Scaling Properties of Continuous Diffusion Spoken Language Models¶
Apple. arXiv: 2604.24416 (2026-04-27).
作者:Jason Ramapuram, Eeshan Gunesh Dhekane, Amitis Shidani, Dan Busbridge, Bogdan Mazoure, Zijin Gu, Russ Webb, Tatiana Likhomanenko, Navdeep Jaitly。
一、研究动机与背景¶
Spoken Language Models (SLMs) — 即直接在语音上做语言建模、不依赖任何文本监督的"纯语音 LLM" — 当前的语言能力大约停留在 3-4 岁儿童水平,远落后于 SOTA 的文本 LLM 与文本-语音多模态模型。已有工作 [Cuervo & Marxer, 2024] 把 SLM 的 scaling law 推到离散自回归 (AR) 框架下,结论是:要让 SLM 达到文本 LLM 的语言流利度,可能需要"几个数量级以上"的算力。
这种 AR-on-discrete-tokens 路线之所以耗算力,根本症结有两条: 1. 离散化瓶颈:把连续语音用 SSL(如 wav2vec2、Spirit)压成离散 token,必然引入压缩失真和重建误差,限制了模型表达上限; 2. 数据稀疏:原始语音的语义密度远低于文本,没有 Wikipedia 这样高度结构化的语料,从声音中抽取通用知识本身就资源密集。
本文沿着另一条思路:既然语音信号本身是连续的(即使其承载的语言是离散的),那么用连续扩散 (continuous diffusion, CD) 模型在 log-mel 上直接建模,是否比 AR-on-discrete 更高效?
为系统性回答这个问题,作者做了两件以前没做过的事:
- 提出 phoneme JSD (pJSD) 作为可与扩散模型兼容的 "languageness" 度量。AR 模型可以直接算序列对数似然,扩散模型不行;而 sWUGGY/sBLIMP/sStoryCloze 这类辨别式指标只能比较成对的"正确 vs 错误"句子,无法广义评估生成语料的语言性。pJSD 通过比较真实语料与生成语料在音素 n-gram 分布上的散度,提供了一个采样型、可扩展的语言性指标。
- 首次给出连续扩散 SLM 的完整 scaling law 分析:在 7 个数量级的 compute 区间(10^18–10^21 FLOPs)和 0.6M–11.5B 参数区间扫 isoFLOP,拟合 (N, D) → 验证 loss 以及 (N, D) → 下游度量的 scaling fit;并将基础架构外推到 16B 参数、数千万小时对话语音,验证最大规模下能否生成富有情感、韵律和多语种的连续语音。
研究结论既有"沿用文本 LLM trend 的部分",也有几条新趋势:
| 趋势 | 类型 | 说明 |
|---|---|---|
| Validation loss 服从 scaling law | 沿用 | 与 AR LM、扩散 transformer、离散扩散 LM 一致 |
| 最优 token-per-parameter 比 r* 随 compute 减小 | 沿用 | 与 [Hoffmann et al. (Chinchilla)] 趋势一致 |
| 高 compute 下 loss 对 (N,D) 分配更不敏感 | 新 | isoFLOP 曲线变扁平,给"小模型/小数据低成本部署"留出空间 |
| pJSD 服从 scaling law,n 越大 fit 越好 | 新 | 5-gram pJSD 的 test MRE 仅 ~1% |
| 标准感知质量 metric (DNSMOS、NISQA) 不服从 scaling law | 新 | 与已知的 MOS↔人工评分相关性差吻合 |
| 部分指标无论多大算力都达不到真实数据基线 | 新 | content understanding 等指标外推后仍未触达 baseline ±σ 区间 |
最后的结论非常坦率:在当前可获得的 compute 和语音数据下,纯 SLM 路线进一步 scale 不切实际——除非出现新的语音表示或建模范式,或者干脆转向 text-speech 模型。
二、核心方法:Continuous Diffusion SLM¶
2.1 数据:SpeechCrawl¶
- 来源:公开渠道收集的大规模对话语音("SpeechCrawl");
- 音频特性:平均 ~30 分钟/段,约 60% 英语;
- 过滤:用 WhisperX + Whisper-large-v3 估算每段英语占比,仅保留时长 > 5 分钟、英语占比 ≥ 99% 的样本;
- 过滤后规模:7M 小时(700 万小时)。
2.2 语音表示:log-mel filterbanks¶
不走主流的 SSL discrete token 路线,而是直接用 log-mel filterbanks,理由有四:
- 物理可解释、保留语义和声学信息、信息损失小;
- 与具体 encoder/decoder 解耦,可直接通过任意 vocoder 重建 waveform;
- 在多种声学环境下表现稳健;
- 是连续生成模型的"原生"输入。
参数:24 kHz 重采样、80 维 mel、50 ms 窗、12.5 ms hop → 80 Hz 帧率。
值得注意的语义密度对比:
文本 LLM ≈ 4 token / 3 词,对话语速 ≈ 3 词/秒 → 4 文本 token/s; 而 80 Hz 的 mel 是 80 帧/s → CD SLM 的 token 数比文本 LLM 高 20×。
这是 CD SLM 在 sequence-length-per-second 上的固有劣势,需要靠后续 architectural choice(如 temporal patching k)部分缓解。
2.3 Continuous Diffusion (CD) 模型¶
前向过程与 velocity 参数化¶
给定数据 $x_0 \sim p_{\text{data}}$,前向加噪:
$$q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar\alpha_t}\, x_0, (1-\bar\alpha_t)\mathbf{I}) \tag{1}$$
其中 $\bar\alpha_t = \prod_{s=1}^t \alpha_s$,$\alpha_t = 1 - \beta_t$。$t \to T$ 时 $q(x_T) \to \mathcal{N}(0, \mathbf{I})$。
不直接预测噪声 $\epsilon$,而是参数化网络 $v_\theta(x_t, t)$ 预测 velocity
$$v_t = \sqrt{\bar\alpha_t}\,\epsilon - \sqrt{1 - \bar\alpha_t}\, x_0$$
在预测 noise 与预测 signal 之间插值。训练目标采用 min-SNR 加权的 denoising loss:
$$\mathcal{L} = \mathbb{E}_{x_0, \epsilon, t}\left[ \min(\text{SNR}(t), \psi)\cdot \|v_\theta(x_t, t) - v_t\|^2 \right] \tag{2}$$
其中 $\text{SNR}(t) = \bar\alpha_t / (1 - \bar\alpha_t)$,$\psi$ 为截断常数。这种重加权抑制了不同 timestep 上 loss 贡献的不均衡,提升训练效率。
MM-DiT 骨干¶
借用 SD3 / Stable Diffusion 体系的 Multimodal Diffusion Transformer (MM-DiT) [Esser et al., ICML 2024],但针对纯语音改造:原 MM-DiT 的"文本流 + 图像流"被替换为"音频上下文流 ($m_\text{ctx}$) + 待生成音频流 ($m_\text{gen}$)"两个 log-mel filterbank stream。
具体流程: 1. 把单声道 waveform 转 80×S' 的 log-mel; 2. 切成 $m_\text{ctx} \in \mathbb{R}^{T \times 80}$(context)和 $m_\text{gen} \in \mathbb{R}^{T' \times 80}$(待生成 continuation); 3. 给 $m_\text{gen}$ 加 Gaussian 噪声; 4. 两个 stream 各自经独立 Linear → MM-DiT block (×L):每层都有独立的 AdaLN-zero、MLP、projection; 5. 唯一的跨流交互发生在 attention 层 — 两 stream 的 Q/K/V 拼接后做完整的 bidirectional self-attention; 6. 重复 L 层后从 continuation stream 抽出去噪结果计算 loss; 7. RoPE 用于位置编码,timestep 通过 AdaLN-zero 调制。
Section 4 中 $m_\text{ctx} = 10$s、$m_\text{gen} = 30$s;模型尺寸通过保持 $d_\text{emb} / L = 128$ 来缩放(典型的 isotropic transformer scaling)。
Classifier-Free Guidance (CFG)¶
不在训练中显式 drop conditioning(即不学无条件分布),而是把 conditioning 全部 FLOPs 投到学习有条件分布上。在推理时,把 $\mathbf{0}$ 信号当作 unconditional 输入:
$$\bar v_\theta(x_t, t, c) = v_\theta(x_t, t, \emptyset) + w\cdot \big(v_\theta(x_t, t, c) - v_\theta(x_t, t, \emptyset)\big) \tag{3}$$
由于 $w=1$(无引导)样本质量太差,论文实际只对比 weak (w=2) 和 strong (w=4) 两档。
2.4 Languageness 指标:Phoneme Jensen-Shannon Divergence (pJSD)¶
动机¶
- AR 离散 token 模型:可以用 sWUGGY (lexical)、sBLIMP (syntactic)、sStoryCloze (semantic) 等 forced-choice 任务评估,本质上是对比"语法正确句子"vs "语法错误句子"的对数似然;
- 扩散模型:算样本的精确 likelihood 在算力上不可行,且这些 forced-choice 数据集本身依赖精心策划的成对样本,不是分布层面的度量。
定义¶
给定生成集 $\mathcal{G}$ 和真实集 $\mathcal{R}$ 的 waveform,使用 Allosaurus 通用音素识别器抽音素序列 $\pi(x) = (p_1, \dots, p_L)$,定义第 $i$ 个 $n$-gram:
$$g_i^{(n)}(x) := (p_i, p_{i+1}, \dots, p_{i+n-1}), \quad i = 1, \dots, L-n+1 \tag{4}$$
记 $C_\mathcal{S}^{(n)}(g)$ 为 $n$-gram $g$ 在语料 $\mathcal{S}$ 中出现总次数,$\Omega^{(n)}$ 为生成 + 真实集观察到的 $n$-gram 全集,则经验分布
$$p_\mathcal{S}^{(n)}(g) := \frac{C_\mathcal{S}^{(n)}(g)}{Z_\mathcal{S}^{(n)}}, \qquad Z_\mathcal{S}^{(n)} := \sum_{g \in \Omega^{(n)}} C_\mathcal{S}^{(n)}(g) \tag{5}$$
令 $m^{(n)} := \tfrac{1}{2}(p_\mathcal{G}^{(n)} + p_\mathcal{R}^{(n)})$,最终的 pJSD:
$$\text{pJSD}_n(\mathcal{G}, \mathcal{R}) := \tfrac{1}{2}\text{KLD}\!\left(p_\mathcal{G}^{(n)} \| m^{(n)}\right) + \tfrac{1}{2}\text{KLD}\!\left(p_\mathcal{R}^{(n)} \| m^{(n)}\right) \tag{6}$$
值越低代表生成与真实在音素 $n$-gram 分布上越接近。在论文中报告 1-gram 与 5-gram 两档。
与 ASR-perplexity 的取舍¶
理想做法是用 ASR 把生成音频转写后跑文本 LM 算 perplexity;但当前 SLM 输出语言能力仍处于幼儿水平,ASR 转写本身就充满错误,方差过大。pJSD 是当下可行的折衷,等 SLM 长大后应迁移回 ASR-perplexity 路径。
2.5 感知质量度量¶
除语言性,作者还系统评估生成语音的"听感",使用:
- DNSMOS P.808 / DNSMOS overall (P.835) / NISQA MOS — 三个主流的非侵入式 MOS 预测器;
- Meta Audiobox Aesthetics — 4 维 no-reference predictor:content enjoyment (CE)、content understanding (CU)、production quality (PQ)、production complexity;report mean。
这些 metric 是否随 compute 提升、是否能达到 real-data baseline,是 Section 4.3 的核心研究问题。
三、Scaling Law 实验设计¶
3.1 总体框架¶
采用 [Kaplan; Hoffmann (Chinchilla)] 风格的 isoFLOP 拟合:
$$L(N, D) = E + \left( \frac{A}{N^\alpha} + \frac{B}{D^\beta} \right)^\gamma \tag{7}$$
- 保留 outer exponent $\gamma$(不像许多工作把它固定为 1),原因是论文实证 $\gamma$ 对 CD SLM 的 fit 稳定性有显著贡献 [Busbridge 2025 蒸馏 scaling 也发现类似];
- 用 basin-hopping + L-BFGS-B,2k iter,Huber loss 拟合 $E, A, B, \alpha, \beta, \gamma$;
- IsoFLOP 估计 $C \approx 6ND$。
3.2 扫的 (N, D) 空间¶
- compute budget $C \in \{10^{18}, 3\cdot 10^{18}, 6\cdot 10^{18}, 10^{19}, 3\cdot 10^{19}, 6\cdot 10^{19}, 10^{20}, 3\cdot 10^{20}, 6\cdot 10^{20}, 10^{21}\}$;
- 模型尺寸 ~0.6M (1 layer) 到 ~11.5B (27 layer);
- 每个组合 ≥3 seed,report mean ± std;
- 超参数用 muP + completeP 跨规模迁移;先在 ~36M 4-layer base 上 sweep lr ∈ {1e-4 .. 2e-3} 和 wd ∈ {0.001 .. 0.2},最优 (lr=0.001, wd=0.03) 用 muP/completeP 推广到所有尺寸;
- 推理步数和 noise scheduler 保持固定。
3.3 isoFLOP 行为定性观察¶
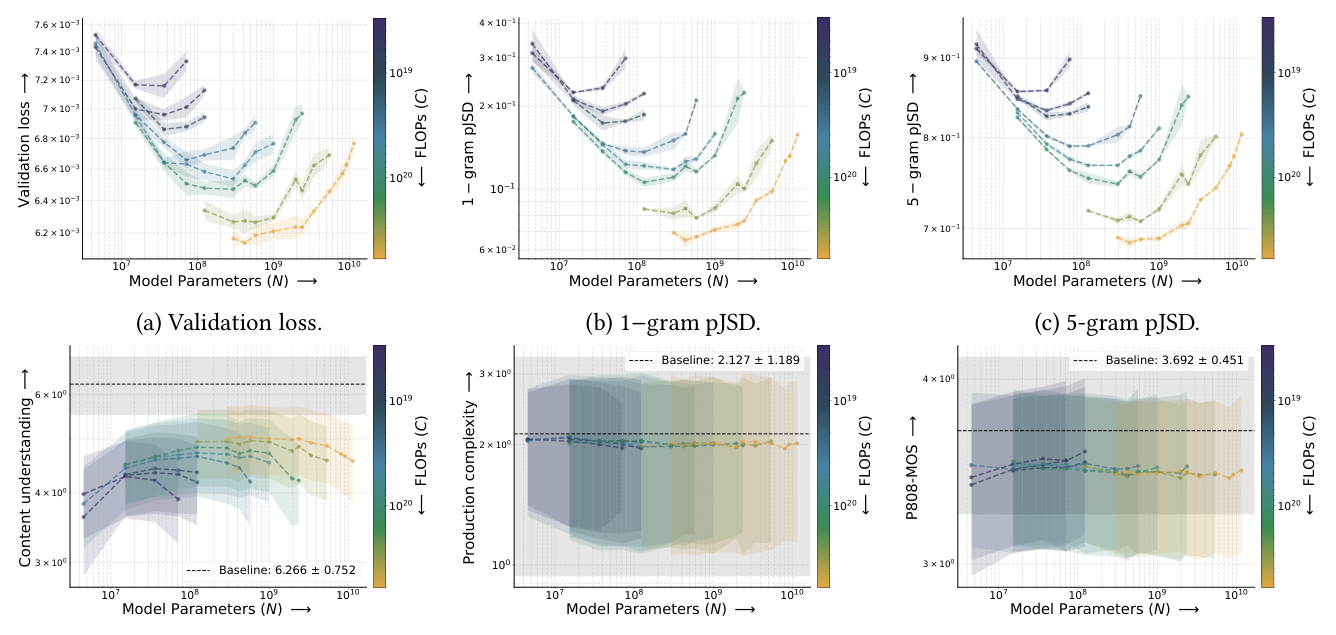
定义 expected isoFLOP behavior = 同一 compute level 下 metric vs N 呈清晰的 U 型(loss)或 ∩ 型(quality),且最优值随 compute 单调改善。
- Validation loss / 1-gram pJSD / 5-gram pJSD:满足 expected isoFLOP behavior(图 3 a-c);
- CU、CE(4 个 Audiobox 中的两个):满足;
- PQ、production complexity、所有 DNSMOS/NISQA MOS:不满足 —— 曲线在 ±σ 实数据 baseline 范围内迅速饱和,模型很快学会"听上去合理"的低成本输出,但更高 compute 无法继续推高。
这与 MOS 类 metric 与人工 mean opinion score 相关性较差的既有结论一致。
四、主要实验结果¶
4.1 Validation loss scaling law¶
最佳 fit(test MRE 0.80%,train MRE 0.49%):
$$L(N, D) = 0.0055 + \left( \frac{0.0638}{N^{0.3995}} + \frac{29.7667}{D^{0.5644}} \right)^{0.7051} \tag{8}$$
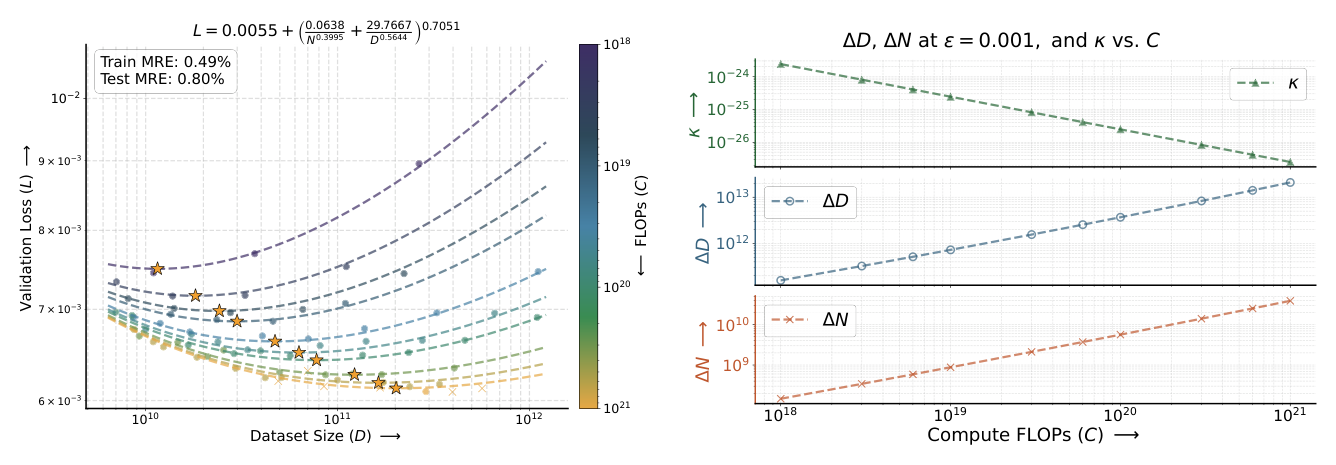
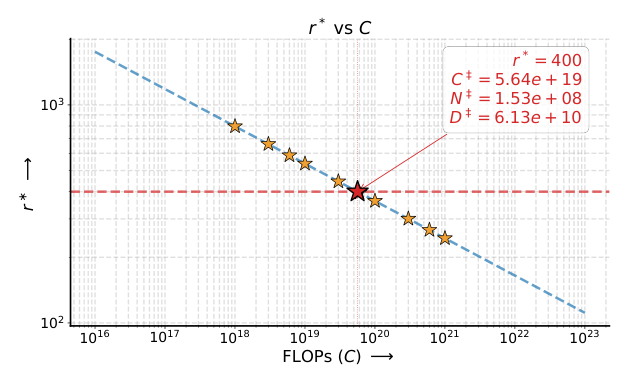
由该 fit 可推导出最优 (N*, D*)(C):
关键观察:
- r*(C) = D*/N* 随 compute 减小(图 4,斜率为负);这与 AR SLM 趋势一致,与 Chinchilla 文本 LM 的趋势相反——在 CD SLM 里,compute 越大越应当往大模型方向倾斜,而不是往大数据方向倾斜。
- 在 $C = 10^{21}$ FLOPs 处,$r^* \approx 245$;考虑文本 token 与语音 token 的 20× 密度差,等效文本 tokens-per-parameter ratio $r^*_{\text{text}} \approx r^*/20 \approx 12.25$。这低于文本 LM 的 chinchilla optimal $r^* \approx 20$,意味着 CD SLM 在 $10^{21}$ FLOPs 时已经比 text AR LM 用 compute 更高效。
- isoFLOP 曲线随 compute 变扁平。把 isoFLOP 在最优点的曲率记为 $\kappa$,并定义"容忍精度" $\epsilon = 10^{-3}$ 内可接受的 (N', D') 范围,则随 compute 增加:
- $\kappa$ 单调下降(图 1 右上);
- $\Delta N$ 和 $\Delta D$ 随 compute 跨数个数量级扩大(图 1 右中/右下);
- 工程含义:高 compute 下,可以用显著更小的模型 / 显著更少的数据,达到与最优点等价的 loss——为 inference-friendly 配置打开空间。
4.2 下游 metric 的 scaling law fit (fused two-stage)¶
单阶段 vs 两阶段的取舍¶
直接拟合 (N, D) → metric (one-stage) 在 MRE 上很差;先拟 (N, D) → loss、再拟 loss → metric (vanilla two-stage) 误差累计也不行。
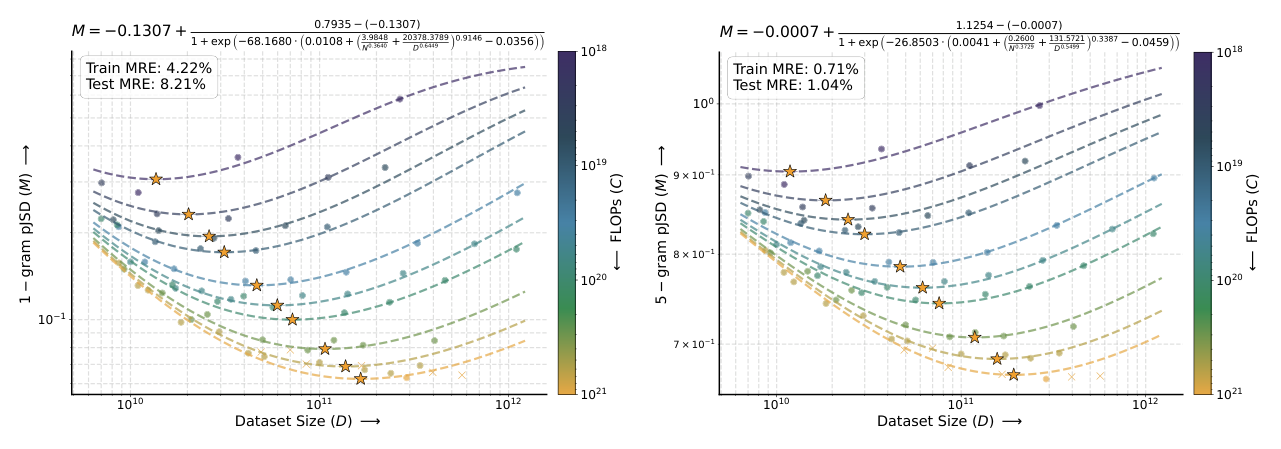
本文提出 fused two-stage approach:先观察到 metric vs validation loss 自然呈 sigmoid 形(饱和到 random performance 与 well-trained optimum 之间):
$$M = \text{sigmoid}(L) = \ell + \frac{h - \ell}{1 + \exp(-k (L - L_0))} \tag{9}$$
把式 (7) 代入:
$$M = \ell + \frac{h - \ell}{1 + \exp\!\left(-k\left(E + \left(\dfrac{A}{N^\alpha} + \dfrac{B}{D^\beta}\right)^\gamma - L_0\right)\right)} \tag{10}$$
所有 8 个参数 $(\ell, h, L_0, k, E, A, B, \alpha, \beta, \gamma)$ 联合优化,避免 vanilla two-stage 的误差累计。
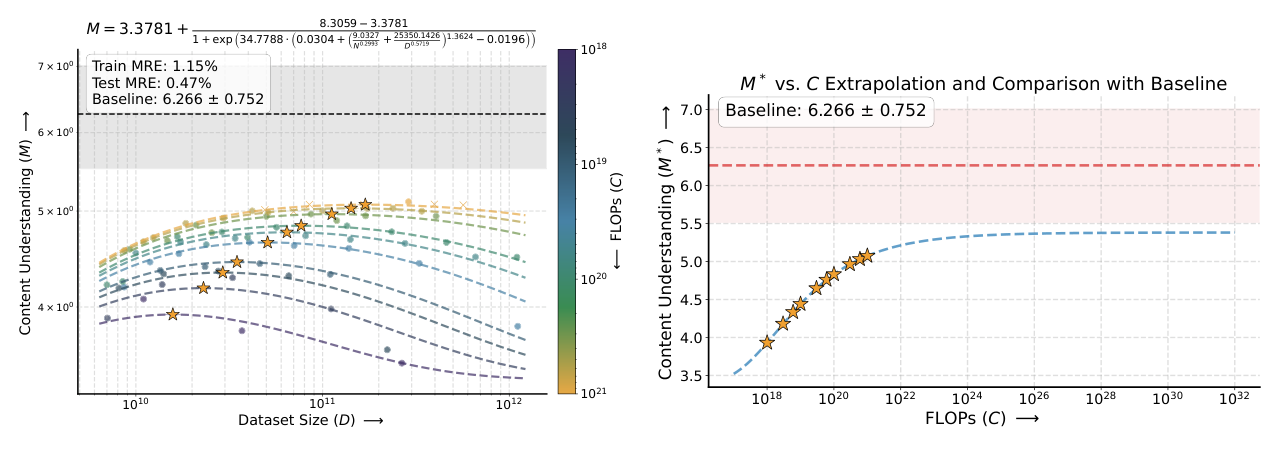
各 metric fit 质量¶
| Metric | Train MRE | Test MRE |
|---|---|---|
| Validation loss (vanilla) | 0.49% | 0.80% |
| 1-gram pJSD | 4.22% | 8.21% |
| 5-gram pJSD | 0.71% | 1.04% |
| Content Understanding (CU) | 1.15% | 0.47% |
结论: 1. n 越大,pJSD fit 越好:5-gram MRE ~1% vs 1-gram ~4.5%;高阶 n-gram 捕捉了更结构化的音节学模式,与 training loss 相关性更强; 2. CE / CU 也呈现 scaling law,但 CE/CU 拟合系数与 loss 拟合系数不完全一致,说明 sigmoid mapping / 联合优化引入了一定 bias; 3. 对 Audiobox CE/CU 这类有真实数据 baseline (mean ± σ) 的 metric,可外推 $M^*(C)$ 与 baseline 区间对比。
关键的负面发现:CU 外推无法触达真实 baseline¶
- CU 的 baseline = 6.266 ± 0.752;
- fit 外推到 $C \to \infty$ 时 $M^*$ saturate 在 baseline ±σ 区间下方;
- 含义:在当前 architecture / data representation / vocoder 设定下,单纯 scale compute 不能让 CD SLM 达到真实数据 CU 水平——某些 perceptual feature 受制于模型表征上限或 vocoder 重建误差,无法仅靠 scaling 突破。
两条 caveat:
- (i) 取决于 functional form 与优化是否充分;
- (ii) 若 fit 正确,则提示 CD SLM 有内在的 representational limitation,必须通过更强 inductive bias、更丰富数据表示,或文本 conditioning 才能弥合。
五、消融实验¶
模型 fix 为 $d_\text{emb}=1024$, 8 layer,训练 512k 小时音频、100 NFE。所有 ablation 单变量扫描,并报告 weak/strong CFG。
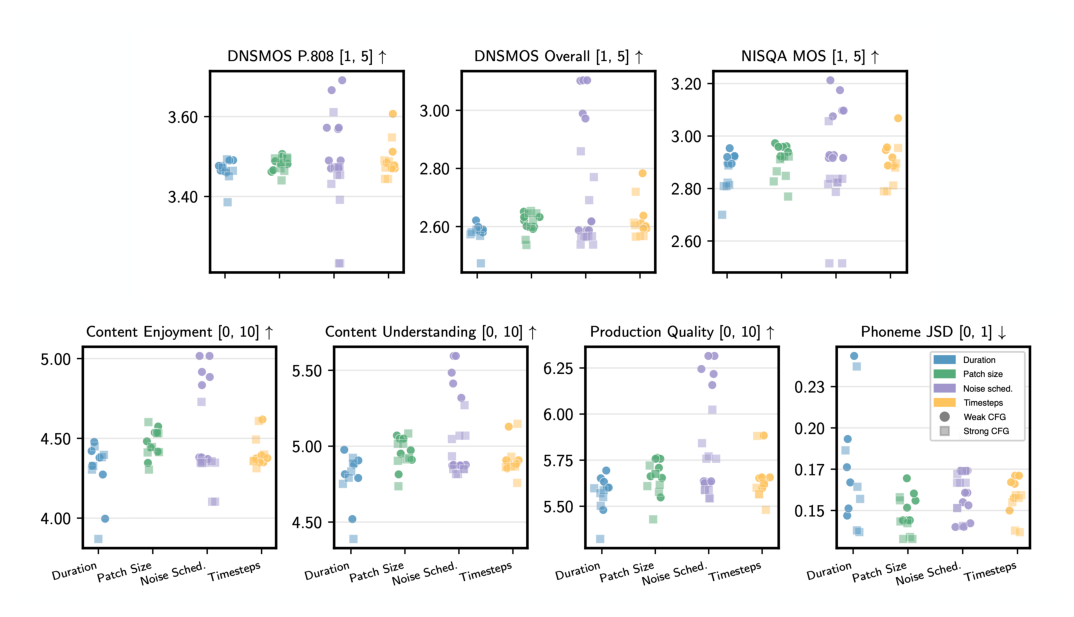
5.1 训练时长 (Duration)¶
- 0.25M – 1.5M hours,0.25M 步进;
- 对 languageness (pJSD) 和 CU/CE 影响最大;与 Section 4 的 scaling 结论一致——data scale 直接驱动 linguistic 学习。
5.2 Temporal patch size $k$¶
- 类似 ViT 的 spatial patching,把 80×T 沿时间方向折叠 $k$ 倍,channel 同步扩 $k$;
- k 从 1 到 6;
- 观察:k 越大、时间分辨率越低,所有 metric 单调退化;
- 结论:高保真生成需要高时间分辨率;patch 虽然能省 sequence length 和 FLOPs,但牺牲了韵律和精细时序细节,对追求自然语音的应用代价过高。
5.3 Noise schedule¶
- 三种 (linear / cosine / exponential) × {with / without zero terminal SNR};
- 对感知质量影响最大(合理:noise schedule 直接决定信号保真);
- cosine 一直跑不过其他两条;
- linear + zero terminal SNR 最好 —— 显式训练 "完全信号被破坏" 的极端有助于 high-noise 端鲁棒性。
5.4 Diffusion timesteps $T$¶
- T ∈ {100, 500, 1000, 2000, 4000},sample 100 steps;
- 更细的 noise level 离散化(更大 T)提供更精确的 noise level target 但提升学习复杂度;
- 论文未给单一最优值,列入 cross-ablation distribution 比较。
5.5 总体观察¶
- noise schedule 是 perceptual quality 的最大杠杆;
- duration 是 languageness 的最大杠杆;
- 这两条耦合 Section 4 的结论:data scale 驱动语言学习,而 model design choice 决定听感上限。
六、Scaling 到 16B 参数¶
6.1 修改架构:注入 Whisper conditioning¶
Section 4 的 scaling law 给出"不可约误差"$E$(式 (7))。该 $E$ 既受架构限制,也受数据表示限制:基础 MM-DiT 用有限上下文 log-mel filterbank 直接 condition,可能存在结构性下界。最近 [Liu et al. 2025] 表明"信息更密集、具有 superposition 性质的表示"能让 scaling 更陡峭。假设:注入信息密度更高的 conditioning 能压低 empirical $E$。
实现: 1. 用 frozen pretrained Whisper-large-v3 encoder 抽 context 的高阶 speech feature(虽然 Whisper 在 speech-text 对上训练,作者只把它当作冻结 feature extractor,不做 text supervision); 2. 输入扩为 300s context、生成 60s continuation; 3. 用 Perceiver [Jaegle et al.] 把 Whisper 特征下采样为 4096 deterministic token; 4. MM-DiT 部分 scale 至 16B parameters; 5. 数据:tens of millions of hours unfiltered conversational speech from SpeechCrawl。
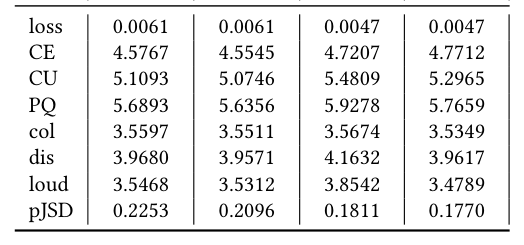
6.2 16B 结果¶
Table 1: 16B CD SLM vs. scaling law trial 中最佳 run。
| Metric | C = 10²¹ CFG=2 | C = 10²¹ CFG=4 | 16B CFG=2 | 16B CFG=4 |
|---|---|---|---|---|
| loss | 0.0061 | 0.0061 | 0.0047 | 0.0047 |
| CE | 4.5767 | 4.5545 | 5.4809 | 5.2965 |
| CU | 5.1093 | 5.0746 | 5.4809 | 5.2965 |
| PQ | 5.6893 | 5.6356 | 5.9278 | 5.7659 |
| col | 3.5597 | 3.5511 | 3.5674 | 3.5349 |
| dis | 3.9680 | 3.9571 | 4.1632 | 3.9617 |
| loud | 3.5468 | 3.5312 | 3.8542 | 3.4789 |
| pJSD | 0.2253 | 0.2096 | 0.1811 | 0.1770 |
注:表中 CE 和 CU 列在原文 Table 1 中数值出现重合(同为 5.4809 和 5.2965),可能是排版错误,但其他指标都呈一致提升。
关键观察: 1. 16B 模型的 validation loss 0.0047 严格低于 base scaling law 的不可约误差 $E = 0.0055$; 2. 这证明 $E$ 不是数据分布的硬下界,而是 architecture + representation 决定的相对下界; 3. 16B 模型生成的语音具有: * 多语种(SpeechCrawl 含约 40% 非英语); * 多说话人; * rich emotion & prosody; * 较短 word n-gram 上的合理 lexical 表现。 4. 但 long-form linguistic coherence 仍然不行 —— 尽管 emotive/prosodic 维度有改进,长篇叙事的逻辑一致性仍有显著差距。
6.3 论文最终立场¶
引用原文(Section 7 Conclusion):
在当前 compute 和语音数据下,进一步 scale SLM 不切实际,除非出现新的语音表示或建模范式,或我们转向 text-speech 模型。
这是一篇罕见地"用 scaling law 论证自身路线 ceiling"的论文。
七、核心贡献总结¶
- 首个 continuous diffusion SLM 的完整 scaling law:覆盖 7 个数量级 compute、4 个数量级 model size、含多种下游 metric。
- pJSD metric:第一个能用于扩散语音模型的、可采样的、可扩展的 languageness metric;并证明 pJSD 自身也服从 scaling law。
- Fused two-stage scaling law fit:把 $L(N,D)$ 与 $L \to M$ sigmoid mapping 联合优化,避免 vanilla two-stage 的误差累计。
- isoFLOP curvature analysis:定量化 "compute 越多越能用 smaller 模型 / 更少 data 达到等价 loss" 的 inference 友好趋势。
- 新的负面发现:标准 MOS metric 不服从 scaling law;某些 perceptual metric (CU) 外推后无法达到 real-data baseline,提示 representational ceiling。
- Whisper-conditioned 16B 模型:证明压低 base architecture 的不可约误差 $E$ 是可行的工程方向,而单纯 scale base architecture 不够。
- 路线判定:基于 quantitative 证据推断,pure-speech SLM 路线在当前条件下不可持续,应转向更丰富表征或 text-speech joint modeling。
八、讨论与局限性¶
与已有 SLM scaling 工作的对比¶
- [Cuervo & Marxer 2024] 给出第一个 AR-on-discrete SLM scaling law,但 fix hyperparameter 跨规模(已知次优 [Bjorck 2024]),可能高估了所需 compute;
- [Maimon 2025] 把 scaling 分析扩展到 interleaved text-speech;
- 本文是 continuous + diffusion 路线的首个 scaling law,与上述两条工作互补,三者拼出 SLM 设计空间的整体 scaling 轮廓。
工程价值¶
- isoFLOP curvature 工程价值最大:实践者可在高 compute 下选 smaller model 而不损失 loss——这对推理成本敏感的语音助手等下游产品意义重大;
- fused two-stage 拟合方法学:可迁移到任何"loss → 下游 metric"的 scaling law 研究,未必局限于语音;
- pJSD 可作为 evaluation harness,被任何在做 generative speech / audio 的实验室复用;
- Whisper conditioning 的成功强化了 frozen pretrained encoder 作为 prior 注入器的价值(无需 text supervision 的形式仍可享受 text-speech pretraining 的红利)。
局限性¶
- fit 范围限制:覆盖的 compute 上限 $10^{21}$ FLOPs,外推到 $10^{30}$ 时函数形式与最优化可能均失效;
fused two-stage 拟合的系数偏差:作者承认 sigmoid mapping 的引入或联合优化引入 bias,base scaling law 系数与单独 loss fit 系数不完全一致;- CU 不可达 baseline 是结论而非证明:文中明确这是依赖 functional form 正确的推断;
- vocoder 依赖:所有生成必须经过 HiFi-GAN vocoder,pJSD 等 metric 部分误差被归因于 vocoder reconstruction,但论文没把 vocoder error 单独 quantify;
- 域窄:训练/评估数据 ≥99% 英语,结论是否在多语言或非英语 dominant 数据上成立仍未知(虽然 16B 模型本身用了 unfiltered multilingual 数据,但 scaling law 部分用的是 filtered 英语);
- "languageness 离 ASR perplexity 还差很远":作者也承认 pJSD 是当下的妥协,长期应迁回 ASR-LM cascade。
对推荐系统研究者的迁移启示¶
虽然本文话题是语音,但 scaling law 的方法论部分对个人文档库中的工业推荐 scaling 研究(如 OneRec / OneTrans / TokenMixer-Large / HSTU 等)具有直接参考价值: 1. fused two-stage approach 可用于推荐场景的 "validation NCE → online metric (CTR、GMV、AB lift)" 拟合,避免直接拟合稀疏在线指标; 2. isoFLOP curvature 分析为"高 compute 下能否用更小模型节省线上 inference 成本"提供量化框架; 3. 保留 outer exponent γ 这一拟合细节对 fit 稳定性的贡献,对推荐 scaling fit 同样适用; 4. "指标无法被 scale 突破"的负面发现对推荐场景同样可能存在——某些用户体验维度(多样性、惊喜度)也许不是单纯 scale 数据/参数能解决的。