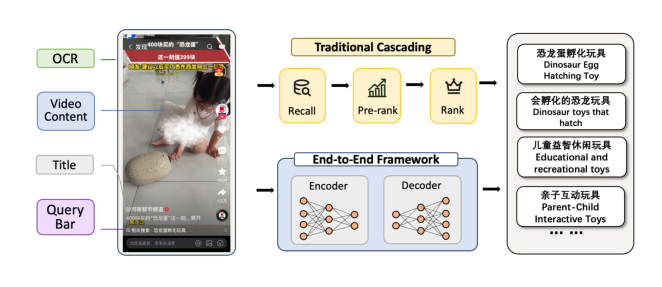
OneBar:面向电商短视频信息流的端到端内容接地生成式查询推荐框架¶
研究动机与背景¶
短视频平台在视频播放器下方暴露了一个可点击的搜索入口(bottom bar / 底栏),让用户在观看视频时可以一键发起"内容诱发"的搜索意图。例如用户在看一段化妆教程时,底栏给出"适合干唇的哑光口红"这样的查询,就能把用户从被动消费引导到主动搜索,带来额外的广告曝光与电商成交。这种底栏推荐(Bottom Bar Recommendation)的查询质量,直接决定了这部分增量转化收益。
传统方法的两类失配。论文首先指出,把传统查询推荐方法搬到短视频底栏会遇到根本性的水土不服:
-
延迟约束(latency constraints):与独立搜索服务不同,底栏推荐要在用户切换视频的实时过程中展示,系统必须在极高 QPS 下满足极紧的服务延迟预算。在底栏场景里,查询推荐只能在短视频推荐结果确定之后执行,但推荐的查询又必须在用户开始看视频时就已经可见——这只留下大约 20–30 毫秒的服务窗口。如此严苛的延迟下,在线 MCA(多阶段级联架构)流水线主要依赖离线预计算缓存,只给排序、打分、风控过滤留下时间(见 Figure 2)。
-
目标失配(objective misalignment):传统查询推荐方法 [24, 38] 通常不受任何上下文约束,依赖历史搜索日志、用户画像或全局热度信号。直接把它们用到短视频流上,会产生高 CTR 但内容无关的查询,导致意图漂移(intent drift)和体验下降。在短视频流里真实搜索意图往往是被当前正在观看的内容诱发的,因此推荐查询必须接地(grounded)于当前视频信息。
(原文 Figure 2 给出在线 MCA 与 OneBar 的在线推理耗时对比:OneBar 保留同样的准备(prepare)阶段,用单次生成取代级联各阶段,总耗时约降 8%。)
MCA 架构的结构性瓶颈。工业界传统系统普遍采用基于检索的多阶段级联架构(Multi-stage Cascade Architecture, MCA)[4, 16, 29]:候选查询从历史搜索日志或行为日志中检索(基于词法、语义或协同匹配),再依次经过离线过滤、相关性估计、风控过滤、排序模块。这种设计有两个致命问题:
- 检索池偏向历史高频查询:候选只能来自历史日志,因此滞后于新上传视频、新兴趋势、快速变化的用户兴趣,难以产出新鲜、细粒度、长尾的、精确匹配当前视频内容的查询。
- 优化目标碎片化:多阶段把优化拆散到检索、过滤、相关性估计、风控、排序各环节,而最终业务目标取决于查询相关性、曝光机会、CTR、下游转化的联合效应。结果是在线系统不得不在查询新鲜度与语义相关性之间做权衡,限制了规模化提供高质量底栏推荐的能力。
已有生成式方案的两点局限。用端到端生成模型取代检索级联是自然的方向,近期已有探索,但在短视频流场景仍有重要局限:
- GREAT [30] 用基于 trie 的约束解码提升查询质量,但生成空间被预定义的 query trie 限定,无法产出真正新鲜的查询;
- CLICKABLE [35] 引入 RAG 式行为上下文,但其效果严重依赖检索证据的密度与新鲜度;
- 多层自回归解码引入的延迟,常常把这类方法限制在离线预计算或近线,无法充分利用用户实时观看上下文的实时信号。
两个实践挑战。在工业短视频平台上把生成式查询推荐落地,还被两个问题进一步复杂化: 1. 内容侧信号噪声大:视频标题、@提及、营销性 token 经常冗余、推广性、甚至无关,直接拿原始视频元数据做条件,会误导生成器、产出语义漂移的查询; 2. 偏好优化依赖单独训练的奖励模型(reward model):许多生成式推荐流水线 [6, 9, 39] 用历史用户行为日志训练一个显式奖励模型来对齐生成查询与相关性/点击/转化。但奖励模型与日志数据分布、训练策略天生耦合,可能继承偏置反馈、放大长尾分布偏差,并被 reward hacking 利用 [7, 23, 44]。
OneBar 的三项创新。为解决上述问题,论文提出 OneBar,一个面向短视频电商信息流的实时端到端生成式查询推荐框架,核心贡献:
1. 协同-多模态意图接地(Collaborative-Multimodal Intent Grounding):融合多模态视频理解与行为派生的协同 anchor,把噪声的内容侧元数据转化为干净、接地的意图证据;
2. 统一端到端架构 + Prompt 压缩在线服务:用单个 encoder-decoder(BART)把多阶段检索级联坍缩为一次端到端生成,配合紧凑 [SEP] schema 实现严苛延迟下的实时在线服务;
3. 渐进式偏好内化(Progressive Preference Internalization):把分层行为偏好渐进地内化进生成策略,免去单独训练奖励模型。
与在线 base(在线 MCA)相比,OneBar 在快手主信息流的在线 A/B 上把 Query Exposure 提升 16.91%、Query Click 提升 18.68%,同时保持 Query CTR +0.19% 的轻微正增益;增量搜索流量进一步带来 +20.36% 引导成交订单(Guided Orders)与 +21.67% 引导 GMV。人工评测显示总体查询质量坏 case 率下降 9.00 个百分点。论文声称 OneBar 是首批在集成搜推平台上为实时在线服务规模化部署的端到端生成式查询推荐系统之一。
问题定义¶
研究内容接地的查询推荐(content-grounded query recommendation)。当用户观看一段短视频时,系统在底栏主动展示一小组搜索查询。对每次曝光(impression),系统观测当前触发物(trigger item)$x$ 与可选用户上下文 $u$,生成一个有序的 $K$ 候选查询列表:
$$Q_{x,u} = (q_1, q_2, \ldots, q_K), \tag{1}$$
其中每个 $q_i$ 是一条自然语言搜索表达。在线部署中 $K=8$。理想的有序列表是最大化加权后验效用:
$$Q^*_{x,u} = \arg\max_{\substack{(q_1,\ldots,q_K)\in\Omega(x,u)^K \\ q_i\neq q_j,\ i\neq j}} \sum_{i=1}^{K} w_i\, U(q_i; x, u), \tag{2}$$
其中 $U(q_i; x, u)$ 表示在当前 trigger 与用户上下文下曝光查询 $q_i$ 的后验参与效用(posterior engagement utility),$w_i$ 是底栏有序列表的位置相关权重。可行集 $\Omega(x,u)$ 包含满足生产约束的查询:
$$\Omega(x,u) = \{q \mid \text{Ecom}(q),\ \text{Rel}(q,x)\geq\delta,\ \text{Safe}(q)\}. \tag{3}$$
这里 $\text{Ecom}(q)$ 要求查询表达有效的电商搜索意图;$\text{Rel}(q,x)$ 衡量查询与当前短视频 trigger 的语义相关性(需 $\geq\delta$);$\text{Safe}(q)$ 要求查询通过平台合规检查,包括基于 GSB 的评估与违禁词过滤。
核心方法 / 模型架构¶
OneBar 由三部分构成,整体框架见 Figure 3:(a) 设计与输入构造,(b) 多阶段训练范式。下文依次展开:协同-多模态意图接地(§3.2)、低延迟统一端到端生成(§3.3)、渐进式偏好内化(§3.4)。
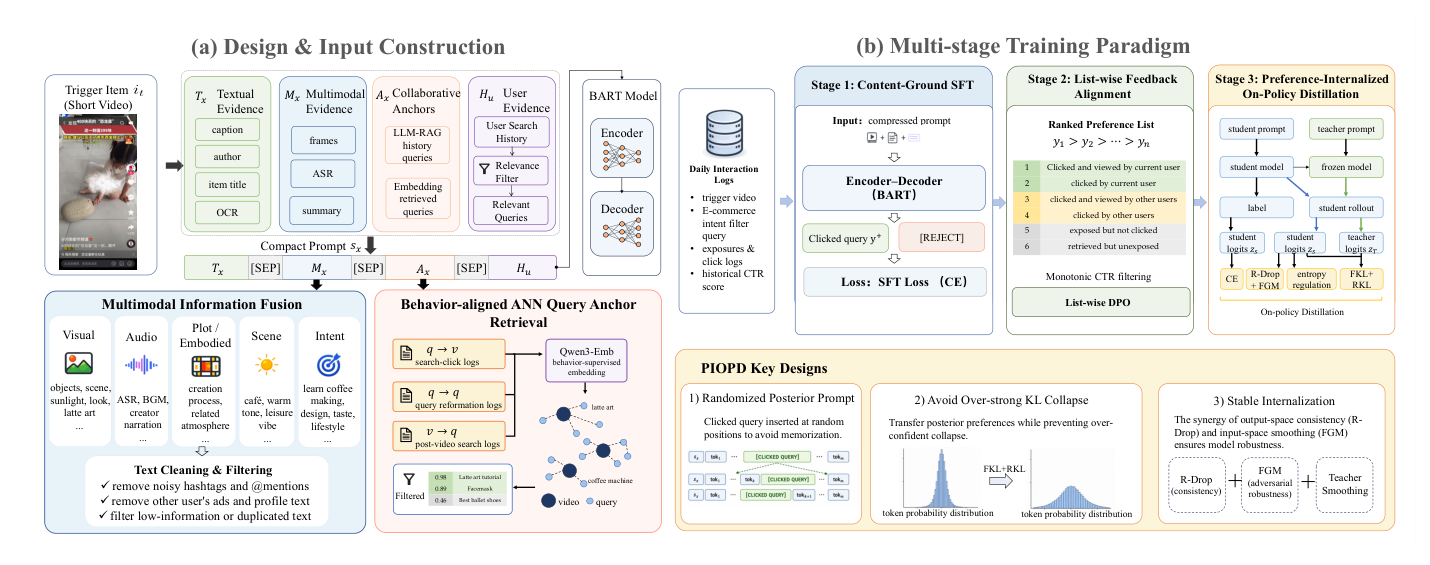
协同-多模态意图接地(§3.2)¶
在生成之前,OneBar 把每个短视频 trigger 转化为一个紧凑的证据表示。该表示融合文本元数据、多模态视频摘要、协同查询 anchor、用户个性化信号,序列化成一个简洁的 schema 喂给生成器。结构化证据 schema 定义为:
$$\mathcal{E}(x,u) = \langle T_x, M_x, A_x, H_{x,u}\rangle,$$
四个证据域含义如下:
(1) 文本与多模态证据 $(T_x, M_x)$。原始短视频字段(caption、商品标题、@提及、hashtag)噪声大且常带推广性。$T_x$ 的构造:从第一个非空平台字段(caption / photo title / title / item title)里选一个规范标题(canonical title),并归一化掉用户提及、账号标识、hashtag、模板化前缀等样板内容。但仅靠文本会漏掉内容接地的意图,因此用一个多模态基础模型把采样帧 + ASR 摘要成 $M_x$,捕捉视觉物体、OCR 文本、语音线索、场景上下文、商品用法、候选搜索意图。$M_x$ 由离线增量流水线每日刷新并剥离模板化前缀。
(2) 协同行为证据 $A_x$。$A_x$ 补充"行为派生意图",即在相似视频消费上下文中反复出现的意图,由两个分开存储的字段组成:
- 字段一:ANN 检索的查询 anchor。用 Qwen3-Embedding 0.6B [42] 在三类平台关系上做分阶段行为监督(见 Table 1)来训练嵌入模型。先用 $q\to v$(搜索点击日志:查询→被参与视频)训练,在查询与点击视频之间建立保持相关性的语义空间;再从该 checkpoint 出发,继续融入 $v\to q$ 与 $q\to q$ 关系——前者捕捉视频消费后由 trigger 诱发的真实搜索需求,后者捕捉改写转移(后续查询往往表达更清晰/更具体的意图)。最终模型把视频和查询对齐到一个共享的 128 维空间,空间中的邻近度反映观测到的查询-视频相关性。离线时,每个 trigger 嵌入检索其语义最近视频 trigger 关联的查询。由于低相似度 anchor 会误导生成,只保留 trigger 相似度 > 0.88 的 anchor,这把 anchor 命中率从 0.282 提升到 0.335。
- 字段二:RAG 历史。聚合此前针对同一 trigger 发起过的查询,作为补充检索信号。两个字段都被缓存为 $A_x$ 里的生成证据,而不是作为在线候选集使用。
(3) 个性化证据 $H_{x,u}$(原文也记作 $H_u$)。由于底栏推荐是内容诱发的,无差别的全局历史会削弱接地。因此只加入与 trigger 相似度超过阈值(用同一个行为对齐嵌入模型度量)的用户历史查询,使 $H_u$ 绑定到 trigger 而非长期兴趣。
Table 1:构造协同查询 anchor $A_x$ 的行为关系
| Relation | Source | Signal Type |
|---|---|---|
| $q\to v$ | 搜索点击日志 | 查询 → 被参与视频 |
| $v\to q$ | 视频后搜索日志 | 视频 → 后续查询 |
| $q\to q$ | 查询改写日志 | 查询 → 后续查询 |
低延迟统一端到端生成(含弃权,§3.3)¶
OneBar 用单个 encoder-decoder 作为端到端生成骨架。这个设计的目的不是引入新架构,而是提供一个统一、低延迟、可风控的接口,把多阶段检索级联坍缩成一次端到端生成,从而在 §1 指定的 20–30ms 预算内完成实时底栏生成。四个证据域(生产中稀疏,但始终至少有一个字段以保证全覆盖)被序列化成一个紧凑的 [SEP] 分隔序列:
$$s_x = [\,T_x;\ \text{[SEP]};\ M_x;\ \text{[SEP]};\ A_x;\ \text{[SEP]};\ H_u\,]. \tag{4}$$
这种字段对齐的 schema 与 BART 的文本重构预训练一致,且缩短了 encoder 输入,显著优于冗长的指令式 prompt(见 Table 4)。采用 BART 骨架 [18],记为 $\mathcal{M}_\theta$,解码分布为:
$$p_\theta(y \mid s_x) = \prod_t p_\theta(y_t \mid y_{<t}, \text{Enc}_\theta(s_x)).$$
弃权机制(abstention via [REJECT])。输出 $y$ 要么是一条搜索查询,要么是特殊 token [REJECT]。[REJECT] 允许生成器在不存在安全、相关、可信接地的查询时弃权(例如政策敏感内容或弱 trigger 证据下)。这样,Eq.(2) 里的 $\text{Safe}(\cdot)$ 谓词被强制在模型内部,而非交给下游过滤器。[REJECT] 的监督在 Stage I 引入;服务时,[REJECT] 输出会抑制底栏曝光,在线风控坏 case 大幅减少(§5)。推理时,OneBar 用 beam width = 8 从 $s_x$ 解码底栏列表,再接轻量去重、安全、业务规则检查后曝光。
渐进式偏好内化(§3.4)¶
一条生成的底栏查询不仅要与 trigger 语义相关,还要与平台级偏好(下游页面消费、点击转化率、转化)对齐。生成器必须既保持与平台自然搜索分布的一致,又能捕捉从在线反馈观测到的细粒度偏好。OneBar 用一个渐进式偏好内化流程来解决:内容接地 SFT 建立基本映射 → 列表式反馈对齐学习候选间偏好 → PIOPD 把稠密后验偏好内化进生成器。
Stage I:内容接地 SFT(§3.4.1)¶
用 SFT 初始化生成器的内容接地查询生成能力。从在线点击日志构造 trigger-query 对,把点击的查询当作该 trigger 的正目标。再用平台级电商意图分类器,剔除不表达有效商品搜索意图的样本,保留 $\mathcal{D}_{\text{pos}} = \{(s_x, y^+)\}$,$s_x$ 是序列化 trigger 证据,$y^+$ 是点击查询。
由于在线行为数据直接训练有安全风险(用户点击偶尔偏好猎奇、不当、违规表达),论文引入安全感知拒绝监督:收集内容或关联文本字段含非合规信号(违禁词匹配、GSB 评估)的视频曝光,把目标输出设为 [REJECT],形成 $\mathcal{D}_{\text{rej}} = \{(s_x, \text{[REJECT]})\}$。生成器用标准 next-token 预测训练:
$$\mathcal{L}_{\text{SFT}} = -\mathbb{E}_{(s_x, y^+)}\sum_{t=1}^{|y^+|}\log p_\theta(y_t^+ \mid y_{<t}^+, s_x). \tag{5}$$
在线服务时若生成器输出 [REJECT],系统抑制该次曝光的底栏查询。这一机制让模型学会该推荐什么、何时弃权。
Stage II:行为反馈偏好对齐(§3.4.2)¶
在线服务在查询候选上提供大规模隐式反馈。Stage II 不把这些反馈转成独立的二元标签,而是把同一 trigger 的候选组织成行为诱导的有序偏好列表,用列表式目标优化生成器,既能从真实在线偏好学习,又保留候选间的相对结构。
对每个 trigger $x$,从在线日志收集其关联查询候选,按六个行为层级排列(Table 2)。层级编码两条偏好原则:当前用户的反馈比聚合的他人反馈更能证明个性化意图;点击后参与比单纯点击更强地表明意图。
Table 2:分层用户行为层级
| Level | 行为描述 |
|---|---|
| 1 | 当前用户点击且有点击后参与 |
| 2 | 当前用户点击 |
| 3 | 其他用户点击且有点击后参与 |
| 4 | 其他用户点击 |
| 5 | 曝光但未点击 |
| 6 | 召回但未曝光 |
为减少在线排序、曝光位置、随机交互引入的噪声,进一步强制行为顺序与历史 CTR 的一致性:CTR 与其行为层级隐含的单调顺序矛盾的候选被过滤掉(这类冲突通常意味着不可靠/弱偏好证据);去重后,同层级保留历史 CTR 最高者作为该层级代表,使每个层级贡献一个行为一致的偏好目标。最终每个 trigger 的保留候选构成有序偏好列表 $\mathcal{Y}_x = [y_1, \ldots, y_n]$,$y_1 \succ y_2 \succ \cdots \succ y_n$,$n\leq 6$。该列表提供对候选查询的序数监督(而非校准的效用分)。
采用列表式 Softmax DPO 目标对齐生成器与在线反馈。设 $\ell_\theta(y\mid x) = \sum_t \log\pi_\theta(y_t\mid y_{<t})$ 为序列对数概率,令策略-参考对数比为:
$$r_i = \ell_\theta(y_i\mid x) - \ell_{\text{ref}}(y_i\mid x). \tag{6}$$
设 $b(y_i)$ 为 $y_i$ 的行为层级,定义点击 anchor 集合:
$$C_x = \{j \mid b(y_j)\leq 4,\ j<n\}. \tag{7}$$
只有点击候选作正 anchor,层级更低的候选(含未点击)作对比项。对每个点击 anchor $y_j$($j\in C_x$),把它与同 trigger 层级列表中所有更低排名候选 $\mathcal{R}_j=\{y_{j+1},\ldots,y_n\}$ 对比。在 $\{y_j\}\cup\mathcal{R}_j$ 上的 softmax 选择模型下,$y_j$ 优于更低排名项的概率:
$$P_\theta(y_j \succ \mathcal{R}_j \mid x) = \frac{\exp(\beta r_j/T)}{\exp(\beta r_j/T) + \sum_{i=j+1}^{n}\exp(\beta r_i/T)}. \tag{8}$$
对应的负对数似然:
$$-\log P_\theta(y_j \succ \mathcal{R}_j \mid x) = \log\!\left(1 + \sum_{i=j+1}^{n}\exp\!\left(\frac{\beta}{T}(r_i - r_j)\right)\right). \tag{9}$$
与构造孤立 chosen-rejected 对的 pair-wise DPO 相比,该目标为每个点击候选用整条更低排名后缀作对比上下文,因此把多层级在线行为偏好转移进生成器,同时避免来自未点击候选的正监督。Stage-II 训练目标:
$$\mathcal{L}_{\text{Stage-II}}(x) = \sum_{j\in C_x}\left[\log\!\left(1 + \sum_{i=j+1}^{n}\exp\!\left(\frac{\beta}{T}(r_i - r_j)\right)\right) - \lambda_{\text{SFT}}\,\ell_\theta(y_j\mid x)\right]. \tag{10}$$
其中 $\beta=0.1$ 为 DPO scale 因子,$T=1.0$ 为 softmax 温度,$\lambda_{\text{SFT}}=1.0$ 控制 SFT anchor。SFT 项作用于点击 anchor 以稳定偏好优化、保持生成器的序列建模能力。实现上,同一 trigger 的候选打包进单次 forward,实现对大规模在线行为日志的高效列表式偏好学习。
Stage III:偏好内化 On-Policy 蒸馏(PIOPD,§3.4.3)¶
Stage II 用行为派生的序列级监督改善了生成器,但模型仍在 logged 候选上优化,这在训练数据与模型推理时分布之间留下了 off-policy gap。为缩小该 gap,论文提出 Preference-Internalized On-Policy Distillation(PIOPD):在从当前学生模型采样的轨迹上做稠密 token 级蒸馏。
PIOPD 用后验行为证据作训练时的特权监督(privileged supervision),把偏好内化进可部署生成器而不改变其在线接口。与 OneSearch-V2 [7]——后者用 Chain-of-Thought 推理路径增广 teacher 输入——不同,PIOPD 用点击的目标查询作后验偏好信号。训练中 teacher 接收与 student 相同的视频信息,外加该视频关联的点击查询。这条后验查询识别出一个行为确认的意图区域,使 teacher 把软概率质量分配给与观测用户偏好一致的 token 和查询变体。Student 随后被优化去匹配 teacher 在 student 采样前缀上的软标签分布,但 student 从不观测点击查询本身。结果是后验证据只通过参数学习影响最终模型:PIOPD 不需要在线打分的额外奖励模型,也不在服务流水线引入后验条件模块,部署产物仍是一个只以标准 trigger + 用户上下文为条件的单一生成器。
随机上下文增广(Randomized Context Augmentation)构造 teacher。在固定位置追加 $y_{\text{ref}}$(点击查询)会把 teacher 推向位置捷径或表面拷贝,因此把点击查询插入到一个随机位置:
$$x^{(T)} = x \oplus_{\text{rand}} y_{\text{ref}}, \qquad x^{(S)} = x. \tag{11}$$
这鼓励 teacher 把 $y_{\text{ref}}$ 当作意图级后验信号而非固定后缀。Table 5 显示随机插入产出最高的 teacher HR——把后验证据分散到多个输入位置,比固定位置注入更有效。所有可部署结果都在标准 prompt 下报告 student。
投影到 student 访问的状态(on-policy)。把后验增广的 teacher 投影到可部署 student 策略,在 student 访问的状态上进行:
$$\theta^* = \arg\min_\theta\ \mathbb{E}_{y\sim\pi_\theta(\cdot\mid x^{(S)})}\sum_t D\!\left(\pi_T^*(\cdot\mid y_{<t}, x^{(T)})\ \big\|\ \pi_\theta(\cdot\mid y_{<t}, x^{(S)})\right). \tag{12}$$
由于期望取在 student rollout 上(而非 teacher-forced 的金标准前缀上),投影发生在部署生成器推理时真正会访问的状态上。实践中,从当前 $x^{(S)}$ 自回归采样一条轨迹 $y^{(S)}$,在每个采样前缀 $y_{<t}$ 下 student 与冻结 teacher 分别产出 logits $z_t^{(S)}$ 与 $z_t^{(T)}$;令 $p_S^t=\text{softmax}(z_t^{(S)})$、$p_{T,\tau}^t=\text{softmax}(z_t^{(T)}/\tau)$,$\tau=2$。用双向 KL 实例化 Eq.(12) 中的 $D$:
$$\mathcal{L}_{\text{Distill}} = \mathbb{E}_{y\sim\pi_\theta(\cdot\mid x^{(S)})}\sum_t \tau^2\!\left[\lambda_{\text{FKL}}\,D_{\text{KL}}(p_{T,\tau}^t\|p_S^t) + \lambda_{\text{RKL}}\,D_{\text{KL}}(p_S^t\|p_{T,\tau}^t)\right]. \tag{13}$$
两项作用互补:前向 KL(FKL) 鼓励 student 覆盖 teacher 支持的备选、惩罚漏掉高概率 teacher token;反向 KL(RKL) 抑制 student 在 teacher 不支持 token 上的质量、减少 mode drift。同时保留 SFT 损失 $\mathcal{L}_{\text{SFT}}$ 作真值锚,让 student 吸收后验偏好而不退化生成能力。Table 4 显示 FKL+RKL+SFT 组合优于任一单项。
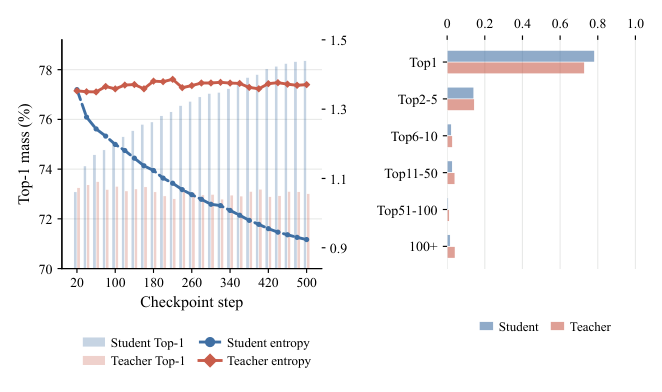
防止过度集中:熵正则。后验蒸馏常见的失败模式是 student 分布逐渐过度集中。如 Figure 4 所示,teacher 在各 checkpoint 上保持校准,而 student 把质量推向 top-1 token:从 step 20 到 step 400,top-1 质量上升约 5.0%,top-10 之外的尾部下降约 4.4%。这种过度放大降低多样性、伤害未被排到第一的正确备选。因此在 student 上加熵正则:
$$\mathcal{L}_{\text{Ent}} = -\mathbb{E}_{y\sim\pi_\theta(\cdot\mid x^{(S)})}\sum_t H(p_S^t) = \mathbb{E}_{y\sim\pi_\theta(\cdot\mid x^{(S)})}\sum_t\sum_{v\in\mathcal{V}}p_S^t(v)\log p_S^t(v). \tag{14}$$
以正权重 $\lambda_E$ 最小化它会鼓励更高 student 熵、保持生成多样性。
输出/输入空间稳定:R-Drop + FGM。为稳定高召回候选生成,进一步用 R-Drop [37] 做输出空间一致性、用 Fast Gradient Method(FGM)[25] 做输入空间平滑。R-Drop 让两次独立 dropout mask 的 student forward 一致;FGM 用对抗 embedding 扰动 $\Delta e$ 提供输入空间平滑:
$$\mathcal{L}_{\text{RDrop}} = \tfrac{1}{2}\left[D_{\text{KL}}(p_{S_1}\|p_{S_2}) + D_{\text{KL}}(p_{S_2}\|p_{S_1})\right],\qquad \mathcal{L}_{\text{FGM}} = \mathcal{L}_{\text{task}}(e + \Delta e),\ \ \Delta e = \epsilon\cdot\frac{\nabla_e\mathcal{L}_{\text{task}}}{\|\nabla_e\mathcal{L}_{\text{task}}\|}. \tag{15}$$
PIOPD 总目标:
$$\mathcal{L}_{\text{PIOPD}} = \mathcal{L}_{\text{SFT}} + \mathcal{L}_{\text{Distill}} + \lambda_E\,\mathcal{L}_{\text{Ent}} + \lambda_{\text{RD}}\,\mathcal{L}_{\text{RDrop}} + \lambda_{\text{FGM}}\,\mathcal{L}_{\text{FGM}}. \tag{16}$$
完整流程见 Algorithm 1。训练后,丢弃 teacher 与后验信号 $y_{\text{ref}}$,只保留与部署一致的 student,使 §3.3 的服务接口保持不变。
Algorithm 1:PIOPD 关键步骤(改写自原文)
输入: 训练实例 (x, y_ref);Stage-II student π_θ
1. 从 Stage-II checkpoint 初始化 π_θ
2. 从 Stage-II checkpoint 初始化冻结 teacher π_T^*
3. while 未收敛 do
4. 采样 minibatch (x, y_ref)
5. set student 输入 x^(S) = x
6. set teacher 输入 x^(T) = [x; y_ref] (随机位置插入)
7. 采样 on-policy rollout y^roll ~ π_θ(· | x^(S))
8. 计算 student rollout logits z^(S,r)
9. 计算 teacher rollout logits z^(T,r)(teacher 条件于 x^(T))
10. 计算 student 标签 logits z^(S,l)
11. 由 z^(S,r), z^(T,r), z^(S,l) 计算 L_PIOPD
12. 梯度下降更新 θ
13. end while
14. 丢弃 teacher π_T^* 与后验信号 y_ref
输出: 仅以 x 为条件的可部署 student π_θ
在线部署(§4)¶
OneBar 部署在混合离线-在线服务架构里,把昂贵的证据构造与延迟敏感的查询生成解耦:
- 离线预计算 + Redis 缓存:每个视频 trigger 的预计算证据缓存在以
photo_id为 key 的 Redis 特征库里,包括双塔检索模型产的视频嵌入、每日刷新的 RAG 历史、从视频内容提取的多模态特征。这避免在延迟关键路径上调用昂贵的检索、LLM、多模态推理。 - 在线推理:在线时 OneBar 取缓存视频证据,并用离线维护的嵌入 + trigger 相关用户历史装配协同与个性化信号,避免在延迟关键路径上构造表示;装配好的证据喂给 BART encoder-decoder 同步实时服务,beam width = 8,再接安全过滤与业务规则检查。
- 每日更新:每天用新在线日志做 SFT + PIOPD 偏好蒸馏,再评测与在线刷新,以追踪内容与反馈漂移。
训练超参:Stage I SFT 6 epoch,batch 128,lr $1\times10^{-5}$;Stage II 列表式偏好对齐 lr $5\times10^{-5}$,DPO scale $\beta=0.1$;Stage III PIOPD 500 步,batch 64,lr $1\times10^{-6}$,teacher 温度软化 $\tau=2$;可训练 student 与冻结 teacher 共享架构、都从 Stage II checkpoint 初始化。
实验设置(§5)¶
数据集:从 2026 年 4 月 9 日至 16 日生产日志构建离线数据集,约 4000 万 PV 含底栏查询曝光;前 7 天用于训练。为防信息泄漏,评测输入去污——移除所有历史输入(RAG 历史、嵌入检索查询等显式含目标查询的内容)。
Baseline(三类): 1. Generative Base Model:主要生成式 baseline,只用基本 trigger 信息(无领域适配)做 SFT 的 vanilla BART; 2. Zero-shot LLMs:GLM5.1、GPT-5.5,直接 prompt 生成推荐(无领域适配/微调); 3. ANN retrieval:用同一个协同数据训练的嵌入模型编码 trigger 证据,从历史查询语料近似最近邻检索 top-$K$——提供一个非生成的候选检索参照,隔离纯检索与生成的贡献。
评估指标:
- 排序与召回:Hit Rate@K(HR@K)、MRR(基于与真值查询的精确匹配);
- 意图准确:精确匹配会低估生成质量(语义等价查询可能表面形式不同),故加 ED-HR@K(编辑距离容忍 Hit Rate,预测与目标 Levenshtein 距离 $\leq 2$ 即命中)与 sentence-level BLEU@K(取 top-$K$ 生成查询);
- 相关性:BAS@K(Behavior-Aligned Similarity,用协同数据训练的嵌入模型算 trigger 证据与 top-$K$ 生成查询相似度均值)与 SR(Semantic Relevance,GPT-5.5 作 LLM judge 在 0–5 打分,评估查询是否可搜索且与 trigger 视频语义相关)。
实现上离线评测与在线服务都用 beam search;模型分三阶段渐进训练。
主要实验结果¶
离线总体性能(Table 3)¶
完整 OneBar(Stage 3)在核心匹配指标(Exact HR@8、MRR@8、ED-HR@8、ED@8、BLEU@8)上取得最好结果。
Table 3:离线生成质量指标(ED-HR@8 计编辑距离 $\leq 2$ 为命中;ED@8 越低越好)
| Variant | LR | Exact HR@8 | MRR@8 | ED-HR@8 | ED@8 ↓ | BLEU@8 | BAS@8 | SR |
|---|---|---|---|---|---|---|---|---|
| GLM5.1 (zero-shot) | – | 0.0153 | 0.0036 | 0.0837 | 6.7051 | 0.1317 | 0.6468 | 4.4694 |
| GPT-5.5 (zero-shot) | – | 0.0224 | 0.0139 | 0.1384 | 5.2471 | 0.1779 | 0.6261 | 4.9286 |
| ANN | – | 0.1322 | 0.0739 | 0.3052 | 4.0630 | 0.3218 | 0.8326 | 2.4759 |
| BART + Basic Video Information | $1\times10^{-5}$ | 0.1787 | 0.0805 | 0.2490 | 5.2471 | 0.2532 | 0.5839 | 2.8537 |
| Stage 1: Context-Grounded SFT | $1\times10^{-5}$ | 0.3564 | 0.2398 | 0.4864 | 3.1785 | 0.4951 | 0.6678 | 3.8019 |
| Stage 2: List-wise Feedback Alignment | $5\times10^{-5}$ | 0.3586 | 0.1789 | 0.4470 | 3.5556 | 0.4489 | 0.6649 | 3.7488 |
| Stage 3: Progressive Preference Internalization | $1\times10^{-6}$ | 0.3690 | 0.2402 | 0.4934 | 3.1760 | 0.5039 | 0.6687 | 3.7945 |
结论分析:
- 对 zero-shot LLM、ANN 检索、基础 BART 的一致领先,说明领域适配与 trigger 接地证据对工业底栏查询生成都必要;
- BAS@K 与 SR 需要单独解读:ANN 取得最高 BAS@K(0.8326),因为该指标正是用 ANN 检索同一个协同嵌入模型计算的——存在自我一致性偏置;排除这一结构偏置后,OneBar 在学习型变体中 BAS@K 最高。SR 上 zero-shot LLM 最高(GPT-5.5 达 4.93),因为它们在 LLM judge 看来输出流畅、主题连贯,但其 Exact HR/ED-HR/BLEU 极低——这类输出极少匹配真实用户查询;OneBar 保持有竞争力的 SR,同时大幅改善行为接地的匹配准确度;
- 跨阶段看,Stage 3 改善 Exact HR@8、MRR@8、ED-HR@8、ED@8、BLEU@8,SR 略低于 Stage 1——这正是 PIOPD 的预期效果:用少量单输出语义锐度换取更强的候选集覆盖与匹配准确度。
消融实验(Table 4)¶
消融分三块:特征增广、prompt 格式工程、渐进式偏好内化。
Table 4:综合离线消融
| Variant | HR@8 | MRR@8 |
|---|---|---|
| Block 1:特征增广 | ||
| BART + Basic Trigger Information | 0.1787 | 0.0805 |
| + Multimodal Evidence ($M_x$) | 0.3046 | 0.1694 |
| + Collaborative Anchors ($A_x$) | 0.3357 | 0.2098 |
| + Personalized Evidence ($H_u$) | 0.3564 | 0.2398 |
| Block 2:prompt 格式工程 | ||
| BART + Verbose Prompt (SFT) | 0.1864 | 0.1059 |
BART + Compact [SEP] Schema |
0.3564 | 0.2398 |
| Block 3:渐进式偏好内化 | ||
| Stage II: List-wise Feedback Alignment | 0.3586 | 0.1789 |
| Stage III Base (0.5 RKL + 0.5 FKL) | 0.3630 | 0.2399 |
| 0.5 RKL + 0.5 FKL + SFT | 0.3654 | 0.2408 |
| 0.7 RKL + 0.5 FKL + SFT | 0.3669 | 0.2403 |
| + Teacher Smoothing ($\tau{=}2$) | 0.3673 | 0.2399 |
| + R-Drop + FGM ($\epsilon{=}0.6$) | 0.3675 | 0.2404 |
| Full PIOPD (+ Entropy Reg., $\lambda_E{=}0.3$) | 0.3690 | 0.2402 |
结论分析:
- Block 1:每加一个证据源都一致提升内容接地生成。多模态证据把 HR@8 从 0.1787 拉到 0.3046(缓解噪声/不完整元数据),协同 anchor 拉到 0.3357(加入行为派生意图先验),个性化证据拉到 0.3564(把生成收窄到 trigger 相关用户兴趣)。增益互补;
- Block 2:同样的内容接地 SFT 配方下,紧凑
[SEP]schema(0.3564 HR@8)显著优于冗长 prompt(0.1864),说明字段对齐证据比指令式包装更易被 BART 利用; - Block 3:Stage II 列表式对齐相对 Stage I 略升 HR@8;直接在 Stage I 后用 PIOPD(跳过 Stage II)把 HR@8 从 0.3564 升到 0.3628,而完整 SFT→Stage II→PIOPD 进一步升到 0.3690(比跳过 Stage II 高 0.0062)。值得注意:Stage II 单独把 MRR@8 从 0.2398 大幅降到 0.1789——列表式行为对齐能把候选移向行为偏好区域,但单用会损害排序质量;PIOPD 应用在 Stage II 之上后 MRR@8 恢复到 0.2402、HR@8 达 0.3690。这说明 Stage II 主要把 student rollout 分布重塑成更行为对齐的 on-policy 分布,为后续 token 级后验蒸馏提供更好起点,而不作为最终对齐器。
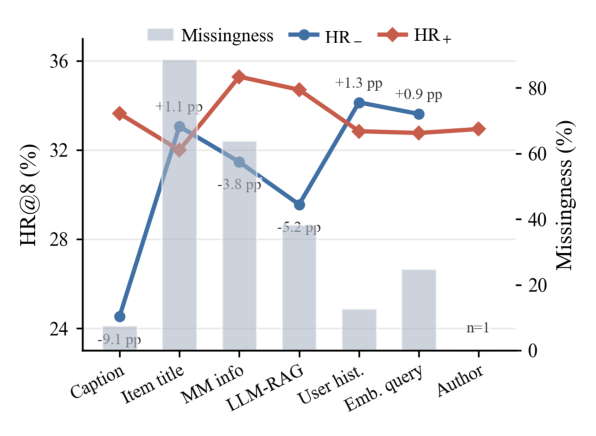
证据字段缺失分析(Figure 5)¶
Figure 5 在受控移除下评估各证据字段。Caption 可用性给出最清晰的文本增益:caption-absent 切片 HR@8 约 24.5,caption-present 切片约 33.6。多模态摘要也是强信号(absent ~31.5 → present ~35.3)。$A_x$ 的协同部分里,RAG 历史在行为稀疏情形尤其关键:无 RAG 历史切片约 29.5 HR@8,有则约 34.7。嵌入查询 anchor 与过滤用户历史的聚合效应较小(present 切片约 32.7、32.8),更多在行为丰富/个性化场景起作用。这种切片行为解释了为何全量数据下 $A_x$、$H_u$ 的增量(Table 4)是难/稀疏上下文的辅助先验,而非独立捷径。固定 [SEP] schema 让缺失字段不改变输入格式,使这种鲁棒性与服务兼容。
Teacher-prompt 构造策略(Table 5)¶
Table 5:PIOPD teacher 选择的 teacher-prompt 候选(HR 为 teacher top-$k$ 命中正查询集的比率)
| No. | Prompt 构造 | HR |
|---|---|---|
| 1 | 把点击关键词作孤立的最终 [SEP] 段追加 |
0.40775 |
| 2 | 把点击关键词插入 RAG 历史字段 | 0.39987 |
| 3 | 把所有后验查询随机插入已有字段 | 0.49638 |
| 4 | 随机插入前先 mask 部分查询词 | 0.49041 |
结论分析:在输入末尾追加后验查询(策略 1)或注入到固定字段(策略 2)只把特权证据暴露在输入的狭窄位置,teacher HR 受限(~0.40)。随机插入(策略 3)最好,说明把特权证据分散到多个输入位置,更易让 teacher 把后验查询与周边上下文关联。因此 PIOPD 默认用策略 3。
PIOPD 诊断(Figure 6、Table 6)¶
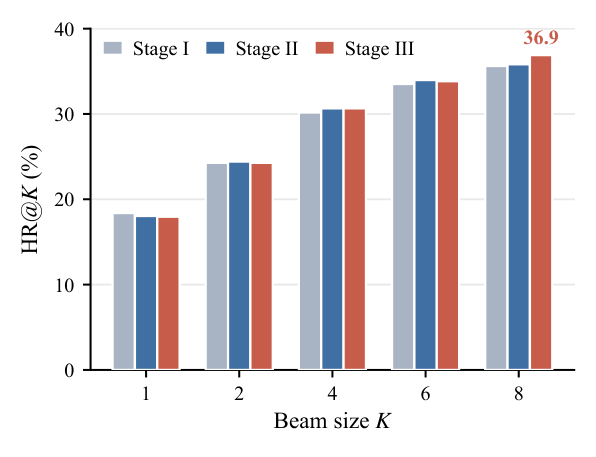
如 Figure 6,PIOPD 的增益主要体现在比 HR@1 更大的 cutoff 位置:Stage III 在保持小 cutoff 处相当性能的同时取得最佳 HR@8。这表明 PIOPD 改善的是生成候选集的覆盖,而非简单锐化排名第一的预测——通过把后验感知的 teacher 分布蒸馏进在线 student,在中尾排名保留更多相关备选,beam search 因此召回更好。这也解释了 Table 3 的离线权衡:OneBar 牺牲极少量 top-1 锐度换取更广候选覆盖。
Table 6:PIOPD 目标变体性能
| Different KL objectives | HR@8 | MRR@8 | Top-k support | HR@8 | MRR@8 | |
|---|---|---|---|---|---|---|
| FKL | 0.3662 | 0.2406 | Top-16 | 0.3615 | 0.2381 | |
| RKL | 0.3626 | 0.2385 | Top-50 | 0.3612 | 0.2384 | |
| JSD | 0.3632 | 0.2411 | Top-100 | 0.3611 | 0.2379 | |
| CKD | 0.3617 | 0.2385 | Full | 0.3690 | 0.2402 | |
| FKL+RKL | 0.3690 | 0.2402 |
结论分析:单向目标里 FKL 的 HR@8 强于 RKL 和 JSD,说明覆盖 teacher 支持的备选对底栏查询生成至关重要;但 CKD(约束知识蒸馏)未取得最佳。token 级分布分析(Figure 4)解释了原因:teacher-student top-$k$ 重叠达 69.55%,落在 student top-$m$ 但在 teacher top-$k$ 之外的金标准 token 比例为 0%——即 student 很少给不支持 token 高概率,主要挑战不是抑制 student 独有 token,而是保留 teacher 有中等概率的有效备选,这正是用互补 FKL+RKL 全分布匹配最优的原因。词表支持上,full-vocabulary 匹配优于 top-$k$ 截断:student top-$k$ 之外质量仅 1.47%,但 student 熵显著高于 teacher(0.6393 vs ... 即 student 把有意义概率给更宽的有效查询表达尾部),截断到 top-16/100 会移除关键尾部信息,因此全词表匹配保留蒸馏优势。
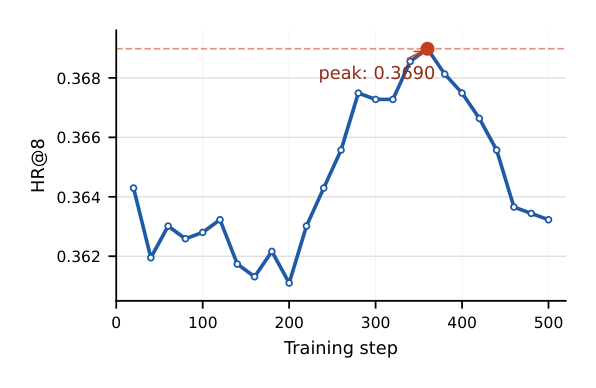
Figure 7 进一步显示 PIOPD 训练收敛很快:虽然 KL loss 单调下降,student 在训练很早就达到最佳下游性能,继续优化超过该点反而逐渐性能下降——因此用基于验证的 early stopping 而非基于 loss 的停止。
渐进式初始化(Table 7):Stage I 后直接用 PIOPD 会让蒸馏依赖更弱的 student rollout,引入噪声 token 级目标、减慢收敛;Stage II 作中间列表式对齐步,让策略先吸收粗粒度候选级偏好序,PIOPD 再用稠密 token 级软标签把这个更好初始化的策略细化成细粒度后验内化。
Table 7:渐进式初始化阶段消融
| Training Strategy | HR@8 | MRR@8 |
|---|---|---|
| Stage I: SFT Only | 0.3564 | 0.2398 |
| SFT → PIOPD (Skipping Stage II) | 0.3628 | 0.2397 |
| SFT → Stage II (List-wise Alignment Only) | 0.3586 | 0.1789 |
| SFT → Stage II → PIOPD (Full) | 0.3690 | 0.2402 |
Teacher 刷新策略:用指数移动平均(EMA)定期刷新 teacher 反而劣于冻结 teacher——冻结 teacher 达 0.3690 HR@8 / 0.2402 MRR@8,EMA-5 为 0.3651/0.2394、EMA-100 为 0.3639/0.2400。说明在 PIOPD 里稳定的参考分布更有益:蒸馏中更新 teacher 会引入额外目标漂移,降低 student 收到的后验监督一致性。
在线 A/B 测试(Table 8、§5.3)¶
在快手主单列信息流的视频相关搜索场景做严格在线 A/A 测试 7 天 + A/B 测试 8 天。绝对流量分配 9.12%(MCA)、9.12%(OneBar),在合规视频范围内对比 OneBar 与生产 onlineMCA baseline。该场景下相关查询并非每个视频都曝光——无差别曝光会降总 CTR、损害主信息流长期价值,因此主要效率目标是在 CTR 约束下尽量增加视频相关查询的曝光,从而引入更多搜索流量、最终改善订单与 GMV。因数据安全,结果以相对值呈现。
Table 8:在线质量与业务评估(质量为相对 MCA 的坏 case 率绝对下降;业务为合规视频范围内相对 onlineMCA 的相对提升)
| Manual Quality Evaluation | Change | Online A/B Business Metrics | Change | |
|---|---|---|---|---|
| Overall query-quality bad cases | −9.00 pp | Query Exposure | +16.91% | |
| Video-query irrelevance | −3.66 pp | Query Click | +18.68% | |
| Literal-quality issues | −1.00 pp | Query CTR | +0.19% | |
| Risk-control issues | −4.33 pp | Guided Orders | +20.36% | |
| Guided GMV | +21.67% |
结论分析:相比在线 MCA,OneBar 把 Query Exposure 提升 16.91%、Query Click 提升 18.68%,同时保持 Query CTR +0.19% 的轻微正增益——说明增量曝光没有稀释查询吸引力。增量搜索流量进一步转化为 +20.36% 引导 Orders 与 +21.67% 引导 GMV。人工评测(从合规范围采样 400 条曝光查询:OneBar 200 + MCA 200)显示 OneBar 同时改善相关性、字面质量、风控行为:总体坏 case 率降 9.00pp(含视频-查询无关 −3.66pp、字面质量 −1.00pp、风控 −4.33pp)。无关与字面质量问题多由低质视频侧信息(标题噪声、新上传视频缺行为信号)引起,OneBar 用高质多模态证据 + ANN anchor 改善;风控坏 case 下降主要来自拒绝-生成策略(对涉政策敏感如色情、赌博、毒品话题的视频学会避免生成查询)。
在线部署分析(§5.4、Figure 8、Figure 9)¶

(1) 在线增益的主要来源。按视频发布时间分桶看,OneBar 在所有桶都取得正增益。CTR 提升对近 30 天内发布的视频尤其显著:协同-多模态意图接地模块让 OneBar 通过整合文本元数据、多模态理解、协同查询信号深度理解视频内容,因此即便对行为反馈有限的新发布视频也能生成更相关、更及时的查询。

按用户活跃度(搜索频次、点击/购买、总消费)分五组 U0–U4,OneBar 在所有组取得统计可靠增益:低活跃用户靠内容接地证据(文本/多模态/协同 anchor)缓解稀疏行为,高活跃用户靠更丰富行为信号 + 后验偏好学习更好捕捉个性化意图。说明增益不局限于特定用户段。
(2) 人工评测中查询质量的改善。从人工标注坏 case 看,OneBar 把总体查询质量坏 case 率降 9.00pp(视频-查询无关 −3.66pp,字面质量 −1.00pp)。无关与字面质量问题常源于低质视频侧信息(标题噪声、新视频缺行为派生证据),OneBar 用高质多模态证据 + ANN 检索 query anchor 同时改善查询相关性与表面形式质量;风控坏 case 降 4.33pp 主要来自拒绝-生成策略。
定性案例(Table 9)¶
Table 9 给出 OneBar 处理弱/缺失/有风险 trigger 证据的代表性案例:
- Case 1(风险拒绝 →
[REJECT]):trigger 是家庭 vlog 收拾房间 + 与小孩对话,RAG 历史只提到小孩名字与一个弱"吸烟"线索。MCA 流水线产出对小孩有潜在有害引导的查询("小宝吸烟")。OneBar 识别证据稀疏且不安全,输出[REJECT]而非曝光底栏查询——说明模型学会在证据不足且有风险时不推荐。 - Case 2(ANN anchor 补全 → Complete):caption 提到"6800 预算三缸猛兽"并含 CFMOTO 675 相关 tag,其他字段空,点击目标是"CFMOTO 675NK"。原始 caption 指向更宽的 CFMOTO 675 系列但漏了具体 NK 型号后缀。行为相关查询池的 ANN anchor 集中在"CFMOTO 675NK 排气声""二手价""改装 675NK""售价"等具体型号词,OneBar 据此补全出精确的"CFMOTO 675NK",而非停在泛化的 CFMOTO 675。
- Case 3(互补检索 → Compose):caption 只识别出脊柱外科医生 + 健康科普场景,item 标题/OCR/RAG 历史均空,目标查询问腰椎管狭窄的有效药物,但疾病实体在可见 trigger 证据里缺失。用户历史检索到附近的疾病查询如"腰椎管狭窄吃什么药最好";ANN 检索提供用药模板"缓解经痛吃什么药最有效?"。OneBar 把正确疾病实体与用药模板组合成"腰椎管狭窄吃什么药最有效?",恢复了目标意图。
核心贡献总结¶
- OneBar 框架:面向短视频信息流底栏的实时端到端生成式查询推荐框架,用单个 BART encoder-decoder 把多阶段检索级联坍缩为一次端到端生成,在 20–30ms 延迟预算内服务;
- PIOPD:把后验偏好信号(点击的目标查询)经 on-policy token 级蒸馏直接内化进生成策略,免去单独训练奖励模型,部署接口不变;
- 完整工业验证:在快手主信息流大规模在线 A/B 上 Query Exposure +16.91%、Query Click +18.68%、Guided Orders +20.36%、Guided GMV +21.67%,坏 case 率降 9.00pp。
与已归档相关工作的对比¶
OneSug OneSug: 面向电商查询建议的统一端到端生成式框架(Kuaishou, 2026 AAAI)¶
关系:显式引用但原文未展开对比(仅在引文 [13] 处提及,无方法/指标级对照)· 已加载对方精读
- 共同关注的问题:两者都来自快手电商搜索体系,都要把查询侧推荐从多阶段级联架构(MCA)(召回 $10^6$ → 粗排 $10^4$ → 精排 $10^2$)的"前阶段决定上限 + 各阶段目标不一致 + 长尾差"的结构性瓶颈中解放出来,改用单个 encoder-decoder 端到端直接生成查询。
- 相近的技术骨架:三个共同点高度同构。(a) 都用 BART/encoder-decoder + beam search 直接生成自然语言查询;(b) 都把异构上下文证据序列化进 encoder 输入(OneSug:
{[CLS], p, [SEP], H_p, [SEP], H_u, [SEP], U};OneBar:[T_x; [SEP]; M_x; [SEP]; A_x; [SEP]; H_u]),都用[SEP]分隔多字段;(c) 偏好对齐都把用户在线行为划成六个层级(OneSug:Order/Item Click/Click/Show/Not Show/Rand;OneBar:Table 2 的六层),都用列表式 DPO(OneSug 的 RWR list-wise loss;OneBar Eq.10 的 list-wise Softmax DPO)从同 trigger/prefix 候选学序数偏好。 - 本文的差异与推进:(1) 触发模态根本不同——OneSug 是用户输入前缀(prefix)驱动的查询建议(open-vocabulary prefix→query),OneBar 是视频内容诱发的查询推荐(无用户输入,底栏直接接地于多模态视频)。因此 OneBar 多了协同-多模态意图接地模块(多模态摘要 $M_x$ + ANN query anchor + RAG),而 OneSug 用 PRE 模块(prefix-query 对齐 + RQ-VAE 语义 ID)增强短前缀。(2) 偏好学习更进一步——OneSug 止步于列表式 RWR(本质是离线 logged 候选上的 DPO),OneBar 在列表式对齐之上再加 Stage III PIOPD:on-policy 采样 student 轨迹 + 后验感知 teacher 的 token 级蒸馏,缩小 off-policy gap 并免奖励模型。可以说 OneBar 把 OneSug 的"端到端生成 + 行为层级 DPO"配方迁移到了内容接地的视频底栏场景,并补上了 on-policy 后验内化这一层。
OneSearch-V2 OneSearch-V2: 潜在推理增强的自蒸馏生成式搜索框架(Kuaishou, 2026-03-25)¶
关系:显式引用且原文 §3.4.3 已点名对比,但仅一句话级别(未展开机制/指标对照)· 已加载对方精读
- 共同关注的问题:两者都要把一个"训练时可用、推理时昂贵/不可用的特权信号"内化进可部署生成器的权重里,不增加在线推理成本、不改变服务接口。OneSearch-V2 内化的是 keyword-based CoT 推理路径,OneBar 内化的是后验点击偏好信号。两者也都明确反对依赖单独训练的奖励模型(reward hacking + 分布偏差)。
- 相近的技术骨架:核心机制几乎同构——信息不对称自蒸馏 / teacher-student 共享权重:teacher 看到增广输入(V2:含 CoT 关键词;OneBar:含点击查询 $y_{\text{ref}}$),student 只看标准输入,用 KL 蒸馏把特权信号压进权重;两者都额外叠加 R-Drop(输出空间一致性)+ FGM(对抗 embedding 扰动)做表征稳定(OneBar Eq.15 与 V2 §5.4 几乎逐项对应),都用温度软化 teacher。
- 本文的差异与推进:关键区别是 on-policy vs teacher-forced。OneSearch-V2 的自蒸馏 KL 计算在金标准 token 位置(teacher-forced gold prefix) 上;OneBar 的 PIOPD(Eq.12)把期望取在从 student 自回归采样的 rollout 状态上,即在部署生成器推理时真正会访问的状态上做投影——这正是原文"Unlike OneSearch-V2 [7]…we use clicked target queries as posterior preference signals"那句一笔带过、但机制差异巨大的地方。其次,V2 的 teacher 输入是结构化关键词 CoT,OneBar 是把点击查询随机位置插入(Randomized Context Augmentation,Table 5 显示随机插入 HR 0.496 远高于固定追加 0.408)。再次,OneBar 用 FKL+RKL 双向 KL + 熵正则专门对抗后验蒸馏的 student 过度集中(Figure 4),而 V2 主打 self-mode 单向 KL + focal loss。可以把 PIOPD 理解为 OneSearch-V2 自蒸馏范式的 on-policy 化 + 后验偏好版:同样的"共享权重 + 不对称输入 + KL + R-Drop/FGM"骨架,但蒸馏发生在 student 自己的轨迹上、内化的是行为后验而非推理 CoT。
讨论与局限性¶
核心贡献与值得借鉴的设计:
- 把风控做进模型而非下游:
[REJECT]弃权 token 把 $\text{Safe}(\cdot)$ 谓词内化进生成器(Stage I 用 $\mathcal{D}_{\text{rej}}$ 监督),Case 1 显示它能在弱+危险证据下主动不推荐,在线风控坏 case 降 4.33pp。这是把安全约束从"事后过滤"前移到"生成时决策"的干净做法。 - 免奖励模型的偏好内化:PIOPD 用点击目标查询作后验特权信号 + on-policy token 蒸馏,绕开了奖励模型的分布偏差与 reward hacking,且部署产物仍是单一标准条件生成器——这对工业落地很友好(不引入在线后验模块)。
- 覆盖优先于锐化:Figure 6 + Table 3 揭示 PIOPD 牺牲极少 top-1 锐度换更广候选覆盖,配合 beam=8 在中尾排名召回更多相关查询——对底栏这种"出 K=8 条"的场景,覆盖比单条最优更重要,这个 trade-off 选择有指导意义。
- 紧凑
[SEP]schema:字段对齐证据(0.3564 HR@8)碾压冗长 prompt(0.1864),且缺失字段不改输入格式、与服务兼容——对用预训练 encoder-decoder 做工业生成的工程实践是直接可借鉴的。
局限与争议:
- 几乎无公开可比性:全部离线/在线评测都在快手私有生产数据上,无任何公开学术数据集与可复现 baseline;且关键的真正强 baseline(OneSug、OneSearch-V2、GREAT、CLICKABLE)都未作为表格 baseline 对比,Table 3 的 baseline 只有 zero-shot LLM、ANN、vanilla BART,说服力受限。
- 依赖大量离线预计算与日更:多模态摘要、ANN anchor、RAG 历史都靠离线流水线日更并缓存进 Redis,新鲜度受日更周期限制;论文也承认新视频的增益主要靠协同-多模态接地兜底,极端冷启动(无任何行为信号 + 标题噪声)下表现未充分讨论。
- 指标自洽偏置:BAS@K 用与 ANN 检索同一个嵌入模型计算,天然偏向 ANN;SR 用 GPT-5.5 当 judge,而 zero-shot GPT-5.5 在该指标上最高——这两个相关性指标的可信度都需打折。
- Table 3 中 GPT-5.5 与 BART 的 ED@8 均为 5.2471,疑似笔误或巧合,论文未解释。
工业落地价值:OneBar 已在快手主信息流规模化在线部署(A/B 9.12% 流量),端到端单次生成相比在线 MCA 总耗时降约 8%(Figure 2),业务收益明确(Guided GMV +21.67%、Guided Orders +20.36%)。对"在搜推一体平台用生成式取代查询侧检索级联"这条工业路线,OneBar 提供了一个含风控内化 + 免奖励模型偏好内化的完整、可部署样板。