ReRec: Reasoning-Augmented LLM-based Recommendation Assistant via Reinforcement Fine-tuning¶
作者:Jiani Huang, Shijie Wang, Liangbo Ning, Wenqi Fan, Qing Li(The Hong Kong Polytechnic University) ArXiv:2604.07851 · 2026-04-09 · 代码开源:https://github.com/jiani-huang/ReRec
1. 研究动机与背景¶
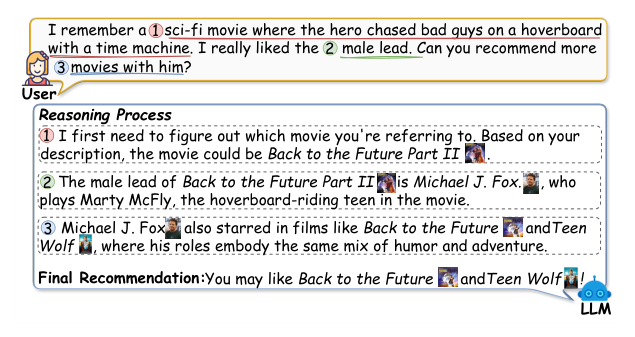
随着 LLM 能力的提升,「智能推荐助手」成为近年活跃方向。理想的助手要能接受复杂的自然语言查询并给出可解释、多步推理后的个性化建议——例如用户描述「我想看一部关于主角从未来回来救世界的科幻片,里面的男主角我很喜欢,有没有其他作品」,系统需要先识别目标影片(《回到未来 2》),再定位主演(Michael J. Fox),再检索他的其它作品并个性化排序。这种场景天然要求多跳推理 (multi-hop reasoning)、反思与纠错 (reflection)、上下文与偏好对齐等能力,远远超出了传统基于 ID 或历史点击的协同过滤/图神经网络方法的能力边界。
现有工作主要有两条路径: 1. LLM-based CRS(如 TallRec、InteRecAgent、CRAG):用 SFT 或 Agent 工具调用在推荐数据上微调 LLM。SFT 容易过拟合、复述训练样本,并造成严重的灾难性遗忘(loss of instruction-following 与 world knowledge)。 2. RFT (Reinforcement Fine-tuning) 推理增强(如 DeepSeek-R1、GRPO、REINFORCE++、RLOO):用规则化 verifiable reward(如 NDCG、Hit)对 LLM 进行在线 RL 训练,鼓励 CoT 风格的多步推理。RL 比 SFT 更能保留通用能力,但把它们直接搬到细粒度的查询驱动推荐场景,有三大核心痛点:
痛点一:奖励信号过粗。 NDCG@K、Hit@K 等任务级奖励只基于最终命中与否;对于「命中但稍微偏离查询约束」的样本或「合理但非 ground-truth」的样本,无法区分好坏,导致信号稀疏、策略崩溃。
痛点二:优势估计只看最终答案。 传统 GRPO/RLOO 把同一 prompt 的多条 rollout 的终局奖励做归一化分配给整条序列的全部 token,无法识别「中间推理步骤错了,但最终被蒙对」或「推理正确但最后答错」的情况,正确与错误的 reasoning token 得到同样的 advantage,削弱了对推理过程的监督。
痛点三:课程难度固定。 复杂查询推荐里不同样本难度差异巨大,均匀采样会导致早期训练阶段被困难样本冲击,策略难以收敛,且大量简单样本被浪费计算。
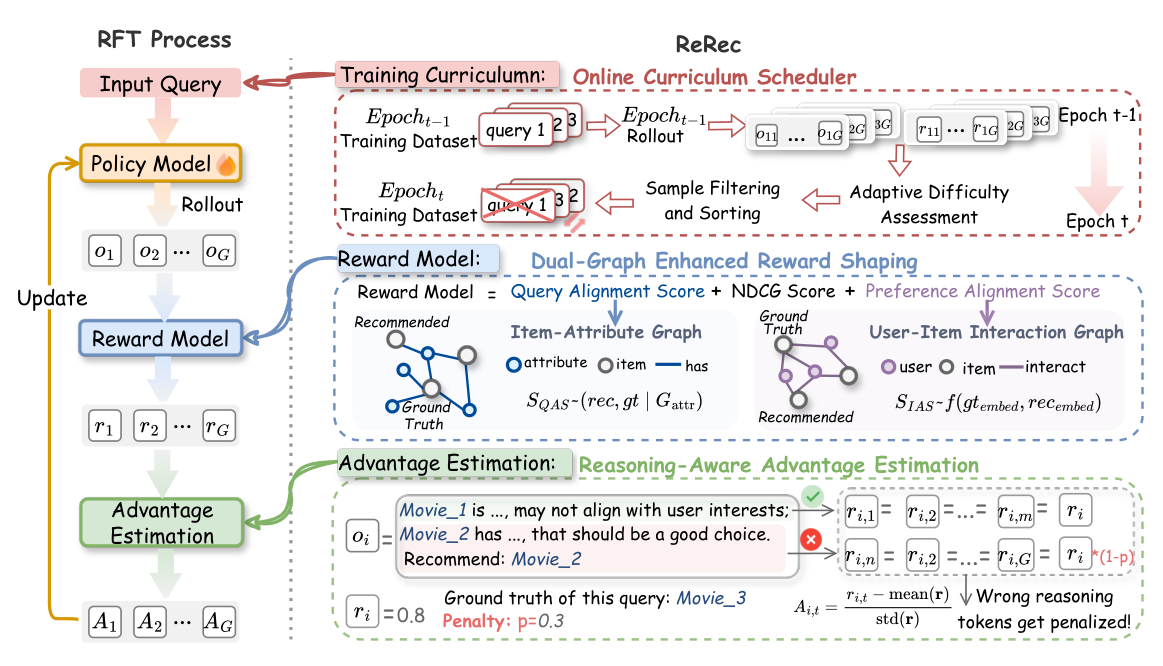
针对以上三点,论文提出 ReRec,一个针对推理增强的 LLM 推荐助手的完整 RFT 框架,核心贡献三件套:
- Dual-Graph Enhanced Reward Shaping:在 NDCG@K 之外,通过 item-attribute graph 和 user-item interaction graph 计算 Query Alignment Score (QAS) 与 Preference Alignment Score (PAS),得到更细粒度的奖励。
- Reasoning-aware Advantage Estimation (RAAE):将 LLM 输出按
\n\n段落切成推理段,对错误推理段施加 token-level penalty,使优势估计对正确/错误推理步骤有区分。 - Online Curriculum Scheduler:在每个 epoch 末,利用之前 rollout 的平均反向奖励作为难度分,做过滤与升序排序,形成下一 epoch 的渐进课程,不引入额外模型或推理开销。
2. 相关工作¶
LLM-based 推荐:RecLLM (Friedman et al. 2023)、TallRec (Bao et al. 2023)、LLM4RecSys 等将 LLM 的世界知识与语言能力引入推荐;但大多基于 SFT,在复杂查询下泛化性差。会话式推荐方面,Yang et al. 2024、Liang et al. 2024 等工作多是简单查询("recommend a sci-fi movie"),缺乏多跳推理。Huang et al. 2025a 的 RecBench+ 数据集首次系统评测复杂推理推荐。
RL for LLM Reasoning:RL-based 推理方法已在数学(DeepSeek-R1、Kimi K1.5)、代码(Logic-R1)、视频理解(Video-R1)、音频(Audio-R1)、机器人(Robot-R1)、图形界面(GUI-R1)等诸多领域验证有效;但推荐场景由于 query-passive、需要领域与世界知识结合等特点,RL for Rec 研究稀少。ReRec 是第一个在细粒度查询驱动推荐里系统引入推理感知 RL 的工作。
3. 方法:ReRec¶
3.1 Preliminaries¶
问题定义:给定查询 $q$,候选池 $C$,LLM 助手 $\pi_\theta$ 生成响应 $o$,其中包含推理段和最终推荐条目 $r_{rec}(q)=o$。目标是最大化生成的最终答案与 ground-truth 的匹配度,并保留原有世界知识与指令遵从能力。
RFT 基础:对每条查询,基于旧策略 $\pi_{\theta_{old}}$ 采样 $G$ 条 rollout $\{o_1,o_2,\ldots,o_G\}$。奖励模型 $\mathcal{R}$ 给每条 rollout 一个分数 $r_i$(默认以 NDCG@K 作为规则化奖励),并对组内做归一化得到 advantage $A_i$:
$$A_i = \frac{r_i - \text{mean}(\{r_1,\ldots,r_G\})}{\text{std}(\{r_1,\ldots,r_G\})} \tag{1}$$
训练目标沿用 GRPO / DAPO 家族的 clipped ratio objective(论文式 (1)):
$$\mathcal{J}(\theta) = \mathbb{E}_{q,\{o_i\}\sim\pi_{\theta_{old}}}\left[\frac{1}{N}\sum_{i=1}^{|G|}\sum_{t=1}^{|o_i|} \min\Big(h_{i,t}(\theta)A_{i,t},\ \text{clip}(h_{i,t}(\theta),\,c_l,\,c_h)A_{i,t}\Big)\right] \tag{2}$$
其中 $N = \sum_{i=1}^{|G|}|o_i|$,$h_{i,t}(\theta)=\frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}$ 为新旧策略比,$c_l=1-\varepsilon$、$c_h=1+\varepsilon$ 为裁剪上下界。
3.2 Dual-Graph Enhanced Reward Shaping¶
只用 NDCG@K 作为奖励过于粗糙:对于「候选中多个 item 都符合 query」的样本,只有 ground-truth 得分,其它合理选项被一视同仁地判错。ReRec 在 NDCG@K 之上增加两路软奖励:
Query Alignment Score (QAS):借助 item-attribute graph $G_{attr}$(节点为 item 与 attribute,边表示 item 具有该 attribute)。令 $R^{G_{attr}}_{p_i}$ 为预测 item $p_i$ 的属性邻居集合,$R^{G_{attr}}_{gt}$ 为 ground-truth $gt$ 的属性邻居集合:
$$S_{QAS}(p_i,gt) = \frac{|R^{G_{attr}}_{p_i} \cap R^{G_{attr}}_{gt}|}{|R^{G_{attr}}_{gt}|} \tag{3}$$
物理含义:预测 item 与 ground-truth 在属性层(如类型、导演、演员)的共享比例。即使没命中原 item,只要属性高度重叠,也给一定奖励,引导模型关注 query 的硬性约束(如「由 Roland Totheroh 担任摄影」必须保留)。
Preference Alignment Score (PAS):仅属性匹配还不够,用户隐含偏好需要用 user–item 交互图 $G_{user}$ 补足。论文在 RecBench+ 数据上预训练一个轻量 LightGCN (He et al. 2020) 得到 item 向量 $\mathcal{M}(\cdot)$,用余弦相似度衡量偏好匹配:
$$S_{PAS}(p_i,gt) = \frac{\mathcal{M}(p_i)\cdot\mathcal{M}(gt)}{\|\mathcal{M}(p_i)\|\,\|\mathcal{M}(gt)\|} \tag{4}$$
物理含义:协同过滤视角下,被相似用户同时喜欢的 item 相似度高,从而惩罚「形式符合 query 但用户不会喜欢」的大众化结果(如 query 里「喜欢 Tom Hanks 的小众片」时,PAS 会压低 Forrest Gump 这种大热门)。
最终综合奖励为 NDCG 与两个图奖励的线性组合:
$$r_i = \text{NDCG} + w_1 S_{QAS} + w_2 S_{PAS} \tag{5}$$
$w_1,w_2$ 控制辅助信号的权重(论文默认 $w_1=w_2=0.01$)。
3.3 Reasoning-Aware Advantage Estimation (RAAE)¶
传统 RFT 把最终奖励分摊给所有 token,这意味着中间推理段即使写了错的结论,只要最终答案对了也会被鼓励;反之即使推理正确,最终答错也会整条受罚。ReRec 的 RAAE 在段落层 (paragraph-level) 引入差分奖励:
段落切分:把 rollout 视为段落序列 $\mathcal{S}=\{s_1,s_2,\ldots,s_K\}$,切分符为 \n\n(问答类 LLM 推理常见格式),满足 $\sum_{k=1}^K|s_k|=|o_i|$。
段落奖励:对每个段落 $s_k$ 判定其推理结论是否正确(通过是否与中间推理目标匹配,如「找到 Michael J. Fox」是否命中);令 $(p,o)\in s_k$ 表示该段中的 (prediction, object) 信号,$r_{s,k}$ 定义为:
$$r_{s,k} = \begin{cases} (1-w_{penalty})\cdot r_i, & \text{if } (p,q)\not\equiv(p,gt) \\ r_i, & \text{otherwise} \end{cases} \tag{6}$$
其中 $w_{penalty}\in(0,1)$ 为超参数,$r_i$ 为该 rollout 的最终综合奖励。含义:错误推理段仍得到 $r_i$ 的一部分奖励,但被 $1-w_{penalty}$ 折算,折损值 $w_{penalty}\cdot r_i$ 直接扣在该段的所有 token 上;正确推理段保留原奖励。
段落级优势:以段落平均奖励为基线,对每个段落单独计算 advantage:
$$A_{s,k} = \frac{r_{s,k} - \text{mean}(r_s)}{\text{std}(r_s)} \tag{7}$$
然后将该段 advantage 广播到段内所有 token:令 token $t$ 属于段落 $s_k$,则 $A_{i,t} = A_{s,k}$。最终 RAAE 产出的 token-level advantage 仍沿用式 (2) 参与策略梯度更新。
物理含义:同一 rollout 内不同段落能得到差异化的 advantage——正确推理段被放大、错误推理段被抑制,在 response 长度内部形成细粒度反馈,显著改善 query-intensive 推荐任务下的学习稳定性与推理精度。
3.4 Online Curriculum Scheduler¶
复杂查询数据集(如 RecBench+)的样本难度跨度极大:简单 Direct Reasoning 与最难的 Misinformed Condition Query 差别巨大。均匀采样既浪费算力又会在训练初期使策略被困难样本冲击发散。ReRec 提出在线课程调度器,不引入额外模型或额外 rollout:
Adaptive Difficulty Assessment:在 epoch $t$ 开始时,用前一个 epoch $t-1$ 的 rollout 结果评估样本难度。对于样本 $q$,用前一个 epoch 的 $G$ 条 rollout 的奖励 $r_i$ 计算难度分:
$$d^{t-1}_q = \frac{1}{G}\sum_{i=1}^G (1 - r_i) \tag{8}$$
即平均「反向奖励」,越高越难。
Sample Filtering and Sorting:设定阈值 $\tau$,滤去 $d^{t-1}_q<\tau$ 的已经学得很好的样本;对剩余样本按 $d^{t-1}_q$ 升序排序,形成新数据集 $\mathcal{D}^t$:
$$\mathcal{D}^t = \left\{(q_{(k)}, d^{t-1}_{(k)})\right\}_{k=1}^{m} \text{ where } \tau \leq d^{t-1}_{(1)}\leq \ldots \leq d^{t-1}_{(m)} \tag{9}$$
Iterative Curriculum Update:$\mathcal{D}^t$ 即 epoch $t$ 的新训练集;过程在每个 epoch 末重复,构建「easy→hard」的渐进课程。由于直接复用 rollout 中已有的 reward,没有引入额外推理或额外模型,几乎零开销。
3.5 整体训练流程¶
伪代码化描述:
- 初始化策略 $\pi_\theta$;预训练 LightGCN 得到 item 向量 $\mathcal{M}$;构建 item-attribute graph $G_{attr}$。
- 对每个 epoch $t$:
a. 对 $\mathcal{D}^t$ 中每个 query $q$ 采样 $G$ 条 rollout。
b. 计算 NDCG@K、QAS(式 3)、PAS(式 4)→ 综合奖励 $r_i$(式 5)。
c. 按
\n\n切段,使用 RAAE(式 6–7)得到段落级 advantage,广播到 token 级。 d. 用 clipped ratio objective(式 2)更新策略 $\pi_\theta$;KL loss coefficient 0.01。 e. 收集本 epoch 奖励;按式 (8)(9) 构建 $\mathcal{D}^{t+1}$。 - 直到 early-stop(patience=1)。
4. 实验设置¶
4.1 数据集¶
在 RecBench+ (Huang et al. 2025a) 上评测,它专门设计来评估复杂查询推荐。覆盖两个 domain——Movie 与 Book,查询分为两大类五子类:
| Category | Sub-category | Movie | Book |
|---|---|---|---|
| Condition-based Query | Explicit Condition (Simple) | 8,426 | 10,681 |
| Implicit Condition (Medium) | 5,790 | 7,741 | |
| Misinformed Condition (Hard) | 5,374 | 7,890 | |
| User Profile-based Query | Interest-based | 2,365 | 1,273 |
| Demographics-based | 209 | — | |
| Total | 22,000 | 27,585 |
五类 query 难度逐级递增:
- Explicit:直接属性匹配(「Charlie Chaplin 主演的影片」)。
- Implicit:多跳推理(「与《Clockers》和《Bamboozled》同一导演的其它作品」)。
- Misinformed:错误前提需要反思纠错(「Mac Ahlberg 担任摄影的《Lorenzo's Oil》」——实际并非)。
- Interest-based:上下文化偏好推理(「浪漫黄金年代的爱情片」)。
- Demographics-based:人口学特征推理(「心理学教授喜欢的片」)。
训练集 10k/10k(Movie/Book),测试集 12k/12k,两个 domain 各自独立训练。
4.2 Baseline 三类¶
- LLM Backbones(zero-shot prompt):Qwen-2.5-3B-Instruct、Llama-3.2-3B-Instruct、DeepSeek-R1-Distill-Qwen-7B、GPT-4o、DeepSeek-R1
- LLM-based CRS:TallRec (LoRA+SFT)、InteRecAgent、CRAG
- RFT-based:GRPO (Shao 2024)、REINFORCE++ (Hu 2025)、RLOO (Ahmadian 2024),均以 accuracy 作为奖励
4.3 实现细节¶
- 硬件:2 张 H20 GPU (96GB)
- Backbone:Qwen-2.5-3B-Instruct、Llama-3.2-3B-Instruct
- 学习率 $5\times 10^{-5}$
- Group size $G=5$
- 最大响应长度 768
- 最多 15 epoch,patience=1 早停
- $w_{penalty}=0.3$
- $w_1=w_2=0.01$
- 难度阈值 $\tau=0.1$
- PyTorch 2.6.0 / vLLM 0.8.5 / Verl 0.3.1 / Ray 2.46
- Batch size 256(策略更新)
- KL loss coefficient 0.01
- Rollout 长度比 1.0
- Clip ratio $\varepsilon=0.2$
- Movie/Book 各 10k 训练、12k 测试
评估指标:Accuracy——每个 query 随机配 19 个负样本 + 1 个正样本(共 20 个候选),模型必须从中选出正确 item,选中即算 accuracy 为 1。
5. 实验结果¶
5.1 RQ1:整体性能¶
Table 2 列出 Movie / Book 两个 domain 下五类 query 的 Accuracy(加粗为最佳、下划线为次佳):
Movie Domain
| Category | Model | Simple | Medium | Hard | Interest | Demographics |
|---|---|---|---|---|---|---|
| LLM Backbone | Qwen-2.5-3B-Instruct | 0.284 | 0.158 | 0.101 | 0.369 | 0.450 |
| Llama-3.2-3B-Instruct | 0.107 | 0.052 | 0.029 | 0.077 | 0.193 | |
| DS-R1-Distill-Qwen-7B | 0.083 | 0.041 | 0.040 | 0.133 | 0.165 | |
| GPT-4o | 0.554 | 0.519 | 0.188 | 0.550 | 0.504 | |
| DeepSeek-R1 | 0.537 | 0.510 | 0.200 | 0.459 | 0.425 | |
| LLM-based CRS | TallRec | 0.453 | 0.513 | 0.284 | 0.571 | 0.509 |
| InteRecAgent | 0.542 | 0.529 | 0.178 | 0.563 | 0.548 | |
| CRAG | 0.560 | 0.531 | 0.195 | 0.557 | 0.543 | |
| RFT on Qwen | GRPO | 0.549 | 0.502 | 0.461 | 0.629 | 0.648 |
| REINFORCE++ | 0.578 | 0.523 | 0.506 | 0.556 | 0.637 | |
| RLOO | 0.560 | 0.495 | 0.529 | 0.573 | 0.614 | |
| ReRec (Qwen) | 0.595 | 0.548 | 0.547 | 0.588 | 0.670 | |
| RFT on Llama | GRPO | 0.686 | 0.600 | 0.644 | 0.651 | 0.642 |
| REINFORCE++ | 0.699 | 0.623 | 0.597 | 0.676 | 0.771 | |
| RLOO | 0.693 | 0.609 | 0.614 | 0.627 | 0.688 | |
| ReRec (Llama) | 0.748 | 0.700 | 0.729 | 0.719 | 0.800 |
Book Domain
| Category | Model | Simple | Medium | Hard | Interest |
|---|---|---|---|---|---|
| LLM Backbone | Qwen-2.5-3B-Instruct | 0.304 | 0.138 | 0.177 | 0.416 |
| Llama-3.2-3B-Instruct | 0.215 | 0.138 | 0.106 | 0.254 | |
| DS-R1-Distill-Qwen-7B | 0.131 | 0.104 | 0.087 | 0.221 | |
| GPT-4o | 0.554 | 0.590 | 0.160 | 0.458 | |
| DeepSeek-R1 | 0.562 | 0.530 | 0.279 | 0.505 | |
| LLM-based CRS | TallRec | 0.563 | 0.591 | 0.251 | 0.477 |
| InteRecAgent | 0.557 | 0.582 | 0.147 | 0.493 | |
| CRAG | 0.573 | 0.621 | 0.211 | 0.518 | |
| RFT on Qwen | GRPO | 0.563 | 0.630 | 0.552 | 0.699 |
| REINFORCE++ | 0.553 | 0.618 | 0.510 | 0.716 | |
| RLOO | 0.567 | 0.649 | 0.532 | 0.716 | |
| ReRec (Qwen) | 0.565 | 0.655 | 0.562 | 0.746 | |
| RFT on Llama | GRPO | 0.664 | 0.725 | 0.713 | 0.786 |
| REINFORCE++ | 0.661 | 0.768 | 0.677 | 0.795 | |
| RLOO | 0.660 | 0.774 | 0.704 | 0.794 | |
| ReRec (Llama) | 0.671 | 0.782 | 0.759 | 0.811 |
结论分析: 1. 基础 LLM 的推理能力决定上限——Llama-3.2-3B 在 zero-shot 条件下远弱于 Qwen-2.5-3B(大概率因为 Llama 3B 的数学/逻辑能力较弱),但经过 ReRec 训练后反而成为 SOTA,说明 RAAE 对「弱 base」的改造收益更大:更弱的模型更容易从 token-level 反馈中学会区分好/坏推理。 2. 越困难的 query,ReRec 相对提升越大:Hard (Misinformed) 上 ReRec 相比次优方法在 Movie 提升 3.76%–13.2%,在 Book 提升亦显著——反映 Dual-Graph reward + RAAE 确实提升了反思纠错与多跳推理能力。 3. LLM-based CRS (TallRec/InteRecAgent/CRAG) 在复杂 query 上塌陷:CRAG 在 Movie Hard 上只有 0.195,远低于 RFT 模型;说明 SFT/Agent 对于推理密集任务的能力有限,RL 的必要性被验证。 4. 纯通用 reasoner (DeepSeek-R1) 并非最优:DeepSeek-R1 在 Hard 的表现(0.200/0.279)低于所有 RFT 模型——说明「通用推理能力 ≠ 推荐场景推理能力」,推荐需要领域奖励信号的塑造。
5.2 RQ2:个性化推荐¶
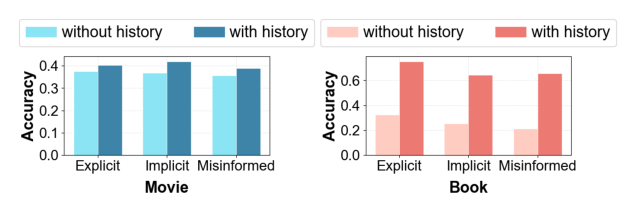
为评估个性化能力,改造 Condition-based Query:给每个 query 配 1 个正样本 + 3 个「硬负样本」(满足 query 但不是用户历史偏好的 item)+ 16 个简单负样本,测试是否引入 user history 能提升选择。对比 without history / with history:
- Movie:Explicit 0.47→0.54;Implicit 0.41→0.52;Misinformed 0.41→0.49
- Book:Explicit 0.54→0.58;Implicit 0.58→0.62;Misinformed 0.50→0.55
结论:引入历史交互后在所有子类、两个域上都有提升,说明 ReRec 能有效融合用户偏好与查询约束,排除「形式符合但偏好不符」的硬负样本——RAAE+PAS 共同作用的体现。
5.3 RQ3:泛化能力¶
跨域泛化(Cross-Domain)¶
Table 3:在 Movie 训练 → Book 测试,反之亦然。
| Training | Method | Base | Movie Test | Book Test |
|---|---|---|---|---|
| zero-shot | prompt | Qwen | 0.240 | 0.301 |
| prompt | Llama | 0.078 | 0.168 | |
| prompt | GPT-4o | 0.470 | 0.453 | |
| prompt | DeepSeek-R1 | 0.411 | 0.474 | |
| Movie (src) | ReRec | Qwen | — | 0.567 |
| ReRec | Llama | — | 0.494 | |
| Book (src) | ReRec | Qwen | 0.406 | — |
| ReRec | Llama | 0.448 | — |
结论:
- Movie→Book:Llama-ReRec 从 0.168→0.494(+181%),显著超过 GPT-4o(0.453)和 DeepSeek-R1(0.474)。
- Book→Movie:Llama-ReRec 从 0.078→0.448(+474%)。
- 跨域迁移不是简单「背答案」,而是学到了可迁移的推理模式(属性抽取→反思→候选排序),验证 ReRec 不过拟合领域语料。
跨任务泛化(Cross-Task)¶
把复杂 query 训练的模型直接迁移到序列推荐(给最近 10 条交互预测第 11 条):
| Model | Accuracy |
|---|---|
| Llama-3.2-3B-Instruct | 0.120 |
| Qwen-2.5-3B-Instruct | 0.286 |
| GRU4Rec | 0.658 |
| SASRec | 0.673 (best specialized) |
| ReRec-Qwen | 0.591 (vs Qwen +107%; best 87.8%) |
| ReRec-Llama | 0.595 (vs Llama +396%; best 88.4%) |
结论:ReRec 在 Movie 复杂 query 上训练,迁移到序列推荐任务无需任何额外微调即可达到 SASRec 的 87.8%–88.4%,实现「推荐助手的跨任务零样本」。
5.4 RQ4:能力保持(Capability Retention)¶
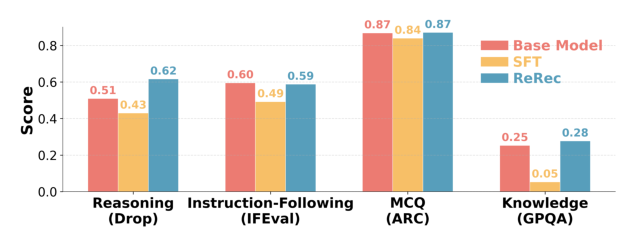
评估对比:base model / SFT / ReRec 在 DROP(阅读推理)、IFEval(指令遵从)、ARC(多选 QA)、GPQA(研究生级 QA)四个通用基准上。
| Benchmark | Base | SFT | ReRec |
|---|---|---|---|
| Reasoning (DROP) | 0.55 | 0.47 | 0.67 |
| Instruction-Following (IFEval) | 0.62 | 0.55 | 0.67 |
| MCQ (ARC) | 0.82 | 0.82 | 0.82 |
| Knowledge (GPQA) | 0.25 | 0.05 | 0.28 |
结论:
- SFT 造成严重灾难性遗忘:DROP -15.7%,GPQA -80%;说明纯 SFT 会让模型退化为「答题机器」。
- ReRec 几乎不损失原始能力,甚至 DROP (+21.6%) 和 GPQA (+12%) 均有提升。因为 RL 的目标是从自身输出分布上微调,未破坏预训练分布;同时 RAAE 的段落级反馈提升了一般推理链。
5.5 消融研究¶
在 Movie 和 Book 上分别移除关键组件后的 Accuracy:
| Variant | Movie | Book |
|---|---|---|
| ReRec (full) | ~0.58 | ~0.59 |
| w/o Dual-graph | ~0.55 | ~0.57 |
| w/o Curriculum | ~0.56 | ~0.58 |
| w/o RAAE | ~0.47 | ~0.51 |
结论: 1. RAAE 是最关键组件(去掉后 Movie 掉到 0.47,降幅最大),验证段落级差分优势估计对推理监督的核心价值。 2. Dual-Graph 次之:提供细粒度 query 与偏好对齐信号。 3. Curriculum:带来稳定性与小幅提升,主要作用是加速收敛。 4. 三个组件相互正交、共同作用才能到达 SOTA。
5.6 参数分析:$w_{penalty}$¶
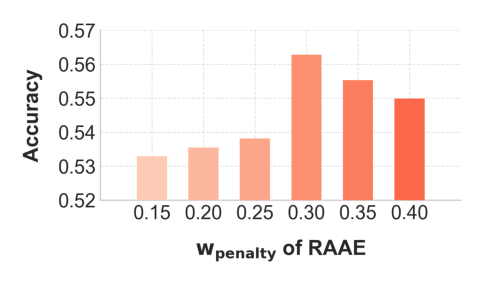
扫 $w_{penalty}\in\{0.15,0.20,0.25,0.30,0.35,0.40\}$:Accuracy 随 $w_{penalty}$ 单调上升到 0.30 后下降。解释:过小则对错误推理惩罚不足,过大则过度抑制探索。默认 $w_{penalty}=0.3$。
5.7 Case Study¶
给定 query「喜欢《Pan's Labyrinth》(2006) 和《Four Rooms》(1995),想找同一摄影师的作品」,ReRec 的推理链: 1. 识别两部影片共同摄影师是 Guillermo Navarro(多跳推理); 2. 列出候选中与 Navarro 相关的影片:《The Long Kiss Goodnight》(1996)、《Hellboy》(2004); 3. 反思——Hellboy 的视觉风格与用户偏好的两部不一致,排除; 4. 最终推荐 The Long Kiss Goodnight。
该案例示范了 Multi-hop Reasoning + Contextual Evaluation 两种能力的组合,正是 ReRec 所追求的「推理增强推荐助手」行为模式。
6. 讨论与局限性¶
核心贡献:
1. 首个针对复杂查询推荐的 RFT 框架,把 reward shaping 与 advantage estimation 两个正交方向一起推进。
2. Dual-Graph Enhanced Reward 把 attribute graph 与 user-item graph 的图信号注入 RL reward,无额外 annotator、无需 reward model 训练。
3. RAAE 是简洁且通用的段落级 advantage 重估方法——\n\n 切段极易实现,可即插即用于 GRPO/RLOO 等主流 RFT;其思想与 process reward model 在精神上相近但开销低得多。
4. Online Curriculum Scheduler 零成本重用训练 rollout 的 reward,避免了昂贵的离线难度标注或额外 inference。
值得借鉴的设计:
- 利用「段落边界」作为 process-level 监督的自然切分点,比 token-level PRM 或 step verifier 便宜得多。
- 在 RL reward 里融入「结构化图信号」而非纯规则化分数,是把传统推荐技巧搬入 LLM Rec 的优雅方法。
- 「在线课程」用 epoch 内已有 reward 代替额外 scoring,零额外算力。
局限性(论文 §7 坦承): 1. 仅单轮对话:ReRec 假设一次查询一次响应,未处理 multi-turn CRS 中意图漂移、对话状态跟踪。 2. 缺少工具调用:对于需要实时检索最新电影上映信息等场景,ReRec 无法联网,必须内生知识。 3. 奖励融合超参较多($w_1,w_2,w_{penalty},\tau$),虽然不大,但在新数据集上可能需要重调。 4. 候选集合较小(20 个 item 选一),与大规模实际召回池差距较大;工业落地前还需研究扩展至千级/万级召回。 5. Domain-specific 图依赖:Dual-Graph 需要 item attribute 与 user–item 交互数据,完全新领域的 cold-start 可能无法预训练 LightGCN。
与已有工作差异:
- vs. TallRec(SFT LoRA):ReRec 用 RL 代替 SFT,保留通用能力;
- vs. GRPO/RLOO(RFT baseline):ReRec 在 reward 层加图信号,在 advantage 层做段落级差分,在 schedule 层引入课程,三维都有改进;
- vs. DeepSeek-R1-Distill(通用 reasoner):ReRec 针对推荐域做定制,Hard query 上大幅超越通用 reasoner。
工业落地想象:复杂查询会话式推荐助手(如 Netflix/豆瓣/Goodreads 的自然语言搜索)是直接应用场景;如果 base LLM 升级到 7B/13B,配合更大候选召回池与 multi-turn,可以作为下一代 CRS 的核心推理引擎。
7. 小结¶
ReRec 用三个相互正交的改进把 RFT 推进到「细粒度查询驱动推荐」这一新场景:Dual-Graph reward shaping 注入属性与偏好图信号、Reasoning-aware Advantage Estimation 提供段落级差分反馈、Online Curriculum Scheduler 以零额外成本构建渐进难度课程。在 RecBench+ 的 Movie/Book 两域五子任务上全面刷新 RFT baselines,特别是在最难的 Misinformed(反思纠错)query 上优势明显;同时跨域迁移(Movie↔Book)和跨任务迁移(→ 序列推荐)均表现出强泛化;更重要的是 ReRec 保持了基础模型的通用推理、指令遵从、世界知识能力,避免了 SFT 的灾难性遗忘。论文定位准确、方法优雅、实验扎实,是 RL for LLM-based Rec 方向的一个重要节点式工作。