Uniboost: Global Coordination with Value Alignment for Fair and Efficient Traffic Allocation¶
Taobao & Tmall Group of Alibaba · SIGIR '26 · arXiv 2605.26424
研究动机与背景¶
现代工业推荐系统普遍采用 Matching(召回)→ Ranking(精排)→ Blending(混排 / Re-ranking) 的多阶段级联架构。召回阶段从海量候选池里捞回一批候选;精排阶段用复杂模型对候选打分、筛出最相关的内容;而 Blending(混排)阶段 负责把来自不同来源的候选融合到一起,并施加流量分配机制,决定最终曝光给用户的内容。本文聚焦的正是这个 Blending 阶段。
混排阶段的复杂性来自一个现实:在工业系统里,不同内容类型(如广告 vs. 自然视频)往往跑在相互独立的流水线上,因为它们的数据分布和业务目标差异很大——自然视频的精排系统优先优化用户观看时长,而广告的精排系统聚焦广告收入。由于广告的后验业务指标(如完播率)通常显著低于自然视频,如果单纯按自然指标排序,会严重压缩广告曝光、削减商业收入。
为了在用户体验与商业目标之间取得平衡,混排系统通常会引入一系列加权 / 调控机制:
- 保量投放(Guaranteed Delivery):用 PID 控制器一类的调控算法,基于广告历史曝光率计算一个调控分(regulation score),加到广告的混排分上,从而抬升广告可见度。
- 冷启动 / 探索加权(Boost Weighting):为了维护生态健康、缓解马太效应(Matthew Effect),系统必须给冷启动内容分配流量、探索用户潜在兴趣。这通常在混排阶段通过一个缩放因子 $w$ 乘到原始混排分上,提升这类内容的曝光概率。
- 运营活动(Operational Campaigns):促销、联盟等大量短期运营活动,又引入一系列短期流量分配计划。
问题就出在这些机制的叠加与耦合上。在传统流水线里,这些计划累积的权重会让混排分不断膨胀(score inflation),失去物理语义、难以解释;并且多个计划彼此紧耦合、相互干扰,严重阻碍混排系统的迭代和优化。已有工作虽然尝试在广告系统里通过对齐用户价值与商业价值来解决类似问题(如本文引用 [3]),但这些方案无法直接搬到内容推荐系统,作者归纳了三个挑战:
- 后验目标选择(Posterior Target Selection):广告系统的目标(收入)是稳定的,而内容推荐涉及复杂、多面的目标(观看时长、点击、评论等),这些目标对 Boost 框架的影响尚未被充分研究,挑选一个稳健的后验目标并不容易。
- 统一加权框架(Unified Weighting Framework):现有加权方案是碎片化的——保量投放用 PID,冷启探索用 Boost 加权。设计一个能容纳这些异构机制、又对现有业务逻辑改动最小的统一框架,非常困难。
- 加权成本的归因(Attribution of Weighting Costs):由于加权计划之间相互耦合、效果重叠,准确评估并追踪每个独立计划的成本和贡献,是重大的系统设计挑战。
针对这三个挑战,本文提出 Uniboost——一个统一了多种内容类型加权与调控的流量分配框架。其两条核心思路是:
- 第一,通过对各种后验目标做相关性分析,作者识别出 "有效完播率"(Effective Completion Rate) 作为锚定指标(Anchor Metric)。通过把混排分的分布对齐到完播率,把抽象的分数转换成带真实业务语义的值,且不改变排序顺序。
- 第二,基于这些对齐后的分数,设计一个 带偏置的统一 Boosting 范式(Unified Boosting Paradigm with Bias)。该范式不仅能覆盖现有的各种加权方案,还能保证所有加权分都保留物理可解释性。Uniboost 为每个业务计划计算独立的 boosting 增益,再通过线性求和聚合,从而支持精确归因,量化每个方案对最终排序的贡献。
在部署形态上,Uniboost 形成一个从策略执行到性能反馈的闭环:在线服务阶段按加权分排序、曝光内容以改善微观性能;近线阶段收集加权分和原始分以更新分布对齐参数;离线阶段聚合数据,为系统迭代提供宏观指导。
论文贡献可总结为三点:
- 提出 Uniboost——一个统一的加权框架,通过后验价值对齐为复杂的混排分注入业务价值,解耦复杂的在线加权方案,为每个独立计划提供可靠的量化评估。
- 设计一个独立的线性 Boosting 范式,实现流量分配成本的精确归因,解决了分数膨胀问题,显著增强了混排机制的可解释性。
- 在大规模推荐系统中通过 A/B 测试部署 Uniboost。结果证明该方法不仅在微观层面提升了流量分配效率,还在宏观层面为系统迭代提供了可执行的指导。
核心方法 / 模型架构¶
Uniboost 部署在推荐系统的 Blending 阶段,主要目标是在提升整体流水线效率的同时,支持灵活的业务干预策略。整个框架由两大组件构成:在线服务流水线(Online Serving Pipeline) 与 近线 / 离线统计系统(Near-line/Offline Statistics System),二者构成一个从策略执行到性能反馈的闭环机制。
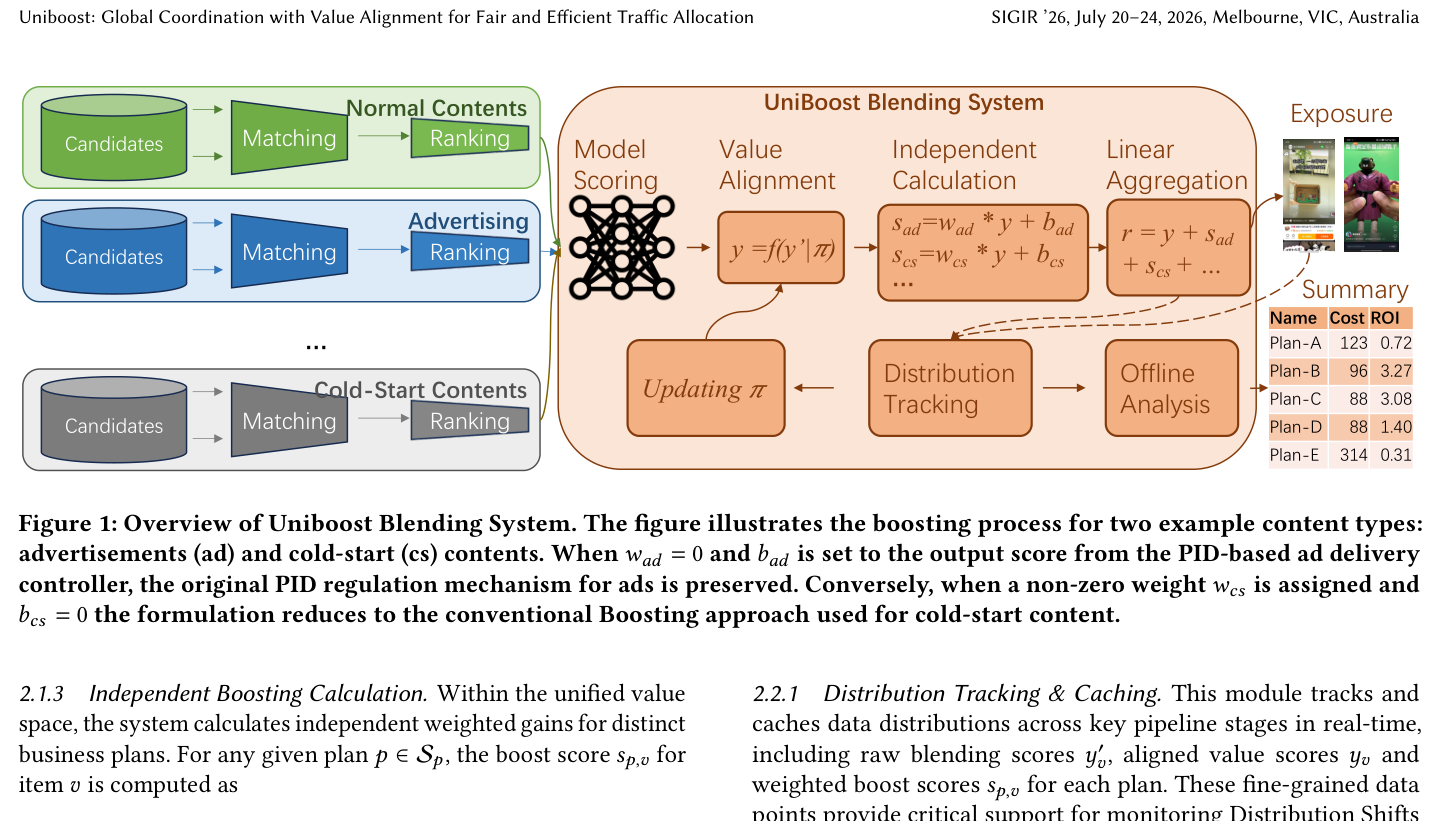
如 Figure 1 所示,左侧是多条相互独立的内容流水线(Normal Contents / Advertising / Cold-Start Contents,各自经过 Matching→Ranking),它们在 Uniboost 混排系统里被统一处理:Model Scoring → Value Alignment → Independent Calculation → Linear Aggregation → Exposure;下方则是近线 / 离线的反馈回路:Updating π ← Distribution Tracking ← Offline Analysis,并产出每个计划的成本 / ROI 汇总表(Summary)。
在线服务流水线(Online Serving Pipeline)¶
在线服务流程是 Uniboost 的核心,需要在毫秒级延迟内完成候选项混排。工作流分为四步。
1. 模型打分(Model Scoring)¶
首先,系统聚合上游召回与混排阶段的输出,形成最终候选集 $\mathcal{V}$。该候选集被送入混排模型,为每个候选项 $v \in \mathcal{V}$ 生成一个原始预测分 $y'_v$。这个分数反映了模型对用户整体偏好的估计。
2. 价值对齐(Value Alignment)¶
原始模型分 $y'_v$ 往往缺乏明确的业务语义,使得直接施加加权干预变得不可控。为此,作者引入 价值对齐模块(Value Alignment Module)。该模块利用全局对齐参数 $\pi$,把模型分映射到一个特定的后验目标空间(即"锚定目标 Anchor Target",例如"有效完播率")。对齐公式为:
$$y_v = F(y'_v \mid \pi) = \frac{y'_v \, \mu_{anchor}}{\mu_{score}} \tag{1}$$
其中 $\mu_{score}$ 和 $\mu_{anchor}$ 分别表示原始混排分和锚定目标分的全局均值。
这一步把抽象的模型分校准为带有清晰业务含义的期望值(Expected Value)。它确保后续的干预权重具备可解释的物理意义,弥合了模型优化目标与业务目标之间的鸿沟。直观理解:式 (1) 本质是一个保序的线性缩放——它不改变候选项之间的相对排序(因为只是乘了一个全局常数比 $\mu_{anchor}/\mu_{score}$),却把分数的"量纲"从抽象模型分变成了"完播率"这一可读业务量纲。
3. 独立 Boosting 计算(Independent Boosting Calculation)¶
在统一的价值空间内,系统为不同业务计划计算独立的加权增益。对任意计划 $p \in S_p$,候选项 $v$ 的 boost 分 $s_{p,v}$ 计算为:
$$s_{p,v} = \mathbb{1}_p(v) \cdot \left( w_p \, y_v + b_p \right) \tag{2}$$
其中 $\mathbb{1}_p(v)$ 是指示函数,当候选项 $v$ 属于计划 $p$ 时取 1、否则取 0;$w_p$ 和 $b_p$ 是可学习的超参数,分别表示权重系数(weight coefficient)和偏置项(bias term)。
由于 $y_v$ 已对齐到锚定指标,计算出的 boost 分 $s_{p,v}$ 与锚定目标共享同一量纲。这意味着所有业务干预都被量化为对锚定指标的具体贡献,实现了对策略效果的标准化度量。这正是后续可归因、可算 ROI 的前提:每个计划"花了多少完播率当量"是可加、可比的。
4. 线性聚合(Linear Aggregation)¶
最后,系统通过线性求和把基础价值和所有业务计划的增益融合,得到最终排序分 $r_v$:
$$r_v = y_v + \sum_{p \in S_{plan}} s_{p,v} \tag{3}$$
其中 $S_{plan}$ 表示线上配置的所有加权方案集合。
作者刻意采用线性求和而非非线性融合,目的是保证可加性(Additivity)。可加性允许做精确的归因(Attribution)——量化某个具体方案对最终排序结果的贡献,这个特性极大方便了下游的策略调优与优化。
最终,候选集 $\mathcal{V}$ 按 $r_v$ 降序排序,截断后曝光给用户。
近线 / 离线监控系统(Near-line/Offline Monitoring System)¶
为了保证系统稳定、支持迭代式策略优化,Uniboost 建立了一套完整的数据统计与反馈机制,分两个阶段。
分布追踪与缓存(Distribution Tracking & Caching)¶
该模块实时追踪并缓存流水线各关键阶段的数据分布,包括原始混排分 $y'_v$、对齐后的价值分 $y_v$、以及每个计划的加权 boost 分 $s_{p,v}$。这些细粒度数据点为监控分布漂移(Distribution Shift) 和诊断在线异常提供了关键支撑。注意:式 (1) 中的全局均值 $\mu_{score}$、$\mu_{anchor}$ 正是由这一近线统计回路持续更新的(对应 Figure 1 的 "Updating π"),从而让对齐参数 $\pi$ 适应数据分布的变化。
聚合与 ROI 分析(Aggregation & ROI Analysis)¶
该模块聚合追踪数据用于下游策略评估。具体地,系统统计每个计划的整体资源消耗(如流量占比)和业务表现(如锚定指标上的提升),据此计算每个加权计划的投资回报率(ROI)。例如,假设有一个旨在提升曝光 Visit View(VV)的计划 $p$,那么该指标的 ROI 定义为:
$$\text{ROI}^{VV} = \frac{\Delta_p^{VV}}{\text{Cost}_p} \tag{4}$$
这个指标直接反映了每个计划的部署效率,指导运营人员动态调整参数,进而基于数据驱动的洞察实现全局最优的资源分配。Figure 1 右下角的 Summary 表正是这一分析的产物(示意数据):
| Name | Cost | ROI |
|---|---|---|
| Plan-A | 123 | 0.72 |
| Plan-B | 96 | 3.27 |
| Plan-C | 88 | 3.08 |
| Plan-D | 88 | 1.40 |
| Plan-E | 314 | 0.31 |
可以看到 Plan-A、Plan-E 的 ROI 明显偏低(0.72、0.31),意味着它们花了很大成本却只换来边际收益——这直接为后文"下线 Plan-A"的消融提供了量化依据。
关键技术细节:一个偏置项如何统一 PID 与 Boost¶
Uniboost 最关键的设计 insight,是用式 (2) 中那个看似平凡的 偏置项 $b_p$ 把两套历史上彼此割裂的机制收编进同一个公式。Figure 1 的标题给出了两个极端特例:
- 广告的保量投放(PID 调控):令 $w_{ad} = 0$,并把 $b_{ad}$ 设为基于 PID 的广告投放控制器的输出分。此时式 (2) 退化为 $s_{ad,v} = b_{ad}$——也就是说,原有的 PID 调控机制被原封不动地保留为一个纯偏置项,不依赖于对齐分 $y_v$。
$$s_{ad,v} = \mathbb{1}_{ad}(v)\cdot\big(0\cdot y_v + b_{ad}\big) = \mathbb{1}_{ad}(v)\cdot b_{ad},\qquad b_{ad}=\text{PID 输出} \tag{5}$$
- 冷启动内容的探索加权(传统 Boosting):令 $w_{cs} \ne 0$ 且 $b_{cs} = 0$。此时式 (2) 退化为 $s_{cs,v} = w_{cs}\,y_v$——这正是冷启动内容常用的传统 Boosting(按比例放大分数)。
$$s_{cs,v} = \mathbb{1}_{cs}(v)\cdot\big(w_{cs}\, y_v + 0\big) = \mathbb{1}_{cs}(v)\cdot w_{cs}\, y_v,\qquad b_{cs}=0 \tag{6}$$
这就回答了"统一加权框架"的挑战:PID 保量是"加性偏置",Boost 探索是"乘性权重",二者只是 $(w_p, b_p)$ 取值的两个端点;任意介于其间的业务计划都可以用同一个 $(w_p, b_p)$ 配置表达。配合价值对齐(式 1)把所有分数拉到同一"完播率量纲",再用线性求和(式 3)保证可加性,整套机制就同时获得了三个性质:
- 统一性:异构的保量 / 探索 / 运营计划共用一套公式与配置接口,对现有业务逻辑改动最小;
- 可解释性:每个 $s_{p,v}$ 都是"对锚定指标贡献了多少完播率当量",分数不再膨胀失义;
- 可归因性:因为是线性可加的,可以把最终分 $r_v$ 拆解到每个计划头上,进而统计每个计划的成本与 ROI(式 4)。
实验设置¶
作者在一个大规模在线推荐系统(Taobao Content Feeds,淘宝内容信息流)上做了 A/B 测试,从微观和宏观两个视角评估 Uniboost。
- 对照组(Control Group):原始加权流水线——分数对齐在加权之后才进行(即先加权、后对齐,二者顺序与 Uniboost 相反,因而分数语义在加权时仍不可控)。
- 实验组(Treatment Group):统一的 Uniboost 加权方案。
- 锚定指标(Anchor Metric):有效完播率(Effective Completion Rate)。
- 此外作者做了深入的在线数据分析,论证锚定指标选择的合理性。
围绕三个研究问题(RQ)展开:
- RQ1:Uniboost 能否在微观层面提供更高效的流量分配策略、从而提升推荐性能,超越基线方案?
- RQ2:所提系统能否通过对单个加权方案的分析,为整体流量分配机制提供宏观层面的指导?
- RQ3:"有效完播率"是否是该框架下锚定指标的稳健选择?
核心指标定义(贯穿 Table 1、Table 2):
- VV(Visit View):内容曝光(impression)总数;
- Valued VV:播放超过 3 秒的内容计数(更能代表"有效消费");
- Duration:总消费时长;
- Valued Score:场景的核心综合指标,由点击、评论等多样用户行为构造,用于评估整体用户体验。
主要实验结果¶
RQ1:整体性能(Overall Performance)¶
在线 A/B 实验结果如下(相对提升):
Table 1:在线 A/B 测试的相对提升
| Metrics | VV | Valued VV | Duration | Valued Score |
|---|---|---|---|---|
| Overall | +1.69% | +3.07% | +0.65% | +2.54% |
结果显示,所提方法在所有核心指标上都取得了一致的提升,确认了 Uniboost 的系统级收益。更值得注意的是监控数据:相比对照组,实验组的广告加权分降低了 92.21%、自然视频加权分降低了 95.81%,但所有加权内容类别的曝光占比保持稳定。
这说明:Uniboost 有效缓解了原系统普遍存在的权重爆炸(weight explosion)问题——它在保证所需曝光水平的前提下,大幅削减了调控策略对核心业务目标的干扰。换句话说,旧系统为了达到同样的曝光保量 / 探索目标,不得不堆叠巨大的加权分(这些分数严重污染了排序信号);而 Uniboost 用对齐 + 带偏置的统一 boost,只需极小的加权分量就能达到等效曝光,从而把排序信号还给了真正的用户偏好。这些结果印证了 Uniboost 解耦各 boosting 计划之间相互依赖的能力,解决了传统 boosting 的局限,最终在微观层面实现更高效的流量分配,显著提升推荐流水线的整体效率。
RQ2:通过离线分析提供宏观指导¶
为了验证 Uniboost 能否提供宏观层面的指导,作者统计分析了每个业务计划的 Cost、VV Lift 和 ROI。基于该分析,识别出 Plan-A 的 ROI 最低(对应 Figure 1 Summary 表里 ROI=0.72)。随后构造了一个消融实验——把 Plan-A 从在线配置中移除,结果如下:
Table 2:移除 Plan-A 的相对提升
| Metrics | VV | Valued VV | Duration | Valued Score |
|---|---|---|---|---|
| w/o Plan-A | +0.95% | +2.83% | +3.49% | +4.13% |
如表所示,移除 Plan-A 反而带来了核心在线指标的显著改善:曝光 VV 小幅上升,而 Valued VV、Duration、Valued Score 大幅提升(Valued Score +4.13%、Duration +3.49%),表明新流水线推荐的内容确实更受用户欢迎。这说明 Plan-A 确实是"高成本、低边际收益",反而拖累了整体推荐流水线的表现。
这个实验的意义不只是"下线一个烂计划",而是证明了 Uniboost 生成的分析报告不仅能追踪单个方案的成本与收益,还能为宏观层面的流量分配提供可执行的指导——运营可以直接依据 ROI 排序去识别并裁撤低效计划,从而提升推荐链路的整体效率、加速策略优化的迭代速度。这是传统"分数膨胀、计划耦合"的系统几乎无法做到的:在旧系统里,Plan-A 的成本与收益被淹没在耦合的加权分里,根本无法被单独量化。
RQ3:锚定指标的选择¶
作者分析了混排模型预测分与若干常见后验指标之间的相关性,候选后验指标包括:Effective Completion(有效完播)、Play Duration(播放时长)、Click(点击)、Buy(购买)、Interaction(互动)、Slide(滑动)。
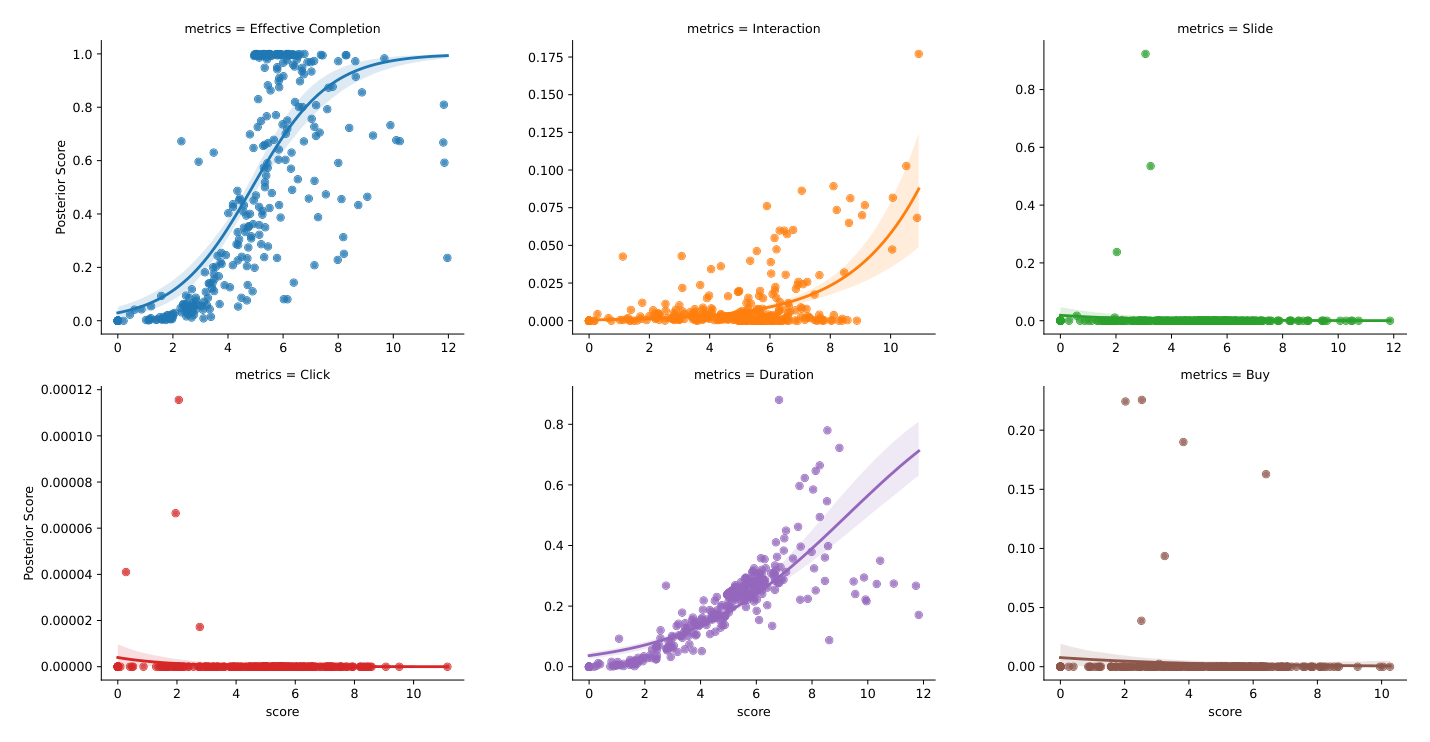
如 Figure 2 所示(横轴为模型预测分,纵轴为后验指标的概率),不同后验指标在不同预测分下的分布差异很大:
- Buy、Interaction、Slide 不适合作锚定指标:它们极度稀疏(sparse)且在各预测分区间高度波动(volatile)。例如 Click 子图的纵轴量级只有 $\sim 10^{-4}$,几乎贴着 0;Buy、Slide 同样稀疏。
- Interaction 和 Play Duration 相对稠密,但它们的分布与分数分布发散,尤其在长尾区域(即高分值区),预测误差显著增大。Duration 子图可见在高分段方差明显放大。
- Effective Completion(有效完播)相对稳定:其取值在混排分的各个区间上均匀分布,校准误差(calibration error)在所有区间上都低且稳定,并呈现漂亮的 S 形(sigmoid 状)单调上升曲线。
这验证了:在视频推荐信息流场景下,有效完播是对齐混排分价值的稳健锚点数据。直觉上,一个好的锚定指标需要满足"在全分数区间都校准良好、且与分数单调相关"——只有这样,式 (1) 的全局线性缩放才能在整个分数域上都把抽象分准确映射成业务量纲;完播率恰好满足,而购买 / 互动这类稀疏强噪指标在长尾区会让对齐失真。
核心贡献总结¶
- 后验价值对齐(Posterior Value Alignment):用一个保序的全局线性缩放(式 1),把缺乏物理语义的抽象混排分校准到一个稳定、可解释的锚定业务指标(有效完播率),让后续所有加权干预都具备业务量纲。
- 带偏置的统一线性 Boosting(Unified Boosting with Bias):用 $s_{p,v}=\mathbb{1}_p(v)(w_p y_v+b_p)$ 一个公式收编 PID 保量($w{=}0$)与传统 Boost 探索($b{=}0$)两套异构机制,并通过线性求和保证可加性,从而解决分数膨胀、实现按计划的精确归因。
- 闭环监控与 ROI 归因:近线追踪分布、更新对齐参数,离线聚合每个计划的成本 / ROI,把"哪个加权计划值不值得留"从拍脑袋变成数据驱动的宏观决策(如下线低 ROI 的 Plan-A 带来 +4.13% Valued Score)。
- 真实工业落地:已全量部署于淘宝内容信息流(Taobao Content Feeds),作为核心流量分配系统稳定运行,在线 A/B 取得 VV +1.69% / Valued VV +3.07% / Valued Score +2.54% 的一致提升。
讨论与局限性¶
值得借鉴的设计。本文最大的价值不在算法复杂度,而在工程哲学:它用极简的线性结构(一次保序缩放 + 一个 $(w,b)$ 配置 + 一次线性求和)换来了三个工业上极其稀缺的性质——统一、可解释、可归因。尤其是"用偏置项 $b_p$ 把 PID 加性调控和 Boost 乘性加权统一进同一公式"这一 insight 很巧妙:它让原本割裂的保量 / 探索 / 运营计划共享一套配置接口,几乎不改动现有业务逻辑就能接入。"先对齐到稳定锚点、再做线性可加 boost"的范式,配合 ROI 看板做计划级成本归因,对任何被"加权分膨胀、策略耦合"困扰的工业混排 / 重排系统都有直接的参考价值。"减小加权分整体权重反而提升微观效率"(92%+ 的加权分削减却维持曝光占比)是一个反直觉但站得住的实证发现。
局限与争议。
- 方法新颖性 / 技术深度有限:核心机制都是线性的(均值比缩放、带偏置的线性 boost、线性求和),数学上相当浅。式 (1) 仅用全局均值做一阶矩对齐,并未对齐分布的高阶矩——当原始分与完播率的关系明显非线性时(Figure 2 显示完播率其实是 S 形而非线性),这种全局线性缩放只能保证排序不变,并不能保证 $y_v$ 真的等于条件期望完播率,"期望值"的说法偏宽松。一个更严谨的做法应是用单调校准(如 isotonic / Platt)拟合 $y'\!\to$ 完播率的非线性映射,但那样会牺牲"全局保序常数缩放"的简洁性与可归因性——这里存在一个简洁可归因 vs. 校准精度的权衡,论文选择了前者。
- 实验偏薄:作为 6 页短文,实验只有淘宝单一场景的在线 A/B(Table 1)外加一个"下线 Plan-A"的单点消融(Table 2),没有任何公开学术数据集 / 可复现实验,对照组只是"原始流水线"。$w_p$、$b_p$ 是"可学习超参",但论文没有交代它们具体如何学习 / 调参(是离线学、在线调、还是人工配),这对复现和判断方法稳健性是个缺口。
- 锚定指标的场景依赖:完播率适合视频信息流,但论文也承认这是"video recommendation feeds"下的结论;换到电商商品流、图文流等没有"完播"概念的场景,需要重新做相关性分析挑锚点,框架的可迁移性依赖于"能否找到一个全区间校准稳定的后验锚点"。
- 多锚点 / 多目标的张力:内容推荐本身是多目标的(时长、点击、评论、购买…),但 Uniboost 把价值对齐绑定到单一锚定指标。当不同业务计划其实服务于不同目标时,统一到单一完播率量纲是否会损失信息、是否需要多锚点对齐,论文未展开。
工业落地价值。尽管方法朴素,这篇短文的部署价值是实打实的:它已作为淘宝内容信息流的核心流量分配系统全量上线,在线指标一致正向,并且把"加权计划值不值得留"这件原本靠经验拍板的事,变成了可以看 ROI 表做决策的数据驱动流程。对工业团队而言,这种"低复杂度、强可解释、易接入、可归因"的方案,落地摩擦小、运营收益直接,这正是它的核心吸引力所在。