worse,不依赖绝对标签,对评估器 bias 更鲁棒)。(3) 稠密化的维度不同:DeGRe 的稠密是时间维度(沿生成步 1..L 给每步价值),NSGR 的稠密是尺度维度(沿 $\log_2 m$ 个粒度给奖励)——这恰是两条独立团队对同一痛点"评估器只能给 list 级稀疏分"给出的两种正交解法。
讨论与局限性¶
核心贡献与借鉴价值:DeGRe 最值得借鉴的是把"探索"与"推理"在时间轴上彻底拆开——离线用充裕算力做 beam search 探索、在线只做一次廉价贪心解码——并用累积回归这一"天然能给子序列打分"的工具把 list 级监督稠密化到每一步,再以蒸馏把这种前瞻规划能力固化进轻量模型。相比 NLGR/GoalRank 依赖稀疏事后奖励、GReF 依赖启发式标签,DeGRe 的稠密 step-wise 监督 + 主动未曝光挖掘是一条清晰且工程友好的新路线,对所有做工业重排的团队有直接参考价值。
局限与可扩展性隐患:
- 评估器上界约束(最关键):DeGRe 是显式的两阶段解耦——生成器蒸馏自一个冻结的评估器的输出,生成器与评估器无法端到端联合优化。生成器能力的天花板被评估器的价值估计质量(R-AUC 仅 0.709)锁死:若评估器在某些未曝光区域估计有偏,beam search 会把"评估器以为好"的序列当硬标签灌进生成器,偏差会被忠实蒸馏下去。消融中 w/o Hard Label 暴跌也反过来说明生成器高度依赖评估器挖出的序列。相比之下 NSGR 的相对奖励对评估器 bias 更鲁棒。
- HR@K% 指标的自评循环:Table 2 由"一个独立外部评估器"评测,但这套 Monte Carlo HR@K% 本质仍是用某个学到的评估器近似"真实最优",绝对提升幅度(+53%)需结合线上 GMV(+3.75%)这一更硬的指标理性看待。
- 参数 scaling 的瓶颈:当扩大参数量时,"如何表征历史"与"如何建模序列"两条路径能否同步增长存在不确定性——核心收益来自离线 beam search 的探索宽度($B$)而非模型容量本身,且 $B$ 已呈边际递减。这是典型的"先离线探索再在线蒸馏"范式的长期上限隐患。
- 短列表假设:高效推理建立在 $L < 10$ 的前提上;对超长列表,自回归 $L$ 步解码相对 NSGR 的 $\log_2 m$ 步树形生成会逐渐失去延迟优势。
工业落地价值:DeGRe 已部署淘宝闪购首页推荐,线上 8 天 A/B 在 CTR/ORDER/GMV 三项均显著正向(GMV +3.75%),延迟仅增 14.8ms,且在新/老用户、淘宝/支付宝多端均稳健正向——这是对"离线-在线解耦 + 稠密蒸馏"路线最硬核的背书。