STAMP: Semantic Trimming and Auxiliary Multi-step Prediction for Generative Recommendation¶
- 作者:Tianyu Zhan, Kairui Fu, Chengfei Lv, Zheqi Lv†, Shengyu Zhang†(浙江大学 & 阿里巴巴)
- Arxiv:2604.05329(2026-04-07)
- 关键词:Large Language Models; Generative Recommendation; Training Acceleration; Semantic ID
研究动机与背景¶
生成式推荐(Generative Recommendation, GR)近期的一个重要转变是从"原子级 item 索引"迁移到"基于 Semantic ID(SID)的框架"。SID 通过 RQ-VAE、RQ-Kmeans 等层次化向量量化把每个 item 编码为若干个编码本中的残差 token s_i = T(i) = RQ(h_i) = [c_{i,1}, c_{i,2}, ..., c_{i,L}],从而在一套共享的小词表 V 上对不同 item 分享语义,带来很强的泛化能力,尤其缓解长尾/冷启动问题。然而这一替换引入两个新的关键可部署性隐患:
- 高计算与慢速训练:一个 item 扩展成 L 个 SID token 后,序列长度乘上 L 倍,训练阶段的 VRAM、计算量以二次方增长(sequence length 与 attention)。对于工业级模型(如 AL-GR-Tiny 的 Qwen2.5-0.5B)这一放大是致命的。
- 大量性能不稳定性:尽管 SID 让模型能做"语义级"泛化,实际效果在不同数据集、不同 backbone 上存在显著抖动,常出现非单调的 Recall/NDCG 曲线——作者通过大量实验发现这一不一致背后的深层病因,并命名为 Semantic Dilution Effect(语义稀释效应)。
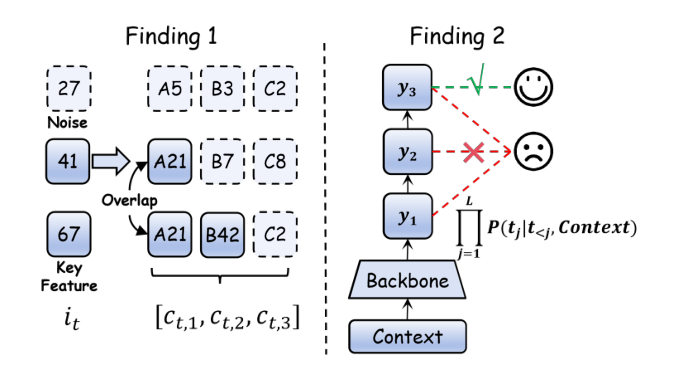
作者把语义稀释效应拆成两个互为因果的现象:
- Finding 1 — Information Non-uniformity(输入端,信息非均匀):用户交互历史
H_u = [i_1, i_2, ..., i_T]经过 SID 展开后得到长度N=T×L的 token 序列,其中真正能反映用户兴趣的通常只是少数关键 token(比如某品类→某品牌→某属性这条链的"品牌"token),其余 token 是噪声或重复模板。SID 的层次化编码放大了结构性冗余: - Feature-level Redundancy:用户兴趣长期由少数关键语义特征主导,交易 attribute 如颜色/材质往往是当前预测任务的无关噪声。
-
Sequence-level Redundancy:同序列内不同 item 经常共享同一 SID 前缀(同类/同品牌),产生大量重复信息,导致边际信息量快速衰减。
-
Finding 2 — Supervision Sparsity(输出端,监督信号稀疏):与原子 ID 模式下"一个 item 一条监督信号"不同,SID-GR 的监督点按 L 同步扩张(需要对 L 个 token 顺序预测),但有效监督依然只在 ground-truth item 的这 L 个 token 上。并且预测一个 item 的概率需要链式相乘:
$$ P(\text{Item}) = \prod_{j=1}^{L} P(y_j \mid y_{<j}, \text{Context}) \tag{1} $$
这意味着任何一个子 token 出错都会经由 chain rule 放大为 item 级错误;粒度越大(L 越大),越需要模型具备长程依赖建模能力,而输入端被噪声稀释后恰恰难以满足。两者互相加剧,形成"Finding1 → Finding2"的恶性循环。
论文据此提出双端框架 STAMP(Semantic Trimming and Auxiliary Multi-step Prediction):输入端用 Semantic Adaptive Pruning(SAP)削减冗余;输出端用 Multi-step Auxiliary Prediction(MAP)增强监督密度,一次性同时治理两端。
核心方法:STAMP 总体架构¶
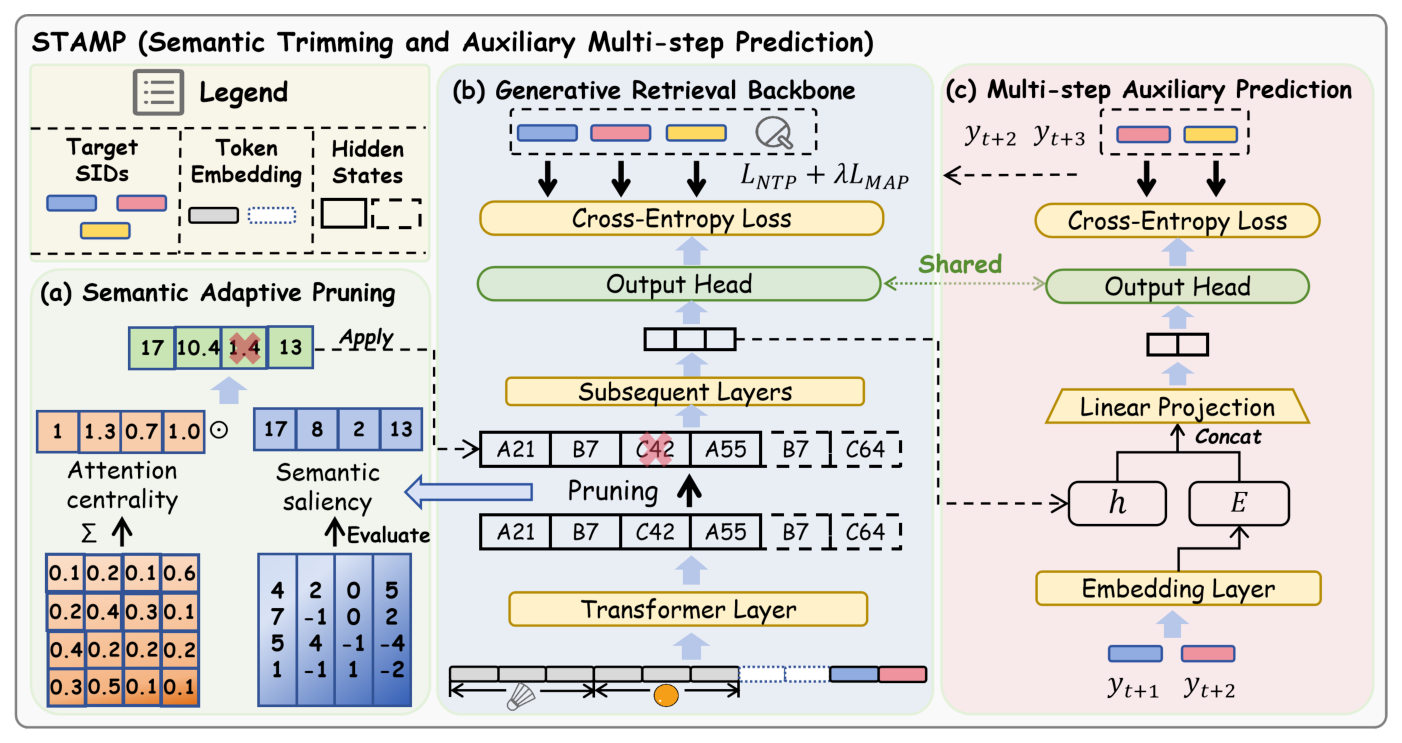
STAMP 在标准 SID-GR 的 Transformer backbone 上嵌入两个模块:
- SAP(Semantic Adaptive Pruning):在 Transformer 的第
l_prune层上,依据每个 token 的"内在语义显著性 + 外在结构中心性"得到一个重要性分数,按比例保留α·N个 token 再送往后续层,直接把后续层的序列长度从 N 降到α·N。 - MAP(Multi-step Auxiliary Prediction):在输出端,除了标准的 Next-Token Prediction(NTP)外,额外要求 backbone 同时预测 next-next item 的 SID(以及之后 1–2 个 item),从而把每个 item 对应的密集监督补回来,相当于在同一套表征上打多个监督点。
Semantic Adaptive Pruning(SAP)¶
SAP 的核心洞察:Transformer 里本身就自带 token 级的两类信号——feature-level 的 hidden-state 幅度,以及 attention 权重里蕴含的 context-level 影响力。把它们融合就能得到"内外兼顾"的 token 重要性评分,完全不引入额外可学习参数。
令第 l 层的 hidden state 为 H^(l) ∈ R^{B×N×d}。
1) Semantic Saliency(语义显著性) —— 用 ℓ2 范数衡量信息密度:
$$ S_{\text{sem}}(i) = \text{Norm}\big(\|h_i^{(l)}\|_2\big) \tag{2} $$
其中 Norm 是一个批/序列内的归一化函数(防止数值不稳定)。作者引用了在 LLM 解释性领域的观察:hidden state 的 ℓ2 范数与 token 语义激活强度正相关,因此可作为一个便宜但可靠的"token 信息密度"代理。
2) Attention Centrality(注意力中心性) —— 刻画一个 token 在整张 attention 图里被多少其他 token"引用":
$$ S_{\text{attn}}(i) = \sum_{h=1}^{H}\sum_{j=1}^{N} A_{h,j,i} \tag{3} $$
其中 A_{h,j,i} 是 head h 下 query j 对 key i 的 attention 权重。一个"被大家重度 attend 到"的 token 通常是 hub 节点,承担大量上下文信息聚合。
3) 融合重要性(element-wise 乘积):
$$ \mathcal{I}_i = S_{\text{sem}}(i)\cdot S_{\text{attn}}(i) \tag{4} $$
一个 token 同时语义密集且被关注,才会得到高分——这有效挑出"同时内部丰富且外部枢纽"的 token。
4) 剪枝与压缩:先设定保留比例 α ∈ (0,1],目标是保留 |K| = ⌊α·N⌋ 个 token。为 decoder-only 架构(如 Qwen),直接预测当下 L 个 SID 的 token 一定要保留(即 W_{\text{recent}} ⊆ K,对应的"保护窗口"),其余位置由 I_i 从高到低填满。
随后为了不破坏序列的时序因果性(GR 中的次序对行为建模至关重要),把被选中的索引按原位置从小到大重新排列:
$$ K_{\text{sorted}} = \text{Sort}(K,\ \text{order}=\text{ascending}) \tag{5} $$
再用 gather 操作压缩 hidden states:
$$ H^{(l)}_{\text{compressed}} = \text{Gather}\big(H^{(l)},\ K_{\text{sorted}}\big) \tag{6} $$
从第 l_prune 层之后开始,序列长度从 N 变为 α·N,后续层的所有 attention / FFN 都在短序列上运作,达到线性级的显存与 FLOPs 节省。SAP 的一个重要优势:它完全挂载在训练阶段,推理时可以"关闭"或保留——论文中主要报告训练效率。
Multi-step Auxiliary Prediction(MAP)¶
SAP 只解决了 Finding 1(输入端噪声),Finding 2(监督稀疏+长程依赖压力)仍然存在。MAP 的思路参考近年 LLM 里的"multi-token prediction"与"dense supervision",在不改变解码器基本结构的前提下增加"前瞻性"监督:
设 h_t 为 backbone 第 t 步的 hidden state,E(y_{t+1}) 为真实 next token 的 embedding(即 lookahead 用的 teacher forcing 信号)。MAP 构造一个"foresight 表征":
$$ h_t^{\text{mtp}} = \text{MLP}\big(\text{Concat}(h_t,\ E(y_{t+1}))\big) \tag{7} $$
然后复用主干的 unembedding 矩阵 \text{LM\_Head} 做"跳一步"预测:
$$ P(y_{t+2}\mid h_t, y_{t+1}) = \text{Softmax}\big(\text{LM\_Head}(h_t^{\text{mtp}})\big) \tag{8} $$
通过共享 LM_Head,foresight 表征被迫与主任务的 token 空间对齐,避免额外参数和潜在的表征漂移。MAP 的损失定义为对 y_{t+2} 做负对数似然(以 y_{t+1} 真值作为条件输入):
$$ \mathcal{L}_{\text{MAP}} = -\sum_{j=1}^{L-1}\log P\big(y_{j+1}\mid h_j, y_j\big) \tag{9} $$
直观地说:MAP 要求模型用当前状态同时预测"下一个 token"和"再下一个 token"(甚至可扩展到 t+3),等价于一次训练步里对同一段 hidden trajectory 打多个监督点,直接对抗 Supervision Sparsity;同时多步预测迫使模型捕获跨多个 SID 的长程依赖,对抗 Finding 2 中的链式误差放大问题。MAP 只在训练阶段启用,推理时整个辅助头被丢弃,部署延迟零增加。
总优化目标¶
最终的训练损失是主任务 NTP 和辅助 MAP 的加权和:
$$ \mathcal{L}_{\text{NTP}} = -\sum_{j=1}^{L}\log P(y_j\mid X, y_{<j};\ \theta) \tag{10} $$
$$ \mathcal{L}_{\text{total}} = \mathcal{L}_{\text{NTP}} + \lambda\cdot\mathcal{L}_{\text{MAP}} \tag{11} $$
λ 作为超参数调节辅助监督强度——作者经验取 λ=0.3。
实验设置¶
数据集与 Backbone¶
作者设计了学术 + 工业两条实验线:
- GRID(Encoder-Decoder T5):在 Beauty / Sports / Toys 三个 Amazon 评论子集上使用 GRID 框架,backbone 为 Flan-T5-XL 的 8 层轻量 Encoder-Decoder(4 enc + 4 dec),隐层 128,4 head,FFN 1024。用 RQ-KMeans 生成 SID,每个 item L=4 个 token。训练 sequence length 120,batch 32,BF16,AdamW,学习率 1e-3,weight decay 1e-4,dropout 0.15,patience 10 次 eval(每 1600 步 eval 一次),5 个种子取平均。
- FORGE(Decoder-Only Qwen):在阿里大规模工业数据集 AL-GR-Tiny(131M 用户、251M item、14B 交互,>250M 多模态特征)上用 Qwen2.5-0.5B-Instruct 初始化 backbone,序列长 1280,其中 1024 给历史 256 给目标,retention ratio α=0.6、MAP 系数 λ=0.3,单 epoch 100,000 步,bfloat16,2×A100-SXM4-80GB。
表1 数据集统计:
| Dataset | #Users | #Items | #Interactions |
|---|---|---|---|
| Sports | 35.6K | 18.4K | 296.3K |
| Beauty | 22.4K | 12.1K | 198.5K |
| Toys | 19.4K | 11.9K | 167.6K |
| AL-GR-Tiny | 131M | 251M | 14B |
评估指标¶
- GRID:Recall@K 和 NDCG@K(K=5,10),分别衡量召回率和排序质量。
- FORGE:HitRate@K(K=20,100,500,1000),衡量 top-K 命中率。
- 效率:Time(秒/训练时长)、Speedup(相对 base)、VRAM(MiB)、VRAM Reduction(%)。
Baseline¶
以各数据集对应框架提供的 Base(纯 NTP,不剪枝)作为对照,再引入 MAP-only 和不同剪枝层 L=1 / L=2 的 SAP 配置用于 ablation,以及其他剪枝策略:Max Pooling、Average Pooling、ℓ2-norm only、Attention only、Random Pruning。
主要实验结果¶
Table 2 —— GRID(T5)在 Beauty/Sports/Toys 上的总体表现¶
| Backbone | Dataset | Method | Recall@5 | Recall@10 | NDCG@5 | NDCG@10 | Time (s) ↓ | Speedup ↑ | VRAM (MiB) ↓ | Reduction ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| GRID (T5) | Beauty | Base | 0.0426 | 0.0645 | 0.0295 | 0.0355 | 212 | – | 22234 | – |
| MAP | 0.0444 | 0.0655 | 0.0295 | 0.0363 | 170s | 1.25× | 13862 | 37.7% | ||
| STAMP (L=2) | 0.0444 | 0.0655 | 0.0295 | 0.0363 | 154s | 1.38× | 10378 | 53.3% | ||
| STAMP (L=1) | 0.0441 | 0.0648 | 0.0293 | 0.0363 | – | – | – | – | ||
| Sports | Base | 0.0234 | 0.0354 | 0.0154 | 0.0193 | 205s | – | 22234 | – | |
| MAP | 0.0244 | 0.0352 | 0.0155 | 0.0193 | 166s | 1.23× | 13814 | 37.6% | ||
| STAMP (L=2) | 0.0244 | 0.0352 | 0.0155 | 0.0193 | 151s | 1.36× | 13302 | 54.7% | ||
| Toys | Base | 0.0345 | 0.0499 | 0.0238 | 0.0287 | 216s | – | 22268 | – | |
| MAP | 0.0356 | 0.0503 | 0.0245 | 0.0293 | 174s | 1.24× | 14256 | 36.0% | ||
| STAMP (L=2) | 0.0344 | 0.0509 | 0.0235 | 0.0286 | 159s | 1.36× | 10658 | 52.1% |
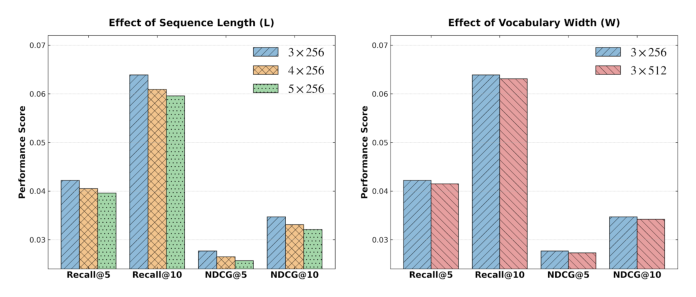
解读:STAMP 在三个 Amazon 数据集上同时实现 1.23–1.38× 训练加速和 ~37–55% 的 VRAM 节省,并且在推荐质量上不输甚至反超 base,在 Beauty 与 Toys 上 Recall@10 甚至有小幅超越。这说明 SAP 的剪枝"不但不损性能,反而去掉了对学习造成干扰的噪声"。剪枝层越靠前(L=1)带来的加速越显著但偶有精度掉点;L=2 是作者在三数据集上保守但稳定的默认选择。
Table 3 —— FORGE(Qwen2.5-0.5B)在工业 AL-GR-Tiny 上的表现¶
| Backbone | Dataset | Method | Hit@20 | Hit@100 | Hit@500 | Hit@1000 | Time (s) ↓ | Speedup ↑ | VRAM (MiB) ↓ | Reduction ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| FORGE (Qwen) | AL-GR-Tiny | Base | 0.0209 | 0.0508 | 0.1155 | 0.1400 | 1139s | – | 2^64232MB | – |
| STAMP (L=6) | 0.0207 | 0.0506 | 0.1149 | 0.1405 | 851s | 1.34× | 2^53196MB | 17.2% |
解读:工业级 Qwen2.5-0.5B 设置下 STAMP(剪枝层 L=6)提供 1.34× 加速 + 17.2% VRAM 降低,Hit@K 几乎完全齐平 Base(Hit@1000 甚至微涨),证明该方法在 decoder-only 大模型 + 真实工业数据分布下依然有效。VRAM 节省相对 T5 更小(17% vs 55%),作者解释这是因为 Qwen 有 24 层、剪枝被放在第 6 层,前 6 层仍在全长序列上运算;同时 0.5B 静态参数本身占掉了一大块显存,激活比例相对较小,所以压缩带来的绝对收益比 T5 少。
Table 4 —— 效率汇总¶
STAMP(L=1) 在 Beauty/Sports/Toys 上可把训练时长从 212/205/216s 分别压到 146/143/147s(1.45×/1.43×/1.46×),VRAM 从 22234 MiB 压到约 10.3K MiB(53–54% reduction)。这一效率优势对于训练规模动辄数十 GPU 天的工业 GR 模型是极为关键的。
消融与分析¶
Ablation(RQ2)—— SAP vs MAP 各自贡献¶
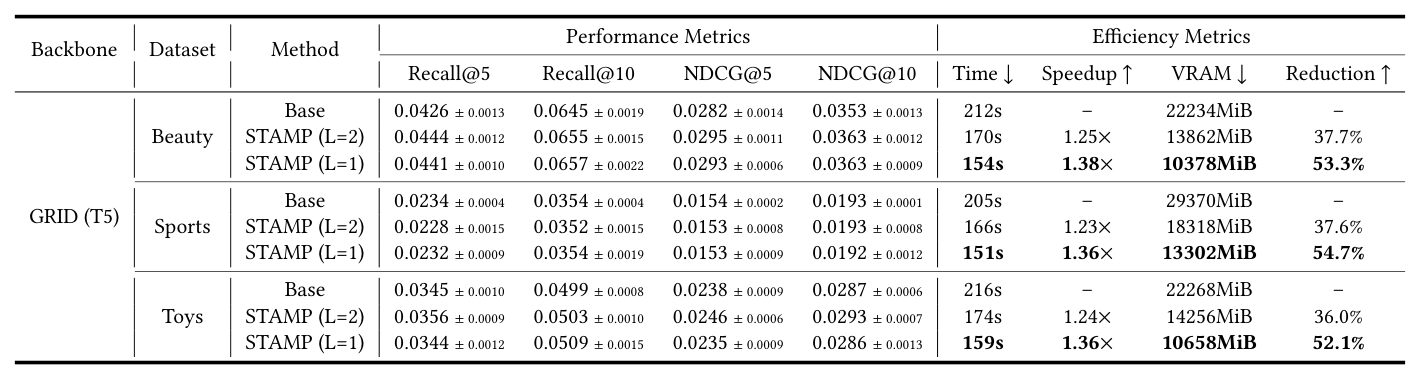
Figure 5 显示:
- MAP-only:在三数据集上全面优于 Base,说明 MAP 并非仅仅"补偿 SAP 丢掉的信息",而是本身作为独立的密集监督机制,提升了 backbone 的长程依赖建模与表征鲁棒性。
- SAP-only:大幅降低训练时间和 VRAM,精度上 Beauty/Toys 可达 Base 相当或略升,Sports 上略掉——这与 Sports 本身噪声结构更杂、在前层剪枝更容易误删有关。
- STAMP (= SAP + MAP):同时获得 SAP 的效率收益和 MAP 的质量提升,两个模块"互补"而非冗余。
Figure 6 则进一步展示"Base vs SAP(L=2)"在 Beauty/Toys 上的逐指标曲线,SAP 不仅没有损失,反而由于"去噪"效应略微超过 Base。
RQ3 —— 剪枝策略与 Pruning Layer / Retention Ratio 敏感性¶
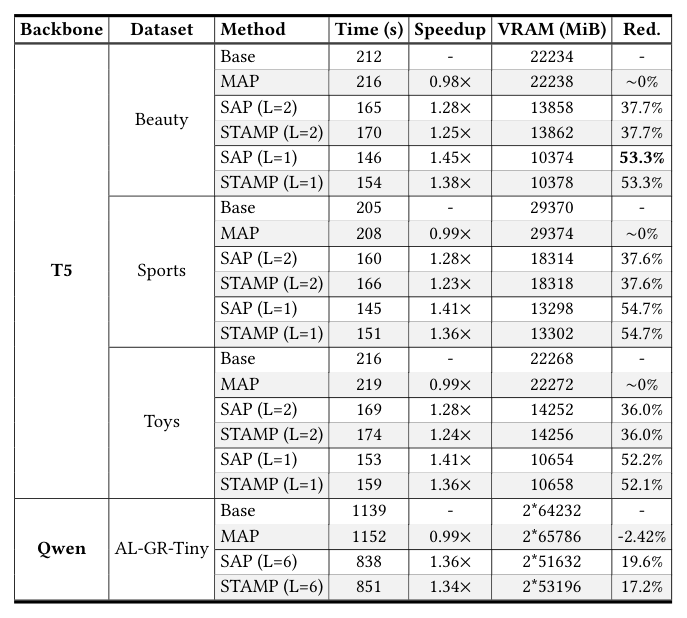
对比 5 类剪枝策略:Max Pool、Avg Pool、ℓ2-norm only、Attention only、Random、SAP:
- 训练曲线(左半)上 SAP 显著高于其他,其中单用 ℓ2-norm 和 attention 的变体比 pooling/random 好但仍不如 SAP,证明"内部语义 × 外部中心性"的乘积是有信息互补的。
- 测试集 HR 和 NDCG(右半)上 SAP 同样明显领先。
- 作者点出两点洞察:(1) 单靠 ℓ2-norm 会丢失"某些 token 低范数但高被引"的 hub;(2) 单靠 attention 会忽略"内部语义密集但被周边弱关注"的关键特征。两者乘积互为校验。
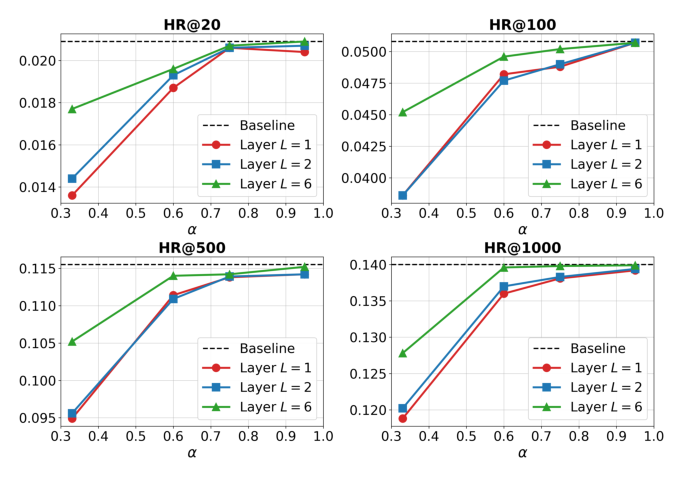
Figure 8 的 HR@20/100/500/1000 面板展示:
- 固定 L,α 从 0.3 拉到 0.9 曲线单调接近 baseline,说明保留更多 token 更安全,但收益递减;
- 固定 α,L 越深越接近 baseline(越浅剪枝越激进越容易损伤),因为浅层正在构建基础特征,"过早剪枝会破坏语义聚合"。
- 实际最优点由"收益 vs 风险"权衡决定,论文在 Qwen 上选 L=6, α=0.6。
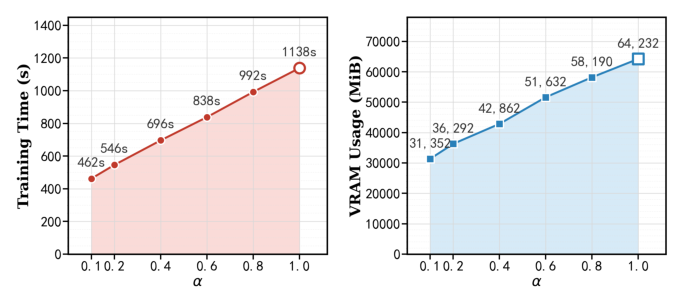
Figure 9 定量:α 从 0.3 到 0.9 时 Training Time 从 540s 升到 1134s,VRAM 从 36.3K MiB 升到 58.5K MiB;α=0.6 是作者的折中点。
RQ4 —— 为什么剪枝是"安全"的?Attention 分布可视化¶

作者从测试集抽取 3 条序列,绘制 T5 encoder 6 层的 attention 热图。观察到:
- 浅层(1–2 层)大量"低 attention 权重"的 token 用于"搭建基础特征"(scaffolding tokens),它们既不是长期关注对象,也不是信息 hub;到了深层会迅速变成 dead weight;
- 深层(4–6 层)attention 变得集中,信息已被头部少数 token 吸收。
- 这解释了为什么剪枝不能做得过早(会破坏基础特征形成)也不能做得过晚(收益小)。中层剪枝既能安全去掉"已冷"的 scaffolding,又能把所有被"吸收"的信息保留在头部 token 里——这正是 SAP 在 L=2(T5)/ L=6(Qwen)附近收敛到最优点的根本原因。
讨论与局限性¶
核心贡献 1. 首次明确定义并诊断 SID-GR 中的 Semantic Dilution Effect,把它分解为输入端的 Information Non-uniformity 与输出端的 Supervision Sparsity。这一框架性诊断对后续 SID-GR 研究具有重要指导意义。 2. 提出 SAP:无需引入额外参数,用"语义显著性 × 注意力中心性"同时刻画 token 内外重要性,从 LLM 的中间表示里便宜地得到剪枝信号。 3. 提出 MAP:通过共享 LM Head 的 multi-step 前瞻预测增稠监督信号,不引入部署延迟。 4. 在学术数据集与工业级 AL-GR-Tiny 基准上跨 Encoder-Decoder(T5)与 Decoder-Only(Qwen)双架构验证,1.23–1.38× 训练加速 + 17.2–54.7% VRAM 降低,并保持或超越精度。
值得借鉴的设计
- "输入稀释 → 剪枝、输出稀释 → 多步监督"的双端对偶思路对其他 SID / Tokenized Recommendation 工作都有参考价值。
- 剪枝层位置不该放在模型最浅处(破坏基础特征)或太深处(增益递减),中层是最优区间。这与 LLM 社区关于 KV cache eviction、token pruning 的一些经验高度一致,但作者把它专门放在推荐语境下验证,非常扎实。
- SAP 完全不需要额外参数或二阶段训练,工程实现简单(gather + sort 即可),并且天然兼容任何 Transformer-based GR backbone。
局限与可扩展方向
- 作者未报告在线 A/B 实验收益——从论文结构看 AL-GR-Tiny 更像离线 benchmark,没有线上流量验证。工业落地的说服力可进一步加强。
- MAP 目前只展示了 1 步前瞻(
y_{t+2});多步(3+ 步)的边际收益与过度监督风险尚未充分刻画。 - 剪枝策略目前依赖 hidden state + attention 的启发式组合,未探索可学习门控或基于重要性采样的替代;在 KV cache 压缩等推理阶段压缩上也未展开。
- 对"Sports 数据集上 SAP-only 略掉点"的问题没有给出机理分析——这可能是 Sports 类目内 feature 分布更分散时,ℓ2 × attention 的 proxy 不够稳健。
- 与 KV Caching / Efficient Attention / Token Pruning 等正交加速技术的叠加效果未测试。
与已有工作的差异
- KV Caching / Efficient Attention(如 FlashAttention)关注推理侧长序列,STAMP 关注训练侧的序列压缩;
- Token Pruning 主要面向 NLP/CV,剪掉"冗余词 / 背景 patch",但 SID-GR 里的"高粒度 SID token"具有严格的层次结构和时序依赖,直接搬用 NLP 剪枝会破坏 item 的完整语义——STAMP 专门为 SID-GR 设计了"Order-Preserving Sequence Compression + 保护窗口"来应对;
- 近期 OneRec/RPG 等工作主要从编码器设计(RQ-Kmeans、OPQ)着手改进 SID 本身,STAMP 则从训练算法角度与之正交,可直接叠加。
结论¶
STAMP 是一篇"问题定义精准 + 方案简洁 + 实验扎实"的训练加速论文。它准确指出了 SID-GR 范式的结构性病灶 Semantic Dilution Effect,并给出一个可插拔、零推理开销、在学术和工业 backbone 上都验证过的双端修复方案。对所有基于 Semantic ID 的生成式推荐模型(OneRec、TIGER、GRID、FORGE 等)都可作为训练阶段的标配加速组件。作者浙大 + 阿里的联合组合也使得该工作兼具学术严谨性与工业可操作性,值得工业 GR 团队直接尝试。