PAD-Rec: Position-Aware Drafting for Inference Acceleration in LLM-Based Generative List-Wise Recommendation¶
- 作者:Jiaju Chen, Chongming Gao†§, Chenxiao Fan, Haoyan Liu, Qingpeng Cai, Peng Jiang, Xiangnan He*§(中国科学技术大学 / 中关村学院 / Independent Researcher)
- Arxiv:2604.27747(2026-04-30,IEEE TKDE 投稿)
- 关键词:Generative Recommender Systems; Speculative Decoding; Large Language Models
- 代码:https://github.com/Jiaju-Chen/PAD-Rec
研究动机与背景¶
LLM-based 生成式 list-wise 推荐近两年已经成为推荐系统的一条主线:用户历史和指令被编码为 prompt,LLM 自回归地产出"下一批 item"的 semantic-ID 序列(典型如 LC-Rec [17] 在 LLaMA 3.2-1B 上做端到端 list 生成)。这条路线最大的工程瓶颈是自回归解码慢——每个 item 通常用 K=4 个 codebook 层级的 SID token 表示(再加 1–2 个分隔符),生成一个 top-10 列表大约要 m·(K+K')≈59 个解码步,单 query 在 1B 模型上要花约 700 ms(见 Table III),远不能满足实时推荐场景。
通用 LLM 加速的主流是 speculative decoding(SD):用一个轻量 draft 模型一次猜 B 步,再让 target 模型用一个 batched forward 校验,接受最长前缀,每轮跳过若干步。EAGLE 系列 [14] 把 hidden state(feature)也喂给 draft,HASS [15] 进一步把 draft 训练成多步 rollout 形式,缓解了 train-decode mismatch。FSPAD [30]、GRIFFIN [29]、CORAL [31] 沿着这条 feature-based SD 路线再细化,但这些方法都是为通用语言生成设计的,对生成式推荐的两个结构性事实视而不见。

具体来说,在 SD 应用到 LLM-GR 时,作者识别出两个被现有方法忽视的关键事实,并将它们形式化为两个 gap:
- Gap (i):Slot-conditioned semantics are underused(槽位语义被忽略)。每个 item 必由 K 个 SID token 构成,token 的语义强烈依赖它的within-item slot(例如第一个 token 表示 high-level 类目,第四个表示细粒度属性);但现有 draft 模型把所有 token 同质看待,没有任何 slot identity 编码,弱化了 intra-item 结构建模和 draft-target 对齐。
- Gap (ii):Depth-driven uncertainty is unmanaged(深度不确定性未管理)。无论 item 边界如何,越深的 draft step 越依赖更长的历史,越易因误差累积被 SD 校验拒绝;而标准 draft 是 step-agnostic 的,无法在不同深度调节它的提议风格/置信度。
作者据此提出 PAD-Rec(Position-Aware Drafting for Generative Recommendation):在标准 SD 草稿模型上加两个互补的位置信号——item position embedding(IPE)显式编码 within-item slot,step position embedding(SPE)显式编码当前 draft step——并通过两个简单门控(item gate 是可学标量、step gate 是 context-driven sigmoid)调和这两路信号与原始 base feature。模块本身可训练、对原 SD 框架/target 模型零侵入,参数量仅占 draft backbone 的 ~0.01%(B=6 时),在四个真实世界数据集上实现最高 3.1× wall-clock 加速 和相对 HASS 平均 5% 的额外 wall-clock 速度收益,几乎不损失推荐质量。
主要贡献(原文 §I 末尾):
- 据作者所知,PAD-Rec 是首次显式利用 within-item token 位置和 draft-step 位置做生成式推荐 SD 的工作。
- 提出通过将 item-position 与 step-position embedding 注入 draft 模型来加速生成式推荐。
- 在四个真实数据集上实证 PAD-Rec 取得最高 3.1× 加速,且基本保持推荐性能。
前置知识:LLM 生成式推荐 + Speculative Decoding¶
LLM-based generative recommendation 的解码流¶
设用户历史 $\boldsymbol{a}_{1:n}=(a_1,\dots,a_n)$,目标列表 $\boldsymbol{b}_{1:m}=(b_1,\dots,b_m)$。LLM 接受指令模板("After interacting with items
设拼接后的扁平 token 流 $X=(x_1,\dots,x_T)$,response segment 起点为 $t_0$,自回归概率分解为:
$$ p_\theta(X_{t_0:T}\mid X_{1:t_0-1}) = \prod_{t=t_0}^{T} p_\theta(x_t\mid X_{1:t-1}) \tag{1} $$
即每生成一个 SID token 都要做一次 target LLM 的前向。一个长度 m 的 list,加上每 item K 个 SID token + 平均 K' 个分隔符,response segment 大约 $m(K+K')$ 步——这正是延迟瓶颈,且深度随 m 线性放大,对实时推荐尤为致命。
Speculative Decoding 与 EAGLE / HASS¶
SD 引入一个小 draft 模型 $\mathcal{M}_\theta$,每轮:(a) draft 提议一段长度 B 的 候选块(或候选树);(b) target LLM 在一次 batched forward 里对所有候选位置打分;(c) 接受最长被验证前缀,从那里继续解码。接受的前缀长度 τ 越大,speedup 越高。
按 draft 形式分三类:
- Prompt-lookup(如 [23][24]):从 prompt 里 suffix-match 候选;
- Retrieval-based(如 REST [25]):从外部缓存检索;
- Lightweight-drafter(包括 EAGLE 系列):用一个小型预测器并行/回归地提议。
PAD-Rec 工作在第三类。EAGLE [14] 让 draft 不仅吃 token embedding 还吃 target 模型的 hidden state("feature"),让 draft 提议更接近 target 的下一个 hidden state;但它单步训练,与多步推理之间存在 train-decode mismatch。HASS [15] 在训练时让 draft "unrolled" 多个 step(progressive replacement of teacher feature with draft feature)以匹配多步推理。后续的 FSPAD [30]、GRIFFIN [29]、CORAL [31] 都在这条 feature-based SD 路线上细化。PAD-Rec 直接挂在 HASS-style distillation 之上。
为后续记号方便:B 表示 speculation depth(每轮 draft 提议的最大未来 token 数),$B_{\text{train}}$ 与 $B_{\text{test}}$ 可独立设置。
应用到 GR 的两个 task-specific gap(图 1b)¶
将 SD 直接套到 LLM-GR 暴露 §I 描述的两个 gap:
- Slot-positional structure underused:每 item 是固定 K-tuple,token 角色严重依赖 within-item slot,但 draft 没有 slot identity;
- Depth-driven uncertainty unmanaged:深 draft step 不确定性更高,但 draft 的提议风格不随 step 动态调整。
两条挑战指向同一类解药:把"位置"(slot 位置 + step 位置)显式注入 draft,且让模块在不同信号之间灵活权衡——即 PAD-Rec。
核心方法:PAD-Rec¶
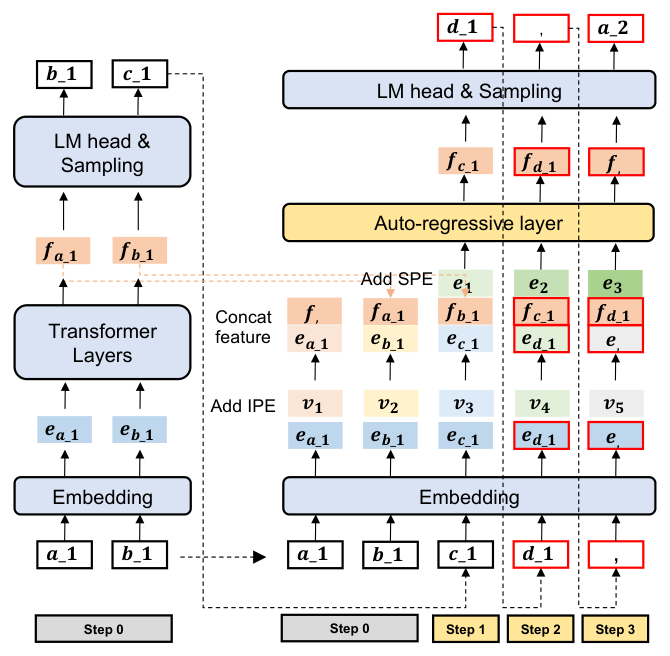
PAD-Rec 在标准 EAGLE/HASS 的 draft 模型基础上插入三件事:(A) Item Position Embedding(IPE),用一个 learnable 标量门 $g_{\text{item}}$ 与 token embedding 融合;(B) Step Position Embedding(SPE),按当前 draft step $j$ 索引的小 embedding 表,再加一个 context-driven sigmoid 门 $g_{\text{step}}(t)$;(C) 一个 HASS-style 多步训练 pipeline,把 IPE/SPE 表 + 门控参数 + draft backbone 全部联合优化。target LLM 完全冻结,draft head 直接复用 target 的 LM head(与 EAGLE 一致)。
A. Item Position Embedding(IPE)¶
每个 item 输出固定 K=4 个 SID token + 分隔符 / 指令 / context token,形成扁平 token 流。作者把 within-item slot 编号 1..K,分隔符与上下文 token 各占独立 marker 编号 sep / ctx,从而对每个流位置 $t$ 得到 slot 标签 $\ell_t \in \{1,\dots,K,\text{sep},\text{ctx}\}$。slot 标签按已知 SID 结构由一个简单规则确定(不需要学习推断)。
对应的 IPE 通过一个 lookup 取得:
$$ \mathbf{v}_t = \text{Emb}^{\text{item}}(\ell_t) \tag{2} $$
$\text{Emb}^{\text{item}}$ 是一个所有位置共享的小 embedding 表。把 IPE 注入 draft 后,draft 同时看到"我现在在生成 item 的第几个 slot",从而学到 intra-item 结构(例如第一个 SID 是粗类目,更安全可早接受;第四个是细属性,分布更杂)。
B. Step Position Embedding(SPE)¶
draft 不只是看流位置,还需要知道当前是 SD 第几步草稿——更深的 step 通常更不可靠。SPE 是另一个 lookup,按 draft 深度 $j$ 索引:
$$ \mathbf{s}_j = \text{Emb}^{\text{step}}(j) \tag{3} $$
实现上 $j$ 从 1 开始,SPE 表大小为 $B_{\text{train}}$(论文用 12,覆盖到推理时所有 $B_{\text{test}}\le12$)。SPE 在训练和推理时一致使用,给 draft 模型显式的"我在第 $j$ 步"条件,使其能针对不同深度调整 proposal 风格。
C. Gating Mechanisms:避免位置信号压垮 base feature¶
直接相加两路位置信号会让原本的 feature/embedding 失衡。作者用两个轻量门控分阶段融合。
设 $\mathbf{e}_t \in \mathbb{R}^d$ 为 token embedding,$\mathbf{f}_{t-1}\in\mathbb{R}^d$ 为前一步的 draft feature,$\mathbf{v}_t\in\mathbb{R}^d$ 为 IPE,$\mathbf{s}_j\in\mathbb{R}^d$ 为当前 draft 深度的 SPE。
Stage-1:slot-aware fusion(IPE 注入)。先把 IPE 加到 token embedding 上(用一个 learnable 标量门 $g_{\text{item}}\in[0,1]$),再与上一步 draft feature 拼接:
$$ \mathbf{f}'_{t-1} = \text{concat}\big(\mathbf{e}_t + g_{\text{item}}\,\mathbf{v}_t,\ \mathbf{f}_{t-1}\big) \tag{4} $$
这一步遵循 EAGLE 的 feature-level drafting 范式(同时基于 token-level embedding 和上一步 draft feature),不打破其结构。
Stage-2:depth-driven fusion(SPE 注入)。把拼接后的 $2d$ 维 feature 投影回 $d$ 维:
$$ \mathbf{z}_{t-1} = \text{FC}_{\text{cat}}(\mathbf{f}'_{t-1}),\quad \mathbf{z}_{t-1}\in\mathbb{R}^d \tag{5} $$
然后用一个 context-driven step gate 调制 SPE 后再加:
$$ \mathbf{f}_t = \mathbf{z}_{t-1} + g_{\text{step}}(t)\,\mathbf{s}_j \tag{6} $$
其中 step gate 不是常数而是与当前 context 相关的 sigmoid:
$$ g_{\text{step}}(t) = \sigma(\mathbf{w}^\top \mathbf{z}_{t-1}) \tag{7} $$
$\mathbf{w}\in\mathbb{R}^d$ 为可学习向量,$\sigma$ 是 sigmoid。这个设计让模型在 draft 不确定性高时自动放大 SPE 影响(更依赖 step prior),而 draft feature 自身 confident 时降权 SPE,避免把"step 信号"当作噪声硬塞进 confident 的预测里。
D. 训练 pipeline(HASS-style multi-step rollout)¶
PAD-Rec 沿用 HASS 的 distillation 框架,target LLM 冻结,draft 端可训参数 = draft backbone(一层 Transformer block)+ IPE/SPE 表 + 门控。蒸馏只在 response segment(SID + 分隔符)上做,instruction/history segment 不算 loss。
设 $\mathbf{x}_{1:T}$ 为 token 流,$t_0$ 为 response 起始;speculation depth 上限 $B$(每轮 draft 至多提议 $B$ 步未来 token)。对每一个 draft 深度 $j\in\{1,\dots,B\}$,将 draft 在深度 $j$ 上的分布与 target 分布做 token 级 cross-entropy(外加 HASS 原有的 Top-$K$ 蒸馏 Aux-loss):
$$ \mathcal{L}_{\text{PAD-Rec}} = \sum_{j=1}^{B}\Bigg\{\sum_{t=t_0}^{T}\text{CE}\Big(P^{(l)}(x_t\mid x_{<t}),\ P^{(s)}_{\theta,j}(x_t\mid x_{<t})\Big) + \text{Aux-loss}\Bigg\} \tag{8} $$
其中 $P^{(l)}$ 是 target LLM 概率,$P^{(s)}_{\theta,j}$ 是 draft 在深度 $j$ 上的条件分布:
$$ P^{(s)}_{\theta,j}(x_t\mid x_{<t}) = \text{Head}\Big(\mathcal{M}_\theta\big(\text{Fuse}(\mathbf{f}_{<t}, \mathbf{v}_t, \mathbf{s}_j)\big)\Big) \tag{9} $$
$\mathcal{M}_\theta$ 是 draft backbone(论文实验用 1 层 Transformer block),$\text{Head}$ 是从 target LLM 复制过来并冻结的 LM head;$\text{Fuse}(\cdot)$ 实现 Eq. (4)–(7) 描述的门控位置融合。
Causal masking & Progressive replacement¶
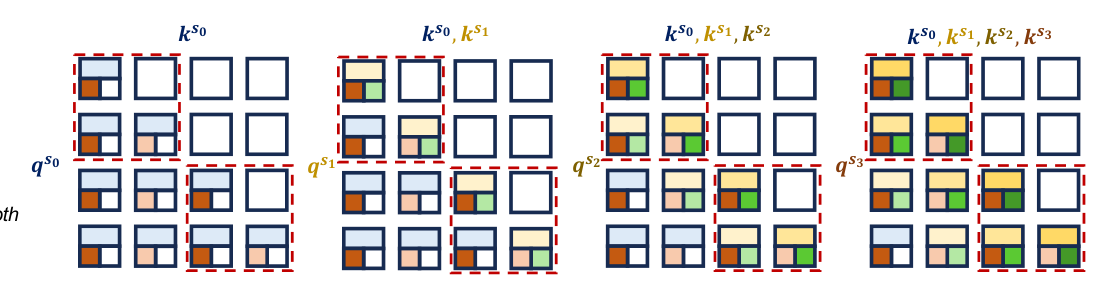
- Causal masking:训练时沿用 HASS 的因果 mask,但调整为"被替换位置只能 attend 到本身 timestep 已可得的状态"(无 look-ahead)。
- Progressive replacement(unrolled rollout):draft 深度 $j=1$ 时 context 全用 target(teacher)feature,深度 $j\ge 2$ 时把 attention context 中最近 $(j-1)$ 个位置渐进地换成早 step 的 draft feature,更早位置仍用 target。这样训练时的 draft 上下文分布与推理时多步 SD 的实际分布一致。每个深度都注入对应的 SPE $\mathbf{s}_j$ 到被替换窗口的 query;IPE 则按 token 位置全程注入(与 step 无关)。
E. Inference¶
推理时,draft 在每一步用对应的 IPE 和 SPE(按当前 draft 深度索引)增强输入,并提议出深度受 $B$ 限制的候选树(采用 EAGLE-2 风格 dynamic tree 的形态:tree width 10,论文超参);target LLM 在一次 batched forward 中校验,接受最长前缀,每轮 batch advance 多个 token。
PAD-Rec 给 draft 加的额外开销:每 token 多两次 lookup(IPE/SPE)+ 两次轻量 scalar gating,相比 draft backbone 本身参数仅约 0.01%(B=6 时)。
实验设置¶
数据与预处理¶
四个公开数据集(Table I):
- Beauty / Instruments / Games:来自 Amazon Reviews [61];
- Yelp:Yelp Open Dataset 的本地商家交互。
| Dataset | #Items | #Inter. | #Seqs | #SD Seqs |
|---|---|---|---|---|
| Beauty | 12,101 | 198,504 | 22,363 | 6,562 |
| Instruments | 9,922 | 206,153 | 24,772 | 5,753 |
| Games | 17,358 | 342,329 | 49,156 | 7,721 |
| Yelp | 20,033 | 316,354 | 30,431 | 13,516 |
预处理流程(沿用 LETTER [40]): 1. 用预训练 encoder(融合语义+协同信号)取 item embedding; 2. RQ-VAE 量化到 SID($K=4$); 3. 按时间排序用户交互,过滤 <11 条交互的用户; 4. 对每个保留用户,最近 10 个 item 作为 target list,前面所有为 history; 5. 8:1:1 user-level split。
SD 数据:先用 LC-Rec [17] 训练 list-wise target LLM;它在 instruction-augmented token 流上的 hidden states 用作 draft 模型的监督信号(feature-level distillation)。
Baselines¶
所有 baseline 共享同一 target LLM、同一 instruction format、同一 EAGLE-2 树式 verification(tree width 10),保证公平对比:
- EAGLE-2 [20]:dynamic draft tree + feature-level 自回归;
- HASS [15]:multi-aligning-step 训练;
- FSPAD [30]:feature sampling + partial alignment distillation;
- GRIFFIN [29]:token-alignable 训练 + token-guided fusion。
评估指标¶
- Wall-clock speedup:autoregressive baseline 的 inference time / SD pipeline 的 inference time(同样配置);
- Average accepted length τ:每个 SD round 平均被接受的 draft token 数,越大表示 target 调用越少;
- Recall@10 / NDCG@10:评估 SD 是否保持推荐质量。
实现细节¶
- 主对比:target LLM = LC-Rec on Llama-3.2-1B-Instruct;scaling 实验另含 3B 与 8B;
- 1B 用 1 张 RTX 3090;3B / 8B 用 4 张 A100;所有延迟测量在 RTX 3090(fp16,batch=1);
- 严格预热生成、CUDA 同步前后计时;只计时 draft proposal + target verify(SD 端)/ 标准生成 loop(AR 端),排除 tokenization / post-decoding / I/O;
- speculative training 用 bf16;学习率 $\in\{1\text{e-4}, 5\text{e-4}, 1\text{e-3}\}$;speculation depth $B=6$;tree width = 10;target/draft 都开 KV cache;
- draft module = 1 层 Transformer(同 backbone);target LLM 冻结;PAD-Rec 只在 draft 侧添加 IPE/SPE 表 + gating。
主实验结果(RQ1)¶
Table II:四数据集 × 两温度 × 五方法(含 Target LLM 对照)¶
报告 Speedup、τ、Recall@10、NDCG@10。Recall/NDCG 旁的 ↑↓ 表示相对 Target LLM 的偏移。
| Dataset | Model | temp=0 Speedup | τ | Recall@10 | NDCG@10 | temp=0.5 Speedup | τ | Recall@10 | NDCG@10 |
|---|---|---|---|---|---|---|---|---|---|
| Beauty | Target LLM | — | — | 0.0486 | 0.0593 | — | — | 0.0569 | 0.0629 |
| EAGLE-2 | 3.00 | 6.83 | 0.0480↓0.0006 | 0.0588↓0.0005 | 2.32 | 5.65 | 0.0531↓0.0038 | 0.0582↓0.0047 | |
| HASS | 3.04 | 6.87 | 0.0483↓0.0003 | 0.0591↓0.0002 | 2.30 | 5.65 | 0.0563↓0.0006 | 0.0628↓0.0001 | |
| FSPAD | 2.83 | 7.21 | 0.0485↓0.0001 | 0.0592↓0.0001 | 2.31 | 5.96 | 0.0541↓0.0028 | 0.0603↓0.0026 | |
| GRIFFIN | 2.82 | 7.83 | 0.0480↓0.0006 | 0.0588↓0.0005 | 2.27 | 6.45 | 0.0523↓0.0046 | 0.0593↓0.0036 | |
| PAD-Rec | 3.07 | 7.35 | 0.0486 | 0.0593 | 2.37 | 6.22 | 0.0546↓0.0023 | 0.0619↓0.0010 | |
| Instruments | Target LLM | — | — | 0.0337 | 0.0462 | — | — | 0.0323 | 0.0382 |
| EAGLE-2 | 2.39 | 4.55 | 0.0337 | 0.0462 | 1.71 | 3.88 | 0.0336↓0.0013 | 0.0411↑0.0029 | |
| HASS | 2.76 | 5.75 | 0.0339↑0.0002 | 0.0463↑0.0001 | 2.24 | 5.01 | 0.0298↓0.0025 | 0.0383↑0.0001 | |
| FSPAD | 3.01 | 7.13 | 0.0339↑0.0002 | 0.0463↑0.0001 | 2.35 | 6.42 | 0.0322↓0.0001 | 0.0390↑0.0008 | |
| GRIFFIN | 3.03 | 7.89 | 0.0351↑0.0014 | 0.0476↑0.0014 | 2.39 | 6.81 | 0.0341↑0.0018 | 0.0400↑0.0018 | |
| PAD-Rec | 3.15 | 7.43 | 0.0337 | 0.0462 | 2.44 | 6.42 | 0.0291↓0.0032 | 0.0376↓0.0006 | |
| Games | Target LLM | — | — | 0.0182 | 0.0221 | — | — | 0.0206 | 0.0220 |
| EAGLE-2 | 2.82 | 7.00 | 0.0182 | 0.0220↓0.0001 | 2.17 | 5.66 | 0.0188↓0.0018 | 0.0202↓0.0018 | |
| HASS | 2.88 | 7.15 | 0.0184↑0.0002 | 0.0222↑0.0001 | 2.21 | 5.93 | 0.0213↑0.0007 | 0.0242↑0.0022 | |
| FSPAD | 2.94 | 7.28 | 0.0182 | 0.0220↓0.0001 | 2.28 | 6.13 | 0.0197↓0.0009 | 0.0229↑0.0009 | |
| GRIFFIN | 2.72 | 8.00 | 0.0180↓0.0002 | 0.0217↓0.0004 | 2.18 | 6.41 | 0.0201↓0.0005 | 0.0217↓0.0003 | |
| PAD-Rec | 2.94 | 7.28 | 0.0182 | 0.0221 | 2.29 | 6.06 | 0.0201↓0.0005 | 0.0221↑0.0001 | |
| Yelp | Target LLM | — | — | 0.0055 | 0.0075 | — | — | 0.0085 | 0.0088 |
| EAGLE-2 | 2.10 | 5.58 | 0.0053↓0.0002 | 0.0074↓0.0001 | 1.68 | 4.80 | 0.0076↓0.0009 | 0.0079↓0.0009 | |
| HASS | 2.29 | 5.84 | 0.0053↓0.0002 | 0.0074↓0.0001 | 1.82 | 4.47 | 0.0076↓0.0009 | 0.0073↓0.0015 | |
| FSPAD | 2.31 | 6.72 | 0.0053↓0.0002 | 0.0074↓0.0001 | 2.06 | 5.31 | 0.0083↓0.0002 | 0.0079↓0.0009 | |
| GRIFFIN | 2.34 | 6.43 | 0.0052↓0.0003 | 0.0070↓0.0005 | 2.13 | 5.32 | 0.0082↓0.0003 | 0.0086↓0.0002 | |
| PAD-Rec | 2.36 | 6.08 | 0.0054↓0.0001 | 0.0074↓0.0001 | 2.20 | 4.77 | 0.0087↑0.0002 | 0.0090↑0.0002 |
Table III:Target LLM naive 自回归延迟(用于把 speedup 还原到绝对 ms)¶
| Dataset | #Queries | temp=0 (ms) | temp=0.5 (ms) |
|---|---|---|---|
| Beauty | 652 | 693.55 | 725.64 |
| Instruments | 588 | 676.70 | 725.43 |
| Games | 757 | 1054.68 | 1060.07 |
| Yelp | 1311 | 882.77 | 917.73 |
例如 Beauty temp=0 下 PAD-Rec 把 693 ms 压到 ≈ 226 ms。
结论分析¶
- HASS vs EAGLE-2:HASS 在所有数据集上 τ 与 wall-clock 都显著优于 EAGLE-2(如 Instruments temp=0:2.76× vs 2.39×;τ 5.75 vs 4.55)。说明把 draft 训练成多步 rollout(暴露 decoding-time 分布)能显著提升验证接受率,而推荐质量基本没变化。这复现了 HASS 在通用语言任务的现象在 GR 上同样成立。
- FSPAD 与 GRIFFIN:两者通过更精细的 feature alignment 提升 τ;GRIFFIN 多次拿到最高 τ(Beauty temp=0:7.83;Instruments temp=0:7.89;Games temp=0:8.00),但其 token-guided fusion 引入额外 MLP 层在 draft 侧,每步的 memory traffic 与 latency 反而拖累 wall-clock,所以"τ 高 ≠ wall-clock 快"。Recall/NDCG 与 Target LLM 基本持平,质量牺牲 marginal。
- PAD-Rec:在 7/8 个 Speedup 列拿到第一名或接近第一(Beauty temp=0 3.07×、Instruments temp=0 3.15×),且 τ 在前两名内。其优势不来自更复杂的 fusion 模块,而来自两个轻量位置信号(IPE+SPE)+ 简单门控——既保住接受率,又压制了 draft 端开销。
- 温度的影响:temp=0 是 deterministic decoding,draft proposal 与 target top-1 高度对齐,所有 SD 方法都能取得长接受前缀和近 max 的 Recall/NDCG。temp=0.5 引入随机性后 speedup 整体下降并出现更大的方差,原因是 draft 训练时基于的是 deterministic 分布,而 stochastic sampling 把生成偏离了训练分布,更容易在中途被验证拒绝。PAD-Rec 在 temp=0.5 下仍稳健(如 Instruments 2.44×),表明 IPE/SPE 提供的结构先验对随机化也有抵抗力。
消融实验(RQ2)¶
主要包含两类消融:embedding ablation(去掉 IPE / SPE / 两者)与 gating ablation(去掉 item gate / step gate / 两者)。空间限制下报告 Beauty 和 Instruments;其余数据集相同结论。
1)Embedding ablation(图 4)¶
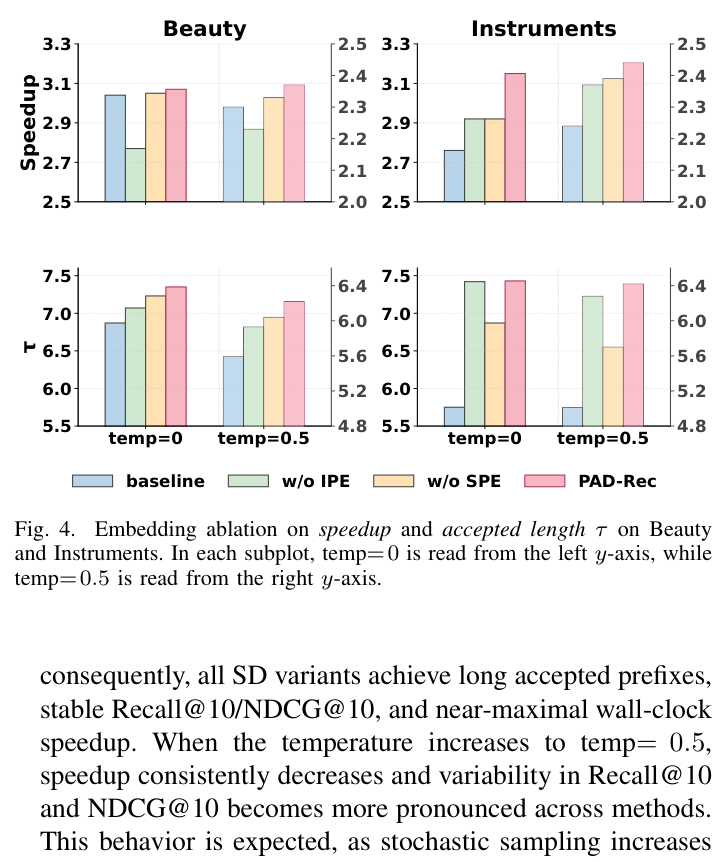
四个变体:Baseline (no PAD-Rec)、PAD-Rec w/o IPE、PAD-Rec w/o SPE、PAD-Rec (full)。
- Full PAD-Rec 最强:在所有数据集与温度上 wall-clock 与 τ 同时拿到第一或接近第一,说明两路位置信号确实增强了 draft-target 对齐。
- Effect of IPE:去掉 IPE 后 speedup 下降明显(结构化 SID 上更甚),说明显式 within-item slot cue 让 draft 提议更易被 target 接受。这解决了 Gap (i)。
- Effect of SPE:在 temp=0.5 下去掉 SPE 损失最大——更深的 draft step 噪声更高,按 step 调节稳定性的 prior 在随机化场景里特别重要。这解决了 Gap (ii)。
- 互补性:两者在所有设置上都能联合超越任一单消融,说明 item-structure 与 depth-adaptive 是正交的有用维度。
2)Gating ablation(图 5)¶
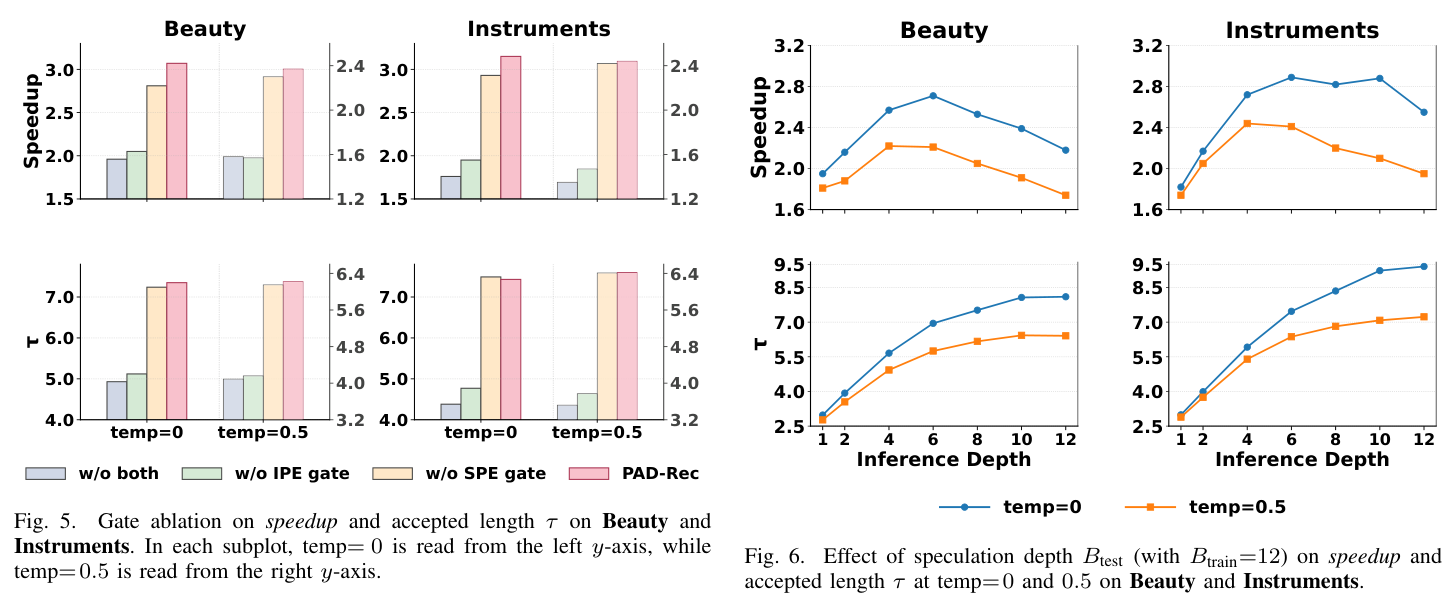
四个变体:w/o both(同时去 item gate 和 step gate,即直接相加)、w/o IPE gate(去 item gate)、w/o SPE gate(去 step gate)、PAD-Rec (full)。
- 去掉两个 gate 最伤:speedup 大幅下降(Beauty temp=0 大约 1.96×,Instruments 大约 1.76×),且 τ 同时降低。把位置信号无门控直接加进去会"砸坏"原本的 base feature,反而拉低接受率。
- Item gate 关键:单独去 item gate 几乎退化到 w/o both 水平。IPE 通常包含较强的离散 slot 标签(K=4 个 slot),不调权直接相加会过度压制 token 语义,需要可学标量门让模型自己决定 slot 信号的注入强度。
- Step gate 增益小但稳定:单独去 step gate(如 Beauty 2.81× vs full 3.07×;Instruments 2.93× vs 3.15×)τ 仅微跌,提示 step gate 主要做"depth-conditioning 微调",是稳定器而不是主驱动。
- Takeaway:item gate 是 slot-cue 主稳定器,step gate 是深度自适应微调器,两者合用得到最稳的接受 + 最好端到端加速。
超参分析(RQ3):speculation depth¶
变化 $B_{\text{test}}\in\{1,2,4,6,8,10,12\}$(训练侧固定 12 以铺满 SPE step):
- τ 单调增长但收益递减:B 增大时 τ 单调上升,B≤6 时近似线性,B>6 后增速明显放缓,τ 收敛在约 7。
- speedup 呈单峰:随 B 增大先升后降,峰值在 $B_{\text{test}}\approx 4$–$6$。这反映出 trade-off:长草稿 → 长接受前缀(增益)vs draft 树越宽越深 → 验证 / 分支开销变大(成本)。结构化输出的"一个 item ≈ 5 个 token"使 $B\approx 4$–$6$ 正好覆盖一个 item 单位,这通常是端到端延迟的 sweet spot。
- 温度差异:trends 一致;temp=0 比 temp=0.5 在 peak 处略快(更稳定的对齐)。
- 部署建议:尽管训练用 $B_{\text{train}}=12$ 来覆盖所有 step(让 SPE 表得到完整训练),实际推理建议用 $B_{\text{test}}=6$ 平衡接受长度与验证 / 分支开销。
模型规模分析(RQ4)¶
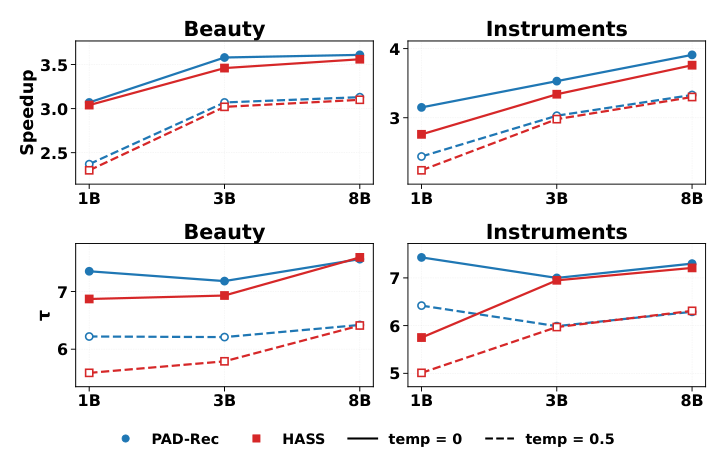
变化 backbone:Llama-3.2-1B-Instruct → Llama-3.2-3B-Instruct → Llama-3-8B-Instruct,固定 $B=6$。每个 backbone 都先做 LC-Rec list-wise fine-tune 得到 target,然后训 draft。
- Speedup 随模型增大而稳健提高:1B → 8B 都呈单调增加,原因是 draft 与 verification 的相对开销随 target 计算量增大而被摊薄。
- 边际收益递减:3B → 8B 的提升小于 1B → 3B,揭示了一个"收益递减"曲线——纯靠 backbone scale 拉 SD speedup 是有上限的。
- PAD-Rec 全程优于 HASS:所有 model size × 温度上 PAD-Rec 都给出更高 wall-clock speedup,且差距未随 size 收敛,说明 IPE/SPE 提供的结构先验对不同规模都有 additive 价值。
- τ 增长温和:τ 随 backbone 增大缓慢上升但变动幅度远小于 speedup,意味着 scaling 主要靠 draft/verify 效率比改善而非接受行为本身的提升。
与已归档相关工作的对比¶
Step 2.5 在归档库中未找到与 PAD-Rec "问题 + 解法双同构"的论文(被剔除候选包括 STAMP、RecoGEM 等:均共享 SID-GR 加速这一上层目标,但解法路径分别为 token pruning + auxiliary multi-step prediction、FP8 PTQ,与 SD 框架内的位置感知草稿模型不构成抽象重合)。本节略。
核心贡献总结¶
- 首次系统化地把 within-item slot 与 draft step 这两个生成式推荐的 task-specific 位置信号引入 speculative decoding,定义并形式化了 "slot-conditioned semantics underused" 与 "depth-driven uncertainty unmanaged" 两个 GR 特有的 SD gap。
- 提出一个插入式、轻量、与 target LLM 完全解耦的 PAD-Rec 模块:两个 lookup 表(IPE / SPE)+ 一个 learnable 标量门 + 一个 context-driven sigmoid 门,参数量仅占 draft backbone 的约 0.01%(B=6)。模块本身可挂在 EAGLE / HASS / FSPAD / GRIFFIN 任一 feature-based draft 之上。
- 在 4 个真实数据集上全面对比:PAD-Rec 拿到 8 个 Speedup 列里 7 个的第一/接近第一,最高 3.1× wall-clock 加速,且对 Recall@10/NDCG@10 几乎无损;相对 HASS 平均额外 5% wall-clock 收益。
- 超参/规模分析揭示了实用部署经验:(a) inference $B^*\approx 4$–$6$ 处于 SD 接受/分支 trade-off 的 sweet spot,对应"一个 item 单位";(b) speedup 随 backbone scale 单调增长但边际递减,且 PAD-Rec 的优势在所有规模下保持。
讨论与局限性¶
值得借鉴的设计:
- 结构感知的位置先验注入 = 极便宜的 SD 改造。PAD-Rec 没动 SD 框架本体(仍是 EAGLE/HASS draft+verify),仅靠两个 embedding lookup 把任务结构注入 draft,就能在 ground baseline 之上稳定再拿 5% wall-clock。这一思路对所有"输出有显式结构"的生成任务(多模态生成、SQL/代码生成、JSON 生成)应该都能直接迁移:把"slot-id"换成"语法 role-id"或"AST node-id",把 step-id 保持。
- context-driven step gate(Eq. 7) 比固定标量门更鲁棒。它让模型在 draft 自身 confident 时压低 step prior,在 uncertain 时放大它。这一 design pattern 对很多 multi-source 信号融合都适用。
- 训练时把 SPE 表训满($B_{\text{train}}=12$)但推理用更小的 $B_{\text{test}}=6$:在保证 step embedding 完整训练覆盖的同时,避免推理时陷入收益递减区。
主要局限:
- 公开数据集 + 离线指标:没有线上 A/B、没有真实流量延迟。1B target 在 RTX 3090 上单 query ≈ 700 ms 的 absolute 数字仍然偏高,3.1× 加速也只到 ≈ 230 ms,离工业 latency budget(10–100 ms 量级)还有距离。要进一步看 PAD-Rec 在 batched 推理 / 分布式部署 / 业务延迟服务质量上的表现。
- temperature=0.5 下 Recall/NDCG 偶有 visible drop(如 Beauty temp=0.5:Recall 0.0546 vs Target 0.0569,下降 4%)。虽然主文 framing 是"largely preserving",但在严格质量约束下 SD 的随机化稳健性仍是一个公开问题。
- K=4 的 SID 假设 较强,PAD-Rec 直接把 IPE 表大小固定在 K+sep+ctx,更大 K 或层次化更深(如 RQ-VAE level=8)的 SID 是否仍以同样形式插入需要再验证。
- draft module = 1 层 Transformer block 是一个固定选择,没有与更大 / 更小 draft 容量做交叉消融,无法判断 PAD-Rec 的收益是否会被更强的 draft 自然吸收。
- 没有与训练加速类工作(如 STAMP 的 SAP/MAP)对比 / 联合。两条路线分别削减训练侧(pruning + denser supervision)和推理侧(structure-aware SD),理论上可以叠加:先用 STAMP 削去冗余 token + 加密监督得到更高质量的 target LLM,再挂 PAD-Rec 做推理加速。这是后续工作的明显方向。
与已有工作的差异:PAD-Rec 不是 SD 的范式革新(仍属 lightweight-drafter / feature-based 派),而是对生成式推荐场景的 SD 适配的一次 surgical 改进——通过 task-aware 位置先验最小化 draft-target gap,而不引入 heavy fusion module(FSPAD、GRIFFIN)的额外开销,从而在 wall-clock 维度上构成新的 Pareto 最优点。