Kwai Summary Attention 技术报告精读¶
研究动机与背景¶
长上下文建模能力已成为下一代大语言模型最重要的迭代方向之一,无论是语义理解、推理、Code Agent 还是推荐系统都对其提出了越来越高的要求。从最初的 1K 序列到当前的 1M 序列窗口(Anthropic 2026、Kimi2.6、LongCat 2026、Qwen3.5),可用上下文持续翻倍。但伴随而来的工程瓶颈也十分尖锐:标准 softmax 注意力对序列长度具有 $O(n^2)$ 时间复杂度,KV cache 又随序列线性增长,使得超长序列的训练与推理代价急速恶化。
KSA 作者把当前的长上下文优化技术划分成两条主路线:
- 路线一:每层 KV cache 减薄——以 Qwen 系列采用的 GQA、DeepSeek 系列采用的 MLA、MLA-DSA、GLM-5 NSA 为代表。GQA 通过把 $h$ 个注意力头分组共享 KV,把 cache 从 $2nhd$ 压到 $2ngd$;MLA 把 KV 投影到低秩 latent 空间;NSA/DSA 走的是稀疏化 + 路由的方向。问题在于这一类方法只压缩了常数因子,KV cache 仍然与序列长度成 1:1 的严格线性关系。
- 路线二:KV-Cache 友好的混合架构——典型代表是 Qwen3.5 的 GDN+GQA 混合、以及 SWA+GQA 混合(Agarwal 2025、Xiao 2026)。这一类方法把大部分层换成 SWA、线性核 GDN 等高效注意力,从根本上把 KV cache 与序列长度解耦。代价也很明显:线性注意力的固定状态本质上是有损压缩,长距离信息会"被涂抹";局部注意力则直接丢弃窗口外的所有信息。
KSA 作者指出,存在一条未被充分挖掘的中间路线:保持 KV cache 与序列长度的线性关系,但通过一个特定的压缩比 $k$ 实施语义级(sequence-level)压缩。这条 $O(n/k)$ 路径不追求"最小 KV cache",而是用可接受的内存代价换取对长距离依赖的完整、可寻址、可解释的保留。相比 SWA 和线性注意力,它在长程依赖上保持完整保真度,对长上下文推理、agent 轨迹和下游 RL 训练信号更友好。DeepSeek V4(2026)已经采用了类似 sequence-level KV cache 压缩的设计,进一步验证了这条路线的工程可行性和长上下文鲁棒性。
基于此,作者提出 Kwai Summary Attention (KSA)——一种通过插入可学习的 summary token 把历史上下文压缩成轻量级摘要的注意力机制。其核心设计是:在输入序列中按固定 chunk 间隔注入 summary token,文本 token 与 summary token 拥有不同的可见域——summary token 只汇总自己所在 chunk 内部的语义;文本 token 则通过短程 sliding chunk 看相邻的真实文本,通过远程 summary tokens 看更早的历史摘要。这种"局部全保真 + 远程压缩中继"的双轨设计同时获得长程表达能力(summary token 提供 distant context)与短程语言流畅性(dense local attention)。
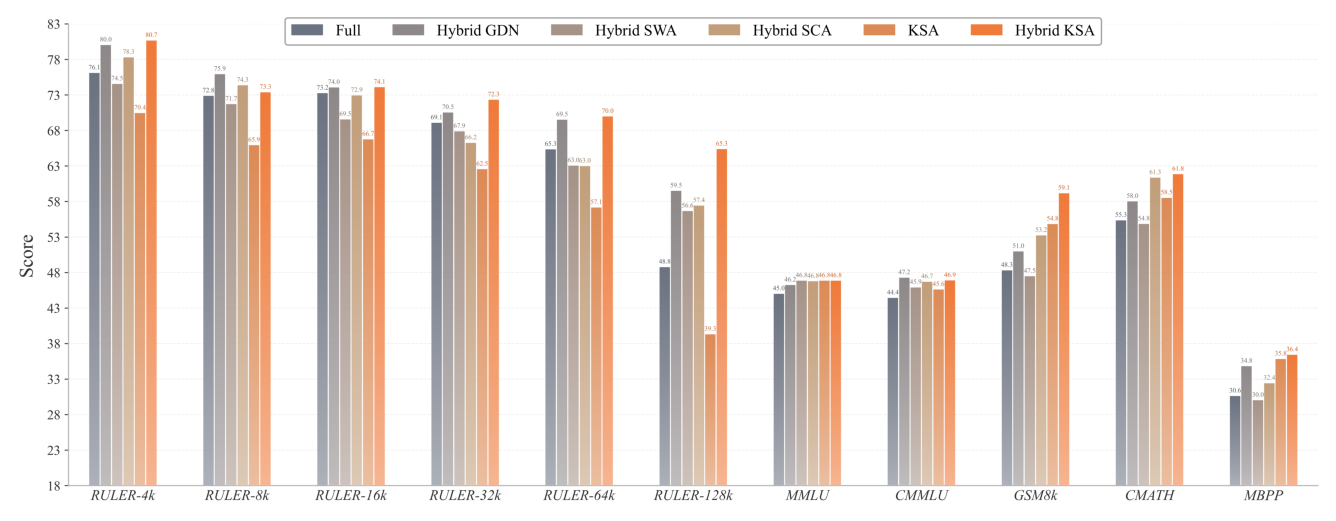
实验结果(Figure 1)显示:在 from-scratch 训练设置下,hybrid-KSA 在 RULER 长上下文基准上以 3:1 KSA/Full 混合比超过 hybrid-GDN 和 hybrid-SWA 等所有 sub-quadratic baseline;在 RULER-128K 上比 hybrid-GDN 高 5.48 分。在 CPT 设置下,hybrid-KSA 比 hybrid-GDN 高 3.69 分。同时,KSA 的 sequence-level 压缩与 GQA、MLA 完全正交——与 GQA 复合后压缩率达到 0.78%,与 MLA 复合后达到 0.22%,可在 KV cache 上叠加约 8× 的进一步压缩。
核心方法 / 模型架构¶
重新思考长上下文建模¶
LLM 长上下文训练与推理面临两大挑战:KV cache 增长和注意力计算开销。回顾两个极端:
- 完整注意力(Full Attention 及其 GQA/MLA 变体):保留完整历史,但 KV cache 线性增长。在长序列推理中变成主要瓶颈。
- 纯线性 / 局部注意力(GDN、SWA):通过固定大小的 recurrent state 或滑动窗口达到线性 scaling,但有限的状态容量难以保持细粒度语义信息。
KSA 在两者之间寻找折中:它把长上下文信息持续压缩到一个不断增长的 summary state 集合——表达性远胜固定状态,存储成本远低于完全保留所有历史 token。区别于纯线性注意力,summary state 不是固定大小,而是随 summary token 数量渐进增长;区别于稀疏注意力,长程建模不依赖稀疏 token-to-token 连接,而是通过 summary token 这个"压缩中继"路由远端信息。综合起来,KSA 可被理解为 local-global 混合注意力——局部用滑动窗口做 token 级 dense attention,全局通过线性增长的 summary token 做压缩 long-range attention,在建模容量、计算效率和内存开销三者间提供更好的平衡。
KSA 设计:Summary Token Compression + Sliding Chunk Attention¶
KSA 由两个关键部件组成:Summary Token Compression 和 Sliding Chunk Attention (SCA)。
Summary Token Compression¶
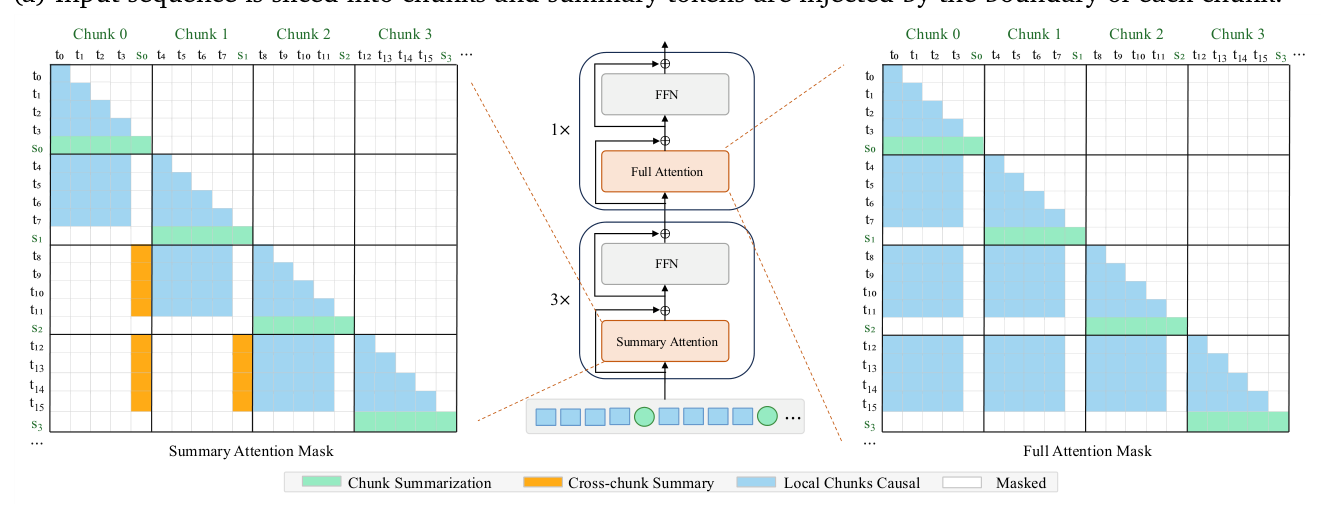
给定输入序列 $\mathcal{T} = [t_0, \ldots, t_{n-1}]$ 和 chunk size $k$,先把序列切分为 $n/k$ 个 chunk(假设 $n$ 整除 $k$),并在每个 chunk 末尾追加一个共享的可学习 summary embedding $s$。记 chunk $j$ 的 summary token 为 $s_j$(所有 $s_j$ 共享同一个特殊 learnable summary token $s$),则增广序列 $\hat{\mathcal{T}}$ 写为:
$$ \hat{\mathcal{T}} = [\text{chunk}_0, \text{chunk}_1, \ldots, \text{chunk}_{\frac{n}{k}-1}], \quad \text{where } \text{chunk}_j = [t_{jk}, t_{jk+1}, \ldots, t_{jk+(k-1)}, s_j] \tag{1} $$
其中 $t_{jk}$ 是 chunk $j$ 的第一个文本 token,$s_j$ 是位于 chunk 末尾的 summary token。每个 summary token 在结构上承担"chunk 内文本语义的提炼"角色。
基于两类 token 的不同角色,作者对信息流的可见性施加了关键的非对称结构约束:
- Summary token 只能看到自己 chunk 内的文本 token,看不到任何其他东西。而且,summary token 的 position id 与该 chunk 最后一个文本 token 的 position id 相同(这一点保证 RoPE 编码下 summary token 与紧随其后的文本不会出现位置突变)。
- Text token 可以看到自己短程窗口内的相邻文本 token 和过去 chunk 的 summary token,但不能直接访问完整文本历史。
这种设计显式地把 token 空间和 state 空间解耦:summary token 专注于短上下文的语义压缩,text token 通过历史 summary token 间接获取远程信息。
Sliding Chunk Attention (SCA)¶
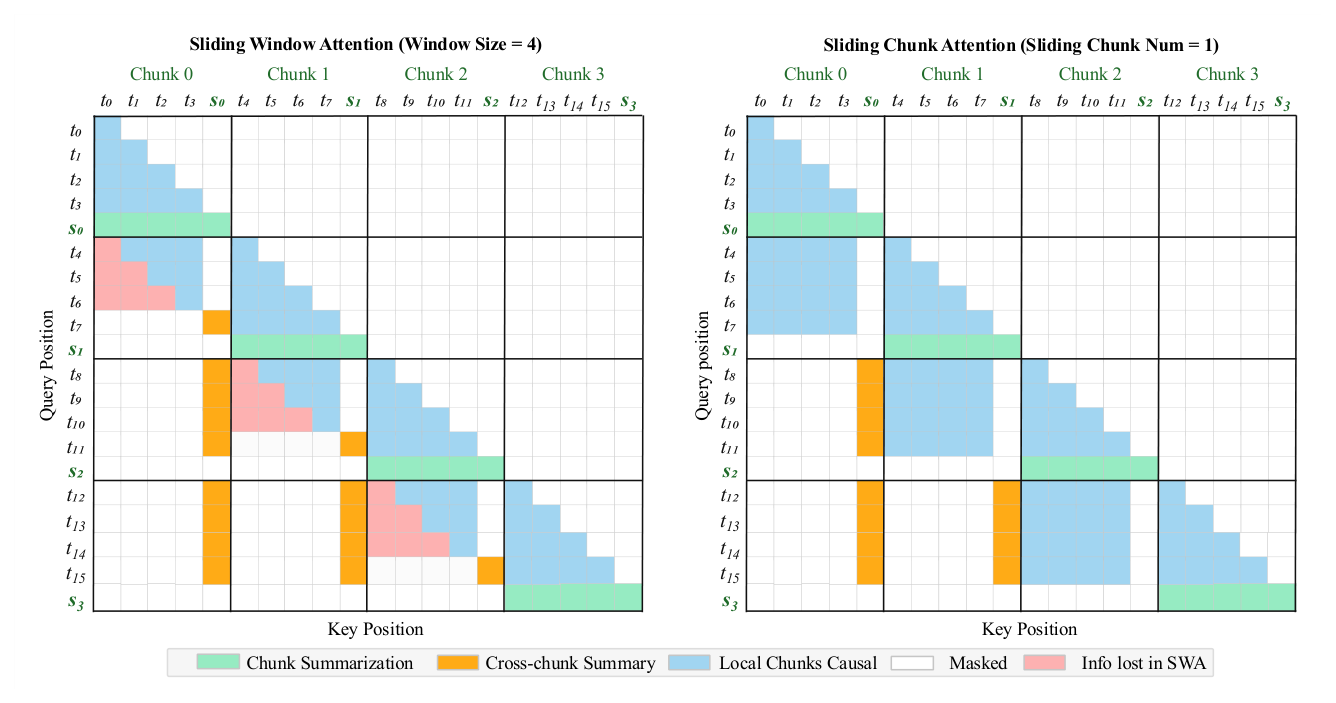
为了让 text token 看到的"短程文本信息"和"远程 summary 信息"完全互补、不重复,作者引入 sliding chunk attention 机制。对一个文本 token $i$(chunk size 为 $k$),标准 SCA 的可见范围为:
$$ \left[t_{(\lfloor \frac{i}{k} \rfloor - C) \cdot k}, \ldots, t_{i-1}, t_i\right] \tag{2} $$
其中 $\lfloor \cdot \rfloor$ 是向下取整,$\lfloor i/k \rfloor - C$ 表示窗口起始 chunk 的索引;$C$ 是窗口包含的 chunk 数。
在 KSA 的总体计算中,SCA 与 summary token 注意力同时作用,让 text token 同时看到短程局部上下文和长程语义摘要。形式化地,对一个 chunk size 为 $k$ 的 text token $i$,其完整可见域为:
$$ \underbrace{\left[s_0, s_1, \ldots, s_{\lfloor \frac{i}{k} \rfloor - C - 1}\right]}_{\text{distant summary tokens}} \cup \underbrace{\left[t_{(\lfloor \frac{i}{k} \rfloor - C) \cdot k}, \ldots, t_{i-1}, t_i\right]}_{\text{sliding chunk text tokens}} \tag{3} $$
左侧覆盖窗口外的远程 summary,右侧覆盖窗口内的真实 text token。注意:sliding chunk 内的 summary token 不被 text token 看到,因为这些 chunk 的原始 text token 已经被覆盖,避免双重计入。
为什么 chunk-level 而不是 token-level 滑动? 一个自然的替代方案是用标准 token-level SWA(如 GPT-OSS 中那样让 text token 看固定大小窗口内最近的 token)。但当 SWA 与 summary token 结合时,token-level 滑动可能 遗漏信息或重复计入:如 Figure 3 所示,如果窗口边界正好横切某个 chunk,文本 token 只能看到该 chunk 中部分原始 text;与此同时,该 chunk 没完全脱离窗口,其 summary token 也不算"远程摘要"。结果是这个被半遮的 chunk 既没被原始文本完整覆盖,又没被 summary 抵消,造成信息丢失。
Sliding Chunk Attention 的对齐保证:SCA 把窗口边界与 chunk 边界严格对齐——任意一个 past chunk 要么完全在窗口内(所有 text token 可见),要么完全在窗口外(只能通过 summary token 访问),不存在中间状态。这一信息路由保证使任何 chunk 的信息都不会丢失,也不会被重复编码。
KSA Kernel Design 与 KV Cache 布局¶
KSA 的注意力 mask 是一个由 text token 局部滑动窗口和 summary token 可见性共同定义的结构化稀疏 mask。当增广输入长度 $L = n + n/k$(其中 $n/k$ 为总 summary token 数)很大时,构建完整的 $O(L^2)$ mask 是不可行的。作者实现了两个专用 kernel:
- 训练 / prefill kernel:block-sparse attention kernel——把 Q/K/V 分割成固定大小的 block。由于 KSA 在稀疏设置下大量 Q-K 交互被丢弃,kernel 只把非零 block 对从 HBM 加载到 SRAM 计算。
- 解码 kernel:summary KV cache 高效访问 kernel——专为解码时的 memory-bandwidth bottleneck 设计,避免在每步生成时频繁 concat / 重分配 KV 段。
Decoding 的高效 KV Cache 结构¶
自回归解码每一步都要访问所有先前 KV,因此瓶颈在 memory bandwidth 而非 compute。朴素实现需要在每步对 KV 段执行 concat、discard、重分配——这些 scattered memory 操作严重拖慢解码循环。
KSA 的 KV cache 设计为连续张量,逻辑上分为三块(Figure 4a):
- Current Chunk:当前正在被填充、还未完成的 chunk。从右向左填,右边界始终对齐 Sliding Chunk 区域。这种对齐保证 cache 物理上连续——text token attention 可以一次性读取所有 KV,无需 concat。
- Sliding Chunk Text:当前已固定的滑动窗口内 text chunks。
- Summary Token Buffer:所有过去 chunk 已生成的 summary token KV。每条 entry 进入 cache 前都已应用 RoPE,物理布局不影响位置编码语义。
KV cache 的生命周期(Figure 4b–e):
- 写入新 text token(4b):直接写到 Current Chunk 区域的下一个空位,attention 读取 当前 chunk + sliding chunk text + distant summary 的连续切片。
- 插入 chunk summary token(4c):summary 的 self-KV 写到 Current Chunk 左侧的 scratch slot,summary attention 也是一次连续切片读。
- 替换最旧 text chunk(4d):刚结束的 chunk 被复制到 ring buffer 的 write pointer 位置,覆盖最旧的 sliding chunk。
- 追加 summary 到 buffer(4e):新生成的 summary KV 追加到 Summary Token Buffer 右端。
这一设计的核心收益:每次解码读取都是一个 contiguous slice,无需 concat、gather 或显式 mask 构建——cache layout 本身天然编码了可见性规则。

KV Cache 内存分析¶
Per-Token KV Cache Cost¶
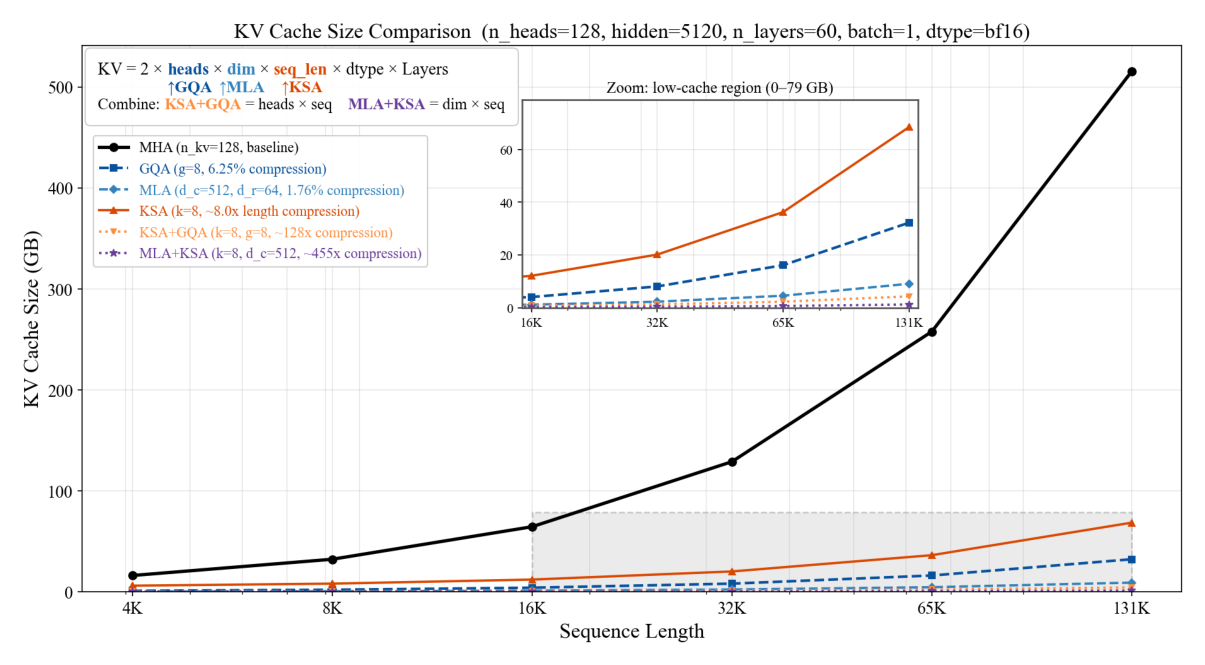
设 chunk 压缩比 $k=8$、注意力头数 $h=128$、head dim $d=128$、GQA group 数 $g=8$、MLA 的 $d_c=512$、$d_r=64$。论文给出 Table 1(重制如下):
| 机制 | 有效上下文 | $n \to \infty$ KV cache 大小 | 压缩率 |
|---|---|---|---|
| MHA | $n$(精确) | $2 \cdot n \cdot h \cdot d$ | – |
| GQA | $n$(精确) | $2 \cdot n \cdot g \cdot d$ | $g/h \approx 6.25\%$ |
| MLA | $n$(精确) | $n \cdot (d_c + d_r)$ | $(d_c + d_r) / (2 \cdot h \cdot d) \approx 1.76\%$ |
| GDN | $n$(模糊) | $2 \cdot h \cdot d^2$ | $d/n \approx 0\%$ |
| SWA | $w$(精确) | $2 \cdot w \cdot g \cdot d$ | $w/n \cdot g/h \approx 0\%$ |
| KSA | $n$(已总结) | $2 \cdot n/k \cdot g \cdot d$ | $1/k \approx 12.5\%$ |
| KSA + GQA | $n$(已总结) | $2 \cdot n/k \cdot g \cdot d$ | $1/k \cdot g/h \approx 0.78\%$ |
| KSA + MLA | $n$(已总结) | $n/k \cdot (d_c + d_r)$ | $1/k \cdot (d_c + d_r) / (2 \cdot h \cdot d) \approx 0.22\%$ |
KSA 在表中处于一个独特位置:
- 与 MHA、GQA、MLA 一样,KSA 保留精确的有效上下文(only 经过 summary token 中继,但不会被 fixed state 涂抹);
- 同时把 KV cache 增长率从 $O(n)$ 降到 $O(n/k)$,即与 GDN、SWA 一样具有亚线性 scaling 优势。
KV Cache 压缩的正交性¶
任意一层 KV cache 可以表示为:
$$ \text{KV Cache} = \underbrace{\text{PastToken}}_{\text{KSA 压缩}} \times \underbrace{\text{HeadNum}}_{\text{GQA 压缩}} \times \underbrace{\text{EmbeddingDim}}_{\text{MLA 压缩}} \tag{4} $$
GQA 压缩 head 维度,MLA 压缩 embedding 维度,KSA 减少需要被注意的 token 数——三者完全正交,压缩率可以乘起来。例如:
$$ \text{KV Cache}_{\text{KSA+GQA}} = \underbrace{n/k}_{\text{KSA}} \times \underbrace{2 \cdot g \cdot d}_{\text{GQA}} \tag{5} $$
$$ \text{KV Cache}_{\text{KSA+MLA}} = \underbrace{n/k}_{\text{KSA}} \times \underbrace{(d_c + d_r)}_{\text{MLA}} \tag{6} $$
值得强调的是:GQA 和 MLA 只能减小 $O(n)$ KV cache 增长的常数因子,而 KSA 把增长速率本身降到 $O(n/k)$——对长序列而言,sub-linear scaling 才能带来真正质变的压缩比(KSA+GQA 0.78%、KSA+MLA 0.22%)。Figure 5 展示了不同机制下 KV cache 随序列长度的增长曲线:在 131K 序列下,MLA baseline 占用 ~500GB,KSA+MLA 仅占用 ~5GB 量级。
实验设置¶
模型超参数配置¶
作者在两种实验设置下评估不同的 attention 架构:train-from-scratch(Scratch,400B token,128K 序列)和continual-pretraining(CPT,85B token,128K 序列)。
Baseline 模型¶
测试的模型变体包括: 1. Pure Full Attention 2. Hybrid-GDN(Yang et al. 2025)/ Ring-Linear(Ling-Team et al. 2025) 3. Hybrid Sliding Window Attention (SWA) 4. Hybrid Sliding Chunk Attention (SCA) 5. Pure KSA 6. Hybrid-KSA
所有 hybrid 变体的 KSA:Full 混合比为 3:1。
模型配置(Table 2)¶
| 配置 | From Scratch | CPT |
|---|---|---|
| 层数 | 24 | 36 |
| Hidden size | 2048 | 2560 |
| Intermediate size | 6144 | 9728 |
| 注意力头数 (Q/KV) | 16/16 | 32/8 |
| Head 维度 | 128 | 128 |
| Hybrid 架构比 (KSA:Full) | 3:1 | 3:1 |
| Summary chunk size | 8 | 8 |
| Sliding chunk number | 128 | 128 |
| Tied embeddings | False | True |
训练超参数(Table 3)¶
| 配置 | From Scratch | CPT |
|---|---|---|
| 序列长度阶段 | 8K / 32K / 64K / 128K | 32K / 64K / 128K |
| 各阶段 token 预算 | 250B / 50B / 50B / 50B | 25B / 35B / 25B |
| 最大 LR | 8K: $4\times 10^{-4}$;≥32K: $1\times 10^{-5}$ | 全阶段 $1\times 10^{-4}$ |
| 最小 LR | $1\times 10^{-7}$ | $1\times 10^{-7}$ |
| RoPE Theta | 8K: $10^4$;≥32K: $10^6$ | $10^6$ |
| Optimizer | AdamW ($\beta_1=0.9$, $\beta_2=0.95$) | – |
| Weight Decay | 0.01 | – |
| LR Schedule | WSD (Yu et al. 2025) | – |
| Gradient Clipping | 1.0 | – |
Train-from-Scratch:从头训一个 1.9B 参数 LM,按渐进 length-extension schedule:先在 8K 序列上训 250B token,再依次在 32K / 64K / 128K 各 50B token,总计 400B token。
Continual Pretraining:从 Qwen3-4B-base 出发,在 85B token 上继续预训练。三阶段渐进 length 扩展:32K(25B)→ 64K(35B)→ 128K(25B)。
数据 Pipeline¶
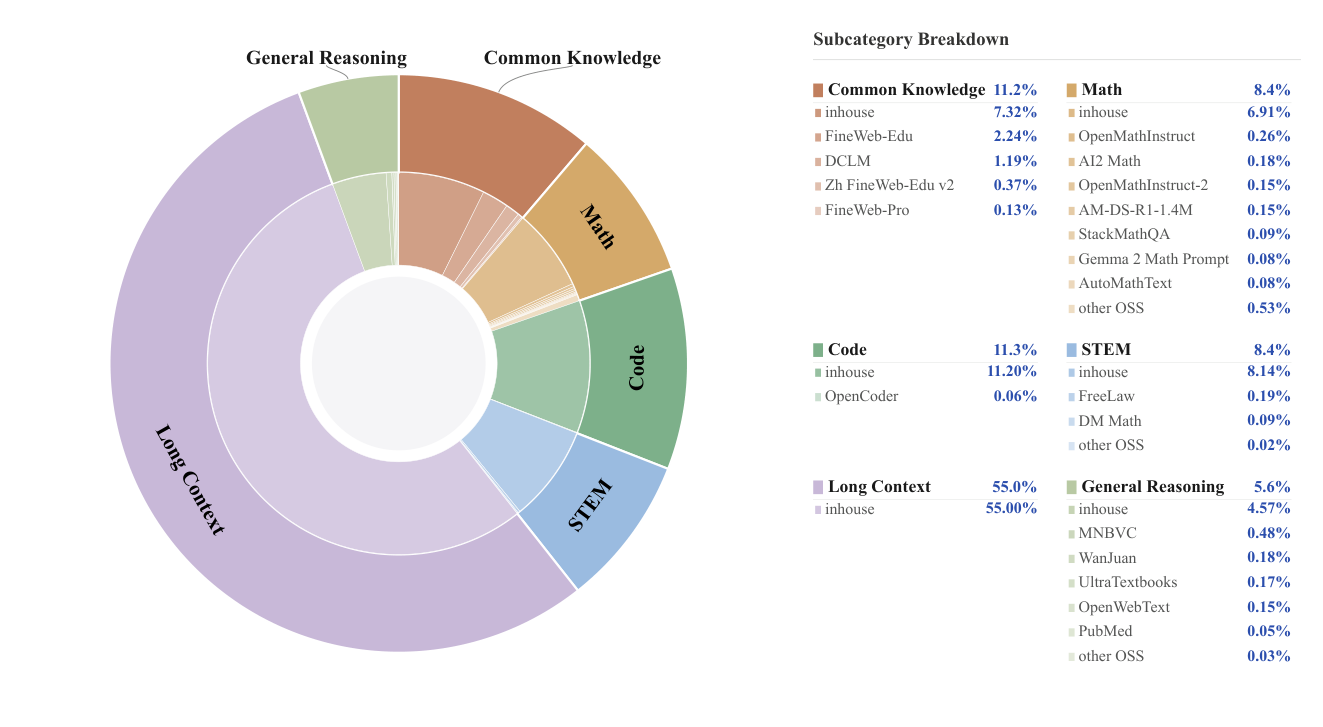
预训练语料分六类:Common Knowledge(11.2%)、Math(8.4%)、Code(11.3%)、STEM(8.4%)、General Reasoning(5.6%)、Long Context(55.0%,包含 inhouse 数据)。其中 Long Context 是核心数据类——包含自然长文档(书籍、跨 code/math/STEM 的长 QA)+ 合成的探测长程信息追踪能力的序列 + benchmark-style 长上下文评测序列。
评测基准¶
长上下文基准:RULER(Hsieh 2024)——多维度长上下文评测套件(检索、多跳追溯、聚合、问答),最长支持 128K。
通用能力基准:
- General Knowledge:MMLU、CMMLU、C-Eval、MMLU-Pro
- Mathematics:GSM8K、CMath、MATH
- Code:MBPP、HumanEval
训练食谱:CPT 三阶段¶
为把 KSA 平滑接入预训练好的 full-attention 模型,作者设计了三阶段 CPT 食谱:summary token 适配 → 参数退火 → 序列长度扩展。
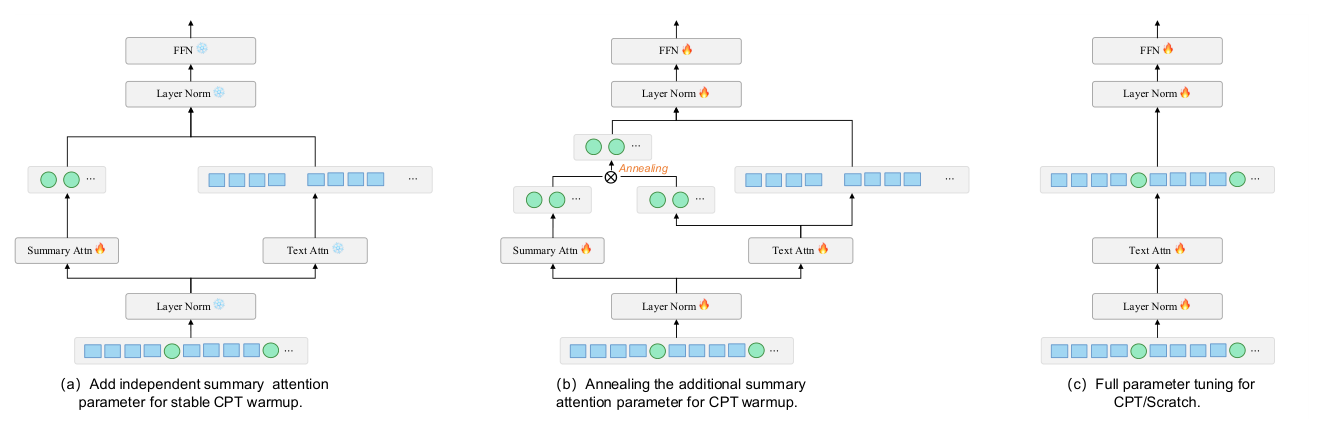
Stage 1:Summary Token Adaptation for CPT¶
为了赋予 summary token 充实有信息量的表征,作者设计了三粒度蒸馏:layer-wise / distribution-wise / objective-wise。具体实现是把 summary token $\mathcal{S}$ 作为新词表项,并为每个 summary 层装备独立的注意力参数 $W^Q_S, W^K_S, W^V_S$。
Layer-wise attention score alignment:记预训练的注意力投影为 $W^Q, W^K, W^V$;为 KSA 引入的独立 summary 矩阵记为 $W^Q_S, W^K_S, W^V_S$。设 $\mathcal{T}$ 为原始输入,$\hat{\mathcal{T}}$ 为带 summary 的增广输入,$\mathcal{S} \subset \{1, \ldots, |\hat{\mathcal{T}}|\}$ 为 summary 位置集合。Teacher branch(vanilla full attention)用预训练权重投影:
$$ X = \mathcal{T} (W^X)^\top, \quad X \in \{Q, K, V\} \tag{7} $$
Student(KSA)使用位置专用投影——text 位置走预训练权重,summary 位置走新引入参数:
$$ \hat{X}_t = \begin{cases} \hat{\mathcal{T}}_t (W^X)^\top, & t \notin \mathcal{S} \\ \hat{\mathcal{T}}_t (W^X_S)^\top, & t \in \mathcal{S} \end{cases}, \quad X \in \{Q, K, V\} \tag{8} $$
注意力 pattern 也不同。Teacher 是标准 full attention:
$$ O = \text{softmax}(QK^\top / \sqrt{d}) V \tag{9} $$
Student 用 KSA mask $\mathcal{M}_{\text{KSA}}$(每个 text token 看 sliding chunk + 前置 summary,每个 summary 只看自己 chunk):
$$ \hat{O} = \text{softmax}(\hat{Q}\hat{K}^\top / \sqrt{d} + \mathcal{M}_{\text{KSA}}) \hat{V} \tag{10} $$
为了让 student 与 teacher 中间表征对齐,作者从 $\hat{O}$ 中剔除 summary 行(这些行在 teacher 中没有对应位置),记为 $\hat{O}|_{\mathcal{T}} \in \mathbb{R}^{|\mathcal{T}| \times d}$,并施加 MSE 损失:
$$ \mathcal{L}_{\text{MSE}} = \frac{1}{L \cdot |\mathcal{T}|} \sum_{\ell=1}^{L} \| O_\ell - \hat{O}_\ell|_{\mathcal{T}} \|_2^2 \tag{11} $$
其中 $L$ 为 transformer 层数。
Distribution-wise regularization:MSE 只约束中间层输出,不直接约束最终预测分布。作者再在最终 logits 上施加 KL 正则。设 $W_h$ 为共享 LM head,$h_L$、$\hat{h}_L$ 为 teacher 与 student 最后一层 hidden state:
$$ p = \text{softmax}(h_L W_h^\top), \quad \hat{p} = \text{softmax}(\hat{h}_L W_h^\top), \quad \mathcal{L}_{\text{KL}} = \text{KL}(p \| \hat{p}) = \sum_v p_v \log \frac{p_v}{\hat{p}_v} \tag{12} $$
Objective-wise training:总蒸馏目标合并 student 的 LM 损失 + 两项对齐损失:
$$ \mathcal{L} = \mathcal{L}_{\text{LM}} + \alpha \mathcal{L}_{\text{MSE}} + \beta \mathcal{L}_{\text{KL}} \tag{13} $$
其中 $\alpha, \beta$ 在 validation split 上调。
关键分析:所有三项 loss($\mathcal{L}_{\text{MSE}}, \mathcal{L}_{\text{KL}}, \mathcal{L}_{\text{LM}}$)都只在 text token 位置上计算——这保证 student 与 teacher 的输出维度一致(teacher 没有 summary 位置),同时保留语义保真度。值得注意的是,loss 限制在 text 位置并不会切断到 summary 参数的梯度流:text token 的注意力 pattern 中(公式 3)天然包含 summary token,梯度会通过注意力交互流回 summary 参数。
Stage 2:Parameter Annealing for CPT¶
为了避免在推理时引入额外的参数(额外参数会增加 inference cost),作者提出参数退火策略——把独立的 summary 参数渐进吸收回主 LLM 权重。具体地,在每个 summary 位置上对同一 hidden state 执行 two QKV projections:一次用共享 LLM 权重得到 $(q_s^{\text{main}}, k_s^{\text{main}}, v_s^{\text{main}})$,一次用独立 summary 权重得到 $(q_s, k_s, v_s)$。送入注意力的 QKV triplet 通过线性插值:
$$ \tilde{x}_s = \lambda x_s + (1-\lambda) x_s^{\text{main}}, \quad x \in \{q, k, v\} \tag{14} $$
插值系数遵循 iteration-dependent schedule:
$$ \lambda(s) = \begin{cases} 1, & s \le s_{\text{start}} \\ 1 - \frac{s - s_{\text{start}}}{s_{\text{end}} - s_{\text{start}}}, & s_{\text{start}} < s < s_{\text{end}} \\ 0, & s \ge s_{\text{end}} \end{cases} \tag{15} $$
其中 $s$ 是当前训练步,$s_{\text{start}}, s_{\text{end}}$ 定义退火窗口。当 $s \le s_{\text{start}}$ 时 summary 完全由独立参数主导;当 $s \ge s_{\text{end}}$ 时退化为完全依赖主 LLM 权重,使得辅助参数可以在推理时无任何架构改动地被移除。这种平滑课程使得从"专门 summary head"过渡到"完全共享表征"。
Stage 3:Sequence Length Extension for CPT/Scratch¶
对 CPT 设置,summary token 引入停在 32K 上下文长度,让新加参数先在中等序列长度上学到稳定表征,再在两阶段中扩展上下文:64K 训 35B token,再到 128K 训 25B token。这种渐进 schedule 使 summary 机制能逐步适配更长上下文。
对 Scratch 设置,作者直接在初始就让 summary token 与 text token 共享注意力权重,并按 8K / 32K / 64K / 128K 训 250B / 50B / 50B / 50B token。注意 8K 训完后 RoPE Theta 从 $10^4$ 切换到 $10^6$,以适配长序列。
CPT 实验结果¶
CPT 设置下,作者评估 KSA 与 hybrid-KSA,与 four 个代表性 baseline 比较:Full Attention、Hybrid-SWA、Hybrid-SCA、Hybrid-Linear。
长上下文基准(RULER)¶
下表为 Table 4 主要结果(CPT 设置):
| Benchmark | Full | Hybrid-SWA | Hybrid-SCA | Hybrid-Linear | KSA | Hybrid-KSA |
|---|---|---|---|---|---|---|
| RULER-4K | 92.88 | 91.30 | 86.02 | 86.39 | 91.55 | 92.97 |
| RULER-8K | 91.38 | 88.03 | 84.28 | 83.86 | 86.78 | 90.53 |
| RULER-16K | 89.12 | 82.87 | 80.67 | 78.06 | 84.78 | 88.86 |
| RULER-32K | 84.74 | 78.94 | 76.89 | 76.48 | 80.30 | 86.65 |
| RULER-64K | 78.16 | 73.88 | 68.88 | 73.50 | 76.09 | 76.04 |
| RULER-128K | 65.86 | 66.27 | 60.94 | 67.98 | 66.81 | 71.67 |
| MMLU | 71.83 | 70.57 | 69.83 | 64.33 | 70.73 | 70.50 |
| CMMLU | 75.00 | 73.69 | 72.59 | 68.41 | 73.29 | 72.63 |
| C-Eval | 73.66 | 72.36 | 71.66 | 67.42 | 72.14 | 72.66 |
| MMLU-Pro | 46.36 | 45.23 | 45.11 | 38.83 | 45.70 | 45.39 |
| CMath | 83.41 | 84.84 | 83.16 | 79.09 | 84.58 | 84.25 |
| GSM8K | 82.75 | 81.92 | 80.10 | 72.44 | 81.09 | 79.50 |
| MATH | 47.48 | 48.24 | 47.45 | 42.57 | 48.15 | 47.56 |
| MBPP | 61.30 | 61.70 | 59.60 | 55.30 | 61.50 | 62.20 |
| HumanEval | 58.54 | 61.89 | 61.89 | 54.58 | 60.97 | 62.50 |
| Average | 73.50 | 72.12 | 69.94 | 67.28 | 72.30 | 73.59 |
结论分析:
i) Hybrid-KSA 展现出最强的长上下文检索能力。它在 RULER-4K(92.97)、RULER-32K(86.65)、RULER-128K(71.67)三个关键尺度上都领先,在最长 128K 上比 Full attention 高 +5.81 分,比最强 hybrid baseline(Hybrid-SWA)高 +5.40 分。这说明 summary token 在 full attention 受限于 prohibitive cost 时,能有效压缩并传递远程上下文。
ii) KSA 信息聚合方式更接近 Full attention 的 faithful approximation。在所有 RULER 长度上,KSA 与 Hybrid-KSA 都比 SWA、SCA、Linear 等 fixed-window 或 linearized 方案领先明显。
iii) CPT summary attention 保留了预训练模型的通用世界知识。MMLU 70.73 / CMMLU 73.29 紧贴 Full attention 的 71.83 / 75.00,远超 Hybrid-Linear 的 64.33 / 68.41——后者受限于 fixed-size memory update 的有限表达容量。
iv) 数学推理能力得以保持甚至超越 Full:KSA 在 CMath 上达到 84.58,比 Full(83.41)还高;GSM8K 81.09 与 Full(82.75)相当。
v) 代码生成性能优秀:Hybrid-KSA 在 MBPP(62.20)和 HumanEval(62.50)上取得所有配置最佳成绩,包括 Full attention。
vi) 整体上,KSA 系列与 Full attention 的能力差距是所有 sub-quadratic baseline 中最小的——平均分 73.59 甚至略高于 Full 的 73.50。
From-Scratch 实验结果¶
From-scratch 是更严格的测试——所有模块都从随机初始化优化,没有 pretrained init 的 head start,更能检验 KSA 的可扩展性和学习动态。下表为 Table 5:
| Benchmark | Full | Hybrid-SWA | Hybrid-SCA | Hybrid-GDN | KSA | Hybrid-KSA |
|---|---|---|---|---|---|---|
| RULER-4K | 76.08 | 74.54 | 77.72 | 79.83 | 70.44 | 80.65 |
| RULER-8K | 72.85 | 71.69 | 75.22 | 76.01 | 65.91 | 73.35 |
| RULER-16K | 73.24 | 69.54 | 72.55 | 74.04 | 66.74 | 74.07 |
| RULER-32K | 69.06 | 67.86 | 67.74 | 70.41 | 62.54 | 72.30 |
| RULER-64K | 65.32 | 63.03 | 63.54 | 69.39 | 57.13 | 69.95 |
| RULER-128K | 48.75 | 56.64 | 58.01 | 59.87 | 39.29 | 65.35 |
| MMLU | 44.99 | 46.84 | 46.77 | 46.23 | 46.83 | 46.83 |
| CMMLU | 44.41 | 45.89 | 46.42 | 47.19 | 45.59 | 46.88 |
| C-Eval | 44.28 | 43.54 | 47.62 | 45.54 | 45.27 | 44.13 |
| MMLU-Pro | 19.48 | 20.46 | 20.10 | 21.22 | 21.72 | 22.52 |
| CMath | 55.33 | 54.83 | 62.33 | 58.00 | 58.50 | 61.83 |
| GSM8K | 48.29 | 47.46 | 52.39 | 50.95 | 54.81 | 59.14 |
| MATH | 23.38 | 31.46 | 28.82 | 33.30 | 30.04 | 36.92 |
| MBPP | 30.60 | 30.00 | 31.60 | 34.80 | 35.80 | 36.40 |
| HumanEval | 25.61 | 28.05 | 26.83 | 27.44 | 29.88 | 31.71 |
| Average | 49.44 | 50.12 | 51.84 | 52.95 | 48.73 | 54.80 |
结论分析:
i) Hybrid-KSA 取得最佳整体性能,在多个 RULER 长度上甚至大幅超过 Full attention。RULER-128K 上 Hybrid-KSA 65.35 vs Full 48.75,领先 +16.60 分——展现出极强的长上下文 scalability。
ii) 极长上下文鲁棒性显著提升:Full attention 从 RULER-4K 76.08 降到 128K 的 48.75(恶化 -36%);而 Hybrid-KSA 从 80.65 降到 65.35(仅恶化 -19%),鲁棒性更佳。
iii) summary-based aggregation 是 efficient attention design 的更好替代方案:相比受限于固定窗口的 Hybrid-SWA、Hybrid-SCA,以及依赖压缩 memory update 的 Hybrid-GDN,Hybrid-KSA 在长上下文区域优势明显(128K 上比 GDN 高 +5.48)。
iv) 数学推理大幅提升:Hybrid-KSA 在 GSM8K(59.14)和 MATH(36.92)上分别比 Full attention 高 +10.85、+13.54 分——表明 summary 机制能有效支持长上下文上的 multi-step reasoning。
v) 代码生成超越所有 baseline:MBPP 36.40 / HumanEval 31.71 双双最佳,包括超过 Full attention。
vi) Hybrid-KSA 提供 efficiency-performance 的更好折中:在所有 benchmarks 上 Hybrid-KSA 都名列前茅,同时维持 sub-quadratic 复杂度。
训练动态与评估趋势¶
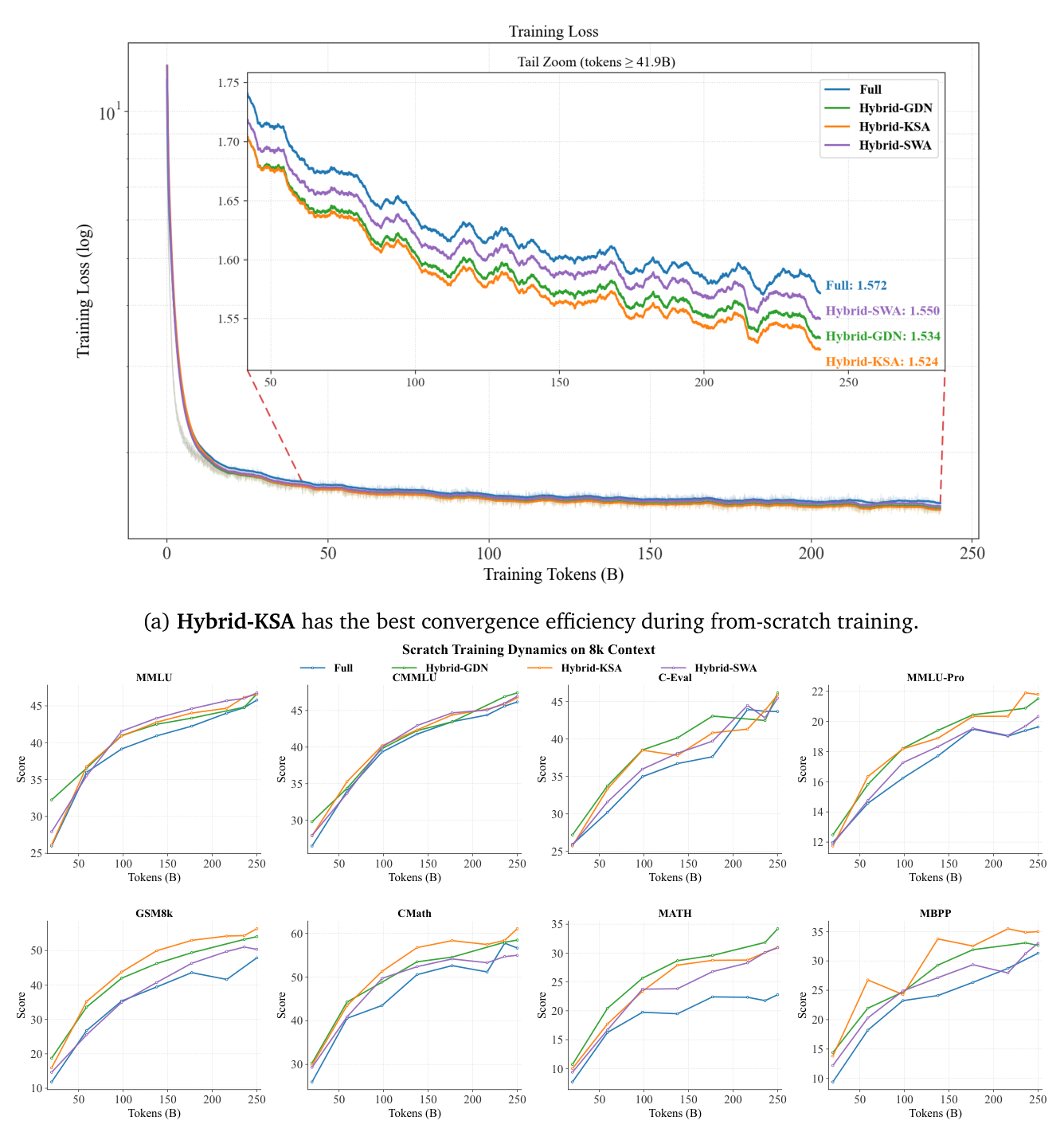
Training Loss(Figure 8a):Hybrid-KSA 在整个训练过程中达到最低 loss(1.524),优于 Hybrid-GDN(1.534)、Hybrid-SWA(1.550)、Full(1.572)。在 long-tail 区间(≥41.9B token)尤其显著,说明优化效率优势随训练量增加而扩大。
Evaluation Scores(Figure 8b):在 MMLU、CMMLU、C-Eval、MMLU-Pro、GSM8K、CMath、MATH、MBPP 八个评测点上,Hybrid-KSA 早期 score 就显著高于 Full attention,到训练末期保持优势。其中 GSM8K、CMath、MATH 等推理密集任务上的领先尤其稳定,证明 summary 机制不仅不损害 multi-step reasoning,反而可能增强。
Needle-in-a-Haystack 实验¶
NIAH(Needle-in-a-Haystack,Martin 2023)测试模型从长上下文中精确检索特定信息的能力——把一个 short factual statement(needle)嵌入到 long context(haystack)中,让模型回答 needle 内容。
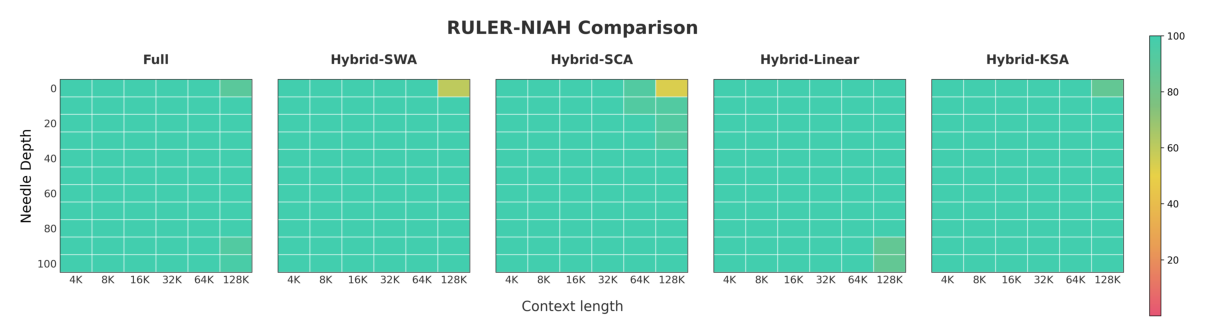
Figure 9 显示 Hybrid-KSA 在 4K-128K 各上下文长度、0%-100% 各 needle 深度上都保持近完美检索,仅在 128K 上有轻微下降——表明少量 full attention 层能有效补偿长序列上的压缩损失。
Table 6 报告了更复杂的 RULER 128K 子任务:
| Subtasks | Full | Hybrid-SWA | Hybrid-SCA | Hybrid-Linear | KSA | Hybrid-KSA |
|---|---|---|---|---|---|---|
| NIAH-Single | 100.00 | 100.00 | 99.16 | 100.00 | 97.50 | 100.00 |
| NIAH-Multikey | 75.00 | 74.16 | 70.84 | 79.16 | 74.16 | 75.84 |
| NIAH-Multivalue | 88.12 | 83.75 | 91.25 | 95.62 | 83.75 | 98.75 |
| NIAH-Multiquery | 95.62 | 93.12 | 98.12 | 99.38 | 95.62 | 98.12 |
| VT | 60.50 | 67.50 | 42.50 | 87.50 | 65.50 | 90.50 |
| FWE | 51.66 | 51.66 | 33.33 | 23.33 | 72.50 | 65.84 |
| SQuAD | 30.00 | 30.00 | 15.00 | 35.00 | 32.50 | 42.50 |
关键观察:
i) NIAH-Multivalue 上 Hybrid-KSA 98.75 超过 Full 88.12 +10.63 分——多 value 检索是该方案的强项。
ii) VT 上 Hybrid-KSA 比 Full 高 +30.00,FWE 比 Full 高 +14.18——证明 KSA 能 robustly 扩展到更复杂的合成子任务。
iii) summary 整体上 act as high-fidelity compressed relays,使得 robust 信息检索和 complex long-sequence reasoning 在 128K token 内不需要 prohibitive overhead 即可实现。
KSA 设计消融分析¶
Inference KV Cache and Speed¶
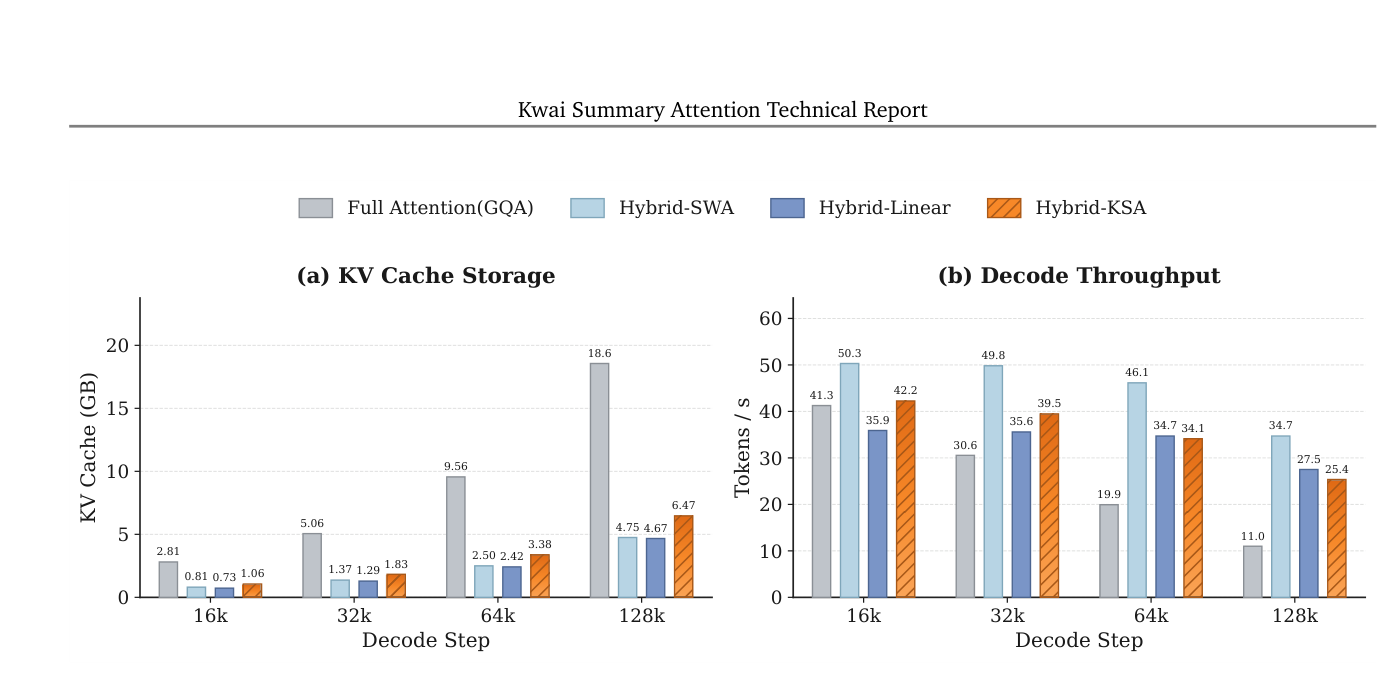
Figure 10 展示了 KV cache 与 decode throughput 的对比:
i) 128K 上下文上,Hybrid-KSA cache footprint 仅 7.5GB,比 Full attention 18.6GB 小 2.5×。
ii) 16K 解码时 Hybrid-KSA 吞吐 1.06× 相对 Full attention,超过 Hybrid-SWA(0.73×)和 Hybrid-Ring-Linear(0.81×)。
iii) KSA 提供了一个有利的 trade-off:把长程上下文压缩到紧凑 state,回收内存而不损失解码速度。
Hybrid-KSA 配置消融(Table 7)¶
作者在 chunk number $N$、chunk size $S$、hybrid ratio 三个维度做了消融:
Chunk Number ($N$)¶
| $N$ | RULER-4K | -8K | -16K | -32K | -64K | RULER-Avg | MMLU | CMMLU | Knowledge-Avg | GSM8K | CMath | MBPP | Reasoning-Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | 91.02 | 89.46 | 84.42 | 78.35 | 70.74 | 82.80 | 69.93 | 72.68 | 71.30 | 81.23 | 83.59 | 60.50 | 75.11 |
| 64 | 93.36 | 88.65 | 87.21 | 76.91 | 69.69 | 83.16 | 70.43 | 72.27 | 71.35 | 80.13 | 83.00 | 61.20 | 74.78 |
| 128 (默认) | 88.69 | 88.01 | 83.62 | 78.19 | 76.35 | 82.97 | 70.18 | 72.16 | 71.17 | 80.75 | 82.48 | 60.20 | 74.48 |
| 256 | 92.05 | 88.30 | 83.86 | 79.40 | 65.73 | 81.87 | 69.94 | 72.53 | 71.23 | 81.16 | 84.92 | 61.60 | 75.89 |
结论:i) 适度增大 $N$ 能改善长上下文性能(RULER avg 82.80 → 83.16),但收益递减或反转——$N=256$ 时 RULER-64K 65.73 比 $N=128$ 的 76.35 退步明显;ii) $N$ 对通用 benchmark 影响很小,仅在大 $N$ 时略有提升(reasoning avg 75.89 at $N=256$)。$N=128$ 在长上下文与通用能力间取得最稳定平衡。
Chunk Size ($S$)¶
| $S$ | RULER-4K | -8K | -16K | -32K | -64K | RULER-Avg | MMLU | CMMLU | Knowledge-Avg | GSM8K | CMath | MBPP | Reasoning-Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 (默认) | 88.69 | 88.01 | 83.62 | 78.19 | 76.35 | 82.97 | 70.18 | 72.16 | 71.17 | 80.75 | 82.48 | 60.20 | 74.48 |
| 16 | 88.77 | 83.78 | 82.20 | 77.34 | 71.97 | 80.82 | 69.75 | 72.50 | 71.13 | 80.81 | 83.59 | 61.20 | 75.20 |
| 32 | 90.21 | 84.66 | 80.26 | 77.31 | 75.09 | 81.50 | 69.91 | 71.99 | 70.95 | 81.23 | 83.25 | 61.20 | 75.23 |
| 64 | 86.50 | 81.61 | 78.12 | 72.63 | 70.09 | 77.79 | 69.83 | 72.28 | 71.05 | 80.48 | 81.84 | 62.10 | 74.80 |
结论:i) 更小的 chunk size 长上下文性能更强($S=8$ RULER avg 82.97,64K 上 76.35);ii) 更大 chunk size 通用能力略胜——$S=32$ reasoning avg 75.23 最佳,GSM8K 81.23 也最高,但代价是 RULER avg 退到 81.50;iii) 默认 $S=8$ 提供平衡 anchor,略偏向长上下文建模。
Hybrid Ratio (Summary : Full)¶
| Ratio | RULER-Avg | Knowledge-Avg | Reasoning-Avg |
|---|---|---|---|
| 1:1 | 78.72 | 71.00 | 75.33 |
| 3:1 (默认) | 82.97 | 71.17 | 74.48 |
| 5:1 | 83.84 | 70.20 | 74.15 |
| 8:1 | 78.73 | 69.69 | 73.67 |
结论:i) summary attention 比例提高改善长上下文但削弱通用能力——3:1 → 5:1 RULER avg 82.97 → 83.84,但 reasoning 74.48 → 74.15;ii) full attention 比例提高增强通用但损害长上下文——1:1 时 reasoning 75.33 但 RULER 78.72;iii) 默认 3:1 在两者间取得最优 trade-off。
Per-Layer 注意力 pattern 分析¶
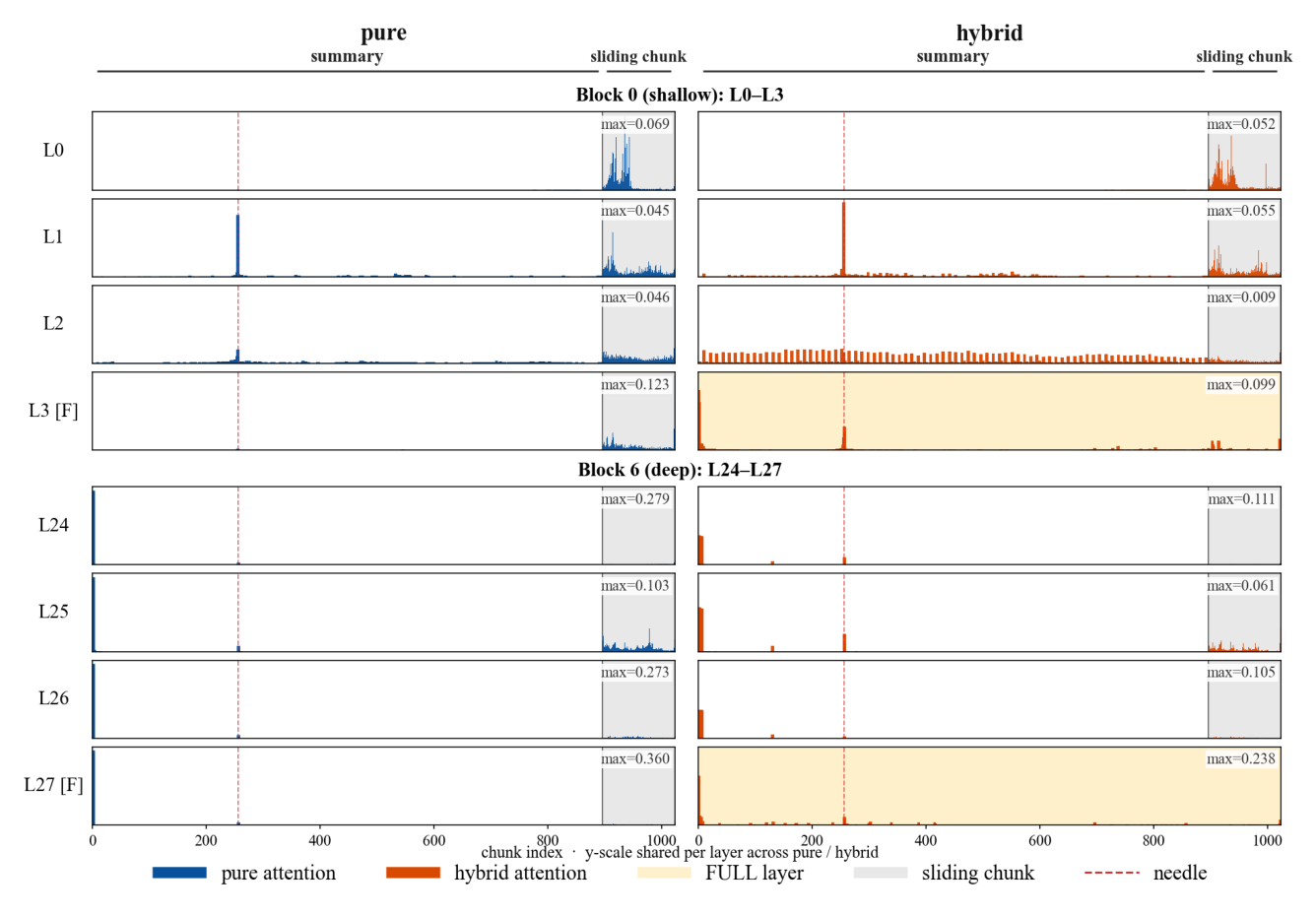
为理解为什么 hybrid 架构对长上下文检索有利,作者可视化了 KSA 与 Hybrid-KSA 在 out-of-window NIAH 例子上的 per-layer 注意力分布。比较第一个 block(浅层 L0-L3)与最后一个 block(深层 L24-L27),y 轴在两个模型间共享,使得 attention magnitude 直接可比。
Hybrid-KSA 中观察到两种 KSA 中没有的 qualitative pattern:
i) Hybrid SA attends to summary tokens more frequently:在浅层 SA 中(最清晰的是 L2),hybrid 模型形成一种周期性"comb"模式,在每个 chunk 边界都注意过去的 summary token;KSA 仅在 needle 位置附近显示一个微弱单峰。
ii) interleaved full-attention 层(L3、L27 标 "[F]")作为 cross-chunk integrator:它们的 attention map 在 needle chunk 显示尖锐 spike;KSA 保持平坦——即 hybrid 拥有 explicit token-level retrieval indicator,而 KSA 只能通过 summary token approximation。
iii) 在深层 block 中两者都重度关注最早的 summary token,但 shape 显著不同:Hybrid-KSA 的 sink 分散在大约 6 个 chunk 上,KSA 的 sink 仅聚焦在 2 个 chunk——hybrid 把 register 角色分布在更宽的 sink basin。
总之,shallow comb pattern + full-layer integrator 共同提供了两种 retrieval indicator 是 KSA 缺失的——这是 Hybrid-KSA 在 out-of-window needle 检索更可靠、长上下文容量更鲁棒的关键原因。
与已归档相关工作的对比¶
Step 2.5: no semantically twin papers found in archive。本档案库以推荐系统为主,IAT/SIF 虽然也"压缩历史信息为 token"但属于推荐域 instance/sample 离线 RVQ 量化(不同 root cause);In-Place TTT 虽同为 LLM 长上下文,但解法是 test-time training 而非 summary token 中继(解法路径实质偏离)。无问题 + 解法双同构候选,跳过本章节。
讨论与局限性¶
核心贡献¶
KSA 这篇技术报告的主要创新与价值:
-
提出 sequence-level token 压缩这一长上下文新视角。在传统的 KV-cache-per-layer 压缩(GQA/MLA)和 KV-Cache-friendly 混合架构(Hybrid SWA/GDN)之间,作者发掘出了"保留线性 KV cache 增长但通过 ratio $k$ 做语义级压缩"的 $O(n/k)$ 中间路径。这条路径在最终 KV cache 大小上不一定比 GDN/SWA 更小,但在完整、可寻址、可解释的长程依赖保留上有质的优势。
-
正交压缩复合。KSA 减少 token 数量,与 GQA 减 head 数、MLA 减 embedding dim 完全正交,可以乘性叠加(KSA+GQA 0.78%、KSA+MLA 0.22%)。这是从工程角度极其友好的设计。
-
完整的工程化技术栈:
- 块稀疏 attention kernel(训练 / prefill)和 contiguous-tensor KV cache 布局(推理)同步开源;
-
三阶段 CPT 食谱:summary token 适配(layer-wise + distribution-wise + objective-wise 三粒度蒸馏)→ parameter annealing(把独立 summary 参数渐进吸收回主权重,避免推理增加参数)→ length extension。
-
清晰的实验对照:从 4K 到 128K 系统地与 Full / SWA / SCA / GDN / Linear 等一组完整 baseline 对比,证明在 from-scratch(1.9B 训 400B token)和 CPT(Qwen3-4B-base 训 85B token)两种设置下都成立。
-
完整的注意力 pattern 解释性分析:通过 per-layer attention map 揭示 hybrid 配置中 shallow "comb" pattern + 全注意力层 cross-chunk integrator 协同提供长上下文检索能力的机制——具有较高的方法论参考价值。
工业落地价值¶
KSA 与 KuaiShou OneRec 系列推荐系统强关联——文末"Unifying with OneRec"明确提出未来方向是构建一个 KSA + OneRec 的生成式推荐基础模型。在用户行为序列推荐场景,KSA 的 chunk-and-summarize 设计能把任意长用户行为轨迹(数千次交互)压缩为 hierarchical summary token 同时保留近期 sliding window 的 fine-grained 行为,理论上可弥合 LLM 风格 world knowledge 和推荐风格用户建模之间的鸿沟。
局限性¶
-
Summary token 在当前设计中是 fully visible 的——所有距离的 summary 在每次 attention 中都被涉及。当上下文极长时,summary buffer 本身也会变得很大。作者在未来工作中提出 Sparse summary attention——通过 query-conditioned 的 learned sparse retriever 只激活相关 summary,但本论文未实现。
-
Chunk size 是静态超参数 $S$。不同 token 类型(如长 code 文档 vs 短对话)对最优 chunk 大小可能差异很大,但 KSA 没有提供 dynamic chunking 机制。
-
Summary token 设计本身假设输入有清晰的 chunk 边界——对结构化文本(书籍、代码)较自然,对自由文本可能存在切割不当问题(虽然 SCA 已经避免了边界切割导致的信息丢失)。
-
CPT 相比 from-scratch 长上下文领先有所收窄:CPT 设置下 RULER-128K 上 Hybrid-KSA 71.67 仅比 Full 65.86 高 +5.81,远不如 from-scratch 的 +16.60。CPT 设置下 Full attention 已经从 Qwen3-4B-base 继承了强大能力,hybrid 架构的相对优势被压缩。
-
后训练(SFT、DPO、RLHF、reasoning RL)尚未做——所有结果都来自预训练阶段。后训练阶段 summary token 与 task-specific gradient 的兼容性还是开放问题,作者列为下一步工作。
-
Scaling laws of compression ratio 还没研究透——chunk size $S$、模型容量、任务难度三者的关系尚未完整理论化。这是把 KSA 推到下一代 frontier model 的必要工作。
总体而言,KSA 是一篇技术含量高、工程实现完整、消融充分、解释性分析详尽的长上下文优化技术报告,其 sequence-level KV cache 压缩 + 局部 dense + 远程 summary 的设计模式很可能成为未来推荐与 LLM 融合范式的重要基础——值得长期跟进其与 OneRec 的整合进展。