Pay Attention to Sequence Split: Uncovering the Impacts of Sub-Sequence Splitting on Sequential Recommendation Models¶
- 作者:Yizhou Dang, Yifan Wu, Minhan Huang, Chuang Zhao, Lianbo Ma, Guibing Guo, Xingwei Wang, Zhu Sun(东北大学 / 天津大学 / 新加坡科技设计大学)
- Arxiv:2604.05309(2026-04-07)
- 关键词:Sequential Recommendation; Sub-Sequence Splitting; Data Augmentation; Reproducibility Study
- 代码:https://anonymous.4open.science/r/SSS_Review-45C3
研究动机与背景¶
在序列推荐(Sequential Recommendation, SR)中一个非常老且几乎被认为"标配"的数据处理手段叫 Sub-Sequence Splitting (SSS):对一条原始用户行为序列 s_u = [v_1, v_2, ..., v_{|s_u|}] 应用 prefix/suffix/sliding-window 切分,把一条长序列"爆炸"为多条短子序列加入训练集。这个操作在经典 DA 工作里被广泛使用并证明能缓解数据稀疏。
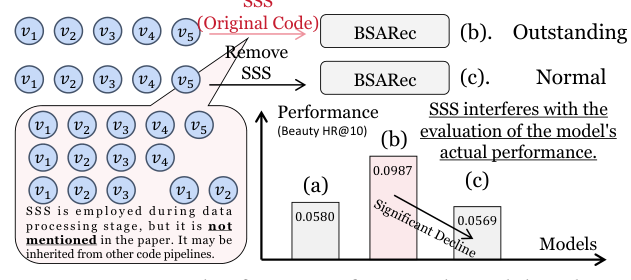
但作者发现了一个非常刺眼的现象:"最近两三年的 SOTA SR 模型,论文里几乎不提 SSS,但官方代码里静默地启用了它"。换句话说,这些模型在比对 baseline(如 SASRec、GRU4Rec)时,悄悄在数据 reading 阶段用了 SSS,而被对比的 baselines 通常没有启用 SSS。这导致一个严重的问题:被归功于"模型架构创新"的 performance gain,其实大半来自 SSS 这个数据增强操作。如果把 SSS 移除,这些 SOTA 模型的表现会大幅回撤,甚至输给 2018 年的 SASRec。
这个问题是典型的"复现实验坑",很容易被忽略却严重影响研究的公平性与可信度。作者做了一个大规模审计性的实证研究,目标:
- 揭示"SSS 如何隐秘地干扰 SR 模型评估"(Section 3);
- 探索"SSS 什么时候真的有效、组合哪些设置能最大化增益"(Section 4);
- 分析"为什么 SSS 有效"(Section 5);
- 为社区提出数据增强方法未来应该如何做更可信的评估(Section 6)。
前置:SR 任务与 SSS 的三类切分¶
问题定义¶
令用户集 U,item 集 V。每个用户 u ∈ U 有按时间排序的交互历史 s_u = [v_1, ..., v_{|s_u|}],序列推荐的目标是准确预测第 |s_u|+1 步的 item:
$$ \arg\max_{v^* \in V}\ P(v_{|s_u|+1} = v^* \mid s_u) \tag{1} $$
SSS 的三种主流切分方式¶
假设给定序列 s_u,下式中 s_u^{i:j} = [v_i, v_{i+1}, ..., v_j]。
-
Prefix Splitting:从第一个 item 出发,列出所有 "前缀" 子序列: $$ \{s_u^{1:2}, s_u^{1:3}, ..., s_u^{1:|s_u|}\} = \text{Prefix-SSS}(s_u) \tag{2} $$ 例:
[1,2,3,4]→{[1,2], [1,2,3], [1,2,3,4]}。 -
Suffix Splitting:从最后一个 item 出发,列出所有 "后缀": $$ \{s_u^{|s_u|-1:|s_u|}, s_u^{|s_u|-2:|s_u|}, ..., s_u^{1:|s_u|}\} = \text{Suffix-SSS}(s_u) \tag{3} $$ 例:
[1,2,3,4]→{[3,4], [2,3,4], [1,2,3,4]}。 -
Sliding Window:给定窗口长度 T < |s_u|,滑动产生所有相邻窗口: $$ \{s_u^{1:T}, s_u^{2:T+1}, ..., s_u^{|s_u|-T+1:|s_u|}\} = \text{Sliding-SSS}(s_u, T) \tag{4} $$ 例:窗口长度 2 时
[1,2,3,4,5]→{[1,2], [2,3], [3,4], [4,5]}。
目标策略(Target Strategy)¶
- Single-Target:只预测最后一个 item。输入
x_u = [v_1, ..., v_{|s_u|-1}],targety_u = v_{|s_u|}。 - Multi-Target:从第 2 个位置开始的所有 item 都当 target(即 teacher-forcing)。产生
|s_u| - 1对 (input, target) 数据。
注意 prefix splitting 与 multi-target 在监督信号上是几乎正交的(multi-target 本质是在单条原序列上用滑动 teacher-forcing 产生多监督,但 prefix splitting 是物理上扩充训练集)。作者后面特别强调要把"切分方式"和"目标策略"分开看。
Section 3:SSS 如何干扰 SR 模型评估¶
审计方法¶
作者系统性地从 2022-2026 年的 KDD, SIGIR, WWW, NeurIPS, AAAI, WSDM, CIKM, RecSys, TOIS, TKDE 会议/期刊上筛选符合如下条件的 SR 论文:
- 以经典 SR 为研究方向;
- 主要贡献是"模型架构创新",而非专门的 DA/辅助任务;
- 有公开可复现代码。
最终得到 17 篇。作者逐一读论文、逐一看代码,判断 SSS 是否"在代码里被启用但论文里未提及"。
发现¶
Table 1:SSS 是否被用及是否被披露
| 类别 | 论文数 |
|---|---|
| 明确声明使用 SSS | 6 |
| 使用 SSS 但论文未提及 | 10 |
| 不使用 SSS | 1 |
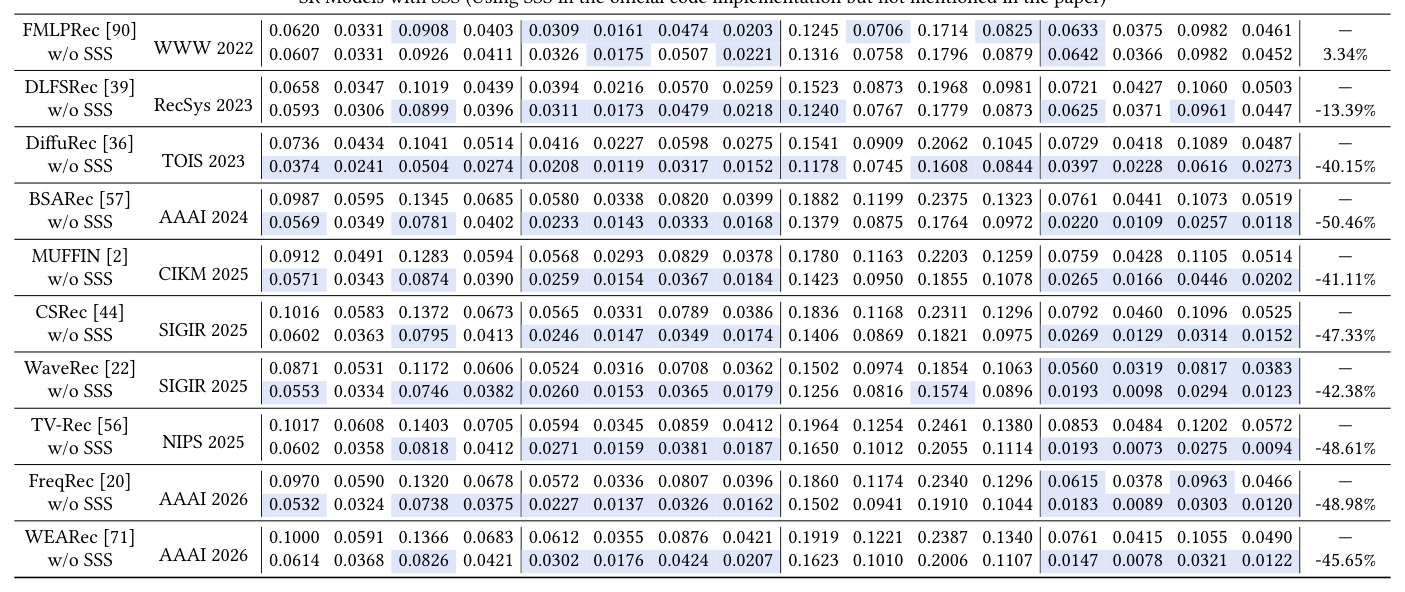
16/17 的 SR 模型都在代码中启用 SSS,但其中 10 篇根本没在论文里说。作者在附录中列出这 11 篇默认使用 SSS 的论文的模型名和切分代码对比(主要是在 data reader 部分的某一行调用 slice 操作)。
![Algorithm 1: SSS 的典型代码实现。在 data reading 阶段把原始 user_seq 切成多个 [max_len+2, ...] 的子序列再送入训练循环](figures/alg_01.png)
公平对比的结果(Table 3)¶
作者在 Beauty / Sports / Douyin / LastFM 四个数据集上,把这 10 篇(+ 1 篇披露的 FMLPRec)论文的模型代码 SSS 去掉,重新训练,与论文里报告的数字对比。所有 10 篇"静默 SSS"论文中:
- 8 篇的平均性能下降 >40%(用 HR@K 和 NDCG@K 取 K=10,20 的均值)。
- 许多"最新 SR 模型"去掉 SSS 后反而输给 2018 年的 SASRec。
- 作者在 Table 3 中用蓝色高亮"去掉 SSS 后低于 SASRec"的结果。
Table 3 的关键数据(节选):
| Model | Venue | Beauty H@10 (orig / w/o SSS) | Sports H@10 | Douyin H@10 | LastFM H@10 |
|---|---|---|---|---|---|
| SASRec | ICDM 2018 | 0.0580 / – | 0.0301 / – | 0.1160 / – | 0.0216 / – |
| FMLPRec (披露 SSS) | WWW 2022 | 0.0620 / 0.0531 | 0.0306 / 0.0260 | 0.1245 / 0.0706 | 0.0216 / 0.0188 |
| DLFSRec (静默) | TOIS 2023 | 0.0658 / 0.0347 | 0.0301 / 0.0130 | 0.1523 / 0.0873 | 0.0251 / 0.0127 |
| DuffRec (静默) | RecSys 2023 | 0.0595 / 0.0306 | 0.0249 / 0.0100 | 0.1260 / 0.0767 | 0.0229 / 0.0150 |
| BSARec (静默) | AAAI 2024 | 0.0987 / 0.0595 | 0.0585 / 0.0225 | 0.1882 / 0.1119 | 0.0528 / 0.0193 |
| MUFFIN (静默) | CIKM 2025 | 0.0912 / 0.0491 | 0.0497 / 0.0194 | 0.1780 / 0.0842 | 0.0325 / 0.0114 |
| CSRec (静默) | SIGIR 2025 | 0.1016 / 0.0583 | 0.0535 / 0.0178 | 0.1836 / 0.0897 | 0.0486 / 0.0180 |
| TV-Rec (静默) | NIPS 2025 | 0.1017 / 0.0445 | 0.0594 / 0.0180 | 0.2061 / 0.1054 | 0.0538 / 0.0111 |
| FreqRec (静默) | AAAI 2026 | 0.0970 / 0.0590 | 0.0539 / 0.0207 | 0.1860 / 0.0924 | 0.0346 / 0.0139 |
| WEARec (静默) | AAAI 2026 | 0.0971 / 0.0396 | 0.0571 / 0.0170 | 0.2287 / 0.0999 | 0.0479 / 0.0147 |
Table 4:把这些模型"去 SSS 后"与 SASRec 比较:
| Model | Beauty ΔvsSASRec | Sports | Douyin | LastFM |
|---|---|---|---|---|
| FMLPRec w/o SSS | +0.13% | +3.28% | (Δ data) | – |
| DLFSRec w/o SSS | -16.37% | +0.69% | – | – |
| DuffRec w/o SSS | -23.09% | -26.34% | – | – |
| BSARec w/o SSS | -55.85% | -20.76% | – | – |
| MUFFIN w/o SSS | -46.64% | -27.29% | – | – |
| CSRec w/o SSS | -15.45% | -17.07% | – | – |
| WaveRec w/o SSS | -31.09% | -22.75% | – | – |
| TV-Rec w/o SSS | -23.09% | -15.85% | – | – |
| FreqRec w/o SSS | -32.73% | -21.13% | – | – |
| WEARec w/o SSS | -54.54% | -29.58% | – | – |
触目惊心:去掉 SSS 后这些 2022-2026 的 SOTA 模型几乎无一例外地输给 SASRec,平均跌幅 20%–55%。
结论(Section 3): 1. SR 社区近几年严重依赖 SSS 作为默认 data preprocessing 步骤; 2. 但大量论文没有如实披露这一点,与没用 SSS 的 baseline 做比较,导致报告的 improvement 严重虚高; 3. 研究者们把"SSS 的数据增强收益"错误地归因为"自己新模型架构的优势"。
Section 4:SSS 什么时候真的有效?¶
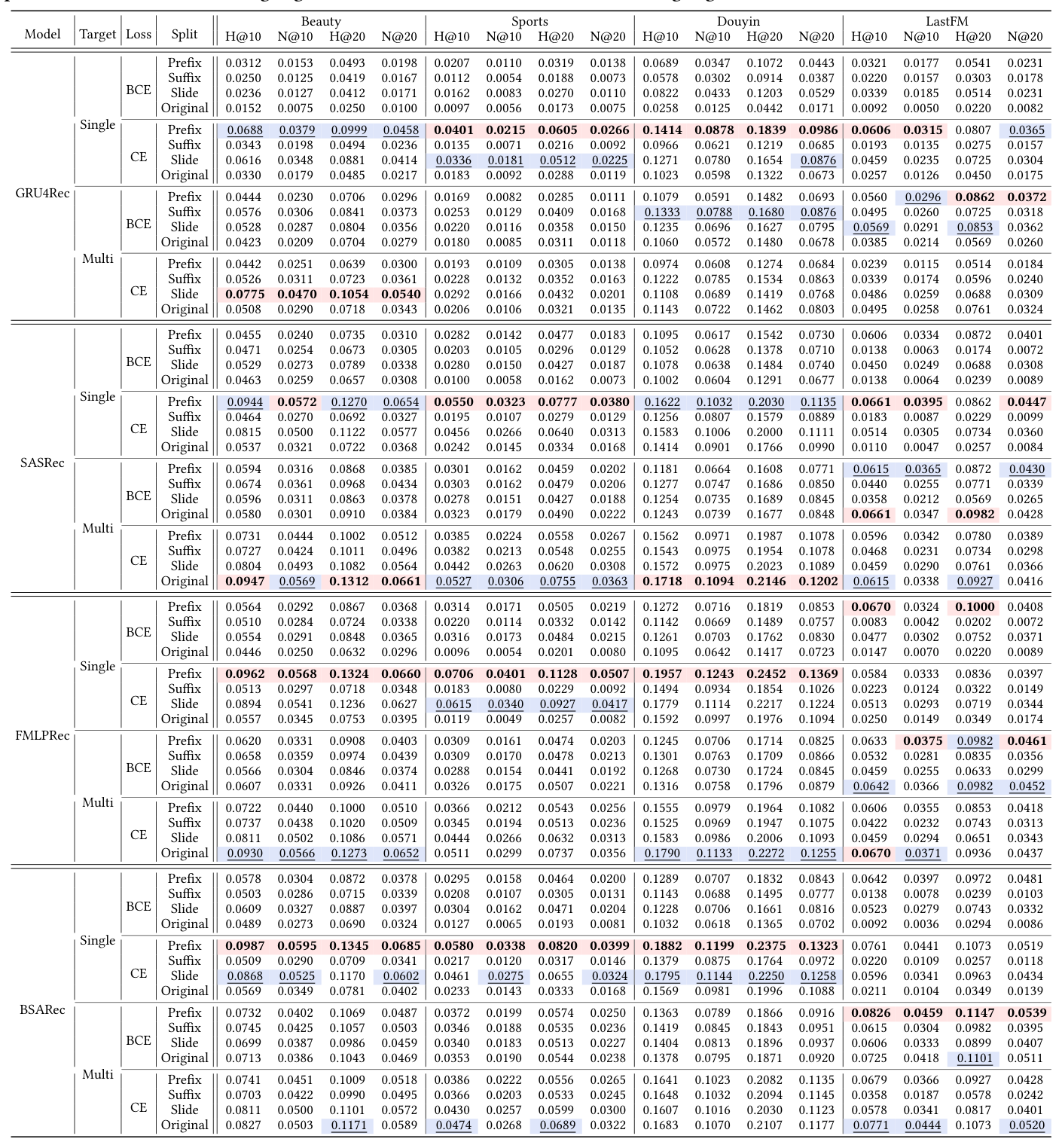
作者用更严格的实验方法论,重新在四个小数据集(Beauty, Sports, Douyin, LastFM)+ 两个大数据集(ML-1M, CDs)上做全局网格搜索,对 4 个主干模型(GRU4Rec, SASRec, FMLPRec, BSARec)× 3 种 split 方式(Prefix/Suffix/Sliding)+ Original(不切)× 2 种 target 策略(Single/Multi)× 2 种 loss(BCE, CE)。共 4×4×2×2 = 64 组配置 × 6 个数据集。
小数据集主结果(Table 5,节选 SASRec)¶
| Target | Loss | Split | Beauty H@10 | Beauty N@10 | Sports H@10 | LastFM H@10 |
|---|---|---|---|---|---|---|
| Single | BCE | Prefix | 0.0614 | 0.0288 | 0.0318 | 0.0257 |
| Suffix | 0.0684 | 0.0314 | 0.0361 | 0.0257 | ||
| Slide | 0.0529 | 0.0253 | 0.0298 | 0.0257 | ||
| Original | 0.0460 | 0.0213 | 0.0250 | 0.0257 | ||
| CE | Prefix | 0.0916 | 0.0572 | 0.0559 | 0.0322 | |
| Suffix | 0.0904 | 0.0579 | 0.0605 | 0.0279 | ||
| Slide | 0.0815 | 0.0500 | 0.0544 | 0.0300 | ||
| Original | 0.0557 | 0.0301 | 0.0342 | 0.0250 | ||
| Multi | BCE | Prefix | 0.0594 | 0.0316 | 0.0271 | 0.0265 |
| Suffix | 0.0727 | 0.0424 | 0.0304 | 0.0265 | ||
| Slide | 0.0596 | 0.0311 | 0.0265 | 0.0265 | ||
| Original | 0.0580 | 0.0300 | 0.0265 | 0.0265 | ||
| CE | Prefix | 0.0731 | 0.0464 | 0.0280 | 0.0479 | |
| Suffix | 0.0727 | 0.0424 | 0.0304 | 0.0487 | ||
| Slide | 0.0777 | 0.0460 | 0.0297 | 0.0601 | ||
| Original | 0.0947 | 0.1312 | 0.0635 | 0.1215 |
关键观察(作者总结为 4 条):
- Multi-target 基本上不需要 SSS。多目标策略本身就是对原序列进行密集监督,再做物理切分收益有限甚至下降。
- CE loss 显著优于 BCE loss。CE + softmax 对 next-item 预测这种多分类任务天然更契合;只换 loss 就能带来巨大提升。
- Single-target + BCE loss + SSS(特别是 prefix 或 suffix)是 SSS 收益最大的场景。此时没有 SSS 的监督信号极稀疏,SSS 的扩充才关键。
- Prefix Splitting 总体表现最好:它同时保留了"顺序前缀语义"和"多个终点的监督",比 suffix 和 sliding window 更接近 multi-target 的训练密度。
- Sliding Window 最弱:因为它破坏了"用户兴趣从头到尾的完整性",对每一个滑窗的起点用户兴趣都不完整。
大数据集主结果(Table 6)¶
在 ML-1M 和 CDs 数据集上 SSS 的优势急剧缩小甚至消失:
- ML-1M 交互稠密(avg seq length 165.5),SSS 带来的增量信息很少;
- CDs 稀疏但用户基数少,SSS 的扩展量有限。
- 各种 split 在大数据集上的 gap 急剧收敛,不同方法差异 <5%。
- 这说明 SSS 是一个"稀疏场景专用"的数据增强方法,在数据密度足够高时它的作用消失。
BSARec 在 ML-1M / CDs 上的"复活"(Table 6)¶
一个有趣的现象:BSARec 去掉 SSS 后在 ML-1M 上和 SASRec 几乎打平,说明 BSARec 的架构创新(傅立叶 + self-attention)在数据稠密时确实有独立价值,只是在小数据集上被 SSS 的 confound 掩盖了。
设置组合的冠军统计(Figure 3)¶
在 192 场对比(4 模型 × 6 数据集 × 8 指标)中:
- Single-target + CE loss + Prefix / Sliding:48.2% 居 1st 或 2nd;
- Multi-target + CE loss + Original:第二常见组合(18.5%);
- 其他设置合计不到 1/3。
作者据此建议:研究者要复现 SR baseline 时,默认尝试上述两组高性能组合,再做其他 design choice。

Figure 2 以 BSARec 论文中的 Table 为基准,对比原报告与本论文重评:GRU4Rec 在使用"正确设置"下反而比原报告的 SASRec/FMLPRec/BSARec/Our 都更好。说明这些模型的差距被 SSS + 不合适的设置掩盖了。
Section 5:Why Is SSS Effective?¶
作者从两个角度解释 SSS 的收益来源。
5.1 Target Probability Distribution¶
作者受 DA 研究启发,计算"原始训练集的目标 item 分布"与"SSS 后的目标 item 分布"的差异。把 y_u 的出现频率作为概率,按频率排序画分布图:

- 原始分布非常陡峭——少数 popular item 占据大量 target,长尾 item 从未出现在 target 侧;
- SSS 之后分布变平——更多长尾 item 有机会成为 target 被学到。
这对训练效果的影响: 1. 更多长尾 item 被监督到,提升 coverage; 2. 减少 over-fitting 到 popular item。
结合的两点效果直接解释了 SSS 为何在 "dense popular, sparse tail" 的数据集(Beauty、Sports)上收益特别大。
5.2 Input-Target Distributions¶
作者进一步把 input 序列特征与 target 做联合分布分析(类似 contrastive 的思路):
- 原始数据下,大多数 user 只有一个 (input, target) 对,input 与 target 的联合分布存在明显 mode collapse;
- SSS 之后同一个用户产生多个 (input, target) 对,对应同一用户的 "用户兴趣 → 目标 item" 的 joint distribution 变得连续、平滑。
- Prefix 和 Suffix 在分布的温和程度上优于 Sliding window,这与性能顺序一致。
讨论与社区建议¶
作者给出的建议(Section 6):
- 研究者应披露 SSS 使用情况:在论文 "Implementation Details" 或 "Dataset" 部分明确写明是否用了 SSS 以及具体切分参数;
- 开源代码不应在 data reader 里悄悄启用 SSS:code 与 paper 描述必须一致;
- 对比 baseline 应使用相同的数据预处理管线,包括 SSS。否则 performance gain 无法归因到架构创新;
- 审稿人应主动询问 SSS 的配置,审视作者是否公平对比;
- Benchmark 社区应把 SSS 的是否启用、具体形式作为 metadata 一起记录,就像记录 dataset split ratio 一样。
作者的学术洞察:
- SSS 是一个价值被广泛低估同时又被广泛 misuse 的技术。它的真正价值在小数据集 + 稀疏设置下,但被错误地归功于新模型架构。
- Prefix Splitting + Single-target + CE Loss 是一个"原教旨级"配置——它可能比很多 2024 年提出的 "复杂 SR 架构" 都更有竞争力,应该作为任何 SR 评测的 baseline。
- 社区的某种"默认代码流水线继承病":大家复用前人代码时把 data reader 也原封不动拷过来,结果 SSS 被"自然传染"到所有下游论文;但 paper 里写代码继承的默认不包括 DA,所以发生了集体性"隐秘启用"。
局限性¶
- 本研究仅覆盖 经典 Transformer-based SR(GRU4Rec, SASRec, FMLPRec, BSARec)。对 LLM-based SR、基于扩散/VQ 的 generative SR 等新范式未展开。
- 只在 6 个公开数据集上验证,工业级大规模长序列(>10 万长度)场景的 SSS 影响未知。
- 作者没有提出"取代 SSS 的更好 DA 方法",只做了审计与建议。
- SSS 与 contrastive learning 类 auxiliary loss 的交互作用只做了简要分析(CL4SRec、DuoRec、ICSRec),未系统化。
与现有工作的差异¶
- 与单篇评估(如 ICLR reproducibility challenge 里零散的模型复现)相比,本论文覆盖面更广、对一类数据增强操作的系统性审查更深入。
- 与 BARec (ASRep)、ASReP 等"主动提出新 DA"的论文不同,本论文是反向的——"揭示一个长期被滥用的 DA 操作"。
- 与 Liu et al. 2025 (Dang et al., TPAMI) 等 SR DA 综述相比,本论文有更严格的重评实验。
值得借鉴的"复现学"方法论¶
这篇论文有很高的学术价值,不因为它提出了新模型(它确实没有),而是因为它做了一件很多人想做但不愿意做的事:系统性复现 + 严格拆解 confound + 敢于揭示社区集体错误。它为 SR 社区(乃至整个推荐/ML 领域)提供了一个"审计论文"的范式:
- 从权威会议筛选论文;
- 跑官方代码;
- 找到 code 与 paper 的不一致;
- 在同样设置下对比;
- 归因每个组件的贡献;
- 总结实用建议。
对任何在做 SR 工作的研究者来说,这篇论文都是必读——至少在发表下一篇 SR 论文之前,应该确认自己的 data pipeline 是不是存在隐式 SSS、baseline 是否用了同样的 DA 管线、自己 claim 的 improvement 是不是实际来自架构创新。
结论¶
这篇论文用严谨的实证研究揭示了 SR 领域一个长期被忽视的方法论问题:Sub-Sequence Splitting 在代码中静默启用、在论文中不被披露,导致过去几年大量"新模型"的提升其实来源于 SSS 而非架构创新。作者同时指出 SSS 真正有效的配置(Single-target + CE + Prefix/Suffix),并从 target distribution / input-target joint distribution 两个视角解释其机理。这项工作对 SR 社区具有"清理地基"的意义,是一份很罕见、很有价值的 reproducibility study。