GAVE: Generative Auto-Bidding with Value-Guided Explorations¶
研究动机与背景¶
自动出价(Auto-bidding)已成为广告平台优化投放效果的核心策略。现有方法主要分两大类:
- 基于规则的策略(PID、OnlineLP 等):计算轻量、部署简单,但静态性质难以适配动态市场
- 基于强化学习(RL)的方法(BCQ、CQL、IQL 等):虽能适应环境变化,但 MDP 的状态独立假设忽略了竞价序列中的时序依赖和历史模式,在高波动的实时竞价环境中效果受限
Decision Transformer (DT) 将 RL 重构为序列建模问题,通过 Transformer 捕捉时序依赖和历史上下文,为离线竞价建模提供了新方向。然而,将 DT 应用于实际广告竞价场景面临三大挑战:
- 复杂广告目标难以建模:实际广告指标不仅是简单的点击/转化总量,还涉及 CPA 阈值、CPC 上限等相互依赖的约束条件,DT 需要适配多种评估指标
- 离线数据的行为坍缩(Behavioral Collapse):在固定离线数据集上训练容易复现已记录的行为模式,但探索数据集外的动作可能引入分布偏移
- OOD(Out-of-Distribution)风险:随机探索新动作可能有益也可能有害,需要稳定的更新机制和方向引导
核心方法 / 模型架构¶
问题定义¶
考虑 $I$ 个展示机会(impression)的序列,广告主提交出价 $\{b_i\}_{i=1}^I$。采用广义二价拍卖(GSP),出价高于竞争对手最高出价 $b_i^-$ 即赢得展示,成本为第二高出价。广告主目标是最大化总价值:
$$\max \sum_{i=1}^{I} x_i v_i \tag{1}$$
其中 $v_i \in \mathbb{R}^+$ 是展示 $i$ 的私有估值(如转化率),$x_i \in \{0, 1\}$ 为竞拍结果:
$$x_i = \begin{cases} 1 & \text{if } b_i > b_i^- \\ 0 & \text{otherwise} \end{cases} \tag{2}$$
同时需满足预算约束和 KPI 约束(以 CPA 为例):
$$\sum_{i=1}^{I} x_i c_i \leq B \tag{3}$$
$$\frac{\sum_{i=1}^{I} x_i c_i}{\sum_{i=1}^{I} x_i v_i} \leq C \tag{4}$$
其中 $B$ 为总预算,$C$ 为最大允许 CPA。
通过线性规划简化,最优出价可表示为:
$$b_i^* = (\lambda_0^* + \lambda_1^* C) v_i = \lambda^* v_i \tag{7}$$
其中 $\lambda^* = \lambda_0^* + \lambda_1^* C$ 是统一出价参数。竞价问题转化为迭代寻找最优 $\lambda^*$ 的序列决策问题。
DT-based 竞价建模¶
将竞价周期离散化为 $T$ 个时间步,每步定义:
- 状态 $s_t$:剩余时间、未用预算、历史竞价统计等特征
- 动作 $a_t$:出价调节参数 $\lambda_t$($a_t = \lambda_t$)
- 奖励 $rw_t$:时间步 $t$ 到 $t+1$ 间的累计赢得价值 $rw_t = \sum_{n=0}^{N_t} x_{n_t} v_{n_t}$
- Return-To-Go (RTG) $r_t$:未来累计奖励 $r_t = \sum_{t'=t}^{T} rw_{t'}$
轨迹表示为:$\tau = (r_1, s_1, a_1, r_2, s_2, a_2, \ldots, r_T, s_T, a_T)$
GAVE 框架总览¶
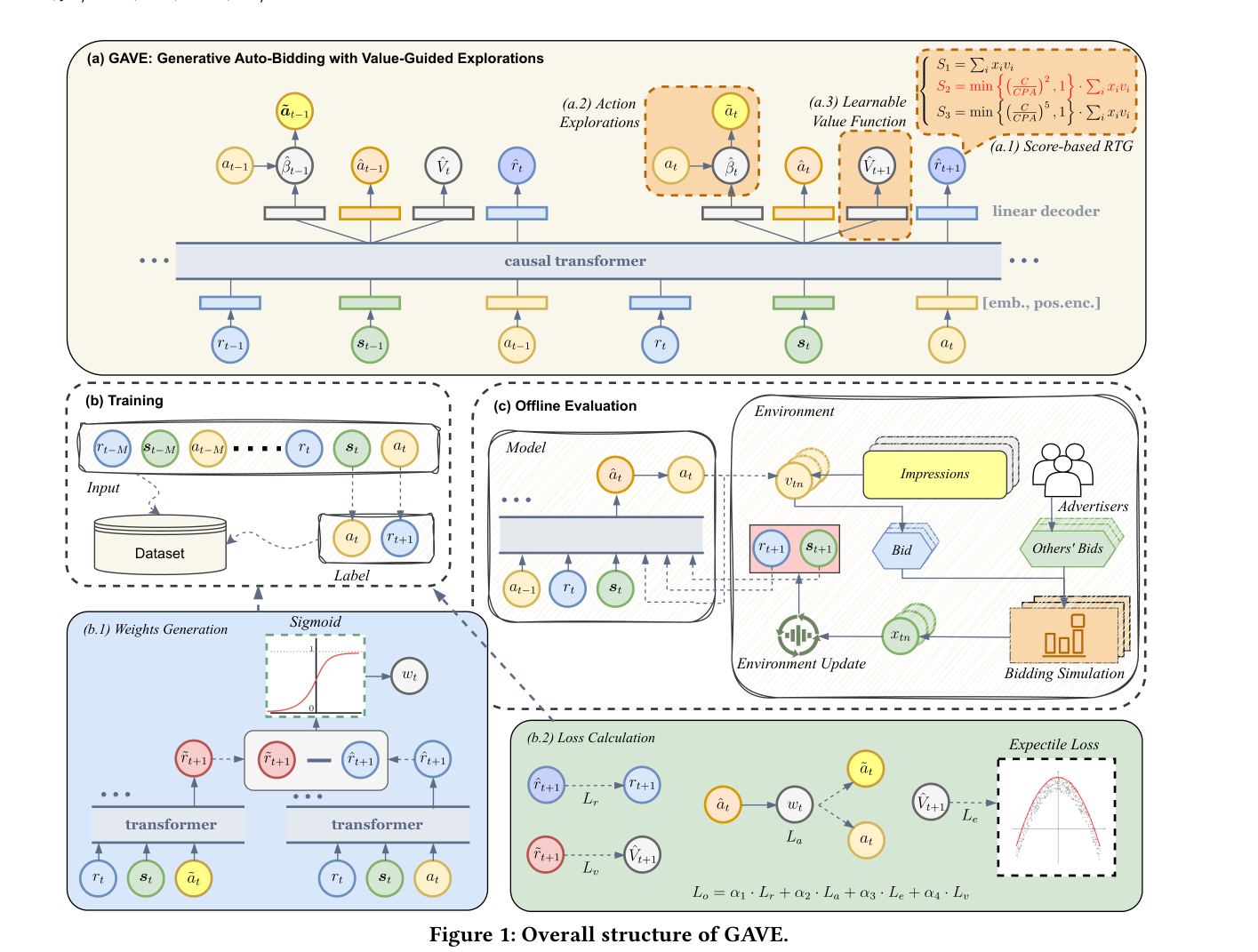
GAVE 基于 DT 架构,输入序列为 $(r_t, s_t, a_t)$ 三元组,引入三大创新:
(a.1) Score-based RTG:可定制的评分函数适配多种广告目标 (a.2) Action Exploration:基于 RTG 评估的动作探索机制 (a.3) Learnable Value Function:可学习价值函数引导探索方向
在时间步 $t$,GAVE 同时预测探索系数 $\hat{\beta}_t$、探索动作 $\hat{a}_t$、可学习价值 $\hat{V}_{t+1}$ 和 RTG 估计 $\hat{r}_{t+1}$:
$$\begin{cases} (\hat{\beta}_t, \hat{a}_t, \hat{V}_{t+1}) = GAVE(r_{t-M}, s_{t-M}, a_{t-M}, \ldots, r_t, s_t) \\ \hat{r}_{t+1} = GAVE(r_{t-M}, s_{t-M}, a_{t-M}, \ldots, r_t, s_t, a_T) \\ \hat{a}_t = \hat{\beta}_t a_t \end{cases} \tag{12}$$
其中 $M$ 是历史窗口长度,输入序列为 $M+1$ 步。
3.2 Score-based RTG¶
直接优化无约束总价值 $\sum_i x_i v_i$ 可能导致 CPA 严重超标。GAVE 设计带约束的评分函数替代无约束 RTG。以 CPA 约束为例,定义评分:
$$\begin{cases} CPA_t = \frac{\sum_i^{I_t} x_i c_i}{\sum_i^{I_t} x_i v_i} \\ \mathbb{P}(CPA_t; C) = \min\left\{\left(\frac{C}{CPA_t}\right)^\gamma, 1\right\} \\ S_t = \mathbb{P}(CPA_t; C) \cdot \sum_i^{I_t} x_i v_i \\ r_t = S_T - S_{t-1} \end{cases} \tag{14}$$
其中 $I_t$ 是截至时间步 $t$ 的展示数,$\gamma$ 控制 CPA 惩罚强度(论文取 $\gamma = 2$)。当 CPA 超标时,$\mathbb{P} < 1$ 对 RTG 施加惩罚;CPA 达标时 $\mathbb{P} = 1$,RTG 等于无约束总价值。
不同广告目标可能对 CPA 的依赖程度不同,但都可通过 $S_t$ 的通用化设计统一处理(Eq. 15):$r_t = S_T - S_{t-1}$。
3.3 Action Exploration¶
离线训练面临两难:只学已有数据会导致行为坍缩,但随机探索新动作可能引发分布偏移。GAVE 的解决方案是基于 RTG 评估的稳定性保持探索。
探索动作生成:GAVE 预测系数 $\hat{\beta}_t$(与 $a_t$ 同维度),通过缩放生成探索动作:
$$\begin{cases} \hat{\beta}_t = \sigma(FC_\beta(DT(r_{t-M}, s_{t-M}, a_{t-M}, \ldots, r_t, s_t))) \\ \hat{a}_t = \hat{\beta}_t a_t \end{cases} \tag{16}$$
其中 $\sigma(x) = \text{Sigmoid}(x) + 0.5$,将 $\hat{\beta}_t$ 约束在 $(0.5, 1.5)$,确保探索动作与原始动作接近。
稳定性保持更新:用探索动作 $\hat{a}_t$ 评估 RTG $\hat{r}_{t+1}$,与原始动作 $a_t$ 对应的 RTG $\tilde{r}_{t+1}$ 对比,计算更新权重:
$$\begin{cases} \tilde{r}_{t+1} = GAVE(r_{t-M}, s_{t-M}, a_{t-M}, \ldots, r_t, s_t, \hat{a}_t) \\ w_t = \text{Sigmoid}(\alpha_r \cdot (\hat{r}_{t+1} - \tilde{r}_{t+1})) \end{cases} \tag{18}$$
当 $w_t > 0.5$(探索动作的 RTG 优于原始),倾向于向 $\hat{a}_t$ 更新;否则保守地向 $a_t$ 更新。
损失函数:
$$\begin{cases} L_r = \frac{1}{M+1} \sum_{t-M}^{t} (\hat{r}_{t+1} - r_{t+1})^2 \\ L_a = \frac{1}{M+1} \sum_{t-M}^{t} ((1 - w_t') \cdot (\hat{a}_t - a_t)^2 + w_t' \cdot (\hat{a}_t - \hat{a}_t')^2) \end{cases} \tag{19}$$
其中 $w_t'$ 和 $\hat{a}_t'$ 是 $w_t$ 和 $\hat{a}_t$ 的梯度冻结版本。$L_r$ 确保 RTG 预测准确,$L_a$ 实现稳定性保持的动作更新。
3.4 Learnable Value Function¶
随机探索不能保证改进。GAVE 引入可学习价值函数 $V_{t+1}$,类似 RL 中的最优状态价值函数,估计 $r_{t+1}$ 的上界:
$$V_{t+1} = \arg\max_{\hat{a}_t \in \mathbb{A}} r_{t+1} \tag{20}$$
由于离线动作空间有限,通过 expectile regression 学习:
$$L_e = \frac{1}{M+1} \sum_{t-M}^{t} (L_2^\tau(r_{t+1} - \hat{V}_{t+1})) = \frac{1}{M+1} \sum_{t-M}^{t} (|\tau - \mathbb{I}((r_{t+1} - \hat{V}_{t+1}) < 0)| (r_{t+1} - \hat{V}_{t+1})^2) \tag{21}$$
其中 $\tau = 0.99$,使 $\hat{V}_{t+1}$ 逼近 $r_{t+1}$ 的上界。
价值函数引导探索动作的更新方向:
$$L_v = \frac{1}{M+1} \sum_{t-M}^{t} (\tilde{r}_{t+1} - \hat{V}_{t+1}')^2 \tag{22}$$
其中 $\hat{V}_{t+1}'$ 是梯度冻结版本。通过 $L_v$ 隐式引导 $\hat{a}_t$ 向 RTG 接近最优值 $\hat{V}_{t+1}$ 的方向探索,锚定在合理区域内,缓解 OOD 风险。
3.5 整体优化目标¶
$$L_o = \alpha_1 \cdot L_r + \alpha_2 \cdot L_a + \alpha_3 \cdot L_e + \alpha_4 \cdot L_v \tag{23}$$
其中 $\{\alpha_1, \alpha_2, \alpha_3, \alpha_4\}$ 为超参数。
推理流程¶
推理时,GAVE 对每个输入序列预测 $\hat{a}_t = \lambda_t$,第 $n$ 个展示的出价为 $b_{tn} = \lambda_t v_{n_t}$,实现实时竞价。
实验设置¶
数据集¶
使用 AuctionNet 框架的两个公开数据集:
| 参数 | AuctionNet | AuctionNet-Sparse |
|---|---|---|
| 轨迹数 | 479,376 | 479,376 |
| 投放周期数 | 9,987 | 9,987 |
| 每条轨迹时间步数 | 48 | 48 |
| 状态维度 | 16 | 16 |
| 动作维度 | 1 | 1 |
| 动作范围 | [0, 493] | [0, 589] |
| 展示价值范围 | [0, 1] | [0, 1] |
| CPA 范围 | [6, 12] | [60, 190] |
每个数据集约 50 万条轨迹,来自 1 万个投放周期,每周期 48 步,模拟 24 小时投放。
评估协议¶
采用 AuctionNet 模拟环境:48 个竞价 agent 进行 round-robin 评估,测试模型依次替换每个 agent 与其余 47 个竞争,最终取平均得分。评分使用 Eq. 13($\gamma = 2$)。
Baselines¶
- 扩散模型:DiffBid
- 在线 RL:USCB
- 离线 RL:CQL, IQL, BCQ
- Decision Transformer 系列:DT, CDT, GAS
实现细节¶
- NVIDIA H100 GPU
- Causal Transformer:8 层,16 注意力头
- Batch size 128,最大 400k 训练步
- AdamW 优化器,学习率 $1 \times 10^{-5}$
- 10 次独立运行取均值
主要实验结果¶
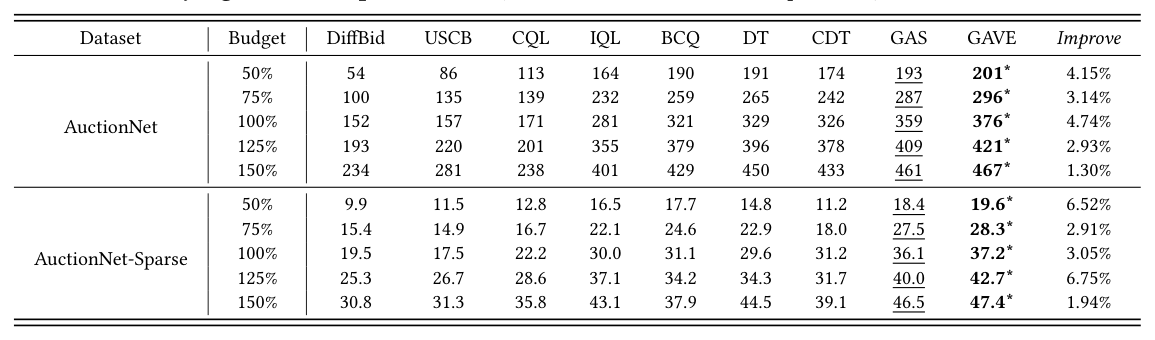
整体性能(Table 2)¶
| Dataset | Budget | DiffBid | USCB | CQL | IQL | BCQ | DT | CDT | GAS | GAVE | Improve |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AuctionNet | 50% | 54 | 86 | 113 | 164 | 190 | 191 | 174 | 193 | 201* | 4.15% |
| 75% | 100 | 135 | 139 | 232 | 259 | 265 | 242 | 287 | 296* | 3.14% | |
| 100% | 152 | 157 | 171 | 281 | 321 | 329 | 326 | 359 | 376* | 4.74% | |
| 125% | 193 | 220 | 201 | 355 | 379 | 396 | 378 | 409 | 421* | 2.93% | |
| 150% | 234 | 281 | 238 | 401 | 429 | 450 | 433 | 461 | 467* | 1.30% | |
| AuctionNet-Sparse | 50% | 9.9 | 11.5 | 12.8 | 16.5 | 17.7 | 14.8 | 11.2 | 18.4 | 19.6* | 6.52% |
| 75% | 15.4 | 14.9 | 16.7 | 22.1 | 24.6 | 22.9 | 18.0 | 27.5 | 28.3* | 2.91% | |
| 100% | 19.5 | 17.5 | 22.2 | 30.0 | 31.1 | 29.6 | 31.2 | 36.1 | 37.2* | 3.05% | |
| 125% | 25.3 | 26.7 | 28.6 | 37.1 | 34.2 | 34.3 | 31.7 | 40.0 | 42.7* | 6.75% | |
| 150% | 30.8 | 31.3 | 35.8 | 43.1 | 37.9 | 44.5 | 39.1 | 46.5 | 47.4* | 1.94% |
(* 表示 $p < 0.05$ 的显著性提升)
关键结论:
- GAVE 在所有预算设定和数据集上一致超越所有基线
- DT 系列方法(GAS, DT, CDT)整体优于传统离线 RL(BCQ, CQL, IQL),证明 DT 结构对竞价序列建模的有效性
- GAS 优于 DT 和 CDT(得益于 MCTS 后搜索),GAVE 进一步优于 GAS
- DiffBid 表现最差,长序列和高动态环境对扩散模型的轨迹预测构成挑战
目标对齐分析(Table 3)¶
在 AuctionNet-Sparse 100% 预算下,使用三种评分函数 $S_1$(无约束)、$S_2$($\gamma=2$)、$S_3$($\gamma=5$):
| Train \ Eval | $S_1$ | $S_2$ | $S_3$ |
|---|---|---|---|
| $S_1$ | 41.4 | 33.0 | 23.6 |
| $S_2$ | 39.9 | 37.2 | 33.3 |
| $S_3$ | 39.1 | 36.8 | 33.5 |
结论:训练时使用的 RTG 评分函数与评估指标对齐时效果最佳,验证了 score-based RTG 的灵活性和必要性。
参数分析(Figure 2)¶
训练过程中 $w_t$ 从约 0.5 逐渐上升并稳定在 0.5 以上,表明探索动作 $\hat{a}_t$ 的 RTG 逐渐超越原始动作 $a_t$,价值函数有效引导了探索方向。
消融实验(Figure 3)¶

| 变体 | 说明 |
|---|---|
| GAVE-V | 去除 Learnable Value Function($L_e$ 和 $L_v$),用增强 RTG 替代 |
| GAVE-VA | 去除 Value Function + Action Exploration |
| DT | 去除所有 GAVE 组件,纯 DT + 无约束 RTG |
逐层分析: 1. DT → GAVE-VA(仅加 score-based RTG):显著提升,证明目标对齐的重要性 2. GAVE-VA → GAVE-V(加 Action Exploration):进一步提升,探索 + RTG 评估发现了数据集外的有益策略 3. GAVE-V → GAVE(加 Value Function):最终提升,价值函数引导探索方向、缓解 OOD 风险
线上 A/B 实验(Table 4)¶
在快手两个工业竞价场景中部署,为期 5 天,分配 25% 预算和流量给 GAVE:
| 场景 | Cost | Conversion | Target Cost | CPA Valid Ratio |
|---|---|---|---|---|
| Nobid(最大化转化,预算内) | +0.8% | +8.0% | +3.2% | / |
| Costcap(最大化转化,CPA/ROI 约束) | +2.0% | +3.6% | +2.2% | +1.9% |
Nobid 场景:在成本仅增 0.8% 的情况下,转化数增长 8.0%,target cost 提升 3.2% Costcap 场景:CPA 有效率提升 1.9%,同时转化增长 3.6%,广告收入和广告主价值均上升
线上部署细节:
- 状态:20 步序列,包含预算、CPA 限制、预测值、流量/成本速度、剩余预算、窗口平均出价系数等
- 动作:基于前 2 小时的窗口平均 $\lambda_t$,$\lambda_t = a_t + \frac{1}{|E|} \sum_{t'=t-E}^{t} \lambda_{t'}$
- RTG:由于实际转化稀疏,训练时用预测转化率 $pcvr_i$ 替代真实转化
此外,GAVE 的核心方法在 NeurIPS 2024 竞赛 "AIGB Track: Learning Auto-Bidding Agents with Generative Models" 中获得第一名。
讨论与局限性¶
核心贡献¶
- Score-based RTG:通过可定制评分函数将 CPA 等广告约束融入 DT 的 RTG 建模,实现训练目标与评估指标的对齐
- Action Exploration + Stability-Preserving Update:基于 RTG 评估的探索机制,通过 $w_t$ 权重自适应平衡探索与稳定
- Learnable Value Function:expectile regression 学习 RTG 上界,锚定探索在合理区域,缓解 OOD 风险
- NeurIPS 2024 竞赛第一名 + 快手线上部署:学术竞赛和工业验证双重背书
值得借鉴的设计¶
- $\hat{\beta}_t$ 的缩放约束:Sigmoid + 0.5 将探索系数限制在 (0.5, 1.5),既允许探索又不过度偏离,简洁有效
- RTG 对比评估动作质量:不直接判断动作好坏,而是通过两次 RTG 前向传播对比,让模型自己评估探索价值
- Score-based RTG 的通用性:同一框架通过换评分函数适配不同广告目标,不需要改模型结构
局限性¶
- 仅验证了竞价场景:GAVE 的核心设计(score-based RTG、action exploration)理论上可泛化到其他序列决策问题,但论文只在 auto-bidding 上验证
- 线上实验细节有限:5 天 A/B 测试,仅分配 25% 流量,长期效果和全量效果未知
- 单步动作空间:当前动作维度为 1(单一 $\lambda$ 参数),多维动作空间(如同时调节多个 KPI 的权重)的效果未验证
- Expectile regression 的 $\tau$ 敏感性:$\tau = 0.99$ 是固定值,不同场景下是否需要调整未讨论