One Pool, Two Caches: Adaptive HBM Partitioning for Accelerating Generative Recommender Serving¶
Wenjun Yu (HKBU)、Shuguang Han (Alibaba)、Amelie Chi Zhou (HKBU)。arXiv 2605.04450, 2026-05-06。
研究动机与背景¶
生成式推荐(GR)serving 的双缓存矛盾¶
生成式推荐(Generative Recommender, GR)以 Meta HSTU [53] 为代表,已在工业级推荐系统中广泛落地(参考 [18,20,26])。HSTU 在线推理由两阶段组成,且对 GPU 内存系统提出截然不同的需求:
- Embedding Table Lookup:从分片于 CPU DRAM 的大型 embedding 表(生产规模 96TB Model-F、200TB+ Persia [25,31])取出与 item ID、类别、上下文等对应的稠密向量;表规模远超单节点 GPU HBM 容量,因此 EMB 表只能 sharded 到 CPU memory,命中失败时通过 PCIe / RDMA 拉取,是端到端延迟的主要构成。
- Transformer Block 计算:堆叠多头自注意力对长用户行为序列(10K+ items)执行 forward pass,工业部署中 KV 状态需要 保留在 HBM 中作为 KV cache 以避免对历史序列重复重算 attention。
GR serving 与 LLM serving 的关键差异在于:LLM 自回归解码时 KV 移动可与 decode 计算 overlap,而 GR 仅有一次 forward pass,KV CPU offloading(如 [13,36])不可行,KV state 只能驻留 GPU HBM。结果是同一块有限的 GPU HBM 上,EMB 热缓存(减少 CPU→GPU PCIe 传输)和 KV 缓存(避免 attention 重算)形成直接资源争抢。
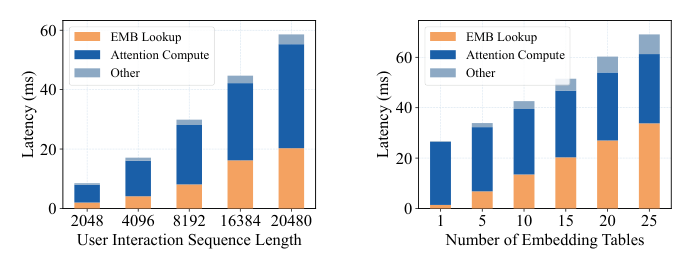
Fig. 1 的 production trace 揭示了两点关键事实:
- EMB lookup 在长序列、多表场景下成为主导瓶颈。在 sequence length=20480 时它单独占总推理时间 40% 以上;当 embedding table 数从 1 表增到 25 表,EMB 时间近似线性增长。生产部署常见数十至数百张 embedding 表 [1,2,11,52],问题被放大。
- KV 计算同时是显著开销。长序列 attention 重算成本随 (L^2/F_{\text{gpu}}) 增长。
因此 EMB Cache 与 KV Cache 都对端到端延迟有关键贡献,两者共抢一块 HBM,必须联合而非独立优化。
HSTU 模型结构与 serving 架构¶
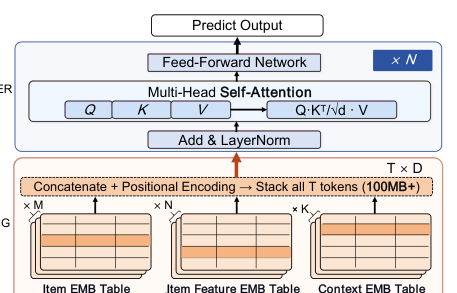
HSTU 把推荐问题重构为序列转换:以历史 user-item interaction 序列为输入,预测下一个 item / item ranking。其层叠 self-attention 在长行为历史(modern GR 通常 10K+ items)上工作,必然带来高计算和高内存成本。
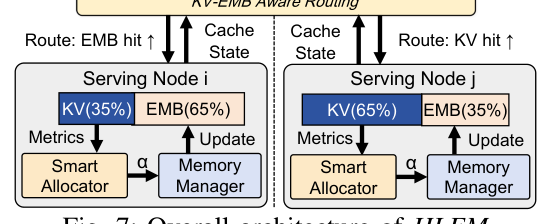
生产 GR serving 集群(如图所示)通常采用双层内存层级:
- Request Router:根据 KV cache 命中、EMB cache 命中、节点负载等信息把每个请求路由到一个 serving node。
- Serving Node:每节点持有 1) EMB cache(GPU HBM 上的 hot embeddings),未命中时从本地 CPU shard 或远端节点 RDMA 拉取;2) KV cache(GPU HBM 上的 attention KV 状态)。
请求处理 4 阶段:(1) Route:路由器选 node;(2) EMB lookup:缺失时从本地 / 远端取;(3) Compute:GPU 跑 HSTU forward,复用本地 KV 与已缓存 embeddings;(4) State sync:完成后异步把 cache residency 与 load 上报路由器。
静态分配的损失:实测 20–30% 的潜力被埋没¶
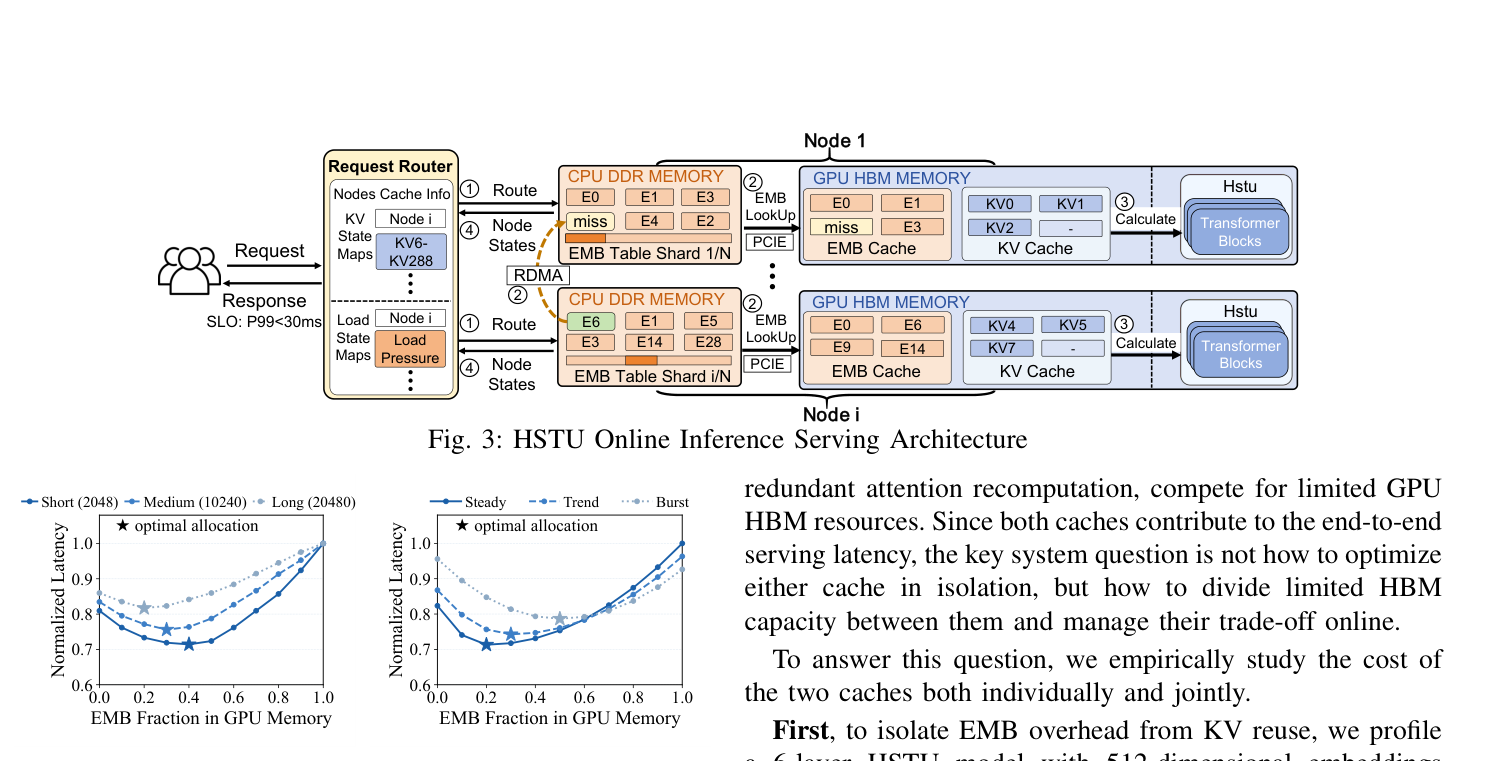
作者把 GPU HBM 中 EMB cache 占比记作 (\alpha),扫描 (\alpha \in [0,1]) 测端到端延迟(Fig. 4),发现:
- 端到端延迟在中间某个 (\alpha) 取最小,而不是任一极端:把 HBM 全给 EMB 会让 KV 失去复用并迫使重算 attention;全给 KV 则 EMB miss 飙升,PCIe 传输堵塞。
- 最优 (\alpha^) 随 sequence length(短→长 0.20→0.55)和 workload(Steady→Burst 0.20→0.55)剧烈漂移*,幅度可达 0.35。
- 跨 workload 的最优分配差异留下了 20–30% 的延迟优化空间;任何静态 (\alpha) 都不可能在所有 regime 下都接近最优。
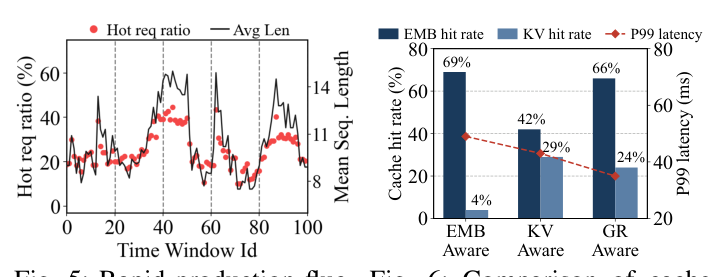
Fig. 5 用 5s 窗口刷新生产 trace 显示,工作负载组成(hot user 比例、mean seq length)会在数十秒内发生剧烈变化,意味着 EMB-KV 管理需要在线快速适应而不能依赖固定分配。
三大核心挑战¶
作者把诉求归纳为三类:
- Multi-factor workload modeling:最优 (\alpha^*) 由 hot-user 比例、KV 命中率、EMB 命中率共同决定(合计 >60% 决策重要性),简单启发式不够。
- Fast and non-intrusive adjustment:哪怕 10% 的 (\alpha) 调整都可能触发 (\sim)8 GB H2D 数据移动;该流量与延迟敏感的 prefill embedding 传输共享 host-to-device PCIe 路径。一次 burst 还能触发 (\sim)10 GB/s H2D 流量,在 30–50 ms P99 SLO 下足以打爆 SLO。
- Joint-aware scheduling:内存分配跨节点异质后,EMB transfer 成本因节点而异,KV-only 路由 [44] 不再够,必须联合 EMB-KV-aware 调度。
核心方法 / HLEM 系统架构¶
HLEM (HBM-level EMB-KV Latency Manager) 由三个紧耦合组件构成,对应 (IV)-A 至 (IV)-C 三节:
IV-A SmartAllocator: 自适应 EMB–KV 内存分配¶
MDP 公式¶
记 GPU 显存预算为 (M),EMB 占比 (\alpha \in [0,1]),则 (M_{\text{Emb}} = \alpha M),(M_{\text{KV}} = (1-\alpha)M)。在每个决策 epoch (t) 选择最优 (\alpha_t^*) 最小化端到端 P99 延迟:
$$\alpha_t^* = \arg\min_{\alpha\in[0,1]} \ell(\alpha, s_t) \tag{1}$$
把动态 EMB-KV 内存分配建模为 MDP ((\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma)),目标是学习策略 (\pi(a_t | s_t)) 最大化期望折扣回报:
$$J(\pi) = \mathbb{E}_\pi\left[\sum_{t=0}^{\infty} \gamma^t r_t\right] \tag{2}$$
由于内存分配会通过 cache refill / eviction / 之后请求复用产生延迟反馈,单步即时指标无法刻画其影响,所以必须用 RL 而非纯启发式。
状态、动作、奖励空间¶
状态:决策 epoch (t) 上观察 7 维向量 (s_t = (h_t, k_t, e_t, L_t, v_t, \alpha_t, p_t) \in \mathbb{R}^7),分别表示 hot-user 请求比例、KV 命中率、EMB 命中率、平均序列长度、SLO violation 比例、当前 EMB 占比、归一化 P99 延迟,所有特征归一化到 [0,1]。
动作:增量更新 (a_t \equiv \Delta\alpha_t),使用小动作集合:
$$\mathcal{A} = \{\pm 0.06, \pm 0.04, \pm 0.02, 0\} \tag{3}$$
下一时刻分配为:
$$\alpha_{t+1} = \text{clip}(\alpha_t + \Delta\alpha_t, \alpha_{\min}, \alpha_{\max}) \tag{4}$$
(\alpha_{\min}=0.1,\alpha_{\max}=0.9) 防止某一缓存被完全饿死,小步增量减弱瞬态 cache imbalance。
奖励:决策窗口结束后
$$r_t = \mathbb{E}_{\tau \sim \mathcal{T}_t}\left[\mathbb{1}[d_\tau \le \tau_{\text{SLO}}]\right] - \lambda \cdot \max(0, \ell_t - \tau_{\text{SLO}}) \tag{5}$$
第一项是窗口内请求的 SLO 满足率(QoS),第二项以 (\lambda = 1/\tau_{\text{SLO}}) 量级惩罚 P99 超出。两者的平衡解决了"只优化 SLO 率会忽视 tail spike,只优化 P99 会忽视整体服务质量"的双重病态。
三层控制器:Decision Loop + Learning Loop¶
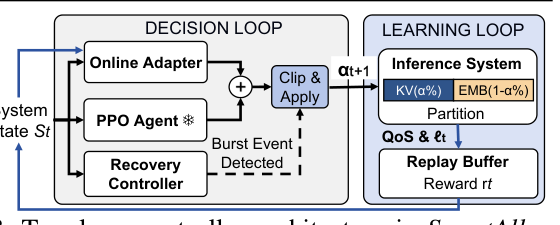
SmartAllocator 把问题拆成 Decision Loop(serving 路径,低开销)和 Learning Loop(后台维护,更新 online adapter)。每 5s 决策一次,三种信号合成新动作:
$$\alpha_{t+1} = \text{clip}(\alpha_t + \Delta\alpha_{\text{ppo}} + \Delta\alpha_{\text{adapt}}, \alpha_{\min}, \alpha_{\max}) \tag{6}$$
或在 burst 触发时由 Recovery Controller 覆盖。三个组件功能如下:
(1) PPO Agent — Base Frozen Policy
- 用 PPO [40] 离线在历史 trace 上训 100 episodes 收敛。Actor-Critic 结构,64/128 隐层的两层 MLP,参数量 <25K。
- 选择 PPO 而非简单 DQN:分配的延迟反馈是延迟的,需通过 cache refill / eviction / reuse 才会显现,单步目标会失真。
- 部署后冻结避免线上不稳定,仅作 dominant control signal (\Delta\alpha_{\text{ppo}})。
(2) Online Adapter — Residual Correction
- 解决离线-在线分布差。3 层 MLP(5 → 16 → 1),输入维度 5(与 PPO 输入子集),输出残差 (\Delta\alpha_{\text{adapt}}),零初始化。
- 维护 P99 延迟的 EMA (\ell_{\text{EMA}}),自适应学习率:
$$\eta_t = \eta_0 \cdot \frac{|\ell_t - \ell_{\text{EMA}}|}{\tau_{\text{SLO}}} \tag{7}$$
(\eta_0 = 10^{-3})。每个 decision window 把 ((s_t, \Delta\alpha_{\text{adapt}}, r_t, \ell_t)) 推进一个大小 1K 的 FIFO replay buffer,bounded memory 同时缓解 catastrophic forgetting。
(3) Recovery Controller — Burst Handling
- 维护近 10 个 epoch 的 P99 延迟 EMA (\ell_{\text{EMA}}) 与标准差 (\sigma_{\text{EMA}})。当:
$$\ell_t > \ell_{\text{EMA}} + 3\sigma_{\text{EMA}} \tag{8}$$
判定 burst 事件。此时绕过正常更新,直接采用保守策略:把 hot-user 比例超过 (\rho^* = 0.2) 时往 KV 偏移,避免 H2D 路径上的 burst 拥塞。
IV-B Memory Manager: 非干扰式分配落地¶
Memory Manager 处理 SmartAllocator 输出的新 (\alpha) 时面对一个根本张力:5s 一次的频繁调整会引入 H2D refill 流量,与延迟关键的 EMB-miss 传输竞争同一条 PCIe 路径。一次 4% 调整对 80GB GPU 大约产生 3.2GB H2D refill;这是真正的瓶颈。
HLEM 把"分配变更"分成逻辑变更(页表/元数据)和物理 refill(PCIe)两步,分别处理两个 PCIe 相关挑战:
(C1) Embedding-only boundary adjustment(zero-copy 分配)¶
为避免移动驻留 KV state,HLEM 强制只调整 EMB cache 边界,KV 物理上不动。具体做法:
- KV cache 组织为 paged block pool(vLLM [23] 风格),每块由显式 free list + page-table metadata 管理。
- EMB cache 实现为 contiguous LRU-managed slab,由 page 粒度反向 backed。
- 当 (\alpha) 增大:EMB 调用
alloc_page()从 KV 池抓 free pages,不触碰驻留 KV entries。 - 当 (\alpha) 减小:调用
evict_lru_entries()回收 EMB pages,通过free_page()还回 KV free list。
由于全部是 metadata-only 操作,page tables 在 1 µs 内更新,调整本身不引起任何 cudaMemcpy / pipeline stall。
(C2) Background refill with bandwidth throttling¶
新分配的 EMB 容量需要被有用 cache content 填满,这是 H2D 流量。要避免这股流量挤压 inference path:
- HLEM 通过
cudaMemcpyAsync在专用高优先级 CUDA stream (cudaStreamCreateWithPriority) 上发起 refill,与默认 compute stream 解耦。 - 进一步根据当前 EMB-miss H2D 流量throttle background refill bandwidth。
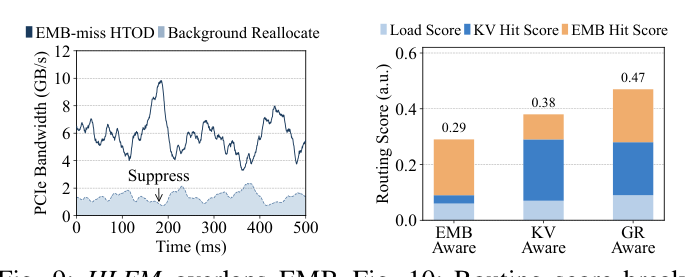
实测:3.2 GB 的 H2D refill 在 ~1 s 内完成,allocator 决策间隔 5 s,因此 refill 成本能完全被摊销而不影响端到端延迟。
IV-C KV-EMB-Aware Request Routing¶
动态分配让节点不再可互换:相同请求在不同 node 上因 KV 驻留 / EMB 命中 / load 不同而经历不同延迟。仅 KV-aware(如 [44])忽视 EMB miss → recomputation 风险;仅 EMB-aware(如 [24])则牺牲 KV 复用。HLEM 用 cost-based routing 显式估两种 miss cost。
Algorithm 1 — KV-EMB Aware GR Request Routing¶
Input: request R from user u; candidate nodes N;
miss costs C_kv, C_emb, C_ld; overload threshold τ; affinity bonus ε
Output: target node n*
Router maintains per-node:
Aff[u]: previous routed node per user
KVM[n]: KV cache HashMap u → {0,1}
EMBM[n]: EMB cache state HashMap
Prof[u]: top-K hot shards for u; l(n): load pressure
1: n_aff ← Aff[u]
2: for each node n ∈ N do
3: h_kv ← KVM[n].get(u) ▷ KV hit rate
4: h_emb ← |Prof[u] ∩ EMBM[n]| / |Prof[u]| ▷ EMB hit rate
5: score(n) ← w_kv h_kv + w_emb h_emb + w_ld(1 - l(n)) + b(n)
6: n* ← argmax_n score(n) ▷ Best node
7: if l(n*) > τ then
8: n* ← argmin_n l(n) ▷ Overloaded: fall back to least-loaded
9: Dispatch R to n*; Update Aff[u] ← n*; Async update KVM[n*]
每节点打分:
$$\text{score}(n) = w_{\text{kv}} h_{\text{kv}} + w_{\text{emb}} h_{\text{emb}} + w_{\text{ld}}(1 - l(n)) + b(n) \tag{9}$$
亲和性 bonus:
$$b(n) = \epsilon \cdot \mathbb{1}[n = n_{\text{aff}}]$$
软偏向上次路由的 node。三个权重 (w_{\text{kv}}, w_{\text{emb}}, w_{\text{ld}}) 由 offline-profiled miss cost (C_{\text{kv}}, C_{\text{emb}}, C_{\text{ld}}) 自动归一化得到((w_i = C_i / Z, Z = C_{\text{kv}} + C_{\text{emb}} + C_{\text{ld}})),不需手调。实现取 (\tau = 0.85),(\epsilon = 0.05),shard-profile size (K = 20)(对 K=10..50 不敏感,覆盖至少 95% 单用户 EMB 访问)。
Residency Tracking:路由器维护轻量 metadata。KV residency 按用户级跟踪(user ID → presence bit hashmap);EMB residency 按 shard 级跟踪(resident embedding-shard identifiers 集合)。每请求 (h_{\text{emb}}) 通过 user 预算的 top-K 与 node 的 EMB-residency set 求交集((O(K)))。结构异步、off 关键路径更新;KV-residency table 在 32-node 下 <24 KB / node,(\alpha = 0.5) 时单节点 typically 持有 3K–6K KV 项。
GR-Aware(HLEM)联合得分 0.47 高于 EMB-Aware 0.29 和 KV-Aware 0.38,证明同时纳入两侧成本能避免单维 routing 的 myopic。
实验设置¶
硬件 & 系统栈¶
- 集群:32 节点,每节点 8× NVIDIA A100 80GB (HBM2e),AMD EPYC 9684X 双路(共 2TB DDR5),200 Gbps InfiniBand HDR。共 5TB EMB tables。
- 软件:基于 open-source HSTU 框架 [53] 实现,user-request 粒度的连续 batching(参考 Orca [49]);FBGEMM [21] 优化 embedding kernel,NCCL [33] 集合通信。
模型配置¶
- HSTU 3-layer(ranking 阶段轻量级)
- HSTU 6-layer(retrieval 阶段重量级)
- 两者均 512-dim item embedding。
数据与负载¶
| 数据集 | 用户数 | Top 5% 用户请求占比 |
|---|---|---|
| Taobao [4] | 0.98 M | 18% |
| Amazon Video-Games [19] | 2.76 M | 24% |
| Amazon Books [19] | 10.3 M | 38% |
按真实 access frequency 重放,user profile 拉伸到 5K–15K tokens,每请求检索 100 candidate items。Embedding 表用 NVIDIA DLRM scripts [3] 扩到 5TB,保留 Zipfian frequency 分布——这点对 HBM miss 与 EMB-KV 敏感性至关重要。
三种 workload regime:
- Steady:均匀到达 + 稳定 hot-user 占比
- Trend:hot-user 比例随时间渐变,测 SmartAllocator 跟踪漂移最优
- Burst:Poisson hot-user 突增持续 3–5 个 decision window,测尾延迟鲁棒性与 Recovery Controller
Baselines¶
第一组(serving system 端):在固定 (\alpha^*) 下隔离测分配控制器外的系统优化。
- KV-Opt:KV-centric serving(如 [37,42,44]),(\alpha = 0)(HBM 全给 KV)。
- KV-EMB-Opt:在 KV-Opt 上加 ML-guided EMB prefetching [38],固定 (\alpha^) 由 grid search ({0.0, 0.1, ..., 1.0}) 离线选最低 P99——最强静态配置*。
第二组(动态分配控制器):固定 serving infra 比较控制器。
- 经典:PID [5],Bayesian Optimization (BO) [41],MILP [17]。
- 预测式 ML:XGBoost [9],LSTM [51] (含 OFT/RC 增强变体)。
- PPO-only:HLEM 把 OnlineAdapter 与 RecoveryController 关掉。
指标¶
- End-to-end serving:P99 latency (ms) 与 QoS(30 ms SLO 满足率)。
- Allocation quality:oracle ratio gap (|\alpha_t - \alpha_t^|),(\alpha_t^) 由 epoch 内全 workload trace 在 ({0,0.01,...,1.0}) 网格穷搜得到。
主要实验结果¶
端到端 P99 与 SLO 满足率¶
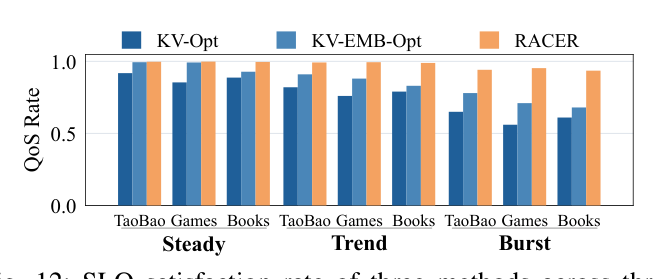
P99 latency(Fig. 11,正文表):
| Setting | KV-Opt | KV-EMB-Opt | RACER (HLEM) |
|---|---|---|---|
| HSTU 3-layer / TaoBao | 33 | 28 | 19 |
| HSTU 3-layer / Games | 38 | 32 | 21 |
| HSTU 3-layer / Books | 38 | 35 | 23 |
| HSTU 6-layer / TaoBao | 44 | 38 | 25 |
| HSTU 6-layer / Games | 51 | 44 | 27 |
| HSTU 6-layer / Books | 46 | 46 | 29 |
(数据均为 ms。HLEM 在 30 ms SLO 下全部满足;KV-EMB-Opt 在 6-layer 上全数据集超出。3-layer 上 HLEM 比 KV-EMB-Opt 降低 P99 25–34%,6-layer 上 28–38%;Amazon Books 上提升尤为明显,因为 hot-user 比例 38% 让 EMB-KV 争抢更剧烈。)
SLO 满足率:HLEM 在 Steady 与 KV-EMB-Opt 差距小(HLEM ≥99.6%,KV-EMB-Opt 92.8–99.4%)。在 Trend 下后者降到 83–91%,HLEM 维持 ≥98.9%。Burst 下静态法降至 56–78%,HLEM 仍 93.5–95.3%。HLEM 的 run-to-run variance 仅 1.2 ms,说明它是稳定降低尾延迟而非简单平移均值。
系统级消融¶
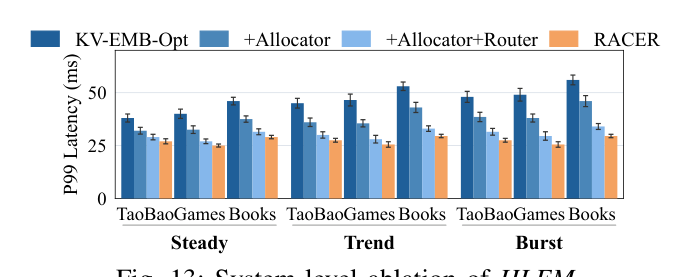
- +SmartAllocator 单独相对 KV-EMB-Opt(固定 (\alpha^*))已降低 P99 ~20%,证明自适应分配本身解决双瓶颈问题的主要部分;提升在 Burst 下最大,因为 fixed allocation 在 active cache 切换时 under-provisions。
- +Router 进一步降 10–25%:通过把 KV residency 集中到回访用户同时保留 embedding locality,每节点 cache 更友好。
Allocator 内部消融¶
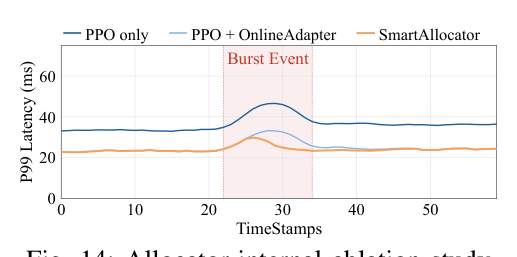
- PPO-only:steady ~33 ms,burst 反应慢,峰值 ~46 ms。
- +OnlineAdapter:稳态降到 ~23 ms,但 burst 不灵敏。
- +RecoveryController(完整):稳态保留,burst 峰被压到 ~31 ms 并快速回落。
与 α 控制策略的对比¶
| Method | Dec. Time | Steady gap | Trend gap | Burst gap |
|---|---|---|---|---|
| Static-α=0.1 | 0 s | 0.292 | 0.341 | 0.331 |
| Static-α=0.3 | 0 s | 0.092 | 0.141 | 0.131 |
| Static-α=0.5 | 0 s | 0.108 | 0.061 | 0.072 |
| Static-α=0.7 | 0 s | 0.308 | 0.259 | 0.269 |
| Static-α=0.9 | 0 s | 0.508 | 0.459 | 0.469 |
| PID | ~1.2 s | 0.094 | 0.108 | 0.167 |
| XGBoost | ~3 ms | 0.053 | 0.083 | 0.156 |
| BO | ~7 s | 0.061 | 0.089 | 0.174 |
| MILP | ~36 s | 0.044 | 0.068 | 0.161 |
| LSTM | ~5 ms | 0.051 | 0.083 | 0.156 |
| LSTM+OFT | ~6 ms | 0.043 | 0.067 | 0.128 |
| LSTM+OFT+RC | ~6 ms | 0.041 | 0.069 | 0.051 |
| PPO-only | 28 µs | 0.043 | 0.051 | 0.042 |
| SmartAllocator | 32 µs | 0.019 | 0.023 | 0.031 |
关键观察:
- 静态 (\alpha) 全 regime 都不行——确认固定分配根本不足。
- 经典法(PID/BO/MILP/XGBoost)目标错配:它们优化单步指标,可分配的延迟反馈跨多个 epoch 才显现,反应过慢或过激。BO 7 s、MILP 36 s 的决策延迟使其在线不可用。
- LSTM 系预测用时序模型部分缓解,加 OFT (Online Fine-Tuning) 与 RC (Recovery Control) 在 Burst 上把 gap 降到 0.041–0.069,但仍不能完全打破响应性 / 长 horizon 控制的权衡。
- PPO-only 已显著好(28 µs),SmartAllocator 把 gap 进一步压到 Steady 0.019 / Trend 0.023 / Burst 0.031;决策时间 32 µs,控制开销最低。
Control Overhead:OnlineAdapter 训练把峰值 CPU 利用率从 20% 推到 46%,平均 32%,全部跑后台不影响 serving。Router 端 affinity table + KV residency 32 节点共 <100 KB / node,metadata cost 可忽略。
Tracking offline-optimal α*¶
Warmup 区域过后,(\alpha_{\text{RL}}) 紧跟 (\alpha^),平均绝对误差 0.023——没有任何未来 workload 知识*。学到的 policy 对 regime 表现非对称:
- Steady(hot ratio ≈0.20):(\alpha_{\text{RL}}) 升到 0.51 偏向 EMB 局部性(EMB/KV hit 55%/21%)。
- Trend(hot ratio ≈0.32):降到 0.38 平衡两侧(50%/18%)。
- Burst(hot ratio ≈0.50):进一步压到 0.26,付 9% EMB-hit 减少换取 25% KV-hit gain 防 SLO violation。
这反映 KV 和 EMB 退化的非对称特征:KV 一旦低于 working set 就断崖式下降,而 EMB 是渐进退化;hot-user 比例升高时 KV working set 超线性扩张,每个 KV miss 成本被放大。
Sensitivity to user hotness & cluster scale¶

热占比上升 → α_RL 下降以保 KV;集群规模上升 → embedding 表 sharded 到更多节点,单节点 EMB working set 缩小,α_RL 进一步降。Heatmap 跨越从 EMB-dominated regime(2 节点 hot 0.05,α_RL=1)到 KV-dominated regime(32 节点 hot 0.60,α_RL≈0.23),证实没有静态 α 在所有 regime 都合适。
Weak-scaling Throughput¶
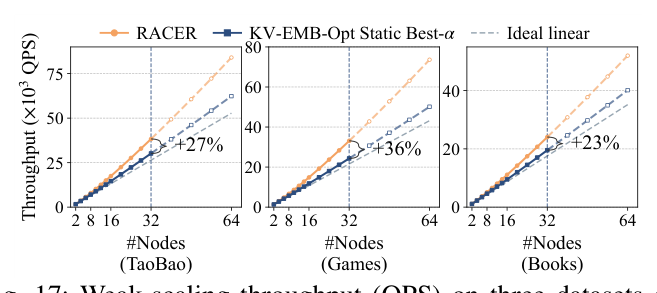
固定每节点 embedding data,集群从 2 扩到 32 节点,HLEM 维持近 linear scaling。32 节点 throughput 优于 KV-EMB-Opt 27%/36%/23%(TaoBao/Games/Books)。差距随集群规模放大,因为静态法跨节点协同代价升高,HLEM workload-aware 分配 + 路由减少跨节点 embedding 流量。
硬件普适性讨论¶
GR serving 双瓶颈本质由比值 (F_{\text{gpu}} / B_{\text{pcie}}) 决定。A100 yields 12.5,H100/H200 15.5,仅 24% 提升——bandwidth 仍是 first-order constraint。即便 H200 有更大 HBM (141 GB),仍无法消除 EMB-KV 零和 trade-off:hot embeddings 仍超 HBM 一个量级以上,序列 8K-15K 的 KV (60–184 MB / 用户) 仍把 8-GPU 节点限制到 ~3K-6K 活跃用户。HLEM 设计在未来 GPU 世代仍 relevant。
讨论与局限性¶
核心贡献¶
- Dual-bottleneck characterization:首次系统刻画 GR serving 中 EMB cache 与 KV cache 共抢 HBM 的张力,证明 (\alpha^*) 跨 workload 漂移高达 0.35,留下 20–30% 优化空间。
- Adaptive EMB–KV allocation:3 层 PPO + Online Adapter + Recovery Controller,决策开销仅 32 µs,offline-optimal gap 仅 0.019–0.031(vs 静态最优 0.061+,PID 0.094+)。
- Non-disruptive memory adjustment:用 paged KV pool + contiguous EMB slab 结构把分配变更分成 zero-copy 边界更新与 throttled background refill,避免 H2D PCIe 干扰关键路径。
- EMB-KV-aware routing:基于 offline miss cost 自动归一化权重的 cost-based scoring,比 KV-only / EMB-only routing 多 15–20% 延迟节省。
值得借鉴的设计¶
- 三层控制器分工:base policy(稳定)+ residual adapter(在线对齐)+ recovery controller(rare-event 保护)的范式可推广到任何"多目标 + delayed reward + 偶发 burst"的工业控制问题。
- Page-pool + contiguous slab 混合内存抽象:用 KV pool 解耦逻辑分配与物理 refill,是 vLLM PagedAttention 思想在 GR serving 双 cache 场景的有效适配。
- 决策周期 5s + refill ~1s 的时间常数选择有意思:决策频率与 refill 完成时间的比例确保不会出现 update 拥塞。
- Hot-user 比例作为 burst 检测信号:相对 raw latency (3\sigma) 检测多了一个语义维度。
局限性 / 争议点¶
- 离线 PPO 训练依赖 100 episodes 历史 trace:跨业务、跨地区迁移时如何 cold-start 没讨论。
- (\alpha_{\min}=0.1, \alpha_{\max}=0.9) 是 hand-set,跨场景可能需要重调。
- Routing 权重 (w_{\text{kv}}, w_{\text{emb}}, w_{\text{ld}}) 由 offline-profiled cost 推得——profile 失效时 routing 可能 myopic,需要在线重 calibrate。
- Burst Recovery 用
ρ* = 0.2与 (3\sigma) 阈值全部 hard-coded,对 dataset 较敏感。 - 单 metric 优化(P99 latency)忽视 throughput cost trade-off 的 explicit 表达;reward 中只用 SLO + tail penalty 没显式包含 cost。
- 未与 ULTRA-HSTU [62] 等 attention sparsity / 混合精度方案 stack——属正交工作但缺 stack 后联合效果。
工业落地价值¶
- 针对的是真实工业部署中"30–50 ms P99 SLO + 5TB EMB + 32-node A100 集群"的具体场景,5TB embedding tables、200 Gbps InfiniBand、双路 EPYC 9684X 等参数明显参考 Alibaba(注意第二作者 Alibaba 隶属)等大厂生产基线。
- "Company X" 匿名 trace 来自 production,符合 double-blind 政策;从评估中 32 节点 weak-scaling 与 5TB 表大小看,体量与 Taobao 商品搜推一致。
- 32 µs 决策开销与 100 KB metadata 的低占用让方案可立即部署到现有 HSTU serving stack 上,无需重构。
- 24–38% P99 减少与 23–36% throughput 提升对推荐系统直接对应硬件成本节省,每台 8×A100 节点价值数十万人民币,集群规模收益可观。