Gated Bidirectional Linear Attention for Generative Retrieval 精读¶
Yandex(Artem Matveev, Vladislav Tytskiy, Sergei Makeev, Sergei Liamaev),SIGIR '26(Melbourne)短论文,5 页。代码开源于
matfu-pixel/GRID。
研究动机与背景¶
在推荐系统中,生成式检索(generative retrieval) 已成为一类主流范式:它通常采用 encoder–decoder 架构——编码器(encoder)处理一段用户的历史交互序列,解码器(decoder)以自回归方式生成被推荐物品的 semantic ID。由于能端到端地直接"生成"候选,这类模型已在 YouTube、KuaiShou(OneRec)、Yandex 等大型流媒体服务中落地。Transformer 是序列建模的事实标准,被 Google、Pinterest、Yandex、ByteDance 等广泛使用。
序列建模的一个经验规律是:用户交互序列越长,推荐质量越好。但 Transformer 依赖 self-attention,其时间与显存开销随序列长度 $L$ 二次增长。对于活跃用户不断累积的超长历史,这种二次复杂度会让在线服务的延迟变得不可接受。本文指出,编码器是整条生成式检索流水线的主要算力开销来源,因此编码器的注意力效率是决定能否把历史拉长的关键瓶颈。
现有的缓解手段大致两类,本文都认为不够根本:
- 输入序列压缩(如 ByteDance Longer [2]):把长历史压成更短的表示。但压缩是有损的,可能丢掉对检索质量重要的信息。
- 系统级优化(context parallelism [4]、hierarchical information pathways [18]):通过工程手段分摊算力,但并不消除注意力对序列长度的二次依赖。
在 LLM 领域,为应对百万级 token,Katharopoulos 等人 [7] 提出了核化线性注意力(kernelized linear attention):把注意力改写为核特征空间中的点积,复杂度从 $O(n^2)$ 降到 $O(n)$;随后 Mamba [5]、带 delta-rule 的硬件高效变体(Gated DeltaNet [16])进一步推进长上下文建模。但这些方法绝大多数只针对 causal(因果)注意力。
而生成式检索的关键差异在于:编码器在经验上强烈受益于双向(bidirectional)掩码——后文 Table 1 会量化这一点。因此"可扩展的双向线性注意力"非常重要,却长期未被充分研究。现有双向线性注意力框架(如 LION [1])只在推理时达到线性复杂度,训练时仍依赖二次注意力。
本文据此提出 Gated Bidirectional Linear Attention(GBLA):一个训练与推理都是线性时间的双向注意力层,相对 FlashAttention-v3 [13] 这类高度优化的二次注意力实现降低延迟,同时把检索质量保持在近乎持平的水平。作者在自有(Yandex Music)与公开(Amazon)基准上都做了验证。
问题设定与方法总览¶
本文研究的生成式检索沿用与 OneRec [3] 相近的 encoder–decoder 设定。给定用户 $u$ 的物品交互序列 $x^u = (i_1^u, i_2^u, \ldots, i_L^u)$,目标是生成用户接下来会交互的物品序列。在很多服务里,推荐系统以批(batch)的形式返回排序后的物品:用户消费完一批,系统接着服务下一批,这天然把交互序列切成了批。作者把单个 batch 内的交互当作 target 物品,训练模型在"之前所有交互"的条件下生成它们。
物品嵌入用 multi-hash 技术 [15]:把物品 ID 用多个不同的哈希函数映射到一张共享嵌入表的多个条目,取出的若干嵌入拼接后再经一个线性层投影,得到该物品的向量。物品向量序列被送入一个双向 Transformer 编码器;解码器通过 cross-attention 以编码器输出为条件,自回归地生成候选物品的 semantic ID [12]。
整篇论文的技术核心,就是把这个编码器里昂贵的双向 softmax 自注意力,替换为线性时间的 GBLA。
核心方法:从双向 softmax 注意力到 GBLA¶
1. 双向 softmax 注意力(baseline)¶
设 $\mathbf{X} \in \mathbb{R}^{L \times d}$ 为嵌入后的用户交互序列。对单个注意力头(head dim 为 $d_h$),令 $\mathbf{Q} = \mathbf{X}\mathbf{W}_Q$,$\mathbf{K} = \mathbf{X}\mathbf{W}_K$,$\mathbf{V} = \mathbf{X}\mathbf{W}_V$,其中 $\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V \in \mathbb{R}^{d \times d_h}$。标准双向自注意力对单个 query $\mathbf{q}_i$ 的输出为:
$$ \text{Attn}(\mathbf{q}_i, \mathbf{K}, \mathbf{V}) = \frac{\sum_{j=1}^{L} \exp\!\left(\mathbf{q}_i^\top \mathbf{k}_j / \sqrt{d_h}\right) \mathbf{v}_j^\top}{\sum_{j=1}^{L} \exp\!\left(\mathbf{q}_i^\top \mathbf{k}_j / \sqrt{d_h}\right)} \tag{1} $$
它在序列长度 $L$ 上是二次复杂度——这正是要消除的瓶颈。
2. 双向线性注意力(BLA)¶
线性注意力 [8] 的核心思想:把指数相似度 $\text{sim}(\mathbf{q}, \mathbf{k}) = \exp(\mathbf{q}^\top \mathbf{k} / \sqrt{d_h})$ 替换为核特征空间中的点积 $\text{sim}(\mathbf{q}, \mathbf{k}) = \phi(\mathbf{q})^\top \phi(\mathbf{k})$,其中 $\phi$ 是逐元素的非负特征映射,例如 $\phi(x) = \text{elu}(x) + 1$。于是单 query 形式为:
$$ \text{Attn}_{\text{BLA}}(\mathbf{q}_i, \mathbf{K}, \mathbf{V}) = \frac{\phi(\mathbf{q}_i)^\top \sum_{j=1}^{L} \phi(\mathbf{k}_j)\,\mathbf{v}_j^\top}{\phi(\mathbf{q}_i)^\top \sum_{j=1}^{L} \phi(\mathbf{k}_j)} \tag{2} $$
矩阵形式为(即原文 Eq. 1):
$$ \text{Attn}_{\text{BLA}}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \big(\phi(\mathbf{Q})(\phi(\mathbf{K})^\top \mathbf{V})\big) \oslash \big(\phi(\mathbf{Q})(\phi(\mathbf{K})^\top \mathbf{1})\big) \tag{3} $$
其中 $\mathbf{1} \in \mathbb{R}^L$ 是全 1 向量,$\oslash$ 表示带广播的逐元素除法。
关键在于计算顺序:先算 $\phi(\mathbf{K})^\top \mathbf{V} \in \mathbb{R}^{d_h \times d_h}$(一个"KV 压缩状态"),再左乘 $\phi(\mathbf{Q})$。这样完全不需要显式构造 $L \times L$ 的注意力矩阵,复杂度从 $O(L^2 d_h)$ 降到 $O(L d_h^2)$——对长序列即线性于 $L$。因为求和遍历 $j = 1 \ldots L$(无因果掩码),它天然是双向的;而这正是因果线性注意力无法直接照搬的地方(因果版本需要做前缀累加/扫描,双向版本则是一次性全局求和,反而更简单,但需要专门 kernel 才能在训练时也保持线性)。
3. Gated Bidirectional Linear Attention(GBLA)¶
GBLA 在公式 (3) 的 BLA 之上,叠加三个廉价组件,在保持线性复杂度的前提下补回表达力(架构见 Figure 1)。
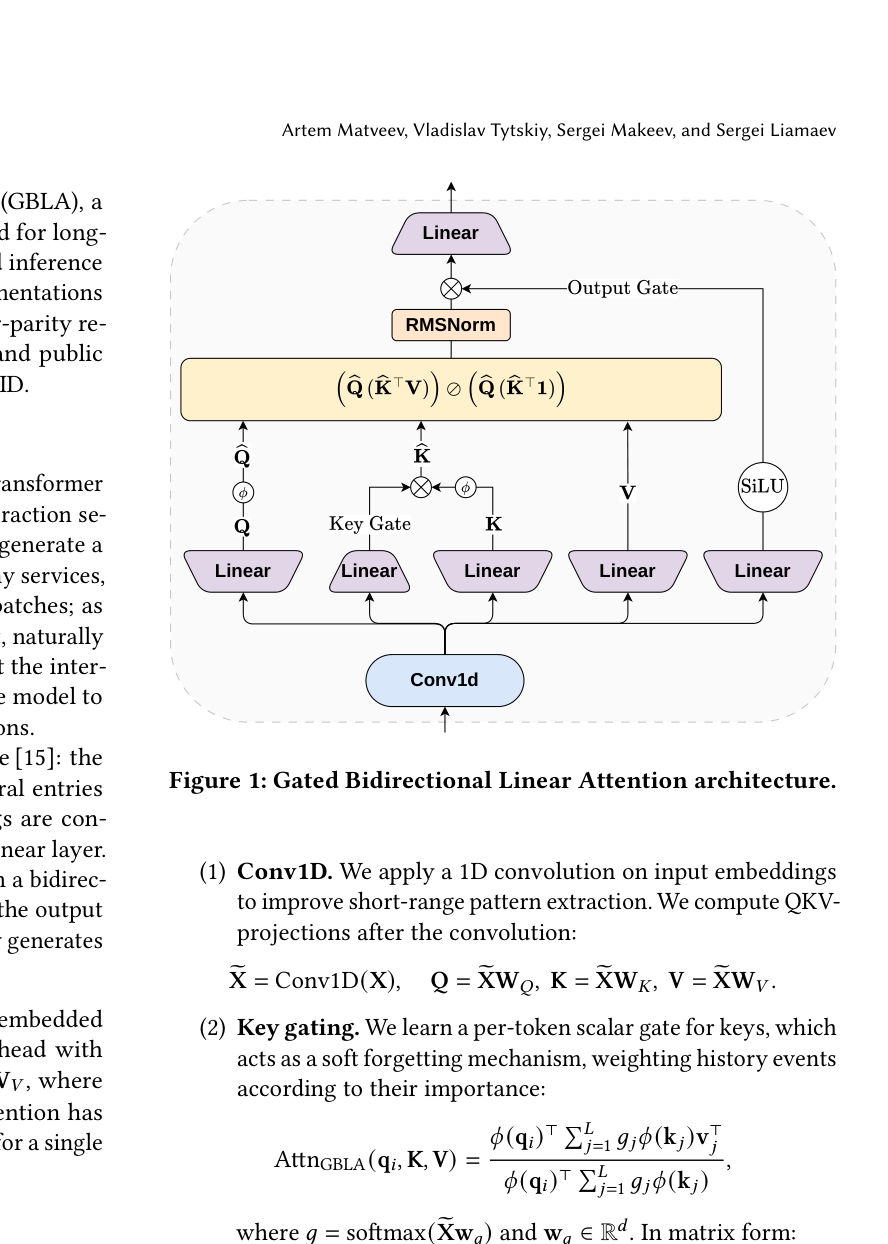
(1) Conv1D(局部因果混合)。 在输入嵌入上先做一维卷积,增强短程模式提取;QKV 投影都在卷积之后计算:
$$ \tilde{\mathbf{X}} = \text{Conv1d}(\mathbf{X}), \quad \mathbf{Q} = \tilde{\mathbf{X}}\mathbf{W}_Q,\ \ \mathbf{K} = \tilde{\mathbf{X}}\mathbf{W}_K,\ \ \mathbf{V} = \tilde{\mathbf{X}}\mathbf{W}_V \tag{4} $$
动机:纯线性注意力把整段历史压成一个固定大小的状态,容易丢失细粒度的短程结构;一个小卷积核(实验中 kernel size = 4)以极低成本补上相邻物品之间的局部依赖。这与 Mamba/Gated DeltaNet 等长上下文设计里"在 token-mixing 前加短卷积"的惯用做法一致。
(2) Key gating(序列级软遗忘)。 为每个 token 的 key 学习一个标量门 $g_j$,充当软遗忘机制,按重要性给历史事件加权:
$$ \text{Attn}_{\text{GBLA}}(\mathbf{q}_i, \mathbf{K}, \mathbf{V}) = \frac{\phi(\mathbf{q}_i)^\top \sum_{j=1}^{L} g_j\, \phi(\mathbf{k}_j)\,\mathbf{v}_j^\top}{\phi(\mathbf{q}_i)^\top \sum_{j=1}^{L} g_j\, \phi(\mathbf{k}_j)} \tag{5} $$
其中门 $g = \text{softmax}(\tilde{\mathbf{X}}\mathbf{w}_g)$,$\mathbf{w}_g \in \mathbb{R}^d$。注意这里用的是 softmax over 序列,因此各 token 的门权重归一化为一个序列级分布——相当于让模型显式地"分配注意预算"给历史中真正重要的交互。矩阵形式:
$$ \text{Attn}_{\text{GBLA}}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \big(\tilde{\mathbf{Q}}(\tilde{\mathbf{K}}^\top \mathbf{V})\big) \oslash \big(\tilde{\mathbf{Q}}(\tilde{\mathbf{K}}^\top \mathbf{1})\big) \tag{6} $$
其中记号 $\tilde{\mathbf{Q}} = \phi(\mathbf{Q})$,$\tilde{\mathbf{K}} = g \odot \phi(\mathbf{K})$,$\odot$ 为带广播的逐元素乘。可见 key gating 只是在进入"KV 压缩状态"前,对每个 key 乘上其门权重,不增加任何复杂度量级。
(3) Gated RMSNorm(门控归一化输出)。 沿用长上下文设计 [16] 的常见做法,对注意力输出 $\mathbf{O} = \text{Attn}_{\text{GBLA}}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) \in \mathbb{R}^{L \times d_h}$ 施加门控归一化:
$$ \text{RmsNormGated}(\mathbf{O}) = \text{RmsNorm}(\mathbf{O}) \odot \text{SiLU}(\tilde{\mathbf{X}}\mathbf{W}_R) \tag{7} $$
其中 $\mathbf{W}_R \in \mathbb{R}^{d \times d_h}$。这就是 Figure 1 中的 "Output Gate":用一条由输入派生的 SiLU 门去调制归一化后的注意力输出,提升数值稳定性与表达力。
多头。 与标准注意力一样使用多个注意力头;每个头 $h$ 有独立的 $\mathbf{W}_Q^h, \mathbf{W}_K^h, \mathbf{W}_V^h, \mathbf{w}_g^h, \mathbf{W}_R^h$。
三个组件的共同点是都极廉价、都不破坏线性复杂度:Conv1D 是固定小核卷积,key gating 是逐 token 标量,gated RMSNorm 是逐元素操作。它们的作用是把"裸 BLA"因状态压缩而损失的表达力,以接近零的算力代价补回来。
实验设置¶
实践中"用线性注意力(LA)整体替换自注意力(SA)很少是最优的" [10]。因此本文采用混合编码器:以 1:2 的比例交错 SA 与 LA,排列顺序为 [SA, LA, LA](一个 SA 块后接两个 GBLA 块)。工程上,BLA 用一个 fused Triton kernel 实现,GBLA 则用 torch.compile 优化。所有实验跑在通过第三方算力商租用的 NVIDIA H100 上。
工业设置(Yandex Music)¶
- 数据:Yandex Music 流媒体平台的大规模生产数据集。训练用连续 7 天的交互、按时间顺序消费,训练集是 400M 样本的子采样;评估用第 8 天。
- 模型容量向编码器倾斜:编码器有 9 层双向 Transformer,hidden size $d = 1024$,16 个注意力头,其中一部分层可替换为 GBLA;解码器只有单层 causal 层(同时含 self-attention 与 cross-attention)。GBLA 的 Conv1D kernel size 设为 4。因为编码器主导算力,线性注意力只引入编码器。
- 学习率:线性 warmup——前 3000 步从 $10^{-5}$ 升到峰值 $x$,再线性衰减到 $0.1x$。最优峰值学习率与架构有关:全自注意力用 $x = 7\times10^{-4}$,混合编码器用 $x = 5\times10^{-4}$。所有实验用相同的有效 batch size。
- 指标:Recall@{10, 100, 1000}。主消融固定最大历史长度 $L = 2048$,并单独研究向更长历史的 scaling。
学术设置(Amazon,复现 GRID 协议)¶
为在公开数据上对标,作者采用 GRID 框架 [6] 的实验协议(用了自己 fork 的官方实现,扩展了对线性注意力变体的支持,开源于 matfu-pixel/GRID):
- 数据:5-core 过滤的 Amazon Beauty / Sports / Toys;每个用户序列最后一个物品作 test、倒数第二个作 validation、其余作 train。
- semantic ID:用相同的物品文本字段(Title、Categories、Description、Price),对 Flan-T5(Large/XL/XXL)最后隐藏层做 mean pooling 得到语义嵌入;tokenizer 用 RK-Means,沿用 GRID 的训练配方(8 GPU,per-device batch size 2048)。
- 模型:GRID 实现的是 Tiger [12] 生成模型。匹配 GRID 的训练配置(Adam,lr $5\times10^{-4}$,weight decay $10^{-6}$,batch size 256)与数据采样/选择策略(滑窗采样 + 基于 validation NDCG@10 的 early stopping)。保持 GRID backbone(encoder-decoder 变体共 8 层 Transformer、6 头、嵌入维 128、MLP 隐层 1024),只把编码器的部分自注意力层换成 GBLA(同样走
[SA, LA, LA]混合设计,Conv1D kernel size = 4)。报告 test 集上 Recall@K 与 NDCG@K($K \in \{5, 10\}$),按 validation Recall@10 选 checkpoint,5 个种子取平均。
主要实验结果(工业)¶
作者特别强调关注 Recall@1000,因为生产流水线会把 top-1000 候选转交下游 ranker,在这一区间哪怕 1% 的绝对下降都很显著。
双向性是关键¶
Table 1(长度 2048,因果 vs 双向编码器掩码):
| Model | Recall@10 | Recall@100 | Recall@1000 |
|---|---|---|---|
| Bidirectional SA mask | 0.2800 | 0.6150 | 0.8667 |
| Causal SA mask | 0.1878 | 0.5130 | 0.8353 |
结论:把编码器从双向掩码换成因果掩码,Recall@10 从 0.2800 暴跌到 0.1878(相对 −33%)。这量化地证明了生成式检索的编码器必须用双向掩码——也正是本文要做"双向"线性注意力(而非沿用现成的因果线性注意力)的根本理由。
混合编码器有用,纯 GBLA 不够¶
Table 2(长度 2048,混合 vs 全 GBLA):
| Model | Recall@10 | Recall@100 | Recall@1000 |
|---|---|---|---|
Hybrid [SA, LA, LA] |
0.2780 | 0.6143 | 0.8668 |
| Fully GBLA | 0.2607 | 0.5940 | 0.8586 |
结论:把自注意力全部移除(Fully GBLA)通常次优——Recall@10 掉到 0.2607。最佳配置是 2:1 的 LA:SA 混合、排列 [SA, LA, LA]:保留少量自注意力层来兜住全局精确交互,其余用 GBLA 换线性复杂度。混合的 Recall@1000(0.8668)甚至略高于纯双向 SA(Table 1 的 0.8667),说明在 top-1000 区间几乎无损。
随序列变长,质量持平¶
Table 3(不同序列长度,双向 SA vs 混合 GBLA):
| SeqLen | Method | Recall@10 | Recall@100 | Recall@1000 |
|---|---|---|---|---|
| 512 | Bidirectional SA | 0.2089 | 0.5072 | 0.8182 |
| 512 | Hybrid GBLA | 0.2102 | 0.5099 | 0.8198 |
| 2048 | Bidirectional SA | 0.2800 | 0.6150 | 0.8667 |
| 2048 | Hybrid GBLA | 0.2780 | 0.6143 | 0.8668 |
| 4096 | Bidirectional SA | 0.2935 | 0.6385 | 0.8784 |
| 4096 | Hybrid GBLA | 0.2897 | 0.6368 | 0.8790 |
| 8192 | Bidirectional SA | 0.3013 | 0.6517 | 0.8854 |
| 8192 | Hybrid GBLA | 0.2948 | 0.6462 | 0.8842 |
结论:以 Recall@1000 计,GBLA 在 $L \in \{512, 2048, 4096\}$ 上略优于双向 SA,到 $L = 8192$ 才出现极小的下降(0.8842 vs 0.8854,−0.0012)。同时也能看到一个普遍趋势——序列越长,两种方法的绝对 Recall 都越高,印证了"拉长历史能提升质量"的动机,从而也凸显了"必须能负担得起长序列"的现实意义。
消融分析¶
Table 4(长度 2048,逐组件消融):
| Model | Recall@10 | Recall@100 | Recall@1000 |
|---|---|---|---|
| GBLA(全部组件) | 0.2780 | 0.6143 | 0.8668 |
| W/o Key gating | 0.2776 | 0.6131 | 0.8661 |
| W/o Conv1D | 0.2747 | 0.6110 | 0.8652 |
| W/o Gated RMSNorm | 0.2726 | 0.6080 | 0.8641 |
| W/o all (= BLA) | 0.2675 | 0.6021 | 0.8620 |
逐项分析:
- 每个组件都带来正向、可叠加的增益。单独去掉 key gating 影响最小(Recall@10 0.2780→0.2776),去掉 Conv1D 次之(→0.2747),去掉 gated RMSNorm 影响最大(→0.2726)——说明门控归一化输出对质量最关键。
- 去掉全部三个组件(即退化为裸 BLA)掉得最多,Recall@10 从 0.2780 跌到 0.2675(相对 −3.8%),Recall@1000 从 0.8668 跌到 0.8620。这印证了 GBLA 的设计立意:裸线性注意力会损失表达力,三个廉价 gating 组件正是把这部分损失补回来的关键,且三者协同的整体收益大于各自单点贡献之和。
性能 Benchmark¶
单层推理延迟(对比 FlashAttention-v3)¶
Table 5(NVIDIA H100,batch = 8,单层延迟,10 次平均):
| SeqLen | Self-Attn (ms) | GBLA (ms) | Speedup (SA/GBLA) |
|---|---|---|---|
| 2048 | 0.585 | 0.618 | 0.95× |
| 4096 | 1.706 | 1.141 | 1.50× |
| 8192 | 5.419 | 2.199 | 2.46× |
| 16384 | 18.353 | 4.266 | 4.30× |
| 32768 | 67.542 | 8.217 | 8.22× |
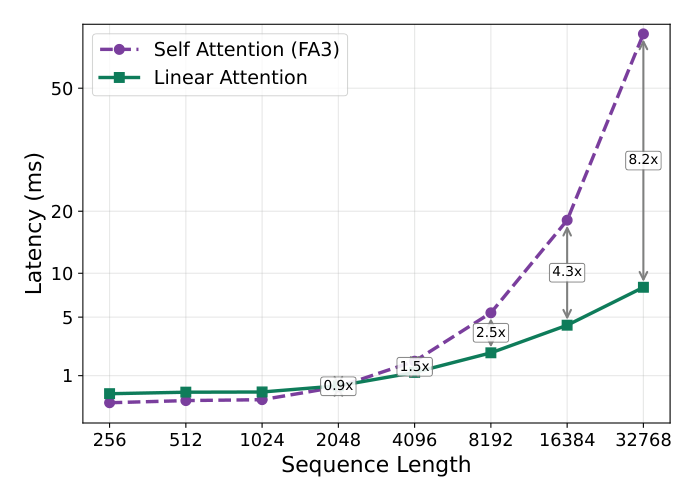
结论:GBLA 从 $L = 4096$ 起开始反超 FlashAttention-v3,加速比随长度增长——到 $L = 32768$ 达到 8.22×。注意 SA 延迟从 $L=8192$ 的 5.4ms 到 $L=32768$ 的 67.5ms(二次爆炸),而 GBLA 仅从 2.2ms 到 8.2ms(近线性)。作者特别说明:在短历史($L \le 2048$)下,自注意力只占端到端推理时间的远不到 25%,因此 GBLA 在 $L=2048$ 的小幅劣势(0.95×)对整体延迟可忽略;而当 $L$ 增大,自注意力块成为主导瓶颈,正是在长上下文区间专门加速注意力才变得关键。Figure 2 给出更细粒度的对比。
完整混合模型的训练加速¶
Table 6(NVIDIA H100,训练单步耗时,10 次平均;$L=2048$ 时 batch=32,$L=8192$ 时 batch=8):
| Method | $L=2048$ (ms) | Speedup | $L=8192$ (ms) | Speedup |
|---|---|---|---|---|
| SA | 3000 | 1.00× | 5400 | 1.00× |
| BLA | 2800 | 1.07× | 3800 | 1.42× |
| GBLA | 3100 | 0.95× | 4200 | 1.29× |
结论:把编码器的一部分自注意力块换成裸 BLA(去掉全部 GBLA 附加件),在 $L=2048$ 单步从 3000ms 降到 2800ms(1.07×),在 $L=8192$ 从 5400ms 降到 3800ms(1.42×)。GBLA 混合变体在 $L=2048$ 仅有可忽略的轻微变慢(0.95×),因为此长度下基于 FlashAttention 的自注意力块只占端到端单步的很小一部分;但到 $L=8192$ 仍带来 1.29× 训练加速。这条结果说明 GBLA 的三个 gating 组件相对 BLA 引入的额外开销很小,且其训练加速同样随序列变长而显现。
学术基准结果(Amazon)¶
Table 7(Tiger vs Tiger+GBLA,5 个种子平均):
| Model | Recall@5 | Recall@10 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|
| Beauty | ||||
| Tiger | 0.0439 | 0.0641 | 0.0289 | 0.0355 |
| Tiger+GBLA | 0.0410 | 0.0611 | 0.0273 | 0.0338 |
| Toys | ||||
| Tiger | 0.0402 | 0.0584 | 0.0274 | 0.0333 |
| Tiger+GBLA | 0.0384 | 0.0579 | 0.0249 | 0.0311 |
| Sports | ||||
| Tiger | 0.0229 | 0.0345 | 0.0150 | 0.0188 |
| Tiger+GBLA | 0.0218 | 0.0329 | 0.0144 | 0.0180 |
结论:在三个 Amazon 数据集上,Tiger 与 Tiger+GBLA 的结果非常接近,所有 delta 都很小。作者坦诚地指出,结合 GRID 报告中本就观察到的结果与消融的方差,这些小差异通常不被认为是显著的。更重要的是解释了为何学术设置不测效率:Amazon 的用户历史很短(最多 128 个物品),自注意力根本不是瓶颈,所以在学术设置里不 benchmark 性能效率。这一节的真实价值是证明 GBLA 的混合设计能泛化到自有生产环境之外,在公开基准上一致地保持自注意力级别的检索质量。
核心贡献总结¶
- 首次系统地把"双向"线性注意力做进生成式检索编码器:明确了 generative retrieval 的编码器需要双向掩码(Table 1 量化:换因果掩码 Recall@10 暴跌 33%),而既有亚二次方法多为因果——填补了"可扩展双向线性注意力"这一空白;区别于只在推理时线性的 LION,GBLA 训练与推理都是线性时间。
- GBLA = BLA + 三个廉价 gating 组件(Conv1D 短程混合、key gating 软遗忘、gated RMSNorm 输出门),在不破坏线性复杂度的前提下把裸线性注意力损失的表达力补回(消融显示三者协同把 Recall@10 从 0.2675 提到 0.2780)。
- 混合
[SA, LA, LA](2:1)编码器架构:在大规模 Yandex Music 数据上匹配双向自注意力的检索质量(Recall@1000 0.8668 vs 0.8667),并随序列变长保持持平(到 8192 仅极小回落)。 - 可观的长上下文加速:H100 上单层从 $L=4096$ 起反超 FlashAttention-v3,$L=32768$ 达 8.22×;完整混合模型在 $L=8192$ 训练加速 1.29×(裸 BLA 达 1.42×)。
- 泛化性验证:复现 GRID/Tiger 协议,在 Amazon Beauty/Toys/Sports 上保持与 Tiger 持平的质量,证明设计不只适用于自有生产环境。代码(含对 GRID 的线性注意力扩展)开源。
讨论与局限性¶
值得借鉴的设计:本文最有价值的判断是把算力账算清楚——它没有泛泛地"用线性注意力替换一切",而是基于"编码器主导算力 + 编码器必须双向 + 短序列下自注意力其实不是瓶颈"三条观察,精准地只在编码器、只在长序列、并以混合而非全替换的方式引入线性注意力。这种"按瓶颈下刀"的工程克制,比单纯追求最低复杂度更务实。三个 gating 组件也都是从 Mamba/Gated DeltaNet 长上下文经验里"拿来即用"的低成本部件,体现了对现有 LLM 高效注意力工具箱的良好复用。
与已有工作的差异:相对输入压缩派(如 Longer [2],以及推荐侧的 IAT、SIF 等"把历史样本压成紧凑 token"的有损方案),GBLA 坚持对全序列做无损的线性注意力,不丢弃历史信息;相对系统级优化(context parallelism、hierarchical pathways),它从算法层消除了二次依赖;相对 LION [1] 只在推理时线性,GBLA 训练也线性;相对 KSA 等"summary-token 压缩 + 稀疏注意力"路线(且 KSA 刻意回避线性注意力、主打 causal LLM 长上下文 KV cache),GBLA 走的是核化线性注意力 + 双向这条相反的解法基元——两者同在"长序列亚二次注意力"方向,但问题域(推荐编码器 vs LLM 长上下文)与解法家族都不同。
局限与争议:
- 学术基准上 GBLA 略逊于 Tiger 且无效率收益(Table 7)。作者归因于 Amazon 历史太短(≤128)使注意力非瓶颈,这解释合理,但也意味着 GBLA 的优势严格依赖超长历史这一前提——在中短序列场景下,它相对自注意力没有质量优势、还可能有微小的额外延迟($L=2048$ 时 0.95×)。
- 核心质量证据来自自有的、不可复现的 Yandex Music 数据。Table 1–6 的关键结论(双向必要性、混合最优、长度持平、加速比)都基于私有数据集,外部无法验证;公开基准虽证明泛化但恰好处在"看不出优势"的短序列区间,二者之间存在一道无法被外部弥合的缝。
- 作为 5 页短论文,方法深度受限:例如 $\phi$ 的具体选择(是否就是 $\text{elu}+1$)、key gating 用 softmax 归一化的设计取舍、Conv1D 是否带因果性、多头之间状态是否共享等细节均未充分展开;$L=8192$ 之外(如 16k/32k)只报告了延迟而未报告质量,长序列下"质量是否仍持平"这一最关键问题在超长区间留有空白。
- 超参对架构敏感:全自注意力与混合编码器的最优峰值学习率不同($7\times10^{-4}$ vs $5\times10^{-4}$),暗示把 GBLA 接入既有系统并非"即插即用",需要重新调参。
工业落地价值:GBLA 面向的是"活跃用户历史无限增长"这一真实的生产痛点,提供了一条在不牺牲检索质量的前提下把生成式检索扩展到更长用户历史的实用路径。对于已经在跑 OneRec 式 encoder–decoder 生成式检索、且用户历史正逼近数千乃至上万长度的大厂,这套"混合编码器 + 双向线性注意力"的方案具备直接的可移植性——尤其其 8.2× 的长序列单层加速,意味着同样的延迟预算下可以服务长得多的历史窗口。