Self-Balancing Gradient Allocation for Heterogeneity-Aware Feature Generation in Click-Through Rate Prediction(HeteGenCTR)¶
Alibaba Group(Moyu Zhang, Yun Chen, Yujun Jin, Jinxin Hu, Yu Zhang, Xiaoyi Zeng),arXiv:2605.24986,2026-05-24。
研究动机与背景¶
CTR 预测的两条范式¶
点击率(Click-Through Rate, CTR)预测是工业推荐系统的基础任务:估计用户对展示物品产生点击的概率。形式化地,给定特征集 $\mathbf{F} = [f^1, f^2, \dots, f^N]$($N$ 个特征域)与二值标签 $y \in \{0,1\}$,学习一个映射 $\mathcal{F}: \mathbf{F} \to [0,1]$ 估计点击概率:
$$P(y\mid\mathbf{F}) = \mathcal{F}(f^1, f^2, \dots, f^N) \tag{1}$$
判别式范式(Discriminative):标准 CTR 模型(WDL、DeepFM、DCN、AutoInt、FiBiNet、MaskNet、PEPNet 等)端到端用二元交叉熵训练。问题在于:监督信号只在输出标量处提供,每个样本仅得到一个二值监督,面对真实推荐流量的极端稀疏性(绝大多数 user-item 特征组合在训练中只出现极少次甚至从未出现)时,稀有特征的表征会坍缩或不可靠。
生成式范式(Generative):把 CTR 重构为一个生成问题——不是预测单一标签,而是从隐分布中重建整个特征样本,对所有特征域同时提供密集监督。典型实现是耦合的两阶段流水线:第一阶段预训练一个生成模型重建特征域;第二阶段直接继承预训练参数与打分函数,做有监督微调。本文的直接前身 DGenCTR([36],同团队,2025)把点击标签当作样本里的一个额外特征域处理,统一了两个阶段——当只 mask 标签时,标签重建损失数学上等价于 CTR 校准损失,使 CTR 估计成为生成式去噪过程的一个特例。扩散模型尤其适合:离散扩散天然契合推荐特征的类别属性,对稀有特征值也能借助共现模式得到密集监督,缓解判别式训练中的稀疏性坍缩。
被所有生成式 CTR 方法共享的根本缺陷¶
作者指出所有现有生成式 CTR 方法(GenCTR、DGenCTR、SGCTR)都有一个被埋进训练目标公式本身的局限:把特征生成当作一个 homogeneous(同质)任务——每个特征域被赋予相同的损失权重,无视其内在重建难度。而这一假设被推荐特征空间的结构根本性地违反了。
CTR 输入特征横跨差异巨大的模态与统计特性:
- 高基数 ID 域($\mathcal{F}^{ID}$):百万级唯一值的用户/物品 ID;
- 稀疏类别属性域($\mathcal{F}^{cat}$):中等基数($10^1$–$10^4$);
- 稠密数值域($\mathcal{F}^{num}$):连续值;
- 变长行为序列域($\mathcal{F}^{seq}$)。
这些域不仅在基数/稀疏性上不同,更在生成复杂度(generative complexity)——即为每个域学一个准确生成模型的内在难度——上不同。高基数 ID 域要在巨大的离散空间里捕捉细粒度模式,而数值域可能服从紧凑的分布形式。
generative difficulty imbalance(生成难度不均衡):当所有域用统一损失权重训练时,优化动态不可避免地失衡。易重建的域(低基数类别、近常数数值)早早收敛,却仍持续施加不成比例的梯度影响,把共享网络参数拉向偏好这些简单域的表征;与此同时,高复杂度域(高基数 ID、行为序列)收敛慢,长期欠拟合。模型在简单域上取得了好的重建质量,却无法捕捉那些真正承载下游 CTR 任务最强预测信号的域的细粒度模式。

这不只是理论问题。ID 域与序列域恰恰携带 CTR 预测中最强的个性化信号:用户 ID 编码长期偏好画像,物品 ID 编码内容身份,序列编码短期意图。当生成模型系统性地欠拟合这些高信号域、让简单域垄断训练梯度时,得到的特征表征恰恰在最关键的地方给出贫弱的监督,下游 CTR 模型在最要紧处收到"营养不良"的训练信号。
与 DGenCTR 的 noise schedule 是正交问题¶
值得强调的是,DGenCTR 已经引入了 per-field noise schedule $\{\gamma^i(t)\}$ 来适配不同词表大小(更大词表需更慢的 masking 速率)——但这解决的是分布不匹配,并没有改变各域在损失聚合 $\mathcal{L}_{gen}$ 中的相对权重(系数仍是 1)。作者明确论证:梯度不均衡源于损失聚合而非 noise schedule,二者正交、需要独立的解。HeteGenCTR 保留了 per-field noise schedule,转而攻击损失层面的梯度不均衡。
本文贡献¶
- 识别并形式化 generative CTR 建模中的 generative difficulty imbalance:对特征域的均匀处理使易域主导训练梯度、压制 ID 与序列域的学习;并论证 DGenCTR 的 per-field noise schedule 处理的是分布不匹配、与梯度不均衡正交,两个问题需各自独立的解。
- 提出 HeteGenCTR:引入一个统一的 per-field 难度信号,同时驱动两个协调的机制——自平衡损失聚合 + 难度引导注意力调制,不引入任何超出 baseline 的额外超参。提供稳定性分析证明自平衡均衡是严格局部最小值,并给出注意力缩放与损失层加权"设计上对齐"的原理推导。
- 五数据集 + 线上 A/B 验证,相对 SOTA 生成式与判别式 baseline 取得一致、统计显著的提升。
核心方法 / 模型架构¶
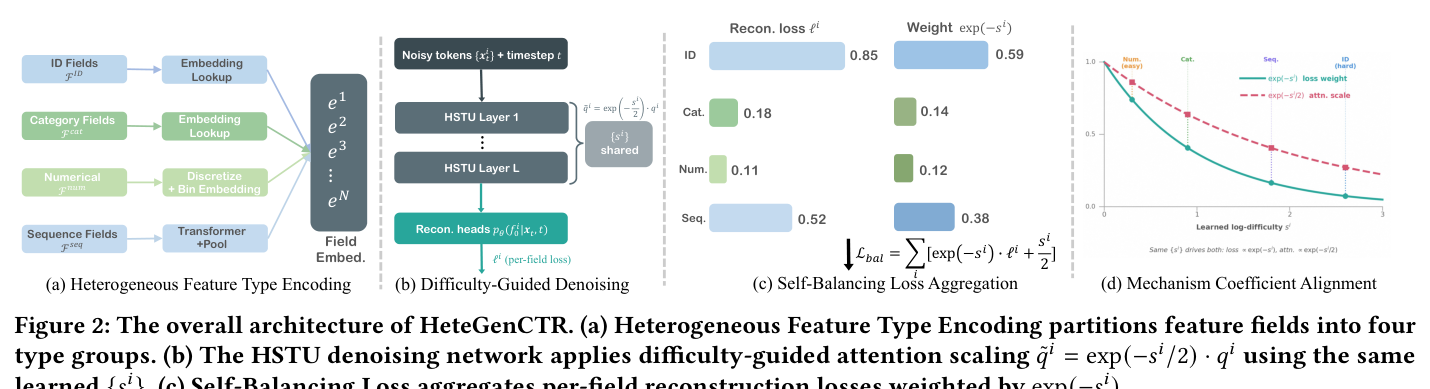
HeteGenCTR 是一个建立在离散扩散之上、带统一域难度估计的异质生成框架。它完全运行在第一阶段(特征重建)之内:改善特征重建质量,第二阶段直接继承预训练打分函数,无需任何架构改动。核心是一组 per-field 可学的 log-难度参数 $\{s^i\}_{i=1}^N$,每个是 $\mathbb{R}$ 上的标量,与去噪网络 $p_\theta$ 联合学习。这个统一信号同时在损失层与注意力层驱动难度不均衡的修正。
4.0 预备:离散扩散下的生成式 CTR¶
DGenCTR 采用 absorbing(吸收态)离散扩散:对每个域 $i$,前向过程是以 per-field masking 速率 $\gamma^i(t)$ 走向吸收态 $[M]$ 的连续时间马尔可夫链;去噪网络 $p_\theta$ 学反向过程——给定 $t$ 时刻部分被 mask 的特征集,预测原始未 mask 的 token。数值域通过 $B$ 个均匀分桶离散化以套用同一框架。由于高基数 ID 域使全词表 softmax 不可行,DGenCTR 用基于当前 batch 负样本的 batch-softmax 近似重建:
$$q_\theta(\hat{e}^i \mid \mathbf{X}_t^{\backslash i}) = \frac{\exp(\cos(\hat{e}^i, G(\mathbf{X}_t^{\backslash i})))}{\sum_{\tilde{e}^i \in \mathcal{B}_i} \exp(\cos(\tilde{e}^i, G(\mathbf{X}_t^{\backslash i})))} \tag{2}$$
其中 $G(\cdot)$ 是打分网络,$\mathcal{B}_i$ 是 batch 负样本集。
耦合两阶段:把样本写成 $X=\{\mathbf{F}, y\}$,扩散模型重建包括标签在内的所有域。当仅 mask 标签时,去噪网络从未 mask 特征 $\mathbf{x}_t^{\backslash y}$ 预测 $y$:
$$\mathcal{L}_{label} = -\log p_\theta(y \mid \mathbf{x}_t^{\backslash y}) \tag{3}$$
$$p_\theta(y=1\mid \mathbf{x}_t^{\backslash y}) = \frac{1}{1+\exp(-(\mathcal{F}(y=1\mid\mathbf{F}) - \mathcal{F}(y=0\mid\mathbf{F})))} \tag{4}$$
由于第二阶段目标用的正是同一个打分函数 $\mathcal{F}(\cdot)$,CTR 估计是生成式去噪过程的特例,两阶段深度耦合。预训练最小化的标准离散扩散目标为:
$$\mathcal{L}_{gen} = -\mathbb{E}_t\!\left[\sum_{i=1}^N \log p_\theta(f_0^i \mid \mathbf{x}_t, t)\right] \tag{5}$$
——它对每个特征域赋予相同权重,无视基数、稀疏性、生成难度。这正是不均衡的来源。
作者用重建损失的收敛行为刻画域 $i$ 的生成难度,定义 $\tau$ 步时的归一化重建难度:
$$d^i(\tau) = \frac{\ell^i(\tau)}{\ell^i(0)} \tag{6}$$
经验上,高基数 ID 域(基数 $>10^5$)在均匀加权下整个训练过程维持 $d^i(\tau) > 0.8$;低基数类别域(基数 $<10^2$)在训练前 10% 内就收敛到 $d^i(\tau) < 0.2$。总损失梯度因此被易域主导。不均衡同时体现在两个层面:损失层(易域贡献不成比例的大梯度 $\nabla_\theta \mathcal{L}_{gen}$)与注意力层(去噪网络内来自已收敛易域的 query 主导注意力输出,压制流向难域的跨域信息)。原则上的解应同时处理两层、且理想地来自一个单一可学的 per-field 信号。
4.1 异质特征类型编码(Heterogeneous Feature Type Encoding)¶
按模态把所有特征分四组(见 Figure 2a):
- ID 域 $\mathcal{F}^{ID}$:高基数用户/物品 ID,每个值映射到可训练 embedding $e^i \in \mathbb{R}^d$;
- 类别属性域 $\mathcal{F}^{cat}$:基数 $10^1$–$10^4$,映射到共享类别 embedding;
- 数值域 $\mathcal{F}^{num}$:连续值 $v^i \in \mathbb{R}$,用 $b^i = \min(\lfloor B\cdot\hat{F}^i(v^i)\rfloor, B-1)$ 离散化到 $B$ 个均匀分桶,其中 $\hat{F}^i$ 是在训练集上算出的经验累积分布函数(CDF);
- 序列域 $\mathcal{F}^{seq}$:变长行为历史,用一个轻量 Transformer 对物品 embedding 编码,再经 mean pooling + 线性层投影到固定尺寸的域 embedding $e^i \in \mathbb{R}^d$。
类型特定编码后,所有 $N$ 个域 embedding $\{e^i\}$ 拼接送入扩散主干。
4.2 自平衡损失(Self-Balancing Loss)¶
把总生成损失分解为 per-field 重建项:
$$\ell^i = -\mathbb{E}_t\!\left[\log p_\theta(f_0^i \mid \{\mathbf{x}_t^j\}_{j=1}^N, t)\right] \tag{7}$$
多任务似然。不靠启发式地手调 per-field 损失,而是从一个原理化的最大似然框架推导聚合规则。把每个特征域当作一个独立的重建"任务",引入 per-task homoscedastic 不确定性 $(\sigma^i)^2 > 0$,刻画重建域 $i$ 固有的任务级噪声(与具体输入样本无关)。沿用 Kendall 等人 [10] 的多任务不确定性加权原理,把域 $i$ 的似然建模为重建残差上的高斯:
$$p(f_0^i \mid \{\mathbf{x}_t^j\}, t; \sigma^i) = \mathcal{N}(f_0^i; \mu_\theta^i(\{\mathbf{x}_t^j\}, t), (\sigma^i)^2) \tag{8}$$
其中 $\mu_\theta^i$ 是模型对域 $i$ 的预测充分统计量。对离散重建任务,同样的函数形式从标准 softmax 似然的温度缩放近似中浮现。由于给定共享网络输出时 $N$ 个域条件独立,联合似然因子化为:
$$p(\{f_0^i\}_{i=1}^N \mid \{\mathbf{x}_t^i\}, t; \{\sigma^i\}) = \prod_{i=1}^N p(f_0^i \mid \mathbf{x}_t^i, t; \sigma^i) \tag{9}$$
对数似然目标。取对数、代入 (8)、丢弃常数项:
$$\log p = -\sum_{i=1}^N \left[\frac{1}{(\sigma^i)^2}\ell^i + \log\sigma^i\right] \tag{10}$$
于是对网络参数 $\theta$ 与任务不确定性 $\{\sigma^i\}$ 同时最小化负对数似然:
$$\mathcal{L}_{ML}(\theta, \{\sigma^i\}) = \sum_{i=1}^N \left[\frac{1}{(\sigma^i)^2}\ell^i + \log\sigma^i\right] \tag{11}$$
权重 $1/(\sigma^i)^2$ 下调高不确定性任务的权重,而正则项 $\log\sigma^i$ 防止模型靠把 $\sigma^i \to \infty$ 平凡地忽略任何域。
梯度分析。对 $\theta$ 求导:
$$\nabla_\theta \mathcal{L}_{ML} = \sum_{i=1}^N \frac{1}{(\sigma^i)^2}\nabla_\theta\ell^i \tag{12}$$
每个域对总梯度的贡献正比于其任务不确定性的倒数:大 $(\sigma^i)^2$(高不确定、难重建)的域权重小、贡献弱;小 $(\sigma^i)^2$(低不确定、易重建)的域主导梯度——这正是 §3.3 描述的不均衡现象。为找到最优不确定性,对 $\sigma^i$ 求导置零:
$$\frac{\partial\mathcal{L}_{ML}}{\partial\sigma^i} = -\frac{2\ell^i}{(\sigma^i)^3} + \frac{1}{\sigma^i} = 0 \;\Longrightarrow\; (\sigma^i)^2 = 2\ell^i \tag{13}$$
最优不确定性下,均衡权重为 $1/(\sigma^i)^2 = 1/(2\ell^i)$,与重建损失成反比。
对数方差重参数化。直接回归 $\sigma^i$ 数值不稳定((11) 的梯度含 $(\sigma^i)^3$ 相除,可能消失)。沿用 [10],用对数方差 $s^i := \log(\sigma^i)^2 \in \mathbb{R}$ 重参数化,则 $(\sigma^i)^2 = \exp(s^i)$、$\log\sigma^i = s^i/2$,目标变为:
$$\mathcal{L}_{bal} = \sum_{i=1}^N \left[\exp(-s^i)\cdot\ell^i + \frac{s^i}{2}\right] \tag{14}$$
映射 $s^i \mapsto \exp(-s^i)$ 自动解决正定域问题,无需约束优化即可保证良定义的正权重。对 $s^i$ 的梯度:
$$\frac{\partial\mathcal{L}_{bal}}{\partial s^i} = \frac{1}{2} - \exp(-s^i)\cdot\ell^i \tag{15}$$
与 (13) 共享同样的均衡条件 $\exp(-s^i) = 1/(2\ell^i)$。
自平衡均衡。令 (15) 为零给出均衡:
$$\exp(-s^i) = \frac{1}{2\ell^i} \tag{16}$$
均衡损失权重与当前重建损失成反比。
均衡稳定性与唯一性。$\mathcal{L}_{bal}$ 对 $s^i$ 的二阶导:
$$\frac{\partial^2\mathcal{L}_{bal}}{\partial(s^i)^2} = \exp(-s^i)\cdot\ell^i > 0 \quad \text{for all } s^i \in \mathbb{R},\, \ell^i > 0 \tag{17}$$
由于目标对每个 $s^i$ 严格凸,均衡 $(s^i)^* = \log(2\ell^i)$ 是唯一全局最小值。在学习率 $\eta$ 下,动态在均衡附近线性化为 $\delta_{t+1} = (1-\eta/2)\delta_t$($\delta_t = s_t^i - (s^i)^*$)。对任意标准学习率 $\eta \in (0,4)$,有 $|1-\eta/2| < 1$,保证指数收敛。该稳定性确保 $s^i$ 在训练中可靠跟踪随 $\theta$ 演化的移动目标 $(s^i)^*$。
动态梯度再分配。$s^i$ 的梯度更新:
$$s_{t+1}^i = s_t^i - \eta\left(\frac{1}{2} - \exp(-s_t^i)\ell_t^i\right) \tag{18}$$
作者的叙述:若域 $i$ 变难($\ell^i$ 增大),括号项在旧均衡处变负,驱动 $s^i$ 下降、增大权重 $\exp(-s^i)$;反之域变易则权重减小——形成负反馈回路,自动把梯度预算重分配给当下最需要的域。训练初期所有域都难、$s^i \approx 0$、权重接近 1;随着易域收敛、其 $s^i$ 增大,机制逐步把容量移向剩余的难域。
与基于梯度的平衡方法对比。GradNorm [13]、PCGrad [27]、MGDA [12] 都在梯度层操作,需要 per-task 梯度访问、投影或 Pareto 优化,开销大且为离散任务边界设计。自平衡损失完全在损失层操作:$\{s^i\}$ 是标量参数,靠标准反向传播更新,仅引入 $N$ 个额外标量。且基于梯度的方法用梯度范数/冲突角度定义难度,训练早期噪声大;自平衡损失沿整条训练轨迹累积 per-field 难度,提供更平滑、更稳定、随特征分布自动适应的信号。
4.3 难度引导去噪(Difficulty-Guided Denoising)¶
同一组学到的 $\{s^i\}$ 处理注意力层的不均衡。去噪网络的每个 HSTU 层中,域 $i$ 的注意力 query 被调制为:
$$\tilde{q}^i = \exp\!\left(-\frac{s^i}{2}\right)\cdot q^i \tag{19}$$
其中 $q^i = W_Q e^i$ 是标准线性 query 投影。缩放因子 $\exp(-s^i/2)$ 是 homoscedastic 标准差的倒数——难域(小 $s^i$)大、易域(大 $s^i$)小。它抑制已收敛易域的注意力影响、放大流向难域的跨域信息流,不引入任何新参数:query 矩阵 $W_Q$ 与标准 HSTU 共享,$\{s^i\}$ 也已为自平衡损失学好。调制后的注意力输出:
$$\text{Attn}^i = \text{softmax}\!\left(\frac{\tilde{q}^i \mathbf{K}^\top}{\sqrt{d}}\right)\mathbf{V} \tag{20}$$
缩放移动注意力分布,使低难度(易)域更均匀地 attend、对池化表征贡献更柔和;高难度(难)域则更选择性地 attend 到最相关上下文。
为何调制 query 而非 key/value?域 $i$ 的 query 决定它多激进地从所有其他域聚合信息。压制易域的 query 降低其外向注意力质量,使其成为更被动的信息接收者——这正是想要的,因为易域已收敛、不该驱动去噪计算。相反,调制 key 会控制其他域多大程度 attend 到域 $i$(即缩放域 $i$ 对其他域输出的贡献),调制 value 会缩放域 $i$ 自身的贡献——二者都不能直接刻画"控制域 $i$ 自身的信息聚合行为"这一目标。
与自平衡损失的系数对齐。选 $\exp(-s^i/2)$ 而非 $\exp(-s^i)$ 是刻意的。自平衡损失里权重 $\exp(-s^i)$ 作为乘子作用在标量损失 $\ell^i$ 上;注意力机制里 query 按 $\exp(-s^i/2)$ 缩放,直接调制 pre-softmax logits 的幅度。难域小 $s^i$ → 更大 query 范数 → 更尖锐注意力分布、更激进地 attend 最相关上下文键;易域大 $s^i$ → 更小 query 范数 → 更柔和、更均匀的注意力、降低其对池化表征的影响。因此注意力调制与损失再加权定性一致——都压制易域、放大难域,两组件相互强化而非冲突(见 Figure 2d)。
4.4 生成训练目标¶
预训练目标。HeteGenCTR 沿用 DGenCTR 的耦合两阶段范式:预训练重建所有域(含被当作额外特征域的点击标签),但把 (5) 的均匀损失聚合替换为自平衡目标;标签域在预训练中仍像 DGenCTR 那样被精确重建。总预训练损失:
$$\mathcal{L}_{pretrain} = \sum_{i=1}^N \left[\exp(-s^i)\cdot\ell^i + \frac{s^i}{2}\right] \tag{21}$$
$\theta$ 与 $\{s^i\}$ 都通过梯度下降更新。
算法 1(HeteGenCTR 生成预训练):
- 输入:训练集 $\mathcal{D}$、扩散步数 $T$、离散化分桶数 $B$;输出:训练好的去噪网络 $p_\theta$ 与 log-难度参数 $\{s^i\}$。
- 初始化 $p_\theta$ 与 $\{s^i = 0\}_{i=1}^N$;
- 对每个训练 batch $\{\mathbf{F}_n\}$:
- 用类型特定编码器把每个域 $f_n^i$ 编码为 $e_n^i$;
- 采样时间步 $t \sim \text{Uniform}(1, T)$;
- 对每个域 $i$:用 per-field schedule $\gamma^i(t)$ 采样 $\mathbf{x}_t^i \sim q(\cdot\mid f_n^i)$;
- 计算难度引导 query $\tilde{q}^{i,n} = \exp(-s^i/2)\cdot W_Q e_n^i$;
- 用调制注意力对所有域预测 $p_\theta(f_0^i \mid \{\mathbf{x}_t^{i,n}\}_j, t)$;
- 计算所有输入域的 per-field 重建损失 $\ell^i$;
- $\mathcal{L} \leftarrow \sum_i[\exp(-s^i)\ell^i + s^i/2]$(仅输入特征损失走自平衡;标签预测损失如 DGenCTR 保留);
- 对 $\mathcal{L}$ 做梯度下降更新 $\theta$ 与 $\{s^i\}$。
CTR 定向微调。第二阶段预训练打分函数与全部网络参数被直接继承、微调用于精确 CTR 预测,与 DGenCTR 一致。关键点:继承的打分函数与训练目标保持不变,唯一区别是预训练网络参数现在编码了更高质量、异质感知的特征表征——自平衡机制确保难域在第一阶段获得充分梯度信号。由于标签感知生成目标((3))数学上等价于 CTR 校准损失,预训练学到的打分函数已与下游 CTR 目标对齐。第二阶段最小化标准二元交叉熵:
$$\mathcal{L}_{SFT} = -y\log\sigma(z) - (1-y)\log(1-\sigma(z)) \tag{22}$$
$$z = \mathcal{F}(y=1\mid\mathbf{F}) - \mathcal{F}(y=0\mid\mathbf{F}) \tag{23}$$
实验设置¶
数据集(4 个大规模公开 + 1 个工业):
| 数据集 | #Fields | #Impressions | #Positive | 特征类型 |
|---|---|---|---|---|
| Criteo | 39 | 45M | 26% | num/cat |
| Avazu | 23 | 40M | 17% | cat |
| KDD12 | 11 | 60M | 4.5% | cat |
| Amazon (Electronics) | 18 | 12M | 8.3% | ID/cat/seq |
| Industrial | 68 | 513M | 2.5% | all |
- Criteo:展示广告 CTR 基准,13 个稠密数值 + 26 个高基数类别,混合特征类型的均衡测试;
- Avazu:10 天移动广告日志,23 个类别域,特征压倒性稀疏,是高稀疏鲁棒性的强测试;
- KDD12:搜索广告,11 个类别域描述 user-query-ad 交互,类别极不均衡(CTR < 5%);
- Amazon (Electronics):含 user ID、item ID、品类、品牌、历史行为序列——是最异质的公开基准,直接测试处理多样域类型的能力;
- Industrial:某大规模电商在线展示广告系统专有数据集,68 个特征域跨数值/低高基数类别/user-item ID/变长行为序列;训练用最近 20 天 impression,测试用次日留出曝光样本,高异质 + 真实长尾分布,是最具挑战的评测。
对手:判别式(DeepFM、DCN、AutoInt、FiBiNet、MaskNet、PEPNet)、通用架构(HSTU)、生成式(GenCTR、DGenCTR、SGCTR)。
实现细节:TensorFlow,8×NVIDIA A100,Adam 优化器,Xavier 初始化,ReLU 激活。embedding 维度公开数据集 32、工业 8;batch size 4096;学习率搜索 $\{3\text{e-}3, \dots, 1\text{e-}5, 0\}$,$L_2$ 正则 $\{3\text{e-}6, \dots, 0\}$。扩散过程 $T = 100$ 步,per-field cosine noise schedule(沿用 DGenCTR);生成预训练默认 $N_{pretrain} = 10$ epoch;数值离散化分桶 $B = 100$;log-难度参数 $\{s^i\}$ 初始化为 0。去噪网络用 HSTU 架构(沿用 DGenCTR,本文核心设计与之正交);推理沿用 SGCTR 的 masked 生成范式以高效服务。
评估指标:AUC(越高越好)、LogLoss(二元交叉熵,越低越好)。
主要实验结果(RQ1)¶
Table 2 给出五数据集整体预测性能($^*$ 表示 $p<0.05$ 显著性检验):
| 方法 | Criteo AUC | Criteo LogLoss | Avazu AUC | Avazu LogLoss | KDD12 AUC | KDD12 LogLoss | Amazon AUC | Amazon LogLoss | Industrial AUC | Industrial LogLoss |
|---|---|---|---|---|---|---|---|---|---|---|
| DeepFM | 0.7692 | 0.4713 | 0.7756 | 0.4469 | 0.7933 | 0.1422 | 0.8021 | 0.2314 | 0.7785 | 0.0852 |
| DCN | 0.7703 | 0.4703 | 0.7762 | 0.4458 | 0.7941 | 0.1426 | 0.8035 | 0.2301 | 0.7792 | 0.0851 |
| AutoInt | 0.7695 | 0.4710 | 0.7748 | 0.4473 | 0.7928 | 0.1429 | 0.8019 | 0.2318 | 0.7823 | 0.0847 |
| FiBiNet | 0.7732 | 0.4691 | 0.7759 | 0.4456 | 0.7968 | 0.1402 | 0.8043 | 0.2287 | 0.7825 | 0.0844 |
| MaskNet | 0.7882 | 0.4644 | 0.7813 | 0.4415 | 0.8012 | 0.1381 | 0.8074 | 0.2265 | 0.7846 | 0.0831 |
| PEPNet | 0.7981 | 0.4498 | 0.7944 | 0.4402 | 0.8041 | 0.1370 | 0.8096 | 0.2247 | 0.7904 | 0.0817 |
| HSTU | 0.7993 | 0.4483 | 0.7902 | 0.4403 | 0.8087 | 0.1358 | 0.8112 | 0.2235 | 0.7926 | 0.0814 |
| GenCTR | 0.8003 | 0.4472 | 0.7931 | 0.4391 | 0.8091 | 0.1354 | 0.8118 | 0.2231 | 0.7934 | 0.0810 |
| DGenCTR | 0.8024 | 0.4459 | 0.7947 | 0.4383 | 0.8106 | 0.1348 | 0.8127 | 0.2219 | 0.7948 | 0.0806 |
| SGCTR | 0.8031 | 0.4455 | 0.7953 | 0.4378 | 0.8118 | 0.1342 | 0.8139 | 0.2211 | 0.7956 | 0.0804 |
| HeteGenCTR | 0.8048$^*$ | 0.4445$^*$ | 0.7962$^*$ | 0.4373$^*$ | 0.8127$^*$ | 0.1334$^*$ | 0.8157$^*$ | 0.2188$^*$ | 0.7974$^*$ | 0.0799$^*$ |
结论分析: 1. 生成式 > 判别式:生成式 baseline(GenCTR/DGenCTR/SGCTR)一致超过最好的判别式模型,证实生成预训练的价值——重建对所有域提供密集监督,判别式每样本只得一个二值信号。 2. HeteGenCTR > 所有生成式 baseline:在最强生成式 baseline SGCTR 之上仍有一致提升(相对 SGCTR:Criteo +0.0017、Avazu +0.0009、KDD12 +0.0009、Amazon +0.0018、Industrial +0.0018 AUC)。现有生成式方法用均匀损失权重让易域主导梯度、把高基数 ID 与序列域留在欠拟合状态;自平衡损失把梯度预算重分配给难域、难度引导注意力阻止已收敛易域垄断跨域信息流,组合产生对承载最强个性化信号的域更高质量的重建。 3. 增益在异质性最高的数据集上最大:Amazon 与 Industrial(特征类型多样性最高)增益最显著——异质性高时易难差距更大、均匀权重 baseline 更次优、再平衡的修正作用更大。Criteo/Avazu 难度差距本就较小,再平衡增益被削弱但仍一致显著。 4. LogLoss 同步改善:对难域更好的重建产出更有信息的 embedding,不仅提升排序质量也改善概率校准。
消融与分析¶
消融研究(RQ2)¶
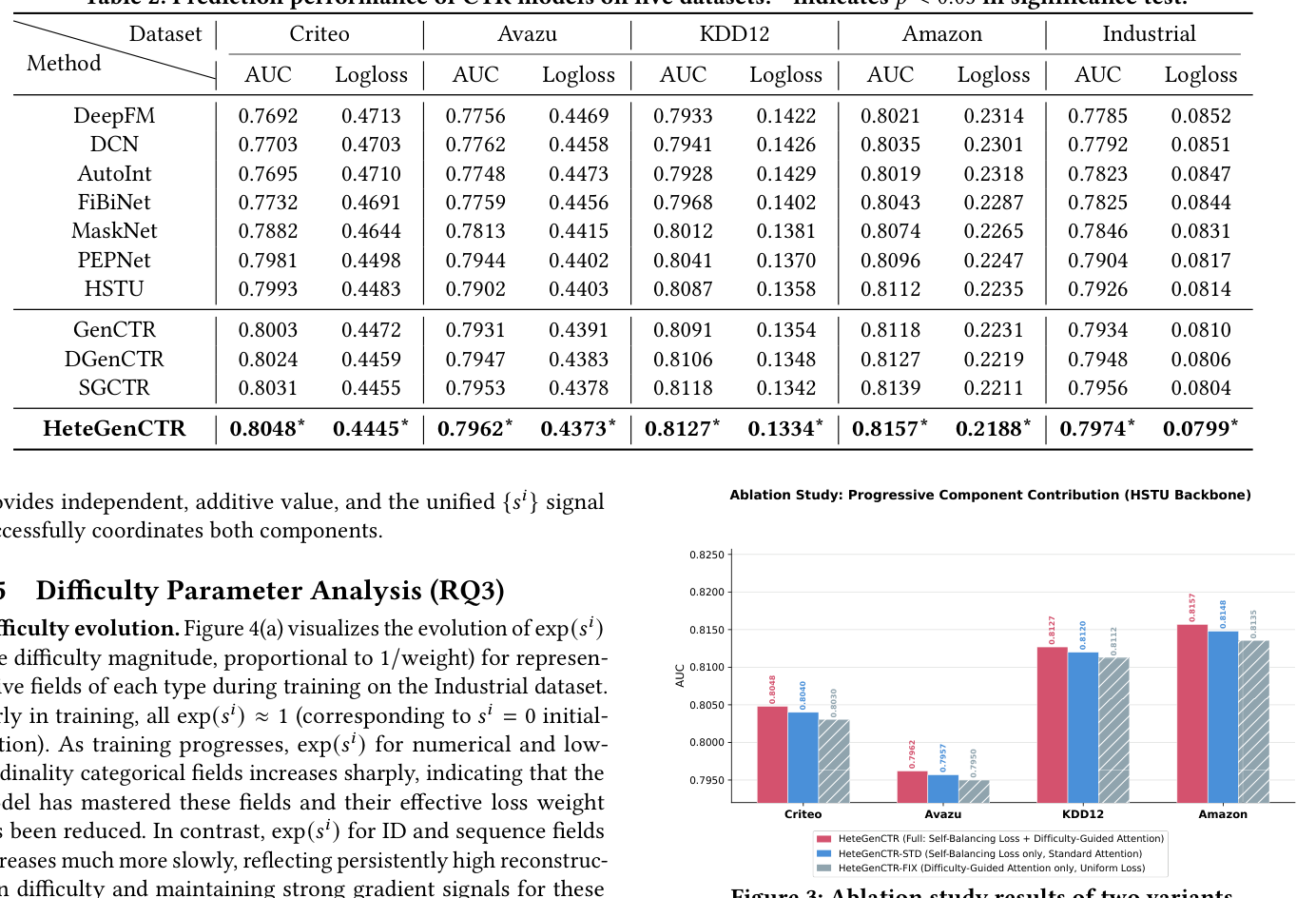
两个变体:
- HeteGenCTR-FIX:禁用自平衡损失(域权重退回均匀),保留难度引导注意力调制;log-难度参数 $\{s^i\}$ 仍学习,但其梯度仅来自注意力调制通路。
- HeteGenCTR-STD:禁用难度引导注意力调制(退回标准未调制注意力),保留自平衡损失;$\{s^i\}$ 仅从损失再加权梯度学习。
结论:FIX 保留注意力调制但用均匀域权重,没有自适应梯度再分配时易域仍主导训练预算,单靠注意力调制无法补偿无监督学到的贫弱 embedding。恢复自平衡损失(Full vs FIX)在每个数据集都带来可观 AUC 提升,证实损失层再加权是主要驱动;增益在 Amazon 与 KDD12(异质性最高)最大。STD 用自平衡损失但标准注意力,即便梯度平衡,HSTU 注意力在表征层仍可能被易域不成比例影响;加入难度引导注意力调制(Full vs STD)进一步提升——抑制易域 query、让难域施加更强跨域影响。$\exp(-s^i/2)$ 系数的推导确保注意力层加权与损失层加权对齐、强化同一难度信号。FIX < STD < Full 的渐进改善确认每个机制提供独立、可加的价值,统一 $\{s^i\}$ 信号成功协调两组件。在 Industrial 上 ID 与序列域是整体 AUC 增益的主要贡献者:单独对 ID 域施加自平衡贡献最大单域增益,其次序列域,类别/数值域增益较小但一致;组件效应次可加(sub-additive,因共享表征空间),完整 HeteGenCTR 取得最大整体增益。
难度参数分析(RQ3)¶
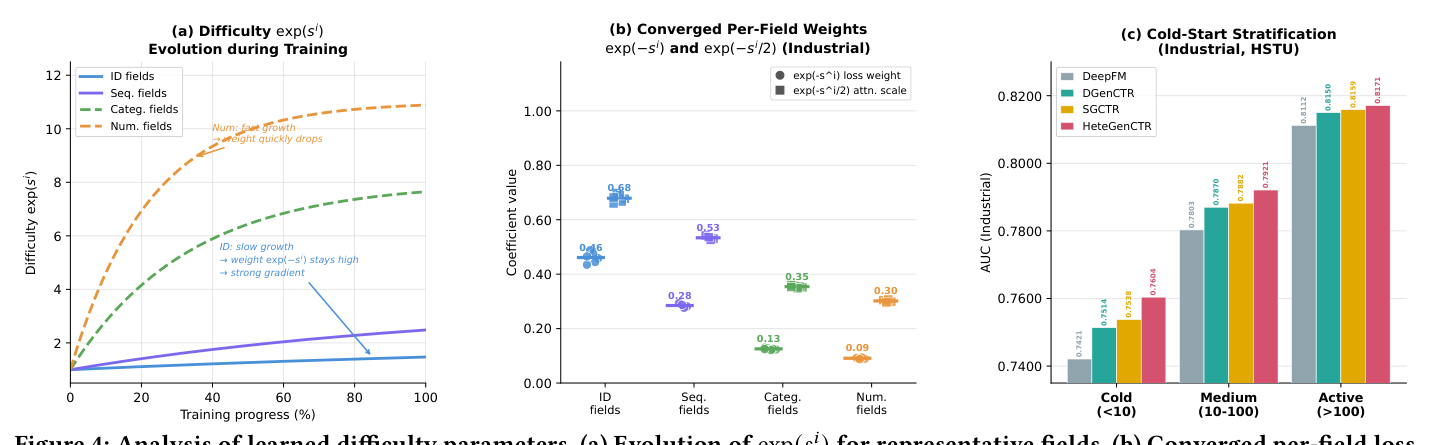
难度演化(Figure 4a):训练初期所有 $\exp(s^i) \approx 1$(对应 $s^i=0$ 初始化)。随训练推进,数值与低基数类别域的 $\exp(s^i)$ 急剧上升,表明模型已掌握这些域、其有效损失权重已被显著减小;而 ID 与序列域的 $\exp(s^i)$ 上升慢得多,反映持续偏高的重建难度、为这些域维持强梯度信号。这一差异化演化确认自平衡机制按设计工作。
收敛权重(Figure 4b):Industrial 上收敛的 per-field 有效损失权重 $\exp(-s^i)$ 与注意力缩放 $\exp(-s^i/2)$——ID 域损失权重约 0.46(注意力缩放 0.68)、序列域 0.28(0.53)、类别域 0.13(0.36)、数值域 0.09(0.30)。论文表述 ID 与序列域收敛到使其保留较大有效权重、数值与低基数类别域获较小有效权重;关键是注意力缩放与损失权重保持同样的秩序,确认两机制由同一学到信号驱动、训练中相互一致。
生成质量与下游 CTR(RQ4)¶
Per-field 生成质量:在留出验证集上测重建准确率(离散域用类别准确率、数值域用分桶准确率)。HeteGenCTR vs DGenCTR:ID 域 +4.3% 绝对提升、序列域 +2.8%、类别域 +1.1%、数值域 +0.9%。这确认自平衡机制专门提升了最难重建、对下游 CTR 最有信息的域类型的生成质量。
按域类型的下游影响:构造受控变体,每次只对一种域类型应用自平衡机制(其余用 DGenCTR 均匀生成)。Industrial 结果确认 ID 与序列域是整体 AUC 增益的主要来源;per-type 效应次可加(共享表征空间所致),完整版取得最大整体增益——验证异质自平衡通过专门增强最难、最有信息的域类型的生成质量来改善下游 CTR。
预训练敏感性与成本(RQ5)¶
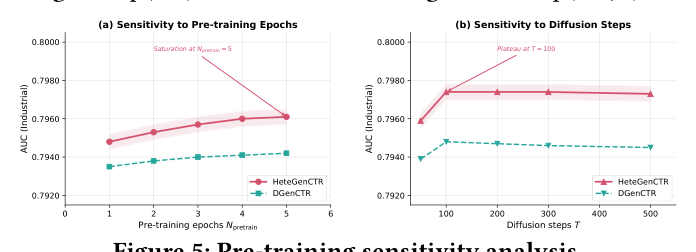
对预训练 epoch $N_{pretrain}$ 的敏感性:下游 AUC 随预训练 epoch 单调改善,从 1 epoch 的 0.7948 升到 5 epoch 的 0.7961,最大边际增益出现在 1→3 epoch(+0.0009)。确认自平衡机制需要足够预训练迭代来发现并稳定 per-field 难度估计;太少 epoch 时 $\{s^i\}$ 未收敛、梯度再分配仍次优;超过 3 epoch 收益递减,表明难度参数已大致达到稳定均衡。
对扩散步数 $T$ 的敏感性:$T=50 \to T=100$ 时 AUC 从 0.7959 升到 0.7974,随后 $T=200/300/500$ 平台化(0.7974/0.7974/0.7973)。与 DGenCTR 观察一致——适中扩散步数提供足够噪声粒度即可有效生成预训练,过多步数只增计算无下游收益。
训练开销(Table 3,相对单阶段 DeepFM 归一化):
| 方法 | 预训练 | 微调 | 总计 |
|---|---|---|---|
| DGenCTR | 1.8× | 0.4× | 2.2× |
| SGCTR | 2.1× | 0.5× | 2.6× |
| HeteGenCTR | 2.0× | 0.4× | 2.4× |
HeteGenCTR 预训练成本与 DGenCTR 相当。额外开销来自两个轻量加项:(1) per-field log-难度参数更新;(2) 难度引导注意力计算(用一个带缩放的变体替换标准 query 投影、无需额外参数),相对 HSTU 骨干都可忽略。第二阶段微调成本所有生成式方法一致(0.4×),生成预训练阶段离线进行,不增加任何在线服务延迟。
冷启动与稀疏用户分析(RQ6)¶
特征异质性对高基数域稀疏观测的实例(冷启动用户、长尾物品)伤害最大。Industrial 测试集按用户活跃度分层(Table 4):
| 方法 | Cold (<10) | Medium (10-100) | Active (>100) | Overall |
|---|---|---|---|---|
| DeepFM | 0.7421 | 0.7803 | 0.8112 | 0.7785 |
| DGenCTR | 0.7514 | 0.7870 | 0.8150 | 0.7948 |
| SGCTR | 0.7538 | 0.7882 | 0.8159 | 0.7956 |
| HeteGenCTR | 0.7604 | 0.7921 | 0.8171 | 0.7974 |
| Δ vs SGCTR | +0.0066 | +0.0039 | +0.0012 | +0.0018 |
结论:相对 SGCTR 的提升随用户活跃度单调递减:冷用户 +0.0066、中活跃 +0.0039、活跃用户 +0.0012。这确认核心机制——冷用户的 ID embedding 最稀疏、在均匀监督下最难重建,自平衡机制专门把训练容量重分配给这些高难度 ID 域,恰在最需要处产出更高质量特征重建(Figure 4c 可视化此分层改善)。物品长尾分析同样:HeteGenCTR 相对 SGCTR 在尾部(<10 曝光)/腰部/头部物品分别 +0.0091/+0.0051/+0.0019 AUC,镜像冷用户结果。
线上 A/B 测试¶
在某大规模电商平台做 7 天线上 A/B(2026-05-07 至 05-13)。生产 baseline 是类 PEPNet 判别式架构、无生成预训练。HeteGenCTR 取得 CTR 相对提升 +4.7%($p<0.01$,随机用户级流量切分的双边 $z$ 检验),七天一致。按用户活跃度拆分:冷启动用户 +9.2% CTR、活跃用户 +3.1%,与离线分层分析一致。
服务延迟:生成预训练完全在离线阶段,服务时不调用任何生成组件;部署的 CTR 模型架构上与 baseline 相同,99 分位服务延迟在 baseline 的 0.5ms 以内,远在生产 SLA 之内。
核心贡献总结¶
- 问题识别:首次形式化生成式 CTR 建模中的 generative difficulty imbalance——对异质特征域的均匀损失处理使易域主导训练梯度、压制 ID 与序列域,且这与 DGenCTR 的 noise schedule(解决分布不匹配)正交。
- 统一单信号双机制:一组 per-field 可学 log-难度 $\{s^i\}$(源自 Kendall homoscedastic 不确定性加权)同时驱动自平衡损失聚合($\exp(-s^i)$ 加权)与难度引导注意力缩放($\exp(-s^i/2)$ 调制 query),零额外超参,两机制系数设计上对齐、相互强化。
- 理论保证:自平衡均衡 $\exp(-s^i)=1/(2\ell^i)$ 是严格凸目标的唯一全局最小值,标准学习率下指数收敛。
- 充分验证:五数据集 + 7 天线上 A/B(+4.7% CTR,冷启动 +9.2%),ID 域生成质量 +4.3%,且无在线服务成本。
讨论与局限性¶
值得借鉴的设计:
- "单一可学信号同时驱动两个层面的修正" 是优雅的设计:用同一组 $\{s^i\}$ 既做损失再加权又做注意力缩放,且通过 $\exp(-s^i)$ 与 $\exp(-s^i/2)$ 的平方根关系保证两者方向一致、不会互相打架——这比 GradNorm/PCGrad 那种重的梯度层操作(需 per-task 梯度、投影、Pareto 求解)便宜得多,仅引入 $N$ 个标量。
- 把特征域当作多任务,借 Kendall 不确定性加权做损失聚合,是把成熟的多任务学习工具迁移到生成式特征重建场景的合理嫁接;冷启动/长尾分层的单调增益对"难域=高信号域"的机制叙事提供了有力的经验支撑。
- 工业落地完整:离线预训练、在线零额外延迟、7 天 A/B、按活跃度/曝光度双重分层验证,部署细节与业务收益(冷启动 +9.2% CTR)都交代清楚,工业参考价值高。
局限、争议与需澄清之处:
- 理论叙述与公式之间存在方向性张力(核心存疑点)。自平衡损失 (14) 与其均衡 (16) $\exp(-s^i)=1/(2\ell^i)$ 是标准的 Kendall homoscedastic 不确定性加权——而该范式的权重与损失成反比。按字面:持续高损失的难域 $\ell^i$ 大 → 均衡权重 $\exp(-s^i)=1/(2\ell^i)$ 小,于是难域在 (12) 中贡献的梯度 $\exp(-s^i)\nabla_\theta\ell^i$ 反而被压低。这与论文反复声称的"把更多梯度预算分配给难域"在均衡处方向相反。进一步推敲动态:由 (15) 梯度下降 $s^i \leftarrow s^i - \eta(1/2 - \exp(-s^i)\ell^i)$,当域偏难($\exp(-s^i)\ell^i > 1/2$)时 $\partial\mathcal{L}/\partial s^i < 0$,更新使 $s^i$ 增大、权重 $\exp(-s^i)$ 减小——这与论文"动态梯度再分配"段落"域变难则驱动 $s^i$ 下降、增大权重"的文字描述、以及 Figure 4a"易域 $s$ 快涨/难域 $s$ 低权重高"的注解都自相矛盾。Figure 2c/4b 给出的收敛权重(ID 难域权重最大、数值易域最小)也无法与闭式均衡 $1/(2\ell^i)$ 在给定难度排序下对上。综合看,论文实证增益是真实的(多基准 + 显著性 + A/B),但其"自平衡=给难域更多梯度"的机制解释可能并不准确:真实收益或许来自不确定性加权提供的自适应损失归一化、正则项 $s^i/2$、以及注意力缩放等其他效应,而非所声称的"梯度向难域倾斜"。这一点强烈建议读者回到原文公式自行验证(本精读已给出完整推导)。
- 核心技术为既有方法迁移。自平衡损失本质是 Kendall et al. [10] 多任务不确定性加权的直接套用,新颖性主要在"应用场景(per-field 特征重建)+ 注意力缩放的同源扩展",而非全新的优化原理;与"开创性工作"尚有距离。
- 两阶段解耦的可扩展性隐患。框架沿用 DGenCTR 的"离线生成预训练 + 在线判别微调"两阶段范式:预训练的去噪/打分函数与下游 CTR 模型无法真正端到端联合优化,参数量 scaling 时"如何表征特征"与"如何建模序列/交互"两条路径难以同步扩张,存在架构瓶颈(参见精读评分标准中对多阶段解耦的提示)。
- 去噪骨干固定为 HSTU,核心机制虽声称正交,但所有实验都基于 HSTU,未在其它去噪骨干上验证迁移性。
- 部分关键数据仅以图(Figure 3/4/5)呈现,缺少精确数表(如各消融变体在每个数据集上的具体 AUC),可复现性与精确比较受限。
与已有工作的差异:相对直接前身 DGenCTR,HeteGenCTR 不动其 per-field noise schedule(解决分布不匹配),转而新增损失层 + 注意力层的难度再平衡(解决梯度不均衡),两者正交互补;相对 GradNorm/PCGrad/MGDA 等梯度层平衡方法,它完全在损失层用标量参数操作、开销可忽略且更稳定。