PIANO:面向音乐搜索优化的信息聚合节点个性化重排¶
NetEase Cloud Music(网易云音乐),arXiv:2606.16641,2026-06-15
一、研究动机与背景¶
音乐流媒体平台高度依赖搜索来连接用户与具体内容。与以"短期新鲜度"为核心的短视频信息流不同,音乐曲目具有很长的生命周期和持久的艺术价值——一首老歌可能在多年后依然被反复收听。这给搜索重排(re-ranking)带来了独特挑战:系统既要对齐用户当下的查询意图,又要兼顾其长期的收听偏好,才能保证持续的满意度。同时,工业场景还要求在用户体验与商业目标之间取得平衡,这就要求对点击率(Click-Through Rate, CTR)与转化率(Conversion Rate, CVR,本文特指点击后触发的付费会员订阅)做联合优化。
作者指出,尽管搜索重排在该领域作用关键,现有重排框架存在两个根本性缺口(gap):
缺口一:意图对齐不充分(intent alignment is insufficient)。 多数序列模型(如 DIN、SASRec)只编码用户的行为序列(item 交互历史),却忽略了历史查询(historical queries)中蕴含的丰富语义信号。即便是近期的 query-aware 工作(如 He et al. [14]),通常也只使用静态的查询表征(如平均池化)。作者举了一个生动的例子:一个平时频繁收听 fast-paced pop(快节奏流行乐) 的用户,可能突然搜索 calm piano for studying(适合学习的舒缓钢琴曲)。如果不显式建模查询序列,系统就无法过滤掉与当前情境不一致的历史偏好,从而推出不相关的结果。
缺口二:列表级多目标优化仍然困难(list-level multi-objective optimization remains challenging)。 现有 listwise 模型大多面向单目标任务(如只优化 CTR),或依赖 item 级代理(item-level proxies)来处理多目标。传统多目标方法在 item 层面平衡 CTR 与 CVR 的冲突,却忽视了这些权衡如何在整个排序列表上体现。作者举例:一个 item 级多目标排序器可能因为某首付费内容歌曲的 CVR 分高,就把它顶到列表最前面,即便把它放在一堆免费独立音乐中反而会损害整个列表的点击率。这种跨 item 的权衡无法被 item-wise 打分捕捉,直接把这类方法套用到音乐搜索上,会无法刻画整个 slate(列表)的整体效用,导致商业目标的次优平衡。
为弥合这两个缺口,作者提出 PIANO(Personalized reranking via Information Aggregation Node for music search Optimization),一个 listwise 重排框架,包含两个核心创新:
- Query-Driven Interest Refiner(QDIR,查询驱动的兴趣精炼器):利用历史查询序列,通过 cross-attention 动态精炼长期偏好,使其对齐当前查询意图;
- Information Aggregation Node(IAN,信息聚合节点):一个可学习的
[CLS]式 token,由 QDIR 输出的 query-conditioned 用户兴趣初始化,用于聚合候选列表的全局上下文,并直接在 list 级别预测 CTR/CVR,实现多目标监督。
主要贡献可总结为三点:
- Query-Aware 兴趣建模:提出 QDIR,用历史查询序列动态对齐长期偏好与短期查询意图;
- 列表级多目标优化:设计 IAN,一个
[CLS]式 token,聚合列表上下文做直接的多目标预测,避免 item 级代理优化; - 工业验证:在公开数据集上做大量离线实验,并在网易云音乐线上 A/B 测试中取得 CTR +0.62%、CVR +4.45% 的显著收益。
二、相关工作与定位¶
序列用户兴趣建模。 自注意力模型(如 SASRec)建模长程依赖,工业系统(BST、DIN、SIM)将行为序列与丰富特征结合。MIR、RAISE 等进一步用多级 set-to-list 交互、基于评论的意图建模来丰富个性化重排。He et al. [14] 通过异质序列把 query 引入序列建模,但依赖静态查询表征(如平均池化),没有针对历史查询做 cross-attention,难以捕捉音乐搜索重排中的快速意图漂移。PIANO 的 QDIR 则用 query-aware cross-attention,基于当前查询动态精炼长期偏好。
Listwise 重排与上下文建模。 现有方法大致分两类:一阶段打分模型——从 RNN(DLCM、Seq2Slate)演进到自注意力机制(PRM、SetRank、RankFormer);两阶段排列框架(PRS、PIER、CLIG),将候选生成与评估解耦以平衡效率与效果。为捕捉全局上下文,这些方法常依赖 [CLS] 式 token 或 set-to-list attention,但这些节点很少受真实 list 级结果的监督。值得特别区分的是 RankFormer [4]:它也给 listwise Transformer 增加了一个 [CLS] token 并用 listwise 目标监督,但其 listwide 标签是合成的(取列表中 item 标签的最大值),而且该 token 本身只是一个通用可学习参数;相比之下,IAN 由 QDIR 的 query-conditioned 用户兴趣初始化,且直接受真实 per-list CTR/CVR 在多目标框架下的监督。在用户上下文整合方面,PEAR [20] 等虽引入历史,但只用 item 历史编码,缺少对过去偏好与当前意图的显式 query-conditioned 对齐——对音乐搜索这类动态场景而言并不理想。
多目标重排。 ESMM、MMoE、PLE 等 item 级多任务模型联合预测多目标,但忽略重排时的跨 item 依赖。Nguyen et al. [26] 用 Kendall tau 正则化做多方利益排序,CMR [9] 用超网络调节任务权重。PRECTR [8] 通过条件概率融合耦合相关性匹配与 CTR 预测,并加 batch-wise listwise 一致性正则,但其监督仍定义在 per-item 点击标签上而非 per-list 结果。SORT-Gen [5] 用带 ordered-regression 监督的自回归生成做 list 级多目标优化;相比之下,PIANO 采用判别式框架,用一个受显式监督的 [CLS] 式聚合器(IAN)在单次前向中预测 per-list CTR/CVR,实现高效的端到端联合优化。
三、问题定义¶
一个多阶段搜索/推荐流水线通常由召回(matching)、排序(ranking)、重排(re-ranking)组成。记排序阶段输出的结果列表为 $I = (i_1, \ldots, i_M)$。令 $\Pi_M$ 为 $\{1, \ldots, M\}$ 所有可能排列的集合,对 $\pi \in \Pi_M$ 记 $\pi(I) = (i_{\pi(1)}, \ldots, i_{\pi(M)})$。则重排器选择:
$$\pi^* \in \arg\max_{\pi \in \Pi_M} \ \lambda\, U_{\text{clk}}(\pi(I), C) + (1-\lambda)\, U_{\text{conv}}(\pi(I), C) \tag{1}$$
其中 $\lambda \in [0,1]$ 控制点击导向与转化导向两个 list 级目标之间的权衡,$C$ 为上下文。在音乐搜索场景中,click 指用户点击/播放返回列表中的歌曲,conversion 指点击交互后触发的付费会员订阅——这是音乐流媒体平台的关键营收指标。$U_{\text{clk}}(\cdot)$ 与 $U_{\text{conv}}(\cdot)$ 是 list-wise 效用函数:$U_{\text{clk}}$ 表示列表上的期望平均点击数,$U_{\text{conv}}$ 表示期望平均转化数,二者都通过在整个排序列表 $\pi(I)$ 上聚合 item 级预测来计算,因此必须有一个能捕捉全局列表依赖的模型。
作者采用加权和标量化(weighted-sum scalarization),通过变化 $\lambda$ 让系统在实践中扫出近似 Pareto 前沿的工作点。
四、核心方法与模型架构¶
4.1 整体架构¶
如图 1 所示,PIANO 由两个核心组件构成:QDIR 与 IAN。给定输入信号(当前 query、用户历史、候选 item),PIANO 首先由 QDIR 抽取 query-conditioned 用户兴趣,并用它初始化 IAN,将 IAN 作为前缀(prepend)拼接到候选列表前。随后通过一个 Transformer,模型同时优化 item 级与 list 级的业务指标。
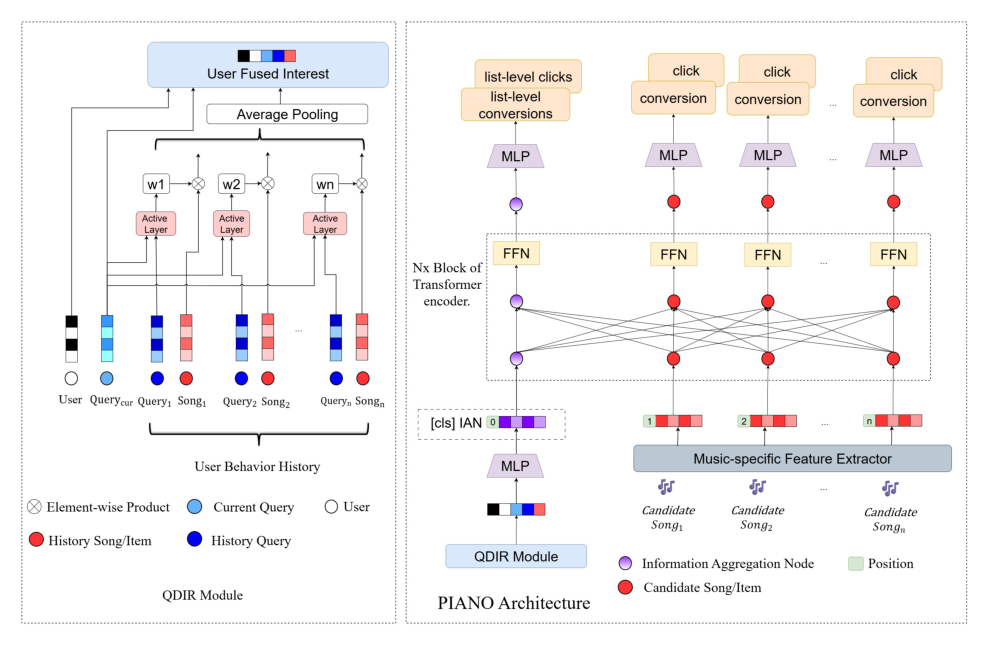
4.2 音乐专用表征模型(Music-specific Representation Model)¶
为捕捉音乐领域的语义,作者基于 Qwen3-Embedding-0.6B 构建表征模型,在域内的 query–song 对上用任务专属 prompt 微调(fine-tune)。如图 2,模型采用双塔(dual-tower)设计:
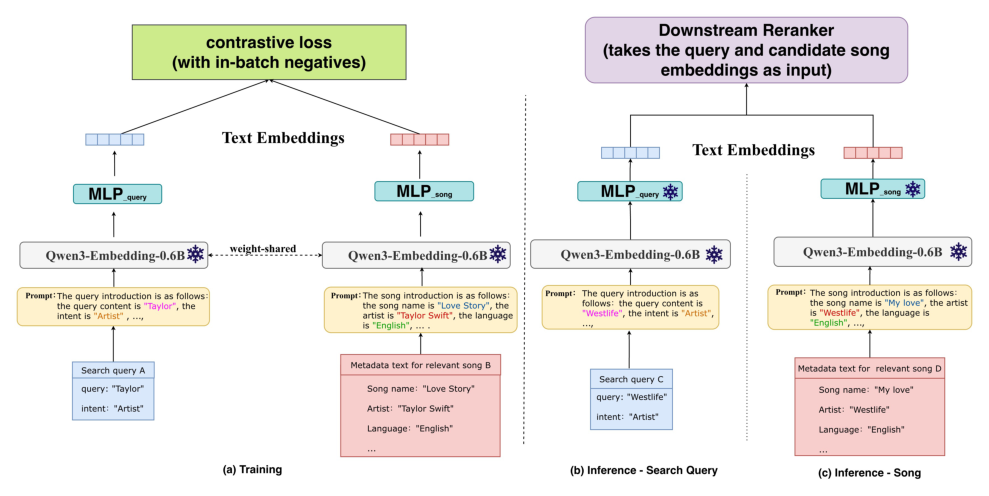
- 训练阶段:一个冻结的 Qwen3-Embedding-0.6B 编码器在 query 塔和 song 塔之间权重共享;两个塔各自的 MLP 投影头($\text{MLP}_{query}$、$\text{MLP}_{song}$)产出文本嵌入,用带 in-batch negatives 的对比损失(contrastive loss)优化。每首歌用 prompt 形式给出元数据(如 Song name: "Love Story", Artist: "Taylor Swift", Language: "English")。
- 推理阶段:编码器和投影头都冻结。song 嵌入离线预计算,query 嵌入按每次搜索请求在线计算。
相比通用编码器,这种设计产生的嵌入更贴合音乐搜索,并把编码器成本与在线延迟解耦(因为歌曲嵌入是离线算好的)。
4.3 Query-Driven Interest Refiner(QDIR)¶
QDIR 旨在把用户的长期偏好与当前查询所表达的短期意图对齐。它包含两个部分:Current Intent Representation 与 Historical Query-aware Preference Refinement。
当前意图表征。 记原始当前查询为 $q_{\text{cur}}$,用 §4.2 的方法嵌入:
$$q_{\text{cur}}^{\text{emb}} = \phi_{\text{music}}(q_{\text{cur}}) \tag{2}$$
再通过一个可学习线性投影形成短期兴趣:
$$r_{\text{short}}^{\text{emb}} = W^E q_{\text{cur}}^{\text{emb}} \tag{3}$$
其中 $W^E$ 是初始化为单位阵(identity)的可学习投影。这样训练初始时 $r_{\text{short}}^{\text{emb}} = q_{\text{cur}}^{\text{emb}}$,再逐渐把当前查询嵌入自适应到下面 cross-attention 所用的融合空间中。这个"恒等初始化"的设计动机是保证训练起步稳定。
历史查询感知的偏好精炼。 为用当前查询过滤过去的偏好,作者用 cross-attention:以 $q_{\text{cur}}^{\text{emb}}$ 为 query,历史查询序列 $q_{\text{seq}}^{\text{emb}} = [q_1^{\text{emb}}, \ldots, q_L^{\text{emb}}]$ 为 key,每个历史查询下交互过的 item $s_{\text{seq}}^{\text{emb}} = [s_1^{\text{emb}}, \ldots, s_L^{\text{emb}}]$ 为 value:
$$r_{\text{long}}^{\text{emb}} = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right) V \tag{4}$$
其中 $Q = W^Q q_{\text{cur}}^{\text{emb}}$,$K = W^K q_{\text{seq}}^{\text{emb}}$,$V = W^V s_{\text{seq}}^{\text{emb}}$,$d$ 为隐藏维度。注意力权重按历史点击 item 与当前查询的相关性重新加权——这正是"过滤掉与当前情境不一致的历史偏好"的机制实现:当用户搜 calm piano 时,历史中与之相关的查询会获得高权重,从而把对应的历史歌曲偏好放大,而无关的 fast-paced pop 历史被抑制。这里 key 是历史 query、value 是历史 item,是 QDIR 区别于一般行为序列建模(key/value 都是 item)的关键。
长短期兴趣融合。 把精炼后的长期偏好 $r_{\text{long}}^{\text{emb}}$、短期意图嵌入 $r_{\text{short}}^{\text{emb}}$ 与用户画像融合成统一的 query-conditioned 用户兴趣表征:
$$r_{\text{user}}^{\text{emb}} = \text{LayerNormalization}\!\left(W_f \cdot \big[\text{concat}(r_{\text{long}}^{\text{emb}}, r_{\text{short}}^{\text{emb}}, r_{\text{user\_profile}})\big] + b\right) \tag{5}$$
其中 $W_f$ 把表征映射到维度 $d_{\text{model}}$,$b$ 为偏置,$r_{\text{user\_profile}}$ 是静态用户画像嵌入。最终的 $r_{\text{user}}^{\text{emb}}$ 作为后续重排阶段 IAN token 的初始化信号。
4.4 Information Aggregation Node(IAN)¶
动机与设计。 受 BERT、ViT 中 [CLS] token 启发,作者把一个可学习的 [CLS] 式 token——即 IAN——前缀拼接到候选列表前(图 1 右)。不同于忽略 item 交互的静态池化(如 mean pooling),IAN 借助自注意力捕捉 list-wise 依赖,学习一个超越简单 item 分数求和的 list 级效用。
初始化与位置编码。 IAN token 用 QDIR 的 query-conditioned 兴趣向量初始化。令 $g = r_{\text{user}}^{\text{emb}} \in \mathbb{R}^{d_{\text{model}}}$。候选歌曲先经音乐专用表征模型(§4.2)得到 item 表征 $h_{1:M} \in \mathbb{R}^{d_{\text{model}}}$。把 $g$ 经一个 MLP 得到原始 IAN 表征:
$$h_0^{\text{raw}} = \text{MLP}_{\text{init}}(g) \tag{6}$$
再给所有位置加位置编码:
$$\tilde{h}_j = \begin{cases} h_0^{\text{raw}} + \text{PE}(0), & \text{if } j = 0, \\ h_j + \text{PE}(j), & \text{if } j \in \{1, \ldots, M\}, \end{cases} \tag{7}$$
其中 $\text{PE}(0)$ 把 IAN 锚定到一个固定参考位置,而 $\text{PE}(j)$($j \ge 1$)为 item 打分保留顺序敏感性。
4.5 上下文化 Transformer 编码器¶
架构。 带位置编码的序列 $[\tilde{h}_0, \tilde{h}_1, \ldots, \tilde{h}_M]$ 被送入 $N_x = 2$ 个 pre-norm Transformer 编码块:
$$[h_0', h_1', \ldots, h_M'] = \text{Transformer}([\tilde{h}_0, \tilde{h}_1, \ldots, \tilde{h}_M]) \tag{8}$$
每个块包含多头自注意力(MHSA)和 position-wise 前馈网络(FFN),都配残差连接与层归一化。
预测头。 编码后,输出序列 $[h_0', h_1', \ldots, h_M']$ 被两个联合训练的头用于多任务预测(如 click 与 conversion,对应图 1 中的橙色框):
$$\hat{\mathbf{p}}_{\text{list}}^{(t)} = \text{Sigmoid}\big(\text{MLP}(h_0')\big) \tag{9a}$$ $$\mathbf{p}_j^{(t)} = \text{Sigmoid}\big(\text{MLP}(h_j')\big) \tag{9b}$$
其中 $h_0'$ 充当 list 级分类器的全局列表表征(global list representation),item 头(式 9b)作用在 item 表征 $h_j'$($j \in \{1, \ldots, M\}$)上。关键在于:$h_0'$ 聚合的全局语义通过自注意力传播到每个 item 表征 $h_j'$,增强其上下文感知能力。这就是 IAN 既能产出 list 级预测、又能反过来调节 item 级打分的双向收益机制。
4.6 模型预测与优化目标¶
PIANO 用两个互补的损失函数联合优化 list 级与 item 级目标。模型在三个层次有三个权重:$\lambda$(式 1,list 级 click vs. conversion 效用)、$\alpha$(式 15,list 级 vs. item 级损失)、$\beta$(item 损失内部 click vs. conversion 的 BCE 权重)。
List 级损失。 与式 (1) 对齐,用两个 BCE 损失在软标签上预测 list 级点击率与转化率:
$$L_{\text{list}} = -\frac{1}{N} \sum_{t=1}^{N} \sum_{m \in \{\text{clk}, \text{conv}\}} \Big[ y_m^{(t)} \log \hat{p}_m^{(t)} + (1 - y_m^{(t)}) \log(1 - \hat{p}_m^{(t)}) \Big] \tag{10}$$
其中 $\mathbf{y}^{(t)} = (y_{\text{clk}}^{(t)}, y_{\text{conv}}^{(t)}) \in [0,1]^2$ 是 per-list 的率目标,$\hat{\mathbf{p}}^{(t)} = (\hat{p}_{\text{clk}}^{(t)}, \hat{p}_{\text{conv}}^{(t)})$ 是预测分,$N$ 为 batch size。软标签定义为:
$$y_{\text{clk}}^{(t)} = \frac{\#\text{clicked items in list } t}{\text{length of list } t} \tag{11}$$ $$y_{\text{conv}}^{(t)} = \frac{\#\text{converted items in list } t}{\text{length of list } t} \tag{12}$$
即 list 标签是该列表中被点击/转化 item 的占比——这正是用真实 per-list CTR/CVR 直接监督 IAN,区别于 RankFormer 用"item 标签最大值"合成 listwide 标签。
Item 级损失。 对 item 标签 $y_j^{(\text{clk})}, y_j^{(\text{conv})} \in \{0, 1\}$,用带转化权重 $\beta \ge 0$ 的二元交叉熵:
$$L_{\text{item}} = \frac{1}{N} \sum_{t=1}^{N} \frac{1}{M} \sum_{j=1}^{M} \Big( \ell_{\text{BCE}}\big(y_j^{(\text{clk})}, p_j^{(\text{clk})}\big) + \beta\, \ell_{\text{BCE}}\big(y_j^{(\text{conv})}, p_j^{(\text{conv})}\big) \Big) \tag{13}$$ $$\ell_{\text{BCE}}(y, p) = -y \log p - (1 - y) \log(1 - p) \tag{14}$$
其中 $\beta$ 平衡转化信号相对点击信号的权重,通常设 $\beta = 1$。
联合目标。 最终训练目标是加权和:
$$L = \alpha\, L_{\text{list}} + (1 - \alpha)\, L_{\text{item}} \tag{15}$$
其中 $\alpha > 0$ 平衡 list 级监督与 item 级监督(§4.4 实验研究其敏感性)。通过自注意力,IAN 把全局列表上下文聚合进 $h_0'$(受 $L_{\text{list}}$ 监督做整体效用预测);同时 item 表征 $h_j'$ 经 attention 受益于该全局上下文,从而实现与式 (1) 多目标目标对齐的联合优化。
五、实验设置¶
5.1 数据集¶
作者在公开的 Yahoo Letor(Yahoo! Webscope v2.0)基准与自建的工业级 Music Search Re-ranking 数据集(取自网易云音乐)上评估。
Table 1. 数据集概览
| Yahoo Letor Dataset | Music Search Re-ranking Dataset | |
|---|---|---|
| #User | - | 4,488,871 |
| #Docs/Items | 709,877 | 642,239 |
| #Queries | - | 236,191 |
| #Records | 29,921 | 31,336,800 |
- Yahoo Letor:遵循 Seq2Slate [2] 的做法,把相关性等级二值化($r \ge T_b$),并用 $P_{\text{exam}}(i) \propto 1/\text{pos}(i)^\eta$ 模拟位置偏差。
- Music Search Re-ranking:含 query 上下文、候选列表、用户反馈。过滤了仅有"首屏完整曝光"的会话以减小偏差。特征包括元数据、行为统计、文本嵌入(§4.2)。标签包括 item 级 click 与 conversion 信号,及其 list-wise 平均作为 list 级 CTR/CVR 目标。采用基于时间的划分防止泄漏,所有方法共享同一候选池与特征。
5.2 研究问题(RQ)¶
- RQ1:PIANO 是否在多个数据集与指标上超越强 baseline?
- RQ2:消融是否确认 QDIR 与 IAN 各自带来可量化的收益?
- RQ3:平衡超参 $\alpha$ 如何影响整体性能?
- RQ4:历史行为序列长度对 QDIR 的排序效果有何影响?
- RQ5:IAN 是否编码了有意义的 list 级语义(用诊断/可视化佐证)?
5.3 Baselines¶
涵盖三个维度:(i) LTR 范式(pointwise/pairwise vs. listwise);(ii) 个性化(有无用户侧信号);(iii) 上下文建模(独立打分 vs. slate-aware 跨 item 交互):
- SVMRank:经典 pairwise LTR,非 listwise、非个性化,作为量化 item 间交互收益的下界。
- LambdaMART:基于 GBDT 的强 listwise LTR,因低延迟推理被工业界广泛部署,是 production-grade 代表。
- DLCM:开创性 listwise 重排器,用 GRU 编码 top-n slate,作为自注意力重排器的对照。
- PRM:把用户嵌入注入 Transformer 自注意力编码器,联合建模 user–item 与 item–item 交互,是 PIANO 最接近的非历史个性化自注意力重排对照。
- SAR:近期 listwise 方法,通过 slate-aware 上下文建模捕捉 item–item 依赖,是无用户历史/无 query-aware 组件的当代 listwise baseline。
- PEAR:通过 Transformer 融合初始列表与用户历史信号做个性化重排,是与 PIANO 架构最相似的 baseline(但只用 item 历史、无 query 信号),是关键参照点。
5.4 实现细节¶
- 超参(所有 baseline 与 PIANO 统一):隐藏维度 $d_{\text{model}} = 128$(两数据集相同);优化器 Adam;dropout $p_{\text{dropout}} = 0.2$;mini-batch size:Yahoo Letor 为 32,Music Search 为 256。
- 评估协议:所有结果报告为 10 次不同随机种子独立运行的均值 ± 标准差。
-
跨数据集特征对齐:工业数据集的 $s_i^{\text{emb}}$ 用音乐专用表征模型(§4.2)产出;Yahoo Letor 缺音乐元数据,改用同宽度 $d_{\text{model}}$ 的可训练 ID 嵌入: $$s_i^{\text{emb}} = E_{\text{item}}[\text{ID}(i)] \tag{16}$$ 其中 $E_{\text{item}} \in \mathbb{R}^{(|\mathcal{D}|+1) \times d_{\text{model}}}$ 为嵌入查找矩阵(多一行
[UNK]给未见 item)。两种情况下 $s_i^{\text{emb}}$ 都占据同样的 $d_{\text{model}}$ 维输入槽,使所有方法收到形状相同的 item 表征。 -
数据集特定适配:PEAR 需要用户行为序列(Yahoo Letor 没有),故只在工业数据集评估;PIANO 在 Yahoo Letor 上禁用 QDIR 的 query 序列组件、保留 IAN,以在相同特征约束下公平比较。
- 评估指标:NDCG@k(按位置做对数折扣)与 MAP(相关 item 位置上 AP 的均值)。因工业音乐搜索只展示 top 5,取 $k=5$ 对齐实际部署。
六、主要实验结果(RQ1)¶
Table 2. Yahoo Letor 数据集性能对比
| Model | NDCG@5 | NDCG@10 | MAP |
|---|---|---|---|
| PIANO | 0.6700±0.0008 | 0.7225±0.0006 | 0.6516±0.0005 |
| PRM | 0.6676±0.0008 | 0.7204±0.0008 | 0.6494±0.0006 |
| SAR | 0.6539±0.0028 | 0.7107±0.0020 | 0.6386±0.0023 |
| DLCM | 0.6530±0.0019 | 0.7044±0.0017 | 0.6353±0.0016 |
| LambdaMART | 0.6388±0.0002 | 0.6992±0.0003 | 0.6153±0.0001 |
| SVM | 0.5943±0.0001 | 0.6556±0.0002 | 0.5768±0.0001 |
Table 3. 工业 Music Search Re-ranking 数据集性能对比
| Model | NDCG@3 | NDCG@5 | MAP |
|---|---|---|---|
| PIANO | 0.8296±0.0002 | 0.8606±0.0002 | 0.8100±0.0003 |
| PEAR | 0.8277±0.0001 | 0.8586±0.0002 | 0.8081±0.0002 |
| PRM | 0.8098±0.0006 | 0.8433±0.0006 | 0.7868±0.0008 |
| SAR | 0.8062±0.0002 | 0.8426±0.0002 | 0.7840±0.0002 |
| DLCM | 0.8042±0.0006 | 0.8398±0.0004 | 0.7822±0.0006 |
| LambdaMART | 0.7767±0.0016 | 0.8247±0.0017 | 0.7622±0.0012 |
| SVM | 0.7640±0.0014 | 0.8188±0.0012 | 0.7542±0.0016 |
结论分析:PIANO 在两个数据集所有指标上一致超越全部 baseline。在 Yahoo Letor 上(注意此时 PIANO 已禁用 query 组件、仅保留 IAN),它对最强神经 baseline PRM 仍有稳定提升(NDCG@5 0.6676→0.6700),说明即便候选列表短、缺乏 query 序列信号,IAN 的 list 级聚合机制本身就有价值。在工业 Music Search 上优势更明显:PIANO 显著超过 PEAR(架构最相似的强 baseline,NDCG@3 0.8277→0.8296、MAP 0.8081→0.8100)和其他 baseline。值得注意的是按 NDCG@3 排序的梯队——PEAR (0.8277) ≫ PRM (0.8098),说明引入用户历史(PEAR、PIANO)相对纯 slate 模型(PRM/SAR/DLCM)有一大截提升,而 PIANO 在 PEAR 基础上再通过 query-conditioned 对齐 + list 级监督进一步推进。这印证了"融合 query-conditioned 兴趣建模 + 显式 list 级多目标优化"能在真实场景中改善重排质量。
七、消融与分析(RQ2–RQ5)¶
7.1 组件消融(RQ2)¶
在工业数据集上做组件消融:
Table 4. PIANO 消融研究(工业 Music Search 数据集)
| Model | NDCG@3 | NDCG@5 | MAP |
|---|---|---|---|
| w/ QDIR, w/ IAN | 0.8296±0.0002 | 0.8606±0.0002 | 0.8100±0.0003 |
| w/o QDIR, w/ IAN | 0.8108±0.0013 | 0.8442±0.0011 | 0.7880±0.0015 |
| w/ QDIR, w/o IAN | 0.8198±0.0002 | 0.8507±0.0002 | 0.8002±0.0003 |
| w/o QDIR, w/o IAN | 0.8103±0.0014 | 0.8437±0.0013 | 0.7874±0.0018 |
结论分析:
- QDIR 的作用:去掉 QDIR(替换为 query-agnostic 池化),NDCG@k 与 MAP 一致下降。对比"w/ QDIR, w/o IAN"(NDCG@3=0.8198) 与 "w/o QDIR, w/o IAN"(0.8103),可见 QDIR 单独贡献约 +0.0095。这证实把长期行为信号与当前查询对齐对有效个性化是必要的——它过滤噪声、捕捉意图漂移。
- IAN 的作用:去掉 IAN 与 list 级头,所有指标一致退化。对比"w/o QDIR, w/ IAN"(0.8108) 与 "w/o QDIR, w/o IAN"(0.8103),IAN 在无 QDIR 时贡献较小;但在有 QDIR 时(0.8296 vs 0.8198)IAN 贡献约 +0.0098,明显更大。这说明两个组件存在正向协同:IAN 需要 QDIR 提供高质量的 query-conditioned 初始化才能充分发挥 list 级监督的价值,二者互补。
7.2 平衡参数 $\alpha$ 的影响(RQ3)¶
$\alpha$(式 15)控制 list 级与 item 级监督的权衡:
Table 5. 不同平衡参数 $\alpha$ 下的 PIANO 性能
| $\alpha$ | NDCG@3 | NDCG@5 | MAP |
|---|---|---|---|
| 0.00 | 0.8199±0.0002 | 0.8508±0.0002 | 0.8004±0.0003 |
| 0.25 | 0.8250±0.0003 | 0.8577±0.0002 | 0.8052±0.0003 |
| 0.50 | 0.8296±0.0002 | 0.8606±0.0002 | 0.8100±0.0003 |
| 0.75 | 0.8262±0.0005 | 0.8576±0.0004 | 0.8060±0.0006 |
结论分析:性能呈清晰的倒 U 形。$\alpha=0$(纯 item 级,无 list 级监督)因缺乏全局指导而次优;$\alpha=0.5$ 取得最佳平衡,说明全局 list 语义与细粒度 item 信号互补;继续增大到 $\alpha=0.75$(偏 list 级)收益递减,过度强调 list 级损失反而会稀释 item 级打分能力。这验证了联合优化的必要性,也确定了后续实验统一用 $\alpha=0.5$。(注:式 15 中 $\alpha$ 是 $L_{\text{list}}$ 的权重,故 $\alpha=0$ 表示纯 item 级,与表中 $\alpha=0$ 行性能偏低、纯 item 级"缺乏全局指导"的叙述一致。)
7.3 历史行为序列长度的影响(RQ4)¶
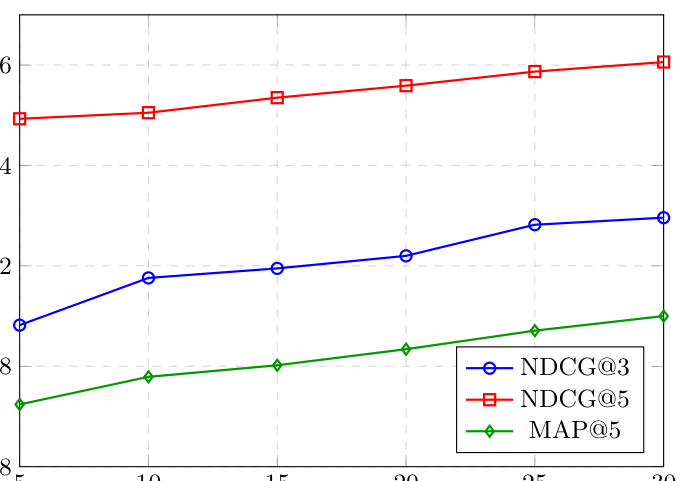
结论分析:如图 3,所有指标随序列从 5 增长到 30 单调提升。这验证:更丰富的历史行为序列为 QDIR 提供更强的长期偏好信号,而其 query-driven cross-attention 会过滤无关历史,所以更长的序列带来更多有用信号而不引入噪声。这与 QDIR "用当前 query 加权历史"的设计自洽——若没有这种过滤,加长序列通常会引入噪声导致性能饱和甚至下降。
7.4 IAN 的可视化(RQ5)¶
为评估 IAN 是否真的编码了 list 级风格信号,作者对一批 held-out 用户提取经 Transformer 后的 IAN 嵌入 $h_0'$,用 t-SNE 投影到二维。考察八个高频曲风标签——Anime/ACG、Children、Chinese Traditional、Electronic、Folk、Rock、Slow DJ、Soundtrack,每个点按候选列表的主导曲风着色。
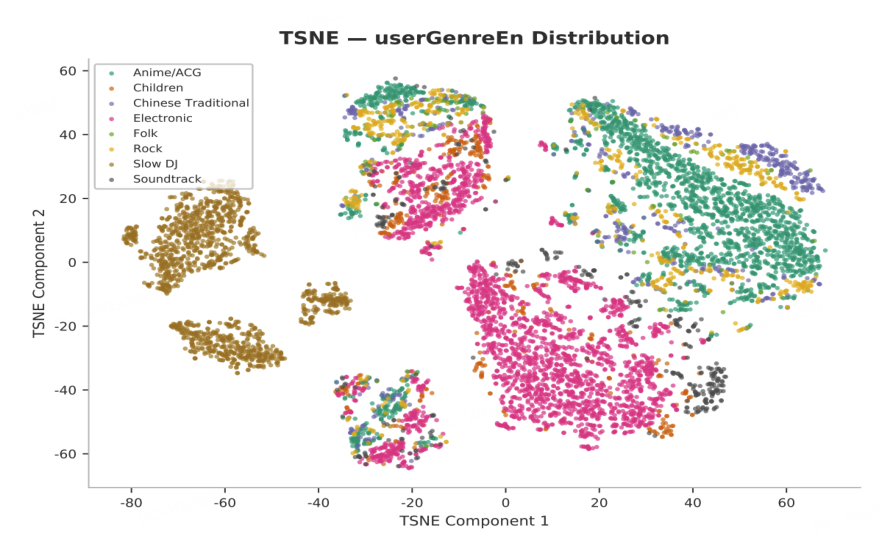
结论分析:可视化显示清晰的曲风对齐聚类:Slow DJ 在左侧形成分离良好的簇,Electronic 与 Anime/ACG 占据下中部和右上部不同区域,其他曲风也呈现可分辨模式(部分重叠反映风格邻近性)。这表明 IAN 成功聚合了全局候选列表信息,产出语义上有意义的表征。关键在于:由于用户参与度随列表构成(如曲风)变化,IAN 区分风格不同列表的能力,给 list 级 MLP 头预测点击/转化提供了有用基础。类比 BERT 的 [CLS],IAN 把 item 级特征聚合成 list 级摘要,同时喂给 list 级头并通过自注意力调节 item 级打分。
八、在线实验与部署¶
8.1 在线 A/B 测试¶
作者在工业音乐搜索栈做了多周在线实验。用户按稳定标识分桶,treatment 用 PIANO、control 用既有重排器。试验显示 CTR +0.62%、CVR +4.45%(均 $p<0.05$,双尾),且收益在工作日/周末与主要 query 类别上都稳定。
Table 6. 在线 A/B 测试结果:相对 control 的绝对与相对变化
| Week | CTR Abs (pp) | CTR Rel (%) | CVR Abs (pp) | CVR Rel (%) |
|---|---|---|---|---|
| Week 1 | +0.13* [0.00, 0.26] | +0.46* | +0.006* [0.003, 0.009] | +4.62* |
| Week 2 | +0.18* [0.05, 0.31] | +0.66* | +0.007* [0.004, 0.009] | +4.91* |
| Week 3 | +0.21* [0.05, 0.36] | +0.73* | +0.006* [0.003, 0.011] | +4.02* |
| Week 4 | +0.17* [0.01, 0.33] | +0.61* | +0.007* [0.004, 0.013] | +4.23* |
| Avg | +0.17 | +0.62 | +0.005 | +4.45 |
注:* 表示 $p<0.05$(双尾)显著。
结论分析:四周内 CTR/CVR 的绝对提升均稳定为正且统计显著,置信区间下界基本在 0 以上。CVR 的相对提升(~+4.45%)远大于 CTR(~+0.62%)——这与 PIANO 显式做 list 级多目标(含 conversion)优化的设计直接对应:转化(付费会员订阅)是稀疏但高价值信号,list 级 CVR 监督让模型更善于把"会促成订阅"的列表组合整体顶上去,这是 item 级代理优化难以达到的。
8.2 在线部署¶
PIANO 已部署于网易云音乐,作为 matching→ranking→re-ranking 流水线中的后排序(post-ranking)服务:上游排序器返回列表 $I$,PIANO 产出最终顺序 $\pi$。稳态下 95% 流量由 PIANO 服务(覆盖数百万 DAU),保留 5% 随机 holdout 路由到 baseline 做长周期 KPI 跟踪。作者用最新交互日志做周期性模型刷新以适应偏好演化。自上线以来关键业务指标持续高于对照组,且不损害在线延迟要求。这证明 list-aware、query-conditioned 的重排可在高流量音乐搜索系统中可靠地规模化运行。
九、核心贡献总结¶
- QDIR——查询驱动的兴趣精炼:首次以"当前 query 为 Q、历史 query 序列为 K、历史交互 item 为 V"的 cross-attention 机制,动态地用当前查询过滤/重加权长期偏好,解决音乐搜索中"快速意图漂移"导致的历史偏好不一致问题;并用恒等初始化的短期投影 + 长短期 + 用户画像融合产出 query-conditioned 用户兴趣。
- IAN——受真实 list 级标签监督的
[CLS]式聚合节点:用 QDIR 兴趣初始化、固定参考位置锚定的全局 token,由真实 per-list CTR/CVR(软标签 = 列表内点击/转化占比)直接监督,实现 list 级多目标优化,并通过自注意力把全局上下文反哺到 item 级打分——区别于 RankFormer 用合成标签 + 通用可学习 token。 - 判别式单次前向的 list 级多目标框架:相对 SORT-Gen 的自回归生成式 list 级优化,PIANO 在单次前向内完成 list 级 + item 级联合预测,兼顾效果与在线延迟,适合 latency-sensitive 工业部署。
- 完整工业验证:公开(Yahoo Letor)+ 工业(网易云音乐)双数据集离线领先,外加多周线上 A/B(CTR +0.62%、CVR +4.45%)与 95% 流量规模化部署。
十、讨论与局限性¶
值得借鉴的设计:
- "key=历史 query、value=历史 item"的 cross-attention 是一个干净且可迁移的 query-conditioned 兴趣建模范式,凡是"既有搜索 query 历史、又有行为历史"的搜索/推荐场景(电商搜索、视频搜索)都可借鉴,比静态 query 池化(如 He et al. [14])更能捕捉意图漂移。
- 用真实 per-list 率(软标签)显式监督
[CLS]式 token,把"list 级多目标"从 item 级代理升格为一等公民,且实现成本低(一个 token + 一个 BCE 头)。$\alpha$ 的倒 U 形曲线给出了 list 级与 item 级监督的实用配比经验(0.5)。 - 音乐专用 Qwen3-Embedding 双塔 + 离线预计算歌曲嵌入:把大模型编码成本与在线延迟解耦,是 LLM 嵌入落地工业重排的务实工程范式。
局限与争议:
- 离线绝对提升偏小:在工业数据集上 PIANO vs PEAR 的 NDCG/MAP 提升只在第三/四位小数(如 NDCG@3 0.8277→0.8296,+0.23%),虽然有 10 次种子的小标准差支撑统计可靠性,但收益幅度有限;线上 CVR +4.45% 与离线小提升之间的"放大"主要来自 list 级 conversion 监督,论文未给出离线 list 级 CTR/CVR 指标来直接佐证这一点(离线只报 NDCG/MAP 这类排序质量指标,与线上 CTR/CVR 之间存在 metric gap)。
- 方法范围较窄:PIANO 是一个重排模块,依赖上游排序给出的候选列表 $I$ 与高质量 query/song 嵌入,整体框架对召回/排序阶段无改动,属于流水线末端的局部优化。
- 多个超参需要调:$\lambda$(式 1)、$\alpha$(式 15)、$\beta$(式 13)三层权重,论文只系统研究了 $\alpha$,$\lambda$ 如何在线扫 Pareto 前沿、$\beta$ 的取值影响缺乏实证。
- Transformer 仅 2 层、$d_{\text{model}}=128$:模型容量较小(为满足在线延迟),论文未探索 scaling 行为,list 长度 $M$ 较大时自注意力 $O(M^2)$ 成本与 IAN 聚合质量的权衡也未讨论。
- 泛化性:QDIR 的价值高度依赖"用户有丰富历史搜索 query",对冷启动用户或 query 历史稀疏的场景效果存疑(图 3 显示序列越短性能越低)。
与已有工作的差异:PIANO 同时攻 query-aware 意图对齐(区别于 PEAR 只用 item 历史、He et al. 用静态 query)与 list 级多目标(区别于 PRM/SAR/DLCM 的单目标或 item 级处理、RankFormer 的合成标签、SORT-Gen 的生成式范式)。其判别式单次前向 + 真实 list 标签监督的组合,是它在工业 latency-sensitive 音乐搜索落地的关键差异点。