How Far Can Unsupervised RLVR Scale LLM Training?¶
ICLR 2026 | Tsinghua / Shanghai AI Lab / SJTU / UIUC / PKU 等 | 2026-03-09
本文是一篇关于 Unsupervised RLVR (URLVR) 的系统性分析论文。作者没有提出新的训练算法,而是对 2025 年前后涌现出的大量「无标签 RLVR」工作做了 分类学 + 理论分析 + 广泛实验 + 新指标,回答一个核心问题:
Intrinsic reward(仅依赖模型自身信号)真的能无限扩展 LLM 训练吗?
结论是清晰的否定:所有 intrinsic URLVR 方法本质上都是在「锐化」(sharpen)模型的初始分布——当模型的先验置信度恰好与正确性对齐时它短期有效,但随着训练进行,一旦模型置信度偏离正确性,同一机制会系统性地放大错误,导致 rise-then-fall(先涨后崩)的训练曲线。作者进一步提出 Model Collapse Step 作为衡量模型先验(RL trainability)的便宜代理指标,并用初步实验论证 external reward(基于生成-验证不对称性或海量无标注数据的外部验证)才是唯一能突破「置信度-正确性天花板」的方向。
1. 研究动机与背景¶
1.1 监督瓶颈与 URLVR 的兴起¶
RLVR (Reinforcement Learning with Verifiable Rewards) 是近年来 DeepSeek-R1、Gemini 2.5、Qwen3 等推理模型得以突破的关键——奖励信号不是人类偏好,而是可被自动校验的客观正确性(数学题答案、代码是否通过测试)。但这条路在「通向超级智能」时会触及一个天花板:
- 需要大规模高质量标签数据,成本随模型能力上升而指数爆炸;
- 当模型在专业领域接近或超越人类专家时,可靠的 ground truth 标签本身就不可得(Burns et al. 2023 的 weak-to-strong generalization;Silver & Sutton 2025)。
于是 Unsupervised RLVR (URLVR) 被提出:在可验证任务上,不依赖人工标签,而是从模型自身或外部结构中派生 proxy reward。作者之所以保留 "Verifiable Rewards" 这个词,是为了与 "Self-Rewarding LLM" 等通用领域方法区分——本文研究的仍是 可校验任务域(数学、代码、推理),只是替代了监督标签的来源。
1.2 核心研究问题¶
近年涌现了大量 intrinsic reward 方法——TTRL 的多数投票、Agarwal 等人的熵最小化、RENT 的 Token-Level Entropy、RLSC 的概率、RLSF 的 Probability Disparity 等——它们都报告了早期训练增益,但后续陆续出现 reward hacking 和 model collapse 的报告(Shafayat et al. 2025;Zhang et al. 2025c)。由于方法碎片化、未在统一设置下对比,整个领域缺少共识:
Can intrinsic rewards truly scale LLM training?
本文的贡献即围绕这一问题展开: 1. 分类学(Section 2):把 URLVR 方法划为 intrinsic / external 两大类; 2. 统一理论(Section 3):证明所有 intrinsic reward 本质上都在最小化同一种 sharpening loss; 3. 大规模实验(Section 4):5 种 intrinsic reward × 多种超参 × 多种模型族,系统展示 rise-then-fall 规律; 4. 安全应用(Section 5):小数据集(≤128 样本)不会崩,适合 test-time training; 5. Model Collapse Step(Section 6):新提出的指标,比 pass@k 更准、比 GT Gain 便宜 5.6×,预测 RL trainability; 6. External reward 初步证据(Section 7):self-verification 在 Countdown 任务上训练 600 步仍单调改善,未见 collapse。
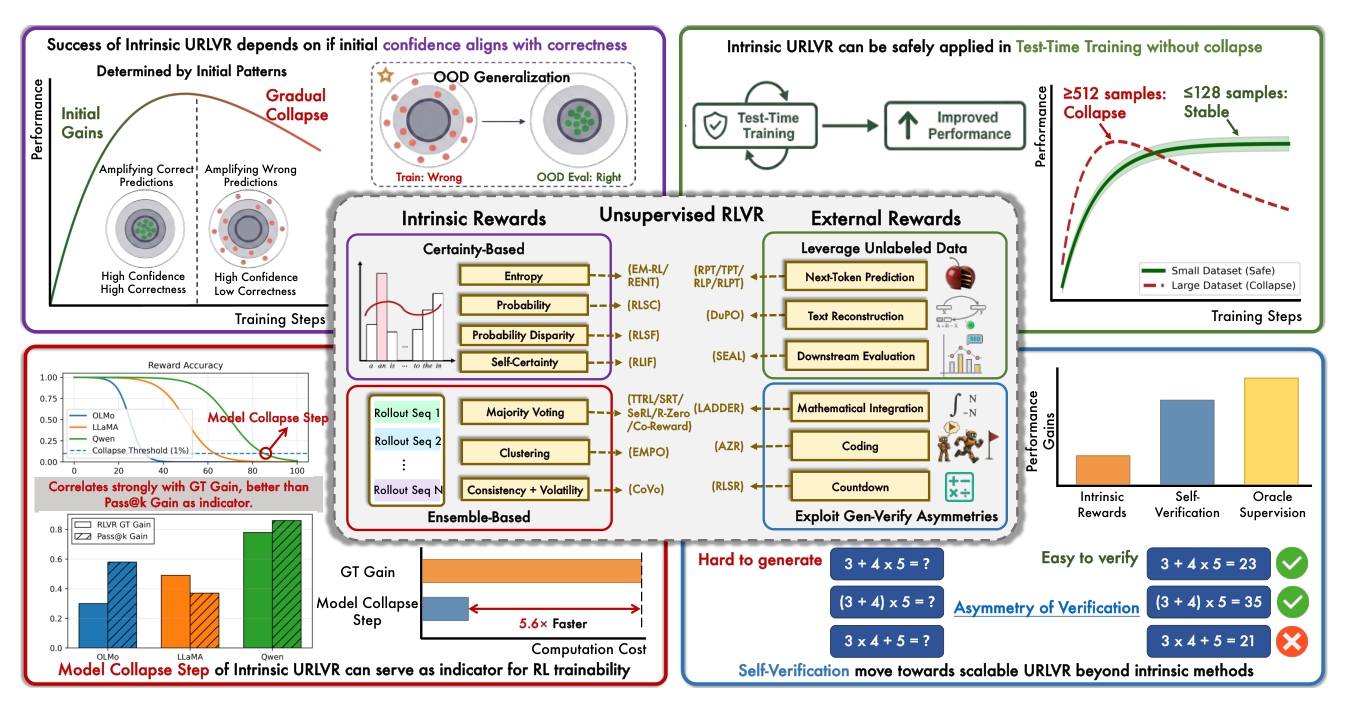
图 1 是整篇论文的总览——中央是 URLVR 分类法,四个外围面板分别对应四项核心发现:初始置信度决定 intrinsic URLVR 成败、小数据集可安全应用于 test-time training、Model Collapse Step 与 GT Gain 强相关、Self-Verification 移向可扩展的外部奖励。
2. Unsupervised RLVR 分类学¶
2.1 Intrinsic Reward Methods¶
Intrinsic reward 只使用模型本身的信号(logits 或多次 rollout 的一致性),无需外部验证器。分两个子族:
Certainty-Based(确定性类):从当前策略的 logits 抽取置信度,鼓励低熵、高置信度的输出。来自传统 TTA(Test-Time Adaptation)和低密度分离原则(Chapelle & Zien 2005)。五种代表方法(表 1):
| Method | Estimator | Formula |
|---|---|---|
| RLIF | Self-Certainty | $r(x,y)=\frac{1}{|y|}\sum_{t=1}^{|y|}D_{\mathrm{KL}}(U\,\|\,\pi_\theta(\cdot\|x,y_{<t}))$ |
| EM-RL | Trajectory-Level Entropy | $r(x,y)=\frac{1}{|y|}\sum_{t=1}^{|y|}\log \pi_\theta(y_t\|x,y_{<t})$ |
| EM-RL, RENT | Token-Level Entropy | $r(x,y)=-\frac{1}{|y|}\sum_{t=1}^{|y|}H(\pi_\theta(\cdot\|x,y_{<t}))$ |
| RLSC | Probability | $r(x,y)=\prod_{t=1}^{|y|}\pi_\theta(y_t\|x,y_{<t})$ |
| RLSF | Probability Disparity | $r(x,y)=\frac{1}{M}\sum_{t=1}^{|a|}\bigl[\max_{a_t}\pi_\theta(a_t\|x,c,a_{<t})-\max_{a_t\ne\arg\max\pi_\theta}\pi_\theta(a_t\|x,c,a_{<t})\bigr]$ |
这些公式都是「置信度」的不同数学形式:Self-Certainty 把模型对词表的分布拉离均匀分布;Token-Level / Trajectory-Level Entropy 直接最小化熵;Probability 是序列联合概率(熵最小的反面);Probability Disparity 关注 top-1 与 top-2 的差距。
Ensemble-Based(集成类):用「多数人的智慧」——对同一个 prompt 生成 N 次 rollout,用一致性充当正确性代理。代表方法见表 2:
| Method | Estimator | Formula |
|---|---|---|
| TTRL, SRT, ETTRL, SeRL, SQLM, R-Zero | Majority Voting | $r(x,y)=\mathbb{1}[y=\arg\max_{y'}\sum_{i=1}^N\mathbb{1}[y_i=y']],\{y_i\}_{i=1}^N\sim\pi_\theta(\cdot\|x)$ |
| Co-Reward | Majority Voting across Rephrased Question | 原 prompt 的 majority + 改写 prompt 的 majority |
| RLCCF | Self-consistency Weighted Voting | 多模型、多次采样的加权投票 |
| EMPO | Semantic Similarity | 基于语义聚类的软多数投票 $r=\|C(y)\|/G$ |
| CoVo | Trajectory Consistency + Volatility | 基于中间推理一致性的奖励 |
额外还有 proposer-solver 架构:R-Zero(让 proposer 生成让 solver 不确定度接近 50% 的题目)、SeRL、SQLM、CPMobius 等。但这些方法本质仍依赖模型自身的一致性假设。
2.2 External Reward Methods¶
External reward 不来自模型内部状态,而来自外部可验证机制。两条路径:
Leveraging Unlabeled Data for Reward Generation:把大规模无标注语料直接转化为奖励信号。
- RPT 在无标注文本上奖励模型「下一个 token 预测对了」;
- TPT 把预测扩展到 step-by-step reasoning;
- RLPT 把 token 扩展到 segment 层;
- RLP 奖励 CoT 对 next-token 预测提供的信息增益;
- DuPO 把主任务与对偶重构任务配对,重构质量作为自监督奖励;
- SEAL 让模型自己生成 QA 对,下游 self-supervised 表现作为奖励;
- Nemotron-CrossThink 从 CommonCrawl 采集多领域 QA,转成可 programmatic 校验的多选格式。
这类方法的 reward 来源是语料本身——随数据量扩展而扩展。
Exploiting Generation-Verification Asymmetries:利用许多推理任务中「生成难、验证易」的不对称性(Burns et al. 2023;Song et al. 2024)。
- LADDER / RLSR:不定积分或 Countdown 算术——构造难,代入验证易;
- Absolute Zero:代码生成——编译执行是确定性验证;
- DeepSeekMath-V2:自校验作为 RL 奖励;
- AlphaProof:数百万 Lean 形式化题目的定理证明。
作者的 Scalability 论断(关键): Intrinsic 与 External 的区别不是分类学上的,而是 本质上的可扩展性差异:
- Intrinsic reward 的信号完全来自模型自身概率分布,因此 被模型已有知识所上限——它无法推动模型超越它原本已知的东西;
- External reward 的两种机制各自独立扩展:
- 无标注数据的 reward 量级随 语料规模 增长;
- 生成-验证不对称的 reward 质量 不随模型能力退化——编译器和 Lean 证明器不会因为模型变强而变弱。
论文明确把 external reward 定位为「长程 URLVR scaling 的唯一可行方向」。
3. Intrinsic Reward 的 Sharpening 机制¶
3.1 单步更新的动力学¶
取 TTRL 的 majority voting 作为代表。经典 KL-regularized RL 目标:
$$ \max_{\pi_\theta}\mathbb{E}_{y\sim\pi_\theta(\cdot|x)}\bigl[r(x,y)\bigr]-\beta D_{\mathrm{KL}}\bigl[\pi_\theta(\cdot|x)\,\|\,\pi_{\mathrm{ref}}(\cdot|x)\bigr] \tag{1} $$
在该目标下最优策略有闭式解(DPO 作者推导过,Rafailov et al. 2023):
$$ \pi_\theta^*(y|x)=\frac{1}{Z(x)}\pi_{\mathrm{ref}}(y|x)\exp\!\left(\frac{1}{\beta}r(x,y)\right) \tag{2} $$
在第 $k$ 次迭代,majority voting 奖励定义为:
$$ r_k(x,y)=\mathbf{1}\bigl[\mathrm{ans}(y)=\mathrm{maj}_k(Y_k)\bigr] \tag{3} $$
其中 $Y_k=\{y^{(1)},\ldots,y^{(N)}\}$ 是从 $\pi_\theta^{(k)}$ 采得的 $N$ 个 rollout,$\mathrm{maj}_k(Y_k)$ 是出现频率最高的答案。若将 $r_k$ 保持固定并用 $\pi_\theta^{(k)}$ 作为参考策略做无限更新,将收敛到:
$$ \pi_\theta^{*,(k+1)}(y|x)=\frac{\pi_\theta^{(k)}(y|x)\cdot\exp\bigl(r_k(x,y)/\beta\bigr)}{Z_k(x)} \tag{4} $$
因为 $r_k$ 只取 0/1,指数项只有两个值 $e^{1/\beta}$ 和 $e^0=1$,所以显式形式是:
$$ \pi_\theta^{*,(k+1)}(y|x)=\begin{cases}\dfrac{\pi_\theta^{(k)}(y|x)\cdot e^{1/\beta}}{Z_k(x)}, & \text{if } \mathrm{ans}(y)=\mathrm{maj}_k(Y_k) \\[3pt] \dfrac{\pi_\theta^{(k)}(y|x)}{Z_k(x)}, & \text{otherwise}\end{cases} \tag{5} $$
配分函数为:
$$ Z_k(x)=p_{\mathrm{maj}}^{(k)}\cdot e^{1/\beta}+(1-p_{\mathrm{maj}}^{(k)}) \tag{6} $$
其中 $p_{\mathrm{maj}}^{(k)}=\sum_{y:\mathrm{ans}(y)=\mathrm{maj}_k(Y_k)}\pi_\theta^{(k)}(y|x)$ 是当前策略放在「多数答案轨迹」上的概率质量。这样最优策略下 majority 轨迹的总质量放大为:
$$ p_{\mathrm{maj}}^{*,(k+1)}=\frac{p_{\mathrm{maj}}^{(k)}\cdot e^{1/\beta}}{p_{\mathrm{maj}}^{(k)}\cdot e^{1/\beta}+(1-p_{\mathrm{maj}}^{(k)})} \tag{7} $$
实际动力学:一次梯度更新不会到达 $\pi_\theta^{*,(k+1)}$,但单调朝它移动:
$$ p_{\mathrm{maj}}^{*,(k+1)}\geq p_{\mathrm{maj}}^{(k+1)}\geq p_{\mathrm{maj}}^{(k)} \tag{8} $$
下界是因为 policy gradient 对 positive-reward 轨迹提升概率质量;上界是因为一步更新无法超过理论最优。作者在附录 A.1.1 用 4 个 MATH-500 问题 × 1024 rollouts × 50 步实证验证了 $p_{\mathrm{maj}}^{(k)}$ 严格单调递增(表 4、表 5 显示某些问题从 11% 一路涨到 99%)。
3.2 Theorem 1: 几何收敛到确定性策略¶
这是全文最核心的理论结果。
Theorem 1 (Geometric Convergence):在 assumption (A1) majority stability($\mathrm{maj}_k(Y_k)=\mathrm{maj}_0(Y_0)$ 对所有 $k$ 成立,要求足够大的 $N$)和 (A2) effective learning($p_{\mathrm{maj}}^{(k+1)}>p_{\mathrm{maj}}^{(k)}$)下,$p_{\mathrm{maj}}^{(k)}$ 以收敛率 $\rho=e^{-1/\beta}$ 几何收敛到 1,且策略收敛到:
$$ \lim_{k\to\infty}\pi_\theta^{(k)}(y|x)=\begin{cases}\dfrac{\pi_{\mathrm{ref}}(y|x)}{\sum_{y':\mathrm{ans}(y')=\mathrm{maj}_0(Y_0)}\pi_{\mathrm{ref}}(y'|x)}, & \text{if }\mathrm{ans}(y)=\mathrm{maj}_0(Y_0) \\ 0, & \text{otherwise}\end{cases} \tag{9} $$
证明分 5 步:
-
Step 1 (Effective Update Rule):建模实际更新 $p_{\mathrm{maj}}^{(k+1)}=p_{\mathrm{maj}}^{(k)}+\eta_k(p_{\mathrm{maj}}^{*,(k+1)}-p_{\mathrm{maj}}^{(k)})$,代入 (7) 化简: $$p_{\mathrm{maj}}^{(k+1)}=p_{\mathrm{maj}}^{(k)}+\eta_k\cdot\frac{(\alpha-1)(1-p_{\mathrm{maj}}^{(k)})p_{\mathrm{maj}}^{(k)}}{1+(\alpha-1)p_{\mathrm{maj}}^{(k)}} \tag{10}$$ 其中 $\alpha:=e^{1/\beta}>1$。
-
Step 2 (Error Dynamics):定义误差 $\epsilon^{(k)}:=1-p_{\mathrm{maj}}^{(k)}$,代入得 $$\epsilon^{(k+1)}=\epsilon^{(k)}\left(1-\eta_k\cdot\frac{(\alpha-1)(1-\epsilon^{(k)})}{\alpha-(\alpha-1)\epsilon^{(k)}}\right) \tag{11}$$
-
Step 3-4 (Monotonic Decrease to Zero):乘数项严格在 $(0,1)$ 内,故 $\epsilon^{(k)}$ 严格单调减;又因 $\eta_k\ge\eta_{\min}>0$,极限 $\ell=0$。
- Step 5 (Geometric Rate):在 $\epsilon^{(k)}$ 小时 $\epsilon^{(k+1)}\approx\epsilon^{(k)}(1-\eta_k\cdot\frac{\alpha-1}{\alpha})$,乘子 $\to 1-\eta_{\min}\cdot\frac{e^{1/\beta}-1}{e^{1/\beta}}=1-\eta_{\min}(1-e^{-1/\beta})$。
作者在附录 A.1.2 的「Fixed Reward Convergence」实验用 batch size 1024、$N=8$、1024 次梯度更新(都用同一批初始 rollout 的 majority)验证:Majority Voting Reward 收敛到 1.0,但 AIME24/AIME25/AMC23 性能降到 0。这印证了 (5) 的最优策略是可达的,并直接证实 sharpening 可完全背离正确性。
3.3 统一奖励框架(附录 A.3)¶
作者把上述 majority voting 分析推广到所有 intrinsic reward。抽象结构有 4 个组件:锚分布 $q$、模型分布 $\pi$、转换 $\psi(z)=\exp(z)$ 或 $z$、粒度 $\mathcal{I}$(词表 / 答案空间)。所有 5 种 intrinsic reward 都是这一框架的实例化。作者还单独推导了 Probability reward 的最优策略(方程 35-36)和 EMPO 的最优策略(方程 37-38),结论完全一致——都是 把概率质量推向初始先验下已是高概率的答案。
3.4 物理含义¶
重要结论:所有 intrinsic reward 都是在放大模型初始偏好,而不是「发现新知识」。
- 若模型的 confidence 与 correctness 对齐,sharpening 是有益的「放大正确」;
- 若 confidence 与 correctness 背离,sharpening 是「放大错误」,必然崩盘。 模型的命运由 prior 决定,而非奖励设计。
4. When Does Intrinsic URLVR Work? (Rise-then-Fall 规律)¶
4.1 数据集级的 Rise-then-Fall¶
Setup:Qwen3-1.7B-Base 在 DAPO-17k 上训练,默认超参(表 7):GRPO、温度 1.0、global batch 64、mini-batch 64、N=8 rollouts、无 KL/Entropy regularization、learning rate 1e-6、max response 7168、1 epoch。评估 AIME 2024 / 2025 / AMC 2023,avg@32(32 次采样平均正确率,温度 0.6 top-p 0.95)。
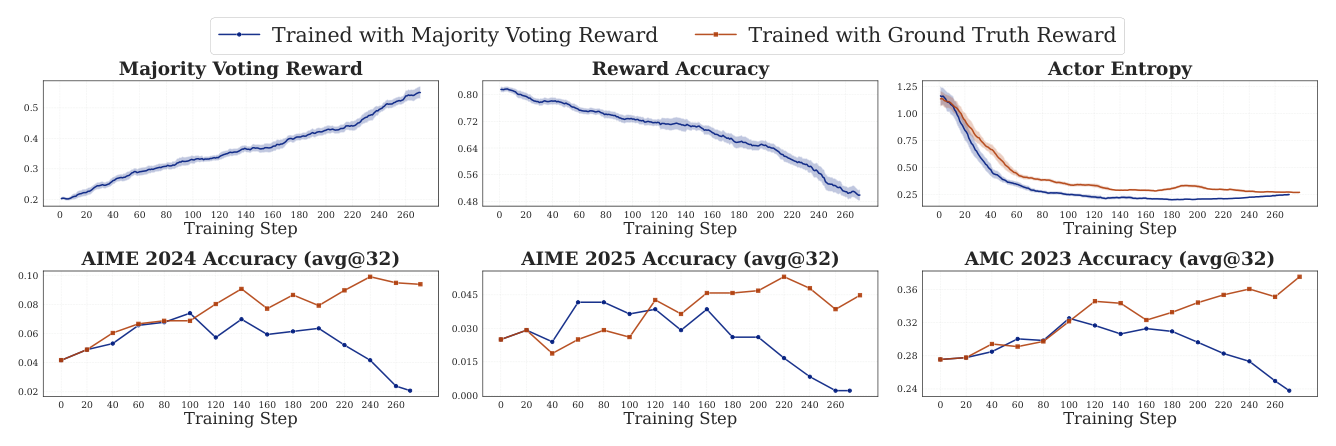
结果(图 2):
- 前 ~100 步,Majority Voting Reward 的三个 benchmark 性能与 ground-truth 训练持平甚至略高;
- 继续训练时,Majority Voting Reward 持续上升,但 Reward Accuracy(pseudo-reward 与 GT reward 的一致率)下降,AIME/AMC 性能反转下跌。这是典型 reward hacking;
- Actor Entropy 在 majority voting 下比 GT 训练下降更快,说明 intrinsic reward 更激进地压低不确定性。
作者系统扫描了 4 个关键超参(训练温度 ∈ {0.6, 0.8, 1.0, 1.2}、mini-batch ∈ {1, 8, 16, 32, 64}、KL 正则 $\beta\in\{0, 0.005\}$、N ∈ {4, 8, 16, 32},详见附录 B.3),结论一致:某些超参显著影响崩盘速度(mini-batch、N),但没有任何设置能避免崩盘。即使用最稳定配置继续训练到 ~1000 步(约 4 epoch),依然崩。
4.2 不同方法,不同崩法¶
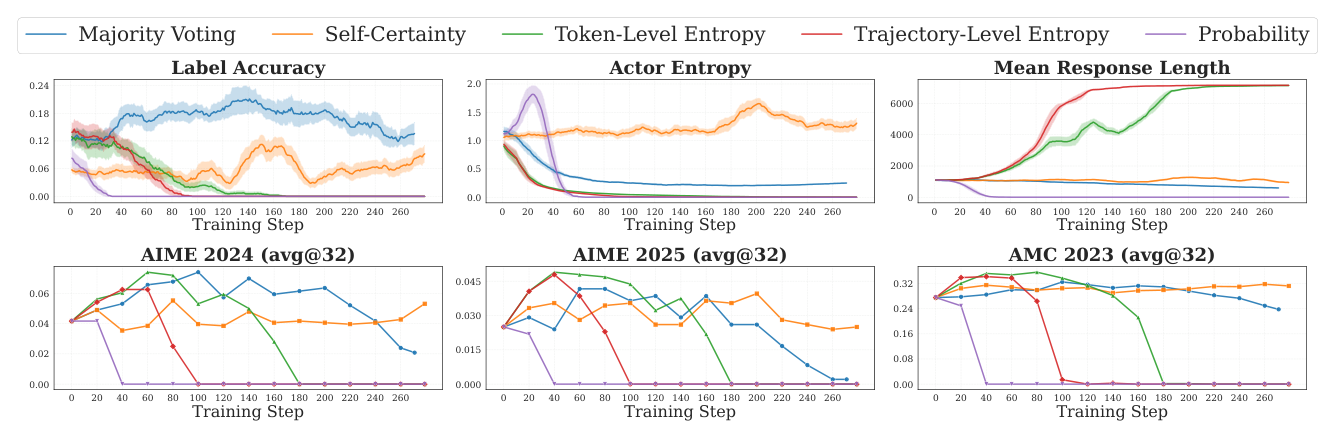
Setup:固定骨干 Qwen3-1.7B-Base + DAPO-17k,对比 Majority Voting、Self-Certainty、Token-Level Entropy、Trajectory-Level Entropy、Probability 五种,各自独立调参。
三种失败模式:
- Gradual degradation(缓降)—Self-Certainty 和 Majority Voting:
- Self-Certainty 锐化的对象是 uniform distribution(表 1 Self-Certainty 的定义),不是直接最大化某 token 概率,所以它的扰动比其他方法温和;
- Majority Voting 工作在 answer level 而非 token level,不会产生 token 级伪影;
- 两者在一个 epoch 内保留相对高的 Label Accuracy,不会完全崩。
- Length collapse(长度崩溃)—Probability 奖励:
- $r_{\mathrm{Prob}}(x,y)=\prod_t\pi_\theta(y_t|x,y_{<t})$ 是序列 token 概率的连乘,短序列天然占便宜;
- 模型学会把置信度(Actor Entropy 下降)集中在「更短的回答」上,Mean Response Length 显著下降。用几何平均或平均 log-prob 能缓解此 bias;
- Repetition collapse(重复崩溃)—Token-Level / Trajectory-Level Entropy:
- 熵是 per-token 平均,既能被「确信」压低,也能被「重复高频 token」压低;
- 因此模型学会用重复文本填充序列。
这直接对 reward 设计提出工程教训:奖励函数的聚合方式(pooling)本身会决定攻击面——均值 vs 乘积、词表维度 vs 答案维度、锚点是 uniform 还是 one-hot,都会产生不同 shortcut。
4.3 Fine-Grained Per-Problem 分析¶
Setup(Section 4.2.1):Qwen3-1.7B-Base 在 MATH-500 中随机选 25 个单个问题,每个问题单独训 100 epoch,REINFORCE,batch size 1,N=8 rollouts,reward 用 Trajectory-Level Entropy。追踪 greedy decoding 的正确性(heatmap)以及最高 reward 样本是否正确(绿色 0/1 波形)。
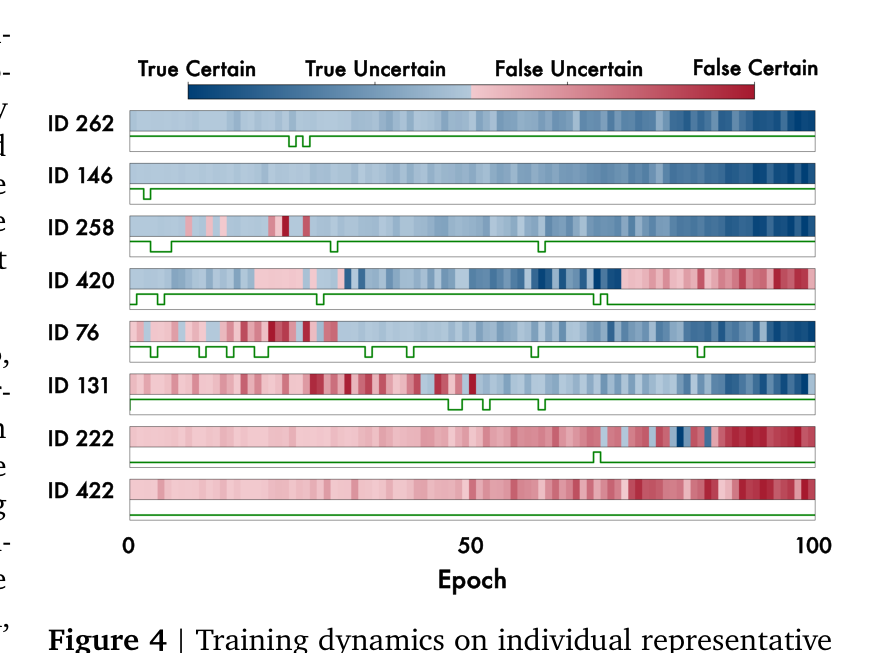
四种轨迹模式:
- Amplifying success(ID 262, 146, 258):问题初始就对,训练放大这一偏好(蓝色加深);
- Amplifying failure(ID 222, 422):最高 reward 样本基本都是错的,训练把错误锁死(红色加深);
- Wrong → Correct(ID 76, 131):greedy 初始错,但最高 reward 样本往往是对的,训练引导模型从错到对;
- Correct → Wrong(ID 420):初始对,但 sampling 不稳定,训练反而把对变错。
在 25 个问题中,只有 3 个(12%)在训练后改变 greedy 正确性,其余 22 个仅仅是放大已有偏好——无论那个偏好是对还是错。这证实 intrinsic URLVR 的作用是「放大」而非「纠正」。
4.4 OOD 跨问题泛化¶
Setup(Section 4.2.2):训练时刻意挑 6 个 MATH-500 问题,其最高 reward 样本绝大多数是错的(即 Training Label Accuracy 很低)。评估时用两个未见过的 OOD 问题 ID 76 和 ID 131。
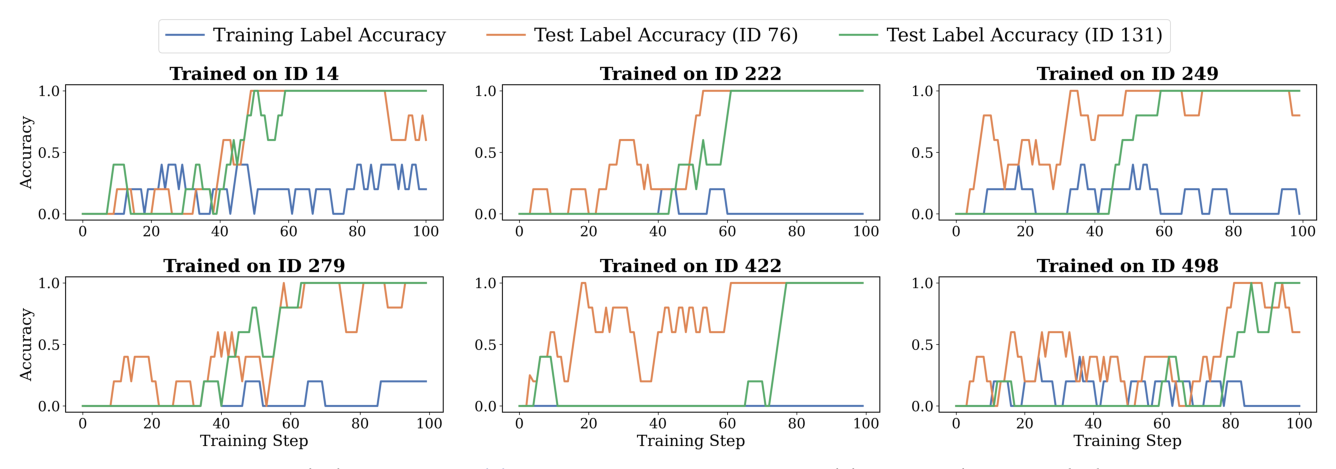
结果:训练时 Label Accuracy 一直低、甚至为 0;但两个测试问题上 Label Accuracy 从 0 稳步升到 1!
关键启示:即使训练数据中所有问题的置信度方向都错,sharpening 在某些 OOD 问题上仍能把模型从错变对——因为模型对 OOD 问题的先验可能恰好与正确答案一致。这解释了为什么 TTRL 等小数据集工作常报告有效:泛化取决于未见问题的先验-正确性对齐,而非训练数据本身的正确性。
5. 如何安全应用 Intrinsic URLVR?¶
5.1 小数据集防止崩溃¶
Setup:Qwen3-1.7B-Base + DAPO-17k 的 {32, 128, 512, 2048, 8192, 16384} 子集,固定 global batch 32,调整 epoch 使每种设置都训 恰好 600 步。监控 Ground Truth Reward / Majority Voting Reward / Reward Accuracy。子集 32/128/512 各跑 3 seed。
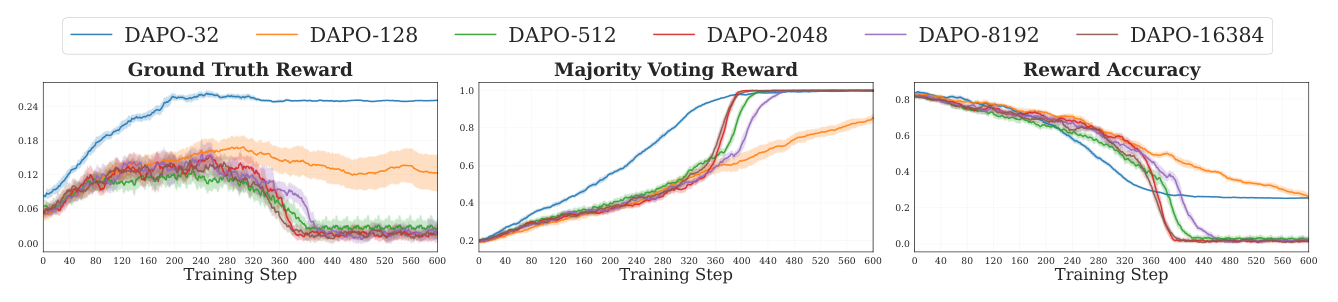
结果:
- DAPO-32 和 DAPO-128 600 步内完全稳定,无崩溃,Majority Voting Reward 稳步上升到 ~1.0,GT Reward 也稳步提升;
- DAPO-512 开始在约 300 步崩盘;
- DAPO-2048/8192/16384 早崩;
- DAPO-32 3 个 seed 均未崩,DAPO-512 3 个 seed 均崩,规律稳健。
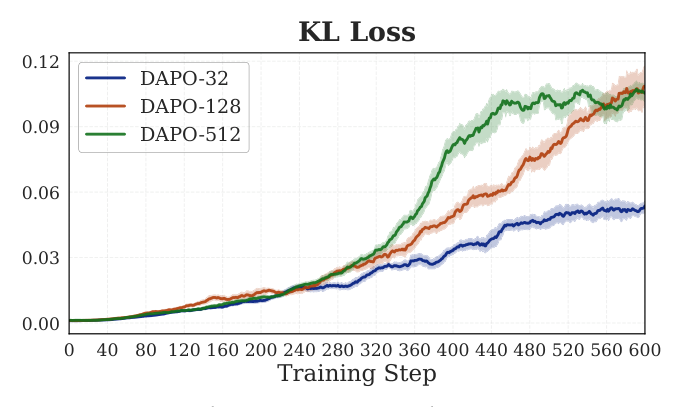
KL 证据(方程 $D_{\mathrm{KL}}^{(t)}=\mathbb{E}_{x\sim\mathcal{D}_{\mathrm{train}}}[\mathbb{E}_{y\sim\pi_\theta^{(t)}}[\log\pi_\theta^{(t)}/\pi_{\mathrm{ref}}]]$):
$$ D_{\mathrm{KL}}^{(t)}(\pi_\theta^{(t)}\|\pi_{\mathrm{ref}})=\mathbb{E}_{x\sim\mathcal{D}_{\mathrm{train}}}\left[\mathbb{E}_{y\sim\pi_\theta^{(t)}(\cdot|x)}\left[\log\frac{\pi_\theta^{(t)}(y|x)}{\pi_{\mathrm{ref}}(y|x)}\right]\right] \tag{12} $$
DAPO-32 在 600 步后 KL ~ 0.057,DAPO-128 更高,DAPO-512 是前者的 2×。小数据集诱导的是局部参数更新(Carlsson et al. 2024 的 "hyperfitting")——模型在特定样本上锐化置信度,但没有系统性位移整体策略,因此对 AIME24/AMC23 的通用推理能力影响小。大数据集反而强迫密集的参数更新,导致全局策略漂移,引发 collapse。
这一发现与 Shenfeld et al. 2025 的 "RL's Razor"(RL 遗忘少是因为分布漂移小)一致。
5.2 Test-Time Training¶
Setup:Qwen3-1.7B-Base + Majority Voting。对比两个训练语料:AMC23(40 题,test-time)vs DAPO-17k(17000 题,train-time)。两者 batch size 都是 40。
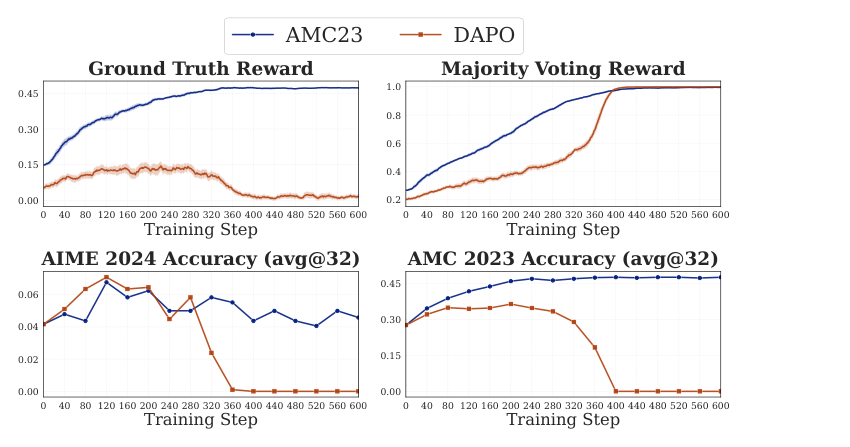
结果:AMC23 训练不崩,GT Reward 和 Majority Voting Reward 双双上升,AMC23 和 AIME24 测试集双双提升;DAPO-17k 仍按老规律先涨后崩。这直接解释了 为什么近期 intrinsic reward 工作(Prabhudesai et al. 2025、Zuo et al. 2025)都聚焦于 test-time 设置——这是 intrinsic URLVR 的安全生态位。
5.3 Extreme 情况:即使初始 majority 几乎全错也能 OOD 增益¶
Setup(Section 5.3):极端情况——先用 maj@64 离线筛出 DAPO-17k 里 32 个初始 majority 几乎都错的问题(大多数答案的投票比例 >40%)。训练时用 maj@8 + 温度 1.0,配置同 DAPO-32。
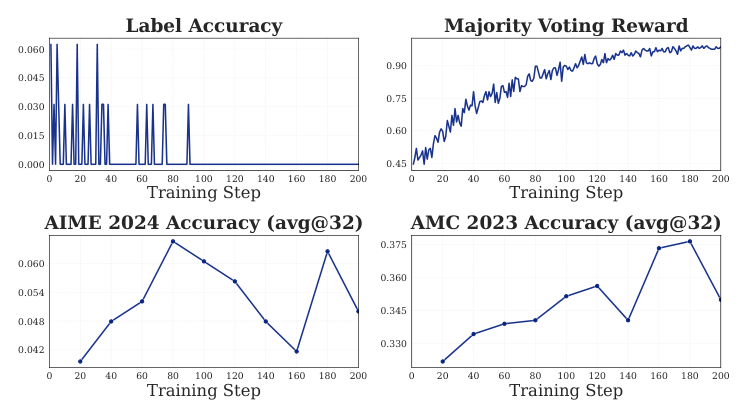
结果:训练 Label Accuracy 几步内就掉到 0 并保持(因为这些题 majority 就是错的),但 AIME24 和 AMC23 仍有非零的增益轨迹。
启示:小数据集训练的是「局部过拟合」——即使放大了错误知识在训练题上的概率质量,这种局部的参数变动不会污染模型在 OOD 题上的先验-正确性对齐。这与 4.2.2 节的跨问题泛化机理一致。
6. 如何衡量 Model Prior?—Model Collapse Step¶
6.1 动机与定义¶
既然 intrinsic URLVR 只在先验对齐时有效,能否用崩盘时间本身当作「model prior 的体温计」,在不跑完整 RL 的前提下评估模型的 RL trainability?
传统做法两种:
- 全量 RL 训练并看 GT Gain:最准确但极贵;
- pass@k(Wu et al. 2025a):采 $k$ 解比 pass@1 看 gain,便宜但不够准,且在多选题上 $k$ 大时 pass@k → 1 失效。
Model Collapse Step 定义为:在默认超参下用 intrinsic URLVR(majority voting)训练时,Reward Accuracy 首次低于 1% 的训练步数。模型先验越强,崩盘越晚。
6.2 Pilot Study: 不同模型族¶
Setup:4 个模型——Qwen2.5-1.5B、DeepSeek-R1-Distill-Qwen-1.5B(Qwen 家),Llama-3.1-8B、Llama-3.1-Tulu-3-8B-SFT(LLaMA 家)。都用 DAPO-17k + majority voting。
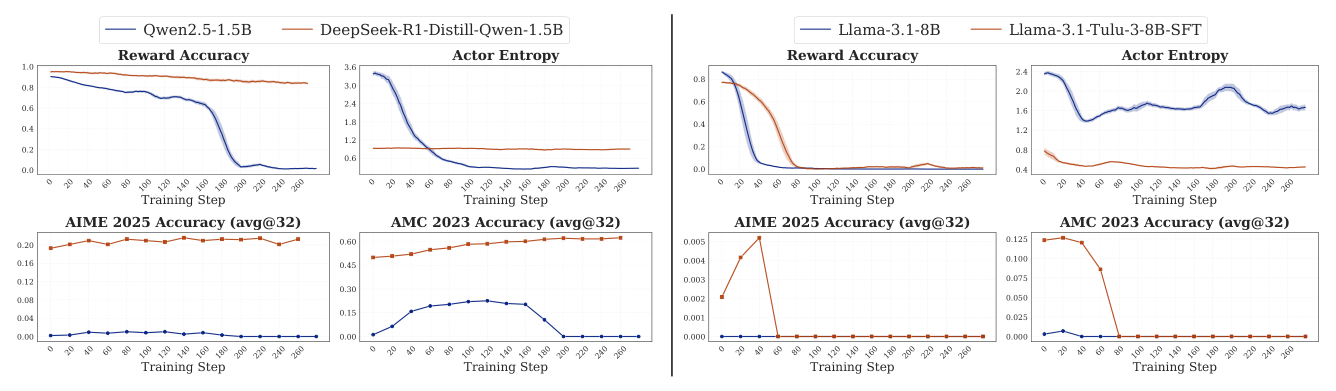
结果:
- Qwen 家的 SFT 变体(R1-Distill)Reward Accuracy 全程维持 0.8+,base 在 200 步后塌到近 0;
- LLaMA 家 base 在 40 步失败、SFT 版本先涨后崩得晚;
- 两家族的Actor Entropy 初始更高的 base 模型反而崩得更快、Reward Accuracy 更低。这反驳了 "high entropy → better reasoning" 的解释——熵是 sharpening 的结果,不是先验强度的决定因素。
6.3 Model Collapse Step 预测 RL Gain¶
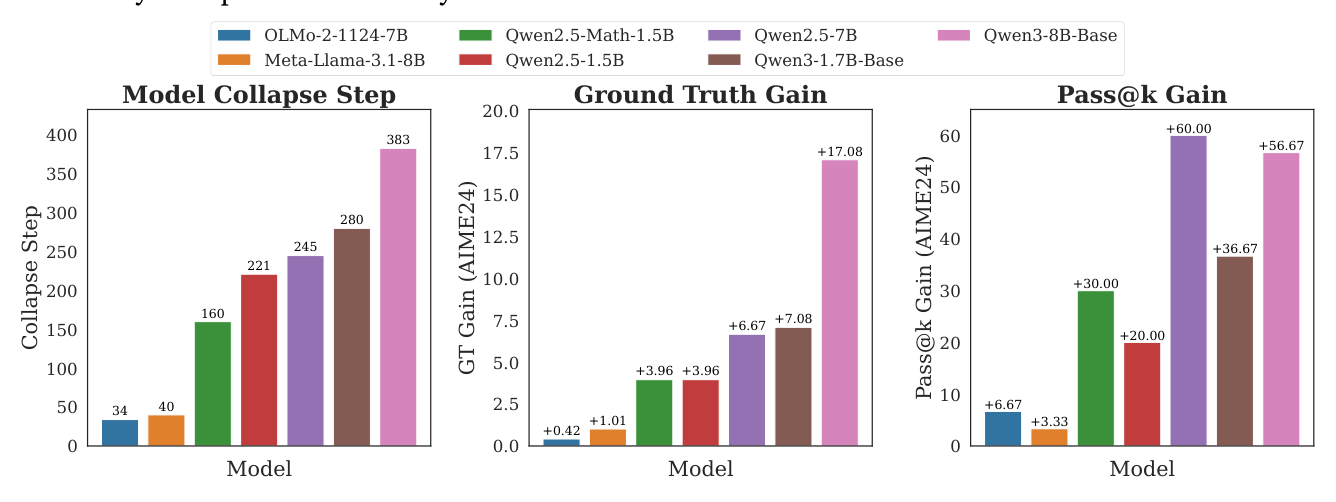
Setup:7 个模型(OLMo-2-1124-7B、Meta-Llama-3.1-8B、Qwen2.5-Math-1.5B、Qwen2.5-1.5B、Qwen2.5-7B、Qwen3-1.7B-Base、Qwen3-8B-Base)× 在 AIME24 上评估:
- GT Gain:全量 1 epoch 监督 RLVR 在 DAPO-17k 上训完后的 AIME24 提升;
- Pass@k Gain:$\text{pass}@256-\text{pass}@1$;
- Model Collapse Step:intrinsic URLVR 崩盘步。
定量结果(论文图 11 数值):
| 模型 | Collapse Step | GT Gain (AIME24) | Pass@k Gain |
|---|---|---|---|
| OLMo-2-1124-7B | 34 | +0.42 | +6.67 |
| Meta-Llama-3.1-8B | 40 | +1.01 | +3.33 |
| Qwen2.5-Math-1.5B | 160 | +3.96 | +30.00 |
| Qwen2.5-1.5B | 221 | +3.96 | +20.00 |
| Qwen2.5-7B | 245 | +6.67 | +60.00 |
| Qwen3-1.7B-Base | 280 | +7.08 | +36.67 |
| Qwen3-8B-Base | 383 | +17.08 | +56.67 |
结论:Collapse Step 与 GT Gain 的秩序强相关(Qwen3-8B-Base collapse 最晚且 GT Gain 最大),甚至比 pass@k gain 更可靠(pass@k 对 Qwen2.5-1.5B 和 Qwen2.5-Math-1.5B 区分度不强但 collapse step 能区分)。
6.4 计算成本¶
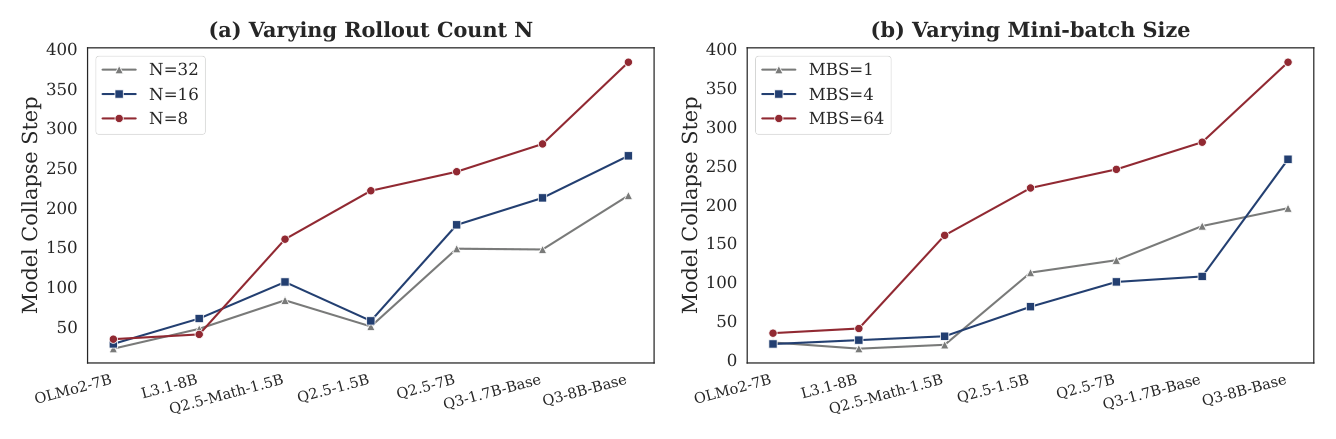
Table 3:
| Indicator | Computation Cost | Total Tokens | Requires GT |
|---|---|---|---|
| GT Gain | $7k \times 8 \times 17k \times 7$ (response × rollouts × problems × models) | 6.66 B | Yes |
| Model Collapse Step | $7k \times 8 \times 662 \times 32$ (response × rollouts × total steps × batch) | 1.19 B (5.6× faster) | No |
Model Collapse Step 比 GT Gain 便宜 5.6×,且完全不需要 ground truth 标签,从而在无标签域也能筛选 base model。
加速技巧(Section 6.3):把 mini-batch size 压到 1、rollouts N 增到 32 能加速崩溃而保持模型排序(图 12)。作者用这些激进配置测 7 个模型,崩盘步数 [22, 14, 19, 112, 128, 172, 195],相比默认配置提前 ≥50 步,但名次稳定。这让 Collapse Step 既「准」又「快」。
7. External Rewards 作为可扩展方向¶
7.1 Self-Verification on Countdown¶
Setup:Qwen3-1.7B-Base 和 Qwen3-4B-Base 在 Countdown-Tasks-3to4(Jiayi-Pan/Countdown-Tasks-3to4)训练,目标是构造算术表达式到达目标值。4k 题训练、1k 题验证。对比三种 reward:
- Oracle Supervision:用 ground truth 验证函数;
- Self-Verification:模型给自己的解输出二元 correctness(见 Appendix C.1 Prompt 2);
- Trajectory-Level Entropy(表 1)。

结果:
- Trajectory-Level Entropy 20 步就崩;
- Self-Verification 训练 600 步持续改善,最终 Countdown avg@16 达 0.75+(Oracle 是 ~0.85);
- Self-Verification 的下方图显示有趣现象:Reward Accuracy 在约步 200 下降(模型试图 hack 自己的 verifier)但随后恢复,最终 Reward Accuracy 和 GT Reward 都稳步上升——生成-验证不对称性产生的 self-corrective 动力学。
7.2 Instruction Alignment 的关键作用¶
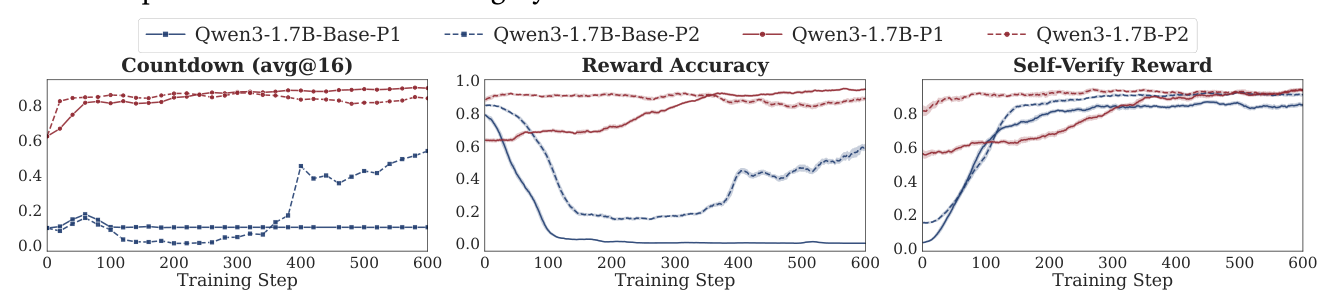
比较 Qwen3-1.7B-Base(-P1/-P2)与 Qwen3-1.7B(-P1/-P2)。指令对齐模型:
- 起点准确率 > 60%(已超过 base 模型最终结果);
- 两种 prompt 都能到达 80%+;
- Reward Accuracy 稳定不 hacking。
Base 模型只有在 P2 prompt 下才工作,P1 下崩。指令对齐使 self-verification 具有 prompt robustness 和 更高起点,是 self-verification 能 scale 的关键。
7.3 External Reward 为何能扩展?¶
论文给出两点本质论证: 1. Verifier 不随模型进步而退化:一个检查算术表达式、执行代码、校验 Lean 证明的外部程序,对更强模型仍然同样可靠。Intrinsic reward 是模型自己的分布,模型越强 reward 就越「肮脏」; 2. Verification 计算可扩展:verification 通常便宜(执行代码、代入求值),而 unlabeled data 范式(如 RPT、RLPT)把验证信号来自已有语料本身——不需人工标注。
这两点共同让 external reward 摆脱 confidence-correctness ceiling。
8. 实验总体设置与超参(Appendix B.1)¶
8.1 默认超参(Table 7)¶
| Advantage | Temperature | Global BS | Mini BS | N Rollouts | Regularization | Max Prompt | Max Response | LR | Epoch |
|---|---|---|---|---|---|---|---|---|---|
| GRPO | 1.0 | 64 | 64 | 8 | w/o KL/Entropy | 1024 | 7168 | 1e-6 | 1 |
所有实验用 veRL(Sheng et al. 2025)+ GRPO advantage estimator,通过 RewardManager 定制五种 intrinsic reward。
8.2 Training Dynamics 定义(Appendix B.2)¶
- Label Accuracy(ensemble):$\frac{1}{M}\sum_{i=1}^M\mathbf{1}[\mathrm{maj}(x_i)=a_i^*]$,衡量伪标签对 GT 的命中率;
- Reward Accuracy:$\frac{1}{MN}\sum_{i,j}\mathbf{1}[r_{\mathrm{mv}}(y_{i,j})=r_{\mathrm{gt}}(y_{i,j})]$,衡量样本级 reward 对 GT reward 的命中,捕获「lucky hits」(majority 投错但个别对的 sample 仍拿到正确 reward=0);
- Ground Truth Reward:$\frac{1}{MN}\sum_{i,j}r_{\mathrm{gt}}(y_{i,j})$,监督基线;
- Majority Voting Reward:$\frac{1}{MN}\sum_{i,j}r_{\mathrm{mv}}(y_{i,j})$,实际训练时使用的 pseudo-reward;
- Certainty-Based Label Accuracy:最高置信度样本的 GT 正确率,$j_i^*=\arg\max_j r_{\mathrm{cert}}(y_{i,j})$。
8.3 超参扫描关键结论(Appendix B.3)¶
Majority Voting(图 16-19):
- T=0.6/0.8 快速锐化但不稳;T=1.2 噪声大;T=1.0 最优;
- Mini-batch size 越大越稳——MBS=1 在 20 步崩,MBS=64(纯 on-policy)稳到 epoch 末;中间 16-32 有梯度;
- KL 正则 ($\beta=0.005$) 只有 marginal 收益,反而增加方差;
- N 越大越快崩——N=32 在 180 步崩、N=16 在 220 步崩、N≤8 稳。推荐 N=8 平衡 voting 可靠性与训练稳定性。
Certainty-Based(图 20-31):
- Token-Level Entropy / Trajectory-Level Entropy / Probability 在 高温(T=1.2) 下崩得最晚,Point-Biserial Correlation(certainty 与 correctness 的相关)更高;
- Self-Certainty 相反——T=1.0 最稳,T=1.2 反而不能收敛。因为 Self-Certainty 的锚分布是均匀分布(不像其他方法直接最大化某 token 概率),受温度影响机制不同;
- Self-Certainty 对 mini-batch size 变化异常鲁棒——Label Accuracy 几乎不随 MBS 变化(图 24)。猜测是因为它用 logit 级 KL 比较,对策略 temporal 不一致性较弱敏感。
9. 讨论与局限¶
9.1 核心贡献¶
- 分类学:首次把碎片化的 URLVR 工作系统归为 intrinsic / external 两大阵营,并基于「scalability 本质」论证两者不是同一条路上的演化,而是天花板不同的两种方案;
- 统一理论:用 KL-regularized RL 的最优策略闭式解(DPO 推导)说明所有 intrinsic reward 都是在锐化先验,且 Theorem 1 给出几何收敛速率;
- Rise-then-Fall 普适律:用 5×超参×模型族的实验矩阵证明这是方法论层面的根本缺陷而非工程问题;
- Model Collapse Step:一个不需 GT 标签、比 GT Gain 便宜 5.6×、比 pass@k 更准的 RL trainability 代理指标;
- 失败模式分类:三种失败模式(gradual/length/repetition collapse)直接对 reward 设计给出工程启示。
9.2 值得借鉴的设计¶
- 把 reward 理解为「锐化方向」:所有 intrinsic reward 都可用「锚分布 + 粒度 + 转换」三要素描述,这是设计新 intrinsic reward 的 principled 框架;
- Pseudo-reward vs Ground truth 双轨监控:论文引入的 Reward Accuracy 指标(只要开发时有少量 GT)可以作为 URLVR 训练的早期预警系统;
- KL divergence 作为局部/全局漂移的探针:小数据集 KL 不到 0.06,大数据集 2× 高,这个 KL 自身就是崩溃前兆;
- External reward 的 self-verification 动力学:Reward Accuracy 先降后升的 U 型曲线(图 13)暗示 self-verification 有内在的 error-correction——论文没细挖,值得后续研究深入。
9.3 局限与争议¶
- Theorem 1 的 Assumption A1 (majority stability) 在实际中并不始终成立:论文用 $N=8$ 的小 N 训练,但理论证明需要 majority 对每次迭代都稳定,作者只在附录用 $N=1024$ 的大 N 实验验证;小 N 下 majority 可能抖动,严格理论仅近似成立;
- Model Collapse Step 的普适性待验证:7 个模型都是数学 / reasoning 领域的,没有跨任务(代码、法律、医疗)验证;
AIME24只是一个窄测集,GT Gain 相关性未必能推广; - External reward 的 scalability 是断言而非证明:Self-Verification 在 Countdown 上 600 步稳定升很有说服力,但 Countdown 任务的答案空间极小、验证函数极简,不能推论到 open-ended 数学、复杂代码等场景;DeepSeekMath-V2 和 AlphaProof 在大规模任务上的 scalability 尚需独立验证;
- 计算开销仍然很大:Model Collapse Step 虽然比 GT Gain 便宜 5.6×,但仍需 1.19B tokens;对中小团队筛选 base model 仍是门槛;
- Sharpening 带来的局部 overfitting 是否伤害下游泛化:Section 5 中 DAPO-32 训练「不崩」,但并未在广泛的 OOD benchmark 套件上评估——可能只是 AIME24/AMC23 上不崩,其他能力已退化;
- 缺少对 proposer-solver 架构(R-Zero、SeRL 等)的直接实验:分类学提到了这一族,但实验全部集中在 single-model intrinsic reward,proposer-solver 的 failure mode 未知;
- 与 Spurious Rewards(Shao et al. 2025a)的关系:论文引用但未直接对比。Spurious Rewards 工作指出 Qwen 系列对随机奖励仍能学习,说明 Qwen 的先验极强——这与 Model Collapse Step 排名 Qwen 靠后崩一致,但论文没放在一个框架下讨论。
9.4 对实际项目的启示¶
- RLVR 数据规模决定是否用 intrinsic:如果只有几十道题(比如某领域特殊问题集),intrinsic URLVR(尤其 majority voting)可以作为廉价 test-time 自适应工具;一旦数据规模上千,就必须引入 external reward;
- 选 base model 时跑 2-3 百步的 intrinsic URLVR:把它作为 RL trainability 的预测指标,免除昂贵的全量 RL 训练做 A/B;
- 警惕 reward hacking 的伪装:Majority Voting Reward、Token Entropy 等指标本身的提升 完全无法证明模型变好——论文的所有崩盘曲线都展示 pseudo-reward 单调上升而 GT 性能下降;
- 设计新 intrinsic reward 时注意聚合粒度:Probability 乘积导致 length bias、Entropy 均值导致 repetition bias——设计时应有意识地对抗这些 shortcut(如用 per-token 几何平均);
- 未来方向:把「生成-验证不对称性」识别并利用起来——不光是代码 / 定理证明这些已知场景,还要发掘如化学反应模拟、物理引擎、游戏规则、SQL 查询校验等更多外部验证器。