LeAP:面向异构稀疏推荐系统的可学习自适应置换特征选择¶
Bilibili Inc.(上海),arXiv:2606.01111v2,2026-05-31。 一句话定位:把传统"逐特征随机置换 + 重复前向"的 Permutation Feature Importance 重构成单次前向内的可学习门控($O(1)$ 复杂度),并用"置换散度"驱动的自适应正则解决异构维度与极端稀疏下特征重要性评估的尺度不公平问题,已在十亿日请求、2TB 规模的工业搜索排序模型上部署,无损剪掉 30%(3600+)冗余维度。
1. 研究动机与背景¶
1.1 工业推荐的特征空间:异构 + 稀疏¶
现代工业搜索/广告/推荐系统的预测精度高度依赖大规模特征工程。生产模型通常要处理数千个特征字段(feature fields),且这些特征呈现两个棘手的结构性特点:
- 维度异构(dimensional heterogeneity):特征维度跨度极大——从 1 维连续标量(实时统计、数值特征)到几十~几百维的向量(用户行为序列 embedding、MLP 压缩的隐表征)。论文中举例 $d_i = 1$(标量统计特征)vs $d_i = 256$(聚合行为序列特征)。
- 极端稀疏(extreme sparsity):稀疏特征在绝大多数样本(>99%)上停留在默认值。
这种复杂度把工业模型规模推到 TB 级,训练与在线 serving 的算力/存储成本极高。因此特征选择(Feature Selection, FS)——剔除过时、冗余信息——成为模型优化的关键一环。
1.2 现有方法的三大瓶颈¶
论文指出现有 FS 方法在工业复杂场景下遭遇三个核心痛点:
-
对异构维度无感(oblivious to dimensional discrepancy):现有方法常假设特征维度同质,或强行把所有特征映射到统一维度空间。这既扭曲了原始信息密度,也使得"在同一把尺子下公平评估 1D 特征 vs 256D 特征的真实贡献"变得极其困难。
-
对稀疏特征极不友好:由于稀疏特征大部分时间停留在默认值,现有选择机制常把它们的"低激活频率"误读为"无用噪声",从而重罚或丢弃,严重损害长尾个性化信号的表达。
-
传统置换法计算上不可行:基于 Permutation Feature Importance(PFI)的方法虽然可解释性强、模型无关,但需要逐特征顺序 shuffle 并重新前向。对于上千特征的超大规模模型,这种"一次只动一个变量"的范式带来不可承受的算力灾难($O(N)$ 次完整前向),完全无法嵌入处理十亿级请求的工业模型日常迭代。
1.3 本文方案概览¶
针对上述困境,作者提出 LeAP(Learnable Adaptive Permutation),一个模型无关(model-agnostic)、即插即用的特征选择模块,核心突破有两点:
-
把离散且昂贵的置换评估,改造成端到端可学习机制:在模型训练的单次前向中,用一个动态门控网络学习"原始特征"与"其 batch-wise 置换噪声对应物"之间的融合权重。这彻底绕过了传统置换法重复推理的性能瓶颈,把复杂度从 $O(N \times \text{model overhead})$ 降到 $O(1 \times \text{model overhead})$,可轻松嵌入处理数百亿样本的日常训练流水线。
-
基于置换散度(Permutation Divergence)的自适应正则:实时计算每个特征"原始 vs 置换"的 $L_2$ 范数差异,并用指数滑动平均(EMA)构造稳定的统计界,作为该特征门控权重的自适应基础惩罚。这一机制带来两个优雅性质:
- 维度自适应:128D/256D 宽特征置换前后的空间距离天然大于 1D 标量,LeAP 自适应地对高维特征施加更强惩罚,从根本上抵消它们在统一正则下"藏匿"的不公平优势;
- 稀疏感知:对 99% 实例都是默认值的极稀疏特征,置换基本是"默认值换默认值",$L_2$ 差异极小,惩罚力度随之收缩——确立了一个关键准则:不应仅因特征稀疏就重罚它,只有当它对预测目标确实无用时才剪除。
得益于这一自适应惩罚,LeAP 不仅输出可解释的特征重要性得分(反映模型对信息损失的敏感度),还会驱动门控权重自然极化(polarize)到 0/1,使冗余特征可通过简单阈值直接剪枝,无需先前方法那种资源密集的重训练,可直接上线 serving、只需极小微调。
1.4 论文主要贡献¶
- 工程架构创新:提出 LeAP,一个模型无关的特征选择插件,把低效、离散的置换评估过程重构为 $O(1)$ 的端到端可学习机制。
- 算法理论突破:设计基于置换散度的自适应正则,数学上克服异构维度(1D vs 256D)与极端稀疏带来的评估偏差,实现真正公平的特征选择。
- 重大工业落地收益:在 2TB 规模、十亿级日请求的真实搜索模型上剪掉 30%+ 特征维度且业务指标零损失(Zero Diff),提供了超大规模推荐系统特征剪枝的高价值实践范式。
代码开源:https://github.com/goldenNormal/LeAP
2. 相关工作¶
2.1 可微 Mask-based 特征选择¶
近期 FS 范式转向可微 mask-based 方法(AutoField、LPFS、SFS 等),把可学习门控直接集成进模型架构。例如 AutoField 用 Gumbel-Softmax 做特征门控,LPFS 用平滑的 $L_0$ 正则。
但这类方法在标准 benchmark 上虽成功,却隐含同质特征空间假设(如假设所有字段都嵌入到同一维度 $D$)。当应用到异构工业输入层(稠密 1D 标量与稀疏高维 embedding 拼接)时,它们通常施加统一的正则尺度。后果是:高维表征产生不成比例的更大梯度和方差,相对 1D 标量被放大;这导致有偏的优化过程——关键的低维信号被重罚并过早剪除。
另一路维度选择(Dimension Selection, DS)(AutoDim、DimReg、i-razor 等)尝试给不同字段分配不同维度,但通常需要先把所有字段初始化到一个统一的 "super-net" embedding 空间再剪枝。把原生 1D 统计特征强塞进高维空间会引入参数冗余和信息稀释。LeAP 的差异:直接作用于原生异构拼接层,不扭曲原始特征表征,保证均衡的重要性评估。
2.2 Permutation-based 特征重要性¶
另一主流范式通过置换(Permutation)评估特征重要性:测量某特征被随机噪声替换后预测退化的程度,提供模型无关评估和清晰可解释性。
但在工业场景应用置换法有两个致命局限:
- 巨大计算开销:标准 Permutation 及其 Taylor 近似变体(如 SHARK)需要 $O(N)$ 次重复推理和迭代式的 "train-prune-train" 循环。
- 对极端稀疏特征天然有偏:对 >99% 实例为默认值的特征,shuffle 主要是"默认值换默认值",观测到的性能下降极小,导致标准置换法低估这些特征的真实重要性,误剪关键长尾信号。
LeAP 作为统一插件模块:协同了可微 mask-based 方法的 $O(1)$ 效率与置换法的可解释性——把标准离散置换评估转为可学习的置换散度机制,规避两套范式各自的陷阱,对现有模型架构改动极小。
3. 方法¶
LeAP 模块整体架构如下图。下文先介绍把传统离散置换转为端到端可学习门控的机制(§3.1),再阐述核心创新——基于置换散度的自适应正则(§3.2),随后给出门控极化的理论分析(§3.3)与实际部署范式(§3.4)。
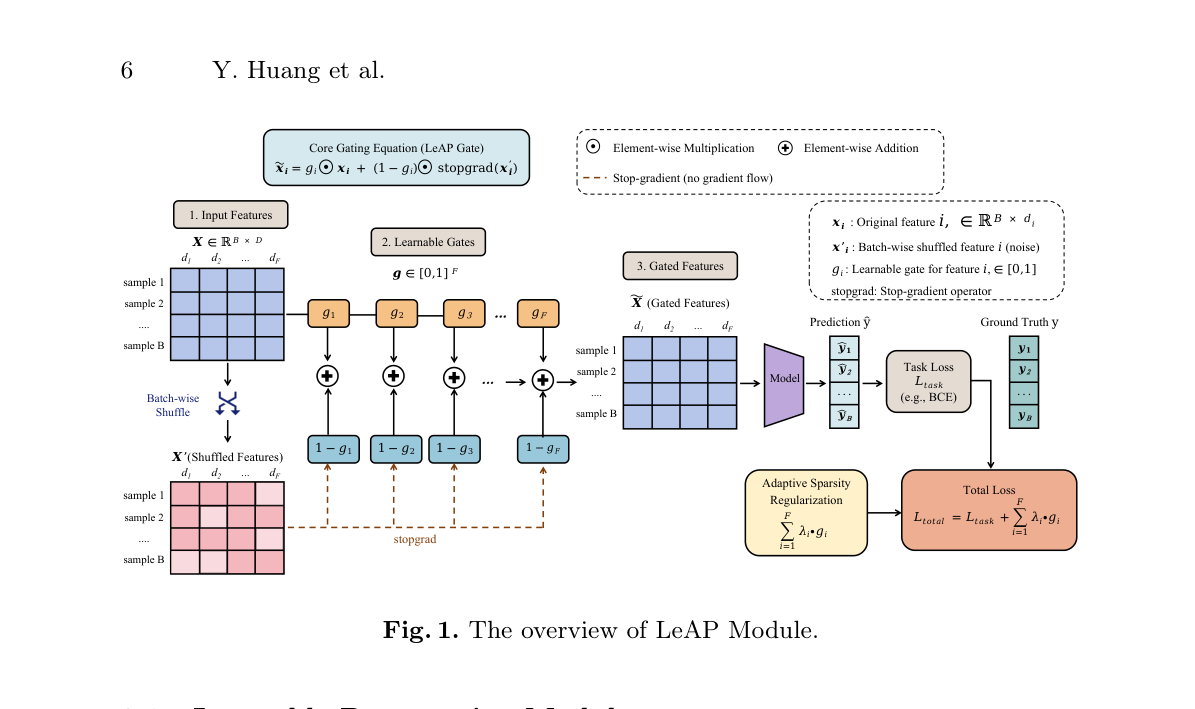
图中数据流:输入特征矩阵 $\mathbf{X}\in\mathbb{R}^{B\times D}$ 经 batch-wise shuffle 得到噪声版 $\mathbf{X}'$;每个特征 $i$ 有一个可学习门控 $g_i$,融合特征为 $g_i\odot\mathbf{x}_i + (1-g_i)\odot\text{stopgrad}(\mathbf{x}'_i)$;门控后的特征 $\widetilde{\mathbf{X}}$ 喂给主模型得到预测 $\hat{y}$,算任务损失 $\mathcal{L}_{task}$;同时自适应稀疏正则项 $\sum_i\lambda_i g_i$ 与任务损失相加构成总损失。
3.1 可学习置换模块(Learnable Permutation Module)¶
设模型输入由 $F$ 个特征字段组成,第 $i$ 个特征表示为 $\mathbf{x}_i\in\mathbb{R}^{d_i}$,其中 $d_i$ 跨度极大(标量统计特征 $d_i=1$,用户行为序列特征 $d_i=256$)。
Batch-wise 可学习置换:在每个训练步,给定 batch 大小 $B$,先沿 batch 维度 shuffle 第 $i$ 个特征 $\mathbf{x}_i$,得到其噪声对应物 $\mathbf{x}'_i$。这个 shuffle 操作不仅打破了"特征 ↔ 目标标签"的相关性,还完美保留了特征原始的边缘分布和稀疏模式(同一列内重排,分布不变)。其实现见 Algorithm 1。
Algorithm 1:Batch Shuffling
Input: X ∈ R^{B×D}:batch 内输入张量,D = Σ d_i
F = {(s_1,e_1), ..., (s_F,e_F)}:各特征的维度区间
Output: X' ∈ R^{B×D}:shuffle 后张量
1 X' ← 0^{B×D} // 初始化输出张量
2 for (s_i, e_i) ∈ F do
3 π_i ← RandomPermutation(B) // 对该特征生成一个 batch 维随机排列
4 X'[:, s_i:e_i] ← X[π_i, s_i:e_i] // 按排列重排该特征列块
5 end
6 return X'
关键点:每个特征用独立的随机排列 $\pi_i$,因此不同特征间的联合相关性被打散,但每个特征自身的取值集合(含默认值比例)原封不动。
可学习门控:引入特征专属的可学习门控变量 $g_i\in(0,1)$ 控制原始特征与 shuffle 特征之间的信息融合。为保证端到端可微,用温度缩放的 Sigmoid 参数化:
$$ g_i = \sigma\!\left(\frac{\theta_i}{\tau}\right) = \frac{1}{1+\exp(-\theta_i/\tau)} \tag{1} $$
其中 $\theta_i\in\mathbb{R}$ 是绑定到第 $i$ 个特征的可学习参数,$\tau$ 是控制平滑度的温度超参。
融合输出:融合特征 $\tilde{\mathbf{x}}_i$ 是原始特征 $\mathbf{x}_i$ 与 shuffle 特征 $\mathbf{x}'_i$ 的凸组合。为确保梯度只更新门控权重、不通过噪声扰乱上游层,对 shuffle 特征施加 stop-gradient 算子 $\text{sg}(\cdot)$:
$$ \tilde{\mathbf{x}}_i = g_i\cdot\mathbf{x}_i + (1-g_i)\cdot\text{sg}(\mathbf{x}'_i) \tag{2} $$
物理解读:$g_i$ 直观反映模型对原始特征的依赖程度。当 $g_i\to 1$,模型完全利用真实特征;当 $g_i\to 0$,模型转而依赖置换后的纯噪声。若某特征冗余,用噪声替换它不会降低预测性能,门控会自然收敛到 0。
3.2 基于置换散度的自适应正则(Adaptive Regularization via Permutation Divergence)¶
标准门控 FS 方法(LPFS、SFS 等)通常对所有门控变量施加统一惩罚(如 $\lambda\sum g_i$)来鼓励稀疏。但直接用于异构稀疏特征层时,统一惩罚会带来严重的评估不公:
- 高维特征因参数体量大,天然产生比 1D 特征更大的梯度波动;
- 极稀疏特征(几乎全零)产生弱梯度,在统一正则下极易被误剪。
LeAP 的创新是抛弃静态统一惩罚,提出数据感知的自适应正则——核心论点是:对一个特征的惩罚强度不应取决于它预设的维度,而应取决于"置换它所引起的信息扰动幅度"。
置换散度:在每个 mini-batch 内,计算原始特征 $\mathbf{x}_i$ 与其 shuffle 版本 $\mathbf{x}'_i$ 的 $L_2$ 范数差异:
$$ \Delta_i = \frac{1}{B}\sum_{b=1}^{B}\left\|\mathbf{x}_i^{(b)} - \mathbf{x}_i'^{(b)}\right\|_2 \tag{3} $$
EMA 平滑:为缓解跨 batch 的数据方差、建立稳定统计界,用指数滑动平均贯穿训练过程平滑该散度:
$$ \bar{\Delta}_i^{(t)} = \beta\cdot\bar{\Delta}_i^{(t-1)} + (1-\beta)\cdot\Delta_i^{(t)} \tag{4} $$
其中 $\beta\in[0,1)$ 是动量系数,$t$ 表示训练步。此外,为识别常量特征,对 $\bar{\Delta}_i$ 施加适当裁剪(clipping)。
自适应正则权重:基于稳定的置换散度,定义特征 $i$ 的自适应正则权重:
$$ \lambda_i = \alpha\cdot\bar{\Delta}_i \tag{5} $$
其中 $\alpha$ 是控制整体特征稀疏度的全局超参。
总损失:端到端优化目标(总损失)= 任务损失 + 自适应正则项:
$$ \mathcal{L}_{total} = \mathcal{L}_{task} + \sum_{i=1}^{F}\lambda_i\cdot g_i \tag{6} $$
这一极简数学设计同时解决两个工业痛点:
-
内在维度归一化:shuffle 后的 128D embedding 的 $L_2$ 散度 $\bar{\Delta}_i$ 本质上远大于 1D 标量,于是高维特征自动承担更大惩罚 $\lambda_i$。这种自适应重加权从根本上抵消了高维空间中无效参数"逃避惩罚"的倾向,确保不同维度间的公平竞争。
-
对稀疏的完美容忍:对 99% 实例为默认值的极稀疏特征,shuffle 高概率是"默认值换默认值",此时 $L_2$ 散度 $\Delta_i\to 0$,正则惩罚 $\lambda_i$ 可忽略。这保证稀疏特征不会仅因"出现频率低"被误剪——只有当它们对任务损失 $\mathcal{L}_{task}$ 确实毫无贡献时,才会被逐渐淘汰。
3.3 理论分析:门控为何会极化¶
现有门控方法(AutoField、SFS 等)常产生模糊的特征重要性分数。LeAP 的核心优势是能驱动门控分数自然极化到 0 或 1。论文从梯度解耦和凸优化两个视角给出理论依据。
1. 梯度解耦与尺度对齐:回顾融合式 $\tilde{\mathbf{x}}_i = g_i\cdot\mathbf{x}_i + (1-g_i)\cdot\mathbf{x}'_i$。期望任务损失 $J(g_i) = \mathbb{E}[\mathcal{L}_{task}]$ 关于门控 $g_i$ 的梯度,可用链式法则解耦:
$$ \frac{\partial J(g_i)}{\partial g_i} = \mathbb{E}\!\left[\underbrace{\left(\frac{\partial \mathcal{L}_{task}}{\partial \tilde{\mathbf{x}}_i}\right)^{\!T}}_{\text{敏感度 } \mathbf{S}_i}\cdot\underbrace{(\mathbf{x}_i - \mathbf{x}'_i)}_{\text{置换散度}}\right] \tag{7} $$
这表明任务梯度的幅度天然正比于置换散度 $\|\mathbf{x}_i-\mathbf{x}'_i\|_2$。因此把自适应惩罚设为 $\lambda_i = \alpha\cdot\Delta_i$,LeAP 在数学上实现了正则项与任务梯度之间的有效尺度对齐,从而消除高维与极稀疏特征在统一惩罚下遭遇的评估偏差。
2. 极化门控保证(Polarized Gate Guarantee):基于对齐后的总目标 $\mathcal{J}_{total}(g_i) = J(g_i) + \lambda_i g_i$,总梯度为 $\frac{\partial\mathcal{J}_{total}}{\partial g_i} = \frac{\partial J(g_i)}{\partial g_i} + \lambda_i$。
定理 1. 假设期望任务损失 $J(g_i)$ 是凸的。令 $\Delta J = J(0) - J(1)$ 表示 shuffle 该特征后的损失增量(即信号强度)。若 $\Delta J > \lambda_i$,则总梯度为负,门控 $g_i$ 被驱向 1。
证明:由凸函数一阶性质,函数曲线位于连接端点的弦下方,即 $J(g_i)\le g_i J(1) + (1-g_i)J(0)$。重排该不等式并对 $g_i$ 求偏导,得到任务梯度的上界:
$$ \frac{\partial J(g_i)}{\partial g_i}\le J(1) - J(0) = -\Delta J \tag{8} $$
代入总梯度:
$$ \frac{\partial\mathcal{J}_{total}}{\partial g_i}\le -\Delta J + \lambda_i \tag{9} $$
给定有效特征的信号强度满足 $\Delta J > \lambda_i$,则 $\frac{\partial\mathcal{J}_{total}}{\partial g_i} < 0$。优化器会持续增大 $g_i$ 直到触及上界 1。∎
推论. 反之,若特征冗余,shuffle 它不影响预测,$\Delta J\approx 0$。此时总梯度退化为 $\approx\lambda_i > 0$,正则项主导优化,迅速把门控 $g_i$ 压向 0。
由此,有用特征极化到 1、冗余特征极化到 0,门控自然形成强可区分性,支持后续简单阈值硬剪枝。
3.4 工业系统的实际部署¶
为满足大规模工业推荐严苛的迭代与延迟要求,LeAP 采用高度解耦的插件部署范式,流水线分三步:
-
插入与评估(Plug-in & Evaluation):抽取在线模型,在特征拼接层之后立即插入 LeAP 模块。模型在在线数据流上正常迭代,累积 EMA 统计并更新门控变量。
-
阈值硬剪枝(Hard Pruning via Thresholding):得益于极化性质,收敛后的门控 $g_i$ 高度可区分。评估阶段结束后,可用两种策略直接剪枝:
- 绝对阈值:设固定阈值(如 $\tau=0.5$),直接丢弃所有 $g_i<\tau$ 的特征;
-
比例排序:当面临严格的系统带宽缩减约束时,按 $g_i$ 降序排序,只保留 Top-$K$ 比例。
-
微调与上线(Fine-tuning & Serving):移除冗余特征及 LeAP 模块本身后,模型只需在一小部分训练数据上微调至收敛即可上线。
4. 实验¶
论文围绕三个核心研究问题展开:
- RQ1(基础有效性):在同质维度的公开数据集上,LeAP 的基础机制能否超越现有 SOTA 特征选择方法?
- RQ2(机制极化):LeAP 是否如理论所证,生成高度极化、具清晰物理解释的门控分数?
- RQ3(工业部署与消融):在极端维度异构 + 稀疏的真实工业场景下,LeAP 的投资回报率(ROI)如何?
4.1 实验设置¶
公开数据集:四个推荐系统广泛采用的 benchmark(来自 ERASE benchmark),其特征维度已被统一为同质尺寸:
Table 1. 数据集统计
| Dataset | Avazu | Criteo | ML-1M | AliCCP |
|---|---|---|---|---|
| Samples | 40,428,967 | 45,850,617 | 1,000,209 | 85,316,519 |
| Label | Click | Click | Rating (1-5) | Click |
| Fields | 23 | 39 | 9 | 23 |
工业数据集:采集自某十亿日请求的长视频平台真实搜索、曝光、点击与交互日志。模型纳入 500+ 个验证过的特征字段,拼接表征超过 12,000 维。维度跨度极大(1D 统计特征到 256D 聚合行为序列 embedding),且包含大量极稀疏特征。
Baseline(7 个代表性 FS 方法,三类):
- 启发式:Lasso、Random Forest(RF)、XGBoost;
- Mask-based:AutoField、LPFS、SFS;
- Permutation-based:SHARK(业界公认的高效置换变体)。
由于公开数据集是同质维度,§4.2 部署的是 LeAP 的 base 版本(不含自适应正则),以纯粹验证其原生可学习置换机制的优越性。
评估指标:公开数据集用 AUC 及跨数据集聚合指标 Normalized AUC($S_{\text{AUC}}$):
$$ S_{\text{AUC}}(A) = \frac{1}{|\Gamma|}\sum_{\mathcal{D}\in\Gamma}\frac{\text{AUC}(A,\mathcal{D})}{\max_{A'\in\mathcal{A}}\text{AUC}(A',\mathcal{D})} \tag{10} $$
即对每个数据集,把方法 $A$ 的 AUC 归一化到该数据集上所有方法的最佳 AUC,再跨数据集平均。工业场景离线用 Group AUC(GAUC)反映核心预测能力;在线做严格 A/B 测试观察核心业务指标(视频播放量、互动、观看时长)。
4.2 公开数据集离线评测(RQ1)¶
遵循 ERASE 标准的 "Search-Retrain" 两阶段评测协议,所有方法用 WideDeep 作骨干网络。Table 2 给出在目标特征保留率(Feature Retention, FR)50% 和 25% 下的重训练性能。
Table 2. 特征选择与重训练 AUC 结果(每列最优加粗;ML-1M 上所有 top 方法收敛到相同特征子集,故重训练 AUC 相同)
| Ratio (FR) | Method | Criteo | Avazu | AliCCP | ML-1M | $S_{\text{AUC}}$ |
|---|---|---|---|---|---|---|
| 50% | No_Select | 0.8014 | 0.7882 | 0.6598 | 0.7950 | 0.9954 |
| Lasso | 0.7462 | 0.7088 | 0.6054 | 0.6484 | 0.8872 | |
| XGBoost | 0.7682 | 0.7412 | 0.6499 | 0.8097 | 0.9710 | |
| RF | 0.7921 | 0.7869 | 0.6549 | 0.7924 | 0.9895 | |
| SHARK | 0.7974 | 0.7870 | 0.6582 | 0.8097 | 0.9977 | |
| LPFS | 0.7944 | 0.7728 | 0.6554 | 0.8097 | 0.9913 | |
| SFS | 0.7969 | 0.7827 | 0.6579 | 0.7946 | 0.9915 | |
| AutoField | 0.7974 | 0.7869 | 0.6567 | 0.8077 | 0.9965 | |
| LeAP (Ours) | 0.7984 | 0.7870 | 0.6583 | 0.8097 | 0.9981 | |
| 25% | No_Select | 0.8014 | 0.7882 | 0.6598 | 0.7950 | 0.9960 |
| Lasso | 0.7003 | 0.6016 | 0.5804 | 0.5286 | 0.7928 | |
| XGBoost | 0.7157 | 0.7091 | 0.5869 | 0.7338 | 0.8977 | |
| RF | 0.7626 | 0.7637 | 0.6032 | 0.6946 | 0.9237 | |
| SHARK | 0.7717 | 0.7723 | 0.6461 | 0.8078 | 0.9805 | |
| LPFS | 0.7609 | 0.7714 | 0.6423 | 0.8078 | 0.9754 | |
| SFS | 0.7569 | 0.7685 | 0.6452 | 0.8078 | 0.9733 | |
| AutoField | 0.7738 | 0.7692 | 0.6485 | 0.8068 | 0.9808 | |
| LeAP (Ours) | 0.7841 | 0.7723 | 0.6489 | 0.8078 | 0.9854 |
结果分析:
-
总体领先:在 50% 和 25% 两种压缩率下,LeAP 都取得最高 $S_{\text{AUC}}$(0.9981 / 0.9854),验证其特征选择的有效性。值得注意的是,在更激进的 25% 压缩下,LeAP 相对次优方法的 $S_{\text{AUC}}$ 领先幅度更大(0.9854 vs SHARK 0.9805 / AutoField 0.9808),说明高压缩时其优势更显著。
-
破除"权重=重要性"假设(vs Mask-based):AutoField、LPFS 等依赖"门控权重小 ⟹ 特征不重要"的假设。但在深度非线性网络中,小权重特征也可能触发显著的"蝴蝶效应"。LeAP 抛弃权重幅度,转而度量对信息损失的敏感度,因此在复杂的 Criteo、AliCCP 上以明显优势超越所有 mask-based 方法(如 Criteo 50%:0.7984 vs AutoField 0.7974;AliCCP 50%:0.6583 vs AutoField 0.6567)。
-
联合优化 vs 贪心搜索(vs Permutation):LeAP 与 SHARK 同为敏感度驱动方法,但 LeAP 略优。原因是 SHARK 采用贪心的逐一特征剔除策略,常忽略特征耦合效应;而 LeAP 在单次前向中联合优化所有门控,能捕捉全局特征重要性。
注:表中 No_Select(全特征)虽然在某些数据集上 AUC 最高(如 Criteo 0.8014),但其 $S_{\text{AUC}}$ 并非最高,因为 $S_{\text{AUC}}$ 是按各数据集 max 归一化后跨集平均——LeAP 在多个数据集上同时贴近各自最优,故综合分最高。这正是 FS 的价值:用一半甚至 1/4 特征逼近全特征性能。
4.3 机制分析:极化(RQ2)¶
为验证理论预言的"门控极化"是否真实反映特征预测效用,作者在 MovieLens-1M 上做了逐步验证。根据收敛门控 $g_i$ 把特征分为"保留区"($g_i>0.5$)和"抑制区"($g_i\approx 0$)。验证分两阶段:先从保留区逐步加特征看性能增益(Step 1-3),再把抑制区特征逐个单独加入峰值模型看冗余度(Step 4-9)。
Table 3. LeAP 特征重要性的逐步验证(MovieLens-1M)
| Step | Feature Set | Gate Score | Val AUC | Δ AUC | Utility Analysis |
|---|---|---|---|---|---|
| Part 1:用保留区特征构建(高门控 > 0.5) | |||||
| 1 | [Title] | 0.995 | 0.7336 | – | 强预测信号 |
| 2 | + User_ID | 0.941 | 0.8073 | +0.0737 | 强预测信号 |
| 3 | + Genres (Peak Model) | 0.757 | 0.8105 | +0.0032 | 弱信号保留 |
| Part 2:验证抑制区特征(Base = 峰值模型 + 单个抑制特征) | |||||
| 4 | + Movie_ID | ≈0.0 | 0.8099 | -0.0006 | 条件冗余 |
| 5 | + Zip | ≈0.0 | 0.8105 | 0.0000 | 无显著影响 |
| 6 | + Age | ≈0.0 | 0.8106 | +0.0001 | 无显著影响 |
| 7 | + Occupation | ≈0.0 | 0.8106 | +0.0001 | 无显著影响 |
| 8 | + Gender | ≈0.0 | 0.8107 | +0.0002 | 无显著影响 |
| 9 | + Timestamp | ≈0.0 | 0.7938 | -0.0167 | 有害噪声 |
结果分析:
- 弱信号保留:Genres 的门控分(0.757)虽低于主特征,但加入后仍把 AUC 提升 0.0032。说明 LeAP 能识别并保留对泛化有益的弱信号,而非简单滤掉低权重特征。
- 过滤条件冗余:Movie_ID 单独使用时有信息量,但在已知 Title 的情况下引入它反而略微降低性能(-0.0006)。LeAP 给它接近 0 的门控分,准确捕捉了 Title 与 Movie_ID 之间的共线性/冗余。
- 抑制噪声:Step 5-8 的特征对性能贡献微乎其微,保留它们只会徒增模型规模。尤其引入 Timestamp 导致 AUC 显著下跌(-0.0167)——LeAP 成功截断这类引发过拟合的噪声特征,证明极化机制在精简特征空间上的可靠性。
4.4 工业部署与消融研究(RQ3)¶
真实工业系统中,搜索排序模型的拼接表征超过 12,000 维,这一巨大输入张量在训练和推理时都带来显著的 CPU-GPU 通信带宽开销。为在不损预测性能下降维,作者对比不同 baseline 的 ROI(剪掉的维度数 vs GAUC 差异)。
实验设置:因工业模型有 500+ 特征字段,传统 Permutation 方法需等量的独立全模型推理。受算力瓶颈约束,Permutation 只能在 1% 均匀采样子集上评估;而 LeAP 及其消融版 LeAP-Base(无自适应正则)凭 $O(1)$ 复杂度,在全量训练集上完成特征重要性搜索。值得注意:LeAP 在全量数据上的总耗时甚至少于传统 Permutation 处理 1% 采样子集的耗时。
Table 4. 工业特征剪枝 ROI 与消融分析(离线 CTR GAUC Diff)($10^{-3}$ 通常被视为该指标的显著差异)
| Pruned Dims | % | Permutation | LeAP-Base (w/o Adaptive Reg.) | LeAP |
|---|---|---|---|---|
| ~500 | ~4% | $-1\times10^{-4}$ | No Diff | No Diff |
| ~1900 | ~15% | $\mathbf{-3\times10^{-3}}$ | $-2\times10^{-4}$ | No Diff |
| ~2500 | ~20% | N/A | $-1\times10^{-3}$ | No Diff |
| ~3600 | ~30% | N/A | $\mathbf{-2\times10^{-2}}$ | No Diff |
| ~4300 | ~35% | N/A | N/A | $-2\times10^{-4}$ |
| ~5100 | ~40% | N/A | N/A | $-3\times10^{-4}$ |
| ~6400 | ~50% | N/A | N/A | $\mathbf{-1\times10^{-3}}$ |
结果与消融分析:
- 训练效率与数据规模的影响:对比 Permutation 与 LeAP-Base,前者在剪 1,900 维时因严重下采样遭受 $3\times10^{-3}$ 的性能下跌;而 LeAP-Base 利用全量数据联合优化,同样剪枝比例下仅损失可忽略的 $2\times10^{-4}$。这凸显了端到端学习机制在海量数据规模上的巨大工程优势。
- 自适应正则的必要性(消融):LeAP-Base(无自适应正则)在剪超过 3,600 维时遭受严重的 GAUC 退化 $2\times10^{-2}$,证实统一正则会重罚异构空间中的高维与稀疏特征。而完整 LeAP 在同样剪枝比例下保持稳定。即使激进到剪 50% 维度(~6400),LeAP 的性能下跌也被严格限制在 $1\times10^{-3}$ 左右,展现出远超基线的鲁棒性。
在线 A/B 测试:基于离线 ROI 评估,作者把"剪掉 3,600+ 维"的策略部署到线上 serving 系统。移除对应网络结构并做轻量微调后,多周在线 A/B 测试显示 LeAP 成功缓解了内存带宽压力,同时核心业务指标完全稳定(Neutral)。这验证了 LeAP 在超大规模复杂工业应用中的巨大实用价值。
5. 核心贡献总结¶
- 机制重构:把 $O(N)$ 的逐特征随机置换重构为单次前向内的 $O(1)$ 可学习门控(温度 Sigmoid + batch-wise shuffle + stop-gradient),让置换式特征重要性首次能嵌入处理数百亿样本的工业训练流水线。
- 自适应正则:用置换散度($L_2$ + EMA)替代统一惩罚,自适应地对高维特征加重惩罚、对稀疏特征豁免惩罚,从尺度对齐角度(式 7)解决异构维度 + 极端稀疏下的评估不公平。
- 极化与硬剪枝:理论证明(凸性假设下)有用特征门控极化到 1、冗余特征极化到 0,使收敛后可用简单阈值/Top-K 直接硬剪枝,无需昂贵重训练,可直接上线只需轻量微调。
- 工业落地:在 12,000+ 维、2TB、十亿日请求的真实搜索排序模型上无损剪掉 30%(3,600+)维度(业务指标 Zero Diff / Neutral),剪枝能力是对比基线的 2-10 倍。
6. 讨论与局限性¶
值得借鉴的设计:
- "置换散度即正则尺度"这一对齐洞见(式 7)是全文最优雅之处:把"惩罚强度"从"预设维度"解耦,绑定到"置换引起的信息扰动幅度"上,一举同时治好了异构维度不公(高维 → 大散度 → 大惩罚)和稀疏误剪(稀疏 → 默认值换默认值 → 小散度 → 小惩罚)两个工业顽疾。这是一个很"便宜"(只多算一个 $L_2$ + EMA)但很对症的设计。
- batch-wise shuffle 保边缘分布:用列内重排构造噪声,完美保留了特征自身的边缘分布与稀疏模式,避免了用"高斯噪声/置零"替换带来的分布漂移问题。
- stop-gradient 隔离上游:融合式只让梯度更新门控、不让噪声污染上游表征,工程上很干净。
- $O(1)$ 单次前向 + 全量数据:相比 Permutation 只能在 1% 采样上评估,LeAP 全量评估反而更快,这是把 PFI 真正搬上工业流水线的关键。
局限与争议:
- 公开数据集增益边际化:在 Criteo/Avazu/AliCCP/ML-1M 上,LeAP 相对 SHARK/AutoField 的领先非常微小(如 50% 时 $S_{\text{AUC}}$ 0.9981 vs 0.9977;多处与次优并列),且公开集是同质维度、用的是 LeAP-Base(无自适应正则)。真正的杀手锏(自适应正则)只在工业异构数据上体现,外部读者难以在公开 benchmark 上复现其核心优势。
- 理论依赖凸性假设:定理 1 的极化保证建立在"期望任务损失 $J(g_i)$ 是凸的"之上,而深度推荐模型的损失关于门控显然非凸。该理论更像是直觉性论证而非严格保证,实际极化效果靠经验(Table 3)支撑。
- 超参敏感性未充分讨论:温度 $\tau$、EMA 动量 $\beta$、全局稀疏系数 $\alpha$、剪枝阈值等都会影响极化与保留率,论文未给出敏感性分析或选取指引。$\Delta J>\lambda_i$ 的"信号强度阈值"如何随 $\alpha$ 平移决定了最终剪多少,工程上需要调参。
- "Zero Diff / Neutral" 是守成而非增益:工业收益是"剪 30% 维度 + 业务指标不掉"(降本),而非提升业务指标。LeAP 的定位是高效降本工具,不是效果增长引擎——这与其 FS 插件的本质一致,但读者应注意其价值在成本侧。
- 方法论可扩展性:作为特征选择插件而非表征/序列建模主干,LeAP 不直接涉及"参数 scaling 时同步扩充表征/序列建模能力"的命题;它是正交的工程优化层,长期上限取决于宿主模型而非自身。
与已有工作的差异:相比 mask-based(AutoField/LPFS/SFS)的"小权重=不重要"假设和同质维度假设,LeAP 改用敏感度度量并直接作用于原生异构层;相比 permutation-based(标准 PFI/SHARK)的 $O(N)$ 重复推理和稀疏偏差,LeAP 用单次前向可学习门控 + 自适应散度正则同时拿到效率与公平。它本质是把"可微 mask 的 $O(1)$ 效率"和"置换法的可解释性 + 稀疏鲁棒"两条路线缝合到一个插件里。
工业落地速览:宿主——某长视频平台十亿日请求的搜索排序模型(2TB,500+ 特征字段,12,000+ 拼接维);插入位置——特征拼接层之后;收益——无损剪掉 3,600+ 维(30%)缓解 CPU-GPU 带宽瓶颈,多周 A/B 业务指标 Neutral;上线代价——移除冗余结构后只需小数据微调。