Multi-Epoch Learning for Deep Click-Through Rate Prediction Models (MEDA)¶
- 作者:Zhaocheng Liu, Zhongxiang Fan, Jian Liang, Dongying Kong, Han Li
- 单位:KuaiShou Technology, Beijing
- arXiv: 2305.19531(2023-05-31)
研究动机与背景¶
工业级 CTR 模型几乎是清一色的 Embedding + MLP 范式:海量极度稀疏的 categorical 特征(item id、user id、shop id 等)先经 embedding 层映射到低维稠密空间,再被 MLP 用于点击率回归。这一范式在工业部署中长期被一个反直觉的现象困扰,即所谓的"单轮过拟合(one-epoch overfitting phenomenon)":模型在第一轮(epoch 1)训练中性能稳步上升,但只要进入第二轮训练,模型在测试集上的指标会立即出现急剧下降。这一现象在 Zhang et al. (CIKM '22) 等工作中被系统观察并刻画,使得绝大多数工业 CTR 模型在生产环境中只敢训练 1 个 epoch,导致样本利用率极低、训练数据需求量大、迭代成本高。
围绕该现象,已有两条研究脉络。第一条来自 Deep Neural Networks (DNNs) 的传统过拟合研究(如 over-parameterization、double descent、过拟合的成因等),但这些工作几乎都不在 CTR 场景下展开。第二条是针对 LLM SFT 的过拟合分析(Long et al.),观察到 LLM 在监督微调时也会出现类似的"单轮最优"现象,并提出"适度过拟合反而有益"的命题,但这一观察并未给出具体的训练范式。
本文的核心立论是:CTR 任务和 DNN/LLM 的本质差异在于输入特征的高维稀疏性。CTR 输入由数十亿低频 categorical 特征组成,这种极端稀疏性使得 embedding 层成为模型中最容易过拟合的组件(Zhang et al. 已通过特征离散化降低稀疏度,间接验证了这一点)。基于此假设,论文提出:只要在多轮训练中阻止 embedding 过拟合、同时维持 MLP 的多轮收敛,就能突破单轮训练的性能上限。
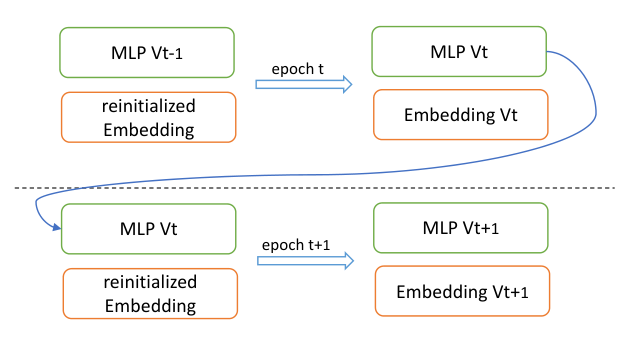
由此衍生出 MEDA(Multi-Epoch learning with Data Augmentation):在每个 epoch 开始时重新随机初始化 embedding 层,让 MLP 在每个 epoch 看到一组"新的、随机的" embedding 表示,相当于对训练数据做了一次数据增强;而 MLP 的参数则正常跨 epoch 累积更新。MEDA 是据作者所知第一个为深度 CTR 模型专门设计的多轮训练范式。
核心方法 / 模型架构¶
Embedding & MLP 架构¶
MEDA 不改变现有 CTR 模型的网络结构,仅修改训练流程。被改造的 base 模型遵循标准 Embedding & MLP 范式:
输入特征包含三类: 1. Item profile:item id 及其 side information(brand id、shop id、category id 等)。 2. User profile:user id、age、gender、income level 等。 3. Long-/Short-Term User Behavior:每个用户 $u \in \mathcal{U}$ 在不同行为类型(impression、click、conversion、payment)和不同时间窗口下的多条历史行为序列。
原始特征先经过特征离散化(feature discretization)和特征选择(feature selection),将连续特征也转换为 categorical 特征。最终绝大多数模型输入都是高维稀疏的 categorical 字段。
Embedding 层:对第 $i$ 个特征字段 $f_i$,定义其 embedding 字典
$$\mathbf{E}^i = [e_1^i, \ldots, e_j^i, \ldots, e_{N^i}^i] \in \mathbb{R}^{D \times N^i} \tag{1}$$
其中 $D$ 是 embedding 维度,$N^i$ 是该字段的特征基数。若 $f_i$ 是 one-hot($f_i[j] = 1$ for some $j$),其 embedding 就是单个向量 $e_j^i$;若 $f_i$ 是 multi-hot($f_i[j] = 1$ for $j \in \{i_1, i_2, \ldots, i_k\}$,例如行为序列),其 embedding 是 $\{e_i^{i_1}, e_i^{i_2}, \ldots, e_i^{i_k}\}$,再通过池化(pooling)操作得到固定长度向量。
MLP 层:将所有字段的 embedding 拼接为 dense 向量,输入 MLP 捕捉特征之间的非线性交互。论文强调:考虑到工业场景中用户历史行为的爆发增长,MLP 设计的关键在于用户行为建模——即 DIN/DIEN/MIMN/ADFM 等以 attention/GRU/memory network 等机制刻画用户兴趣演化的方法。MEDA 在这一层不引入任何新结构。
MEDA 训练算法¶
MEDA 的核心思想可以一句话概括:让 MLP 跨 epoch 持续训练,但在每个 epoch 开始时把 embedding 层"扔掉",重新随机初始化。这样:
- Embedding 层:每个 epoch 都是从随机初始化开始,做的是一次单 epoch 训练 → 不会出现 embedding 过拟合(因为它根本没机会学超过 1 个 epoch)。
- MLP 层:每个 epoch 看到的是经过新一轮 embedding 重学后的 dense 表示,但 MLP 自己的参数 $\theta$ 跨 epoch 持续优化 → MLP 的容量得到充分利用,能学到比单 epoch 更深的非线性模式。
这一设计的关键 insight 是:MLP 学到的不是某个具体 embedding 形态下的模式,而是 id 本身(即 categorical 特征的"重要性"或"模式")。每一个 epoch 提供的随机 embedding 都相当于对 id 做了一次新的"编码方式",MLP 只能依赖 id 的结构性信息而不是 embedding 的几何细节,从而具备跨 embedding 视角的泛化能力。这与传统数据增强的 motivation 一致——给同一份数据多种"视角",迫使模型学到更鲁棒的语义。
形式化:
Algorithm 1: Training process of MEDA
Input: Training dataset D_tr, maximum training epoch n
Output: MLP variable θ and embedding E
1. random initialize MLP variable θ_0 and embedding E
2. for i = 0 to n - 1 do
3. if i > 0 then
4. random initialize E
5. end if
6. update θ_i, E by one-epoch training
7. θ_{i+1} = θ_i
8. end for
9. return θ = θ_n, E
值得注意的几点:
- Embedding 与 MLP 的耦合:line 6 中 $\theta_i, E$ 都被 one-epoch 训练更新;只是从下一个 epoch 开始,$E$ 会被丢弃重置,而 $\theta$ 持续保留。
- 最终输出:返回的 embedding $E$ 是最后一个 epoch 训练完的 embedding(仅经历了 1 个 epoch 训练),而 MLP $\theta = \theta_n$ 经历了完整的 $n$ 个 epoch 训练。
- 替代方案的负面探索:作者在 §3.2 提到他们尝试过几种"温和"变体——只在第二个 epoch 开始时冻结 embedding、训练 MLP 多次、从头冻结 embedding 只训练 MLP 等——但这些方案要么不收敛、要么仍然过拟合,只有完全重新初始化 embedding 才有效。这一负面结果间接强化了"embedding 过拟合是主因"的命题:仅冻结无法消除已学到的过拟合模式,必须重置才能彻底打破。
MEDA 为何能起到"数据增强"的效果¶
论文对"数据增强"这一比喻给出了实证支持(Figure 2/3,见下文):在不使用 MEDA 的多轮训练中,第二个 epoch 开始时 training loss 会急剧下降(说明模型在重复样本上很快记忆),同时 test AUC 急剧崩塌(过拟合)。而启用 MEDA 后,每个 epoch 开始时 training loss 会轻微回升,随后再缓慢下降——这正是模型遇到"新数据"时的典型曲线形状(如同看到新 domain 的样本会先识别错误、再逐步学习),从而支持"重新初始化 embedding 等价于让模型看到一份新的、增强后的训练数据"。
关键技术细节¶
为什么是 embedding 而不是 MLP 过拟合?¶
论文继承 Zhang et al. (CIKM '22) 的实证结论:通过特征离散化(feature discretization)降低输入特征的稀疏度,可以有效缓解单轮过拟合现象。这一观察反向证明了过拟合的根源在 embedding 层——稀疏度越高,每个特征 id 出现的次数越少,embedding 也就越容易记住特定样本而非学到泛化的模式。
但是,特征离散化又会降低特征基数,从而牺牲模型表达能力——这是 CTR 任务的固有矛盾。MEDA 提出的"维持稀疏度同时避免 embedding 过拟合"是对这一矛盾的解耦:
- 稀疏度(sparsity)作为 CTR 任务的本质特征被保留 → 不损失原始特征表达力;
- Embedding 的过拟合通过"反复重置"被根本性消除 → 不需要降低 embedding 容量;
- MLP 由于持续训练且每 epoch 见到新视角的 embedding,反而获得超过单轮训练的收敛深度。
MEDA 与 DNN 普通 dropout / 正则化的区别¶
直观看,MEDA 是一种"极端 dropout"——把整个 embedding 表完全置零并重新采样。但与传统正则化的关键区别在于:MEDA 的"丢弃"是 epoch 边界级的、全局的、彻底的,而不是 batch 内或 dimension 级的随机抑制。这种"硬重置"让 MLP 不可能在 embedding 的几何坐标上记忆任何模式,必须依赖 id 的统计本质(如某个用户对某品类的偏好的"权重")。论文用"reinitializing the embedding ... thereby treating the MLP can not only learn more deeply over multiple epochs, but also come to understand that the real significance lies in the id itself, not the corresponding embedding"这句话明确点出了这一机制。
实验设置¶
数据集¶
两个公开 CTR 数据集:
- Amazon Books:51M 条记录,1.5M 用户,2.9M items(1252 categories);将商品评论视为点击行为。
- Taobao:89M 条记录,1M 用户,4M items(9407 categories);只考虑用户的点击行为。
两个数据集都是大规模稀疏 CTR 评测的经典 benchmark。
Baselines¶
MEDA 是一个训练范式,可以"插入" 到任何 Embedding + MLP 架构上。论文选取了 5 个有代表性的 base 模型:
- DNN:基础深度 CTR 模型,embedding 层 + 前馈 ReLU 网络。
- DIN(Zhou et al. 2018):用 attention 机制建模用户对候选物品的相关兴趣。
- DIEN(Zhou et al. 2019):用 GRU 建模用户兴趣演化。
- MIMN(Pi et al. 2019):用 memory network 建模多通道用户长兴趣漂移。
- ADFM(Li et al. 2022):对长期用户行为序列的对抗性过滤模型。
记原模型为 Base,启用 MEDA 后为 Base+MEDA。
训练配置¶
- Optimizer:Adam,学习率 0.001。
- Loss:binary cross-entropy。
- Metric:AUC。
- Hyperparameters:所有 base 模型沿用各自原论文中的最优超参数。
- Epoch 数:Base 训练 1 epoch;Base+MEDA 训练 2 epoch。论文强调 2 epoch 是"最经济实用"的配置——MEDA 多一个 epoch 即可大幅超越 Base。
主要实验结果¶
Performance Evaluation: 第二轮性能即超越单轮最优¶
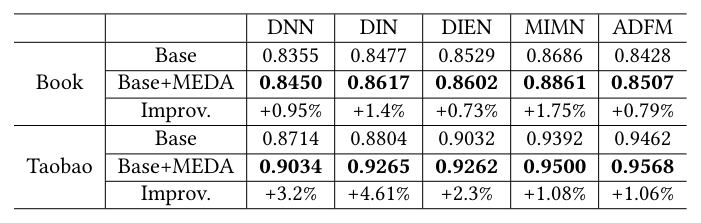
Table 1(重排为 Markdown 表):
| 数据集 | 方法 | DNN | DIN | DIEN | MIMN | ADFM |
|---|---|---|---|---|---|---|
| Book | Base | 0.8355 | 0.8477 | 0.8529 | 0.8686 | 0.8428 |
| Book | Base+MEDA | 0.8450 | 0.8617 | 0.8602 | 0.8861 | 0.8507 |
| Book | Improv. | +0.95% | +1.4% | +0.73% | +1.75% | +0.79% |
| Taobao | Base | 0.8714 | 0.8804 | 0.9032 | 0.9392 | 0.9462 |
| Taobao | Base+MEDA | 0.9034 | 0.9265 | 0.9262 | 0.9500 | 0.9568 |
| Taobao | Improv. | +3.2% | +4.61% | +2.3% | +1.08% | +1.06% |
结论分析:
- Base+MEDA 在所有 5 个 base 模型 + 2 个数据集(共 10 个组合)上都稳定超越 Base 的单轮最优——这是论文的核心主张:MEDA 不是某个特定架构的 trick,而是适用于一类 Embedding & MLP 模型的训练范式。
- Taobao 上的提升幅度(+1% 到 +4.61%)显著大于 Book,原因可能是 Taobao 数据集规模更大、稀疏度更高,embedding 过拟合的代价更显著,MEDA 修复的空间更大。
- CTR 领域 1% 的 AUC 提升通常对应明显的线上收入增长(业内经验),所以 +3% 量级的离线提升非常可观。
- DNN(最简单的 baseline)受益最大——在 Taobao 上 +3.2%。这说明即使在没有 attention/memory 等先进用户行为建模结构的 base 模型上,MEDA 也能带来非平凡提升。这反过来意味着部分被业界归功于"复杂用户行为建模"的提升,可能其实可以通过更好的训练范式获得。
单轮过拟合现象的可视化¶
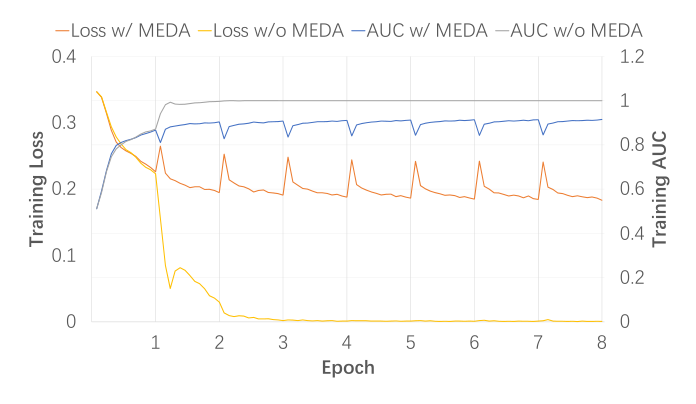
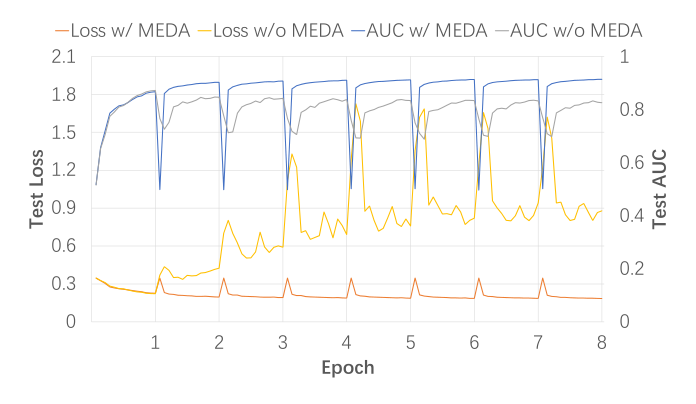
Figure 2/3 用 DNN 在 Taobao 上的训练曲线进一步支持作者的"数据增强"诠释:
- Loss w/o MEDA:第一个 epoch 内训练 loss 平稳下降(0.4 → 约 0.3);进入第二个 epoch 时断崖式下降到接近 0(说明模型把训练样本几乎完全记忆住了)。同时 Test AUC 在第二个 epoch 开始断崖式崩塌(约 0.85 → 0.5 量级)——这就是经典的单轮过拟合现象。
- Loss w/ MEDA:第一个 epoch 与 baseline 类似,但每次进入新 epoch(embedding 重置后),训练 loss 都会先轻微反弹再缓慢下降——曲线呈"锯齿状但整体平稳"。Test AUC 不仅没有崩塌,反而在每轮 epoch 后小幅提升或保持稳定,最终高于 Base 的单轮最优。
这一对照实验以可视化的方式证明:MEDA 改变了多轮训练的优化轨迹,把"快速记忆 + 测试崩塌"扭转为"持续小幅改进"。论文以此作为"MEDA 具有数据增强语义"的定性证据:Loss 曲线的反弹形态与模型遇到新 domain 数据时的表现一致。
Ablation: 8-epoch 的稳定上升趋势¶
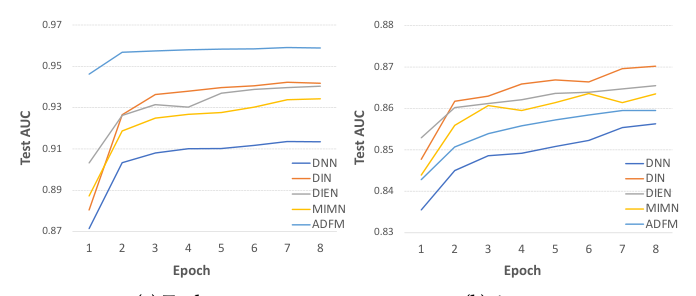
为了验证 MEDA 在更多轮训练下的可扩展性,作者把所有 base+MEDA 训练到 8 epoch,并在每个 epoch 末记录 Test AUC:
- Taobao:所有 5 个模型(DNN/DIN/DIEN/MIMN/ADFM)的 Test AUC 在 8 个 epoch 内持续平稳上升,没有出现崩塌或剧烈震荡,呈现单调或近单调改进。
- Amazon:曲线形状类似,但提升幅度略小。
这有重要的工业意义:在工业场景下,由于数据规模动辄数十亿样本、计算资源有限,通常只能训练 3-4 个 epoch。MEDA 的曲线显示,即使提前停止在任意 epoch,模型也能比单轮训练好,且多训一个 epoch 几乎总能再小幅提升——这给运维人员提供了"按算力预算自由选 epoch 数"的操作空间。
样本效率:用更少数据恢复完整数据集的效果¶
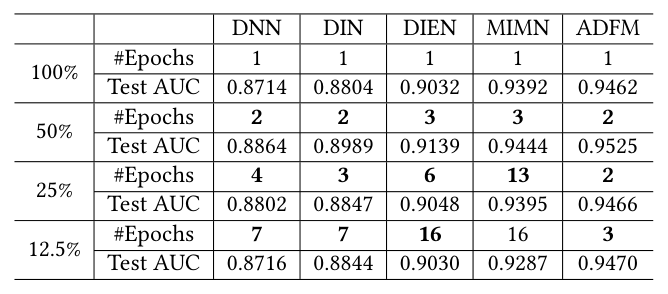
为定量刻画 MEDA 的"数据增强"效益,作者把 Taobao 训练集随机降采样到 50% / 25% / 12.5% 三档,分别看 MEDA 训练多少个 epoch 才能匹配 1-epoch 全量 Base 的 Test AUC(基线 Test AUC 见 100% 行):
| 数据规模 | DNN #Epochs | DNN AUC | DIN #Epochs | DIN AUC | DIEN #Epochs | DIEN AUC | MIMN #Epochs | MIMN AUC | ADFM #Epochs | ADFM AUC |
|---|---|---|---|---|---|---|---|---|---|---|
| 100% | 1 | 0.8714 | 1 | 0.8804 | 1 | 0.9032 | 1 | 0.9392 | 1 | 0.9462 |
| 50% | 2 | 0.8864 | 2 | 0.8989 | 3 | 0.9139 | 3 | 0.9444 | 2 | 0.9525 |
| 25% | 4 | 0.8802 | 3 | 0.8847 | 6 | 0.9048 | 13 | 0.9395 | 2 | 0.9466 |
| 12.5% | 7 | 0.8716 | 7 | 0.8844 | 16 | 0.9030 | 16 | 0.9287 | 3 | 0.9470 |
结论分析:
- MEDA 在仅 12.5% 数据 + 至多 16 个 epoch 的预算下,即可恢复 4 个模型(DNN/DIN/DIEN/ADFM)单轮全量训练的效果——这意味着样本利用率提升了 8 倍,对工业级数据迭代周期非常有意义。
- MIMN 例外:在 12.5% 数据下,即使训练 16 个 epoch 也仅能达到 AUC 0.9287(不及全量 0.9392)。作者推测这是因为 MIMN 是为长用户行为窗口设计的 memory network,行为窗口越长,id 特征之间的交互关系越复杂,MEDA 的"重置 embedding"虽然消除了过拟合,但失去了已学到的 id 间细致交互关系,需要更多数据来重建。
- ADFM 表现优异:在 12.5% 数据 + 仅 3 个 epoch 下就匹配了全量效果。原因可能是 ADFM 的对抗过滤机制使得它对 id-level 噪声更鲁棒,而不是过度依赖 embedding 几何,因此 MEDA 的 reset 不会损失太多既有信息。
这一表格进一步细化了 MEDA 的适用边界:对依赖 id-level 关系建模的简单/中等模型(DNN/DIN/DIEN/ADFM),MEDA 是高效的"训练数据放大器";对依赖跨 id 长期记忆的 memory network 类模型(MIMN),MEDA 仍有效但效率打折。
消融与分析¶
§4.3 的消融实验(即 Figure 4 + Table 2)已与主表实验交织讨论。论文未独立列出"去掉某个组件"的消融——因为 MEDA 本身就是一个极简训练范式,唯一可调的就是"是否在每个 epoch 开始重置 embedding",这点已经被 Figure 2/3 的 w/ vs w/o MEDA 对比 + Table 1 的全模型 sweep 充分验证。
§3.2 中讨论的若干负面替代方案(论文未给数值,仅文字说明),可视为隐式消融:
- 第二个 epoch 开始冻结 embedding,训练 MLP 多次:仍然过拟合。原因:embedding 已经被第一个 epoch 学到了过拟合模式,冻结只是阻止它继续偏移,但已经学到的偏置仍然误导 MLP。
- 从头冻结 embedding(从随机初始化开始就只训 MLP):不收敛。原因:MLP 必须依赖学到的 embedding 才能做出有意义的预测,完全随机的 embedding 提供的信号过弱。
- 训练 MLP 多次但 embedding 不重置:与基线相同,过拟合。
- 从第二个 epoch 开始才重置 embedding:未明确报告,但暗示效果不如每轮重置。
这些负面结果共同指向一个收紧的结论:只有"每 epoch 都做一次完整的 embedding-reset + MLP-continue"才能同时享受多轮训练的容量收益和单轮训练的泛化保护。
在线 A/B 实验:Kuaishou 真实部署¶
§4.4 描述了在 Kuaishou 推荐场景下的为期 9 天的线上 A/B 实验:
- Baseline:之前的 SOTA 在线方法(论文未具体命名,但应是 Kuaishou 内部已部署的某种 Embedding + MLP CTR 模型)。
- MEDA online metric 提升:
- AUC: +0.14%
- Cumulative revenue: +4.6%
- Social welfare: +7.4%
这里 "social welfare" 是 Kuaishou 衡量广告生态健康度的复合指标(同时考虑广告主、平台、用户三方利益)。+4.6% 累计收入和 +7.4% social welfare 在工业 A/B 实验中是显著且实用的量级。
更值得关注的是样本规模的削减:
"achieving sufficient model performance for this scenario on Kuaishou requires training on approximately one month's worth of data. However, by employing the MEDA approach, comparable results can be achieved after training on just two weeks of data."
也就是说,在 Kuaishou 的实际生产环境下,MEDA 把所需训练数据从 1 个月降到 2 周,训练成本(计算 + 存储 + 数据 ETL)几乎减半。考虑到 Kuaishou 推广业务每天的样本量可能在数十亿至百亿级,这种削减带来的实际节省非常可观。这是论文最具工业价值的一条贡献。
作者同时声称:MEDA 是据他们所知第一个解决大规模稀疏模型多轮训练过拟合问题的工业部署方案(第一句话:"To our best knowledge, this is the first approach that resolves the problem of overfitting in multi-epoch training of large-scale sparse models for advertising recommendations")。
讨论与局限性¶
核心贡献¶
- 首次提出 CTR 多轮训练范式:在长期被业界视为"无法多轮训练"的工业 CTR 任务上,给出了可工程化、可即插即用的多轮范式。
- 机制层面定位过拟合根源:明确指出 embedding 层是单轮过拟合的主因(通过反证:reset embedding 即可解决,仅 freeze 不行),加深了社区对 CTR 过拟合现象的理解。
- 数据增强的新解释:把"reset embedding"重新诠释为对 dense 表示的数据增强,连接了多轮训练范式与传统数据增强方法论,为后续工作提供了一个新视角。
- 工业级落地验证:Kuaishou 9 天 A/B 实验给出 +0.14% AUC / +4.6% revenue / +7.4% social welfare,并把训练数据需求减半。
值得借鉴的设计¶
- 极简哲学:MEDA 的算法仅有 8 行伪代码,不引入任何新参数、新模块、新损失函数,但效果显著。这种"通过修改训练流程而不是模型结构来获得性能提升"的范式在工业场景下尤其有价值,因为它对现有部署管线几乎没有侵入。
- id-vs-embedding 的解耦视角:论文反复强调 MLP 学到的应该是"id 本身的重要性"而不是"特定 embedding 形态下的几何关系",这一抽象有助于设计其他形式的 robust 训练范式(如 embedding noise injection、orthogonal embedding rotation、permutation-invariant pretraining 等)。
局限与争议¶
- 理论解释偏弱:论文的核心主张"embedding 是单轮过拟合的根源"主要靠现象学证据(reset embedding 有效 vs freeze embedding 无效),缺乏严格的理论分析。例如,没有从 generalization bound、信息论或 NTK 视角给出可验证的 formal claim。
- MIMN 类长期记忆模型上的退化:Table 2 显示 MIMN 在低数据状态下 MEDA 难以恢复全量效果。这暗示对依赖 cross-epoch id-level 记忆的模型,"硬 reset embedding" 可能是过度激进的——折中方案(如部分 reset、re-init 但保留某种统计 prior)值得探索但论文未触及。
- 缺乏更多公开模型/数据集 generalization 实证:论文只在两个公开 CTR 数据集 + 5 个 base 模型上实验,未在 KDD/RecSys 主流的更多 sequential recommendation 模型(如 SASRec、BERT4Rec)或更近的 Transformer-based ranking 模型上验证。
- 与 LLM SFT 类似现象的连接被搁置:作者引用 Long et al. 关于 LLM SFT "适度过拟合 beneficial" 的观察,但未深究 MEDA 的"避免 embedding 过拟合"是否能延伸到 LLM 词嵌入层;是否所有"输入是 categorical id 序列"的模型都适用 MEDA 范式,留待未来工作。
- Online A/B 实验细节较少:仅给出 3 个聚合指标,未披露 baseline 模型架构、流量切分大小、置信区间,使得复现难度较高。
- 2-epoch 是否就是上限?:Figure 4 显示 8 epoch 仍在缓慢上升,但论文推荐"2 epoch 最经济"。何时收益递减、计算成本与收益的最优 trade-off 没有给出一般性的结论。
与已有工作的差异¶
- vs. 传统 DNN over-parameterization 研究([1, 2, 15, 17, 24]):那些工作大多关注 vision/dense-feature 任务的 double descent 现象,而 CTR 任务的高维稀疏特征带来的过拟合机制不同,MEDA 是首个针对 CTR 域的专门方案。
- vs. Zhang et al. CIKM '22([19]):Zhang 等通过特征离散化降低稀疏度来缓解单轮过拟合,但代价是损失模型表达能力。MEDA 走相反路径——保留稀疏度、改造训练流程。
- vs. LLM SFT 单轮过拟合([12]):Long et al. 的观察是 LLM 上单轮过拟合现象与 CTR 类似,但他们认为"适度过拟合反而有益"。MEDA 隐含的立场是"过拟合一律坏,只是有些(MLP)能容纳多轮训练,有些(embedding)不行"。两者在实证现象上吻合,但在干预策略上分歧。
核心贡献总结¶
| 维度 | 内容 |
|---|---|
| 问题 | 工业级深度 CTR 模型的"单轮过拟合"现象阻止了多轮训练的应用 |
| 假设 | 过拟合主要来自 embedding 层(因高维稀疏 categorical 特征) |
| 方案 | MEDA:每 epoch 开始时重新随机初始化 embedding,MLP 持续训练 |
| 离线效果 | Book +0.7~1.8% AUC,Taobao +1~4.6% AUC,跨 5 个 base 模型一致提升 |
| 在线效果 | Kuaishou 9 天 A/B:+0.14% AUC, +4.6% revenue, +7.4% social welfare;训练数据需求减半 |
| 创新点 | 业界首个可工业部署的 CTR 多轮训练范式 |
与已归档相关工作的对比¶
文档库中暂未归档与 MEDA 在"问题 + 解法双同构"上能配对的论文——多数已归档工业推荐论文聚焦于生成式架构、长序列建模、SID 量化等正交方向,无人直接处理"CTR 单轮过拟合 / embedding-level 训练范式"这一根本问题。因此本节略过。