In-Place Test-Time Training¶
研究动机与背景¶
大语言模型(LLM)的成功建立在"先训练再部署"的静态范式上:模型在海量语料上预训练后,推理阶段权重固定不变。这意味着模型无法根据推理时流入的连续信息流动态调整自身权重,从而限制了其在长上下文推理、持续演化任务和无界经验学习中的能力。
In-context Learning 通过保留所有历史 token 缓解了部分问题,但受限于注意力机制的二次复杂度,其有效性与上下文窗口大小绑定。Test-Time Training (TTT) 作为另一范式被提出:在推理时通过自监督目标动态更新模型参数的一个子集(称为 fast weights),使其充当压缩和检索上下文信息的在线演化状态。
然而,TTT 在当前 LLM 生态中面临三大障碍:
- 架构不兼容(Architectural Incompatibility):现有 TTT 方法通常引入专门的新层替代注意力机制,需要从头预训练,无法直接用于已有的数十亿参数预训练模型
- 计算低效(Computational Inefficiency):TTT 的逐 token 更新本质上是串行的,严重瓶颈 GPU/TPU 的并行能力;虽然 chunk-wise 更新被探索过,但 TTT 作为主要 token mixer 时仍依赖小 chunk 维持性能
- 目标函数不对齐(Misaligned Objective):TTT 普遍使用重建(reconstruction)目标,即 key 和 value 都来自同一 token,但这与 LLM 的核心目标——Next-Token Prediction (NTP)——并不直接对齐
核心方法 / 模型架构¶
TTT 机制回顾¶
TTT 的核心是 fast weights $\mathbf{W}$,构成一个小型神经网络 $f_{\mathbf{W}}(\cdot): \mathbb{R}^d \to \mathbb{R}^d$,在推理时被快速更新。对输入序列 $\mathbf{x} = [x_1, x_2, \ldots, x_N]$,每个 token $x_i \in \mathbb{R}^d$ 被投影为 query ($q_i$)、key ($k_i$)、value ($v_i$),然后执行:
-
Update 操作:用 $(k_i, v_i)$ 对更新 fast weights: $$\mathbf{W}_i \leftarrow \mathbf{W}_{i-1} - \eta \nabla_{\mathbf{W}} \mathcal{L}\left(f_{\mathbf{W}_{i-1}}(k_i), v_i\right) \tag{1}$$
-
Apply 操作:用更新后的 $\mathbf{W}_i$ 处理 query:$o_i = f_{\mathbf{W}_i}(q_i)$
In-Place TTT 的三大设计¶
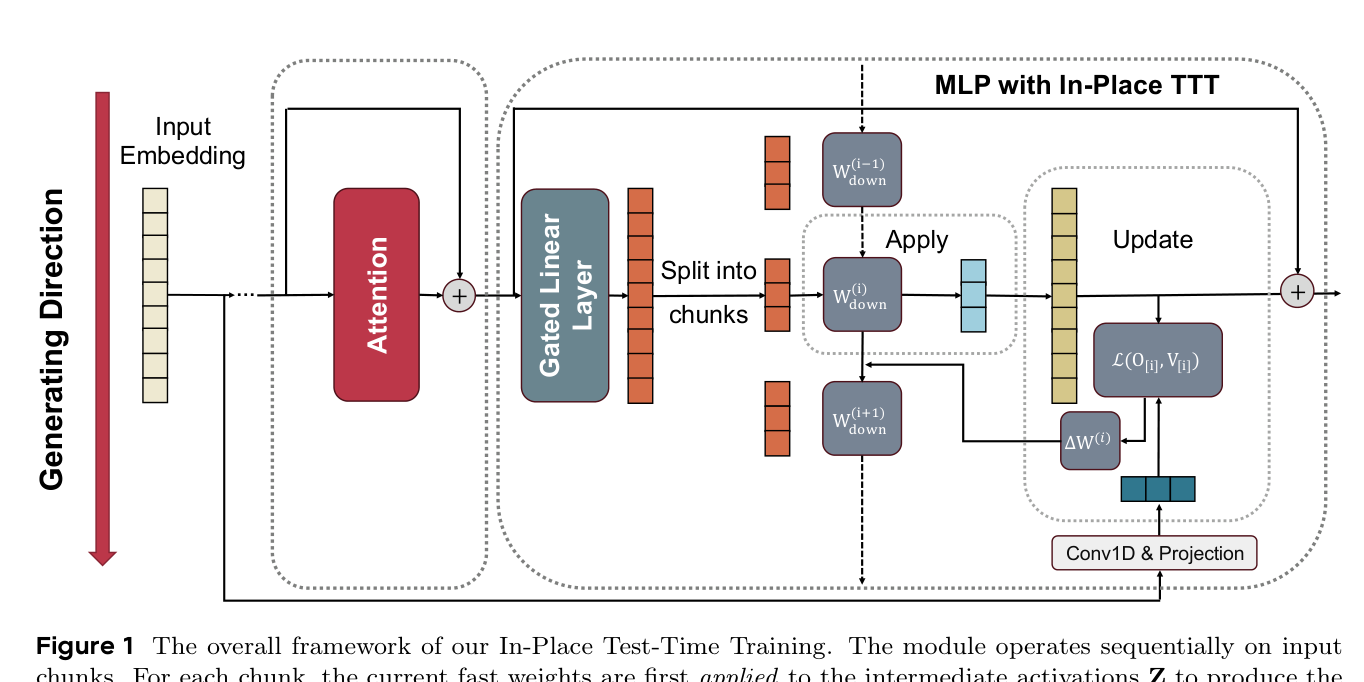
3.1 复用 MLP Block 作为 Fast Weights(解决架构兼容性)¶
核心洞察:不引入新层,而是将已有 MLP block 的最终投影矩阵 $\mathbf{W}_{\text{down}}$ 作为 fast weights 进行原地更新。
对于 gated MLP,输出计算为:
$$\mathbf{O} = \left(\phi(\mathbf{H}\mathbf{W}_{\text{gate}}^\top) \odot (\mathbf{H}\mathbf{W}_{\text{up}}^\top)\right) \mathbf{W}_{\text{down}} \tag{2}$$
其中 $\mathbf{H}$ 是隐藏表示,$\mathbf{W}_{\text{gate}}$ 和 $\mathbf{W}_{\text{up}}$ 作为 frozen slow weights 保持不变,仅 $\mathbf{W}_{\text{down}}$ 被动态更新。这种设计是一个 "drop-in" 增强,不改变模型架构,保留预训练权重的完整性。
Chunk-wise 更新:将中间激活 $\mathbf{Z} = \phi(\mathbf{H}\mathbf{W}_{\text{gate}}^\top) \odot (\mathbf{H}\mathbf{W}_{\text{up}}^\top) \in \mathbb{R}^{n \times d_H}$ 和对应的输出 $\mathbf{V}, \mathbf{O} \in \mathbb{R}^{n \times d_{\text{model}}}$ 分成 $k$ 个不重叠的 chunk,每个 chunk 大小为 $C$。记 $\square_{[i]} = \square_{iC+1:(i+1)C}$,对每个 chunk $i \in [k]$ 执行:
- Apply:$\mathbf{O}_{[i]} = \mathbf{Z}_{[i]}(\mathbf{W}_{\text{down}}^{(i)})^\top$
- Update:$\mathbf{W}_{\text{down}}^{(i+1)} = \mathbf{W}_{\text{down}}^{(i)} - \eta \nabla_{\mathbf{W}} \mathcal{L}\left(\mathbf{Z}_{[i]}(\mathbf{W}_{\text{down}}^{(i)})^\top, \mathbf{V}_{[i]}\right)$
由于是 MLP 适配而非注意力替代,chunk 大小不受小 chunk 约束,实验中 $C = 512$ 或 $C = 1024$ 效果最佳。
3.2 LM-Aligned 目标函数(解决目标不对齐)¶
传统 TTT 的重建目标中,$k$ 和 $v$ 都来自同一 token $x$,模型只需记忆当前 token 表示。本文提出 LM-Aligned Objective:将 target $v$ 设计为包含未来 token 信息,显式对齐 NTP 目标。
具体地,定义目标 value 为:
$$\bar{\mathbf{V}} = \text{Conv1D}(\mathbf{X}_0) \mathbf{W}_{\text{target}} \tag{3}$$
其中 $\mathbf{X}_0 \in \mathbb{R}^{n \times d_{\text{model}}}$ 是 token embedding,$\text{Conv1D}(\cdot)$ 是因果 1D 卷积算子,$\mathbf{W}_{\text{target}} \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}}$ 是可训练投影矩阵。通过参数化 $\mathbf{W}_{\text{target}}$ 为恒等变换、$\text{Conv1D}$ 的 kernel weights 为 next token 权重 1 其余为 0,即可实现精确的 Next-Token target。
使用相似度度量作为损失函数 $\mathcal{L}(\cdot, \cdot) = -\langle \cdot, \cdot \rangle_F$,fast weights 的更新规则可直接推导为:
$$\mathbf{W}_{\text{down}}^{(i)} = \mathbf{W}_{\text{down}}^{(i-1)} + \eta \bar{\mathbf{V}}_{[i]}^\top \mathbf{Z}_{[i]} \tag{4}$$
这是一个简洁的外积累加形式,计算高效。
3.3 理论分析:LM-Aligned vs 重建目标¶
论文在 induction head 设定下给出了理论对比。设某 key-value 对 $(k^*, v^*)$ 出现在位置 $t^*$,query 位置 $n > t^*$ 出现相同 key $x_n = k^*$,模型需预测 $x_{n+1} = v^*$。
Theorem 1(Logit-wise Effect):在近似正交 embedding 和 key-query 对齐假设下,使用 LM-Aligned target 进行一步更新后:
$$(正确\ logit\ 增大) \quad \mathbb{E}[\Delta \ell_n[v^*]] \geq \lambda_{\text{lr}} \cdot c_{\text{norm}}^2 \cdot c_{\text{align}} \tag{5}$$
$$(其他\ logit\ 几乎不变) \quad |\mathbb{E}[\Delta \ell_n[w]]| \leq \lambda_{\text{lr}} \cdot \epsilon \cdot c_{\text{align}}, \quad \forall w \neq v^* \tag{6}$$
相比之下,重建目标对正确 token 的 logit 变化是 negligible 的:$|\mathbb{E}[\Delta \ell_n[v^*]]| \leq \lambda_{\text{lr}} \cdot \epsilon \cdot c_{\text{align}}$。
直觉:LM-Aligned 目标让 fast weights 存储的是预测未来的有用信息,而重建目标只存储当前 token 的表示,对 NTP 无直接帮助。
3.4 实现细节¶
Context Parallelism (CP) 兼容:公式 (4) 的更新规则具有结合律(associative),天然支持 context parallel 实现:
- 对所有 chunk $i \in \{1, \ldots, T\}$,并行计算 $\mathbf{Z}_{[i]}$ 和 $\Delta \mathbf{W}_{\text{down}}^{(i)} = (\bar{\mathbf{V}}_{[i]})^\top \mathbf{Z}_{[i]}$
- 执行 prefix sum 聚合:$\Delta \mathbf{S}_i = \sum_{j=1}^{i-1} \Delta \mathbf{W}_j$
- 计算有效 fast weights:$W_{\text{down}}^{(i-1)} = \mathbf{W}_{\text{down}}^{(0)} + \eta \Delta \mathbf{S}_i$,并行算出 $\mathbf{O}_{[i]} = \mathbf{Z}_{[i]}(W_{\text{down}}^{(i-1)})^\top$
因果性保证:对 1D 卷积应用因果 padding,确保更新 delta 不包含未来信息。文档边界处 fast weights 重置为预训练状态。
实验设置¶
论文围绕三个研究问题设计实验:
- Q1:In-Place TTT 作为预训练 LLM 的 drop-in 增强效果如何?
- Q2:从头训练时与其他 TTT 方法对比如何?
- Q3:关键设计选择的影响?
数据集与评估¶
- Drop-in 增强实验:以 Qwen3-4B-Base 为基座,continual training ~20B tokens (32k) + ~15B tokens (128k),使用 YaRN 处理长序列。在 RULER benchmark 上评估 4k-256k 上下文
- 从头训练实验:在 TogetherAI 数据上训练 500M/1.5B/4B 模型,32k 上下文。评估 Sliding Window Perplexity (Pile + Proof-Pile-2) 和下游任务(HellaSwag, ARC, MMLU, PIQA, RULER)
- 消融实验:1.7B 模型在 RULER 上评估
主要实验结果¶
Q1: Drop-in 增强预训练 LLM(Table 1)¶
在 Qwen3-4B-Base 上的 RULER 评估(平均 accuracy %):
| Model | 4k | 8k | 16k | 32k | 64k | 128k | 256k |
|---|---|---|---|---|---|---|---|
| Mistral-7B | 93.6 | 91.2 | 87.2 | 75.4 | 49.0 | 13.8 | - |
| GLM3-6B | 87.8 | 83.4 | 78.6 | 69.9 | 56.0 | 42.0 | - |
| Phi3-medium-14B | 93.3 | 93.2 | 91.1 | 86.8 | 78.6 | 46.1 | - |
| Llama3-8B | 92.8 | 90.3 | 85.7 | 79.9 | 76.3 | 69.5 | - |
| Qwen3-4B (Instruct) | 95.1 | 93.6 | 91.0 | 87.8 | 77.8 | 66.0 | - |
| Baseline (Qwen3-4B-Base) | 96.6 | 94.1 | 92.1 | 88.7 | 74.3 | 74.8 | 41.7 |
| In-Place TTT | 96.1 | 95.6 | 92.7 | 89.3 | 78.7 | 77.0 | 43.9 |
结论:短上下文(4k)两者相当,但从 8k 开始 In-Place TTT 建立一致且持续扩大的优势。64k 时提升 4.4%,128k 时提升 2.2%。外推到 256k(超出训练窗口)仍有提升(41.7→43.9),展现了优越的泛化能力。
扩展到更多模型(Table 2)¶
| Base Model | Method | 4k | 8k | 16k | 32k | 64k | 64k+YaRN |
|---|---|---|---|---|---|---|---|
| LLaMA-3.1-8B | Baseline | 93.9 | 92.1 | 92.5 | 91.1 | 81.6 | - |
| In-Place TTT | 94.4 | 93.0 | 93.3 | 91.7 | 83.7 | - | |
| Qwen3-14B | Baseline | 96.8 | 95.0 | 94.6 | 90.7 | 67.9 | 81.3 |
| In-Place TTT | 97.2 | 95.7 | 95.2 | 91.2 | 70.6 | 82.5 |
在 LLaMA-3.1-8B 和 Qwen3-14B 上一致有效,跨模型家族(4B-14B)泛化良好。长上下文增益尤为显著(64k: +2.1/+2.7)。
Q2: 从头训练对比(500M/1.5B)¶
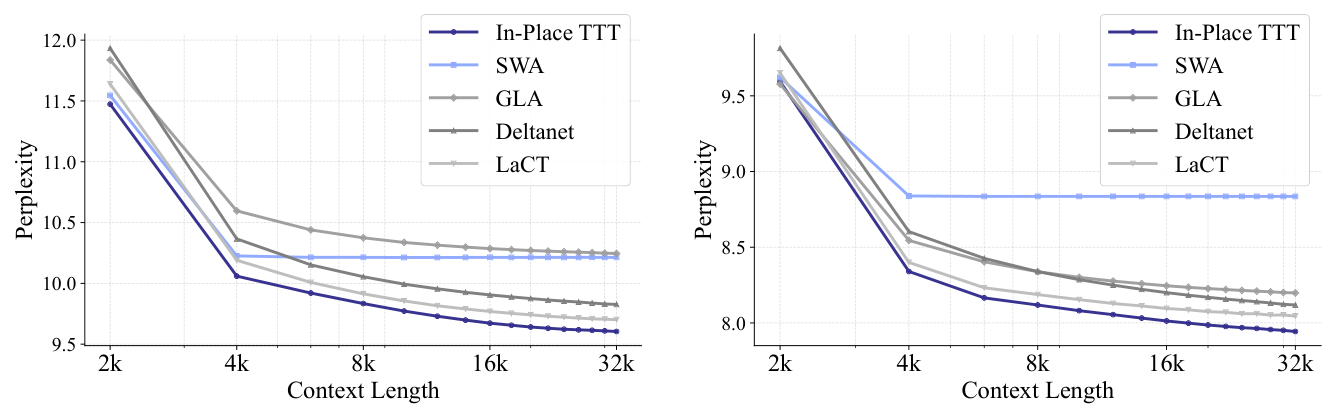
In-Place TTT 在 500M 和 1.5B 规模上均一致低于所有竞争基线(SWA, GLA, DeltaNet, LaCT)的 perplexity,且随上下文长度增长优势稳步扩大。
4B 模型从头训练(Table 3)¶
| Model | Architecture | HellaSwag | ARC-E | ARC-C | MMLU | PIQA | RULER-4k | RULER-8k | RULER-16k |
|---|---|---|---|---|---|---|---|---|---|
| Baselines | Full Attn. | 55.67 | 64.52 | 33.19 | 36.43 | 72.63 | 45.77 | 38.09 | 6.58 |
| SWA | 54.92 | 64.18 | 32.85 | 36.06 | 72.58 | 14.77 | 9.91 | 5.07 | |
| I.P. TTT | Full Attn. | 55.85 | 64.98 | 32.34 | 37.42 | 73.29 | 49.98 | 43.82 | 19.99 |
| SWA | 55.24 | 64.60 | 33.70 | 36.48 | 72.03 | 28.33 | 26.80 | 7.57 |
结论:
- 常识推理任务上,In-Place TTT + Full Attention 在大部分指标上最优
- 长上下文评估上提升巨大:RULER-16k 从 6.58 提升到 19.99(Full Attn),从 5.07 到 7.57(SWA)
- In-Place TTT 与 Full Attention 和 SWA 两种架构都兼容
Q3: 消融实验¶
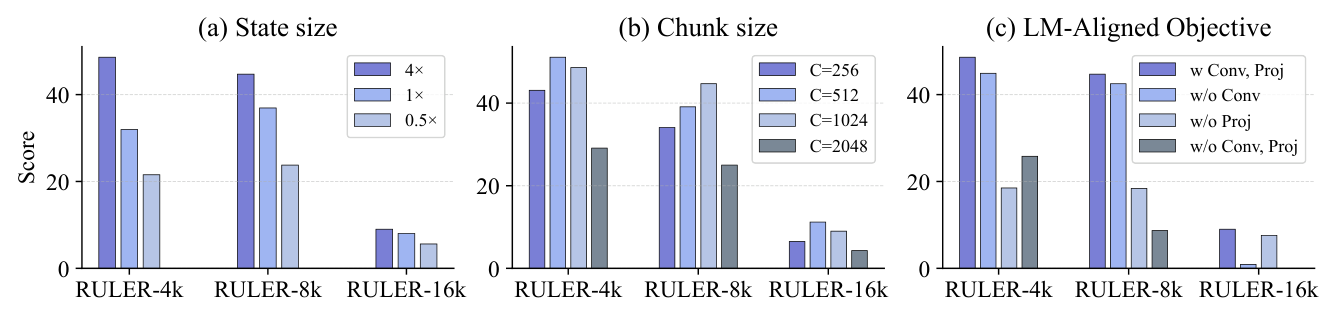
在 1.7B 模型上使用 RULER benchmark 进行消融:
State Size(TTT 层数):0.5x、1x、4x 三种配置,性能随 state size 单调提升,说明更多 MLP 层参与 TTT 带来更强的上下文适应能力。
Chunk Size:$C \in \{256, 512, 1024, 2048\}$,$C = 512$ 和 $C = 1024$ 效果最佳,性能与效率的最优平衡。过小的 chunk (256) 和过大的 chunk (2048) 都有性能下降。
LM-Aligned Objective:消融 Conv1D 和 $\mathbf{W}_{\text{target}}$ 两个组件:
- 去除 Conv1D:长上下文性能显著下降
- 去除 $\mathbf{W}_{\text{target}}$(投影矩阵):各长度均有下降
- 两者都去除:退化为重建目标,性能最差
- Conv1D 在长上下文上至关重要,$\mathbf{W}_{\text{target}}$ 提供全面的性能保障
效率分析¶

对比 4B 模型(SWA 和 Full Attention)在 8k/32k/128k 上下文下的 prefill 吞吐量和峰值内存:In-Place TTT 引入的额外开销可忽略不计,吞吐量和内存消耗与 baseline 基本持平。
讨论与局限性¶
核心贡献¶
- 架构兼容的 drop-in 设计:复用 MLP block 的 $\mathbf{W}_{\text{down}}$ 作为 fast weights,无需修改模型架构,可直接应用于任何已有预训练 LLM
- LM-Aligned 目标函数:通过 Conv1D + 投影矩阵将 target 从当前 token 扩展到未来 token,理论证明其在 induction head 设定下能有效增大正确 token 的 logit
- 高效 chunk-wise 更新 + Context Parallelism:更新规则的结合律使其天然兼容 CP,无串行瓶颈
- 广泛的实验验证:drop-in 增强(Qwen3-4B/14B, LLaMA-3.1-8B)和从头训练(500M/1.5B/4B)两种场景均一致有效
值得借鉴的设计¶
- "不替代,而是复用"的理念:与其设计新层替代注意力(如 TTT-Linear),不如直接复用已有的 MLP 作为 fast weights,这大幅降低了落地门槛
- 目标函数与任务对齐:从重建目标到 NTP-aligned 目标的转变,本质上是让 fast weights 存储"对预测有用的信息"而非"对记忆有用的信息"
- 理论分析的 induction head 框架:提供了清晰的理论理解,虽然假设较强,但方向正确
局限性¶
- 仅在语言建模任务上验证:论文将 LM 任务作为 TTT 能力的 proxy,但未验证在下游 NLU/NLG 任务(如 QA、摘要、代码生成)上的效果
- continual training 的成本:虽然是 "drop-in",但仍需 ~35B tokens 的 continual training,这在工业场景中不算便宜
- 理论分析假设较强:近似正交 embedding 和 key-query 对齐假设在实际中可能不严格成立
- 损失函数和优化器的探索有限:论文承认核心框架与具体损失函数和优化器正交,但只实验了相似度损失和单步 GD,更复杂的选择留作未来工作
- 与 SSM/线性注意力的结合未验证:论文提到 In-Place TTT 可自然集成到 GLA、SSM 等高效架构中(因为它们也有 MLP block),但未实验验证