Mult-DPO: Multinomial Direct Preference Optimization for Recommender Systems¶
Yaochen Zhu¹, Harald Steck², James McInerney², Aditya Sinha², Yinhan He¹, Nathan Kallus²,³, Jundong Li¹ ¹University of Virginia ²Netflix ³Cornell University · arXiv:2606.10078 [cs.IR] · 2026-06-08 代码:https://github.com/yaochenzhu/Mult_DPO
研究动机与背景¶
Direct Preference Optimization(DPO)已经成为大语言模型(LLM)偏好对齐的主流方案:它绕开 RLHF 中显式训练奖励模型 + RL 优化的两阶段流程,利用「最优策略与奖励函数之间的闭式关系」把对齐化简成偏好数据上的一个分类式目标,因其简洁与强经验表现被广泛用于摘要、代码生成、数学推理等任务。
当 LLM 越来越多地作为推荐系统(Recommender System, RS)的骨干时,一个自然的问题是:能否直接用 DPO 来对齐 LLM-based RS 与用户偏好?答案被一个根本性的数据结构错配复杂化了:
- Vanilla DPO 假设成对(pairwise)偏好——每个 context 只有一个正样本和一个负样本。这适合 QA 式长回答任务(候选难以批量生成)。
- 但 RS 中的用户反馈几乎从不是成对的。给定一个 context $x$(用户画像、交互历史,或一段 user–RS 对话),我们通常观察到集合式(set-wise)偏好:一个包含多个正样本的正集合 $\mathcal{E}^p$(被点击 / 喜欢的 item)与一个负集合 $\mathcal{E}^d$(未交互或被显式拒绝的 item)。从偏好对齐的视角看,每一个正样本都应被排在每一个负样本之前,但正样本之间、负样本之间不施加任何顺序。
直接把 vanilla DPO 套到 set-wise 偏好上,需要枚举所有正–负组合对,既计算昂贵,又丢弃了反馈的联合排序结构(joint rank structure)。已有工作沿两条技术路线尝试解决:
- 泛化 Bradley–Terry 到 Plackett–Luce(PL):把 vanilla DPO 背后的成对 BT 奖励模型升级为 listwise 的 PL 模型(如 PRO、KPO 等)。但用于 set-wise 偏好时,PL 似然必须在所有与观测一致的正样本排序上做边缘化(marginalize),其复杂度是组合爆炸的。
- 限制监督形式来回避难处理性:把监督退化为「每个 context 仅一个正样本 + 多个负样本」。例如 DMPO 在 BT 模型内把正样本对比负样本对数比的算术平均;S-DPO 证明在单正样本约束下,边缘化后的 PL 似然坍缩为一个闭式的 softmax DPO 损失,把正样本联合对比所有采样负样本。
然而,这两条路都没有忠实保留反馈的 set-wise 联合结构——使得「多正样本偏好对齐」依然是一个根本上未解决的挑战。
本文贡献。 作者提出 Mult-DPO(Multinomial DPO),用一个可处理的多项式(multinomial, MN)代理事件模型替代难处理的边缘化 PL 似然,核心要点:
- 在与 BT / PL 相同的奖励诱导权重空间上定义一个 MN 代理似然,虽然它本身不是一个排序分布,却允许通过标准 RLHF 策略–奖励重参数化导出一个闭式、分类式的 DPO 风格目标,从而直接用多个候选对齐 LLM;
- 理论上证明:最小化 MN-DPO 损失等价于优化难处理的边缘化 PL-DPO 损失的一个可处理上界(Theorem 1 + Corollary 1),并以闭式刻画该上界的紧致性(Theorem 2)——紧致性由正样本相对总权重与负样本总权重之比决定,揭示出选更丰富 / 更难的负样本会收紧上界;
- 进一步把 Mult-DPO 推广到多偏好层级(如显式评分),通过序列多项式(sequential multinomial, SMN)代理得到 Mult²-DPO,二层级时退化为 binary Mult-DPO;
- 在通用推荐与对话式推荐 benchmark 上,Mult-DPO 及其多层级扩展一致超越各类 DPO baseline。
预备知识与问题形式化¶
问题设定¶
令 $x$ 表示推荐 context(可含用户画像、交互历史或对话),$\mathcal{C}$ 表示 item 目录,每个 item $e$ 渲染成一段 token 序列 $y(e)=(y_1,\dots,y_{m_e})$。对偏好数据集 $\mathcal{D}$ 中的每个 context $x$,观测到形如 $(x,\mathcal{E}^p,\mathcal{E}^d)$ 的用户偏好,其中 $\mathcal{E}^p=\{e_1,\dots,e_k\}$ 与 $\mathcal{E}^d=\{e_{k+1},\dots,e_K\}$ 分别是与 $x$ 关联的正、负 item 集合(不相交)。$\mathcal{E}=\mathcal{E}^p\cup\mathcal{E}^d\subset\mathcal{C}$ 是全候选集,$k=|\mathcal{E}^p|$、$K-k=|\mathcal{E}^d|$。
用户偏好蕴含一个 set-wise ranking 约束:$\mathcal{E}^p$ 中每个正样本都应排在 $\mathcal{E}^d$ 中每个负样本之前:
$$\Omega_x := \{\, e \succ e' \mid e\in\mathcal{E}^p,\; e'\in\mathcal{E}^d \,\}, \tag{1}$$
但正样本内部、负样本内部不施加顺序。令 $\pi_\theta(e\mid x)$ 为 LLM-based RS 策略,给每个候选 $e$ 赋一个生成概率。目标是让 $\pi_\theta$ 对齐到 $\Omega_x$ 所刻画的 set-wise 偏好结构,充分利用多正/多负联合结构,同时保持推理时计算高效、可对整个目录 $\mathcal{C}$ 排序。
RLHF 与 DPO 回顾¶
对每个 context–item 对 $(x,e)$ 假设隐奖励 $r(x,e)\in\mathbb{R}$,定义关联权重 $w(e\mid x):=\exp(r(x,e))>0$。Bradley–Terry(BT)模型给出成对偏好概率:
$$P(e_p\succ e_d\mid x)=\sigma\big(r(x,e_p)-r(x,e_d)\big)=\frac{w(e_p\mid x)}{w(e_p\mid x)+w(e_d\mid x)}, \tag{2}$$
$\sigma(\cdot)$ 为 sigmoid。给定固定参考策略 $\pi_{\text{ref}}$ 与学到的奖励 $r(x,e)$,RLHF 目标为:
$$\max_{\pi(\cdot\mid x)}\ \mathbb{E}_{e\sim\pi(\cdot\mid x)}[r(x,e)]-\beta\,\mathrm{KL}\big(\pi(\cdot\mid x)\,\|\,\pi_{\text{ref}}(\cdot\mid x)\big), \tag{3}$$
$\beta>0$ 控制正则强度。DPO 观察到 (3) 有闭式解,从而奖励可由最优策略与参考策略表示:
$$r(x,e)=\beta\log\frac{\pi^*(e\mid x)}{\pi_{\text{ref}}(e\mid x)}+\beta\log Z(x), \tag{4}$$
其中 $Z(x)$ 为难处理的配分函数。由于 BT 似然 (2) 只依赖奖励差,代入后 $Z(x)$ 抵消,把 $\pi^*$ 换成可训练策略 $\pi_\theta$ 得到 DPO 目标:
$$\mathcal{L}_{\text{DPO}}(x,e_p,e_d)=-\log\sigma\!\left(\beta\log\frac{\pi_\theta(e_p\mid x)}{\pi_{\text{ref}}(e_p\mid x)}-\beta\log\frac{\pi_\theta(e_d\mid x)}{\pi_{\text{ref}}(e_d\mid x)}\right), \tag{5}$$
即把 RLHF 对齐化简为偏好数据上的分类式目标。
边缘化 Plackett–Luce DPO 目标(朴素扩展)¶
Vanilla DPO 受限于 BT 的成对结构,只能对齐两个候选。BT 到多候选的自然泛化是 Plackett–Luce(PL)模型:对候选集 $\mathcal{E}$ 的一个排列 $\tau$,PL 似然为序贯选择过程:
$$p_{\text{PL}}(\tau\mid x,\mathcal{E};w)=\prod_{t=1}^{|\mathcal{E}|}\frac{w(e_{\tau(t)}\mid x)}{\sum_{j=t}^{|\mathcal{E}|}w(e_{\tau(j)}\mid x)}, \tag{6}$$
即每一步按剩余候选中的权重比例采样下一个 item。要用 PL 建模 set-wise 偏好事件 $\Omega_x$,由于正/负内部顺序未知,必须在所有与观测一致的排列上边缘化。定义正集合、负集合、全集合的累积权重:
$$A:=\sum_{e\in\mathcal{E}^p}w(e\mid x),\quad B:=\sum_{e\in\mathcal{E}^d}w(e\mid x),\quad W:=A+B=\sum_{e\in\mathcal{E}}w(e\mid x). \tag{7}$$
设 $S_k$ 为正样本下标 $\{1,\dots,k\}$ 的全排列集合。边缘化 (6) 后得到 marginalized PL event model:
$$p_{\text{PL}}(\Omega_x\mid x,\mathcal{E};w)=\sum_{\rho\in S_k}\prod_{t=1}^{k}\frac{w(e_{\rho(t)}\mid x)}{B+\sum_{j=t}^{k}w(e_{\rho(j)}\mid x)}. \tag{8}$$
关键观察:对负样本排序的边缘化优雅地消失了,全部并入累积权重 $B$(附录 A.2 用 PL 在负集合后缀排序上归一化为 1 的 Lemma 证明)。附录 A.3 进一步用 PL 的「指数竞速(exponential-race)」表示给出一个 inclusion–exclusion 形式,把项数从 $k!$ 降到 $2^k$,但仍随 $k$ 指数增长。因此即使 $k$ 中等大小,直接把 (8) 当 DPO 目标优化也不可行——这正是 Mult-DPO 要解决的根本难处理性。
核心方法:Mult-DPO¶
多项式代理事件模型¶
为得到 marginalized PL event model 的一个有效且可处理的代理,作者在同一权重空间 $w(e\mid x)$ 上构造 multinomial(MN)代理。首先把权重归一化成候选上的类别分布:
$$p(e\mid x):=\frac{w(e\mid x)}{W},\quad e\in\mathcal{E}. \tag{9}$$
MN 代理把 set-wise 事件 $\Omega_x$ 定义为:在从 $p(\cdot\mid x)$ 独立抽 $k$ 次的过程中,每个正样本恰好出现一次,且不抽到任何负样本的概率。由于 $k$ 个正样本可以以任意先后顺序出现,有 $k!$ 个等价序列对应该事件,故 MN 代理似然为:
$$p_{\text{MN}}(\Omega_x\mid x,\mathcal{E};w)=k!\prod_{e\in\mathcal{E}^p}\frac{w(e\mid x)}{W}, \tag{10}$$
可在 $\mathcal{O}(k)$ 复杂度内计算。与 PL 不同,MN 构造不是排列上的分布:它是一个 IID 事件似然,会把概率质量分配给「有重复抽样、落在合法排序空间之外」的序列。作者用它作为观测正集合的可处理代理,并证明它是精确 marginalized PL 的下界,从而是一个保守代理:
Theorem 1. 对任意不相交集合 $\mathcal{E}^p,\mathcal{E}^d$($|\mathcal{E}^p|\ge1$)与任意正权重 $\{w(e\mid x)\}$, $$p_{\text{PL}}(\Omega_x\mid x,\mathcal{E};w)\ \ge\ p_{\text{MN}}(\Omega_x\mid x,\mathcal{E};w). \tag{11}$$
证明思路(附录 A.5):PL 在每个 rank $t$ 的分母 $B+\sum_{j=t}^{k}w(e_{\rho(j)}\mid x)\le W$,故每一项的逐点不等式 $\frac{w(e_{\rho(t)})}{B+\cdots}\ge\frac{w(e_{\rho(t)})}{W}$ 连乘并对 $\rho\in S_k$ 求和,即得 (11)。
进一步刻画 PL 与 MN 之比的紧致性:
Theorem 2. 对任意不相交 $\mathcal{E}^p,\mathcal{E}^d$($|\mathcal{E}^p|\ge1,|\mathcal{E}^d|\ge1$)与任意正权重, $$1\ \le\ \frac{p_{\text{PL}}(\Omega_x\mid x,\mathcal{E};w)}{p_{\text{MN}}(\Omega_x\mid x,\mathcal{E};w)}\ \le\ \left(1+\frac{A}{B}\right)^{k-1}. \tag{12}$$
证明(附录 A.6)固定 $\rho\in S_k$、定义正权重前缀和 $H_{t-1}(\rho)=\sum_{j=1}^{t-1}w(e_{\rho(j)})$,则 PL 在 rank $t$ 的分母为 $D_t(\rho)=W-H_{t-1}(\rho)$,逐 $\rho$ 之比 $\prod_{t=2}^{k}\frac{1}{1-H_{t-1}(\rho)/W}\le\big(\frac{W}{W-A}\big)^{k-1}=(1+A/B)^{k-1}$,因对所有 $\rho$ 一致成立故对 $S_k$ 求和后仍成立。当 $k=1$ 时上界精确,此时 MN 代理坍缩为 S-DPO 的类别似然——S-DPO 正是 Mult-DPO 在「单正样本 + 多负样本」下的特例。
Mult-DPO 对齐目标¶
MN 代理与 DPO 共用 RLHF 奖励–策略重参数化:由 (4) 知 $r(x,e)=\beta\log\frac{\pi^*(e\mid x)}{\pi_{\text{ref}}(e\mid x)}+\beta\log Z(x)$,而 $w(e\mid x)=\exp(r(x,e))$,把最优策略换成可训练 $\pi_\theta$ 得到 policy-induced weights:
$$w_{\pi_\theta}(e\mid x)\ \propto\ \left(\frac{\pi_\theta(e\mid x)}{\pi_{\text{ref}}(e\mid x)}\right)^{\beta}, \tag{13}$$
其中省略的比例常数 $Z_{\pi_\theta}(x)^\beta$ 在所有候选间共享、在 PL 与 MN 似然中均抵消。代入 MN 似然 (10) 并取负对数,得到 Mult-DPO 目标:
$$ \mathcal{L}_{\text{Mult-DPO}}(x,\mathcal{E}^p,\mathcal{E}^d) = -\beta\sum_{e\in\mathcal{E}^p}\log\frac{\pi_\theta(e\mid x)}{\pi_{\text{ref}}(e\mid x)} \;+\; k\log\sum_{e\in\mathcal{E}}\left(\frac{\pi_\theta(e\mid x)}{\pi_{\text{ref}}(e\mid x)}\right)^{\beta} \;+\; C, \tag{14} $$
$C$ 仅依赖 $k$、优化时可略。直观理解:第一项拉高所有正样本相对参考的对数概率比之和;第二项是一个 $\log\text{-}\sum\text{-}\exp$ 型配分项,把所有候选(含正负)联合压低——区别于 vanilla DPO 的成对对比,Mult-DPO 让每个正样本同时对抗整个候选集的累积权重,从而保留 set-wise 联合结构。
与边缘化 PL-DPO 的关系¶
定义 policy-induced 累积权重(类比 (7)):
$$A_{\pi_\theta}:=\sum_{e\in\mathcal{E}^p}w_{\pi_\theta}(e\mid x),\qquad B_{\pi_\theta}:=\sum_{e\in\mathcal{E}^d}w_{\pi_\theta}(e\mid x), \tag{15}$$
把 (13) 代入 (8)、取负对数得到「理想但难处理」的 PL-DPO 损失:
$$\mathcal{L}_{\text{PL-DPO}}(x,\mathcal{E}^p,\mathcal{E}^d):=-\log p_{\text{PL}}(\Omega_x\mid x,\mathcal{E};w_{\pi_\theta}). \tag{16}$$
Theorem 1、2 立即给出:
Corollary 1. 对每个 context $x$ 与每个训练样本 $(x,\mathcal{E}^p,\mathcal{E}^d)$, $$\mathcal{L}_{\text{PL-DPO}}(x,\mathcal{E}^p,\mathcal{E}^d)\ \le\ \mathcal{L}_{\text{Mult-DPO}}(x,\mathcal{E}^p,\mathcal{E}^d), \tag{17}$$ 且 $$0\ \le\ \mathcal{L}_{\text{Mult-DPO}}-\mathcal{L}_{\text{PL-DPO}}\ \le\ (k-1)\log\!\left(1+\frac{A_{\pi_\theta}}{B_{\pi_\theta}}\right). \tag{18}$$
这说明 Mult-DPO 损失是难处理的 marginalized PL-DPO 损失的一个可处理上界。更重要的是它揭示:对固定的 $k$-正样本集合与当前策略,增大负样本的非可忽略 policy-induced 权重 $B_{\pi_\theta}$ 会收紧最坏情况 gap——即当选更丰富 / 更难的负样本时,MN 代理对难处理的 marginalized PL-DPO 是更好的逼近。这为后文「动态难负样本采样」提供了理论依据。
Mult-DPO 的多层级扩展(Mult²-DPO)¶
前述假设二元偏好(隐式反馈)。实际中用户反馈常更细粒度(如显式评分),诱导出多层级偏好结构:候选 $\mathcal{E}$ 被划分为 $G\ge2$ 个有序偏好组:
$$\mathcal{E}=\bigcup_{g=1}^{G}\mathcal{E}^{(g)},\quad |\mathcal{E}^{(g)}|=k_g,\quad \sum_{g=1}^{G}k_g=K, \tag{19}$$
组号即偏好层级($g<h$ 则 $\mathcal{E}^{(g)}$ 中 item 应排在 $\mathcal{E}^{(h)}$ 之前,组内无序)。多层级偏好事件:
$$\Omega_x^{\text{grp}}:=\big\{\,e\succ e'\mid e\in\mathcal{E}^{(g)},\,e'\in\mathcal{E}^{(h)},\,1\le g<h\le G\,\big\}. \tag{20}$$
对每个边界 $g=1,\dots,G-1$ 定义组 $g$ 特定事件 $\Omega_x^{(g)}$(视 $\mathcal{E}^{(g)}$ 为正、$\bigcup_{h>g}\mathcal{E}^{(h)}$ 为负,与二元情形同构),并有 $\Omega_x^{\text{grp}}=\bigcap_{g=1}^{G-1}\Omega_x^{(g)}$;对应累积权重 $A_g=\sum_{e\in\mathcal{E}^{(g)}}w(e\mid x)$、$B_g=\sum_{h>g}\sum_{e\in\mathcal{E}^{(h)}}w(e\mid x)$、$W_g=A_g+B_g$。
由 PL 的序贯选择性质,高层级组放置完毕后 $\Omega_x^{(g)}$ 在 $g$ 上条件独立,marginalized PL 似然递归分解:
$$p_{\text{PL}}(\Omega_x^{\text{grp}}\mid x,\mathcal{E};w)=\prod_{g=1}^{G-1}p_{\text{PL}}\!\left(\Omega_x^{(g)}\,\Big|\,x,\bigcup_{h=g}^{G}\mathcal{E}^{(h)};w\right), \tag{21}$$
每个因子与第 3.1 节研究的 set-wise marginalized PL 似然同形。把二元 MN 代理逐组应用即得 sequential multinomial(SMN)代理:
$$p_{\text{SMN}}(\Omega_x^{\text{grp}}\mid x,\mathcal{E};w):=\prod_{g=1}^{G-1}\left(k_g!\prod_{e\in\mathcal{E}^{(g)}}\frac{w(e\mid x)}{W_g}\right). \tag{22}$$
代入 policy-induced 权重、取负对数得到 Mult²-DPO 目标:
$$ \mathcal{L}_{\text{Mult}^2\text{-DPO}} =\sum_{g=1}^{G-1}\left[-\beta\sum_{e\in\mathcal{E}^{(g)}}\log\frac{\pi_\theta(e\mid x)}{\pi_{\text{ref}}(e\mid x)} +k_g\log\sum_{h=g}^{G}\sum_{e\in\mathcal{E}^{(h)}}\left(\frac{\pi_\theta(e\mid x)}{\pi_{\text{ref}}(e\mid x)}\right)^{\beta}\right]+C', \tag{23} $$
$C'=-\sum_{g}\log k_g!$ 与 $\theta$ 无关、可略。当 $G=2$ 时 (23) 退化为二元 Mult-DPO (14)。同样有多层级版的上界(附录 A.9):
Corollary 2(多层级 loss-gap 上界). 对每个 context 与每个非空有序组的多层级偏好样本, $$0\ \le\ \mathcal{L}_{\text{Mult}^2\text{-DPO}}-\mathcal{L}_{\text{PL-DPO}}^{\text{grp}}\ \le\ \sum_{g=1}^{G-1}(k_g-1)\log\!\left(1+\frac{A_{\pi_\theta,g}}{B_{\pi_\theta,g}}\right). \tag{24}$$
复杂度分析¶
虽然 Mult-DPO 每步对齐比单正样本方法(vanilla DPO、S-DPO)涉及更多候选,但得益于共享 prompt 前缀允许 KV-cache 复用,每步复杂度可比。设 $N_x$ 为 prompt token 数、$N_i$ 为每个 item 的平均 token 数,每步自注意力代价为:
$$\mathcal{O}\big(N_x^2+c\,N_xN_i+c\,N_i^2\big), \tag{25}$$
其中 $c$ 为每步打分的候选数:vanilla DPO $c=2$、S-DPO $c=1+(K-k)$、Mult-DPO $c=K$。由于 RS 中 prompt 通常含用户上下文 / 特征 / 历史 / 对话,$K\ll N_x$,prompt 级自注意力项 $N_x^2$ 主导;实验中 Mult-DPO 的 wall-clock 与 vanilla DPO / S-DPO 相近。
实验设置¶
数据集。 通用推荐用 MovieLens-10M 与 Goodreads;对话式推荐用 Reddit-V2(改编自 He et al. 2023 / Zhu et al. 2026,把同一对话上不同 Reddit 用户的推荐合并为多个 ground truth)。MovieLens-10M 有显式评分,正集合取 rating=5、负样本从未评分 item 随机采样,并把不同评分作为不同偏好层级用于 Mult²-DPO(§4.5)。验证用 200 个采样负样本做高效模型选择,测试在全目录上报告。
指标。 NDCG@$K$,$K\in\{5,15,20\}$。
骨干。 Qwen2.5-0.5B-Instruct、Qwen2.5-3B-Instruct(主实验),并用 0.5B/1.5B/3B/7B 做 scaling 分析。
实现(附录 C.1)。 0.5B–1.5B 用 2×NVIDIA H100,3B–7B 用 2×NVIDIA B200;据数据集最大序列长度与候选数采用从纯数据并行到 ZeRO-2 的不同并行策略,并行策略在 baseline 间保持一致以公平对比;所有方法用 AdamW、学习率 $1\text{e-}6$;训练与推理始终复用同一 context 下 prompt 的 KV cache。
Baseline。 两类 LLM-based 推荐:(i) SFT-only——BIGRec(基于交互历史生成候选再 grounding 到目录)、D³(解码时去偏多样化);(ii) DPO 式对齐——Vanilla DPO、DMPO(BT 内对负样本对数比取算术平均)、S-DPO(softmax DPO,marginalized PL 的 $k=1$ 特例)、LiPO (BT)(listwise 学习排序,把所有正负对的成对 BT 损失逐步相加)。所有 DPO 式 baseline 共享同一参考骨干与训练协议。
主要实验结果¶
训练动态与超参分析¶
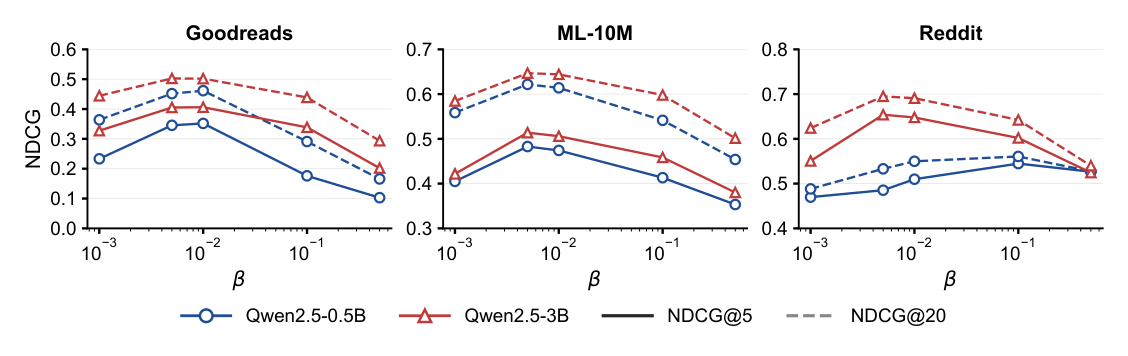
图 1 在验证集上扫 $\beta$(公式 (3) 的正则强度):$\beta$ 太小则 $\pi_\theta$ 偏离强 $\pi_{\text{ref}}$ 太远,太大则过度正则、侵蚀对齐信号。MovieLens-10M 与 Goodreads 的最优 $\beta$ 一致小于 Reddit-V2——可能因为对话式推荐中参考骨干提供了更强初始化(对话上下文可被语言理解利用),而通用推荐更依赖预训练 LLM 不具备的协同过滤信号。scaling 实验中固定 $\beta=0.005$。
与 baseline 的对比(RQ1)¶
下表为 Table 1:Goodreads / MovieLens-10M / Reddit-V2 测试集(全目录候选)上 Mult-DPO 与 DPO 式 baseline 的对比,大多数结果在 N@5、N@20 上的标准误为 0.0020–0.0035。粗体为该列最优。
Qwen2.5-0.5B-Instruct:
| Method | GR N@5 | GR N@15 | GR N@20 | ML N@5 | ML N@15 | ML N@20 | RD N@5 | RD N@15 | RD N@20 |
|---|---|---|---|---|---|---|---|---|---|
| zero-shot | 0.0085 | 0.0090 | 0.0090 | 0.0136 | 0.0156 | 0.0156 | 0.0175 | 0.0207 | 0.0216 |
| SFT:+BigRec | 0.0776 | 0.1069 | 0.1177 | 0.0657 | 0.0884 | 0.0962 | 0.1043 | 0.1056 | 0.1083 |
| SFT:+D³ | 0.0818 | 0.1122 | 0.1210 | 0.0612 | 0.0881 | 0.0948 | 0.1015 | 0.1037 | 0.1064 |
| DPO:+Vanilla DPO | 0.0389 | 0.0558 | 0.0622 | 0.0426 | 0.0710 | 0.0834 | 0.0816 | 0.0819 | 0.0838 |
| DPO:+DMPO | 0.0586 | 0.0805 | 0.0845 | 0.0461 | 0.0701 | 0.0758 | 0.0875 | 0.0893 | 0.0912 |
| DPO:+S-DPO | 0.0762 | 0.1105 | 0.1192 | 0.0592 | 0.0920 | 0.1049 | 0.0931 | 0.0938 | 0.0985 |
| DPO:+LiPO (BT) | 0.0862 | 0.1198 | 0.1294 | 0.0622 | 0.0980 | 0.1100 | 0.0963 | 0.1020 | 0.1060 |
| +Mult-DPO (ours) | 0.0947 | 0.1292 | 0.1406 | 0.0650 | 0.1001 | 0.1103 | 0.1097 | 0.1101 | 0.1154 |
Qwen2.5-3B-Instruct:
| Method | GR N@5 | GR N@15 | GR N@20 | ML N@5 | ML N@15 | ML N@20 | RD N@5 | RD N@15 | RD N@20 |
|---|---|---|---|---|---|---|---|---|---|
| zero-shot | 0.0149 | 0.0184 | 0.0184 | 0.0232 | 0.0340 | 0.0359 | 0.0633 | 0.0617 | 0.0641 |
| SFT:+BigRec | 0.1109 | 0.1527 | 0.1682 | 0.0747 | 0.1069 | 0.1180 | 0.1228 | 0.1247 | 0.1364 |
| SFT:+D³ | 0.1254 | 0.1531 | 0.1678 | 0.0710 | 0.1038 | 0.1159 | 0.1195 | 0.1214 | 0.1332 |
| DPO:+Vanilla DPO | 0.0870 | 0.1120 | 0.1202 | 0.0559 | 0.0806 | 0.0903 | 0.0915 | 0.0960 | 0.0998 |
| DPO:+DMPO | 0.0932 | 0.1200 | 0.1359 | 0.0562 | 0.0875 | 0.0938 | 0.0981 | 0.1009 | 0.1032 |
| DPO:+S-DPO | 0.1181 | 0.1586 | 0.1693 | 0.0631 | 0.0989 | 0.1122 | 0.1043 | 0.1132 | 0.1219 |
| DPO:+LiPO (BT) | 0.1252 | 0.1611 | 0.1731 | 0.0672 | 0.1046 | 0.1185 | 0.1147 | 0.1234 | 0.1329 |
| +Mult-DPO (ours) | 0.1288 | 0.1678 | 0.1785 | 0.0751 | 0.1155 | 0.1300 | 0.1369 | 0.1431 | 0.1503 |
结论分析。
- DMPO 用算术平均处理多负样本,但该平均落在 BT sigmoid 内是一个缺乏一致排序似然解释的 ad-hoc 构造,表现普遍偏弱。
- S-DPO 用 marginalized PL 的 $k=1$ 闭式 softmax 替代该平均,是对「单正多负」的有原则处理,故优于 DMPO。
- LiPO (BT) 进一步允许多正样本监督(逐对 BT 损失求和),但它把 set-wise 事件分解为独立成对 BT,丢弃了「正样本应联合压制负样本集」的约束——是最强的 DPO baseline。
- Mult-DPO 从根本上移除这种虚假独立:在 MN 代理下每个正样本对抗累积负权重 $B$,保留联合 set-wise 结构、且可证是 marginalized PL-DPO 的上界。它对 LiPO (BT) 的优势在 Reddit-V2(多正样本 ground truth 最密集)上最显著,并随骨干规模放大(3B 比 0.5B 提升更大),说明联合信号在策略有能力利用时收益最大。
- Mult-DPO 还超越 SFT 系的 BIGRec / D³(从同一 SFT 初始化出发),表明 set-wise 对齐提供了「示例匹配(demonstration matching)无法恢复」的监督。唯一例外是 0.5B 骨干上 MovieLens-10M N@5(Mult-DPO 0.0650 略低于 BigRec 0.0657),但在 N@15/N@20 上仍最优。
- 效率:相比最强 baseline LiPO (BT),Mult-DPO 因跨正样本共享 $B$,把损失聚合代价从 $\mathcal{O}((K-k)\cdot k)$ 降到 $\mathcal{O}(K)$。
MN-DPO 对 marginalized PL-DPO 的上界与紧致性(RQ2)¶
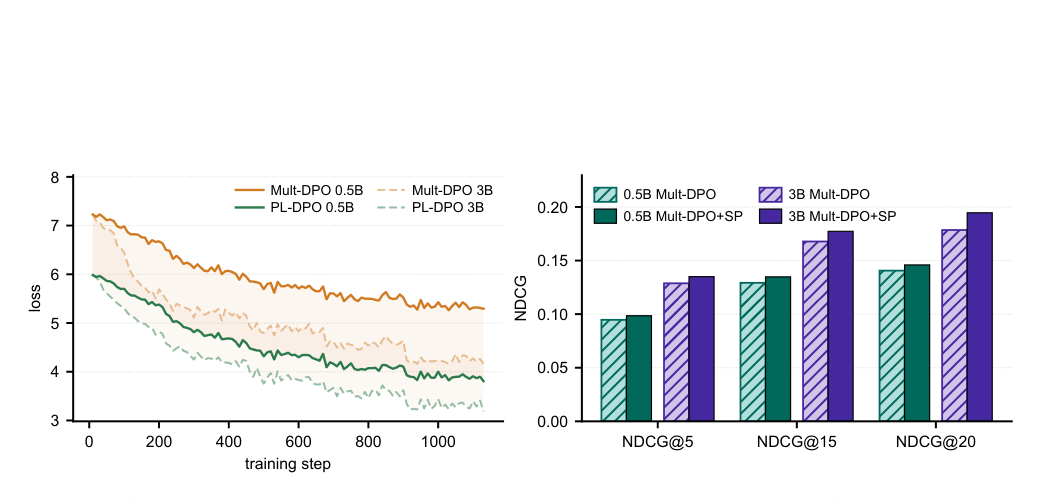
为验证 Corollary 1 的上界关系,作者把训练集限制到至多 3 个正样本的样本(此时精确 marginalized PL-DPO 损失可算)。图 2(左) 显示在该过滤子集上,Mult-DPO 损失与精确 marginalized PL-DPO 损失的训练动态验证了上界关系(前者始终在后者之上)。但该限制移除了大部分训练样本,使其 test-set 评估信息量不足。
为进一步检验「更难的负样本是否收紧上界并改善多正样本对齐」,作者引入动态负样本采样:由于负样本难度与策略相关、训练中变化,借鉴 SPRec 在 epoch 级重采样负样本——每个 epoch 开始时按当前策略权重诱导的温度缩放(温度 0.1)类别分布抽负样本。图 2(右) 显示引入更难负样本(Mult-DPO+SP)确实提升 Mult-DPO 的对齐能力,与 Corollary 1 关于「增大 $B_{\pi_\theta}$ 收紧 gap」的理论预测一致。
多层级偏好扩展(RQ3)¶
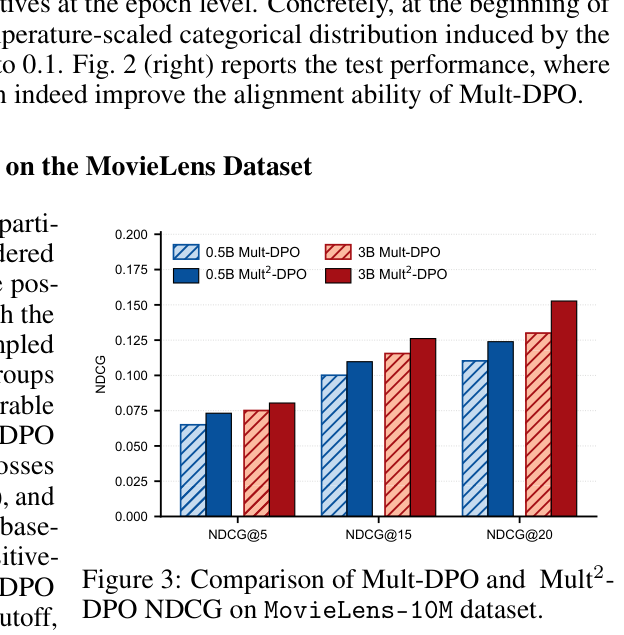
在 MovieLens-10M 上把 item 按评分划分为 $G=4$ 个有序偏好组(rating=5 为最高偏好组,即二元情形的正集合;随机采样的未评分 item 接在高评分组之后以保持候选集与二元设定可比)。Mult²-DPO 按 (23) 跨三个组边界聚合逐边界多项式损失,对比把四组合并为单一正负二分的 binary Mult-DPO baseline。图 3 显示 Mult²-DPO 在每个 cutoff 都优于二元版,0.5B 骨干上 NDCG@5 提升约 12%(0.0732 vs 0.0650),且改进可推广到 3B 骨干。这进一步证明 Mult²-DPO 通过保留显式评分更丰富的偏好结构提供了更强的对齐信号。
Scaling 分析(附录 C.3)¶
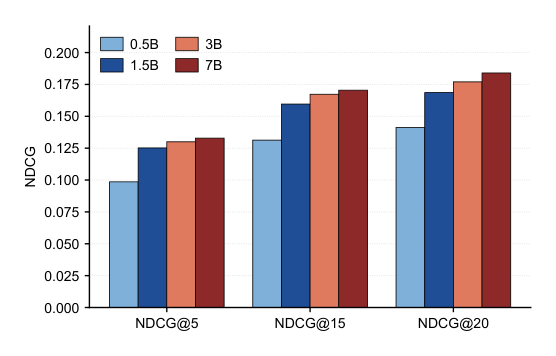
在 Goodreads 上用 Qwen2.5-{0.5B,1.5B,3B,7B} 训 Mult-DPO(复用 0.5B/3B 验证扫出的 $\beta=0.005$,避免在每个规模重跑昂贵的 $\beta$ 扫)。图 4 显示 NDCG 从 0.5B 到 1.5B 陡升、之后在 1.5B/3B/7B 间逐渐平缓(每次翻倍收益递减)。这表明 Mult-DPO 在中等规模已提取了大部分可用的 set-wise 信号,而 7B 上的持续改进确认 set-wise 对齐的收益可推广到大骨干。
讨论与局限性¶
核心贡献。 Mult-DPO 的关键 insight 是:用一个定义在同一奖励诱导权重空间、但不要求是排序分布的多项式代理事件,去替代难处理的 marginalized PL 似然——这一「放松到非排序的 IID 事件」换来了闭式 DPO 风格目标,且代价(与精确 PL 的 gap)被两条定理严格控制并以 $A/B$ 比刻画其紧致性。这把「set-wise / 多正样本偏好对齐」从一个组合难题,化简为与 vanilla DPO 同量级的分类式优化,并优雅地推广到多偏好层级(Mult²-DPO,SMN 代理递归分解)。理论与方法的优雅性是本文最大的亮点,值得借鉴的设计是「用可处理的代理似然 + 可证上界」来对齐 listwise/set-wise 结构。
值得借鉴的设计。
- 「共享 prompt 前缀 → KV-cache 复用」使每步对 $K$ 个候选打分的复杂度由 prompt 项主导,从而 set-wise 对齐几乎不增加 wall-clock,这是把多候选监督落到 LLM-based RS 的关键工程点。
- 「收紧上界 ⇔ 选更难负样本」的理论联系,直接落地为 SPRec 式动态难负样本采样并验证有效——理论分析对实践有指导意义。
局限与争议(部分作者已在附录 D 自陈)。
- MN 构造是代理事件似然、而非归一化排序分布,因此可能不是唯一或最紧的代理;目标对同层级正样本用均匀 target,最适合「正样本可交换」的设定,当正样本相关性差异大时,rating-aware 分组或加权变体可能更优。作者指出 EM(引入未观测排序的隐分配变量)或变分下界是值得探索的替代路线。
- 无任何线上 / 工业 A/B 实验:尽管有 4 位 Netflix 作者,全部实验都是离线公开数据集(Goodreads / MovieLens-10M / Reddit-V2),缺少部署收益证据;这与 score_reason 中「理论扎实但无线上实验」的判断一致。
- 绝对指标提升温和,且 RQ2 的紧致性验证只能在「至多 3 个正样本」的过滤子集上做,作者自承其 test-set 评估信息量不足——上界的实证检验偏弱。
- 方法本质是一个训练目标,对 LLM 骨干无架构侵入,参数量 scaling 时表征与序列建模能力随骨干一起增长(图 4 验证到 7B),无明显方法论扩展瓶颈——这是相对许多「先压缩再建模」两阶段方案的优势。
适用范围。 作者(附录 E)指出 Mult-DPO 适用于任何「存在一组偏好回复、回复间无可靠内部顺序」的 set-wise 偏好场景,包括信息检索 / 搜索排序(多个相关文档)、开放域 QA(多个可接受答案)、代码生成(多个正确程序),不限于推荐。
评分(reading_score = 8): 理论新颖且严谨(多项式代理是难处理 marginalized PL-DPO 的可证上界,并刻画紧致性,干净地推广到多层级),DPO baseline 对比充分(3 数据集 × 4 骨干),方法对骨干 scaling 友好;但离线评估、无线上 A/B、绝对增益温和、RQ2 紧致性验证受限使其止步于「扎实工作」上沿而非开创性。