OneRetrieval:用一个「可编辑」的生成式模型统一电商多路召回¶
Kuaishou Technology(快手)· 2026-06-11 · arXiv:2606.13533 已部署于快手「站外搜索」(out-of-mall search),服务数百万用户,日均生成数亿 PV。代码:https://github.com/xuxinzhang/oneretrieval
研究动机与背景¶
工业电商搜索的召回阶段几乎无一例外地采用多路(multi-branch)架构:稀疏的倒排索引分支负责词法召回,稠密向量分支负责语义召回,协同过滤分支负责行为召回;三路各自独立训练,再由一套人工调参的融合(hand-tuned merge)把候选合并、送入下游粗排/精排。这种设计鲁棒、易调试,但每条分支都带着结构性弱点:
- 倒排索引分支:词法上忠实,但语义上盲——它会召回「字面命中 query 但完全不懂买家意图」的商品;
- 稠密分支:跨表面形态泛化,但匹配粗糙、对新内容反应慢;
- 协同分支:继承头部偏置,压制长尾和新品的可见性。
把三路拼在一起还额外引入系统级成本:分支独立训练、靠人工融合,排除了联合优化,跨分支冗余成了换取鲁棒性的代价。
生成式检索(Generative Retrieval, GR)把召回重构为「在 query 与用户上下文条件下,自回归地生成商品标识符(identifier)」,理论上可以把整个召回阶段坍缩进一个联合优化的模型。但本文的核心论点是:统一不止由检索质量把关,更由「实时可编辑性(real-time editability)」把关。
可编辑性悖论(The Editability Paradox)¶
快手的内部度量显示了一个反直觉的事实:倒排索引分支占据了相当大的曝光份额,但它的转化率却显著低于平台均值。按理说应该替换掉它——然而几乎没人敢动,原因是:倒排分支是几乎唯一能让运营在数小时内、无需任何模型更新就注入一个新词的通道。一个新出现的商品、品牌、品类词(如突然爆火的 IP「LABUBU」或「POP MART」),一条营销 slogan,运营通过同义词词典/打标字典挂上去、增量刷新索引,几小时内就能生效并把流量精确路由到目标商品集合。
倒排分支留存下来,不是因为它检索得更好,而是因为它可编辑。要用一个模型替换它,新模型就必须保留这种「当天可编辑」的能力。
为什么生成式检索至今没补上这一环¶
已有 GR 工作按标识符的构造方式分为两类,二者都结构性地缺失实时可编辑性:
- 闭码本(closed-codebook)方法(DSI、TIGER、LC-Rec、OneSearch):通过残差/乘积量化学出紧凑的整数码,每个码槽在训练时就绑死到一个量化嵌入,推理时几乎没有空间容纳一个新出现的属性词。要接纳新词必须重训量化器和策略。
- 开放词表(open-vocabulary)方法(SEAL、GLEN、GenRPO、GRAM、LTRGR):直接生成商品文本片段(n-gram、标题 span),新词能否被可靠路由到目标商品,几乎完全依赖模型自身的泛化,没有任何显式机制把一个词「绑定」到一个指定的商品集合。
UniDex [18] 用语义 ID 索引替换词项倒排索引,在生产规模上确认了「词法分支值得重新思考」——但它是判别式而非生成式,仍停留在多路布局内,且标识符是训练时固定的量化码,原分支的字典级当天可编辑性是被放弃而非被恢复。
本文方案:OneRetrieval¶
本文提出 OneRetrieval,一个单模型生成式检索框架,建立在 Keyword-Aligned Encoding(KAE,关键词对齐编码) 之上:把每个标识符位置(identifier position)对齐到一个可解释的「关键属性词(key attribute word)」,而非一个量化嵌入。这样它既保留了与最强生成式 baseline 相当的召回质量,又恢复了倒排索引的实时可编辑性。据作者所知,这是第一个有潜力接管几乎整个在线召回阶段的、可编辑的生成式方法。
三个相互咬合的关键设计:
- 信息论属性分组合并:把 18 个细粒度关键属性类别,沿信息损失曲线的拐点合并为 6 组,并按密度做非均匀容量分配;
- 可扩展码本(extensible codebook):每个码本保留一小块预留槽(reserved slots),运营在部署后无需重训即可把新词绑到这些槽上;
- 属性锚定的四阶段有监督微调:Stage 0 把每个码本槽锚定到一个具体属性词,Stage 3 用预留槽自路由监督收尾,让检索质量与可编辑性被联合保障,而非互相牺牲。
Table 1 精确刻画了 OneRetrieval 在「标识符构造 × 推理时可编辑性」坐标系里的独特位置:
| 家族 | 代表方法 | 标识符 | 语义锚 | 对新词可编辑 |
|---|---|---|---|---|
| 稀疏倒排索引 | BM25, TF-IDF, query expansion | 词法项 | 表面字符串 | ✓ |
| 模型化稀疏 | UniDex | 量化语义 ID | 学到的量化 | ✗ |
| 稠密 | DPR, ColBERT, SimCSE | 稠密向量 | 学到的相似度 | ✗ |
| 协同 | ItemCF, SASRec, SIM | item ID | 共现交互历史 | ✗ |
| 闭码本 GR | DSI, TIGER, LC-Rec, OneSearch | 固定整数码 | 量化嵌入 | ✗ |
| 开放词表 GR | SEAL, GLEN, GenR-PO, GRAM, LTRGR | 自由文本 span | 自然语言文本 | ✗ |
| 可扩展码本 GR | OneRetrieval(本文) | 整数码 + 预留槽 | 关键属性词 | ✓ |
在所有经典家族里,只有建立在倒排基底上的方法能在生产中提供可编辑性;OneRetrieval 是据作者所知第一个把这一性质「拿回来」的生成式方法。
核心方法与模型架构¶
3.1 问题形式化¶
记 $\mathcal{Q}$ 为用户 query 空间,$\mathcal{I}$ 为商品库。每个商品 $i \in \mathcal{I}$ 携带一条结构化记录:标题、结构化属性、详情页文本、图片 OCR。用户 $u$ 发起 query $q$,附带可选上下文 $\mathbf{c}_u$(近期搜索历史与近期交互商品)。召回阶段须返回候选集 $\mathcal{R}(q, \mathbf{c}_u) \subseteq \mathcal{I}$。
OneRetrieval 把 $\mathcal{R}$ 实现为自回归生成。每个商品 $i$ 被赋予一个结构化语义标识符(SID):
$$\mathbf{s}_i = (s_i^{(1)}, s_i^{(2)}, \ldots, s_i^{(L)}), \tag{1}$$
长度为 $L$,第 $\ell$ 个 token 取自位置专属(position-specific)码本 $\mathcal{V}_\ell$。推理时策略 $\pi_\theta$ 产出 $K$ 个最可能的 SID 并解析为商品:
$$\mathcal{R}(q, \mathbf{c}_u) = \mathcal{T}\!\left(\underset{\mathbf{s}}{\text{TopK}}\, \pi_\theta(\mathbf{s} \mid q, \mathbf{c}_u)\right), \tag{2}$$
其中 top-$K$ 用无约束 beam search 近似,$\mathcal{T}$ 是预先算好的 SID→商品查找索引。由于 $\mathcal{T}$ 是一对多的——语义等价的商品可以共享一个 SID——解析出的集合通常包含多于 $K$ 个商品。策略自回归分解:$\pi_\theta(\mathbf{s}\mid q,\mathbf{c}_u) = \prod_{\ell=1}^{L}\pi_\theta(s^{(\ell)}\mid s^{(<\ell)}, q, \mathbf{c}_u)$,并以位置求和的最大似然目标训练:
$$\mathcal{L}(\theta) = -\sum_{(q,\mathbf{c}_u,\mathbf{s}) \in \mathcal{D}} \sum_{\ell=1}^{L} \log \pi_\theta\!\left(s^{(\ell)} \mid s^{(<\ell)}, q, \mathbf{c}_u\right), \tag{3}$$
$\mathcal{D}$ 是训练三元组 $(q,\mathbf{c}_u,\mathbf{s})$ 的集合,其中 $\mathbf{s}$ 是在 $(q,\mathbf{c}_u)$ 下被交互商品的 SID。式 (3) 是部署目标;§3.5 的四个微调阶段都复用这一逐 token 形式,只是替换各自的输入-目标对。
这一形式化把设计空间收敛为两个耦合的问题:(i) 如何构造 $L$ 个位置专属码本,使 SID 紧凑、语义可解释、可编辑;(ii) 如何把 $\pi_\theta$ 对齐到 SID 空间,使预训练 backbone 的语言模型先验被充分利用。分别在 §3.4 与 §3.5 回答。
3.2 框架总览¶
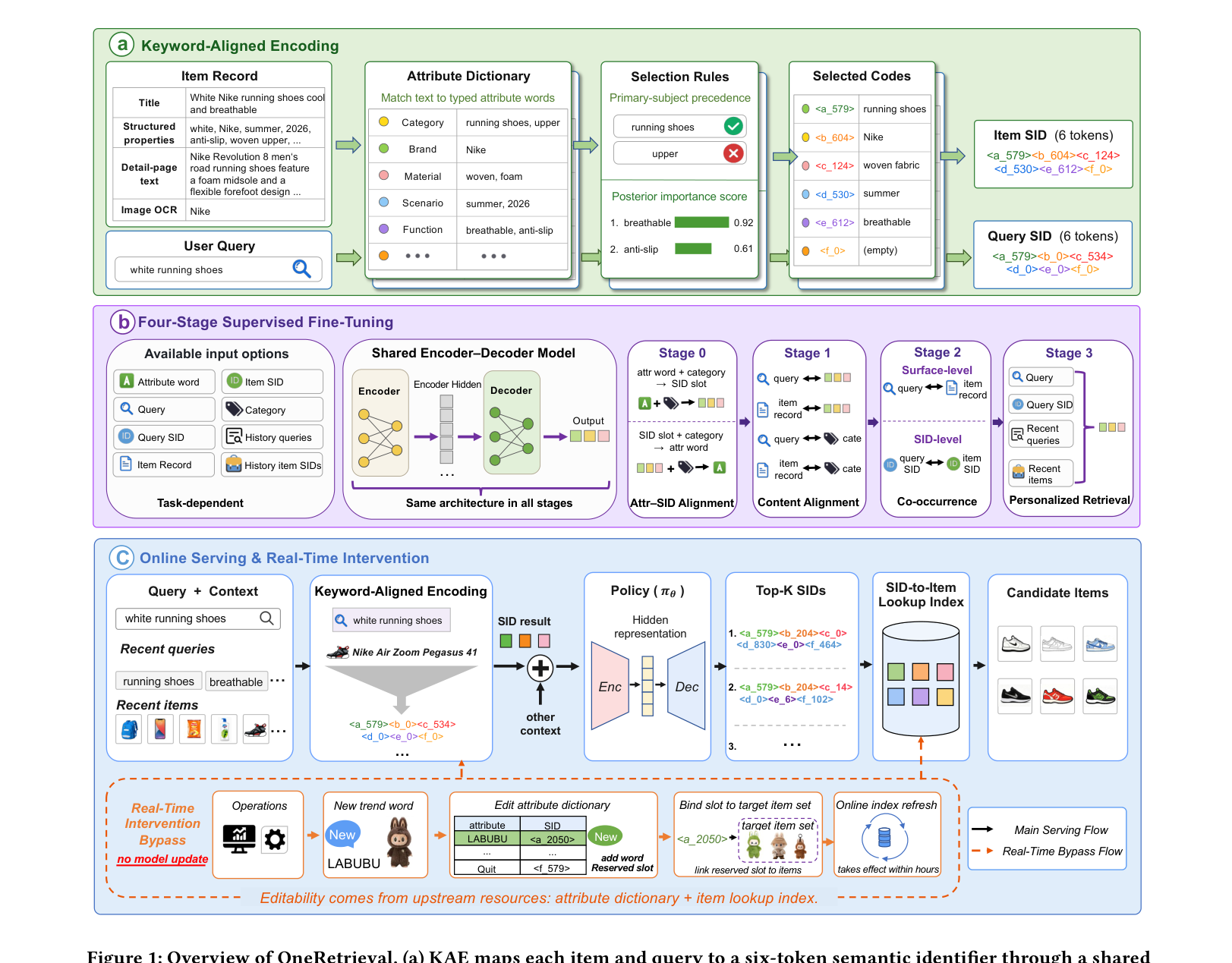
框架分三块(对应 Figure 1 的三个面板):
(a) 关键词对齐编码(KAE,Figure 1a)。 KAE 把每个 query 与商品映射到一个 SID,对照的是单一共享资源:一部生产用的属性字典 $\mathcal{A}$,它列出每个打过类型标签的属性词及其关键属性类别。输入文本字段用一个确定性过程与 $\mathcal{A}$ 匹配,每个命中词被分配到 6 个合并组之一(§3.3);当多个词落入同一组时,由一套选择规则(含主体优先 primary-subject precedence + 后验重要度 posteriori importance score)选出单一代表词;把各组的 SID 槽拼接起来就得到 SID。这一过程对商品和 query 对称地施加,query 侧 SID $\mathbf{s}_q$ 既作为推理输入、又作为 Stage 2/3 的协同训练信号。
(b) 四阶段有监督微调(Figure 1b)。 在一个共享的 encoder-decoder 上分四阶段顺序训练:Stage 0 锚定 SID 字母表,Stage 1 对齐 query/item 与 SID,Stage 2 注入协同共现信号,Stage 3 产出带个性化的部署策略(§3.5)。
(c) 在线服务(Figure 1c,实线主流程)。 推理时 encoder 用与离线相同的字典驱动编码从 query 与上下文产出 $\mathbf{s}_q$,请求路径上除策略外不调用任何神经模块。$\pi_\theta$ 用无约束 beam search 解出 top-$K$ SID 列表,每个经 $\mathcal{T}$ 解析为候选商品,送入下游粗排。
实时干预旁路(Figure 1c,虚线旁路流程)。 一条在策略训练中从未被走过的侧路,让运营无需任何模型更新就能提升一个新爆词,镜像倒排索引被编辑的方式:运营把新词加入字典、分配给所在合并组的一个未用预留槽 $\langle r_v\rangle$、再在 $\mathcal{T}$ 中把该预留槽绑到目标商品集——于是任何之后含该词的 query 或商品都会落到这个槽上。两处编辑都是增量的,通过既有索引刷新在数小时内传播到线上,既不动策略也不动码本结构。§3.4.4 解释为何即使训练中从未有样本把预留槽和这个词配过对,策略在解码时仍能发出正确的标识符。
3.3 信息论属性分组合并¶
一条内部属性抽取流水线用 18 种细粒度关键属性类型给商品和 query 的子串打标:ENTITY、BRAND、ANCHOR、CROWD、COLOR、GOOD_MODEL、SPECIFICATION、MATERIAL、SCENE、LOCATION、SEASON、MARKETING、QUALITY、MODIFIER、FUNCTION、STYLE、PATTERN、NEW。经 PV 剪枝和去重后,生产词表约含 $1.08 \times 10^6$ 个打标属性词。
若给每个类别各分一个位置则 $L=18$,线性放大推理成本、且稀释每位置密度。所以要找保留类别判别信息的最小 $L$,把搜索框定为信息论凝聚聚类。
把每个类别 $X$ 看作一个 Bernoulli 激活变量:$X(i)=1$ 当商品 $i$ 至少携带一个被打成 $X$ 的属性词。记 $p_X = \Pr[X(i)=1]$,$H(X)$ 为二元熵,$\text{MI}(X,Y)$ 为一对类别的互信息,则把 $X$ 与 $Y$ 折叠到同一位置的损失用对称条件熵度量:
$$\text{IL}(X, Y) = \tfrac{1}{2}\big(H(X \mid Y) + H(Y \mid X)\big) = \tfrac{1}{2}\big(H(X) + H(Y)\big) - \text{MI}(X, Y), \tag{4}$$
这恰是「当一个标签必须替代另一个时」所招致的残余双向不确定性。它对称、非负、等于 variation of information 的一半,因此在类别上表现得像一个度量(metric)。
按平均组间距离做凝聚聚类:
$$\overline{\text{IL}}(g_a, g_b) = \frac{1}{|g_a||g_b|} \sum_{X \in g_a,\, Y \in g_b} \text{IL}(X, Y),$$
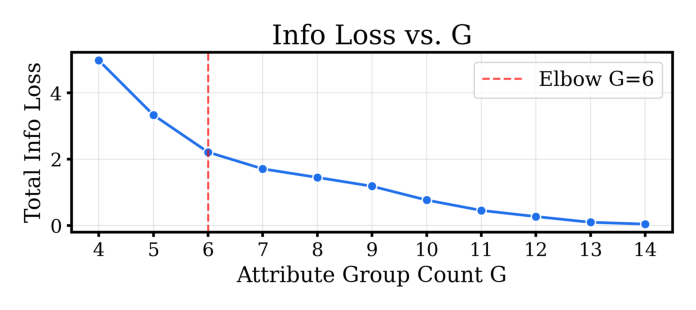
每步合并 $\overline{\text{IL}}$ 最小的一对。18 个标签中 ENTITY 被单独留作 singleton 锚——它是指代「所买之物」的名词,是其它每个属性都依附其上的主语义锚。剩下 17 个类别在三个轻量正则下合并:组内熵与激活率同质化、语义相邻先验、组大小软上限,使各组保持均衡。组数的确定方式:把合并跑到每个目标组数、画出累积信息损失对组数的曲线(Figure 2),其二阶差分在 6 处达到峰值(拐点)。于是取 $L=6$,命名该划分为 ECOM6。
ECOM6 的六个组及密度见原文 Figure 3a,其中三个最密的组(Product Core / Audience & Endorsement / Material & Quality,各约 220K–242K 词)促成了下文的非均匀分配;$L=6$ 的选择又被 §4.3 的检索质量长度扫描所佐证。
3.4 码本构造¶
3.4.1 非均匀容量(Non-uniform capacity)¶
对每个合并组 $\ell$ 构造码本 $\mathcal{V}_\ell$,其大小 $V_\ell$ 按组的属性词密度非均匀分配:推荐配置在三个最密位置设 $V_\ell = 2048$,其余三个设 $V_\ell = 1024$,共 $\sum_\ell V_\ell = 9{,}216$ 个核心槽、$L=6$。记法 $\text{L}\langle L\rangle\text{-D}\langle k\rangle$,$k$ 是被加倍到 2048 的位置数(其余保持 1024);均匀-1024 写作 $\text{L}\langle L\rangle$,实体条件变体(§3.6)追加 +Hier。于是均匀基线是 L6,推荐分配是 L6-D3,即部署的 OneRetrieval。
动机很直接:每位置的「属性词→槽」绑定是位置内碰撞率的约束瓶颈,均匀分配会迫使最密位置每槽塞下比最稀位置多一个数量级的词,碰撞率被它主导。
3.4.2 四块布局(Four-block layout)¶
每个码本内,$V_\ell$ 个核心槽占三个连续块——empty、cluster、solo——再在 $V_\ell$ 之外追加第四个预留块 $V_\ell^{\text{rsv}}$(原文 Figure 3b):
- Empty 槽:索引 0,编码「本组无任何属性词」或「词不在生产词表内」。
- Cluster 槽:索引 $[1,\ V_\ell - V_\ell^{\text{solo}} - 1]$,存放对组内尾部属性词嵌入做 $k$-means 得到的簇质心,每个覆盖一个同义词邻域;代表词被保留用于 Stage 0 监督。
- Solo 槽:接下来的 $V_\ell^{\text{solo}}$ 个索引,存放最高频的头部词,大致一槽一词;极近的表面变体(双语别名、常见错拼)若超过相似度阈值则共享一个槽。密位置取 $V_\ell^{\text{solo}}=1024$,稀位置取 512。
- Reserved 槽(预留槽):最后 $V_\ell^{\text{rsv}}$ 个索引,训练时不绑定任何属性词,部署后才绑到新爆词。它们在 Stage 0–2 中缺席,仅在 Stage 3 中作为未绑定的身份路由目标被暴露给策略(§3.5),从而在解码时可被发出而无需在训练时绑死任何具体词。
$L=6$ 与推荐分配下,每个 SID 是 6 个 token。码本给 backbone 词表添加 $\sum_\ell V_\ell = 9{,}216$ 个核心 token 和 $\sum_\ell V_\ell^{\text{rsv}} = 60$ 个预留 token,共 9,276 个;60 个预留 token 的预算足以吸纳平台上一个完整周度趋势周期且有余量。
3.4.3 商品记录 → SID¶
对每个商品,拼接标题、结构化属性、详情页文本、图片 OCR,用 Aho-Corasick 自动机 [1] 对照生产词表恢复出打标属性词。词表是离线用内部属性抽取模型跑历史语料引导出来的,编码时无需神经推理。同样的匹配施加到 query。当多个词落入同一组时,用一张重要度表选代表词,含两条准则:
- 主体优先(primary-subject precedence):离线问一次 LLM 构造——对任意同类型共现词对,哪个是主语主体。例如一条商品记录里「ice cream(冰淇淋)」和「mold(模具)」都被打成 ENTITY,LLM 把这对解析为「mold」——真正在卖的物件。
- 后验重要度分数:在主体固定后,用 PV、CTR 等行为统计对其余候选排序。
代表词映射到其码本槽,拼接各组槽即得 SID(Figure 1a 给出图示)。
3.4.4 为何预留槽支持实时干预¶
设 $w_{\text{new}}$ 是新爆属性词,$\ell$ 是其合并组,$\langle r_v\rangle$ 是一个未用预留槽。这里精确说明为何「无需任何对 $\pi_\theta$ 的更新」就能正确检索。三条性质支撑这一行为,(P1)(P3) 由构造成立,(P2) 由监督建立:
- (P1) 句法可达性(Syntactic reachability):无约束 beam search 下,解码器在任一位置可发出码本字母表中的任一 token。预留槽是训练时该字母表的一个固定子集,所以策略保留了在解码时发出它们的能力,即使训练中从无样本把它绑到某个具体词。
- (P2) 词无关身份路由(Word-agnostic identity routing):预留槽在 Stage 0–2 缺席。Stage 3 加一小块形如 $\text{PREFIX}(\langle r_v\rangle) \to \text{PREFIX}(\langle r_v\rangle)$ 的自路由监督,教策略把任意前缀当作身份路由器:一条 SID 落到 $\langle r_v\rangle$ 的 query,解码到一个同样以 $\langle r_v\rangle$ 开头的商品 SID。这与 $\langle r_v\rangle$ 最终代表什么词无关,因为路由由训练数据而非绑定建立。路由是被训练出的行为而非硬保证,其强度由 §4.4 的干预探针量化。
- (P3) Encoder 侧确定性(Encoder-side determinism):query 时 $w_{\text{new}}$ 由 Aho-Corasick 扫描更新后的字典恢复、分到组 $\ell$、由确定性查表映射到 $\langle r_v\rangle$。槽被哪个词占用由字典固定、而非由策略选择,所以运营对绑定保持完全控制;每条含 $w_{\text{new}}$ 的 query 都呈现同一个单位置前缀 $\langle r_v\rangle$——正是 (P2) 的自路由监督训练策略去映射回去的那个模式。
闭码本 GR baseline(如 RQ-VAE)对 (P1)–(P3) 一条都不满足:码本由训练时量化导出,每个槽绑死到固定质心,没有任何位置携带可供新词注册的语义锚。§4.4 的探针经验证实:OneRetrieval 的 RQ-VAE 对应物总 IHR@350 仅 0.0025,与「偶发码碰撞」而非「可控绑定」相一致。
3.5 四阶段有监督微调¶
采用 BART-base [15] 作为 encoder-decoder backbone,把词表扩展 9,276 个 SID token,按顺序训练四个阶段,每阶段初始化下一阶段,全部共享式 (3) 的目标。
- Stage 0:属性–SID 对齐。 通过正向模板「Attribute word is $\langle$ATTR$\rangle$, category $\langle$CATE$\rangle$, id is:」$\to \langle a_v\rangle$ 及其逆向,教每个已填充槽与它代表的属性词之间的双向映射,覆盖每个 solo 与 cluster 槽。Stage 0 后每个已填充槽获得一个位置条件下的、对兼容属性词的分布,策略内化了「打到组 $\ell$ 的词应在位置 $\ell$ 发出」的偏置。这个位置偏置也帮助一个后来绑到预留槽的词在其正确位置被发出;预留槽本身不参与 Stage 0。
- Stage 1:内容对齐。 对齐 query 与商品的表面形态与其 SID。四个双向任务把 query 和商品标题与其 SID 配对;两个类目预测任务 $q\to\text{CATE}_q$、$\text{TITLE}_i\to\text{CATE}_i$ 把 SID 空间正则化到平台分类体系。作为提供绝大部分 query→SID 与 item→SID 监督的阶段,Stage 1 是检索质量的主要来源。
- Stage 2:协同共现。 在两个层面注入协同信号。对每条来自点击/下单日志的 $(q,i)$ 对,两个表面级任务把 query 与商品标题配对,两个 SID 级任务把 $\mathbf{s}_q$ 与 $\mathbf{s}_i$ 配对。SID 级任务教策略「一条 query 与它转化的商品占据 SID 空间的兼容区域」,建立起预留槽机制后来所依赖的 query-SID → item-SID 路由。作为唯一把策略暴露给 query 侧 SID 的阶段,Stage 2 在 §4.5 消融中被识别为可编辑性的承重阶段。
- Stage 3:个性化检索。 产出部署策略。每条 query 用完整用户侧上下文增广——当前会话 query $q$、其派生 SID $\mathbf{s}_q$、近期搜索 query $\text{HIST}_q$、近期交互商品的 SID 短序列 $\text{HIST}_s$——主任务为:
$$(q,\ \mathbf{s}_q,\ \text{HIST}_q,\ \text{HIST}_s) \rightarrow \mathbf{s}_i, \tag{5}$$
$\mathbf{s}_i$ 是真正被交互商品的 SID。滑窗数据刷新使个性化信号与最新流量分布对齐。
预留槽自路由监督。 Stage 3 内额外加一小块,把每个预留槽作为词无关身份路由目标来锻炼,将 Stage 2 在已填充槽上建立的路由延伸到预留槽。它还有一个用途:一个从不作为目标出现的 token 只会累积负梯度、在解码时被抑制;而把它作为身份路由目标锻炼,保持它可发出。这一块极小(约 Stage 3 集合的 $10^{-5}$ 量级),不指涉任何具体属性词,所以预留槽被纯粹训练成身份路由器,只有当运营在部署时把一个词绑上去才获得意义。它与 Stage 2 的广义路由一起夯实 §3.4.4 的 (P2),把「绑定」留作唯一推迟到部署的操作。
3.6 为何不用层次化编码¶
一个自然的扩展是层次化编码:让每个非 ENTITY 属性词的标识符条件于商品的 entity,于是品牌「ZARA」在 entity=dress 下占 $\langle b_5\rangle$、在 entity=lipstick 下占 $\langle b_{17}\rangle$。它在两点上很诱人:ENTITY-singleton 约束已经把其它每个属性视作 entity 的一个 facet;且因为多数属性词只在一小撮 entity 下激活,条件化可把每位置密度降低多达一个数量级。
作者测了两个变体——一个在均匀 L6 上把所有非 ENTITY 位置条件化,一个在推荐 L6-D3 上仅把品牌位置条件化——两者都不及各自的非层次化基线(§4.3)。失败是系统性的,有三个与配置无关的成因:
- 条件化把「槽→义」关系从一个函数变成一对多映射,稀释了 Stage 0 本要利用的语言模型先验;
- 因为每个非 ENTITY 属性词在生产中跨许多 entity 复现,实体条件编码碎片化了它的训练信号、削弱尾位置泛化;
- 自回归解码器在位置一就承诺了 entity,那里一旦出错会传播到后续每个位置;在本文采用的无约束解码下(无前缀树纠正)效应被放大。
因此检索策略按设计就是非层次化的——一个有意的方法学立场,由 §4.3 的负向消融背书,其它工业 GR 系统可直接采纳。
实验设置¶
基准。 离线基准取自某工业电商平台 31 个连续日的搜索日志:前 30 天随机采 $5\times10^6$ 条带交互的用户请求日志为训练集,第 31 天抽 29,964 条 click 与 29,953 条 order 样本为测试集。去重后(含每个用户近期搜索历史),query 侧共 7,629,195 条 query,item 侧(含每个目标商品及历史交互集中的每个商品)共 20,165,617 个商品。用于码本构造的打标关键属性词去重后约 $1.08\times10^6$ 个。
Baseline。 两组:传统组 BM25、docT5query、DPR;生成式组 TIGER、DSI、LTRGR、LC-Rec、OneSearch。OneSearch 是作者前一项全链路生成式系统(统一召回、粗排、精排,召回阶段建立在关键词增强的层次化量化上)。OneSearch 的闭码本召回编码本质上无推理时可编辑性,所以在干预轴上由 Table 5 的闭码本范式(RQ-OPQ)代表,后者构造上 IHR 近零。Table 2 中所有生成式 baseline 共享 BART-base backbone、相同训练数据、与 OneRetrieval 相同的「每 SID 物化至多 5 个商品」。
指标。 离线报告 Hit Rate(HR@K)与 Mean Reciprocal Rank(MRR@K),在 click 与 order 两个目标上、$K\in\{10,100,350\}$。两个互补的实时干预指标:
- 干预命中率(IHR@K):与 HR@K 计算方式完全相同,但目标是一个伪造商品而非真实交互商品;它度量「只能通过新注入的码触达的伪造目标」出现在 top-K 的样本比例。
- 干预激活率(IAR@K):IHR@K 的词级对应物;不要求恢复某个伪造商品,而是度量「注入的属性词在 top-K 召回结果中至少激活一次」的干预 query 比例,匹配「运营把词绑到一个商品群体而非单个商品」的生产设定。IAR@K 对任何能路由注入词的方法都有定义,因此用作 OneRetrieval 与可编辑的倒排索引分支对比的指标(Table 6)。
在线。 在站外搜索报告 Item CTR、Buyer count、Order volume,0.05 显著性水平。人工 side-by-side 评测沿三轴(query-商品相关性、商品质量、页面好评率),并给出相对 CTR 增益的分行业拆解。
实现。 Backbone 为 BART-base,SID 字母表大小随码本配置变化。模型在 H800 训练、在 RTX 4090 服务,正文所有离线数字用 beam size 512 的无约束 beam search。每个生成的 SID 经查找索引物化至多 5 个商品,所有检索指标在商品级计算;如 HR@350 是 beam-search SID 映射回商品后 top-350 商品上的命中率。四个 SFT 阶段都用学习率 $1\times10^{-4}$、batch size 512;Stage 0–2 各 5 epoch,Stage 3 跑 40 epoch,各阶段样本量分别约 0.8M、74.3M、10.6M、6.4M。每位置 $k$-means 簇数等于该位置的 cluster-block 大小。
主要实验结果¶
RQ1:对比 Baseline 的离线检索质量¶
Table 2:click 与 order 测试集上的离线检索结果(部署配置 OneRetrieval 加阴影)。
Order:
| 方法 | HR@10 | MRR@10 | HR@100 | MRR@100 | HR@350 | MRR@350 |
|---|---|---|---|---|---|---|
| BM25 | 0.0344 | 0.0133 | 0.1230 | 0.0161 | 0.2215 | 0.0166 |
| docT5query | 0.0423 | 0.0165 | 0.1640 | 0.0203 | 0.2926 | 0.0210 |
| DPR | 0.0612 | 0.0221 | 0.2605 | 0.0283 | 0.4346 | 0.0293 |
| TIGER | 0.1253 | 0.0632 | 0.2265 | 0.0673 | 0.2624 | 0.0675 |
| DSI | 0.1427 | 0.0720 | 0.2569 | 0.0764 | 0.2967 | 0.0767 |
| LTRGR | 0.1566 | 0.0797 | 0.2837 | 0.0846 | 0.3315 | 0.0849 |
| LC-Rec | 0.1667 | 0.0810 | 0.3130 | 0.0865 | 0.3751 | 0.0869 |
| OneSearch | 0.2551 | 0.1242 | 0.4766 | 0.1328 | 0.5550 | 0.1333 |
| OneRetrieval | 0.1846 | 0.0825 | 0.4225 | 0.0868 | 0.5482 | 0.0880 |
Click:
| 方法 | HR@10 | MRR@10 | HR@100 | MRR@100 | HR@350 | MRR@350 |
|---|---|---|---|---|---|---|
| BM25 | 0.0583 | 0.0236 | 0.1798 | 0.0276 | 0.2914 | 0.0282 |
| docT5query | 0.0754 | 0.0304 | 0.2314 | 0.0355 | 0.3699 | 0.0363 |
| DPR | 0.0956 | 0.0367 | 0.3340 | 0.0445 | 0.5027 | 0.0455 |
| TIGER | 0.1393 | 0.0684 | 0.2565 | 0.0730 | 0.2982 | 0.0732 |
| DSI | 0.1585 | 0.0800 | 0.2855 | 0.0849 | 0.3306 | 0.0852 |
| LTRGR | 0.1768 | 0.0900 | 0.3174 | 0.0954 | 0.3682 | 0.0957 |
| LC-Rec | 0.1892 | 0.0915 | 0.3537 | 0.0978 | 0.4164 | 0.0982 |
| OneSearch | 0.2909 | 0.1443 | 0.5238 | 0.1534 | 0.6007 | 0.1539 |
| OneRetrieval | 0.2034 | 0.1010 | 0.4602 | 0.1060 | 0.6055 | 0.1076 |
结论分析(why,而非仅 what):
-
OneRetrieval 在深召回上与最强生成式 baseline 打平。 OneSearch 在浅/中截断和所有 MRR@K 上领先——这是其设计目标的结果:OneSearch 把召回、粗排、精排统一进一个端到端优化排序精度的级联,其闭码本层次化量化被调成「把最相关商品放到列表最前」。OneRetrieval 只针对召回阶段,故在浅截断处落后,但随 $K$ 增大缩小差距,直到 HR@350 处两者实质打平:order 0.5482 vs 0.5550、click 0.6055 vs 0.6007(后者反超)。两者孤悬于深召回前沿——次优 baseline 稠密 DPR 在 order HR 上落后 11 个百分点以上,最强的其余生成式方法 LC-Rec 落后约 17 点。打平不延伸到列表顶部,那里 OneRetrieval 的 MRR@350(order 0.0880)逼近但低于 OneSearch(0.1333)。所以 OneRetrieval 对检索质量的贡献是深列表覆盖——召回分支真正在乎的性质,而非精确的顶部摆放。
-
决定性的轴是可编辑性,而非检索质量。 OneSearch 是闭码本、本质上无实时干预能力(约 §4.4 中 RQ-OPQ 的 0.0021 总 IHR@350,一个闭码本生成式方法构造上几乎无法克服的缺口);OneRetrieval 则恢复了倒排索引的可编辑性。在深召回前沿的两个方法里,OneRetrieval 提供了另一个几乎无法获得的能力,浅截断处那点精度差是为它付的有界代价。
RQ2:码本设计选择¶
码本设计空间沿三个正交轴分解:序列长度 $L$、每位置容量分配、条件式 vs 全局编码。
长度轴(Figure 4): 在均匀 $V_\ell=1024$ 非层次族内,Order HR@350 在 $L=6$ 达峰,而每-SID 延迟随 $L$ 线性增长,两条曲线在 $L=6$ 交叉——成本-质量拐点。固定 $L=6$。
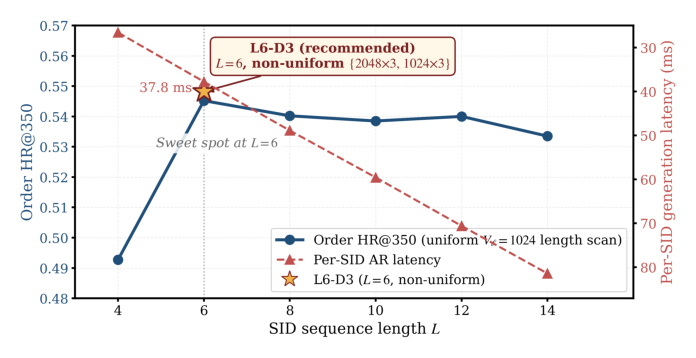
分配轴(Table 3): 固定 $L=6$,在 ECOM6 下扫五种分配(均非层次;Total V 为六位置核心码本之和;部署 L6-D3 加阴影)。
| ID | 分配 | Total V | Order HR@350 | Click HR@350 |
|---|---|---|---|---|
| L6 | $6\times1024$ | 6144 | 0.5452 | 0.6033 |
| L6-D1 | $\{2048,\ 1024\times5\}$ | 7168 | 0.5459 | 0.6023 |
| L6-D2 | $\{2048\times2,\ 1024\times4\}$ | 8192 | 0.5476 | 0.6035 |
| L6-D3 | $\{2048\times3,\ 1024\times3\}$ | 9216 | 0.5482 | 0.6055 |
| L6-D6 | $6\times2048$ | 12288 | 0.5522 | 0.6072 |
Order HR@350 随总容量单调上升,但关键在容量放在哪里、而非放多少。ECOM6 的三个领先组携带远多于尾部三组的属性词表,把位置劈成「密头」与「轻尾」,L6-D3 给密头分 2048、轻尾分 1024。中间的 L6-D1/L6-D2 没给密头配足、即便花了容量也落后;L6-D6 仅靠无差别加 33% 容量才略超 L6-D3。因 L6-D1/D2/D3 之差落在 run-to-run 噪声内,把 L6-D3 读作质量-容量的 Pareto 拐点——「恰好配满密头的最小分配」,而非全局 HR 最大。在 $L=6$ 它还以一半自回归成本超过两倍长的均匀 L12 标识符,说明非均匀精化是在已最优的长度上捕获、而非补偿一个次优长度。
条件轴(Table 4): 层次化编码欠佳(Hier. scope 是被条件于预测 entity 的位置集,$\Delta_{HR}$ 是对匹配的非层次基线的 Order HR@350 变化)。
| ID | Hier. scope | Order HR@350 | Click HR@350 | $\Delta_{HR}$ |
|---|---|---|---|---|
| L6 | 无 | 0.5452 | 0.6033 | ref. |
| L6+Hier(all) | 全部 5 个非-entity | 0.5313 | 0.5872 | −1.39 |
| L6-D3 | 无 | 0.5482 | 0.6055 | ref. |
| L6-D3+Hier(brand) | 仅品牌 | 0.5350 | 0.5916 | −1.32 |
条件化全部 5 个非-entity 位置丢 1.39 个 Order HR 点,仅条件化单个品牌位置丢 1.32 点,与 §3.6 三个机制吻合。综合(Synthesis): L6-D3 同时站在三轴的有利侧——长度的成本-质量拐点、分配的密度感知最优、条件的非层次侧;它对两倍长均匀标识符的优势只源于三个选择相互加强。
RQ3:编码范式对比(KAE vs 量化)¶
§4.3 固定了 L6-D3 的码本结构;这里隔离上游的编码范式选择——KAE vs 闭码本 GR 的嵌入量化惯例。为把差异归因到范式而非容量,给四种范式固定均匀 $6\times1024$ 核心布局(L6;预留槽不计入 $V_\ell$ 但在 KAE 布局中保留),只改「码如何赋值」。KAE 对比三个量化对手:RQ-VAE(学习残差量化)、RQ-kmeans(迭代 $k$-means 残差量化)、RQ-OPQ(RQ-kmeans 基础上加 $2\times64$ OPQ 码)。四者共享 Stage 1–3、计算预算、物化,只在 Stage 0 不同——Stage 0 对 KAE 做属性-SID 对齐,但对量化码本无定义(其码无独立属性语义可对齐)。
为离线探测干预,把测试数据转成模拟在线干预请求的样本:一个 LLM(Qwen3-7B)生成 2,000 个近似属性字典的词;围绕每个词构造一个 query-item 对,按被测范式编码——KAE 把词赋到一个随机选的预留槽,量化 baseline 从其嵌入编码。用这些伪造对覆盖 1,000 click + 1,000 order 测试样本,得 2,000 个干预样本,用总 IHR@K 评分。
Table 5:共享 L6 码本布局/训练/评测协议下的编码范式对比。Order/Click HR@350 量检索质量,total IHR@350 量实时干预能力。
| 编码范式 | Order HR@350 | Click HR@350 | Total IHR@350 |
|---|---|---|---|
| KAE | 0.5452 | 0.6033 | 0.0806 |
| RQ-VAE | 0.5075 | 0.5516 | 0.0025 |
| RQ-kmeans | 0.5355 | 0.5837 | 0.0030 |
| RQ-OPQ | 0.5376 | 0.5848 | 0.0021 |
KAE 在检索上领先、在干预上远超量化器。 检索质量上 KAE 在两个目标都最高(0.5452/0.6033),甚至超过用更大 $V_\ell$ 的量化器。检索余量是适中的,但干预差距不是:total IHR@350 KAE 0.0806 对 RQ-VAE/RQ-kmeans/RQ-OPQ 的 0.0025/0.0030/0.0021——高出一个数量级以上,没有任何量化器接近。这一差距是结构性的而非调参假象:量化码本对 (P1)–(P3) 一条都不满足,那点非零基线值反映偶发码碰撞。这一对比只确立了「闭码本 GR 几乎无法支持干预」,而非 OneRetrieval 绝对意义上做得多好;真正的参照是已在生产中具备可编辑性的现任——BM25 倒排索引分支,下面对比。
Table 6:对可编辑现任的对比,在相同注入词上。Order/Click HR@350 重述 Table 2 的检索质量,total IAR@350 是词级干预激活率。
| 方法 | Order HR@350 | Click HR@350 | Total IAR@350 |
|---|---|---|---|
| BM25 倒排索引 | 0.2215 | 0.2914 | 0.7610 |
| OneRetrieval | 0.5482 | 0.6055 | 0.5530 |
OneRetrieval 的 IAR@350 达 0.553,对倒排索引的 0.761——约为现任率的四分之三,平均 15.5% 的解码 SID 携带注入码;与此同时检索质量翻倍以上(Order HR@350 0.5482 vs 0.2215、Click 0.6055 vs 0.2914)。倒排索引在原始激活上仍更强(符合一个原生操作就是「浮现注入词」的词法分支的预期);OneRetrieval 的贡献是在单个生成式模型内恢复了那激活的大部分,且相关性与转化都远更强。
RQ4:四阶段 SFT 消融¶
在固定 L6-D3 码本下做 leave-one-out,每次去掉 Stage 0–2 之一。Stage 3 始终保留(它产出个性化部署策略,去掉它是删除部署目标而非测试可换组件)。
Table 7:固定 L6-D3 码本下 SFT 流水线的 leave-one-out 消融。
| 配置 | Order HR@350 | Click HR@350 | Total IHR@350 |
|---|---|---|---|
| OneRetrieval | 0.5482 | 0.6055 | 0.1340 |
| w/o Stage 0 | 0.5500 | 0.6072 | 0.1020 |
| w/o Stage 1 | 0.5434 | 0.5967 | 0.1580 |
| w/o Stage 2 | 0.5485 | 0.6035 | 0.0030 |
(注:此处全流水线 IHR@350 为 0.1340,高于 §4.4 的 0.0806,因这里用 L6-D3 而非均匀 L6 码本。)
检索质量由 Stage 1 承载,可编辑性由 Stage 2(加 Stage 0 辅助)承载。 去掉 Stage 0 或 Stage 2,Order/Click HR@350 都落在测量噪声内——去掉 Stage 0 甚至把点估计微抬(Order 0.5500 vs 0.5482),所以 Stage 0 是为可编辑性与可解释性而保留,而非为检索质量。只有去掉 Stage 1 才在两个目标上压低 HR,与「Stage 1 提供绝大部分 query→SID / item→SID 对齐」一致。Total IHR@350 一列讲了相反的故事:去掉 Stage 2 把它坍到 0.0030(可编辑性的承重阶段),去掉 Stage 0 降到 0.1020,去掉 Stage 1 基本不变(0.1580,甚至略高)。Stage 2 是唯一把策略暴露给 query 侧 SID 的阶段,建立了 (P2) 在干预时所需的 query-SID→item-SID 路由;Stage 0 锚定字母表与其位置偏置,贡献更小但非平凡。每个阶段都对它主导的目标必要、对另一目标基本可有可无,没有任何单次移除对两者都无害,从而 justified 保留完整流水线。
RQ5:在线 A/B 测试¶
先在站外搜索中用 OneRetrieval(L6-D3)替换生产倒排索引分支,与离线同样的无约束 beam search,对照与实验桶各服务约 20.0% 相对流量(约 8.2% 绝对),7 天 AA 窗 + 11 天 AB 窗。
Table 8:OneRetrieval 在站外搜索的在线 A/B 提升(实验桶相对对照桶的相对变化)。第一行仅替换倒排索引分支;第二行额外替换稠密(向量)分支。$\dagger$ 表 0.05 显著。
| 配置 | Item CTR | Buyer | Order |
|---|---|---|---|
| 替换倒排索引 | +0.074% | +0.450% | +0.710%$^\dagger$ |
| 替换近乎全部 | +0.821%$^\dagger$ | −0.028% | +0.255% |
-
单分支替换抬升转化。 仅替换倒排分支时,转化指标上升而 CTR 近乎持平(+0.074%),与「OneRetrieval 浮现更高转化倾向的商品而非灌水点击」一致;Order +0.710% 显著。增益归因于 OneRetrieval 本身而非退役一个差分支:一个单独的 7 天 arm,只移除倒排分支而不启用 OneRetrieval,未产生统计显著的业务变动。
-
人工评测确认更好的搜索体验。 受训标注员对比 OneRetrieval 与生产 baseline 在相同曝光位浮现的商品,沿三轴标 Good/Same/Bad(GSB)、算净胜率。OneRetrieval 三轴全胜:query-商品相关性 +0.82%、商品质量 +1.36%、页面好评率 +0.54%。增益源自 KAE——它把 query 解析为属性词、按底层意图而非表面字符串召回商品,故召回集既更相关、商品质量也高于倒排分支的词法匹配集。
-
走向统一的单模型召回阶段。 第二次部署用 OneRetrieval 同时替换倒排索引与稠密(向量)两条分支,同协议、20.0% 相对流量、7 天 AA + 11 天 AB。转化指标 Order/Buyer 无统计显著变化(+0.255% Order,−0.028% Buyer),而 Item CTR 显著上升 +0.821%。一个生成式模型由此能几乎替换全部召回分支,且转化无显著损失、点击质量显著增益。这指向把召回阶段收敛进单个模型——移除多路架构的人工两分支融合与跨分支冗余,同时把倒排索引的当天可编辑性带入生成式范式。
-
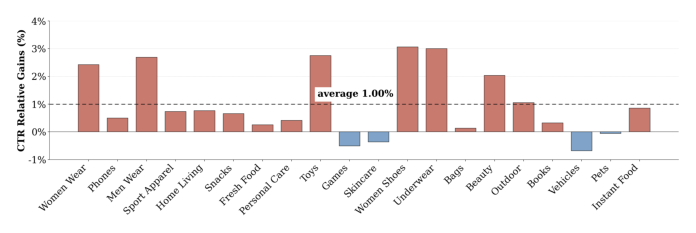
行业增益广泛(Figure 5)。 把第二次部署的相对 CTR 增益按 query volume 拆到 top 20 行业:20 个里 16 个为正,平均相对改进 1.00%。最大增益集中在服饰、鞋类、个护:女鞋 +3.05%、内衣 +3.00%、玩具 +2.75%、男装 +2.70%、女装 +2.42%、美妆 +2.05%。这些正是「query 携带丰富属性结构(品牌、风格、人群、颜色)、细粒度产品区分决定买家意图」的垂类,KAE 通过属性词路由这类 query、恢复倒排分支漏掉的匹配。四个有边际负效应的行业(游戏、护肤、车辆、宠物)都界于 −0.7% 内且不显著。
核心贡献总结¶
- 问题侧的再定位:把「能否用单个生成式模型替换多路召回」的瓶颈从「检索质量」重新定位到「实时可编辑性」,并用「可编辑性悖论」精确刻画——倒排分支转化低却不可替代,只因它可编辑。Table 1 把七个检索家族按「标识符构造 × 可编辑性」精确归位。
- Keyword-Aligned Encoding(KAE):把每个 SID 位置对齐到一个可解释的关键属性词而非量化嵌入,配合预留槽实现部署后无重训的字典级编辑。给出 (P1) 句法可达 / (P2) 词无关身份路由 / (P3) Encoder 确定性三条性质,论证为何闭码本 GR 构造上无法获得这一能力。
- 信息论 ECOM6 + 非均匀容量:用对称条件熵(式 4)做凝聚聚类,把 18 类属性沿信息损失拐点合并为 6 组,并按密度非均匀分配容量(L6-D3);论证了「在已最优长度上做非均匀精化」优于「两倍长均匀标识符」。
- 属性锚定四阶段 SFT:Stage 0 锚定槽↔词、Stage 1 承载检索质量、Stage 2 承载可编辑性、Stage 3 个性化 + 预留槽自路由;消融证明检索质量与可编辑性被分配到近乎不相交的阶段子集,从而联合而非互斥地达成。
- 工业证据:5M 真实流量基准上深召回与最强生成式 baseline OneSearch 打平、干预命中率高出闭码本一个数量级以上;在线替换倒排分支显著抬升转化,进一步替换近乎全部分支后转化不变而 CTR 显著上升——指向召回阶段被单个可编辑生成式模型收编。
与已归档相关工作的对比¶
CQ-SID CQ-SID:用语义簇 ID + Expert-Guided RL 做高效电商生成式召回(Alibaba TmallAPP, 2026-05-14)¶
关系:独立并发(本文未引用 CQ-SID,两者相隔约 4 周、殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直击「工业电商搜索的生成式召回」这一具体瓶颈——亿级商品库下,追求 one-item-one-ID 会让 beam size 撑爆延迟、长尾覆盖坍塌、马太效应放大。两者都主动放弃 SID 唯一性、让多个语义相近商品共享一个 SID(OneRetrieval:$\mathcal{T}$ 一对多、每 SID 物化至多 5 商品;CQ-SID:语义簇 ID + Algorithm 1 过大簇随机切分),并都用类目/分类体系作结构先验(OneRetrieval:ENTITY-singleton 锚 + Stage 1 类目预测任务;CQ-SID:第一层 codebook 强制对齐 1711 个 category bin)。
- 相近的技术骨架:两者都走渐进式四阶段 SFT,且阶段次序高度同构——CQ-SID:Item2SID → Query2SID → User+Query2SID → EG-GRPO;OneRetrieval:Stage 0 属性-SID 对齐 → Stage 1 内容对齐 → Stage 2 协同共现 → Stage 3 个性化(+ 预留槽自路由)。前三阶段都是「先教模型读懂 SID,再桥接 query→SID,再注入个性化」。
- 本文的差异与推进:最关键的分叉在编码范式与目标。CQ-SID 的 CQ-SID tokenizer 本质仍是闭码本 RQ-VAE(类目引导残差量化 + query-item 双向 InfoNCE),码由嵌入量化导出、训练时固定——正是 OneRetrieval 在 Table 5 中论证「对 (P1)–(P3) 一条不满足、IHR≈0.0025」的那一族;CQ-SID 把生成式召回定位为召回阶段的补充,靠 EG-GRPO 做排序对齐。OneRetrieval 则把标识符直接对齐到属性词、靠预留槽实现部署后可编辑,目标是替换近乎整个召回阶段且不引入 RL。一句话:CQ-SID 把工程重心放在「碰撞效率 + 排序对齐」,OneRetrieval 放在「可编辑性 + 多分支统一」。
- 可比的方法/实验差异:CQ-SID 用 Qwen2.5-0.5B、三层 codebook $2048\times1024\times1024$、EG-GRPO 在 group 中注入 K 条 ground-truth SID 稳定稀疏奖励;OneRetrieval 用 BART-base、六位置 L6-D3、60 个预留 token。两者都报告了强劲在线收益(CQ-SID:单通道贡献 72.63% 购买、GMV +1.15%;OneRetrieval:替换倒排 Order +0.710%、替换近乎全部 CTR +0.821%),但 OneRetrieval 额外定义了 IHR/IAR 这套可编辑性专属指标,是 CQ-SID 完全没有涉及的评测维度。
OneSearch OneSearch:面向电商搜索的统一端到端生成式框架(Kuaishou, 2025-09-03)¶
关系:显式引用(本文 [3],Table 2 最强 baseline)· 同一团队前作,原文 §2.2/§4.2 已充分对比 · 已加载对方精读补充机制叙事
- 共同关注的问题:同一团队、同一业务(快手电商搜索)、同一大目标——用生成式模型统一传统多阶段/多路架构。两篇甚至共用同一套属性工程基建:18 种结构化属性(NER 打标)+ Aho-Corasick 实时匹配 + 按 PV 排序的高频关键词表。
- 机制层面的关键演进(keyword-enhanced → keyword-aligned):OneSearch 用这 18 类属性做的是 Core Keyword Enhancement——把核心关键词嵌入加权融入 query/item 表征(式 $e^o = \frac12(e + \frac1m\sum e^f)$),再喂给 RQ-OPQ 层次化量化(RQ-Kmeans 管层次语义 + OPQ 管横向独特特征)产出 SID。也就是说,关键词只是用来「增强」被量化的嵌入,码本仍是闭的、训练时固定的。OneRetrieval 把同一个关键词思路推到底:不再量化嵌入,而是把每个 SID 槽直接绑定到一个属性词(Keyword-Aligned Encoding),于是码本变成可由字典扩展的开放结构——这正是「从增强到对齐」一步带来可编辑性的根本转变。
- 本文相对它的差异与定位:OneSearch 是全链路系统(召回+粗排+精排,PARS 奖励优化排序精度),其闭码本 RQ-OPQ 构造上几乎无推理时可编辑性(本文把它在干预轴上等同于 Table 5 的 RQ-OPQ,IHR≈0.0021)。OneRetrieval 只针对召回、换取可编辑性。
- 原文已充分对比的数据点(转录自 Table 2):HR@350 上两者实质打平——Order 0.5482(OneRetrieval)vs 0.5550(OneSearch)、Click 0.6055 vs 0.6007(OneRetrieval 反超);但浅截断与所有 MRR@K OneSearch 领先(Order MRR@350 0.1333 vs 0.0880),因 OneSearch 端到端优化排序精度而 OneRetrieval 只做召回深覆盖。本文的论点是:在深召回前沿两者并列,OneRetrieval 多出了 OneSearch 几乎无法获得的可编辑性,浅截断的精度差是为它付的有界代价。详细精读见 OneSearch。
讨论与局限性¶
值得借鉴的设计。 (1) 把「可编辑性」上升为一等公民:多数 GR 工作只比 HR/NDCG,本文指出工业落地的真正闸门是「运营能否数小时内注入新词」,并把它形式化为 IHR/IAR 两个可测指标——这套问题框架对任何想替换倒排分支的团队都直接有用。(2) 预留槽 + 自路由监督这套机制极其轻量(60 token、$10^{-5}$ 量级监督)却把「绑定」干净地推迟到部署期,运营保有完全控制权,是「字典级可编辑」在生成式范式里的优雅实现。(3) 用信息论拐点决定 $L$、用密度决定容量分配,把一个原本靠拍脑袋的超参(码本长度/大小)转成有原则、可复现的设计流程。(4) 非层次化是有意选择:作者用三条配置无关的机制(函数→一对多、训练信号碎片化、自回归早期错误传播)论证层次编码在无约束解码下反而有害——这个负向结论对社区有警示价值。
局限与争议。 (1) 强依赖一部高质量生产属性字典:KAE 的全部能力建立在「内部属性抽取流水线 + 1.08M 打标词表 + LLM 主体优先判断」之上,没有这套基建的团队难以复刻;字典覆盖不到的长尾/视觉区分性商品(作者也承认)会落到 empty 槽。(2) 浅截断精度有明显代价:MRR@350 仅 0.0880 对 OneSearch 0.1333,作为召回分支可接受,但若想真正接管「召回+排序」全链路,顶部摆放仍需下游补足。(3) 可编辑性是「训练出的行为而非硬保证」:(P2) 的自路由是统计性的,IAR@350 只到现任倒排的 ~3/4(0.553 vs 0.761),平均仅 15.5% 解码 SID 携带注入码——对「必须 100% 路由」的强运营场景仍有差距。(4) 在线转化增益偏小(替换倒排 Order +0.710%、替换近乎全部转化不显著),其主要卖点是「不掉转化的前提下统一架构 + 拿回可编辑性 + 提 CTR/省融合成本」,而非转化的大幅跃升。
工业落地价值。 该系统已部署在快手站外搜索,服务数百万用户、日均数亿 PV,在 H800 训练 / RTX 4090 服务,beam size 512。两次部署证明了一条清晰的收编路径:先替换最弱但可编辑的倒排分支(转化 +0.710%),再扩展到「倒排 + 稠密」近乎全部分支(转化不变、CTR +0.821%)——把多路融合的人工调参与跨分支冗余消掉,同时把当天可编辑性带进单一生成式召回模型。未来工作:用多模态信号扩展 SID 字母表以覆盖视觉区分性长尾品、用 RL over 转化信号强化头部 query、学习从流入流量自动激活预留槽以自动化趋势响应。