PowLU:面向 LLM 稳定预训练的激活函数¶
Ling Team, Ant Group · 2026-05-25 · arXiv:2605.25704 作者:Peijie Jiang, Yuqi Feng, Cunyin Peng, Qian Zhao, Jia Liu, KunLong Chen, Zhiqiang Zhang, Jun Zhou
研究动机与背景¶
在当代大语言模型(LLM)中,Transformer block 内部的前馈网络(FFN)层对整体性能起到关键作用,其核心在于两层线性变换之间的激活函数所提供的非线性。当前主流 LLM(如 Llama 3、Qwen3)普遍采用 SwiGLU(swish-gated linear unit)激活函数(Shazeer, 2020),因为它通过门控机制自适应地调控信息流,能有效提升模型的表达能力与泛化能力。
SwiGLU 的形式是输入 $x$ 与 $\text{SiLU}(x)$ 的乘积,其中 $\text{SiLU}(x) = x \cdot \text{sigmoid}(x)$,因此 $\text{SwiGLU}(x) = x^2 \cdot \text{sigmoid}(x)$。本文指出,正是这一形式带来了数值不稳定的根因:当输入 $x$ 变大时,$\text{sigmoid}(x) \to 1$,于是 SwiGLU 的输出趋近于二次函数 $x^2$。二次函数对大输入有强烈的放大效应,会在前向传播中产生大量 outlier(离群值)。
这一问题随着模型层数增加会因累积效应而急剧恶化,使预训练过程变得不稳定、容易崩溃(collapse)。更严峻的是,当采用低精度训练技术(如 FP8、FP4)时,稳定性挑战进一步加剧——低精度训练对数据分布的范围更加敏感(Chavan et al., 2024; Lee et al., 2024; Hao et al., 2025),SwiGLU 的放大效应会使部分激活值超出对应精度的表示范围,从而限制整体性能与训练稳定性。
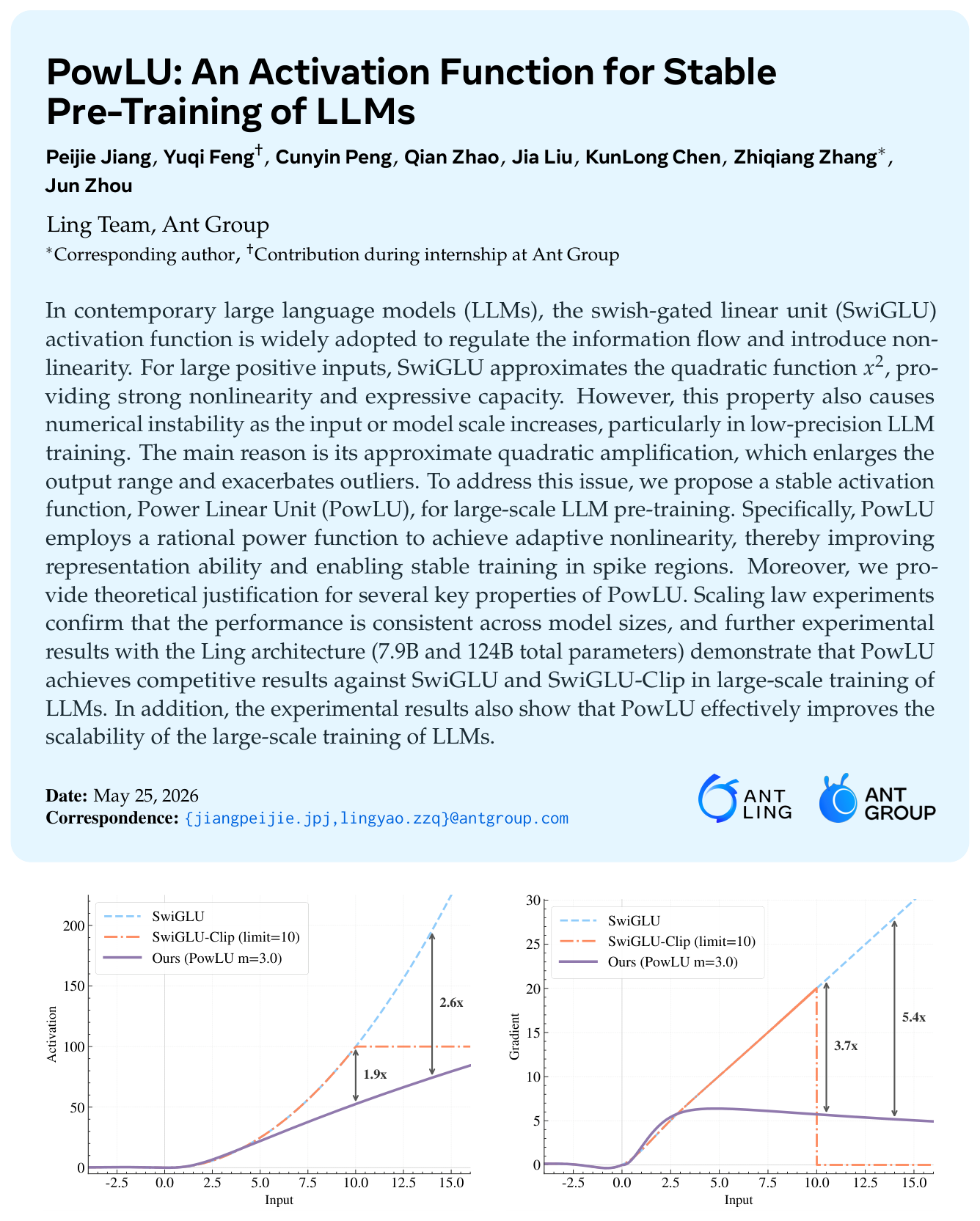
下图(Figure 1)直观对比了 SwiGLU、SwiGLU-Clip 与 PowLU 三者的函数曲线与一阶导数。可以看到,无论是激活输出还是一阶导数,SwiGLU 都显著大于 PowLU,且随输入增大差距持续拉大,最终导致严重的 outlier。在输入约为 15 时,SwiGLU 的激活值约为 PowLU 的 2.6 倍、梯度约为 5.4 倍;SwiGLU-Clip 虽然把激活硬截断到 10,但其梯度在截断点处会出现剧烈的不连续。
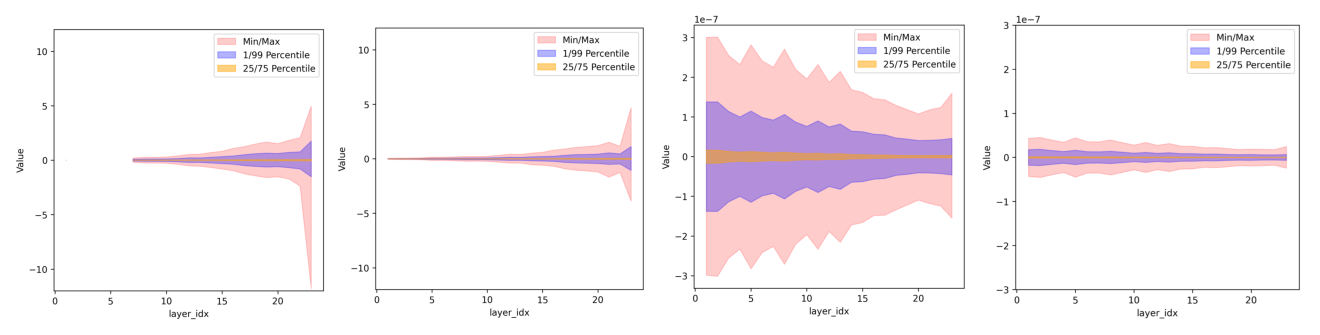
下图(Figure 2)展示了在 7.9B MoE LLM 上以 BF16 精度训练、消耗 400B token 后,专家(experts)线性层的 P99 数值分布可视化。红色带表示从最小值到最大值的全范围(含极端 outlier),紫色带表示 P1–P99(覆盖 98% 分布、反映有效动态范围),橙色带表示 P25–P75(中心 50%)。对比可见:SwiGLU 在前向传播中(Figure 2a)红色带很宽、最大值延伸很大;反向传播中(Figure 2c)这一现象更加突出。而 PowLU(Figure 2b/2d)的红色带明显收窄、极端值被有效压制。这表明 SwiGLU 在预训练过程中引入了大量 outlier,而 PowLU 缓解了这一问题。
为解决上述问题,本文提出新的激活函数 PowLU(Power Linear Unit,幂线性单元)。其核心思想是:当 $x > 0$ 且变大时,PowLU 能有效限制激活值的增长,同时保持非线性以保证表达能力;而当 $x \le 0$ 时,PowLU 的形式与 SwiGLU 完全相同。PowLU 引入一个有理幂函数(rational power function),以输入平方根 $\sqrt{x}$ 来自适应地调节非线性程度,并进一步整合 sigmoid 函数增强非线性。
核心贡献¶
- 提出稳定的激活函数 PowLU:在正输入较大时有效限制输出数据分布的范围,同时保证非线性,缓解了 SwiGLU 输出范围扩张的缺陷。
- 理论刻画 PowLU 的性质:从理论上论证了 PowLU 的连续性、可微性、单调性与有界增长(bounded growth)性质,为其设计提供理论支撑。
- 大规模实验验证:通过 scaling law 实验证明 PowLU 在不同模型规模下表现一致;在 7.9B(B)与 124B 参数的 LLM 大规模预训练中验证有效性,取得与 SwiGLU / SwiGLU-Clip 相当的结果,同时显著降低 loss spike、维持训练稳定性。
与相关工作的定位¶
- 激活函数演进:从 ReLU(不可微于 0,训练不稳)→ GeLU(BERT/GPT 采用)→ GLU 门控机制 → SwiGLU(用 SiLU 替换 sigmoid 门控,提升表达力)。SwiGLU 的二次本质带来训练稳定性挑战,PowLU 在保持非线性的同时限制输出范围。
- LLM 稳定训练:训练不稳定主要表现为 loss spike / gradient spike,可能严重损害性能甚至导致崩溃。已有方法从三方面应对:(a) 优化器视角——梯度裁剪(gradient clipping)、spike-aware Adam with momentum reset(Huang et al., 2025b)及其自适应阈值与动态缩放的稳定变体(Huang et al., 2025a);(b) 架构设计视角——残差连接、层归一化,以及较新的 attention residuals(用对前序层的 softmax 注意力替代固定累加,使各层输出幅度与梯度分布更均匀,Kimi Team, 2026);(c) 激活函数设计视角——SwiGLU-Clip(Agarwal et al., 2025)通过裁剪线性分量、封顶门控分量来抑制激活 outlier,但硬截断会丢弃有用信息。PowLU 正是针对这一痛点:以更平滑的方式抑制激活增长,同时更好地保留表征能力。
核心方法:PowLU 激活函数¶
函数形式¶
PowLU 的形式化定义如下(分段函数):
$$ \text{PowLU}(x) = \begin{cases} x \cdot x^{\frac{m}{\sqrt{x}+1}} \cdot \text{sigmoid}(x), & x > 0 \\[4pt] x^2 \cdot \text{sigmoid}(x), & x \le 0 \end{cases} \tag{1} $$
其中 $x$ 为输入,$m$ 是取值范围 $0 < m < 10$ 的超参数,$\text{sigmoid}(x) = 1/(1 + e^{-x})$ 用于保证 PowLU 的非线性。注意当 $x \le 0$ 时,PowLU 与 SwiGLU 形式完全一致(即 $x^2 \cdot \text{sigmoid}(x)$)。正区间可等价改写为 $\text{PowLU}(x) = x^{1 + \frac{m}{\sqrt{x}+1}} \cdot \text{sigmoid}(x)$。
在实际训练中,PowLU 以门控线性单元(GLU)形式实现,记 $x_1, x_2$ 为同一输入 $x$ 的两路线性投影:
$$ \text{PowLU}(x_1, x_2) = x_1 \cdot f(x_2), \quad f(x_2) = \begin{cases} x_2^{\frac{m}{\sqrt{x_2}+1}} \cdot \text{sigmoid}(x_2), & x_2 > 0 \\[4pt] \text{SiLU}(x_2), & x_2 \le 0 \end{cases} \tag{2} $$
即门控函数 $f(x_2)$ 在正区间用有理幂 + sigmoid,在非正区间退化为 SiLU。
设计动机(为什么是这个形式)¶
公式 (1) 的两个关键设计——指数中的 $\sqrt{x}$ 与分母里的 $+1$——都有明确的动机:
-
为什么用 $\sqrt{x}$:在 $x > 0$ 时,$\sqrt{x}$ 用来减慢激活函数随 $x$ 增大而退化为线性的速度。具体地,当 $x$ 增大时,$m/(\sqrt{x}+1) \to 0$、$\text{sigmoid}(x) \to 1$,PowLU 近似等于 $x$(线性)。$\sqrt{x}$ 能降低 $m/(\sqrt{x}+1) \to 0$ 的速度,从而减慢退化为线性的速度,相比直接用 $x$ 进一步增强了非线性。换言之,$\sqrt{x}$ 让"幂指数偏离 1"这件事衰减得更慢,保留了更多非线性。
-
为什么分母要 $+1$(即 $\sqrt{x}+1$ 而非 $\sqrt{x}$):这是为了保证 $x \to 0^+$ 时的可微性。当 $x \to 0^+$ 时,$m/(\sqrt{x}+1) \to m$,导数可保证存在;但若改成 $m/\sqrt{x}$,则该项在 $x \to 0^+$ 时趋于 $+\infty$,可微性无法保证。因此在分母加常数 1 来规避这一问题。(此设计动机在后文消融实验 Figure 8b 中得到验证:$x^{1+m/x}$ 的梯度在 $x \in (0, 0.5)$ 上几乎消失。)
关键技术细节:理论分析¶
本文在 $m = 3$ 的设定下,理论分析了 PowLU 的四个性质:连续性、可微性、单调性、有界增长性。
连续性(Continuity)¶
当 $x \ne 0$ 时,PowLU 由初等函数复合而成,连续。在 $x = 0$ 处:函数值 $\text{PowLU}(0) = 0$;左极限 $\lim_{x \to 0^-} \text{PowLU}(x) = 0^2 \cdot 1/(1 + e^0) = 0$;右极限 $\lim_{x \to 0^+} 0^{1+m} \cdot 1/2 = 0$(因 $m > 0$ 故右极限为 0)。左极限、函数值、右极限三者皆为 0,故 PowLU 在 $x = 0$ 处连续。
可微性(Differentiability)¶
$x \ne 0$ 时由可微初等函数复合而成,可微。在 $x = 0$ 处分别考察左右导数:
- 左导数:$\text{PowLU}'_-(0) = \lim_{h \to 0^-} (\text{PowLU}(h) - \text{PowLU}(0))/h = \lim_{h \to 0^-} h \cdot \text{sigmoid}(h) = 0$;
- 右导数:$\text{PowLU}'_+(0) = \lim_{h \to 0^+} h^{m/(\sqrt{h}+1)} \cdot \text{sigmoid}(h) = 0$(因 $m > 0$)。
左导数等于右导数(均为 0),故 PowLU 在 $x = 0$ 处可微。
单调性(Monotonicity)¶
$x > 0$ 时,当超参数满足 $0 < m < 10$,PowLU 单调递增。详细推导见附录 A.1(见下文"附录:单调性的完整证明")。
有界增长性(Bounded Growth Property)¶
考察 $x \to \pm\infty$ 两个方向:
- $x \to -\infty$:PowLU 与 SwiGLU 性质一致,收敛到 0。
- $x \to +\infty$:$\text{PowLU}(x) = \lim_{x \to +\infty} x^{1+m/(\sqrt{x}+1)} \cdot \text{sigmoid}(x)$。此时 $\text{sigmoid}(x) \to 1$,指数 $1 + m/(\sqrt{x}+1) \to 1$,故 PowLU 的行为近似 $\lim_{x \to +\infty} x^1 \cdot 1 = +\infty$。
因此 PowLU 在正方向无界、呈近似线性增长,但其增长速率仍低于原始 SwiGLU($x^2$ 的二次增长)。这正是 PowLU 抑制 outlier 的关键:既不像 SwiGLU 那样二次爆炸,也不像 SwiGLU-Clip 那样硬截断丢信息,而是把增长速率平滑地控制在"亚二次、近线性"区间。
实验设置¶
训练设置¶
将三种激活函数(SwiGLU、SwiGLU-Clip、PowLU)放置在 MoE 模型 experts 与 shared experts 的两层线性层之间,遵循 Ling 架构(Team et al., 2025)。模型规模分多档:用一系列小模型做 scaling law 实验;并训练 7.9B 与 124B 参数的大模型(耗费大量 GPU 时)以验证大规模有效性。超参数 $m$ 在主实验中取 3.0(参数研究见消融实验)。所有模型序列长度均为 4096。
评测基准¶
遵循 Ling(Team et al., 2025)的惯例,从三类共 17 个基准评测:
- 世界知识(World Knowledge):AGIEval、MMLU、MMLU-Pro、MMMLU、C-Eval、CMMLU、SuperGPQA、TriviaQA、ARC-challenge。
- 语言与推理(Language & Reasoning):BBH、HellaSwag、WinoGrande。
- 数学与代码(Math & Code):HumanEval、GSM8K、MATH、MGSM、CMATH。
主要实验结果¶
Scaling Law 实验¶
在一系列 MoE LLM(激活参数 26M–368M)上做 scaling law 实验,配置如下(Table 1):
| Act. Params | Layer | Hidden | lr | batch size |
|---|---|---|---|---|
| 26M | 10 | 512 | 0.00156 | 128 |
| 47M | 12 | 640 | 0.0013 | 192 |
| 92M | 16 | 768 | 0.0011 | 256 |
| 199M | 20 | 1024 | 0.00091 | 448 |
| 368M | 24 | 1280 | 0.00077 | 640 |
SwiGLU 与 PowLU 配置保持一致。拟合得到的 loss-scaling 曲线为:
$$ \text{SwiGLU: } \text{loss} = 36.2682 \cdot C^{-0.0659}, \qquad \text{PowLU: } \text{loss} = 36.5547 \cdot C^{-0.0661} \tag{3} $$
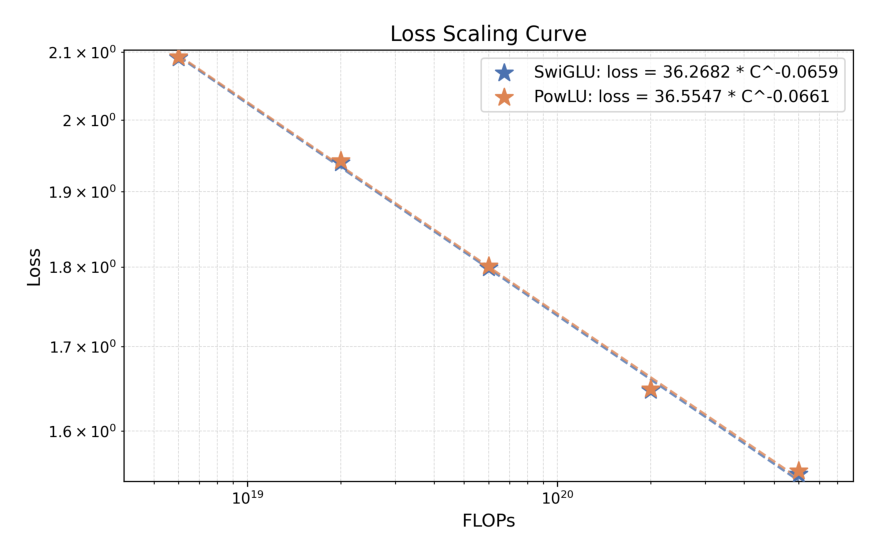
两条曲线几乎完全重合,说明在 26M–368M 激活参数范围内,SwiGLU 与 PowLU 在 MoE LLM 上性能大致相同。结论:PowLU 不会牺牲 scaling 性质——它把"稳定性收益"叠加在了与 SwiGLU 相当的拟合质量之上,而非以损失质量为代价换取稳定。
7.9B 模型结果¶
7.9B 总参数模型,预训练 600B token,PowLU 对比 SwiGLU 与 SwiGLU-Clip 两个 baseline(加粗为最高、下划线为次高,本文用粗体标注最优):
| 类别 | Benchmark | SwiGLU | SwiGLU-Clip | PowLU |
|---|---|---|---|---|
| Trained Tokens | 600B | 600B | 600B | |
| World Knowledge | AGIEval | 31.75 | 30.23 | 31.13 |
| MMLU | 53.95 | 54.12 | 54.92 | |
| MMLU-Pro | 21.56 | 21.79 | 24.00 | |
| MMMLU | 31.77 | 32.40 | 32.61 | |
| C-Eval | 51.99 | 52.62 | 52.96 | |
| CMMLU | 52.69 | 50.24 | 52.82 | |
| SuperGPQA | 17.67 | 17.14 | 17.02 | |
| TriviaQA | 47.86 | 48.87 | 48.18 | |
| ARC-challenge | 51.53 | 51.86 | 55.93 | |
| Language & Reasoning | BBH | 38.82 | 38.22 | 38.96 |
| HellaSwag | 66.24 | 66.31 | 66.46 | |
| WinoGrande | 63.14 | 64.56 | 65.90 | |
| Math & Code | HumanEval | 25.61 | 23.17 | 26.83 |
| GSM8K | 30.40 | 32.30 | 33.74 | |
| MATH | 22.98 | 22.64 | 23.98 | |
| MGSM | 15.93 | 17.40 | 18.40 | |
| CMATH | 63.21 | 63.39 | 63.11 |
结论分析:PowLU 在 17 个基准中绝大多数取得最高分(共 13 项最优),尤其在 ARC-challenge(55.93 vs 51.53,+4.4)、MMLU-Pro(24.00 vs 21.56,+2.44)、GSM8K(33.74 vs 30.40)等推理/数学/知识类基准上提升明显。这表明 PowLU 在增强训练稳定性的同时,保留了理想的非线性变换能力(即未因抑制 outlier 而牺牲表达力),从而有效保持了模型的表征能力。SwiGLU-Clip 由于硬截断丢失信息,整体并未稳定优于 SwiGLU。
124B 模型结果¶
为验证更大规模的有效性,训练 124B 总参数模型,预训练 800B token,对比 SwiGLU 与 PowLU:
| 类别 | Benchmark | SwiGLU | PowLU |
|---|---|---|---|
| Trained Tokens | 800B | 800B | |
| World Knowledge | AGIEval | 53.03 | 53.75 |
| MMLU | 69.10 | 69.14 | |
| MMLU-Pro | 40.75 | 40.12 | |
| MMMLU | 46.27 | 48.10 | |
| C-Eval | 71.74 | 71.56 | |
| CMMLU | 71.58 | 71.41 | |
| SuperGPQA | 25.93 | 26.16 | |
| TriviaQA | 66.31 | 66.91 | |
| ARC-challenge | 77.29 | 83.05 | |
| Language & Reasoning | BBH | 62.07 | 63.36 |
| HellaSwag | 76.23 | 76.24 | |
| WinoGrande | 75.45 | 73.72 | |
| Math & Code | HumanEval | 54.27 | 55.49 |
| GSM8K | 70.81 | 69.90 | |
| MATH | 42.22 | 44.98 | |
| MGSM | 54.00 | 54.80 | |
| CMATH | 80.69 | 83.33 |
结论分析:在 124B 大规模下,PowLU 在多数基准上仍领先(13/17 项最优),ARC-challenge(83.05 vs 77.29,+5.76)与 CMATH(83.33 vs 80.69)、MATH(44.98 vs 42.22)的提升尤为突出。这进一步确认:在更大规模 LLM 上集成 PowLU 能在增强训练稳定性的同时有效保持性能。
稳定性评估¶
本文从 loss spike、张量数值分布、outlier channels 三个角度评估 PowLU 的稳定性。
Loss Spike 分析¶
在大规模 LLM 用 SwiGLU / SwiGLU-Clip 训练时会遭遇 loss spike 导致训练不稳。实验中 loss spike 主要出现在 76,200 训练步之后。
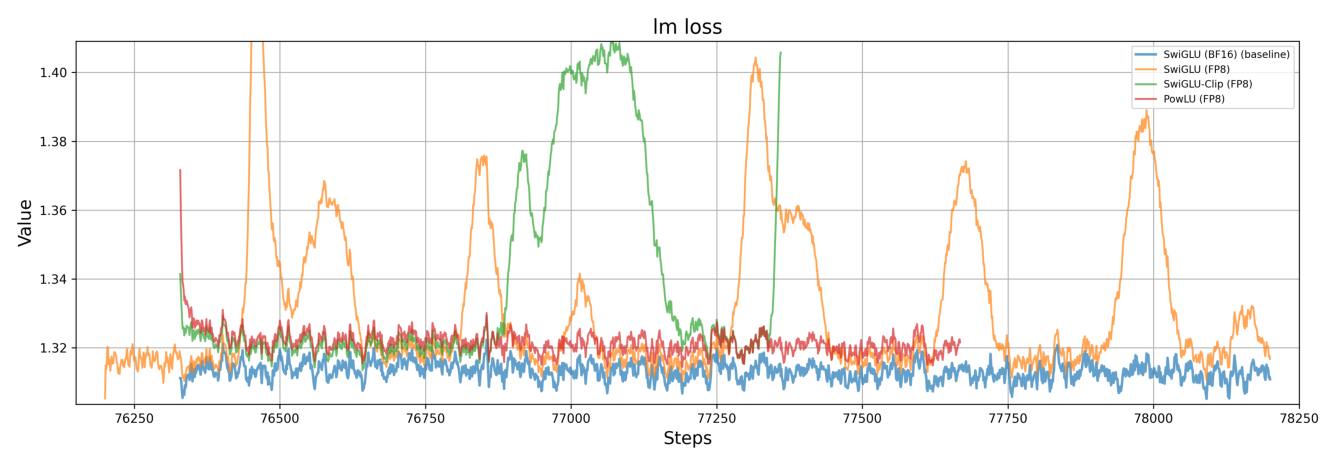
- 蓝线(SwiGLU BF16 基线):loss 较低且稳定。原因有二:其一,BF16 精度高于其他实验(FP8),故 loss 更低;其二,SwiGLU-Clip 与 PowLU 是在训练若干步后替换 SwiGLU 接续训练的,存在 loss 恢复过程,故 loss 值偏高。
- 橙线(SwiGLU FP8):出现明显 loss spike。
- 绿线(SwiGLU-Clip FP8):相比 SwiGLU FP8 延迟了 spike 时机,但在约 77,000 步附近仍发生 loss spike。
- 红线(PowLU FP8):始终维持平滑、低 loss 轨迹,稳定徘徊在约 1.32,无明显偏离。
结论:PowLU 有效缓解了 loss spike,相比 SwiGLU 与 SwiGLU-Clip 显著增强了大规模 LLM 的训练稳定性。
张量数值分布¶
引入分布图监控各层张量数值分布以诊断训练不稳定。与 Figure 2 类似,针对 shared experts 的两类张量收集六个分位统计:前向传播中激活函数后第二层线性层的输入激活张量,反向传播中激活函数前第一层线性层的梯度张量。
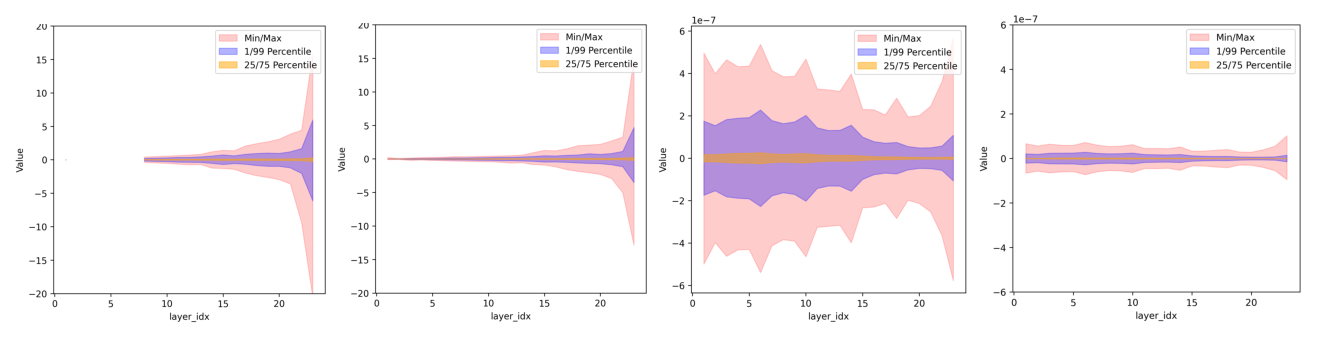
- 前向(Figure 5a vs 5b):SwiGLU 红色带更宽、最大值高得多;PowLU 更收敛。
- 反向(Figure 5c vs 5d):差异更明显。SwiGLU 梯度呈高度波动、扩张的红色带,存在严重梯度 outlier,会破坏训练稳定性;PowLU 反向传播红色带更受约束、最大值更低。
结论:PowLU 在前向与反向传播中都能维持更紧致的 min–max 范围,缓解 outlier,确保更稳定的数值分布。
Outlier Channels 分析¶
为进一步刻画 experts 与 shared experts 张量中的 outlier,对每个张量沿 channel 轴(隐藏维度)计算 $L_2$ 范数并按范数大小降序排列,可视化 outlier channels。


Figure 6 中,SwiGLU(6a/6c)存在大量高强度红蓝区域,表明特定 channel 在前向与反向传播中幅值很大;PowLU 对应可视化(6b/6d)颜色分布更均匀、动态范围被压缩。Figure 7(shared experts)可得到类似观察。
结论:PowLU 有效缓解了极端 outlier,得到更平滑的张量分布,本质上更利于大规模 LLM 训练。
消融与分析¶
超参数 $m$ 的参数研究¶
$m$ 影响 $x$ 较小时的非线性程度。用激活参数 47M 的 MoE LLM、训练 29.8B token,将 $m$ 设为 2、3、4,对比 SwiGLU baseline(Table 4):
| Functions | $m$ | Loss |
|---|---|---|
| SwiGLU | N/A | 1.910 |
| PowLU | 2 | 1.913 (+0.003) |
| PowLU | 3 | 1.912 (+0.002) |
| PowLU | 4 | 1.914 (+0.004) |
结论:SwiGLU baseline loss 为 1.910;PowLU 在 $m=3$ 时取得最佳(1.912,仅比 baseline 高 +0.002)。$m=2$、$m=4$ 分别为 1.913、1.914,略高。这说明 PowLU 的有效性对 $m$ 的取值不敏感,$m=3$ 为本实验最优设置。注意 $m$ 可连续取值,作者仅按 PowLU 与 SwiGLU 曲线间距离选取了 2/3/4 三个代表值。需要强调:这里 loss 略高于 SwiGLU 是合理的——SwiGLU 以牺牲稳定性换取了略低的拟合 loss,而 PowLU 用极小的 loss 代价换来了显著的稳定性收益。
核心组件消融¶
为验证激活函数设计的合理性,针对三个核心组件做消融:指数分母中的 $+1$ 项、sigmoid 函数、指数分母中的 $\sqrt{x}$ 项。为此设计三个对照激活函数(在 $x > 0$ 部分):$x^{1+m/x}$、$x^{1+m/(x+1)}$、$x^{1+m/(x+1)} \cdot \text{sigmoid}(x)$($x \le 0$ 部分均与 SwiGLU 相同)。
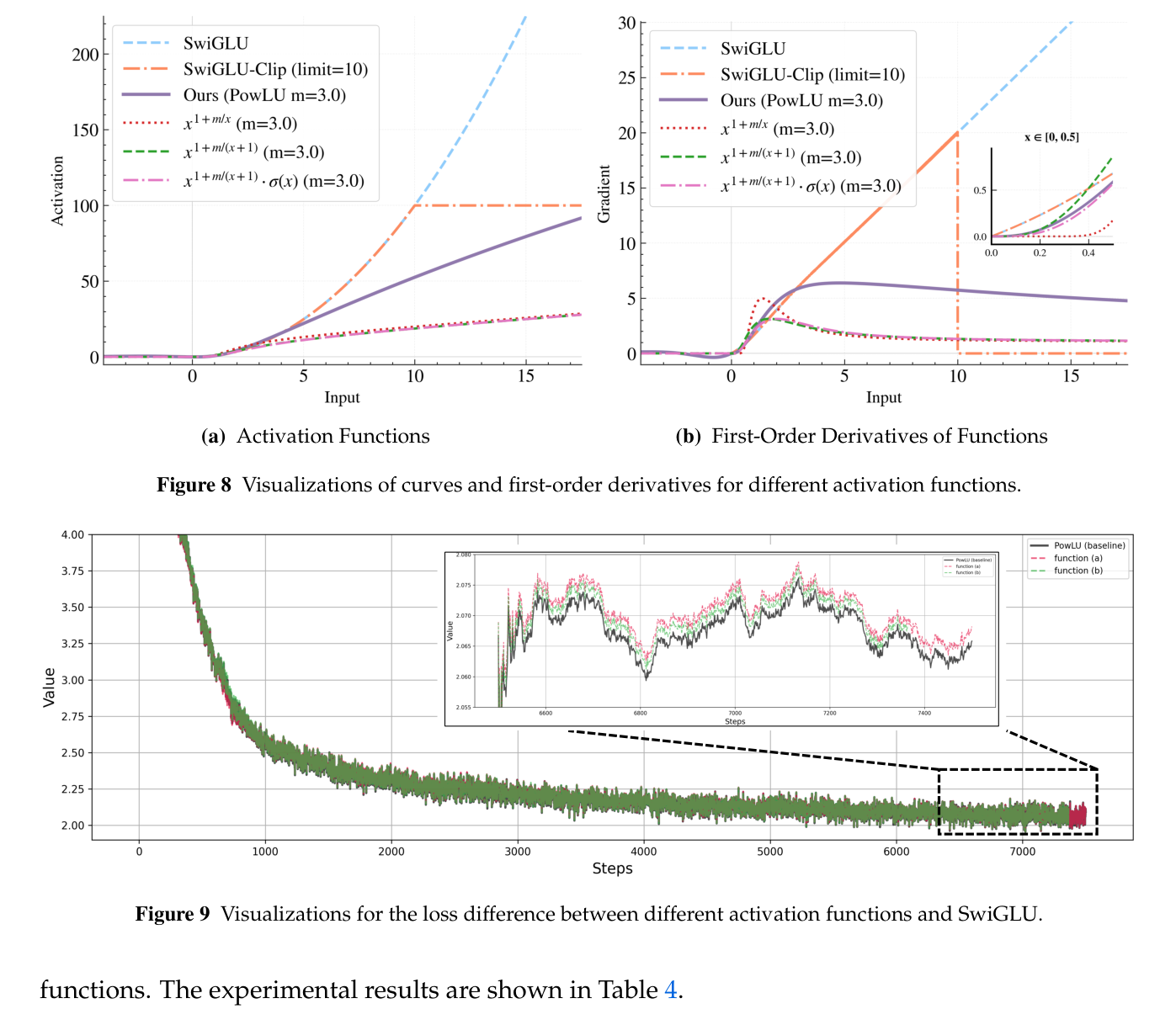
- 曲线(Figure 8a):PowLU 的增长率介于 SwiGLU 与三个对照函数之间;三个对照函数随 $x$ 增大有相似的增长趋势。
- 导数(Figure 8b):PowLU 与三个对照函数的导数都在上升后趋于平台;PowLU 的导数大于三个对照函数。关键观察:子图显示 $x^{1+m/x}$ 的梯度在区间 $x \in (0, 0.5)$ 上几乎不可见——这是因为 $m/x \to +\infty$ 当 $x \to 0^+$。正是为规避这一数值不稳定问题,PowLU 才在指数分母中引入了 $+1$ 项(验证了前文设计动机)。
- 训练 loss(Figure 9):图中 function (a) 指 $x^{1+m/(x+1)}$,function (b) 指 $x^{1+m/(\sqrt{x}+1)} \cdot \text{sigmoid}(x)$。PowLU 相比另两个对照函数取得最低 loss,从而验证了在 PowLU 形式中引入 $\sqrt{x}$ 与 $\text{sigmoid}(x)$ 两项的合理性。
结论:三个核心组件——分母 $+1$(保证 $x \to 0^+$ 可微)、$\sqrt{x}$(减慢退化为线性、增强非线性)、sigmoid(增强非线性)——分别对应解决了"小 $x$ 梯度爆炸"与"非线性不足"两个问题,每一项都对最终性能有贡献。
附录:单调性的完整证明(Appendix A.1)¶
分析 $x > 0$ 时 PowLU 的单调性。记 $x > 0$ 时 $f(x) = x^{1+m/(\sqrt{x}+1)} \sigma(x)$,其中 $\sigma(x) = 1/(1+e^{-x})$。由于 $f(x) > 0$,分析 $f$ 的单调性等价于分析 $g(x) = \ln f(x)$:
$$ g(x) = \left(1 + \frac{m}{\sqrt{x}+1}\right) \ln x + \ln \sigma(x) \tag{4} $$
令 $t = \sqrt{x} > 0$,$g(x)$ 的一阶导数为:
$$ g'(x) = \frac{(t+1)^2 + m \cdot \phi(t)}{t^2 (t+1)^2} + \frac{1}{1 + e^{t^2}}, \qquad \phi(t) = t + 1 - t \ln t \tag{5} $$
分析辅助函数 $\phi(t)$:其导数 $\phi'(t) = -\ln t$,故 $\phi$ 在 $0 < t < 1$ 上递增、在 $t > 1$ 上递减,$t = 1$ 处取全局最大 $\phi(1) = 2$;又 $\lim_{t \to 0^+} \phi(t) = 1$,存在唯一零点 $t_0 \approx 3.59$,使 $\phi(t) < 0$ 当 $t > t_0$、$\phi(t) > 0$ 当 $0 < t < t_0$。
- 当 $0 < t \le t_0$(即 $\phi \ge 0$):
$$ g'(x) \ge \frac{(t+1)^2}{t^2 (t+1)^2} + \frac{1}{1+e^{t^2}} = \frac{1}{t^2} + \frac{1}{1+e^{t^2}} > 0 \tag{6} $$
- 当 $t > t_0$(即 $\phi < 0$):因 $1/(1+e^{t^2}) > 0$,$g'(x) > 0$ 的充分条件是 $(t+1)^2 + m\phi(t) \ge 0$,即:
$$ (t+1)^2 + m\phi(t) \ge 0 \iff m \le \frac{(t+1)^2}{t \ln t - t - 1} \equiv M(t) \tag{7} $$
对 $M(t)$ 求极小:驻点满足 $\ln t = 2 + 4/(t-1)$,解得 $t^* \approx 11.02$,对应 $M(t)$ 最小值约为 $10.02$。因此 $m$ 的上界约为 $10.02$。综上,当超参数满足 $0 < m < 10$ 时,PowLU 单调递增。
附录 A.2 进一步说明非线性:$x > 0$ 时 PowLU 是 $x^{1+m/(\sqrt{x}+1)}$ 与 sigmoid 的乘积,且指数本身是 $x$ 的函数使 $x^{1+m/(\sqrt{x}+1)}$ 非线性,两非线性函数之积仍非线性;$x \le 0$ 时是 $x^2$ 与 sigmoid 之积,同样非线性。故 PowLU 整体为非线性函数。
讨论与局限性¶
核心贡献与可借鉴设计:PowLU 的核心洞察是把 SwiGLU 训练不稳定的根因精确定位到"$x \to +\infty$ 时趋近 $x^2$ 的二次放大",并给出一个比 SwiGLU-Clip"硬截断"更优雅的解法——用有理幂指数 $1 + m/(\sqrt{x}+1)$ 把正区间增长速率从二次平滑压到"亚二次、近线性",既抑制 outlier,又通过 $\sqrt{x}$ 与 sigmoid 保留非线性。三个设计细节($\sqrt{x}$、分母 $+1$、sigmoid)都有明确的理论动机并通过消融逐一验证,工程上是一个 drop-in 替换(只改激活函数,不动其余架构),落地成本极低。从工业落地看,PowLU 直接服务于 FP8/FP4 低精度大规模预训练这一现实痛点:在 7.9B/124B Ling 架构上将 loss 稳定在约 1.32、消除了 SwiGLU/SwiGLU-Clip 在 77k 步附近的 spike,对训练吞吐与成本(避免回滚重训)有实际价值。
局限与争议: 1. 拟合 loss 略逊于 SwiGLU:消融中 PowLU 的 loss 始终比 SwiGLU baseline 高 $+0.002 \sim +0.004$,scaling law 拟合系数也略差(指数 −0.0661 vs −0.0659,常数 36.55 vs 36.27)。PowLU 的价值在于"以极小拟合代价换稳定性",但在不追求低精度/超大规模、SwiGLU 本就稳定的场景下,这一权衡未必划算。 2. 创新偏增量:PowLU 本质是 SwiGLU 的"亚二次化"改造,与 SwiGLU-Clip 同属"激活函数设计抑制 outlier"路线,理论分析虽完整但属于对已有形式的精细打磨,而非全新机制。 3. 稳定性实验的可比性:Figure 4 的核心稳定性证据采用了"训练若干步后替换 SwiGLU 接续训练"的设置(故 PowLU/SwiGLU-Clip 起点 loss 偏高),并非完全从零的同等对照;BF16 基线与 FP8 实验混在同图也使部分对比不够干净。 4. 超参 $m$ 的最优性:仅离散测试了 $m \in \{2,3,4\}$,虽声称不敏感,但未给出连续扫描或不同规模下 $m$ 是否需要调整的证据。
与已有工作的差异:相比 SwiGLU-Clip 的硬截断(丢信息、梯度不连续),PowLU 是平滑抑制(保信息、处处可微);相比优化器侧(spike-aware Adam)与架构侧(attention residuals)的稳定化路线,PowLU 走的是激活函数侧、与前两者正交且可叠加。本文未与优化器侧/架构侧方案做联合实验,三条路线的协同收益有待后续探索。