Gryphon: 为语义 ID 生成与 item 级打分设计的统一架构¶
Yandex(Daria Tikhonovich, Oleg Sorokin, Vladislav Dodonov, Mariia Ulianova, Ilya Murzin),2026-06,工业音乐推荐场景。Gryphon 是项目名,并非缩写。
研究动机与背景¶
基于语义 ID(Semantic ID, SID)的生成式检索(Generative Retrieval, GR)已经成为大规模候选生成的一种可扩展范式。其核心思路是:通过 RQ-VAE 这样的层次化量化器,给每个 item 分配一段很短的离散 token 序列(即 SID);用 Transformer encoder 编码用户交互历史,再用 decoder 以自回归方式生成"用户下一个会交互的 item"的 SID。把检索建模成在紧凑语义标识符上的序列生成,使得 GR 能端到端训练、在数千万级 item 语料上可扩展地做候选生成,同时利用 item 之间的语义因子分解。
然而工业推荐系统最终是在 item 这个粒度上被评估的,而标准 GR 是按累积的 SID 级 beam likelihood 来排序候选。本文指出,这里存在一个结构性错配(structural mismatch):beam search 给 semantic id(token 序列) 打分,而推荐质量取决于给 concrete item(具体物品) 打分。这个错配通过两个失败模式显现:
-
序列似然失准(Sequence likelihood miscalibration):自回归生成在训练时用 teacher forcing(条件于 ground-truth 前缀),但推理时条件于模型自己生成的前缀。在层次化 SID 解码中,一个早期 token 的错误会把 beam 推入另一棵子树,使相关 item 落在评分更低的 SID 路径上。早期 token 的误差不断累积,导致相关 item 的 SID 似然被严重失准地估计。
-
语义 ID 碰撞(Semantic ID collisions):当多个 item 共享同一个 SID 时,beam likelihood 给它们分配完全相同的分数,无法表达它们之间的相关性差异。
这两个失败模式反映的是同一个底层 gap:beam likelihood 评分的对象是 SID 序列,而推荐器真正需要排序的是具体 item。近期工作(HiD-VAE、QuaSID、Snapchat SID)改进了 SID 的分配方式并指出了 SID 级解码与碰撞的局限,但都没有回答一个关键问题——如何在一个统一的生成式检索架构里,对"解析出的具体 item"而非"SID 序列"进行排序。
本文提出 Gryphon:一个统一架构,在 encoder–decoder GR 之上增加一个联合训练的 item 级打分模块(Item-Level Scoring Module, ILSM)。Gryphon 用共享 encoder 做一次前向传播,得到的用户状态被两个组件复用:自回归 decoder 用它生成 SID 候选,ILSM 用同样的用户状态去给"从生成的 SID 解析出来的具体 item"打分。通过用 item 级分数(而非 beam likelihood)重新排序候选,Gryphon 既降低了对可能失准的序列级分数的依赖,又能区分共享同一 SID 的 item。
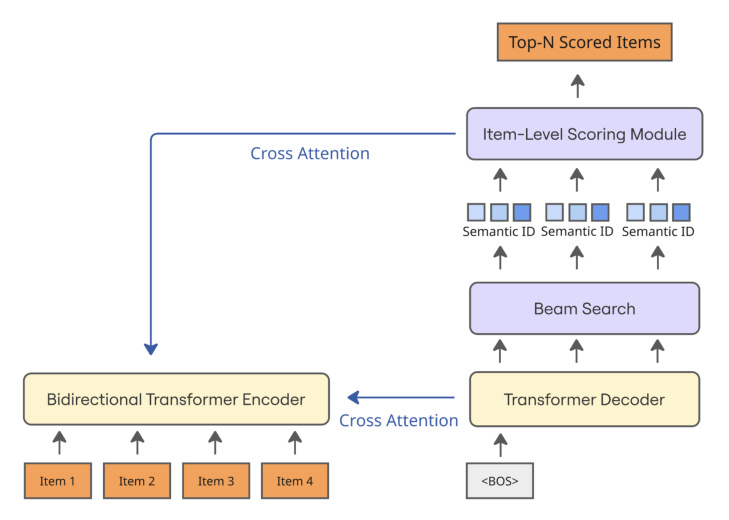
核心方法 / 模型架构¶
背景形式化:SID 生成式检索与其两个失败模式¶
SID 定义。 量化器 $\Phi$ 把每个 item $x \in \mathcal{X}$ 映射为一段 $L$ 层的离散 token 序列:
$$\Phi : \mathcal{X} \to \prod_{b=1}^{L}\{1, \ldots, M_b\}, \qquad \Phi(x) = (s_1, \ldots, s_L). \tag{1}$$
Beam 似然评分。 给定用户历史 $u$,GR 自回归地预测候选 SID。对候选 SID $\sigma = (s_1, \ldots, s_L)$,beam search 按累积的 code 级 log-likelihood 排序:
$$\ell_\theta(\sigma \mid u) = \sum_{b=1}^{L} \log p_\theta(s_b \mid u, s_{<b}). \tag{2}$$
这个分数对"解码标识符"是自然的,但它定义在 token 序列上,而推荐质量是在具体 item 上评估的。
碰撞使评分 gap 变成"严格相等"。 设 $C_\sigma = \Phi^{-1}(\sigma)$ 为 SID $\sigma$ 的碰撞组(即共享 $\sigma$ 的具体 item 集合)。对任意两个 item $x_i, x_j \in C_\sigma$:
$$\ell_\theta(\Phi(x_i) \mid u) = \ell_\theta(\Phi(x_j) \mid u), \tag{3}$$
因为它们映射到同一个 SID。于是 beam likelihood 给碰撞组内所有 item 分配相同分数,无法通过 SID 分数本身表达它们的相关性差异。碰撞暴露了纯 SID 级评分的结构性局限:生成器给语义标识符打分,而推荐器必须排序具体 item。
前人工作(TIGER [11])通过在有序语义码后追加一个额外 token来消除碰撞,使 SID 唯一。本文认为这种做法更适合静态离线场景:唯一的终止 token 把"解析词表"绑定到目录上,在 item 持续涌入的动态目录下,这个解析层必须无限增长并不断重新拟合——这是部署的严重障碍。这一论点也是后文 Gryphon 与"Resolved GR"基线区别对待的根本原因。
Gryphon 方法概览¶
Gryphon 在一个 vanilla encoder–decoder 生成式检索器之上增加 ILSM。对每个用户请求,用户行为序列被编码一次为 encoder 状态 $E_u$。$E_u$ 被两个组件共享:自回归 decoder 用 $E_u$ 生成 SID 候选,ILSM 复用同一个 $E_u$ 去给"与生成的 SID 关联的 item"打分。其结果是:最终的 item 分数不再绑定到可能失准的序列似然,且 Gryphon 能区分同一碰撞组内的不同 item。
1. 生成式检索(Generative Retrieval)¶
decoder 在给定编码后的用户历史下,自回归地预测下一个 item 的 SID。对观测到的下一个 item $i^+$(其 SID 为 $\Phi(i^+) = (s_1^+, \ldots, s_L^+)$),生成损失为:
$$\mathcal{L}_{\text{gen}} = -\sum_{t=1}^{L} \log p_\theta(s_t^+ \mid s_{<t}^+, E_u). \tag{4}$$
2. Item 级打分模块(ILSM)¶
为缓解 SID 生成与 item 级推荐之间的不一致,引入一个 item 级打分器。每个候选 item $i$ 由一个 item tower 产生的 item-query embedding 表示:
$$e_i = \mathcal{T}_{\text{item}}(\Phi(i), h_i), \tag{5}$$
其中 $h_i$ 表示 item 的原生 item 级特征,例如 item-ID 哈希、元数据和内容特征。打分器再把这个 item query 条件于共享的用户 encoder 状态 $E_u$:
$$r_\phi(u, i) = f_\phi(E_u, e_i). \tag{6}$$
实践中,$f_\phi$ 是一个轻量级的 item-to-user 交叉注意力块(cross-attention),后接一个 MLP head,输出标量相关性分数。
ILSM 直接解决了 SID 碰撞:共享同一 SID 的 item 仍可以通过各自的 item 级特征获得不同的相关性估计。ILSM 也缓解但不消除自回归解码中的误差累积——beam search 仍然决定哪些 SID 进入候选池;但一旦某个 SID 被生成,最终 item 的选择就不再依赖 SID-token 似然的乘积。这降低了"可达 item"(即通过生成的 SID 集合能触及的 item)之间序列似然失准的影响。
3. 训练目标¶
ILSM 在架构上不绑定到任何特定监督信号,可以用多种 item 级目标训练,包括多目标互动预测、ranker 蒸馏、长期价值优化等。本文用下一个 item 预测(next-item prediction, NIP)目标实例化 ILSM,并用 sampled softmax 优化,把更丰富的 item 级目标留给未来工作。ILSM 被训练去最大化 item 的概率:
$$p_\phi(i_{t+1} = i \mid E_u) \propto \exp\left(\frac{r_\phi(u, i)}{\tau}\right), \tag{7}$$
条件于用户历史。给定用户 $u$、观测到的下一个 item $i^+$,以及一组 in-batch 采样的负 item $\mathcal{B}^-$,定义 $\mathcal{L}_{\text{NIP}}$:
$$-\log \frac{\exp\!\left(\frac{r_\phi(u, i^+)}{\tau} - \log Q_{i^+}\right)}{\exp\!\left(\frac{r_\phi(u, i^+)}{\tau} - \log Q_{i^+}\right) + \sum_{i^- \in \mathcal{B}^-} \exp\!\left(\frac{r_\phi(u, i^-)}{\tau} - \log Q_{i^-}\right)}, \tag{8}$$
其中 $\tau$ 是温度参数,$Q_i$ 是 item $i$ 的采样概率。$-\log Q_i$ 这一采样修正项(LogQ correction)用于减少流行度引起的偏差。
完整的 Gryphon 目标联合训练 SID 生成与 item 级打分:
$$\mathcal{L} = \mathcal{L}_{\text{gen}} + \lambda \mathcal{L}_{\text{NIP}}, \tag{9}$$
其中 $\lambda$ 控制 item 级损失的贡献。两个损失共享同一组 encoder 状态 $E_u$,促使用户表征同时支撑 SID 级候选生成与 item 级相关性估计。
4. 推理¶
在服务时,Gryphon 先做一次 encoder 前向传播计算 $E_u$。decoder 用 beam search 生成一个 top-$K$ 的 SID 候选集合 $\mathcal{B}_u$。beam likelihood 只用于决定哪些 SID 进入 $\mathcal{B}_u$(成员资格),而不作为最终 item 分数——这一设计有意地把 item 选择与可能失准的 SID-token 乘积解耦,同时仍用 decoder 提出一个紧凑的 SID 集合。
每个生成的 SID 被扩展为它的碰撞组,Gryphon 再用 ILSM 给得到的 item 打分:
$$\text{TopN}(u) = \text{TopN}_{i \in \mathcal{I}_u}\; r_\phi(u, i), \qquad \mathcal{I}_u = \{i \mid \exists\, \sigma \in \mathcal{B}_u \text{ s.t. } i \in C_\sigma\}. \tag{10}$$
得到的 Gryphon 候选池可以传给下游 ranker 做最终动作预测。
实验设置¶
研究问题。 RQ1:在 item 级下一个 item 预测上,Gryphon 与 Transformer 生产基线、SID 生成式检索基线相比如何?RQ2:Gryphon 能否在不损害线上互动的前提下,替换已部署的生产候选生成栈?
数据集。 来自一个大规模音乐推荐平台一周的真实用户日志,平台有数千万级活跃用户与 item。
基线。
- ARGUS [9]:一个已部署的自回归双塔 Transformer 候选生成器,用 sampled softmax 训练做序列化下一个 item 预测,是当前在线运行的最大推荐模型之一,作为强生产基线。
- Vanilla Generative Retrieval(vanilla GR):把目标 item 表示为 SID 序列并自回归生成。由于多个 item 可能共享同一生成序列,按 beam 顺序展开生成的标识符、累积关联 item,直到达到候选预算来解析碰撞。
- Vanilla GR Resolved:由于碰撞可能压低 item 级 recall,额外实现一个"解析"变体——在 SID 序列末尾追加一个额外 token(沿用 TIGER [11])使其唯一。该基线仅用于离线对比,因为解析层在生产目录变化下会无界增长,作者认为它在生产部署中不切实际。
实现细节。
- 所有 SID 模型用 residual K-Means 把 item 量化为 SID。独立调优每个模型的 codebook 数量(1–4)、codebook 大小(1,024–32,000)、encoder–decoder 层数比。
- ARGUS:10 个 Transformer encoder block。
- Vanilla GR:7 个 encoder block + 3 个 decoder block + 3 个大小为 32,000 的 codebook。
- Gryphon:与 vanilla GR 用相同的 codebook 设置,但把一个 decoder block 替换为单层 ILSM,使得参数量与推理时间相对 vanilla GR 的差异小于 1%。ILSM 中只用 item-id 特征,因此 Gryphon 相对 GR 基线没有 item 特征上的优势(保证公平对比)。$\lambda$ 设为 1。
- Vanilla GR Resolved:9 个 encoder block + 1 个 decoder block + 2 个大小为 1024 的 codebook(作者发现更大的 codebook 会大幅退化该基线的表现)。
- 所有模型:beam size $K = 2048$,用户序列长度 512,hidden size 1024。负样本来自跨设备 gather 的 in-batch 采样,用于 ARGUS 和 ILSM 的 LogQ 修正 sampled softmax。所有模型用 Adam 训练,线性 warmup 后线性学习率衰减,encoder 输入用相同特征。
评估指标。 Recall@$k$ 衡量"出现在 top-$k$ 返回结果中的、与某次用户曝光关联的 ground-truth item 的比例"。由于检索候选随后会被生产 ranker 处理,Recall@1000 是衡量候选生成器质量的主要离线指标。由于重复实验计算代价高,作者没有做跨多随机种子的正式显著性检验;作为对随机性的实用估计,他们用不同随机初始化做了少量预实验,观察到 Recall@10 与 Recall@1000 的波动约 ±0.003,因此对小于等于这个量级的差异持谨慎解读态度。
主要实验结果¶
Table 1:离线 item 级下一个 item 预测结果。
| Method | SIDs | Recall@10 | Recall@1000 |
|---|---|---|---|
| ARGUS | — | 0.0996 | 0.6582 |
| Vanilla GR | 3×32000 | 0.1961 | 0.8245 |
| Vanilla GR Resolved | 2×1024 | 0.2077 | 0.8343 |
| Gryphon (ours) | 3×32000 | 0.2178 | 0.8552 |
结论分析。 Gryphon 在两个 cutoff 上都取得最高的 item 级 Recall@$k$。相对 Vanilla GR,Recall@1000 从 0.8245 提升到 0.8552(+3.7%);相对 Vanilla GR Resolved,从 0.8343 提升到 0.8552(+2.5%)。这些提升超过了 ±0.003 的初始化方差经验估计(尽管没有正式多种子检验)。值得注意的是,所有 SID 类方法都远超 ARGUS 这个双塔生产基线(Recall@1000 0.6582),说明 SID 生成式检索本身在该场景下相对传统双塔召回有大幅优势;而 Gryphon 在 GR 范式内部进一步把 item 级 recall 推到最高。
消融与分析:item 级重打分 vs. beam 似然¶
Table 2:在共享候选池($K=2048$)上的 ILSM 消融。 为隔离 Gryphon 增益的来源,作者对同一个($K=2048$)beam 生成的 SID 池,用三种方式打分:
| Variant | Scoring | Recall@1000 |
|---|---|---|
| Gryphon w/o ILSM | SID-level(beam scores) | 0.8404 |
| Gryphon w/o ILSM | item-level(beam scores) | 0.8209 |
| Gryphon | item-level(ILSM) | 0.8552 |
结论分析。 这张表是全文最关键的机制证据:
- 碰撞解析的代价:在 beam-likelihood 排序下,把分数下放到 item 级(item-level beam scores,0.8209)反而低于 SID 级 beam 排序(0.8404)。这量化了碰撞解析的代价——beam likelihood 无法区分共享同一 SID 的 item,强行展开到 item 级只会让同分 item 互相稀释排名。
- ILSM 越过了 beam 天花板:ILSM 对同一批 item 重新打分,把 item 级 Recall@1000 提升到 0.8552,高于 SID 级 beam 天花板(0.8404)。相对 item-level beam scores(0.8209),ILSM 带来 +4.2% 的增益。
- 关键推断:item 级 recall 只有在"把 beam 排在其 top-100 之外的 SID 中的 item 提拔上来"时才可能超过这个天花板。因此这个"交叉"现象证明——beam likelihood 对那些本就可达(reachable)的候选做了失准排序,而 item 级打分能把它们找回来。这把瓶颈精确定位为 beam-likelihood 失准,而非候选 recall 不足。
换句话说,消融实验从两个方向夹击地证明了 Gryphon 的论点:碰撞使 beam 评分必然失真(机制 1),而 beam 误差累积又使可达 item 被错排(机制 3),ILSM 同时治理两者。
在线 A/B 实验¶
作者在一个音乐推荐应用上做了 7 天在线 A/B 实验,将 Gryphon 与生产候选生成栈对比。用户随机分到对照组与实验组,4% 的合格用户分到实验组。
- 对照组:现有生产候选生成流水线,由 15+ 个异构候选生成器组成,每次请求产生 10,000 个候选,经生产 preranker 过滤后把 3,000 个候选传给最终 ranker。
- 实验组:这一整套候选生成 + preranking 栈被 Gryphon 替换。Gryphon 作为唯一候选源,直接给同一个最终 ranker 提供 1,000 个候选。
Table 3:在线 A/B 结果。
| Production stack | Gryphon | |
|---|---|---|
| Candidate generators | 15+ | 1 |
| Initial candidates | 10,000 | 1,000 |
| Preranking stage | Yes | No |
| Candidates passed to ranker | 3,000 | 1,000 |
| Total listening time | — | +0.25% |
| Active users ratio | — | +0.43%* |
| Unfinished tracks | — | −1.3%* |
(相对对照组的变化。* 表示在 $p < 0.001$ 下显著。)
结论分析。 主互动指标是总收听时长(Total Listening Time, TLT)。Gryphon 把 TLT 改变了 +0.25%,在实验设计内不具统计显著性。在次要质量指标上,Gryphon 出现了统计显著的有利变动:更高的活跃用户比例(+0.43%)、更少的未播完曲目(−1.3%)。作者把这解读为证据:Gryphon 可以作为唯一候选源,在主互动指标上不带来统计显著变化的同时,大幅简化候选生成与 preranking 流水线——用 1 个生成器替换 15+ 个,去掉 preranking 阶段,传给 ranker 的候选数从 3,000 降到 1,000(减少 66.7%)。
核心贡献总结¶
- 识别并刻画结构性错配:指出 SID 生成式检索中 beam search 排序的是 SID 序列 而非 item,并刻画两个由此产生的失败模式——序列似然失准与语义 ID 碰撞。
- 提出 Gryphon:一个共享 encoder 架构,在大致匹配的参数量与推理预算下,联合训练 SID 生成与 item 级打分,把最终 item 选择从 beam likelihood 中解耦出来。
- 工业验证:离线在大致匹配的参数量/推理预算下取得所有评估基线中最高的 item 级 Recall@1000;并证明 item 级重打分能越过 SID 级 beam 天花板——把限制因素隔离为 beam 似然失准而非候选 recall。在 7 天在线 A/B 中,作为唯一候选源不带来 TLT 的统计显著变化,同时给 ranker 少传 66.7% 的候选并完全移除 preranking 阶段。
与已归档相关工作的对比¶
Gryphon 的核心论点可拆为三块:(A) beam 似然对 item 失准(失败模式 1);(B) SID 碰撞(失败模式 2);(C) 统一的补救——加一个 item 级重打分模块,把 item 选择与 beam 似然解耦。文档库里恰好有三篇分别从这三个角度切入、问题同构但解法路径各异的论文,对照价值很高。
APAO APAO: Adaptive Prefix-Aware Optimization(清华 DCST,2026-03-03)¶
关系:独立并发(本文未引用 APAO,两者针对同一失败模式殊途同归)· 已加载对方精读
- 共同关注的问题:两文都直指 Gryphon 的失败模式 1——beam search 带来的训练-推理不一致 / 序列似然失准。APAO 形式化得更彻底:训练时 CE loss 优化的是 token 平均似然(弱前缀可被后续 token 补偿,成功条件只看最终累积和 $\mathbb{I}_{\text{Full}}(y) = \mathbb{I}(\text{rank}_y(S(y|x)) \le K)$),而 beam search 在每一步都做 top-K 剪枝(成功条件是 $\mathbb{I}_{\text{Beam}}(y) = \prod_t \mathbb{I}(\text{rank}_t \le K)$,任何一步掉出 beam 即永久淘汰)。这与 Gryphon"早期 token 错误把 beam 推入错误子树、相关 item 落到低分路径"是同一个 root cause。
- 相近的技术骨架:两者都承认"beam 是好的候选生成机制,但 beam 似然不是完整的 item 相关性信号"。
- 本文的差异与推进:补救方向完全相反。APAO 修的是 beam 排序本身——在 CE loss 上加前缀级 pointwise/pairwise 损失 + 自适应最差前缀加权(闭式软权重 $w_m^{t+1} \propto w_m^t \exp(\eta \mathcal{L}_m)$),让训练目标与 beam 的逐步排名机制对齐,并证明最小化前缀 pairwise loss 等价于最大化 beam recall 下界。Gryphon 则干脆放弃 beam 似然作为最终分数,让 beam 只决定候选成员资格,再用独立的 ILSM 在 item 级重打分。一个是"把生成器训得对 beam 鲁棒",一个是"绕开 beam 评分、换一个判别式打分器"。
- 可比的方法/实验差异:APAO 在 Amazon/Yelp 四个公开数据集上做学术评测(leave-one-out,Llama-3.1-8B 提语义 + 4 层 RQ-K-Means),关心 NDCG/Recall;Gryphon 在工业音乐场景做 Recall@1000 + 7 天 A/B。APAO 不改架构、零额外前向;Gryphon 用单层 ILSM 替换一个 decoder block(<1% 参数差)。两者可视作"治理 beam 失准"的训练侧 vs. 架构侧两条互补路线。
QuaSID QuaSID: Qualification-Aware Semantic ID Learning(电子科技大学,2026-02-28)¶
关系:显式引用 [6],但原文仅在 §2.2 碰撞讨论一笔带过、未做方法/指标对比 · 已加载对方精读
- 共同关注的问题:两文都聚焦 Gryphon 的失败模式 2——SID 碰撞导致语义纠缠 / item 无法区分。QuaSID 进一步细分出"碰撞信号异质性":并非所有碰撞都有害,重复采样、同 item 多次曝光、对比学习正样本对带来的低 Hamming 距离重叠是良性的,一刀切排斥会误伤。
- 相近的技术骨架:都认为"SID 级评分给碰撞组内 item 同分"是结构性缺陷,必须让同 SID 的 item 可区分。
- 本文的差异与推进:解法层级相反。QuaSID 在 tokenizer 侧治理碰撞——通过 HaMR(Hamming 引导的 margin 排斥)+ CVPM(冲突感知有效对掩码)只对"资质合格的有害碰撞对"施加排斥,从源头减少有害碰撞,产出新的 SID lookup table。Gryphon 则保留碰撞、在打分侧解决——不动 tokenizer,让 ILSM 用 item 级特征给碰撞组内 item 打出不同分数。耐人寻味的是,Gryphon 在 §2.2 明确反对"靠解析层把 SID 变唯一"(TIGER 式追加 token)的做法,理由是动态目录下解析层须无限增长重训;而 QuaSID 正是"周期性离线重训 tokenizer + 重建 lookup table"的代表,恰好落在 Gryphon 批评的运维负担一侧。两文构成"防碰撞(tokenizer)vs. 解碰撞(scoring)"的鲜明对照。
- 可比的方法/实验差异:QuaSID 已在快手部署,SID 同时用于检索与排序的特征增强;Gryphon 在 Yandex 音乐做唯一召回源。QuaSID 的产物是更干净的离散接口,Gryphon 的产物是绕开离散接口缺陷的连续重打分器。
DIG DIG: Discrimination Is Generation(美团,2026-05-14)¶
关系:独立并发(本文未引用 DIG,两者共享同一统一性洞察)· 已加载对方精读
- 共同关注的问题:两文撞上了几乎相同的元层洞察——"排序与检索是同一优化问题在不同粒度上的两面"。DIG 写成 $\arg\max_{v}f(u,v)$(item 空间,判别式排序)vs. $\arg\max_{(s_1,\dots,s_L)}g(\cdot)$(token 空间,生成式检索);Gryphon 写成"beam search 给 semantic ids 打分,而推荐质量取决于给 items 打分"。两者都把 SID 视为判别与生成之间的桥梁,都要把"token 粒度评分 ≠ item 粒度评分"的 gap 在一个统一模型内弥合。
- 相近的技术骨架:都用"共享用户表征 / 共享主干 + 双重用途"实现统一——一次训练同时得到生成式检索能力与 item 级判别能力,而非串接两个独立模型。
- 本文的差异与推进:实现机制差异显著。DIG 把 tokenizer 嵌进判别式排序器内部(DIN+DCNv2+MoE),让排序 BCE loss 直接驱动 codebook 构造,并把 SID 的"寻址"与"语义表达"解耦成两套参数(codebook 向量管 argmin 寻址、SID embedding 由判别 loss 端到端更新、免 STE),同一个 Mixer 既出排序分 $\hat{y}_{\text{rank}}$ 又出逐层召回分 $\hat{y}_{\text{recall}}^{(l)}$;用 u2t(u2i 交叉特征的 token 级聚合)补回检索时缺失的个性化信号。Gryphon 不动 tokenizer(沿用 residual K-Means SID),而是在 GR 之上挂一个 item-to-user cross-attention + MLP 的 ILSM,对 beam 解析出的 item 重打分。一句话:DIG 让"判别梯度回流改造 SID 本身",Gryphon 让"SID 照旧、另起一个判别头在 item 级兜底"。两者是"统一检索与排序"的 tokenizer 改造派 vs. 打分器外挂派。
- 可比的方法/实验差异:DIG 强调 u2i 交叉特征从未进入 codebook 是 GR 落后判别式排序的根因,并报告对五个 SID 基线 +52%~+220% R@10、同时提升排序 AUC(公开 3 + 美团工业 2 数据集);Gryphon 强调 beam 似然失准 + 碰撞是根因,报告 item 级 Recall@1000 越过 beam 天花板 + 7 天 A/B 唯一召回源不掉 TLT。二者从不同根因诊断出发,却都收敛到"用一个模型统一生成与判别"。
讨论与局限性¶
核心贡献与可借鉴的设计。 Gryphon 最值得借鉴的,是把"生成式检索"重新定位为纯候选生成机制、把"item 排序"交给一个共享编码器的轻量判别头——这一解耦在工程上极其务实:(1) ILSM 只替换一个 decoder block,参数/延迟差 <1%,几乎零额外成本就拿到 +3.7% Recall@1000;(2) 不碰 tokenizer,规避了"解析层随动态目录无限增长"的运维陷阱;(3) Table 2 的"item 级越过 beam 天花板"是干净的因果隔离实验,把增益来源钉死在"beam 失准 + 碰撞"而非 recall 不足,方法论上很有说服力;(4) 在线把 15+ 召回器 + preranking 压成单一召回源、候选数砍 66.7% 而主指标不掉,对工业召回栈的简化价值巨大。
局限与争议。
- 统计严谨性偏弱:离线无多种子显著性检验(仅 ±0.003 经验方差),主指标 TLT +0.25% 本身不显著——严格说在线证据是"非劣(non-inferior)+ 简化流水线",而非"互动提升"。次要指标(活跃用户 +0.43%、未播完 −1.3%)虽显著,但属辅助证据。
- ILSM 监督信号单一:本文只用 next-item prediction + sampled softmax 实例化 ILSM,作者也承认在该目标下 Gryphon 并不能消除对生产 ranker 的需求。多目标互动、ranker 蒸馏、长期价值优化都留作未来工作。
- beam 仍是召回上界:ILSM 只能在 beam 召回的 SID 集合内重排,无法找回 beam 完全没生成的 SID 对应的 item——它治的是"可达 item 的错排",治不了"召回缺失"。
- 场景局限:仅在单一工业音乐平台、4% 流量、7 天验证,跨域/跨品类的可迁移性未知。
与已有工作的差异定位。 面对 SID-GR 的同一组结构性缺陷,社区出现了三条并行路线:训练侧对齐 beam(APAO)、tokenizer 侧防碰撞(QuaSID/AdaSID)、tokenizer 侧统一判别与生成(DIG)。Gryphon 选择了第四条最"外科手术式"的路线——保持 SID 与 beam 不变,仅在 item 级外挂一个判别式重打分器,用最小的架构改动换取最大的部署简化。这条路线的代价是它本质上是"打补丁"而非"根治"(beam 召回上界与 ranker 依赖都仍在),但在工业落地的成本/收益比上极具竞争力。