NSGR: Next-Scale Generative Reranking — A Tree-based Generative Rerank Method at Meituan¶
- 作者:Shuli Wang, Changhao Li, Ke Fan, Senjie Kou, Junwei Yin, Chi Wang, Yinhua Zhu, Haitao Wang, Xingxing Wang(Meituan,成都/北京)
- Arxiv:2604.05314(2026-04-07)
- 关键词:Recommender Systems; Reranking; Generative Model; Tree-based Generation
- 部署:美团外卖(Meituan Food Delivery)线上 A/B 已部署
研究动机与背景¶
在典型的多阶段推荐系统 matching → ranking → reranking 里,reranking 负责对最后 top-N 个候选做"排列优化"——不再独立地为每个 item 打分,而要考虑整页上下文(context,列表内其他 item 的相互影响),输出一个全局最优的顺序列表。这是一个组合爆炸问题:m 个候选排 n 个坑,潜在排列数高达 $A_m^n$,工业系统(如 Meituan CPS 线上从 24 选 20)下已达 $2.43×10^18$,无法穷举。
现有 reranking 方法大致分三类:
- Generator-based(生成式):一次性或多步产出整个排列,代表 Seq2Slate、MIRNN、DCDR、PRM、GRN、NAR4Rec、NLGR、YOLOR 等;
- Evaluator-based(评估式):枚举大量候选排列用上下文感知模型打分,代表 PIER、EXTR、MIR;
- 两阶段 Evaluator-Generator:生成器先产生若干候选排列,评估器再挑最好,如 PIER、YOLOR。
作者指出当前生成式 reranking 方案存在两个深层结构性缺陷(后续的 NSGR 正是针对它们设计的):
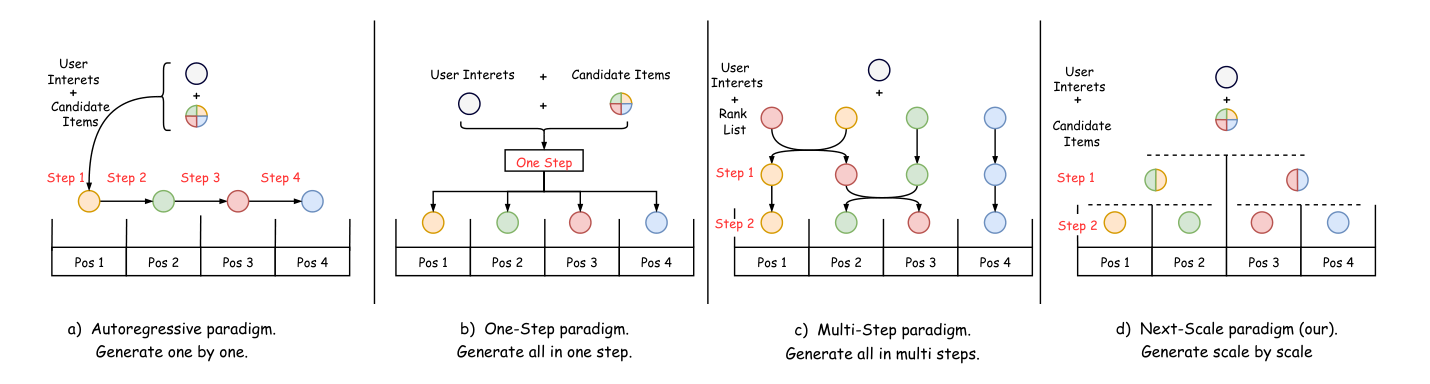
- 生成粒度不匹配全局/局部视角。已有生成策略分三种 paradigm:
- Autoregressive paradigm(如 PRM、GRN):逐位置 one-by-one,天然只能看到已生成的前缀,缺乏对后续位置的前瞻;容易陷入局部最优。
- One-step paradigm(如 NAR4Rec):一次性 non-autoregressive 生成整个 list,全局视野但对长列表里的 item 间细粒度互影响建模过弱。
-
Multi-step paradigm(如 DCDR、NLGR):迭代式 1–2 次 swap,优点是兼有全局初始化 + 局部精修,但起始列表来自 ranking 模型,容易被锁死在 non-monotonic 排列空间的局部最优。 论文认为这三者都没有同时拿到"全局视野 + 局部精细 + 从粗到细的多尺度渐进优化"。
-
Goal Inconsistency(评估器-生成器目标错位)。生成器在训练时优化"列表生成概率",而评估器(Evaluator)是在历史暴露数据上学出的 list-wise utility 预测器,暴露分布严重偏斜——评估器见过的排列只是一小部分,未见过的区域 utility 预估不可靠;因此用评估器直接当 reward 指导生成训练往往导致"评估器奖励高但真实体验差"。NLGR 尝试用 neighbor list 去近似局部奖励分布,但只适用 multi-step paradigm,无法泛化到其他 paradigm;另外 neighbor list 本身是否全面覆盖也没有理论/实验保证。
作者把这两个问题合并解决,提出 Next-Scale Generative Reranking(NSGR):一个 tree-based generative framework,通过"next-scale"层次化粗到细的生成机制渐进扩张推荐列表,同时用 Multi-Scale Evaluator (MSE) 在多尺度上对生成器提供 scale-specific 指导,并用 Multi-Scale Neighbor Loss (MSNL) 作为训练奖励替代。
问题定义¶
令用户集合 $U = {u_1, ..., u_{|U|}}$,每个用户有 profile 特征 $X$,物品集合 $S = {x_1, ..., x_n}$(n 个候选,有 SID 和 item features);reranking 目标是选出长度 m 的有序列表 $L = {x_1, x_2, ..., x_m}$,总排列空间 $A_m^n$。分解为两个子目标:
-
Evaluator 目标:准确估计任意排列 L 的 listwise utility $R(u, L)$: $$ E^* = \arg\min_E \mathcal{L}(E(u, L),\ \mathcal{R}(u, L)) \tag{1} $$ 其中 $L_*$ 是损失函数(通常 BCE on click/order)。
-
Generator 目标:在 S 中选出使评估器效用最大的最优列表: $$ G^* = \arg\max_G E^*(G(u, S)) \tag{2} $$ $$ L^* = G^*(u, S) \tag{3} $$
NSGR 架构总览¶
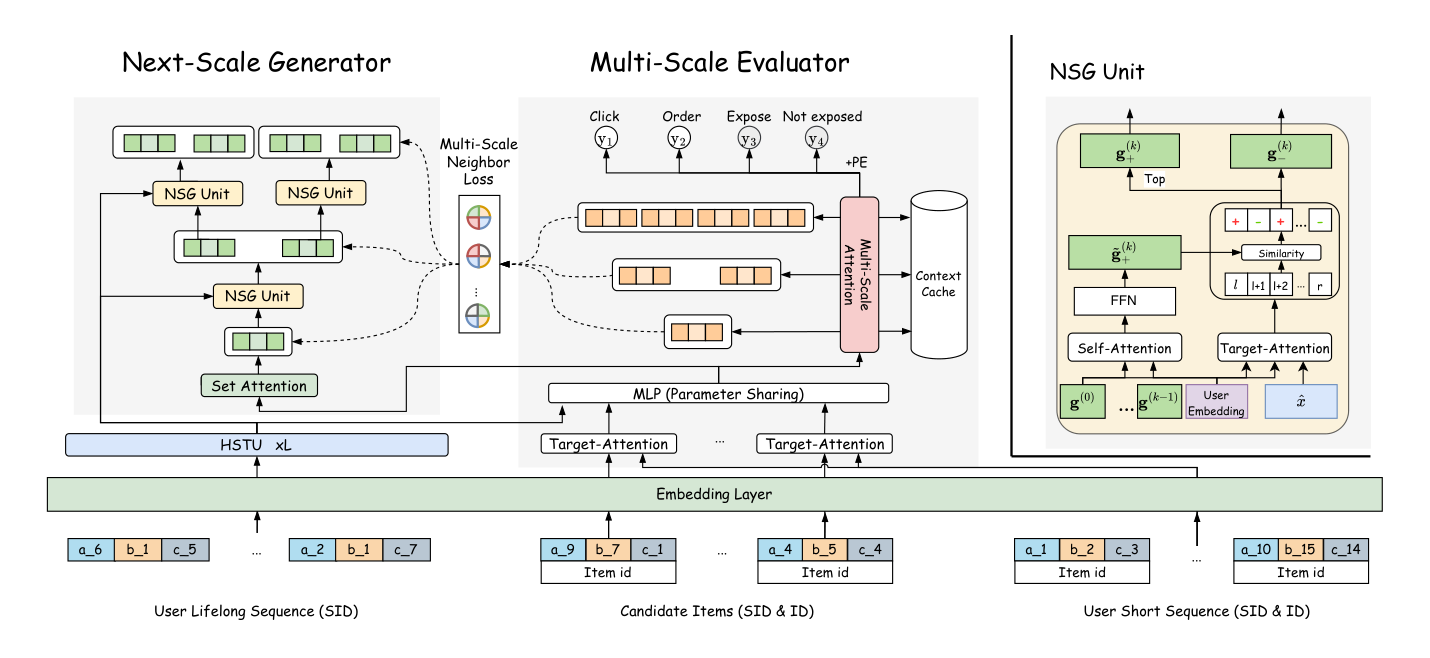
NSGR 由两个核心组件构成: 1. Multi-Scale Evaluator (MSE):在多个尺度上为列表 L 估计 utility; 2. Next-Scale Generator (NSG):从整个候选集合 S 出发,通过 tree-based 二分细化在 $log_2(m)$ 步内产出最终长度 m 的有序列表。
训练分两步:
- Step 1:用真实曝光日志训练 MSE(listwise 预测 click/order/expose,pointwise CTR 监督);
- Step 2:冻结 MSE,用 MSE 对 NSG 生成列表及其 neighbor lists 打分,通过 Multi-Scale Neighbor Loss (MSNL) 指导 NSG 训练。
Multi-Scale Evaluator (MSE)¶
MSE 的输入:
-
用户全局兴趣 $e_u$:由用户终身行为序列 $H_u = {x_1, ..., x_H}$ 过一个 HSTU (Hierarchical Sequential Transduction Unit) 变体再做 AvgPool 得到: $$ e_u = \text{AvgPool}(\text{HSTU}(H_u)) \tag{4} $$ HSTU 用 Next-Token Prediction 离线预训练,推理时 $e_u$ 被缓存避免重复计算。
-
候选 items embeddings $X_i ∈ R^D$(item ID + SID 的 concat embedding)。
- 用户最近行为嵌入 $e^{\text{short}} = \{x_1, ..., x_{n-1}\}$ 编码。
每个候选的语义表征通过一个 cross-feature MLP: $$ x_i^s = \text{MLP}(x_i \| \text{TA}(x_i, H_u^{\text{short}}) \| e^u),\ \forall i \in [n] \tag{5} $$ 其中 TA 是 target-attention 算子(item 对短期行为的定向 attention)。
然后把全体候选堆成列表级向量:$L^s = \{x_1^s, x_2^s, ..., x_m^s\}$。
Multi-Scale Context 提取:对每个位置 t ∈ [m],通过 $K = log_2 m$ 个不同尺度的 Self-Attention(SA)层,提取从局部到全局的上下文向量:
$$ \begin{aligned} e_t^{(1)} &= e_{1,m} = \text{SA}(x_1^s \| x_2^s \| ... \| x_m^s), \\ e_t^{(2)} &= e_{1,m/2} = \text{SA}(x_1^s \| ... \| x_{m/2}^s), \\ &\vdots \\ e_t^{(K)} &= e_{t,t+1} = \text{SA}(x_t^s \| x_{t+1}^s) \end{aligned} \tag{6} $$
注意 SA 层里没有 position encoding,以提升 reuse 和减少计算;不同尺度的 SA 向量被拼接:$x_t^c = [e_t^{(1)}; e_t^{(2)}; ...; e_t^{(log_2 m)}] \in R^{log_2 m · D}$。
Position-aware CTR 预测(融合语义/上下文/位置): $$ \hat{y}_t = \sigma\big(\text{MLP}(\underbrace{x_t^s}_{\text{semantics}} \| \underbrace{x_t^c}_{\text{context}} \| \underbrace{e_t^p}_{\text{position}})\big) \tag{7} $$ 其中 $e_t^p ∈ R^D$ 是位置嵌入。列表级 utility: $$ \hat{y}_L = \sum_{t=1}^{m} \hat{y}_t \tag{8} $$
这一 list-wise 聚合值可根据业务目标灵活替换为 IMPR/CVR/GMV 等,使 MSE 能为不同业务提供 reward。
训练 loss(pointwise BCE): $$ \mathcal{L}_E = -\sum_{t=1}^{m} \big[y_t \log(\hat{y}_t) + (1-y_t)\log(1-\hat{y}_t)\big] \tag{9} $$ 其中 m 为 pageview list 的长度,包含未曝光样本。
Next-Scale Generator (NSG)¶
NSG 是本文最核心创新——一个 tree-based、coarse-to-fine 的逐尺度扩张过程。
思想直觉:传统方法"1→m 逐位置决策"或"一次性 m 个位置同时决策"都丢失了"粒度-视野"的权衡。NSG 反过来:第 1 步把整个候选集 ${x_1, ..., x_n}$ 看作一个"超级节点",判断每个 item 是否进入上半区(位置 1~m/2)还是下半区(位置 m/2+1~m);第 2 步把上/下两半再各自做二分;依此类推,log_2(m) 步后每个 item 被分到唯一的位置槽里,形成完整有序列表。每一步都是"相对粒度 2 倍细化"的决策——类似决策树的 BFS 分裂,每步在兼顾前后半区所有 item 的全局视野下,只做粗粒度决策。
定义第 k 步的候选子集 $S_{l,r}^{(k)} = {x_l^s, x_{l+1}^s, ..., x_r^s}$,对应位置区间 [l, r],需要将其二分为"上半"与"下半"两个子集:
Item Priority(每个 item 的个体相关性): $$ p_i^{(k)} = \text{MLP}_p(x_i^s) \in R \tag{10} $$
Pairwise Relationship Classification(item 两两关系):对任意 $(i, j) ∈ S_{l,r}^{(k)}$ 计算一个 3 类 softmax:抑制(competitive suppression)、互补增强(complementary enhancement)、中性(neutral coexistence): $$ r_{ij}^{(k)} = [r_{ij}^{\text{sup}},\ r_{ij}^{\text{enh}},\ r_{ij}^{\text{neu}}] = \text{softmax}\big(\text{MLP}_{\text{rel}}([x_i^s;\ x_j^s;\ x_i^s - x_j^s;\ x_i^s \odot x_j^s])\big) \tag{11} $$ 三类互斥且和为 1。
Asymmetric Influence Weight(考虑 priority 差异的有向影响): $$ w_{ij} = -r_{ij}^{\text{sup}} \cdot \text{ReLU}(p_i - p_j) + r_{ij}^{\text{enh}} \cdot \frac{p_i + p_j}{2} \tag{12} $$ 直观:抑制是非对称的(高 priority 抑制低 priority 更严重),增强是对称的,中性对近乎为 0。
Set-Conditioned Item Refinement(用集合级 context + 两两交互来 refine 每个 item): $$ \hat{x}_j^s = x_j^s + W_\Delta \text{MLP}_{\text{set}}\big(\big[x_j^s;\ \sum_{i\ne j} w_{ij}^{(k)} x_i^s;\ g^{(k-1)}\big]\big),\ \forall x_j^s \in S_{l,r}^{(k)} \tag{13} $$ $g^{(k-1)}$ 是上一步的 subset-level 上下文 anchor,下一段公式描述。
Item-to-Tree Attention Scoring and Binary Split:为当前子集生成一个 anchor 向量(全局 set-level 表示): $$ \tilde{g}^{(k)} = \text{FFN}\big(\text{SA}(e_u \| g^{(0)} \| \cdots \| g^{(k-1)})\big) \tag{14} $$
为每个 item 通过 target-attention 查询用户一生与历史 tree 节点,得到 personalized context: $$ a_j^{(k)} = \text{TA}\big(\hat{x}_j^s,\ [e_u \| g^{(0)} \| \cdots \| g^{(k-1)}]\big) \tag{15} $$
item-specific relevance 得分: $$ \text{Sim}_j^{(k)} = \text{MLP}_{\text{score}}([\hat{x}_j^s;\ a_j^{(k)};\ \tilde{g}^{(k)}]) \tag{16} $$
按 $Sim_j^{(k)}$ 排序做二分: $$ \text{Flag}_j^{(k)} = \mathbb{1}[\text{rank}(j) \le (r-l)/2] \tag{17} $$
分出的上/下两半各自再产生 subset-level 下一轮 anchor(用加权平均作为 pooling): $$ g_+^{(k)} = \text{AvgPool}(\hat{x}_j^s \cdot \text{Flag}_j^{(k)}) \tag{18} $$ $$ g_-^{(k)} = \text{AvgPool}(\hat{x}_j^s \cdot (1 - \text{Flag}_j^{(k)})) \tag{19} $$
递归 $K = log_2 m$ 步,最终把 $Flag^{(k)}$ 一路累乘得到每个位置的 mask $g^{(K)} \in R^{m \times D}$,即最终的有序列表。
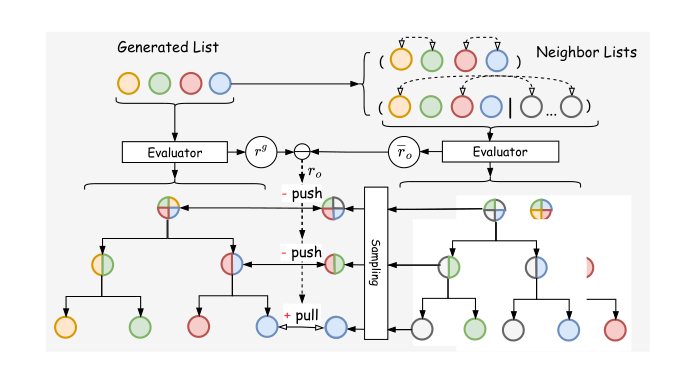
多尺度 Neighbor Loss(MSNL)—— 解决 goal inconsistency¶
直接用 MSE 做 NSG 训练奖励会导致 exposure bias。作者借鉴 NLGR 的 neighbor list 思想但推广到 multi-scale 场景:对于 NSG 生成的列表 $L^g$,通过 swap 构造 O 个 neighbor 列表 $\tilde{L} = [\tilde{L}_1, ..., \tilde{L}_O]$。两种 swap: 1. 同列表内 item 间互换位置; 2. 列表内 item 与未入选候选互换。
由于 NSG 和 MSE 的 multi-scale 架构对齐,可以直接复用 MSE 的 $e^{(k)}_*$(Eq. 6)作为 NSG 的 $g^{(k)}_*$——这样 MSE 算出的 list scale-level utility $r^g$ 与 neighbor 的 $\tilde{r} = [\tilde{r}_1, ..., \tilde{r}_O]$ 都可以直接比较。
相对奖励: $$ r_o = \tilde{r}_o - r^g,\ \forall o \in [O] \tag{20} $$
NSG 的训练 loss 是一个 softmax-style contrastive: $$ \mathcal{L}_G = -\sum_{k=1}^{K}\sum_{o=1}^{O}\log\frac{\mathbb{1}_{r_o > \tilde{r}_o}\cdot \exp(\tilde{g}_o^{(k)\top} e_o^{(k)} / \tau)}{\sum_{o'=1}^{O}\mathbb{1}_{r_{o'} < \tilde{r}_{o'}}\cdot \exp(\tilde{g}_{o'}^{(k)\top}e_{o'}^{(k)}/\tau)} \tag{21} $$
其中 $τ$ 是温度系数。直观:把"比生成列表更好的 neighbor"作为正例、"更差的 neighbor"作为负例,在多个尺度上同时做对比学习——这样 NSG 被同步在全局和局部尺度上推向更优。MSE 的参数训练时冻结,HSTU 用 NTP 预训练。
实验设置¶
数据集(Table 1)¶
| Dataset | #Users | #Items | #Records |
|---|---|---|---|
| Taobao Ad | 1,141,729 | 99,815 | 26,557,961 |
| Meituan | 5,685,119 | 17,264,613 | 242,549,848 |
- Taobao Ad:展示广告 8 天、1.14M 交互、5 类特征(user/time/behavior/item-brand/category),前 7 天训练、第 8 天测试;
- Meituan:工业数据集,2025-08 起 14 天训练、1 天测试、242M 条 pageview 日志、5.6M 用户、239 特征、3 类标签(expose/click/conversion)。过滤掉 label 全 0 或全 1 的样本。
Baselines¶
- PRM(autoregressive)
- GRN(autoregressive)
- NAR4Rec(one-step)
- DCDR(multi-step 扩散)
- NLGR(multi-step + neighbor list)
- YOLOR(evaluator-based tree-search)
指标¶
- 离线:AUC、GAUC(Group AUC,分用户组)、Loss(越低越好);HR@1%、HR@10% 衡量生成器与真实最优列表重合率。
- 线上:CTR、CVR、GMV、Cost(ms)。
实现细节¶
- TensorFlow 1.15.0,A100-80G,Adam (lr=0.001), BS=512, emb size=8;MLP hidden size (1024, 256, 128)。
- Taobao Ad:ranking list 长度 4,permutation 长度 24。
- Meituan:ranking list 长度 20,permutation 长度 24,24 选 20 排列空间 $A_24^{20} ≈ 2.43×10^{18}$。
- 所有实验重复 5 次取均值。
主要实验结果¶
Evaluator 性能(Table 2 & 3)¶
Table 2(Taobao Ad):
| Model | AUC | GAUC | Loss |
|---|---|---|---|
| PRM | 0.6052 | 0.8163 | 0.1842 |
| GRN | 0.6101 | 0.8209 | 0.1820 |
| NAR4Rec | 0.6306 | 0.8288 | 0.1786 |
| DCDR | 0.6217 | 0.8288 | 0.1792 |
| NLGR | 0.6344 | 0.8311 | 0.1752 |
| YOLOR | 0.6351 | 0.8323 | 0.1743 |
| NSGR (Ours) | 0.6396 | 0.8389 | 0.1713 |
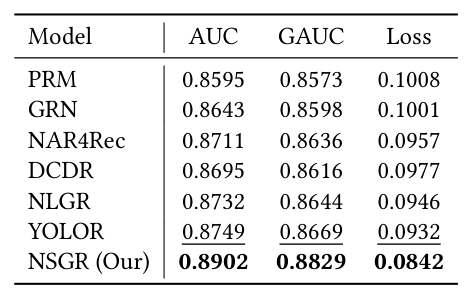
Table 3(Meituan):
| Model | AUC | GAUC | Loss |
|---|---|---|---|
| PRM | 0.8595 | 0.8573 | 0.1008 |
| GRN | 0.8643 | 0.8598 | 0.1001 |
| NAR4Rec | 0.8711 | 0.8636 | 0.0957 |
| DCDR | 0.8695 | 0.8616 | 0.0977 |
| NLGR | 0.8732 | 0.8644 | 0.0946 |
| YOLOR | 0.8749 | 0.8669 | 0.0932 |
| NSGR (Ours) | 0.8902 | 0.8829 | 0.0842 |
结论: 1. 所有 listwise 方法(含 DeepFM、DIN)均优于 pointwise,说明上下文建模确实关键; 2. NSGR 在 Taobao Ad 上比 SOTA YOLOR 提升 +0.0045 AUC / +0.0066 GAUC;在 Meituan 数据上提升更大(+0.0153 AUC / +0.0160 GAUC / loss -9.7%)。 3. 原因:MSE 的 multi-scale self-attention 设计显式捕获跨尺度 list 级 mutual influence,比单尺度 self-attention 更能反映真实 list-wise utility。
Generator 性能(Table 4)—— HR(Hit Ratio,衡量与真实最优列表一致性)¶
| Model | PRM | GRN | NAR4Rec | NLGR | YOLOR | NSGR |
|---|---|---|---|---|---|---|
| HR@1% | 0.510 | 0.632 | 0.658 | 0.784 | 0.822 | 0.861 |
| HR@10% | 0.691 | 0.844 | 0.897 | 0.916 | 0.943 | 0.987 |
由于 Meituan 的排列空间 $A_24^{20}$ 天文数字,作者随机采样 1000 个候选排列估计 generator 的目标命中率:NSGR 最高,YOLOR 次之,NAR4Rec 在三个 baseline 里最稳定。next-scale 生成能持续产出接近最优的 list。
Table 5:NSGR 与 optimal list 的相似度(对 2000 个用户的日志做测试,允许 diff 1/2/3/4 个位置):
| Model | Same | Diff_2 | Diff_3 | Diff_4 |
|---|---|---|---|---|
| NSGR | 0.689 | 0.909 | 0.933 | 0.968 |
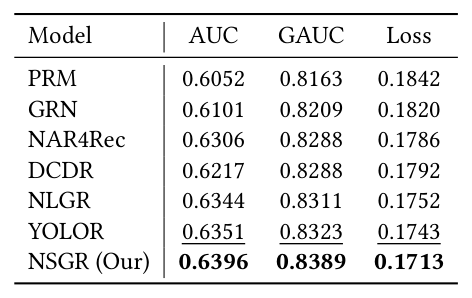
作者还做了一个额外实验:限定排列空间 $A_8^4 = 40,320$,每条 list 都能穷举评估,NSGR 在该受限空间里仍达到 0.978,而不做 rerank 的 greedy 排序仅 0.66,说明 NSGR 的"几乎贴近最优"不是因为评估器放水。
位置分布分析¶
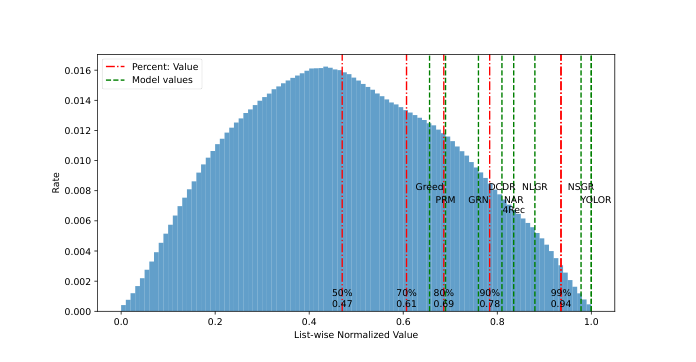
观察三个现象: 1. Positional Inertia:NSG 对原 top 位置保留较多惯性; 2. Distance-Decay:原 position 与 final position 越远,概率越低; 3. 早位 vs 后位:前面位置分布尖锐集中,后面位置更平滑——这反映了"早位带来边际收益更大,模型需要更果决;后位边际收益小,模型分布更平滑"的合理权衡。
消融实验(Table 6)¶
| Variant | AUC | GAUC | HR@1% |
|---|---|---|---|
| w/o SID | 0.8761 | 0.8692 | 0.834 |
| w/o MSEU | 0.8835 | 0.8742 | 0.846 |
| w/o NSGU | 0.8902 | 0.8829 | 0.796 |
| w/o MSNL | 0.8902 | 0.8829 | 0.772 |
| NSGR (full) | 0.8902 | 0.8829 | 0.861 |
结论: 1. SID 非常重要:去掉 SID 同时拉低 evaluator 和 generator 的指标(AUC -0.014, HR@1% -0.027),说明 item ID+SID 的联合嵌入在 listwise 学习中提供了关键泛化能力。 2. MSE Unit (w/o MSEU) 对 evaluator 更关键:单尺度 self-attention 替换后 context 提取能力明显变弱。 3. NSG Unit (w/o NSGU) 对 generator 最关键:用单 softmax 替代后 HR@1% 从 0.861 跌到 0.796。 4. MSNL 对 generator 至关重要:用 r_g 直接监督后 HR@1% 从 0.861 跌到 0.772(最大跌幅),证明相对 neighbor 奖励+多尺度对比学习是整个方法的灵魂。
超参数分析(Table 7)¶
| τ | 0.01 | 0.1 | 0.5 | 1.0 | 2.0 |
|---|---|---|---|---|---|
| HR@1% | 0.842 | 0.861 | 0.858 | 0.851 | 0.849 |
| HR@10% | 0.977 | 0.987 | 0.983 | 0.980 | 0.979 |
| β | 0.1 | 0.5 | 1 | 2 | 5 |
|---|---|---|---|---|---|
| HR@1% | 0.823 | 0.859 | 0.861 | 0.860 | 0.860 |
| HR@10% | 0.951 | 0.975 | 0.986 | 0.987 | 0.987 |
τ 稍小(0.1)效果最好;β(neighbor sampling ratio)超过 1 之后无额外收益但增加训练时间,作者采用 β=1(每个位置采样一个 neighbor)。
线上 A/B(Table 8) —— Meituan 食品配送业务,2025-08 至 2025-10 八周测试¶
| Method | CTR | CVR | GMV | Cost(ms) |
|---|---|---|---|---|
| NSGR(8) | -0.42% | -0.18% | -1.02% | -2.1 |
| NSGR(20) | +2.89% | +0.58% | +3.15% | -1.4 |
- 30% 流量跑 YOLOR(8)(baseline),70% 流量跑 NSGR:先测 NSGR(8) 表示 $A_8^4$ 排列空间,再测 NSGR(20) $A_{24}^{20}$ 空间;
- NSGR(8) 因为候选空间过小略逊 YOLOR(8);
- NSGR(20) CTR +2.89%、CVR +0.58%、GMV +3.15%,是一个极显著的工业级提升;
- Cost(ms) 还稍微下降,因为 NSG 可以直接复用 ranking model 的 $e^u$ 和 $x^o$ 输出作为输入。
- 现已部署到 Meituan 食品配送平台服务千万级用户。
讨论与局限性¶
核心贡献 1. 提出 next-scale generative reranking 新 paradigm,把生成过程从"逐位置 / 一次性 / 迭代 swap"变成"log_2(m) 步的粗到细二分树",同时具备全局视野、局部精调和渐进优化。 2. 设计 NSG Unit:item priority + pairwise relationship (suppression/enhancement/neutral) + set-conditioned item refinement + tree anchor attention,把"个体相关性""两两竞争合作""集合层面上下文"三个维度融合在一个可微分模块里。 3. 针对 goal inconsistency 提出 Multi-Scale Neighbor Loss,把 NLGR 的 neighbor list 思想推广到 multi-scale 场景,并让 NSG 和 MSE 共享 multi-scale 结构。 4. 工业级 A/B 验证:CTR +2.89%、CVR +0.58%、GMV +3.15%、线上延迟不升反降。
值得借鉴的设计
- 树形的 log_2(m) 步推理天然兼容并行计算,比 autoregressive 的 m 步推理更可伸缩,在长列表 rerank 上延迟优势越来越大。
- MSE 和 NSG 共享 multi-scale 结构是一个很聪明的工程 trick:前向可以直接缓存 $e_*^{(k)}$→$g_*^{(k)}$,neighbor 比较时无需重复 forward,显著降低训练开销。
- pairwise relationship 用 softmax(3 类) 而不是 scalar 打分,便于显式解释 item 间互补/抑制的关系。
- 使用 HSTU 离线预训练 user embedding,既减少推理开销又带来更强的长期兴趣表达。
局限与可扩展方向
- 树是严格二分的,对 list 长度要求是 2 的幂;非 2 幂长度需要 padding 或不规则分裂。论文未讨论如何处理。
- NSG 的训练依赖 MSE 作为 reward model,MSE 的 bias 仍会残留;虽然 MSNL 用相对 reward 缓解,但无法完全消除。
- multi-scale attention 复杂度和 K=log_2(m) 成正比,虽然比 autoregressive 好,但对超长 list(m=100)K=7 层会带来显著计算开销。
- 论文没对比 Beam Search / Diffusion-based 等非 neighbor-swap 的 neighbor 构造策略。
- 对小排列空间(NSGR(8))性能反而不如 YOLOR,说明在可穷举场景 YOLOR 仍有优势——NSGR 的优势专门体现在大排列空间。
与已有工作的差异
- vs PRM/GRN:放弃 autoregressive 顺序约束,用 log_2(m) 步并行扩张;
- vs NAR4Rec:不是一次性输出,而是"渐进细化",保留对多粒度上下文的感知;
- vs DCDR/NLGR:multi-step swap 依赖初始 ranking 列表,容易陷入其非单调邻域的局部最优;NSGR 从全量候选集出发,无初始偏见;
- vs YOLOR:YOLOR 是 evaluator-based 的枚举,NSGR 是 generator-based,工业级排列空间下 YOLOR 无法穷举,NSGR 用 log_2(m) 步直达近似最优。
结论¶
NSGR 是一篇"paradigm 级创新 + 工业级落地"的 reranking 工作。核心贡献是把重排任务建模为一个 log_2(m) 步的树状粗到细决策问题,并通过共享 multi-scale 结构的 MSE 与 MSNL 解决了生成器-评估器目标错位的长期痛点。对所有做工业 reranking 的团队(电商、外卖、信息流)都有直接借鉴价值:在需要高质量 listwise 优化 + 低延迟 + 高稳定性的真实场景中,NSGR 的设计代表了当前 generative reranking 的一个新高度。美团把它部署到千万用户级别的食品配送业务并取得 CTR +2.89% / GMV +3.15% 的增长,是对该方法最硬核的背书。