Selective Test-Time Compute Scaling for Click-Through Rate Prediction via Uncertainty-Triggered Feature Path Exploration¶
作者:Moyu Zhang, Yun Chen, Yujun Jin, Jinxin Hu(通讯), Yu Zhang, Xiaoyi Zeng 机构:Alibaba Group(北京)/ Taobao ArXiv:2605.24989 · 2026-05-24 · Preprint 模型名:UTTSI(Uncertainty-Triggered Test-Time Selective Inference)
1. 研究动机与背景¶
点击率(Click-Through Rate, CTR)预测是推荐系统的核心模块,通过预测用户对目标 item 的点击概率来为候选排序。其本质是建模海量输入特征(用户画像、item 属性、上下文等)之间的交互——因此"如何准确建模特征交互"一直是 CTR 研究的主线,从 WDL、DeepFM、DCN、xDeepFM 等低阶/高阶特征交叉网络,到自适应门控(gating)、注意力机制,再到用生成式范式绕开判别式二分类局限的尝试。
但本文指出,所有这些工作几乎都聚焦于训练阶段,推理阶段的优化潜力被严重忽视。即便是充分训练好的模型,在推理时对不同实例的预测可靠性也存在巨大差异:
- 对训练数据中充分出现的特征组合,模型给出自信而准确的预测;
- 对稀疏或未见过的特征组合,模型的学习表征不可靠,往往导致表征塌陷(representation collapse)和高预测不确定性。
这种"per-instance 可靠性差异"无法靠纯训练阶段机制弥补。论文进一步剖析了根因——训练与推理的目标是内在不对称的:
- 训练应当从多样模式(包括稀疏模式)中学习可泛化的特征表征,受益于接触各种组合;
- 推理则应当只利用模型已经学会可靠评估的特征组合,从而避免不可靠特征对预测的干扰。
虽然自适应门控、注意力机制([3,5,17,40])被设计来动态加权特征,但它们学到的是一个确定性的、训练期固定的选择函数,这个函数本身同样受制于数据稀疏性:当某个特征组合在训练中观测不足时,它的门控决策同样不可靠。换言之,现有方案对所有实例施加统一的推理流程,缺乏部署时的逐实例补救手段。
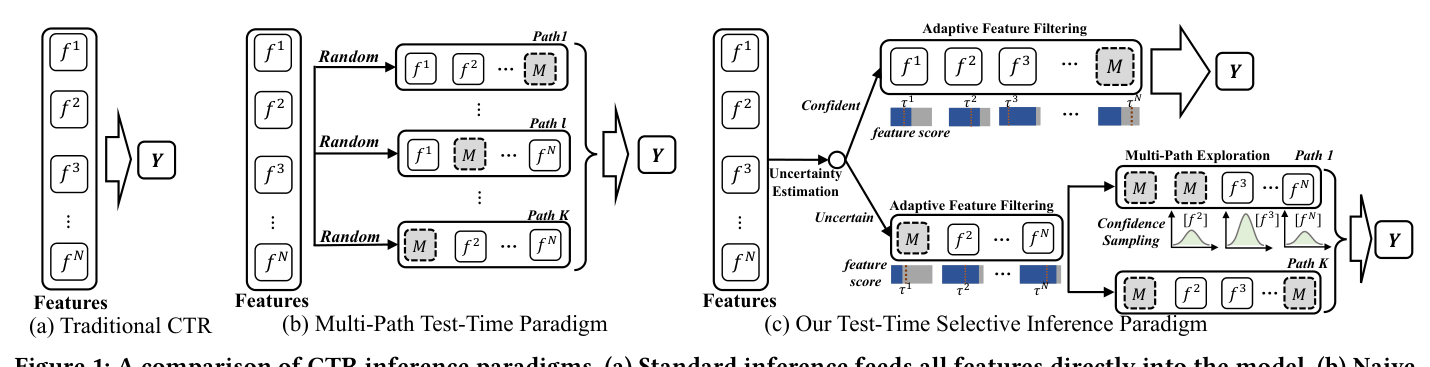
这一动机促使作者重新思考"CTR 的测试时优化应该长什么样"。其核心挑战不仅仅是生成多个特征视图,而是要让这件事扎根于 per-instance 可靠性。如图 1(b) 所示,即便把多路径探索朴素地搬到 CTR——生成多个特征子集再聚合预测——也无法解决根本问题:在不知道哪些特征对当前实例不可靠的情况下,探索路径会反复纳入噪声特征,聚合也无法从冗余变化中区分出有用的多样性。问题的严重性被工业 CTR 数据的幂律频率分布进一步放大:一小撮特征值主导了训练观测,而绝大多数特征只出现寥寥数次,已有工作证明这类长尾低频特征值的 embedding 在统计上与随机初始化几乎无法区分([12,27])。
因此,为 CTR 设计有效的、不确定性驱动的测试时范式需解决两个问题:(1) 如何在不破坏严格工业延迟约束的前提下,利用内置置信信号高效估计 per-instance 预测不确定性;(2) 如何探索有益的特征组合。
作者由此提出 UTTSI——一个免训练(training-free)、模型无关(model-agnostic)的框架,运行在任何已训练好的 CTR 模型之上,不修改其参数、不重训、不改架构。推理时它根据每个实例的估计不确定性,选择性地决定该实例应额外获得多少计算。UTTSI 由三个紧密耦合的组件构成:
- 频率先验估计(Frequency Prior Estimation):用 Count-Min Sketch 启发的概率哈希结构量化每个特征值在训练数据中"被观测得有多充分",提供离线的数据级可靠性信号;
- 双信号不确定性估计(Dual-Signal Uncertainty Estimation):把"attribution 加权的频率先验"与"模型内部 logit 置信"结合,产出 per-instance 不确定性分数,并据此连续分配探索路径数量;
- 特征过滤与路径探索(Feature Filtering and Path Exploration):每个实例先经过自适应特征过滤(按离线计算的 per-field 阈值去除不可靠特征),不确定实例额外通过随机采样精炼后的特征子集生成多条探索路径,最终用一致性加权方案聚合;自信实例完全跳过探索。
2. 问题设定与测试时优化范式(Preliminary)¶
2.1 CTR 预测任务¶
CTR 预测估计用户点击目标 item 的概率,被建模为监督二分类问题。给定完整特征集 $\mathbf{F}_{full}$ 与标签 $y \in \{0,1\}$,CTR 任务学习排序函数 $\mathcal{F}: \mathbf{F}_{full} \to y$。特征空间含用户画像、item 属性等多个 field,定义 $\mathbf{F}_{full} = [f^1, f^2, \dots, f^N]$,$N$ 为特征 field 数:
$$P(y \mid \mathbf{F}_{full}) = \mathcal{F}(f^1, f^2, \dots, f^N) \tag{1}$$
2.2 CTR 的测试时优化¶
问题设定:考虑一个训练后参数被冻结的 CTR 模型 $\mathcal{F}_\theta$。测试时优化(Test-Time Optimization)在推理时增强预测,但不更新 $\theta$、不引入新的可学习参数、不访问训练标签。
测试时范式:一种典型做法是用一个附加过程包裹 $\mathcal{F}_\theta$。在多路径设定下,方法从 $\mathbf{F}_{full}$ 派生出 $K$ 个特征视图 $[\mathbf{F}^1, \mathbf{F}^2, \dots, \mathbf{F}^K]$,对每个视图得到一个预测,再聚合:
$$\hat{y}_{TTO} = \text{Agg}\Big(\big\{\mathcal{F}_\theta(\mathbf{F}^k)\big\}_{k=1}^K\Big) \tag{2}$$
其中 $\text{Agg}(\cdot)$ 是聚合函数(如均值或一致性加权平均),$K$ 可固定或自适应。三个关键设计选择是:(1) 如何生成多样但语义连贯的特征视图 $\mathbf{F}^k$;(2) 如何为每个实例决定路径数 $K$;(3) 如何在聚合中加权各路径预测。朴素做法对所有实例用统一的特征 dropout 和固定 $K$(图 1(b)),既忽视了实例级可靠性差异,又对已经可靠的实例浪费计算。
UTTSI 的不确定性感知实例化让上述三个选择都依赖于一个 per-instance 可靠性信号 $u(x) \in [0,1]$:先用轻量特征过滤去除不可靠表征,再按 $u(x)$ 比例分配额外探索路径,最后按路径预测的相互一致性加权。
3. 核心方法¶
UTTSI 运行在冻结模型 $\mathcal{F}_\theta$ 之上,先估计 per-instance 不确定性,再对所有实例做自适应特征过滤、对不确定实例按不确定性比例扩展推理深度。整体结构见图 2。
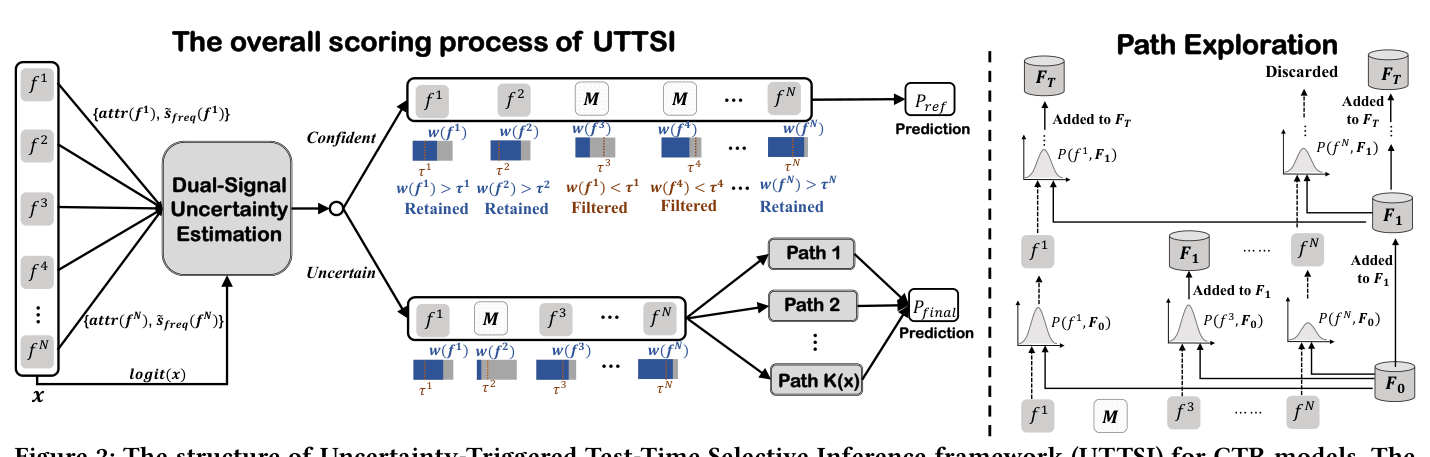
3.1 频率先验估计(Frequency Prior Estimation)¶
不确定性估计的数据级关键组件是频率先验,用来量化每个特征值在训练数据中"被观测得有多充分"。直觉很直接:训练中频繁出现的特征值会产生训练充分的 embedding,而稀有特征值的 embedding 不可靠。作者强调,频率只是双信号框架中的一个信号,而非独立的置信度量。
由于唯一特征值数量可能极大,作者采用 Count-Min Sketch([18])启发的概率哈希结构:维护 $L$ 个每 field 的哈希表,通过取多个表的最小值来估计每个值的计数,从而提供一个紧的上界、缓解哈希碰撞带来的高估。得到的 per-field 频率计数 $\text{cnt}(f^i)$ 被预计算,在线检索成本可忽略。再用一个饱和阈值 $\eta$ 归一化每个计数:
$$\tilde{s}_{freq}(f^i) = \min(\text{cnt}(f^i), \eta)/\eta \in [0,1] \tag{*}$$
该归一化频率同时用于不确定性估计(§3.2)和特征过滤(§3.3)。
3.2 双信号不确定性估计(Dual-Signal Uncertainty Estimation)¶
该模块决定分配给每个实例的选择性推理计算量。核心洞察是:模型置信度和数据频率单独都无法可靠识别不确定实例。 一个接近 0 的预测 logit 可能反映真正的认知不确定性(模型缺乏知识),也可能反映固有的偶然模糊性(真实点击概率接近 50%);而频率只能标记带稀有特征值的实例,无法区分"在未见组合上不可靠"和"个体特征交互模式新颖但每个特征都频繁"这两种情况。两个信号结合才能更好识别真正能从额外计算中获益的实例。
对给定输入实例 $x$、特征集 $\mathbf{F}_{full}$,先做一次标准前向得到预测 logit:
$$\text{logit}(x) = \mathcal{F}_\theta(\mathbf{F}_{full}) \tag{3}$$
再从输出 logit 反向传播,得到每个特征 embedding 的梯度范数:
$$\text{attr}(f^i) = \|\nabla_{e_i}\text{logit}(x)\|_2 \tag{4}$$
这个计算是完全模型无关的:只要 backbone 可微即可,且不更新任何模型参数。反向传播只计算输入 embedding 梯度(不计算模型参数梯度),开销约为一次前向的 $0.5$–$1\times$(取决于架构)。梯度范数衡量"对该特征 embedding 的微小扰动会多大程度改变预测",提供了一个跨任意架构统一的特征影响度量。这个 attribution 在不确定性估计与 §3.3 的特征过滤中复用。
模型内部置信(model-internal confidence) 捕捉模型预测的决断程度:
$$s_{model}(x) = \min\Big(\frac{|\text{logit}(x)|}{\gamma}, 1\Big) \tag{5}$$
其中 $\gamma$ 是归一化常数,设为验证集上 $|\text{logit}|$ 值的 95 分位。接近 0 表示模型处于决策边界;接近 1 表示决断预测。
数据级频率置信(data-level frequency confidence) 是 attribution 加权的 per-field 频率平均:
$$s_{freq}(x) = \frac{\sum_{i=1}^N \text{attr}(f^i)\cdot \tilde{s}_{freq}(f^i)}{\sum_{i=1}^N \text{attr}(f^i)} \tag{6}$$
其中 $\tilde{s}_{freq}(f^i)$ 是来自离线索引(§3.1)的归一化频率。用 attribution 给每个特征频率加权,反映的不是"样本特征平均有多频繁",而是"实际驱动当前预测的特征有多频繁"。 这个 attribution 加权解决了一个关键盲点:若实例同时含"高频但低 attribution"和"低频但高 attribution"的特征,未加权平均会误导性地抬高置信;而加权和能正确识别出"预测信号来自训练不足的 embedding"这一不确定情形。
per-instance 不确定性是上述置信的补:
$$u(x) = 1 - \big[\alpha \cdot s_{model}(x) + (1-\alpha)\cdot s_{freq}(x)\big] \tag{7}$$
其中 $\alpha \in [0,1]$ 平衡两个信号。额外推理路径数为:
$$K(x) = \lfloor K_{\max}\cdot u(x) \rfloor \tag{8}$$
$K_{\max}$ 是超参,设定任何实例能获得的最大探索路径数,直接控制最坏情况计算开销。
直觉:连续分配 $K(x) = \lfloor K_{\max}\cdot u(x)\rfloor$ 有一个理想性质——估计不确定性越高的实例获得越多探索路径。由于 $u(x)$ 被设计为与预测方差正相关,把路径分配给不确定实例等于优先在方差最大处降低方差。计算开销被 $1 + K_{\max}\cdot\mathbb{E}[u(x)]$ 上界约束,经验上约为 base 模型的 $2$–$3\times$。
3.3 特征过滤与路径探索(Feature Filtering and Path Exploration)¶
该模块用两阶段实现 UTTSI 的核心推理机制。一个自然的问题是"为什么不确定性估计先于过滤",而非反过来(过滤本就对所有实例统一进行)。原因有二:其一,不确定性估计阶段算出的梯度 attribution $\text{attr}(f^i)$ 被过滤步骤复用来形成组合分 $w(f^i)$,反过来会要求在过滤后的输入上再做一次反向传播,增加不必要计算;其二,不确定性应反映实例的原始难度,包括不可靠特征的存在——若先过滤掉那些特征,会人为压低不确定性分数,导致去噪后仍受"组合级不确定性"困扰的实例分配不到探索预算。
Stage 1 — 自适应特征过滤(Adaptive Feature Filtering)¶
用前面算出的梯度 attribution $\text{attr}(f^i) = \|\nabla_{e_i}\text{logit}(x)\|_2$,为每个特征构造组合分:
$$w(f^i) = \beta\cdot \tilde{s}_{freq}(f^i) + (1-\beta)\cdot \text{attr}(f^i) \tag{**}$$
该组合分同时利用数据级频率信号(特征值被观测得多充分)和模型级 attribution 信号(特征对当前预测多有影响),使得在两个维度上都被判为噪声的特征才成为删除候选。
不同于对所有 field 用单一全局阈值,作者采用 per-field 阈值 $\tau^i$,离线从训练数据计算。动机在于工业推荐里特征的异质性很强:用户身份 field、item 属性 field、统计上下文 field 的组合分分布差异很大,单一全局阈值会系统性地过度过滤高方差 field、又对低方差 field 过滤不足。具体地,对每个 field 内全部训练实例算 $w(f^i)$,把 $\tau^i$ 设为该 field 分布的 $\rho$ 分位,$\rho \in (0,1)$ 是跨 field 共享的超参,控制过滤激进程度。推理时,特征 $f^i$ 当且仅当 $w(f^i) \ge \tau^i$ 才保留;所有特征都超阈值的实例被完整保留。保留特征构成精炼集 $\hat{\mathbf{F}}$,前向得到精炼预测:
$$P_{ref} = \mathcal{F}_\theta(\hat{\mathbf{F}}) \tag{9}$$
该过滤策略是保守的:只有在频率和 attribution 上双双低分的特征才被丢弃。信号冲突的特征(如低频但高 attribution)被保留,因为丢弃一个真正有信息量的稀有特征,代价超过保留一点噪声——后者可被 Stage 2 的多路径聚合平均掉。
为什么仅靠过滤就足够覆盖高置信实例? 一个自然的担忧是 $K(x)=0$ 的实例只做了过滤、没有多路径补偿,似乎会损失信息。作者认为这种不对称设计是合理的,因为过滤和探索处理的是不同层次的错误:特征过滤去除的是 feature-level noise(单个特征 embedding 不可靠),这对所有实例都有益;而过滤之后,低置信实例仍受 combination-level uncertainty 困扰——即便每个保留特征单独可靠,它们的联合交互模式在训练中仍观测稀疏,预测方差高。多路径探索通过对 $\hat{\mathbf{F}}$ 采样多样子集再聚合来平均这种残差方差。高置信实例残差方差低,单个精炼预测就够。这一偏差-方差分解论证了不对称设计:过滤为所有实例降偏差,多路径探索仅在残差方差仍显著处降方差。
Stage 2 — 特征路径探索(Feature Path Exploration,仅当 $K(x)>0$)¶
对有非可忽略不确定性的实例,UTTSI 通过随机扰动精炼集 $\hat{\mathbf{F}}$ 生成 $K(x)$ 条额外推理路径。与原始特征集(可能含损害预测准确性的不可靠组合)不同,目标是构造多个高质量特征子集并聚合其预测。
由于不存在"区分可靠/不可靠特征组合"的绝对阈值,作者采用跨多路径的随机采样而非确定性选择,以确保多样探索并保留潜在有效的特征信息。一条路径在 $T$ 步内迭代构建:每步 $t$,算法从尚未纳入当前路径 $\mathbf{F}_{t-1}$ 的特征中采样,每个候选的概率正比于其组合 attribution 分:
$$p_i^t = \frac{w(f^i)}{\sum_{f^j\in\hat{\mathbf{F}},\, f^j\notin \mathbf{F}_{t-1}} w(f^j)} \tag{10}$$
其中 $w(f^i) = \beta\cdot\tilde{s}_{freq}(f^i) + (1-\beta)\cdot\text{attr}(f^i)$,$\beta$ 平衡频率与 attribution 两个分量。这确保"高 attribution 的有信息量稀有特征"被优先选中,而"既不频繁又弱 attribution"的特征更可能被排除。对每个候选特征做独立 Bernoulli 采样决定是否加入路径:
$$\mathbb{1}_i^t = \begin{cases} f^i, & r_t^i = 1 \\ \varnothing, & r_t^i = 0 \end{cases} \tag{11}$$
$$\mathbf{F}_t = \mathbf{F}_{t-1} \cup \big\{\mathbb{1}_i^t\big\}_{f^i\in\hat{\mathbf{F}}} \tag{12}$$
其中 $r_t^i \sim \text{Bernoulli}(p_i^t)$。$T$ 次迭代后得到实例特定的特征集 $\mathbf{F}_T$(派生自精炼基 $\hat{\mathbf{F}}$)。构造新输入时,把未被该路径选中的所有特征掩码掉:
$$\mathcal{G}(f^i) = \begin{cases} f^i, & f^i\in \mathbf{F}_T \\ 0, & f^i\notin \mathbf{F}_T \end{cases} \tag{13}$$
$$P(y\mid \mathbf{F}_T) = \mathcal{F}_\theta\big(\{\mathcal{G}(f^i)\}_{f^i\in\hat{\mathbf{F}}}\big) \tag{14}$$
由于单条随机路径不保证找到全局最优特征组合,作者并行采样 $K(x)$ 条独立路径,得到一组不同的最终特征集 $L = \{\mathbf{F}_T^1, \mathbf{F}_T^2, \dots, \mathbf{F}_T^{K(x)}\}$。加上精炼预测 $P_{ref}$,共得到 $K(x)+1$ 个预测分。这种多路径设计让特征空间得到更全面的探索,推理深度随实例不确定性 $K(x)$ 自动 scale。
3.3.* 一致性加权聚合(Consistency-Weighted Aggregation)¶
给定 $K(x)$ 条探索路径预测加上精炼预测 $P_{ref}=\mathcal{F}_\theta(\hat{\mathbf{F}})$,共 $K(x)+1$ 个分,用一致性加权投票聚合。令 $\mathcal{P} = \{P_{ref}\}\cup\{P(y\mid\mathbf{F}_T^k)\}_{k=1}^{K(x)}$ 为全部预测集。先算所有路径(含 base)的均值预测:
$$\bar{P} = \frac{1}{K(x)+1}\sum_{P_i\in\mathcal{P}} P_i \tag{15}$$
再按与集成均值的一致性给每个预测加权:
$$w_i = \exp(-\lambda\,|P_i - \bar{P}|),\quad \text{for each } P_i\in\mathcal{P} \tag{16}$$
$$P_{final} = \frac{\sum_{P_i\in\mathcal{P}} w_i\cdot P_i}{\sum_{P_i\in\mathcal{P}} w_i} \tag{17}$$
$\lambda$ 控制一致性加权的锐度,$w_i$ 给与多数对齐的预测更高权重。产生离群预测的路径(很可能因为掩掉了关键特征)被自然降权。 当 $K(x)=0$ 时不生成额外路径,$P_{final}=P_{ref}$。
对 $\lambda$ 的敏感性:锐度参数 $\lambda$ 控制离群路径被压制的激进程度,默认 $\lambda=5$(敏感性见 §6.3)。
3.4 完整算法¶
Algorithm 1: UTTSI Inference Procedure 输入:训练好的 CTR 模型 $\mathcal{F}_\theta$;输入实例特征集 $\mathbf{F}_{full}$;预计算 per-field 频率计数 $\text{cnt}(\cdot)$;预计算 per-field 阈值 $\{\tau^i\}$;超参 $K_{\max}, \alpha, \beta, T, \gamma, \eta, \lambda$。 输出:最终 CTR 预测 $P_{final}$。
Step 1 — 基前向 + attribution 1. $\text{logit}(x)\leftarrow \mathcal{F}_\theta(\mathbf{F}_{full})$ 2. 反向传播算 $\text{attr}(f^i)=\|\nabla_{e_i}\text{logit}(x)\|_2$,对所有 $f^i\in\mathbf{F}_{full}$
Step 2 — 双信号不确定性估计 3. $s_{model}(x)\leftarrow \min(|\text{logit}(x)|/\gamma, 1)$ 4. $s_{freq}(x)\leftarrow \frac{\sum_i \text{attr}(f^i)\tilde{s}_{freq}(f^i)}{\sum_i \text{attr}(f^i)}$ 5. $u(x)\leftarrow 1-[\alpha\cdot s_{model}(x)+(1-\alpha)\cdot s_{freq}(x)]$ 6. $K(x)\leftarrow \lfloor K_{\max}\cdot u(x)\rfloor$
Step 3 — 自适应特征过滤 7. 算组合权重 $w(f^i)=\beta\cdot\tilde{s}_{freq}(f^i)+(1-\beta)\cdot\text{attr}(f^i)$ 8. 保留 $w(f^i)\ge\tau^i$ 的特征构成 $\hat{\mathbf{F}}$ 9. $P_{ref}\leftarrow \mathcal{F}_\theta(\hat{\mathbf{F}})$ 10. 若 $K(x)=0$ 则 返回 $P_{ref}$
Step 4 — 特征路径探索(可并行) 13. $\mathcal{P}\leftarrow\{P_{ref}\}$ 14. for $k\leftarrow 1$ to $K(x)$(并行): 15. $\mathbf{F}_0^k\leftarrow\varnothing$ 16. for $t\leftarrow 1$ to $T$:算未选特征的路径权重 $w(f^i)$,按 $r_t^i\sim\text{Bernoulli}(p_i^t)$ 采样,更新 $\mathbf{F}_t^k$ 21. 用 $\mathbf{F}_T^k$ 构造掩码输入 $\{\mathcal{G}(f^i)\}$ 22. $P^k\leftarrow\mathcal{F}_\theta(\{\mathcal{G}(f^i)\})$;$\mathcal{P}\leftarrow\mathcal{P}\cup\{P^k\}$
Step 5 — 一致性加权聚合 25. $\bar{P}\leftarrow\frac{1}{|\mathcal{P}|}\sum_{P_i\in\mathcal{P}}P_i$ 26. $w_i\leftarrow\exp(-\lambda|P_i-\bar{P}|)$ 27. $P_{final}\leftarrow\sum w_iP_i/\sum w_i$ 28. 返回 $P_{final}$
聚合的深度(集成预测数)随实例不确定性 $K(x)$ 自动 scale:自信实例($K(x)=0$)零探索,不确定实例渐进加深。由于所有探索路径完全独立且可并行,当服务基础设施支持至少 $K_{\max}$ 个并行打分 worker 时,UTTSI 的最坏情况延迟等于两次 base 模型前向(一次原始 + 一次 $\hat{\mathbf{F}}$ 上的精炼),与原始服务延迟相当——这使其特别适合"并行算力充足但延迟 SLA 严格"的工业系统。
4. 实验设置¶
4.1 数据集¶
三个公开 benchmark + 一个工业数据集,统计见表 1。
表 1:四个 benchmark 数据集统计
| Dataset | # Feature Fields | # Impressions | # Positive |
|---|---|---|---|
| Criteo | 39 | 45M | 26% |
| Avazu | 23 | 40M | 17% |
| KDD12 | 11 | 60M | 4.5% |
| Industrial | 68 | 513M | 2.5% |
- Criteo:CTR 经典 benchmark,一周真实广告点击数据,13 个连续特征 + 26 个类别特征。
- Avazu:另一广用 benchmark,10 天按时间排序的广告点击日志,样本含 23 个特征 field。
- KDD12:源自搜索 session 日志的训练实例,11 个类别 field,点击 field 是用户点击广告的次数。
- Industrial:来自某国际电商平台在线展示广告的真实数据集;训练集取最近 20 天样本,测试集取次日曝光样本。注意其正样本率仅 2.5%、特征稀疏度最高(68 field、513M impression),最能反映 UTTSI 针对稀疏特征实例的改进。
4.2 对比方法¶
分三类 SOTA CTR 模型: 1. 深度特征交互模型:FM、DNN、Wide&Deep、DeepFM、DCN、AutoInt、FiBiNet、GDCN、MaskNet、PEPNet、HSTU。 2. 多专家架构:MMoE、PLE。 3. 神经架构搜索(NAS):AutoCTR、OptFu。
4.3 实现细节¶
全部模型用 TensorFlow 实现,在 8 卡 NVIDIA A100 上用 Adam + Xavier 初始化训练,默认激活 ReLU。最优超参经网格搜索。embedding 维度:Criteo/Avazu 为 32,KDD12 为 16,Industrial 为 8;batch size 4096;学习率搜索范围 $\{3e\text{-}3, \dots, 1e\text{-}5\}$,L2 正则 $\{3e\text{-}6, \dots, 0\}$。
UTTSI 默认超参:最大路径预算 $K_{\max}=8$,$\alpha=0.05$,组合权重平衡 $\beta=0.4$,per-field 自适应过滤阈值的共享分位 $\rho=0.2$,迭代采样步数 $T=10$,一致性加权锐度 $\lambda=5$。
评估指标:遵循 CTR 研究惯例,用 AUC(ROC 曲线下面积)和 LogLoss(二元交叉熵)。
5. 主要实验结果(RQ1)¶
研究问题:RQ1 UTTSI 是否在 SOTA CTR 模型上稳定提升预测性能;RQ2 各组件贡献;RQ3 超参敏感性与不确定性触发分配的行为;RQ4 不确定性分数是否与预测误差相关、UTTSI 在不同不确定性分层上的表现。
表 2 给出全部数据集上的整体预测性能,$\Delta_{AUC}$ 和 $\Delta_{Logloss}$ 是相对 DeepFM 的平均变化,$*$ 表示显著性检验 $p<0.05$。
表 2:四个数据集上 CTR 模型的预测性能
| Method | Criteo AUC | Criteo Logloss | Avazu AUC | Avazu Logloss | KDD12 AUC | KDD12 Logloss | Industrial AUC | Industrial Logloss | $\Delta_{AUC}\uparrow$ | $\Delta_{Logloss}\downarrow$ |
|---|---|---|---|---|---|---|---|---|---|---|
| FM | 0.7695 | 0.4716 | 0.7758 | 0.4469 | 0.7914 | 0.1431 | 0.7788 | 0.0852 | -0.03% | +0.0003 |
| DNN | 0.7657 | 0.4739 | 0.7699 | 0.4475 | 0.7902 | 0.1437 | 0.7801 | 0.0849 | -0.34% | +0.0011 |
| Wide&Deep | 0.7677 | 0.4728 | 0.7755 | 0.4465 | 0.7921 | 0.1426 | 0.7783 | 0.0854 | -0.09% | +0.0004 |
| DeepFM | 0.7692 | 0.4713 | 0.7756 | 0.4469 | 0.7933 | 0.1422 | 0.7785 | 0.0852 | — | — |
| DCN | 0.7703 | 0.4703 | 0.7762 | 0.4458 | 0.7941 | 0.1426 | 0.7792 | 0.0851 | +0.11% | -0.0005 |
| AutoInt | 0.7695 | 0.4710 | 0.7748 | 0.4473 | 0.7928 | 0.1429 | 0.7823 | 0.0847 | +0.09% | -0.0001 |
| FiBiNET | 0.7732 | 0.4691 | 0.7759 | 0.4456 | 0.7968 | 0.1402 | 0.7825 | 0.0844 | +0.38% | -0.0016 |
| GDCN | 0.7796 | 0.4663 | 0.7809 | 0.4428 | 0.7989 | 0.1399 | 0.7884 | 0.0839 | +1.00% | -0.0032 |
| MaskNet | 0.7882 | 0.4644 | 0.7813 | 0.4415 | 0.8012 | 0.1381 | 0.7846 | 0.0831 | +1.25% | -0.0046 |
| PEPNet | 0.7981 | 0.4498 | 0.7944 | 0.4402 | 0.8041 | 0.1370 | 0.7904 | 0.0817 | +2.27% | -0.0092 |
| HSTU | 0.7993 | 0.4483 | 0.7902 | 0.4403 | 0.8087 | 0.1358 | 0.7926 | 0.0814 | +2.39% | -0.0099 |
| MMOE | 0.7906 | 0.4565 | 0.7879 | 0.4420 | 0.8021 | 0.1377 | 0.7899 | 0.0826 | +1.74% | -0.0067 |
| PLE | 0.7937 | 0.4536 | 0.7856 | 0.4441 | 0.8035 | 0.1370 | 0.7905 | 0.0823 | +1.83% | -0.0072 |
| AutoCTR | 0.7987 | 0.4487 | 0.7908 | 0.4396 | 0.8029 | 0.1373 | 0.7893 | 0.0828 | +2.10% | -0.0093 |
| OptFu | 0.8014 | 0.4480 | 0.7924 | 0.4383 | 0.8125 | 0.1326 | 0.7933 | 0.0803 | +2.27% | -0.0116 |
| HSTU+UTTSI | 0.8041 | 0.4452 | 0.7963 | 0.4351 | 0.8137 | 0.1314 | 0.7969 | 0.0790 | +3.04% | -0.0137 |
| PLE+UTTSI | 0.7998 | 0.4473 | 0.7916 | 0.4390 | 0.8097 | 0.1338 | 0.7954 | 0.0796 | +2.57% | -0.0115 |
| OptFu+UTTSI | 0.8051* | 0.4448* | 0.7972* | 0.4359* | 0.8169* | 0.1297* | 0.7979* | 0.0786* | +3.23% | -0.0142 |
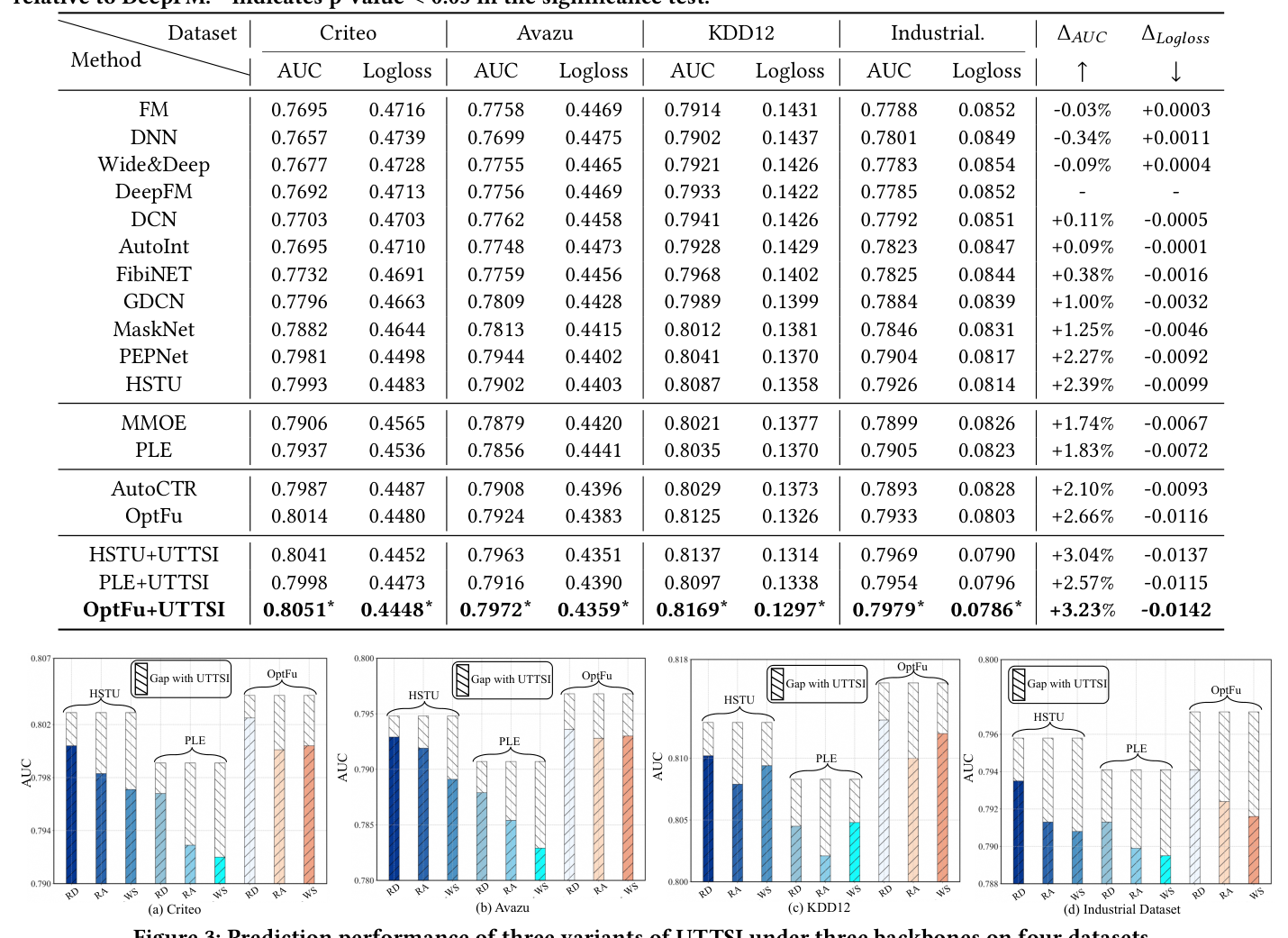
结论分析: 1. UTTSI 在三种代表性 backbone 上一致超越所有 baseline,且不改 backbone 参数、不重训。增益统计显著($p<0.05$)。 2. 几个值得注意的观察:拥有复杂交叉架构的 GDCN、MaskNet 比简单 baseline 有提升,但随模型复杂度增加增益趋于饱和;多专家(MMoE、PLE)与 NAS 方法(AutoCTR、OptFu)通过多样化特征交互空间进一步提升,但它们都有共同局限——所有优化都局限在训练阶段、对每个实例统一施加。UTTSI 通过 per-instance 选择性分配额外计算解决了这一点:不确定样本得多路径探索,自信样本零开销,与训练阶段 backbone 互补而非竞争。 3. OptFu+UTTSI 取得整体最佳:相对最强 baseline,在 Criteo/Avazu/KDD12/Industrial 上 AUC 分别 +0.0037 / +0.0048 / +0.0044 / +0.0046,并伴随对应 LogLoss 下降。 4. 增益在 KDD12 和 Industrial 上最显著——这两个数据集特征稀疏度更高、尾部特征占比更大,直接印证了 UTTSI 针对稀疏特征实例的定向改进。相对 DeepFM,OptFu+UTTSI 取得 $\Delta_{AUC}=+3.23\%$、$\Delta_{Logloss}=-0.0142$,超越所有训练阶段 baseline。(CTR 领域 0.001 量级的 AUC 提升即被视为显著。)
6. 消融实验(RQ2)¶
为验证各模块贡献,构造三个消融变体,在全部四个数据集上评估(结果即图 3 中的三组柱):
- w/o-Dual (RD):移除双信号不确定性估计,用单一 logit-only 置信分替代,禁用频率先验。
- w/o-Attr (RA):移除 attribution 引导的采样,路径构造时用均匀随机特征采样替代。
- w-Single (WS):移除多路径探索,每个不确定实例只用单条推理路径(即对所有不确定样本 $K(x)=1$)。
移除任一组件都导致性能退化,确认各组件的贡献。
双信号估计的作用(w/o-Dual, RD):用 logit-only 置信替代双信号估计,在所有数据集与 backbone 上一致退化。根因是模型 logit 置信混淆了两种不同来源的不确定性——稀疏特征覆盖导致的认知不确定性,与决策边界附近固有点击模糊性导致的偶然不确定性。一个真实偏好打平(接近 50% 点击概率)的样本会产生低置信 logit,但其特征表征可能完全可靠。频率先验正确地给这类样本赋低不确定性,避免无谓探索。完整 UTTSI 一致优于 w/o-Dual,证明两个信号结合对准确不确定性估计是必要的。
attribution 引导采样的作用(w/o-Attr, RA):用均匀随机采样替代 attribution 加权采样导致显著退化,尤其在高特征稀疏度数据集(KDD12、Industrial)。均匀采样下,把一个高信号稀有特征纳入任一路径的概率正比于 $1/N$,当 $N$ 大时极小。attribution 分直接反映 base 模型对每个特征当前预测贡献的评估,用它上加权有信息量特征,能确保探索路径保留原始输入的预测信号、同时朝远离不可靠组合的方向多样化。w/o-Attr 在 Industrial 上的退化幅度大于 w/o-Dual,说明在高维设定下单条探索路径的质量比不确定性分数准确性影响更大。
多路径聚合的作用(w-Single, WS):即便双信号估计与 attribution 引导采样都正确施加,每个不确定实例只用单路径仍不如完整多路径集成。因为探索采样本质随机,任何单条路径都可能错过给定实例的全局最优特征子集。多路径采样通过独立探索 $K(x)$ 个多样配置并经一致性加权投票聚合来对冲此风险,一致性加权进一步缓解任何离群路径主导最终预测的风险。这些结果确认 UTTSI 的核心原则:对不确定实例的鲁棒性来自集成探索的多样性,而非找到单个最优特征配置。
7. 超参数敏感性(RQ3)¶
在 Industrial 数据集上分析关键超参敏感性,其余超参固定为默认值。
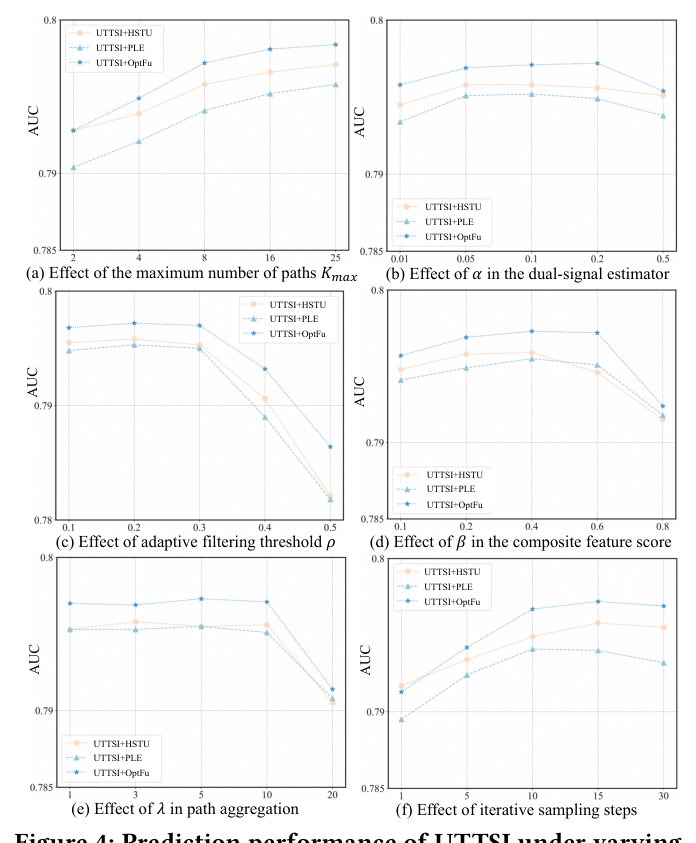
最大路径数 $K_{\max}$ 的影响:$K_{\max}$ 是任一实例能分到的最大探索路径数,控制 per-instance 推理深度上界。在 $\{2,4,8,16,25\}$ 上变化,性能随 $K_{\max}$ 从 2 增到 8 提升,超过 8 后收益递减。关键的是,连续分配 $K(x)=\lfloor K_{\max}\cdot u(x)\rfloor$ 意味着大多数低不确定样本 $K(x)=0$、直接服务,故每实例平均执行路径数仍远低于 $K_{\max}$。这印证了增大 $K_{\max}$ 只提升最难样本的性能、对高效自信样本无影响。
$\alpha$ 的影响:$\alpha$ 控制频率先验相对模型 logit 置信的权重。在 $\{0.01,0.05,0.1,0.2\}$ 上变化,性能在宽范围(0.05–0.2)内稳定,说明双信号不确定性分数对频率先验的精确权重鲁棒。$\alpha$ 太小会低估群体级特征稀疏信号、削弱对稀疏样本的不确定性区分;$\alpha$ 太大则压过模型自身置信。默认 $\alpha=0.05$ 取得最佳平衡。
自适应过滤阈值 $\rho$ 的影响:$\rho$ 是共享 per-field 分位,决定 Stage 1 过滤激进程度。在 $\{0.1,0.2,0.3,0.4,0.5\}$ 上变化,$\rho\in[0.1,0.3]$ 时性能稳定,$\rho=0.2$ 在去噪与信号保留之间达到最佳平衡。$\rho=0$(不过滤)时自信和不确定样本都受未过滤噪声特征干扰,整体 AUC 下降;$\rho>0.4$ 时过度过滤开始移除有信息量的稀有特征,损害尾部样本性能。
$\beta$ 的影响:$\beta$ 平衡组合分 $w(f^i)$ 中的频率可靠性与梯度 attribution,被 Stage 1 过滤和 Stage 2 路径采样共享。在 $\{0.1,0.2,0.4,0.6,0.8\}$ 上变化,$\beta\in[0.2,0.6]$ 稳定,$\beta=0.4$ 最优。$\beta$ 极小过度加权 attribution、保留高梯度范数的噪声特征;$\beta$ 极大过度加权频率、丢弃有信息量的稀有特征。
$\lambda$ 的影响:$\lambda$ 控制聚合中一致性加权的锐度,即离群路径相对多数被压制的强度。在 $\{1,3,5,10,20\}$ 上变化,AUC 在 $[1,10]$ 内对 $\lambda$ 不敏感(所有值都在最优的 0.0005 AUC 内),因为一致性加权主要抑制灾难性离群路径、中等 $\lambda$ 已达此效果。$\lambda>20$ 时过锐加权趋近"赢家通吃"选择,失去集成收益。
$T$ 的影响:$T$ 是 Stage 2 每条路径的迭代 Bernoulli 采样步数,控制每条探索路径的覆盖度与多样性。在 $\{1,5,10,20,30\}$ 上变化,性能从 $T=1$ 到 $T=10$ 稳步提升(更多步允许构造更广的特征组合集),超过 10 后增益趋平。$T=1$ 时路径过早终止、采样特征太少,限制探索多样性。默认 $T=10$ 在探索质量与计算成本间取得平衡。
总结:UTTSI 对所有关键超参鲁棒,跨设定泛化可靠。
8. 不确定性校准与分层分析(RQ4)¶
不确定性触发系统的根本要求是:估计的不确定性分数应与真实预测误差相关。若校准差,高不确定样本未必真的更难预测,路由它们做多路径探索就无收益。
不确定性-误差相关:在 Industrial 测试集上把全部实例按估计不确定性 $u(x)$ 排序并分成十组(deciles),对每组计算 base 模型直接预测(不用 UTTSI)的平均平方预测误差 $|\sigma(\text{logit}(x)) - y|^2$。结果显示平均预测误差随估计不确定性单调递增。$u(x)$ 与平方预测误差的 Spearman 秩相关在 Industrial 上达 $\rho=0.91$,确认双信号估计器可靠识别 base 模型易出错的实例。作为对比,仅用 logit 置信(UTTSI-w/o-Dual 变体)的 Spearman 相关大幅降至 $\rho=0.76$,与 RQ2 的消融结果一致,验证频率先验对不确定性区分的必要性。在 Criteo/Avazu 上双信号估计器分别取得 $\rho=0.88$ / $\rho=0.86$,对应 logit-only 仅 $\rho=0.71$ / $\rho=0.73$。三个数据集上一致的校准优越性确认双信号设计可泛化到工业设定之外。
跨不确定性分层的表现:把 Industrial 测试集按 $u(x)$ 分成低(底 30%)、中(中 40%)、高(顶 30%)三层,对比 base 模型 OptFu 与 OptFu+UTTSI 的 AUC。
表 3:Industrial 数据集上按不确定性分层的 AUC(OptFu backbone)
| Stratum | OptFu | UTTSI | $\Delta$ |
|---|---|---|---|
| Low ($u(x)<0.3$) | 0.8241 | 0.8254 | +0.0013 |
| Medium ($0.3\le u(x)<0.7$) | 0.7985 | 0.8012 | +0.0027 |
| High ($u(x)\ge 0.7$) | 0.7621 | 0.7709 | +0.0088 |
| Overall | 0.7933 | 0.7979 | +0.0046 |
结论分析:UTTSI 在所有不确定性分层上都带来一致正增益。即便对低不确定样本($K(x)=0$,仅做自适应特征过滤、无多路径),AUC 也有 +0.0013 的稳定提升($p<0.05$,配对置换检验),说明过滤本身有益、增益非噪声。中不确定样本获益更明显,高不确定样本获得最大增益 +0.0088——这正得益于多路径探索。这种分层模式确认 UTTSI 的设计是自洽的:特征过滤惠及所有实例,额外探索路径只为最难实例保留——它把额外推理资源恰好投到 base 模型最弱处,同时不损害系统整体效率。 这进一步印证不确定性校准和多路径探索两者都必要:前者保证预算不浪费在简单实例,后者把预算转化为难实例上的性能增益。
9. 在线 A/B 测试、计算开销与部署¶
9.1 在线 A/B 测试结果¶
为验证真实效果,作者在某大规模电商平台部署 UTTSI 做 7 天在线 A/B(2026 年 4 月 15–21 日)。对比一个采用 PEPNet-like 架构的生产 baseline,UTTSI 在 7 天 CTR 指标上取得 +5.3% 的相对点击率提升($p<0.01$,每日 CTR 的双侧 $z$ 检验,按用户随机分流)。作者特别指出,这一 CTR 提升明显大于离线 AUC delta,原因是在线 CTR 衡量的是 top-ranked item 的真实点击产出——推荐列表头部即便很小的排序改进也能转化为大幅相对 CTR 增益。这一统计显著的线上增益为框架的实用价值提供了有力证据。
9.2 计算开销分析¶
在 Industrial 上量化 UTTSI 引入的实际开销,度量每实例平均模型调用数。在 $K_{\max}=8$、$\alpha=0.05$、$\rho=0.2$ 下,$K(x)$ 的经验分布揭示:约 62% 的样本 $K(x)=0$(仅自适应特征过滤),21% 的样本 $K(x)\in\{1,2\}$,剩余 17% 的样本 $K(x)\ge 3$。每实例都需一次 base 模型调用(带梯度 attribution 的前向)+ 一次 $\hat{\mathbf{F}}$ 上的精炼前向;不确定实例额外接受 $K(x)$ 条探索前向。平均约 2.8 次模型调用/实例,即相对 base 模型约 $2.8\times$ 开销。 精炼前向用相同模型架构、掩码输入,成本与 base 前向相当。
由于所有探索路径完全独立且可并行,这个开销直接转化为对额外并行算力的需求,而非增加的 wall-clock 延迟。当服务基础设施支持至多 $K_{\max}$ 个并行打分 worker 时,UTTSI 最坏情况延迟等于两次 base 模型前向,等价于原始服务延迟。这使其特别适合"并行算力充足、但严格延迟 SLA 必须维持"的工业系统。
9.3 频率索引维护¶
生产中频率索引并非静态:每天有新 item、新用户引入,已有特征值也累积新曝光。为保持频率先验时新,作者每天用增量更新维护 Count-Min Sketch:每天结束时把前一天的曝光日志重放(hash-and-increment)合并进 sketch。由于 Count-Min Sketch 支持单调增量、且其最小值估计在增量更新后仍有效,无需全量重算——只需处理新增记录,更新成本正比于当日曝光量而非全量历史语料。归一化计数 $\tilde{s}_{freq}(f^i)$ 和 per-field 阈值 $\{\tau^i\}$ 在每晚合并后从更新的 sketch 重算,并在次日流量前推送到服务层,确保不确定性估计与过滤决策反映最新特征覆盖。A/B 测试窗口内这一每日刷新维持了稳定校准:7 天内 $u(x)$ 与观测预测误差的 Spearman 相关未退化,证明增量更新足以跟踪特征频率分布。
10. 核心贡献总结¶
- 据作者所知,UTTSI 是第一个免训练、模型无关的测试时框架,通过把推理深度选择性 scale 到 per-instance 不确定性来改善 CTR 性能,把 LLM 的 test-time compute scaling 思想首次成功迁移到工业 CTR 预测。
- 引入双信号不确定性估计器:把 logit 置信与基于频率的先验结合,配合一个去除不可靠表征的自适应特征过滤机制、以及一个为不确定实例派生鲁棒性的路径分配机制。
- 四个数据集 × 三种 backbone + 7 天在线 A/B(+5.3% CTR) 证明 UTTSI 对 SOTA CTR 模型取得一致、统计显著的提升,确认其广泛兼容性和实用价值;$2.8\times$ 平均计算开销在工业服务约束下可控(并行设施下最坏延迟仅一次额外前向)。
11. 与已归档相关工作的对比¶
TwiSTAR TwiSTAR: Think Fast, Think Slow, Then Act(清华深圳国际研究生院, 2026-05-12)¶
关系:独立并发(本文未引用 TwiSTAR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇论文独立地诊断出同一个 root cause——推理阶段对所有实例施加统一的计算/推理强度是次优的。TwiSTAR 把它表述为"现有生成式推荐要么全量 fast、要么全量 slow,fast-only 在 hard/sparse/ambiguous 样本上欠拟合,slow-only 在 easy 样本上既浪费算力又可能掉点";UTTSI 表述为"标准推理对所有实例统一处理,自信实例无谓占用、不确定实例得不到补救"。两者都把"按 per-instance 难度分配测试时计算"当作核心命题,灵感都直指 LLM 的 test-time compute scaling / System 1-2 自适应推理。
- 相近的技术骨架:两者方法流程图可抽象重合为「per-instance 难度/不确定性估计 → 据此分配可变的测试时计算 → 聚合/输出」。TwiSTAR 用 learned planner $\mathcal{M}_\text{agent}$ 把每个用户序列路由到 {fast retrieval, rank, slow CoT} 三种工具;UTTSI 用 $u(x)$ 把每个实例路由到 $K(x)=\lfloor K_{\max}\cdot u(x)\rfloor$ 条特征探索路径。两者都只把额外计算投向最难的样本(TwiSTAR 只在 hard 样本上训 slow 模型 / 触发 slow 推理,UTTSI 仅对高 $u(x)$ 实例 $K(x)>0$)。
- 本文的差异与推进:(1) 范式:TwiSTAR 在生成式推荐(SID、自回归、LLM)里,UTTSI 在判别式 CTR(二分类、特征交互)里;(2) 训练需求:TwiSTAR 的 planner 需两阶段训练(监督模仿 + agentic GRPO,含 NDCG/tool/latency 奖励),而 UTTSI 完全免训练、模型无关,套在任意冻结 backbone 上即可——这是 UTTSI 在工业落地上的最大差异化优势;(3) "计算"的载体:TwiSTAR 增加的是自回归 CoT reasoning token(串行、延迟敏感,CoT 一次约 1.6s),UTTSI 增加的是并行的特征子集前向(最坏延迟仅一次额外前向)。
- 可比的方法/实验差异:TwiSTAR 在 Amazon Beauty/Toys/Sports 上对比 OneRec-Think,强调排序精度 + 延迟(3.3× wall-clock 节省);UTTSI 在 Criteo/Avazu/KDD12/Industrial + 7 天线上 A/B(+5.3% CTR)上验证。两者都用"难度估计是否校准"作为关键诊断(TwiSTAR 靠 planner 学习路由,UTTSI 靠 $u(x)$ 与预测误差的 Spearman $\rho=0.91$ 验证校准)。
LASAR LASAR: Latent Adaptive Semantic Aligned Reasoning(北京航空航天大学 & 百度, 2026-05-11)¶
关系:独立并发(本文未引用 LASAR,两者殊途同归)· 已加载对方精读
- 共同关注的问题:LASAR 的第三个核心挑战"Inflexible fixed-step reasoning"与 UTTSI 的动机直接同构——用全局固定的推理深度对待所有样本是不合理的,简单样本只需浅推理、复杂样本需要深推理。LASAR 在生成式推荐的 latent reasoning 语境下提出这一点,UTTSI 在 CTR 的特征探索语境下提出,两者都拒绝"对所有实例统一深度"的范式。
- 相近的技术骨架:两者都用一个 per-sample 难度信号驱动一个可变深度的推理过程。LASAR 用 Policy Head + REINFORCE 在 RL 阶段动态决定每个样本的 latent reasoning 步数 $N$(带 step penalty 抑制过度推理);UTTSI 用 $u(x)$ 直接连续映射出 $K(x)$ 条探索路径数。两者都把"自适应深度"作为效率-效果权衡的关键旋钮。
- 本文的差异与推进:(1) 机制粒度:LASAR 的自适应深度是单模型内的 latent recurrent 步数(Coconut 风格 hidden-state feedback loop),UTTSI 是多条并行特征路径的数量;(2) 训练 vs 免训练:LASAR 的自适应步数需 RL 训练 Policy Head、还需 SFT 两阶段解耦 + bidirectional KL 对齐解决表征漂移,UTTSI 的 $K(x)$ 是闭式映射、零训练;(3) 不确定性来源:LASAR 的深度由学习到的 policy 决定,UTTSI 的深度由显式的双信号不确定性(logit 置信 + 频率先验)决定,后者天然带可解释的校准诊断。LASAR 的核心 novelty 在 latent reasoning 机制本身(grounding gap、representation drift),自适应深度只是其三个子机制之一;UTTSI 则把"选择性测试时计算"作为全部核心。
12. 讨论与局限性¶
核心贡献与可借鉴之处:UTTSI 把"测试时计算扩展"这一在 LLM 上被反复验证有效的范式,第一次成功迁移到工业 CTR 预测。它的优雅之处在于完全 plug-and-play:不动 backbone 参数、不重训、不改架构,套在任意可微 CTR 模型之上即可。三个设计尤其值得借鉴:
- 双信号不确定性估计——清晰区分了认知不确定性(频率先验)与偶然不确定性(logit 置信),并用 attribution 加权把"实际驱动预测的特征频率"而非"样本平均特征频率"纳入计算,这个 attribution 加权频率是全文最精巧的设计点(消融显示去掉它后 Spearman 校准从 0.91 掉到 0.76)。
- 偏差-方差视角的不对称设计——过滤(降偏差,惠及所有实例)与多路径探索(降残差方差,仅惠及高不确定实例)处理不同层次的错误,论证了为何 $K(x)=0$ 的自信实例只过滤、不探索仍足够。
- 连续分配 $K(x)=\lfloor K_{\max}\cdot u(x)\rfloor$ + 完全并行路径——使最坏延迟仅为一次额外前向,把"算力换性能"巧妙转化为"并行算力换性能",契合工业"算力富裕但延迟严格"的现实。
局限与争议:
- $2.8\times$ 平均模型调用开销:虽然在并行设施下延迟可控,但对算力本身是实打实的 $2.8\times$ 增量,在算力受限或并行 worker 不足的部署里,最坏延迟会退化为串行的多次前向,论文对此情形未给出降级方案。
- 梯度 attribution 的在线成本:每个实例都要一次反向传播算 $\text{attr}(f^i)$(约 0.5–1× 前向开销),这对所有实例(包括最终 $K(x)=0$ 的 62%)都不可省,是固定税;论文未讨论能否用更廉价的 attribution 近似(如 input×gradient 或缓存)替代。
- 离线索引与阈值的时新性:频率 Count-Min Sketch 和 per-field 阈值靠每晚增量更新,对突发流量/特征分布漂移(如大促、热点事件)的日内适应性存疑;7 天 A/B 未覆盖极端分布漂移场景。
- 超参数虽鲁棒但仍需调:$K_{\max}, \alpha, \beta, \rho, T, \lambda, \gamma, \eta$ 共 8 个超参,虽各自在宽范围内稳定,但 per-field 阈值 $\tau^i$ 的离线计算依赖训练数据分布,跨域迁移时需重算。
- 与生成式范式的关系未展开:论文把 HSTU 作为 backbone 之一(HSTU+UTTSI),但未深入讨论 UTTSI 与生成式 CTR(如同作者团队的 DGenCTR)等新范式的协同——测试时探索在生成式离散标签空间里的形态可能截然不同。
工业落地价值:7 天真实电商 A/B 的 +5.3% CTR($p<0.01$)、明确的 $2.8\times$ 开销量化、可并行的服务架构、每晚增量索引维护方案,共同构成一个可直接落地的工程蓝图。对任何已部署训练好 CTR 模型、且并行算力相对充裕的工业团队,UTTSI 提供了一条"不重训即可榨取额外收益"的低风险路径——这是其相对所有训练阶段 baseline 最现实的差异化价值。