Taming Curvature: Architecture Warm-Up for Stable Transformer Training¶
Pluralis Research(Sameera Ramasinghe, Ajanthan Thalaiyasingam, Hadi Mohaghegh Dolatabadi, Chamin Hewa Koneputugodage, Gil Avraham, Violetta Shevchenko, Yan Zuo, Karol Pajak, Alexander Long),arXiv:2606.16768,2026-06-15。
研究动机与背景¶
训练十亿参数级 Transformer 时,训练过程往往很脆弱:会出现瞬态的 loss spike(损失尖峰)、梯度爆炸甚至整体发散,这些不稳定现象浪费大量算力、拖慢 wall-clock 时间,并损害可复现性。随着十亿参数训练成为常态,稳定性成了头等大事——稳定的优化能降低货币与环境成本、提升吞吐,使规模化进展变得可靠。
工程界目前主要靠一系列经验性的控制手段来稳定大模型训练:对 attention logits 做 soft-capping(软封顶,Gemma 2)、对 query/key 做 $QK$-normalization 或 $QK$-clip 来约束点积量级(Henry et al. 2020;Dehghani et al. 2023;Kimi K2 2025)、以及用 learning-rate / batch warmup 来缓和早期更新(Llama 3)。这些方法都是针对 loss spike 的近因(proximate cause)做修补,缺乏统一的理论解释。
与此并行,Edge of Stability(EoS,稳定边缘)理论给出了一个统一视角:梯度方法会被拉向「步长 × 曲率」逼近稳定边界的区域。对于全批量梯度下降(GD),训练会长期处于 $\eta\,\lambda_{\max}(H)\approx 2$ 的状态(其中 $\lambda_{\max}(H)$ 是 Hessian 的最大特征值,$\eta$ 是步长);对于带预条件的自适应方法(如 Adam),起作用的量是预条件 Hessian(preconditioned Hessian)的曲率。于是稳定阈值与步长成反比,并由最大(预条件)特征值主导。
核心痛点:虽然许多稳定化技巧都可解读为「把 $\eta\,\lambda_{\max}(H)$ 压在边界以下」,但在实践中验证这一点非常困难——因为对十亿参数 Transformer 在线估计曲率(Hessian 谱)在内存和计算上代价高昂。已有的 EoS 理论验证只在 $\lesssim 25\text{M}$ 参数的小模型上做过。
本文据此提出两件事:
-
一个高效的在线曲率估计器:基于 warm-started power iteration(热启动幂迭代) + Hessian-Vector Product(HVP)。关键洞察是:(预条件)Hessian 的顶特征向量是缓慢移动(slow-moving)的,因此用上一步的特征向量热启动当前步的幂迭代,既能大幅减少迭代次数,又能提升精度——每步只需 少于 5 次 HVP($\lesssim 5$),比已有方法(如 Hessformer/Granziol 2025)低一个数量级,并无缝扩展到自适应方法的时变预条件矩阵。
-
architecture warm-up(架构 warm-up):用上述工具确认「大模型 loss spike 与预条件曲率的尖峰相关,且曲率随网络深度增长」之后,提出渐进增长网络深度来主动控制曲率。其思路是:在早期 learning-rate warmup 阶段(此时阈值最严),让网络保持浅层(低曲率);当 LR 开始衰减、稳定阈值放宽时,再逐步解锁更多层,从而让(预条件)曲率始终跟随稳定阈值的走势,保证 EoS 稳定准则全程成立。
该方法可直接嵌入现有训练配方与标准架构,不需要动态计算图手术(computation graph surgery),在不带来任何性能损失的前提下拓宽了可用学习率范围,并优于现有稳定化技术。
预备知识¶
Edge of Stability(EoS)¶
对二次目标 $\mathcal{L}(\theta) = \tfrac{1}{2}\theta^\top A\theta + b^\top\theta + c$,步长 $\eta$ 的梯度下降稳定当且仅当 $\eta < 2/\lambda_{\max}(A)$。在神经网络局部,训练可用二次近似:
$$\mathcal{L}(\theta+\Delta) \approx \mathcal{L}(\theta) + \nabla\mathcal{L}(\theta)^\top\Delta + \tfrac{1}{2}\Delta^\top H(\theta)\Delta \tag{1}$$
于是 Hessian $H(\theta)$ 扮演 $A$ 的角色,$\lambda_{\max}(H(\theta))$ 决定最大稳定步长:违反 $\eta\le 2/\lambda_{\max}(H)$ 会沿最陡方向震荡或发散。经验上全批量 GD 常运行在 $\eta\,\lambda_{\max}(H)\approx 2$ 的 EoS 状态。
自适应方法(如 Adam)表现出类似行为,但起作用的是时变的预条件曲率 $\lambda_{\max}(P_t^{-1/2}HP_t^{-1/2})$,其中 $P_t^{-1}$ 是更新的预条件。对 Adam,预条件取 $P_t = \mathrm{diag}(\sqrt{v_t}+\varepsilon)$,$v_{t+1} = \beta_2 v_t + (1-\beta_2)g_t^2$。注意稳定准则是优化器相关的:对 $\beta_1=0.9$ 的 Adam,自适应 EoS 的阈值约为 $\eta\,\lambda_{\max}(P_t^{-1/2}HP_t^{-1/2})\approx 38$(而非 GD 的 $\approx 2$)。
用 HVP 幂迭代估计最大 Hessian 特征值¶
给定 $\theta\in\mathbb{R}^d$ 与损失 $f$,可在不显式构造 $H(\theta)$ 的情况下估计顶特征对 $\{\lambda_{\max}, v_{\max}\}$。对任意向量 $v$:
$$H(\theta)v = \nabla_\theta\big(g(\theta)^\top v\big) = \frac{d}{d\epsilon}g(\theta+\epsilon v)\Big|_{\epsilon=0} \tag{2}$$
即 HVP 是梯度沿 $v$ 方向的方向导数(Pearlmutter 技巧),代价约两次反向传播、额外内存 $O(1)$。在此基础上做幂迭代:从单位向量 $y^{(0)}$ 出发,
$$z^{(t+1)}\leftarrow Hy^{(t)},\quad y^{(t+1)}\leftarrow\frac{z^{(t+1)}}{\|z^{(t+1)}\|_2},\quad \hat\lambda^{(t+1)}\leftarrow\langle y^{(t+1)}, Hy^{(t+1)}\rangle \tag{3}$$
当 $t\to\infty$,$z^{(t)}\to v_{\max}$、$\hat\lambda^{(t)}\to\lambda_{\max}$。问题是:从随机初始化收敛需要多步,每步两次反向传播,代价昂贵;尤其在高维下,随机向量与首特征向量的初始对齐度期望仅为 $O(1/\sqrt{d})$,$d$ 是参数维度。这正是已有方法只能在小模型上做的原因。
核心方法¶
方法一:基于热启动幂迭代的在线曲率追踪¶
核心洞察:神经网络 Hessian 的顶特征方向沿优化轨迹演化缓慢。在 Hessian 的 Lipschitz 连续性($\|\nabla^3 f(\theta)\|_{\mathrm{op}}\le L_H$)与非零谱隙 $\gamma$ 假设下,可精确界定相邻两步顶特征向量的变化:
$$\sin\angle(v_{1,k+1}, v_{1,k}) \le \frac{L_H}{\gamma}\|\theta_{k+1}-\theta_k\| \tag{4}$$
也就是说,当步长与梯度在训练后期收缩时,$v_{1,k}$ 越来越成为 $v_{1,k+1}$ 的精确初始化。这一结果由 Theorem 1 形式化(证明用 Davis–Kahan $\sin\Theta$ 定理):
Theorem 1. 设参数序列 $\{\theta_k\}$,$H_k:=H(\theta_k)$,存在 $L_H<\infty$ 使 $\|H(\theta)-H(\theta')\|\le L_H\|\theta-\theta'\|$,沿路径谱隙 $\gamma(\theta):=\lambda_1(H)-\lambda_2(H)\ge\gamma>0$。则以 $v_{1,k}$ 为 $H_k$ 的单位顶特征向量、$\varepsilon_k:=\angle(v_{1,k+1}, v_{1,k})$,有
$$\sin\varepsilon_k \le \frac{\|H_{k+1}-H_k\|}{\gamma} \le \frac{L_H}{\gamma}\|\theta_{k+1}-\theta_k\| \tag{5}$$
进一步,对 SGD($\theta_{k+1}=\theta_k-\eta_k g_k$,$\mathbb{E}[g_k|\theta_k]=\nabla f(\theta_k)$,$\mathbb{E}\|g_k\|^2\le G^2$):
$$\mathbb{E}[\sin\varepsilon_k\,|\,\theta_k] \le (L_H/\gamma)\,\eta_k\,\mathbb{E}\|g_k\| \le (L_H/\gamma)\,\eta_k G \tag{6}$$
热启动幂迭代:在第 $k$ 步已得到 $H_k$ 顶特征向量 $v_{1,k}$ 的估计,下一步不再从随机向量重启,而是以 $v_{1,k}$ 为初值在 $H_{k+1}$ 上做幂迭代。Theorem 2 量化了由此带来的迭代节省:
Theorem 2. 设 $H_{k+1}$ 特征值 $\lambda_{1,k+1}\ge\lambda_{2,k+1}\ge\cdots$,谱比 $\rho_{k+1}:=\lambda_{2,k+1}/\lambda_{1,k+1}\in[0,1)$,初始失配 $\varepsilon_k:=\angle(v_{1,k+1}, v_{1,k})$。在 $H_{k+1}$ 上做归一化幂迭代 $y^{(t+1)}=H_{k+1}y^{(t)}/\|H_{k+1}y^{(t)}\|$,$y^{(0)}=v_{1,k}$,令 $\alpha_t:=\angle(y^{(t)}, v_{1,k+1})$,则:
$$0 \le \lambda_{1,k+1} - y^{(t)\top}H_{k+1}y^{(t)} \le (\lambda_{1,k+1}-\lambda_{2,k+1})\sin^2\alpha_t \le (1-\rho_{k+1})\lambda_{1,k+1}\rho_{k+1}^{2t}\tan^2\varepsilon_k \tag{8}$$
令 $t$、$t_{\mathrm{rand}}$ 分别为热启动与随机初始化达到同等收敛所需迭代数,则以高概率:
$$t_{\mathrm{rand}} - t \approx \frac{\tfrac{1}{2}\log d - \log\big(\tfrac{L_H}{\gamma}\|\theta_{k+1}-\theta_k\|\big)}{\log(1/\rho_{k+1})} \tag{9}$$
只要 $\tfrac{L_H}{\gamma}\|\theta_{k+1}-\theta_k\|\ll d^{1/2}$,热启动就严格占优——这在高维($d$ 巨大)和后期(步长收缩)同时成立,正是大模型的典型情形。
扩展到预条件 Hessian¶
当优化器带动量和自适应缩放(即预条件)时,稳定性取决于预条件曲率。考虑 Adam 更新 $\theta_{t+1}=\theta_t-\eta P_t^{-1}m_{t+1}$,有效曲率是:
$$G_t := P_t^{-1/2}H(\theta_t)P_t^{-1/2} \tag{10}$$
而非 $H(\theta_t)$ 本身。因为 $\beta_2\approx 1$ 时预条件 $P_t$ 缓慢变化、$H(\theta_t)$ Lipschitz 光滑,$G_t$ 沿轨迹平滑演化。于是热启动分析逐字迁移到预条件情形,把 $H$ 换成 $G_t$ 即可:
$$\sin\angle(u_{1,t+1}, u_{1,t}) \le \frac{\|G_{t+1}-G_t\|_2}{\gamma_t^{\mathrm{eff}}} \tag{11}$$
预条件 HVP 的热启动追踪:第 $t$ 步从优化器状态形成对角预条件 $P_t=\mathrm{diag}(\sqrt{v_t}+\varepsilon)$,用上一步的特征向量热启动估计 $G_t$ 的顶特征对。具体地:(i) 用迁移后的特征向量 $y^{(0)}=\mathrm{normalize}(P_t^{1/2}P_{t-1}^{-1/2}u_{1,t-1})$ 初始化(若省略迁移则 $y^{(0)}=u_{1,t-1}$);(ii) 对 $\tau=0,1,\dots$ 执行一次预条件 HVP 幂步:
$$u = P_t^{-1/2}y^{(\tau)},\quad v = H(\theta_t)u\ (\text{HVP}),\quad z = P_t^{-1/2}v,\quad y^{(\tau+1)}=z/\|z\|_2 \tag{12}$$
(iii) 计算 Rayleigh 估计 $\hat\lambda_t=(y^{(\tau)})^\top G_t y^{(\tau)}=u^\top v$,当 $\hat\lambda_t$ 变化小于容差时停止。每次迭代仅一次 HVP 加廉价的逐元素 $P_t^{\pm 1/2}$ 缩放;热启动下 $\tau^\star$ 通常 $<5$,实现对支配 Adam/动量稳定性的有效曲率的高效逐步追踪。
完整算法见原文 Algorithm 1(Warm-Start HVP Power Iteration),含早退检查(若上一步估计 $\hat\lambda_{\mathrm{warm}}$ 的残差 $r^{(0)}\le\varepsilon|\hat\lambda_{\mathrm{warm}}|$ 则直接返回,仅 1 次 HVP)、数值下溢守护(重置随机单位向量)、可选的动量混合稳定($y^{(1)}\leftarrow\mathrm{normalize}(\alpha y^{(1)}+(1-\alpha)y_{\mathrm{warm}})$,$1-\alpha\approx 0.1$)与余弦守护。
方法二:Architecture Warm-Up(架构 warm-up)¶
深层网络增大曲率、收缩稳定阈值¶
设 $g_\theta=\Phi_L\circ\cdots\circ\Phi_1$ 为 $L$ 块残差 Transformer,$\Phi_\ell(x)=x+B_\ell(x)$。对输入 Jacobian:
$$\|J_x g_\theta(x)\| \le \prod_{\ell=1}^L\|I+\partial B_\ell(x_{\ell-1})\| \le \exp\Big(\sum_{\ell=1}^L\|\partial B_\ell(x_{\ell-1})\|\Big) \tag{13}$$
对损失 $\mathcal{L}(\theta)=\mathbb{E}_{(x,y)}[\ell(g_\theta(x), y)]$、$\lambda_{\max}(\nabla_z^2\ell)\le L_\ell$,Gauss–Newton 界给出:
$$\lambda_{\max}(\nabla_\theta^2\mathcal{L}(\theta)) \le L_\ell\big(\sup_x\|J_\theta g_\theta(x)\|\big)^2 \tag{14}$$
而 $J_\theta g_\theta$ 通过反向传播继承了 Eq.(13) 的乘性增长。因此 $\lambda_{\max}(H)$(在 PSD 对角预条件下,$\lambda_{\max}(G_t)$ 也)随深度 $L$ 增加而增大,收缩一阶稳定裕度。
Remarks(重要 caveat):Eq.(14) 只是上界,不足以严格断言曲率必随深度单调增长——经验上曲率可能因残差连接、归一化等架构组件而被压低,或因特定参数化而异。但作者强调,预条件几何才是与在线稳定相关的对象,对 $\lambda_{\max}(G_t)$ 的在线追踪比初始化/局部最优处的逐点分析更具信息量。在多达数十亿参数的 Transformer 上,他们观察到 (i) 预条件曲率主要在 LR warmup 阶段尖峰,(ii) 曲率随深度增加(见实验 §4.3)。
通过把块权重约束为零实现渐进深度¶
在稳定阈值处,预条件曲率 $\lambda_{\max}(G_t)\sim O(1/\eta)$:$\eta$ 越大,可容许的 $\lambda_{\max}(G_t)$ 越小。因此在 warmup 期间 $\eta$ 爬升(阈值收紧)时,把网络有效深度压低以限制 $\lambda_{\max}(G_t)$;待峰值学习率过后/LR 衰减、阈值放宽时,再逐步启用更多深度。
技术上,Transformer 块可写成递归结构。设第 $l$ 层输入 $\mathbf{X}^l\in\mathbb{R}^{b\times n\times d}$(批量、序列、嵌入维),块函数:
$$\mathbf{X}^{l+1} = \mathbf{X}^l_{\mathrm{hidden}}\mathbf{W}^l_{p_2} + \mathbf{X}^l_{\mathrm{concat}}\mathbf{W}^l_{p_1} + \mathbf{X}^l \tag{15}$$
其中 hidden、concat 分别是 FFN 隐层与注意力头拼接输出,$\mathbf{W}^l_{p_1}, \mathbf{W}^l_{p_2}$ 是线性投影权重。
朴素做法的陷阱:只把投影矩阵置零($\mathbf{W}^l_{p_1}=\mathbf{W}^l_{p_2}=0$),块即恒等映射,之后再「解锁」。但即便其余权重保持随机初始化,解锁瞬间会在网络 Lipschitz 常数上引入不连续跳变——因为预存的随机 attention/FFN 路径会立刻被注入残差流。块的输入-输出 Jacobian 满足:
$$\|J_{\mathbf{X}^l}\Phi_l - I\| \le \|\mathbf{W}^l_{p_1}\|\,\|J_{\mathbf{X}^l}\mathbf{X}^l_{\mathrm{concat}}\| + \|\mathbf{W}^l_{p_2}\|\,\|J_{\mathbf{X}^l}\mathbf{X}^l_{\mathrm{hidden}}\| \tag{16}$$
若其它权重仍是随机的,$\|J_{\mathbf{X}^l}\mathbf{X}^l_{\mathrm{concat}}\|$、$\|J_{\mathbf{X}^l}\mathbf{X}^l_{\mathrm{hidden}}\|$ 在解锁时已经很大,于是对 $\mathbf{W}^l_{p_1}, \mathbf{W}^l_{p_2}$ 的微小更新就会骤然抬高 $\|J_{\mathbf{X}^l}\Phi_l\|$,放大 Eq.(14) 的界、激增曲率,把模型推过稳定阈值,表现为 loss spike。
本文解法:为保证函数及其一阶导在解锁时都连续,把块内全部权重(除 RMSNorm 权重外)置零,并在锁定期间把这些参数排除在优化器之外。约束下 $\mathbf{X}^l_{\mathrm{concat}}=0$、$\mathbf{X}^l_{\mathrm{hidden}}=0$,故 $\mathbf{X}^{l+1}=\mathbf{X}^l$ 是Jacobian 上无任何增量的精确恒等($J_{\mathbf{X}^l}\Phi_l=I$)。解锁时所有路径从零出发,Jacobian 扰动随新可训练权重离开零而平滑增长,避免有效 Jacobian 的瞬时跳变,从而避免曲率尖峰。实践中:块权重保持为零并冻结(不在优化器内)直到曲率准则满足,然后从零初始化开始训练它们。
注:排除 RMSNorm 权重很关键,因为它们从零初始化时收敛较差。
这套架构 warm-up 把 $\eta\,\lambda_{\max}(G_t)$ 维持在稳定包络内,同时深度递增,得到更平滑的 loss 与更可靠的训练。
架构 warm-up 会损害表征能力吗?¶
作者从两个角度给出否定的直觉:(i) Spectral bias / F-principle:深网络先拟合低频结构,高频后学;早期浅栈即够,临时限深不会瓶颈实际所学。(ii) Function-space / NTK 视角:早期训练运行在近线性、低曲率区,函数空间动力学对齐低复杂度成分;之后再启用更多层提升表达力,不限制可达解类。其收敛结果及 progressive function-preserving growth 的既有工作都佐证:延迟深度不损害最终性能。
实验设置¶
- 模型:decoder-only Transformer(Llama 3 风格),规模最大到 3B 参数。
- 语料:FineWeb、DCLM、OLMo-Mix 三个大规模语料,留出验证集。
- 默认超参:context length 1024,embedding dim 2048,32 heads,global batch 1024,weight decay 0.01,AdamW(标准参数),2000 步 linear warmup 后 linear decay,GPT-2 tokenizer(vocab 50,000)。
- 曲率追踪:5 次热启动幂迭代。
- 架构 warm-up 调度:默认在 LR warmup 完成前保持半深度,随后把剩余层分 4 组、每组间隔 500 步逐步解锁至满深度(性能对此间距不敏感,见附录 §11)。
- 深度/规模对照:8 层(640M)、16 层(1B)、32 层(3B)。
主要实验结果¶
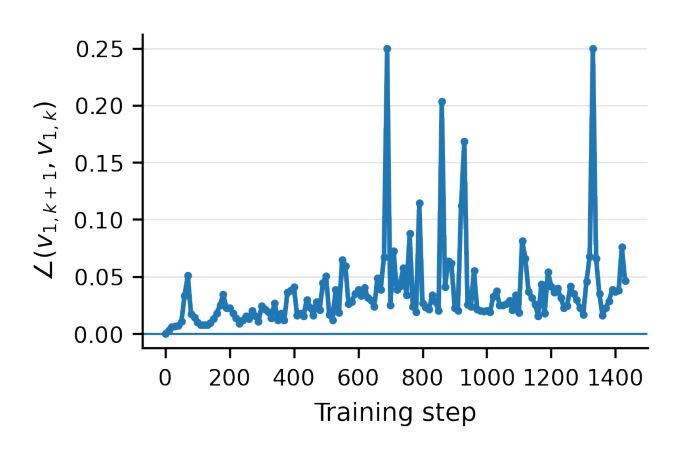
顶特征向量缓慢移动(验证 Theorem 1)¶
对 4 层 Transformer 逐步计算精确 Hessian(无估计器偏差),测相邻顶特征向量主夹角。Fig.1 显示夹角通常 $<0.1$ 弧度($\approx 5.7°$,除少量尖峰外),证实「缓慢漂移」性质。选浅网络是因为大模型的精确 Hessian 计算不可行。
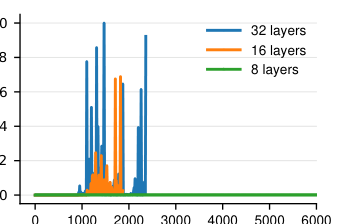
热启动幂迭代的有效性¶
在 4 层模型上,以相对误差 $|\hat\lambda-\lambda_{\mathrm{exact}}|$ 为指标,对比热启动与冷启动(随机)幂迭代,每实验跑 5 次。结论:
- 热启动即使只用 5 次 HVP 也能拿到高精度估计($\approx 5$ 次迭代收敛);冷启动即使 $\ge 20$ 次迭代误差仍偏高。
- 冷启动误差方差始终很高,源于个别步对初始化敏感导致的偶发大误差(即使高迭代数也无法消除)。
- 这证实:复用上一步顶方向能大幅削减 HVP 预算并稳定幂迭代收敛。
深度、有效曲率与稳定性¶
在 FineWeb 上以峰值学习率 $8\times 10^{-3}$ 训练 8、16、32 层模型,追踪 loss、$\lambda_{\max}(H)$、$\lambda_{\max}(G_t)$(Fig.3):
- 8 层:曲率低而稳定,loss 轨迹平滑。
- 深度增加:$\lambda_{\max}(H)$ 与 $\lambda_{\max}(G_t)$ 的水平和波动都上升,16/32 层在 LR warmup 期出现显著尖峰、越过稳定边界并发散,loss 出现 spike。
这支持「更深的栈在 warmup 期超出稳定裕度」的假设,直接动机出架构 warm-up:起步浅(低曲率),在 LR warmup 期(阈值最严)逐步解锁,待稳定裕度变高再加层。
架构 warm-up 的稳定性(学习率扫描)¶
稳定阈值按 $O(1/\eta)$ 缩放,$\eta$ 越大要求曲率越小。作者扫描峰值 $\eta$ 对比 arch warm-up 与未改动的 baseline(Fig.4,FineWeb,$\eta\in\{3,6,8\}\times 10^{-3}$):随 $\eta$ 增大($1/\eta$ 裕度变小),baseline 越来越不稳定、曲率快速失控;而 arch warm-up 始终维持有界的 $\lambda_{\max}(G_t)$、避免 loss spike,在整个区间内稳定收敛。
与其它稳定化方法的对比¶
在 16 层、1B 参数模型上,以峰值 LR $8\times 10^{-3}$(故意用高学习率以观察更小稳定阈值下的表现)对比 QK-Norm、QK-Clip、Softcap 与未改动 baseline。表 1 为三语料上的验证 perplexity($\downarrow$,* 表示发散):
| Dataset | Baseline | QK-Norm | QK-Clip | Softcap | Arch-Warmup |
|---|---|---|---|---|---|
| FineWeb | * | 49.88±0.003 | * | 51.41±0.002 | 25.02±0.001 |
| DCLM | 165.62±0.04 | 61.57±0.012 | * | 43.38±0.03 | 22.64±0.002 |
| OLMo-Mix | * | * | * | * | 18.54±0.001 |
结论分析:在这个偏高学习率的严苛设置下,Arch-Warmup 是唯一在全部三个语料上都不发散且 perplexity 显著最低的方法,大幅领先所有 baseline(在 DCLM 上 22.64 vs 次优 Softcap 43.38)。QK-Clip 尤其不稳定,常在训练中途发散到 NaN。QK-Norm、Softcap 在部分语料可收敛但 perplexity 远高。Arch-Warmup 在别的方法失稳的地方仍稳定收敛、且训练更快,跨语料更可靠。Fig.5 进一步显示竞争方法收敛更慢、频繁 loss spike、有时发散,而本方法保持稳定且一致更快。
Chinchilla 计算最优下的验证¶
由于 QK-Norm 在较短的 FineWeb 跑中表现最好,作者在 Chinchilla 计算最优设置(1B 参数、16 层、FineWeb 上训 25B tokens)下做了更长跑的对比。表 2:
| Method | Val PPL $\downarrow$ |
|---|---|
| QK-Norm | 20.28 |
| Softcap | 32.44 |
| Arch-Warmup | 18.35 |
结论:Arch-Warmup 在计算最优预算下仍优于 QK-Norm,表明早期阶段的稳定性增益能延续到计算最优区,而非只是短跑现象。
架构 warm-up 能替代学习率 warmup 吗?¶
LR warmup 通过在曲率高时放大稳定裕度($\propto O(1/\eta)$)稳定早期训练;architecture warm-up 则扮演互补角色——直接控制曲率(让 $\lambda_{\max}(G_t)$ 早期低、随训练进程升高)。作者据此问:若曲率已由架构门控,LR warmup 还必要吗?
- baseline 用标准良调的 LR schedule(带 warmup):LLaMA 风格超参,峰值 LR $4\times 10^{-4}$,weight decay 0.1,2000 warmup 步,cosine decay。
- arch-warm-up-only 变体:在此 baseline 上仅去掉 LR warmup(warmup 步设为 0),保持峰值 LR、衰减 schedule、所有优化器超参不变,启用架构 warm-up。
Fig.6 显示:配备架构 warm-up 的模型在没有 LR warmup 的情况下达到了与 LR warmup 同等的收敛,且稳定性更好。这表明架构 warm-up 有潜力在实践中替代 LR warmup,或与之组合以获得更宽的稳定操作区。
消融与附录分析¶
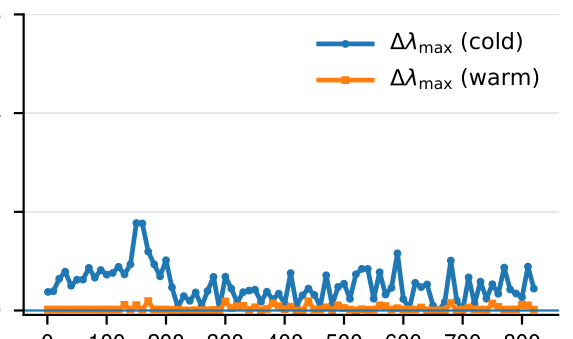
自稳定(self-stabilization)现象(附录 §9)¶
作者追踪 16 层(1B)模型的原始曲率 $\lambda_{\max}(H)$、有效曲率 $\lambda_{\max}(G_t)$ 与预条件逆 $P_t^{-1}$(Fig.7、Fig.8):初始瞬态后,$\lambda_{\max}(G_t)$ 在窄带内震荡(符合 EoS 图景),说明曲率会自行稳定下来——这支持「在训练后期再加深度」。值得注意的是 $P_t^{-1}$ 持续增长,表明优化器的预条件效果稳步增强。
机制上,Adam 类方法存在隐式自稳定:曲率或梯度能量激增时 $g_t^{\odot 2}$ 增大,经 EMA 平滑后 $M_{t+1}\uparrow$,于是 $M_{t+1}^{-1/2}\downarrow$、$G_{t+1}$ 的所有 Rayleigh 商下降,把 $\eta\lambda_{\max}(G_t)$ 推向稳定带。一个简单界:
$$\lambda_{\max}(G_{t+1}) \le \|M_{t+1}^{-1/2}\|_2^2\,\lambda_{\max}(H_{t+1}) = \frac{\lambda_{\max}(H_{t+1})}{\min_i(\sqrt{v_{t+1,i}}+\varepsilon)^2}$$
但自稳定不足以保证稳定收敛,有三种失效模式:(i) 滞后(lag):$v_t$ 在 $\sim 1/(1-\beta_2)$ 步的时间尺度上反应,尖锐的步级 spike 会在 $M_t$ 跟上之前把 $\eta\lambda_{\max}(G_t)$ 推过边界;(ii) 各向异性:$M_t$ 是对角的,而 $H_t$ 可能高度各向异性,逐坐标预条件无法瞬时压制稠密方向上的尖锐曲率;(iii) 与动量耦合:$\beta_1>0$ 时大 $m_t$ 可能在 $M_t$ 开始增长时过冲。架构 warm-up 通过主动作用于 $H_t$ 本身(早期压低中间 Jacobian 的算子范数、后期解锁)来弥补这种被动机制,即便优化器预条件尚未适应也能把系统留在稳定包络内。
深度–Lipschitz–曲率的形式化结果(附录 §8)¶
- Lemma 1(深度–Lipschitz 界):由链式法则与次可乘性得 Eq.(13) 的乘性/指数界。
- Lemma 2(参数敏感度增长):$\|J_\theta g_\theta(x)\|\le C\prod_\ell\|J_\ell(x_{\ell-1})\|$,$J_\theta g_\theta$ 继承 Lemma 1 的乘性增长。
- Proposition 1(Gauss–Newton 曲率界):即 Eq.(14)。
- Corollary 1(预条件曲率):对 SPD 对角 $P_t$($m_tI\preceq P_t\preceq M_tI$),$\tfrac{1}{M_t}\lambda_{\max}(H)\le\lambda_{\max}(G_t)\le\tfrac{1}{m_t}\lambda_{\max}(H)$,故 $\lambda_{\max}(G_t)$ 的深度依赖性在常数因子内镜像 $\lambda_{\max}(H)$。
- Corollary 2(稳定裕度 $\sim 1/\lambda_{\max}$):综合 Lemma 1、2 与 Prop 1,增加深度 $L$ 抬高 $\lambda_{\max}(H)$(及 $\lambda_{\max}(G_t)$),收缩稳定裕度。
对 warm-up 调度的敏感性(附录 §11)¶
默认在 LR warmup 完成前保持半深度,然后分 4 组每组间隔 500 步解锁至满深。Fig.9 显示即便用零间距(在峰值 LR 时一次解锁全部剩余层)结果也相近——因为新启用的块是零初始化的,它们对 Jacobian/Hessian(从而总预条件曲率)的贡献从半深度 baseline 渐进增长,模型从不遭遇「满深度曲率跳变」,容量与曲率随权重离开零而逐步实现。这印证零初始化方案是无 spike 的根本原因。
核心贡献总结¶
- 可扩展的曲率感知训练框架:首次让在线(预条件)Hessian 顶特征值追踪在十亿参数 Transformer上可行——核心是复用上一步特征向量的 warm-started power iteration,在缓慢漂移假设下证明了热启动幂迭代的快速几何收敛(Theorem 1、2),每步 $<5$ 次 HVP,比已有方法低一个数量级。
- 诊断:用该工具确证大模型 loss spike 与预条件曲率尖峰相关,且曲率随深度增长——把 EoS 理论从 $\le 25\text{M}$ 的小模型验证推进到十亿参数级。
- Architecture warm-up:一种函数保持(function-preserving)机制,按曲率预算渐进增加有效深度(零初始化 + 锁定期排除优化器),控制有效曲率的增长,拓宽可用学习率范围、减少 loss spike、提升训练可靠性,且无需计算图手术、可直接嵌入标准配方。
讨论与局限性¶
值得借鉴的设计:
- 缓慢漂移 → 热启动这一观察极其朴素却有效——把数值线代里标准的「continuation-style」幂迭代复用思想引入深度学习曲率估计,作者称此前文献未探索过。预条件 HVP 幂步(Eq.12)只需一次 HVP 加廉价对角缩放,工程上很轻量,可作为大模型训练的在线监控原语。
- 零初始化 + 排除优化器保证函数与一阶导在解锁时连续(Eq.16 的分析很到位),是「progressive growth 为何会引入 spike」这一问题的精确诊断与干净修复,优于朴素的「只置零投影矩阵」。
- 把稳定化从「修补近因」(QK-norm/clip/softcap)上升到「按 EoS 稳定准则主动调度曲率」的统一视角,具有方法论价值。
局限与争议:
- 深度增大曲率只有上界、无严格充分性:作者自己在 Remarks 中承认 Eq.(14) 只是上界,不能严格断言曲率必随深度单调增长(残差/归一化/参数化都可能压低曲率),核心论证更多依赖经验观察。理论与经验之间存在缝隙。
- 实验呈现偏薄:表 1 多数 baseline 直接发散(
*),是在故意调高学习率的严苛设置下取得的对比,虽凸显鲁棒性,但「在正常良调学习率下 Arch-Warmup 相对各 baseline 的净增益」缺少同等充分的展示;许多图(Fig.3–5、7–10)是小幅定性曲线,缺少数值表。Chinchilla 对比(表 2)只列 3 个方法。 - 与 progressive growth 谱系的区分度:深度渐进增长本身与 Progressively Stacking(BERT)、Net2Net/Network Morphism、LiGO 等函数保持扩展高度相关,作者的差异化在于「保持全图在初始化即存在 + 用显式稳定准则触发解锁 + 不做图手术」,但深度增长机制本身的新颖性偏增量;真正原创的是曲率追踪工具 + EoS 框架下的解锁时机。
- 超参与谱隙假设:Theorem 依赖非零谱隙 $\gamma$ 与 Hessian Lipschitz $L_H$,在谱隙塌缩(简并)时热启动优势会退化;曲率准则的阈值如何自动设定,文中未深入。
对大规模推荐模型训练的迁移价值(本文未直接验证推荐场景):本工作是通用且可迁移的大模型训练技术。当前工业生成式推荐(如 HSTU、OneRec、RankMixer 等)正把 Transformer 推向十亿参数级,同样面临 loss spike、发散、对学习率敏感等训练稳定性问题。本文的在线预条件曲率追踪可作为这类大规模推荐模型训练的稳定性监控原语,架构 warm-up 的零初始化渐进深度也可直接套用到推荐 Transformer 的训练配方中。缺乏推荐场景的直接验证是它在本库语境下的主要减分点,但方法路线对推荐模型 scaling 的潜在适用性是明确的。